22. Справляемся с каскадными сбоями
Автор — Майк Ульрих
Если вы не преуспели сразу, отступайте экспоненциально.
Дэн Сэндлер, инженер-программист компании Google
Почему люди всегда забывают о том, что нужно учитывать небольшую погрешность?
Аде Ошинай, Developer Advocate Google
Каскадный сбой — это сбой, который распространяется с течением времени в результате положительной обратной связи. Он может произойти, когда часть системы дает сбой, повышая вероятность того, что дадут сбой и другие ее части. Например, одна реплика для сервиса может дать сбой из-за перегрузки, повышая нагрузку на оставшиеся реплики и увеличивая вероятность того, что и они дадут сбой, вызвав эффект домино, который приведет к сбою всех реплик. В качестве примера в этой главе мы будем использовать поисковый сервис, который рассмотрели в конце главы 2. Его конфигурация может выглядеть так, как показано на рис. 22.1.
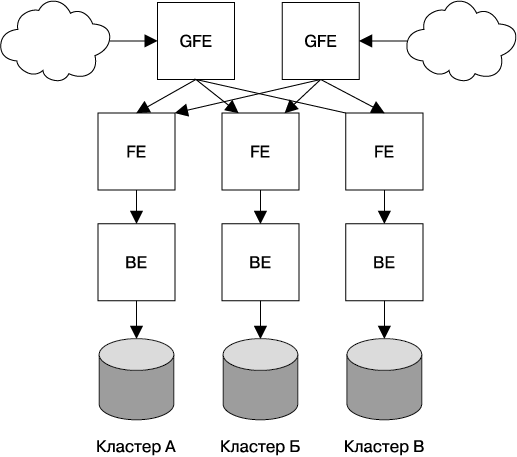
Рис. 22.1. Пример производственной конфигурации поискового сервиса
Причины каскадных сбоев и способы их избежать
Хорошо продуманный дизайн системы должен принимать во внимание некоторые типичные сценарии, которые учитывают большую часть каскадных сбоев
Перегруженность сервера
Наиболее часто причиной каскадных сбоев становится перегруженность. Бо'льшая часть каскадных сбоев, описанная здесь, произошла либо непосредственно из-за перегруженности сервера, либо из-за последствий или вариаций такого сценария.
Предположим, что фронтенд в кластере А обрабатывает 1000 запросов в секунду (requests per second, QPS), как показано на рис. 22.2.
Если кластер Б дает сбой (рис. 22.3), уровень запросов к кластеру A повышается до 1200 QPS. Фронтенды кластера А не могут обработать 1200 QPS, поэтому у них заканчиваются ресурсы, что приводит к сбоям, пропущенным дедлайнам и другим вариантам неправильного поведения. В результате количество успешно обработанных запросов для кластера А падает ниже 1000 QPS.
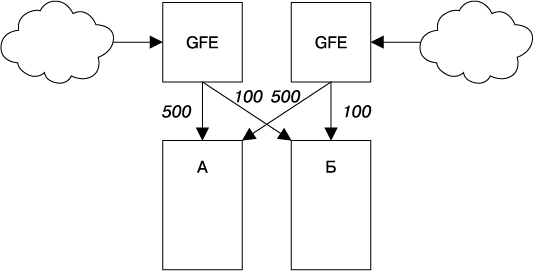
Рис. 22.2. Нормальное распределение загрузки между кластерами А и Б
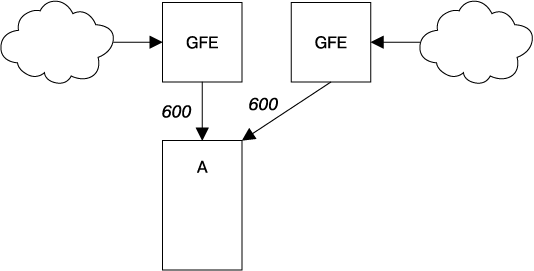
Рис. 22.3. Кластер Б дает сбой, отправляя весь трафик на кластер А
Такое снижение уровня успешно выполняемой работы может распространиться на другие области отказов, возможно, даже глобально. Например, локальная перегруженность одного кластера может привести к падению его серверов; из-за этого контроллер балансировки нагрузки отправляет запрос на другие кластеры, перегружая и их серверы, что вызывает перегрузку на уровне всего сервиса. Эти события могут быть обнаружены довольно быстро, иногда за несколько минут, поскольку системы балансировки нагрузки и планирования задач могут действовать с большой скоростью.
Истощение ресурсов
Истощение ресурсов может привести к увеличенной задержке, повышенному количеству ошибок или предоставлению недостоверных результатов. Фактически перечислены желательные эффекты нехватки ресурсов: за превышение допустимой загрузки сервера вы должны чем-то расплачиваться.
В зависимости от того, какие ресурсы истощаются на сервере, а также от его конфигурации нехватка ресурсов может сделать сервер менее эффективным или заставить его «упасть», в результате чего балансировщик нагрузки распространит проблемы с ресурсами на другие серверы. Когда это происходит, уровень успешно обработанных запросов может снизиться и, возможно, отправить кластер или весь сервис в состояние каскадного сбоя.
Истощиться могут ресурсы разных типов, это оказывает на серверы разное воздействие.
Процессор
Если для обработки загрузки запроса не хватает ресурсов процессора, то, как правило, все запросы выполняются медленнее. Этот сценарий может привести к проявлению разных вторичных эффектов, включая следующие.
• Увеличение количества активных запросов. Поскольку запросы обрабатываются дольше, одновременно начинает обрабатываться большее их количество — вплоть до максимально возможного, по достижении которого они могут начать попадать в очереди. Это влияет практически на все ресурсы, включая память, количество активных потоков (если используется модель «поток на запрос»), количество дескрипторов файлов и ресурсы бэкенда (что, в свою очередь, может вызвать другой эффект).
• Чрезмерно длинные очереди. Если для обработки всех запросов с постоянной скоростью недостаточно производительности, сервер начинает заполнять свои очереди. Это означает увеличение задержки использования памяти пакетами запросов (запросы находятся в очереди дольше). Стратегии выхода из таких ситуаций рассматриваются в подразделе «Управление очередями» далее.
• Зависание потоков. Если поток не может выполняться, поскольку ожидает заблокированный ресурс, то проверка состояния может дать сбой, если невозможно вовремя обслужить конечную точку проверки состояния.
• Перегруженность процессора или зависание запроса. Внутренние сторожевые таймеры на сервере могут обнаружить, что сервер не выполняет обслуживание вследствие сбоев из-за перегруженности процессора, или, если сторожевой таймер запускается удаленно, зависают его запросы в общем потоке запросов.
• Пропущенные дедлайны RPC. Когда сервер оказывается перегруженным, его ответы на RPC клиентов будут приходить позже, и из-за этого могут быть упущены дедлайны, установленные для этих клиентов. Работа, которую сервер выполнил для того, чтобы сгенерировать ответ, проделана впустую, и клиенты могут попробовать снова вызвать RPC, что приведет к еще большей перегрузке.
• Уменьшенные преимущества кэширования процессора. Чем больше процессоров действует, тем выше вероятность того, что задача будет выполнена на большем количестве ядер, а это уменьшает степень использования локального кэша и снижает эффективность процессора.
Память
Большее количество запросов потребляет большее количество памяти, которая требуется для выделения объектам запроса, ответа и RPC. Истощение памяти может привести к следующим результатам.
• Умирающие задачи. Например, задача может быть исключена менеджером контейнера (VM или чем-то другим) за превышение доступных ресурсов или характерных для приложения сбоев, которые могут вызвать остановку задач.
• Повышенная частота сборки мусора (garbage collection, GC) в Java, что приводит к усиленному использованию процессора. В этом сценарии может получиться замкнутый круг: будет доступно меньше процессоров, что приведет к медленному выполнению запросов, что вызовет повышение степени использования памяти, что приведет к более частой сборке мусора и, как результат, к еще меньшей доступности процессоров. Эта ситуация известна как «спираль смерти GC».
• Снижение частоты попаданий кэша. Уменьшение доступного объема памяти может понизить частоту попадания кэша приложения, что приведет к большему количеству вызовов бэкендов со стороны RPC, из-за чего бэкенды могут оказаться перегруженными.
Потоки
Зависание потоков может вызывать ошибки или приводить к сбоям проверки состояния. Если сервер по мере надобности добавляет потоки, они могут начать использовать слишком большое количество памяти. В наиболее вопиющих случаях зависание потоков может привести к тому, что у вас закончатся идентификаторы процессов.
Дескрипторы файлов
Израсходование свободных дескрипторов файлов может привести к неспособности инициализировать сетевые соединения, что, в свою очередь, заставит проверки состояния генерировать сбои.
Зависимости между ресурсами
Обратите внимание на то, что многие сценарии израсходования ресурсов проистекают один из другого — перегруженный сервис зачастую имеет вторичные симптомы, которые могут выглядеть как основная причина, что затрудняет отладку.
Например, представьте следующий сценарий.
1. Фронтенд, написанный на Java, имеет плохо настроенные параметры сборки мусора (GC).
2. Под высокой, но ожидаемой нагрузкой у фронтенда заканчивается память из-за GC.
3. Перегруженность процессора замедляет выполнение запросов.
4. Увеличение количества выполняющихся запросов приводит к тому, что для их обработки используется больший объем памяти.
5. Недостаток памяти из-за запросов вкупе с фиксированным выделением памяти для всего процесса фронтенда приводит к тому, что для кэширования остается меньше памяти.
6. Уменьшенный размер кэша означает, что в нем будет храниться меньше записей, а также снизится частота попаданий.
7. Увеличение промахов кэша приведет к тому, что большее количество запросов будет попадать на бэкенд для обслуживания.
8. У бэкенда, в свою очередь, закончатся ресурсы процессора или потоков.
9. Наконец, перегруженность процессора приведет к сбоям при проверке состояния, запуская каскадный сбой.
В сложных ситуациях наподобие предыдущего сценария маловероятно, что причинно-следственная цепочка будет полностью продиагностирована во время отключения. Бывает очень трудно определить, что сбой бэкенда вызван снижением частоты попаданий кэша на фронтенде, особенно если у фронтенда и бэкенда разные владельцы.
Недоступность сервисов
Израсходование ресурсов может привести к падению серверов. Например, серверы могут начать сбоить, если контейнеру выделено слишком много памяти. Как только несколько серверов «упадут» из-за перегруженности, нагрузка на оставшиеся может возрасти, что вызовет и их сбои. Обычно проблема растет как снежный ком, и вскоре все серверы войдут в состояние сбоя. Зачастую избежать такого сценария сложно, поскольку, как только серверы вернутся в строй, они будут бомбардированы чрезвычайно большим количеством запросов и практически моментально дадут сбой.
Например, если при 10 000 QPS сервис был работоспособен, но запустил каскадный сбой из-за того, что «упал» при 11 000 QPS, снижение нагрузки до 9000 QPS, скорее всего, не остановит процесс. Это происходит потому, что сервис будет обрабатывать повышенный спрос с пониженной производительностью, и только малая доля серверов будет достаточно работоспособна для того, чтобы обрабатывать запросы. Доля серверов, которые останутся работоспособными, определяется на основе нескольких факторов: как быстро система может начать запускать задачи, как быстро приложение может начать работать на полную мощность и как долго только что созданная задача сможет выдерживать нагрузку. В нашем примере, если 10 % серверов достаточно работоспособны, чтобы обрабатывать запросы, интенсивность запросов должна будет снизиться примерно до 1000 QPS для того, чтобы система смогла стабилизироваться и восстановиться.
Аналогично серверы могут представляться неработоспособными для уровня балансировки нагрузки, что приведет к снижению производительности балансировщика нагрузки: серверы могут войти в состояние «хромой утки» (см. подраздел «Усовершенствованный подход к контролю работоспособности задач: состояние “хромой утки”» на с. 293) или давать сбои при проверке состояния, не «падая» при этом. Эффект может оказаться аналогичным «падению»: большее количество серверов представляются неработоспособными, работоспособные серверы принимают запросы лишь очень короткий промежуток времени перед тем, как выйти из строя, и еще меньшее количество серверов участвует в обработке запросов. Политики балансировки нагрузки, которые исключают серверы, возвращающие ошибки, могут еще больше усугубить проблему — несколько бэкендов вернули ошибки и поэтому больше не вносят вклад в повышение производительность сервиса. Это повышает нагрузку на оставшиеся серверы, запуская эффект снежного кома.
Предотвращаем перегруженность сервера
В следующем списке представлены стратегии по предотвращению перегруженности серверов в порядке приоритетности.
• Запустите нагрузочный тест для анализа производительности сервера и проверьте режим восстановления при перегруженности. Это самое главное, что вы должны сделать, чтобы предотвратить перегрузку сервера. Если вы не выполняете тесты в реалистичной среде, очень трудно предсказать, какой ресурс будет исчерпан и как это повлияет на систему. Для получения более подробной информации прочтите раздел «Тестирование на предмет каскадных сбоев» далее в этой главе.
• Отправляйте деградированные результаты. Отправляйте пользователю низкокачественные, но более дешевые для вычисления результаты. Ваша стратегия будет зависеть от конкретного сервиса. Для получения более подробной информации прочтите подраздел «Сегментация нагрузки и мягкая деградация» далее.
• Укажите серверу отклонять запросы при перегруженности. Серверы должны защищать себя от перегрузки и «падений». При перегруженности на уровне фронтенда или бэкенда генерируйте сбой рано и дешево. Более подробную информацию об этом вы найдете в подразделе «Сегментация нагрузки и мягкая деградация» далее.
• Укажите высокоуровневым системам отклонять запросы, а не перегружать сервера. Обратите внимание на то, что, поскольку ограничение уровня запросов зачастую не учитывает состояние всего сервиса, это не сможет остановить уже начавшийся сбой. Простые реализации ограничения уровня запросов приведут также к тому, что некоторые ресурсы не будут использоваться. Ограничить уровень запросов можно в нескольких местах:
• на уровне обратных прокси путем ограничения объема запросов по таким критериям, как IP-адрес, для того чтобы справиться с попытками DDoS-атак и злоупотребляющими клиентами;
• на уровне балансировщиков нагрузки путем отклонения поступающих запросов, когда сервис вошел в состояние глобальной перегруженности. В зависимости от характера и сложности сервиса такое ограничение уровня запросов может быть как общим («отклонять весь трафик, превышающий х запросов в секунду»), так и избирательным («отклонять запросы, которые пришли не от пользователей, взаимодействовавших с сервисом недавно» или «отклонять запросы от операций с низким приоритетом наподобие фоновой синхронизации, но продолжать обслуживать интерактивные сессии пользователя»);
• на уровне отдельных задач для того, чтобы предотвратить ситуацию, когда случайные флуктуации при балансировке нагрузки вызовут перегруженность сервера.
• Планирование производительности. Хорошее планирование производительности может снизить вероятность каскадного сбоя. Его нужно объединить с тестированием производительности для того, чтобы определить нагрузку, при которой сервер начнет давать сбой. Например, если каждый кластер дает сбой при 5000 QPS, нагрузка равномерно распределена между кластерами, а пиковая нагрузка сервиса достигает 19 000 QPS, то для того, чтобы сервис работал на уровне N + 2, вам понадобится примерно шесть кластеров.
Планирование производительности снижает вероятность того, что произойдет каскадный сбой, но его может быть недостаточно. Если вы теряете значительные части своей инфраструктуры из-за запланированного или незапланированного события, никакого планирования производительности не будет достаточно для того, чтобы предотвратить каскадные сбои. Проблемы с балансировкой нагрузки, нарушение связности сети или неожиданное увеличение трафика могут вывести пики высокой нагрузки за пределы спланированных значений. Некоторые системы способны наращивать количество обслуживающих задач для сервиса по запросу, что может предотвратить перегруженность, однако планировать производительность все же необходимо.
Управление очередями
Бо'льшая часть серверов, работающих по принципу «поток на запрос», использует для обработки запросов очередь, расположенную перед пулом потоков. Входящие запросы попадают в очередь, и затем поток выбирает их из нее и выполняет реальную работу (любые действия, которые должен реализовать сервер). Обычно, если очередь заполнена, сервер будет отклонять новые запросы.
Если уровень запросов и задержка обработки заданной задачи являются константными, нет необходимости помещать запросы в очередь: константное количество потоков должно быть занятым. Согласно этому идеализированному сценарию запросы могут быть помещены в очередь только в том случае, если количество входящих запросов превышает некоторое граничное значение и сервер не может обработать их все, что приводит к насыщению пула потоков и возникновению очереди.
Запросы, помещенные в очередь, потребляют память и увеличивают задержку обработки данных. Например, если размер очереди равен количеству потоков, умноженному на 10, время обработки запроса в потоке составляет 100 миллисекунд. Если очередь заполнена, то на обработку запроса потребуется 1,1 секунды, при этом бо'льшую часть времени он проведет в очереди.
Для системы, чей поток трафика с течением времени остается относительно равномерным, обычно следует иметь очереди, длина которых незначительно превышает размер пула потоков, например, на 50 % или меньше, в результате чего сервер заранее будет отклонять запросы, которые не сможет обработать. Например, сервис Gmail зачастую использует серверы без очередей, полагаясь на процесс восстановления после сбоев других серверных задач, когда потоки заполнены. В то же время системы с периодически возникающей пиковой нагрузкой, при которой шаблоны поступления трафика могут значительно изменяться, работают лучше, когда размер очереди основан на текущем количестве потоков, времени обработки каждого запроса, а также размере и частоте пиков запросов.
Сегментация нагрузки и мягкая деградация
Сегментация позволяет убрать некоторую часть нагрузки, отклоняя трафик, когда сервер начинает перегружаться. Цель заключается в том, чтобы предотвратить ситуацию, когда у сервера закончится свободная оперативная память и он начнет проваливать проверки состояния, обслуживать запросы с высокой задержкой или показывать какие-нибудь другие симптомы, связанные с перегруженностью, при этом выполняя максимально возможное количество полезной работы. Одним из наиболее простейших способов сегментации нагрузки является позадачное подавление, основанное на показателях использования процессора, памяти или длины очереди. Ограничение длины очереди, о котором говорилось в подразделе «Управление очередями» ранее в данной главе, является одной из форм такой стратегии. Например, одним из эффективных подходов является возвращение кода HTTP 503 («сервис недоступен») любому входящему запросу, когда количество поступивших запросов превышает заданное.
Изменение метода формирования очереди со стандартного «первым вошел, первым вышел» (first-in, first-out, FIFO) на «последним вошел, первым вышел» (last-in, first-out, LIFO) или применение алгоритма контролируемой задержки (controlled delay, CoDel) [Nichols, 2012] или похожих подходов может снизить нагрузку путем избавления от запросов, которые, скорее всего, не стоит обрабатывать [Maurer, 2015]. Если пользовательский поисковый запрос в Интернете выполняется медленно из-за того, что RPC находилась в очереди 10 секунд, весьма вероятно, что пользователь устал ждать и обновил браузер, отправив новый запрос: нет смысла отвечать на первый запрос, поскольку ответ будет проигнорирован! Эта стратегия работает хорошо, если ее объединить с распространением дедлайнов RPC по всему стеку, как описано в подразделе «Задержка и дедлайны» далее.
Более сложные подходы заключаются в определении клиентов, более требовательных к качеству работы или определению самых важных или приоритетных запросов. Такие стратегии, скорее всего, подойдут для создания разделяемых сервисов.
Мягкая деградация использует концепцию сегментации нагрузки и выводит ее на новый уровень, снижая объем выполняемой работы. В некоторых приложениях можно значительно уменьшить объем работы или время, требующееся для выполнения запроса, ухудшив качество ответа. Например, поисковое приложение может выполнять поиск лишь в небольшом подмножестве данных, хранящихся в расположенных в памяти кэшах, вместо того чтобы искать во всей базе данных. Или же задействовать менее точный, но более быстрый алгоритм ранжирования при перегруженности.
При оценке вариантов сегментации нагрузки или мягкой деградации для сервиса вам нужно принять во внимание следующее.
• Какие показатели вы можете применить для определения момента, в который можно начинать сегментацию нагрузки или мягкую деградацию (например, загруженность процессора, задержку, длину очереди, количество использованных потоков, а также решение о том, должен ли сервис входить в деградированный режим автоматически, или ему необходимо ручное вмешательство)?
• Какие действия нужно предпринять, если сервер вошел в деградированный режим?
• На каком слое нужно реализовывать сегментацию нагрузки и мягкую деградацию? Имеет ли смысл реализовывать эти стратегии на каждом слое стека или достаточно сделать это на одном проблемном участке?
При оценке вариантов и внедрении помните о следующем.
• Мягкая деградация не должна запускаться очень часто — только при снижении запланированной производительности или неожиданном изменении нагрузки. Пусть ваша система будет простой и понятной, особенно если ее станут использовать не так уж часто.
• Помните, что часть кода, которую вы никогда не применяете, зачастую является неработающей. При обслуживании запросов в обычном темпе режим мягкой деградации задействоваться не будет, что подразумевает, что вы получите гораздо меньше операционного опыта в этом режиме и вряд ли будете понимать его особенности, что повышает уровень риска. Вы можете убедиться, что мягкая деградация продолжает работать, регулярно допуская ситуацию, когда небольшое подмножество серверов работает почти на пределе, просто чтобы проверить этот сценарий.
• Отслеживайте ситуацию, когда слишком большое количество серверов входит в эти режимы, и оповещайте о ней.
• Сложная сегментация нагрузки и мягкая деградация могут вызвать проблемы сами по себе — избыточная сложность может заставить сервер войти в деградированный режим или в циклы обратной связи, когда это нежелательно. Разработайте способ быстро отключать сложную мягкую деградацию или настраивать ее параметры по необходимости.
Сохранение этой конфигурации в устойчивой системе, в которой каждый сервер наподобие Chubby следит за изменениями, может повысить скорость развертывания, но в то же время вы будете не защищены от рисков сбоя синхронизации.
Повторные попытки
Предположим, что код фронтенда, который общается с бэкендом, просто выполняет повторные попытки.
Он делает это после того, как произойдет сбой, и ограничивает количество RPC бэкенда для одного запроса десятью. Рассмотрим код фронтенда, в котором используются gRPC и Go:
func exampleRpcCall(client pb.ExampleClient, request pb.Request) *pb.Response {
// Set RPC timeout to 5 seconds.
opts := grpc.WithTimeout(5 * time.Second)
// Try up to 20 times to make the RPC call.
attempts := 20
for attempts > 0 {
conn, err := grpc.Dial(*serverAddr, opts...)
if err != nil {
// Something went wrong in setting up the connection. Try again.
attempts--
continue
}
defer conn.Close()
// Create a client stub and make the RPC call.
client := pb.NewBackendClient(conn)
response, err := client.MakeRequest(context.Background, request)
if err != nil {
// Something went wrong in making the call. Try again.
attempts--
continue
}
return response
}
grpclog.Fatalf("ran out of attempts")
}
Эта система может функционировать следующим образом.
1. Предположим, что наш бэкенд имеет известную границу 10 000 QPS на задачу, после чего все дальнейшие запросы отклоняются и для них выполняется мягкая деградация.
2. Фронтенд вызывает MakeRequest с заданным уровнем 10 100 QPS и перегружает бэкенд на 100 QPS, которые тот отклоняет.
3. Для этих 100 QPS, вызвавших сбой, MakeRequest выполняет повторные попытки каждые 1000 миллисекунд, и они, возможно, успешно выполняются. Но повторные попытки сами по себе увеличивают количество запросов, отправляемых на бэкенд, — теперь он получает 10 200 QPS, 200 из которых вызывают сбой из-за перегрузки.
4. Количество повторных попыток растет: 100 QPS повторных попыток в первую секунду приводят к 200 QPS повторных попыток, затем к 300 QPS и т.д. Все меньшее количество запросов успешно реализуется с первой попытки, поэтому полезную работу выполняет все меньшее количество запросов.
5. Если задача бэкенда не может обработать повышение загрузки, которое потребляет дескрипторы файлов, память и процессорное время бэкенда, она может дать сбой под нагрузкой, создаваемой запросами и повторными попытками. Из-за этого запросы, получаемые бэкендом, перераспределятся между оставшимися задачами, что, в свою очередь, приведет и к их перегрузке.
Чтобы проиллюстрировать этот сценарий, были сделаны некоторые упрощающие предположения, но общий смысл заключается в том, что повторные попытки могут дестабилизировать систему. Обратите внимание на то, что как временные всплески нагрузки, так и медленное ее повышение могут вызвать такой эффект.
Даже если уровень вызовов MakeRequest окажется ниже катастрофического (например, 9000 QPS), вы можете не избавиться от проблемы. Это будет зависеть от того, во что бэкенду обошлось возвращение ошибки. Здесь играют роль два фактора.
• Если бэкенд тратит значительное количество ресурсов на обработку запросов, которые в итоге завершатся с ошибкой из-за перегруженности, то повторные попытки сами по себе могут поддерживать бэкенд в режиме перегруженности.
• Серверы бэкенда сами могут быть нестабильны. Повторные попытки могут усилить эффекты, о которых говорилось в разделе «Перегруженность сервера» ранее.
Если выполняется хотя бы одно из этих условий, то для того, чтобы справиться со сбоем, вы должны значительно снизить нагрузку (или вовсе избавиться от нее) на фронтендах до тех пор, пока повторные попытки не прекратятся и бэкенд не стабилизируется.
Такая схема стала причиной нескольких каскадных сбоев, в которых либо фронтенд, либо бэкенд общались посредством сообщений RPC, где фронтенд — код клиента JavaScript — отправлял вызовы XmlHttpRequest к конечной точке и повторял попытки при сбоях.
При автоматическом выполнении повторных попыток имейте в виду следующее.
• В этом случае применима бо'льшая часть стратегий защиты бэкенда, описанных ранее в разделе «Предотвращаем перегруженность сервера». В частности, тестирование системы может выявить проблемы, а мягкая деградация — ослабить воздействие, который повторные попытки оказывают на бэкенд.
• При планировании повторных попыток всегда используйте рандомизированный экспоненциальный откат (см. статью Exponential Backoff and Jitter в блоге AWS Architecture Blog [Brooker, 2015]). Если повторные попытки не распределены случайным образом в рамках окна повторов, небольшие проблемы, например связанные с сетью, могут вызвать ураган повторных попыток, запланированных на одно и то же время, что может увеличить их количество [Floyd, 1994].
• Ограничивайте количество повторных попыток для запроса. Не пытайтесь выполнить запрос бесконечное количество раз.
• Рассмотрите возможность введения лимита повторных попыток для сервера. Например, позволяйте процессу выполнять 60 повторных попыток в минуту и, если это количество будет превышено, не продолжайте — просто возвращайте ошибку. Эта стратегия может продемонстрировать разницу между ошибкой при планировании производительности, которая вызывает отклонение некоторых запросов, и глобальным каскадным сбоем.
• Подумайте о сервере как о едином объекте и решите, хотите ли вы выполнять повторные попытки на заданном уровне. В частности, избегайте увеличения числа повторных попыток, выполняя их на всех уровнях: один запрос на верхнем уровне может создать количество повторных попыток, равное произведению количества попыток на каждом уровне вплоть до нижнего. Если база данных не может обработать запросы сервиса, поскольку он перегружен, и уровни бэкенда, фронтенда и JavaScript выполнят по три повторные попытки (четыре вызова), одно действие пользователя может создать 64 обращения (43) к базе данных. Нежелательно такое поведение, при котором база данных возвращает эти ошибки из-за перегруженности.
• Используйте понятные коды ответов и обдумывайте, как нужно обрабатывать разные ошибки. Например, разделите ошибочные состояния, при которых можно повторять запросы, и состояния, при которых этого делать нельзя. Не пытайтесь выполнять повторные попытки для постоянных ошибок или плохо сформированных запросов в клиенте, поскольку это не принесет пользы. Верните определенный статус при перегруженности, чтобы клиент и другие уровни не пытались выполнить повторные попытки самостоятельно.
В экстренных случаях может казаться неочевидным, что сбой вызван некорректным поведением при выполнении повторных попыток. Графики уровня повторных попыток могут служить индикатором некорректного поведения при выполнении повторных попыток, но это можно принять за симптом, а не за причину. Что касается смягчения последствий — это особый случай проблемы недостаточной производительности, имеющий дополнительный подводный камень: вам нужно либо исправить поведение при повторных попытках (это обычно требует изменения кода), либо значительно снизить нагрузку, либо полностью избавиться от запросов.
Задержка и дедлайны
Когда фронтенд отправляет RPC серверу бэкенда, фронтенд потребляет ресурсы, ожидая ответа. Дедлайны RPC определяют, как долго можно ждать запрос до того, как фронтенд вернет управление, ограничивая время, в которое бэкенд может потреблять ресурсы фронтенда.
Выбор дедлайна
Как правило, надо установить разумный дедлайн. Установка очень длинного дедлайна или его игнорирование может заставить краткосрочные задачи, которые давно решены, продолжать потреблять ресурсы сервера до его перезапуска.
Установка длинных дедлайнов может привести к тому, что на высоких уровнях стека будет потребляться больше ресурсов, когда на низких уровнях возникают какие-то проблемы. Короткие дедлайны могут вызвать сбои у некоторых особо дорогих запросов. Выбор сбалансированного дедлайна — это в чем-то искусство.
Пропущенные дедлайны
Распространенной причиной многих каскадных сбоев является ситуация, когда серверы тратят ресурсы на обработку запросов, которые превышают свои дедлайны на клиенте. В результате ресурсы тратятся впустую, а вы не получаете следующих заданий RPC.
Предположим, RPC имеет десятисекундный дедлайн, установленный клиентом. Сервер очень перегружен, и, чтобы перейти из очереди в пул потоков, требуется 11 секунд. В этот момент клиент уже отказался от запроса. В большинстве случаев для сервера будет неразумно пытаться выполнить этот запрос, поскольку клиенту после истечения дедлайна уже неважно, будет ли запрос выполнен, так как клиент уже отказался от него.
Если обработка запроса выполняется в несколько этапов (например, имеется несколько обратных вызовов или вызовов RPC), сервер должен проверять оставшееся на выполнение запроса время на каждом этапе перед тем, как делать еще какую-то работу по обработке запроса. Например, если запрос разделен на этапы анализа, запроса бэкенда и обработки, имеет смысл проверять, достаточно ли осталось времени для обработки запроса, перед началом каждого этапа.
Распространение дедлайнов
Вместо того чтобы просто указывать дедлайн при отправке RPC бэкендам, серверы должны использовать распространение дедлайнов и сигналов об отмене.
При распространении дедлайн устанавливается в верхней части стека, например на фронтенде. Дерево RPC исходя из первоначального запроса будет иметь тот же самый абсолютный дедлайн. Например, если сервер А выберет в качестве значения для дедлайна 30 секунд, обработает запрос за 7 секунд и отправит RPC серверу Б, эта RPC будет иметь значение дедлайна, равное 23 секундам. Если серверу Б на обработку запроса потребуется 4 секунды, то для RPC, которая будет отправлена на сервер В, значение дедлайна составит 19 секунд, и т.д. В идеале каждый сервер в дереве запросов реализует распространение дедлайна. Без применения этого приема может возникнуть следующая ситуация.
1. Сервер А отправляет RPC серверу Б с десятисекундным дедлайном.
2. Сервер Б тратит 8 секунд на обработку запроса и отправляет RPC на сервер В.
3. Если сервер Б использует распространение дедлайна, он должен задать его значение, равное 2 секундам, но предположим, что он применяет жестко закодированное значение, равное 20 секундам.
4. Сервер В выберет запрос из очереди спустя 5 секунд.
Если бы сервер Б использовал распространение дедлайна, сервер В мгновенно отказался бы от запроса, поскольку дедлайн на его выполнение был бы превышен. Однако в нашем сценарии сервер В обрабатывает запрос, думая, что у него есть еще 15 секунд, но он не выполняет полезную работу, поскольку запрос от сервера А к серверу Б уже превысил дедлайн.
Вы можете захотеть немного снизить исходящий дедлайн (например, на несколько сотен миллисекунд), чтобы учесть время передачи по сети и последующую обработку на клиенте. Также рассмотрите возможность установки верхней границы для исходящих дедлайнов. Вы можете захотеть ограничить время ожидания сервером исходящих RPC к некритичным бэкендам. Однако убедитесь, что понимаете структуру своего трафика, поскольку в противном случае вы можете непреднамеренно заставить каждый раз давать сбой некоторые типы запросов, например запросы с большим объемом полезной нагрузки или те, которые для ответа требуют большого количества вычислений.
Существуют исключения, когда серверы могут продолжить обрабатывать запрос, когда дедлайн уже истек. Например, если сервер получает запрос, который включает в себя выполнение затратных операций для достижения некоего состояния и периодическую фиксацию контрольных точек процесса, удачным приемом может быть проверка дедлайна только после контрольной точки вместо проверки после выполнения затратной операции.
Распространение сигналов об отмене позволяет избежать потенциальной утечки RPC, которая происходит в том случае, когда исходный RPC имеет длинный дедлайн, но RPC, находящиеся между более глубокими слоями стека, имеют короткий дедлайн и тайм-аут. Используя простое распространение дедлайна, исходный RPC продолжает задействовать ресурсы сервера до тех пор, пока не завершится по тайм-ауту, несмотря на невозможность продвинуться в выполнении задачи.
Бимодальная задержка
Предположим, что фронтенд из предыдущего примера состоит из десяти серверов, каждый из которых имеет 100 рабочих потоков. Это означает, что фронтенд имеет производительность, равную 1000 потоков. Во время работы в обычном режиме фронтенд выполняет 1000 QPS и запросы завершаются за 100 миллисекунд. Это означает, что у фронтенда заняты 100 рабочих потоков из 1000 сконфигурированных (1000 QPS · 0,1 с). Предположим, что некоторое событие заставляет 5 % запросов остаться незавершенными. Это может быть результатом недоступности некоторых диапазонов строк Bigtable, из-за чего запросы, связанные с этим ключевым пространством, становятся необслуживаемыми. В результате 5 % запросов пропускают дедлайн, а остальные 95 % затрачивают обычные 100 миллисекунд. Имея дедлайн 100 миллисекунд, 5 % запросов потребят 5000 потоков (50 QPS · 100 с), но у фронтенда нет такого количества доступных потоков. Если других вторичных воздействий не наблюдается, фронтенд сможет обработать только 19,6 % запросов (1000 доступных потоков / (5000 + 95) потоков, необходимых для работы), в результате уровень ошибок составит 80,4 %.
Поэтому ошибку станут возвращать не 5 % запросов, которые не могут быть выполнены из-за недоступности ключевого пространства, а их большая часть. Следующие рекомендации могут помочь справиться с проблемами такого рода.
• Определить такую проблему может быть очень трудно. В частности, не сразу можно понять, что причиной сбоев является бимодальная задержка, когда вы смотрите на среднее значение задержки. Увидев, что задержка увеличивается, попробуйте проанализировать распределение задержек в дополнение к их средним значениям.
• Проблемы можно избежать, если запросы, которые не завершаются, возвращают ошибку досрочно, а не ожидают конца дедлайна. Например, если бэкенд недоступен, то лучше сразу вернуть для него ошибку, чем потреблять ресурсы до конца дедлайна. Если ваш уровень RPC поддерживает вариант fail-fast, используйте его.
• Наличие дедлайнов, на несколько порядков превышающих среднюю задержку обработки запроса, — это обычно плохо. В предыдущем примере пропускают дедлайн небольшое количество запросов, но значение дедлайна на три порядка больше, чем обычная средняя задержка, поэтому пул потоков истощился.
• При задействовании общих ресурсов, которые могут быть истощены некоторыми ключевыми пространствами, рассмотрим возможность либо ограничения запросов в этом ключевом пространстве, либо применения других видов отслеживания некорректного использования. Предположим, что бэкенд обрабатывает запросы для разных клиентов, имеющих разные производительность и характеристики запросов. Вы можете позволить одному клиенту занять лишь 25 % потоков, чтобы обеспечить одинаковое качество обслуживания при возможности высокой нагрузки одним неверно ведущим себя клиентом.
Холодный запуск и холодное кэширование
Процессы сразу после запуска зачастую отвечают на запросы медленнее, чем тогда, когда их состояние стабилизировалось. Это может быть вызвано одной из следующих причин.
• Необходимость инициализации. Настройка соединений при получении первого запроса, которому требуется заданный бэкенд.
• Улучшение производительности во время выполнения программы в некоторых языках, в особенности Java. Компиляция Just-In-Time, hotspot-оптимизация и отложенная загрузка классов.
Аналогично некоторые приложения менее эффективны, когда кэши не заполнены. Например, в некоторых сервисах Google большая часть запросов обслуживается из кэша, поэтому запросы, для которых не происходит попадания кэша, стоят гораздо больше. При работе в стабильном состоянии, когда кэш разогрет, промахов немного, но когда он совсем пустой, дорогими становятся 100 % запросов. Другие сервисы могут использовать кэш для сохранения состояния пользователя в оперативной памяти. Этого можно добиться с помощью «липкости», реализованной аппаратно или программно, между обратными прокси и фронтендами сервиса.
Если сервис не имеет достаточного количества ресурсов для обработки запросов из холодного кэша, риск возникновения сбоев возрастет и вам следует что-то предпринять, чтобы их избежать.
Кэш может оказаться холодным в следующих ситуациях.
• Включение нового кластера. У добавленного недавно кластера будет холодный кэш.
• Возврат кластера сервису после обслуживания. Кэш может оказаться устаревшим.
• Перезапуски. Если задача с кэшем была недавно перезапущена, заполнение ее кэша может занять некоторое время. Возможно, имеет смысл переместить кэширование с сервера в отдельное приложение вроде memcache, что позволит организовать общий кэш для нескольких серверов, пусть и ценой добавления дополнительного RPC и небольшого роста задержки.
Если кэширование значительно влияет на сервис, вы можете воспользоваться одной из следующих стратегий.
• Предоставление сервису избыточного количества ресурсов. Важно иметь в виду разницу между кэшем задержки и кэшем производительности: когда вы пользуетесь кэшем задержки, сервис может поддерживать ожидаемую нагрузку с помощью пустого кэша, но сервис, который использует кэш производительности, так делать не может. Владельцы сервиса должны внимательно добавлять кэши для него и убеждаться в том, что все новые кэши являются либо кэшами задержки, либо достаточно хорошо спроектированы для того, чтобы безопасно функционировать как кэши производительности. Иногда кэши добавляют в сервис для улучшения производительности, но в итоге они становятся необходимостью.
• Используйте общие техники предотвращения каскадных сбоев. В частности, перегруженные серверы должны отклонять запросы или входить в деградированные режимы. Также нужно выполнять тестирование для того, чтобы увидеть, как сервис будет вести себя после событий наподобие крупного перезапуска.
• При добавлении к кластеру нагрузки повышайте ее уровень медленно. Небольшое количество запросов на начальном этапе разогреет кэш. Как только он прогреется, можете добавить трафика. Вам стоит гарантировать, что все кластеры поддерживают номинальную нагрузку, а кэши остаются прогретыми.
Всегда спускайтесь вниз по стеку. Рассмотрим пример: в сервисе Shakespeare фронтенд взаимодействует с бэкендом, который, в свою очередь, взаимодействует с уровнем хранилища. Проблема, проявляющаяся на уровне хранилища, может вызвать проблемы на серверах, которые взаимодействуют с этим уровнем, но исправление ситуации на уровне хранилища в большинстве случаев исправит также уровни фронтенда и бэкенда.
Однако предположим, что бэкенды взаимодействуют друг с другом. Например, они могут отправлять друг другу прокси-запросы для того, чтобы изменить обработчик запросов пользователя, когда уровень хранилища не может обработать запрос. При таком взаимодействии в рамках одного уровня проблемы могут возникнуть по нескольким причинам.
• При взаимодействии может произойти распределенная взаимоблокировка. Бэкенды могут использовать один и тот же пул потоков для ожидания результата RPC, отправленных удаленным бэкендам, которые одновременно получают запросы от удаленных бэкендов. Предположим, что пул потоков бэкенда А исчерпан. Бэкенд Б отправляет запрос бэкенду А и задействует очередной поток бэкенда Б на время, пока один из потоков из пула бэкенда А не освободится. Такое поведение может вызвать распространение переполнения пула потоков.
• Если интенсивность взаимодействия внутри уровня повышается в ответ на некий сбой или при большой нагрузке (например, балансировщик нагрузки более активен при высокой нагрузке), взаимодействие между уровнями может быстро измениться.
Предположим, что пользователь имеет основной бэкенд и заранее определенный, готовый к работе вторичный бэкенд в другом кластере, который может принять этого пользователя. Основной бэкенд проксирует запросы на вторичный бэкенд из-за возникновения ошибок на более низком уровне или когда нагрузка на него серьезно возрастет. Если вся система перегружена, такое проксирование, скорее всего, еще больше нагрузит ее из-за дополнительной стоимости анализа запроса и ожидания его выполнения на вторичном бэкенде.
• В зависимости от критичности взаимодействия между уровнями автонастройка системы может стать более сложной.
Как правило, стоит избегать взаимодействия внутри одного уровня. Вместо этого предоставьте клиенту заботиться о взаимодействии. Например, если фронтенд общается с бэкендом, но выбирает неправильный бэкенд, последний не должен проксировать на правильный бэкенд. Вместо этого бэкенд должен предложить фронтенду выполнить запрос повторно уже для правильного бэкенда.
Срабатывание условий каскадного сбоя
Если сервис подвержен каскадным сбоям, то инициировать эффект домино могут несколько возможных нарушений в работе. В этом разделе рассматриваются факторы, приводящие к каскадным сбоям.
«Гибель» процесса
Некоторые задачи сервера могут «погибнуть», снижая уровень доступной производительности. Это может произойти из-за «запроса смерти» (RPC, чье содержимое заставит процесс сгенерировать сбой), проблем с кластером, контроля условий выполнения и по множеству других причин. Элементарное событие, например несколько «падений» или перенос выполнения задач на другие машины, может привести к сбою сервера.
Обновления процессов
Отправка новой версии приложения или обновление его конфигурации может вызвать каскадный сбой, если большое количество задач будет затронуто одновременно. Для того чтобы предотвратить этот сценарий, следует либо учитывать необходимую нагрузку на производительность при настройке инфраструктуры обновления сервиса, либо отправлять новую версию во время непиковой нагрузки. Динамическая корректировка количества работающих обновлений задач, основанная на объеме запросов и доступной производительности, может оказаться удачным подходом.
Новые релизы
Новый бинарный файл, коррективы конфигурации или изменение лежащей в основе стека инфраструктуры могут вызвать изменения в профиле запроса, использовании ресурсов и их ограничениях, бэкендах и других системных компонентах, которые могут спровоцировать каскадный сбой.
Во время каскадного сбоя стоит проверить недавние изменения и рассмотреть возможность откатить их, особенно если они повлияли на производительность или изменили профиль запросов.
Сервис должен журналировать изменения в какой-нибудь форме, что может помочь быстро определить выполненные недавно.
Органический рост
Во многих случая каскадный сбой бывает вызван не конкретным изменением сервиса, а тем, что активизация использования сервиса не сопровождалась корректировкой производительности.
Запланированные изменения, исчерпание ресурсов или отключения
Если сервис располагается в нескольких кластерах, может оказаться невозможно задействовать часть производительности из-за обслуживания или сбоев кластера. Аналогично одна из критически важных зависимостей сервиса может быть перегружена, что приведет к снижению производительности работающего сервиса или увеличению задержки из-за необходимости отправлять запросы в более удаленный кластер.
Изменение профиля запросов
Сервис бэкенда может получать запросы из разных кластеров, поскольку сервис фронтенда перемещает свой трафик из-за изменения конфигурации балансировщика нагрузки и структуры трафика или переполненности кластера. Кроме того, средняя стоимость обработки индивидуальной нагрузки могла поменяться из-за кода фронтенда или изменения конфигурации. Аналогично данные, обрабатываемые сервисом, могли измениться естественным образом из-за увеличения объема или изменения формата: например, со временем количество и объем изображений для каждого пользователя сервиса хранения фотографий только увеличивается.
Ограничения ресурсов
Некоторые кластерные операционные системы могут предоставлять избыток ресурсов. Процессор — это измеримый ресурс, зачастую машины имеют свободные ресурсы процессора, что в какой-то степени защищает их от всплесков использования. Доступность этих ресурсов различается в разных сегментах, а также на различных машинах одного сегмента.
Зависимость от свободных ресурсов может быть опасной. Их доступность полностью зависит от поведения других задач в кластере, поэтому они могут закончиться в любое время. Например, если команда запускает MapReduce, которая потребляет большую часть ресурсов процессора и планирует задачи на нескольких машинах, общее количество свободных ресурсов процессора может внезапно уменьшиться и процессор окажется перегруженным для других задач. При выполнении нагрузочных тестов убедитесь, что вы остаетесь в заявленных рамках использования ресурсов.
Тестирование на предмет каскадных сбоев
Определить точные причины сбоя сервиса может быть очень трудно. В этом разделе рассматриваются стратегии тестирования, которые помогут определить вероятность того, что сервис вызовет каскадный сбой.
Вы должны протестировать свой сервис, чтобы определить, как он ведет себя при высоких нагрузках, чтобы быть уверенными в том, что он не войдет в состояние каскадного сбоя при определенных обстоятельствах.
Тестируйте до возникновения сбоев и после
Понять, как поведет себя сервис под высокой нагрузкой, — это, возможно, самый важный первый шаг, помогающий избежать каскадных сбоев. Зная, как система ведет себя при перегрузках, вы сможете определить, какие инженерные задачи более важны в долгосрочной перспективе. По крайней мере, это знание может помочь вам самостоятельно запустить процесс отладки, когда приходится срочно вызывать дежурных инженеров.
Тестируйте компоненты под нагрузкой до тех пор, пока они не дадут сбой. Обычно по мере повышения нагрузки компонент успешно обрабатывает запросы до тех пор, пока не достигает точки, когда уже не может справиться с бо'льшим количеством запросов. В идеале в этот момент в ответ на дополнительную нагрузку он должен начать выдавать ошибки или деградировавшие результаты, но незначительно снизить уровень, при котором успешно обрабатывает запросы. В момент, когда наступает перегрузка, компонент, сильно подверженный каскадным сбоям, упадет или начнет выдавать большое количество ошибок, тогда как более качественно спроектированный будет отклонять некоторые запросы и выживет.
Нагрузочное тестирование также показывает, где находится точка перелома, что очень важно для планирования производительности. Это позволяет выполнять регрессионное тестирование, чтобы в худших случаях найти компромисс, выбирая между полезностью и безопасностью.
Из-за эффектов кэширования постепенное увеличение нагрузки может дать результаты, отличающиеся от мгновенного повышения нагрузки до ожидаемого уровня. Поэтому рассмотрите возможность тестирования постепенных и импульсных сценариев подачи нагрузки.
Вы также должны протестировать компонент в момент, когда он вернется к номинальной нагрузке после того, как поработал под нагрузкой, значительно ее превышающей, и понять, как он ведет себя в данной ситуации. Такое тестирование может ответить на следующие вопросы.
• Если при высокой нагрузке компонент входит в деградированный режим, может ли он выйти из него без вмешательства человека?
• Если несколько серверов падают под высокой нагрузкой, насколько нужно снизить ее, чтобы стабилизировать систему?
Если вы тестируете сервис с сохранением состояния (stateful) или использующий кэширование, нагрузочный тест должен отслеживать состояние при разных взаимодействиях и проверять правильность при высоких нагрузках, поскольку в этот момент зачастую проявляются труднонаходимые ошибки, связанные с распараллеливанием.
Имейте в виду, что отдельные компоненты могут иметь разные точки перелома, поэтому выполняйте нагрузочное тестирование для них по отдельности. Вы не можете заранее знать, какой компонент даст сбой первым, и хотите знать, как ведет себя система, если сбой все-таки произошел. Если вы уверены в том, что система хорошо защищена от перегрузок, рассмотрите выполнение тестов для небольшого фрагмента производственных данных, чтобы определить места, где может произойти сбой в процессе работы с реальным трафиком. Эти ограничения могут быть не отражены в синтезированном трафике нагрузочного тестирования, поэтому тесты с реальным трафиком дают более реальные результаты, правда, при этом есть риск повлиять на пользователей. Будьте осторожны при тестировании с реальным трафиком: убедитесь, что имеется резерв производительности на случай, если автоматическая защита не сработает и понадобится исправлять сбой вручную. Вы можете рассмотреть выполнение следующих производственных тестов:
• быстрое или постепенное уменьшение количества задач до значений, выходящих за пределы ожидаемых объемов трафика;
• быстрая утрата кластером производительности;
• эмуляция отказов разных бэкендов.
Тестируйте популярные клиенты
Разберитесь в том, как крупные клиенты используют сервис. Например, вы должны знать, что клиенты:
• могут ставить задачи в очередь, если сервис не работает;
• применяют рандомизированные экспоненциальные откаты при ошибках;
• уязвимы к внешним сигналам, которые могут создать большую загрузку (например, вызванное извне обновление ПО может очистить кэш офлайн-клиента).
В зависимости от сервиса вы можете иметь или не иметь возможности управлять всем кодом клиента, который общается с сервисом. Однако в любом случае не помешает понимать, как поведут себя крупные клиенты, которые взаимодействуют с сервисом.
Эти же принципы применимы и к крупным внутренним клиентам. Симулируйте системные сбои для крупных клиентов и посмотрите, как они будут реагировать. Спросите у внутренних клиентов, как они получают доступ к вашему сервису и какие механизмы используют для обработки сбоев бэкенда.
Тестируйте некритические бэкенды
Тестируйте некритичные бэкенды и убедитесь, что их недоступность не повлияет на критически важные компоненты вашего сервиса.
Предположим, что у фронтенда имеются критически важные и некритичные бэкенды. Зачастую заданный запрос включает в себя как критические компоненты (например, результаты запросов), так и некритические (например, варианты правописания). Выполнение ваших запросов может значительно замедлиться и потреблять ресурсы, ожидая завершения некритических бэкендов.
В дополнение к тестированию поведения, когда некритические бэкенды недоступны, протестируйте поведение фронтенда, если некритический бэкенд никогда не отвечает (например, если он поглощает запросы). Бэкенды, указанные как некритические, все же могут создавать проблемы для фронтендов, если их запросы имеют длинные дедлайны. Фронтенд не должен начинать отклонять большое количество запросов, истощать свои ресурсы или обслуживать запросы с очень высокой задержкой, если некритический бэкенд начинает поглощать запросы.
Мгновенное реагирование на каскадные сбои
Как только вы поняли, что сервис вошел в состояние каскадного сбоя, можете реализовать несколько разных стратегий для исправления ситуации. И конечно, каскадный сбой — это отличная возможность использовать протокол управления инцидентами (см. главу 14).
Увеличьте количество ресурсов
Если система работает с деградированной производительностью и у вас имеются свободные ресурсы, то добавление задач может стать самым быстрым способом восстановления после сбоя. Однако если сервис вошел в некую «спираль смерти», добавления новых ресурсов может оказаться недостаточно.
Прекратите выполнять проверки на сбои/«гибель»
Некоторые системы планирования задач для кластеров, например Borg, проверяют работоспособность задач и перезапускают неработающие. Этот прием может вызвать режим сбоя, при котором сама проверка состояния может сделать сервис неработоспособным. Например, если половина задач в данный момент стартует, а другая половина скоро будет «убита», так как эти задачи перегружены и проваливают проверки состояния, временное отключение таких проверок может позволить системе стабилизироваться так, что начнут выполняться все задачи. Проверка состояния процесса («Отвечает ли этот бинарный файл?») и сервиса («Может ли этот бинарный файл отвечать на запросы данного вида прямо сейчас?») — это две концептуально разные операции. Проверка состояния процесса важна для планировщика задач кластера, а проверка состояния сервиса — для балансировщика нагрузки. Четкое различение двух типов проверок состояния позволяет избежать рассмотренного сценария.
Перезапускайте серверы
Если серверы зависли и не выполняют работу, может помочь их перезапуск.
Попробуйте перезапускать серверы в следующих ситуациях.
• Серверы Java вошли в «спираль смерти GC».
• Некоторые запросы не имеют дедлайнов, но потребляют ресурсы, что приводит к блокировке потоков.
• Серверы находятся в ситуации взаимной блокировки.
Убедитесь, что нашли источник каскадных сбоев, до того, как перезапустите серверы. Убедитесь, что это действие не приведет к простому перераспределению нагрузки. Проверьте корректность этого изменения и выполните его медленно. Ваши действия могут лишь усугубить ситуацию, если каскадный сбой вызван, например, холодным кэшем.
Отбрасывайте трафик
Отбрасывание трафика — это способ, зарезервированный для ситуаций, когда у вас случился реальный каскадный сбой и вы никак не можете иначе исправить ситуацию. Например, если высокая нагрузка заставляет серверы «падать» сразу же, как только они стали работоспособными, вы можете вернуть сервис к работе так.
1. Исправьте изначальную причину сбоя, например добавив производительность.
2. Уменьшите нагрузку настолько, чтобы сбои прекратились. Постарайтесь сделать это агрессивно — если сбои дает весь сервис, позвольте ему обрабатывать, например, всего 1 % трафика.
3. Позвольте большинству серверов выздороветь.
4. Постепенно увеличьте нагрузку.
Эта стратегия позволит прогреть кэши, установить соединения и т.д., прежде чем нагрузка достигнет обычного уровня.
Очевидно, что эта тактика позволит пользователям заметить нанесенный во время сбоя урон. Можете ли вы (или должны ли) отбрасывать весь трафик, зависит от конфигурации сервиса. Если у вас есть какой-то механизм, который позволяет отбрасывать не слишком важный трафик (например, механизм предварительной выборки), следует им воспользоваться.
Важно помнить, что эта стратегия позволяет восстановиться от каскадного отключения только тогда, когда устранена проблема, лежащая в его основе. Если она не ликвидирована — например, не хватает глобальной производительности, то каскадный сбой может повториться вскоре после того, как нагрузка выйдет на нормальный уровень. Поэтому, прежде чем использовать эту стратегию, рассмотрите возможность устранения (или хотя бы компенсации) основной причины или условия сбоя. Например, если у сервиса закончилась память и он вошел в «спираль смерти», добавление дополнительной памяти или новых задач должно стать первым шагом к исправлению ситуации.
Входите в деградированные режимы
Выдавайте деградированные результаты, выполняя меньше работы или отбрасывая неважный трафик. Эта стратегия должна быть встроена в сервис, и ее можно реализовать только в том случае, если вы знаете, как трафик может быть ухудшен, и у вас есть возможность определять разные виды полезной нагрузки.
Избавляйтесь от пакетной нагрузки
Нагрузка на некоторые сервисы важна, но некритична. Рассмотрите возможность отключения этих источников нагрузки. Например, если обновления индекса, копирование данных или генерация статистики потребляют ресурсы, подумайте, нельзя ли отключить эти источники нагрузки во время сбоя.
Избавляйтесь от плохого трафика
Если некоторые запросы создают высокую нагрузку или приводят к сбоям (например, «запросы смерти»), попробуйте блокировать их или избавляться от них другими способами.
| КАСКАДНЫЕ СБОИ И СЕРВИС SHAKESPEARE В Японии выходит документальный фильм о творчестве Шекспира, где упоминается в том числе о сервисе Shakespeare. Из-за этой передачи трафик, идущий к азиатским дата-центрам, превышает все возможности сервиса. Эта проблема, связанная с производительностью, еще больше осложнена крупным обновлением сервиса Shakespeare, которое в это же время происходит в дата-центре. К счастью, определенные меры безопасности помогут предотвратить потенциальный сбой. Процесс Production Readiness Review определил проблемы, которые команда уже решила. Например, разработчики внедрили в сервис механизм мягкой деградации. Как только производительность становится недостаточной, сервис больше не возвращает картинки или небольшие карты, иллюстрирующие остальной материал. И в зависимости от предназначения RPC, которая выходит по тайм-ауту, или не выполняется повторно (например, в случае вышеупомянутых картинок) или выполняется с рандомизированным экспоненциальным откатом. Несмотря на эти меры безопасности, задачи дают сбой одна за другой, и Borg их перезапускает, что еще больше снижает количество рабочих задач. В результате некоторые графы на информационной панели становятся красными, и уходит вызов SR-инженерам. В ответ на это инженеры временно увеличивают производительность азиатских дата-центров, повышая количество доступных задач для сервиса Shakespeare. Это позволяет восстановить работу сервиса в азиатском кластере. После этого команда SR-инженеров делает постмортем, где детально описывает цепочку событий, варианты улучшения сервиса и количество действий, которые необходимо предпринять для того, чтобы этот сценарий не реализовался вновь. Например, в случае перегрузки сервиса балансировщик нагрузки GSLB перенаправит некоторое количество трафика в соседние дата-центры, чтобы вам не пришлось опять волноваться из-за этой проблемы. |
Итоги главы
Если системы перегружены, нужно что-то предпринять для того, чтобы это исправить. Как только сервис проходит пороговую точку, лучше допустить заметное пользователям снижение качества работы и появление отдельных ошибок, чем продолжать пытаться полностью обслужить каждый запрос. Понимание того, где находятся эти пороги и как система ведет себя за их пределами, критически важно для владельцев сервисов, желающих избежать каскадных сбоев.
Без должного внимания некоторые изменения в системе, призванные снизить количество фоновых ошибок или способствовать поддержанию устойчивого состояния, могут подвергнуть сервис гораздо большему риску полного отключения. Повторные попытки выполнения запросов, отвод нагрузки от проблемных серверов и их отключение, выделение дополнительных ресурсов для улучшения производительности или снижения задержки — все это может помочь в нормальной ситуации, но также может и повысить вероятность возникновения крупномасштабного отказа. Будьте осторожны при оценке изменений, чтобы гарантировать, что вы не создадите новых проблем, исправив предыдущие.
Иногда встречается перевод «технический евангелист». — Примеч. пер.
О положительной обратной связи вы можете прочитать в «Википедии»: .
Сторожевой таймер зачастую реализуется как поток, который периодически пробуждается, чтобы проверить, была ли выполнена работа с момента последней проверки. Если нет, он предполагает, что сервер завис, и убивает его. Например, запросы определенного типа могут отправляться на сервер с заданным интервалом; то, что один из них не был получен или обработан в ожидаемое время, может указывать на сбой — сбой сервера, системы, отправляющей запросы, или промежуточной сети.
Такое предположение не всегда работает по географическим причинам, см. также подраздел «Организация задач и данных» раздела «Shakespeare: пример сервиса» главы 2.
Упражнение для читателя: напишите простой симулятор и посмотрите, сколько полезной работы может выполнить бэкенд в зависимости от того, насколько он перегружен, и какое количество повторных попыток можно предпринять.
Когда запросы клиента обслуживаются конкретным сервером. — Примеч. пер.
В какой-то момент вы обнаружите, что значительная часть фактической нагрузочной способности вашего сервиса — это результат работы сервиса кэширования, и если доступ к этому кэшу будет утрачен, вы никогда не сможете обслуживать так много запросов. Это же наблюдение актуально и для задержки. Кэш может помочь достичь целевых значений задержки (уменьшая среднее время ответа, когда запрос обслуживается из кэша), которые без него будут недостижимы.

