18. Разработка ПО службой SRE
Авторы — Дейв Хелструм и Триша Вейр
при участии Эвана Леонарда и Курта Делимона
Под редакцией Кавиты Джулиани
Попросите кого-либо назвать программный продукт компании Google, и вы услышите название одного из пользовательских продуктов вроде Gmail или Maps; кто-то даже может упомянуть инфраструктурные решения вроде Bigtable или Colossus. В действительности же существует также огромный объем ПО «за кулисами», которое пользователи никогда не видят. Некоторые из этих программных продуктов разработаны внутри Google SRE.
Производственная среда компании Google по некоторым показателям одна из самых сложных систем, построенных человеком. SR-инженеры имеют из первых рук опыт работы с хитросплетениями производственной среды. Это делает их уникальным образом подходящими для разработки необходимых инструментов для решения внутренних задач в ситуациях, связанных с обеспечением доступности систем в промышленной эксплуатации. Большая часть этих инструментов направлена на обеспечение доступности сервисов и низкой задержки отклика, но они могут принимать различные формы, например механизмы развертывания исполняемых файлов, системы мониторинга или среды разработки на основе динамической компоновки сервера. В целом, эти разработанные службой SRE инструменты представляют собой законченные программные проекты, которые отличаются от одноразовых решений и быстрых «костылей», а в основе образа мыслей разработавших их SR-инженеров лежит программный продукт, и это заставляет принимать в расчет как запросы внутренних потребителей, так и перспективные направления развития.
Почему так важна разработка ПО внутри службы SRE
Для большинства промышленных систем компании Google требуется внутреннее ПО, поскольку лишь немногие сторонние инструменты могут работать в необходимых нам масштабах. История успешных проектов нашей компании убедительно показала нам преимущества разработки ПО непосредственно внутри службы SRE.
SR-инженеры находятся в уникальном положении, позволяющем эффективно разрабатывать внутреннее ПО, по нескольким причинам.
• Широта и глубина знаний SR-инженеров о продуктах Google позволяет им разрабатывать и создавать ПО с учетом масштабируемости, предсказуемой и управляемой деградации во время сбоев, а также возможностей взаимодействия с другой инфраструктурой или инструментами.
• Поскольку SR-инженеры сами работают в той же области, они легко могут понять постановку задачи и требования для разрабатываемого инструмента.
• Прямая связь с потенциальными пользователями — коллегами по SRE — позволяет получать честную и подробную обратную связь. Создавая инструмент для внутренней аудитории, хорошо знакомой с предметной областью, команда разработки может быстрее выпустить продукт и затем обновлять его. Внутренние пользователи с бо'льшим пониманием относятся к минималистичному интерфейсу и другим недостаткам альфа-версии продукта.
С чисто прагматической точки зрения компания Google только выигрывает от того, что SR-инженеры разрабатывают ПО. Согласно плану темпы роста сервисов, поддерживаемых службой SRE, опережают темпы расширения ее штатов; один из основных принципов SRE заключается в том, что «численность команды не должна увеличиваться прямо пропорционально росту сервисов». Линейный рост команды при экпоненциальном росте поддерживаемых ею сервисов требует постоянного внедрения решений по автоматизации и усилий по упрощению инструментов, процессов и других аспектов сервиса для эффективного повседневного функционирования систем. Имеет смысл участие людей с опытом эксплуатации промышленных систем в разработке инструментов, служащих достижению требуемых целевых показателей доступности и задержки отклика.
С другой стороны, отдельные SR-инженеры, а также вся служба SRE тоже выигрывают от использования такого подхода.
Полноценные проекты по разработке ПО внутри службы SRE дают возможности карьерного роста SR-инженерам, а также возможность реализовать себя тем из них, кто желает поддерживать свои навыки программирования. Работа над долгосрочными проектами служит столь необходимым противовесом для дежурств и авралов, а также позволяет почувствовать удовлетворение от работы тем инженерам, которые хотели бы заниматься не только проектированием систем, но и разработкой ПО.
Помимо разработки средств автоматизации и иных мер по снижению нагрузки на SR-инженеров, проекты по разработке ПО могут принести и другую пользу службе SRE, привлекая и помогая сохранять инженеров с широким спектром навыков. Желание иметь в команде таких специалистов особенно уместно для SRE, где сочетание знаний из разных областей и разных подходов позволяет избежать «слепых пятен». Поэтому в компании Google всегда стремятся формировать команды SR-инженеров как специалистами в традиционной разработке ПО, так и теми, кто имеет навыки сопровождения систем.
Пример Auxon: история проекта и предметная область
В этом примере рассматривается Auxon — мощный инструмент, разработанный в Google SRE и предназначенный для автоматизации планирования производительности «промышленных» сервисов Google. Чтобы лучше понять, как был создан Auxon и каковы решаемые им задачи, мы рассмотрим предметную область, связанную с планированием производительности, а также сложности, с которыми сталкиваются разработчики при использовании традиционного подхода как в Google, так и в других компаниях. Значение терминов «сервис» и «кластер» в компании Google см. в главе 2.
Традиционное планирование производительности
Существует множество тактик планирования вычислительных ресурсов (см. [Hixson, 2015a]), но большая часть подходов сводится к циклу, который выглядит примерно так.
1. Спрогнозировать потребности. Сколько ресурсов потребуется? Когда и где понадобятся эти ресурсы?
• Лучшие данные, доступные сегодня, используются для планирования ситуаций, возможных в будущем.
• Обычно охватывается период от нескольких кварталов до нескольких лет.
2. Разработать план ввода и распределения ресурсов. Учитывая полученный прогноз, как мы можем наилучшим образом удовлетворить спрос с помощью дополнительных ресурсов? Сколько ресурсов потребуется и на каких площадках?
3. Проанализировать и утвердить план. Адекватен ли этот прогноз? Соответствует ли этот план требованиям к бюджету, продукту и реализации?
4. Провести развертывание и конфигурирование ресурсов. Как только ресурсы окажутся в нашем распоряжении (потенциально это будет происходить поэтапно, на протяжении некоторого периода времени), какие сервисы смогут воспользоваться этими ресурсами? Как можно обеспечить наибольшую пользу для сервисов от типичных низкоуровневых ресурсов (вроде ЦП, диска и т.д.)?
Нужно отметить, что такое планирование — это бесконечный цикл: предположения меняются, доставка и установка ПО задерживаются, а бюджеты урезаются, что приводит к постоянным пересмотрам Плана. Влияние каждого пересмотра распространяется на все планы всех последующих кварталов. Например, недовыполнение плана в текущем квартале должно быть скомпенсировано в последующих. При традиционном планировании производительности в качестве основного «двигателя» выступает уровень спроса, и уровень снабжения изменяется вручную так, чтобы соответствовать изменениям спроса.
Врожденная неустойчивость
План выделения ресурсов, формируемый при традиционном планировании выделения ресурсов, может быть легко нарушен любым небольшим изменением. Например:
• снижается эффективность сервиса, и ему требуется больше ресурсов для того, чтобы обслужить то же количество запросов;
• растет уровень популярности у клиентов, что приводит к повышению спроса на ресурсы;
• срываются сроки поставки нового вычислительного кластера;
• решение об изменении целевого показателя производительности приводит к изменению количества установленных экземпляров сервиса и требуемых для них ресурсов.
Небольшие изменения требуют проверки всего плана выделения ресурсов для того, чтобы убедиться, остается ли план валидным; более крупные изменения (вроде задержки поставки оборудования или изменений в стратегии продукта) потенциально потребуют строить план заново. Срыв поставки для одного кластера может повлиять на отказоустойчивость или требования к задержке отклика многих сервисов: выделение ресурсов в других кластерах придется увеличивать, чтобы скомпенсировать этот срыв. Эти и другие изменения могут оказать влияние на весь план.
Следует также иметь в виду, что план производительности для любого заданного квартала (или другого промежутка времени) основывается на ожидаемом результате выполнения планов предыдущих кварталов, а это означает, что изменения в любом квартале потребуют корректировок в последующих кварталах.
Трудоемкость и неточность
Для многих команд процесс сбора данных, необходимых для прогнозирования спроса, оказывается слишком медленным и подверженным ошибкам. А когда наступает время для расчета производительности, соответствующей запросам, не все ресурсы одинаково хороши. Например, если по требованиям к задержке отклика сервис должен быть размещен на том же континенте, что и его пользователи, получение дополнительных ресурсов в Северной Америке не поможет скомпенсировать их нехватку в Азии. Каждый прогноз имеет ограничения — граничные условия, которым он должен соответствовать; ограничения неразрывно связаны с целями, то есть теми характеристиками сервиса, которые стремится получить пользователь, и это рассматривается в следующем разделе.
Преобразование запросов ресурсов с учетом ограничений в план фактического их выделения из числа доступных также происходит медленно: задача оптимального размещения в ограниченном пространстве (в математике ее обычно называют «задачей об укладке ранца». — Примеч. пер.), а также поиск решений, соответствующих ограниченному бюджету, очень сложные и трудоемкие, если выполнять их вручную.
Из-за этого у вас уже может сложиться мрачная картина, но ситуацию усугубляет еще и то, что требуемые для этого процесса инструменты, как правило, ненадежны или громоздки. Электронные таблицы очень плохо масштабируются и почти не предоставляют средств для проверки на ошибки. Данные устаревают, и отслеживание изменений становится затруднительным. Команды зачастую должны делать упрощающие предположения и снижать сложность своих требований только для того, чтобы сделать задачу поддержания достаточной производительности подъемной.
Когда владельцы сервисов сталкиваются с необходимостью выделить нужные ресурсы с целью обеспечения требуемой производительности для серий запросов и при этом соблюсти все возможные ограничения, возникает дополнительная неточность. Оптимальная укладка — это NP-сложная задача, которую людям трудно решить вручную. Помимо этого, запрос ресурсов для сервиса зачастую представляет собой негибкий набор требований: Х ядер в кластере Y. Причины, по которым требуется именно Х ядер или именно кластер Y, а также любые возможные отклонения от этого запроса, теряются по мере достижения запросом человека, который пытается втиснуть все эти запросы в заданный объем ресурсов.
В результате вы потратите кучу сил на то, чтобы найти алгоритм выделения ресурсов, который в лучшем случае будет приблизительным. Этот процесс слишком чувствителен к изменениям, а диапазон значений оптимального решения неизвестен.
Наше решение: планирование производительности, основанное на целях
Укажите требования, а не реализацию.
Многие команды Google перешли на использование подхода, который мы называем планированием производительности, основанном на целях. Главная идея этого подхода заключается в том, чтобы формализовать и запрограммировать зависимости и требуемые параметры (цели) пользователей сервиса, а затем на основе этого автоматически сгенерировать план выделения ресурсов, в котором уже будет детально указано, какие ресурсы и в каком кластере может использовать каждый сервис. Если спрос, предложение или требования сервиса изменяются, мы легко можем сгенерировать новый план соответственно изменившимся параметрам, который будет наилучшим образом представлять распределение ресурсов.
Как только мы будем обладать реальными данными о требованиях и гибкости сервиса, план производительности станет гораздо более гибким и мы сможем находить оптимальное решение, соответствующее наибольшему числу параметров. Перепоручив поиск оптимального решения компьютерам, мы значительно снизили уровень рутинной ручной работы, и владельцы сервисов смогли сосредоточиться на более приоритетных задачах вроде соответствия SLO, зависимостях производства и требованиях к инфраструктуре сервиса вместо того, чтобы выпрашивать низкоуровневые ресурсы.
Кроме того, алгоритмизация и использование вычислительных методов для поиска оптимальной реализации распределения ресурсов в соответствии с целями обеспечивает более высокую точность, что в итоге тоже дает экономию в масштабах организации. Задача об оптимальной укладке по-прежнему остается не решенной окончательно, поскольку некоторые ее разновидности все еще считаются NP-сложными; однако существующие алгоритмы вполне эффективны для известных оптимальных решений.
Планирование производительности, основанное на целях
Цель — это то, чем владелец сервиса аргументирует запрашиваемые для него параметры функционирования. Переход от запросов конкретных ресурсов к истинным целям этих запросов в ходе составления плана требует нескольких уровней абстракции. Рассмотрим следующую их цепочку.
1. «Мне нужно 50 ядер в кластерах X, Y и Z для сервиса Foo». Так выглядит явный запрос ресурсов. Но… зачем нам нужно именно столько ресурсов именно в этих кластерах?
2. «Мне нужен 50-ядерный ресурс в любых трех кластерах в географическом регионе YYY для сервиса Foo». Этот запрос чуть более гибок, и его проще осуществить, несмотря на то что он еще не объясняет цель таких требований. Но… почему нам нужно именно столько ресурсов, и почему три кластера?
3. «Мне нужно соответствовать спросу на сервис Foo в каждом географическом регионе и иметь избыточность N + 2». Теперь запрос еще более гибок, и мы можем понять на более «человеческом» уровне последствия того, что сервис Foo не получит свои ресурсы. Но… зачем нам нужна избыточность N + 2 для сервиса Foo?
4. «Я хочу, чтобы сервис Foo работал на пяти девятках надежности». Это требование более абстрактно, и последствия несоответствия требованиям становятся очевидными: пострадает надежность. Здесь мы имеем еще большую гибкость: возможно, избыточность N + 2 окажется недостаточной или неоптимальной, и найдется более подходящий план развертывания сервиса.
На каком уровне следует формулировать цели для планирования производительности, основанного на целях? В идеале мы должны поддерживать все уровни для тех сервисов, которые выигрывают от формулирования требований в виде целей вместо конкретных реализаций.
По опыту Google, для большинства сервисов выгоден выход на уровень 3: мы получаем достаточную гибкость, а результаты решений формулируются на более высоком уровне и их проще понять. Отдельные сложные сервисы могут тяготеть к уровню 4.
Предпосылки для целей
Что нужно знать о сервисе, чтобы определить цели? Давайте познакомимся с зависимостями, показателями производительности и приоритизацией.
Зависимости
Сервисы Google зависят от множества других инфраструктурных и пользовательских сервисов, и эти зависимости значительно влияют на расположение сервиса. Например, представим пользовательский сервис Foo, который зависит от Bar — инфраструктурного сервиса хранения данных. Сервис Foo предъявляет требование к расположению сервиса Bar — задержка отклика не должна превышать 30 миллисекунд. Это требование имеет важные последствия для размещения сервисов Foo и Bar, и при планировании производительности, основанном на целях, мы должны принимать во внимание эти ограничения.
Помимо этого, зависимости могут быть вложенными: основываясь на предыдущем примере предположим, что сервис Bar имеет собственные зависимости от сервисов Baz, более низкоуровневого сервиса распределенного хранения данных, и Qux, сервиса управления приложениями. Теперь расположение сервиса Foo зависит от расположения сервисов Bar, Baz и Qux. Набор зависимостей может быть общим для нескольких целей, возможно имея различные допущения.
Показатели производительности
Спрос на один сервис может влиять на спрос на один или несколько других сервисов. Понимание цепочки зависимостей помогает более масштабно взглянуть на задачу распределения ресурсов, но нам все еще нужно больше информации об ожидаемом уровне их использования. Как много вычислительных ресурсов сервиса Foo нужно для обслуживания N пользовательских запросов? Сколько мегабайт в секунду будет отправлено сервису Bar для каждых N запросов к сервису Foo?
Показатели производительности служат своего рода «клеем» для зависимостей. Они помогают выполнить переход от одного высокоуровневого типа ресурсов или более к одному низкоуровневому типу или более. Получение соответствующих показателей для сервиса может предполагать также тестирование нагрузки и наблюдение за использованием ресурсов.
Приоритизация
Ограничения в ресурсах неизбежно приведут к компромиссам и непростым решениям: какими требованиями можно пожертвовать, если ресурсов не хватает?
Возможно, избыточность N + 2 для сервиса Foo более важна, нежели избыточность N + 1 для сервиса Bar. Или, возможно, запуск функциональности X менее важен, чем избыточность N + 0 для сервиса Baz.
Планирование, основанное на целях, делает эти решения прозрачными, открытыми и целостными. Ограничения по ресурсам влекут за собой такие же компромиссы, но слишком часто приоритизация бывает ситуативной и непрозрачной для владельцев сервисов. А планирование, основанное на целях, позволяет проводить приоритизацию с любым требуемым уровнем детализации.
Знакомимся с Auxon
Auxon — это решение компании Google для планирования производительности, основанного на целях, и распределения ресурсов. Auxon — самый заметный пример программного продукта, разработанного в Google SRE: эта система создавалась небольшой группой программистов и техническим менеджером SRE в течение двух лет. Это идеальный пример того, как разработка ПО может органично вписаться в работу службы SRE.
Система Auxon активно применяется для планирования использования многомиллионных вычислительных ресурсов компании Google. Она стала критически важным компонентом планирования производительности для ряда подразделений компании Google.
Auxon предоставляет способ сбора описаний требований сервиса к ресурсам, основанных на целях, а также его зависимостей. Эти пользовательские цели выражены как требования к обеспечению сервиса ресурсами. Требования могут быть выражены как запросы, например: «Мой сервис должен иметь избыточность N + 2 для каждого континента» или «Фронтенд-серверы должны находиться не далее чем в 50 миллисекунд от бэкенд-серверов». Auxon собирает эту информацию либо с помощью языка пользовательских конфигураций, либо с помощью программного интерфейса (API), преобразуя сформулированные человеком цели в понятные машине ограничения. Требования могут иметь приоритеты, это полезно в ситуации, когда ресурсов недостаточно для того, чтобы выполнить все требования, и приходится прибегать к компромиссам. Эти требования (которые, собственно, и составляют цель) в итоге представляются внутри системы как гигантская задача частично-целочисленного или линейного программирования. Auxon решает эту задачу и использует полученное решение для формирования плана распределения ресурсов.
Рисунок 18.1 с последующими разъяснениями показывает основные компоненты Auxon.
Данные о производительности описывают масштабирование сервиса: сколько единиц зависимости Z используется для каждой единицы спроса Х в кластере Y? Эти данные о масштабировании могут быть получены несколькими способами в зависимости от стадии жизненного цикла конкретного сервиса. Для одних сервисов есть результаты нагрузочного тестирования, для других же предположения о масштабировании делаются на основе ранее наблюдавшейся производительности.
Данные о прогнозируемом спросе для каждого сервиса описывают тенденцию использования для спрогнозированных сигналов запроса. Некоторые сервисы узнают об уровне использования их в будущем через прогнозы спроса — прогнозы количества запросов в секунду, отдельно по континентам. Прогнозы спроса существуют не для всех сервисов: некоторые сервисы (например, сервисы хранения данных вроде Colossus) получают сведения о спросе на них от зависимых сервисов.
Доступные ресурсы — это данные о доступности базовых ресурсов: например, количество машин, которые можно будет использовать в заданный момент времени в будущем. В терминологии линейного программирования этот показатель служит верхней границей роста сервисов, который также влияет на их размещение. В конечном счете мы хотим использовать наши ресурсы наилучшим образом, насколько нам это позволит основанное на целях описание всей группы сервисов.
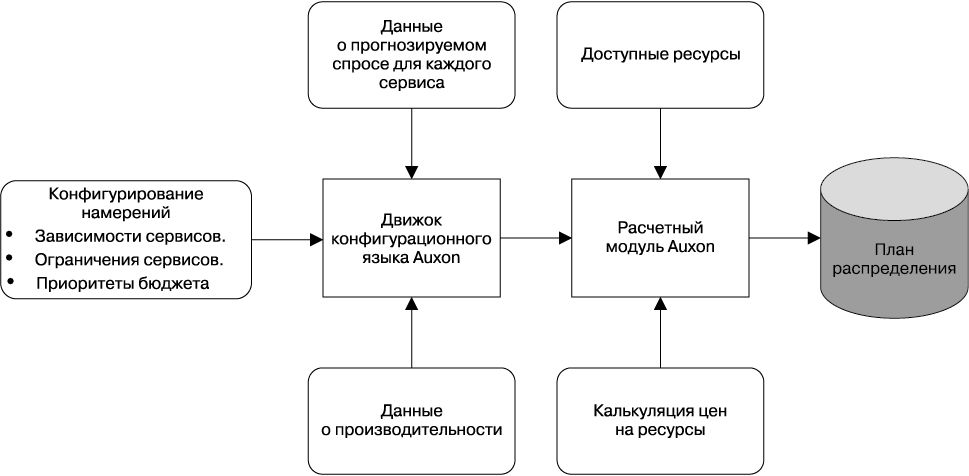
Рис. 18.1. Основные компоненты системы Auxon
Калькуляция цен на ресурсы предоставляет данные о стоимости базовых ресурсов. Например, стоимость машин в глобальной системе может значительно различаться в зависимости от стоимости площадей/энергии на различных площадках. В терминологии линейного программирования цены влияют на общую рассчитанную стоимость, выступающую в качестве целевого значения, которое мы хотим минимизировать.
Конфигурация цели — это способ, с помощью которого информация о намерениях попадает в Auxon. Она определяет, из чего состоит сервис, а также отношения между сервисами. Конфигурация выступает в качестве слоя, обеспечивающего связь между всеми остальными компонентами. Она разработана так, чтобы быть удобной для понимания и изменения людьми.
Интерпретатор («движок») языка конфигураций Auxon действует на основе информации, полученной из конфигурации. Этот компонент формирует в понятном для машины виде запрос (в формате «протокольных буферов»), который может быть понят расчетным блоком Auxon. Он выполняет небольшую проверку доступности конфигурации и ведет себя как шлюз между конфигурируемым человеком описанием целей и понимаемым машиной запросом по оптимизации.
Расчетный модуль Auxon — это мозг системы. Он формирует гигантскую задачу частично-целочисленного или линейного программирования на основе запроса по оптимизации, полученного от интерпретатора конфигураций. При его разработке бала заложена высокая масштабируемость, что позволяет ему работать в кластерах Google на сотнях или даже тысячах машин. В дополнение к инструментарию частично-целочисленного линейного программирования, в расчетном модуле Auxon также имеются компоненты, которые работают с задачами планирования, управления пулом рабочих процессов и спуска по деревьям решений.
План распределения ресурсов — это результат работы расчетного модуля Auxon. Он указывает, какие ресурсы могут быть получены конкретными сервисами в заданных локациях. Этот план представляет собой рассчитанную детальную реализацию исполнения требований, описанных на основе целей. План также включает в себя информацию о тех требованиях, которые не удалось выполнить, например, из-за нехватки ресурсов или из-за того, что существует другой сервис, претендующий на те же ресурсы.
От требований до реализации: достижения и полученные уроки
Изначально Auxon был задуман SR-инженерами и техническими менеджерами, которым независимо друг от друга команды ставили задачу планирования производительности для крупных фрагментов инфраструктуры Google. Выполняя планирование вручную с помощью электронных таблиц, они поняли неэффективность такого подхода и пути его улучшения с помощью автоматизации, а также какая функциональность может при этом понадобиться.
В течение всего времени разработки Auxon команда SRE, стоящая за продуктом, продолжала принимать участие в жизни промышленно эксплуатируемых систем. Команда участвовала в дежурных сменах на сопровождении нескольких сервисов, а также в обсуждениях проектов этих сервисов и техническом руководстве. Благодаря этому непрекращающемуся взаимодействию команда могла оставаться в курсе того, что происходит в промышленном окружении: они выступали и как потребитель, и как разработчик собственного продукта. Если продукт оказывался неудачным, это непосредственно влияло на саму команду. Запрашиваемая функциональность была обоснована непосредственно опытом из первых рук. Такой опыт не только позволил ощутить свой вклад в успех продукта, но и способствовал укреплению доверия к нему внутри службы SRE.
Упрощенная модель. Не концентрируйтесь на идеальном и чистом решении, особенно если масштабы проблемы еще не известны. Просто запускайте свой продукт поскорее, работайте с ним и дорабатывайте его.
В любом достаточно сложном проекте разработки ПО обычно приходится иметь дело с неопределенностью: как должен быть спроектирован компонент или как должна быть решена задача. Разработчики Auxon столкнулись с такой неопределенностью на ранних этапах проекта, поскольку для членов команды мир линейного программирования представлял собой неисследованную территорию. Ограничения линейного программирования, которое должно было стать ядром продукта, не были известны досконально. Чтобы преодолеть опасения команды, которая должна была работать с этой недостаточно понятой зависимостью, мы решили создать для начала упрощенный расчетный модуль (мы назвали его Stupid Solver — «тупой вычислитель»), который применял простую эвристику для выстраивания сервисов согласно пользовательским требованиям. Хотя Stupid Solver никогда не смог бы дать действительно оптимальное решение, он помог команде понять, что создать Auxon вполне реально, даже несмотря на то, что поначалу у нас не все будет получаться.
При развертывании упрощенной модели, призванной ускорить разработку, важно было заложить возможность вносить в нее улучшения в будущем и возвращаться к ней. В случае Stupid Solver весь интерфейс решающей программы был абстрагирован внутри Auxon для того, чтобы его содержимое могло быть изменено в будущем. В дальнейшем, когда мы уже были уверены в унифицированной модели линейного программирования, оставалось лишь переключиться на использование чего-то «поумнее».
Требования продукта Auxon также содержали ряд неопределенностей. Создание ПО с запутанными требованиями может оказаться крайне сложным, но эта неопределенность не смогла нас остановить. Она послужила нам стимулом добиваться того, чтобы ПО было одновременно достаточно обобщенным и модульным. Например, одной из целей проекта Auxon являлась интеграция с автоматическими системами внутри Google для того, чтобы реализовывать план распределения ресурсов непосредственно в промышленной среде (распределение ресурсов, а также включение/выключение/изменение размера сервисов по мере необходимости). Однако в то время мир автоматических систем находился в постоянном движении, использовалось огромное множество подходов. Вместо того чтобы попытаться разработать специализированные решения, позволяющие Auxon работать с каждым конкретным инструментом, мы сделали план распределения ресурсов универсальным. Это позволило нашим системам автоматизации работать с ним собственными средствами. Такой «агностический» подход оказался ключевым в деле привлечения и адаптации новых пользователей, поскольку он не требовал от них менять используемые инструменты.
Мы также воспользовались модульным дизайном, чтобы справиться с запутанными требованиями при сборке модели производительности машины внутри Auxon. Данные, описывающие ресурсы (например, ЦП) будущей машинной платформы, были пугающими, но наши пользователи хотели иметь способ моделирования различных сценариев по использованию мощности машины. Мы абстрагировались от данных машины, скрыв их за одним интерфейсом, что позволило пользователям менять разные модели конфигураций будущей машины. Позже на основе постоянно уточняющихся требований мы развили идею такой модульности еще дальше и создали простую библиотеку моделирования производительности машин, которая работала в рамках нашего интерфейса.
Если бы необходимо было выбрать из нашего примера всего одну идею, она заключалась бы в том, что при разработке ПО внутри службы SRE старый девиз «запускайте и дорабатывайте» особенно актуален. Не ждите идеального дизайна; вместо этого при проектировании и разработке представляйте общую картину. Когда вы столкнетесь с неопределенностью, разрабатывайте ПО так, чтобы оно было достаточно гибким на случай, если процесс или стратегия изменится на более высоком уровне, чтобы не понести огромные затраты на переписывание ПО. Но в то же время не забывайте и о более приземленном: обеспечивайте наличие у общих решений специализированных реализаций для конкретных реальных задач, демонстрируя таким образом практичность дизайна.
Повышаем осведомленность и способствуем внедрению
Как и в случае с другими проектами, разработка ПО службой SRE должна учитывать знания о пользователях и требованиях. Внедрению ПО содействуют его полезность, эффективность и способность как служить целям повышения надежности продуктов Google, так и улучшать жизнь SR-инженеров. Процесс «социализации» продукта и принятия его внутри организации является ключевым для успеха проекта.
Не стоит недооценивать усилия, затрачиваемые для повышения осведомленности о вашем программном продукте и заинтересованности в нем, — одной презентации или электронного письма будет недостаточно. «Социализация» внутренних программных инструментов для крупной аудитории требует:
• понятного и неизменного подхода;
• рекламы среди пользователей;
• сотрудничества со стороны инженеров и менеджеров, которым вы будете демонстрировать полезность вашего продукта.
При создании продукта важно учитывать точку зрения пользователя. Инженер может не иметь времени или желания разбираться в исходном коде для того, чтобы понять, как использовать инструмент. Несмотря на то что внутренние клиенты зачастую более терпимы к шероховатостям и ранним альфа-версиям, нежели внешние, вам все же нужно предоставлять документацию. SR-инженеры — занятые люди, и, если ваше решение слишком сложное или запутанное, они напишут собственное.
Задавайте уровень ожиданий
Когда за разработку продукта берется инженер, давно знакомый с предметной областью, воображение охотно рисует утопическую картину результатов его работы. Однако важно различать амбициозные «максимальные» цели и минимальные критерии успеха (критерии минимально жизнеспособного продукта — minimum viable product). Проекты могут потерять доверие и провалиться, если было обещано дать слишком много за короткий промежуток времени; в то же время может быть трудно убедить команды попробовать что-то новое, если этот продукт не обещает быть достаточно полезным. Демонстрация постепенного прогресса путем выпуска небольших обновлений повышает уверенность пользователей в том, что ваша команда сможет создать полезное ПО.
В случае Auxon мы достигли баланса, создав долгосрочный план с возможностью внесения в него оперативных исправлений. Мы пообещали командам следующее.
• Любые усилия по внедрению проекта или совершенствованию его конфигураций будут немедленно давать отдачу в виде избавления от необходимости оптимизировать распределение запрашиваемых ресурсов вручную.
• По мере разработки дополнительной функциональности для Auxon мы будем использовать одни и те же конфигурационные файлы и предоставлять новые, гораздо более действенные способы снижения затрат и другие преимущества. План проекта позволил владельцам сервисов быстро определить, будет ли разработана необходимая им функциональность в ранних версиях. В то же время итерационный подход к разработке Auxon позволил менять приоритеты и вводить новые этапы развития продукта.
Определите наиболее подходящих клиентов
Команда, разрабатывающая Auxon, понимала, что одно-единственное решение не может удовлетворить всех; многие более крупные команды уже имели собственные решения по планированию производительности, которые достаточно хорошо работали. Несмотря на то что их собственные инструменты не были идеальны, эти команды не испытывали значительных проблем с планированием производительности и не чувствовали необходимости пробовать новый инструмент, особенно если он находится в альфа-версии.
Ранние версии Auxon были нацелены на команды, которые еще не наладили свой процесс планирования производительности. Поскольку время на конфигурирование пришлось бы потратить в любом случае, выбери они существующее решение или наш подход, эти команды были заинтересованы в том, чтобы воспользоваться новейшим инструментом. Своих первых успехов система Auxon добилась благодаря тому, что этим командам была продемонстрирована полезность проекта, и потребители в итоге стали его защитниками.
Оценка и подсчет выгод от применения продукта оказались полезными и в дальнейшем; когда мы брались за очередное направление в нашем бизнесе, команда проводила тщательный анализ, детально сравнивая результаты до и после внедрения системы. Экономия времени и снижение человеческой рутины еще больше подогрели интерес других команд к Auxon.
Поддержка пользователей
Даже несмотря на то, что основной аудиторией для разработанного службой SRE ПО являются TPM и инженеры, имеющие высокую техническую подготовку, любое достаточно инновационное ПО требует определенной программы обучения для новых пользователей. Не бойтесь предоставить специальную поддержку для новых пользователей, чтобы помочь им освоиться. Иногда автоматизация влечет за собой эмоциональные вопросы, например опасение, что чья-то должность будет заменена автоматически выполняемым скриптом. Работая с первыми пользователями персонально, вы сможете помочь им справиться с таким страхом и продемонстрировать, что вместо рутины, связанной с выполнением утомительной работы вручную, команда получит конфигурацию, процессы и в конечном итоге будет обладать всеми результатами их технической работы. Пример довольных первых пользователей послужит убеждению последующих.
Более того, поскольку команды SR-инженеров компании Google распределены по всему земному шару, первые пользователи, выступающие в поддержку вашего проекта, особенно полезны, поскольку они могут стать локальными экспертами для других команд, которым было бы интересно попробовать ваш проект.
Правильный выбор уровня разработки
Идея, которую мы назвали «агностицизмом», — написание обобщенного ПО, которое может принимать множество источников данных в качестве входной информации, — является основным принципом дизайна Auxon. Агностицизм означает, что от клиентов не требуется использовать строго определенные инструменты для того, чтобы применять фреймворк. Такой подход позволил Auxon оставаться полезным, даже когда его начали использовать команды с иным инструментарием. Мы обратились к потенциальным пользователям: «Приходите как есть; мы будем работать с тем, что вы предложите». Избегая чрезмерной подстройки под одного-двух крупных пользователей, мы достигли того, что наш проект стал пользоваться большим успехом в организации, а также снизили «порог вхождения» для новых сервисов.
Но мы также сознательно избежали ловушки определения успеха как достижения 100%-ного принятия нашего продукта в организации. Во многих случаях создание функциональности, которая бы подходила для абсолютно всех сервисов компании, не стоит затраченных усилий.
Команда в развитии
Отбирая SR-инженеров для работы над программными продуктами, мы обнаружили, что наиболее эффективны команды, ядро которых совмещает в себе универсалов, способных быстро включаться в работу над новой темой, и инженеров с широкими познаниями и опытом. Такое разнообразие знаний помогает закрыть белые пятна, а также не дает считать аксиомой то, что каждая команда будет пользоваться продуктом так же, как и ваша.
Важно, чтобы в вашей команде установились рабочие отношения с нужными специалистами, а также чтобы вашим инженерам было комфортно работать над новой областью задач. Для большинства команд SRE во многих компаниях работа в этой новой области задач требует перепоручать часть задач сторонним исполнителям или работать с консультантами, но команды SRE в более крупных организациях имеют возможность объединиться с собственными экспертами компании. На начальных этапах проектирования Auxon мы представили наш проект командам, которые специализируются в области исследования операций и количественного анализа, чтобы воспользоваться их опытом в этой области и повысить уровень компетенции команды разработчиков Auxon, необходимой для задачи планирования производительности.
По мере разработки проекта и расширения функциональности Auxon к команде присоединились специалисты, имеющие опыт работы со статистикой и математической оптимизацией, что было равносильно привлечению стороннего консультанта для малой компании. Эти новые члены команды после завершения работы над базовой функциональностью смогли наметить направления возможных улучшений, и главным нашим приоритетом стало повышение мастерства.
Удачный момент для привлечения специалистов, конечно же, разнится от проекта к проекту. Упрощенно говоря, проект должен стать успешным с первой версии, и это поможет вашей команде повысить свои навыки с помощью сторонних специалистов.
Культивирование разработки ПО в службе SRE
Что позволяет программе перестать быть одноразовым инструментом и превратиться в полноценный программный проект? Этому могут значительно поспособствовать инженеры, имеющие опыт из первых рук в требуемых областях, заинтересованные в работе над проектом, а также целевая база пользователей, имеющих технические навыки (такие пользователи могут представлять полезные отчеты о недочетах и ошибках на ранних этапах разработки). Проект должен предоставлять заметные преимущества — например, снижение рутины для сотрудников SRE, улучшение существующей инфраструктуры или упрощение сложного процесса.
Проекту важно вписаться в набор целей организации, чтобы ведущие инженеры смогли оценить его потенциальное влияние и впоследствии рекомендовать ваш проект как опираясь на свои подчиненные команды, так и посредством команд, с которыми они взаимодействуют. Кросс-организационная социализация и обзоры помогают предотвратить ситуацию разрозненных или перекрывающихся усилий, и для продукта, который легко может способствовать выполнению целей подразделения, становится легче выделить персонал и поддерживать его.
Какой проект считается плохим кандидатом? На такой проект указывает множество признаков — он связан с изменением слишком многих частей, его дизайн требует подхода «все или ничего», который мешает выполнять разработку итерационно. Поскольку команды Google SRE в данный момент организованы вокруг поддерживаемых ими сервисов, проекты, которые они разрабатывают, могут оказаться слишком узкоспециализированными, закрывая лишь небольшую часть потребностей организации. Поскольку команды мотивированы предоставлять возможность комфортной работы в первую очередь своим пользователям со своим сервисом, проекты, как правило, не могут быть обобщены для более широкого применения, так как стандартизация между SRE-командами проводится лишь во вторую очередь. С другой стороны, слишком общие фреймворки могут также оказаться проблемными; если инструмент является слишком гибким и слишком универсальным, он может не подойти в полной мере ни для одного конкретного применения и поэтому окажется практически бесполезен. Проекты с большой областью действия и абстрактными целями зачастую требуют приложения значительных усилий для их разработки, и при этом им недостает конкретных практик использования, необходимых для того, чтобы проект принес пользу конечному пользователю за разумный промежуток времени.
Примером продукта широкого применения может служить балансировщик нагрузки третьего уровня, разработанный SR-инженерами компании Google: он был настолько успешным на протяжении многих лет, что стал пользовательским продуктом Google Cloud Load Balancer [Eisenbud, 2016].
Успешное создание культуры разработки ПО службой SRE: набор персонала и время разработки
SR-инженеры зачастую являются универсалами, поскольку желание получить широкие знания вместо глубоких способствует пониманию общей картины (найдется немного примеров систем, которые масштабнее сложной кухни современной технической инфраструктуры). Эти инженеры зачастую имеют серьезные навыки кодирования и разработки ПО, но могут не иметь традиционного опыта разработки ПО, который заключается в том, чтобы состоять в команде разработчиков продукта и в необходимости думать о пользовательских запросах функциональности. Один инженер, который работал в ранних проектах по разработке ПО, подытожил традиционный для SRE подход к разработке следующей фразой: «У меня есть описание архитектуры; зачем нам нужны требования?» Взаимодействуя с инженерами, менеджеры, имеющие опыт разработки пользовательского ПО, могут помочь создать культуру разработки ПО, в которой соединится лучшее из опыта разработки продукта и работы с уже эксплуатируемыми системами.
Любой проект должен разрабатываться без помех и перерывов. Это очень важно, поскольку практически невозможно писать код — и тем более сосредотачиваться на крупных и весомых проектах, — когда вы переключаетесь от задачи к задаче в течение одного часа. Поэтому возможность работать над проектом не прерываясь — это хороший стимул для инженера начать над ним работать.
Большая часть программных продуктов, разработанных внутри службы SRE, начинают свой путь как побочные проекты, чья полезность приводит к их росту и оформлению в более завершенном виде. В этот момент продукт может пойти по одному из следующих путей.
• Оставаться второстепенной низкоприоритетной работой, которой будут заниматься в свободное время.
• Пройти процесс структурирования и получить формальный статус проекта (см. подраздел «Движемся к успеху» далее).
• Получить поддержку от руководства SRE и стать полноценным проектом по разработке ПО с выделенным для него персоналом.
Однако при любом сценарии — и на это стоит обратить внимание — важно, чтобы SR-инженеры, участвующие в разработке, продолжали свою деятельность как SR-инженеры, а не становились приписанными к SRE разработчиками на полную ставку. Погружение в мир эксплуатируемых систем дает SR-инженерам, в том числе и занятым в разработке, бесценный опыт и делает их точку зрения уникальной, поскольку они выступают в роли как создателя, так и потребителя продукта.
Движемся к успеху
Если вам нравится идея организовать разработку ПО в службе SRE, вы, возможно, задумались о том, как внедрить модель разработки ПО в подразделении, организованном вокруг поддержки продукта.
Во-первых, вам нужно понять, что эта цель является не только организационной, но еще и технической задачей. SR-инженеры привыкли работать вместе со своими коллегами, быстро анализируя проблемы и реагируя на них. Поэтому вы движетесь против естественного инстинкта SR-инженера, который заключается в быстром написании кода, соответствующего его сиюминутным потребностям. Если ваша команда SRE мала, это не станет проблемой. Однако по мере роста вашей организации этот подход не будет масштабироваться, став вместо многофункционального решения узким или специализированным, а созданными программными решениями нельзя будет поделиться, что неизбежно приведет к повторному выполнению работы снова и снова.
Далее подумайте о том, чего вы хотите достигнуть, разрабатывая ПО силами SRЕ. Вы просто хотите поспособствовать появлению хороших приемов разработки ПО внутри своей команды или же вы заинтересованы в разработке ПО, в итоге которой вы получите результаты, которые пригодны для использования другими командами и которые, возможно, станут стандартом в организации? В более крупных сформировавшихся организациях второй путь займет какое-то время, возможно даже несколько лет. Такие преобразования приходится вести по всем фронтам, но они дают и большие преимущества. Из нашего опыта мы можем посоветовать следующее.
• Четко сформулируйте задачу и доведите ее до сведения остальных. Важно определить и распространить вашу стратегию, планы и — что наиболее важно — преимущества, которые служба SRE получит благодаря таким изменениям. SR-инженеры довольно скептичны (фактически скептицизм — это черта, за которую мы их нанимаем); первой их реакцией будет ответ вроде «выглядит как лишняя нагрузка» или «это никогда не сработает». Начните с того, что расскажите, как эта стратегия поможет работе SRE, например:
• устойчивые и поддерживаемые программные решения ускорят обучение новых SR-инженеров;
• снижение количества способов выполнения одной и той же задачи позволит всем получить пользу от навыков, выработанных в одной команде, что даст возможность передавать знания между командами и объединять усилия.
Когда SR-инженер начнет задавать вопросы о том, почему ваша стратегия сработает, вместо вопросов о том, стоит ли ею заниматься вообще, можете считать, что первый этап пройден успешно.
• Оцените возможности вашей организации. SR-инженеры имеют множество навыков, но, как правило, им недостает навыка работы в команде, которая уже создала и поставила продукт множеству пользователей. Для того чтобы разрабатывать полезное ПО, вы, по сути, создаете команду продукта. Эта команда включает в себя требуемые роли и навыки, которые могли не требоваться ранее в вашей службе SRE. Будет ли кто-то играть роль менеджера продукта, выступая в защиту интересов потребителя? Имеет ли ваш ведущий инженер или менеджер проектов навыки или опыт для ведения процесса разработки по методологии Agile?
Начните заполнять эти пробелы, опираясь на те навыки, которые уже имеются в вашей компании. Попросите вашу команду разработчиков продуктов помочь наладить процесс Agile путем обучения или тренировок. Запросите консультацию у менеджеров продуктов для того, чтобы определить требования к продукту и расставить приоритеты в работе над функциональностью. При достаточно большом объеме программных разработок вполне допустимо нанять отдельных специалистов для выполнения этих функций. Нанять людей на эти должности станет проще, как только вы добьетесь первых положительных результатов.
• Запускайте и дорабатывайте. Как только вы запустите программу по разработке ПО службой SRE, за вашими усилиями будет следить множество глаз. Очень важно завоевать доверие, предоставив хоть сколько-нибудь полезный продукт за приемлемый промежуток времени. Перед продуктом первого выпуска должны стоять относительно простые и достижимые цели — цели, которые не содержат противоречивых или уже существующих решений. Мы также обнаружили, что удобно объединять такой подход с шестимесячным циклом выпуска обновлений продукта, в которых становится доступной дополнительная полезная функциональность. Такой цикл позволяет командам сосредоточиться на определении подходящего набора функций для очередной итерации, а затем на реализации этих функций, одновременно обучаясь быть «продуктовой» командой разработчиков. После запуска результатов первой итерации некоторые команды переходят на модель push-on-green для еще более быстрой выдачи обновлений и получения обратной связи.
• Не занижайте ваши стандарты. Как только вы начнете разрабатывать ПО, вам может захотеться «срезать углы». Вы должны сопротивляться этому искушению, придерживаясь стандартов, которые установлены для ваших команд разработчиков. Например:
• спросите себя: если бы этот продукт был создан отдельной командой разработчиков, воспользовались ли бы вы им;
• если ваше решение принято широким кругом пользователей, оно может стать критически важным для SR-инженеров, поскольку позволит более успешно выполнять их работу. Поэтому надежность для вас крайне важна. Пользуетесь ли вы правилами экспертизы кода? Проводится ли у вас непрерывное или интеграционное тестирование? Попросите другую команду SR-инженеров выполнить инспекцию готовности продукта, как если бы они это делали, принимая на сопровождение любой другой сервис.
Для того чтобы ваш продукт завоевал доверие, потребуется много времени, причем это доверие может быть утрачено из-за одного-единственного промаха.
Итоги главы
Проекты по разработке ПО службой SRE процветают по мере роста организации, и во многих случаях полученный опыт успешного выполнения подобных проектов проложил дорогу для последующих начинаний. Уникальный практический опыт работы со средой промышленной эксплуатации, который SR-инженеры применяют при разработке проектов, может способствовать появлению инновационных подходов к решению старых проблем, как это видно на примере разработки системы Auxon, предназначенной для решения сложной задачи планирования производительности. Программные проекты, выполняемые специалистами SRE, также приносят пользу компании, так как такой подход помогает выстроить устойчивую модель поддержки сервисов разных масштабов. Поскольку SR-инженеры часто разрабатывают ПО для упрощения неэффективных процессов или для автоматизации выполнения часто встречающихся задач, такие проекты означают, что команда SRE не будет разрастаться пропорционально росту поддерживаемых ими сервисов. Таким образом, наличие SR-инженеров, которые посвящают часть своего времени разработке ПО, приносит пользу компании, службе SRE и самим инженерам.
Здесь под «производительностью» (англ. capacity) понимается обобщенное количество ресурсов, которыми располагает вычислительная система, и, соответственно, ее «емкость» в отношении выполняемой работы. — Примеч. пер.

