ГЛАВА 5
ЭВОЛЮЦИЯ: ОБУЧАЮЩИЙСЯ АЛГОРИТМ ПРИРОДЫ
Перед вами Robotic Park — огромная фабрика по производству роботов. Вокруг нее — тысяча квадратных миль джунглей, каменных и не очень. Джунгли окружает самая высокая и толстая в мире стена, утыканная наблюдательными вышками, прожекторами и орудийными гнездами. У стены две задачи: не пустить на фабрику нарушителей и не выпустить ее обитателей — миллионы роботов, сражающихся за выживание и власть. Роботы-победители размножаются путем доступа к программированию 3D-принтеров. Шаг за шагом роботы становятся умнее, быстрее и смертоноснее. Robotic Park принадлежит Армии США и призван путем эволюции вывести совершенного солдата.
Пока такой фабрики не существует, но однажды она может появиться. Несколько лет назад на мастер-классе DARPA я предложил эту идею в рамках мысленного эксперимента, и один из присутствующих в зале высших чинов сухо заметил: «Да, это реализуемо». Его решимость будет выглядеть не такой пугающей, если вспомнить, что для обучения своих подразделений американская армия построила в калифорнийской пустыне полноценный макет афганской деревни вместе с жителями, так что несколько миллиардов долларов — небольшая цена за идеального бойца.
Первые шаги в этом направлении уже сделаны. В лаборатории Creative Machines Lab в Корнелльском университете, которой руководит Ход Липсон, роботы причудливых форм учатся плавать и летать — возможно, прямо сейчас, когда вы читаете эти строки. Один из них похож на ползающую башню из резиновых блоков, другой — на вертолет со стрекозиными крыльями, еще один — на меняющий форму конструктор Tinkertoy. Эти роботы созданы не инженерами, а эволюцией — тем самым процессом, который породил разнообразие жизни на Земле. Изначально роботы эволюционируют внутри компьютерной симуляции, но, как только они становятся достаточно перспективными, чтобы выйти в реальный мир, их автоматически печатают на 3D-принтере. Творения Липсона пока не готовы захватить мир, но они уже далеко ушли от первобытного набора элементов в компьютерной программе, в которой они родились.
Алгоритм, обеспечивший эволюцию этих роботов, изобрел в XIX веке Чарльз Дарвин. В то время он не воспринимал эволюцию как алгоритм, отчасти потому, что в ней недоставало ключевой подпрограммы. Как только Джеймс Уотсон и Фрэнсис Крик в 1953 году открыли ее, все было готово для второго пришествия: эволюция in silico вместо in vivo, происходящая в миллиард раз быстрее. Ее пророком стал Джон Холланд — румяный улыбчивый парень со Среднего Запада.
Алгоритм Дарвина
Как и многие другие ученые, работавшие над ранними этапами машинного обучения, Холланд начинал с нейронных сетей, но, после того как он — тогда еще студент Мичиганского университета — прочитал классический трактат Рональда Фишера The Genetical Theory of Natural Selection, его интересы приобрели другое направление. В своей книге Фишер, который также был основателем современной статистики, сформулировал первую математическую теорию эволюции. Теория Фишера была блестящей, но Холланд чувствовал, что в ней не хватает самой сути эволюции: автор рассматривал каждый ген изолированно, а ведь приспособленность организма — комплексная функция всех его генов. Если бы гены были независимы, частотность их вариантов очень быстро сошлась бы в точку максимальной приспособленности и после этого оставалась бы в равновесии. Но если гены взаимодействуют, эволюция — поиск максимальной приспособленности — становится невообразимо сложнее. Когда в геноме тысяча генов и у каждого два варианта, это даст 21000 возможных состояний: во Вселенной нет такой древней и большой планеты, чтобы все перепробовать. И тем не менее эволюция на Земле сумела создать ряд замечательно приспособленных организмов, и теория естественного отбора Дарвина объясняет, как именно это происходит, по крайней мере качественно, а не количественно. Холланд решил превратить все это в алгоритм.
Но сначала ему надо было окончить университет. Он благоразумно выбрал более традиционную тему — булевы схемы с циклами — и в 1959 году защитил первую в мире диссертацию по информатике. Научный руководитель Холланда Артур Бёркс поощрял интерес к эволюционным вычислениям: помог ему устроиться по совместительству на работу в Мичиганском университете и защищал его от нападок старших коллег, которые вообще не считали эту тему информатикой. Сам Бёркс был таким открытым для новых идей, потому что тесно сотрудничал с Джоном фон Нейманом, доказавшим принципиальную возможность существования самовоспроизводящихся машин. Бёрксу выпало завершить эту работу после того, как в 1957 году фон Нейман умер от рака. То, что фон Нейману удалось доказать возможность существования таких машин, — замечательное достижение, учитывая примитивное состояние генетики и информатики в то время, однако его автомат просто делал точные копии самого себя: эволюционирующие автоматы ждали Холланда.
Ключевой вход генетического алгоритма, как назвали творение Холланда, — функция приспособленности. Если имеется программа-кандидат и некая цель, которую эта программа должна выполнить, функция приспособленности присваивает программе баллы, показывающие, насколько хорошо она справилась с задачей. Можно ли так интерпретировать приспособленность в естественном отборе — большой вопрос: приспособленность крыла к полету интуитивно понятна, однако цель эволюции как таковой неизвестна. Тем не менее в машинном обучении необходимость чего-то похожего на функцию приспособленности не вызывает никаких сомнений. Если нам нужно поставить диагноз, то программа, которая дает правильный результат у 60 процентов пациентов в нашей базе данных, будет лучше, чем та, что попадает в точку только в 55 процентах случаев, и здесь возможной функцией приспособленности станет доля правильно диагностированных случаев.
В этом отношении генетические алгоритмы во многом похожи на искусственную селекцию. Дарвин открывает «Происхождение видов» дискуссией на эту тему, чтобы, оттолкнувшись от нее, перейти к более сложной концепции естественного отбора. Все одомашненные растения и животные, которые мы сегодня воспринимаем как должное, появились в результате многих поколений отбора и спаривания организмов, лучше всего подходящих для наших целей: кукурузы с самыми крупными початками, деревьев с самыми сладкими фруктами, самых длинношерстных овец, самых выносливых лошадей. Генетические алгоритмы делают то же самое, только выращивают они не живых существ, а программы, и поколение длится несколько секунд компьютерного времени, а не целую жизнь.
Функция приспособленности воплощает роль человека в этом процессе, но более тонкий аспект — это роль природы. Начав с популяции не очень подходящих кандидатов — возможно, совершенно случайных, — генетический алгоритм должен прийти к вариантам, которые затем можно будет отобрать на основе приспособленности. Как это делает природа? Дарвин этого не знал. Здесь в игру вступает генетическая часть алгоритма. Точно так же как ДНК кодирует организм в последовательности пар азотистых оснований, программу можно закодировать в строке битов. Вместо нулей и единиц алфавит ДНК состоит из четырех символов — аденина, тимина, гуанина и цитозина. Но различие лишь поверхностное. Вариативность последовательности ДНК, или строки битов, можно получить несколькими способами. Самый простой подход — это точечная мутация, смена значения произвольного бита в строке или изменение одного основания в спирали ДНК. Но Холланд видел настоящую мощь генетических алгоритмов в более сложном процессе: половом размножении.
Если снять с полового размножения все лишнее (не хихикайте), останется суть: обмен генетического материала между хромосомами отца и матери. Этот процесс называется кроссинговер, и его результат — появление двух новых хромосом. Первая состоит из материнской хромосомы до точки перекреста, после которой идет отцовская, вторая — наоборот:
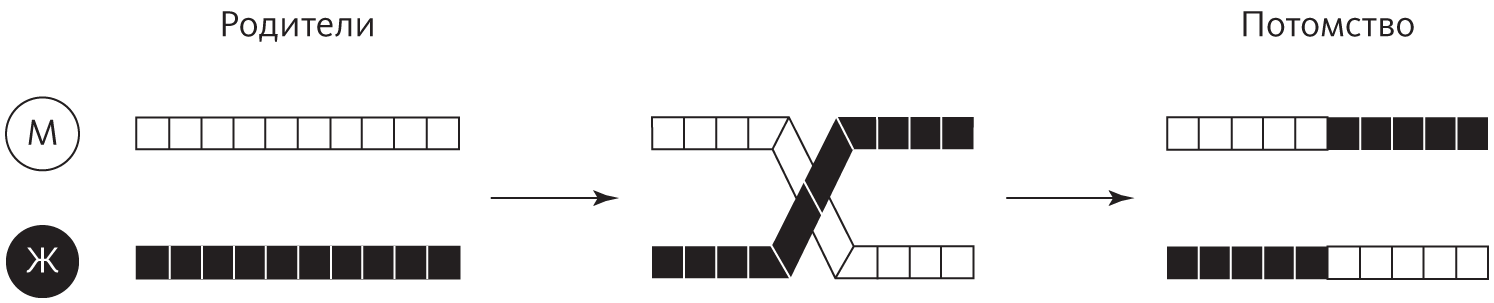
Генетический алгоритм основан на подражании этому процессу. В каждом поколении он сводит друг с другом самые приспособленные особи, перекрещивает их битовые строки в произвольной точке и получает двух потомков от каждой пары родителей. После этого алгоритм делает в новых строках точечные мутации и отпускает в виртуальный мир. Когда строки возвращаются с присвоенным значением приспособленности, процесс повторяется заново. Каждое новое поколение более приспособлено, чем предыдущее, и процесс прерывается либо после достижения желаемой приспособленности, либо когда заканчивается время.
Представьте, например, что нам нужно вывести правило для фильтрации спама. Если в обучающих данных десять тысяч разных слов, каждое правило-кандидат можно представить в виде строки из 20 тысяч битов, по два для каждого слова. Первый бит для слова «бесплатно» будет равен единице, если письмам, содержащим слово «бесплатно», разрешено соответствовать правилу, и нулю, если не разрешено. Второй бит противоположен: один, если письма, не содержащие слова «бесплатно», соответствуют правилу, и ноль — если не соответствуют. Если единице равны оба бита, письмо будет соответствовать правилу вне зависимости от того, содержит оно слово «бесплатно» или нет, то есть правило, по сути, не содержит условий для этого слова. С другой стороны, если оба бита равны нулю, правилу не будут соответствовать никакие письма, поскольку либо один, либо другой бит всегда ошибается и такой фильтр пропустит любые письма (ой!). В целом письмо соответствует правилу, только если оно разрешает весь паттерн содержащихся и отсутствующих в нем слов. Приспособленностью правила может быть, например, процент писем, который оно правильно классифицирует. Начиная с популяции произвольных строк, каждая из которых представляет собой правило с произвольными условиями, генетический алгоритм будет выводить все более хорошие правила путем повторяющегося кроссинговера и мутаций самых подходящих строк в каждом поколении. Например, если в текущей популяции есть правило «Если письмо содержит слово “бесплатный” — это спам» и «Если письмо содержит слово “легко” — это спам», перекрещивание их даст, вероятно, более подходящее правило «Если письмо содержит слова “бесплатный” и “легко” — это спам», при условии, что перекрест не придется между двумя битами, соответствующими одному из этих слов. Кроссинговер также породит правило «Все письма — спам», которое появится в результате отбрасывания обоих условий. Но у этого правила вряд ли будет много потомков в следующем поколении.
Поскольку наша цель — создать лучший спам-фильтр из всех возможных, мы не обязаны честно симулировать настоящий естественный отбор и можем свободно хитрить, подгоняя алгоритм под свои нужды. Одна из частых уловок — допущение бессмертия (жаль, что в реальной жизни его нет): хорошо подходящая особь будет конкурировать за размножение не только в своем поколении, но и с детьми, внуками, правнуками и так далее — до тех пор пока остается одной из самых приспособленных в популяции. В реальном мире все не так. Лучшее, что может сделать очень приспособленная особь, — передать половину своих генов многочисленным детям, каждый из которых будет, вероятно, менее приспособлен, так как другую половину генов унаследует от второго родителя. Бессмертие позволяет избежать отката назад, и при некотором везении алгоритм быстрее достигнет желаемой приспособленности. Конечно, если оценивать по количеству потомков, самые приспособленные индивидуумы в истории были похожи на Чингисхана — предка одного из двух сотен живущих сегодня людей. Так что, наверное, не так плохо, что в реальной жизни бессмертие не дозволено.
Если мы хотим вывести не одно, а целый набор правил фильтрации спама, можно представить набор — кандидат из n правил в виде строки n × 20 000 битов (20 тысяч для каждого правила, если в данных, как раньше, 10 тысяч разных слов). Правила, содержащие для каких-то слов 00, выпадают из набора, поскольку они, как мы видели выше, не подходят ни к каким письмам. Если письмо подходит к любому правилу в наборе, оно классифицируется как спам. В противном случае оно допустимо. Мы по-прежнему можем сформулировать приспособленность как процент правильно классифицированных писем, но для борьбы с переобучением, вероятно, будет целесообразно вычитать из результата штраф, пропорциональный сумме активных условий в наборе правил.
Мы поступим еще изящнее, если разрешим выводить правила для промежуточных концепций, а затем выстраивать цепочки из этих правил в процессе работы. Например, мы можем получить правила «Если письмо содержит слово “кредит” — это мошенничество» и «Если письмо — мошенничество, значит, это письмо — спам». Поскольку теперь следствие из правила не всегда «спам», требуется ввести в строки правил дополнительные биты, чтобы представить эти следствия. Конечно, компьютер не использует слово «мошенничество» буквально: он просто выдает некую строку битов, представляющую это понятие, но для наших целей этого вполне достаточно. Такие наборы правил Холланд называет системами классификации. Они «рабочие лошадки» эволюционистов — основанного им племени машинного обучения. Как и многослойные перцептроны, системы классификации сталкиваются с проблемой присвоения коэффициентов доверия — какова приспособленность правил к промежуточным понятиям? — и для ее решения Холланд разработал так называемый алгоритм пожарной цепочки. Тем не менее системы классификации используются намного реже, чем многослойные перцептроны.
По сравнению с простой моделью, описанной в книге Фишера, генетические алгоритмы — довольно большой скачок. Дарвин жаловался, что ему не хватает математических способностей, но, живи он на столетие позже, то, вероятно, горевал бы из-за неумения программировать. Поймать естественный отбор в серии уравнений действительно крайне сложно, однако выразить его в виде алгоритма — совсем другое дело, и это могло бы пролить свет на многие мучающие человечество вопросы. Почему виды появляются в палеонтологической летописи внезапно? Где доказательства, что они постепенно эволюционировали из более ранних видов? В 1972 году Нильс Элдридж и Стивен Джей Гулд предположили, что эволюция состоит из ряда «прерывистых равновесий»: перемежающихся длинных периодов застоя и коротких всплесков быстрых изменений, одним из которых стал кембрийский взрыв. Эта теория породила жаркие дебаты: критики прозвали ее «дерганной эволюцией». На это Элдридж и Гулд отвечали, что постепенную эволюцию можно назвать «ползучей». Эксперименты с генетическими алгоритмами говорят в пользу скачков. Если запустить такой алгоритм на 100 тысяч поколений и понаблюдать за популяцией в тысячепоколенных отрезках, график зависимости приспособленности от времени будет, вероятно, похож на неровную лестницу с внезапными скачками улучшений, за которыми идут плоские периоды затишья, со временем длящиеся все дольше. Несложно догадаться, почему так происходит: когда алгоритм достигнет локального максимума — пика на ландшафте приспособленности, — он будет оставаться там до тех пор, пока в результате счастливой мутации или кроссинговера какая-то особь не окажется на склоне более высокого пика: в этот момент такая особь начнет размножаться и с каждым поколением взбираться по склону все выше. Чем выше текущий пик, тем дольше приходится ждать такого события. Конечно, в природе эволюция сложнее: во-первых, среда может меняться — как физически, так и потому, что другие организмы тоже эволюционируют, и особь на пике приспособленности вдруг может почувствовать давление и будет вынуждена эволюционировать снова. Так что текущие генетические алгоритмы полезны, но конец пути еще очень далеко.
Дилемма изучения–применения
Обратите внимание, насколько генетические алгоритмы отличаются от многослойных перцептронов. Метод обратного распространения в любой момент времени рассматривает одну гипотезу, и эта гипотеза постепенно меняется, пока не найдет локальный оптимум. Генетические алгоритмы на каждом этапе рассматривают всю популяцию гипотез и благодаря кроссинговеру способны делать большие скачки от одного поколения к другому. После установления небольших произвольных исходных весов обратное распространение действует детерминистски, а в генетических алгоритмах много случайных выборов: какие гипотезы оставить в живых и подвергнуть кроссинговеру (более вероятные кандидаты — лучше приспособленные гипотезы), где скрестить две строки, какие биты мутировать. Процесс обратного распространения получает веса для заранее определенной архитектуры сети: более густые сети эластичнее, но их сложнее обучать. Генетические алгоритмы не делают априорных допущений об изучаемой структуре, кроме общей формы.
Благодаря этому генетические алгоритмы с намного меньшей вероятностью, чем обратное распространение ошибки, застревают в локальном оптимуме и в принципе более способны прийти к чему-то по-настоящему новому. В то же время их намного сложнее анализировать. Откуда нам знать, что генетический алгоритм получит что-то осмысленное, а не будет, как пьяный, слоняться вокруг да около? Главное здесь — мыслить в категориях кирпичиков. Каждый поднабор битов в строке потенциально кодирует полезный кирпичик, и, если скрестить две строки, кирпичики сольются в более крупный блок, который мы будем использовать в дальнейшем. Иллюстрировать силу кирпичиков Холланд любил с помощью фотороботов. До появления компьютеров полицейские художники умели по показаниям свидетелей быстро рисовать портрет подозреваемого: подбирали бумажную полоску из набора типичных форм рта, потом полоску с глазами, носом, подбородком и так далее. Система из десяти элементов по десять вариантов каждого позволяла составить 10 миллиардов разных лиц. Это больше, чем людей на планете.
В машинном обучении и вообще в информатике нет ничего лучше, чем сделать комбинаторный взрыв не врагом, а союзником. В генетических алгоритмах интересно то, что каждая строка косвенно содержит экспоненциальное число строительных блоков — схем, — поэтому поиск намного эффективнее, чем кажется. Дело в том, что каждый поднабор битов в строке — это схема, представляющая некую потенциально подходящую комбинацию свойств, а количество поднаборов в строке экспоненциально. Схему можно представить, заменив не входящие в нее биты звездочкой: например, строка 110 содержит схемы ***, **0, *1*, 1**, *10, 11*, 1*0 и 110. Каждый выбор битов дает свою схему, а поскольку для каждого бита у нас есть два варианта действий (включать / не включать в схему), это дает 2n схем. И наоборот, конкретную схему в популяции могут представлять многие строки, и каждый раз схема неявно оценивается. Представьте, что вероятность выживания и перехода гипотезы в следующее поколение пропорциональна ее приспособленности. Холланд показал, что в таком случае чем более приспособлены представления схемы в одном поколении по сравнению со средним значением, тем с большей вероятностью можно ожидать увидеть их в следующем поколении. Поэтому, хотя генетический алгоритм явно оперирует строками, косвенно он ищет в гораздо более обширном пространстве схем. Со временем в популяции начинают доминировать более приспособленные схемы, и, в отличие от пьяного, генетические алгоритмы находят дорогу домой.
Одна из самых важных проблем как машинного обучения, так и жизни — дилемма изучения–применения. Если вы нашли что-то работающее, лучше просто это использовать или попытаться поискать дальше, зная, что это может оказаться пустой тратой времени, а может привести к более хорошему решению. Лучше быть ковбоем или фермером? Основать новую компанию или управлять уже существующей? Поддерживать постоянные отношения или непрерывно искать свою половинку? Кризис среднего возраста — тяга к изучению после многих лет применения. Человек срывается с места и летит в Лас-Вегас, полный решимости потратить сбережения всей жизни ради шанса стать миллионером. Он входит в первое попавшееся казино и видит ряд игровых автоматов. Сыграть надо в тот, который даст в среднем лучший выигрыш, но где он стоит — неизвестно. Чтобы разобраться, надо попробовать каждый автомат достаточное количество раз, но, если заниматься этим слишком долго, все деньги уйдут на проигрышные варианты. И наоборот, если перестать пробовать слишком рано и выбрать автомат, который случайно показался удачным в первые несколько раундов, но на самом деле не самый хороший, можно играть на нем остаток ночи и просадить все деньги. В этом суть дилеммы изучения–применения: каждый раз приходится выбирать между повторением хода, принесшего наибольший на данный момент выигрыш, и другими шагами, которые дадут информацию, ведущую, возможно, к еще большему выигрышу. Холланд доказал, что для двух игровых автоматов оптимальная стратегия — каждый раз подбрасывать неправильную монету, которая по мере развития событий становится экспоненциально более неправильной. (Только не подавайте на меня в суд, если этот метод не сработает. Помните, что в конечном счете казино всегда выигрывает.) Чем перспективнее выглядит игровой автомат, тем дольше вы должны в него играть, но нельзя совсем отказываться от второго на случай, если в конце концов он окажется лучшим.
Генетический алгоритм похож на вожака банды профессиональных игроков, которые играют в автоматы сразу во всех казино города. Две схемы конкурируют друг с другом, если включают одни и те же биты, но отличаются по крайней мере одним из них, например *10 и *11, а n конкурирующих схем — как n игровых автоматов. Каждый набор конкурирующих схем — это казино, и генетический алгоритм одновременно определяет автомат-победитель в каждом из них, следуя оптимальной стратегии: игре на самых перспективных машинах с экспоненциально увеличивающейся частотой. Хорошо придумано.
В книге «Автостопом по галактике» инопланетная цивилизация строит огромный суперкомпьютер, чтобы ответить на Главный Вопрос, и спустя долгое время компьютер выдает ответ: «42». При этом компьютер добавляет, что инопланетяне не знают, в чем заключается этот вопрос, поэтому те строят еще больший компьютер, чтобы это определить. К сожалению, этот компьютер, известный также как планета Земля, уничтожают, чтобы освободить место для космического шоссе, за несколько минут до завершения вычислений, длившихся много миллионов лет. Теперь можно только гадать, какой это был вопрос, но, наверное, он звучал так: «На каком автомате мне сыграть?»
Выживание самых приспособленных программ
Первые несколько десятилетий сообщество, занимавшееся генетическими алгоритмами, состояло в основном из самого Джона Холланда, его студентов и студентов его студентов. Примерно в 1983 году самой большой проблемой, которую умели решать генетические алгоритмы, было обучение управлению системами газопроводов. Но затем, примерно в период второго пришествия нейронных сетей, интерес к эволюционным вычислениям начал набирать обороты. Первая международная конференция по генетическим алгоритмам состоялась в 1985 году в Питтсбурге, а потом произошел кембрийский взрыв разновидностей генетических алгоритмов. Некоторые из них пробовали моделировать эволюцию более точно: в конце концов, базовый генетический алгоритм был только грубым ее приближением. Другие шли в самых разных направлениях, скрещивая эволюционные идеи с концепциями из области информатики, которые смутили бы Дарвина.
Одним из самых выдающихся студентов Холланда был Джон Коза. В 1987 году он возвращался на самолете в Калифорнию с конференции в Италии, и его озарило: почему бы не получать путем эволюции полноценные компьютерные программы, а не сравнительно простые вещи вроде правил «Если…, то…» и контроллеров газопроводов? А если поставить себе такую цель, зачем держаться за битовые строки как их представление? Программа на самом деле — дерево обращений к подпрограммам, поэтому лучше непосредственно скрещивать эти поддеревья, а не втискивать их в битовые строки и рисковать разрушить отличные подпрограммы, перекрещивая их в произвольной точке.
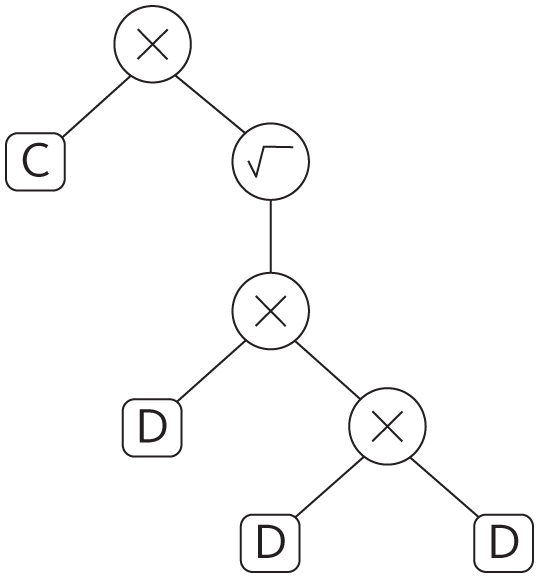
Например, представьте, что вы хотите вывести программу, вычисляющую длину года на некой планете (T) на основе ее расстояния от солнца (D). По третьему закону Кеплера, T — это квадратный корень из D в кубе, умноженный на постоянную C, которая зависит от используемых единиц времени и расстояния. Генетический алгоритм должен уметь работать на основе данных Тихо Браге о планетарных движениях, как когда-то сам Кеплер работал. В подходе Коза D и C — это листья программного дерева, а операции, которые их соединяют, например умножение и извлечение квадратного корня, — это внутренние узлы. Вот программное дерево, которое правильно вычисляет T:
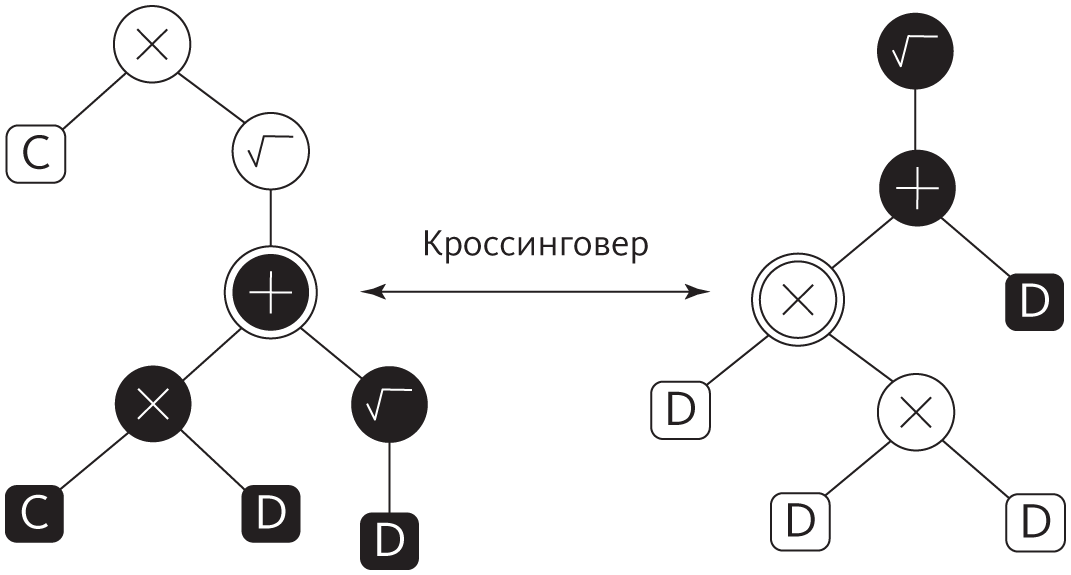
В генетическом программировании, как Коза назвал свой метод, мы скрещиваем два программных дерева, произвольно меняя местами два их поддерева. Например, одним из результатов кроссинговера деревьев на рисунке ниже, проведенного в выделенных узлах, будет правильная программа для вычисления T:
Мы можем измерить приспособленность программы (или ее неприспособленность) по расстоянию между ее фактическим выходом и правильным выходом на обучающих данных. Например, если программа говорит, что на Земле в году 300 дней, это вычтет из ее приспособленности 65 пунктов. Генетическое программирование начинает с популяции случайных программных деревьев, а потом использует кроссинговер, мутации и выживание для постепенного выведения лучших программ, пока не будет удовлетворено результатом.
Конечно, расчет продолжительности планетарного года — очень простая задача: в ней есть только умножение и квадратный корень. В целом программные деревья могут включать полный спектр элементов программирования, например утверждения «если… то…», циклы и рекурсию. Более показательный пример возможностей генетического программирования — это определение последовательности действий робота для достижения определенной цели. Представьте, что я попросил своего офисного робота принести мне степлер из кладовки. У робота для этого есть большой набор возможных действий: пройти по коридору, открыть дверь, взять предмет и так далее. Каждое из них, в свою очередь, может состоять из различных поддействий: например, протянуть манипулятор к предмету, схватить его в самых разных точках. В зависимости от результатов предыдущих действий новые действия могут выполняться или не выполняться, иногда нужно их повторить некоторое количество раз и так далее. Задача состоит в том, чтобы составить правильную структуру действий и поддействий, а также определить параметры каждого из них, например, как далеко выдвинуть манипулятор. Из «атомарных», мельчайших действий робота и их допустимых комбинаций генетическое программирование может собрать сложное поведение для достижения желаемой цели. Многие ученые таким образом выводили стратегии для роботов-футболистов.
Одно из последствий применения кроссинговера к программным деревьям вместо битовых строк заключается в том, что получающиеся в результате программы могут быть любого размера и обучение делается более гибким. Однако такие программы имеют тенденцию к разбуханию: по мере эволюции деревья становятся все больше и больше (это еще называют «выживанием толстейших»). Эволюционисты могут утешиться фактом, что программы, написанные человеком, в этом отношении не лучше — Microsoft Windows содержит 45 миллионов строк кода, — к тому же к созданному человеком коду нельзя применить такие простые решения, как прибавление к функции приспособленности штрафа за сложность.
Первым успехом генетического программирования стала в 1995 году разработка электронных схем. Начав с кучи элементов — транзисторов, резисторов и конденсаторов, — система Коза вновь изобрела запатентованный ранее фильтр нижних частот, который можно использовать, например, для усиления басов в танцевальной музыке. С тех пор Коза превратил повторное изобретение запатентованных устройств в своего рода спорт и начал выдавать их дюжинами. Следующей вехой стал патент на разработанную таким образом промышленную систему оптимизации, выданный в 2005 году Ведомством США по патентам и торговым знакам. Если бы тест Тьюринга заключался в обмане патентного эксперта, а не собеседника, 25 января 2005 года вошло бы в учебники истории.
Своей самоуверенностью Коза выделяется даже среди представителей дисциплины, где скромность не в чести. Он видит в генетическом программировании машину для изобретений, Кремниевого Эдисона XXI столетия. Коза и другие эволюционисты верят, что такой алгоритм может получить любую программу, и ставят на него в гонке за Верховным алгоритмом. В 2004 году они учредили ежегодную премию Humies, которую вручают за «соперничающие с человеком» генетические творения. На сегодняшний день присуждено 39 премий.
Зачем нужен секс?
Несмотря на все успехи и озарения, которые принесли нам генетические алгоритмы в таких вопросах, как градуализм против прерывистого равновесия, одна великая тайна остается неразгаданной: какую роль в эволюции играет половое размножение. Эволюционисты возлагают большие надежды на кроссинговер, однако представители других «племен» считают, что игра не стоит свеч. Ни один из теоретических результатов Холланда не показывает, что кроссинговер полезен: чтобы со временем экспоненциально увеличить частоту наиболее подходящих схем в популяции, достаточно мутаций, а логика «строительных блоков» привлекательна, но быстро сталкивается с проблемами даже при использовании генетического программирования. Когда в ходе эволюции появляются крупные блоки, кроссинговер со все большей вероятностью начинает их разбивать, а если удается вывести очень приспособленную особь, ее потомки, как правило, быстро захватывают популяцию и закрывают собой потенциально более перспективные схемы, содержащиеся в менее приспособленных в целом особях. В результате поиск вариантов сводится к определению чемпиона по приспособленности. Исследователи придумали много приемов сохранения разнообразия в популяции, но результаты пока неубедительны. Инженеры, несомненно, широко используют строительные блоки, но для их правильного соединения нужно, скажем так, много инженерии: сложить их вместе любым старым способом непросто, и неясно, может ли кроссинговер здесь помочь.
Если исключить половое размножение, у эволюционистов в качестве двигателя останутся одни мутации. Когда размер популяции значительно превышает количество генов, есть шанс, что все точечные мутации в ней уже представлены, и тогда поиск становится разновидностью восхождения по выпуклой поверхности: попробуй все возможные шаги, выбери лучший и повтори. (Или выбери несколько лучших вариантов: в таком случае это называется лучевой поиск.) Символисты, например, постоянно используют такой подход для получения наборов правил и не считают его формой эволюции. Чтобы не застрять в локальном максимуме, восхождение можно усилить случайностью (допустить с некоторой вероятностью движение вниз) и случайными перезапусками (через некоторое время перепрыгнуть в произвольное состояние и продолжать восхождение там). Этого достаточно, чтобы найти удачные решения проблем. Оправдывает ли польза от добавления кроссинговера лишние затраты на вычисления — вопрос открытый.
Никто точно не знает, почему половое размножение так распространено в природе. Было выдвинуто несколько теорий, но ни одна из них не стала общепринятой. Ведущее положение занимает гипотеза Черной Королевы, популяризированная Мэттом Ридли в книге The Red Queen: Sex and the Evolution of Human Nature («Черная королева. Секс и эволюция человеческой натуры»). Черная Королева говорит Алисе: «Приходится бежать со всех ног, чтобы только остаться на том же месте». Организмы находятся в постоянной гонке с паразитами, и половое размножение помогает популяции быть настолько разнообразной, чтобы ни один микроб не смог заразить ее целиком. Если дело в этом, тогда половое размножение не имеет отношения к машинному обучению, по крайней мере пока полученные путем эволюции программы не начнут соревноваться с компьютерными вирусами за время работы процессора и память. (Что интересно, Дэнни Хиллис утверждает, что целенаправленное введение в генетический алгоритм попутно эволюционирующих паразитов может помочь избежать локальных максимумов путем постепенного наращивания сложности, однако пока по этому пути никто не пошел.) Христос Пападимитриу и его коллеги показали, что половое размножение оптимизирует не приспособленность, а то, что они назвали смешиваемостью: способность гена в среднем хорошо справляться при соединении с другими генами. Это может пригодиться, если функция приспособленности либо неизвестна, либо непостоянна, как в естественном отборе, однако в машинном обучении и оптимизации, как правило, лучше справляется восхождение на выпуклые поверхности.
На этом проблемы генетического программирования не заканчиваются. Получается, что даже его успехи, возможно, совсем не такие «генетические», как хотелось бы эволюционистам. Возьмем разработку электронных схем — знаковый успех генетического программирования. Как правило, даже относительно простые схемы требуют огромного объема поиска, причем неясно, насколько мы обязаны результатами грубой силе, а насколько — генетическому интеллекту. Чтобы ответить растущему хору критиков, Коза включил в свою опубликованную в 1992 году книгу Genetic Programming эксперименты, показывающие, что генетическое программирование превосходит случайно сгенерированных кандидатов в проблеме синтеза булевых схем, но отрыв был небольшой. В 1995 году на Международной конференции по машинному обучению (International Conference on Machine Learning, ICML) в Лейк-Тахо Кевин Лэнг опубликовал статью о том, что восхождение на выпуклые поверхности побеждает генетическое программирование в тех же самых программах, причем часто со значительным перевесом. Коза и другие эволюционисты неоднократно пытались опубликовать свои работы в материалах ICML, ведущем мероприятии в этой области, но, к их растущему разочарованию, их постоянно отклоняли из-за недостаточной эмпирической обоснованности. Коза и так был раздосадован тем, что его не публикуют, поэтому работа Лэнга просто вывела его из равновесия. На скорую руку он написал статью на 23 страницах в два столбца, в которой опровергал выводы Лэнга и обвинял рецензентов ICML в нарушении научной этики, а затем положил по экземпляру на каждое кресло в конференц-зале. Статья Лэнга (а может, и ответ Коза — как посмотреть) стали последней каплей: инцидент в Тахо привел к окончательному расхождению между эволюционистами и остальным сообществом ученых, занимающихся машинным обучением. Эволюционисты хлопнули дверью. Специалисты по генетическому программированию начали проводить собственные конференции, которые впоследствии слились с конференциями по генетическим алгоритмам в GECCO — Genetic and Evolutionary Computing Conference. А мейнстрим машинного обучения во многом просто забыл об их существовании. Печальная развязка, но не первый случай в истории, когда секс приводит к разводу.
Может быть, секс не преуспел в машинном обучении, но в утешение можно сказать, что он все же сыграл видную роль в эволюции технологий. Порнография стала непризнанным «приложением-приманкой» Глобальной сети, не говоря уже о печатной прессе, фотографии и видео. Вибратор был первым ручным электрическим устройством, на столетие опередившим мобильные телефоны. Мотороллеры получили распространение в послевоенной Европе, особенно в Италии, потому что на них молодые пары могли скрыться от своих семей. Одной из «приманок» огня, который миллион лет назад открыл Homo erectus, было, несомненно, то, что с его помощью легче стало назначать свидания. Несомненно и то, что индустрия секс-ботов станет мотором, толкающим человекоподобных роботов ко все большей реалистичности. Просто секс, по-видимому, не средство, а цель технологической эволюции.
Воспитание природы
У эволюционистов и коннекционистов есть одно важное сходство: и те и другие разрабатывают обучающиеся алгоритмы, вдохновленные природой. Однако потом их пути расходятся. Эволюционисты сосредоточены на получении структур: для них тонкая настройка результата путем оптимизации параметров имеет второстепенное значение. Коннекционисты же предпочитают брать простые, вручную написанные структуры со множеством соединений и предоставлять весовому обучению делать всю работу. Это все тот же извечный вопрос о приоритете природы и воспитания, на этот раз в машинном обучении, и у обоих оппонентов имеются веские аргументы.
С одной стороны, эволюция породила много удивительных вещей, самая чудесная из которых — вы сами. С кроссинговером или без него, получение структур путем эволюции — существенный элемент Верховного алгоритма. Мозг может узнать все, но он не может получить еще один мозг. Если как следует разобраться в его архитектуре, можно просто воплотить его в «железе», но пока мы очень далеки от этого, поэтому однозначно надо обратиться за поддержкой к компьютерной симуляции эволюции. Более того, путем эволюции мы хотим получать мозг для роботов, системы с произвольными сенсорами и искусственный сверхинтеллект: нет причин держаться за устройство человеческого мозга, если для этих целей что-то подойдет лучше. С другой стороны, эволюция работает ужасно медленно. Вся жизнь организма дает всего лишь один фрагмент информации о его геноме: приспособленность, выраженную в числе потомков. Это колоссальная расточительность, которую нейронное обучение избегает путем получения информации в месте использования (если можно так выразиться). Как любят подчеркивать коннекционисты, например Джефф Хинтон, нет смысла носить в геноме информацию, если мы легко можем получить ее из органов чувств. Когда новорожденный открывает глаза, в его мозг начинает потоком литься видимый мир, и нужно просто все организовать, а в геноме должна быть задана архитектура машины, которая займется этой организацией.
Как и в дебатах по поводу наследственности и воспитания, ни у одной стороны нет полного ответа, и нужно понять, как соединить оба фактора. Верховный алгоритм — это не генетическое программирование и не обратное распространение ошибки, однако он должен включать основные элементы обоих подходов: обучение структурам и весам. С традиционной точки зрения первую часть дает природа, которая создает мозг в ходе эволюции, а затем за дело берется воспитание, заполняя мозг информацией. Это можно легко воспроизвести в алгоритмах машинного обучения. Сначала происходит обучение структуре сети с использованием (например) восхождения на выпуклые поверхности для определения, какие нейроны соединены друг с другом: надо попробовать добавить в сеть все возможные новые соединения, сохранить те, которые больше всего улучшают ее результативность, и повторить процедуру. Затем нужно узнать вес соединений методом обратного распространения ошибки — и новенький мозг готов к использованию.
Однако в этом месте и в естественной, и в искусственной эволюции появляется важная тонкость: вес надо узнать для всех рассматриваемых структур-кандидатов, а не только для последней, чтобы посмотреть, как хорошо она будет справляться с борьбой за выживание (в природе) или с обучающими данными (в искусственной системе). На каждом этапе нам будут нужны структуры, которые работают лучше всех не до, а после нахождения весов. Поэтому в реальности природа не предшествует воспитанию: они скорее перемежаются, и каждый раунд обучения «воспитанием» готовит сцену для следующего раунда обучения «природой», и наоборот. Природа эволюционирует ради воспитания, которое получает. Эволюционный рост ассоциативных зон коры головного мозга основан на нейронном обучении в сенсорных зонах — без этого он был бы бесполезным. Гусята постоянно ходят за своей мамой (поведение, сформировавшееся в ходе эволюции), но для этого они должны ее узнавать (выученная способность). Если вместо гусыни вылупившиеся птенцы увидят человека, они будут следовать за ним: это замечательно показал Конрад Лоренц. В мозге новорожденного свойства среды уже закодированы, но косвенно: эволюция оптимизирует мозг для извлечения этих свойств из ожидаемых вводных. Аналогично для алгоритма, который итерационно учится новым структурам и весам, каждая новая структура неявно — функция весов, которые он получил в предыдущих раундах.
Из всех возможных геномов лишь немногие соответствуют жизнеспособным организмам, поэтому типичный ландшафт приспособленности представляет собой обширные равнины с периодическими резкими пиками, что очень затрудняет эволюцию. Если начать в Канзасе путь с завязанными глазами, не имея представления, в какой стороне Скалистые горы, можно очень долго блуждать в поисках предгорий и только потом начать восхождение. Однако если соединить эволюцию с нейронным обучением, результат будет очень интересный. Если вы стоите на плоской поверхности, но горы не слишком далеко, нейронное обучение может вас туда привести, причем чем ближе вы к горам, тем с большей вероятностью до них доберетесь. Это как способность видеть горизонт: в степях Уичито такая способность вам не пригодится, зато в Денвере вы увидите вдали Скалистые горы и направитесь к ним. Денвер, таким образом, станет намного более подходящим местом, чем Канзас, где у вас на глазах была повязка. Суммарный эффект — расширение пиков приспособленности и возможность найти путь к ним из мест, которые раньше были проблемными, например точки A на графике ниже:
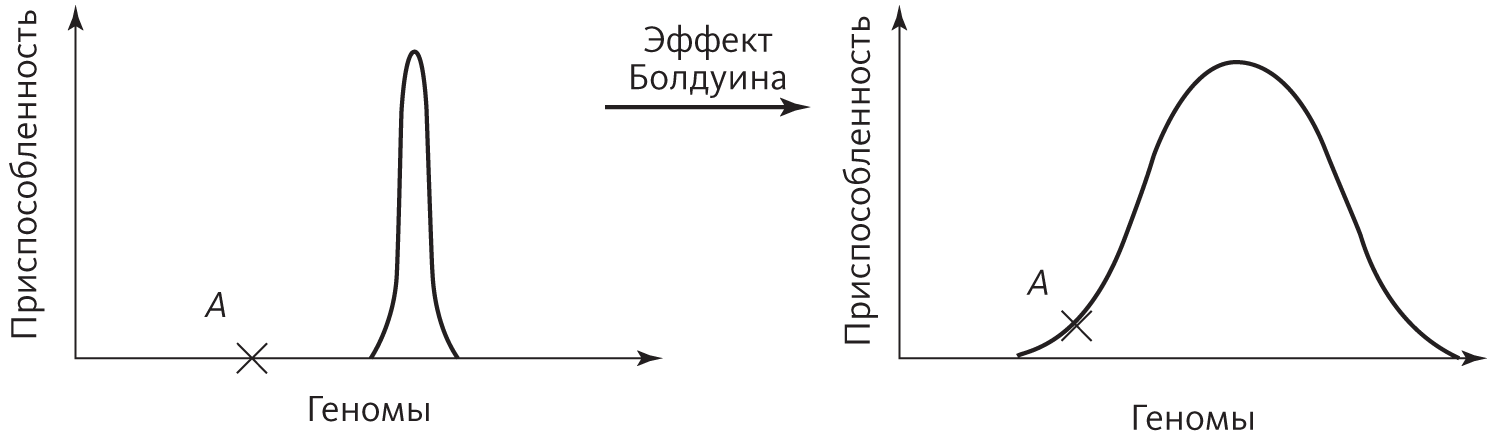
В биологии это называется эффектом Болдуина, в честь Джеймса Марка Болдуина, предложившего его в 1896 году. В эволюции, по Болдуину, выученное поведение впоследствии становится генетически обусловленным: если похожие на собак млекопитающие способны научиться плавать, у них больше шансов эволюционировать в морских котиков (как это и произошло), чем у животных, которые плавать не умеют. Таким образом, индивидуальное обучение может повлиять на эволюцию и без ламаркистских теорий. Джефф Хинтон и Стивен Нолан продемонстрировали эффект Болдуина в машинном обучении путем применения генетических алгоритмов: они получили с помощью эволюции структуру нейронной сети и обнаружили, что ее приспособленность со временем увеличивается, только если разрешено индивидуальное обучение.
Побеждает тот, кто быстрее учится
Эволюция ищет удачные структуры, а нейронное обучение их заполняет: такое сочетание — самый легкий шаг к Верховному алгоритму. Этот подход может удивить любого, кто знаком с бесконечными перипетиями спора о роли природы и воспитания, который не утихает две с половиной тысячи лет. Однако если смотреть на жизнь глазами компьютера, многое проясняется. «Природа» для компьютера — это программа, которую он выполняет, а «воспитание» — получаемые им данные. Вопрос, что важнее, очевидно абсурден. И без программы, и без данных никакого результата не будет, и нельзя сказать, что программа дает 60 процентов результата, а данные — 40. Знакомство с машинным обучением — прививка от такого прямолинейного мышления.
С другой стороны, возникает вопрос: почему наши поиски до сих пор не увенчались успехом? Ведь если соединить два верховных алгоритма природы — эволюцию и головной мозг, — большего и пожелать нельзя! К сожалению, пока мы имеем лишь очень грубую картину того, как учится природа: достаточно хорошую для множества применений, но все еще бледную тень реальности. Например, критически важная часть жизни — развитие эмбриона, а в машинном обучении ему нет аналога: «организм» — самая непосредственная функция генома, и, возможно, здесь нам не хватает чего-то важного. Но еще одна причина в том, что даже полное понимание того, как учится природа, будет недостаточным. Во-первых, природа работает слишком медленно: у эволюции обучение отнимает миллиарды лет, а у мозга — всю жизнь. Культура в этом отношении лучше: результат целой жизни обучения можно дистиллировать в книге, которую человек прочтет за несколько часов. Но обучающиеся алгоритмы должны уметь учиться за минуты или секунды. Побеждает тот, кто учится быстрее, будь то эффект Болдуина, ускоряющий эволюцию, устное общение, ускоряющее человеческое обучение, или компьютеры, открывающие паттерны со скоростью света. Машинное обучение — последняя глава в гонке жизни на Земле, и более быстрое «железо» — лишь половина успеха. Вторая часть — это более умное программное обеспечение.
Важнейшая цель машинного обучения — любой ценой найти лучший обучающийся алгоритм из всех возможных, и эволюция и головной мозг вряд ли на это способны. У порождений эволюции много очевидных изъянов. Например, зрительный нерв млекопитающих связан с передней, а не с задней частью сетчатки, из-за чего рядом с центральной ямкой, областью самого четкого зрения, появляется просто вопиюще ненужное слепое пятно. Молекулярная биология живых клеток — это хаос, поэтому специалисты часто шутят, что верить в разумный замысел могут только люди, которые об этом не подозревают. В архитектуре головного мозга тоже могут быть недостатки: у мозга много ограничений, которых лишены компьютеры — например, очень ограниченная краткосрочная память, — и нет причин их сохранять. Более того, известно много ситуаций, в которых люди постоянно поступают неправильно, и Даниэль Канеман пространно иллюстрирует это в своей книге Thinking, Fast and Slow.
В отличие от коннекционистов и эволюционистов, символисты и байесовцы не верят в подражание природе и скорее хотят чисто теоретически понять, что надо делать при обучении — и алгоритмам, и людям. Например, если мы хотим научиться диагностировать рак, недостаточно сказать: «Вот так учится природа, давайте сделаем то же самое». Ставки слишком высоки: ошибки стоят жизней. Врачи должны диагностировать болезнь самым надежным способом, какой только можно придумать, и методы должны быть схожими с теми, которыми математики доказывают теоремы, или хотя бы максимально близкими к ним, учитывая, что такая строгость встречается нечасто. Надо взвешивать доказательства, чтобы свести к минимуму вероятность неверного диагноза, или, точнее, чтобы чем дороже была ошибка, тем меньше была бы вероятность ее совершить. (Например, неспособность найти имеющуюся опухоль потенциально намного опаснее, чем ложное подозрение.) Врачи должны принимать оптимальные решения, а не просто такие, которые кажутся удачными.
Это частный случай линии разлома, проходящего через значительную часть науки и философии: различия между дескриптивными и нормативными теориями, между «есть вот так» и «должно быть вот так». В то же время символисты и байесовцы любят подчеркивать, что попытки понять, как мы должны учиться, могут помочь разобраться, как мы учимся на самом деле, потому что и то и другое предположительно очень даже взаимосвязано. В частности, поведение, которое важно для выживания и которое долго эволюционировало, должно быть близко к оптимальному. Человек не очень хорошо умеет отвечать на письменные вопросы о вероятностях, зато прекрасно, не задумываясь выбирает движение руки и кисти, чтобы попасть в мишень. Многие психологи применяли символистские и байесовские модели для объяснения некоторых аспектов человеческого поведения. Символисты доминировали в первые несколько десятилетий когнитивной психологии. В 1980-х и 1990-х власть захватили коннекционисты, а теперь на взлете сторонники байесовского подхода.
Для самых сложных проблем — тех, которые мы по-настоящему хотим, но не можем решить, например для лечения рака, — истинные «природные» подходы, вероятно, слишком просты и не принесут успеха, даже если дать им огромное количество данных. В принципе можно узнать полную модель метаболической сети клетки путем сочетания поиска структур, с кроссинговером или без, и подбора параметров методом обратного распространения ошибки, однако есть слишком много локальных экстремумов, в которых можно крепко увязнуть. Рассуждать нужно более крупными блоками, собирая и переставляя их при необходимости и используя обратную дедукцию, чтобы заполнить пробелы. А направлять обучение должна цель — оптимальная диагностика рака и нахождение наилучших лекарств для его лечения.
Оптимальное обучение — это главная цель байесовцев, и они не сомневаются, что поняли, как ее достичь. Сюда, пожалуйста…

