shows the initial bytes of one of these files.. Notice the WriteFile call on the right in the block labeled loc_40122a. Also notice that the xor ebx, eax instruction is in the loop that may occur just before the write block (loc_40122a).The left-hand block contains a call to sub_40112F, and at the end of the block, we see a counter incremented by 1 (the counter has the label var_4). After the call to sub_40112F, we see the return value in EAX used in an XOR operation with EBX. At this point, the results of the XOR function are in bl (the low byte of EBX). The byte value in bl is then written to the buffer (at lpBuffer plus the current counter).
Putting all of these pieces of evidence together, a good guess is that the call to sub_40112F is a call to get a single pseudorandom byte, which is XORed with the current byte of the buffer. The buffer is labeled lpBuffer, since it is used later in the WriteFile function. sub_40112F does not appear to have any parameters, and seems to return only a single byte in EAX.
shows the relationships among the encryption functions. Notice the relationship between sub_40106C and sub_40112F, which both have a common subroutine. sub_40106C also has no parameters and will always occur before the call to sub_40112F. If sub_40106C is an initialization function for the cryptographic routine, then it should share some global variables with sub_40112F.Investigating further, we find that both sub_40106C and sub_40112F contain multiple references to three global variables (two DWORD values and a 256-byte array), which support the hypothesis that these are a cryptographic initialization function and a stream cipher function. (A stream cipher generates a pseudorandom bit stream that can be combined with plaintext via XOR.) One oddity with this example is that the initialization function took no password as an argument, containing only references to the two DWORD values and a pointer to an empty 256-byte array.
We’re lucky in this case. The encoding functions were very close to the output function that wrote the encrypted content, and it was easy to locate the encoding functions.
For the attacker, custom-encoding methods have their advantages, often because they can retain the characteristics of simple encoding schemes (small size and nonobvious use of encryption), while making the job of the reverse engineer more difficult. It is arguable that the reverse-engineering tasks for this type of encoding (identifying the encoding process and developing a decoder) are more difficult than for many types of standard cryptography.
With many types of standard cryptography, if the cryptographic algorithm is identified and the key found, it is fairly easy to write a decryptor using standard libraries. With custom encoding, attackers can create any encoding scheme they want, which may or may not use an explicit key. As you saw in the previous example, the key is effectively embedded (and obscured) within the code itself. Even if the attacker does use a key and the key is found, it is unlikely that a freely available library will be available to assist with the decryption.
Назад: Common Cryptographic Algorithms
Дальше: Decoding
WriteFile call on the right in the block labeled loc_40122a. Also notice that the xor ebx, eax instruction is in the loop that may occur just before the write block (loc_40122a).The left-hand block contains a call to sub_40112F, and at the end of the block, we see a counter incremented by 1 (the counter has the label var_4). After the call to sub_40112F, we see the return value in EAX used in an XOR operation with EBX. At this point, the results of the XOR function are in bl (the low byte of EBX). The byte value in bl is then written to the buffer (at lpBuffer plus the current counter).
Putting all of these pieces of evidence together, a good guess is that the call to sub_40112F is a call to get a single pseudorandom byte, which is XORed with the current byte of the buffer. The buffer is labeled lpBuffer, since it is used later in the WriteFile function. sub_40112F does not appear to have any parameters, and seems to return only a single byte in EAX.
sub_40106C and sub_40112F, which both have a common subroutine. sub_40106C also has no parameters and will always occur before the call to sub_40112F. If sub_40106C is an initialization function for the cryptographic routine, then it should share some global variables with sub_40112F.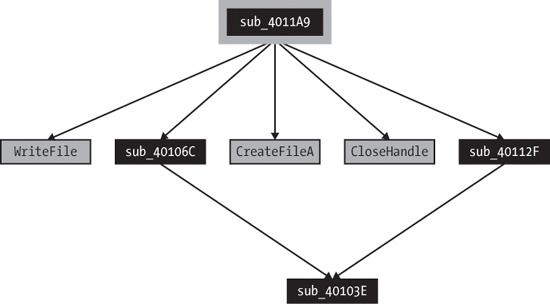
Investigating further, we find that both sub_40106C and sub_40112F contain multiple references to three global variables (two DWORD values and a 256-byte array), which support the hypothesis that these are a cryptographic initialization function and a stream cipher function. (A stream cipher generates a pseudorandom bit stream that can be combined with plaintext via XOR.) One oddity with this example is that the initialization function took no password as an argument, containing only references to the two DWORD values and a pointer to an empty 256-byte array.
We’re lucky in this case. The encoding functions were very close to the output function that wrote the encrypted content, and it was easy to locate the encoding functions.
For the attacker, custom-encoding methods have their advantages, often because they can retain the characteristics of simple encoding schemes (small size and nonobvious use of encryption), while making the job of the reverse engineer more difficult. It is arguable that the reverse-engineering tasks for this type of encoding (identifying the encoding process and developing a decoder) are more difficult than for many types of standard cryptography.
With many types of standard cryptography, if the cryptographic algorithm is identified and the key found, it is fairly easy to write a decryptor using standard libraries. With custom encoding, attackers can create any encoding scheme they want, which may or may not use an explicit key. As you saw in the previous example, the key is effectively embedded (and obscured) within the code itself. Even if the attacker does use a key and the key is found, it is unlikely that a freely available library will be available to assist with the decryption.
Войти в систему
Войти с помощью соц. сетей:

