17. Тестирование надежности систем
Авторы — Алекс Перри и Макс Люббе
Под редакцией Дианы Бейтс
Пока вы не проверили сами, считайте, что это сломано.
Неизвестный
Одной из основных обязанностей SR-инженеров являются измерение и оценка надежности обслуживаемых ими систем. Для этого SR-инженеры применяют классические методы тестирования программ, адаптируя их для своих систем в требуемом масштабе. Надежность можно оценить через ее текущий уровень и через будущий (ожидаемый). Текущий уровень надежности определяется путем анализа данных мониторинга системы, а ожидаемый прогнозируется на основе имеющихся сведений о поведении системы в прошлом. Чтобы эти прогнозы были достаточно точными и полезными, должно выполняться одно из следующих условий.
• Сайт не претерпевает никаких изменений с течением времени, для него не выпускается новое ПО и не меняется парк серверов; следовательно, будущее поведение будет аналогично текущему.
• Все изменения, происходящие с сайтом, могут быть исчерпывающим образом описаны; следовательно, вносимые ими неопределенности могут быть проанализированы и учтены.
Тестирование — это механизм, позволяющий выявить отдельные области эквивалентного поведения системы в ходе внесения в нее изменений. Каждый тест, проходящий успешно как до, так и после внесения изменений, сокращает неопределенность, которую необходимо изучать и анализировать. Тщательное (в идеале — исчерпывающее) тестирование помогает спрогнозировать будущую надежность для заданного сайта с достаточной для практического использования степенью детализации.
Необходимый объем тестирования зависит от требований к надежности системы. По мере повышения степени покрытия тестами вашего кода сокращается неопределенность и уменьшается вероятность снижения надежности в результате каждого изменения. Адекватное покрытие тестами позволяет внести больше изменений, прежде чем надежность снизится до неприемлемого уровня. Если вы вносите слишком много изменений и делаете это слишком быстро, прогнозируемый уровень надежности будет снижаться вплоть до допустимого порога. С этого момента вы, вероятно, предпочтете приостановить изменения, пока не накопятся новые данные мониторинга. Эти данные дополняют покрытие тестами, которые подтверждают надежность уже протестированных сценариев выполнения. Учитывая, что для обслуживаемых клиентов сценарии распределены случайным образом [Wood, 1996], благодаря статистической обработке наблюдаемых показателей можно экстраполировать их и на новые (еще не протестированные) сценарии. Эта статистика позволяет также определить области, для которых нужно провести более качественное тестирование или внести иные доработки.
| Связь между тестированием и средним временем восстановления Успешное прохождение теста или серии тестов еще не доказывает надежность программы. С другой стороны, если тест провалился, то это обычно доказывает ее ненадежность. Ошибки может обнаруживать и система мониторинга, но не быстрее, чем срабатывает система оповещения о них. Среднее время восстановления (Mean Time to Repair, MTTR) показывает, сколько времени требуется команде эксплуатации, чтобы ликвидировать последствия ошибки вне зависимости от способа восстановления — путем отката изменений или как-то иначе. |
| Тестирующая система может обнаруживать ошибки с нулевым временем восстановления1. Это происходит при тестировании уже собранной системы, когда тест находит ту же проблему, которая была бы обнаружена средствами мониторинга. При таком тестировании можно заблокировать проблемный код, и в «промышленную» версию эта ошибка не попадет (хотя ее все еще нужно исправить в исходном коде). Восстановление с нулевым временем восстановления путем блокирования конкретного обновления — это быстрый и удобный способ решения проблемы. Чем больше ошибок удастся найти и исправить при нулевом времени восстановления, тем больше будет среднее время между сбоями (Mean Time Between Failures, MTBF) для ваших пользователей. Рост MTBF по мере повышения степени оттестированности системы позволяет разработчикам ускорять выпуск новых функций. Некоторые из них, конечно, будут содержать ошибки. Новые ошибки снова приведут к замедлению выпуска новых версий, поскольку потребуется исправление обнаруженных ошибок. |
Авторы, пишущие о тестировании ПО, обычно сходятся в том, каково должно быть покрытие тестами. Большая часть разногласий происходит от противоречивой терминологии и различий в расстановке акцентов при оценке влияния тестирования в разных фазах жизненного цикла ПО или на разные характеристики тестируемых систем. Обсуждение тестирования в компании Google в целом вы можете найти по ссылке [Whittaker, 2012]. Следующие разделы знакомят с относящейся к тестированию терминологией, используемой в этой главе.
Виды тестирования ПО
Тесты для ПО делятся на две большие группы: традиционные и производственные. Традиционные тесты обычно применяются в ходе разработки ПО для оценки корректности обособленных программ. Производственные тесты выполняются на веб-сервисе, работающем в «промышленной» среде для того, чтобы оценить, насколько корректно ведет себя развернутая система в реальных условиях.
Традиционное тестирование
Как показано на рис. 17.1, традиционное тестирование начинается с модульного (юнит-тестов). Тестирование более сложной функциональности располагается в иерархии выше модульного.
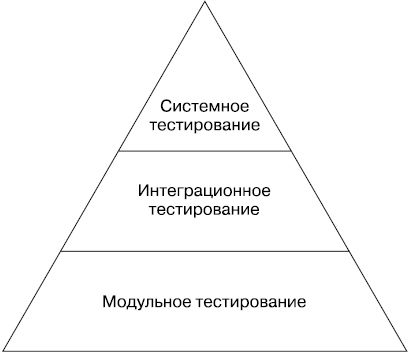
Рис. 17.1. Иерархия традиционных тестов
Модульное тестирование
Модульные тесты — это наиболее простая и наименее масштабная разновидность тестирования ПО. Они используются для того, чтобы можно было убедиться в корректности отдельного модуля или компонента («юнита») программы, например класса или функции, независимо от более крупной программы, содержащей этот компонент. Они также могут использоваться в качестве спецификации компонента, чтобы гарантировать, что функция или модуль соответствует требованиям системы. Именно модульные тесты обычно применяются для организации процесса «разработки через тестирование» (test driven development, TDD).
Интеграционное тестирование
Программные компоненты, прошедшие индивидуальное тестирование, объединяются в более крупные единицы. Для них выполняются интеграционные тесты, позволяющие убедиться, что эти компоненты корректно функционируют. Так называемая инъекция зависимостей (dependency injection), выполняемая с помощью инструментов вроде Dagger, — это очень мощный метод создания так называемых «моков» (англ. mock), моделирующих сложные зависимости и упрощающих тестирование программы. Распространенным примером этого приема служит подмена полноценной базы данных облегченным «моком», реализующим явно заданное поведение.
Системное тестирование
Системные тесты — это наиболее масштабные тесты, которые запускаются для всей развернутой системы. В систему объединяются все модули, относящиеся к определенным ее компонентам (например, серверам), которые уже прошли интеграционные тесты. Далее необходимо тестировать функциональность всей системы в целом. Системные тесты имеют множество разновидностей.
• Тесты на общую доступность (smoke tests). Это одни из самых простых системных тестов, в рамках которых проверяются очень простые, но очень важные аспекты поведения. Тесты на общую доступность также иногда называются sanity testing («тестирование исправности»), и они создают основу для более сложных тестов.
• Тесты производительности (performance tests). Как только мы убедились в работоспособности базовой функциональности системы, следующим шагом станет написание очередного системного теста, который позволит убедиться, что производительность системы будет оставаться на приемлемом уровне в течение всего жизненного цикла ПО. Поскольку время отклика для взаимосвязанных компонентов или используемых ресурсов может значительно изменяться в течение всего периода разработки, систему нужно протестировать и убедиться, что она не станет замедляться на глазах пользователей. Например, некая программа может потребовать 32 Гбайт оперативной памяти, хотя раньше она обходилась восемью, или же время ответа, равное 10 миллисекундам, увеличится сначала до 50, а затем и до 100 миллисекунд. Тесты производительности позволяют гарантировать, что с течением времени система не деградирует или не станет слишком дорогостоящей из-за необходимости наращивать ее мощность.
• Регрессионные тесты (regression tests). Еще один вид системных тестов призван предотвратить повторное проникновение ошибок в код. Регрессионные тесты можно представить как галерею ошибок, которые когда-либо привели к сбоям системы или к неверным результатам. Документирование этих ошибок как тестов системного или интеграционного уровня позволяет при переписывании кода убедиться, что в нем снова не появились те ошибки, на поиск и исправление которых уже были потрачены время и силы.
Важно отметить, что все эти тесты имеют свою стоимость как с точки зрения затрат времени, так и с точки зрения необходимых вычислительных ресурсов. На одном конце шкалы находятся модульные тесты, которые очень дешевы с обеих точек зрения, поскольку их можно выполнить в считаные миллисекунды на лэптопе. На другом — создание полноценного сервера со всеми взаимосвязанными компонентами (или замещающими их эквивалентами), необходимыми для запуска соответствующих тестов, может потребовать значительно больше времени — от нескольких минут до нескольких часов — и, возможно, выделения дополнительных вычислительных ресурсов. Понимание этого важно для повышения продуктивности труда разработчиков, а также способствует более эффективному использованию средств тестирования.
Тестирование в промышленном окружении
Тесты в промышленном окружении (тесты в рабочей среде, production tests), в противоположность тестам в изолированной тестовой среде, взаимодействуют с реально работающей системой. Они очень похожи на мониторинг по методу черного ящика (см. главу 6), поэтому такой подход иногда называют тестированием методом черного ящика. Такие тесты критически важны для обеспечения надежной работы сервиса под реальной нагрузкой.
| Путаница из-за обновлений Часто говорят, что тестирование выполняется (или должно выполняться) в изолированной (герметичной) среде [Narla, 2012]. Это утверждение подразумевает, что промышленная среда — не изолированная. Конечно, она обычно не бывает изолированной, поскольку установка обновлений в виде небольших, хорошо изученных и протестированных фрагментов регулярно вносит изменения в действующую систему и ее окружение. Чтобы справиться с неопределенностью и оградить пользователей от рисков, изменения можно устанавливать в действующую систему не в том порядке, в котором они появляются в системе контроля версий. Обновления часто проходят в несколько этапов с помощью механизмов, которые последовательно модифицируют пользовательскую среду, сопровождая это мониторингом на каждом шаге, чтобы гарантировать отсутствие неожиданных, хотя и предсказуемых проблем в новом окружении. В результате все «промышленное» окружение в целом заведомо не соответствует полностью какой-либо конкретной версии, хранящейся в системе контроля версий. Система контроля версий позволяет иметь несколько версий исполняемых файлов и связанных с ними конфигураций, ожидающих переноса на действующую систему. В такой ситуации могут возникнуть проблемы, если тесты выполняются в этой системе. Например, тест может использовать последнюю версию конфигурационного |
| файла из системы контроля версий в сочетании с работающей более старой версией файла программы. Или же вы можете запустить тест с более старой версией конфигурационного файла и увидеть ошибку, которая уже исправлена в более новой версии этого файла. Аналогично системный тест может использовать конфигурационные файлы для сборки своих модулей перед запуском теста. Если этот тест проходит успешно, но конфигурационный тест (их мы рассмотрим в следующем разделе) для этой версии — неуспешно, то результат нашего теста будет корректен в изолированной среде, но не для реально функционирующей системы. Такой результат нас не устраивает. |
Тестирование конфигураций
В компании Google конфигурации веб-сервисов описаны в файлах, которые хранятся в нашей системе контроля версий. Для каждого конфигурационного файла отдельный тест конфигурации проверяет, как реально настраивается конкретная программа, и сообщает о найденных несоответствиях. Такие тесты изначально не являются изолированными, поскольку работают за пределами «песочницы» тестового окружения.
Тесты конфигурации создаются (и тоже тестируются!) для каждой конкретной версии конфигурационного файла, сохраненного в системе контроля версий. Сопоставляя то, какая версия теста проходит относительно целевой версии, можно косвенно судить о том, насколько текущая «промышленная» версия системы отстает от «разработчицкой».
Эти негерметичные конфигурационные тесты оказываются особенно полезны как часть распределенной системы мониторинга, поскольку закономерности их успешного и неуспешного прохождения в промышленном окружении помогает выявлять в иерархии сервисов сценарии, для которых нет адекватной комбинации локальных конфигураций. Правила мониторинга пытаются найти эти нежелательные сценарии среди сценариев выполнения реальных запросов пользователей, взятых из журналов трассировки. Любые найденные совпадения становятся оповещениями о небезопасности текущей версии и/или выполняемой модификации, и нужно это каким-то образом исправить.
Конфигурационные тесты могут быть очень простыми, когда при развертывании в промышленной среде используется реальное содержимое файла и выполняется запрос в реальном времени для получения копии содержимого. В таком случае код теста просто выполняет этот запрос и сравнивает полученный ответ с файлом. Тесты становятся более сложными, если конфигурации:
• неявно содержат (то есть учитывают) значения по умолчанию, присутствующие в файле программы (это означает, что тесты соответствуют только «своим» версиям программ);
• проходят через препроцессор (например, скрипт bash), превращаясь в параметры командной строки (происходит преобразование тестовой конфигурации по заданным правилам);
• относятся к разделяемой среде выполнения (это делает тесты зависимыми от графика установки обновлений других компонентов в ней).
Нагрузочное тестирование
Для того чтобы безопасно эксплуатировать систему, SR-инженерам необходимо знать ограничения как самой системы, так и отдельных ее компонентов. Компоненты под нагрузкой в определенный момент вместо корректного прекращения работы нередко терпят аварии или порождают катастрофические сбои. Нагрузочные тесты (или стресс-тесты) служат для того, чтобы определить допустимые границы нагрузки для веб-сервиса. Нагрузочное тестирование отвечает на следующие вопросы.
• Насколько заполненной может быть база данных, прежде чем она начнет давать сбои?
• Сколько запросов в секунду может быть отправлено на сервер, прежде чем начнутся его отказы из-за перегрузки?
Канареечное тестирование
Как можно заметить, канареечные тесты (canary) отсутствуют в списке тестов промышленного окружения. Термин canary происходит от выражения canary in a coal mine («канарейка в угольной шахте») и изначально относился к практике использования живой птицы для обнаружения ядовитых газов в шахте до того, как ими отравятся люди.
В ходе канареечного теста обновление версии программ или конфигурации устанавливается на определенную часть серверов, которые остаются в этом состоянии на время «инкубационного периода». Если за это время не случается никаких неожиданностей, установка обновлений продолжается для остальных серверов прогрессирующими темпами. Если же что-то идет не так, то каждый отдельно взятый сервер можно откатить до известного предыдущего стабильного состояния. Такой прием с инкубационным периодом мы обычно называем «просушкой» (англ. baking the binary).
Канареечный тест — это не столько тест, сколько спланированная и организованная приемка версии пользователями. В то время как конфигурационные и нагрузочные тесты подтверждают наличие особых состояний в конкретных программах, канареечный тест решает другую задачу. Он лишь показывает, как программа работает с менее предсказуемым реальным трафиком, при этом он не всегда обнаруживает новые ошибки, и в этом его несовершенство.
Рассмотрим конкретный пример канареечного теста: возьмем некую ошибку, которая относительно редко влияет на пользовательский трафик, и посмотрим, как она себя проявляет в экспоненциально распространяемом обновлении. Накапливающееся количество зафиксированных отклонений ожидается равным CU = RK, где U — это порядок ошибки (эта величина будет определена позже), R — частота появления ошибок, а K — период, в течение которого объем трафика возрастает в e раз (или, что то же самое, на 172 %).
Чтобы избежать негативной реакции пользователей, версию с нежелательными отклонениями в работе нужно быстро откатить к предыдущей конфигурации. За то короткое время, которое потребуется для обнаружения проблемы и исправления, будет, скорее всего, сгенерировано еще несколько отчетов. Когда пыль осядет и все успокоится, с помощью этих отчетов можно будет оценить накопленное количество ошибок C и частоту R.
Путем деления и масштабирования на величину периода K получим примерное значение U — порядок ошибки. Рассмотрим несколько примеров.
• U = 1. Пользовательский запрос столкнулся с кодом, который попросту не работает.
• U = 2. Пользовательский запрос случайным образом повреждает данные, которые может увидеть один из последующих пользовательских запросов.
• U = 3. Данные, поврежденные случайным образом, также являются корректным идентификатором для предыдущего запроса.
Большинство дефектов имеют первый порядок: они масштабируются линейно относительно роста пользовательского трафика [Perry, 2007]. Как правило, их можно отследить, преобразовав в регрессионные тесты журналы всех запросов с ненормальными результатами. Для дефектов более высокого порядка эта стратегия не работает: запрос, который регулярно выдает ошибку, выполняясь по порядку после ряда предыдущих, внезапно начинает работать нормально, если опустить некоторые из них. Важно выявить эти и подобные дефекты еще в процессе установки обновлений, поскольку эксплуатационная нагрузка возрастает очень быстро — экспоненциально.
Учитывая соотношение дефектов высокого и низкого порядков, при использовании стратегии экспоненциального распространения обновлений не обязательно добиваться полностью сбалансированного деления пользовательского трафика. Пока каждый метод для заданной части трафика применяет один и тот же интервал K, примерное значение U будет корректным, даже если вы не можете определить, какой именно метод помог обнаружить ошибку. Последовательно применяя множество методов и допуская при этом некоторые перекрытия, удается поддерживать значение K небольшим. Такая стратегия минимизирует общее количество встречаемых пользователем отклонений C, позволяя получить раннюю оценку величины U (конечно же, вы надеетесь получить 1).
Окружения сборки и тестирования проекта
Было бы здорово продумывать эти тесты и прорабатывать сценарии сбоя с первого же дня работы над проектом, но зачастую SR-инженеры присоединяются к разработчикам уже на стадии реализации — когда выбранная модель проверена и утверждена, библиотеки проверены на масштабируемость алгоритмов и, возможно, уже готовы макеты всех пользовательских интерфейсов. Но база кода команды все еще остается в состоянии прототипов, а полноценное тестирование еще не внедрено и, вероятно, даже не спланировано. С чего вы должны начинать тестирование проекта в таких ситуациях? Строить полное покрытие модульными тестами всех ключевых функций и классов — удручающая перспектива, если текущее тестовое покрытие невелико или вовсе отсутствует. Лучше начинать тестировать так, чтобы с минимальными усилиями получить наибольшую отдачу.
Вы можете начать работу, задав следующие вопросы.
• Можно ли каким-либо способом выделить наиболее важное место в базе кода? Экстраполируя принцип, известный из разработки и управления проектами, если все задачи имеют одинаково высокий приоритет, то высокого приоритета не имеет ни одна из них. Можно ли отсортировать по важности компоненты тестируемой системы?
• Существуют ли функции и классы, которые однозначно необходимы для конкретной задачи или для потребительских качеств? Например, код, который отвечает за биллинг, обычно важен для заказчика. Код биллинга также зачастую отделен от других частей системы.
• С какими API будут работать другие команды? Даже если ошибки будут выявлены финальными тестами и не затронут пользователей, они способны дезориентировать другую команду разработчиков, которые из-за этого могут написать неверные (или неоптимальные) приложения для вашего API.
Передача в эксплуатацию некорректно работающего ПО — это главный смертный грех разработчика. Создать набор тестов на общую доступность для каждой выпускаемой версии совсем не трудно. Давая большой эффект при малых затратах, это может стать первым шагом на пути к созданию хорошо протестированного, надежного ПО.
Одним из способов создания строгой культуры тестирования является документирование всех обнаруженных ошибок и дефектов как «тестовых случаев». Если каждый дефект превратится в тест, то ожидаемо, что каждый тест поначалу будет проходить неуспешно, поскольку дефект еще не устранен. По мере того как инженеры будут исправлять ошибки, программа начнет успешно проходить тесты и вы встанете на путь создания полного набора регрессионных тестов.
Еще один ключевой фактор для создания хорошо протестированного ПО — настройка инфраструктуры тестирования. Основой для мощной инфраструктуры тестирования служит система контроля версий, которая отслеживает каждое изменение в базе кода.
Как только настроите систему контроля версий, вы сможете добавить систему непрерывной сборки, которая будет автоматически выполнять сборку программ при каждом изменении в базе кода. По нашим наблюдениям, инженеров следует сразу же оповещать, если очередные изменения привели к ошибкам. Я рискую озвучить очевидное, но очень важно, чтобы последняя версия программного проекта в системе контроля версий всегда была полностью работоспособной. Когда система, отвечающая за сборку проекта, оповещает разработчиков о неработающем коде, они должны приостановить выполнение всех других задач и заняться решением этой проблемы. Относиться к дефектам с такой серьезностью важно по нескольким причинам.
• Как правило, новые изменения, внесенные после появления дефекта, затрудняют его исправление.
• Дефектное ПО замедляет команду, поскольку приходится искать способы временно обойти проблему.
• Регулярный выпуск новых версий, например ночные и еженедельные сборки, становятся бесполезными.
• Намного проблематичнее становится выпускать срочные обновления (например, для устранения уязвимости в системе безопасности).
Так сложилось, что в мире SRE концепции стабильности и гибкости обычно противоположны друг другу. В последнем пункте показан интересный случай, когда стабильность приносит с собой гибкость. Когда сборка работает надежно, разработчики могут быстрее создавать новые версии!
Некоторые системы для сборки ПО, вроде Bazel, имеют ценную функциональность, которая позволяет более четко управлять процессом тестирования. Например, Bazel создает графы зависимостей для программных проектов. Когда в некий файл вносится изменение, Bazel выполняет повторную сборку только той части проекта, которая зависит от этого файла. Такие системы обеспечивают возможность воспроизводимых сборок. Вместо запуска всего набора тестов при каждом изменении в проекте тесты будут выполняться только для изменившихся файлов. В результате тестирование становится дешевле и быстрее.
Существует множество инструментов, которые помогут вам рассчитать и визуализировать необходимый уровень тестового покрытия [Cranmer, 2010]. Используйте их для формулирования целей и расстановки приоритетов тестирования: вам нужно подойти к процессу создания хорошо протестированного кода как к инженерному проекту, а не к философскому упражнению. Вместо того чтобы повторять двусмысленную фразу «Нам нужно больше тестов», установите явные цели и сроки.
Помните, что не все программы создаются одинаково. Критически важные системы требуют гораздо более качественного тестирования и гораздо лучшего покрытия тестами, чем скрипт, не устанавливаемый на «промышленный» сервер и имеющий небольшой срок жизни.
Масштабирование тестирования
Теперь, когда мы рассмотрели основы тестирования, взглянем, как служба SRE, применяя системный подход к тестированию, обеспечивает сохранение надежности при масштабировании систем.
Небольшой тест отдельного модуля может иметь короткий список зависимостей: один файл исходного кода, тестирующая библиотека, динамически подключаемые библиотеки, компилятор и аппаратная платформа, на которой запускаются тесты. Правильно построенная среда тестирования требует наличия тестовых покрытий для всех этих зависимостей, и их тесты должны проверять все специфические варианты использования, ожидаемые другими компонентами среды. Если реализация теста зависит от участка кода внутри подключаемой библиотеки, не покрытого тестами, то не связанное с ним напрямую изменение среды может привести к тому, что модуль будет проходить тест успешно независимо от наличия в нем ошибок.
В противоположность этому, тест готового продукта может зависеть от огромного множества других компонентов системы, потенциально — от каждого объекта кода. Если тест должен выполняться в чистом промышленном окружении, то каждое небольшое изменение потребует полного восстановления среды. На практике для тестовой среды стараются выбирать точки ветвления версий. Это позволяет протестировать как можно больше зависимостей за минимальное количество итераций. Конечно, если в какой-либо ветви обнаруживается ошибка, необходимо выбрать дополнительные точки ветвлений.
Тестирование масштабируемых инструментов
Инструменты SRE нуждаются в тестировании так же, как и любые другие программы. Инструменты, разработанные в отделе SRE, могут выполнять следующие задачи.
• Съем показателей производительности баз данных.
• Прогнозирование показателей использования для планирования рисков, связанных с емкостью.
• Рефакторинг данных «теневого» экземпляра сервиса, недоступного пользователю.
• Изменение файлов на сервере.
Инструменты SRE имеют две общие характеристики.
• Их побочные эффекты остаются скрыты внутри протестированного основного API.
• Они изолированы от запущенных пользовательских систем существующим барьером валидации процедур выпуска обновлений.
| Барьеры для защиты от небезопасного ПО Использование программ, работающих в обход обычного хорошо протестированного API (даже если это делается без злого умысла), может обернуться хаосом на промышленном сервисе. Например, реализация ядра СУБД может позволить администраторам временно отключить механизм транзакций, чтобы сократить затраты времени на обслуживание. Если эта же реализация используется и для ПО, выполняющего запись в базу в пакетном режиме, изоляция пользователей может оказаться нарушенной при любом обращении к доступной многим пользователям действующей копии базы. Предотвратить риск таких разрушительных последствий позволяют проектные решения. 1. Используйте отдельный инструмент для того, чтобы настроить барьер в конфигурации процедуры репликации таким образом, чтобы копия не проходила проверку работоспособности. В результате эта копия не будет доступна для пользователей. 2. Конфигурируйте небезопасное ПО так, чтобы оно при запуске проверяло наличие барьера. Позволяйте небезопасному ПО работать только с неактивными копиями базы. 3. Используйте средства проверки работоспособности копий базы при мониторинге методом черного ящика для корректного преодоления барьера. |
Средства автоматизации — это тоже программы. Поскольку связанные с ними риски оказываются на другом уровне в иерархии сервисов, они не нуждаются в столь тщательном тестировании. Средства автоматизации выполняют следующие задачи.
• Выбор индексов базы данных.
• Балансировка нагрузки между дата-центрами.
• Выборка и сортировка содержимого журналов активных узлов сети для быстрого ремастеринга.
Все средства автоматизации обладают двумя общими свойствами.
• Работают с устойчивым, предсказуемым и хорошо протестированным API.
• Результаты их работы можно рассматривать как побочный эффект, невидимый для других клиентов этого API.
Тестирование позволяет продемонстрировать желаемое поведение других уровней иерархии сервисов до и после внесения изменений. Часто также можно проверить, изменяется ли внутреннее состояние инструмента за время его работы, насколько это видно посредством API. Например, базы данных продолжают выдавать корректные ответы на запросы, даже если для них нет подходящих индексов. С другой стороны, некоторые сущности API, документированные как неизменяемые (например, кэш DNS, содержимое которого сохраняется в течение времени TTL), могут изменяться от операции к операции. Скажем, если изменение уровня (режима) исполнения сервиса заменяет локальный сервер имен кэширующим прокси-сервером, в обоих случаях результаты запросов должны сохраняться сервером на протяжении достаточно длительного времени, однако вряд ли состояние кэша будет при переключении передано от одного сервера другому.
Если средства автоматизации подразумевают дополнительные тесты исполняемых файлов для проверки поведения в различном окружении, то как вы определите, в каком именно окружении они работают? В конце концов, инструмент автоматизации, реализующий перемещение программных контейнеров для оптимального перераспределения нагрузки, скорее всего, попытается в какой-то момент оптимизировать сам себя, если он тоже работает как контейнер. И было бы крайне неприятно, если бы новая версия его внутреннего алгоритма заполняла страницы памяти так быстро, что полоса пропускания сети и промежуточных зеркал оказалась бы исчерпана, не позволяя завершить перемещение работающего кода. Даже при наличии интеграционного теста, для которого бинарный файл целенаправленно перетасовывает сам себя, он, скорее всего, использует гораздо меньший набор контейнеров, чем в реальном промышленном окружении. Ему вряд ли дадут использовать дефицитные и обладающие большой задержкой глобальные каналы связи для тестирования таких ситуаций.
Интереснее бывает, когда один инструмент автоматизации может изменять окружение, в котором работает другой. Или же два инструмента одновременно меняют окружение друг друга! Например, инструмент для установки обновлений парка машин скорее всего постарается забрать себе как можно больше ресурсов в ходе такой установки обновлений. В результате балансировщик контейнеров решит переместить контейнер с этим инструментом. Но в этот момент очередь обновляться может дойти до самого балансировщика. Такая круговая зависимость может и не причинить вреда, но только если для используемых API реализована возможность перезапуска, если эту логику не забыли протестировать и если есть независимая проверка работоспособности инструментов.
Тестируем катастрофы
Многие средства восстановления после аварий сознательно проектируются так, чтобы они работали автономно (офлайн). Они выполняют следующие задачи.
• Определение состояний в контрольных точках, соответствующих нормальной остановке сервиса.
• Сохранение состояний в контрольных точках для использования их существующими средствами проверки, применяемыми в нормальном (не аварийном) режиме.
• Поддержка обычных средств организации барьеров, которые инициируют процедуру корректного старта.
Во многих случаях вы можете реализовать эти фазы так, чтобы связанные с ними тесты было удобно писать и они покрывали большую часть программы. Если же приходится нарушать какие-либо из ограничений (работа в режиме офлайн, контрольные точки, загружаемость, барьеры или корректный старт), то вам будет гораздо труднее обеспечить уверенность в том, что соответствующий инструмент сработает в любой момент по первому требованию.
Онлайн-инструментам восстановления свойственно работать вне рамок основных API, поэтому их тестирование более интересно. Одна из проблем, с которой вы можете столкнуться при тестировании распределенной системы, — выявление ситуации, когда нормальное поведение, корректное по своей сути, неправильно взаимодействует с процедурами восстановления. Например, рассмотрим попытку анализировать условия возникновения гонок с помощью офлайн-инструментов. Офлайн-инструменты в общем случае рассчитаны на более простую проверку корректности состояния в конкретный отдельно взятый момент, а не в процессе функционирования в течение некоторого промежутка времени. Положение осложняется тем, что участвующие в гонках исполняемые файлы (работающая промышленная версия и предназначенная для восстановления) обычно собираются отдельно друг от друга. Следовательно, для использования в этих тестах вам понадобится специальный исполняемый файл с предусмотренным унифицированным интерфейсом для инструментов, чтобы они могли отслеживать транзакции.
| Использование статистических тестов Статистические методы вроде Lemon (Ana07) для «нечеткого тестирования», Chaos Monkey1 и Jepsen2 для состояния распределенных систем не обязательно будут повторяемыми. Простой перезапуск таких тестов после изменения кода не может однозначно доказать, что наблюдаемая ошибка исправлена3. Однако в ряде случаев они могут быть полезны. Они могут обеспечить журналирование всех случайно выбранных операций, выполнявшихся при заданном прогоне, — иногда просто записывая в журнал начальное значение генератора случайных чисел. Если такой журнал служит для тестирования готового продукта, может быть полезно выполнить несколько прогонов до создания отчета об ошибке. Процент успешно завершившихся тестов покажет вам, насколько сложно будет в дальнейшем доказать, что ошибка исправлена. Различные варианты проявления ошибки могут помочь вам более точно определить подозрительные области вашего кода. При последующих запусках могут обнаружиться более серьезные сбойные ситуации. Поэтому, возможно, вам потребуется усугубить влияние этой ошибки в тестах. |
В погоне за скоростью
Для каждой версии или обновления-заплатки (патча) в репозитории кода каждый отдельно взятый тест показывает, пройден он или нет. Эти данные могут меняться при повторяющихся и, казалось бы, идентичных запусках. Вы можете оценить вероятность прохождения теста, взяв среднее значение для достаточно большого количества запусков, а также вычислить статистическую неопределенность этой оценки. Однако трудоемкость таких расчетов делает их выполнение для каждого теста и каждой версии практически невозможным.
Вместо этого лучше определить предположительное количество интересующих сценариев и запустить заданное количество прогонов каждого теста каждой версии, чтобы можно было сделать обоснованные выводы. Некоторые из этих сценариев будут исполняться благополучно (с точки зрения качества кода), а другие потребуют принять меры. Эти сценарии сказываются во всех тестах в разных масштабах, и, поскольку они связаны с гипотезами, надежное и быстрое получение списка требующих дальнейшей работы гипотез (например, о компонентах, которые сейчас неисправны) означает одновременно и получение оценки всех сценариев.
Обращаясь к инфраструктуре тестирования, разработчики хотят выяснить, работает ли их код — обычно это только небольшая часть исходного кода, которая покрыта данным тестом. И если он исправен, то зачастую подразумевается, что ответственность за все наблюдаемые сбои можно переложить на чей-то другой код. Другими словами, инженер хочет знать, возникают ли в его коде непредвиденные ситуации гонок, из-за чего прохождение теста становится нестабильным (или более нестабильным, чем оно было под действием других факторов).
| Ограничение длительности теста Большинство тестов являются простыми в том смысле, что они запускаются как замкнутый («герметичный») исполняемый файл, который за считаные секунды упаковывается в небольшой программный контейнер. Эти тесты обеспечивают разработчикам интерактивную обратную связь, которая успевает сообщить об ошибках раньше, чем инженер переключится на работу над следующей проблемой или новой задачей. Время старта тестов, которые требуют взаимодействия между несколькими исполняемыми файлами и/или всего множества контейнеров, может измеряться секундами. Такие тесты обычно не обеспечивают достаточно малое время отклика, поэтому их можно назвать уже не интерактивными, а пакетными. Вместо того чтобы сказать выполняющему тест инженеру: «Не закрывайте вкладку редактора», такие тесты завершаются как неуспешные и говорят: «Этот код не готов к проверке». Неформально длительность теста ограничивается тем моментом, когда инженер переключается на другую задачу. Результаты теста надо давать инженеру до того, как он (или она) переключится, иначе новая задача может быть как та компиляция из XCKD1. |
Предположим, инженер работает над сервисом, для которого есть около 21 000 простых тестов, и время от времени вносит исправления в кодовую базу сервиса. Чтобы протестировать каждое такое исправление, нужно сравнить векторы результатов прохождения/непрохождения теста всем содержащимся в базе кодом до и после поправки. Совпадение этих двух векторов позволяет считать текущую версию кода в базе «предварительно допущенной» к выпуску. За этим последует запуск множества финальных и интеграционных тестов, а также прочие распределенные тесты исполняемых файлов, проверяющих систему на масштабируемость (если дополнение использует значительно больше локальных вычислительных ресурсов) и на сложность (если оно порождает сверхлинейный рост нагрузки где-либо еще).
Как часто вы можете ошибаться, помечая пользовательские обновления как деструктивные из-за неверной оценки нестабильности среды тестирования? Скорее всего, пользователи будут бурно возмущаться отклонением каждого десятого обновления, но отказ в одном случае из 100 возражений вызвать не должен.
Это значит, что вам нужен корень степени 42 000 (по одному прогону каждого из 21 000 тестов до и после обновления) из 0,99 (доля обоснованно отклоняемых тестов). Формула:
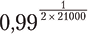
говорит, что каждый отдельный тест должен работать корректно в 99,9999 % случаев. Хм-м.
Передача в промышленную эксплуатацию
Управление конфигурациями промышленных экземпляров систем, как правило, тоже возлагается на репозиторий системы контроля версий, но конфигурации чаще хранятся отдельно от исходного кода, с которым работают программисты. Аналогично тестирующая инфраструктура часто не может «видеть» конфигурацию реальной промышленной системы. Даже если они находятся в одном репозитории, изменения в конфигурациях выполняются в разных его ветках и/или в изолированном дереве каталогов, которые в сложившейся практике игнорируются средствами автоматизации тестирования.
Традиционно программисты разрабатывают программы в своем окружении и затем переправляют их администраторам для установки на серверы. При этом разграничение конфигураций тестирования и промышленной эксплуатации в лучшем случае раздражает, а в худшем — вредит надежности и гибкости системы. Это может также приводить к дублированию программных инструментов. В результате ухудшается устойчивость и предсказуемость находящегося в эксплуатации окружения, которое должно было бы быть интегрированным, из-за неочевидных несоответствий между поведением двух наборов программ. Наконец, конфликты между конкурирующими обращениями к системам контроля версий ограничивают скорость разработки проекта.
В рамках концепции SRE также можно наблюдать негативное влияние разграничения тестовой и промышленной конфигураций — оно нарушает соответствие между моделями, которые описывают промышленную систему и поведение приложений. Это мешает выявлению еще на этапе разработки статистических несоответствий планируемым показателям. Однако вред от замедления разработки оказывается не так велик, как польза от предотвращения повреждения структуры системы, поскольку невозможно полностью избавиться от рисков при миграции.
Рассмотрим порядок унифицированного управления версиями и унифицированного тестирования, при которых применима методология SRE. Как повлияет ошибка при миграции распределенной архитектуры? Вероятно, будет выполнено какое-то достаточно большое количество тестов. Далее, предположим, что программист, скорее всего, согласится с тем, что система тестирования ошибается один раз из десяти или около того. На какие риски вы готовы пойти при миграции, зная, что тесты могут ошибаться и ситуация может стать действительно тревожной, причем очень быстро? Очевидно, некоторые области покрытия должны тестироваться более параноидально, чем другие. Эту особенность можно обобщить: ошибки, найденные одними тестами, более критичны для системы, чем найденные другими.
Ожидание сбоя тестов
Не так давно программный продукт мог выпускаться всего раз в год. Его исполняемые файлы компилировались на протяжении нескольких часов или дней, и большая часть тестирования выполнялась людьми вручную и согласно написанным вручную инструкциям. Такой процесс был неэффективным, но не было практической необходимости автоматизировать его. Затраты на выпуск новой версии в основном были связаны с документацией, миграцией данных, переобучением пользователей и другими факторами. Среднее время между сбоями (Mean Time Between Failure, MTBF) составляло один год, независимо от того, какой объем тестирования был выполнен. В новой версии появлялось так много изменений, что некоторые сбои, видимые пользователям, оказывались скрыты внутри ПО. По сути, надежность, достигнутая в предыдущей версии, не имела отношения к следующей.
Эффективные инструменты для управления API/ABI и интерпретируемые языки, масштабируемые для крупных программных систем, теперь обеспечивают возможность сборки и запуска новой версии продукта каждые несколько минут. В принципе, достаточно большая армия людей тоже может обеспечивать тестирование с тем же уровнем качества каждой новой версии (в том числе промежуточных) с помощью методов, описанных ранее. И хотя в конечном счете для одного и того же кода будут выполняться одни и те же тесты, качество финальной ежегодной версии продукта будет выше, поскольку в дополнение к ежегодным версиям будут протестированы и промежуточные версии. Благодаря промежуточным версиям вы можете однозначно соотносить найденные при тестировании проблемы с их причинами и быть уверенными в том, что устранили именно проблему, а не только ее симптом. Точно так же сокращение цикла обратной связи эффективно и применительно к автоматическому тестированию.
Если вы позволите пользователям испытать за год больше версий продукта, MTFB ухудшится, поскольку появится больше возможностей для возникновения сбоев, заметных пользователям. Однако вместе с тем вы сможете выявить области, которым пойдет на пользу дополнительное тестовое покрытие. Если эти тесты будут реализованы, каждое улучшение будет защищать от каких-то сбоев в будущем. При продуманном управлении надежностью соблюдается баланс достоверности тестового покрытия и допустимого количества видимых пользователям сбоев, а также соответствующим образом корректируется частота выпуска новых версий. Это позволяет максимизировать полезную информацию, получаемую в результате тестирования и от конечных пользователей. В итоге можно управлять тестовым покрытием и, в свою очередь, скоростью выпуска версий продукта.
Когда SR-инженеры модифицируют конфигурационный файл или оптимизируют стратегию средств автоматизации, то эта инженерная работа (противоположная реализации пользовательских функций) соответствует той же концептуальной модели. Когда вы определяете частоту выпуска версий, исходя из надежности, зачастую имеет смысл разделить «бюджет надежности» по функциональности или (что более удобно) по командам. При таком сценарии команда, разрабатывающая функциональность, стремится достичь заданного уровня достоверности тестирования, который влияет на частоту инициированных ими выпусков версий. Команда SRE, имея свой отдельный бюджет и свои критерии достоверности, может выпускать новые версии с большей частотой.
Для того чтобы оставаться надежным и при этом избегать линейного увеличения количества SR-инженеров, поддерживающих сервис, промышленное окружение должно функционировать практически без участия человека. Для этого оно должно быть устойчивым к небольшим сбоям. В случае же более серьезного происшествия, требующего ручного вмешательства SR-инженеров, используемые ими инструменты должны быть хорошо протестированы. В противном случае такое вмешательство только снижает уверенность в том, что уже накопленные данные останутся доступными и актуальными и в ближайшем будущем. Когда происходит такое снижение надежности, необходимо дождаться результатов анализа данных мониторинга, чтобы устранить неопределенность. Если подраздел «Тестирование масштабируемых инструментов» выше был в основном о том, как добиться с помощью инструментария SR-инженеров требуемого тестового покрытия, то здесь вы видите, как определить, насколько часто следует применять эти инструменты в промышленной среде.
Конфигурационные файлы существуют в общем потому, что вносить в них изменения можно гораздо быстрее, чем заново пересобирать программы. Такая оперативность зачастую бывает важным фактором поддержания низкого MTTR. Однако частые изменения в этих файлах могут иметь и другие причины. В частности, с точки зрения надежности.
• Конфигурационный файл, служащий для обеспечения малого MTTR и модифицируемый только после сбоев, имеет период обновления больший, чем MTBF. Это может привести к существенной неопределенности, является ли такое изменение (сделанное вручную) действительно оптимальным без тех изменений, которые снижали общую надежность сайта.
• Конфигурационный файл, который меняется несколько раз за время между выпусками новых версий приложения (например, потому, что в нем хранится текущее состояние приложения), может представлять серьезный риск, и к ним нужно относиться так же, как и к изменениям приложения. Такой конфигурационный файл будет снижать надежность сайта, если только покрытие тестами и средствами мониторинга для него не будет даже лучше, чем для приложения.
Один из подходов к конфигурационным файлам состоит в том, что вы должны или убедиться, что каждый конфигурационный файл попадает только в одну из описанных выше категорий, или каким-то образом обеспечить это. Если вы выберете второе, то убедитесь в следующем.
• Каждый конфигурационный файл имеет достаточное тестовое покрытие для поддержки рутинных изменений.
• Перед выпуском новой версии изменения файла каким-то образом приостанавливаются, пока не будут получены результаты финального тестирования.
• Предоставьте механизм «красной кнопки» для принудительной отправки файла на установку до завершения тестирования. Поскольку «красная кнопка» снижает надежность, то, как правило, хорошей идеей будет оповещать о сбое как можно более заметно, например создавая отчет об этой ошибке с требованием более надежного решения в следующий раз.
| «Красная кнопка» и тестирование Вы можете предусмотреть механизм «красной кнопки» для прерывания или отключения тестов собранной версии перед установкой. Это будет означать, что все, кто в последний момент вносил изменения вручную, не узнают об ошибках, пока система мониторинга не сообщит о проблемах у реальных пользователей. Лучше дать тесту продолжать выполняться, связать событие досрочной передачи версии приложения на установку с будущими событиями отсроченного тестирования и как можно оперативнее отметить и описать все неуспешные тесты. Таким образом, за принудительно установленной дефектной версией быстро последует другая (можно надеяться, более качественная). В идеале такая реализация «красной кнопки» автоматически повышает приоритет финальных тестов так, чтобы они могли опережать уже выполняющиеся рутинные инкрементальные проверки и нагрузочные тесты. |
Интеграция
После тестирования отдельно взятого конфигурационного файла с целью снижения его возможного негативного влияния на надежность также важно рассмотреть интеграционное тестирование конфигурационных файлов. Содержимое конфигурационных файлов (с точки зрения тестирования) представляет собой потенциально вредоносное содержимое для интерпретатора, читающего конфигурацию. Интерпретируемые языки вроде Python часто используются в конфигурационных файлах, поскольку их интерпретаторы могут быть встроены в программные системы; для защиты от непреднамеренных ошибок в них существуют простые «песочницы».
Написание конфигурационных файлов на интерпретируемом языке рискованно, так как такой подход чреват скрытыми сбоями, которые трудно обнаружить. Поскольку загрузка конфигурации предполагает и выполнение прочитанного содержимого, невозможно определить естественный предел трудоемкости этого процесса. Этот вид интеграционного тестирования необходим в дополнение ко всем прочим тестам. При этом следует тщательно контролировать длительность выполнения всех тестов, и тесты, которые не завершаются за заданное время, считаются неуспешными.
Если же конфигурация представляет собой текст с произвольным синтаксисом, каждая категория тестов нуждается в создании с нуля отдельного покрытия. Использование существующего синтаксиса, например YAML, в сочетании с хорошо протестированным парсером, скажем safe_load для Python, избавляет вас от части рутинной работы, связанной с конфигурационным файлом. Тщательный выбор синтаксиса и парсера может гарантировать, что у вас будет выдерживаться жесткий верхний предел времени выполнения всех операций загрузки. Однако тому, кто пишет конфигурации, приходится иметь дело с ошибками в данных и в их структуре, и наиболее простое решение состоит в отмене верхнего предела во время выполнения программы. К сожалению, эти стратегии бывают, как правило, плохо покрыты модульными тестами.
Использование ранее упоминавшихся двоичных протоколов обмена — протокольных буферов (protocol buffers, protobuf) — обеспечивает важное преимущество: структура данных (схема) определена заранее и во время загрузки проверяется автоматически, избавляя вас от еще большего количества рутины. При этом среда выполнения сохраняет ограничения.
Работа SR-инженера предполагает в том числе и написание служебных программных инструментов (если это не делает уже кто-то другой) и обеспечение тестового покрытия для проверки устойчивости системы. Все инструменты могут вести себя непредсказуемо из-за ошибок, не обнаруженных при тестировании, поэтому защиту рекомендуется строить многоуровневой. И когда один из них ведет себя неожиданно, инженеры должны быть максимально уверены в том, что большинство остальных их инструментов работает корректно, чтобы иметь возможность справиться с последствиями такого поведения. Ключевую роль в обеспечении надежности сайта играют поиск всевозможных видов неправильного поведения и обеспечение того, что какой-либо тест (или протестированный валидатор входных данных другого инструмента) сообщит об этом поведении. Инструмент, который обнаружил проблему, может и не иметь возможности ее исправить или хотя бы остановить ее развитие, но он обязан как минимум сообщить о проблеме до того, как произойдет катастрофический сбой.
Рассмотрим сконфигурированный список всех пользователей (например, /etc/passwd на работающей на базе Unix машине, не подключенной к сети) и представим, что внесенное изменение непреднамеренно приводит к остановке парсера после обработки всего половины файла. Поскольку в результате не будут загружены лишь пользователи, созданные недавно, машина, скорее всего, продолжит работать без проблем и многие пользователи не заметят ошибки. Инструмент, который обслуживает домашние каталоги пользователей, может легко найти несоответствие списка существующих каталогов загруженному неполному списку пользователей и оперативно сообщит об этом. Роль этого инструмента заключается именно в том, чтобы сообщить о проблеме, и он не должен исправлять ее самостоятельно (путем удаления данных пользователей).
Зондирование системы в промышленной эксплуатации
Если тестирование обеспечивает корректность поведения для известных данных, а система мониторинга подтверждает ее для неизвестных, может показаться, что большинство источников рисков — как известных, так и неизвестных — будут покрыты этой совокупностью тестирования и мониторинга. К сожалению, реальные риски зачастую куда более сложны.
Известные «хорошие» (корректные) запросы должны выполняться успешно, а известные «плохие» — завершаться с ошибкой. Удачное решение — реализовать покрытия и тех и других в виде интеграционных тестов. Тот же набор тестовых запросов может быть повторен и как финальный тест. Разбиение известных «хороших» запросов на группы, которые могут быть воспроизведены в условиях реальной промышленной эксплуатации и которые так воспроизводить нельзя, приводит к выделению трех категорий, таких как:
• известные «плохие» запросы;
• известные «хорошие» запросы, которые можно воспроизвести в промышленной среде;
• известные «хорошие» запросы, которые нельзя воспроизвести в промышленной среде.
Вы можете использовать запросы из каждой категории в качестве как интеграционных, так и финальных тестов. Большая часть этих тестов также может быть использована для мониторинга в качестве зондов.
Может показаться избыточным и, в принципе, бессмысленным разворачивать такую систему мониторинга, поскольку точно такие же запросы уже были испытаны путем выполнения их двумя другими способами. Однако эти два способа отличаются по нескольким критериям.
• При финальном тестировании, вероятно, собранный сервер был снабжен фронтендом и искусственным «тестовым» бэкендом.
• При нагрузочном тестировании, возможно, проверяемый исполняемый файл работал с фронтендом, балансирующим нагрузку, и с отдельным масштабируемым устойчивым бэкендом.
• Фронтенды и бэкенды могут иметь независимые циклы выпуска новых версий. И, скорее всего, запланированные версии будут выходить с разной частотой (из-за адаптивных интервалов).
В результате зондирующие запросы мониторинга, выполняемые в промышленной среде, будут работать в конфигурации, которая не была протестирована ранее.
Эти запросы всегда должны работать корректно, но что будет означать их ошибка, если она все-таки произойдет? Либо API фронтенда (балансировщика нагрузки), либо API бэкенда (постоянного хранилища данных) для промышленного и тестового окружения оказались неэквивалентными. Если только вы не знаете заранее, почему эти окружения не эквивалентны, сайт считается нерабочим.
Та же программа для обновления промышленного окружения, которая постепенно заменяет приложение, постепенно заменяет и зондирующие запросы мониторинга, поэтому все четыре комбинации старых или новых зондов, которые отправляются старым или новым приложениям, продолжат генерироваться. Эта программа обновления может обнаружить, что одна из четырех комбинаций генерирует ошибки, и откатиться к последнему известному корректному состоянию. Обычно программа обновления предполагает, что каждое только что запущенное приложение является неработоспособным в течение некоторого небольшого времени, пока не будет готово принимать большой объем пользовательского трафика. Если анализ зондов мониторинга включен в проверку готовности, обновление будет постоянно считаться неработоспособным и пользовательский трафик к новой версии приложения отправляться не будет. Обновление будет приостановлено, пока у инженеров не появится время и желание диагностировать сбой, а затем указать программе обновления выполнить откат.
Такой производственный тест с помощью зондов мониторинга защищает сайт и дает прямую, понятную обратную связь для инженеров. Эта обратная связь тем полезнее, чем раньше она доставляет инженерам информацию. Предпочтительно также, чтобы тесты были автоматизированы для масштабируемости механизмов оповещения инженеров.
Предположим, что каждый компонент имеет более старую версию, которая была заменена, и новую, которая выпускается (сейчас или очень скоро). Новая версия одного компонента может взаимодействовать со старой версией другого, что заставляет ее использовать устаревший API. Или же старая версия может взаимодействовать с новой версией хоста, используя API, который на момент выпуска старой версии еще не работал должным образом. Но теперь он работает, честно! Вам остается надеяться на лучшее — что эти тесты для будущей совместимости (которые работают как зонды мониторинга) имеют хорошее покрытие API.
| Имитация бэкендов При создании финальных тестов имитаторы бэкендов зачастую поддерживаются командой разработчиков сервиса, с которым необходимо взаимодействовать, и просто включаются в список зависимостей сборки. Герметичный тест, выполняемый инфраструктурой тестирования, всегда объединяет имитационный бэкенд и тестовый фронтенд в одной точке сборки в истории контроля версий. Эта зависимость может представлять собой герметичный исполняемый файл, и в идеале команда, которая его поддерживает, выпускает этот имитатор бэкенда вместе с выпуском основного приложения бэкенда и его тестов-зондов для мониторинга. Когда такая версия бэкенда собрана, может иметь смысл включить герметичные финальные тесты фронтенда (без имитатора бэкенда) в пакет новой версии фронтенда. Ваша система мониторинга должна знать обо всех выпускаемых версиях с обеих сторон заданного интерфейса сервиса. Это позволяет гарантировать, что воссоздание любой из комбинаций двух версий и проверка прохождения теста, не потребуют трудоемкого дополнительного конфигурирования. Такой мониторинг не должен быть постоянным — вам нужно запустить лишь новые комбинации, являющиеся результатом выпуска новой версии обеими командами. Такие проблемы сами по себе не должны блокировать эту новую версию. С другой стороны, средства автоматизации установки в идеале должны блокировать соответствующее промышленное обновление до тех пор, пока проблемные комбинации не будут исключены. Аналогично средства автоматизации команды взаимодействующего сервиса могут постараться отвести трафик от экземпляров сервиса, имеющих проблемные комбинации, и обновить их. |
Итоги главы
Тестирование — это одно из наиболее эффективных вложений в надежность программного продукта. Тестирование выполняется не раз и не два, а непрерывно на протяжении всего жизненного цикла проекта. Написание хороших тестов требует достаточно больших усилий, равно как и построение и поддержание инфраструктуры, которая поощряет хорошую культуру тестирования. Вы не можете исправить проблему до тех пор, пока не поймете ее, а в технике вы можете понять проблему, только измерив ее. Методологии и приемы, рассмотренные в этой главе, дают серьезную основу для количественной оценки ошибок и уровня достоверности в программных системах, чем помогают инженерам делать выводы о надежности ПО, когда оно уже выпущено и передано пользователям.
В этой главе объясняется, как получить наибольший эффект от усилий, затрачиваемых на тестирование. Как только инженер сможет представить тесты, требуемые для заданной системы, в некотором обобщенном виде, остальная часть процесса будет одинакова для всех SRE-команд и к ней можно будет относиться как к общей инфраструктуре. Эта инфраструктура состоит из планировщика (для совместного доступа не связанных друг с другом проектов к общим ресурсам) и ряда «исполнителей» (которые тестируют бинарные файлы в «песочнице», что позволяет не беспокоиться об их безопасности). Оба этих компонента инфраструктуры можно рассматривать как обычные службы, поддерживаемые SR-инженерами и наиболее похожие на хранилище масштаба кластера. Здесь эта тема подробно рассматриваться не будет.
Более подробно об эквивалентности можно прочитать по следующей ссылке: .
Ошибки, выявленные на этапе тестирования, не требуют восстановления как такового, так как система еще не работает с реальными данными. — Примеч. пер.
Этот уровень тестирования называют также «тестированием компонентов», но в данной книге термин «компоненты» применяется обычно к более крупным структурным единицам. — Примеч. пер.
См. /.
«Мок» (англ. mock) — используемая при тестировании и отладке вставка-имитатор для замещения более сложного компонента, обращение к которому неудобно или невозможно. При этом «мок» воспроизводит упрощенную логику имитируемого компонента, чем отличается от простейшей заглушки — «стаба» (англ. stub). — Примеч. пер.
«Песочница» (англ. sandbox) — искусственное замкнутое окружение, создаваемое для выполнения некоторой программы или программ. Все результаты работы этих программ ограничиваются рамками «песочиницы». — Примеч. пер.
Типичная практика состоит в том, что обновление затрагивает сначала только 0,1 % пользовательского трафика, а затем эта величина возрастает на порядок каждые 24 часа с одновременным изменением географии обновлений (во второй день 1 %, в третий — 10 %, в четвертый — 100 %).
Практика канареечного тестирования выглядит не вполне честно по отношению к пользователям, которые в роли «канареек» рискуют временем и данными. Однако в ряде случаев воспроизвести все особенности реальных сценариев в изолированной тестовой среде практически невозможно. — Примеч. пер.
Например, предполагая, что мы имеем 24-часовой интервал непрерывного экспоненциального роста от 1 до 10 %, получим
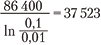
секунды, или примерно 10 часов 25 минут.
Мы используем понятие «порядок» в смысле нотаций «“О” большое» и «“о” малое». Для получения более подробной информации пройдите по ссылке .
Если вы хотите получить более подробную информацию по этой теме, рекомендуем вам прочесть книгу [Bland, 2014], написанную нашим бывшим коллегой Майком Бландом.
Можно отметить парадоксальный эффект: чем больше ошибок в программе изначально, тем лучше ее покрытие тестами такого рода. — Примеч. пер.
Сейчас чаще говорят о «непрерывной интеграции», имея в виду практически то же самое: сборка и затем тестирование инициируются не как отдельные стадии, а после любых изменений в файлах проекта. Для сложного проекта это позволяет более оперативно выявлять дефекты. — Примеч. пер.
См. .
С графами зависимостей работали еще утилита make и ей подобные, но здесь речь идет о более высоком уровне автоматизации процесса и о включении в него также и тестирования. Под воспроизводимостью, вероятно, авторы имеют в виду возможность повторять такую частичную сборку (и тестирование) быстрее и чаще. — Примеч. пер.
Например, тестируемый код служит оберткой для нетривиального API и обеспечивает более простую абстракцию с обратной совместимостью. Этот API, который привыкли считать синхронным, становится асинхронным и возвращает future — особую разновидность результата, значение которого не всегда определно. Ошибка аргументов вызова по-прежнему приводит к исключению, но лишь после того, как значение future перестанет быть неопределенным. Тестируемый код передает возвращенный из API результат вызывающей стороне напрямую, не анализируя его. При этом многие случаи ошибочных аргументов могут остаться незамеченными.
В этом разделе рассматриваются инструменты службы SRE, которые должны быть масштабируемыми. Однако SR-инженеры разрабатывают и используют также и инструменты, которым масштабируемымость не нужна. Такие инструменты тоже необходимо тестировать, но они в этом разделе не рассматриваются. Поскольку по характерным проблемам они схожи с пользовательскими приложениями, для них могут применяться аналогичные стратегии тестирования.
См. .
См. .
Даже если запуск теста повторяется с одинаковым начальным состоянием генератора случайных чисел и сигналы для процессов генерируются в одном и том же порядке, синхронизация между этими сигналами и тестовым пользовательским трафиком не соблюдается. Поэтому нельзя гарантировать, что воспроизведены те же пути выполнения кода, которые наблюдались ранее.
См. /.
Возможно, набранных с помощью Mechanical Turk или похожих служб.
Имеется в виду, что файл содержит не данные (числовые, текстовые и т.п.), а фрагменты кода на некотором языке. Фактически это можно рассматривать как часть программного кода системы, который, однако, устанавливается в обход правил и ограничений, действующих для исполняемых файлов. — Примеч. пер.
См. .
Не потому, что программисты не должны их писать. Инструменты, которые нарушают обычную иерархию программных средств и охватывают несколько уровней абстракции, с командами системных инженеров обычно соотносятся несколько лучше, чем с большинством команд разработчиков.

