Глава 4. Данные
Хорошие программисты беспокоятся о структурах данных и их отношениях.
Линус Торвальдс
Контроль над данными в computer science имеет принципиальное значение: вычислительные процессы состоят из операций над данными, которые преобразуют вход в выход. Но алгоритмы обычно не конкретизируют, как они выполняются. К примеру, алгоритм merge (см. раздел «Итерация» главы 3) опирается на неустановленный внешний исходный код, который создает списки чисел, проверяет наличие в них элементов и добавляет эти элементы в списки. Алгоритм queens (раздел «Поиск (перебор) с возвратом») делает то же самое: он не заботится о том, как выполняются операции на шахматной доске или как позиции хранятся в памяти. Эти детали скрыты позади так называемых абстракций. В главе 4 мы узнаем:
 как абстрактные типы данных делают код чистым;
как абстрактные типы данных делают код чистым;
 какие общие абстракции желательно знать и уметь ими пользоваться;
какие общие абстракции желательно знать и уметь ими пользоваться;
 какие существуют способы структурирования данных в памяти.
какие существуют способы структурирования данных в памяти.
Но прежде чем мы углубимся в эту тему, давайте разберемся, что означают термины «абстракция» и «тип данных».
Абстракции
Абстракции позволяют нам опускать детали; они представляют простой интерфейс для доступа к функциональности сложных объектов. Например, автомобиль скрывает сложный механизм за панелью управления, причем таким образом, что любой человек может легко научиться водить без необходимости разбираться в машиностроении.
В программном обеспечении процедурные абстракции скрывают за вызовом процедур сложности реализации процесса. В алгоритме trade (см. раздел «Разделяй и властвуй» главы 3) процедуры min и max скрывают механику поиска минимальных и максимальных чисел и тем самым упрощают алгоритм. При помощи абстракций можно создавать модули, которые позволяют выполнять сложные операции вызовом одной единственной процедуры, вроде этой:
html ← fetch_source("")
Всего одной строкой кода мы получили страницу сайта, несмотря на то что внутренние операции для этой задачи чрезвычайно сложны.
Абстракции данных будут центральной темой главы. Они скрывают детали процессов обработки данных. Но прежде чем мы сможем понять, как работает абстракция, нам необходимо освежить наше понимание типов данных.
Тип данных
Мы различаем разные типы крепежных изделий (как, например, винты, гайки и гвозди) согласно операциям, которые можем с ними выполнить (к примеру, используя отвертку, гаечный ключ или молоток). Точно так же мы различаем разные типы данных согласно операциям, которые могут быть выполнены с ними.
Например, переменная, содержащая последовательность символов, которые можно преобразовать в верхний или нижний регистр, и допускающая добавление новых символов, имеет тип String (строка). Строки представляют текстовые данные. Переменная, которую можно инвертировать и которая допускает операции XOR, OR и AND, имеет тип Boolean (логический). Такие булевы переменные принимают одно из двух значений: True или False. Переменные, которые можно складывать, делить и вычитать, имеют тип Number (численный).
Каждый тип данных связан с конкретным набором процедур. Процедуры, которые предназначены для работы с переменными, хранящими списки, отличаются от процедур, которые предназначены для работы с переменными, хранящими множества, а те, в свою очередь, отличаются от процедур, которые предназначены для работы с числами.
4.1. Абстрактные типы данных
Абстрактный тип данных (АТД) — это подробное описание группы операций, применимых к конкретному типу данных. Они определяют интерфейс для работы с переменными, содержащими данные конкретного типа, и скрывают все подробности хранения данных в памяти и управления ими.
Когда нашим алгоритмам приходится оперировать данными, мы не включаем в них команды чтения и записи в память компьютера. Мы используем внешние модули обработки данных, которые предоставляют процедуры, определенные в АТД.
Например, для работы с переменными, хранящими списки, нам нужны: процедуры для создания и удаления списков; процедуры для доступа к n-му элементу списка и его удаления; процедура для добавления нового элемента в список. Определения этих процедур (их имена и что они делают) содержатся в АТД «Список». Мы можем работать со списками, руководствуясь исключительно этими процедурами. Так что мы никогда не управляем памятью компьютера непосредственно.
Преимущества использования АТД
Простота. АТД делает наш код доступнее для понимания и изменения. Опустив детали в процедурах обработки данных, вы сможете сосредоточиться на самом главном — на алгоритмическом процессе решения задачи.
Гибкость. Существуют разные способы структурирования данных в памяти и, как следствие, разные модули обработки одного и того же типа данных. Мы должны выбрать тот, что лучше соответствует текущей ситуации. Модули, которые реализуют тот же АТД, предлагают одинаковые процедуры. Это означает, что мы можем изменить способ хранения данных и выполнения операций, просто применив другой модуль обработки данных. Это как с автомобилями: все автомобили на электрической и бензиновой тяге имеют одинаковый интерфейс. Если вы умеете управлять одним автомобилем, вы сумеете управлять и любыми другими.
Повторное использование. Мы задействуем одни и те же модули в проектах, где обрабатываются данные одинакового типа. Например, процедуры power_set и recursive_power_set из предыдущей главы работают с переменными, представляющими множества, Set. Это означает, что мы можем использовать один и тот же модуль Set в обоих алгоритмах.
Организация. Нам, как правило, приходится оперировать несколькими типами данных: числами, текстом, географическими координатами, изображениями и пр. Чтобы лучше организовать нашу программу, мы создаем отдельные модули, каждый из которых содержит код, работающий исключительно с конкретным типом данных. Это называется разделением функциональности: части кода, которые имеют дело с одним и тем же логическим аспектом, должны быть сгруппированы в собственном, отдельном модуле. Когда они перемешаны с чем-то посторонним, это называется запутанным кодом.
Удобство. Мы берем модуль обработки данных, написанный кем-то другим, разбираемся с использованием определенных в его АТД процедур, и сразу после этого можем их использовать, чтобы оперировать данными нового типа. Нам не нужно понимать, как функционирует этот модуль.
Устранение программных ошибок. Если вы используете модуль обработки данных, то в вашем программном коде не будет ошибок обработки данных. Если же вы найдете ошибку в модуле обработки данных, то, устранив ее один раз, вы немедленно исправите все части своего кода, которые она затрагивала.
4.2. Общие абстракции
Чтобы решить вычислительную задачу, крайне важно знать тип обрабатываемых данных и операции, которые вам предстоит выполнять с этими данными. Не менее важно принять решение, какой АТД вы будете использовать.
Далее мы представим хорошо известные абстрактные типы данных, которые вы должны знать. Они встречаются во множестве алгоритмов. Они даже поставляются в комплекте вместе со многими языками программирования.
Примитивные типы данных
Примитивные типы данных — это типы данных со встроенной поддержкой в языке программирования, который вы используете. Для работы с ними на нужны внешние модули. Сюда относятся целые числа, числа с плавающей точкой и универсальные операции с ними (сложение, вычитание, деление). Большинство языков также по умолчанию поддерживают хранение в своих переменных текста, логических значений и других простых данных.
Стек
Представьте стопку бумаги. Вы можете положить на нее еще один лист либо взять верхний. Лист, который добавили в стопку первым, всегда будет удален из стопки в последнюю очередь. Стек (stack) представляет такую стопку и позволяет работать только с ее верхним элементом. Элемент на вершине стека — это всегда элемент, который был добавлен последним. Реализация стека должна обеспечивать по крайней мере две операции:
• push(e) — добавить элемент e на вершину стека;
• pop() — получить и удалить элемент с вершины стека.
Более совершенные разновидности стеков могут поддерживать дополнительные операции: проверку наличия в стеке элементов или получение их текущего количества.
Такая обработка данных известна под названием LIFO (Last-In, First-Out, «последним пришел, первым вышел»); мы можем удалить только верхний элемент, который был добавлен последним. Стек — это важный тип данных, он встречается во многих алгоритмах. Для реализации функции «Отменить ввод» в текстовом редакторе каждая вносимая вами правка помещается в стек. Если вы хотите ее отменить, то текстовый редактор выталкивает правку из стека и возвращается к предыдущему состоянию.
Чтобы реализовать поиск с возвратом (см. соответствующий раздел главы 3) без рекурсии, вы должны запоминать в стеке последовательность вариантов, которые привели вас к текущей точке. Обследуя новый узел, мы помещаем ссылку на него в стек. Чтобы вернуться на шаг назад, мы просто выталкиваем (pop()) последний элемент из стека, заодно получая ссылку на предыдущее состояние.
Очередь
Очередь (queue) — это полная противоположность стека. Она тоже позволяет сохранять и извлекать данные, но элементы всегда берутся из начала очереди — тот, который находился в очереди дольше всего. Звучит пугающе? В действительности это то же самое, что и реальная очередь из людей, стоящих у раздачи в столовой! Вот основные операции с очередями:
• enqueue(e) — добавить элемент e в конец очереди;
• dequeue() — удалить элемент из начала очереди.
Очередь работает по принципу организации данных FIFO (First-In, FirstOut, «первый пришел, первый вышел»), потому что первый помещенный в очередь элемент всегда покидает ее первым.
Очереди используются во многих вычислительных сценариях. Если вы реализуете онлайновую службу доставки пиццы, то вы, скорее всего, будете хранить заказы в очереди. В качестве мысленного эксперимента подумайте, что вышло бы, если б ваша пиццерия обслуживала заказы с использованием стека вместо очереди. 
Очередь с приоритетом
Очередь с приоритетом (priority queue) аналогична обычной очереди с той лишь разницей, что помещенным в нее элементам присваивается приоритет. Люди, ожидающие медицинской помощи в больнице, — вот реальный пример очереди с приоритетом. Экстренные случаи получают высший приоритет и переходят непосредственно в начало очереди, тогда как незначительные добавляются в ее конец. Основные операции, реализуемые очередью с приоритетом, таковы:
• enqueue(e, p) — добавить элемент e в очередь согласно уровню приоритетности p;
• dequeue() — вернуть элемент, расположенный в начале очереди, и удалить его.
В компьютере, как правило, много рабочих процессов — и всего один или несколько ЦП, предназначенных для их выполнения. Операционная система ставит все процессы, ожидающие выполнения, в очередь с приоритетом. Каждый процесс получает свой уровень приоритетности. Операционная система исключает процесс из очереди и позволяет ему некоторое время поработать. Позднее, если процесс не завершился, он снова ставится в очередь. Операционная система раз за разом повторяет эту процедуру.
Некоторые процессы более важны и безотлагательно получают процессорное время, другие ожидают в очереди дольше. Процесс, который получает ввод с клавиатуры, как правило, получает самый высокий приоритет — ведь если компьютер не реагирует на нажатия клавиш, то пользователь может подумать, что он завис, и попробует сделать «холодный» перезапуск, что всегда вредно.
Список
При работе с группами элементов иногда требуется гибкость. Например, может понадобиться переупорядочить элементы или извлекать, вставлять и удалять их в произвольном порядке. В этих случаях удобно использовать список (list). Чаще всего АТД «Список» поддерживает следующие операции:
• insert(n, e) — вставить элемент e в позицию n;
• remove(n) — удалить элемент, находящийся в позиции n;
• get(n) — получить элемент, находящийся в позиции n;
• sort() — отсортировать элементы;
• slice(start, end) — вернуть фрагмент списка, начинающийся с позиции start и заканчивающийся в позиции end;
• reverse() — изменить порядок следования элементов на обратный.
Список — один из наиболее используемых АТД. Например, если вам нужно хранить ссылки на часто запрашиваемые файлы в системе, то список — идеальное решение: вы можете сортировать ссылки для отображения и удалять их, если к соответствующим файлам стали обращаться реже.
Стеку и очереди следует отдавать предпочтение, когда гибкость, предоставляемая списком, не нужна. Использование более простого АТД гарантирует, что данные будут обрабатываться строгим и предсказуемым образом (по принципу FIFO или LIFO). Это также делает код яснее: зная, что переменная представляет собой стек, легче понять характер потоков данных на входе и выходе.
Сортированный список
Сортированный список (sorted list) бывает полезен, когда нужна постоянная упорядоченность элементов. В этих случаях вместо поиска правильной позиции перед каждой вставкой в список (и периодической сортировки его вручную) мы используем сортированный список. Что бы в него ни помещали, элементы всегда будут стоять по порядку. Ни одна из операций этого АТД не позволяет переупорядочить его элементы. Сортированный список поддерживает меньше операций, чем обычный:
• insert(e) — вставить элемент e в автоматически определяемую позицию в списке;
• delete(n) — удалить элемент, находящийся в позиции n;
• get(n): получить элемент, находящийся в позиции n.
Словарь (map) используется для хранения соответствий между двумя объектами: ключом key и значением value. Вы можете осуществить поиск по ключу и получить связанное с ним значение. Словарь хорошо подходит, например, для хранения идентификационных номеров пользователей в качестве ключей и полных имен в качестве значений. Такой словарь по заданному идентификационному номеру вернет связанное с ним имя. Существуют следующие операции для словарей:
• set(key, value) — добавить элемент с заданным ключом и значением;
• delete(key) — удалить ключ key и связанное с ним значение;
• get(key) — получить значение, связанное с ключом key.
Множество
Множество (set) представляет неупорядоченные группы уникальных элементов, подобные математическим множествам, которые описаны в приложении III. Этот АТД используется, когда неважен порядок следования элементов либо когда нужно обеспечить уникальность элементов в группе. Стандартный набор операций для множества включает в себя:
• add(e) — добавить элемент в множество или вернуть ошибку, если элемент уже присутствует в множестве;
• list() — перечислить все элементы, присутствующие в множестве;
• delete(e) — удалить элемент из множества.
АТД для программиста — как приборная панель для водителя. Но давайте все-таки попробуем понять, как проложены провода за этой приборной панелью.
4.3. Структуры
Абстрактный тип данных лишь описывает, какие действия можно совершать с переменными конкретного типа. Он определяет список операций, но не объясняет, как они выполняются. Со структурами данных — обратная ситуация: они описывают, как данные организованы и как к ним получить доступ в памяти компьютера. Структуры данных обеспечивают реализацию АТД в модулях обработки данных.
Есть множество разных способов реализации АТД, потому что существуют самые разные структуры данных. Выбор реализации АТД, которая использует структуру данных, лучше соответствующую вашим потребностям, имеет существенное значение для создания эффективных компьютерных программ. Далее мы рассмотрим наиболее распространенные структуры данных и узнаем об их сильных и слабых сторонах.
Массив
Массив (array) — это самый простой способ хранения набора элементов в памяти компьютера. Он заключается в выделении единого пространства в памяти и последовательной записи в него ваших элементов. Конец последовательности отмечается специальным маркером NULL (рис. 4.1).
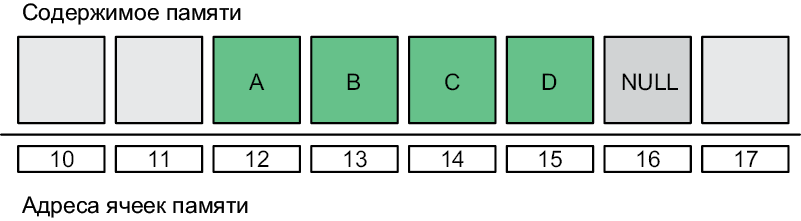
Рис. 4.1. Массив в памяти компьютера
Каждый объект в массиве занимает такой же объем памяти, что и любой другой. Представим массив, начинающийся с адреса ячейки памяти s, где каждый элемент занимает b байт. Чтобы получить n-й элемент, нужно извлечь b байт, начиная с позиции в памяти s + (b × n).
Это позволяет напрямую обращаться к любому элементу массива. Массив наиболее полезен для реализации стека, однако он может также использоваться для списков и очередей. Массивы легко программируются и имеют преимущество, позволяя мгновенно обращаться к любым элементам. Но есть у них и недостатки.
Может оказаться практически нецелесообразным выделять большие непрерывные блоки памяти. Если вам нужно наращивать массив, то в памяти может не оказаться смежного с ним достаточного большого пространства. Удаление элемента из середины массива сопряжено с определенными проблемами: вам придется сдвинуть все последующие элементы на одну позицию к началу либо отметить пространство памяти удаленного элемента как свободное. Ни один из этих вариантов не желателен. Аналогично вставка элемента внутрь массива вынудит вас сдвинуть все последующие элементы на одну позицию к концу.
Связный список
Cвязный список (linked list) позволяет хранить элементы в цепи ячеек, которые не обязательно должны находиться в последовательных адресах памяти. Память для ячеек выделяется по мере необходимости. Каждая ячейка имеет указатель, сообщающей об адресе следующей в цепи. Ячейка с пустым указателем (NULL) отмечает конец цепи (рис. 4.2).
Связные списки используются для реализации стеков, списков и очередей. При наращивании связного списка не возникает никаких проблем: любая ячейка может храниться в любой части памяти. Таким образом, размер списка ограничен только объемом имеющейся свободной памяти. Также не составит труда вставить элементы в середину списка или удалить их — достаточно просто изменить указатели ячеек (рис. 4.3).
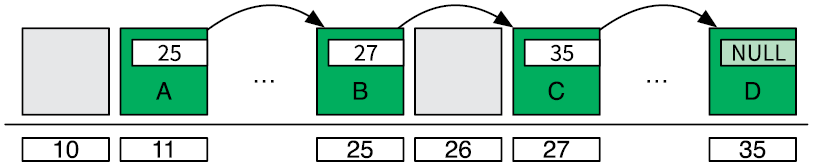
Рис. 4.2. Связный список в памяти компьютера
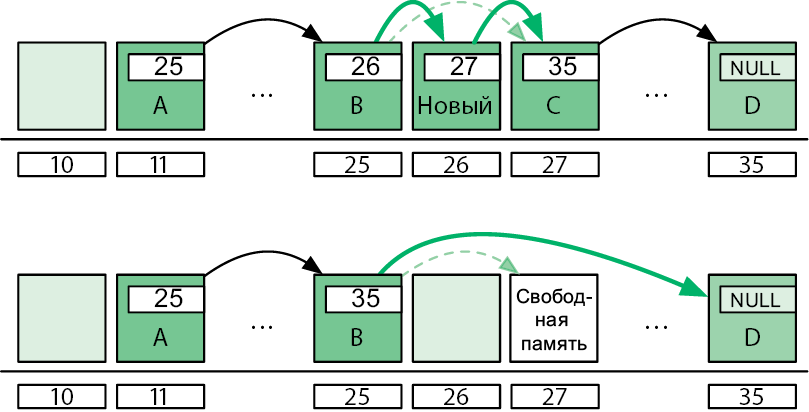
Рис. 4.3. Добавление элемента между B и C. Удаление C
Связный список тоже имеет свои недостатки: мы не можем сразу получить n-й элемент. Сначала придется прочитать первую ячейку, извлечь из нее адрес второй ячейки, затем прочитать вторую ячейку, извлечь из нее указатель на следующую ячейку и т.д., пока мы не доберемся до n-й ячейки.
Кроме того, когда известен адрес всего одной ячейки, не так просто ее удалить или переместиться по списку назад. Не имея другой информации, нельзя узнать адрес предыдущей ячейки в цепи.
Двусвязный список
Двусвязный список (double linked list) — это связный список, где ячейки имеют два указателя: один на предыдущую ячейку, другой — на следующую (рис. 4.4).
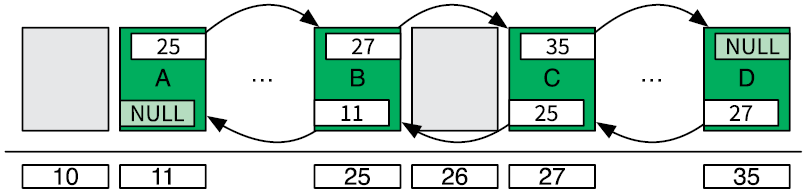
Рис. 4.4. Двусвязный список в памяти компьютера
Он обладает тем же преимуществом, что и связный список: не требует предварительного выделения большого блока памяти, потому что пространство для новых ячеек может выделяться по мере необходимости. При этом дополнительные указатели позволяют двигаться по цепи ячеек вперед и назад. В таком случае, если известен адрес всего одной ячейки, мы сможем быстро ее удалить.
И тем не менее мы по-прежнему не имеем прямого доступа к n-му элементу. Кроме того, для поддержки двух указателей в каждой ячейке требуется более сложный код и больше памяти.
Массивы против связных списков
Языки программирования с богатым набором средств обычно включают встроенные реализации списка, очереди, стека и других АТД. Эти реализации часто основаны на некоторой стандартной структуре данных. Некоторые из них могут даже автоматически переключаться с одной структуры данных на другую во время выполнения программ, в зависимости от способа доступа к данным.
Когда производительность не является проблемой, мы можем опереться на эти универсальные реализации АТД и не переживать по поводу структур данных. Но когда производительность должна быть оптимальной либо когда вы имеете дело с низкоуровневым языком, не имеющим таких встроенных средств, вы сами должны решать, какие структуры данных использовать. Проанализируйте операции, посредством которых вы будете обрабатывать информацию, и выберите реализацию с надлежащей структурой данных. Связные списки предпочтительнее массивов, когда:
• нужно, чтобы операции вставки и удаления выполнялись чрезвычайно быстро;
• не требуется произвольный доступ к данным;
• приходится вставлять или удалять элементы между других элементов;
• заранее не известно количество элементов (оно будет расти или уменьшится по ходу выполнения программы).
Массивы предпочтительнее связных списков, когда:
• нужен произвольный доступ к данным;
• нужен очень быстрый доступ к элементам;
• число элементов не изменяется во время выполнения программы, благодаря чему легко выделить непрерывное пространство памяти.
Дерево
Как и связный список, дерево (tree) использует элементы, которым для хранения объектов не нужно располагаться в физической памяти непрерывно. Ячейки здесь тоже имеют указатели на другие ячейки, однако, в отличие от связных списков, они располагаются не линейно, а в виде ветвящейся структуры. Деревья особенно удобны для иерархических данных, таких как каталоги с файлами или система субординации (рис. 4.5).
В терминологии деревьев ячейка называется узлом, а указатель из одной ячейки на другую — ребром. Самая первая ячейка — это корневой узел, он единственный не имеет родителя. Все остальные узлы в деревьях должны иметь строго одного родителя.
Два узла с общим родителем называются братскими. Родитель узла, прародитель, прапрародитель (и т.д. вплоть до корневого узла) — это предки. Аналогично дочерние узлы, внуки, правнуки (и т.д. вплоть до нижней части дерева) называются потомками.
Узлы, не имеющие дочерних узлов, — это листья (по аналогии с листьями настоящего дерева  ). Путь между двумя узлами определяется множеством узлов и ребер.
). Путь между двумя узлами определяется множеством узлов и ребер.
Уровень узла — это длина пути от него до корневого узла, высота дерева — уровень самого глубокого узла в дереве (рис. 4.6). И, наконец, множество деревьев называется лесом.
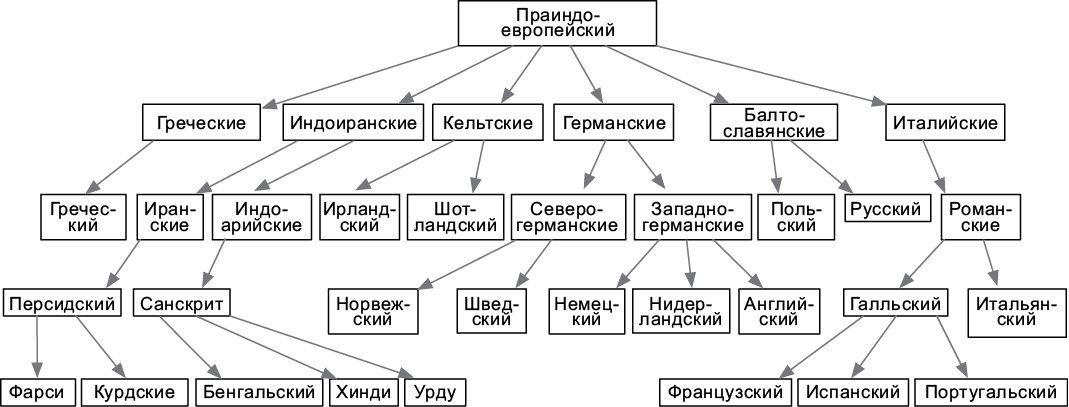
Рис. 4.5. Дерево происхождения индоевропейских языков
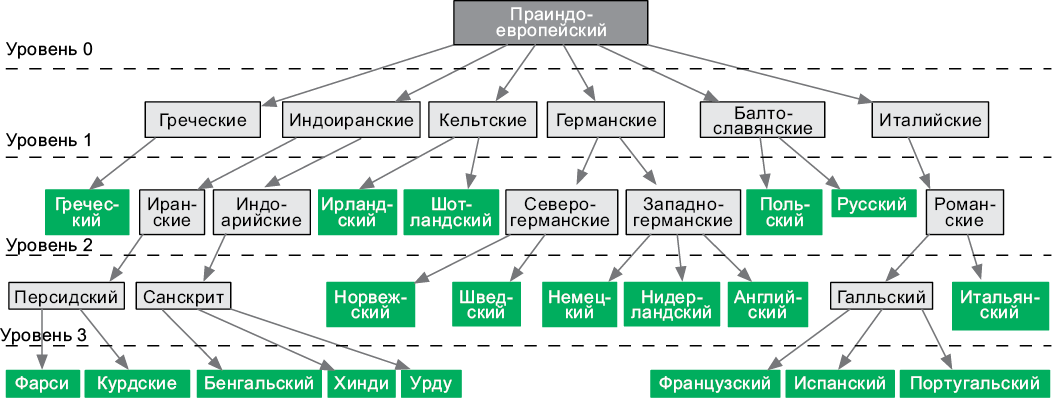
Рис. 4.6. Листья этого дерева представляют современные языки
Двоичное дерево поиска
Двоичное дерево поиска (binary search tree) — это особый тип дерева, поиск в котором выполняется особенно эффективно. Узлы в двоичном дереве поиска могут иметь не более двух дочерних узлов. Кроме того, узлы располагаются согласно их значению/ключу. Дочерние узлы слева от родителя должны быть меньше него, а справа — больше (рис. 4.7).
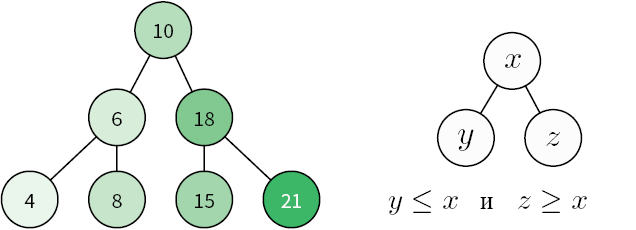
Рис. 4.7. Пример двоичного дерева поиска
Если дерево соблюдает это свойство, в нем легко отыскать узел с заданным ключом/значением:
function find_node(binary_tree, value)
node ← binary_tree.root_node
while node
if node.value = value
return node
if value > node.value
node ← node.right
else
node ← node.left
return "NOT FOUND"
Чтобы вставить элемент, находим последний узел, следуя правилам построения дерева поиска, и подключаем к нему новый узел справа или слева:
function insert_node(binary_tree, new_node)
node ← binary_tree.root_node
while node
last_node ← node
if new_node.value > node.value
node ← node.right
else
node ← node.left
if new_node.value > last_node.value
last_node.right ← new_node
else
last_node.left ← new_node
Балансировка дерева. Если вставить в двоичное дерево поиска слишком много узлов, в итоге получится очень высокое дерево, где большинство узлов имеют всего один дочерний узел. Например, если последовательно вставлять узлы с ключами/значениями, которые всегда больше предыдущих, в итоге получится нечто, похожее на связный список. Однако мы можем перестроить узлы в дереве так, что его высота уменьшится. Эта процедура вызывается балансировкой дерева. Идеально сбалансированное дерево имеет минимальную высоту (рис. 4.8).
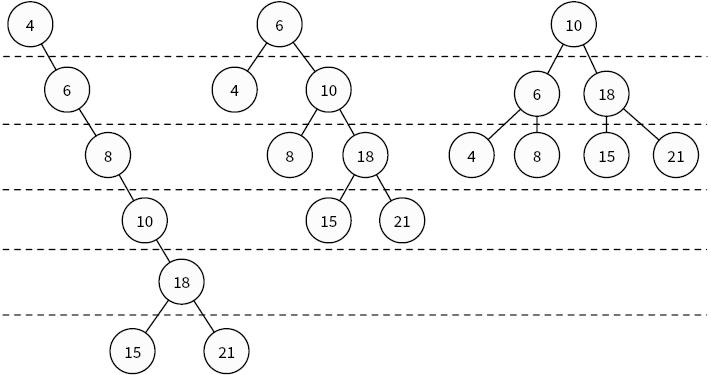
Рис. 4.8. Одно и то же двоичное дерево поиска с разной балансировкой: сбалансированное плохо, средне и идеально
Большинство операций с деревом требует обхода узлов по ссылкам, пока не будет найден конкретный узел. Чем больше высота дерева, тем длиннее средний путь между узлами и тем чаще приходится обращаться к памяти. Поэтому важно уменьшать высоту деревьев. Идеально сбалансированное двоичное дерево поиска можно создать из сортированного списка узлов следующим образом:
function build_balanced(nodes)
if nodes is empty
return NULL
middle ← nodes.length/2
left ← nodes.slice(0, middle - 1)
right ← nodes.slice(middle + 1, nodes.length)
balanced ← BinaryTree.new(root=nodes[middle])
balanced.left ← build_balanced(left)
balanced.right ← build_balanced(right)
return balanced
Рассмотрим двоичное дерево поиска с n узлами и с максимально возможной высотой n. В этом случае оно похоже на связный список. Минимальная высота идеально сбалансированного дерева равняется log2 n. Сложность поиска элемента в дереве пропорциональна его высоте. В худшем случае, чтобы найти элемент, придется опускаться до самого нижнего уровня листьев. Поиск в сбалансированном дереве с n элементами, следовательно, имеет O(log n). Вот почему эта структура данных часто выбирается для реализации множеств (где предполагается проверка присутствия элементов) и словарей (где нужно искать пары «ключ — значение»).
Однако балансировка дерева — дорогостоящая операция, поскольку требует сортировки всех узлов. Если делать балансировку после каждой вставки или удаления, операции станут значительно медленнее. Обычно деревья подвергаются этой процедуре после нескольких вставок и удалений. Но балансировка от случая к случаю является разумной стратегией только в отношении редко изменяемых деревьев.
Для эффективной обработки двоичных деревьев, которые изменяются часто, были придуманы сбалансированные двоичные деревья (self-balancing binary tree). Их процедуры вставки или удаления элементов гарантируют, что дерево остается сбалансированным. Красно-черное дерево (red-black tree) — это хорошо известный пример сбалансированного дерева, которое окрашивает узлы красным либо черным цветом в зависимости от стратегии балансировки. Красно-черные деревья часто используются для реализации словарей: словарь может подвергаться интенсивной правке, но конкретные ключи в нем по-прежнему будут находиться быстро вследствие балансировки.
AVL-дерево (AVL tree) — это еще один подвид сбалансированных деревьев. Оно требует немного большего времени для вставки и удаления элементов, чем красно-черное дерево, но, как правило, обладает лучшим балансом. Это означает, что оно позволяет получать элементы быстрее, чем красно-черное дерево. AVL-деревья часто используются для оптимизации производительности в сценариях, для которых характерна высокая интенсивность чтения.
Данные часто хранятся на магнитных дисках, которые считывают их большими блоками. В этих случаях используется обобщенное двоичное B-дерево (B-tree). В таких деревьях узлы могут хранить более одного элемента и иметь более двух дочерних узлов, что позволяет им эффективно оперировать данными в больших блоках. Как мы вскоре увидим, B-деревья обычно используются в системах управления базами данных.
Двоичная куча
Двоичная куча (binary heap) — особый тип двоичного дерева поиска, в котором можно мгновенно найти самый маленький (или самый большой) элемент. Эта структура данных особенно полезна для реализации очередей с приоритетом. Операция получения минимального (или максимального) элемента имеет сложность O(1), потому что он всегда является корневым узлом дерева. Поиск и вставка узлов здесь по-прежнему стоят O(log n). Кучи подчиняются тем же правилам размещения узлов, что и двоичные деревья поиска, но есть одно ограничение: родительский узел должен быть больше (либо меньше) обоих своих дочерних узлов (рис. 4.9).
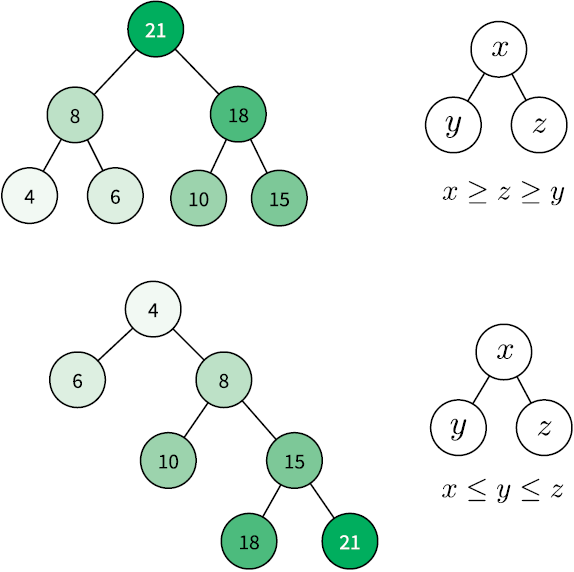
Рис. 4.9. Узлы, организованные как двоичная куча max-heap (вверху) и двоичная куча min-heap (внизу)
Обращайтесь к двоичной куче всегда, когда планируете часто иметь дело с максимальным (либо минимальным) элементом множества.
Граф
Граф (graph) аналогичен дереву. Разница состоит в том, что у него нет ни дочерних, ни родительских узлов (вершин) и, следовательно, нет корневого узла. Данные свободно организованы в виде узлов (вершин) и дуг (ребер) так, что любой узел может иметь произвольное число входящих и исходящих ребер.
Это самая гибкая из всех структур, она используется для представления почти всех типов данных. Например, графы идеальны для социальной сети, где узлы — это люди, а ребра — дружеские связи.
Хеш-таблица
Хеш-таблица (hash table) — это структура данных, которая позволяет находить элементы за O(1). Поиск занимает постоянное время вне зависимости от того, ищете вы среди 10 млн элементов или всего среди 10.
Так же, как массив, хеш для хранения данных требует предварительного выделения большого блока последовательной памяти. Но, в отличие от массива, его элементы хранятся не в упорядоченной последовательности. Позиция, занимаемая элементом, «волшебным образом» задается хеш-функцией. Это специальная функция, которая на входе получает данные, предназначенные для хранения, и возвращает число, кажущееся случайным. Оно интерпретируется как позиция в памяти, куда будет помещен элемент.
Это позволяет нам получать элементы немедленно. Заданное значение сначала пропускается через хеш-функцию. Она выдает точную позицию, где элемент должен находиться в памяти. Если элемент был сохранен, то вы найдете его в этой позиции.
Однако с хеш-таблицами возникают проблемы: иногда хеш-функция возвращает одинаковую позицию для разных входных данных. Такая ситуация называется хеш-коллизией. Когда она происходит, все такие элементы должны быть сохранены в одной позиции в памяти (эта проблема решается, например, посредством связного списка, который начинается с заданного адреса). Хеш-коллизии влекут за собой издержки процессорного времени и памяти, поэтому их желательно избегать.
Хорошая хеш-функция должна возвращать разные значения для разных входных данных. Следовательно, чем шире диапазон значений, которые может вернуть хеш-функция, тем больше будет доступно позиций для данных и меньше вероятность возникновения хеш-коллизии. Поэтому нужно гарантировать, чтобы в хеш-таблице оставалось незанятым по крайней мере 50 % пространства. В противном случае коллизии начнут происходить слишком часто и производительность хеш-таблицы значительно упадет.
Хеш-таблицы часто используются для реализации словарей и множеств. Они позволяют выполнять операции вставки и удаления быстрее, чем структуры данных, основанные на деревьях.
С другой стороны, для корректной работы хеш-таблицы требуют выделения очень большого блока непрерывной памяти.
Подведем итоги
Мы узнали, что структуры данных определяют конкретные способы организации элементов в памяти компьютера. Разные структуры данных требуют разных операций для хранения, удаления, поиска и обхода хранящихся данных. Чудодейственного средства не существует: всякий раз нужно выбирать, какую структуру данных использовать в соответствии с текущей ситуацией.
Еще мы узнали, что вместо структур данных лучше иметь дело с АТД. Они освобождают код от деталей, связанных с обработкой данных, и позволяют легко переключаться с одной структуры на другую без каких-либо изменений в коде.
Не изобретайте колесо заново, пытаясь с нуля создавать базовые структуры данных и абстрактные типы данных (если только вы не делаете это ради забавы, обучения или исследования). Пользуйтесь проверенными временем сторонними библиотеками обработки данных. Большинство языков имеет встроенную поддержку этих структур.
Полезные материалы
• Балансировка двоичного дерева поиска (Balancing a Binary Search Tree, Stoimen, см. ).
• Лекция Корнелльского университета по абстрактным типам данных и структурам данных (Cornell Lecture on Abstract Data Types and Data Structures, см. ).
• Конспекты IITKGP по абстрактным типам данных (IITKGP notes on Abstract Data Types, см. ).
• Реализация дерева поиска на «интерактивном Python» (Search Tree Implementation by “Interactive Python”, см. ).
Модуль, или библиотека, — это структурная часть программного обеспечения, которая предлагает универсальные вычислительные процедуры. Их можно включать при необходимости в другие части программного обеспечения.
Они сопряжены с разрешением доменного имени, созданием сетевого сокета, установлением шифрованного SSL-соединения и многим другим.
Числа с плавающей точкой — это общепринятый способ представления чисел, имеющих десятичный разделитель.
В англоязычных странах в качестве десятичного разделителя используется точка, в большинстве остальных — запятая. — Примеч. пер.
Если узел нарушает это правило, многие алгоритмы поиска по дереву не будут работать.
Иногда их называют двоичными деревьями с автоматической балансировкой, или самоуравновешивающимися двоичными деревьями. — Примеч. пер.
Стратегии автоматической балансировки выходят за рамки этой книги. Если вам любопытно, то в Интернете имеются видеоматериалы, которые показывают, как работают эти алгоритмы.
Двоичная куча min-heap характерна тем, что значение в любой ее вершине не больше, чем значения ее потомков; в двоичной куче max-heap, наоборот, значение в любой вершине не меньше, чем значения ее потомков. — Примеч. пер.

