Книга: Крестовый поход ИТ-руководителя
Назад: Глава 10 Когда на все не хватает времени
Дальше: Часть III Внешний круг
Глава 11
Memento mori. Disaster Recovery Plan, или В ожидании катастрофы
«Business continuity plan – дословно план непрерывности бизнеса, или более привычное сочетание «непрерывность бизнес-процессов».RPO (Recovery point objective) – максимальный объем данных, которые могут быть потеряны по итогам восстановления услуги после ее прерывания. Выражается в «отрезке времени» до сбоя. Например, целевая точка восстановления в «один день» обеспечивается ежедневным резервным копированием, при этом допустима потеря данных не более чем за 24 часа. Для каждой ИТ-услуги RPO должна быть обсуждена, согласована и задокументирована, после чего используется как требование для проектирования услуг и плана обеспечения непрерывности ИТ-услуг.RTO (Recovery time objective) – максимальное время, отведенное для восстановления ИТ-услуги после ее прерывания. Предоставляемое при этом качество может быть ниже нормальных значений целевых показателей. Проще говоря, мы предоставляем доступ к серверам и службам, но, возможно, не в полном объеме (его определяет PRO). Например, как часто делается в Exchange Server 2010/2013, пользователей переключают на работу с резервным сервером, на котором создают пустую базу данных. Продолжаются получение и отправка почты, но архив еще не доступен, так как восстанавливается из резервной копии, а это может занять несколько часов. Затем «временный» и «старый почтовый ящик» сливаются вместе, и наступает момент полного восстановления сервиса.Interruption window (окно недоступности сервиса) – ожидаемое время от начала происшествия до восстановления доступа к сервису и его предоставление.SDO (Service DeliveryObjective) – уровень предоставления сервиса, который может быть достигнут на альтернативном оборудовании до возврата на основное.
«Всякое неприятное событие неожиданно даже, если к нему готовились». Управляя ИТ-инфраструктурой, эффективный руководитель должен всегда быть готовым к моменту, что то, чем он управляет, умрет. Умрет целиком, или умрет какая-либо часть. В нашей среде часто именно такими словами характеризуют разрушение компонентов ИТ-инфраструктуры.
Одна из обязанностей руководителя ИТ-подразделения сводится к тому, чтобы провести такие мероприятия, которые могли бы гарантировать, что любой катаклизм – будь то выход из строя жесткого диска или землетрясение, не смогут разрушить бизнес. Не все компании дорастают до геораспределенных дата-центров на разных континентах. Первый шаг – не просто задуматься о наступлении сбоя. Главное – сформировать список рисков, выявить те, которые наиболее разрушительны для бизнеса, привести список возможных вариантов их нивелирования и согласовать с ББ (большой босс). Во многом рамки, в которых нужно «помнить о смерти», для ИТ-руководителя закладывает бизнес, и бесмысленно планировать кластеризацию важных служб или резервный ЦОД, если не будет финансирования ваших планов.
Вот наступил момент, когда мы настроили новый сервер. Протестировали его работу под нагрузкой, установили службы и запустили в промышленную эксплуатацию. Разослали всем ответственным лицам письмо о том, как получить доступ к новым возможностям, которые должны облегчать жизнь и помогать экономить время и деньги.
Вроде все хорошо, но не покидает чувство, что чего-то не учли или забыли. В погоне за скорым завершением проекта мы не подумали, что будет, если наступит тот «самый день», когда произойдет авария.
Итак, надо продумать процесс восстановления уровня сервиса в полном объеме. Многие системные администраторы ассоциируют этот план со списком резервного копирования, но это только крупица в огромном списке мыслительной работы. И первый же сбой покажет, что бекап полезен, но без дополнительных «манипуляций» это всего лишь занятое место на диске. В терминологии ITIL и ИТ-менеджменте укоренился термин DRP – Disaster Recovery Plan, свод документов и заранее подготовленных процессов, помогающих в минимально возможные сроки восстановить работу ИТ-сервисов.
Из этого документа должно четко следовать, в какой последовательности необходимо приступать к восстановлению систем, какие из них имеют решающее значение для бизнеса и какие условия требуются для их скорейшего восстановления. В ITIL описывается специальный процесс управления непрерывностью ИТ-услуг (IT Service Continuity Management (ITSCM)), предназначенный для противодействия наступлению случаев чрезвычайных обстоятельств и восстановления все необходимых бизнесу сервисов.
В ITSCM учтены разработка, тестирование и поддержка плана восстановления ИТ-услуги с достаточным уровнем детализации, который призван помочь пережить чрезвычайную ситуацию и восстановить нормальную работу за заданный промежуток времени. Даже в небольшой компании выкладки и принципы, используемые при его создании, могут оказаться полезными в повседневной работе.
В любом случае, все наши действия, направленные на поиск способов устранения последствий сбоев, – это попытки угадать будущие неопределенные события, которые могут меняться от случая к случаю. Если система работает четко, очень необходимо получение живого опыта организации работы во время сбоев и аварий. Самым простым и дешевым способом остаются эмуляция и учения. Сначала на бумаге (штабные учения), потом в тестовой лаборатории в условиях, «максимально приближенных к боевым».
С точки зрения рисков и угроз, необходимо предусматривать покрытие следующих больших групп:
• ошибки и действия пользователей (от 70 до 90 % сбоев приходится на эту группу, необходимо очень внимательно подходить к тому, чтобы отладить устранение этих сбоев максимально эффективно);
• сбои ПО и аппаратуры;
• аварии инженерных систем (это не только кабельные сети или электричество, но и кондиционирование, которое для серверных помещений имеет ключевое значение);
• катастрофы (техногенные и природные).
Мы все прекрасно понимаем, что нарушение работы информационных сервисов или невозможность подключиться к ним ведет к финансовым потерям, потере репутации и, возможно, даже закрытию бизнеса.
Сам по себе документ с названием «План восстановления» ничего не значит и является просто пачкой бумаги. Его эффективность напрямую зависит от субъективного окружения положений, описываемых в нем. Требуется, чтобы все без исключения ответственные лица знали, что существует такой документ и как до него добраться. А когда добрались, то каждый должен понимать свою роль в описываемом документе, уже заранее знать, хотя бы обзорно, как действовать и какие средства связи следует использовать.
Если вышеперечисленного не будет, тогда не придется ожидать слаженного и четкого выполнения описанных действий в плане. А значит, убытки будут выше всех нормативов, и это меньшие из неприятностей, которые могут случиться.
Давайте рассмотрим сценарий, в котором задействуется Microsoft Exchange Server. Несколько серверов с разными ролями почтового сервера, контроллер домена, система резервного копирования. Аппаратные или виртуальные серверы будут расположены в центре обработки данных. Почта – один из критически необходимых сервисов и элемент репутации компании перед партнерами. Теперь составим список рисков с точки зрения возможных потерь, начиная с отсутствия подключения к ЦОД. В связи с участившимися стихийными бедствиями и «блек-аутами» вполне возможный сценарий. Результат отображен на рис. 11.1. По вертикали у нас условные убытки от наступления указанного риска. Красная восходящая стрелка символизирует нарастание последствий для компании, а зеленая нисходящая – путь, по которому необходимо пройти в плане восстановления. И, как видим, не все сценарии покрываются наличием резервной копии. Ну и сразу хочу обратить внимание на то, что, раздумывая над планом восстановления, главное – не оказаться в ловушке «замкнутого круга». Например, в нашем сценарии с размещением в дата-центре Exchange Server может оказаться, что потребуется развернуть альтернативную среду в другом дата-центре или на территории офиса. А необходимые резервные копии находятся на жестких дисках вышедшего из строя сервера или в недоступном в данный момент ЦОДе. Ну и, разумеется, в случае, например, «химической аварии», затронувшей территорию ЦОД, вряд ли пустят внутрь, пока не устранят последствия. Именно по принципу «не класть все яйца в одну корзину» в США президент и вице-президент никогда не летают вместе. Поэтому план призван предусматривать различные варианты наступивших катастроф и способы преодоления последствий.
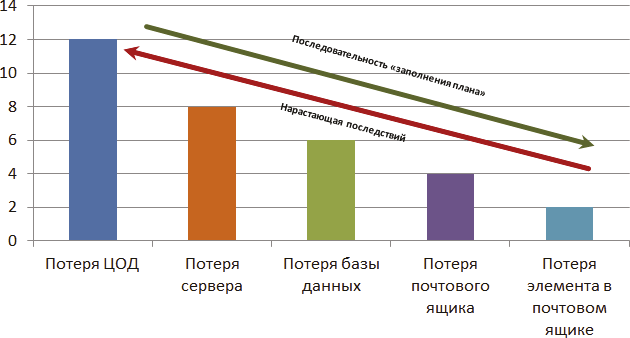
Рис. 11.1. Схема возможного наступления последствий по нарастающей
Потеря писем или даже одного почтового ящика неприятна, но на осуществление повседневной работы всей компании в целом повлиять не может. Тем более что встроенные средства Exchange Server позволят нам восстановить с минимальными временными затратами данные, просто «погуглив» решение. В любом случае все происходит в обычном штатном режиме. А вот следующие потери связаны с необходимостью осуществлять целый цикл мероприятий, которые должны вернуть возможность работы всех сервисов в полном объеме. И начинать планирование надо с самого разрушительного сценария, не опираясь на его вероятность наступления. В примере на рис. 11.1 начнем с потери центра обработки данных. Постепенно, спускаясь к частным вопросам отказов.
Обязательно при составлении плана учитывайте особенности работы системы. Одно дело – восстановить испорченный файл со скриптом PowerShell, другое – почтовую базу данных и вытащить из нее письмо. Возможно, потребуется подключение дополнительных специалистов (а как правило, контактов и телефонов под рукой не будет), или может оказаться, что встроенных средств системы достаточно, просто про них нужно знать.
Итак, что же должно включаться в план по восстановлению в случае сбоев? Прежде всего сформулируйте то, чего хотите добиться, определите цели восстановления и возможные потери, а после приступайте к работе с документами. В план включают всю информацию о защите и восстановлении служб и программ. При этом это не просто табличка того, откуда берутся данные, в какие резервные копии пишутся и с какой периодичностью. Также в документе указывают требования по времени восстановления и допустимости размеров потерянных данных (PRO, RTO). По правде говоря, очень редко бизнес сообщает реалистичные и обоснованные цифры для этих показателей. ИТ-специалистами по результатам проведенных учебных тревог должны быть получены значения «по времени». Используя такие характеристики, необходимо приходить к руководителям и вести уже предметный разговор. Ну и приобретенные договоренности пересматривать не реже, чем раз в год, а лучше в полгода, ведь инфраструктура, объемы хранимых данных, требования постоянно изменяются.
Не обязательно вытягивать весь процесс восстановления силами ИТ-подразделения. В зависимости от степени воздействия необходимо предусматривать привлечение сторонних специалистов. И обязательно привлекать сотрудников, отвечающих за информационную безопасность, которые должны проконтролировать, что в процессе восстановления не возникли новые угрозы.
Отношения PRO, RTO и денег легко изобразить в виде треугольника, где размер каждой грани влияет на другие, а площадь (количество и объем предоставляемых сервисов) остается неизменным.
План восстановления в случае сбоев – это не одна большая толстая книга, в которую записаны рецепты на все случаи аварий в жизни. Это несколько разобщенных документов, каждый из которых должен покрывать свою определенную область, службу или сервер. Информация из них, как мозаика, должна собираться в моменты наступления критических событий и помогать осуществлять процедуры по восстановлению.
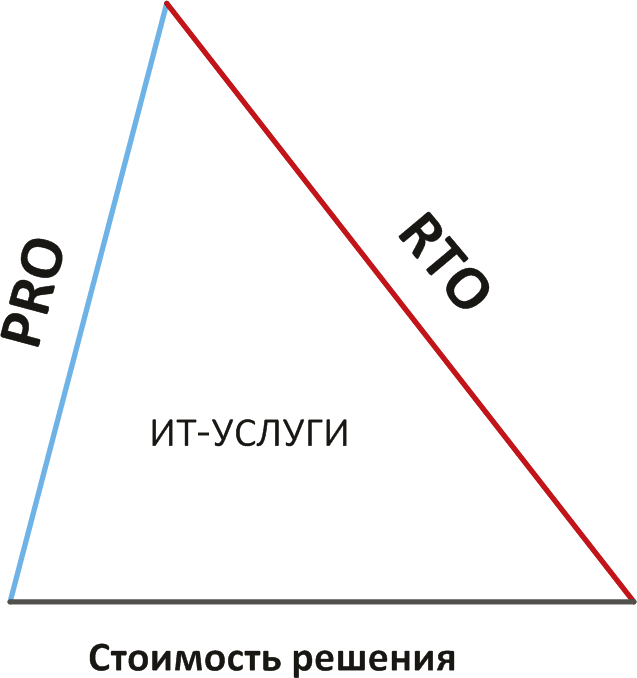
Рис. 11.2. Треугольник связей по стоимости восстановления
Исходя из вашей ИТ-инфраструктуры, в набор документов можно включить:
• политики резервного копирования (что, куда, как часто, каким средством);
• совокупные определения PRO, RTO, общего времени восстановления сервисов;
• инструкцию по использованию средств резервного копирования (в рамках восстановления), последовательность и предполагаемое время восстановления требуемых данных с конкретных носителей;
• в случае, когда развернуты кластеры высокой доступности или средства репликации данных, подробная инструкция по процессам переключения между узлами и активация резервной копии;
• эксплуатационная документация по системам (планы, чертежи, таблицы кроссировки).
В наш век размещения серверов в ЦОДах системные администраторы годами могут не видеть и не помнить, что же установлено внутри серверов. Чтобы не запутаться, удобно использовать «индекс-таблицы» (см. рис. 11.3), четко показывающие, какой сервис представлен, на каких серверах запущен и где брать инструкцию в случае выявления причины сбоя. Быстрое нахождение каталога сервисов позволит ознакомиться с условиями SLA, которые в нем прописаны, и определить рамки времени. А паспорт сервера дает возможность более адекватно подыскивать замену вышедшему из строя оборудованию или же корректно осуществить сетевые настройки.

Рис. 11.3. Индекс-таблица документов составляющих план восстановления
Давайте будем реалистами. Только в идеальной ИТ-среде можно рассчитывать, что существуют все указанные документы в таблице, они завершены и находятся в актуальном состоянии. Список угроз постоянно обрастает новыми пунктами, и закрыть «железобетонно все» почти не возможно и стоит очень дорого. Поэтому нормальный подход строится на проработке защиты от угроз, дающих наибольшие убытки, плюс предпринимается попытка получить максимальную экономию при возможных простоях. А когда будут проработаны первостепенные риски, можно начинать работать с менее важными.
Основными причинами провалов даже очень хорошо продуманных планов восстановления мне встречались такие:
• план устарел, так как тестирований в связи с текучкой никто не проводил;
• информирования сотрудников о DRP-процедурах не проводилось, в результате слаженной работы не получилось, сплошная импровизация и нарастающие ошибки;
• попытки извлечь данные из резервных копий были неудачными, или не были выдержаны требования RPO;
• ошибки резервирования питания (как пример продумано резервирование питания на серверное и коммутационное оборудование, но забыты системы вентилирования и кондиционирования, а высокая температура заставляет отключаться серверы, находящиеся на резервном питании).
Составляя список резервного копирования, нужно учитывать, что туда необходимо включить и сохранение не только электронных данных, размещенных на жестких дисках (образы ОС, настройки БД и прочее), но и бумажные экземпляры документов (например, подтверждающие право на использование ПО). А они могут оказаться в единственном экземпляре, и их потеря может иметь неприятные последствия. Как вариант все документы отсканировать и положить в резервную копию.
«Бекапов лишних не бывает», гласит народная мудрость. Для информации, потеря которой критична для бизнеса, рекомендуют соблюдать правило хранения резервных копий – «3-2-1», автором которого был далекий от сложных информационных технологий человек – фотограф Питер Крох. Он впервые упомянул о нем в своей книге «Управление цифровыми активами для фотографов».
По его постулатам считается, что для обеспечения надежного хранения данных необходимо иметь как минимум:
• три резервные копии;
• копии должны храниться на двух различных физических носителях;
• одна копия должна находиться вне офиса.
Использование такого сложного механизма резервного копирования может оказаться излишним и дорогостоящим. Поэтому необходимо внимательно проанализировать матрицу угроз и решить, в какой степени его можно применять.
Говоря о вопросах подготовки, нельзя упустить такой термин, как EDC (англ. Everyday carry – носить каждый день), он часто используется в кругах «выживальщиков» – людей, готовящихся выжить в чрезвычайных обстоятельствах, которые, по его мнению, непременно должны произойти. Под EDC понимается совокупность предметов, носимых с собой ежедневно, которыми пользуются регулярно или необходимость в которых может возникнуть в различных нестандартных и экстремальных ситуациях. Как правило, в него входят нож, фонарик, веревка и другие необходимые во время ЧС предметы. Для нашей компьютерной среды такими предметами могут оказаться шестигранный ключ для болтов стойки, GSM-модем, дежурная флэшка, лишний патч-корд, запасные батарейки для ноутбука и сотового телефона.
Последние особенно полезны, когда в момент аварии сотовый телефон остается последним средством связи и информирования, в процессе долгих разговоров может сесть в самый неподходящий момент, а банальной розетки, в которой есть напряжение, может не оказаться рядом. Также нелишним будет заранее подготовленный комплект запасных кабелей питания, коннекторов, набор отверток и дисков с образами дистрибутивов.
В процессе составления плана необходимо предусмотреть возможность сообщить о сбое или вариант его устранения с использованием альтернативных методов связи.
Если «упала» почта, глупо писать всем письмо – все равно никто не прочитает. А вот рассылка СМС-сообщений будет эффективным способом информирования.
И в плане по устранению аварий, и в повседневной работе необходимо исходить, как мне кажется, из принципа обратной эскалации. Это когда руководители компании, да и просто пострадавшие пользователи не отвлекают участников, непосредственно выполняющих процесс восстановления классическим вопросом «Когда все починят?». Раз в полчаса о ходе восстановления сообщается начальнику подразделения, а он, выполняя роль живого firewall, держит связь с остальными, информируя их. Ведь психологически во время аварии, когда счет идет на часы, если еще говорят под руку и нет возможности сосредоточиться на процессе восстановления, SLA может быть нарушен, а ошибки человеческого фактора могут заставить откатиться на начальный этап и все начать с начала.
В моменты, когда ответственного системного администратора нет на месте, как узнать нужные пароли и процедуры резервного копирования и кто при необходимости может восстановить систему?
В ответ на такой вопрос может быть только одна рекомендация – пойти по пути военных. Иметь специальный конверт, в котором описаны все необходимые процедуры, указаны логины, пароли, способы доступа к ресурсам. Он опечатан, и несколько экземпляров хранятся в разных сейфах. Ну и производить вскрытие его по распоряжению руководства компании. Самое сложное для этого конверта – его актуальность, поскольку изменения в информационной структуре компании, не отраженные в документах, приведут к тому, что действия по «плану» связаны с рисками восстановить данные не там, не так, как надо, и что еще опаснее – могут стать причиной возникновения дыр в системе безопасности.
Почему-то первое, о чем задумываются сотрудники ИТ-отдела, – потеря серверов, коммуникаций или сервисов. Но сценарии, когда все серверы в дата-центре целые и невредимые, но работать с ними неоткуда, потому что затопило офис или произошел пожар, не рассчитываются, однако и их тоже нельзя сбрасывать со счетов.
• Возможность быстрой закупки оборудования.
• Перемещение сотрудников в альтернативный офис или быстрый запуск технологии доступа в ЦОД для всех сотрудников с их домашних компьютеров.
• Использование IP-АТС и софт-телефонов для объединения разобщенных сотрудников, работающих из дома.
• Использование альтернативных методов доступа в ЦОД.
• Процесс интеграции принесенных из дома устройств для работы сотрудников.
Вот краткий список вопросов, ответы на которые надо заранее продумывать. Например, непромаркированные системные блоки, которые при массовой миграции сотрудников из помещения, где нельзя работать, могут вызвать массу путаницы при последующей рассадке сотрудников и коммуникации. А это потерянное время и убытки.
Помните, законы Мерфи проявляются в полную силу в таких случаях, как восстановление после сбоя, и только выдержка, профессионализм смогут помочь восстановить нормальное функционирование организации, пережившей аварию. Не бойтесь резервировать время на проведение учений, пересмотр планов восстановления, их прогонов в тестовой среде. «Тяжело в учении, легко в бою», – фраза, хоть и заезженная, но ее формула столетия спустя все так же работает. Текучка будет всегда, ее победить не удастся, и тратить на нее все рабочее время было бы неправильно и может дорого обойтись. Результаты тестирования доносите до сведения руководства, пытайтесь заручиться в вашем нелегком пути его поддержкой.
Назад: Глава 10 Когда на все не хватает времени
Дальше: Часть III Внешний круг

