6. Функциональное программирование

Многие идеи функционального программирования появились задолго до появления самого программирования. Эта парадигма в значительной мере основана на  -исчислении, изобретенном Алонзо Чёрчем в 1930-х годах.
-исчислении, изобретенном Алонзо Чёрчем в 1930-х годах.
Квадраты целых чисел
Суть функционального программирования проще объяснить на примерах. С этой целью исследуем решение простой задачи: вывод квадратов первых 25 целых чисел (то есть от 0 до 24).
В языках, подобных Java, эту задачу можно решить так:
public class Squint {
public static void main(String args[]) {
for (int i=0; i<25; i++)
System.out.println(i*i);
}
}
В Clojure, функциональном языке и производном от языка Lisp, аналогичную программу можно записать так:
(println (take 25 (map (fn [x] (* x x)) (range))))
Этот код может показаться немного странным, если вы не знакомы с Lisp. Поэтому я, с вашего позволения, немного переоформлю его и добавлю несколько комментариев.
(println ;___________________ Вывести
(take 25 ;_________________ первые 25
(map (fn [x] (* x x)) ;__ квадратов
(range)))) ;___________ целых чисел
Совершенно понятно, что println, take, map и range — это функции. В языке Lisp вызов функции производится помещением ее имени в круглые скобки. Например, (range) — это вызов функции range.
Выражение (fn [x] (* x x)) — это анонимная функция, которая, в свою очередь, вызывает функцию умножения и передает ей две копии входного аргумента. Иными словами, она вычисляет квадрат заданного числа.
Взглянем на эту программу еще раз, начав с самого внутреннего вызова функции:
• функция range возвращает бесконечный список целых чисел, начиная с 0;
• этот список передается функции map, которая вызывает анонимную функцию для вычисления квадрата каждого элемента и производит бесконечный список квадратов;
• список квадратов передается функции take, которая возвращает новый список, содержащий только первые 25 элементов;
• функция println выводит этот самый список квадратов первых 25 целых чисел.
Если вас напугало упоминание бесконечных списков, не волнуйтесь. В действительности программа создаст только первые 25 элементов этих бесконечных списков. Дело в том, что новые элементы бесконечных списков не создаются, пока программа не обратится к ним.
Если все вышесказанное показалось вам запутанным и непонятным, тогда можете отложить эту книгу и прекрасно провести время, изучая функциональное программирование и язык Clojure. В этой книге я не буду рассматривать эти темы, так как не это является моей целью.
Моя цель — показать важнейшее отличие между программами на Clojure и Java. В программе на Java используется изменяемая переменная — переменная, состояние которой изменяется в ходе выполнения программы. Это переменная i — переменная цикла. В программе на Clojure, напротив, нет изменяемых переменных. В ней присутствуют инициализируемые переменные, такие как x, но они никогда не изменяются.
В результате мы пришли к удивительному утверждению: переменные в функциональных языках не изменяются.
Неизменяемость и архитектура
Почему этот аспект важен с архитектурной точки зрения? Почему архитектора должна волновать изменчивость переменных? Ответ на этот вопрос до нелепого прост: все состояния гонки (race condition), взаимоблокировки (deadlocks) и проблемы параллельного обновления обусловлены изменяемостью переменных. Если в программе нет изменяемых переменных, она никогда не окажется в состоянии гонки и никогда не столкнется с проблемами одновременного изменения. В отсутствие изменяемых блокировок программа не может попасть в состояние взаимоблокировки.
Иными словами, все проблемы, характерные для приложений с конкурирующими вычислениями, — с которыми нам приходится сталкиваться, когда требуется организовать многопоточное выполнение и задействовать вычислительную мощность нескольких процессоров, исчезают сами собой в отсутствие изменяемых переменных.
Вы, как архитектор, обязаны интересоваться проблемами конкуренции. Вы должны гарантировать надежность и устойчивость проектируемых вами систем в многопоточном и многопроцессорном окружении. И один из главных вопросов, которые вы должны задать себе: достижима ли неизменяемость на практике?
Ответ на этот вопрос таков: да, если у вас есть неограниченный объем памяти и процессор с неограниченной скоростью вычислений. В отсутствие этих бесконечных ресурсов ответ выглядит не так однозначно. Да, неизменяемость достижима, но при определенных компромиссах.
Рассмотрим некоторые из этих компромиссов.
Ограничение изменяемости
Один из самых общих компромиссов, на которые приходится идти ради неизменяемости, — деление приложения или служб внутри приложения на изменяемые и неизменяемые компоненты. Неизменяемые компоненты решают свои задачи исключительно функциональным способом, без использования изменяемых переменных. Они взаимодействуют с другими компонентами, не являющимися чисто функциональными и допускающими изменение состояний переменных (рис. 6.1).
Изменяемое состояние этих других компонентов открыто всем проблемам многопоточного выполнения, поэтому для защиты изменяемых переменных от конкурирующих обновлений и состояния гонки часто используется некоторая разновидность транзакционной памяти.
Транзакционная память интерпретирует переменные в оперативной памяти подобно тому, как база данных интерпретирует записи на диске. Она защищает переменные, применяя механизм транзакций с повторениями.
Простым примером могут служить атомы в Clojure:
(def counter (atom 0)) ; инициализировать счетчик нулем
(swap! counter inc) ; безопасно увеличить счетчик counter.
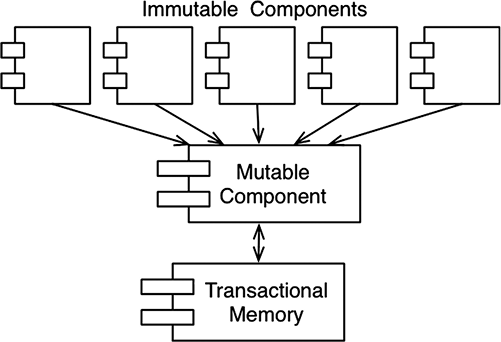
Рис. 6.1. Изменяемое состояние и транзакционная память
В этом фрагменте переменная counter определяется как атом (с помощью функции atom). Атом в языке Clojure — это особая переменная, способная изменяться при очень ограниченных условиях, соблюдение которых гарантирует функция swap!.
Функция swap!, показанная в предыдущем фрагменте, принимает два аргумента: атом, подлежащий изменению, и функцию, вычисляющую новое значение для сохранения в атоме. В данном примере атом counter получит значение, вычисленное функцией inc, которая просто увеличивает свой аргумент на единицу.
Функция swap! реализует традиционный алгоритм сравнить и присвоить. Она читает значение counter и передает его функции inc. Когда inc вернет управление, доступ к переменной counter блокируется и ее значение сравнивается со значением, переданным в inc. Если они равны, в counter записывается значение, которое вернула функция inc, и блокировка освобождается. Иначе блокировка освобождается и попытка повторяется.
Механизм атомов эффективен для простых приложений. Но, к сожалению, он не гарантирует абсолютную защищенность от конкурирующих обновлений и взаимоблокировок, когда в игру вступает несколько взаимозависимых изменяемых переменных. В таких ситуациях предпочтительнее использовать более надежные средства.
Суть в том, что правильно организованные приложения должны делиться на компоненты, имеющие и не имеющие изменяемых переменных. Такое деление обеспечивается использованием подходящих дисциплин для защиты изменяемых переменных.
Со стороны архитекторов было бы разумно как можно больше кода поместить в неизменяемые компоненты и как можно меньше — в компоненты, допускающие возможность изменения.
Регистрация событий
Проблема ограниченности объема памяти и конечной вычислительной мощности процессоров очень быстро теряет свою актуальность. В настоящее время обычными стали компьютеры с процессорами, выполняющими миллиарды инструкций в секунду, и имеющие объем оперативной памяти в несколько миллиардов байтов. Чем больше памяти, тем быстрее работает компьютер и тем меньше потребность в изменяемом состоянии.
Как простой пример, представьте банковское приложение, управляющее счетами клиентов. Оно изменяет счета, когда выполняются операции зачисления или списания средств.
Теперь вообразите, что вместо сумм на счетах мы сохраняем только информацию об операциях. Всякий раз, когда кто-то пожелает узнать баланс своего счета, мы просто выполняем все транзакции с состоянием счета от момента его открытия. Эта схема не требует изменяемых переменных.
Очевидно, такой подход кажется абсурдным. С течением времени количество транзакций растет и в какой-то момент объем вычислений, необходимый для определения баланса счета, станет недопустимо большим. Чтобы такая схема могла работать всегда, мы должны иметь неограниченный объем памяти и процессор с бесконечно высокой скоростью вычислений.
Но иногда не требуется, чтобы эта схема работала всегда. Иногда у нас достаточно памяти и вычислительной мощности, чтобы подобная схема работала в течение времени выполнения приложения.
Эта идея положена в основу технологии регистрации событий (event sourcing). Регистрация событий (event sourcing) — это стратегия, согласно которой сохраняются транзакции, а не состояние. Когда требуется получить состояние, мы просто применяем все транзакции с самого начала.
Конечно, реализуя подобную стратегию, можно использовать компромиссные решения для экономии ресурсов. Например, вычислять и сохранять состояние каждую полночь. А затем, когда потребуется получить информацию о состоянии, выполнить лишь транзакции, имевшие место после полуночи.
Теперь представьте хранилище данных, которое потребуется для поддержки этой схемы: оно должно быть о-о-очень большим. В настоящее время объемы хранилищ данных растут так быстро, что, например, триллион байтов мы уже не считаем большим объемом — то есть нам понадобится намного, намного больше.
Что особенно важно, никакая информация не удаляется из такого хранилища и не изменяется. Как следствие, от набора CRUD-операций в приложениях остаются только CR. Также отсутствие операций изменения и/или удаления с хранилищем устраняет любые проблемы конкурирующих обновлений.
Обладая хранилищем достаточного объема и достаточной вычислительной мощностью, мы можем сделать свои приложения полностью неизменяемыми — и, как следствие, полностью функциональными.
Если это все еще кажется вам абсурдным, вспомните, как работают системы управления версиями исходного кода.
Заключение
Итак:
• Структурное программирование накладывает ограничение на прямую передачу управления.
• Объектно-ориентированное программирование накладывает ограничение на косвенную передачу управления.
• Функциональное программирование накладывает ограничение на присваивание.
Каждая из этих парадигм что-то отнимает у нас. Каждая ограничивает подходы к написанию исходного кода. Ни одна не добавляет новых возможностей.
Фактически последние полвека мы учились тому, как не надо делать.
Осознав это, мы должны признать неприятный факт: разработка программного обеспечения не является быстро развивающейся индустрией. Правила остаются теми же, какими они были в 1946 году, когда Алан Тьюринг написал первый код, который мог выполнить электронный компьютер. Инструменты изменились, аппаратура изменилась, но суть программного обеспечения осталась прежней.
Программное обеспечение — материал для компьютерных программ — состоит из последовательностей, выбора, итераций и косвенности. Ни больше ни меньше.
Спасибо Грегу Янгу, что объяснил мне суть этого понятия.
CRUD — аббревиатура, обозначающая набор основных операций с данными: Create (создание), Read (чтение), Update (изменение) и Delete (удаление). — Примеч. пер.

