5. Объектно- ориентированное программирование

Как мы увидим далее, для создания хорошей архитектуры необходимо понимать и уметь применять принципы объектно-ориентированного программирования (ОО). Но что такое ОО?
Один из возможных ответов на этот вопрос: «комбинация данных и функций». Однако, несмотря на частое цитирование, этот ответ нельзя признать точным, потому что он предполагает, что o.f() — это нечто отличное от f(o). Это абсурд. Программисты передавали структуры в функции задолго до 1966 года, когда Даль и Нюгор перенесли кадр стека функции в динамическую память и изобрели ОО.
Другой распространенный ответ: «способ моделирования реального мира». Это слишком уклончивый ответ. Что в действительности означает «моделирование реального мира» и почему нам может понадобиться такое моделирование? Возможно, эта фраза подразумевает, что ОО делает программное обеспечение проще для понимания, потому что оно становится ближе к реальному миру, но и такое объяснение слишком размыто и уклончиво. Оно не отвечает на вопрос, что же такое ОО.
Некоторые, чтобы объяснить природу ОО, прибегают к трем волшебным словам: инкапсуляция, наследование и полиморфизм. Они подразумевают, что ОО является комплексом из этих трех понятий или, по крайней мере, что объектно-ориентированный язык должен их поддерживать.
Давайте исследуем эти понятия по очереди.
Инкапсуляция?
Инкапсуляция упоминается как часть определения ОО потому, что языки ОО поддерживают простой и эффективный способ инкапсуляции данных и функций. Как результат, есть возможность очертить круг связанных данных и функций. За пределами круга эти данные невидимы и доступны только некоторые функции. Воплощение этого понятия можно наблюдать в виде приватных членов данных и общедоступных членов-функций класса.
Эта идея определенно не уникальная для ОО. Например, в языке C имеется превосходная поддержка инкапсуляции. Рассмотрим простую программу на C:
point.h
struct Point;
struct Point* makePoint(double x, double y);
double distance (struct Point *p1, struct Point *p2);
point.c
#include "point.h"
#include <stdlib.h>
#include <math.h>
struct Point {
double x,y;
};
struct Point* makepoint(double x, double y) {
struct Point* p = malloc(sizeof(struct Point));
p->x = x;
p->y = y;
return p;
}
double distance(struct Point* p1, struct Point* p2) {
double dx = p1->x - p2->x;
double dy = p1->y - p2->y;
return sqrt(dx*dx+dy*dy);
}
Пользователи point.h не имеют доступа к членам структуры Point. Они могут вызывать функции makePoint() и distance(), но не имеют никакого представления о реализации структуры Point и функций для работы с ней.
Это отличный пример поддержки инкапсуляции не в объектно-ориентированном языке. Программисты на C постоянно использовали подобные приемы. Мы можем объявить структуры данных и функции в заголовочных файлах и реализовать их в файлах реализации. И наши пользователи никогда не получат доступа к элементам в этих файлах реализации.
Но затем пришел объектно-ориентированный C++ и превосходная инкапсуляция в C оказалась разрушенной.
По техническим причинам компилятор C++ требует определять переменные-члены класса в заголовочном файле. В результате объектно-ориентированная версия предыдущей программы Point приобретает такой вид:
point.h
class Point {
public:
Point(double x, double y);
double distance(const Point& p) const;
private:
double x;
double y;
};
point.cc
#include "point.h"
#include <math.h>
Point::Point(double x, double y)
: x(x), y(y)
{}
double Point::distance(const Point& p) const {
double dx = x-p.x;
double dy = y-p.y;
return sqrt(dx*dx + dy*dy);
}
Теперь пользователи заголовочного файла point.h знают о переменных-членах x и y! Компилятор не позволит обратиться к ним непосредственно, но клиент все равно знает об их существовании. Например, если имена этих членов изменятся, файл point.cc придется скомпилировать заново! Инкапсуляция оказалась разрушенной.
Введением в язык ключевых слов public, private и protected инкапсуляция была частично восстановлена. Однако это был лишь грубый прием (хак), обусловленный технической необходимостью компилятора видеть все переменные-члены в заголовочном файле.
Языки Java и C# полностью отменили деление на заголовок/реализацию, ослабив инкапсуляцию еще больше. В этих языках невозможно разделить объявление и определение класса.
По описанным причинам трудно согласиться, что ОО зависит от строгой инкапсуляции. В действительности многие языки ОО практически не имеют принудительной инкапсуляции.
ОО безусловно полагается на поведение программистов — что они не станут использовать обходные приемы для работы с инкапсулированными данными. То есть языки, заявляющие о поддержке OO, фактически ослабили превосходную инкапсуляцию, некогда существовавшую в C.
Наследование?
Языки ОО не улучшили инкапсуляцию, зато они дали нам наследование.
Точнее — ее разновидность. По сути, наследование — это всего лишь повторное объявление группы переменных и функций в ограниченной области видимости. Нечто похожее программисты на C проделывали вручную задолго до появления языков ОО.
Взгляните на дополнение к нашей исходной программе point.h на языке C:
namedPoint.h
struct NamedPoint;
struct NamedPoint* makeNamedPoint(double x, double y, char* name);
void setName(struct NamedPoint* np, char* name);
char* getName(struct NamedPoint* np);
namedPoint.c
#include "namedPoint.h"
#include <stdlib.h>
struct NamedPoint {
double x,y;
char* name;
};
struct NamedPoint* makeNamedPoint(double x, double y, char* name) {
struct NamedPoint* p = malloc(sizeof(struct NamedPoint));
p->x = x;
p->y = y;
p->name = name;
return p;
}
void setName(struct NamedPoint* np, char* name) {
np->name = name;
}
char* getName(struct NamedPoint* np) {
return np->name;
}
main.c
#include "point.h"
#include "namedPoint.h"
#include <stdio.h>
int main(int ac, char** av) {
struct NamedPoint* origin = makeNamedPoint(0.0, 0.0, "origin");
struct NamedPoint* upperRight = makeNamedPoint
(1.0, 1.0, "upperRight");
printf("distance=%f\n",
distance(
(struct Point*) origin,
(struct Point*) upperRight));
}
Внимательно рассмотрев основной код в файле main.c, можно заметить, что структура данных NamedPoint используется, как если бы она была производной от структуры Point. Такое оказалось возможным потому, что первые два поля в NamedPoint совпадают с полями в Point. Проще говоря, NamedPoint может маскироваться под Point, потому что NamedPoint фактически является надмножеством Point и имеет члены, соответствующие структуре Point, следующие в том же порядке.
Этот прием широко применялся программистами до появления ОО. Фактически именно так C++ реализует единственное наследование.
То есть можно сказать, что некоторая разновидность наследования у нас имелась задолго до появления языков ОО. Впрочем, это утверждение не совсем истинно. У нас имелся трюк, хитрость, не настолько удобный, как настоящее наследование. Кроме того, с помощью описанного приема очень сложно получить что-то похожее на множественное наследование.
Обратите также внимание, как в main.c мне пришлось приводить аргументы NamedPoint к типу Point. В настоящем языке ОО такое приведение к родительскому типу производится неявно.
Справедливости ради следует отметить, что языки ОО действительно сделали маскировку структур данных более удобной, хотя это и не совсем новая особенность.
Итак, мы не можем дать идее ОО ни одного очка за инкапсуляцию и можем дать лишь пол-очка за наследование. Пока что общий счет не впечатляет.
Но у нас есть еще одно понятие.
Полиморфизм?
Была ли возможность реализовать полиморфное поведение до появления языков ОО? Конечно! Взгляните на следующую простую программу copy на языке C.
#include <stdio.h>
void copy() {
int c;
while ((c=getchar()) != EOF)
putchar(c);
}
Функция getchar() читает символы из STDIN. Но какое устройство в действительности скрыто за ширмой STDIN? Функция putchar() записывает символы в устройство STDOUT. Но что это за устройство? Эти функции являются полиморфными — их поведение зависит от типов устройств STDIN и STDOUT.
В некотором смысле STDIN и STDOUT похожи на интерфейсы в силе Java, когда для каждого устройства имеется своя реализация этих интерфейсов. Конечно, в примере программы на C нет никаких интерфейсов, но как тогда вызов getchar() передается драйверу устройства, который фактически читает символ?
Ответ на этот вопрос прост: операционная система UNIX требует, чтобы каждый драйвер устройства ввода/вывода реализовал пять стандартных функций: open, close, read, write и seek. Сигнатуры этих функций должны совпадать для всех драйверов.
Структура FILE имеет пять указателей на функции. В нашем случае она могла бы выглядеть как-то так:
struct FILE {
void (*open)(char* name, int mode);
void (*close)();
int (*read)();
void (*write)(char);
void (*seek)(long index, int mode);
};
Драйвер консоли определяет эти функции и инициализирует указатели на них в структуре FILE примерно так:
#include "file.h"
void open(char* name, int mode) {/*...*/}
void close() {/*...*/};
int read() {int c;/*...*/ return c;}
void write(char c) {/*...*/}
void seek(long index, int mode) {/*...*/}
struct FILE console = {open, close, read, write, seek};
Если теперь предположить, что символ STDIN определен как указатель FILE* и ссылается на структуру console, тогда getchar() можно реализовать как-то так:
extern struct FILE* STDIN;
int getchar() {
return STDIN->read();
}
Иными словами, getchar() просто вызывает функцию, на которую ссылается указатель read в структуре FILE, на которую, в свою очередь, ссылается STDIN.
Этот простой трюк составляет основу полиморфизма в ОО. В C++, например, каждая виртуальная функция в классе представлена указателем в таблице виртуальных методов vtable и все вызовы виртуальных функций выполняются через эту таблицу. Конструкторы производных классов просто инициализируют таблицу vtable объекта указателями на свои версии функций.
Суть полиморфизма заключается в применении указателей на функции. Программисты использовали указатели на функции для достижения полиморфного поведения еще со времен появления архитектуры фон Неймана в конце 1940-х годов. Иными словами, парадигма ОО не принесла ничего нового.
Впрочем, это не совсем верно. Пусть полиморфизм появился раньше языков ОО, но они сделали его намного надежнее и удобнее.
Проблема явного использования указателей на функции для создания полиморфного поведения в том, что указатели на функции по своей природе опасны. Такое их применение оговаривается множеством соглашений. Вы должны помнить об этих соглашениях и инициализировать указатели. Вы должны помнить об этих соглашениях и вызывать функции посредством указателей. Если какой-то программист забудет о соглашениях, возникшую в результате ошибку будет чертовски трудно отыскать и устранить.
Языки ОО избавляют от необходимости помнить об этих соглашениях и, соответственно, устраняют опасности, связанные с этим. Поддержка полиморфизма на уровне языка делает его использование тривиально простым. Это обстоятельство открывает новые возможности, о которых программисты на C могли только мечтать. Отсюда можно заключить, что ОО накладывает ограничение на косвенную передачу управления.
Сильные стороны полиморфизма
Какими положительными чертами обладает полиморфизм? Чтобы в полной мере оценить их, рассмотрим пример программы copy. Что случится с программой, если создать новое устройство ввода/вывода? Допустим, мы решили использовать программу copy для копирования данных из устройства распознавания рукописного текста в устройство синтеза речи: что нужно изменить в программе copy, чтобы она смогла работать с новыми устройствами?
Самое интересное, что никаких изменений не требуется! В действительности нам не придется даже перекомпилировать программу copy. Почему? Потому что исходный код программы copy не зависит от исходного кода драйверов ввода/вывода. Пока драйверы реализуют пять стандартных функций, определяемых структурой FILE, программа copy сможет с успехом их использовать.
Проще говоря, устройства ввода/вывода превратились в плагины для программы copy.
Почему операционная система UNIX превратила устройства ввода/вывода в плагины? Потому что в конце 1950-х годов мы поняли, что наши программы не должны зависеть от конкретных устройств. Почему? Потому что мы успели написать массу программ, зависящих от устройств, прежде чем смогли понять, что в действительности мы хотели бы, чтобы эти программы, выполняя свою работу, могли бы использовать разные устройства.
Например, раньше часто писались программы, читавшие исходные данные из пакета перфокарт и пробивавшие на перфораторе новую стопку перфокарт с результатами. Позднее наши клиенты стали передавать исходные данные не на перфокартах, а на магнитных лентах. Это было неудобно, потому что приходилось переписывать большие фрагменты первоначальных программ. Было бы намного удобнее, если бы та же программа могла работать и с перфокартами, и с магнитной лентой.
Для поддержки независимости от устройств ввода/вывода была придумана архитектура плагинов и реализована практически во всех операционных системах. Но даже после этого большинство программистов не давали распространения этой идее в своих программах, потому что использование указателей на функции было опасно.
Объектно-ориентированная парадигма позволила использовать архитектуру плагинов повсеместно.
Инверсия зависимости
Представьте, на что походило программное обеспечение до появления надежного и удобного механизма полиморфизма. В типичном дереве вызовов главная функция вызывала функции верхнего уровня, которые вызывали функции среднего уровня, в свою очередь, вызывавшие функции нижнего уровня. Однако в таком дереве вызовов зависимости исходного кода непреклонно следовали за потоком управления (рис. 5.1).
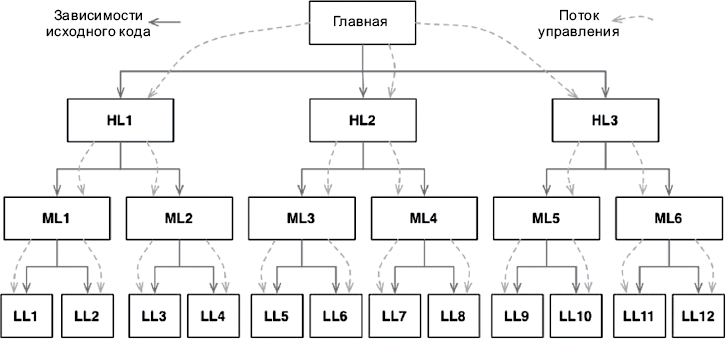
Рис. 5.1. Зависимости исходного кода следуют за потоком управления
Чтобы вызвать одну из функций верхнего уровня, функция main должна сослаться на модуль, содержащий эту функцию. В языке C для этой цели используется директива #include. В Java — инструкция import. В C# — инструкция using. В действительности любой вызывающий код был вынужден ссылаться на модуль, содержащий вызываемый код.
Эти требования предоставляли архитектору программного обеспечения несколько вариантов. Поток управления определяется поведением системы, а зависимости исходного кода определяются этим потоком управления.
Однако когда в игру включился полиморфизм, стало возможным нечто совершенно иное (рис. 5.2).
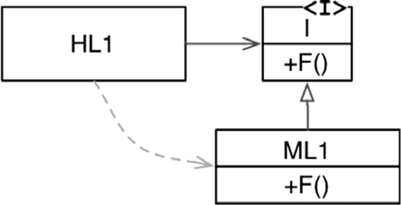
Рис. 5.2. Инверсия зависимости
На рис. 5.2 модуль верхнего уровня HL1 вызывает функцию F() из модуля среднего уровня ML1. Вызов посредством интерфейса является уловкой лишь для исходного кода. Во время выполнения интерфейсов не существует. Модуль HL1 просто вызывает F() внутри ML1.
Но обратите внимание, что направление зависимости в исходном коде (отношение наследования) между ML1 и интерфейсом I поменялось на противоположное по отношению к потоку управления. Этот эффект называют инверсией зависимости (dependency inversion), и он имеет далеко идущие последствия для архитекторов программного обеспечения.
Факт поддержки языками ОО надежного и удобного механизма полиморфизма означает, что любую зависимость исходного кода, где бы она ни находилась, можно инвертировать.
Теперь вернемся к дереву вызовов, изображенному на рис. 5.1, и к множеству зависимостей в его исходном коде. Любую из зависимостей в этом исходном коде можно обратить, добавив интерфейс.
При таком подходе архитекторы, работающие в системах, которые написаны на объектно-ориентированных языках, получают абсолютный контроль над направлением всех зависимостей в исходном коде. Они не ограничены только направлением потока управления. Неважно, какой модуль вызывает и какой модуль вызывается, архитектор может определить зависимость в исходном коде в любом направлении.
Какая возможность! И эту возможность открывает ОО. Собственно, это все, что дает ОО, — по крайней мере с точки зрения архитектора.
Что можно сделать, обладая этой возможностью? Можно, например, переупорядочить зависимости в исходном коде так, что база данных и пользовательский интерфейс (ПИ) в вашей системе будут зависеть от бизнес-правил (рис. 5.3), а не наоборот.

Рис. 5.3. База данных и пользовательский интерфейс зависят от бизнес-правил
Это означает, что ПИ и база данных могут быть плагинами к бизнес-правилам. То есть в исходном коде с реализацией бизнес-правил могут отсутствовать любые ссылки на ПИ или базу данных.
Как следствие, бизнес-правила, ПИ и базу данных можно скомпилировать в три разных компонента или единицы развертывания (например, jar-файлы, библиотеки DLL или файлы Gem), имеющих те же зависимости, как в исходном коде. Компонент с бизнес-правилами не будет зависеть от компонентов, реализующих ПИ и базу данных.
Как результат, появляется возможность развертывать бизнес-правила независимо от ПИ и базы данных. Изменения в ПИ или в базе данных не должны оказывать никакого влияния на бизнес-правила. То есть компоненты можно развертывать отдельно и независимо.
Проще говоря, когда реализация компонента изменится, достаточно повторно развернуть только этот компонент. Это независимость развертывания.
Если система состоит из модулей, которые можно развертывать независимо, их можно разрабатывать независимо, разными командами. Это независимость разработки.
Заключение
Что такое ОО? Существует много взглядов и ответов на этот вопрос. Однако для программного архитектора ответ очевиден: ОО дает, посредством поддержки полиморфизма, абсолютный контроль над всеми зависимостями в исходном коде. Это позволяет архитектору создать архитектуру со сменными модулями (плагинами), в которой модули верхнего уровня не зависят от модулей нижнего уровня. Низкоуровневые детали не выходят за рамки модулей плагинов, которые можно развертывать и разрабатывать независимо от модулей верхнего уровня.
Чтобы иметь возможность определить размер экземпляра каждого класса.
Например, Smalltalk, Python, JavaScript, Lua и Ruby.
И не только программисты на C: большинство языков той эпохи позволяли маскировать одни структуры данных под другие.
И продолжает применяться.
В разных версиях UNIX требования разные; это всего лишь пример.
Перфокарты IBM Hollerith имели ширину 80 колонок. Я уверен, что многие из вас никогда даже не видели их, но они широко были распространены в 1950-е, 1960-е и даже в 1970-е годы.
Хотя и косвенно.

