Книга: Мусорная ДНК. Путешествие в темную материю генома
Назад: Почему XX отличается от XXX
Дальше: Множественные параметры
Глава 14. Проект ENCODE, или Как большая наука взялась за мусорную ДНК
Если вы когда-нибудь окажетесь в безлунную и безоблачную ночь вдали от огней большого города, раздобудьте одеяло, расстелите его на земле и, улегшись, посмотрите вверх, на звезды. Это одно из самых чудесных зрелищ, какие только можно себе вообразить. Особенно поражает оно тех, кто всю жизнь проводит в мегаполисе. Кажется, что серебристых блесток на черном бархате небес так много, что их и не сосчитать.
Но если у вас под рукой телескоп, вы поймете, что на небосводе много такого, чего не различишь невооруженным глазом. Взять хотя бы кольца Сатурна. И звезд вы обнаружите неизмеримо больше, чем могли бы себе представить. В мнимой черноте Вселенной куда больше объектов, чем можно разглядеть без помощи приборов. Это становится еще очевиднее, если применить оборудование, способное распознавать излучение, находящиеся за пределами диапазона видимых нами волн. К нам сразу потоком хлынет новая информация, поставляемая самыми разными волнами, от гамма-лучей до фонового микроволнового излучения. Эти звезды и прочие космические объекты столетия назад были там, где они находятся сейчас, просто мы не могли обнаружить их, используя лишь собственные глаза.
В 2012 году появилась масса статей, посвященных попыткам обратить своего рода телескоп на самые таинственные закоулки человеческого генома. Этой работой занялся консорциум ENCODE, объединивший усилия сотен ученых из самых разных исследовательских организаций. ENCODE — сокращение, которое расшифровывается как «Encyclopaedia Of DNA Elements» («Энциклопедия элементов ДНК»)1. При помощи самых чувствительных методов, доступных сейчас науке, исследователи изучали многочисленные свойства человеческого генома. Удалось проанализировать около 150 различных типов клеток. Получаемые данные объединяли, а затем обрабатывали по одной и той же схеме, чтобы корректно сравнивать информацию, полученную при помощи разных методик и технологий. Это очень важно, поскольку обычно чрезвычайно трудно сопоставлять наборы данных, получаемых и анализируемых независимо друг от друга. А ведь раньше нам приходилось опираться именно на такую мешанину результатов.
Публикация результатов, полученных в рамках проекта ENCODE, привлекла колоссальное внимание прессы, а также научного сообщества. Средства массовой информации запестрели заголовками типа: «Научный прорыв. Теория „мусорной ДНК“ генома опровергнута»2; «ДНК-проект интерпретирует „Книгу Жизни“»3 или «Международная армия ученых взламывает код „мусорной ДНК“»4. Надо сказать, что многие ученые действительно были приятно удивлены, увидя результаты, полученные в рамках проекта ENCODE, и теперь ежедневно используют их в собственных работах. Но возгласы одобрения звучали отнюдь не отовсюду. Критика раздавалась главным образом из двух научных лагерей. В первый входили «мусорные скептики», во второй — эволюционисты-теоретики.
Чтобы понять чувства, обуявшие ученых первой группы, обратимся к одному из самых амбициозных заявлений, приведенных в статьях ENCODE:
Эти данные позволили нам приписать биохимические функции 80% генома. Особенно это касается зон, лежащих за пределами хорошо изученных участков, то есть за пределами областей, которые кодируют белки5.
Иными словами, участники проекта ENCODE как бы заявляли: перед нами не темное небо, лишь менее чем на 2% занятое звездами. Они утверждали: небосвод нашего генома на четыре пятых заполнен всевозможными объектами. Причем большинство объектов — отнюдь не звезды (если считать, что звезды в этом сравнении — гены, кодирующие белки). Вероятно, это астероиды, планеты, естественные спутники планет, метеоры, кометы и прочие межзвездные тела, какие только можно себе представить.
Как мы видели, многие исследовательские группы уже и до этого приписали определенные функции каким-то из этих темных областей: вспомним промоторы, энхансеры, теломеры, центромеры, длинные некодирующие РНК (это лишь несколько примеров). Так что большинство ученых вполне устраивала идея, согласно которой в нашем геноме содержится не только эта небольшая доля генетического материала, кодирующая белки. Но 80% генома, обладающие функциями? Это казалось чересчур смелым заявлением.
Данные ENCODE многих поразили. Тем не менее их предвестием стали результаты многочисленных косвенных исследований, на протяжении предыдущего десятилетия проводившихся учеными, которые все пытались понять, отчего человек так сложно устроен. Над этой проблемой ломало голову немало специалистов и неспециалистов с тех самых пор, как выяснилось: полная расшифровка человеческого генома не выявила у человека большего числа генов, кодирующих белки, по сравнению с куда более простыми организмами. Исследователи проанализировали размеры части генома, кодирующей белки, у различных представителей царства животных, и процентную долю, которую составлял мусор в общем объеме генома. Результаты этого анализа (мы уже бегло коснулись их в главе 3) сжато показаны на рис. 14.1.
Как мы уже знаем, количество генетического материала, кодирующего белки, не очень-то соотносится со сложностью организма. Куда более убедительная зависимость существует между процентной долей мусора в геноме и тем, насколько сложно устроен носитель этого генома. Пытаясь интерпретировать этот факт, исследователи предположили, что различия между простыми и сложными существами порождаются главным образом именно мусорной ДНК. Возможно, это означает, что существенная доля мусорной ДНК все-таки обладает какими-то функциями6.
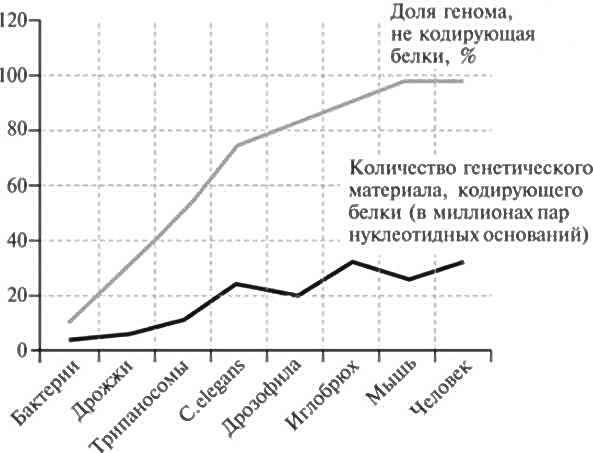
Рис. 14.1. График показывает, что по мерю увеличения сложности организма доля мусорной ДНК в геноме нарастает быстрее и отчетливее, чем размер части, кодирующей белки.
Назад: Почему XX отличается от XXX
Дальше: Множественные параметры

