Книга: Руководство по DevOps
Назад: Глава 14. Создайте телеметрию, позволяющую замечать проблемы и решать их
Дальше: Глава 16. Настройте обратную связь, чтобы разработчики и инженеры эксплуатации могли безопасно разворачивать код
Глава 15. Анализируйте телеметрию, чтобы лучше предсказывать проблемы и добиваться поставленных целей
Как мы видели в предыдущей главе, нам нужно достаточное количество телеметрии в наших приложениях и инфраструктуре, для того чтобы видеть и решать проблемы в момент появления. В этой главе мы создадим инструменты для обнаружения спрятанных в наших данных отклонений и слабых сигналов о неполадках, помогающих избежать катастрофических последствий. Мы опишем многочисленные статистические методики, а также покажем на реальных примерах, как они работают.
Отличный пример анализа телеметрии для проактивного поиска ошибок до того, как они повлияют на клиентов, — компания Netflix, крупнейший провайдер фильмов и сериалов на основе потокового мультимедиа. В 2015 г. доход Netflix от 75 миллионов подписчиков составлял 6,2 миллиарда долларов. Одна из ее целей — обеспечить наилучшие впечатления от просмотра видео онлайн во всех уголках земного шара. Для этого нужна устойчивая, масштабируемая и гибкая инфраструктура. Рой Рапопорт описывает одну из сложных задач управления облачной службой доставки видео: «Допустим, у вас есть стадо скота. В нем все должны выглядеть и вести себя одинаково. Какая корова отличается от остальных? Или, более конкретно, у нас есть вычислительный кластер с тысячью узлов. Они не фиксируют свое состояние, на них работает одно и то же программное обеспечение, и через них проходит один и тот же объем трафика. Задача в том, чтобы найти узлы, не похожие на остальные».
Одной из статистических методик, использованных в Netflix в 2012 г., было обнаружение выбросов. Виктория Ходж и Джим Остин из Йоркского университета определяют ее как обнаружение «аномальных рабочих состояний, приводящих к значительному ухудшению работоспособности, например дефект вращения двигателя самолета или нарушение потока в трубопроводе».
Рапопорт объясняет, что Netflix «обнаруживал выбросы очень простым способом. Сначала определялась отправная точка, то, что считалось нормальным прямо сейчас в этом наборе узлов вычислительного кластера. Затем искали узлы, выбивающиеся из общей картины, и удаляли их из эксплуатации».
Он продолжает: «Мы можем автоматически помечать неправильно ведущие себя узлы без того, чтобы выяснять, что же такое правильное поведение. И поскольку мы настроены на гибкую работу в облаке, инженеров эксплуатации мы ни о чем не просим. Мы просто отстреливаем больной или безобразничающий узел, затем составляем лог или сообщаем об этом инженерам так, как им удобно».
Применяя методику обнаружения выбросов среди серверов, Netflix, по словам Рапопорта, «существенно сократил усилия на выявление больных серверов и, что более важно, сильно уменьшил время на их починку. Результат — улучшение качества услуг. Выигрыш от этих методик для сохранения рассудка сотрудников, баланса работы и жизни и качества услуг переоценить сложно». Сделанное Netflix подчеркивает один очень конкретный способ использования телеметрии для устранения проблем, прежде чем они повлияют на клиентов.
В этой главе мы исследуем разные статистические и визуализирующие методики (включая обнаружение выбросов) для анализа телеметрии и предсказывания возможных проблем. Это позволит решать проблемы быстрее, дешевле и раньше, до того как их заметят клиенты или ваши коллеги. Кроме того, мы более полно опишем связь собранных данных и особенностей ситуации, что позволит нам принимать более эффективные решения и добиваться целей организации.
Используйте средние и стандартные отклонения для обнаружения потенциальных проблем
Один из простейших статистических способов анализа производственного показателя — это расчет среднего и стандартных отклонений. С их помощью мы можем создать фильтр, оповещающий, что показатель сильно отклоняется от обычных значений, и даже настроить систему оповещения, чтобы мы могли сразу предпринять нужные действия (например, если запросы в базе данных обрабатываются значительно медленнее, то в 2:00 система сообщит дежурным сотрудникам, что нужно провести расследование).
Когда в важнейших службах возникает проблема, будить людей в два часа ночи — правильно. Однако, когда мы создаем оповещения, не содержащие никакой программы разумных действий, или же когда происходит ложное срабатывание, исполнителей мы будим зря. Как отмечает Джон Винсент, стоявший у истоков движения DevOps, «переутомление от чрезмерного количества сигналов тревоги — наша самая главная проблема на этот момент… Нужно разумнее подходить к оповещениям, или мы все сойдем с ума».
Оповещения можно сделать лучше, если увеличить отношение сигнала к шуму, фокусируясь на значимых отклонениях или выбросах. Предположим, что нам надо проанализировать число несанкционированных входов в систему в день. У собранных данных — распределение Гаусса (то есть нормальное распределение), совпадающее с графиком на рис. 29. Вертикальная линия в середине колоколообразной кривой — среднее, а первые, вторые и третьи стандартные отклонения, обозначенные другими вертикальными линиями, содержат 68, 95 и 99,7 % наблюдений соответственно.
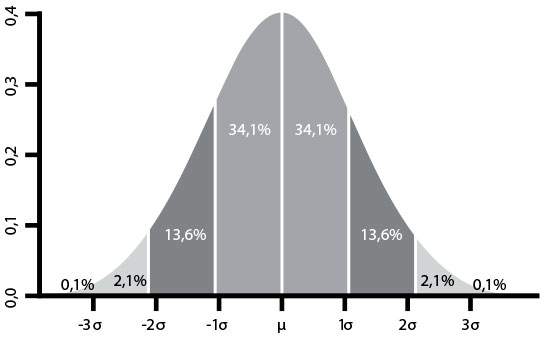
Рис. 29. Стандартные отклонения (σ) и среднее (µ) распределения Гаусса (источник: «Википедия», статья Normal Distribution, )
Обычный способ использовать стандартные отклонения — время от времени проверять набор данных по какому-то показателю и сообщать, если он сильно отличается от среднего значения. Например, оповещение сработает, если число попыток несанкционированных входов в систему в день больше среднего на три величины стандартного отклонения. При условии, что данные распределены нормально, только 0,3 % всех событий будут включать сигнал тревоги.
Даже такая простая методика статистического анализа ценна, потому что никому не нужно определять пороговое значение. При отслеживании тысяч и сотен тысяч показателей это было бы невыполнимой задачей.
Далее в тексте термины телеметрия, показатель и наборы данных будут использоваться как синонимы. Другими словами, показатель (например, время загрузки страницы) будет увязываться с набором данных (например, 2 мс, 8 мс, 11 мс и так далее) Набор данных — статистический термин, обозначающий матрицу значений показателей, где каждый столбец представляет переменную, над которой производятся те или иные статистические операции.
Создайте инструменты фиксации и оповещения о нежелательных событиях
Том Лимончелли, соавтор книги The Practice of Cloud System Administration: Designing and Operating Large Distributed Systems и бывший инженер по обеспечению надежности сайтов компании Google, говорит о мониторинге показателей следующее: «Когда коллеги просят меня объяснить, что именно нужно мониторить, я шучу, что в идеальном мире мы удалили бы все имеющиеся оповещения в нашей системе наблюдения. Затем после каждого сбоя мы спрашивали бы себя: какие индикаторы могли бы предсказать этот сбой? И добавляли бы эти индикаторы в систему, настраивая соответствующие оповещения. И так снова и снова. В итоге у нас были бы только оповещения, предотвращающие сбои, тогда как обычно нас заваливает сигналами тревоги уже после того, как что-то сломалось».
На этом шаге мы воспроизведем результаты такого упражнения. Один из простейших способов добиться этого — это проанализировать самые серьезные инциденты за недавнее время (например, 30 дней) и создать список телеметрии, делающей возможной более раннюю и быструю фиксацию и диагностику проблемы, а также легкое и быстрое подтверждение того, что лекарство применено успешно.
Например, если наш веб-сервер NGINX перестал отвечать на запросы, мы могли бы взглянуть на индикаторы: они заблаговременно предупредили бы нас — что-то идет не так. Такими показателями могут быть:
• уровень приложения: увеличившееся время загрузки веб-страниц и так далее;
• уровень ОС: низкий уровень свободной памяти сервера, заканчивающееся место на диске и так далее;
• уровень баз данных: более долгие транзакции баз данных и так далее;
• уровень сети: упавшее число функционирующих серверов на балансировщике нагрузки и так далее.
Каждый из этих показателей — потенциальный предвестник аварии. Для каждого мы могли бы настроить систему оповещения, если они будут сильно отклоняться от среднего значения, чтобы мы могли принять меры.
Повторяя этот процесс для все более слабых сигналов, мы будем обнаруживать проблемы все раньше, и в результате ошибки будут затрагивать все меньше клиентов. Другими словами, мы и предотвращаем проблемы, и быстрее их замечаем и устраняем.
Проблемы телеметрии, имеющей негауссово распределение
Использование средних и стандартных отклонений для фиксации выбросов может быть очень полезным. Однако на некоторых наборах данных, используемых в эксплуатации, эти методики не будут давать желаемых результатов. Как отмечает Туфик Бубе, «нас будут будить не только в два часа ночи, но и в 2:37, 4:13, 5:17. Это происходит, когда у наших данных не нормальное распределение».
Другими словами, когда плотность распределения наблюдений описывается не показанной выше колоколообразной кривой, привычные свойства стандартных отклонений использовать нельзя. Например, представим, что мы наблюдаем за количеством скачиваний файла с нашего сайта в минуту. Нам нужно определить периоды, когда у нас необычно высокое число скачиваний. Пусть это число будет больше, чем три стандартных отклонения от среднего. Тогда мы сможем заранее увеличивать мощность или пропускную способность.
Рис. 30 показывает число одновременных скачиваний в минуту. Когда участок линии сверху графика выделен черным цветом, количество скачиваний в заданный период (иногда называемый «скользящим окном») превышает заданную величину. В противном случае линия окрашена в серый цвет.
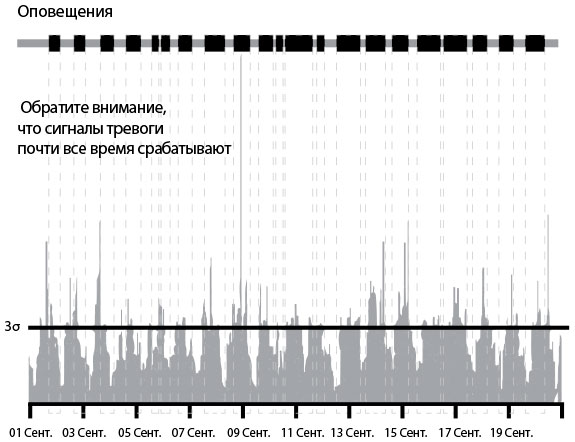
Рис. 30. Число загрузок в минуту: чрезмерное оповещение о проблемах при использовании правила трех стандартных отклонений (источник: Туфик Бубе, “Simple math for anomaly detection”)
График наглядно показывает очевидную проблему: оповещения идут практически непрерывным потоком. Это происходит потому, что почти в любой период у нас есть моменты, когда число скачиваний превышает порог в три стандартных отклонения.
Чтобы доказать это, построим гистограмму (рис. 31). На ней показана частота скачиваний в минуту. Форма гистограммы отличается от классической куполообразной кривой. Вместо этого распределение явно скошено к левому краю. Это говорит нам о том, что большую часть времени у нас малое число скачиваний в минуту, но при этом число скачиваний очень часто превышает предел в три стандартных отклонения.
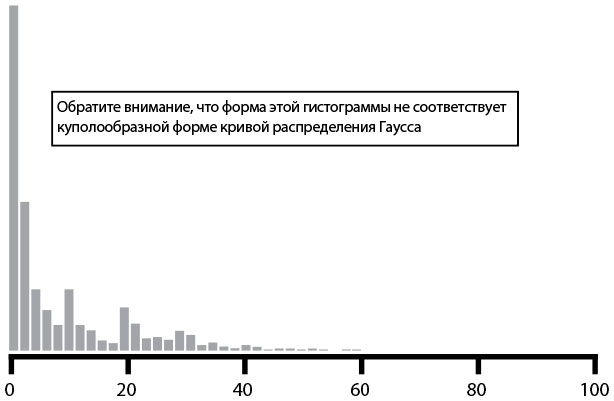
Рис. 31. Число скачиваний в минуту: гистограмма данных, имеющих негауссово распределение (источник: Туфик Бубе, “Simple math for anomaly detection”)
У многих реальных наборов данных распределение не нормально. Николь Форсгрен объясняет: «В эксплуатации у многих наших комплектов данных так называемое распределение хи-квадрат. Использование стандартных отклонений для них не только приводит к чрезмерному или недостаточному количеству оповещений, но и просто выдает бессмысленные результаты». Далее, Николь отмечает: «Когда вы считаете число одновременных скачиваний, которое на три стандартных отклонения меньше среднего, вы получаете отрицательное число. А это явно бессмысленно».
Чрезмерное количество оповещений приводит к тому, что инженеров эксплуатации часто будят среди ночи и долго держат на ногах, даже когда они мало что могут сделать. Проблема недостаточного оповещения о проблемах также весьма значительна. Например, предположим, что мы наблюдаем число завершенных транзакций и из-за отказа какого-то компонента количество транзакций в середине дня внезапно падает на 50 %. Если эта величина находится в пределах трех стандартных отклонений от среднего, никакого сигнала тревоги подано не будет, а значит, наши клиенты обнаружат эту проблему раньше, чем мы. Если дойдет до этого, решить проблему будет гораздо сложнее.
К счастью, для выявления аномалий в наборах данных, имеющих не нормальное распределение, тоже есть специальные методики. О них мы расскажем ниже.
Практический пример
Автоматическая масштабируемость ресурсов, Netflix (2012 г.)
Еще один инструмент, разработанный в Netflix для улучшения качества услуг, Scryer, борется с некоторыми недостатками сервиса Auto Scaling компании Amazon (далее — AAS), который динамически увеличивает и уменьшает количество вычислительных серверов AWS в зависимости от данных по нагрузке. Система Scryer на основе прошлого поведения пользователя предсказывает, что именно ему может потребоваться, и предоставляет нужные ресурсы.Scryer решил три проблемы AAS. Первая заключалась в обработке резких пиков нагрузки. Поскольку время включения инстансов AWS составляет от 10 до 45 минут, дополнительные вычислительные мощности часто загружались слишком поздно, чтобы справиться с пиковыми нагрузками. Суть второй проблемы в следующем: после сбоев быстрый спад пользовательского спроса приводил к тому, что AAS отключал слишком много вычислительных мощностей и потом не справлялся с последующим увеличением нагрузки. Третья проблема — AAS не учитывал в расчетах известные ему паттерны использования трафика.Netflix воспользовался тем фактом, что паттерны поведения его пользователей были на удивление устойчивыми и предсказуемыми, несмотря на то что их распределение не было нормальным. На графике выше отображено количество пользовательских запросов в секунду на протяжении рабочей недели. Схема активности клиентов с понедельника по пятницу постоянна и устойчива.
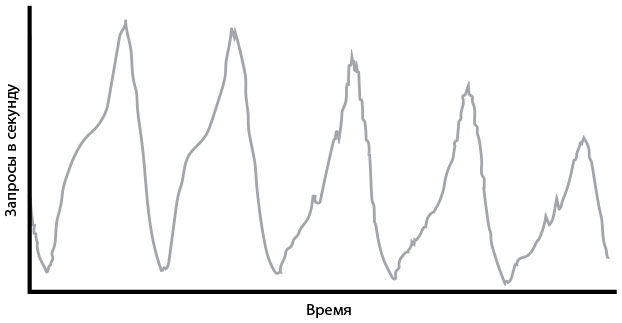
Рис. 32. Пользовательский спрос в течение пяти дней, по данным компании Netflix (источник: Дэниэл Джейкобсон, Дэнни Юан и Нирадж Джоши, “Scryer: Netflix’s Predictive Auto Scaling Engine,” The Netflix Tech Blog, 5 ноября 2013 г., )
Scryer использует комбинацию методик выявления выбросов, чтобы избавляться от сомнительных наблюдений, и затем для сглаживания данных применяет такие методики, как быстрое преобразование Фурье или линейная регрессия, в то же время сохраняя структуру повторяющихся пиков. В результате Netflix может предсказывать требуемый объем трафика с удивительной точностью.
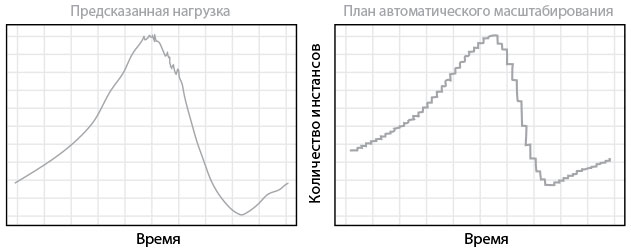
Рис. 33. Предсказание пользовательского трафика системой Scryer компании Netflix и итоговый план распределения вычислительных ресурсов AWS (источник: Джейкобсон, Юан, Джоши, “Scryer: Netflix’s Predictive Auto Scaling Engine”)
Всего лишь за несколько месяцев после введения в эксплуатацию системы Scryer Netflix значительно улучшил качество обслуживания клиентов и доступность своих сервисов, а также уменьшил расходы на использование Amazon EC2 (сервис облачного хостинга).
Использование методик выявления аномалий
Когда у наших данных распределение не нормально, мы все равно можем обнаружить значимые отклонения с помощью разных методов. Здесь пригодится обширный класс методик выявления аномалий, часто определяемых как «поиск явлений и событий, не подчиняющихся ожидаемым правилам и моделям». Некоторые подобные возможности имеются среди наших инструментов мониторинга, для использования других может потребоваться помощь тех, кто разбирается в статистике.
Тарун Редди, вице-президент по разработке и эксплуатации компании Rally Software, выступает за активное сотрудничество между эксплуатацией и статистикой: «Чтобы поддерживать качество наших услуг, мы помещаем все наши производственные показатели в Tableau, программный пакет статистического анализа. У нас даже есть обученный статистике инженер эксплуатации, пишущий код на R (еще один статистический пакет). У этого инженера есть свой журнал запросов, заполненный просьбами других команд посчитать отклонения как можно раньше, прежде чем они приведут к более значительным отклонениям, которые могли бы повлиять на заказчиков».
Одна из пригодных статистических методик — это сглаживание. Оно особенно хорошо подходит, если данные — временные ряды: если у каждого наблюдения есть отметка о времени (например, скачивание файла, завершенная транзакция и так далее). Сглаживание часто использует скользящее среднее, преобразующее наши данные с помощью усреднения каждого наблюдения с соседними наблюдениями в пределах заданного «окна». Это сглаживает кратковременные колебания и подчеркивает долговременные тренды или циклы.
Пример сглаживающего эффекта показан на рис. 34. Синяя линия показывает необработанные данные, тогда как черная отображает тридцатидневное скользящее среднее (то есть среднее последних тридцати дней).
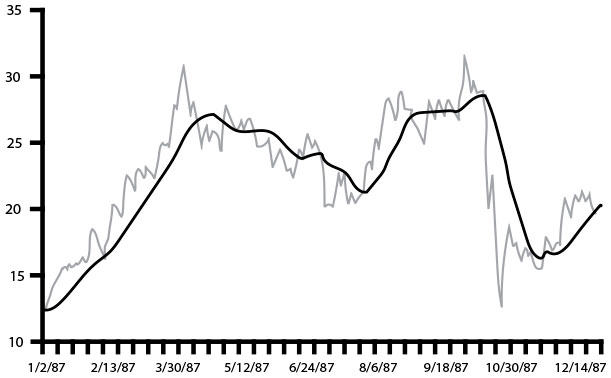
Рис. 34. Цена акции компании Autodesk и сглаживание с помощью тридцатидневного скользящего среднего (источник: Джейкобсон, Юан, Джоши, “Scryer: Netflix’s Predictive Auto Scaling Engine”)
Существуют и более экзотические методики обработки данных, например быстрое преобразование Фурье. Оно широко использовалось в обработке изображений. Или тест Колмогорова — Смирнова (он включен в Graphite и Grafana), часто используемый, чтобы найти сходства или различия в периодических или сезонных данных.
Можно с уверенностью ожидать, что большой процент нашей телеметрии о поведении пользователей будет иметь периодический или сезонный характер: веб-трафик, покупки, просмотр фильмов и многие другие действия клиентов регулярны и имеют на удивление предсказуемые ежедневные, недельные или годовые паттерны. Благодаря этому мы можем фиксировать отклоняющиеся от привычных поведенческих схем ситуации, например если уровень транзакций, связанных с заказами, вечером во вторник вдруг упадет на 50 % по сравнению с обычным значением.
Эти методики очень ценны для построения прогнозов, поэтому можно попробовать поискать в отделах маркетинга или бизнес-аналитики специалистов, обладающих нужными для анализа знаниями и навыками. Возможно, с такими сотрудниками мы сможем определить общие проблемы и использовать улучшенные методики выявления аномалий и предсказания ошибок для достижения общих целей.
Практический пример
Продвинутое выявление аномалий (2014 г.)
На конференции Monitorama в 2014 г. Туфик Бубе поведал о мощности методик по выявлению аномалий, особо подчеркивая эффективность теста Колмогорова — Смирнова. Его часто используют в статистике для определения значимости различий между двумя наборами данных (его можно найти в таких популярных инструментах, как Graphite и Grafana). Цель разбора этого практического примера — не показать алгоритм решения какой-то проблемы, а продемонстрировать, как класс определенных статистических методик можно использовать в работе и как он используется в нашей организации в совершенно разных приложениях.На рис 35 показано количество транзакций в минуту на сайте электронной торговли. Обратите внимание на недельную периодичность графика: число транзакций падает в выходные. Просто взглянув на этот график, можно заметить, что на четвертой неделе произошло что-то необычное: количество транзакций в понедельник не вернулось к обычному уровню. Это происшествие стоит исследовать.
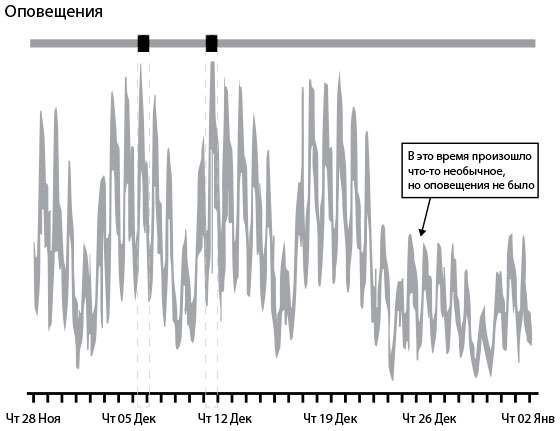
Рис. 35. Количество транзакций: отсутствие нужного оповещения при использовании правила трех отклонений (источник: Туфик Бубе, “Simple math for anomaly detection”)
Использование правила трех стандартных отклонений выдало бы оповещения только дважды и пропустило бы важное падение количества транзакций в понедельник четвертой недели. В идеале мы хотели бы получить оповещение и о том, что данные отклонились от привычного паттерна.«Даже просто сказать слова “Колмогоров — Смирнов” — отличный способ всех впечатлить, — шутит Бубе. — Но вот о чем инженеры эксплуатации должны сказать специалистам по статистике, так это то, что эти непараметрические критерии отлично подходят для данных со стадии эксплуатации, потому что не нужно делать никаких допущений о нормальности или других свойствах распределения. А ведь крайне важно понять, что же происходит в наших сложных системах. Пользуясь методиками, мы сравниваем два вероятностных распределения, в данном случае периодические и сезонные данные. Это помогает нам найти отклонения в ежедневно или еженедельно меняющихся данных».На рис. 36 показан тот же самый набор данных, но с примененным фильтром Колмогорова — Смирнова. Третий выделенный черным участок соотносится с аномальным понедельником, когда уровень транзакций не вернулся к обычному уровню. Применение этой методики оповещает о проблемах в системе, практически не видных с помощью простого визуального осмотра или стандартных отклонений. При таком подходе раннее обнаружение не позволит проблеме повлиять на клиентов, а также поможет реализовать цели организации.
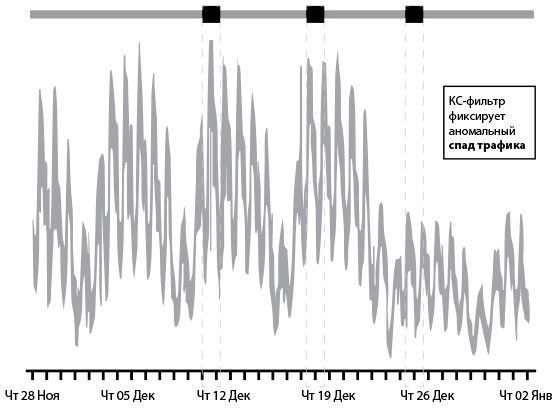
Рис. 36. Количество транзакций: использование теста Колмогорова — Смирнова для оповещения об аномалиях (источник: Туфик Бубе, “Simple math for anomaly detection”)
Заключение
В этой главе мы исследовали несколько разных статистических методик. Их можно использовать для анализа производственной телеметрии, чтобы заблаговременно находить и устранять возможные проблемы, пока они достаточно малы и еще не успели привести к катастрофическим последствиям. Эти методики позволяют находить слабые сигналы о неполадках. На их основе можно предпринять реальные действия, создать более безопасную систему, а также успешно добиваться поставленных целей.
Мы разобрали конкретные случаи деятельности реальных компаний, например то, как Netflix использовал эти подходы для проактивного удаления плохих вычислительных серверов и автоматического масштабирования своей вычислительной инфраструктуры. Мы также обсудили, как использовать скользящее среднее и тест Колмогорова — Смирнова. Его можно найти в популярных руководствах для построения графиков.
В следующей главе мы опишем, как интегрировать производственную телеметрию в повседневную деятельность команды разработки, чтобы сделать развертывание более безопасным и улучшить всю систему в целом.
Назад: Глава 14. Создайте телеметрию, позволяющую замечать проблемы и решать их
Дальше: Глава 16. Настройте обратную связь, чтобы разработчики и инженеры эксплуатации могли безопасно разворачивать код

