20. Балансировка нагрузки в дата-центре
Автор — Алехандро Фореро Куэрво
Под редакцией Сары Чевис
В этой главе рассматривается вопрос балансировки нагрузки внутри дата-центра. В частности, речь пойдет об алгоритмах для распределения работы внутри заданного дата-центра для потока запросов. Мы рассмотрим политики уровня приложений для направления запросов к конкретным серверам, которые могут их обработать. Принципы работы с сетью на нижнем уровне (например, использование коммутаторов, маршрутизация пакетов) и выбор дата-центров в этой главе не рассматриваются.
Предположим, что существует поток запросов, поступающих в дата-центр — они могут исходить из самого дата-центра, из удаленных дата-центров, или и то и другое одновременно — в таком объеме, который не превышает возможностей дата-центра по их обработке (или превышает, но лишь на короткий промежуток времени). Предположим также, что в дата-центре работают сервисы, к которым поступают эти запросы. Эти сервисы реализованы в виде однотипных (гомогенных) взаимозаменяемых серверных процессов, работающих, как правило, на разных машинах. Самые маленькие сервисы обычно имеют как минимум три таких процесса (использование меньшего количества процессов означает потерю как минимум 50 % вашей производительности при потере одной машины), а самые крупные — более 10 000 (в зависимости от размера дата-центра).
Типичное количество процессов сервиса — от ста до тысячи. Мы называем эти процессы задачами бэкенда (или просто бэкендами). Другие задачи, называемые задачами клиентов, хранят соединения с задачами бэкенда. Для каждого входящего запроса задача клиента должна решить, какая из задач бэкенда должна обрабатывать этот запрос. Задачи клиентов и бэкенда общаются между собой с помощью протокола, реализованного на основе комбинации TCP и UDP.
Следует заметить, что в дата-центрах компании Google представлен обширный набор разнообразных сервисов, которые реализуют различные комбинации политик, рассматриваемых в этой главе. Рассматриваемый нами пример не соответствует в точности ни одному конкретному сервису. Он представляет собой обобщенный случай, позволяющий нам обсудить разнообразные технологии и методы, которые мы находим полезными для разных сервисов. Некоторые из них могут быть более или менее применимы для конкретных случаев, но все они разрабатывались и реализовывались множеством инженеров Google на протяжении многих лет.
Эти технологии и методы применимы для многих элементов нашего стека. Например, большая часть внешних HTTP-запросов достигают GFE (Google Frontend), нашей системы обратного проксирования HTTP. GFE использует описываемые алгоритмы (наряду с описанными в главе 19) для направления запросов и их метаданных конкретным процессам приложений, которые могут их обработать. Используемая при этом конфигурация соотносит различные шаблоны URL с отдельными приложениями, находящимися в ведении разных команд. Чтобы сгенерировать содержимое ответов (которые будут возвращены GFE и затем в браузеры), эти приложения зачастую используют эти же алгоритмы для взаимодействия с инфраструктурными или дополнительными сервисами, от которых они зависят. Иногда стек зависимостей оказывается достаточно глубоким: один входящий HTTP-запрос может запустить длинную цепочку промежуточных зависимых запросов к различным системам, потенциально разветвляющуюся в нескольких местах.
Идеальный случай
В идеальном случае нагрузка для заданного сервиса распределяется равномерно по всем задачам бэкенда, и в любой момент времени наименее и наиболее загруженные задачи бэкенда потребляют ресурсы процессора примерно в одинаковом объеме.
Мы можем отправлять трафик в дата-центр только до тех пор, пока наиболее загруженная задача не достигнет предела нагрузочной способности; это показано на рис. 20.1 для двух ситуаций с одинаковым временным интервалом. В это время алгоритм балансировки нагрузки между дата-центрами должен избегать отправки дополнительного трафика в этот дата-центр, поскольку возможна перегрузка некоторых задач.
Как показано на левой гистограмме на рис. 20.2, значительная часть вычислительных ресурсов тратится впустую: у каждой задачи, кроме наиболее загруженной, остается запас производительности.
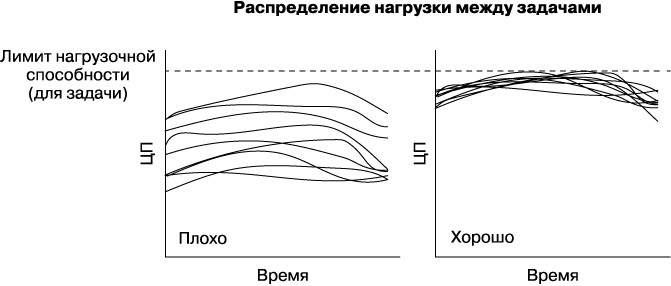
Рис. 20.1. Два сценария распределения нагрузки для задач с течением времени
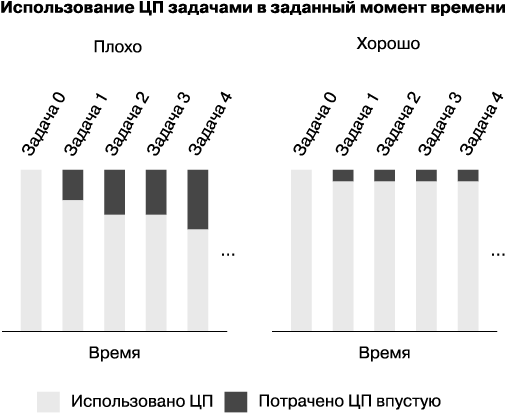
Рис. 20.2. Гистограммы использования процессоров в двух сценариях
Говоря более формально, пусть CPU(i) — уровень использования ЦП задачей i в любой заданный момент времени. Предположим, что самой загруженной задачей будет задача 0. Тогда в случае большой дисперсии мы теряем сумму разностей между уровнем использования ЦП самой загруженной задачи и каждой из оставшихся задач: это значит, что будет потеряна сумма значений (CPU(0) — CPU(i)) для всех i-х задач. В данном случае «потеряна» означает «зарезервирована, но не использована».
Этот пример иллюстрирует, как неудачные внутренние методы балансировки нагрузки искусственным образом ограничивают доступность ресурсов: вы можете зарезервировать 1000 процессоров для своего сервиса в определенном дата-центре, но реально сможете использовать, например, не более 700 из них.
Выявляем плохие задачи: управление потоками и «хромые утки»
Прежде чем решить, какая задача бэкенда должна принять запрос клиента, нам нужно выявить неработоспособные задачи в нашем пуле бэкендов и найти способ избежать их появления.
Простой подход к контролю работоспособности задач: управление потоками
Предположим, что наши задачи клиентов отслеживают количество активных («открытых») запросов, которые они отправили через соответствующее соединение каждой задаче бэкенда. Когда это число активных запросов достигнет указанного лимита, бэкенд будет считаться неработоспособным, и новые запросы ему перестанут отправляться. Для большинства бэкендов разумно ставить ограничение в 100 запросов; как правило, запросы завершаются достаточно быстро, и вероятность достижения заданного лимита в обычных условиях достаточно низка. Эта (очень простая!) форма управления потоками действует так же, как простейшая балансировка нагрузки: если заданная задача бэкенда оказывается перегруженной и начинают накапливаться необслуженные запросы, задачи клиентов станут избегать использования этого бэкенда и нагрузка будет естественным образом распределена между другими задачами бэкенда.
К сожалению, такой подход защищает задачи бэкенда лишь от самых крайних случаев перегрузки, и бэкенды могут оказаться перегруженными, даже не достигнув этого лимита. Противоположное тоже верно: в некоторых случаях клиенты могут достичь этого лимита, а у их бэкендов все еще будет в распоряжении достаточно ресурсов. Например, отдельные бэкенды могут иметь запросы с очень большой длительностью выполнения, быстро ответить на которые невозможно. Бывают случаи, когда заданный по умолчанию лимит отрабатывал неправильно, делая все задачи бэкенда недостижимыми, при том, что все запросы были заблокированы в клиенте до завершения по тайм-ауту или из-за ошибки. Повышение лимита активных запросов поможет избежать возникновения такой ситуации, но не решит основной проблемы — мы не можем определить, стала ли задача неработоспособной или она просто медленно отвечает.
Усовершенствованный подход к контролю работоспособности задач: состояние «хромой утки»
С точки зрения клиента заданная задача бэкенда может находиться в одном из следующих состояний.
• Полная работоспособность. Задача бэкенда была корректно проинициализирована и теперь обрабатывает запросы.
• Отказ в соединении. Задача бэкенда не отвечает. Это может случиться, если задача еще только запускается или уже завершается либо если бэкенд находится в ненормальном состоянии (однако иногда бывает так, что бэкенд перестает слушать свой порт, но сам не отключается).
• «Хромая утка» (частичная работоспособность). Задача бэкенда слушает порт и может обслуживать запросы, но явно просит клиентов перестать их отправлять.
Когда задача входит в состояние «хромой утки», она информирует об этом всех активных клиентов. Но как быть с неактивными клиентами? Согласно реализации RPC компании Google, неактивные клиенты (то есть клиенты, не имеющие активных соединений TCP) продолжают периодически слать запросы проверки состояния посредством протокола UDP. В результате о состоянии задачи будут быстро проинформированы все клиенты — как правило, за один или два интервала RTT — независимо от их текущего состояния.
Основное преимущество того, что задача может существовать в квазиоперационном состоянии «хромой утки», состоит в том, что это упрощает ее корректное отключение. Это позволяет избежать возврата ошибок вместо ожидаемого ответа всем неудачным запросам, которым не посчастливилось быть активными в момент начала отключения задачи бэкенда. Отключение задачи бэкенда, имеющей активные запросы, без генерации ошибок облегчает выполнение обновлений кода, поддержание доступности и восстановление после сбоев, которые могут потребовать перезапуска всех связанных задач. Такое отключение должно пройти следующие этапы.
1. Планировщик отправляет сигнал SIGTERM задаче бэкенда.
2. Задача бэкенда входит в состояние «хромой утки» и сообщает своим клиентам о необходимости отправлять новые запросы другим задачам бэкенда. Это выполняется с помощью вызова API в реализации RPC, которая явно вызывается в обработчике сигнала SIGTERM.
3. Любые запросы, чье выполнение началось до перехода в состояние «хромой утки» (или после этого перехода, но до того, как клиент это обнаружил), выполняются как обычно.
4. По мере того как ответы возвращаются клиентам, количество активных запросов бэкенда постепенно уменьшается до нуля.
5. По прошествии заданного времени задача бэкенда либо сама завершает работу, либо ее планировщик завершает ее принудительно. Интервал должен быть достаточно велик, чтобы все типичные запросы имели достаточно времени для своего завершения. Это значение зависит от сервиса, но мы рекомендуем устанавливать его в промежутке от 10 до 150 секунд в зависимости от сложности.
Эта стратегия также позволяет клиенту устанавливать соединения с задачами бэкендов во время выполнения потенциально длительных инициализирующих процедур, когда они еще не готовы начать обслуживать запросы. В противном случае задачи бэкенда могут начать принимать соединения, только когда они уже готовы начать обслуживание, а это неоправданно задержало бы установление соединений. Как только задача бэкенда будет готова начать обслуживание, она явно просигнализирует об этом своим клиентам.
Ограничение пула соединений с помощью подмножеств
В дополнение к управлению состоянием, еще одним подходом к балансировке нагрузки является использование подмножеств: ограничение пула потенциальных задач бэкенда, с которыми может взаимодействовать задача клиента.
Каждый клиент в нашей системе RPC поддерживает пул долгоживущих соединений с бэкендами, которые он использует для отправки новых запросов. Эти соединения обычно устанавливаются, как только запускается клиент, и чаще всего остаются открытыми. Запросы проходят через них вплоть до «смерти» клиента. Альтернативной моделью будет установление и уничтожение соединения для каждого запроса, но эта модель имеет высокую стоимость в плане расхода ресурсов и задержки обработки данных. Если соединение простаивает слишком долгое время, наша реализация RPC включает оптимизацию: переводит соединение в более экономный «неактивный» режим, в котором, например, частота проверок работоспособности снижена, и базовое TCP-соединение сбрасывается, заменяясь на UDP.
Каждое соединение требует расхода некоторого объема памяти и времени процессора (из-за периодических проверок работоспособности) на обоих концах. Несмотря на то что такая нагрузка в теории невелика, она быстро становится заметной, когда это случается с большим количеством машин. Подмножества позволяют избежать ситуации, в которой один клиент соединяется со слишком многими задачами бэкенда или одна задача бэкенда получает соединения от слишком многих задач клиентов. В обоих случаях вы потенциально потратите слишком много ресурсов без существенной пользы.
Выбираем правильное подмножество
Выбор правильного подмножества сводится к выбору количества задач бэкенда, с которыми будет соединяться каждый клиент, — размеру подмножества — и алгоритму выбора. Мы обычно используем подмножества размером от 20 до 100 задач бэкенда, но «правильный» размер подмножества для системы сильно зависит от типичного поведения вашего сервиса. Например, более крупное подмножество вам может понадобиться, если:
• количество клиентов значительно меньше, чем число бэкендов. В этом случае вы хотите, чтобы количество бэкендов, приходящихся на клиент, было достаточно большим и у вас не осталось задач бэкенда, которые никогда не получают запросов;
• нагрузка внутри заданий клиента часто бывает неравномерной (например, одна задача отправляет больше запросов, чем другая). Это типично в случаях, когда клиент время от времени отправляет целые пакеты запросов. При этом сами клиенты принимают от других клиентов запросы, которые время от времени бывают «веерными» (к примеру, «считать всю информацию обо всех пользователях, связанных с заданным»). Поскольку весь пакет запросов будет направлен в одно подмножество, назначенное клиенту, вам понадобится подмножество большего размера, чтобы обеспечить равномерное распределение нагрузки между большим набором доступных задач бэкенда.
Как только вы определитесь с размером подмножества, понадобится алгоритм для определения подмножества задач бэкенда, который будет использовать каждая задача клиента. Это может показаться простой задачей, но она очень быстро становится сложной, когда вы начнете работать с крупномасштабными системами, для которых важна эффективность выделения ресурсов, а перезапуски будут обычным делом.
Алгоритм выбора для клиентов должен единообразно назначать бэкенды для оптимизации распределения ресурсов. Например, если при выделении подмножеств один бэкенд перегружается на 10 %, все бэкенды должны получить на 10 % больше ресурсов, чем им необходимо. Алгоритм также должен корректно обрабатывать перезапуски и сбои, продолжая нагружать бэкенды настолько единообразно, насколько это возможно, и при этом минимизируя отток клиентов. В этом случае «отток» связан с выбором бэкенда на замену. Например, когда задача бэкенда становится недоступной, ее клиентам потребуется выбрать бэкенд для временной замены. Когда такой бэкенд выбран, клиенты должны создать новые соединения TCP (и, скорее всего, повторно провести согласование на уровне приложений), что создает дополнительную нагрузку. Аналогично, когда задача клиента перезапускается, она должна повторно открыть соединения со всеми своими бэкендами.
Кроме того, алгоритм должен обрабатывать изменение количества клиентов и/или бэкендов с минимальной потерей соединений и не зная этого количества наперед. Эта возможность особенно важна (и сложна в реализации), когда множество задач клиентов или бэкендов перезапускается целиком одновременно (например, для обновления версии). Мы хотим, чтобы после запуска обновления бэкендов клиенты продолжили работать прозрачно и с минимально возможной потерей соединений.
Алгоритм выбора подмножества: случайное подмножество
Примитивная реализация алгоритма выбора подмножества может состоять в случайной перетасовке клиентом списка бэкендов и заполнении своего подмножества доступными и работоспособными бэкендами из этого списка. Однократная перетасовка и последующий выбор бэкендов из начала списка позволяет надежно справляться с последствиями перезапусков и сбоев (сопровождающихся относительно небольшим перетоком соединений), поскольку они явно исключаются из рассмотрения. Однако мы обнаружили, что эта стратегия плохо работает в наиболее актуальных сценариях, поскольку очень неравномерно распределяет нагрузку.
Работая над балансировкой нагрузки, мы первоначально реализовали случайные подмножества и рассчитали ожидаемую нагрузку для разных случаев. В качестве примера рассмотрим следующую ситуацию:
• 300 клиентов;
• 300 бэкендов;
• размер подмножества равен 30 % (каждый клиент соединяется с 90 бэкендами).
Как показано на рис. 20.3, наименее загруженный бэкенд имеет всего 63 % от средней загрузки (57 соединений при среднем значении 90 соединений), а наиболее загруженный — 121 % (109 соединений). В большинстве случаев размер подмножества, равный 30 %, уже превышает то значение, которое мы хотели бы использовать на практике. Рассчитанное распределение нагрузки изменяется каждый раз, когда мы запускаем симуляцию, но общая картина остается той же.
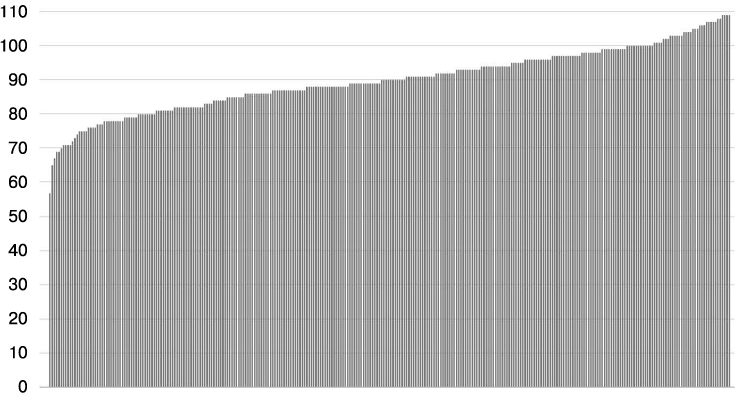
Рис. 20.3. Распределение соединений между 300 клиентами и 300 бэкендами при размере подмножества, равном 30 %
К сожалению, использование меньшего размера подмножества приводит к еще большему дисбалансу. Например, на рис. 20.4 показаны результаты снижения размера подмножества до 10 % (клиент соединяется с 30 бэкендами). В этом случае наименее загруженный бэкенд получает 50 % от средней загрузки (15 соединений), а наиболее загруженный — 150 % (45 соединений).
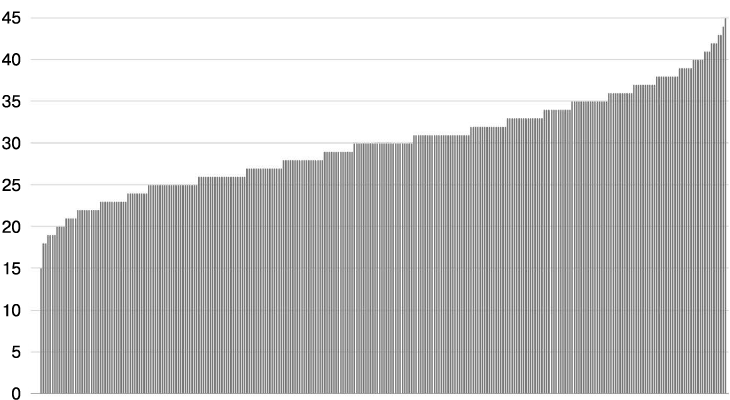
Рис. 20.4. Распределение соединений между 300 клиентами и 300 бэкендами при размере подмножества, равном 10 %
Мы пришли к выводу: чтобы в случайных подмножествах нагрузка распределялась относительно равномерно между всеми доступными задачами, нам понадобятся подмножества размером 75 %. Использовать подмножества такого размера попросту непрактично; колебания количества клиентов, связывающихся с задачей, слишком велики для того, чтобы считать такое формирование подмножеств хорошим решением при работе с крупными системами.
Алгоритм определения подмножества: предопределенное подмножество
Решение Google для преодоления ограничений случайного формирования подмножеств состоит в использовании детерминированного алгоритма. Следующий код реализует этот алгоритм (детально он описан далее):
def Subset(backends, client_id, subset_size):
subset_count = len(backends) / subset_size
# Group clients into rounds; each round uses the same shuffled list:
round = client_id / subset_count
random.seed(round)
random.shuffle(backends)
# The subset id corresponding to the current client:
subset_id = client_id % subset_count
start = subset_id * subset_size
return backends(start:start + subset_size)
Мы делим клиентские задачи на «ряды» (rounds), где i-й «ряд» содержит subset_count задач клиентов с подряд идущими номерами, начиная с subset_count х i, а subset_count — это количество подмножеств (равное общему количеству задач бэкенда, разделенному на желаемый размер подмножества). Внутри каждого «ряда» каждый бэкенд присваивается ровно одному клиенту (кроме, возможно, последнего «круга», поскольку клиентов уже может не хватать, поэтому некоторые бэкенды не будут присвоены).
Например, если у нас есть 12 задач бэкендов (0, 11) и желаемый размер подмножества равен 3, у нас будет 4 «ряда» из 4 клиентов каждый (subset_count = 12/3). Если бы у нас было 10 клиентов, приведенный выше алгоритм мог бы сформировать такие «ряды»:
• «ряд» 0 — (0, 6, 3, 5, 1, 7, 11, 9, 2, 4, 8, 10);
• «ряд» 1 — (8, 11, 4, 0, 5, 6, 10, 3, 2, 7, 9, 1);
• «ряд» 2 — (8, 3, 7, 2, 1, 4, 9, 10, 6, 5, 0, 11).
Следует отметить, что в каждом «ряду» каждый бэкенд назначается ровно одному клиенту (кроме последнего, если клиенты заканчиваются). В этом примере каждый бэкенд назначается двум или трем клиентам.
Список должен быть перетасован; в ином случае клиентам будет присвоена группа задач бэкенда с последовательными номерами, которые могут все стать временно недоступными (например, если обновление задания бэкенда выполняется последовательно в порядке номеров задач). Для разных «рядов» используются разные инициализирующие значения генератора случайных чисел. Если этого не сделать, то после сбоя бэкенда нагрузка, которую он обрабатывал, распределяется лишь между оставшимися бэкендами его подмножества. Если дают сбой и другие бэкенды, то эффект суммируется, и ситуация быстро ухудшается: если N бэкендов подмножества отключены, их нагрузка распределяется между оставшимися (subset_size – N) бэкендами. Гораздо лучшим решением будет распределение этой нагрузки между всеми оставшимися бэкендами, для этого перетасовка выполняется заново для каждого «ряда».
Если мы заново перетасуем бэкенды для каждого «ряда», клиенты из одного «ряда» начнут с одинакового перетасованного списка, однако клиенты разных «рядов» будут иметь разные списки. С этого момента алгоритм строит определения подмножеств, исходя из перетасованного списка бэкендов и желаемого размера подмножества. Например:
• Subset(0) — от shuffled_backends(0) до shuffled_backends(2);
• Subset(1) — от shuffled_backends(3) до shuffled_backends(5);
• Subset(2) — от shuffled_backends(6) до shuffled_backends(8);
• Subset(3) — от shuffled_backends(9) до shuffled_backends(11),
где shuffled_backend — это перетасованный список, создаваемый для каждого клиента. Для того чтобы назначить подмножество задаче клиента, мы просто возьмем подмножество, которое соответствует его позиции внутри «ряда» (например (i % 4) для client(i) при четырех подмножествах:
• client(0), client(4), client(8) будут использовать subset(0);
• client(1), client(5), client(9) будут использовать subset(1);
• client(2), client(6), client(10) будут использовать subset(2);
• client(3), client(7), client(11) будут использовать subset(3).
Поскольку клиенты разных «рядов» будут применять разные значения для shuffled_backends (и, соответственно, для subset), а клиенты внутри «рядов» используют разные подмножества, нагрузка соединения будет распределена равномерно. В случаях, когда общее количество бэкендов не делится нацело на желаемый размер подмножества, мы позволим новым подмножествам быть чуть больше, чем другим, но в большинстве случаев количество клиентов, назначенных бэкенду, будет отличаться не более чем на единицу.
Как показано на рис. 20.5, такое распределение для предыдущего примера, где 300 клиентов соединяются с 10–300 бэкендами, дает очень хорошие результаты: каждый бэкенд получает одинаковое количество соединений.

Рис. 20.5. Распределение соединений с 300 клиентами и предопределенными подмножествами, состоящими из 10–300 бэкендов
Политики балансировки нагрузки
Теперь, когда мы рассмотрели основы того, как отдельная задача клиента обслуживает набор соединений с известной работоспособностью, рассмотрим политики балансировки нагрузки. Они представляют собой механизмы и правила, используемые задачами клиентов для выбора задачи бэкенда, которой будет передан запрос. Большой вклад в сложность политик балансировки вносят распределенный характер процесса принятия решений, когда клиенту нужно в реальном времени решить, какой бэкенд следует использовать для каждого запроса, имея лишь частичную и/или устаревшую информацию о состоянии бэкенда.
Политики балансировки нагрузки могут быть очень простыми. Они могут не принимать во внимание состояние бэкендов (например, алгоритм Round Robin — циклический алгоритм) или же могут действовать на основе информации о бэкендах (например, Least-Loaded Round Robin — циклический алгоритм поиска наименее загруженного элемента или Weighted Round Robin — взвешенный циклический алгоритм).
Простой Round Robin
Простой подход к балансировке нагрузки заключается в том, что каждый клиент отправляет очередные запросы последовательно каждой задаче бэкенда своего подмножества, кроме тех, с которыми невозможно соединиться, или находящимися в состоянии «хромой утки». На протяжении многих лет мы использовали этот подход, и он до сих пор работает во многих сервисах.
К сожалению, несмотря на то что алгоритм Round Robin выигрывает у конкурентов за счет своей простоты, и при этом работает значительно лучше метода произвольного выбора бэкендов, результаты этой политики могут оказаться очень плохими.
Реальные показатели зависят от многих факторов, например, от изменяющейся «стоимости» запроса и разнообразия машин, и мы обнаружили, что использование алгоритма Round Robin может привести к почти двукратному разбросу уровня потребления ресурсов процессора между наименее и наиболее загруженными задачами. Такой разброс крайне расточителен и может происходить по многим причинам, включая:
• малый размер подмножества;
• изменение стоимости запросов;
• разнообразие машин;
• непредсказуемые факторы, влияющие на производительность.
Малый размер подмножества
Одна из самых простых причин, по которым алгоритм Round Robin плохо распределяет нагрузку, заключается в том, что все его клиенты могут генерировать разное количество запросов. Появление разного количества запросов среди клиентов особенно вероятно, когда совершенно разные процессы работают на одних бэкендах. В этом случае, особенно если вы используете относительно небольшой размер подмножеств, бэкенды подмножеств для клиентов, которые генерируют наибольший объем трафика, естественным образом будут загружены больше.
Изменение стоимости запросов
Многие сервисы обрабатывают запросы, которые требуют разного объема ресурсов для своего выполнения. На практике мы обнаружили, что семантика многих сервисов Google такова, что самые «дорогие» запросы потребляют в 1000 раз больше ресурсов (или даже больше), чем самые «дешевые». Балансировка нагрузки с помощью алгоритма Round Robin еще больше затрудняется, когда стоимость запроса нельзя предсказать заранее. Например, запрос вроде «получить все электронные письма, полученные пользователем XYZ за последний день» может быть как очень дешевым (если пользователь в течение дня получил мало писем), так и крайне дорогим.
Балансировка нагрузки в системе, имеющей большие расхождения в потенциальной стоимости запроса, очень проблематична. Возможно, придется скорректировать интерфейсы сервисов, чтобы функционально ограничить трудоемкость запросов. Например, в случае рассмотренного выше запроса на получение электронных писем вы можете предусмотреть в интерфейсе разбиение на страницы и изменить семантику запроса на «вернуть 100 последних писем (или меньше), полученных пользователем XYZ за последний день». К сожалению, ввести такие изменения семантики зачастую очень сложно. Это не только потребует изменения всего клиентского кода, но и повлечет за собой потенциальные проблемы со стабильностью. Например, пользователь может получать новые электронные письма или удалять их в тот момент, когда клиент получает письма постранично. В этом случае клиент, который просто проходит по результатам и объединяет ответы (вместо того, чтобы выполнять разбиение на страницы, основываясь на фиксированном представлении данных), получит, скорее всего, нестабильное представление, дублируя одни сообщения и/или опуская другие.
Для того чтобы интерфейс (и его реализация) оставались простыми, сервисы зачастую позволяют самым «дорогим» запросам потреблять в 100, 1000 или даже 10 000 раз больше ресурсов, чем самым «дешевым». Однако изменение требований к ресурсам для выполнения запросов означает, что некоторые задачи бэкенда будут менее удачливыми, чем другие — им придется обработать больше дорогостоящих запросов. Степень влияния этого на балансировку нагрузки зависит от того, насколько дорогостоящими являются самые «дорогие» запросы. Например, для одного из наших бэкендов Java запросы потребляют в среднем примерно 15 миллисекунд процессорного времени, но на выполнение некоторых запросов может потребоваться до 10 секунд. Каждая задача этого бэкенда резервирует несколько ядер процессора, что снижает задержку отклика за счет параллельного выполнения некоторых вычислений. Но, несмотря эти зарезервированные ядра, при получении одного из таких «тяжелых» запросов, его загрузка на несколько секунд значительно возрастает. Плохо ведущая себя задача может израсходовать всю память или даже полностью перестать отвечать (например, из-за засорения памяти), но даже в обычном случае (то есть когда бэкенд имеет достаточное количество ресурсов, и его загрузка нормализуется, как только завершится выполнение длительного запроса) задержка выполнения других запросов может пострадать из-за необходимости конкурировать за использование ресурсов с дорогостоящим запросом.
Разнообразие машин
Еще одной сложностью использования простого алгоритма Round Robin является то, что не все машины в одном дата-центре одинаковы. В любом дата-центре могут найтись машины с разной производительностью, и поэтому выполнение одного и того же запроса на разных машинах может занимать разное время.
Решение проблемы разнообразия машин — без требования строгой гомогенности — многие годы было одной из насущных задач компании Google. Теоретически решение, позволяющее работать с гетерогенными вычислительными ресурсами во всем парке техники, выглядит просто: мы масштабируем резервирование ЦП в зависимости от типа процессора и машины. Однако на практике реализация этого решения требовала больших усилий, поскольку планировщик должен был пересчитывать соответствие ресурсов, основываясь на средней производительности машин для выбранных сервисов. Например, два ЦП на машине Х («медленной» машине) эквивалентны 0,8 ЦП на машине Y («быстрой» машине). Имея эту информацию, планировщик должен скорректировать резервирование ЦП для процесса, учитывая коэффициент соответствия и тип машины, на которой запланировано выполнение этого процесса. Пытаясь справиться с этой проблемой, мы ввели виртуальный элемент для измерения уровня CPU, который назвали GCU (Google Compute Unit — вычислительный элемент Google). GCU стал стандартом для моделирования возможностей CPU и использовался для описания соотношения между архитектурой каждого процессора в наших дата-центрах с соответствующим CGU, основываясь на их производительности.
Непредсказуемые факторы, влияющие на производительность
Возможно, самым крупным фактором, усложняющим использование простого алгоритма Round Robin, было то обстоятельство, что машины — или, говоря более точно, производительность задач бэкендов на разных машинах — могли значительно отличаться из-за некоторых непредсказуемых факторов.
Рассмотрим два таких фактора.
• Соседи-антагонисты. Другие процессы (зачастую никак не связанные с вашими и запущенные другими командами) могут оказывать значительное влияние на производительность ваших процессов. Мы наблюдали, как это меняло производительность на целых 20 %. Причиной колебаний производительности обычно бывает конкуренция за использование разделяемых ресурсов, таких как место в кэширующей памяти или полоса пропускания сети, причем не самым очевидным образом. Например, если задержка отклика для исходящих от задачи бэкенда запросов увеличивается (из-за конкуренции за ресурсы сети с соседом-антагонистом), количество активных запросов также будет расти, что может вызвать более интенсивное выполнение сборки мусора.
• Перезапуски задач. Когда задача перезапускается, ей часто требуется много ресурсов на протяжении нескольких минут. Мы заметили, что такое состояние чаще влияет на платформы вроде Java, которые динамически оптимизируют код. В ответ на это мы добавили в логику немного серверного кода — мы задерживаем серверы в состоянии «хромой утки» и предварительно «прогреваем» их (заставляем срабатывать эти оптимизации) какое-то время после запуска до тех пор, пока их производительность не достигнет номинальной. Эффект от перезапуска задач может стать заметной проблемой, если нужно обновлять много серверов (например, устанавливать новые сборки, что потребует перезапуска этих задач) каждый день.
Если ваша политика балансировки нагрузки не может адаптироваться к непредвиденным ограничениям производительности, вы однозначно получите неоптимальное распределение нагрузки при масштабировании системы.
Least-Loaded Round Robin
Альтернативой простому алгоритму Round Robin является подход, при котором каждая задача клиента должна отслеживать количество активных запросов к каждой задаче бэкенда своего подмножества и использовать алгоритм Round Robin среди множества задач с минимальным количеством активных запросов.
Например, пусть клиент использует подмножество задач бэкенда от t0 до t9, и количество активных запросов для них составляет:
| t0 | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 |
| 2 | 1 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 1 |
При поступлении нового запроса клиент должен отфильтровать список потенциальных задач бэкенда так, чтобы в нем остались лишь задачи с наименьшим количеством соединений (t2, t3, t5, t7 и t8), и затем выбрать из него бэкенд. Предположим, что был выбран бэкенд t2. Таблица состояний соединений клиента теперь будет выглядеть следующим образом:
| t0 | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 |
| 2 | 1 | 1 | 0 | 1 | 0 | 2 | 0 | 0 | 1 |
Предположим, что ни один из текущих запросов не был завершен, поэтому для следующего запроса пул кандидатов выглядит как t3, t5, t7 и t8.
Переместимся в тот момент времени, когда у нас появится четыре новых запроса. Мы все еще предполагаем, что ни один запрос за это время не завершится, поэтому после приема этих запросов таблица соединений будет выглядеть следующим образом:
| t0 | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8 | t9 |
| 2 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 |
В этот момент в множестве кандидатов будут рассматриваться все задачи, кроме t0 и t6. Однако если запрос к задаче t4 завершится, ее текущим состоянием станет «0 активных запросов» и новый запрос будет направлен ей.
В этой реализации также используется алгоритм Round Robin, но он применяется только к множеству задач с минимальным количеством активных запросов. Без такой фильтрации политика может не суметь распределить запросы достаточно хорошо, чтобы избежать простоя части доступных бэкендов. Идея, лежащая в основе этой политики, заключается в том, что у сильно загруженных задач задержка отклика скорее всего окажется больше, чем у свободных, а эта стратегия естественным образом снимает нагрузку с этих загруженных задач.
С учетом вышесказанного, мы узнали (сложным способом!) об одной очень опасной ловушке, которую таит подход Least-Loaded Round Robin: если задача совсем неработоспособна, она может начать возвращать 100 % ошибок. В зависимости от природы этих ошибок они могут иметь очень низкую задержку отклика; зачастую сообщить «Я неисправен!» можно гораздо быстрее, чем выполнить запрос. В результате клиенты могут начать отправлять очень много трафика неработоспособным задачам, ошибочно считая их доступными, однако задача просто быстро генерирует сбои! В таких случаях мы говорим, что задача теперь «поглощает трафик».
К счастью, этой ловушки можно избежать, слегка модифицировав политику и начав подсчитывать недавние ошибки так же, как если бы они были активными запросами. Таким образом, если задача бэкенда становится неработоспособной, политика балансировки нагрузки начинает отводить от нее нагрузку так же, как если бы она отводила нагрузку от перегруженной задачи.
Алгоритм Least-Loaded Round Robin имеет два важных ограничения.
• Количество активных запросов может оказаться не очень хорошим индикатором возможностей заданного бэкенда. Многие запросы проводят значительную часть своей жизни, ожидая ответа сети (например, ожидая ответов на запросы, которые они инициировали для других бэкендов), и лишь очень малое время они действительно выполняются. Например, одна задача бэкенда может обработать в два раза больше запросов, чем другая (поскольку она запущена на машине с вдвое более быстрым процессором по сравнению с остальными), но задержка отклика для ее запросов будет почти равна задержке отклика для другой аналогичной задачи (поскольку запросы проводят большую часть своей жизни, ожидая ответа сети). В этом случае, поскольку заблокированный в ожидании ввод/вывод обычно потребляет нулевое время процессора, очень мало оперативной памяти и не затрагивает полосу пропускания сети, мы все еще хотим отправлять вдвое более быстрому бэкенду вдвое больше запросов. Однако политика Least-Loaded Round Robin будет считать обе задачи бэкенда одинаково загруженными.
• Количество активных запросов в каждом клиенте не учитывает запросы других клиентов к этим бэкендам. Соответственно, каждая из задач клиентов имеет очень ограниченное представление о состоянии своей задачи бэкенда: она видит только собственные запросы.
На практике мы обнаружили, что крупные сервисы, использующие политику Least-Loaded Round Robin, будут видеть, что их наиболее загруженные задачи бэкенда задействуют в два раза больше ресурсов процессора, чем наименее загруженные. Следовательно, она работает почти так же плохо, как и простая политика Round Robin.
Weighted Round Robin
Weighted Round Robin (взвешенный циклический алгоритм) — это важная политика балансировки нагрузки, которая улучшает предыдущие версии, добавляя в процесс принятия решения информацию, предоставленную бэкендом.
Идея, лежащая в основе политики Weighted Round Robin, довольно проста: каждая задача клиента ведет подсчет «возможностей» для каждого бэкенда своего подмножества. Запросы распределяются так же, как и при политике Round Robin, но задачи клиентов пропорционально взвешивают распределения запросов по бэкендам. Для каждого ответа (включая ответы на проверку работоспособности) бэкенды включают текущее наблюдаемое соотношение запросов и ошибок в секунду в дополнение к показателю используемости (обычно использованию процессора). Клиенты периодически корректируют подсчитанные «возможности» для того, чтобы выбирать задачи бэкенда, основываясь на их текущем количестве обработанных успешных запросов и стоимости выполнения; запросы, завершившиеся сбоем, приводят к штрафам, которые повлияют на будущие решения.
Алгоритм Weighted Round Robin достаточно хорошо показал себя на практике и значительно снизил разницу между наиболее и наименее загруженными задачами. На рис. 20.6 представлены соотношения использования процессора для произвольного подмножества задач бэкенда до и после перехода клиентов с алгоритма Least-Loaded Round Robin на алгоритм Weighted Round Robin. Разница между наименее и наиболее загруженными задачами значительно уменьшилась.
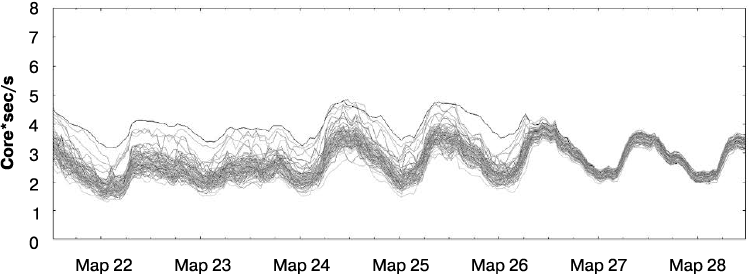
Рис. 20.6. Распределение уровня использования процессора до и после перехода на алгоритм Weighted Round Robin
Здесь под неработоспособными (unhealthy) понимаются задачи (процессы), которые не работают из-за нехватки ресурсов, но не из-за ошибки, сбоя и т.п. — Примеч. пер.
Предположительно имеется в виду исключение из рассмотрения тех задач, которые подверглись сбою или перезапуску. — Примеч. пер.

