Книга: Руководство по DevOps
Назад: Глава 15. Анализируйте телеметрию, чтобы лучше предсказывать проблемы и добиваться поставленных целей
Дальше: Глава 17. Встройте основанную на гипотезах разработку и A/B-тестирование в свою повседневную работу
Глава 16. Настройте обратную связь, чтобы разработчики и инженеры эксплуатации могли безопасно разворачивать код
В 2006 г. Ник Галбрет был техническим директором в компании Right Media, отвечавшим и за разработку, и за эксплуатацию одной платформы онлайн-рекламы, отображавшей и обслуживавшей более 10 миллионов показов в день.
Галбрет так описывает конкурентную среду, где ему приходилось функционировать:
«В нашем бизнесе рекламные инструменты крайне изменчивы, поэтому нам нужно отвечать на запросы рынка за считаные минуты. Это означает, что отдел разработки должен вносить изменения в код очень быстро и переводить их в эксплуатацию как можно скорее, иначе мы проиграем более быстрым конкурентам. Мы обнаружили, что наличие отдельной группы для тестирования и даже для развертывания сильно тормозило процесс. Нужно было соединить все эти функции в одной группе, с общей ответственностью и общими целями. Хотите верьте, хотите нет, но самой большой трудностью оказался страх разработчиков перед развертыванием их собственного кода!»
В этом есть ирония: разработчики часто жалуются, что инженеры эксплуатации боятся развертывать код. Но в этом случае, получив возможность внедрять собственный код, разработчики точно так же боялись проводить развертывание.
Такой страх не есть нечто необычное. Однако Галбрет отметил: более быстрая и частая обратная связь для проводящих развертывание сотрудников (будь то разработчики или отдел IT-эксплуатации), а также сокращение размеров новой порции работы создали атмосферу безопасности и уверенности.
Наблюдая за множеством команд, прошедших через такую трансформацию, Галбрет так описывает последовательность изменений:
«Начинаем мы с того, что никто в разработке или эксплуатации не хочет нажимать на кнопку “развертывание кода”. Эту кнопку мы разработали специально для автоматизации процесса внедрения кода. Страх, что именно ты окажешься тем, из-за кого сломается вся производственная система, парализует всех сотрудников до единого. В конце концов находится смелый доброволец, решающийся первым вывести свой код в производственную среду. Но из-за неверных предположений или невыявленных тонкостей первое развертывание неизбежно идет не так гладко, как хотелось бы. И, поскольку у нас нет достаточной телеметрии, о проблемах мы узнаем от заказчиков».
Чтобы исправить проблему, наша команда в спешном порядке исправляет код и направляет его на внедрение, но на этот раз сопровождая его сбором телеметрии в приложениях и в окружении. Так мы можем убедиться, что наши поправки восстановили работоспособность системы и в следующий раз мы сможем отследить подобную ошибку до того, как нам об этом сообщат клиенты.
Далее, все больше разработчиков начинают отправлять свой код в эксплуатацию. И, поскольку мы действуем в довольно сложной системе, мы наверняка что-то сломаем. Но теперь мы сможем быстро понять, какая именно функциональность вышла из строя, и быстро решить, нужно ли откатывать все назад или же можно решить все меньшей кровью. Это огромная победа для всей команды, все празднуют — мы на коне!
Однако команда хочет улучшить результаты развертывания, поэтому разработчики стараются проактивно получить больше отзывов от коллег о своем коде (это описано в ), все помогают друг другу писать лучшие автоматизированные тесты, чтобы находить ошибки до развертывания. И, поскольку все теперь в курсе, что чем меньше вносимые изменения, тем меньше проблем у нас будет, разработчики начинают все чаще посылать все меньшие фрагменты кода в эксплуатацию. Таким образом, они убеждаются, что эти изменения проведены вполне успешно и можно переходить к следующей задаче.
Теперь мы развертываем код чаще, чем раньше, и надежность сервиса тоже становится лучше. Мы заново открыли, что секрет спокойного и непрерывного потока — в небольших и частых изменениях. Изучить и понять их может любой сотрудник.
Галбрет отмечает, что такое развитие событий идет на пользу всем, включая отдел разработки, эксплуатации и службу безопасности. «Поскольку я отвечаю и за безопасность тоже, мне становится спокойно от мысли, что мы можем быстро развертывать поправки в коде, потому что изменения внедряются на протяжении всего рабочего дня. Кроме того, меня всегда поражает, насколько все инженеры становятся заинтересованы в безопасности, когда ты находишь проблему в их коде и они могут быстро исправить ее сами».
История компании Right Media демонстрирует, что недостаточно просто автоматизировать процесс развертывания — мы также должны встроить мониторинг телеметрии в процесс внедрения кода, а также создать культурные нормы, гласящие, что все одинаково ответственны за хорошее состояние потока создания ценности.
В этой главе мы создадим механизмы обратной связи, помогающие улучшить состояние потока создания ценности на каждой стадии жизненного цикла сервиса или услуги, от проектирования продукта и его разработки до развертывания, сопровождения и снятия с эксплуатации. Такие механизмы помогут нам убедиться, что наши сервисы всегда «готовы к эксплуатации», даже если они находятся на ранних стадиях разработки. Кроме того, такой подход поможет встроить новый опыт после каждого релиза и после каждой проблемы в нашу систему, и работа станет для всех и безопаснее, и продуктивнее.
Используйте телеметрию для более безопасного развертывания
На этом шаге мы убедимся в том, что мы ведем активный мониторинг всей телеметрии, когда кто-нибудь проводит развертывание, как было продемонстрировано в истории Right Media. Благодаря этому после отправки нового релиза в эксплуатацию любой сотрудник (и из разработки, и из отдела эксплуатации) сможет быстро определить, все ли компоненты взаимодействуют так, как нужно. В конце концов, мы никогда не должны рассматривать развертывание кода или изменение продукта, пока оно не будет осуществляться в соответствии с производственной средой.
Мы добьемся цели благодаря активному мониторингу показателей нужного элемента функциональности во время развертывания кода. Так мы убедимся, что мы в продукте ничего случайно не сломали или — что еще хуже — что мы ничего не сломали в другом сервисе. Если изменения портят программу или наносят ущерб ее функциональности, мы быстро восстанавливаем ее, привлекая нужных для этого специалистов.
Как было описано в части III, наша цель — отловить ошибки в процессе непрерывного развертывания до того, как они дадут о себе знать в эксплуатации. Однако все равно будут ошибки, и мы их упустим, поэтому мы полагаемся на телеметрию, чтобы быстро восстановить работоспособность сервисов. Мы можем либо отключить неисправные компоненты функциональности с помощью флажков (часто это самый простой и безопасный способ, поскольку он не требует развертывания), либо закрепиться на передовой (fix forward) (то есть переписать код, чтобы избавиться от проблемы; этот код затем отправляется в эксплуатацию), либо откатывать изменения назад (roll back) (то есть возвращаться к предыдущему релизу с помощью флажков-переключателей или удаления сломанных сервисов с помощью таких стратегий развертывания, как Blue-Green и канареечные релизы и так далее).
Хотя закрепление на передовой часто рискованно, оно может быть очень надежным, если у нас есть автоматизированные тесты и процессы быстрого развертывания, а также достаточно телеметрии для быстрого подтверждения, что в эксплуатации все осуществляется правильно.
На рис. 37 показано развертывание кода на PHP в компании Etsy. После окончания оно выдало предупреждение о превышении времени исполнения. Разработчик заметил проблему через несколько минут, переписал код и отправил его в производство. Решение проблемы заняло меньше десяти минут.
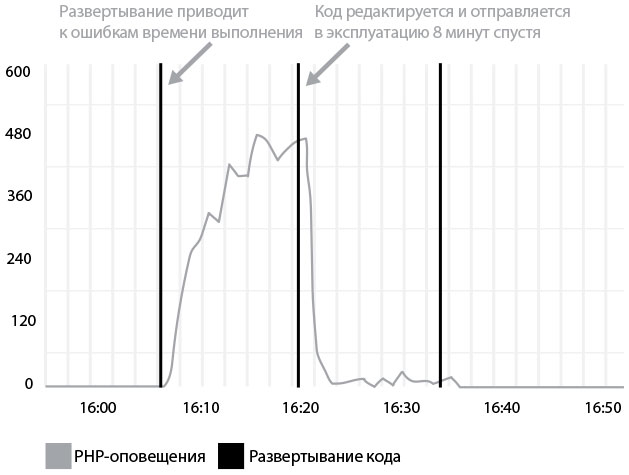
Рис. 37. Развертывание кода в генерирует оповещения об ошибках времени выполнения. Они исправляются довольно быстро (источник: Майк Бриттен, “Tracking every release”)
Поскольку производственное развертывание — одна из главных причин неполадок в эксплуатации, информация о каждом внедрении и внесении изменений отображается на графиках, чтобы все сотрудники в потоке создания ценности были в курсе происходящих процессов. Благодаря этому улучшаются координация и коммуникация, а также быстрее замечаются и исправляются ошибки.
Разработчики дежурят наравне с сотрудниками эксплуатации
Даже если развертывания кода и релизы проходят гладко, в любой сложной системе всегда будут неожиданные проблемы, например сбои и падения в самое неподходящее время (каждую ночь в 2:00). Если их оставить без исправления, они будут источником постоянных проблем для инженеров в нижней части потока. Особенно если неполадки не видны инженерам в верхней части, ответственным за создание задач с проблемами.
Даже если устранение неполадки поручают команде разработчиков, его приоритет может быть ниже, чем создание новой функциональности. Проблема может возникать снова и снова на протяжении недель, месяцев и даже лет, приводя к хаосу и дестабилизации эксплуатации. Это хороший пример того, как команды в верхней части потока создания ценности могут оптимизировать работу для себя и в то же время ухудшить производительность всего потока создания ценности.
Чтобы не допустить этого, сделаем так, чтобы все исполнители в потоке создания ценности делили ответственность по устранению сбоев в эксплуатации. Этого можно добиться, если разработчики, руководители разработки и архитекторы будут участвовать в дежурствах. Именно так в 2009 г. поступил Педро Канауати, директор по организации производства компании Facebook. Все сотрудники получат конкретную и практическую обратную связь по любым принятым решениям в отношении архитектуры или кода.
Благодаря такому подходу инженеры эксплуатации не остаются один на один с проблемами эксплуатации, возникшими из-за плохого кода. Вместо этого все, вне зависимости от положения в потоке создания ценности, помогают друг другу найти подходящий баланс между исправлением проблем на стадии эксплуатации и разработкой новой функциональности. Как заметил Патрик Лайтбоди, SVP по управлению продукцией компании New Relic, «мы обнаружили, что, если будить разработчиков в два часа ночи, дефекты исправляются как никогда быстро».
Побочный эффект такой практики — то, что менеджмент разработки начинает понимать: бизнес-цель достигнута не тогда, когда напротив нового элемента функциональности ставится пометка «сделано». Вместо этого элемент считается выполненным, когда работает в эксплуатации именно так, как задумывалось, без чрезмерного количества оповещений о проблемах или незапланированной работы для девелоперов и отдела эксплуатации.
Такая методика подходит и для ориентированных на рынок команд, отвечающих за разработку функциональности и за ввод ее в эксплуатацию, и для команд, ориентированных только на разработку приложения. Как в своей презентации 2014 г. отметил Аруп Чакрабарти, менеджер по эксплуатации в компании PagerDuty, «компании все реже и реже содержат специальные дежурные команды; вместо этого любой сотрудник, притрагивающийся к коду или окружению, должен быть доступен во время сбоя».
Независимо от того, как мы организуем команды, основополагающие принципы остаются все теми же: когда разработчики получают обратную связь, как работают их приложения, в том числе участвуя в устранении неполадок, они становятся ближе к заказчику. А это ведет к задействованности всех участников потока создания ценности.
Убедитесь, что разработчики следят за низкоуровневым кодом
Одна из самых эффективных методик по взаимодействию с пользователем и проектированию пользовательского интерфейса (UX) — это исследование в контексте (contextual inquiry). Суть этой методики в том, что команда разработчиков наблюдает, как заказчик использует приложение в естественной среде, зачастую прямо на своем рабочем месте. В результате часто открываются пугающие подробности, с каким трудом пользователи продираются сквозь дебри интерфейса: десятки кликов для выполнения простейших ежедневных задач, копирование вручную или перемещение текста между несколькими окнами, записывание важной информации на обычных бумажках. Все это — примеры компенсирующего поведения и обходных решений там, где удобство и практичность должны быть в первую очередь.
Самая частая реакция разработчиков после такого исследования — смятение. «Ужасно видеть многочисленные способы расстроить наших клиентов». Такие наблюдения почти всегда приводят к значительным открытиям и жгучему желанию улучшить результат для заказчика.
Наша цель — использовать ту же самую методику для понимания, как наша деятельность влияет на внутренних заказчиков. Разработчики должны отслеживать ситуацию со своим кодом на протяжении всего потока ценности, чтобы понимать, как коллеги справляются с результатами их работы при вводе кода в эксплуатацию.
Разработчики сами хотят следить за судьбой своего кода: видя трудности пользователей, они принимают более взвешенные и эффективные решения в повседневной работе.
Благодаря этому мы создаем обратную связь по нефункциональным аспектам кода — всем компонентам, не связанным с пользовательским интерфейсом, — и находим способы, как улучшить процесс развертывания, управляемость, удобство эксплуатации и так далее.
Исследование в контексте часто производит большое впечатление на заказчиков. Описывая свое первое наблюдение за работой пользователя, Жене Ким, соавтор этой книги и основатель компании Tripwire, проработавший в ней 13 лет на должности CTO, отмечает:
Один из худших моментов в моей профессиональной карьере произошел в 2006 г. Я целое утро наблюдал, как один из наших заказчиков работал с нашим продуктом. Он выполнял операцию, которую, как мы думали, клиенты будут выполнять еженедельно, и, к нашему ужасу, ему потребовалось 63 клика. Представитель заказчика все время извинялся: «Простите, наверняка есть способ сделать это лучше».К несчастью, способа лучше не имелось. Другой клиент рассказал, что установка и настройка нашего продукта заняли у него 1300 шагов. Внезапно я понял, почему работа по сопровождению нашего приложения всегда доставалась новичкам в команде: никто не хотел брать это на себя. Такова одна из причин моего участия в создании методики наблюдения за работой пользователей в моей компании: я хотел искупить вину перед нашими заказчиками.
Наблюдение в контексте улучшает качество итогового продукта и развивает эмпатию по отношению к коллегам. В идеале эта методика помогает создавать четкие нефункциональные требования, позволяя проактивно встраивать их в каждый сервис или продукт. Это важная часть создания рабочей культуры DevOps.
Пусть поначалу разработчики сами сопровождают свой продукт
Даже когда разработчики каждый день пишут и проверяют код в среде, похожей на среду заказчика, у эксплуатации все равно могут случаться неудачные релизы, потому что это все равно первый раз, когда мы на самом деле видим, как ведет себя код в реальных эксплуатационных условиях. Такой результат возможен потому, что новый опыт в цикле разработки ПО наступает слишком поздно.
Если оставить это без внимания, то готовый продукт становится трудно сопровождать. Как однажды сказал один анонимный инженер из отдела эксплуатации, «в нашей группе большинство системных администраторов не задерживалось дольше, чем на шесть месяцев. В эксплуатации все время что-то ломалось, рабочие часы превращались в безумие, развертывание приложений было невероятно болезненным. Самое худшее — объединение серверных кластеров приложения, на что у нас иногда уходило по шесть часов. В такие моменты мы думали, что разработчики нас ненавидят».
Это может быть результатом недостаточного количества IT-инженеров, поддерживающих все команды по разработке конкретного продукта и все программное обеспечение, уже находящееся в эксплуатации. Такое возможно и в командах, ориентированных непосредственно на рынок, и в командах, чья цель — разработка функциональности.
Одна из возможных мер — сделать как Google: там все группы разработчиков сами поддерживают и управляют своими сервисами, пока они не перейдут к централизованной группе инженеров эксплуатации. Если разработчики сами будут отвечать за развертывание и сопровождение своего кода, переход к централизованной команде эксплуатации будет гораздо более гладким.
Чтобы сомнительные самоуправляемые сервисы не попадали в эксплуатацию и не создавали ненужных рисков для организации, можно задать четкие требования для запуска готового приложения. Кроме того, чтобы помочь командам, разрабатывающим продукт, инженеры эксплуатации должны время от времени консультировать их, чтобы сервисы точно были готовы к внедрению.
Создавая ориентиры по запуску продукта, мы удостоверимся, что все команды извлекают пользу из коллективного опыта организации, особенно опыта отдела эксплуатации. Эти ориентиры и требования, скорее всего, будут включать в себя следующее.
• Количество дефектов и их серьезность. Работает ли приложение так, как было запланировано?
• Тип и частота оповещений о проблемах. Не выдает ли приложение чрезмерное количество оповещений на стадии эксплуатации?
• Уровень мониторинга. Достаточен ли уровень мониторинга для восстановления работоспособности сервиса, если что-то идет не так?
• Системная архитектура. Достаточно ли автономны компоненты сервиса для того, чтобы поддерживать высокий темп изменений и развертываний?
• Процесс развертывания. Есть ли предсказуемый, четкий и достаточно автоматизированный процесс развертывания кода в эксплуатацию?
• Гигиена эксплуатации. Достаточно ли доказательств того, что процесс сопровождения хорошо организован, чтобы можно было быстро и без проблем передать его в другие руки?
На первый взгляд эти требования похожи на традиционные контрольные перечни, использованные ранее. Однако ключевое различие в том, что требуется наличие эффективного мониторинга, процесс развертывания должен быть четким и надежным, а архитектура — поддерживать быстрое и частое внедрение кода.
Если во время оценки найдены недостатки, инженер эксплуатации должен помочь команде разработчиков решить проблемы и при необходимости даже перепроектировать продукт, чтобы его было легко развернуть и сопровождать.
Возможно, на этом этапе стоит проверить, соответствует ли наш сервис нормативным требованиям или должен ли он будет соответствовать в будущем.
• Приносит ли продукт достаточно дохода (например, если доход составляет более 5 % общего дохода открытого акционерного общества компании в США, он считается «значительной частью» и подлежит регулированию в соответствии с разделом 404 Акта Сарбейнза — Оксли (SOX) 2002 г.)?
• Высок ли у приложения пользовательский трафик? Высокая ли у него цена простоя? Например, могут ли проблемы эксплуатации повлечь за собой репутационные издержки или риски доступности?
• Хранит ли сервис информацию о владельцах платежных карт, например номера таких карт, или какую-либо личную информацию, например номера социального страхования или записи о лечении пациентов? Есть ли проблемы с безопасностью, влекущие за собой нормативные, репутационные риски, риски по выполнению контрактных обязательств или по нарушению права на сохранение личной информации?
• Есть ли у сервиса какие-нибудь другие нормативные или контрактные обязательства, например в связи с правилами экспорта, стандартами безопасности данных индустрии платежных карт (PCI-DSS), законом об ответственности и переносе данных о страховании здоровья граждан (HIPAA)?
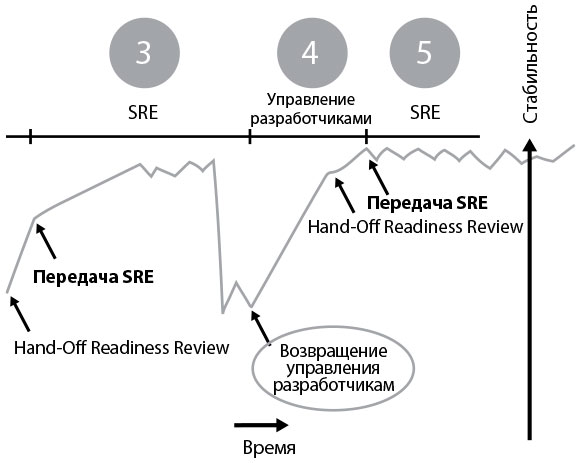
Рис. 38. Service Handback (Передача управления приложением), Google (источник: «SRE@Google: Thousands of DevOps Since 2004», видео с сайта YouTube, 45:57, выложено пользователем USENIX, 12 января 2012 г., )
Эта информация поможет проверить, что мы управляем не только техническими рисками, связанными с нашим продуктом, но также и потенциальными рисками, связанными с нормативным регулированием и обеспечением безопасности. Подобные соображения также будут полезными при проектировании среды контроля над производством продукции.
Благодаря встраиванию требований к эксплуатации в ранние стадии процесса разработки и переносу ответственности за первоначальное сопровождение приложений на разработчиков процесс внедрения новых продуктов становится более гладким, простым и предсказуемым. Однако, если сервис уже находится в эксплуатации, нужен другой механизм, чтобы отдел эксплуатации не оказался один на один с неподдерживаемым приложением. Это особенно важно для функционально ориентированных организаций.
В этом случае можно создать механизм возвращения сервиса разработчикам. Другими словами, когда продукт становится достаточно неустойчивым, у эксплуатации есть возможность вернуть ответственность за его поддержку обратно разработчикам.
Когда сервис переходит под крыло разработчиков, роль отдела эксплуатации меняется на консультационную: теперь они помогают команде снова сделать продукт готовым к эксплуатации.
Этот механизм служит подобием парового клапана, чтобы инженеры эксплуатации никогда не оказывались в такой ситуации, что им нужно поддерживать нестабильно работающее приложение, в то время как все увеличивающееся количество долгов погребает их с головой и локальные проблемы превращаются в одну глобальную. Эта методика также гарантирует, что у эксплуатации всегда есть время на улучшение и оптимизацию работы и на разные профилактические меры.
Механизм возврата — одна из практик-долгожительниц компании Google и, пожалуй, отличный способ показать взаимное уважение между инженерами разработки и эксплуатации. С его помощью разработчики могут быстро создавать новые сервисы, а отдел эксплуатации может подключаться, когда продукты становятся стратегически важными для компании, и в редких случаях возвращать их обратно, когда поддерживать становится слишком проблематично. Следующий пример из практики подразделения по обеспечению стабильности сайтов компании Google показывает, как эволюционировали проверки на готовность к смене сопроводителя и на готовность к запуску и какую пользу это принесло.
Практический пример
Обзор готовности к релизу и передаче продукта в компании Google (2010 г.)
Один из многих удивительных фактов о компании Google заключается в том, что ее инженеры эксплуатации ориентированы на функциональность. Этот отдел именуют обеспечением надежности сайтов (Site Reliability Engineering, SRE), название было придумано Беном Трейнором Слоссом в 2004 г. В этом году он начинал работу с семью инженерами, а в 2014 г. в отделе работало уже более 1200 сотрудников. По его словам, «если Google когда-нибудь пойдет ко дну, это будет моя вина». Трейнор Слосс сопротивлялся всем попыткам как-то определить, что же такое SRE, но однажды описал это подразделение так: SRE — это то, «что происходит, когда разработчик занимается тем, что обычно называли эксплуатацией».Каждый инженер SRE находится в подчинении организации Трейнора Слосса, чтобы качество персонала всегда было на должном уровне. Они есть в каждой команде компании, обеспечивающей их финансирование. Однако SRE-инженеров так мало, что их приписывают только к тем командам, чья работа важнее всего для организации или должна соответствовать специальным нормативным требованиям. Кроме того, у этих сервисов должна быть низкая операционная нагрузка. Продукты, не соответствующие этим критериям, остаются под управлением разработчиков.Даже когда новые продукты становятся достаточно важными для компании, чтобы можно было передать их SRE, разработчики должны сопровождать свои продукты как минимум в течение шести месяцев, прежде чем к команде можно будет прикрепить SRE-инженеров.Чтобы самостоятельные команды все же могли воспользоваться опытом организации SRE, Google создал два списка проверок для двух важнейших стадий релиза нового сервиса. Это проверка на готовность к передаче, к смене сопроводителя (Hand-Off Readiness Review, HRR), и проверка на готовность к запуску продукта (Launch Readiness Review, LRR).Проверка на готовность к запуску должна проводиться перед введением в эксплуатацию любого нового сервиса Google, тогда как проверка на готовность к смене сопроводителя проводится в том случае, когда сервис передается под контроль эксплуатации, обычно через несколько месяцев после запуска. Чек-листы (контрольные списки) процессов LRR и HRR похожи, но проверка на смену управления более строгая, ее стандарты выше, в то время как проверку перед внедрением устраивают сами команды.Всем командам, проходящим через любую проверку, помогает инженер SRE. В его задачи входит помочь им понять требования и выполнить их. Со временем чек-листы изменялись и дополнялись, и теперь любая команда может извлечь пользу из коллективного опыта всех предыдущих запусков, как успешных, так и не очень. Во время своей презентации «SRE@Google: тысячи DevOps с 2004 г.» Том Лимончелли отметил: «Каждый раз, выпуская новый продукт, мы учимся чему-то новому. Всегда будут те, у кого меньше опыта в организации релизов и запусков. Чек-листы LRR и HRR — хороший способ создать память компании».Благодаря требованию управлять своими собственными сервисами на стадии эксплуатации разработчики могут понять, каково это — работать в эксплуатации. Списки LRR и HRR не только делают передачу управления более простой и предсказуемой, но также помогают развивать эмпатию между сотрудниками в начале и конце потока создания ценности.
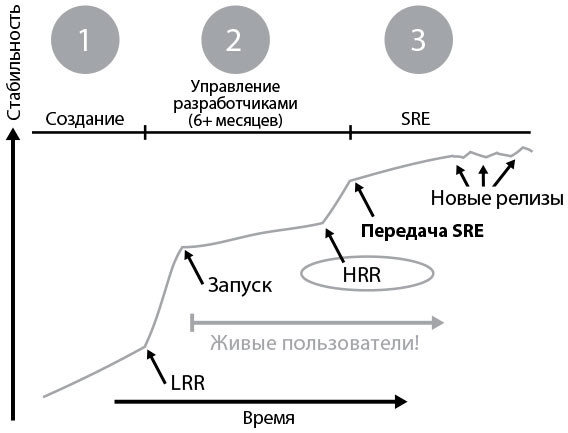
Рис. 39. Проверка на готовность к запуску и проверка на готовность к смене сопроводителя в компании Google (источник: “SRE@Google: Thousands of DevOps Since 2004”, видео с сайта YouTube, 45:57, выложено пользователем USENIX, 12 января 2012 г., )
Лимончелли отмечает: «Согласно идеальному сценарию, команды разработчиков используют чек-лист LRR в качестве руководства, работая над соблюдением его требований параллельно с разработкой своего продукта. Если же им нужна помощь, они консультируются с инженерами SRE».Кроме того, Лимончелли замечает: «Команды, быстрее всего добивающиеся одобрения проверки HRR, работают с инженерами SRE дольше всего, с начальных этапов проектирования и до запуска сервиса. Самое хорошее то, что получить помощь сотрудника SRE всегда очень просто. Каждый инженер ценит возможность дать совет команде на ранних этапах и, скорее всего, добровольно выделит только для этого несколько часов или дней».Обычай инженеров SRE помогать командам на первых стадиях проекта — важная культурная норма, постоянно укрепляемая в Google. Лимончелли объясняет: «Помощь разработчикам — долговременная инвестиция, приносящая плоды много месяцев спустя, когда настает время запуска. Эта форма “социально ответственной позиции” и “работы на благо общества” здесь очень ценится. Ее регулярно рассматривают, когда оценивают SRE-инженеров на предмет возможного повышения».
Заключение
В этой главе мы обсудили механизмы обратной связи, позволяющие улучшить продукты на каждом этапе ежедневной работы, будь то изменения в процессе развертывания, исправление кода после сбоев и срочных вызовов инженеров, обязанности разработчиков отслеживать состояние своего кода в конце потока создания ценности, создание нефункциональных требований, помогающих разработчикам писать более подходящий для эксплуатации код, или возвращение проблематичных сервисов разработчикам на доработку.
Создавая такие цепи обратной связи, мы делаем развертывание кода более безопасным, увеличиваем степень его готовности к эксплуатации и помогаем улучшить отношения между разработчиками и эксплуатацией, укрепляя понимание общих целей, общей ответственности и эмпатии.
В следующей главе мы исследуем, как телеметрия может помочь основанной на выдвижении гипотез разработке и A/B-тестированию и как проводить эксперименты, помогающие быстрее добиться целей компании и завоевать рынок.
Назад: Глава 15. Анализируйте телеметрию, чтобы лучше предсказывать проблемы и добиваться поставленных целей
Дальше: Глава 17. Встройте основанную на гипотезах разработку и A/B-тестирование в свою повседневную работу

