21. Справляемся с перегрузками
Автор — Алехандро Фореро Куэрво
Под редакцией Сары Чевис
Целью любой политики балансировки нагрузки является отсутствие перегрузок. Но независимо от того, насколько эффективна политика балансировки нагрузки, в конечном счете какая-то часть вашей системы окажется перегруженной. Мягкая обработка состояний перегрузки очень важна для того, чтобы обслуживающая система надежно работала.
Одним из вариантов обработки перегрузки является выдача деградировавших ответов. Эти ответы не такие точные, как обычные, и могут содержать меньше данных, но их легче сгенерировать. Например:
• вместо поиска по всей текстовой базе данных для предоставления лучших результатов поискового запроса вы выполняете поиск по небольшому количеству вариантов;
• вы полагаетесь только на локальную копию результатов, которая может быть не полностью обновлена, но дешевле использовать ее, а не основное хранилище.
Однако в условиях серьезных перегрузок сервис даже может не иметь возможности вычислять и выдавать деградировавшие ответы. В такой ситуации у него не будет других вариантов, кроме возвращения ошибок. Одним из способов решения этой проблемы является балансировка трафика между дата-центрами таким образом, чтобы ни один из них не принимал больше трафика, чем может обработать. Например, если в дата-центре запущены 100 задач бэкенда и каждая может обработать до 500 запросов в секунду, алгоритм балансировки нагрузки не позволит отправить этому дата-центру больше 50 000 запросов в секунду. Однако даже этого ограничения может оказаться недостаточно для того, чтобы избежать перегрузки, если вы работаете с крупномасштабными сервисами. В конечном счете лучше всего создавать клиенты и бэкенды, которые могут справляться с ограничениями по ресурсам мягко: выполнять перенаправление везде, где это возможно, отправлять деградировавшие результаты, когда необходимо, и обрабатывать ошибки ресурсов прозрачно, когда все остальные этого не могут.
Ловушки понятия «запросов в секунду»
Различные запросы имеют совершенно разные требования к ресурсам. Стоимость запроса может изменяться в зависимости от произвольных факторов, таких как код клиента, который их отправляет (для сервисов, которые могут иметь разные клиенты), или даже время суток (например, пользователи, работающие из дома, против пользователей, работающих из офиса, или интерактивный трафик конечных пользователей против пакетного трафика).
Этот урок дался нам нелегко: моделирование производительности с помощью понятия «запросы в секунду» или использование статической функциональности запросов, которые считаются прокси для потребляемых ими ресурсов (например, «сколько ключей считывают запросы»), зачастую являются неудачными сценариями. Даже если в какой-то момент времени они сработают как следует, соотношение может измениться. Иногда такие изменения проходят постепенно, а иногда — мгновенно (например, в новой версии ПО некоторая функциональность запросов требует значительно меньше ресурсов). Постоянно изменяющаяся величина — плохой показатель для проектирования и реализации балансировки нагрузки.
Более удачный вариант — измерять производительность непосредственно в доступных ресурсах. Например, для одного сервиса в заданном дата-центре у вас зарезервированы 500 ядер процессоров и 1 Тбайт памяти. Естественно, гораздо лучше использовать эти значения непосредственно для моделирования производительности дата-центра. Мы зачастую говорим о стоимости запроса, когда хотим сказать о нормализованной мере того, сколько времени процессора он потребил (для разных архитектур процессоров учитывается разница в производительности).
Мы обнаружили, что в большинстве случаев (конечно, не во всех) удобно ориентироваться на показатель потребления ресурсов процессора.
• На платформах, для которых предусмотрена сборка мусора, нехватка памяти естественным образом преобразуется в повышенное потребление ресурсов процессора.
• На других платформах возможно выполнение поставок других ресурсов таким образом, что они вряд ли закончатся до того, как будут исчерпаны ресурсы процессора.
В случаях, когда чрезмерные поставки непроцессорных ресурсов крайне дороги, мы рассматриваем потребление ресурсов для каждой системы отдельно.
Лимиты потребителей
Очень важно выработать перечень действий на случай глобальной перегрузки. В идеальном мире, где команды осторожно координируют свой запуск с владельцами зависимостей своих бэкендов, глобальная перегрузка никогда не наступает и производительности сервисов бэкендов всегда достаточно для обслуживания потребителей. К несчастью, мы живем не в идеальном мире. В реальности глобальные перегрузки происходят довольно часто (это особенно верно для внутренних сервисов, для которых большое количество команд запускают множество клиентов).
Когда глобальная перегрузка все-таки происходит, очень важно, чтобы сервис возвращал ошибки только неправильно ведущим себя потребителям, не затрагивая остальных. Для того чтобы этого добиться, владельцы сервисов поставляют для них производительность, основываясь на их используемости, и определяют квоты для потребителей в соответствии с этими данными.
Например, если сервис бэкенда имеет 10 000 процессоров, размещенных по всему миру (в разных дата-центрах), их лимиты для потребителей могут выглядеть так:
• сервису Gmail можно использовать до 4000 секунд процессорного времени за секунду реального времени;
• сервису Calendar — до 4000 секунд процессорного времени за секунду реального времени;
• сервису Android — до 3000 секунд процессорного времени за секунду реального времени;
• сервису Google+ — до 2000 секунд процессорного времени за секунду реального времени;
• любому другому потребителю — до 500 секунд процессорного времени за секунду реального времени.
Обратите внимание на то, что сумма этих чисел больше чем 10 000. Владельцы сервиса полагаются на то, что ситуация, когда все их потребители запросят все полагающиеся им ресурсы, маловероятна.
Мы собираем глобальную информацию об использовании ресурсов в реальном времени всеми задачами бэкенда и применяем эти данные для того, чтобы раздвинуть границы индивидуальных задач бэкенда. Подробное рассмотрение системы, которая реализует эту логику, в данной книге не предусмотрено, но стоит сказать, что мы пишем большие объемы кода для ее реализации в задачах бэкенда. Интересным фрагментом головоломки является вычисление в реальном времени количества ресурсов, особенно процессорных, потребляемых каждым отдельным запросом. Такие расчеты особенно запутаны для серверов, которые не придерживаются модели «поток на запрос», где пул потоков выполняет разные части всех поступающих запросов, применяя неблокирующие API.
Регулирование на стороне клиента
Когда клиент превышает свою квоту, задача бэкенда должна быстро отклонять запросы, ожидая, что возврат ошибки «для клиента закончилась квота» потребляет значительно меньшее количество ресурсов, чем реальная обработка запроса и отправка корректного ответа. Однако эта логика действует не для всех сервисов. Например, отклонять запросы, для обслуживания которых требуется выполнить простой поиск в памяти (где нагрузка обработки протокола запроса/ответа значительно выше нагрузки для выработки ответа), так же дорого, как и их выполнять. И даже в случае, когда отказ от запроса экономит значительные ресурсы, эти запросы все еще потребляют некоторое их количество. Если отклоненных запросов много, эти числа довольно быстро увеличиваются. В таких случаях бэкенд может оказаться перегруженным, даже если большое количество ресурсов процессора затрачивается на то, чтобы отклонять запросы!
Эту проблему можно решить регулированием количества запросов на стороне клиента. Когда клиент обнаруживает, что значительная часть его недавних запросов отклоняется из-за ошибки «закончилась квота», он начинает самостоятельно регулировать и ограничивать количество генерируемого им исходящего трафика. Запросы, вышедшие за этот предел, даже не достигнут сети.
Мы реализовали такой подход с помощью приема, который называем адаптивным регулированием. В частности, каждая задача клиента на протяжении 2 минут сохраняет следующую информацию:
• requests — количество запросов, выполненное на уровне приложения (на клиенте на основе системы адаптивного регулирования);
• accepts — количество запросов, принятых бэкендом.
При нормальных условиях эти два значения равны. Как только бэкенд начинает отклонять трафик, значение accepts становится меньше значения requests. Клиенты могут продолжать отправлять запросы на бэкенд до тех пор, пока значение requests не превысит значение accepts в K раз. По достижении этой точки клиент начинает самостоятельно регулировать себя, и новые запросы будут отклоняться локально (на клиенте) с вероятностью, рассчитанной по следующей формуле:
|
|
| (21.1) |
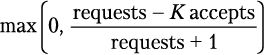
Когда сам клиент начнет отклонять запросы, значение requests по-прежнему будет превышать значение accepts. Это может показаться нелогичным, учитывая, что локально отклоненные запросы не отправляются на бэкенд, но такое поведение более предпочтительно. По мере увеличения этого соотношения (относительно уровня, при котором бэкенд принимает запросы) мы хотим повысить вероятность того, что новые запросы не будут срабатывать.
Мы обнаружили, что адаптивное подавление хорошо работает на практике, это привело к стабильным соотношениям запросов в целом. Даже при сильной перегрузке бэкенд начинает отклонять по одному запросу на каждый уже обрабатываемый им запрос. Одним из преимуществ такого подхода является то, что решение принимается задачей клиента на базе только локальной информации и с использованием относительно простой реализации: не существует зависимостей или штрафов, дополняющих задержку обработки данных.
Для сервисов, для которых стоимость обработки запроса примерно равна стоимости его отклонения, выделение примерно половины ресурсов бэкенда на отклонение запросов может быть неприемлемым. В этом случае решение выглядит просто: модифицируйте множитель K (задайте ему, например, значение 2) в формуле (21.1), выражающей вероятность отклонения запросов. Таким образом:
• уменьшение множителя сделает адаптивное подавление более агрессивным;
• увеличение множителя сделает адаптивное подавление менее агрессивным.
Например, вместо того, чтобы клиент саморегулировался, когда requests = 2 · accepts, он будет делать это при равенстве requests = 1,1 · accepts. Уменьшение множителя до 1,1 означает, что будет отклоняться только один запрос на десять обработанных.
Обычно мы используем множитель 2х. Позволив количеству запросов, превышающему ожидаемое, достичь бэкенда, мы тратим впустую больше ресурсов бэкенда, но в то же время ускоряем распространение состояния от бэкенда клиентам. Например, если бэкенд решит прекратить отклонять трафик задач клиента, задержка обнаружения этого состояния задачами клиента уменьшится.
Еще одна проблема заключается в том, что подавление на стороне клиента может оказаться неэффективным для клиентов, которые очень нерегулярно отправляют запросы бэкендам. В этом случае объем информации, которую каждый клиент имеет о состоянии бэкенда, значительно снижается и приемы увеличения ее доступности, как правило, дорогие.
Критичность
Критичность — это еще одно понятие, которое мы считаем очень полезным в контексте глобальных квот и регулирования количества запросов. Запрос, сделанный на бэкенд, связан с одним из четырех возможных значений критичности в зависимости от того, насколько критичным мы его считаем.
• CRITICAL_PLUS. Зарезервирован для наиболее критичных запросов, сбои в которых значительно повлияют на пользователей.
• CRITICAL. Стандартное значение для запросов, отправленных задачами в производственной среде. Эти запросы оказывают влияние на пользователей, но оно значительно меньше, чем влияние запросов с критичностью CRITICAL_PLUS. Сервисы должны иметь достаточную производительность для всего трафика, помеченного как CRITICAL и CRITICAL_PLUS.
• SHEDDABLE_PLUS. Трафик, частичная недоступность которого ожидается. Это значение по умолчанию имеют пакетные задачи, которые могут повторять свои запросы спустя несколько минут или часов.
• SHEDDABLE. Трафик, для которого часто ожидается частичная, а иногда и полная недоступность.
Мы обнаружили, что для моделирования практически любого сервиса достаточно четырех значений. И много раз обсуждали возможность добавления новых значений, поскольку это позволило бы нам более качественно классифицировать запросы. Однако определение дополнительных значений потребует большего количества ресурсов для работы множества систем, следящих за критичностью. Мы сделали критичность основным понятием системы RPC и хорошо поработали, интегрировав ее в механизмы управления, чтобы ее можно было учитывать, когда происходит реакция на перегрузки.
• Когда у клиента заканчивается глобальная квота, задача бэкенда будет отклонять запросы с заданной критичностью, если она уже отклоняет все запросы с более низкой критичностью (фактически лимиты для клиентов, поддерживаемые нашей системой и описанные ранее, могут быть установлены для разных значений критичности).
• Когда задача перегружена сама по себе, она будет быстрее отклонять запросы с меньшей критичностью.
• Система адаптивного подавления также сохраняет отдельную статистику для каждого уровня критичности.
Критичность запроса не зависит от требований к задержке обработки, поэтому используется лежащий в ее основе показатель качества обслуживания (quality of service, QoS). Например, когда после ввода пользователем поискового запроса система отображает результаты поиска или рекомендации, лежащие в основе этого процесса, запросы можно значительно сегментировать (если система перегружена, приемлемо не отображать результаты), но они, как правило, имеют строгие требования к задержке обработки данных.
Мы также значительно расширили систему RPC для того, чтобы распространять значение критичности автоматически. Если бэкенд получает запрос A и в качестве одного из этапов его выполнения отправляет запросы В и С другим бэкендам, то запросы В и С по умолчанию будут использовать тот же уровень критичности, что и запрос А.
В прошлом многие системы компании Google выработали свои представления о критичности, которые не всегда подходили для других сервисов. Стандартизировав и распространив критичность как часть системы RPC, мы теперь можем единообразно задавать значение критичности в определенных точках. Это означает, что мы можем быть уверены в том, что перегруженные зависимые системы будут принимать во внимание заданный высокий уровень критичности при отклонении трафика независимо от того, насколько глубоко в стеке RPC они находятся. Практическое воплощение заключается в том, что мы задаем критичность настолько точно, насколько это возможно в браузерах и мобильных клиентах — обычно во фронтендах HTTP, которые создают возвращаемый код HTML, — и переопределяем эти значения в особых случаях, когда это имеет смысл сделать в заданных местах стека.
Сигналы загруженности
Реализация защиты от перегрузок на уровне задач основана на понятии загруженности. Во многих случаях загруженность — это всего лишь показатель уровня загруженности процессоров (наблюдаемый в настоящее время уровень загруженности процессоров, разделенный на общее количество процессоров, зарезервированных для выполнения этой задачи), но в некоторых случаях мы также учитываем показатели наподобие порции зарезервированной памяти, которая используется в данный момент. По мере того как загруженность приближается к заданным границам, мы начинаем отклонять запросы, основываясь на их критичности (для более высоких уровней критичности задаются более высокие границы). Применяемые сигналы загруженности основаны на состоянии задачи поскольку цель этих сигналов заключается в том, чтобы защитить ее, и у нас есть реализации для разных сигналов.
Наиболее полезный сигнал основан на загрузке процесса, которая определяется системой, называемой средней нагрузкой исполнителя.
Для того чтобы найти среднюю нагрузку исполнителя, мы подсчитываем количество активных потоков в процессах. В этом случае под активными потоками подразумеваются потоки, которые либо работают, либо готовы к запуску и ожидают появления свободного процессора. Мы сглаживаем это значение с помощью экспоненциального уменьшения и начинаем отклонять запросы, когда количество активных потоков превышает количество процессоров, доступных для выполнения задачи. Это означает, что сильно разветвленный входящий запрос вызовет кратковременный всплеск загрузки, но сглаживание поглотит большую его часть. Однако если операции не краткосрочные (загрузка растет и долго остается высокой), задача начнет отклонять запросы.
Несмотря на то что средняя нагрузка исполнителя доказала свою полезность, наша система может воспользоваться любым сигналом загруженности, который может понадобиться конкретному бэкенду. Например, мы можем использовать недостаток памяти, который покажет, превысило ли потребление памяти нормальное значение, как еще один возможный сигнал загруженности. Также мы можем сконфигурировать систему таким образом, чтобы она задействовала несколько сигналов и отклоняла запросы, которые превзойдут объединенные (или индивидуальные) целевые значения загруженности.
Обработка ошибок, связанных с перегрузкой
Мы много размышляли не только о мягкой обработке загрузки, но и о том, как клиенты должны реагировать на получение сообщения об ошибке, связанной с загрузкой. В случае ошибок, связанных с перегрузкой, мы выделяем две возможные ситуации.
• Большое подмножество задач бэкенда в дата-центре перегружено. Если система балансировки нагрузки между дата-центрами работает идеально, то есть может распространять состояние и реагировать на изменения трафика мгновенно, это условие не сработает.
• Небольшое подмножество задач бэкенда в дата-центре перегружено. Эта ситуация обычно вызывается неидеальностью балансировки нагрузки внутри дата-центра. Например, если недавно задача получила очень дорогой запрос. В этом случае вполне вероятно, что другие дата-центры обладают производительностью, необходимой для обработки запроса.
Если перегружено большое подмножество задач дата-центра, запросы повторять не нужно и на вызывающей стороне должны появиться ошибки (например, следует вернуть ошибку конечному пользователю). Гораздо шире распространена ситуация, когда лишь небольшая часть задач становится перегруженной, в этом случае лучше всего немедленно повторить запрос. Как правило, система балансировки нагрузки между дата-центрами пытается направить трафик клиентов к ближайшему доступному дата-центру. В некоторых случаях ближайший дата-центр находится далеко (например, ближайший доступный клиенту бэкенд находится на другом континенте), но мы обычно стараемся размещать клиентов поближе к их бэкендам. Таким образом, дополнительной задержкой, вызванной повторной отправкой запроса, — она представляет собой несколько обращений к сети — можно пренебречь.
С точки зрения политики балансировки нагрузки повторные отправки запросов нельзя отличить от новых запросов. Соответственно, мы не используем явную логику, чтобы гарантировать, что повторная попытка отправится на другой бэкенд, — мы полагаемся на то, что это событие произойдет с высокой вероятностью, основываясь на том, что в подмножестве находится много бэкендов. Гарантия того, что все повторные попытки будут отправляться другим задачам бэкенда, потребует излишнего усложнения наших API.
Когда бэкенд перегружен лишь немного, запрос клиента зачастую лучше обслуживается, если бэкенд отклоняет повторные попытки и новые запросы одинаково и быстро. Эти запросы могут быть мгновенно выполнены повторно на другой задаче бэкенда, которая может иметь свободные ресурсы. Последствия того, что мы не разграничиваем повторные попытки и новые запросы на бэкенде, заключаются в том, что повторная отправка запросов становится формой органичной балансировки нагрузки: она перенаправляет нагрузку задачам, которые лучше подходят для обработки запросов.
Решаем выполнить повторную попытку
Когда клиент получает ошибку «Задача перегружена», он должен решить, выполнять ли запрос повторно. У нас есть несколько механизмов, которые позволяют избежать выполнения повторных запросов, если большая порция задач кластера перегружена.
Во-первых, для каждого запроса мы реализуем бюджет повторных попыток — максимум три. Если запрос уже дал сбой три раза, мы позволяем ошибке попасть к вызывающей стороне. Обоснование такого поведения заключается в следующем: если запрос попал на перегруженные задачи три раза подряд, то маловероятно, что следующая попытка будет плодотворной, поскольку весь дата-центр, скорее всего, перегружен.
Во-вторых, мы реализуем бюджет повторных попыток для каждого клиента. Каждый клиент отслеживает соотношение запросов и повторных попыток. Запрос будет выполняться до тех пор, пока оно не превышает 10 %. Обоснование таково: если перегружен лишь небольшой объем задач, потребность в выполнении повторных запросов будет довольно небольшой.
В качестве конкретного примера (худшего случая) предположим, что дата-центр принимает небольшое количество запросов и отклоняет остальные. Пусть х — общий уровень запросов, отправленных дата-центру в соответствии с логикой клиента. Из-за повторных запросов общее их количество значительно увеличится — почти до 3х. Хотя мы и ограничили рост, вызванный повторными попытками, тройное увеличение количества запросов выглядит значительно, особенно если стоимость отклонения запроса существенна по сравнению со стоимостью его обработки. Однако создание слоев бюджета повторных запросов клиента (соотношение повторных запросов равно 10 %) в общем случае снижает рост до 1,1х — это значительное улучшение.
Третий подход заключается в том, что клиенты включают в метаданные счетчик количества попыток отправки запроса. Например, при первой попытке счетчик равен 0 и увеличивается при каждой попытке до тех пор, пока не получит значение 2. В этот момент бюджет повторных запросов указывает прекратить выполнять запросы повторно. Бэкенды хранят гистограммы этих значений за недавнее время. Когда бэкенду нужно отклонить запрос, он консультируется с этими гистограммами, чтобы определить вероятность того, что другие бэкенды также перегружены. Если гистограммы показывают значительное количество повторений (это говорит о том, что другие задачи, скорее всего, также перегружены), они вернут ошибку «Перегружен; не повторять» вместо стандартного ответа «Задача перегружена», который вызывает отправку повторных запросов.
На рис. 21.1 показано количество попыток для каждого запроса, полученного заданной задачей бэкенда в разных ситуациях в рамках скользящего окна (в соответствии с 1000 исходных запросов, не считая повторных). Для простоты бюджет повторных запросов клиента будет проигнорирован (то есть эти числа показывают, что единственным ограничителем количества повторных запросов является бюджет, равный трем попыткам), и подмножество может каким-то образом изменить эти числа.
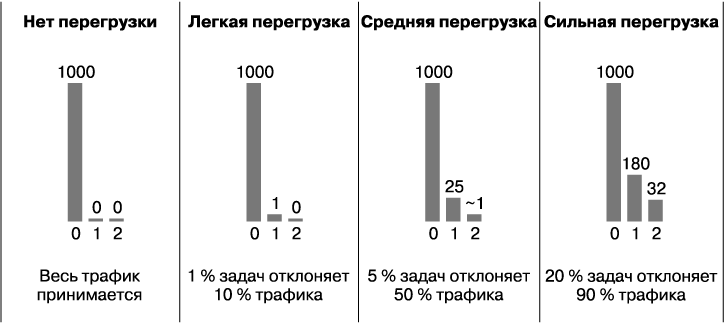
Рис. 21.1. Гистограммы попыток при разных условиях
Более крупные системы, как правило, представляют собой большие стеки систем, которые, в свою очередь, могут зависеть друг от друга. При такой архитектуре запросы должны выполняться повторно только на том слое, который находится выше слоя, который их отклоняет. Когда мы решаем, что заданный запрос не может быть обслужен и его нельзя выполнить повторно, мы используем ошибку «Перегружен; не повторять» и поэтому избегаем комбинаторного взрыва повторений.
Рассмотрим пример, показанный на рис. 21.2 (на практике наши стеки зачастую гораздо более сложны). Представим, что фронтенд базы данных перегружен и отклоняет запрос. В этом случае происходит следующее.
• Бэкенд Б выполнит запрос повторно в соответствии с заданным планом.
• Как только бэкенд Б определит, что запрос к фронтенду базы данных не может быть обслужен, например, поскольку запрос уже отклоняли три раза, он должен вернуть бэкенду А ошибку «Перегружен; не повторять» или деградировавшие ответы, предполагая, что может дать умеренно полезный ответ, даже если запрос к базе данных дал сбой.
• Бэкенд А имеет те же самые варианты для запроса, который получил от фронтенда, и будет действовать точно так же.
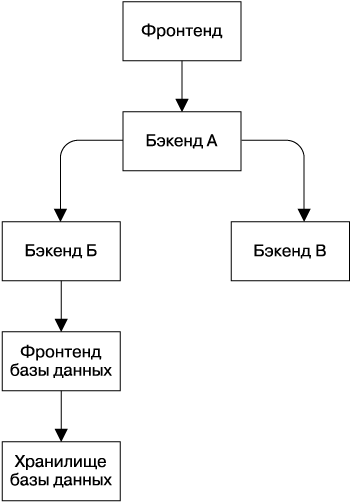
Рис. 21.2. Стек зависимостей
Основной смысл процесса заключается в том, что запрос, давший сбой на фронтенде базы данных, будет выполнен повторно только бэкендом Б — слоем, который находится непосредственно над фронтендом. Если повторные запросы будут выполнены на нескольких уровнях, возникнет комбинаторный взрыв.
Нагрузка от соединений
Нагрузка, связанная с соединениями, — это последний фактор, который стоит упомянуть. Мы иногда принимаем во внимание только ту нагрузку бэкендов, которая вызвана непосредственно получаемыми ими запросами, что является одной из проблем подходов, опирающихся на модель нагрузки, основанную на показателе «запросов в секунду». Однако такой подход мешает увидеть стоимость поддержания большого пула соединений или стоимость быстрого оттока соединений, выраженную в потреблении ресурсов процессора и памяти. Такой информацией в небольших системах можно пренебречь, но это быстро становится проблемой для очень крупных систем RPC.
Как упоминалось ранее, протокол RPC требует, чтобы неактивные клиенты периодически проверяли состояние. По окончании заданного промежутка времени, в течение которого соединение не использовалось, клиент разрывает соединение TCP и переключается на UDP для проверки состояния.
К сожалению, это поведение вызывает проблемы, когда у вас имеется большое количество задач клиента, отправляющих небольшое количество запросов: проверка состояния соединений может потребовать большего количества ресурсов, чем обслуживание запросов. Подход, заключающийся в тщательной настройке параметров соединения (например, значительном снижении частоты проверок состояния) или даже создании и уничтожении соединений динамически, может значительно улучшить эту ситуацию.
Обработка очередей новых запросов на соединение — это вторая, но связанная с первой проблема. Мы видели, что очереди такого типа возникают, когда очень крупные пакетные задачи создают очень большое количество рабочих задач клиента одновременно. Необходимость согласовывать и поддерживать избыточное количество новых соединений одновременно может легко перегрузить группу бэкендов. Мы, исходя из собственного опыта, определили несколько стратегий, которые помогают справиться с такой загрузкой.
• Учитывать нагрузку в алгоритме балансировки нагрузки между дата-центрами (например, базовая балансировка нагрузки основана на степени использования кластера, а не на количестве запросов). В этом случае загрузка от запросов, по сути, уходит к другим дата-центрам, которые имеют резерв производительности.
• Указать, что пакетные задачи клиента должны применять отдельный набор пакетных прокси-задач бэкендов, которые только организованно перенаправляют запросы к лежащим в их основе бэкендам и передают клиентам полученные ответы. Поэтому вместо схемы «пакетный клиент → бэкенд» у вас получается схема «пакетный клиент → пакетный прокси → бэкенд». Когда начинает работать самая крупная задача, пострадает только пакетная прокси-задача, защищая реальные бэкенды и клиенты с высоким приоритетом. По сути, пакетный прокси действует как предохранитель. Еще одним преимуществом использования прокси является снижение количества соединений с бэкендом, что улучшает балансировку нагрузки для этого бэкенда (например, прокси-задачи могут задействовать большие подмножества и, возможно, лучше представлять себе состояние задач бэкендов).
Итоги главы
В этой главе и в главе 20 мы рассмотрели, как различные методы (предопределенные подмножества, «взвешенный» циклический алгоритм Weighted Round Robin, регулирование фронтенда, квоты для клиентов и т.д.) могут помочь относительно равномерно распределить нагрузку между задачами в дата-центре. Однако работа этих механизмов зависит от состояния всей распределенной системы и от распространения информации в ней. И хотя в общем случае они работают достаточно хорошо, при реальной эксплуатации могут иногда возникать ситуации, когда они будут действовать неоптимально.
В результате мы считаем критически важным обеспечить защиту от перегрузки каждой задачи. Проще говоря, задача бэкенда, имеющая техническую возможность обрабатывать трафик на некотором уровне производительности, должна продолжить обрабатывать его на этом уровне, и объем отправленного задаче «лишнего» трафика не должен оказывать существенного влияния на задержку отклика. Из этого следует, что задача бэкенда не должна давать отказы и сбои под нагрузкой. Это утверждение должно оставаться верным для определенного объема трафика — выше 2x или даже 10x от того значения, которое задача имеет техническую возможность обработать. Мы принимаем, что существует определенный порог, после которого система начнет давать сбой, но превысить его должно быть достаточно трудно.
Суть в том, чтобы серьезно отнестись к условиям, при которых возникает деградация. Если их проигнорировать, то многие системы будут работать плохо. По мере увеличения нагрузки задачи из-за нехватки памяти будут регулярно «падать» или тратить все ресурсы процессора на обработку переполнения памяти, время отклика возрастет, трафик будет теряться, а задачи — конкурировать за доступ к ресурсам. Оставленный без внимания отдельный сбой (например, в одной из задач бэкенда) может спровоцировать сбои в других компонентах системы, и это потенциально может привести к краху всей системы или значительной ее части. Последствия таких каскадных сбоев могут быть очень серьезными, поэтому любая крупномасштабная система должна иметь средства защиты от них (см. главу 22).
Зачастую ошибочно предполагают, что перегруженный бэкенд должен перестать принимать трафик и отключиться. Но это идет вразрез с концепцией надежной балансировки нагрузки. Мы хотим, чтобы бэкенд принимал максимально возможный объем трафика. Хорошо функционирующий бэкенд, поддерживаемый продуманной политикой балансировки нагрузки, должен принимать только те запросы, которые может обработать, и корректно отклонять остальные.
Несмотря на большой выбор инструментов для реализации хорошей системы балансировки нагрузки и защиты от перегрузок, панацеи не существует: для балансировки нагрузки зачастую требуется глубокое понимание системы и семантики ее запросов. Приемы, описанные в этой главе, развивались вместе с потребностями многих систем компании Google и, скорее всего, продолжат развиваться, поскольку характер систем постоянно меняется.
Например, взгляните на Doorman — корпоративную распределенную систему регулирования на стороне клиента.

