ГЛАВА 6
В СВЯТИЛИЩЕ ПРЕПОДОБНОГО БАЙЕСА
Из ночной тьмы выступает глыба кафедрального собора. Мозаичные окна льют свет на мостовую и соседние здания, проецируя замысловатые уравнения. Вы подходите ближе и слышите, что изнутри доносятся песнопения. Кажется, это латынь или, может быть, язык математики, но «вавилонская рыбка» у вас в ухе переводит слова на понятный язык: «Поверни ручку! Поверни ручку!» Как только вы входите, пение переходит во вздох удовлетворения. По толпе проносится ропот: «Постериор! Постериор!» Вы проталкиваетесь вперед. Над алтарем возвышается массивная каменная таблица. На ней трехметровыми буквами выгравирована формула:
P(A|B) = P(A) P(B|A) / P(B)
Вы непонимающе смотрите на нее, но очки Google Glass услужливо подсказывают: «Теорема Байеса». Толпа начинает петь: «Больше данных! Больше данных!» Вереницу жертв безжалостно толкают к алтарю. Вдруг вы понимаете, что вы тоже среди них, но слишком поздно. Над вами нависла ручка. Вы кричите: «Нет! Я не хочу быть точкой данных! Пусти-и-ите!» И — просыпаетесь в холодном поту. На коленях у вас лежит книга под названием «Верховный алгоритм». Трясясь от пережитого кошмара, вы продолжаете читать с того места, где остановились.
Теорема, которая правит миром
О формуле, с которой начинается путь к оптимальному обучению, многие слышали: это теорема Байеса. Но в этой главе мы посмотрим на нее в совершенно другом свете и увидим, что она намного мощнее, чем может показаться, если судить по ее повседневному применению. По правде говоря, теорема Байеса — это просто несложное правило обновления уровня доверия к гипотезе при получении новых доказательств: если свидетельство совпадает с гипотезой, ее вероятность идет вверх, если нет — вниз. Например, если тест на СПИД положительный, вероятность соответствующего диагноза повышается. Но когда доказательств — например, результатов анализов — много, все становится интереснее. Чтобы соединить их без риска комбинаторного взрыва, нужно сделать упрощающие допущения. Еще любопытнее рассматривать одновременно большое количество гипотез, например все возможные диагнозы у пациента. Вычисление на основе симптомов вероятности каждого заболевания за разумное время — серьезный интеллектуальный вызов. Когда мы поймем, как это сделать, мы будем готовы учиться по-байесовски. Для этого «племени» обучение — это «просто» еще одно применение теоремы Байеса, где целые модели — гипотезы, а данные — доказательства: по мере накопления данных некоторые модели становятся более вероятными, а некоторые — менее, пока в идеале одна модель не побеждает вчистую. Байесовцы изобрели дьявольски хитрые разновидности моделей, так что давайте приступим.
Томас Байес — английский священник, живший в XVIII веке, — сам того не подозревая, стал центром новой религии. Такой поворот может показаться удивительным, но стоит заметить, что то же самое произошло и с Иисусом: христианство в том виде, в котором мы его знаем, изобрел апостол Павел, а сам Иисус видел в себе вершину иудейской веры. Аналогично байесианство в привычном для нас виде было изобретено Пьер-Симоном де Лапласом — французом, родившимся на пять десятилетий позже Байеса. Байес был проповедником и первым описал новый подход к вероятностям, но именно Лаплас выразил его идеи в виде теоремы.
Лаплас, один из величайших математиков всех времен и народов, наверное, больше всего известен своей мечтой о ньютоновском детерминизме:
Разум, которому в каждый определенный момент были бы известны все силы, приводящие природу в движение, и положение всех тел, из которых она состоит, будь он также достаточно обширен, чтобы подвергнуть эти данные анализу, смог бы объять единым законом движение величайших тел Вселенной и мельчайшего атома; для такого разума ничего не было бы неясного и будущее существовало бы в его глазах точно так же, как прошлое.
Это забавно, поскольку Лаплас был отцом теории вероятностей, которая, как он полагал, представляла собой просто здравый смысл, сведенный к вычислениям. В сердце его исследований вероятности лежала озабоченность вопросом Юма. Откуда, например, мы знаем, что завтра взойдет солнце? Каждый день, вплоть до сегодняшнего, это происходило, но ведь нет никаких гарантий, что так будет и впредь. Ответ Лапласа состоит из двух частей. Первая — то, что мы теперь называем принципом безразличия или принципом недостаточного основания. Однажды — скажем, в начале времен, которое для Лапласа было приблизительно 5 тысяч лет назад, — мы просыпаемся, прекрасно проводим день, а вечером видим, что солнце заходит. Вернется ли оно? Мы никогда не видели восхода, и у нас нет причин полагать, что оно взойдет или не взойдет. Таким образом мы должны рассмотреть два одинаково вероятных сценария и сказать, что солнце снова взойдет с вероятностью 1⁄2. Но, продолжал Лаплас, если прошлое хоть как-то указывает на будущее, каждый день, когда солнце восходит, должен укреплять нашу уверенность, что так будет происходить и дальше. Спустя пять тысячелетий вероятность, что солнце завтра снова взойдет, должна быть очень близка единице, но не равняться ей, потому что полной уверенности никогда не будет. Из этого мысленного эксперимента Лаплас вывел свое так называемое правило следования, согласно которому вероятность, что солнце снова взойдет после n восходов, равна (n + 1) / (n + 2). Если n = 0, то это просто 1⁄2, а когда n увеличивается, растет и вероятность, стремясь к единице, когда n стремится к бесконечности.
Это правило вытекает из более общего принципа. Представьте, что вы проснулись посреди ночи на чужой планете. Хотя над вами только звездное небо, у вас есть причины полагать, что солнце в какой-то момент взойдет, поскольку большинство планет вращаются вокруг своей оси и вокруг звезды. Поэтому оценка соответствующей вероятности должна быть больше 1⁄2 (скажем, 2⁄3). Это называется априорной вероятностью восхода солнца, поскольку она предшествует любым доказательствам: вы не исходите из подсчета восходов на этой планете в прошлом, потому что вас там не было и вы их не видели. Априорная вероятность скорее отражает наши убеждения по поводу того, что может произойти, основанные на общих знаниях о Вселенной. Но вот звезды начинают бледнеть, и уверенность, что солнце на этой планете действительно восходит, начинает расти, подкрепляемая земным опытом. Ваша уверенность теперь — это апостериорная вероятность, поскольку она возникает после того, как вы увидели некие доказательства. Небо светлеет, и апостериорная вероятность подскакивает еще раз. Наконец над горизонтом показывается краешек яркого диска, и солнечный луч «ловит башню гордую султана… в огненный силок», как в «Рубаи» Омара Хайяма. Если вы не страдаете галлюцинациями, то можете быть уверены, что солнце взойдет.
Возникает важнейший вопрос: как именно должна меняться апостериорная вероятность при появлении все большего объема доказательств? Ответ дает теорема Байеса. Мы можем рассматривать ее в причинно-следственных категориях. Восход солнца заставляет звезды угасать и делает небо светлее, однако последний факт — более сильное доказательство в пользу рассвета, поскольку звезды могут угасать и посреди ночи, скажем, из-за спустившегося тумана. Поэтому после того, как посветлело небо, вероятность рассвета должна увеличиться больше, чем после того, как вы заметили блекнущие звезды. Математики скажут, что P(рассвет | светлое-небо), то есть условная вероятность восхода солнца при условии, что небо светлеет, будет больше, чем P(рассвет | гаснущие-звезды) — условной вероятности при условии, что звезды блекнут. Согласно теореме Байеса, чем более вероятно, что следствие вызвано причиной, тем более вероятно, что причина связана со следствием: если P(светлое-небо | рассвет) выше, чем P(гаснущие-звезды | рассвет), — может быть, потому что некоторые планеты настолько удалены от своих солнц, что звезды там продолжают светить и после восхода, — следовательно, P(рассвет | светлое-небо) тоже будет выше, чем P(рассвет | гаснущие-звезды).
Однако это еще не все. Если мы наблюдаем следствие, которое может произойти даже без данной причины, то, несомненно, имеется недостаточно доказательств наличия этой причины. Теорема Байеса учитывает это, говоря, что P(причина | следствие) уменьшается вместе с P(следствие), априорной вероятностью следствия (то есть ее вероятностью при отсутствии какого-либо знания о причинах). Наконец, при прочих равных, чем выше априорная вероятность причины, тем выше должна быть апостериорная вероятность. Если собрать все это вместе, получится теорема Байеса, которая гласит:
P(причина | следствие) = P(причина) × P(следствие | причина) / P(следствие).
Замените слово «причина» на A, а «следствие» на B, для краткости опустите все знаки умножения, и вы получите трехметровую формулу из кафедрального собора.
Это, конечно, просто формулировка теоремы, а не ее доказательство. Но и доказательство на удивление простое. Мы можем проиллюстрировать его на примере из медицинской диагностики, одной из «приманок» байесовского вывода. Представьте, что вы врач и за последний месяц поставили диагноз сотне пациентов. Четырнадцать из них болели гриппом, у 20 была высокая температура, а у 11 — и то и другое. Условная вероятность температуры при гриппе, таким образом, составляет одиннадцать из четырнадцати, или 11⁄14. Обусловленность уменьшает размеры рассматриваемой нами вселенной, в данном случае от всех пациентов только до пациентов с гриппом. Во вселенной всех пациентов вероятность высокой температуры составляет 20⁄100, а во вселенной пациентов, больных гриппом, — 11⁄14. Вероятность того, что у пациента грипп и высокая температура, равна доле пациентов, больных гриппом, умноженной на долю пациентов с высокой температурой: P(грипп, температура) = P(грипп) × P(температура | грипп) = 14⁄100 × 11⁄14 = 11⁄100. Но верно и следующее: P(грипп, температура) = P(температура) × P(грипп | температура). Таким образом, поскольку и то, и другое равно P(грипп, температура), то P(температура) × P(грипп | температура) = P(грипп) × P(температура | грипп). Разделите обе стороны на P(температура), и вы получите P(грипп | температура) = P(грипп) × P(температура | грипп) / P(температура).
Вот и все! Это теорема Байеса, где грипп — это причина, а высокая температура — следствие.
Люди, оказывается, не очень хорошо владеют байесовским выводом, по крайней мере в устных рассуждениях. Проблема в том, что мы склонны пренебрегать априорной вероятностью причины. Если анализ показал наличие ВИЧ и этот тест дает только один процент ложных положительных результатов, стоит ли паниковать? На первый взгляд может показаться, что, увы, шанс наличия СПИДа — 99 процентов. Но давайте сохраним хладнокровие и последовательно применим теорему Байеса: P(ВИЧ | положительный) = P(ВИЧ) × P(положительный | ВИЧ) / P(положительный). P(ВИЧ) — это распространенность данного вируса в общей популяции, которая в США составляет 0,3 процента. P(положительный) — это вероятность, что тест даст положительный результат независимо от того, есть у человека СПИД или нет. Скажем, это 1 процент. Поэтому P(ВИЧ | положительный) = 0,003 × 0,99 / 0,01 = 0,297. Это далеко не 0,99! Причина в том, что ВИЧ в общей популяции встречается редко. Положительный результат теста на два порядка увеличивает вероятность, что человек болен СПИДом, но она все еще меньше 1⁄2. Так что, если анализы дали положительный результат, разумнее будет сохранить спокойствие и провести еще один, более доказательный тест. Есть шанс, что все будет хорошо.
Теорема Байеса полезна, потому что обычно известна вероятность следствий при данных причинах, а узнать хотим вероятность причин при данных следствиях. Например, мы знаем процент пациентов с гриппом, у которых повышена температура, но на самом деле нам нужно определить вероятность, что пациент с температурой болен гриппом. Теорема Байеса позволяет нам перейти от одного к другому. Ее значимость, однако, этим далеко не ограничивается. Для байесовцев эта невинно выглядящая формула — настоящее F = ma машинного обучения, основа, из которой вытекает множество результатов и практических применений. Каков бы ни был Верховный алгоритм, он должен быть «всего лишь» вычислительным воплощением теоремы Байеса. Я пишу «всего лишь» в кавычках, потому что применение теоремы Байеса в компьютерах оказалось дьявольски непростой задачей для всех проблем, кроме простейших. Скоро мы увидим почему.
Теорема Байеса как основа статистики и машинного обучения страдает не только от вычислительной сложности, но и от крайней противоречивости. Вы можете удивиться: разве она не прямое следствие идеи условной вероятности, как мы видели на примере гриппа? Действительно, с формулой как таковой ни у кого проблем не возникает. Противоречие заключается в том, как именно байесовцы получают вероятности, которые в нее включены, и что эти вероятности означают. Для большинства статистиков единственный допустимый способ оценки вероятностей — вычисление частоты соответствующего события. Например, вероятность гриппа равна 0,2, потому что им болело 20 из 100 обследованных пациентов. Это «частотная» интерпретация вероятности, и она дала название господствующему учению в статистике. Но обратите внимание, что в принципе безразличия Лапласа и в примере с восходом солнца мы просто высасываем вероятность из пальца. Чем оправдано априорное предположение, что вероятность восхода солнца равна одной второй, двум третьим или еще какой-то величине? На это байесовцы отвечают, что вероятность — это не частота, а субъективная степень убежденности, поэтому вам решать, какая она будет, а байесовский вывод просто позволяет обновлять априорные убеждения после появления новых доказательств, чтобы получать апостериорные убеждения (это называется «провернуть ручку Байеса»). Поклонники теоремы Байеса верят в эту идею с почти религиозным рвением и 200 лет выдерживают нападки и возражения. С появлением на сцене достаточно мощных компьютеров и больших наборов данных байесовский вывод начал брать верх.
Все модели неверны, но некоторые полезны
Настоящие врачи не диагностируют грипп на основе высокой температуры, а учитывают целый комплекс симптомов, включая боль в горле, кашель, насморк, головную боль, озноб и так далее. Поэтому, когда нам действительно надо вычислить по теореме Байеса P(грипп | температура, кашель, больное горло, насморк, головная боль, озноб, …), мы знаем, что эта вероятность пропорциональна P(температура, кашель, больное горло, насморк, головная боль, озноб, … | грипп). Но здесь мы сталкиваемся с проблемой. Как оценить эту вероятность? Если каждый симптом — булева переменная (он либо есть, либо нет) и врач учитывает n симптомов, у пациента может быть 2n комбинаций симптомов. Если у нас, скажем, 20 симптомов и база данных из 10 тысяч пациентов, мы увидим лишь малую долю из примерно миллиона возможных комбинаций. Еще хуже то, что для точной оценки вероятности конкретного сочетания симптомов нужны как минимум десятки его наблюдений, а это значит, что база данных должна включать десятки миллионов пациентов. Добавьте еще десяток симптомов, и нам понадобится больше пациентов, чем людей на Земле. Если симптомов сто и мы каким-то чудом получим такие данные, не хватит места на всех жестких дисках в мире, чтобы сохранить все эти вероятности. А если в кабинет войдет пациент с не встречавшимся ранее сочетанием симптомов, будет непонятно, как поставить ему диагноз. То есть мы столкнемся с давним врагом: комбинаторным взрывом.
Поэтому мы поступим так, как всегда стоит поступать: пойдем на компромисс. Нужно сделать упрощающие допущения, которые срежут количество подлежащих оценке вероятностей до уровня, с которым под силу справиться. Одно из простых и очень популярных допущений заключается в том, что все следствия данной причины независимы. Это значит, например, что наличие высокой температуры не влияет на вероятность кашля, если уже известно, что у больного грипп. Математически это значит, что P(температура, кашель | грипп) — просто P(температура | грипп) × P(кашель | грипп). Получается, что и то и другое легко оценить на основании небольшого количества наблюдений. В предыдущем разделе мы уже сделали это для высокой температуры, и для кашля или любого другого симптома все будет так же. Необходимое количество наблюдений больше не растет экспоненциально с количеством симптомов. На самом деле оно вообще не растет.
Обратите внимание: речь идет о том, что высокая температура и кашель независимы не в принципе, а только при условии, что у больного грипп. Если неизвестно, есть грипп или нет, температура и кашель будут очень сильно коррелировать, поскольку вероятность кашля при высокой температуре намного выше. P(температура, кашель) не равно P(температура) × P(кашель). Смысл в том, что если уже известно, что у больного грипп, то информация о высокой температуре не даст никакой дополнительной информации о том, есть ли у него кашель. Аналогично, если вы видите, что звезды гаснут, но не знаете, должно ли взойти солнце, ваши ожидания, что небо прояснится, должны возрасти. Но если вы уже знаете, что восход неизбежен, гаснущие звезды не важны.
Следует отметить, что такой фокус можно проделать только благодаря теореме Байеса. Если бы мы хотели прямо оценить P(грипп | температура, кашель и так далее) без предварительного преобразования с помощью теоремы в P(температура, кашель и так далее | грипп), по-прежнему требовалось бы экспоненциальное число вероятностей, по одной для каждого сочетания «симптомы — грипп / не грипп».
Алгоритм машинного обучения, который применяет теорему Байеса и исходит из того, что следствия данной причины независимы, называется наивный байесовский классификатор. Дело в том, что такое допущение, прямо скажем, довольно наивное: в реальности температура увеличивает вероятность кашля, даже если уже известно, что у больного грипп, потому что она, например, повышает вероятность тяжелого гриппа. Однако машинное обучение — это искусство безнаказанно делать ложные допущения, а как заметил статистик Джордж Бокс, «все модели неверны, но некоторые полезны». Чрезмерно упрощенная модель, для оценки которой у вас есть достаточно данных, лучше, чем идеальная, для которой данных нет. Просто поразительно, насколько ошибочны и одновременно полезны бывают некоторые модели. Экономист Милтон Фридман в одном очень влиятельном эссе даже утверждал, что чрезмерно упрощенные теории — лучшие, при условии, что они дают точные предсказания: они объясняют больше с наименьшими усилиями. По-моему, это перебор, однако это хорошая иллюстрация того, что, вопреки Эйнштейну, наука часто развивается по принципу «упрощай до тех пор, пока это возможно, а потом упрости еще немного».
Точно неизвестно, кто изобрел наивный байесовский алгоритм. Он был упомянут без автора в 1973 году в учебнике по распознаванию паттернов, но распространение получил лишь в 1990-е, когда исследователи заметили, что, как ни странно, он часто бывает точнее, чем намного более сложные обучающиеся алгоритмы. В то время я был старшекурсником. Запоздало решил включить наивный байесовский алгоритм в свои эксперименты и был шокирован, потому что оказалось, что он работает лучше, чем все другие, которые я сравнивал. К счастью, было одно исключение — алгоритм, который я разрабатывал для дипломной работы, — иначе, наверное, я не писал бы эти строки.
Наивный байесовский алгоритм сейчас используется очень широко: на нем основаны, например, многие спам-фильтры. Это применение придумал Дэвид Хекерман, выдающийся ученый-байесовец, врач. Ему пришла в голову мысль, что к спаму надо относиться как к заболеванию, симптомы которого — слова в электронном письме. «Виагра» — это симптом, и «халява» тоже, а имя лучшего друга, вероятно, указывает, что письмо настоящее. Затем можно использовать наивный байесовский алгоритм для классификации писем на спам и не-спам, но только при условии, что спамеры генерируют свои письма путем произвольного выбора слова. Это, конечно, странное допущение, которое было бы верно, не будь у предложений ни синтаксиса, ни содержания. Но тем же летом Мехран Сахами, тогда еще студент Стэнфорда, попробовал применить этот подход во время стажировки в Microsoft Research, и все отлично сработало. Когда Билл Гейтс спросил Хекермана, как это может быть, тот ответил, что для выявления спама вникать в подробности сообщения не обязательно: достаточно просто уловить суть, посмотрев, какие слова оно содержит.
В простейших поисковых системах алгоритмы, довольно похожие на наивный байесовский, используются, чтобы определить, какие сайты выдавать в ответ на запрос. Основное различие в том, что вместо классификации на спам и не спам нужно определить, подходит сайт к запросу или не подходит. Список проблем прогнозирования, к которым был применен наивный байесовский алгоритм, можно продолжать бесконечно. Питер Норвиг, директор по исследованиям в Google, как-то рассказал, что у них этот подход используется шире всего, а ведь Google применяет машинное обучение везде где только можно. Несложно догадаться, почему наивный Байес приобрел в Google такую популярность. Даже не говоря о неожиданной точности, он позволяет легко увеличить масштаб. Обучение наивного байесовского классификатора сводится к простому подсчету, сколько раз каждый атрибут появляется с каждым классом, а это едва ли занимает больше времени, чем считывание данных с диска.
Наивный байесовский алгоритм в шутку можно использовать даже в большем масштабе, чем Google, и смоделировать с его помощью всю Вселенную. Действительно, если верить в существование всемогущего бога, можно создать модель Вселенной как обширного распределения, где все происходит независимо при условии божьей воли. Ловушка, конечно, в том, что божественный разум нам недоступен, но в главе 8 мы узнаем, как получать наивные байесовские модели, даже не зная классов примеров.
Поначалу может показаться, что это не так, но наивный байесовский алгоритм тесно связан с перцептронами. Перцептрон добавляет веса, а байесовский алгоритм умножает вероятности, но, если логарифмировать, последнее сведется к первому. И то и другое можно рассматривать как обобщение простых правил «Если…, то…», где каждый предшественник может вносить больший или меньший вклад в вывод, вместо подхода «все или ничего». Этот факт — еще один пример глубокой связи между алгоритмами машинного обучения и намек на существование Верховного алгоритма. Вы можете не знать теорему Байеса (хотя теперь уже знаете), но в какой-то степени каждый из десяти миллиардов нейронов в вашем мозге — это ее крохотный частный случай.
Наивный байесовский алгоритм — хорошая концептуальная модель обучающегося алгоритма для чтения прессы: улавливает попарные корреляции между каждым из входов и выходов. Но машинное обучение, конечно, не просто парные корреляции, не в большей степени, чем мозг — это нейрон. Настоящее действие начинается, если посмотреть на более сложные паттерны.
От «Евгения Онегина» до Siri
В преддверии Первой мировой войны русский математик Андрей Марков опубликовал статью, где вероятности применялись, помимо всего прочего, к поэзии. В своей работе он моделировал классику русской литературы — пушкинского «Евгения Онегина» — с помощью подхода, который мы сейчас называем цепью Маркова. Вместо того чтобы предположить, что каждая буква сгенерирована случайно, независимо от остальных, Марков ввел абсолютный минимум последовательной структуры: допустил, что вероятность появления той или иной буквы зависит от буквы, непосредственно ей предшествующей. Он показал, что, например, гласные и согласные обычно чередуются, поэтому, если вы видите согласную, следующая буква (если игнорировать знаки пунктуации и пробелы) с намного большей вероятностью будет гласной, чем если бы буквы друг от друга не зависели. Может показаться, что это невеликое достижение, но до появления компьютеров требовалось много часов вручную подсчитывать символы, и идея была довольно новой. Если гласнаяi — это булева переменная, которая верна, если i-я по счету буква «Евгения Онегина» — гласная, и неверна, если она согласная, можно представить модель Маркова как похожий на цепочку график со стрелками между узлами, указывающими на прямую зависимость между соответствующими переменными:

Марков сделал предположение (неверное, но полезное), что в каждом месте текста вероятности одинаковы. Таким образом нам нужно оценить только три вероятности: P(гласная1 = верно); P(гласнаяi+1 = верно | гласнаяi = верно) и P(гласнаяi+1 = верно | гласнаяi = верно). (Поскольку сумма вероятностей равна единице, из этого можно сразу получить P(гласная1 = ложно) и так далее.) Как и в случае наивного байесовского алгоритма, переменных можно взять сколько угодно, не опасаясь, что число вероятностей, которые надо оценить, пробьет потолок, однако теперь переменные зависят друг от друга.
Если измерять не только вероятность гласных в зависимости от согласных, но и вероятность следования друг за другом для всех букв алфавита, можно поиграть в генерирование новых текстов, имеющих ту же статистику, что и «Евгений Онегин»: выбирайте первую букву, потом вторую, исходя из первой, и так далее. Получится, конечно, полная чепуха, но, если мы поставим буквы в зависимость от нескольких предыдущих букв, а не от одной, текст начнет напоминать скорее бессвязную речь пьяного — местами разборчиво, хотя в целом бессмыслица. Все еще недостаточно, чтобы пройти тест Тьюринга, но модели вроде этой — ключевой компонент систем машинного перевода, например Google Translate, которые позволяют увидеть весь интернет на английском (или почти английском), независимо от того, на каком языке написана исходная страница.
PageRank — алгоритм, благодаря которому появился Google, — тоже представляет собой марковскую цепь. Идея Ларри Пейджа заключалась в том, что веб-страницы, к которым ведут много ссылок, вероятно, важнее, чем страницы, где их мало, а ссылки с важных страниц должны сами по себе считаться больше. Из-за этого возникает бесконечная регрессия, но и с ней можно справиться с помощью цепи Маркова. Представьте, что человек посещает один сайт за другим, случайно проходя по ссылкам. Состояния в этой цепи Маркова — это не символы, а веб-страницы, что увеличивает масштаб проблемы, однако математика все та же. Суммой баллов страницы тогда будет доля времени, которую человек на ней проводит, либо вероятность, что он окажется на этой странице после долгого блуждания вокруг нее.
Цепи Маркова появляются повсюду, это одна из самых активно изучаемых тем в математике, но это все еще сильно ограниченная разновидность вероятностных моделей. Сделать шаг вперед можно с помощью такой модели:
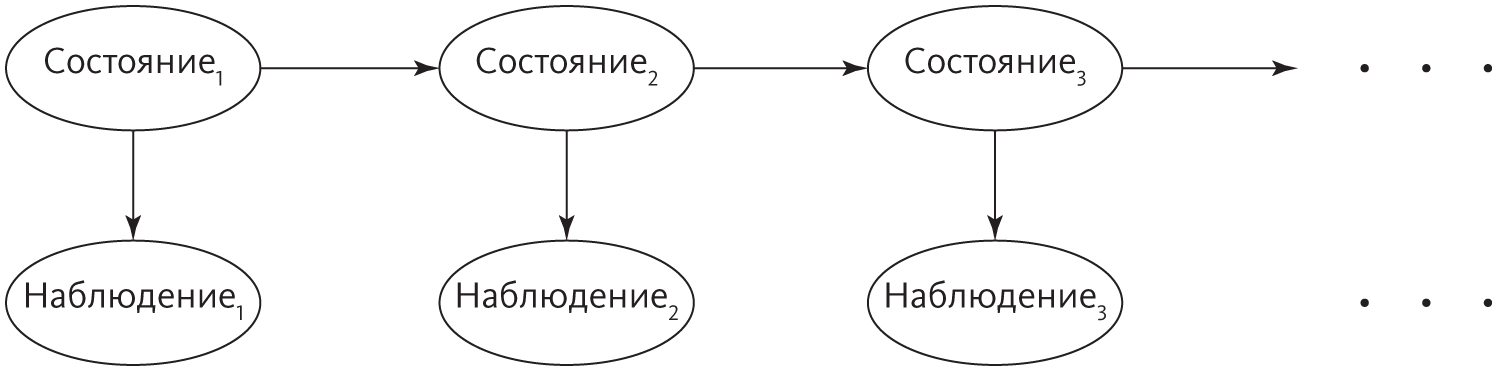
Состояния, как и ранее, образуют марковскую цепь, но мы их не видим, и надо вывести их из наблюдений. Это называется скрытой марковской моделью, сокращенно СММ (название немного неоднозначное, потому что скрыта не модель, а состояния). СММ — сердце систем распознавания речи, например Siri. В задачах такого рода скрытые состояния — это написанные слова, наблюдения — это звуки, которые слышит Siri, а цель — определить слова на основе звуков. В модели есть два элемента: вероятность следующего слова при известном текущем, как в цепи Маркова, и вероятность услышать различные звуки, когда произносят слово. (Как именно сделать такой вывод — интересная проблема, к которой мы обратимся после следующего раздела.)
Кроме Siri, вы используете СММ каждый раз, когда разговариваете по мобильному телефону. Дело в том, что ваши слова передаются по воздуху в виде потока битов, а биты при передаче искажаются. СММ определяет, какими они должны быть (скрытые состояния), на основе полученных данных (наблюдений), и, если испортилось не слишком много битов, у нее обычно все получается.
Скрытая марковская модель — любимый инструмент специалистов по вычислительной биологии. Белок представляет собой последовательность аминокислот, а ДНК — последовательность азотистых оснований. Если мы хотим предсказать, например, в какую трехмерную форму сложится белок, можно считать аминокислоты наблюдениями, а тип складывания в каждой точке — скрытым состоянием. Аналогично можно использовать СММ для определения мест в ДНК, где инициируется транскрипция генов, а также многих других свойств.
Если состояния и наблюдения — не дискретные, а непрерывные переменные, СММ превращается в так называемый фильтр Калмана. Экономисты используют эти фильтры, чтобы убрать шум из временных рядов таких величин, как внутренний валовой продукт (ВВП), инфляция и безработица. «Истинные» значения ВВП — это скрытые состояния. На каждом временном отрезке истинное значение должно быть схоже и с наблюдаемым, и с предыдущим истинным значением, поскольку в экономике резкие скачки встречаются нечасто. Фильтр Калмана находит компромисс между этими условиями и позволяет получить более гладкую, но соответствующую наблюдениям кривую. Кроме того, фильтры Калмана не дают ракетам сбиться с курса, и без них человек не побывал бы на Луне.
Все связано, но не напрямую
Скрытые марковские модели хорошо подходят для моделирования последовательностей всех видов, но им все еще очень далеко до гибкости символистских правил типа «если…, то…», где условием может быть все, а вывод может стать условием в любом последующем правиле. Однако если допустить такую произвольную структуру на практике, это приведет к взрывному росту количества вероятностей, которые нам надо определить. Ученые долго не могли справиться с этой квадратурой круга и прибегали к ситуативным схемам, например приписывали правилам оценочную достоверность и кое-как их соединяли. Если из A с достоверностью 0,8 следует B, а из B с достоверностью 0,7 вытекает C, то, наверное, C следует из A с достоверностью 0,8 × 0,7.
Проблема таких схем в том, что они могут приводить к сильным искажениям. Из двух совершенно разумных правил «если ороситель включен, трава будет мокрая» и «если трава мокрая, значит шел дождь» я могу вывести бессмысленное правило «если ороситель включен, значит шел дождь». Еще более коварная проблема заключается в том, что при применении правил с оценками достоверности одни и те же доказательства могут засчитываться дважды. Представьте, что вы читаете в New York Times сообщение о приземлении инопланетян. Не исключено, что это розыгрыш, хотя сегодня не первое апреля. Потом вы видите подобные заголовки в Wall Street Journal, USA Today и Washington Post и начинаете паниковать, как слушатели печально известной передачи Орсона Уэллса, которые приняли радиоспектакль «Война миров» за чистую монету. Если, однако, вы обратите внимание на мелкий шрифт и поймете, что все четыре газеты получили новость от Associated Press, можно снова заподозрить розыгрыш, на этот раз со стороны репортера новостного агентства. Системы правил неспособны справиться с этой проблемой, равно как и наивный байесовский алгоритм: если в качестве предикторов того, что новость правдива, используются такие свойства, как «сообщила New York Times», он может только добавить «сообщило агентство Associated Press», а это лишь испортит дело.
Прорыв был сделан в начале 1980-х годов, когда Джуда Перл, профессор информатики в Калифорнийском университете в Лос-Анджелесе, изобрел новое представление — байесовские сети. Перл — один из самых заслуженных авторитетов в компьютерных науках, и его методы оставили отпечаток в машинном обучении, искусственном интеллекте и многих других дисциплинах. В 2012 году ему была присуждена премия Тьюринга.
Перл понял, что вполне допустимо иметь сложную сеть зависимостей между случайными переменными при условии, что каждая переменная прямо зависит только от нескольких других. Эти зависимости можно представить в виде графика, аналогичного тому, который мы видели при обсуждении цепей Маркова и СММ, однако теперь он может иметь любую структуру, если только стрелки не образуют замкнутые петли. Один из любимых примеров Перла — охранная сигнализация. Она должна сработать, если в дом пытается влезть грабитель, но может включиться и при землетрясении. (В Лос-Анджелесе, где живет Перл, землетрясения почти так же часты, как кражи со взломом.) Представьте, что вы засиделись на работе и вам позвонил сосед Боб, чтобы предупредить, что у вас сработала сигнализация. Соседка Клэр не звонит. Надо ли звонить в полицию? Вот график зависимостей:
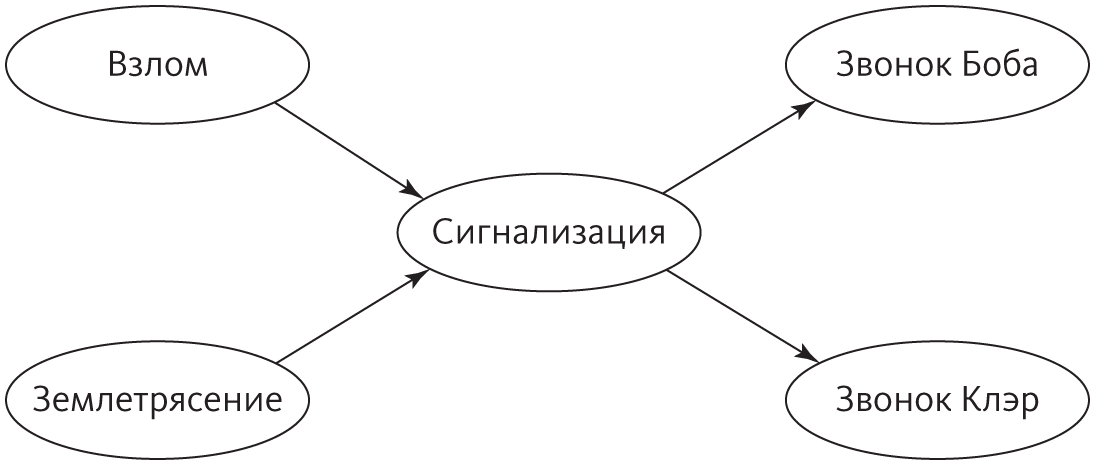
Если на этом графике есть стрелка от одного узла к другому, мы говорим, что первый узел — родительский для второго. Следовательно, родители узла «Сигнализация» — «Взлом» и «Землетрясение», а «Сигнализация» будет единственным родителем узлов «Звонок Боба» и «Звонок Клэр». Байесовская сеть — это аналогичный график зависимостей, но каждой переменной присвоена табличка с ее вероятностью при всех сочетаниях ее родителей. У узлов «Взлом» и «Землетрясение» родителей нет, поэтому вероятность у них будет только одна. У «Сигнализации» их будет уже четыре: вероятность срабатывания, если нет ни взлома, ни землетрясения; вероятность срабатывания при взломе, но без землетрясения, и так далее. У узла «Звонок Боба» будут две вероятности (при наличии и отсутствии срабатывания сигнализации), и то же самое для звонка Клэр.
Это ключевой момент. Звонок Боба зависит от узлов «Взлом» и «Землетрясение», но только посредством узла «Сигнализация», то есть условно независим от взлома и землетрясения при условии срабатывания сигнализации, и то же самое с Клэр. Если сигнализация не сработала, соседи будут крепко спать и грабитель спокойно cделает свое дело. Также при условии срабатывания сигнализации звонки Боба и Клэр будут независимы друг от друга. Если бы этой структуры независимости не было, пришлось бы определить 25 = 32 вероятности, по одной для каждого возможного состояния пяти переменных. (Или 31, если вы педант, поскольку последнюю можно оставить неявной.) Если ввести условную независимость, останется определить всего 1 + 1 + 4 + 2 + 2 = 10 вероятностей, то есть экономия составит 68 процентов. И это только в этом маленьком примере. Когда переменных сотни и тысячи, экономия может приближаться к 100 процентам.
Первый закон экологии, согласно биологу Барри Коммонеру, заключается в том, что все взаимосвязано. Может быть, это действительно так, но в таком случае мир был бы непостижим, если бы не спасительная условная независимость: все связано, но лишь косвенно. Если что-то происходит на расстоянии километра, повлиять на меня это может только посредством чего-нибудь в моем соседстве, пусть даже это будут световые лучи. Как заметил один шутник, благодаря пространству с нами происходит не все сразу. Иначе говоря, структура пространства — это частный случай условной независимости.
В примере с ограблением полная таблица из 32 вероятностей не представлена явно, но она содержится в наборе меньших таблиц и структуре графа. Чтобы получить P(взлом, землетрясение, сигнализация, звонок Боба, звонок Клэр), нужно только перемножить P(взлом), P(землетрясение), P(сигнализация | взлом, землетрясение), P(звонок Боба | сигнализация) и P(звонок Клэр | сигнализация). То же самое в любой байесовской сети: чтобы получить вероятность полного состояния, просто перемножьте вероятности соответствующих линий в таблицах отдельных переменных. Поэтому при условной независимости информация не теряется из-за перехода на более компактное представление, и можно легко вычислить вероятности крайне необычных состояний, включая те, что до этого никогда не наблюдались. Байесовские сети показывают ошибочность расхожего мнения, будто машинное обучение неспособно предсказывать очень редкие события — «черных лебедей», как их называет Нассим Талеб.
Оглядываясь назад, можно заметить, что наивный байесовский алгоритм, цепи Маркова и СММ — это частные случаи байесовских сетей. Вот структура наивного Байеса:
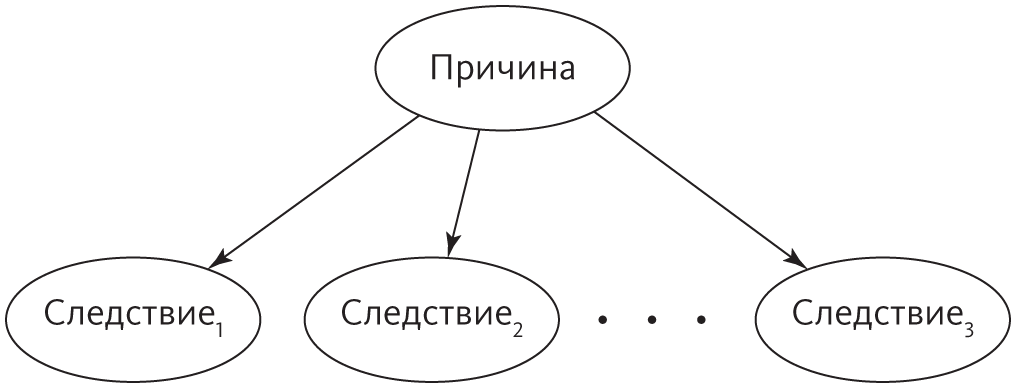
Цепи Маркова кодируют допущение, что будущее условно независимо от прошлого при известном настоящем, а СММ дополнительно предполагает, что каждое наблюдение зависит только от соответствующего состояния. Байесовские сети для байесовцев — то же самое, что логика для символистов: лингва франка, который позволяет элегантно кодировать головокружительное разнообразие ситуаций и придумывать алгоритмы, которые будут работать в каждой из них.
Байесовские сети можно воспринимать как «порождающую модель», рецепт вероятностного генерирования состояния мира: сначала надо независимо решить, что произошло — взлом и/или землетрясение, — затем, исходя из этого, понять, срабатывает ли сигнализация, а затем, на этой основе, звонят ли Боб и Клэр. Байесовская сеть как будто рассказывает историю: происходит A, которое ведет к B. Одновременно с B происходит C, и вместе они вызывают D. Чтобы вычислить вероятность конкретной истории, надо просто перемножить все вероятности в разных ее цепочках.
Одна из самых потрясающих областей применения байесовских сетей — моделирование взаимной регуляции генов в клетке. Попытки открыть парные корреляции между конкретными генами и заболеваниями стоили миллиарды долларов, но дали обидно скромные результаты. Теперь это не удивляет — ведь поведение клетки складывается из сложнейших взаимодействий между генами и средой, и единичный ген имеет ограниченную прогностическую силу. Однако благодаря байесовским сетям мы можем открыть эти взаимодействия при условии, что в нашем распоряжении имеются необходимые данные, а с распространением ДНК-микрочипов данных появляется все больше.
После новаторского применения машинного обучения для фильтрации спама Дэвид Хекерман решил попробовать использовать байесовские сети в борьбе со СПИДом. ВИЧ — сильный противник. Он очень быстро мутирует, поэтому к нему сложно подобрать вакцину и надолго сдержать его с помощью лекарств. Хекерман заметил, что это те же кошки-мышки, как между спамом и фильтрами, и решил применить аналогичный прием: атаковать самое слабое звено. В случае спама слабыми звеньями были в том числе URL, которые приходится использовать для приема платежа от клиента. В случае ВИЧ ими оказались небольшие участки вирусного белка, которые не могут меняться без ущерба для вируса. Если бы получилось натренировать иммунную систему узнавать такие области и атаковать содержащие их клетки, было бы несложно разработать вакцину от СПИДа. Хекерман и его коллеги использовали байесовскую сеть, чтобы выявить эти уязвимые области, и разработали механизм доставки вакцины, которая способна научить иммунную систему атаковать их. Система работает у мышей, и в настоящее время готовятся клинические исследования.
Часто бывает, что даже после того, как все условные независимости учтены, у некоторых узлов байесовской сети все равно остается слишком много родителей. В некоторых сетях так густо от стрелок, что, если их распечатать, страница будет черной (физик Марк Ньюман называет их «абсурдограммы»). Врачу нужно одновременно диагностировать все возможные у пациента заболевания, а не только одно, а каждая болезнь — это родительский узел многих симптомов. Высокая температура может быть вызвана не только гриппом, а любым количеством состояний, и совершенно безнадежно пытаться предсказать ее вероятность при каждом возможном их сочетании. Но не все потеряно. Вместо таблицы, в которой указаны условные вероятности узла для каждого состояния родителей, можно получить более простое распределение. Самый популярный вариант — это вероятностная версия операции «логическое ИЛИ»: любая причина сама по себе может вызвать высокую температуру, но каждая причина с определенной вероятностью этого не сделает, даже если обычно ее достаточно. Хекерман и другие обучили байесовские сети, которые диагностируют таким образом сотни инфекционных заболеваний, а Google применяет гигантские сети такого рода в AdSense — системе автоматического подбора рекламы для размещения на веб-страницах. Сети связывают миллионы относящихся к контенту переменных друг с другом и с 12 миллионами слов и фраз более чем 300 миллионами стрелок, каждая из которых получена на основе сотни миллиардов отрывков текстов и поисковых запросов.
Более веселый пример — сервис Microsoft Xbox Live, в котором байесовская сеть используется для оценки игроков и подбора игроков схожего уровня. Результат игры — вероятностная функция уровня навыков противника, и благодаря теореме Байеса можно сделать вывод о навыках игрока на основании его побед и поражений.
Проблема логического вывода
Во всем этом есть, к сожалению, большая загвоздка. Само то, что байесовская сеть позволяет компактно представлять вероятностное распределение, еще не означает, что с ее помощью можно эффективно рассуждать. Представьте, что вы хотите вычислить P(взлом | звонок Боба, нет звонка Клэр). Из теоремы Байеса вы знаете, что это просто P(взлом) P(звонок Боба, нет звонка Клэр | взлом) / P(звонок Боба, нет звонка Клэр), или, эквивалентно, P(взлом, звонок Боба, нет звонка Клэр) / P(звонок Боба, нет звонка Клэр). Если бы в нашем распоряжении была полная таблица вероятностей всех состояний, можно было бы вычислить обе эти вероятности, сложив соответствующие строки в таблице. Например, P(звонок Боба, нет звонка Клэр) — это сумма вероятностей во всех линейках, где Боб звонит, а Клэр не звонит. Но байесовская сеть не дает полной таблицы. Ее всегда можно построить на основе отдельных таблиц, но необходимое для этого время и пространство растет экспоненциально. На самом деле мы хотим вычислить P(взлом | звонок Боба, нет звонка Клэр) без построения полной таблицы. К этому, в сущности, сводится проблема логического вывода в байесовских сетях.
Во многих случаях удается это сделать и без экспоненциального взрыва. Представьте, что вы командир отряда, который колонной по одному глубокой ночью пробирается по вражеским тылам. Надо убедиться, что никто не отстал и не потерялся. Можно остановиться и всех пересчитать, но нет времени. Более разумное решение — спросить идущего за вами солдата, сколько за ним человек. Солдаты будут задавать тот же самый вопрос по цепочке друг другу, пока последний не скажет: «Никого нет». Теперь предпоследний солдат может сказать: «один», — и так далее обратно к голове колонны, и каждый солдат будет добавлять единицу к количеству за ним. Так вы узнаете, сколько солдат за вами идет, и останавливаться не придется.
В Siri та же самая идея используется, чтобы по звукам, которые она улавливает микрофоном, вычислить вероятность, что вы сказали, например, «позвони в полицию». Эту фразу можно считать отрядом слов, марширующих друг за другом по странице. Слово «полиция» хочет знать вероятность своего появления, но для этого ему надо определить вероятность «в», а предлог, в свою очередь, должен узнать вероятность слова «позвони». Поэтому «позвони» вычисляет собственную вероятность и передает ее предлогу «в», который делает то же самое и передает результат слову «полиция». Теперь «полиция» знает свою вероятность, на которую повлияли все слова в предложении, и при этом не надо составлять полную таблицу из восьми вероятностей (первое слово «позвони» или нет, второе слово «в» или нет, третье слово «полиция» или нет). В реальности Siri учитывает все слова, которые могли бы появиться в каждой позиции, а не просто стоит ли первым слово «позвони» и так далее, однако алгоритм тот же самый. Наверное, Siri слышит звуки и предполагает, что первое слово либо «позвони», либо «позови», второе либо «в», либо «к», а третье — либо «полицию», либо «позицию». Может быть, по отдельности самые вероятные слова — это «позови», «к» и «позицию». Но тогда получится бессмысленное предложение: «Позови к позицию». Поэтому, принимая во внимание другие слова, Siri делает вывод, что на самом деле предложение — «Позвони в полицию». Программа звонит, и, к счастью, полицейские успевают вовремя и ловят забравшегося к вам вора.
Та же идея работает и в случае, если граф представляет собой не цепь, а дерево. Если вместо взвода вы командуете целой армией, то можете спросить каждого ротного, сколько солдат за ним идет, а потом сложить их ответы. Каждый командир роты, в свою очередь, спросит своих взводных и так далее. Но если граф образует петлю, у вас появятся проблемы. Допустим, какой-то офицер-связной входит сразу в два взвода. Тогда два раза посчитают не только его самого, но и всех идущих за ним солдат. Именно это произойдет в примере с высадкой инопланетян, если вы захотите вычислить, скажем, вероятность паники:
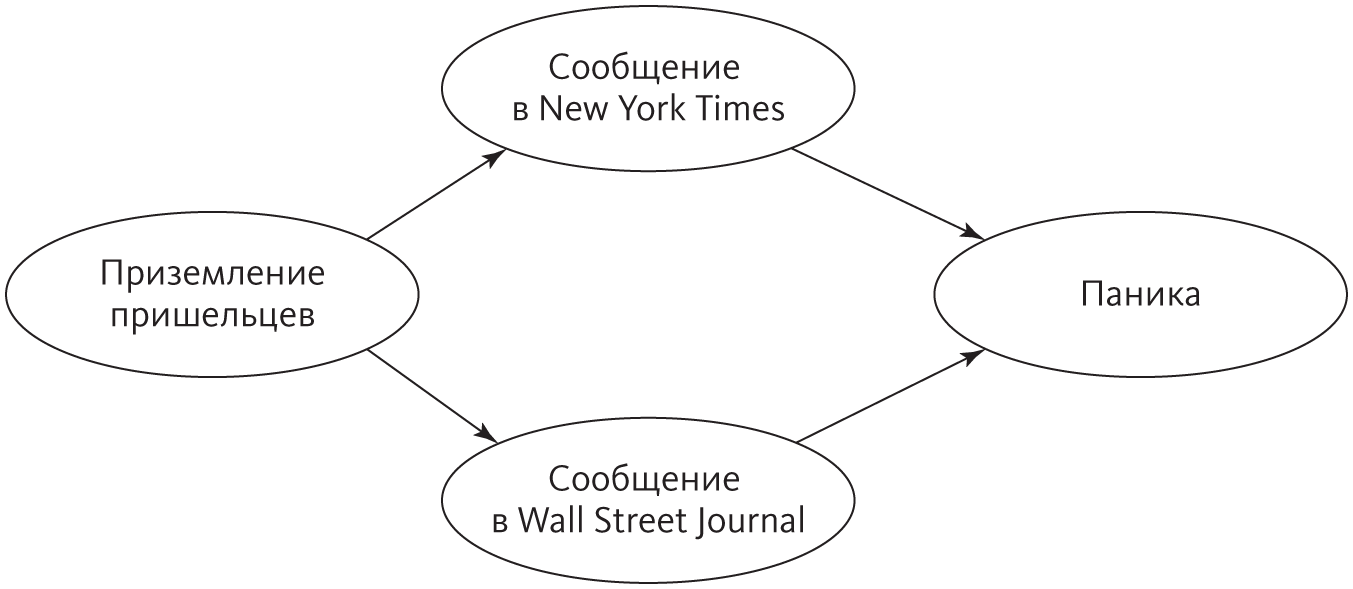
Одно из решений — соединить «Сообщение в New York Times» и «Сообщение в Wall Street Journal» в одну мегапеременную с четырьмя значениями: «ДаДа», если сообщают оба источника, «ДаНет», если о приземлении сообщает New York Times, но не Wall Street Journal, и так далее. Это превратит граф в цепочку из трех переменных, и все хорошо. Однако с добавлением каждого нового источника новости число значений в мегапеременной будет удваиваться. Если вместо двух источников у вас целых 50, мегапеременная получит 250 значений. Поэтому такой метод на большее не способен, а ничего лучше не придумали.
Проблема сложнее, чем может показаться на первый взгляд, потому что у байесовских сетей появляются «невидимые» стрелки, идущие вместе с видимыми. «Взлом» и «землетрясение» априорно независимы, но сработавшая сигнализация их связывает: она заставляет подозревать ограбление. Но если вы услышите по радио, что было землетрясение, то начнете предполагать, что оно и виновато. Землетрясение оправдывает срабатывание сигнализации и делает ограбление менее вероятным, а следовательно, между ними появляется зависимость. В байесовской сети все родители той же переменной таким образом оказываются взаимозависимы, что, в свою очередь, порождает еще больше зависимостей, и результирующий граф часто получается намного плотнее, чем исходный.
Критически важный вопрос для логического вывода: можно ли сделать заполненный график «похожим на дерево», чтобы ствол при этом был не слишком толстый. Если у мегапеременной в стволе слишком много возможных значений, дерево будет расти бесконтрольно, пока не заполонит всю планету, как баобабы в «Маленьком принце». В древе жизни каждый вид — это ветвь, но внутри каждой ветви есть граф, где у каждого создания имеются двое родителей, четыре внука, какое-то количество потомков и так далее. «Толщина» ветви — это размер популяции данного вида. Если ветви слишком толстые, единственный выбор — прибегнуть к приближенному выводу.
Одно из решений, приведенное Перлом в качестве упражнения в его книге о байесовских сетях, — делать вид, что в графе нет петель, и продолжать распространять вероятности туда-сюда, пока они не сойдутся. Такой алгоритм известен как циклическое распространение доверия. Вообще говоря, идея странная, но, как оказалось, во многих случаях она довольно хорошо работает. Например, это один из современных методов беспроводной связи, где случайные переменные — хитрым образом закодированные биты сообщения. Но циклическое распространение доверия может сходиться и к неправильным ответам или бесконечно изменяться (осциллировать). Еще одно решение проблемы возникло в физике, было импортировано в машинное обучение и значительно расширено Майклом Джорданом и другими учеными. Оно заключается в том, чтобы приблизить неразрешимое распределение с помощью разрешимого, оптимизировать параметры последнего и как можно ближе приблизить его к первому.
Но самый популярный вариант — утопить наши печали в вине и бродить всю ночь пьяным. По-научному это называется метод Монте-Карло в марковских цепях, или сокращенно MCMC. «Монте-Карло» потому, что в методе есть шансы, как в казино в одноименном городе, а марковские цепи упоминаются потому, что в этот метод входит последовательность шагов, каждый из которых зависит только от предыдущего. Идея MCMC заключается в том, чтобы совершать случайные прогулки, как упомянутый пьяница, перепрыгивая из одного состояния сети в другое таким образом, чтобы в долгосрочной перспективе число посещений каждого состояния было пропорционально вероятности этого состояния. Затем мы можем оценить вероятность взлома, скажем, как долю посещений состояния, в котором происходит ограбление. Удобная для анализа цепь Маркова сводится к стабильному распределению и через какое-то время начинает давать приблизительно те же ответы. Например, если вы тасуете колоду карт, через какое-то время все порядки карт станут одинаково вероятными, независимо от исходного порядка, поэтому вы будете знать, что при n возможных вариантов вероятность каждого из них будет равна 1⁄n. Весь фокус в MCMC заключается в том, чтобы разработать цепь Маркова, которая сходится к распределению нашей байесовской сети. Простой вариант — многократно циклически проходить через переменные, делая выборку каждой в соответствии с ее условной вероятностью, исходя из состояния соседей. Люди часто говорят об MCMC как о своего рода симуляции, но это не так: цепь Маркова не имитирует какой-то реальный процесс — скорее, она придумана для того, чтобы эффективно генерировать примеры из байесовской сети, которая сама по себе не является последовательной моделью.
Истоки MCMC восходят к Манхэттенскому проекту, в котором физики оценивали вероятность столкновения нейтронов с атомами, вызывающего цепную реакцию. В последующие десятилетия метод произвел такую революцию, что его часто называют одним из самых важных алгоритмов всех времен. MCMC хорош не только для вычисления вероятностей, но и для интегрирования любых функций. Без него ученые были бы ограничены функциями, которые можно интегрировать аналитически, или низкоразмерными, удобными для анализа интегралами, которые можно приблизить методом трапеций. MCMC позволяет свободно строить сложные модели, делая всю трудную работу за вас. Байесовцы, со своей стороны, обязаны MCMC растущей популярностью своих методов, вероятно, больше, чем чему-то другому.
Отрицательный момент — то, что MCMC зачастую мучительно медленно сходится или начинает обманывать, потому что кажется, что он сошелся, а на самом деле нет. В реальных распределениях обычно очень много пиков, которые, как Эвересты, взлетают над широкой равниной крохотных вероятностей. Цепь Маркова, следовательно, будет сходиться к ближайшему пику и останется там, а оценка вероятности окажется очень пристрастной: как если бы пьяница учуял запах спиртного и завис на всю ночь в ближайшей забегаловке, вместо того чтобы бесцельно слоняться по городу, как нам нужно. С другой стороны, если вместо цепи Маркова сгенерировать независимые пробы, как в более простых методах Монте-Карло, никакого запаха не будет и, вероятно, наш пьяница даже не найдет первый кабак. Это все равно что бросать дротики в карту города, надеясь, что они попадут прямиком в паб.
Логический вывод в байесовских сетях не ограничен вычислением вероятностей. К нему относится и нахождение наиболее вероятного объяснения признаков, например заболевания, которое лучше всего объясняет симптомы, или слов, которые лучше всего объясняют звуки, услышанные Siri. Это не то же самое, что просто выбрать на каждом этапе самое вероятное слово, потому что слова, которые схожи по отдельности исходя из звуков, могут реже встречаться вместе, как в примере «Позови к позицию». Однако и в таких задачах срабатывают аналогичные виды алгоритмов (именно их использует большинство распознавателей речи). Самое главное, что вывод предусматривает принятие наилучших решений не только на основе вероятности разных исходов, но и с учетом соответствующих затрат (или, говоря научным языком, полезности). Затраты, связанные с проигнорированным письмом от начальника, который просит что-то сделать завтра, будут намного выше, чем затраты на ознакомление с ненужным рекламным письмом, поэтому часто целесообразно пропустить письма через фильтр, даже если они довольно сильно напоминают спам.
Беспилотные автомобили и другие роботы — показательный пример работы вероятностного вывода. Машина ездит туда-сюда, создает карту территории и все увереннее определяет свое положение. Согласно недавнему исследованию, у лондонских таксистов увеличиваются размеры задней части гиппокампа — области мозга, участвующей в создании карт и запоминании, — когда они учатся ориентироваться в городе. Наверное, здесь действуют аналогичные алгоритмы вероятностного вывода с той лишь важной разницей, что людям алкоголь, по-видимому, не помогает.
Учимся по-байесовски
Теперь, когда мы знаем, как (более-менее) решать проблему логического вывода, можно приступать к обучению байесовских сетей на основе данных, ведь для байесовцев обучение — это всего лишь очередная разновидность вероятностного вывода. Все что нужно — применить теорему Байеса, где гипотезы будут возможными причинами, а данные — наблюдаемым следствием:
P(гипотеза | данные) = P(гипотеза) × P(данные | гипотеза) / P(данные).
Гипотеза может быть сложна, как целая байесовская сеть, или проста, как вероятность, что монетка упадет орлом вверх. В последнем случае данные — это просто результат серии подбрасываний. Если, скажем, мы получили 70 орлов в сотне подбрасываний, сторонник частотного подхода оценит, что вероятность выпадения орла составляет 0,7. Это оправдано так называемым принципом наибольшего правдоподобия: из всех возможных вероятностей орлов 0,7 — то значение, при котором вероятность увидеть 70 орлов при 100 подбрасываниях максимальна. Эта вероятность — P(данные | гипотеза), и принцип гласит, что нужно выбирать гипотезу, которая ее максимизирует. Байесовцы, однако, поступают разумнее. Они говорят, что никогда точно не известно, какая из гипотез верна, и поэтому нельзя просто выбирать одну гипотезу, например значение 0,7 для вероятности выпадения орла. Надо скорее вычислить апостериорную вероятность каждой возможной гипотезы и при прогнозировании учесть все. Сумма вероятностей должна равняться единице, поэтому, если какая-то гипотеза становится вероятнее, вероятность других уменьшается. Для байесовца на самом деле не существует такого понятия, как истина: есть априорное распределение гипотез, и после появления данных оно становится апостериорным распределением по теореме Байеса. Вот и все.
Это радикальный отход от традиционных научных методов. Все равно что сказать: «Вообще, ни Коперник, ни Птолемей не правы. Давайте лучше предскажем будущие траектории планет исходя из того, что Земля вращается вокруг Солнца, а потом — что Солнце вращается вокруг Земли, а результаты усредним».
Конечно, здесь речь идет о взвешенном среднем, где вес гипотезы — это ее апостериорная вероятность, поэтому гипотеза, которая лучше объясняет данные, будет иметь большее значение. Тем не менее ученые шутят, что быть байесовцем — значит никогда не говорить, что ты хоть в чем-то уверен.
Не стоит упоминать, что постоянно таскать за собой множество гипотез вместо одной тяжело. При обучении байесовской сети приходится делать предсказания путем усреднения всех возможных сетей, включая все возможные структуры графов и все возможные параметры значений для каждой структуры. В некоторых случаях можно вычислить среднее по параметрам в замкнутой форме, но с варьирующимися структурами такого везения ждать не приходится. Остается, например, применить MCMC в пространстве сетей, перепрыгивая из одной возможной сети к другой по ходу цепи Маркова. Соедините эту сложность и вычислительные затраты с неоднозначностью байесовской идеи о том, что объективной реальности вообще не существует, и вы поймете, почему в науке последние 100 лет доминирует частотный подход.
У байесовского метода есть, однако, спасительное свойство и ряд серьезных плюсов. В большинстве случаев апостериорная вероятность практически всех гипотез чрезвычайно мала и их можно спокойно проигнорировать: даже рассмотрение одной, наиболее вероятной гипотезы обычно дает очень хорошее приближение. Представьте, что наше априорное распределение для проблемы броска монетки заключается в том, что все вероятности орлов одинаково правдоподобны. После появления результатов последовательных подбрасываний распределение будет все больше и больше концентрироваться на гипотезе, которая лучше всего согласуется с данными. Например, если h пробегает по возможным вероятностям орлов, а монета падает орлом вверх в 70 процентах случаев, получится что-то вроде:
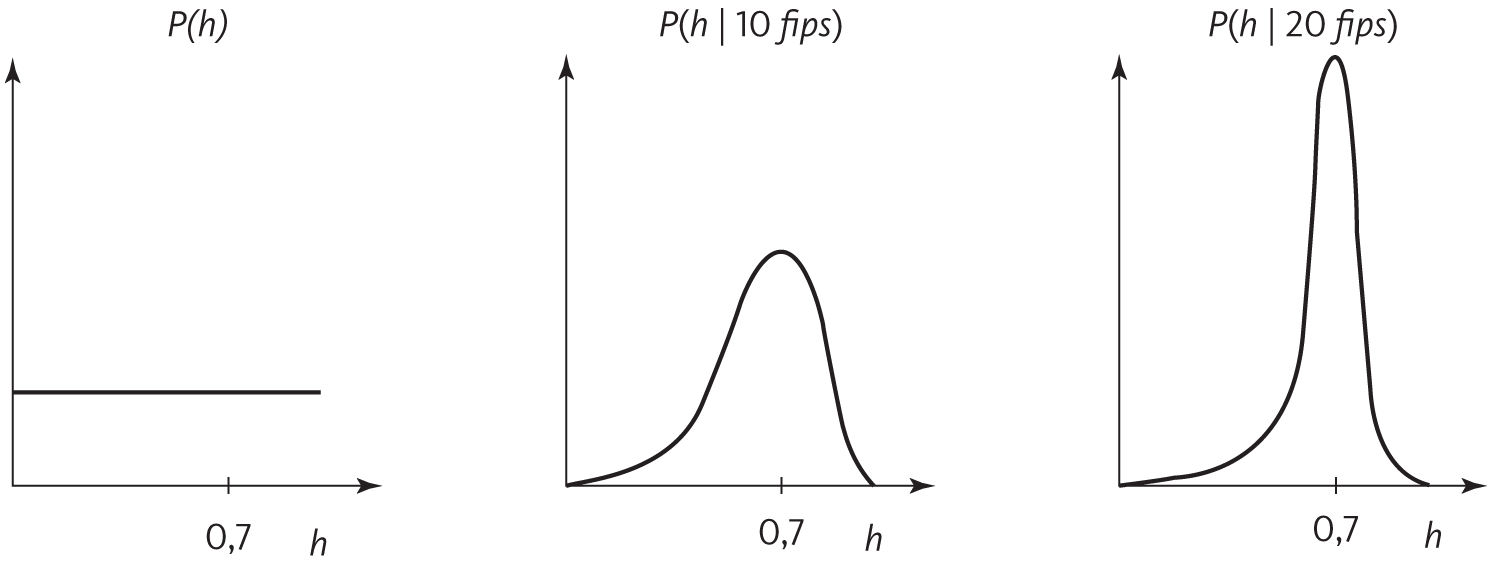
Апостериорная вероятность броска становится априорной для следующего броска, и, бросок за броском, мы все больше убеждаемся, что h = 0,7. Если просто взять одну наиболее вероятную гипотезу (в данном случае h = 0,7), байесовский подход станет довольно похож на частотный, но с одним очень важным отличием: байесовцы учитывают априорную P(гипотеза), а не просто вероятность P(данные | гипотеза). (Данные до P(данные) можно проигнорировать, потому что они одинаковы для всех гипотез и, следовательно, не влияют на выбор победителя.) Если мы хотим сделать допущение, что все гипотезы априори одинаково вероятны, байесовский подход сведется к принципу наибольшего правдоподобия. Поэтому байесовцы могут заявить сторонникам частотного подхода: «Смотрите, то, что вы делаете, — частный случай того, что делаем мы, но наши допущения хотя бы явные». А если гипотезы не одинаково правдоподобны априори, неявное допущение наибольшей правдоподобности заключается в том, что они ведут к неправильным ответам.
Это может показаться чисто теоретической дискуссией, но на самом деле ее практические последствия огромны. Если мы видели, что монету подбросили только один раз и выпал орел, принцип наибольшего правдоподобия подскажет, что вероятность выпадения орла должна быть равна единице. Это будет крайне неточно, и мы окажемся совершенно неподготовлены, если монетка упадет решкой. После многократных подбрасываний оценка станет надежнее, но во многих проблемах подбрасываний никогда не будет достаточно, как бы ни был велик объем данных. Представьте, что в наших обучающих данных слово «суперархиэкстраультрамегаграндиозно» никогда не появляется в спаме, но однажды встречается в письме про Мэри Поппинс. Спам-фильтр, основанный на наивном байесовском алгоритме с оценкой вероятности наибольшего правдоподобия, решит, что такое письмо не может быть спамом, пусть даже все остальные слова вопиют: «Спам! Спам!» Напротив, сторонник байесовского подхода дал бы этому слову низкую, но не нулевую вероятность появления в спаме, и в таком случае другие слова бы его перевесили.
Проблема лишь усугубится, если попытаться узнать и структуру байесовской сети, и ее параметры. Мы можем сделать это путем восхождения по выпуклой поверхности, начиная с пустой сети (без стрелок) и добавляя стрелки, которые больше всего увеличивают вероятность, пока ни одна из них не будет приводить к улучшению. К сожалению, это быстро вызовет очень сильное переобучение, и получится сеть, приписывающая нулевую вероятность всем состояниям, которые не появляются в данных. Байесовцы могут сделать нечто гораздо более интересное: использовать априорное распределение, чтобы закодировать экспертное знание о проблеме. Это их ответ на вопрос Юма. Например, можно разработать исходную байесовскую сеть для медицинской диагностики, опросив врачей, какие заболевания, по их мнению, вызывают те или иные симптомы, и добавить соответствующие стрелки. Это «априорная сеть», и априорное распределение может штрафовать альтернативные сети по числу стрелок, которые они в нее добавляют или убирают. Тем не менее врачам свойственно ошибаться, и данным разрешено перевесить их мнение: если рост правдоподобия в результате добавления стрелки перевешивает штраф, она будет добавлена.
Конечно, сторонникам частотного подхода известно об этой проблеме, и у них есть свои решения: например, умножить правдоподобие на фактор, который штрафует более сложные сети. Но в этот момент частотный и байесовский подходы становятся неразличимыми, и как вы назовете функцию, подсчитывающую очки: «оштрафованным правдоподобием» или «апостериорной вероятностью», — просто дело вкуса.
Несмотря на то что частотный и байесовский типы мышления по некоторым вопросам сходятся, между ними остается философское различие в отношении значения вероятности. Многим ученым неприятно рассматривать его как нечто субъективное, хотя благодаря этому становятся возможными многие применения, которые в противном случае запрещены. Если вы сторонник частотного подхода, можно оценивать вероятности только тех событий, которые происходят более одного раза, и вопросы вроде «Какова вероятность, что Хиллари Клинтон победит Джеба Буша на следующих президентских выборах?» не имеют ответа, потому что еще не было выборов, в которых сошлись бы эти кандидаты. Для байесовца же вероятность — субъективная степень веры, поэтому он волен выдвигать обоснованные предположения, и анализ суждений делает все его предположения состоятельными.
Байесовский метод применим не только к обучению байесовских сетей и их частных случаев. (Наоборот, вопреки названию, байесовские сети не обязательно байесовские: сторонники частотного подхода тоже могут их обучать, как мы только что видели.) Можно применить априорное распределение к любому классу гипотез — наборам правил, нейронным сетям, программам, — а затем обновлять правдоподобие гипотез при получении данных. Байесовская точка зрения заключается в том, что вы можете выбирать представление, но затем его надо обучать с помощью теоремы Байеса. В 1990-х годах байесовцы произвели эффектный захват Конференции по системам обработки нейронной информации (Neural Information Processing Systems, NIPS) — главного мероприятия для коннекционистских исследований. Зачинщиками были Дэвид Маккей, Редфорд Нил и Майкл Джордан. Маккей, британец и студент Джона Хопфилда в Калифорнийском техническом университете, позднее ставший главным научным консультантом Департамента энергетики Великобритании, показал, как обучать по-байесовски многослойные перцептроны, Нил познакомил коннекционистов с MCMC, а Джордан — с вариационным выводом. Наконец, они указали, что в пределе можно «проинтегрировать» нейроны многослойного перцептрона, оставляя тип байесовской модели, которая на них не ссылается. Вскоре после этого слово «нейронный» в заголовках статей, поданных на конференцию по системам обработки нейронной информации, стало резко уменьшать шансы на публикацию. Некоторые шутили, что надо переименовать NIPS в BIPS — «Байесовские системы обработки информации».
Марков взвешивает доказательства
Байесовцы шли к мировому господству, но тут произошло нечто забавное. Ученые, пользующиеся байесовскими моделями, стали постоянно замечать, что результат получается лучше, если манипулировать вероятностями недозволенными методами. Например, возведение P(слова) в определенную степень улучшало точность распознавания речи, но тогда это переставало быть теоремой Байеса. Что произошло? Как оказалось, виновата ложная независимость допущений, которые делают порождающие модели. Благодаря упрощенной структуре графа модели становятся обучающимися и стоящими сохранения, но тогда больше даст простое получение наилучших параметров для имеющейся задачи, независимо от того, представляют ли они собой вероятности. Настоящая сила, скажем, наивного байесовского алгоритма заключается в том, что он дает небольшой информативный набор свойств, на основании которого можно предсказать класс, а также быстрый надежный способ узнать соответствующие параметры. В спам-фильтре каждое свойство — это частота определенного слова в спаме, а соответствующий параметр — то, как часто оно встречается. То же самое для не-спама. Если смотреть с этой точки зрения, наивный байесовский алгоритм может оказаться оптимальным в том смысле, что он делает лучшие возможные предсказания, причем зачастую там, где независимость допущений сильно нарушена. Когда я это понял и в 1996 году опубликовал статью на эту тему, подозрение к наивному Байесу уменьшилось и его популярность выросла. Но это стало шагом на пути к модели другого рода, которая в последние два десятилетия все больше вытесняет байесовские сети из машинного обучения, — к сетям Маркова.
Сеть Маркова — это набор свойств и соответствующих весов, которые вместе определяют распределение вероятности. Свойство может быть простое, например «это медленная песня», или сложное, например «это медленный хип-хоп с саксофонной импровизацией и нисходящим аккордовым пассажем». В сервисе Pandora используется большой набор свойств, который создатели называют Music Genome Project. Он помогает отобрать песни, которые вам стоит послушать. Представьте, что мы подключили ее к сети Маркова. Если вы любите медленные песни, веса соответствующих свойств пойдут вверх и вы с большей вероятностью будете слышать такую музыку, если включите Pandora. Если вы при этом любите исполнителей хип-хопа, вес этого свойства тоже вырастет. Песни, которые вы, скорее всего, услышите, теперь объединят обе черты: это будут медленные композиции в исполнении хип-хоперов. Если вы не любите медленные песни или хип-хоперов как таковых и вам нравится только их сочетание, понадобится более сложная черта — «медленная песня в исполнении хип-хопера». Свойства Pandora созданы вручную, но в сетях Маркова их можно получить путем восхождения на выпуклые поверхности, аналогично выведению правил. В любом случае хороший способ узнать веса — градиентный спуск.
Как и байесовские сети, сети Маркова можно представить в виде графов, но вместо стрелок будут ненаправленные дуги. Когда две переменные соединены, это значит, что они прямо зависят друг от друга, если появляются вместе в каком-то свойстве, как «медленная песня» и «песня в исполнении хип-хопера» в свойстве «медленная песня в исполнении хип-хопера».
Сети Маркова — базовая методика во многих областях, например компьютерном зрении. В частности, беспилотный автомобиль должен разделить любое увиденное изображение на дорогу, небо и окружающую местность. Один из вариантов — присвоить каждому пикселю, в зависимости от цвета, один из трех ярлыков, но этого совершенно недостаточно. Изображения очень зашумлены и разнообразны, поэтому у машины постоянно будут галлюцинации: разбросанные по всей дороге камни, куски дороги в небе. В то же время известно, что соседние пиксели на изображении обычно входят в один и тот же объект, и можно ввести соответствующий набор свойств: для каждой пары соседних пикселей свойство верно, если пиксели относятся к тому же самому объекту, и ложно, если это не так. Теперь изображения с крупными, сплошными блоками дороги и неба становятся намного более вероятными, чем изображения без них, и машина начинает ехать прямо, вместо того чтобы вилять то влево, то вправо, уворачиваясь от привидевшихся булыжников.
Сети Маркова можно обучить максимизировать либо правдоподобие всех данных, либо условную функцию правдоподобия того, что мы хотим предсказать, исходя из имеющихся знаний. Для Siri вероятность всех данных — это P(слова, звуки), а условное правдоподобие того, что нас интересует, — P(слова | звуки). Оптимизируя последнее, можно проигнорировать P(звуки), потому что оно только отвлекает от цели, и, если его не проигнорировать, оно может быть произвольно сложным. Это намного лучше, чем нереалистичное допущение СММ, что звуки зависят исключительно от соответствующих слов без какого-либо влияния среды. На самом деле Siri важно только понять, какие слова вы произнесли, и, наверное, даже не стоит беспокоиться о вероятностях: достаточно просто убедиться, что при подсчете весов свойств у правильных слов сумма пунктов будет больше, чем у неправильных. В идеале намного больше, просто для безопасности.
Как мы увидим в следующей главе, аналогизаторы довели эту линию рассуждения до логического завершения и в первом десятилетии нового тысячелетия завоевали конференцию NIPS. Коннекционисты еще раз взяли верх, теперь уже под знаменем глубокого обучения. Некоторые говорят, что наука развивается циклами, но она больше похожа на спираль вокруг вектора прогресса. Спираль машинного обучения сходится в Верховном алгоритме.
Логика и вероятность: несчастная любовь
Вы ошибаетесь, если думаете, что байесовцы и символисты отлично поладят, потому что и те и другие верят в теоретический, а не естественно-научный подход к обучению. Символисты не любят вероятностей и рассказывают анекдоты вроде «Сколько байесовцев нужно, чтобы поменять лампочку? Они сами точно не знают. Если подумать, они даже не уверены, перегорела ли лампочка». А если серьезно, символисты показывают, какую высокую цену приходится платить за вероятность. Логический вывод внезапно становится намного затратнее, все эти числа сложно понять, надо что-то делать с априорной информацией и постоянно убегать от полчищ гипотез-зомби. Пропадает столь милая сердцу символистов способность на лету складывать элементы знаний. Хуже всего то, что неизвестно, как применить распределение вероятностей ко многим проблемам, которые нам надо решить. Байесовская сеть — это распределение по вектору переменных. А что с распределениями по сетям, базам данных, базам знаний, языкам, планам, компьютерным программам и многому другому? Со всем этим легко справляется логика, и, раз алгоритм на это неспособен, это явно не Верховный алгоритм.
Байесовцы, в свою очередь, указывают на хрупкость логики. Если у меня есть правило вроде «Птицы летают», мир даже с одной нелетающей птицей невозможен. Если попытаться залатать все дыры исключениями, например «Птицы летают, если они не пингвины», их получится бесконечно много. (Что со страусами? С птицами в клетке? Мертвыми птицами? Птицами со сломанными крыльями? С промокшими крыльями?) Врач диагностирует рак, и больной решает проконсультироваться еще у одного специалиста. Если второй доктор не согласен с первым, ситуация заходит в тупик. Мнения нельзя взвесить, приходится просто верить обоим. В результате происходит катастрофа: свиньи летают, вечный двигатель возможен, а Земли не существует — потому что в логике из противоречий можно вывести что угодно. Более того, если знание получено из данных, никогда нельзя быть уверенным, что оно истинно. Почему символисты делают вид, что это не так? Юм, несомненно, не одобрил бы такую беззаботность.
Байесовцы и символисты соглашаются, что априорные допущения неизбежны, но расходятся в том, какое априорное знание разрешено. Для байесовцев знание выражается в априорном распределении по структуре и параметрам модели. Априорными параметрами в принципе может быть все что угодно, но, по иронии, байесовцы, как правило, выбирают неинформативные (например, приписывают всем гипотезам одну и ту же вероятность), потому что им так удобнее делать расчеты. И в любом случае люди не очень хорошо умеют оценивать вероятности. Что касается структуры, байесовские сети предполагают интуитивное инкорпорирование знаний: нарисуй стрелку из A в B, если думаешь, что A прямо вызывает B. Символисты намного гибче: можно дать алгоритму машинного обучения в качестве априорного знания все, что можно закодировать путем логики, а логикой можно закодировать практически все при условии, что это «все» — черно-белое.
Очевидно, что нужны и логика, и вероятности. Хороший пример — лечение рака. Байесовская сеть может моделировать отдельный аспект функционирования клеток, например регуляцию генов или фолдинг белка, но только логика может сложить фрагменты в связную картину. С другой стороны, логика не может работать с неполной или зашумленной информацией, которой очень много в экспериментальной биологии, а байесовские сети прекрасно с этим справляются.
Байесовское обучение работает на одной таблице данных, где столбцы представляют переменные (например, уровень экспрессии гена), а строки — случаи (например, наблюдаемый в отдельных экспериментах с микрочипом уровень экспрессии каждого гена). Ничего страшного, если в таблице есть «дыры» и ошибочные измерения, потому что можно применить вероятностный вывод, чтобы заполнить пробелы и сгладить ошибки путем усреднения. Но когда таблиц больше, байесовское обучение заходит в тупик. Оно не знает, например, как соединить данные об экспрессии генов с данными о том, какой сегмент ДНК кодирует белки, и как, в свою очередь, трехмерная форма этих белков заставляет их прикрепляться к разным частям молекулы ДНК, влияя на экспрессию других генов. В случае логики мы легко можем составить правила, связывающие все эти аспекты, и получить соответствующие комбинации таблиц, но только при условии, что в таблицах нет ошибок и белых пятен.
Соединить коннекционизм и эволюционизм довольно легко: просто эволюционируйте структуру сети и получите параметры путем обратного распространения ошибки. Объединить логику и вероятностный подход намного сложнее. Попытки решить эту проблему предпринимал еще Лейбниц, который был пионером в обеих областях, а после него — лучшие философы и математики XIX и XX века, например Джордж Буль и Рудольф Карнап. Несмотря на все усилия, результаты были очень скромными. Позднее в бой вступили информатики и исследователи искусственного интеллекта, но к началу нового тысячелетия они достигли лишь частичных успехов, например, к байесовским сетям добавили логические конструкты. Большинство экспертов были убеждены, что объединить логику и вероятности вообще невозможно. Перспективы создания Верховного алгоритма выглядели неважно, особенно потому, что существовавшие тогда эволюционистские и коннекционистские алгоритмы тоже не могли справиться с неполной информацией и множественными наборами данных.
К счастью, с тех пор мы продвинулись вперед на пути к решению проблемы, и сегодня Верховный алгоритм кажется намного ближе. Решение мы увидим в главе 9, но сначала надо подобрать все еще недостающую очень важную часть мозаики: как учиться, если данных очень мало. Здесь вступает в игру одна из самых важных идей в машинном обучении: аналогия. У всех «племен», которые мы до сих пор встретили, есть одна общая черта: они получают явную модель рассматриваемого явления, будь то набор правил, многослойный перцептрон, генетическая программа или байесовская сеть. Если у них для этого недостаточно данных, они заходят в тупик. А аналогизаторам для обучения достаточно всего одного примера, потому что они модели не формируют. Давайте посмотрим, чем они вместо этого занимаются.

