16. Контроль неисправностей
Автор — Гейб Крэбби
Под редакцией Лиза Кэри
Совершенствование в направлении повышения надежности предполагает, что мы, начав с некоторого «исходного уровня», можем постоянно наблюдать за прогрессом. Именно для этого мы используем Outalator — наше средство контроля сбоев и неисправностей. Outalator — это система, которая пассивно принимает все оповещения, отправляемые нашими системами слежения, и позволяет эти данные хранить, помечать, группировать и анализировать.
Систематическое обучение на опыте прошлых проблем — одна из основ эффективного управления сервисом. Постмортемы (см. главу 15) предоставляют детальную информацию о конкретных сбоях, но это лишь часть решения. Они создаются только для инцидентов с серьезными последствиями, а те происшествия, которые сами по себе наносят небольшой ущерб, зато происходят часто и имеют тенденцию повторяться, в поле зрения не попадают. Аналогично постмортемы чаще предоставляют информацию, полезную для совершенствования одного или нескольких сервисов, но могут упускать из виду те возможные изменения, эффект которых в конкретных случаях невелик либо они невыгодны по соотношению эффекта и затрат, но имеют большое «горизонтальное» влияние.
Мы также можем получить полезную информацию, задавая вопросы вроде: «Сколько оповещений получает каждая команда в свою дежурную смену?», «Каким было соотношение требующих и не требующих принятие мер оповещений за последний квартал?», и даже самый очевидный — «Какой из сервисов, которыми занимается эта команда, потребовал от них усилий?».
Escalator
В Google все адресованные SR-инженерам оповещения проходят через единую реплицируемую систему, которая контролирует, подтверждено ли человеком их получение. Если в течение установленного времени подтверждение не получено, система обращается к следующему заданному адресату (или адресатам) — к примеру, от главного дежурного к замещающему. Эта система, названная The Escalator, изначально была разработана как максимально открытое средство, получающее копии электронных писем, отправляемых дежурным сотрудникам. Такой функционал позволил легко интегрировать Escalator в существующие рабочие потоки без необходимости менять поведение пользователя (или в тот период времени — поведение системы мониторинга).
Outalator
По примеру Escalator, когда мы добавляли полезные элементы к уже действующей инфраструктуре, мы создали систему, работающую не только с отдельными «восходящими» уведомлениями, но и с новым уровнем абстракции: сбоями (или дефектами).
Outalator позволяет пользователю просматривать список уведомлений с временным разделением, поступающих сразу из нескольких очередей, не требуя переключаться между ними вручную. На рис. 16.1 показано несколько очередей из списка Outalator. Такой подход удобен, поскольку первичный получатель оповещений от многих сервисов — это одна и та же SRE-команда, и лишь при необходимости они перенаправляются другим получателям, обычно различным командам разработчиков.
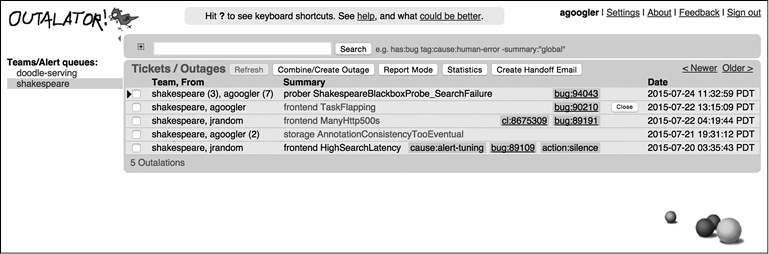
Рис. 16.1. Просмотр очередей Outalator
Outalator сохраняет копию первоначального сообщения и позволяет комментировать инциденты. Для удобства программа также молча принимает и сохраняет копию любого ответного электронного письма. Поскольку в цепочках писем есть менее информативные (к примеру, письмо, сгенерированное как «ответ всем», чтобы добавить больше адресов в список получателей копий), аннотации могут помечаться как важные. В таком случае интерфейс скрывает другие части сообщения, чтобы не создавать неразбериху. Все вместе это более информативное представление инцидента, чем просто поток писем, возможно разрозненных.
Outalator позволяет объединить несколько сообщений (оповещений) в единое целое (инцидент). Они могут относиться к одному и тому же инциденту, а могут быть не связанными между собой и не представляющими интереса событиями вроде привилегированного доступа к базе данных или даже просто ошибками системы мониторинга. Функция группировки, показанная на рис. 16.2, разгружает интерфейс и позволяет изучать инциденты, а не просто отдельные оповещения.
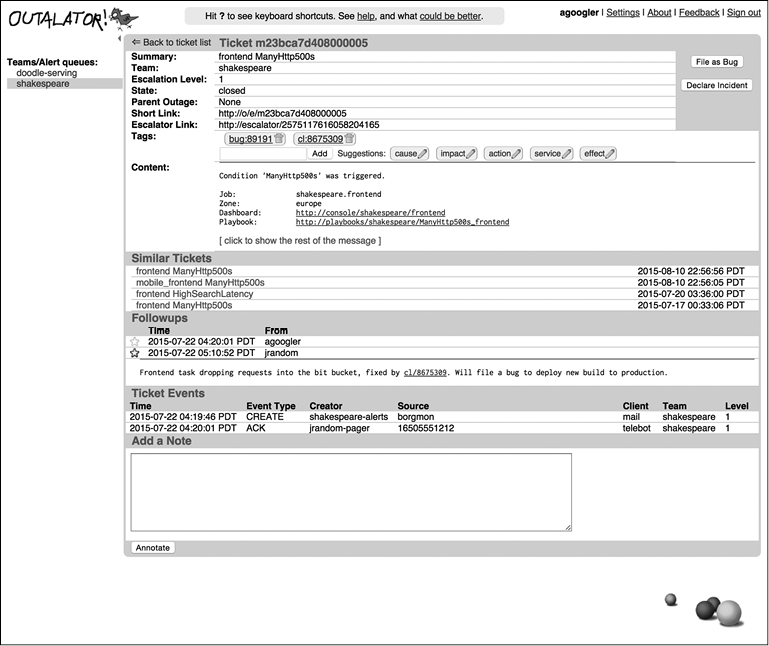
Рис. 16.2. Функция группировки
| Если вы делаете свой Outalator Многие организации используют такие системы обмена сообщениями, как Slack, Hipchat или даже IRC для внутреннего общения и/или обновления статуса информационных страниц. Все эти средства прекрасно подходят для включения в системы вроде Outalator. |
Агрегирование
Одно и то же событие может порождать и часто порождает несколько оповещений. Например, сбои в работе сети становятся причинами превышения лимитов ожидания и недоступности сервисов и все соответствующие команды получат собственные оповещения, включая владельцев сервисов. А это значит, что в центре управления сетями одновременно зазвучат отдельные сирены. Впрочем, даже незначительные происшествия, затрагивающие отдельный сервис, могут породить несколько оповещений, если они сопровождаются неоднократными ошибками. Конечно, нужно стараться свести к минимуму количество оповещений, вызываемых одним и тем же событием, но полностью избежать их обычно не удается, поскольку необходимо обеспечивать баланс между ложноположительными и ложноотрицательными срабатываниями.
Возможность объединять несколько оповещений в единый инцидент весьма важна, чтобы справляться с таким дублированием. Письмо с текстом «Это то же самое, что и вон то, и все это признаки одного инцидента» подойдет для одного определенного оповещения: оно предотвратит ненужную повторную отладку или лишнюю панику. Однако сопровождать письмом каждое оповещение — непрактичное и плохо масштабируемое решение, если требуется устранить дублирующиеся оповещения внутри даже одной команды, не говоря уже о более продолжительных периодах времени или о взаимодействии нескольких групп.
Маркировка
Разумеется, не каждое оповещение о событии означает инцидент. Бывают ложные срабатывания, а также тестовые события или письма, ошибочно отправленные человеком. Сам сервис Outalator не различает эти события, но позволяет делать универсальную маркировку — добавлять к сообщениям метаданные на всех уровнях. Маркеры (теги) записываются в произвольной форме, в виде отдельных слов. Двоеточия, впрочем, распознаются как семантические разделители, которые естественным образом дают возможность использовать иерархические пространства имен и применять некоторые средства автоматической обработки. Для поддержки пространств имен служат также рекомендованные префиксы маркеров, в первую очередь cause и action, но в целом используемый набор маркеров зависит от конкретной команды и обусловлен «историческими причинами». Например, для одних команд пометка cause:network может содержать достаточное количество информации, в то время как другие могут предпочесть более подробные формулировки, например cause:network:switch или cause:network:cable. Некоторые команды могут часто использовать метки типа customer:132456, поэтому можно закрепить за ними префикс customer, но для других потребуется придумать что-то другое.
Маркеры могут быть распознаны и преобразованы в ссылку, пригодную для дальнейшего использования (например, bug:76543 ссылается на систему контроля ошибок — «баг-трекер»). Другие метки представляют собой единственное слово (например, bogus обычно применяется для пометки сообщений, сгенерированных в результате ложного срабатывания). Конечно, некоторые маркеры могут быть записаны с ошибками (cause:netwrok), а какие-то — вообще не содержать сколько-то полезной информации (problem-went-away), но лучше избегать жестко заданных предопределенных списков, позволяя командам искать собственные стандарты и предпочтения, в результате чего мы получим более эффективное средство и в конечном итоге — надежные данные. В целом метки оказались весьма мощным инструментом, позволяющим командам выявлять и описывать проблемные места отдельно взятого сервиса, причем с минимальной формализацией этого анализа или даже совсем без нее. Каким бы простым ни казался механизм маркировки, он, вероятно, является одной из наиболее полезных уникальных возможностей Outalator.
Анализ
Разумеется, в обязанности SR-инженеров входит куда больше, чем просто устранение проблем и последствий инцидентов. Архивные данные полезны при реагировании на инциденты — вопрос «А что мы делали в прошлый раз?» всегда будет хорошей отправной точкой. Но архивная информация куда более полезна, если мы имеем дело с проблемами системными, повторяющимися или иными столь же широкого характера. Применение подобного анализа — одна из наиболее важных составляющих системы контроля неисправностей.
Нижний уровень анализа включает подсчет и базовое обобщение статистических данных для отчетности. Подробности зависят от конкретной команды, но такая информация, как количество инцидентов за неделю/месяц/квартал и количество оповещений в течение инцидента, присутствует обязательно. Следующий уровень более важен, но при этом прост в реализации: сравнения между командами/сервисами в динамике для раннего выявления закономерностей и тенденций. Этот уровень позволяет командам определить, является ли данная нагрузка «нормальной» относительно их собственной истории практики и других сервисов. Фраза «Это уже третий раз за неделю» может быть как плохим, так и хорошим знаком, но если «это» обычно случается пять раз в день или, например, пять раз в месяц, то это уже дает почву для анализа.
Следующим шагом в анализе данных является поиск более сложных и масштабных проблем, что уже потребует не просто подсчетов, а более глубокого анализа. Прозрачный доступ к такой информации наряду с данными об инцидентах требуется, например, для определения компонента инфраструктуры, являющегося причиной наибольшего количества инцидентов, и затем оценки выигрыша от повышения стабильности или производительности данного компонента. Простой пример: у разных команд действуют специфические для сервисов условия оповещений, такие как «устаревшие данные» или «большая задержка». Оба состояния могут быть вызваны перегрузкой сети, которая приведет к задержке репликации базы данных и потребует вмешательства. Они также могут объективно не превышать номинальный для данного сервиса уровень, но уже не соответствовать возросшим субъективным требованиям пользователей. Изучение этой информации с участием нескольких команд позволяет выявлять системные проблемы и выбирать правильное решение, особенно если речь идет о наиболее изощренных сбоях, чтобы предотвратить перерасход вычислительных мощностей.
Отчетность и общение
Среди наиболее востребованных SR-инженерами функций можно также назвать возможность отбирать несколько (возможно, ни одного) объектов из Outalator и включать их темы, метки и важные аннотации в письмо следующему дежурному инженеру (с произвольным списком адресов для копий письма), чтобы сообщать о текущем состоянии при передаче смены. Для периодических проверок сервисов в промышленной эксплуатации (которые большинство команд проводит еженедельно) Outalator поддерживает «режим отчета», когда важные примечания разворачиваются параллельно с основным списком для обеспечения быстрого просмотра.
Неочевидная польза
Эффект от возможности определить, что оповещение или поток оповещений связаны с другим, уже известным сбоем, очевиден: ускоряется диагностика и снижается нагрузка на другие команды, которые будут знать, что данный инцидент уже учтен. Но есть и другие, менее очевидные преимущества. Возьмем, например, Bigtable: если в некотором сервисе выявлено нарушение функционирования, однозначно вызванное проблемами именно в Bigtable, но вы видите, что соответствующая SRE-команда не была оповещена, то, вероятно, следует сообщить им об этом самостоятельно. Улучшение взаимодействия между командами может внести и вносит значительный вклад в разрешение инцидентов или хотя бы смягчает их последствия.
Некоторые команды в компании зашли настолько далеко, что настраивают Escalator на простое перенаправление сообщений в Outalator, где они могут быть промаркированы, снабжены аннотациями и проанализированы. Одним из примеров применения такой «системы учета» является регистрация и проверка использования привилегированных или служебных учетных записей (стоит, однако, отметить, что это простейший функционал, пригодный скорее для технических внутренних проверок, чем для полноценного внешнего аудита). Другой вариант использования — запись и снабжение аннотациями хода выполнения периодических задач, которые могут производить существенные изменения — например, автоматическое применение изменений схем, исходящее из системы контроля версий и достигающее баз данных.
Например, некоторое изменение в сервисе Bigtable, дающее небольшой положительный эффект в случае одной конкретной неисправности, может требовать слишком больших усилий разработчиков. Однако если улучшение будет проявляться и во многих других случаях, эти усилия будут оправданными.
С одной стороны, «порождает наибольшее количество инцидентов» — хороший критерий выбора при поиске путей сокращения числа происшествий и совершенствования системы в целом. С другой — эта метрика может говорить и просто об избыточной чувствительности средств мониторинга или о работе некоторых клиентских систем вне заданных параметров. И наконец, с третьей стороны, само по себе количество инцидентов не отражает ни сложность устранения их причин, ни степень тяжести их последствий.

