Книга: Руководство по DevOps
Назад: Введение
Дальше: Глава 15. Анализируйте телеметрию, чтобы лучше предсказывать проблемы и добиваться поставленных целей
Глава 14. Создайте телеметрию, позволяющую замечать проблемы и решать их
Суровая реальность жизни отдела IT-эксплуатации — не все идет так гладко, как хотелось бы. Небольшие изменения приводят к многообразным и неожиданным последствиям, включая задержки, простои в работе и масштабные сбои, влияющие на всех наших клиентов. Это реальность управления сложными системами; ни один человек не в состоянии охватить взглядом всю систему и понять, как ее части взаимодействуют друг с другом.
Когда в нашей повседневной работе происходит какой-нибудь неожиданный сбой, у нас не всегда есть информация, необходимая для решения проблемы. Например, не всегда можно определить, произошел ли сбой из-за проблемы в нашем приложении (например, из-за дефекта кода), в окружении (например, вследствие проблемы с передачей данных по сетям или с конфигурацией сервера) или в чем-то полностью внешнем (к примеру, DoS-атака).
В подразделении IT-эксплуатации с этими проблемами можно бороться с помощью золотого правила: что-то пошло не так — перезагрузи сервер. Если это не сработало, перезагрузи сервер рядом с предыдущим. Если и это не сработало, перезагрузи все серверы. Если же и это не исправило ситуацию, свали все на разработчиков, все сбои ведь происходят из-за них.
В то же время исследование, проведенное Microsoft Operations Framework (MOF) в 2001 г., показало, что организации с самым высоким уровнем обслуживания перезагружали свои серверы в 20 раз реже, чем условная средняя компания, и они в пять раз реже сталкивались с «синим экраном смерти». Другими словами, они обнаружили, что самые успешные компании гораздо лучше диагностировали и исправляли проблемы с серверами, применяя на практике то, что Кевин Бер, Жене Ким и Джордж Спаффорд назвали в своей книге The Visible Ops Handbook «культурой причинно-следственных связей». Успешные фирмы последовательно решали проблемы, используя производственную телеметрию, чтобы понять возможные причины неполадок и найти рабочие методы их устранения, в отличие от менее успешных фирм, слепо перезагружавших серверы.
Чтобы образ действий был направлен на решение проблем, нужно выстроить системы на основе непрерывно поступающих телеметрических данных. Под телеметрией обычно понимают «процесс автоматической коммуникации, с помощью которого измерения и другие данные собираются в удаленных точках и затем передаются на приемные устройства для последующего контроля». Наша цель в том, чтобы создать систему телеметрии в наших приложениях и окружении как внутри процесса разработки, так и в процессе развертывания и внедрения.
Майкл Рембетси и Патрик Макдоннелл описали, как наблюдение и контроль над созданием продукции были важнейшей частью начавшегося в 2009 г. перехода к системе DevOps в компании Etsy. Это было связано с тем, что они стандартизировали и перевели весь свой стек технологий в LAMP (Linux, Apache, MySQL и PHP), избавляясь от множества других технологий, поддерживать которые становилось все труднее.
В 2012 г. на конференции Velocity Макдоннелл рассказал, насколько рискованно это было: «Мы меняли нашу важнейшую инфраструктуру, чего клиенты никогда не заметили бы. Однако они точно заметили бы, если бы мы где-то напортачили. Нам нужно было больше показателей, чтобы можно было быть уверенными в том, что мы ничего не ломаем, проводя эти большие перемены. Это было нужно как для наших технических служб, так и для нетехнических, например для отдела маркетинга».
Далее Макдоннелл объясняет: «Мы начали аккумулировать все данные по серверам в систему мониторинга Ganglia, визуализировать ее в Graphite, программе с открытым исходным кодом, в которую мы много инвестировали. Мы собирали все данные в единое целое, начиная с бизнес-показателей и заканчивая количеством развертываний. Тогда мы модифицировали Graphite с помощью того, что называем “нашей уникальной и неповторимой методикой вертикальных линий”, отображающей на все графики показателей моменты, когда происходило развертывание. Благодаря такому подходу мы могли быстро замечать любые непредусмотренные побочные эффекты развертывания и внедрения. Мы даже начали ставить по всему офису мониторы, чтобы все могли видеть, как работают наши системы».
Обеспечивая возможность разработчикам добавлять телеметрию к их повседневной работе, они создали достаточно телеметрических систем, чтобы развертывания стали безопасными. К 2011 г. Etsy отслеживала более 200 тысяч производственных показателей на каждом уровне стека приложений (например, функциональные возможности приложения, работоспособность приложения, базы данных, операционная система, память, сетевые соединения, безопасность и так далее), а 30 наиболее важных показателей постоянно отображались на «информационной панели развертывания». К 2014 г. они отслеживали более 800 тысяч индикаторов, тем самым демонстрируя непреклонное стремление измерить все, что можно, и максимально упростить сам процесс измерения.
Как пошутил один из инженеров Etsy Йен Малпасс, «если в Etsy и есть религия, то это церковь графиков. Если что-то меняется, мы это отслеживаем. Иногда мы рисуем график того, что еще не меняется, на тот случай, если оно вдруг решит пуститься во все тяжкие… Отслеживание всего, что только можно, — ключ к быстрому продвижению вперед, но единственный способ воплотить этот принцип в жизнь — сделать так, чтобы отслеживание показателей было простым… Мы облегчаем сотрудникам задачу наблюдения за нужными им показателями сразу же, без поглощающих время изменений конфигурации или других сложных процессов».
Одним из открытий доклада 2015 State of DevOps Report было то, что в успешных организациях проблемы в процессе создания программного продукта решались в 168 раз быстрее, чем в других фирмах, причем у ведущих организаций медианное значение MTTR измерялось в минутах, тогда как медианный показатель MTTR фирм с низкими показателями измерялся в днях. Две самые важные методики, позволившие минимизировать MTTR, заключались в использовании контроля версий IT-эксплуатацией и применении телеметрии и проактивного мониторинга рабочей среды.
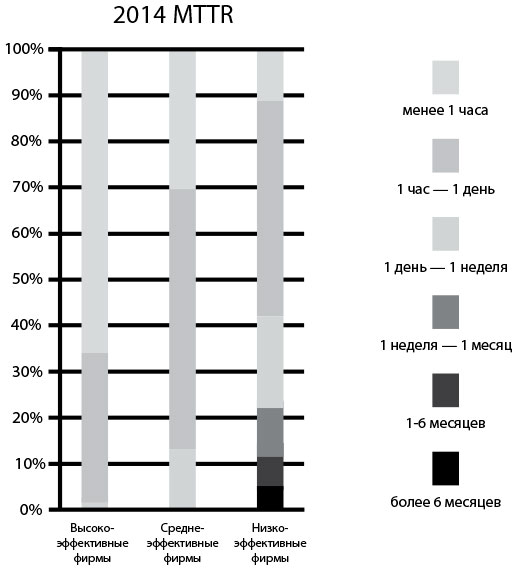
Рис. 25. Время устранения проблемы для высокоэффективных, среднеэффективных и низкоэффективных организаций (источник: отчет 2014 State of DevOps Report компании Puppet Labs)
Наша цель в этой главе — вслед за Etsy построить такую систему телеметрии, чтобы мы всегда были уверены, что наши процессы в производстве протекают так, как нужно. И когда проблемы все-таки случаются, мы можем быстро определить, что пошло не так, и принять обоснованные решения, как лучше всего их разрешить, в идеале — задолго до того, как они повлияют на наших клиентов. Более того, телеметрия как раз и становится средством, позволяющим составить правильное представление о реальности и обнаружить места, где наше понимание расходится с истинным положением дел.
Создайте централизованную телеметрическую инфраструктуру
Эксплуатационный мониторинг и логирование — процедуры далеко не новые; многие поколения инженеров эксплуатации использовали и настраивали под себя разные платформы мониторинга (например, HP OpenView, IBM Tivoli, BMC Patrol/BladeLogic), чтобы обеспечить работоспособность производственных систем. Данные обычно собирались с помощью работающих на серверах агентов или с помощью мониторинга без агентов (например, SNMP-ловушки или наблюдение с помощью опросов). Часто для front-end был специальный графический интерфейс (GUI), а отчеты для back-end делались подробнее с помощью таких инструментов, как Crystal Reports.
Точно так же методики разработки приложений с помощью эффективного логирования и использования результатов телеметрии не есть нечто новое: практически для любого языка программирования существует множество разнообразных проработанных библиотек для логирования.
Однако в течение долгих десятилетий все, что у нас было — лишь разрозненные данные, логи созданные разработчиками, интересные только разработчикам, в эксплуатации же следят только за тем, работает ли среда или нет. В результате, когда происходит сбой, никто не может определить, почему вся система работает не так, как должна, или почему конкретный компонент выходит из строя. В результате, когда происходит сбой, никто не может определить, почему вся система работает не так, как должна, или почему конкретный компонент выходит из строя. Все это сильно осложняет попытки вернуть систему в рабочее состояние.
Чтобы отслеживать проблемы в момент возникновения, необходимо так спроектировать и организовать приложения и среду, чтобы они предоставляли телеметрию, позволяющую понять, как работает система в целом. Когда на всех уровнях стека приложения есть мониторинг и логирование, можно применять другие важные инструменты, например создание графиков и визуализацию показателей, обнаружение аномалий, проактивное оповещение и распространение информации и так далее.
В книге The Art of Monitoring Джеймс Торнбулл описал современную архитектуру мониторинга, разработанную и используемую инженерами эксплуатации в масштабных интернет-компаниях (например, Google, Amazon, Facebook). Эта архитектура часто состояла из инструментов с открытым исходным кодом (например, Nagios и Zenoss), измененных под заказчика и использованных в огромных масштабах: этого сложно было бы достичь с помощью лицензированных коммерческих программ того времени. Архитектура состоит из следующих компонентов.
• Сбор данных на уровнях бизнес-логики, приложения и среды. На каждом из этих уровней мы создаем телеметрию в виде событий, логов и показателей. Логи могут храниться в специфичных для приложения файлах на каждом сервере (например, /var/log/httpd-error.log), но будет лучше, если все логи будут отсылаться в одно и то же место, что упростит централизацию, ротацию и удаление. Такая услуга обеспечивается большинством операционных систем, например syslog для Linux, Event Log («Журнал событий») для Windows и так далее. Кроме того, мы собираем показатели на всех уровнях стека приложения, чтобы лучше понять, как ведет себя наша система. На уровне операционной системы можно собрать телеметрию работы центрального процессора, памяти, диска или использования сети с помощью таких инструментов, как collectd, Ganglia и так далее. Среди других собирающих данные инструментов можно назвать AppDynamics, New Relic и Pingdom.
• Маршрутизатор событий, ответственный за хранение событий и показателей. Этот компонент отвечает за визуализацию, отслеживание трендов, оповещение, обнаружение аномалий и многое другое. Собирая, храня и агрегируя нашу телеметрию, мы упрощаем последующий анализ и проверки работоспособности. Здесь же мы храним конфигурации, связанные с нашими службами (а также со связанными с ними приложениями и средой), и где, вероятно, оповещаем о превышении пороговых значений и проводим проверки работоспособности.
Собрав логи в одном месте, мы можем преобразовать их в показатели, подсчитывая их в маршрутизаторе событий; например, такое событие, как «child pid 14024 exit signal Segmentation fault», может быть подсчитано и просуммировано как один из показателей ошибки сегментации во всей производственной инфраструктуре.
Преобразовав логи в показатели, мы можем применить к ним статистические методы, например обнаружение отклонений от нормального состояния, чтобы выявлять выбросы и отклонения еще раньше. Скажем, настроить систему оповещения так, чтобы она сообщала о переходе от десяти ошибок сегментации на прошлой неделе к тысячам таких ошибок за последний час, что, конечно, требует тщательного расследования.
В дополнение к сбору телеметрии из служб и окружения необходимо также фиксировать важные события в процессе развертывания, например, когда программа проходит или проваливает автоматизированные тесты или когда мы развертываем продукт в любой среде. Кроме того, надо собирать данные, сколько времени требуется на выполнение сборок и на прохождение тестов. Так мы можем заметить условия, свидетельствующие о возможных проблемах, например если тест качества работы или сборка занимают в два раза больше времени, чем нужно. Это позволит найти и исправить ошибки до того, как они перейдут в фазу эксплуатации.
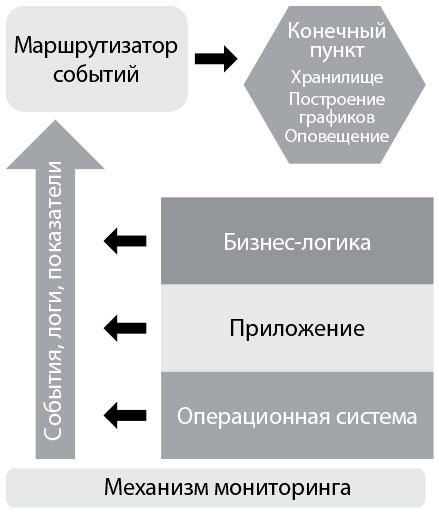
Рис. 26. Механизм мониторинга (источник: Торнбулл. The Art of Monitoring, Kindle edition, глава 2)
Далее нужно убедиться, что в нашу телеметрическую инфраструктуру легко заносить новую информацию и извлекать старую. Хорошо, если все будет организовано с помощью самообслуживающихся API, чтобы не приходилось оформлять тикет и долго ждать отчета.
В идеале нужно создать телеметрическую систему, информирующую нас, когда, а также где и как именно произошло нечто интересное. Эта система должна быть удобна для анализа вручную и автоматизированно, а также данные должны быть доступны для анализа без доступа к самому приложению, предоставившему логи. Как заметил Адриан Коккрофт, «Мониторинг настолько важен, что наши системы мониторинга должны быть более доступными и более гибкими, чем то, за чем они наблюдают».
Термин «телеметрия» синонимичен слову «показатели»: это все логи событий и все индикаторы служб на всех уровнях стека приложения, полученные как на этапе эксплуатации, так и до него, а также в процессе развертывания продукта.
Создайте телеметрию логирования приложений, полезную на этапе эксплуатации
Теперь, когда у нас есть инфраструктура централизованной телеметрии, мы должны удостовериться в том, что все разрабатываемые и используемые приложения поставляют достаточное количество нужных данных. Для этого инженеры разработки и эксплуатации должны генерировать телеметрию эксплуатации в процессе своей повседневной работы как для новых, так и для уже существующих служб.
Скотт Праф, главный архитектор и вице-президент отдела разработки компании CSG, отметил: «Каждый раз, когда NASA запускает ракету, тысячи автоматизированных сенсоров в ней отчитываются о состоянии каждого компонента этого ценнейшего объекта. А мы же часто не принимаем таких же мер предосторожности с нашими программами. Мы обнаружили, что создание телеметрии на уровнях приложения и инфраструктуры — одна из самых выгодных инвестиций, что мы когда-либо делали. В 2014 г. мы фиксировали более миллиарда событий в день, причем данные поступали из более чем сотни тысяч мест в коде».
В создаваемых и используемых нами приложениях каждый элемент функциональности должен находиться под наблюдением: если он был достаточно важен, чтобы его реализовать, значит, он достаточно важен, чтобы собирать о нем данные. Так мы сможем контролировать, что он работает именно так, как и предполагалось, и что итог работы такой, какого мы и хотели добиться.
Каждый участник процесса разработки и эксплуатации будет использовать телеметрию множеством разных способов. Например, разработчики могут временно увеличить количество собираемых данных, чтобы лучше определить проблему, а инженеры по эксплуатации будут опираться на телеметрию, чтобы лучше справляться с проблемами на стадии эксплуатации. Кроме того, служба информационной безопасности и аудиторы могут анализировать сведения о работе приложения, чтобы убедиться в эффективности требуемого контроля, а менеджер по продукции будет использовать их для отслеживания бизнес-показателей, статистики использования функций программы или коэффициента конверсии.
Чтобы поддержать разнообразные модели использования, мы предлагаем разные уровни логирования. В них также можно настроить оповещения. Уровни могут быть такие.
• Уровень отладки. На этом уровне собирается информация обо всем, что происходит внутри приложения. Чаще всего этот уровень используется при соответственно отладке. Часто на стадии эксплуатации логи отладки отключают, но временно возвращаются к ним, если возникли какие-то проблемы.
• Информационный уровень. На этом уровне данные состоят из специфических для конкретной системы действий или же действий, совершаемых пользователем (например, «начало транзакции с использованием кредитной карты»).
• Уровень предупреждений. Здесь телеметрия сообщает нам о состояниях, потенциально порождающих проблемы (например, обращение к базе данных занимает больше времени, чем заранее запланировано). Эти условия, вероятно, выдадут оповещение и потребуют выявить и устранить неполадку, тогда как другие сообщения логов помогут нам лучше понять, какие действия привели к такому состоянию.
• Уровень ошибок. На этом уровне собирается информация об ошибках (например, падение при API-вызове или внутренняя ошибка).
• Критический уровень. Данные на этом уровне сообщают нам, когда мы должны прервать работу (например, сетевой агент (так называемый демон) не может подключиться к сетевому соединителю («сокету»)).
Выбор правильного уровня логирования важен. Дэн Норт, бывший консультант компании ThoughtWorks, принимавший участие в нескольких проектах, где были сформированы основные принципы непрерывной поставки ПО, замечает: «Когда вы решаете, должно ли сообщение звучать как ОШИБКА или ПРЕДУПРЕЖДЕНИЕ, представьте, что вас разбудили в четыре утра. Закончился тонер в принтере — это не ОШИБКА».
Чтобы убедиться, что у нас есть вся относящаяся к устойчивой и надежной работе приложения информация, нужно удостовериться, что все потенциально значимые события генерируют логи. Обязательно нужно учесть группы событий, собранные в списке Антона Чувакина, вице-президента по исследованиям, работающего в группе безопасности и риск-менеджмента подразделения GTP (Gartner for Technical Professionals) компании Gartner:
• решения о подтверждении прав доступа/авторизации (включая выход из системы);
• доступ в систему и доступ к данным;
• изменения системы и приложения (особенно изменения, связанные с правами доступа);
• изменения данных, такие как добавление, правка и удаление данных;
• некорректный ввод (возможный ввод вредоносных данных, угрозы и так далее);
• ресурсы (RAM, диск, процессор, пропускная способность соединения и любые другие ресурсы, имеющие жесткие или мягкие ограничения);
• работоспособность и доступность;
• загрузка и завершение работы;
• сбои и ошибки;
• срабатывание автоматического выключателя;
• задержки;
• успешное или неудачное резервное копирование.
Чтобы все эти логи было проще интерпретировать и понимать, стоит создать иерархические категории, такие как нефункциональные характеристики (например, качество работы, безопасность) и характеристики, связанные с функциональностью программы (например, поиск, ранжирование).
Используйте телеметрию в решении проблем
Как было описано в начале этой главы, высокопроизводительные компании используют дисциплинированный подход к решению проблем. Такой подход противоположен более распространенной практике использования слухов и домыслов, приводящей к столь печальному показателю, как количество среднего времени до признания невиновным: как быстро мы сможем убедить всех, что это не мы были причиной сбоя или простоя в работе.
Когда вокруг сбоев и проблем создана культура обвинений, команды могут не документировать изменения и скрывать показатели: ведь все могут увидеть, что они стараются избежать вины за возникновение проблем.
Другие негативные последствия отсутствия открытой телеметрии — напряженная атмосфера, необходимость защищаться от обвинений и, что хуже всего, неспособность получать общедоступные знания, как возникают проблемы и что необходимо, чтобы предотвратить их в будущем.
Телеметрия же позволяет нам использовать научный метод, чтобы формулировать гипотезы о причинах проблемы и о средствах ее устранения. Ниже следуют примеры вопросов, на которые можно ответить во время исправления ошибок и корректирования сбоев.
• Каковы доказательства того, что проблема действительно существует?
• Какие значимые события и изменения в наших приложениях и окружении могли привести к этой проблеме?
• Какие гипотезы мы можем сформулировать, чтобы подтвердить связь между предложенными причинами и следствиями?
• Как мы можем доказать, какие из гипотез верны и ведут к решению проблемы?
Ценность основанного на фактах решения проблем заключается не только в гораздо меньшем MTTR (и в лучших результатах для клиентов), но и в усилении взаимовыгодного сотрудничества между разработкой и IT-эксплуатацией.
Обеспечьте сбор показателей эксплуатации в процессе ежедневной работы
Чтобы все могли выявлять и исправлять проблемы в процессе своей ежедневной работы, нужно выработать показатели, которые легко собирать, визуализировать и анализировать. Для этого мы должны создать такую инфраструктуру и библиотеки, чтобы всем и в разработке, и в эксплуатации было как можно проще придумывать и генерировать телеметрию для любой функциональности. Ее созданием они занимаются. В идеале это должна быть одна строка кода, создающая новый показатель и выводящая его на общий экран индикаторов, где его могут видеть все участвующие в процессе создания программы.
Эта философия привела к разработке одной из самых используемых библиотек показателей StatsD. Она появилась на свет в компании Etsy. Как сказал Джон Оллспоу, «Мы создали StatsD для того, чтобы разработчики больше не говорили: “Добавлять в мой код средства измерения слишком напряжно”. Теперь они могут делать это одной строчкой кода. Нам было важно, чтобы разработчики не считали добавление телеметрии такой же сложной задачей, как изменение схемы базы данных».
Программа StatsD может генерировать таймеры и счетчики с помощью одной строки кода (на Ruby, Perl, Python, Java и других языках), и ее часто используют вместе с Graphite или Grafana, преобразующих события в графики и панели индикаторов.
На рис. 27 приведен пример того, как одна строчка кода создает событие «вход пользователя в систему» (в этом случае строка на PHP: “StatsD:: increment(“login.successes”)). Итоговый график показывает количество успешных и неудачных входов за минуту, а вертикальные линии обозначают моменты, когда происходило развертывание продукта.
Количество входов в систему
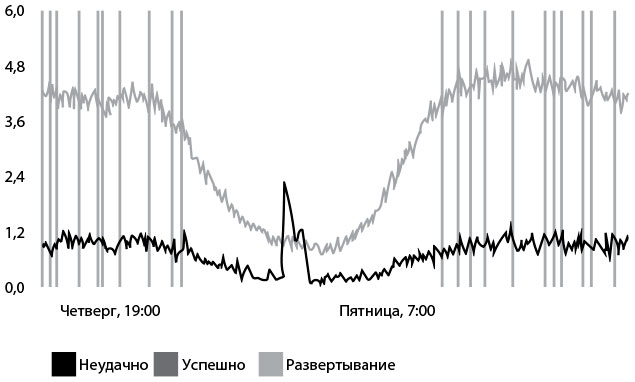
Рис. 27. Одна строка кода для генерирования телеметрии с помощью StatsD и Graphite в компании Etsy (источник: Йен Малпасс, Measure Anything, Measure Everything)
Когда мы будем создавать графики по нашей телеметрии, мы также будем накладывать на них значимые события, возникающие в процессе эксплуатации, потому что нам известно, что большинство проблем на стадии эксплуатации происходит именно из-за эксплуатационных изменений, включая развертывание кода. Это часть того, что позволяет нам сохранять высокие темпы изменений и в то же время поддерживать высокий уровень безопасности системы.
Среди альтернативных StatsD библиотек, позволяющих разработчикам генерировать легко агрегируемую и анализируемую эксплуатационную телеметрию, можно назвать JMX и codahale metrics. Другие инструменты для сбора показателей — New Relic, AppDynamics и Dynatrace. Для того чтобы добиться схожей функциональности, можно также использовать munin и collectd.
Сделайте доступ к телеметрии свободным и создайте распространители информации
На предыдущих шагах мы рассмотрели, как отделы эксплуатации могут создавать и улучшать эксплуатационную телеметрию в процессе ежедневной работы. На этом шаге нашей целью будет распространение этих сведений по всей организации. Нужно сделать так, чтобы любой сотрудник, нуждающийся в информации о любой службе или программе компании, мог получить ее без доступа к системе эксплуатации, без аккаунта со специальными правами доступа, без тикетов и без многодневного ожидания, пока кто-нибудь наконец построит нужный график.
Если телеметрия будет быстрой, легкодоступной и достаточно централизованной, у всех сотрудников будет одно и то же представление о реальном положении дел. Обычно это значит, что производственная телеметрия отображается на веб-страницах, сгенерированных централизованным сервером, например Graphite или любым другим, описанным в предыдущем разделе.
Мы хотим, чтобы телеметрия была очень заметной. Ее следует размещать там, где трудятся разработчики и работники служб эксплуатации. Так все заинтересованные смогут наблюдать за работой наших служб. Как минимум в число таких сотрудников нужно включить отдел разработки, IT-эксплуатации, менеджеров по продукции и службу информационной безопасности.
Такая система часто называется распространителем информации. Он определяется сообществом Agile Alliance как «общий для любого количества написанных от руки, нарисованных, напечатанных или электронных экранов, панелей, карт и мониторов, размещенных в визуально заметных местах таким образом, что любой сотрудник или прохожий может увидеть самую свежую информацию о количестве автоматизированных тестов, скорости, отчетах об ошибках, статусе непрерывной интеграции и так далее. Эта идея появилась как часть системы производства Тойота».
Размещая информационные распространители на видных местах, мы поощряем ответственность в нашей команде, активно воплощая следующие ценности:
• команде нечего прятать от посетителей (клиентов, стейкхолдеров и так далее);
• команде нечего прятать от себя: она признает проблемы и смотрит им в лицо.
Теперь, когда у нас есть инфраструктура для того, чтобы создавать и распространять телеметрию по всей организации, мы можем предоставлять эти данные как нашим внутренним клиентам, так и внешним. Например, можно вывесить доступные для широкой публики интернет-страницы. На них клиенты смогут узнавать, как работают необходимые им службы.
Эрнест Мюллер считает, что установление высокой степени прозрачности важно, хотя и встречает некоторое сопротивление:
«Одно из моих первых действий в новой организации — это использование распространителей информации для сообщения о проблемах и уточнения текущих изменений. Обычно это принимается подразделениями на ура. До этого они зачастую просто оставались в неведении. А для разработки и IT-эксплуатации, которые должны осуществляться вместе, чтобы получился хороший продукт, нужно постоянное взаимодействие, информирование и обратная связь».
Можно распространить эту прозрачность еще шире — вместо того чтобы оставлять проблемы, влияющие на клиентов, в секрете, мы можем передавать подобные сведения и нашим внешним клиентам. Это покажет, что мы ценим прозрачность, и тем самым поможет нам заслужить доверие заказчиков (см. ).
Практический пример
Создание показателей самообслуживания в компании LinkedIn (2011 г.)
Как уже было сказано в части III, компания LinkedIn появилась в 2003 г. Цель организации заключалась в том, чтобы ее пользователи благодаря своим связям «могли найти лучшие вакансии». К ноябрю 2015 г. у LinkedIn было более 350 миллионов участников, генерировавших десятки тысяч запросов в секунду, из-за чего на серверные системы компании приходилась нагрузка в миллионы запросов в секунду.Прачи Гупта, технический директор организации LinkedIn, в 2011 г. написала о важности производственной телеметрии следующее: «В LinkedIn мы тщательно следим за тем, чтобы сайт был доступен и чтобы у наших пользователей в любой момент был доступ ко всей функциональности нашего сайта. Для выполнения этого обязательства необходимо обнаруживать сбои и разбираться с ними сразу, как только они возникают. Именно поэтому мы используем временные графики для наблюдения за сайтом, чтобы замечать инциденты и реагировать на них в течение нескольких минут… Такие методики мониторинга оказались отличным инструментом для инженеров. Они позволяют не терять темпа и дают время на обнаружение, приоритизацию и решение проблем».Однако в 2010 г., несмотря на невероятно большие объемы генерирования телеметрии, инженерам было очень трудно получить доступ к данным, не говоря уже о том, чтобы проанализировать их. Так появилась на свет идея практики Эрика Вонга, проходившего летнюю стажировку в LinkedIn. Впоследствии она переросла в проект по созданию телеметрии, породивший инструмент InGraph.Вонг писал: «Чтобы получить данные о чем-то простом, как, например, загрузка процессоров всех хостов, занятых каким-то конкретным процессом, нужно было заполнять тикет и ждать, пока что-нибудь потратит полчаса на составление отчета».В то время для сбора телеметрии LinkedIn использовала Zenoss, но, как объясняет Вонг, «для получения данных из Zenoss надо было продираться сквозь медленный веб-интерфейс, поэтому, чтобы упростить процесс, я написал несколько скриптов на Python. Хотя там для установки сбора данных все равно требовалась настройка вручную, мне удалось уменьшить время на работу с интерфейсом Zenoss».За лето Вонг продолжил наращивать функциональность InGraph, чтобы инженеры могли видеть то, что им нужно. Он добавил вычисления на нескольких наборах данных одновременно, еженедельные тренды для сравнения результативности и даже возможность создания заданных пользователем сводок, чтобы можно было выбирать, какие именно показатели будут отображаться на одной странице.Говоря о результатах увеличенной функциональности InGraph и о ценности таких возможностей, Гупта отмечает: «Эффективность нашей системы мониторинга ярко проявилась в тот момент, когда у нас начали снижаться показатели, связанные с одним крупным веб-мейл-провайдером, и этот провайдер обнаружил, что у них есть проблема в системе, только после того, как мы сообщили ему об этом!»То, что началось как проект одной летней стажировки, теперь одна из самых заметных частей IT-эксплуатации LinkedIn. InGraph был настолько успешен, что теперь строящиеся в реальном времени графики всегда на виду в технических офисах компании, где не заметить их просто невозможно.
Найдите и устраните пробелы в системе вашей телеметрии
К этому моменту мы создали инфраструктуру, необходимую для быстрого сбора телеметрии на всех уровнях стека приложения и ее распространения по всей организации.
На этом шаге мы найдем все пробелы в нашей телеметрии, мешающие нам быстро обнаруживать и устранять проблемы. Это особенно важно, если у разработки и IT-эксплуатации на нынешний момент очень мало данных (или их вообще нет). Мы потом используем эти сведения, чтобы лучше предсказывать возникновение проблем, а также чтобы все могли получать необходимую для принятия верных решений информацию.
Для достижения этой цели нам нужно создать достаточно телеметрии на всех уровнях стека приложений для всех окружений, а также для связанных с ними этапов непрерывного развертывания. Нам необходима телеметрия следующих уровней:
• бизнес-уровень. Примерами могут быть количество торговых сделок, доход от сделок, количество регистраций пользователей, коэффициент утечки клиентов, результаты A/B-тестирования и так далее;
• уровень приложения. Это, например, время проведения транзакций, время ответа пользователя, сбои в работе приложения и так далее;
• уровень инфраструктуры (базы данных, операционная система, сетевые подключения, память). Здесь примеры — трафик веб-сервера, загруженность процессора, использование диска и так далее;
• уровень клиентского ПО (JavaScript клиентского браузера, мобильное приложение). Это, например, ошибки и падения приложения, время транзакций пользователя и так далее;
• уровень развертывания. Примерами могут быть статус сборки (красный или зеленый для разных наборов автоматизированных тестов), изменение необходимого на развертывание времени, частота развертываний, улучшение тестовой среды и статус среды.
Если у нас будет достаточная телеметрия во всех этих областях, мы сможем увидеть работоспособность всего того, от чего зависит наш продукт. Вместо слухов, домыслов и обвинений у нас окажутся факты и данные.
Далее, регистрируя все дефекты и сбои в приложениях и инфраструктуре (например, аварийные завершения работы, ошибки приложения, исключения, ошибки в работе запоминающих устройств и серверов), мы можем лучше фиксировать события, связанные с безопасностью. Такая телеметрия не только информирует разработку и эксплуатацию о падении программ и служб, но также сообщает о возможных уязвимых местах системы безопасности.
Раньше замечая и корректируя ошибки, мы можем разбираться с ними, пока они еще невелики и легко исправимы, а число клиентов, испытывающих последствия, мало. Кроме того, после каждого сбоя в производстве нужно определить, какой телеметрии не хватает, какие данные могли бы обеспечить более быстрое обнаружение и восстановление. Еще лучше, если бы мы могли заполнить эти пробелы на стадии разработки функциональности с помощью проверки нашей работы коллегами.
Приложения и бизнес-метрики
На уровне приложения наша цель — убедиться, что мы создаем телеметрию, не только отражающую работоспособность этого приложения (например, использование памяти, число транзакций и ттак далее), но также измеряющую, насколько мы достигаем целей нашей организации (например, число новых пользователей, количество входов в систему, длина пользовательской сессии, процент активных пользователей, частота использования тех или иных функциональных возможностей и тому подобное).
К примеру, если у нас есть сервис, поддерживающий электронную торговлю, нам нужно удостовериться, что у нас есть данные обо всех пользовательских событиях, ведущих к успешной транзакции, приносящей доход. Затем мы можем отслеживать все действия пользователя, необходимые для достижения желаемого результата.
Эти показатели будут разными в зависимости от сферы деятельности и целей компании. Например, для сайтов электронной торговли целью может быть максимизация времени, проведенного на сайте. Однако поисковым службам нужно ориентироваться на сокращение времени пребывания на странице, поскольку долгие сессии говорят о том, что пользователи не могут найти то, что хотят.
В общем случае бизнес-метрики будут частью воронки приобретения клиентов, то есть образного представления теоретических шагов, совершаемых потенциальным покупателем, решившим сделать покупку. Например, для сайта электронной торговли измеримыми событиями на этом пути будут общее время, проведенное на сайте, переходы по ссылкам на товары, добавление товаров в корзину и завершенные заказы.
Эд Бланкеншип, старший менеджер по продукции Microsoft Visual Studio Team Services, пишет: «Часто команды по разработке элемента функциональности определяют свои цели с помощью воронки приобретения клиентов. Их цель — сделать так, чтобы клиенты пользовались их функциональностью каждый день. Разные группы пользователей иногда неформально называют “зеваками”, “активными пользователями”, “вовлеченными пользователями” и “глубоко вовлеченными пользователями”. Для каждой такой стадии есть своя телеметрия».
Наша цель — сделать каждый бизнес-показатель действенным. Эти важнейшие индикаторы должны сообщать нам, как изменить продукт, и быть гибкими для экспериментирования и A/B-тестирования. Когда метрика не ведет к непосредственным действиям, скорее всего, это просто пустые индикаторы, предоставляющие мало полезной информации. Такие данные стоит хранить, но вот выставлять на обозрение не нужно и уж тем более не стоит бить из-за них тревогу.
В идеале любой, кто смотрит на наши распространители информации, должен суметь понять, как отображенные сведения связаны с целями компании, такими как доход, приобретение покупателей, коэффициент конверсии и так далее. Нужно определить и связать каждый показатель с бизнес-показателями на самых ранних стадиях определения функциональности и разработки и измерять результаты после развертывания в стадию эксплуатации. Кроме того, это помогает представителям заказчика описывать бизнес-контекст каждого элемента функциональности для всех в потоке создания ценности.
Сообщения на форуме
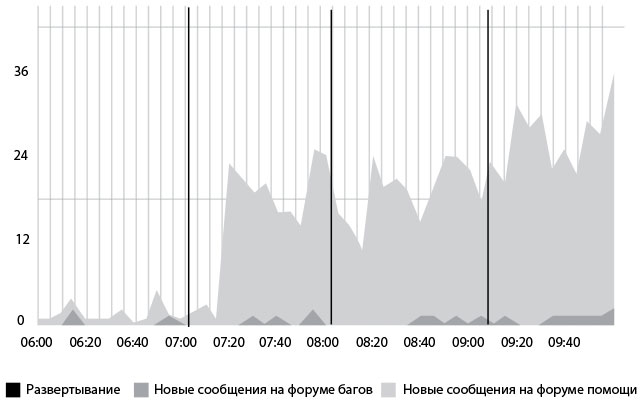
Рис. 28. Активность пользователей в связи с новой функциональностью после развертываний, измеренная в количестве форумных сообщений (источник: Майк Бриттен, “Tracking Every Release”, взято с сайта , 8 декабря 2010 г., )
Можно задать более общий бизнес-контекст, если иметь в виду и отображать на графиках периоды, важные с точки зрения ведения деятельности и высокоуровневого бизнес-планирования. Примерами могут служить временные отрезки, на которые приходится большое число транзакций: пики продаж, связанные с праздниками, закрытие финансовых периодов в конце кварталов или запланированные аудиторские проверки. Эту информацию можно использовать как напоминание для того, чтобы не вносить существенные изменения в периоды, когда доступность сервиса крайне важна, или избегать каких-либо действий в разгар аудиторской проверки.
Распространяя информацию о действиях пользователей в контексте наших целей, мы получаем быструю обратную связь для команд, занятых конкретными элементами функциональности. Так они могут выяснить, действительно ли их сервисы используются и в какой степени они соответствуют бизнес-целям. В результате мы закрепляем ожидания, что мониторинг и анализ действий клиентов также часть нашей ежедневной работы, и сами лучше понимаем, как наша работа способствует достижению целей организации.
Показатели инфраструктуры
Точно так же, как и для показателей на уровне приложения, для индикаторов эксплуатационной и не эксплуатационной инфраструктуры наша цель — убедиться, что мы создаем достаточно телеметрии, чтобы быстро выяснить, действительно ли инфраструктура — одна из причин неполадки или нет. Кроме того, мы должны быть способны четко определить, что именно в инфраструктуре создает проблемы (например, базы данных, операционная система, запоминающее устройство, сетевые соединения и так далее).
Мы хотим сделать прозрачной как можно большую часть инфраструктурной телеметрии, по всем компаниям, чьи программы и продукты мы используем. В идеале она должна быть организована по сервисам или по приложениям. Другими словами, когда в нашем окружении что-то идет не так, мы должны точно знать, на какие приложения и сервисы это влияет или может потенциально повлиять.
Раньше связи между сервисом и эксплуатационной инфраструктурой, от которой он зависел, создавались вручную (например, База данных управления конфигурациями (CMDB), ITIL или создание определений конфигурации в инструментах оповещения, например в Nagios). Однако сейчас эти связи все чаще регистрируются в сервисах автоматически, затем они открываются в динамическом режиме и используются в эксплуатации с помощью таких инструментов, как Zookeeper, Etcd, Consul и так далее.
Эти инструменты позволяют сервисам регистрироваться самостоятельно, сохраняя информацию, необходимую для других сервисов (например, IP-адрес, номера портов, URI). Такой подход решает проблему управления вручную базой данных конфигураций ITIL. Это особенно необходимо, когда сервисы состоят из сотен (а иногда тысяч и даже миллионов) узлов, каждый с динамически присваиваемым IP-адресом.
Вне зависимости от того, насколько просты или сложны наши службы, составление графиков по бизнес-метрикам и показателям инфраструктуры одновременно позволяет отслеживать разные проблемы. Например, мы можем увидеть, что регистрация новых пользователей упала на 20 % по сравнению с ежедневной нормой и в то же время все запросы к базам данных стали проводиться в пять раз дольше. Причины проблемы стали более ясными.
Кроме того, бизнес-метрика создает контекст для индикаторов инфраструктуры, благодаря чему облегчается совместная работа разработки и эксплуатации. По наблюдениям Джоди Малки, CTO компании Ticketmaster/LiveNation, «вместо того чтобы оценивать отдел эксплуатации относительно потерянного времени, я считаю, что гораздо лучше оценивать разработку и эксплуатацию относительно реальных бизнес-последствий потерянного времени: какой доход мы должны были получить, но не смогли».
Отметим, что вдобавок к мониторингу служб эксплуатации нам также необходима телеметрия этих же служб в доэксплуатационном окружении (например, окружение разработчика, тестовое окружение, окружение, эмулирующее реальную среду, и так далее). Это позволяет нам обнаружить и устранить проблемы до того, как они перейдут в эксплуатацию, например такую неприятность, как все увеличивающееся время на внесение новых сведений в базу данных из-за отсутствующего индекса таблицы.
Наложение новой информации на старые показатели
Даже после того как мы создали систему непрерывного развертывания, позволяющую вносить частые и небольшие изменения, все равно остается риск. Эксплуатационные побочные эффекты — это не только сбои и простои в работе, но и значительные срывы и отклонения от привычного процесса сопровождения продукта.
Чтобы сделать изменения видимыми, мы накладываем всю информацию о развертывании и эксплуатации на графики. Например, для службы, управляющей большим количеством входящих транзакций, такие изменения могут приводить к долгому периоду с низкой работоспособностью, пока не восстановится система поиска в кэш-памяти.
Чтобы лучше понимать и сохранять качество служб, нужно понять, насколько быстро уровень работоспособности вернется в норму, и, если это необходимо, принять меры для улучшения этого уровня.
Нам также нужно визуализировать сведения о действиях по развертыванию и эксплуатации (например, о том, что проводится техобслуживание или резервное копирование) в тех местах, где мы хотим отображать оповещения или же, наоборот, отменить их вывод.
Заключение
Польза эксплуатационной телеметрии от Etsy и LinkedIn показывает, насколько важно замечать проблемы сразу в момент появления, чтобы можно было найти и устранить их причину и быстро исправить ситуацию. Когда все элементы нашей службы, будь то приложение, база данных или окружение, создают легко анализируемую телеметрию, к которой есть удобный доступ, мы можем отловить неполадки задолго до того, как они приведут к катастрофическим последствиям. В идеале — задолго до того, как заказчик заметит, что что-то пошло не так. Результат — не только счастливые клиенты, но и благодаря отсутствию кризисов и авралов более благоприятная и продуктивная рабочая атмосфера без стрессов и выгораний.
Назад: Введение
Дальше: Глава 15. Анализируйте телеметрию, чтобы лучше предсказывать проблемы и добиваться поставленных целей

