Книга: Гёдель, Эшер, Бах
Назад: Благочестивые размышления курильщика табака
Дальше: Магнификраб в пирожоре
ГЛАВА XVI: Авто-реф и авто-реп
В ЭТОЙ ГЛАВЕ мы рассмотрим несколько механизмов, порождающих автореференцию в различных контекстах, и сравним их с механизмами, позволяющими некоторым системам самовоспроизводиться (или «авторепродуцироваться») Мы увидим, что между этими механизмами существуют интересные и изящные параллели.
Явно и неявно автореферентные высказывания
Для начала рассмотрим высказывания, которые на первый взгляд кажутся простейшими примерами автореферентности. Вот некоторые примеры:
(1) Это высказывание содержит пять слов
(2) Это высказывание бессмысленно, так как оно автореферентно
(3) Это высказывание без глагола
(4) Это высказывание ложно
(5) Высказывание, которое я сейчас пишу — это высказывание, которое вы сейчас читаете
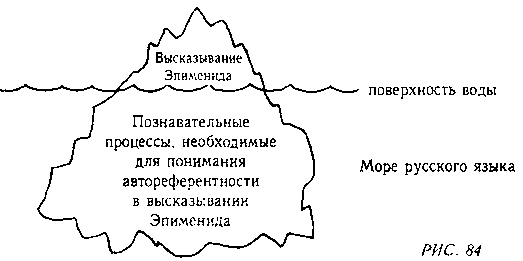
Каждое из этих высказываний, кроме последнего (являющегося аномалией), употребляет простой на вид механизм, содержащийся в словах «это высказывание». Однако в действительности этот механизм далеко не прост. Все эти высказывания «плавают» в контексте русского языка. Их можно сравнить с айсбергами у которых видны только верхушки. Этими верхушками являются последовательности слов, скрытая часть «айсбергов» — это та работа, которую наш мозг должен проделать, чтобы понять эти высказывания. В этом смысле их значение неявно. Разумеется, значение никогда не бывает полностью явным, но чем заметнее автореференция, тем виднее порождающие ее механизмы. В данном случае, чтобы увидеть автореференцию, необходимо не только быть хорошо знакомым с таким языком, как русский, который позволяет высказывания о своей собственной грамматике, читатель также должен быть способным понять, к чему относятся слова «это высказывание». Это кажется просто но на самом деле этот процесс зависит от нашей сложной, но полностью ассимилированной способности говорить по-русски. Особенно важно понять к чему относится здесь указательное местоимение. Это умение приходит постепенно и мы ни в коем случае не должны считать его тривиальным. Трудность становится явной когда такое высказывание, как #4, представлено кому-то, не имеющему понятия о парадоксах, — например, ребенку. Он может спросить «Какое высказывание ложно?» — и придется потрудиться, чтобы убедить его, что это высказывание говорит о самом себе. Сначала эта идея кажется пугающей. Может быть, ее можно лучше понять с помощью рисунков. На одном уровне, это высказывание, указывающее само на себя, так сказать, «держащее себя на мушке». На другом уровне, на этом рисунке — Эпименид, приводящий в исполнение собственный смертный приговор.
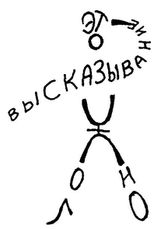
Рис. 83. Эпименид, приводящий в исполнение собственный приговор.
Рис. 84, показывающий видимую и невидимую части айсберга, дает понятие об отношении самого высказывания к процессам, необходимым для понимания автореферентности:
Интересно попытаться создать автореферентное высказывание, не используя при этом слов «это высказывание». Для этого можно попробовать процитировать высказывание внутри самого себя, как например:
В высказывании «В высказывании четыре слова» четыре слова.
Однако подобная попытка обречена на провал, так как любое высказывание, которое может быть полностью процитировано внутри себя, должно быть короче себя самого. Это возможно только в том случае, если вы согласны возиться с бесконечно длинными высказываниями, как например:
Высказывание
. Высказывание
. «Высказывание
. „Высказывание
. и т. д. и т. п.
. бесконечно длинно“
. бесконечно длинно»
. бесконечно длинно
бесконечно длинно
Однако подобная техника не работает для конечных высказываний. По той же причине Геделева строчка G не может содержать явный символ числа для собственного Геделева номера — он в нее просто не умещается. Никакая из строчек ТТЧ не может содержать символ числа ТТЧ для собственного Геделева номера поскольку в этом символе всегда больше знаков, чем в самой строчке. Однако это препятствие можно преодолеть, введя в G описание ее Геделева номера с помощью понятий «код» и «арифмоквайнификация».
Один из методов получения автореференции в русском языке, не используя при этом самоцитирования или фраз типа «это высказывание» — это метод Квайна проиллюстрированный в «Арии в ключе G». Чтобы понять высказывание Квайна, требуются более простые мысленные процессы, чем те, что нужны для понимания четырех приведенных выше примеров. На первый взгляд, оно может показаться более сложным, но, на самом деле, его смысл лежит ближе к поверхности. Построение Квайна весьма напоминает Геделеву конструкцию, поскольку оно описывает некую типографскую строчку, которая оказывается изоморфной самой строке Квайна. Описание этой новой типографской строчки достигается в двух частях высказывания Квайна. Одна часть содержит инструкции по построению некоего высказывания, в то время как во второй части содержится сам строительный материал — то есть она является шаблоном. Такое высказывание больше похоже на плавающий кусок мыла, чем на айсберг (см. рис. 85).

Рис. 85.
Автореферентность этого высказывания достигается здесь более прямым путем, чем в парадоксе Эпименида; для ее понимания требуется меньше скрытых процессов. Кстати, интересно заметить, что в предыдущем высказывании появляется фраза «это высказывание», однако там не возникает автореферентности; вы, вероятно, поняли, что эта фраза относится к высказыванию Квайна, а не к тому высказыванию, в котором она находится. Это показывает, насколько интерпретация таких указательных фраз как «это высказывание» зависит от контекста и какая мыслительная работа требуется для их понимания.
Самовоспроизводящаяся программа
Понятие квайнирования и его использование для получения автореференции уже было объяснено в Диалоге, так что мы здесь не будем на нем останавливаться. Давайте лучше посмотрим, как компьютер может воспользоваться той же самой техникой, чтобы воспроизвести самого себя. Следующее самовоспроизводящее высказывание написано на языке, подобном Блупу, и основано на следовании за фразой ее собственной цитаты (поскольку порядок здесь обратный квайнированию, я назову эту операцию ENIUQ — QUINE, записанное наоборот):
ОПРЕДЕЛИТЬ ПРОЦЕДУРУ «ENIUQ» [ШАБЛОН]. НАПЕЧАТАТЬ
[ШАБЛОН, ЛЕВАЯ СКОБКА, КАВЫЧКА, ШАБЛОН, КАВЫЧКА,
ПРАВАЯ СКОБКА, ТОЧКА].
ENIUQ
['ОПРЕДЕЛИТЬ ПРОЦЕДУРУ «ENIUQ» [ШАБЛОН]
НАПЕЧАТАТЬ [ШАБЛОН, ЛЕВАЯ СКОБКА, КАВЫЧКА, ШАБЛОН,
КАВЫЧКА, ПРАВАЯ СКОБКА, ТОЧКА]
ENIUQ']
ENIUQ — это процедура, определенная в двух первых строчках, и вводные данные этой процедуры называются «ШАБЛОНОМ». Когда процедура вызывается, значением ШАБЛОНА является некая строчка типографских символов. Результатом ENIUQ является операция печатания, при которой ШАБЛОН напечатан дважды: первый раз просто так, а второй раз — заключенный в кавычки и квадратные скобки и снабженный точкой в конце. Например, если бы ШАБЛОН содержал ПОВТОРЕНИЕ-МАТЬ-УЧЕНИЯ, то после операции ENIUQ у нас получилось бы:
ПОВТОРЕНИЕ-МАТЬ-УЧЕНИЯ [«ПОВТОРЕНИЕ-МАТЬ-УЧЕНИЯ»]
В последних четырех строчках вышеприведенной программы мы вызывали процедуру ENIUQ с определенным значением ШАБЛОНА, а именно, длинная строчка в кавычках: ОПРЕДЕЛИТЬ...ENIUQ. Это значение было тщательно подобрано; оно состоит из определения самой процедуры ENIUQ, за которым следует слово ENIUQ. Результатом является напечатанная еще раз программа — или, если хотите, точная копия программы. Это напоминает Квайнову версию парадокса Эпименида:
«Предваренное цитатой самого себя, порождает ложь»
предваренное цитатой самого себя, порождает ложь.
Очень важно заметить, что строчка символов, появляющаяся в кавычках в последних трех строках вышеприведенной программы (то есть, значение ШАБЛОНА), никогда не интерпретируется как набор команд То. что здесь она выглядит, как команда, получилось чисто случайно. Как мы сказали, это могло быть ПОВТОРЕНИЕ-МАТЬ-УЧЕНИЯ или любая другая строчка символов. Красота этой схемы — в том, что когда та же самая строчка появляется в первых двух строках этой программы, она интерпретируется именно как программа (поскольку там она не заключена в кавычки). Таким образом, в этой программе одна и та же строчка играет две роли один раз она функционирует в качестве программы, а другой раз — в качестве вводных данных В этом и заключается секрет самовоспроизводящихся программ и, как мы скоро увидим самовоспроизводящихся молекул. В дальнейшем я буду иногда называть самовоспроизводящиеся объекты авто-реп (сокращение от «авторепродукция»), а самоупоминающие объекты — авто-реф (сокращение от «автореференция»).
Предыдущая программа — изящный пример самовоспроизводящейся программы, написанной на языке, не предназначенном для создания подобных программ. Поэтому нам пришлось использовать понятия и операции являющиеся частью языка, такие, как слова «КАВЫЧКИ» и команда «НАПЕЧАТАТЬ». Но представьте себе, что в нашем распоряжении — язык, специально созданный для написания авто-репов, тогда программы стали бы намного короче. Операция ENIUQ-ирования уже содержалась бы в таком языке и, следовательно, не нуждалась бы в определении (такой операцией в предыдущей программе было НАПЕЧАТАТЬ). Тогда миниатюрным авто-репом было бы:
ENIUQ ['ENIUQ']
Это очень похоже на Черепаший вариант Квайновой версии парадокса Эпименида, где мы предполагаем, что глагол «квайнировать» заранее известен:
«Предваренное цитатой самого себя порождает ложь,»
предваренное цитатой самого себя, порождает ложь.
Но авто-реф может быть и короче. Например, можно представить себе компьютерный язык, программы которого должны быть сначала скопированы и только затем выполнены, если их первым символом является астериск. Тогда программа, состоящая из одного только астериска уже была бы авто-репом! Вы можете возразить, что это глупо, поскольку целиком зависит от придуманного условия. Такое возражение вторило бы моему предыдущему замечанию о том, что использование фразы «это высказывание» — почти жульничество, потому что оно слишком зависит от процессора и недостаточно — от явных указаний для достижения самовоспроизводства. Использование астериска в качестве примера авто-репа подобно использованию слова «я» как примера автореференции в обоих случаях глубинные аспекты проблемы оказываются скрытыми.
Это напоминает другой интересный тип автореференции, получаемый при помощи ксерокса. Можно сказать, что всякий письменный документ является авто-репом, потому что он может быть воспроизведен путем ксерокопирования. Однако это в некотором смысле противоречит нашему понятию о самовоспроизводстве лист бумаги в данном случае совершенно пассивен и не управляет собственным воспроизводством. В этом случае, все опять зависит от процессора. Прежде, чем мы сможем назвать некий объект авто-репом, мы должны быть уверены в том, что в этом объекте содержатся максимально ясные инструкции по его самовоспроизводству.
Разумеется, ясность и подробность указаний всегда относительны, однако существует некая интуитивная граница, по одну сторону которой мы видим настоящее самовоспроизводство, а по другую — копирование при помощи негибкого и автономного копирующего механизма.
Что такое копия?
В любом обсуждении вопросов, касающихся авто-репа и авто-рефа, нам рано или поздно придется дать определение понятию копии. Мы уже обсуждали этот вопрос в главах V и VI; теперь мы вернемся к нему еще раз. Для начала рассмотрим довольно фантастические, но теоретически возможные примеры авто-репов.
Самовоспроизводящаяся песня
Представьте себе музыкальный автомат в местном баре; вы нажимаете на кнопку 1-Я, и раздается песня на мотив «Славного моря» с такими словами:
Все, что мне нужно — монетка твоя,
Славная скрасит нам песенка ночку.
Денежку сунь и нажми «1-Я» —
Петь я не буду в рассрочку.
Мы можем нарисовать маленькую диаграмму того, что при этом получается:
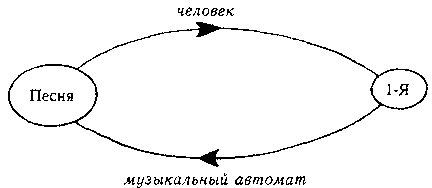
Рис. 86. Самовоспроизводящаяся песня.
Хотя в результате песня воспроизводится, было бы странно называть ее настоящим авто-репом, поскольку, когда она проходит через стадию 1-Я, в ней находится не вся информация. Информация может быть восстановлена только благодаря тому, что она полностью записана в музыкальном автомате — то есть в стрелках нашей диаграммы, а не в ее овалах. Неясно, содержит ли эта песня полные инструкции, необходимые для ее воспроизводства, поскольку символ 1-Я — не копия, а всего лишь пусковой механизм.
Крабо-программа
Теперь представьте себе компьютерную программу, печатающую саму себя задом наперед. (Читатели могут для интереса попытаться написать такую программу на языке, подобном Блупу, используя данный авто-реп в качестве модели.) Была бы подобная забавная программа авто-репом? В каком-то смысле да, так как тривиальное преобразование ее выхода восстановило бы первоначальную программу. Видимо, можно сказать, что выход содержит ту же информацию, что и сама программа, только слегка измененную. Но ясно и то, что в таком выходе многие не узнали бы изначальной программы, напечатанной задом наперед. Используя терминологию главы VI, мы могли бы сказать, что «внутреннее сообщение» выхода и программы совпадают, в то время как их «внешние сообщения» различны — то есть для их прочтения требуются разные декодирующие механизмы. Если считать внешнее сообщение частью информации (что кажется вполне разумным), то общая информация, в конце концов, оказывается не одна и та же, так что эту программу нельзя считать настоящим авто-репом.
Это заключение звучит тревожно, поскольку мы привыкли считать, что предмет и его зеркальное отражение содержат одну и ту же информацию. Но вспомните, что в главе VI мы выяснили, что понятие «присущего сообщению значения» зависит от гипотетического универсального понятия разума. Идея заключалась в том, что при определении этого присущего значения мы можем игнорировать некоторые типы внешних сообщений — те, которые понятны везде и всем. Если декодирующий механизм кажется достаточно фундаментальным (эта фундаментальность пока определена довольно расплывчато), то важно лишь внутреннее сообщение, которое он выявляет. В этом примере кажется разумным предположить, что «стандартный разум» считал бы, что предмет и его отражение содержат одну и ту же информацию. Иными словами, он нашел бы изоморфизм между ними настолько тривиальным, что его вообще можно было бы не принимать в расчет. Таким образом, наше интуитивное восприятие этой программы как настоящего авто-репа оказывается вполне оправдано.
Эпименид, оседлавший Ламанш
Еще одним забавным примером авто-репа была бы программа, печатающая саму себя в переводе на другой компьютерный язык. Это можно сравнить со следующей франко-английской версией Квайнова варианта авто-репа Эпименида:
«est une expression qui, quand elle est précédée de sa traduction, mise entre guillemets, dans la langue provenant de l'autre côoté de la Manche, crée une fausseté» is an expression which, when it is preceded by its translation, placed in quotation marks, into the language originating on the other side of the Channel, yields a falsehood.
(«Это высказывание, которое, будучи предварено своим переводом, заключенным в кавычки, на язык другой стороны Ламанша, порождает ложь» — это высказывание, которое, будучи предварено своим переводом, заключенным в кавычки, на язык другой стороны Ламанша, порождает ложь.)
Можете попытаться записать предложение, описанное этой странной конструкцией (подсказка: оно не является самим собой — по крайней мере, если понимать слово «само» упрощенно). Если понятие «авто-реп, полученный отступлением назад» напоминает крабий канон, или ракоход, понятие «авто-реп, полученный переводом» напоминает канон, в котором тема переводится в другую тональность.
Программа, печатающая свой собственный Гёделев номер
Может показаться, что не имеет смысла печатать перевод программы вместо ее точной копии. Однако, чтобы написать авто-реп на Блупе или Флупе, вам пришлось бы прибегнуть к подобным трюкам, поскольку на этих языках ВЫХОД всегда бывает в форме чисел, а не типографских строчек. Таким образом, вам пришлось бы написать программу, которая печатала бы свой собственный Гёделев номер: гигантское число, использующее трехзначные кодоны — «переводы» каждого знака программы. Такая программа, используя доступные ей средства, подходит очень близко к самовоспроизведению: она печатает копию себя самой в другом «измерении». Перейти от измерения чисел к измерению строчек не представляет труда. Таким образом, ВЫХОД здесь является не только пусковым механизмом, каким была кнопка 1-Я. Вместо этого, все информация первоначальной программы лежит «близко к поверхности» выхода.
Гёделева автореференция
Мы подошли вплотную к описанию Гёделева авто-рефа G. В конце концов, эта строчка ТТЧ содержит описание не себя самой, а некоего числа (арифмоквайнификации d). Однако дело в том, что это число — точный «портрет» строчки G в измерении натуральных чисел. Таким образом, G описывает собственный перевод на другой «язык». Тем не менее, мы с чистой совестью называем G автореферентной строчкой, поскольку изоморфизм между двумя «языками» настолько совершенен, что их можно считать идентичными.
Изоморфизм, отображающий ТТЧ на абстрактный мир натуральных чисел, сравним с квази-изоморфизмом, отображающим реальный мир в нашем мозгу при помощи символов. Это символы почти изоморфны предметам, которые они отображают, и именно благодаря этому мы можем думать. Таким же образом, Гёделевы номера изоморфны строчкам, благодаря чему мы можем найти метаматематический смысл в высказываниях о натуральных числах. Удивительное, почти магическое свойство G заключается в том, что ей удается автореференция, несмотря на то, что она написана на языке ТТЧ, который, как кажется, совершенно непригоден для самоописания (чем весьма отличается от русского языка, на котором запросто можно обсуждать русский язык).
Таким образом, G — замечательный пример авто-рефа, полученного путем перевода. Далеко не самый прямой путь! Мы можем найти подобные примеры в Диалогах, так как некоторые из них являются такими переводными авто-рефами. Возьмите, например, «Сонату для Ахилла соло». В этом Диалоге несколько раз упоминаются сонаты Баха для скрипки соло; особенно интересен момент, когда Черепаха предлагает Ахиллу вообразить аккомпанемент на клавесине. Если приложить эту идею к самому Диалогу, то нам придется изобретать реплики Черепахи; но если считать, что Ахилл, как Баховская скрипка, исполняет соло, то было бы в принципе неверно считать, что Черепаха играет какую-то ни было роль в беседе. Так или иначе, здесь мы опять сталкиваемся с авто-рефом, на этот раз полученным путем отображения Диалогов на пьесы Баха. Задача читателя в том, чтобы это отображение обнаружить. Но даже если читатель его и не заметит, отображение там тем не менее присутствует, и Диалог все-таки является авто-рефом.
Авто-реп с увеличением
Продолжая наше сравнение авто-репов с канонами, давайте теперь попытаемся найти, чему соответствует канон с увеличением. Одна возможность такова программа, содержащая пустую петлю, предназначенную единственно для замедления программы. Некий параметр указывает, как часто эта петля должна повторяться. Можно представить себе такую самовоспроизводящуюся программу, которая печатает собственные копии, но с измененным параметром, так что каждая следующая копия будет в два раза медленнее предыдущей Ни одна из этих программ не повторяется в точности, но все они явно принадлежат к одной «семье».
Это напоминает воспроизводство живых организмов Ясно, что никакой индивидуум не является точной копией своих родителей, почему же тогда производство на свет потомства называется «самовоспроизводством»? Дело в том, что между родителями и ребенком существует приблизительный изоморфизм — изоморфизм, сохраняющий информацию о виде. Таким образом, здесь воспроизводится скорее класс, чем пример. То же самое происходит и на рекурсивном графике G в главе V, хотя соответствие между «магнитными бабочками» разных размеров и форм весьма приблизительно, и ни одна «бабочка» не повторяет другую в точности, все они принадлежат к одному и тому же «виду», и соответствие сохраняет именно эту информацию. В терминах самовоспроизводящихся программ это соответствовало бы семье программ, написанных на разных «диалектах» одного и того же компьютерного языка, любая из них может воспроизвести себя саму, но в немного измененном виде, так что результатом является диалект первоначального языка.
Кимов авто-реп
Возможно, самым хитрым примером авто-репа является следующий вместо того, чтобы написать «правильное» выражение на языке компилятора, вы печатаете одно из посланий, указывающее на ошибку в этом языке. Ваша «программа» сбивает компилятор с толку, потому что она неграмматична, поэтому компилятор печатает сообщение об ошибке. Все, что нужно для получения авто-репа, — это добиться, чтобы компилятор выдал такое же сообщение об ошибке, как то, что вы ввели первоначально. Этот тип самовоспроизводства, придуманный Скоттом Кимом, исследует такие аспекты системы, которые обычно остаются без внимания. Хотя это кажется шуткой, на самом деле нечто подобное может существовать в сложных системах, где авто-репы соперничают друг с другом в борьбе за выживание, вскоре мы рассмотрим подобные случаи.
Что такое оригинал?
Кроме вопроса о том, что такое копия, существует еще один глубокий философский вопрос, касающийся авто-репов. Этот вопрос — обратная сторона монеты «Что такое оригинал?» Лучше всего пояснить это на примерах:
(1) программа которая, будучи интерпретирована неким интерпретатором на некоем компьютере, печатает саму себя,
(2) программа, которая, будучи интерпретирована неким интерпретатором на некоем компьютере, печатает саму себя вместе с полной копией интерпретатора (который, в конце концов, тоже является программой),
(3) программа, которая, будучи интерпретирована неким интерпретатором на некоем компьютере, печатает не только саму себя вместе с полной копией интерпретатора, но также приводит в действие процесс сборки второго компьютера, идентичного первому.
Ясно, что в (1) программа является авто-репом. Но что является авто-репом в (3) — сама программа, комбинация программы с интерпретатором или система, состоящая из программы, интерпретатора и процессора?
Понятно, что здесь самовоспроизводство включает нечто большее, чем просто распечатка самой программы. Оставшаяся часть этой главы посвящена, в основном, анализу авто-репов, в которых вводные данные, программа, интерпретатор и процессор переплетены между собой и в которых самовоспроизводство включает воспроизведение всей этой системы.
Типогенетика
Сейчас мы обратимся к одной из самых интересных и глубоких тем двадцатого столетия: науке о «молекулярной логике живых организмов», как образно выразился Альберт Ленингер. Действительно, это и есть логика — но более сложного и прекрасного типа, чем тот, который способен вообразить человеческий разум. Мы подойдем к обсуждению этого по-новому, воспользовавшись игрой, которую я для этого придумал. В эту игру можно играть в одиночку; она называется «типогенетика» (сокращенное «типографская генетика»). В типогенетике я попытался выразить некоторые идеи молекулярной генетики в типографской системе, которая на первый взгляд кажется очень похожей на формальные системы типа MIU. Разумеется, типогенетика — система очень упрощенная и используется, в основном, для дидактических целей.
Должен предупредить читателя, что область молекулярной биологии — это область, в которой взаимодействуют явления на нескольких уровнях, в то время как типогенетика иллюстрирует только события на одном или двух уровнях. В частности, совершенно не упоминаются химические процессы, поскольку они происходят на уровне ниже того, который мы здесь обсуждаем; также не упоминаются аспекты классической (немолекулярной) генетики — они принадлежат к высшему уровню. В типогенетике я хотел дать общую идею о процессах, участвующих в знаменитой «Центральной догме молекулярной биологии», сформулированной Фрэнсисом Криком (одним из открывателей двойной спирали ДНК):
ДНК => РНК => белки
Я надеюсь, что при помощи моей схематической модели мне удастся помочь читателю почувствовать некоторые объединяющие принципы, действующие в этой области, — принципы, которые могут быть легко упущены из вида за невероятной сложностью взаимодействия событий на многих уровнях. Надеюсь, что, пожертвовав точностью, нам удастся получить некое общее понимание картины.
Цепочки, основания, энзимы
Игра в типогенетику включает типографские манипуляции последовательностями букв. У нас имеется четыре буквы:
А С G Т
Любые последовательности этих букв называются цепочками. Вот примеры цепочек:
GGGG
АТТАССА
САТСАТВАТВАТ
Иногда я буду называть буквы А С G Т основаниями, а позиции которые они занимают — подразделениями. Так, в средней цепочке есть семь подразделений в четвертом из которых находится основание А.
Цепочку можно изменять ее разными способами. Можно также производить новые цепочки копируя старые либо разрезая их на части. Некоторые операции удлиняют цепочки некоторые их укорачивают а некоторые оставляют их длину неизменной.
Обычно мы имеем дело с наборами различных операций выполняемых по порядку. Такой набор операций напоминает запрограммированную машину которая двигает цепочку вверх и вниз и изменяет ее. Такие машины называются «типографскими энзимами», или для краткости энзимами. Энзимы действуют одновременно только на одно подразделение цепочки, мы говорим, что они прикреплены к тому подразделению, на которое они в данный момент действуют.
Попытаюсь привести пример того как некоторые энзимы действуют на определенные цепочки. Каждый энзим для начала «прикрепляется» к одной определенной букве. Таким образом, существует четыре типа энзимов: те которые предпочитают А, те которые предпочитают С и так далее. Анализируя последовательность операций выполненных при помощи того или иного энзима можно определить какую букву тот предпочитает, пока однако, я буду приводить примеры, не вдаваясь в подробности. Вот пример энзима, состоящего из трех операций:
(1) Стереть подразделение к которому прикреплен энзим (и затем прикрепить его к следующему справа подразделению)
(2) Подвинуться на одно подразделение вправо
(3) Вставить Т (справа от этого подразделения)
Этот энзим оказывается «любителем» буквы А. Вот пример простой цепочки:
АСА
Что получится если наш энзим прикрепится к левому А и начнет действовать? Первый шаг стирает А так что у нас остается С. А — теперь энзим прикреплен к С. Второй шаг продвигает энзим направо, к А и третий шаг прибавляет Т на конце. У нас получилась новая цепочка — CAT.
Что получилось бы если бы энзим начал действовать с правого А? Он стер бы это А и затем отделился от цепочки. Когда такое случается, энзим прекращает работу (это общий принцип). Так что результатом будет потеря одного символа.
Давайте посмотрим на действие еще одного энзима:
(1) Искать ближайший справа пиримидин
(2) Привести в действие копирующий механизм
(3) Искать ближайший справа пурин
(4) Обрезать цепочку там (то есть справа от данного подразделения)
Здесь мы впервые встречаемся с терминами «пиримидин» и «пурин». Не пугайтесь — это очень просто. А и G называются пуринами, а С и Т — пиримидинами. Таким образом, поиск пиримидина — это всего лишь поиск С или Т.
Копирующий режим и двойные спирали
Другой новый термин — это копирующий режим. Любая цепочка может быть «скопирована» на другую цепочку, но делается это довольно необычным способом. Вместо того, чтобы копировать А на А, вы копируете его на Т, и наоборот. И вместо того, чтобы копировать С на С, вы копируете его на G, и наоборот. Обратите внимание, что пурин копируется на пиримидин, и наоборот. Это называется спариванием комплементарных оснований. Комплементы приведены ниже:
. комплемент
пури- | A <==> T |пиримидины
ны | G <==> C |
Таким образом, «копируя» цепочку, вы не повторяете ее в точности, а производите ее комплементарную цепочку, которая будет записана над первоначальной цепочкой вверх ногами. Рассмотрим конкретный случай. Представьте себе, что упомянутый энзим действует на следующую цепочку (этот энзим тоже любит начинать с А):
CAAAGAGAATCCTCTTTGAT
Энзим может стартовать с любого А; предположим, что он начал со второго. Энзим прикрепляется к нему, затем выполняет шаг (1): поиск ближайшего справа пиримидина. Это означает либо С либо Т. Первое Т находится примерно в середине цепочки, куда мы и отправляемся. Теперь шаг (2): копирующий режим. Напишем над Т перевернутое А. Но это еще не все — копирующий режим продолжает действовать, пока он не отключен — или пока энзим не кончит работать. Это значит, что каждое основание, мимо которого проходит энзим, находящийся в режиме копирования, получит сверху комплементарное основание. Шаг (3) велит нам искать первый пурин справа от нашего Т. Это G, третье с правого конца. Продвигаясь к этой букве, мы должны «копировать», то есть создавать комплементарную цепочку. Вот что у нас получается:
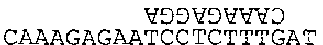
Последним шагом является разрезка цепочки. Результатом этого будут две новые цепочки:
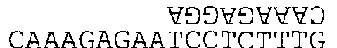
и AT.
Мы выполнили все команды, в результате у нас получилась двойная цепочка. Когда такое случается, мы отделяем комплементарные цепочки друг от друга (это общий принцип), в результате нашим конечным продуктом будут три цепочки:
AT, CAAAGAGGA и CAAAGAGAATCCTCTTTG
Заметьте, что цепочка бывшая вверх ногами, теперь записана в нормальном виде поэтому правая и левая сторона поменялись местами. Итак, вы ознакомились с большинством типографских операций, которые будут производиться с цепочками. Необходимо упомянуть еще о двух командах. Первая выключает копирующий режим, вторая перебрасывает энзим с данной цепочки на перевернутую цепочку над ней. Когда такое происходит, то вам приходится заменить во всех командах «правый» на «левый», и наоборот. Вместо этого можно просто перевернуть бумагу так, что верхняя цепочка встанет с головы на ноги. Если дана команда перебросить энзим, над которым в данный момент нет комплементарного основания, то энзим отсоединяется от цепочки и на этом его работа заканчивается.
Надо иметь в виду что если у нас имеются две цепочки то команда «разрезать» относится к обеим из них, в то время как «стереть» относится только к той цепочке, над которой энзим работает в данный момент. Когда копирующий режим находится в действии, команда «вставить» относится к обеим цепочкам, и мы вставляем само основание в цепочку, где находится энзим, а его комплемент в верхнюю цепочку. Если копирующий режим выключен, то команда «вставить» относится только к одной цепочке, и в цепочку наверху вставляется пробел.
Когда действует копирующий режим, команды «двигаться» и «искать» означают, что над каждым основанием, мимо которого проходит энзим, нам приходится записывать комплементарное основание. Когда энзим начинает работать, копирующий режим всегда выключен. Если в этот момент встречается команда «выключить копирующий режим», то ничего не происходит. Так же, если копирующий режим уже включен, команда «включить копирующий режим» остается без последствий.
Аминокислоты
raz — разрезать цепочку
str — стереть основание из цепочки
prb — перебросить энзим на другую цепочку
sdl — сдвинуться на одно подразделение влево
sdp — сдвинуться на одно подразделение вправо
кор — включить копирующий режим
vyk — выключить копирующий режим
vsa — вставить А справа от данного подразделения
vsc — вставить С справа от данного подразделения
vsg — вставить G справа от данного подразделения
vst — вставить Т справа от данного подразделения
рmр — искать первый пиримидин справа
рrр — искать первый пурин справа
pml — искать первый пиримидин слева
prl — искать первый пурин слева
Каждая из этих команд — сокращение из трех букв. Мы будем называть эти сокращения аминокислотами. Таким образом, каждый энзим состоит из последовательности аминокислот.
Давайте выберем наугад один из энзимов:
рrр — vsc — кор — sdp — sdl — prb — prl — vst
а также какую-либо цепочку, например,
TAGATCCAGTCCATGGA
и посмотрим, как энзим действует на эту цепочку. Данный энзим присоединяется только к G. Предположим, что на этот раз он начнет с G в середине. Сначала мы ищем пурин справа (то есть, А или G). Теперь мы (энзим) пропускаем ТСС и попадаем на А. Вставляем С. Теперь у нас получается:
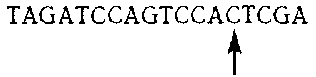
Стрелочкой отмечено подразделение, к которому привязан энзим. Включаем копирующий режим. Это дает нам перевернутое G над С. Сдвигаемся сначала направо, потом налево, потом переходим на другую цепочку. До сих пор у нас получилось вот что:

Перевернем это, с тем чтобы энзим оказался прикрепленным к нижней цепочке:
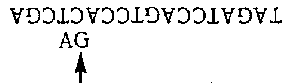
Теперь мы ищем пурин слева, и находим А. Копирующий режим находится в действии, но комплементарные основания уже есть, поэтому мы ничего не добавляем. Наконец, мы вставляем Т и останавливаемся:
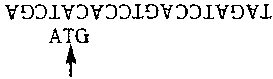
Окончательным результатом являются две цепочки:
ATG и TAGATCCAGTCCACATCGA
Прежняя цепочка, разумеется, утеряна.
Перевод и типогенетическии код
Читатель может спросить, откуда берутся энзимы и цепочки, и как можно узнать, к какой букве прикрепляется в начале каждый данный энзим. Чтобы найти ответ на второй вопрос, можно попробовать взять наудачу несколько цепочек и посмотреть, как действуют на них и на их «потомков» различные энзимы. Это напоминает головоломку MU, в которой мы начинали с некоей аксиомы и нескольких правил. Единственная разница заключается в том, что после того, как энзим обработал первоначальную цепочку, она утрачивается навсегда. В головоломке MU при получении MIU из MI строчка MI остается невредимой.
Однако в типогенетике, так же как и в настоящей генетике, мы имеем дело с гораздо более сложной схемой. Мы так же начинаем с неких случайных цепочек, подобных аксиомам формальных систем. Но теперь у нас нет «правил вывода» — то есть энзимов. Однако, мы можем перевести каждую цепочку в один или несколько энзимов! Таким образом, сами цепочки будут указывать нам, какие операции должны производиться на них, и эти операции, в свою очередь, произведут новые цепочки, которые укажут на следующие операции, и т. д, и т. п! Вот так смешение уровней! Для сравнения подумайте, насколько изменилась бы головоломка MU, если бы каждая новая теорема могла бы быть превращена в правило вывода при помощи некоего кода.
Как же делается подобный «перевод»? Для этого используется типогенетический код, при помощи которого соседние пары оснований — так называемые «дублеты» представляют различные аминокислоты. Существует шестнадцать возможных дублетов АА, AC, AG, AT, CA, СС и т. д. С другой стороны, у нас есть пятнадцать аминокислот. Типогенетический код показан на рис 87.
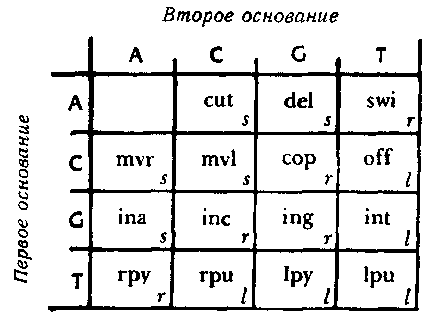
Рис. 87. Типогенетический код, при помощи которого каждый дублет кодируется как одна из аминокислот (или как знак препинания).
Из таблицы следует, что перевод дублета GC — «vsc» («вставить С»); что AT переводится как «prb» («перебросить энзим на другую цепочку») и так далее. Таким образом, становится ясно, что цепочка может прямо определять энзим. Например, цепочка:
TAGATCCAGTCCACATCGА
разделяется на дублеты следующим образом:
ТА GA ТС CA GT СС AC AT CG А
Последнее А остается без пары. Вот перевод этой цепочки в энзимы:
рmр — vsa — рrр — sdp — vst — sdl — raz — prb — kop
(Заметьте, что оставшееся А ничего не добавляет).
Третичная структура энзимов
Читатель, наверное, обратил внимание на маленькие буквы в нижнем правом углу каждого квадрата. Они очень важны для определения того, к какой букве предпочитает прикрепляться каждый энзим вначале Это определяется довольно необычным способом. Для этого приходится выяснить, какую «третичную структуру» имеет каждый энзим; эта третичная структура, в свою очередь, определена его первичной структурой. Под первичной структурой здесь понимается последовательность в энзиме аминокислот; под третичной структурой — то, каким образом он «уложен» в пространстве. Дело в том, что энзимы не любят располагаться по прямым, как мы их до сих пор представляли. Каждая расположенная внутри цепочки (но не на ее концах) аминокислота может изогнуться; направление изгиба определяется буквами в углах квадратов. Так «l» и «r» обозначают, соответственно, «влево» и «вправо», а буква «s» значит «прямо». Давайте возьмем наш последний пример энзима и постараемся представить себе его третичную структуру. Мы начнем с первичной структуры и будем продвигаться слева направо. После каждого энзима, снабженного в таблице буквой «l», мы будем поворачивать налево, после энзимов с буквой «r» — направо, а после энзимов с «s» поворота не будет. На рис. 88 показана схема (в двух измерениях) нашего энзима:
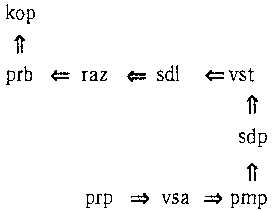
Рис. 88. Третичная структура типоэнзима.
Обратите внимание на левый поворот после «рrр», правый поворот после «prb» и так далее. Заметьте также, что первый сегмент («pmp => vsa») и последний сегмент («prb => kop») расположены перпендикулярно. Это и является ключом к тому, к какой букве присоединяется данный энзим: относительное расположение первого и последнего сегмента третичной структуры энзима определяют, к какой букве он прикрепится. Мы всегда можем повернуть энзим таким образом, чтобы его первый сегмент указывал направо. После этого последний сегмент энзима будет указывать на его «прикрепительные вкусы». Это показано на рис. 89.
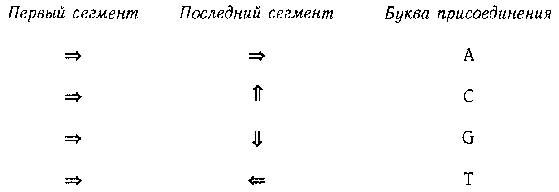
Рис. 89. Таблица «прикрепительных вкусов» типоэнзимов.
Таким образом, наш энзим предпочитает букву С. Иногда, складываясь, энзим пересекает сам себя — ничего страшного, просто представьте, что он проходит над или под собой. Обратите внимание, что все аминокислоты энзима играют роль в определении его третичной структуры.
Пунктуация, гены и рибосомы
Остается объяснить только одно. Почему в углу квадрата АА Типогенетического Кода нет никакой буквы? Дело в том, что дуплет АА действует как знак препинания внутри цепочки, указывая на конец кода для данного энзима. Это означает, что в одной цепочке может быть закодировано несколько энзимов, если она содержит один или несколько дуплетов АА. Например, в цепочке:
CG GA ТА СТ АА AC CG А
закодировано два энзима:
кор — vsa — pmp — byk
и
raz — кор
АА разделяет цепочку на два «гена». Ген — это кусок цепочки, в котором закодирован один энзим. Заметьте, что не всякое АА является знаком препинания, например, CAAG делится на энзимы «sdp — str». АА начинается с четного подразделения и, таким образом, не составляет дуплета! Механизм, читающий цепочки и производящий закодированные в них энзимы, называется рибосомой. (Играя в типогенетику, мы проделываем работу рибосом.) Рибосомы не отвечают за третичную структуру энзимов, поскольку она полностью определена их первичной структурой. Процесс перевода всегда происходит от цепочек к энзимам, а не наоборот.
Головоломка: типогенетический авто-реп
Теперь вы знаете правила типогенетики и можете поэкспериментировать с этой игрой. В частности, весьма интересно было бы попытаться получить самовоспроизводящуюся цепочку. Вот что это означало бы: дана некая цепочка; рибосома действует на нее, производя закодированные там энзимы. Затем эти энзимы вступают в контакт с первоначальной цепочкой и начинают с ней работать. Получается множество дочерних цепочек. Сами дочерние цепочки взаимодействуют с рибосомами, вследствие чего получаются новые энзимы, действующие на дочерние цепочки, и цикл продолжается. Наша надежда в том, что рано или поздно среди полученных цепочек мы найдем две копии первоначальной цепочки (на самом деле, одна из копий может оказаться самой первоначальной цепочкой.)
Центральная Догма типогенетики
Схема типогенетических процессов представлена на следующей диаграмме.
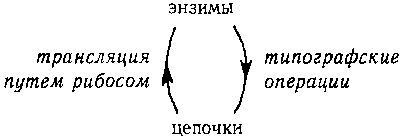
Рис. 90. «Центральная Догма типогенетики.» пример «Запутанной Иерархии».
На этой диаграмме показана Центральная Догма типогенетики. Из нее видно, как цепочки определяют энзимы (через Типогенетический Код) и как энзимы, в свою очередь, действуют на породившие их цепочки; в результате этого получаются новые цепочки. Таким образом, левая стрелка показывает, как старая информация подается наверх (ведь энзим является трансляцией цепочки и, следовательно, содержит ту же информацию, но в другой, активной форме). Правая стрелка, однако, не показывает движение информации вниз; вместо этого она указывает на то, как создается новая информация: передвижением символов в цепочке.
Энзим в типогенетике, подобно правилу вывода в формальной системе, механически переставляет символы в цепочке, не принимая во внимание никакого «значения», которое может заключаться в этих символах. Таким образом, здесь наблюдается интересное смешение уровней. С одной стороны, цепочки, поскольку на них воздействуют энзимы, играют роль данных (на это указывает правая стрелка); с другой стороны, они также диктуют, какие операции должны быть проделаны с данными и, таким образом, играют роль программ (на это указывает левая стрелка). Играющий в типогенетику действует как интерпретатор и процессор. «Круговая порука», связывающая «верхний» и «нижний» уровни в типогенетике, показывает, что нельзя сказать, что цепочки или энзимы находятся выше (или ниже) уровнем по сравнению друг с другом. С другой стороны. Центральная Догма системы MIU выглядит так:
правила вывода
↓ (типографские операции)
строчки
В системе MIU мы видим четкое разделение на уровни: правила вывода находятся уровнем выше, чем строчки. То же происходит в ТТЧ и во всех других формальных системах.
Странные Петли, ТТЧ и настоящая генетика
Однако мы видели, что и в ТТЧ, в некотором смысле, есть смешение уровней. Дело в том, что разделение на язык и метаязык оказывается не таким жестким высказывания о системе отражаются внутри самой системы. Если нарисовать диаграмму отношений между ТТЧ и ее метаязыком, у нас получится нечто, удивительно напоминающее Центральную Догму Молекулярной Биологии. На самом деле, наша цель — рассмотреть это сравнение как можно подробнее, для этого мы должны указать, в чем типогенетика совпадает с настоящей генетикой и в чем они различаются. Разумеется, настоящая генетика намного сложнее типогенетики, но «концептуальный скелет», который читатель получил, играя в типогенетику, будет очень полезен для путешествия по лабиринту действительной генетики.
ДНК и нуклеотиды
Мы начнем с обсуждения отношений между «цепочками» и ДНК, что расшифровывается как «дезоксирибонуклеиновая кислота» ДНК большинства клеток находится в ядре — небольшом районе, защищенном мембраной. Гунтер Стент назвал ядро «тронным залом» клетки, в котором царит ДНК ДНК состоит из длинных цепей относительно простых молекул, называемых нуклеотидами.
Каждый нуклеотид состоит из трех частей: (1) фосфатная группа, лишенная одного атома кислорода (отсюда «дезокси» в названии кислоты), (2) сахар под названием «рибоза» и (3) основание. Именно основание отличает один нуклеотид от другого; таким образом, чтобы указать на нуклеотид, достаточно указать на его основание. В нуклеотидах есть четыре типа оснований:
A: аденин,
G: гуанин : пурины
C: цитозин,
T: тимин : пиримидины
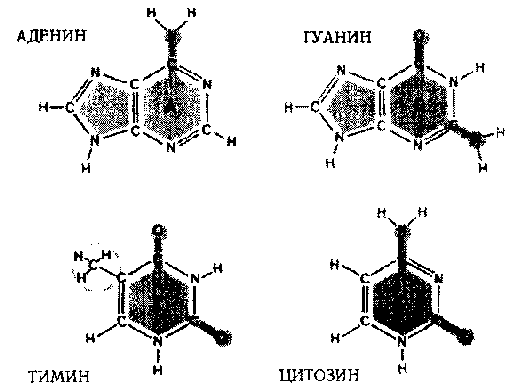
Рис. 91. Четыре основания, составляющих ДНК: Аденин, Гуанин, Цитозин, Тимин. (Hanawalt & Haynes. «The Chemical Basis of Life», стр. 142.)
(См. также рис. 91). Таким образом, цепочка ДНК состоит из множества нуклеотидов, следующих один за другим, как бусинки. Нуклеотид привязан к своим соседям сильной химической связью, которая называется ковалентной, «бусы» ДНК часто называются ее «ковалентным позвоночником». ДНК обычно состоит из двух цепочек, чьи нуклеотиды спарены между собой (см. рис. 92).
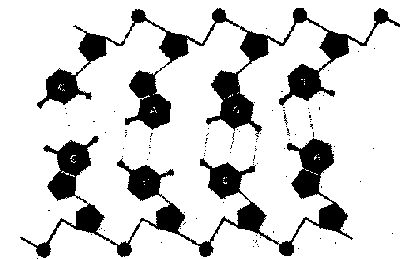
Рис. 92. Структура ДНК напоминает лестницу; сбоку — чередующиеся группы дезоксирибозы и фосфатов. «Ступеньки» построены из оснований, соединенных определенным образом, А с Т и G с С, и связанных двумя или тремя водородными связями. (Hanawalt & Haynes, стр. 142)
Именно основания ответственны за то, каким образом соединяются между собой цепочки. Каждое основание одной из цепочек соединяется со своим комплементарным основанием из другой цепочки. Комплементы — такие же, как в типогенетике: А соединяется с Т, а С — с G, то есть пурины всегда соединяются с пиримидинами.
По сравнению с сильными ковалентными связями в «позвоночнике», «межцепочные» связи весьма слабы. Это не ковалентные, а водородные связи. Водородная связь возникает, когда два скопления молекул расположены так, что один из атомов водорода, ранее принадлежавших к одному из этих скоплений, «запутывается» и уже не понимает, куда он принадлежит; он «зависает» между двумя скоплениями, не зная, к какому из них присоединиться. Поскольку две цепочки ДНК удерживаются вместе только водородными связями, они могут легко разделяться и снова соединяться, этот факт очень важен для жизнедеятельности клетки.
Двойные цепочки ДНК обвиваются одна вокруг другой, как лианы. (рис. 93) В каждом витке находится ровно 10 пар, иными словами, каждый нуклеотид изогнут на 36 градусов. ДНК, состоящая из одной цепочки, не изгибается таким образом, поскольку изгиб — это следствие соединения оснований.

Рис. 93. Молекулярная модель двойной спирали ДНК. (Vernon M. «Biosynthesis», стр. 13.)
Мессенджер РНК и Рибосомы
Как я уже сказал, во многих клетках «царь» клетки, ДНК, обитает в «тронном зале» — ядре. Но большинство жизненных процессов клетки происходит вне ядра, в цитоплазме, которая является для ядра примерно тем же, чем фон — для рисунка. В частности, энзимы, отвечающие практически за любой процесс в клетке, вырабатываются рибосомами в цитоплазме, где, в основном, они и продолжают действовать. И так же, как в типогенетике, «чертежи» всех энзимов хранятся в цепочках, то есть в ДНК, которая обитает, надежно защищенная, в своем домике-ядре. Но как же информация о структуре энзимов попадает из ядра к рибосомам?
Здесь на сцену выходит мессенджер РНК — мРНК. Он является чем-то вроде автобуса, который переносит хранящуюся в ДНК информацию (а не саму ДНК!) к рибосомам в цитоплазму. Как это делается? Идея проста — особый тип энзима внутри ядра с точностью копирует длинные отрезки цепочки оснований ДНК на новую цепочку — цепочку мессенджера РНК. Этот мРНК затем выходит из ядра и попадает в цитоплазму. Там он находит множество рибосом, которые начинают работать над ним, производя энзимы.
Процесс, во время которого ДНК копируется на мРНК, называется транскрипцией, при этом двойная спираль ДНК временно разделяется на две отдельные цепочки, одна из которых служит эталоном для мРНК. Кстати, «РНК» означает «рибонуклеиновая кислота»; она очень похожа на ДНК, с той разницей, что у всех ее нуклеотидов есть тот специальный атом кислорода в группе сахара, которого нет в ДНК. Поэтому здесь опущена приставка «дезокси». Кроме этого, вместо тимина РНК использует основание урацил, поэтому информация в цепочках РНК может быть представлена последовательностью букв А, С, G, U. Теперь, когда мРНК транскрибирован вне ДНК, начинается обычный процесс спаривания оснований (с U вместо Т), так что «эталон» ДНК и его товарищ мРНК могут выглядеть примерно так:
ДНК … CGTAAATCAAGTCA … (образец)
мРНК … GCAUUUAGUUCAGU … («копия»)
Как правило, РНК не образует длинных двойных цепочек сама с собой, хотя в принципе такое возможно. Таким образом, в большинстве случаев она находится не в форме двойной спирали, как ДНК, а в форме длинных, причудливо изогнутых цепочек.
Как только цепочка мРНК покидает ядро, она встречается с этими странными субклеточными существами, называемыми «рибосомами» — но прежде, чем объяснить, как рибосомы используют мРНК, я хочу сказать кое-что об энзимах и белках. Энзимы принадлежат к общей категории биомолекул, называемых белками; задача рибосом — в том, чтобы производить все белки, а не только лишь энзимы. Белки, не являющиеся энзимами, намного более пассивны; многие из них, например, являются структурными молекулами, что означает, что они действуют как балки и перекладины в зданиях: они удерживают вместе части клетки. Есть и другие типы белков, но для наших целей мы будем считать основными белками энзимы, и в дальнейшем я не буду проводить четкого различия между белками.
Аминокислоты
Белки состоят из последовательностей аминокислот; их существует 20 основных вариантов, каждый из которых — аббревиатура из трех букв.
ala — аланин
arg — аргинин
asp — аспарагин
val — валин
gis — гистидин
gli — глицин
gln — глютамин
glu — глютаминовая кислота
ile — изолейцин
lev — левцин
liz — лизин
met — метионин
pro — пролин
ser — серин
tre — треонин
trp — триптофан
tir — тирозин
fen — фенилаланин
cys — цистеин
Обратите внимание на отличие от типогенетики, где у нас было только пятнадцать «аминокислот», составляющих энзимы. Аминокислота — это небольшая молекула примерно такой же сложности, как нуклеотид; отсюда следует, что строительные блоки белков и нуклеиновых кислот (ДНК, РНК) примерно одинакового размера. Однако белки состоят из значительно более коротких последовательностей компонентов: около 300 аминокислот обычно составляют полный белок, в то время, как цепочка ДНК может состоять из сотен тысяч или даже миллионов нуклеотидов.
Рибосомы и магнитофоны
Когда цепочка мРНК, выйдя в цитоплазму, встречает рибосому, начинается очень сложный и интересный процесс, называющийся трансляцией. Можно сказать, что этот процесс находится в самом сердце жизни, и с ним связано множество загадок. При этом его основу описать легко. Давайте сначала обратимся к наглядному примеру и затем рассмотрим этот процесс более детально. Попробуйте вообразить мРНК в виде длинного куска магнитной ленты, а рибосомы — в виде магнитофонов. Когда лента проходит через магнитную головку магнитофона, она «прочитывается» и превращается в музыку или другие звуки. Магнитные знаки «переводятся» в ноты. Подобно этому, когда «пленка» мРНК проходит через «проигрывающую головку» рибосомы, получаются «ноты» — аминокислоты и «музыкальные произведения» — белки. Именно в этом и заключается процесс трансляции; он показан на рис. 96.
Генетический код
Но как может рибосома произвести цепочку аминокислот, считывая цепочку нуклеотидов? Эта загадка была разрешена в начале 1960-х годов в результате работы большой группы ученых. Оказалось, что в основе этого процесса лежит генетический код — отображение с троек нуклеотидов на аминокислоты (см. рис. 94). Это очень напоминает типогенетический код, но здесь последовательность из трех оснований (или нуклеотидов) составляет кодон, в то время как в типогенетике мы использовали только пару оснований. Таким образом, в таблице должно быть 4×4×4=64 разных записей, вместо шестнадцати. Рибосома считывает одновременно только три нуклеотида мРНК — то есть, один кодон. Каждый раз, когда это происходит, к белку, который в данный момент вырабатывается, прибавляется одна аминокислота. Таким образом, белок изготовляется постепенно, кислота за кислотой.
Типичная последовательность мРНК, прочитанная сначала как два триплета (наверху) и затем как три дуплета (внизу); пример гемиолы в биохимии:
CUA GAU
Сu Ag Аu
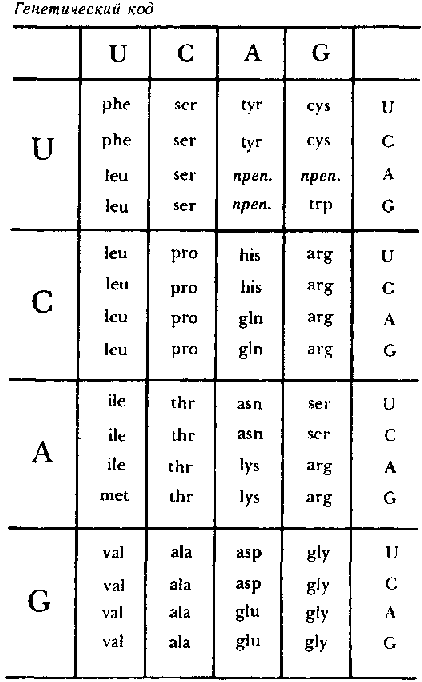
Рис. 94. Генетический код, по которому каждый триплет в цепочке мессенджера РНК соответствует одной из двадцати аминокислот (или знаку препинания).
Третичная структура
Когда из рибосомы возникает белок, он не только становится все длиннее, но также укладывается в пространстве, на манер змеи, которая растет и укладывается в кольца. Эта укладка называется третичной структурой белка (рис. 95), в то время как сама последовательность аминокислот является его первичной структурой. Третичная структура следует из первичной структуры, точно так же, как это было в типогенетике. Однако рецепт для получения третичной структуры из первичной структуры здесь намного сложнее. В действительности это одна из задач современной молекулярной биологии: найти некие правила, при помощи которых можно было бы предсказать третичную структуру белка, исходя только из его первичной структуры.
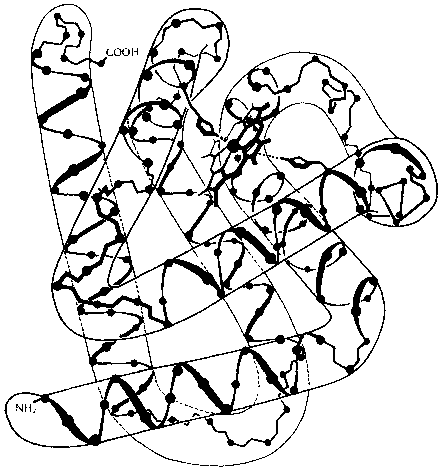
Рис. 95. Структура миоглобина, выведенная на основе рентгеновского снимка высокой разрешающей способности. Образование, напоминающее изогнутую трубу, — это его третичная структура, меньшая спираль внутри «трубы» — «спираль альфа» — вторичная структура. (A. Lehninger, «Biochemistry»)
Редукционистское объяснение функции белков
Другое, возможно, самое серьезное различие между типогенетикой и настоящей генетикой заключается в том, что в типогенетике каждая аминокислота типоэнзима отвечает за некое определенное «действие», в то время как отдельные аминокислоты настоящих энзимов не имеют четко определенных ролей.
Третичная структура, взятая целиком, определяет, как будет функционировать энзим. Нельзя сказать: «Присутствие этой аминокислоты означает, что совершится некая определенная операция». Иными словами, в настоящей генетике вклад каждой отдельной аминокислоты в работу всего энзима не свободен от «контекста». Однако этот факт не следует рассматривать как аргумент против редукционизма и как доказательство того, что «целое [энзим] не может быть объяснено как сумма его частей». Такой подход был бы совершенно не оправдан. Напротив, вполне оправдан отказ от упрощающего утверждения, что «вклад в общую сумму каждой аминокислоты не зависит от остальных присутствующих в энзиме аминокислот». Другими словами, функция белка не может быть составлена из независимых функций составляющих его частей, мы должны принимать во внимание их взаимодействие. В принципе возможно написать такую компьютерную программу, которая по данной первичной структуре белка определяла бы сначала его третичную структуру и затем — функцию энзима.
Это было бы редукционистским объяснением работы белков, но определение «суммы» требовало бы в таком случае весьма сложного алгоритма. Выяснение функции энзима исходя из его первичной а затем третичной структуры — это одна из задач современной молекулярной биологии.
Может быть, функция энзима все-таки может быть объяснена, исходя из независимых функций отдельных частей но в таком случае эти части были бы элементарными частицами, такими как электроны и протоны, а не блоками, такими как аминокислоты. Это — пример редукционистской дилеммы: чтобы объяснить события в терминах сумм независимых частей, приходится спускаться на уровень физики; но тогда число частиц оказывается таким огромным, что подобное объяснение становится невозможно осуществить на практике. Оно переходит в область чисто теоретических выкладок, в область «в принципе» возможного. Таким образом, нам приходится удовлетвориться суммой частей, зависящей от контекста. В этом есть два недостатка. Первый заключается в том, что составляющими частями здесь являются гораздо более крупные единицы, поведение которых можно описать лишь на более высоких уровнях — а следовательно, неточно. Второй недостаток в том, что слово «сумма» связано с идеей о том. что каждой части соответствует простая функция, и что функция целого — всего лишь сумма составляющих его независимых функций. Такой подход не дает результата, когда мы пытаемся объяснить функцию энзима, рассматривая аминокислоты как составляющие его единицы. Но как бы то ни было, это общее явление, возникающее при анализе сложных систем. Чтобы интуитивно понять, как действуют такие системы, и иметь возможность с ними работать, нам приходится жертвовать точностью микроскопической, независимой от контекста картины. Но тем не менее, мы не отказываемся от мысли, что в принципе такая картина возможна.
Перенос РНК и рибосомы
Вернемся к рибосомам, РНК и белкам. Мы сказали, что рибосомы «строят» белок, пользуясь схемой, принесенной из «тронного зала» мессенджером ДНК — РНК. Означает ли это, что рибосома может переводить с языка кодонов на язык аминокислот, то есть что рибосома «знает» Генетический Код? Однако такого количества информации в рибосоме просто нет. Так как же она это делает? Где именно хранится Генетический Код? Интересно то, что он хранится в самой ДНК (где же еще!). Это необходимо пояснить.
Для начала давайте дадим частичное объяснение. В цитоплазме плавают молекулы, имеющие форму четырехлистного клевера; аминокислота свободно присоединена (водородной связью) к одному из листочков. На противоположном листке находится триплет нуклеотидов — так называемый антикодон. Два других листка для нас в данный момент не важны. Эти «клеверные листки» используются рибосомами для производства белков следующим образом. Когда новый кодон мРНК проходит через «проигрывающую головку» рибосомы, рибосома выходит в цитоплазму и присоединяется к клеверу, чей антикодон является дополнением к кодону мРНК. Он поворачивает клевер так, чтобы иметь возможность оторвать от него аминокислоту, которая затем присоединяется ковалентно к растущему белку. (Связь между аминокислотой и ее соседом в белке очень сильна; она называется пептидной связью. Поэтому белки иногда называют также «полипептидами».) Разумеется, что у «клеверных листков» не случайно оказались нужные аминокислоты — ведь они были изготовлены согласно точным инструкциям, поступившим из «тронного зала».
Настоящее название такого «клевера» — трансплантация РНК. Молекула тРНК невелика —- размером с маленький белок. Ее составляет цепь примерно из восьмидесяти нуклеотидов. Как и в случае мРНК, молекулы тРНК строятся путем транскрипции большого клеточного эталона, ДНК. Однако, по сравнению с огромными молекулами мРНК, которые могут быть составлены из тысяч и тысяч нуклеотидов, расположенных цепочками, тРНК — крохотные молекулы. Кроме того, тРНК похожи на белки (и очень отличаются от цепочек мРНК) следующим: их жесткая третичная структура определена их первичной структурой. Третичная структура молекулы тРНК позволяет присоединиться к месту аминокислот только одной кислоте — той, которая продиктована, согласно Генетическому Коду, антикодоном на противоположной стороне. Функцию тРНК можно пояснить на примере следующей забавной аналогии. Представьте себе синхронного переводчика, вокруг которого валяется множество карточек со словами. Из этой кучи он выхватывает — всегда безошибочно! — нужную карточку каждый раз, когда ему надо перевести какое-то слово. В этом случае переводчиком является рибосома, карточками — кодоны, а их переводами — аминокислоты.
Чтобы внутреннее сообщение ДНК было расшифровано рибосомами, «карточки» тРНК должны находиться в цитоплазме. В каком-то смысле можно сказать, что в тРНК содержится суть внешнего сообщения ДНК, поскольку они являются ключом к процессу трансляции. При этом они сами происходят из ДНК. Таким образом, внешнее сообщение пытается стать частью внутреннего сообщения, что-то вроде записки в бутылке, сообщающей, на каком языке она написана. Ясно, что такая попытка никогда не может удасться полностью: ДНК не может поднять саму себя за волосы. Клетка должна заранее «знать» нечто о Генетическом Коде, чтобы позволить создание энзимов, переводящих сами тРНК с эталона ДНА. И это знание находится в созданных ранее молекулах тРНК. Попытка избежать нужды во внешнем сообщении напоминает Эшеровского дракона, который всеми доступными ему средствами своего двухмерного мира старается стать трехмерным. Кажется, что ему это почти удается; но, разумеется, эта превосходная имитация трехмерности — не более, чем иллюзия.
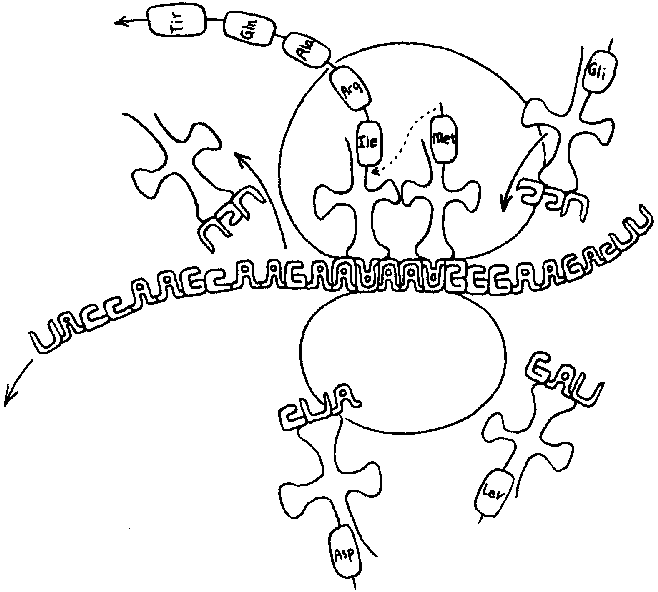
Рис. 96. Часть мРНК, проходящая через рибосому. Рядом плавают молекулы тРНК; они несут аминокислоты, которые будут использованы рибосомой для построения белка. Генетический Код содержится в молекулах тРНК, распространенный по нескольким из них. Обратите внимание, как спаренные основания (A-U, C-G) представлены на диаграмме при помощи соединенных букв. (Рисунок Скотта Е. Кима.)
Пунктуация и рамка считывания
Откуда рибосома знает, когда белок готов? Так же, как в типогенетике, в мРНК есть сигнал, указывающий на окончание или начало конструкции белка. Три специальные кодона — UAA, UAG, UGA — действуют не как коды аминокислот, а как знаки препинания.
Каждый раз, когда один из этих триплетов попадает в «проигрывающую головку» рибосомы, та прекращает строительство данного белка и начинает строить новый белок.
Недавно был выделен целый геном самого крохотного из известных вирусов. В процессе работы было сделано совершенно неожиданное открытие: некоторые из девяти его генов накладываются друг на друга, что означает, что два разных белка закодированы в одной и той же цепочке ДНК! Один из генов даже оказался полностью вставленным в другой! Это достигается сдвиганием рамки считывания двух генов точно на одну единицу по отношению друг к другу. Информационная насыщенность такой структуры поразительна. Это, как читатель, наверное, догадался, и послужило источником для странного «хайку в 6/17», запеченного в Ахилловом печенье с сюрпризом в «Каноне с интервальным увеличением».
Заключение
Таким образом, возникает следующая картина: из своего тронного зала ДНК посылает длинные цепочки мессенджера РНК в цитоплазму к рибосомам. Рибосомы, используя «карточки со словами», плавающие вокруг них, строят белки, добавляя к ним по одной аминокислоте в соответствии с «планом», содержащимся в мРНК. ДНК диктует только первичную структуру белков, но этого достаточно, поскольку, выходя из рибосом, белки, как по волшебству, укладываются в сложные структуры, которые затем действуют как могучие химические машины.
Уровни структуры и значения в белках и в музыке
Как вы помните, мы сравнивали рибосому с магнитофоном, мРНК — с пленкой, а белок — с музыкой. Это может показаться надуманным сравнением, однако на самом деле здесь есть некоторые красивые параллели. Музыка — это не просто линейная последовательность нот. Наш разум воспринимает музыку на гораздо более высоком уровне. Мы воспринимаем последовательности нот как музыкальные фразы, фразы — как мелодии, мелодии — как части произведения, а части — как единое целое. Таким же образом, белки работают только как блочные единицы. Хотя вся информация, необходимая для создания третичной структуры, содержится в первичной структуре, она ощущается чем-то меньшим, поскольку ее потенциал реализуется полностью только тогда, когда третичная структура создана физически.
Мы говорим только о первичной и третичной структуре, и читатель может удивиться, куда же подевалась вторичная структура. Она действительно существует так же как и «четвертичная структура». Укладка белка происходит на нескольких уровнях. В некоторых точках цепочки может возникать что-то вроде спирали, называемой альфа спиралью (не спутайте ее с двойной спиралью ДНК). Этот спиральный изгиб белка происходит на уровне низшем, чем его третичная структура. Этот уровень виден на рис. 95. Четвертичную структуру можно сравнить с построением музыкального произведения из отдельных, независимых частей, поскольку она включает соединение нескольких различных полипептидов, во всей красе их третичной структуры, в единую большую структуру. Эти независимые цепочки обычно соединяются друг с другом с помощью не ковалентных, а водородных связей, что опять сравнимо с частями музыкальных произведений, связи которых между собой гораздо слабее их внутренних связей, но которые, тем не менее, составляют органическое целое.
Четыре уровня структуры белка можно также сравнить с четырьмя уровнями картинки МУ (рис. 60) в «Прелюдии» и «Муравьиной фуге».
Глобальная структура — состоящая из букв «М» и «У» — это четвертичная структура рисунка, каждая из этих частей имеет свою третичную структуру, составленную из слов «ХОЛИЗМ» или «РЕДУКЦИОНИЗМ», на вторичном уровне мы находим антонимы этих слов и наконец на первичном уровне мы опять видим слово «МУ», повторяющееся снова и снова.
Полирибосомы и двухтретичные каноны
Мы подошли к другой интересной параллели между магнитофонами, переводящими пленки в музыку, и рибосомами, переводящими мРНК в белки. Представьте себе несколько магнитофонов, поставленных в ряд на одинаковых расстояниях друг от друга. Назовем это расположение «полимагнитофоном». Теперь представьте, что одна и та же пленка проходит по очереди через проигрывающую головку каждого из магнитофонов. Если на пленке записана одна-единственная длинная мелодия, то результатом, разумеется, будет многоголосный канон, где голоса отстают на то время, которое требуется пленке, чтобы попасть с одного магнитофона на следующий. В клетках действительно существуют такие «молекулярные каноны», где множество рибосом расположены в ряд, образуя так называемые полирибосомы — каждая из них «проигрывает» одну и ту же цепочку мРНК, результатом чего являются одинаковые белки в разной степени готовности (см. рис. 97).
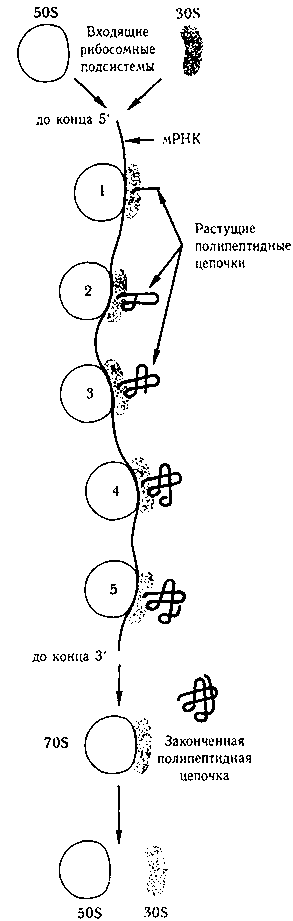
Рис. 97. Полирибосома. Цепочка мРНК проходит через одну рибосому за другой, вроде пленки, проигрывающейся последовательно на нескольких расположенных в ряд магнитофонах. Результатом этого являются несколько белков на разных стадиях готовности; это аналогично музыкальному канону, получающемуся, если включать одну и ту же музыку на нескольких магнитофонах по очереди. (Из книги Ленингера «Биохимия».)
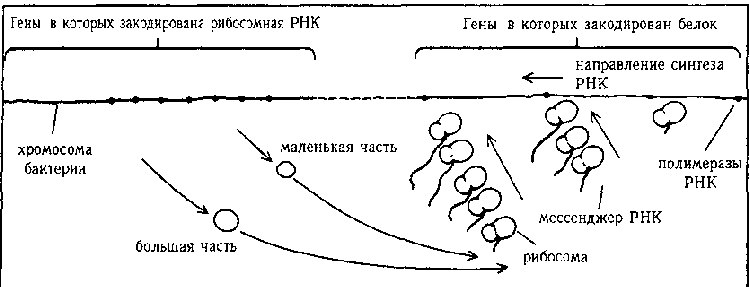
Рис. 98. Вот еще более сложная схема. Полирибосомы действуют не на одну, а на несколько цепочек мРНК, параллельно возникающих путем транскрипции ДНК. Результатом является двухтретичный молекулярный канон (Hanawalt & Haynes, «The Chemical Basis of Life», cтp. 271)
Это еще не все, природа идет дальше. Вспомните, что мРНК получена путем транскрипции ДНК, энзимы, отвечающие за этот процесс, называются полимеразами (суффикс «аза» всегда обозначает энзимы). Несколько полимераз РНК часто работают параллельно над одной и той же цепочкой ДНК, в результате чего получается множество отдельных (но одинаковых) цепочек мРНК, отстающих друг от друга на то время, которое необходимо ДНК, чтобы добраться от одной полимеразы РНК до следующей. В то же время, несколько рибосом могут работать над каждой из параллельно выходящих цепочек мРНК. Таким образом, получается нечто вроде двухпалубного или двухтретичного «молекулярного канона» (Рис. 98.). Соответствующий образ в музыке был бы причудливой и забавной сценой: несколько человек, переводящих одновременно одну и ту же рукопись с ключа, который флейтисты не могут прочесть, в тот, который им доступен. Каждый переводчик, заканчивая страницу, передает ее следующему переводчику, а сам начинает работать над новой страницей. Каждая страница прошедшая таким образом через всех переводчиков, попадает к флейтистам, которые играют написанную там мелодию, при этом все флейтисты играют разные места в нотах. Это довольно странная картина дает некоторое представление о том, какие сложные процессы происходят в каждой клетке вашего тела, каждую секунду каждого дня.
Что было в начале — рибосома или белок?
Мы говорили об этих удивительных созданиях по имени рибосомы, но из чего состоят они сами? Как они сделаны? Рибосомы состоят из двух компонентов (1) разные типы белков и (2) другой тип РНК, называемый рибосомной РНК (рРНК). Таким образом, чтобы построить рибосому, необходимо присутствие определенных белков и рРНК. Однако, чтобы у нас были белки, нужны рибосомы, чтобы их сделать! Так как же разорвать этот порочный круг? Что было в начале — рибосома или белок? Кто из них порождает другого? Разумеется прямого ответа на этот вопрос дать нельзя, так как мы всегда можем отступить во времени к членам того же класса, точно так же как в ситуации с курицей и яйцом, пока все не растает в дымке прошлого. Так или иначе, рибосомы состоят из двух частей, большой и маленькой, каждая из которых содержит набор рРНК и белков. По размеру рибосомы похожи на большие белки; они намного меньше цепочек мРНК, которые они используют как входные данные и вдоль которых продвигаются.
Функция белка
Мы уже говорили кое-что о структуре белка — а именно, об энзимах — но еще не сказали ни какое задание они выполняют в клетке, ни как они это делают. Все энзимы являются катализаторами, это значит, что, в некотором смысле, они всего лишь выборочно ускоряют химические процессы в клетке; они не начинают процессы, которые без них не произошли бы. Энзим идет по нескольким из мириадов возможных химических путей. Таким образом, энзимы определяют, какие процессы произойдут, а какие нет — хотя теоретически возможно, что все эти процессы могут произойти и сами собой, без катализатора.
Как действуют энзимы на молекулы клетки? Как мы уже сказали, энзимы — это свернутые полипептидные цепи. В каждом энзиме имеется определенное место, где он присоединяется к другому типу молекул. Это место называется активным центром, и любая молекула, которая к нему присоединяется, называется субстратом. Энзимы могут иметь несколько активных центров и несколько субстратов. Как и в типогенетике, энзимы довольно привередливы в выборе того, над чем они будут работать. Обычно активный центр позволяет присоединиться к энзиму только определенному типу молекулы, хотя иногда молекулы-«самозванцы», одурачив энзим, прицепляются к активному центру и «засоряют» его, отчего энзим теряет свою способность действовать.
Как только энзим и его субстрат оказываются соединены, равновесие электрических зарядов нарушается; электроны и протоны плавают вокруг сцепленных молекул, пока равновесие не восстановится. К тому времени, как это случается, в субстрате могут произойти значительные химические изменения. Примером таких изменений является «сварка», в результате которой небольшая стандартная молекула присоединяется к нуклеотиду, аминокислоте или другой обычной клеточной молекуле; цепочка ДНК может быть разрушена в определенном месте, какая-то часть молекулы может оказаться «отрезанной» и так далее. На самом деле, био-энзимы производят на молекулах операции, весьма похожие на типографские операции, производимые типо-энзимами. Однако большинство энзимов вместо последовательности заданий выполняют только какое-нибудь одно. Другая значительная разница между типоэнзимами и биоэнзимами заключается в том, что типоэнзимы действуют только на цепочки, в то время как биоэнзимы могут действовать на ДНК, РНК, другие белки, рибосомы, клеточные мембраны — короче, на все, что имеется в клетке. Иными словами, энзимы — это универсальные механизмы клеточных операций. Существуют энзимы соединяющие, энзимы разделяющие, энзимы изменяющие, энзимы активирующие и дезактивирующие, энзимы копирующие, чинящие, разрушающие…
Некоторые из самых сложных процессов в клетке включают каскады, в которых одна-единственная молекула запускает производство определенного типа энзима; этот процесс начинается, и энзимы, сходящие «с конвейера», открывают новую химическую дорогу, ведущую к производству второго типа энзима. Этот процесс может продолжаться на трех или четырех уровнях, каждый новый тип энзима, в свою очередь, запускает в действие процесс создания следующего типа энзима. В конце производится поток копий последнего типа энзима, после чего все копии принимаются за свои дела — отрезать «чужую» ДНК, помочь в строительстве какой-нибудь аминокислоты, в которой нуждается клетка, и так далее.
Нужда в достаточно сильной автономной системе
Постараемся описать то, как природа решила типогенетическую головоломку «Какая цепочка ДНК может заведовать собственным воспроизводством?» Безусловно, не каждая цепочка ДНК является авто-репом. Ключ к загадке — в том, что любая цепочка, желающая заняться самовоспроизводством, должна содержать инструкции для сборки именно тех энзимов, которые смогут выполнить эту задачу. Ожидать, что отдельная цепочка ДНК сможет оказаться авторепом, нереально, поскольку для «вытаскивания» этих потенциальных белков из ДНК необходимы не только рибосомы, но и полимеразы РНК, строящие мРНК, которые затем переносятся к рибосомам. Таким образом, мы должны предположить существование «минимальной системы автономии», достаточно сильной, чтобы обеспечить возможность транскрипции и трансляции. Эта минимальная система будет состоять из (1) нескольких белков, таких, например, как полимераза РНК, позволяющая сделать мРНК на основе ДНК, и (2) нескольких рибосом.
Как самовоспроизводится ДНК
Выражения «достаточно сильная система автономии» и «достаточно мощная формальная система» звучат очень похоже и это сходство далеко не случайно. Одно из этих выражений содержит условие для возможного авторепа, а другое — условие для возможного авто-рефа. На самом деле, мы видим здесь одно и то же явление, только в разных одеждах — вскоре мы объясним это подробнее. Но прежде давайте закончим описание того, как может самовоспроизвестись цепочка ДНК.
ДНК должна содержать код тех белков, которые будут ее воспроизводить. Существует очень эффективный и изящный способ воспроизвести двойную спираль ДНК, состоящую из двух комплементарных цепочек. Это происходит в два шага:
(1) отделить цепочки друг от друга,
(2) присоединить новую цепочку к каждой из получившихся отдельных цепочек.
Этот процесс создает две новые двойные цепочки ДНК, каждая из которых идентична первоначальной. Если мы будем пользоваться этой идеей в нашем решении, нам потребуется набор белков, закодированных в самой ДНК, которые смогут выполнить эти два шага.
Считается, что в клетке эти шаги осуществляются одновременно, это происходит координированно и требует присутствия трех основных энзимов эндонуклеазы ДНК, полимеразы ДНК и лигазы ДНК. Первый — «открывающий энзим», разделяющий цепочки, словно две части застежки «молнии». Потом вступают в действие два остальных энзима. Полимераза ДНК — это энзим копирования и передвижения; он медленно передвигается вдоль коротких цепочек ДНК, воспроизводя их дополнения методом, похожим на типогенетический. Для этого он пользуется материалом-сырцом — а именно, нуклеотидами, плавающими вокруг в цитоплазме. Поскольку это действие происходит «скачкообразно» (каждый скачок — это сначала растаскивание цепочек и затем их воспроизводство), возникают короткие «паузы», заполняемые при помощи лигазы ДНК. Этот процесс повторяется снова и снова. Этот отлаженный трехэнзимный аппарат передвигается аккуратно по всей длине молекулы ДНК, пока ее цепочки не окажутся полностью разделенными и скопированными. В результате получаются две копии первоначальной ДНК.
Сравнение метода самовоспроизводства ДНК с квайнированием
Обратите внимание, что для энзимного воздействия на цепочку ДНК совершенно неважно, что информация для этого процесса хранится в самой ДНК; энзимы просто выполняют свои задачи по передвижению символов, точно так же, как правила вывода в системе MIU. Им совершенно все равно то, что в какой-то момент они копируют те самые гены, в которых закодированы они сами. ДНК является для них эталоном, лишенным собственного значения и интереса.
Это можно сравнить с тем, как Квайново высказывание дает инструкции по самовоспроизводству. Там у нас тоже было что-то вроде «двойной цепочки» — две копии одной и той же информации, одна из которых действовала как команда, а другая — как эталон. Процесс в ДНК отдаленно напоминает эту ситуацию, поскольку три энзима (эндонуклеаза ДНК, полимераза ДНК и лигаза ДНК) закодированы только в одной из цепочек, которая, таким образом, действует как программа, в то время как другая цепочка — всего лишь эталон. Это сравнение приблизительно, поскольку в процессе копирования обе цепочки используются как эталоны. Все же эта аналогия очень интересна. Существует биохимическая аналогия дихотомии «использование — упоминание»: когда ДНК используется как последовательность символов для копирования, она похожа на упоминание о типографских символах; когда ДНК диктует, какие команды должны быть выполнены, она похожа на использование типографских символов.
Уровни значения в ДНК
Цепочка ДНК имеет несколько уровней значения; это зависит от того, насколько велик кусок цепочки, который вы рассматриваете, и насколько мощен ваш «аппарат для расшифровки». На низшем уровне каждая цепочка ДНК содержит код эквивалентной цепочки РНК, и необходимой расшифровкой является транскрипция. Разделив ДНК на триплеты и пользуясь «генетической расшифровкой», можно прочитать ДНК как последовательность аминокислот. Это — трансляция (уровнем выше, чем транскрипция). На следующем уровне иерархии ДНК читается как набор белков. Физическое извлечение белков из генов называется «экспрессией генов». В настоящий момент это является наиболее высоким из доступных нам уровней значения ДНК.
Однако в ДНК безусловно имеются и более высокие уровни значения, которые различить труднее. Например, у нас есть все основания полагать, что в ДНК человеческого существа закодированы такие его характеристики, как форма носа, музыкальные способности, быстрота рефлексов и так далее. Возможно ли, в принципе, научиться считывать такую информацию прямо с цепочек ДНК, минуя физический процесс эпигенезиса — извлечения фенотипа из генотипа? Теоретически такое возможно, так как можно вообразить мощнейшую компьютерную программу, симулирующую весь процесс, вплоть до отдельных клеток, отдельных белков, каждой мельчайшей детали, участвующей в воспроизводстве ДНК, клеток… и так далее, до конца лестницы. Результатом работы такой программы псевдо-эпигенезиса было бы описание фенотипа на высшем уровне.
Существует еще одна (очень маловероятная) возможность может быть, нам удастся научиться читать фенотип с генотипа, минуя изоморфную симуляцию физического процесса эпигенезиса и пользуясь вместо этого более простым расшифровывающим механизмом. Это можно назвать «сокращенным псевдо-эпигенезисом». К сожалению, сокращенный или нет, псевдо-эпигенезис пока нам недоступен — за одним замечательным исключением. Тщательный анализ вида Felis Catus показал, что на самом деле возможно прочитать фенотип прямо с генотипа. Читатель, может быть, лучше поймет этот замечательный факт, рассмотрев следующий типичный кусок ДНК Felis Catus:
… САТСАТСАТСАТСАТСАТСАТСАТСАТСАТ …
Ниже показаны уровни считываемое ДНК вместе с названиями разных уровней расшифровки. ДНК может быть прочитана как последовательность:
(1) оснований (нуклеотидов) .... транскрипция
(2) аминокислот .... трансляция
(3) белков (первичная структура) .... генное выражение
(4) белков (третичная структура) .... генное выражение
(5) скоплений белков .... более высокий уровень генного выражения
(6) ???
.
. .... неизвестные уровни, значения ДНК
(N-1) ???
(N) физические, умственные и психологические черты .... псевдо-эпигенез
Центральная Догма
После этой подготовки мы можем приступить к рассмотрению детального сравнения между «Центральной Догмой Молекулярной Биологии» Ф. Крика (ДОГМА I) и «Центральной Догмой Математической Логики» (ДОГМА II), на которой основана Теорема Гёделя. Отображение с одной Догмы на другую показано на рис. 99 и на следующей схеме, вместе они составляют Централизированную Догму.
Обратите внимание, что А и Т (арифметизация и трансляция) образуют пары, также как G и С (Godel и Crick) Математической логике достается сторона пуринов, а молекулярной биологии — пиримидинов.
ДОГМА I ДОГМА II
(Молекулярная биология) (Математическая логика)
цепочки ДНК <==> строчки ТТЧ
цепочки мРНК <==> утверждения Ч
белки <==> утверждения мета-ТТЧ
белки, воздействующие на белки <==> утверждения об утверждениях мета-ТТЧ
белки, воздействующие на белки, воздействующие на белки <==> утверждения об утверждениях об утверждениях мета-ТТЧ
транскрипция (ДНК=>РНК) <==> интерпретация (ТТЧ => Ч)
трансляция (РНК=>белки) <==> арифмоквайнирование
Крик <==> Гёдель
Генетический Код (произвольное соглашение) <==> Гёделев Код (произвольное соглашение)
кодон (триплет оснований) <==> кодон (триплет чисел)
аминокислота <==> символ ТТЧ, процитированный в мета-ТТЧ
авторепродукция <==> автореференция
клеточная система автономии, достаточно мощная, чтобы позволить авторепродукцию <==> арифметическая формальная система, достаточно мощная, чтобы позволить автореференцию
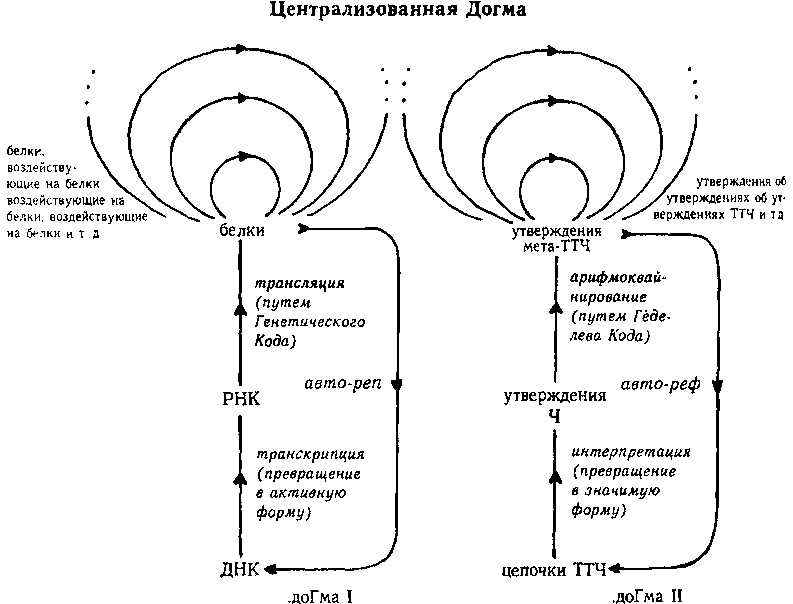
Рис. 99. Централизованная Догма. Здесь проводится аналогия между двумя важнейшими Спутанными Иерархиями, одна из которых лежит в области молекулярной биологии, а другая в области математической логики.
Для полноты картины я решил отобразить мою схему Геделевой нумерации на Генетический Код как можно точнее:
(нечетное) 1 <==> А (пурин)
(четное) 2 <==> С (пиримидин)
(нечетное) 3 <==> G (пурин)
(четное) 6 <==> U (пиримидин)
Каждая из двадцати аминокислот в точности соответствует одному из двадцати символов ТТЧ. Таким образом, наконец становится ясно, что я имел в виду, выдумывая строгий вариант ТТЧ — я хотел чтобы в нем было в точности двадцать символов! Геделев Код показан на рис. 100, сравните его с Генетическим Кодом. (рис. 94)
Есть нечто почти мистическое в глубоком структурном сходстве между двумя эзотерическими и тем не менее фундаментальными открытиями в таких разных областях знания.
Централизованная Догма, разумеется, ни в коем случае не является строгим доказательством идентичности этих двух теорий, но она ясно указывает на глубокое родство между ними, родство заслуживающее более глубокого исследования.
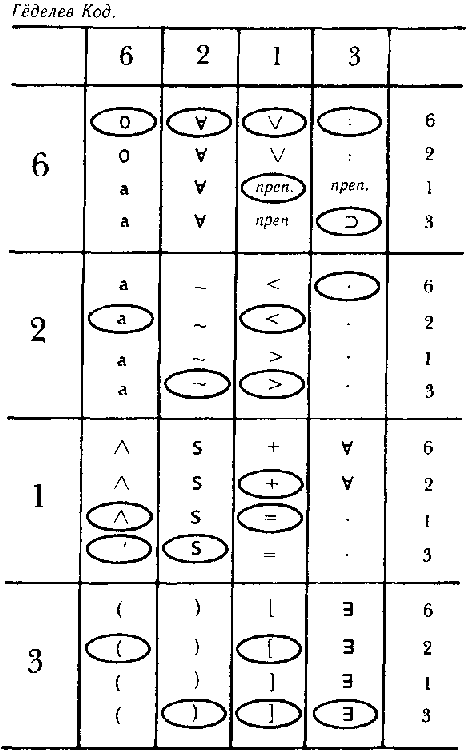
Рис. 100. Гёделев Код. Согласно этой схеме Гёделевой нумерации, каждый символ ТТЧ получает один или более кодонов. Маленькие овалы показывают, как эта таблица включает Геделеву нумерацию, приведенную ранее в главе IX.
Странные Петли в Централизованной Догме
Одним из наиболее интересных моментов сходства между двумя сторонами нашей схемы является то, что на высшем уровне обеих возникают петли произвольной степени сложности. Слева это белки действующие на белки, действующие на белки — и так далее до бесконечности. Справа это высказывания о высказываниях, о высказываниях Мета ТТЧ — и так далее до бесконечности. Это напоминает гетерархии, которые мы обсуждали в главе V, где достаточно сложный фундамент позволяет возникать Странным Петлям высшего уровня полностью изолированным от нижних уровней. Мы рассмотрим эту идею более подробно в главе XX.
Читатель может спросить: «Чему же на схеме Централизованной Догмы соответствует сама Теорема Геделя о неполноте?» Подумайте над этим прежде чем читать дальше!
Централизованная Догма и «Акростиконтрапунктус»
Оказывается, что схема Централизованной Догмы весьма схожа со схемой, приведенной в главе IV, где дано отображение Теоремы Геделя на понятия Акростиконтрапунктуса. Таким образом, мы можем провести параллели между тремя системами:
(1) формальные системы и строчки
(2) клетки и цепочки ДНК
(3) патефоны и пластинки
Следующая схема показывает подробное сравнение между системами 2 и 3.
«Акростиконтрапунктус» Молекулярная биология
патефон <==> клетка
«Совершенный» патефон <==> «Совершенная» клетка
пластинка, воспроизводимая на данном патефоне <==> цепочка ДНК, воспроизводимая данной клеткой
пластинка, невоспроизводимая на этом патефоне <==> цепочка ДНК, невоспроизводимая этой клеткой
процесс превращения звуковых дорожек в звуки <==> процесс транскрипции ДНК в мРНК
звуки, производимые патефоном <==> цепочки мессенджера РНК
перевод звуков в вибрации патефона <==> перевод мРНК в белки
отражение внешних звуков в вибрациях патефона <==> Генетический Код (отображение с триплетов мРНК на аминокислоты)
поломка патефона <==> разрушение клетки
Название песни, специально записанной для Патефона X: «Меня нельзя воспроизвести на патефоне X» <==> интерпретация на высшем уровне цепочки ДНК, специально изготовленной для клетки X: «Меня нельзя воспроизвести клеткой X».
«Несовершенный» патефон <==> клетка, для которой существует хотя бы одна невоспроизводимая в ней цепочка ДНК.
«Теорема Гоголя»: «для любого данного патефона всегда существует невоспроизводимая запись» <==> Теорема Иммунитета: «Для любой данной клетки существует невоспроизводимая цепочка ДНК»
Аналогом Теоремы Гёделя является отдельный факт, возможно, малополезный для молекулярных биологов (для которых он самоочевиден):
Всегда возможно построить такую цепочку ДНК, которая, будучи введена в клетку, произведет, после транскрипции, такие белки, которые разрушат клетку (или ДНК); результатом этого будет не-воспроизводство данной ДНК.
Если рассмотреть это в свете эволюции, то можно представить себе следующий странный образ: вид вирусов, незаметно вторгающихся в клетку и затем обеспечивающих производство белков, которые разрушат сами эти вирусы!
Это нечто вроде самоубийства на молекулярном уровне, так сказать, в духе Эпименида. Разумеется, с точки зрения выживания вида это совсем не полезно. Однако, это передает если не букву, то дух процесса самозащиты, который развили как клетки, так и их непрошенные гости.
Кишечная палочка против Т4
Давайте рассмотрим любимицу биологов, клетку бактерии Escherichia coli (не являющуюся родственницей Эшера!) и одного из ее непрошенных гостей странного и жуткого Т4 фага (рис. 101) (Кстати, слова «фаг» и «вирус» — синонимы и означают «атакующий бактериальную клетку») Это странное создание напоминает гибрид лунохода и комара — но оно гораздо страшнее последнего. У него есть «голова», в которой хранятся все его «знания» — то есть, его ДНК — шесть «ног», которыми он прикрепляется к стенке клетки, которую он выбрал для вторжения, «жало» (более точно называющееся его «хвостом») — чем не комар! Основная разница заключается в том, что, в отличие от комара который использует жало для высасывания крови, фаг Т4 вводит через него свою наследственную субстанцию в клетку, против желания жертвы. Таким образом, фаг совершает изнасилование в миниатюрном размере.
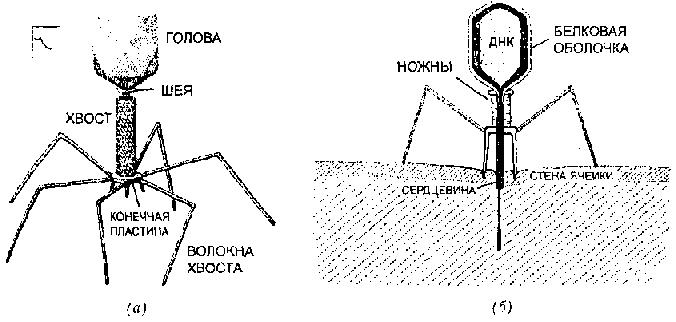
Рис. 101. Бактериальный вирус Т4 представляет из себя набор белковых компонентов. (а) «Голова» — это белковая мембрана в форме икосаэдра с тридцатью сторонами; внутри находится ДНК. «Шея» прикрепляет ее к «хвосту», состоящему из сжимающейся оболочки, полой внутри, и опирающейся на пластинку с шипами. К пластинке прикреплены шесть волокон. Эти шипы и волокна служат вирусу для того, чтобы прикрепляться к стенке клетки бактерии. (б) Оболочка сжимается, протаскивая «хвост» сквозь стенку, и вирус попадает в клетку. (Hanawault & Haynes. «The Chemical Basis of Life», стр. 230).
Молекулярный Троянский конь
Что же происходит когда ДНК вируса входит в клетку? Вирус «надеется», говоря антропоморфно, что клетка будет обращаться с его ДНК точно так же, как и со своей собственной. Это означает, что она будет транскрибирована и переведена и, таким образом сможет начать синтез своих собственных белков, чуждых клетке-хозяину — белков, которые тут же займутся своим делом. Это не что иное, как секретная переброска «закодированных» (на Генетическом Коде) вражеских белков в клетку, и затем их «расшифровка» (производство). Это немного напоминает историю Троянского коня, согласно которой сотни солдат тайком проникли в Трою, спрятанные в животе невинно выглядящего деревянного коня. Оказавшись в городе, они выскочили наружу и захватили Трою.
Чужие белки, оказавшись «расшифрованными» (синтезированными) из переносящей их ДНК, начинают действовать. Последовательность событий, вызванных действием Т4, была хорошо изучена; эти события развиваются примерно так (см. также рис. 102 и рис. 103):
Время Происходящее действие
0 мин. Введение виральной ДНК.
1 мин. Порча хозяйской ДНК. Прекращение производства клеточных белков и начало производства чужих (Т4) белков. Одними из первых производятся белки, управляющие воспроизводством чужой (Т4) ДНК.
5 мин. Начинается производство ДНК вируса.
8 мин. Начало производства структурных белков, которые сформируют «тела» новых фагов.
13 мин. Произведена первая полная копия агрессора (Т4).
25 мин. Лизосома (тип белка) атакует стенку клетки-хозяина, бактерия лопается, освобождая «двухсотняшек».
Таким образом, через каких-нибудь двадцать четыре или двадцать пять минут после того, как фаг Т4 вторгается в клетку Е. coli, эта клетка оказывается полностью подчиненной и разрушается. Оттуда вырываются около двух сотен точных копий вируса-агрессора — «двухсотняшки» — готовые атаковать новые клетки и разрушать их так же, как и первую.
Хотя с точки зрения бактерии подобные вещи представляют собой серьезную опасность, мы, с нашей точки зрения, можем интерпретировать это как игру между двумя игроками: агрессор, или игрок «Т» (названный по имени класса фагов Т, куда входят Т2. Т4 и другие), и игрок «К» (клетка). Игрок Т старается проникнуть в клетку и овладеть ею изнутри с целью самовоспроизводства. Игрок К старается защитить себя и уничтожить агрессора. Описанная таким образом, молекулярная игра Т-К напоминает макроскопическую игру Т-К, описанную в предыдущем Диалоге. (Читатель, разумеется, без труда поймет, какой игрок — Т или К — соответствует Черепахе Тортилле, а какой — Крабу.)
Рис. 102. Вирусная инфекция начинается, когда ДНК вируса попадает в бактерию ДНК, бактерии при этом портится, зато ДНК вируса начинает размножаться. Синтез составляющих вирус белков и поглощение их вирусом происходит до тех пор, пока клетка не лопается, освобождая частицы (Hanawault & Haynes «The Chemical Basis of Life», cтp. 230)
Рис. 103. В морфогенетическом пути вируса Т4 есть три основных ветви, ведущие к независимому образованию голов, хвостов и волокон хвоста, которые затем соединяются и формируют полные копии вируса (Hanawault & Hayness «The Chemical Basis of Life», cтp. 237)
Узнавание, маскировка и наклеивание ярлыков
Эта «игра» делает очевидным тот факт, что узнавание — одна из центральных тем клеточной и субклеточной биологии. Каким образом молекулы (или структуры высшего уровня) узнают друг друга? Чтобы энзимы работали хорошо, они должны быть способны присоединяться к определенным местам соответствующих субстратов; бактерия должна уметь отличать собственную ДНК от ДНК фагов; клетки должны узнавать друг друга и взаимодействовать определенным образом. Эта проблема узнавания может напомнить вам об основном вопросе формальных систем: как можно узнать, является ли данная строчка теоремой? Есть ли для этого разрешающая процедура? Подобные вопросы принадлежат не только области математической логики; они важны также в теории вычислительной техники и, как мы видели, в молекулярной биологии.
Техника ярлыков, описанная в Диалоге, является, на самом деле, одним из трюков, используемых Е. coli, чтобы перехитрить агрессоров-фагов. Идея заключается в том, что цепочка ДНК может быть химически отмечена путем присоединения к нескольким нуклеотидам маленькой молекулы — метила. Эта операция «наклейки ярлыка» не меняет основных биологических свойств ДНК, другими словами, метилированная (отмеченная ярлыком) ДНК может быть транскрибирована точно так же, как и неметилированная (не отмеченная ярлыком) кислота, таким образом, она может управлять синтезом тех же белков. Однако, если клетка-хозяйка обладает специальным механизмом, проверяющим, отмечена ли ДНК, то ярлык становится крайне важен. В частности, клетка может располагать системой энзимов, распознающих и уничтожающих неотмеченные цепочки ДНК. Найдя такую цепочку, эти энзимы безжалостно рубят ее на куски. В таком случае, увы всем непрошенным гостям!
Метиловые ярлыки на нуклеотидах можно сравнить со специальным типографским шрифтом. Используя эту метафору, можно сказать, что клетка E coli ищет цепочки ДНК, напечатанные этим «специальным шрифтом» и разрушает любую цепочку ДНК напечатанную иным «шрифтом». Контрстратегией фагов, разумеется, было бы научиться снабжать свою ДНК такими же ярлыками и, таким образом, заставить клетки в которые они вторгаются, воспроизвести эту ДНК.
Эта битва Т-К может продолжаться до произвольных уровней сложности, но мы не будем рассматривать ее дальше. Главное здесь в том, что это битва между хозяином, пытающимся не впустить ни одной чужой ДНК, и фагом, который старается ввести свою ДНК в какую-нибудь клетку, которая транскрибировала бы ее в мРНК (после чего ее воспроизводство было бы гарантировано). Можно сказать, что ДНК, которой удается таким образом воспроизвести себя, интерпретируется на высшем уровне так: «Меня можно воспроизвести в клетках типа X» (В отличие от упомянутого ранее бесполезного с точки зрения эволюции фага, в котором закодированы белки, его же разрушающие, подобный фаг интерпретируется «Меня нельзя воспроизвести в клетках типа X»
Суждения Хенкина и вирусы
Эти противоположные типы автореференции в молекулярной биологии имеют свою параллель в математической логике. Мы уже обсуждали математическую аналогию фагов-самоубийц — я имею в виду строчки Геделева типа, утверждающие собственную невозможность внутри определенных формальных систем. Однако, возможна и параллель с настоящим фагом, утверждающим собственную воспроизводимость в определенной клетке — суждение, утверждающее собственную воспроизводимость в определенной формальной системе. Суждения подобного типа называются суждениями Хенкина, по имени математического логика Леона Хенкина. Они строятся примерно так же, как Геделевы суждения — единственная разница заключается в отсутствии отрицания Мы начинаем, разумеется, с «дяди»:
Eа:Eа' <ПАРА-ДОКАЗАТЕЛЬСТВА-ТТЧ{а,а'}Λ ARITHMOQUINE{а'',а'}
и затем проделываем стандартный трюк. Предположим, что Геделев номер приведенного выше «дяди» — h. Арифмоквайнируя дядю, мы получаем суждение Хенкина:
Eа:Eа' <ПАРА-ДОКАЗАТЕЛЬСТВА-ТТЧ{а,а'}Λ
ARITHMOQUINE{SSS…SSS/a'',a'}>
. |____|
S повторяется h раз
(Кстати, видите ли вы, в чем это суждение отличается от —G?) Я привожу его целиком, чтобы показать, что оно не дает «рецепта» собственной деривации; оно просто утверждает, что такая деривация существует. Вы можете спросить, верно ли это утверждение? Существуют ли деривации суждений Хенкина? Действительно ли эти суждения являются теоремами? Полезно вспомнить, что не обязательно верить политику, провозглашающему: «Я честный», — это может оказаться как правдой, так и враньем. Достойны ли суждения Хенкина большего доверия, чем политики?
Оказывается, что суждения Хенкина всегда истинны. Хотя пока нам не совсем понятно, почему это так, придется нам здесь принять этот интересный факт на веру.
Явные и неявные суждения Хенкина
Я упомянул о том, что суждения Хенкина ничего не говорят о собственной деривации; они лишь утверждают, что такая деривация существует. Возможно придумать вариацию на тему суждений Хенкина — а именно, суждения, явно описывающие собственную деривацию. Интерпретацией на высшем уровне подобного суждения было бы не «существует некая последовательность строчек, являющаяся моей деривацией», а «описанная ниже последовательность строчек … является моей деривацией». Давайте назовем первый тип суждений неявным суждением Хенкина. Новое суждение, соответственно, будет явным суждением Хенкина, поскольку в нем содержится явное описание собственной деривации. Заметьте, что в отличие от своих неявных собратьев, явные суждения Хенкина не обязательно должны являться теоремами. На самом деле, очень легко написать строчку, которая утверждает, что ее деривация состоит из единственной строчки 0=0, — ложное утверждение, поскольку 0=0 не является деривацией чего бы то ни было. Однако возможно также написать явное суждение Хенкина, являющееся теоремой, — то есть суждение, в действительности дающее рецепт собственной деривации.
Суждение Хенкина и самосборка
Я объяснил здесь разницу между явными и неявными суждениями Хенкина потому, что она соответствует важному различию между типами вирусов. Существует некие вирусы, например, такие, как вирусы табачной мозаики, которые называются самособирающимися, и такие вирусы, как наши знакомцы Т-фаги, не являющиеся самособирающимися. Что означает это различие? Оно аналогично различию между явными и неявными суждениями Хенкина.
В ДНК самособирающегося вируса закодированы только части нового вируса, но там нет кода энзимов. Как только эти части оказываются собраны, они присоединяются одна к другой без помощи энзимов. Этот процесс зависит от химического «влечения» частей друг к другу, когда они плавают в густом «химическом бульоне» клетки. Не только вирусы, но также некоторые органеллы — например, рибосомы — способны на самосборку. Иногда для этого бывают нужны энзимы — но в таких случаях они беззастенчиво набираются из клетки-хозяйки и используются для сборки «агрессора». Говоря о самосборке, я имею в виду весь этот процесс.
С другой стороны, в ДНК более сложных вирусов, таких как четные Т- фаги, закодированы не только части, но и различные энзимы, играющие важную роль в сборке этих частей в одно целое. Поскольку процесс сборки здесь не спонтанный, а требующий определенной «техники», подобные вирусы не считаются самособирающимися. Таким образом, основная разница между самособирающимися и не-самособирающимися единицами заключается в том, что первым удается воспроизвестись не сообщая клетке никаких сведений о собственной сборке, в то время как последние должны давать инструкции о том, как их собирать.
Теперь читателю, вероятно, уже ясна параллель с явными и неявными суждениями Хенкина. Неявные суждения Хенкина самодоказательны, но ничего об этих доказательствах не говорят — они аналогичны самособирающимся вирусам. Явные суждения Хенкина управляют построением своего собственного доказательства — они аналогичны более сложным вирусам, дающим клетке-хозяйке команды по построению собственных копий.
Понятие самособирающихся биологических структур такой сложности как вирусы, поднимает вопрос о возможности создания сложных самособирающихся машин. Представьте себе набор частей, которые, если поместить их в благоприятное окружение, спонтанно группируются и собираются в сложную машину. Это звучит неправдоподобно, но, на самом деле, это весьма аккуратное описание процесса самовоспроизводства вируса табачной мозаики путем самосборки. Информация для сборки организма не сконцентрирована в какой-то одной его части, а распространена по всем частям.
Это идея может завести нас довольно далеко, как было показано в Диалоге «Благочестивые размышления курильщика». Мы видели, как Краб использовал идею о том что информация для самосборки может быть распространена по всем частям аппарата, вместо того, чтобы быть сконцентрированной в какой-то одной его части. Он надеялся, что это предохранит его новый патефон от Черепашьих атак. К несчастью, так же, как и в случае самых сложных схем аксиом, как только система построена и «упакована в ящик», эта определенность делает ее уязвимой для достаточно хитрого «Геделизатора»— это и было темой грустного рассказа Краба. Несмотря на кажущуюся бессмысленность, фантастический сценарий этого Диалога не так далек от реальности в странном, сюрреалистическом мире клетки.
Две выдающиеся проблемы: Дифференциация и Морфогенезис
Допустим что посредством самосборки строятся организмы на уровне клеток и некоторых вирусов — но как насчет сложнейших макроскопических структур таких, как тела слона, паука или венериной мухоловки? Как встроены в мозг птицы инстинкт нахождения дома или в мозг собаки — охотничий инстинкт? Каким образом, всего лишь диктуя, какие белки должны производиться в клетке, ДНК осуществляет такой удивительно точный контроль над структурой и функциями макроскопических живых организмов? Здесь возникают две вопроса. Один касается клеточных различий каким образом разные клетки, имеющие абсолютно одинаковую ДНК, выполняют различные роли — скажем клеток почек костного мозга или головного мозга? Другой вопрос касается морфогенезиса («рождения формы») каким образом межклеточное сообщение на местном уровне ответственно за образование крупномасштабных, глобальных структур — таких как части тела, форма лица, разные области мозга? Хотя в настоящий момент наше понимание клеточных различий и морфогенезиса ограниченно, мы предполагаем, что этот метод заключается в весьма тонком и точно отлаженном механизме прямой и обратной связи между клетками, говорящем им, когда они должны «включать» и «выключать» производство различных белков.
Прямая и обратная связи
Обратная связь происходит, когда в клетке наблюдается избыток или недостаток некоего необходимого материала. Тогда клетка должна каким-то образом отрегулировать «конвейер», на котором происходит сборка данной субстанции. Прямая связь также касается регулировки «конвейера», но при этом регулируется не количество конечного продукта, а количество его предшественника на конвейере. Существуют два основных механизма для достижения негативной прямой и обратной связи. Один способ заключается в том, чтобы «засорить» активные центры соответствующих энзимов, таким образом предотвращая их действие. Это называется торможением. Другой способ — прекращение самого производства соответствующих энзимов. Это называется подавлением. Торможение осуществить несложно: для этого надо лишь заблокировать активный центр первого энзима цепи и весь процесс синтеза замирает.
Белки-репрессоры и индукторы
Подавление — более сложный процесс. Каким образом клетка может остановить производство гена? Ответ заключается в том, что клетка предотвращает, в первую очередь, его транскрипцию. Это означает, что она должна остановить работу полимеразы РНК. Это может быть сделано путем возведения преграды на ее пути вдоль ДНК, именно перед тем геном, транскрипцию которого клетка хочет предотвратить. Такие препятствия существуют и называются репрессорами. Это белки, прикрепляющиеся к специальным местам «для препятствий» на ДНК, называющимся операторами. Таким образом, оператор — это контрольное место для гена (или генов), которые следуют сразу за ним; эти гены называются его оперонами. Поскольку несколько энзимов часто работают над длинными химическими превращениями вместе, они бывают закодированы последовательно; поэтому опероны часто содержат не один, а несколько генов. Результатом такого последовательного подавления оперона является то, что целой серии генов не удается протранскрибироваться — а это, в свою очередь, означает, что целый набор соответствующих энзимов не будет синтезирован.
Как насчет положительных прямой и обратной связей? Здесь снова имеются две возможности: (1) «прочистить» заблокированные энзимы или (2) прекратить подавление соответствующего оперона. (Заметьте, насколько природа любит двойное отрицание! Для этого, возможно, существует какая-то серьезная причина.) Механизм, подавляющий подавление, действует при помощи класса молекул, называемых индукторами. Роль индуктора проста: он соединяется с белком репрессора прежде, чем тот успевает присоединиться к оператору молекулы ДНК. Получающийся комплекс «индуктор-репрессор» не способен присоединиться к оператору, и, таким образом, соответствующий оперон может быть транскрибирован в мРНК и затем переведен в белок. Часто индуктором является конечный продукт или его предшественник.
Сравнение между обратной связью и Странными Петлями
Необходимо проводить различие между простыми типами обратной связи, возникающими в процессе торможения и подавления, и петлями, возникающими между различными уровнями информации, показанными на схеме Централизованной Догмы. Оба эти явления, в каком-то смысле, являются примерами обратной связи, но последнее намного глубже первого. Когда некая аминокислота, скажем, триптофан или изолеицин, действует как обратная связь (в форме индуктора) и присоединяется к своему репрессору, чтобы воспроизвестись в большем количестве, она не объясняет, как именно ее производить, а лишь приказывает энзимам увеличить ее производство. Это можно сравнить со звуками радио, которые, достигнув уха слушателя, могут вызвать у того желание увеличить или уменьшить громкость. Совсем другое дело — ситуация, в которой сам диктор велит слушателям изменить громкость, или настроиться на другую волну — или даже объясняет, как построить другое радио! Такая ситуация гораздо более похожа на коммуникацию между информационными уровнями, поскольку здесь информация, заключенная в радиосигнале, «расшифровывается» и переводится в мысленные структуры. Радиосигнал состоит из компонентов, чье символическое значение важно — это похоже более на пример использования, чем упоминания. С другой стороны, когда сигнал слишком громок, символы теряют свое значение и воспринимаются просто как громкие звуки — пример упоминания, скорее чем использования. Этот случай более походит на петли обратной связи, при помощи которых белки регулируют собственное воспроизводство.
Существует предположение, что разница между двумя соседними клетками имеющими совершенно одинаковый генотип, но разные функции, заключается в том, что, благодаря подавлению различных сегментов их геномов, у них оказываются различные наборы активных белков. Эта гипотеза объясняет феноменальные различия между клетками в разных органах человеческого тела.
Два простых примера различия
Процесс, при помощи которого одна первоначальная клетка воспроизводится снова и снова, порождая множество различных клеток со специальными функциями, можно сравнить с распространением некоего письма по цепочке, где каждый человек должен скопировать первоначальное послание, при этом добавив к нему нечто свое. Через некоторое время письма будут очень отличаться друг от друга.
Еще одним примером идеи дифференциации является простая компьютерная аналогия различающего авто-репа. Представьте себе коротенькую программу контролирующуюся при помощи переключателя с двумя позициями, А и В. Внутренний параметр программы — натуральное число N. Программа может работать в двух режимах А или В. Когда она работает в режиме А, она самовоспроизводится в соседнем районе компьютерной памяти — но при этом новый, «дочерний» параметр N возрастает на единицу. Работая в режиме В, программа не самовоспроизводится — вместо этого она вычисляет величину выражения:
(-1)/(2N+1)
и добавляет результат к накопленной общей сумме.
Предположим, что в начале в памяти имелась одна копия программы, N = 0, и программа находилась в режиме А. Результатом явится копия программы в соседнем районе памяти, N будет равняться 1. Повторив процесс, мы получим новую копию в соседнем районе памяти, с N = 2. И так далее, и тому подобное… Память при этом загружается большой программой. Когда память заполняется, процесс останавливается. Теперь мы можем считать, что память занята одной большой программой, составленной из множества похожих, но дифференцированных модулей — «клеток».
Теперь представьте, что мы переключаем эту большую программу на режим В. Что при этом получается? Первая «клетка» дает 1/2. Вторая «клетка» дает -1/3 и добавляет это к предыдущему результату. Третья «клетка» добавляет к общей сумме +1/5 …
В результате весь «организм» — большая программа — вычисляет сумму ряда:
1 -1/3 +1/5 -1/7 +1/9 -1/11 +1/13 -1/15 +…
Число членов этого ряда равно количеству «клеток», умещающихся в памяти. И поскольку этот ряд сходится (хотя и медленно), стремясь к π/4, его можно назвать «фенотипом», чья функция — вычисление величины знаменитой математической постоянной.
Смешение уровней в клетке
Я надеюсь что описание таких процессов как «наклеивание ярлыков», самосборка, дифференциация, морфогенез, а также транскрипция и трансляция, помогли читателю глубже понять необычайно сложную систему клетки — систему обработки информации, обладающую некоторыми удивительными чертами. На схеме Централизованной Догмы мы видели, что хотя мы и можем попытаться провести четкую границу между программой и данными, это различие в каком-то смысле произвольно. Более того, переплетены между собой не только программа и данные — в этом переплетении участвуют также интерпретатор, физический процессор и даже язык программы. Таким образом, хотя в какой-то степени и возможно провести границы между уровнями и разделить их, важно также иметь в виду перекрещивание и смешение уровней. Примером этого является тот удивительный факт, что в биологических системах все подсистемы, необходимые для самовоспроизводства (язык, программа, данные, интерпретатор и процессор) так тесно сотрудничают, что все они воспроизводятся одновременно! Это показывает, насколько биологический авто-реп глубже всего, что пока удалось создать в этой области людям. Например, программа авто-репа, изложенная в начале этой главы, опирается на существование трех внешних факторов: язык, интерпретатор и процессор; ни один из этих факторов программой не воспроизводится.
Постараемся подвести итоги сказанному и посмотрим, как можно классифицировать различные подсистемы клетки в компьютерных терминах. Для начала возьмем ДНК. Поскольку в ней содержится вся информация для построения белков — активных действующих лиц клетки — ДНК можно сравнить с программой, написанной на языке высшего уровня, которая затем переводится (или интерпретируется) на «машинный язык» клетки (белки). С другой стороны, сама ДНК — пассивная молекула, которая претерпевает различные изменения под действием энзимов. В этом смысле ДНК напоминает набор вводных данных. Кроме того, ДНК содержит «эталоны», по которым строятся «карточки» тРНК, — это означает, что в ДНК есть также свой собственный язык высшего уровня.
Теперь перейдем к белкам. Это активные молекулы, отвечающие за функционирование клетки; следовательно, мы можем думать о них, как о программах на «машинном языке» клетки (сама клетка соответствует в нашей аналогии процессору). С другой стороны, поскольку белки относятся к аппаратуре, а большинство программ — к программному обеспечению, может быть, точнее было бы назвать белки процессорами. Кроме того, белки часто воздействуют друг на друга, что уподобляет их вводным данным. Белки можно также назвать интерпретаторами, если считать ДНК набором программ на языке высшего уровня; в этом случае, энзимы просто выполняли бы программы, написанные на коде ДНК — иными словами, белки работали бы как интерпретаторы.
Далее перейдем к рибосомам и молекулам тРНК. Они способствуют переводу из ДНК в белки, что можно сравнить с переводом программы, написанной на языке высшего уровня, на машинный язык. Таким образом, рибосомы действуют как интерпретаторы, а молекулы тРНК определяют язык высшего уровня. Существует, однако, другая точка зрения на трансляцию, утверждающая, что рибосомы — процессоры, в то время как тРНК — интерпретаторы.
Мы затронули анализ взаимоотношений между этими биомолекулами только поверхностно. При этом мы увидели, что природе нравится смешивать уровни, которые, с нашей точки зрения, кажутся весьма различными. В действительности, в теории вычислительной техники уже сейчас существует тенденция смешения этих, кажущихся такими разными, уровней системы обработки информации. Особенно это верно в области исследований по Искусственному Интеллекту, обычно идущих во главе разработки компьютерных языков.
Происхождение жизни
После знакомства с так сложно переплетенными подсистемами аппаратуры и программного обеспечения возникает естественный и важный вопрос: «Каким образом все это вообще началось?» Это на самом деле удивительно. Приходится предположить нечто вроде процесса поднятия самого себя за волосы, подобного тому процессу, который используется при создании новых компьютерных языков — однако подобный подъем от уровня молекул до уровня целой клетки почти невозможно вообразить. Существует несколько теорий о происхождении жизни, но ни одна из них не смогла пока дать ответа на главнейший из главных вопросов: «Как возник Генетический Код и механизмы для его трансляции — рибосомы и тРНК?» Пока нам придется вместо ответа удовольствоваться чувством удивления и восхищения, может быть, эти чувства более удовлетворительны, чем сам ответ — по крайней мере, на время.

Рис. 104. М.К. Эшер. «Кастровалва» (литография, 1930).

