7. Тестирование
С тех пор как я только начал создавать программный код, автоматизированное тестирование существенно усовершенствовалось. Похоже, что новое средство или технология в этой области появляются чуть ли не каждый месяц, делая такое тестирование еще лучше. Но и когда функциональность распространена по всей распределенной системе, проблемы выполнения эффективного и рационального тестирования все еще остаются нерешенными. В этой главе разбираются проблемы, связанные с тестированием систем с высокой степенью детализации, и дается ряд решений, помогающих убедиться в возможности выпуска созданных вами новых функциональных возможностей, будучи уверенными в их работоспособности.
Тестирование охватывает множество понятий. Даже если говорить только об автоматизированных тестах, возникает большое количество требующих рассмотрения вопросов. С появлением микросервисов добавился еще один уровень сложности. Понимание того, какого рода тесты можно запускать, играет важную роль в содействии установлению баланса между порой противоречащими друг другу устремлениями, чтобы как можно быстрее довести программные продукты до работы в производственном режиме, помимо того чтобы просто удостовериться в их надлежащем качестве.
Разновидности тестов
Мне, как консультанту, нравится способ распределения по категориям путем деления на секторы, и я уже начал переживать, что в этой книге его так и не придется применить. Но так уж удачно вышло, что Брайан Марик (Brian Marick) предоставил нам великолепную систему распределения тестов по категориям. На рис. 7.1 показан помогающий определить категории различных тестов вариант секторов, выделенных Мариком, который был позаимствован из книги Лизы Криспин (Lisa Crispin) и Джанет Грегори (Janet Gregory) Agile Testing (Addison-Wesley).
В нижней части показаны тесты технологической направленности, то есть в первую очередь помогающие разработчикам в создании системы. В эту категорию попадают тесты производительности и имеющие весьма ограниченную область действия блочные тесты, которые, как правило, автоматизированы. Это описание дается в сравнении с секторами верхней части, где показаны тесты, помогающие понять характеристики работы вашей системы тем партнерам, которые не связаны с техническими сторонами разработки. Это могут быть сквозные тесты с весьма широкой областью действия, такие как показанное в верхнем левом секторе приемо-сдаточное тестирование или помещенное в сектор исследовательского тестирования ручное проведение тестов, представляющее собой типичное пользовательское тестирование, выполняемое с целью проверки приемлемости системы для пользователя.

Рис. 7.1. Секторы тестирования по Брайану Марику. Lisa Crispin, Janet Gregory. Agile Testing: A Practical Guide for Testers and Agile Teams, 1st Ed. © 2009. С разрешения Pearson Education, Inc., Upper Saddle River, NJ
Каждой разновидности тестов, показанной в этих секторах, отводится своя роль. В каком конкретном объеме требуется проводить каждый тест именно вам, зависит от характера вашей системы, но здесь важно понять, что для ее тестирования у вас есть богатый выбор. В последнее время наметилась тенденция отказа от ручного тестирования с широкой областью действия и преимущественного перехода по мере возможности к автоматизированному тестированию, и я с таким подходом, конечно же, согласен. Если вы все еще применяете большие объемы ручного тестирования, то прежде, чем всерьез заняться микросервисами, последуйте моему совету и обратите внимание на эту тенденцию, поскольку вы не сможете получить многие из предполагаемых преимуществ микросервисов, если не сумеете проверять свои программные продукты быстро и эффективно.
Чтобы выполнить те задачи, которые ставятся в этой главе, ручное тестирование мы просто проигнорируем. Хотя тестирование этого рода может принести немалую пользу и, безусловно, играет свою собственную и весьма важную роль, разница в тестировании архитектуры микросервисов в основном проявляется в контексте различных типов автоматизированных тестов, поэтому ими мы и займемся.
Но если дело доходит до автоматизированных тестов, то в каких объемах нам нужно проводить каждое тестирование? Чтобы ответить на данный вопрос и разобраться с возможными разнообразными компромиссами, пригодится еще одна модель.
Области применения тестов
В своей книге Succeeding with Agile (Addison-Wesley) Майк Кон, чтобы помочь разобраться в том, какие типы автоматизированных тестов вам нужны, начертил модель под названием «Пирамида тестов». Эта пирамида помогает нам обдумать область применения тестов, а также очерчивает пропорции тестов различного типа, которых мы должны придерживаться. Как показано на рис. 7.2, в исходной модели Кона автоматизированные тесты разбиты на блочные, сервисные и тесты пользовательского интерфейса.
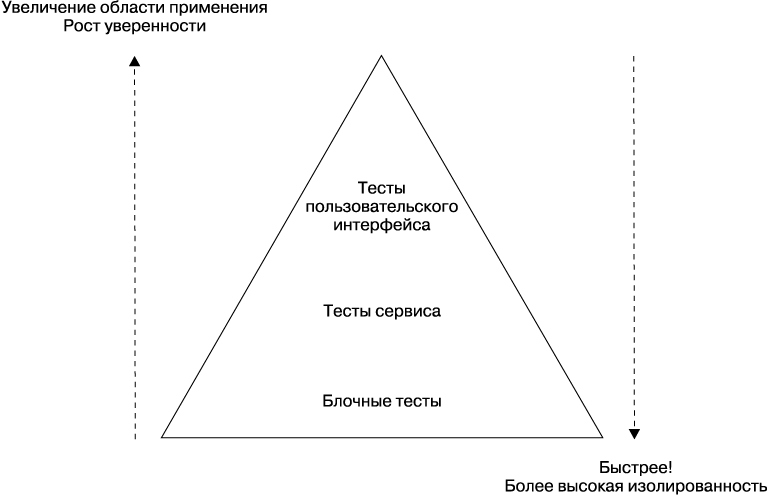
Рис. 7.2. Пирамида тестов Майка Кона из его книги Succeeding with Agile: Software Development Using Scrum, 1st Ed. © 2010. С разрешения Pearson Education, Inc., Upper Saddle River, NJ
Проблема данной модели в том, что все эти понятия не имеют однозначного толкования. Особенно много значений имеет понятие «сервис», достаточно определений имеется и у понятия «блочное тестирование». Можно ли считать блочным тест, проверяющий только одну строку кода? Я бы сказал, что да. А можно ли считать блочным тест нескольких функций или классов? А тут я бы сказал, что нет, но многие со мной не согласятся! Несмотря на терминологическую неоднозначность, я все же склоняюсь к выбору названий «блочное тестирование» и «тестирование сервиса», но тесты пользовательского интерфейса предпочитаю называть сквозными тестами, именно так они далее и будут называться.
Учитывая возникшую неразбериху, нам все же стоит разобраться в том, что означают все эти различные уровни.
Рассмотрим рабочий пример. На рис. 7.3 показаны приложение сервиса технической поддержки и наш основной сайт, и оба эти компонента взаимодействуют с клиентским сервисом для извлечения, просмотра и редактирования клиентских данных. В свою очередь, клиентский сервис связывается с нашим банком бонусных баллов, где клиенты накапливают баллы, покупая компакт-диски Джастина Бибера. Наверное. Конечно, это всего лишь малая часть общей системы музыкального магазина, но и ее вполне хватает, чтобы разобрать несколько различных сценариев, которые нам может потребоваться протестировать.

Рис. 7.3. Часть музыкального магазина, подвергаемая тестированию
Блочные тесты
Это тесты, с помощью которых тестируется, как правило, отдельный вызов функции или метода. Под эту категорию подпадают тесты, созданные в рамках концепции разработки под контролем тестирования (Test-Driven Design (TDD)), а также разновидности тестов, созданных с помощью такой технологии, как тестирование на основе свойств (Property-Based Testing). Сам сервис здесь не запускается, мы также ограничены в использовании внешних файлов или сетевых подключений. По сути, тестов такого рода требуется очень много. Если они правильно сделаны, то выполняются очень и очень быстро и можно рассчитывать на выполнение на современном оборудовании многих тысяч таких тестов меньше чем за минуту.
Это тесты, помогающие нам, разработчикам, и поэтому в соответствии с терминологией, предложенной Мариком, должны иметь технологическую, а не бизнес-направленность. В ходе их проведения мы надеемся отловить основную часть своих ошибок. Итак, в нашем примере, когда мы занимаемся клиентским сервисом, блочные тесты будут охватывать небольшую изолированную часть кода (рис. 7.4).
Основной целью этих тестов является получение очень быстрых ответных результатов, говорящих о качестве функционирования кода. Тесты могут играть весьма важную роль в поддержке разбиения кода на части, позволяя проводить реструктуризацию кода по мере выполнения работы. При этом мы будем знать, что имеющие весьма ограниченную область действия тесты тут же нас остановят, если будет допущена ошибка.
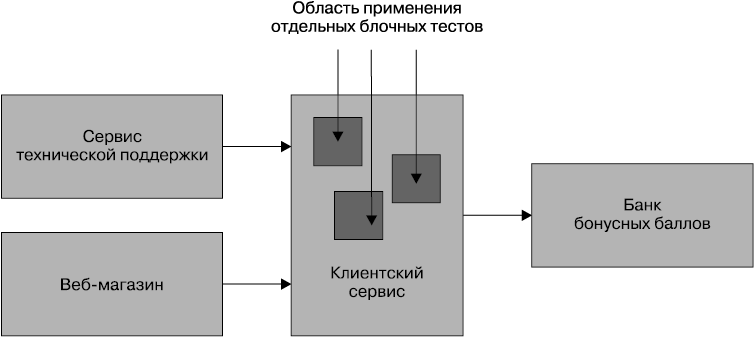
Рис. 7.4. Область применения блочных тестов в нашей взятой для примера системе
Тесты сервиса
Тесты сервиса разрабатываются для того, чтобы в обход пользовательского интерфейса выполнять непосредственное тестирование сервиса. В монолитном приложении могут тестироваться коллекции классов, предоставляющие сервис пользовательскому интерфейсу. В системе, содержащей несколько сервисов, тест сервиса используется для тестирования возможностей отдельного сервиса.
Причина, по которой требуется протестировать отдельно взятый сервис, состоит в улучшении изолированности теста с целью более быстрого обнаружения и устранения проблем. Для достижения изолированности нужно заглушить все внешние сотрудничающие компоненты, чтобы в область действия теста попадал только сам сервис (рис. 7.5).
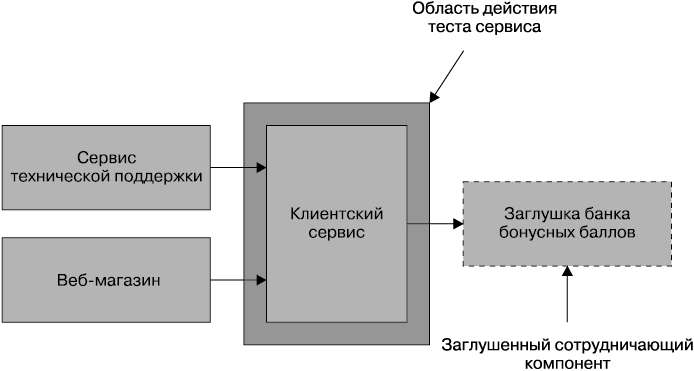
Рис. 7.5. Область применения тестов сервиса в нашей взятой для примера системе
Некоторые из этих тестов могут выполняться так же быстро, как и небольшие тесты, но, если задумать тестирование с участием реальной базы данных или с переходом по сети к заглушенным нижестоящим сотрудничающим компонентам, время проведения теста может увеличиться. Кроме того, эти тесты имеют более широкую область действия, чем простой блочный тест, поэтому, если тест не будет пройден, причину окажется найти труднее, чем при проведении блочного теста. Тем не менее в их область действия попадает гораздо меньше активных компонентов, чем при проведении широкомасштабного тестирования, поэтому проходят проще.
Сквозные тесты
Сквозные тесты проводятся в отношении всей системы. Зачастую управляют ими через графический интерфейс пользователя, имеющийся у браузера, но с возможностью без каких-либо затруднений имитировать другие виды взаимодействия с пользователем, например выкладывание файла.
Как показано на рис. 7.6, этими тестами охвачен большой объем кода, предназначенного для работы в производственном режиме. Следовательно, при прохождении этих тестов возникает удовлетворенность: с большой долей уверенности можно сказать, что протестированный код будет работать в производственном режиме. Но этой увеличенной области действия присущи некоторые недостатки, и, как мы вскоре увидим, в контексте микросервисов они могут иметь весьма запутанный характер.
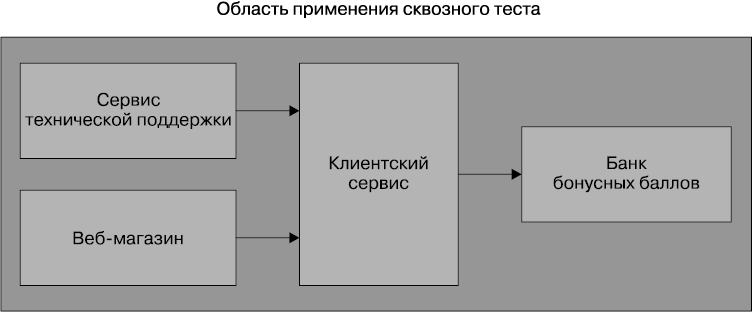
Рис. 7.6. Область применения сквозных тестов в нашей взятой для примера системе
Компромиссы
При изучении пирамиды ключевым моментом, который требуется усвоить, является то, что по мере движения к ее вершине область действия тестов увеличивается вместе с уверенностью в том, что протестированные функциональные возможности окажутся вполне работоспособными. Однако время ожидания отдачи от тестов увеличивается, поскольку времени на их выполнение уходит больше, и когда тест дает сбой, установить отказавшую функцию может быть намного сложнее. При движении сверху вниз по направлению к основанию пирамиды тесты выполняются, как правило, намного быстрее, поэтому мы получаем намного более быстрые циклы обратной реакции. Быстрее обнаруживаются отказавшие функции, быстрее создаются сборки непрерывной интеграции, и уменьшается вероятность того, что мы перейдем к другой задаче, прежде чем обнаружится, что мы что-нибудь вывели из строя. Когда сбой происходит при проведении таких имеющих весьма ограниченную область действия тестов, мы стремимся обнаружить место сбоя, зачастую вплоть до отдельной строки кода. В то же время, если тестируется отдельная строка кода, мы не получаем никакой уверенности в работоспособности системы в целом!
Когда сбой происходит при проведении тестов с широкой областью действия вроде тестов сервиса или сквозных тестов, мы стараемся написать быстрый блочный тест, для того чтобы в будущем с его помощью определить причину возникшей проблемы. Таким образом, мы постоянно пытаемся сократить время циклов обратной реакции.
Фактически каждая команда, с которой мне приходилось работать, по-разному называла то, что Кон использует в своей пирамиде. Но как бы все это ни называть, главное — понять, что вам понадобятся различные тесты, проводимые с разными целями.
Что и в каком объеме проводить
Итак, если при проведении всех этих тестов не обойтись без компромиссов, то в каком объеме понадобится проведение каждого из них? Опыт показывает, что по мере продвижения по пирамиде сверху вниз понадобится, наверное, на порядок больше тестов, но при этом важно знать, что в вашем распоряжении имеется множество различных автоматизированных тестов, и чувствовать момент, когда текущий баланс того и другого превращается в серьезную проблему!
К примеру, мне приходилось участвовать в разработке одной монолитной системы, где у нас было 4000 блочных тестов, 1000 тестов сервисов и 60 сквозных тестов. Мы решили, что с точки зрения получения ответных результатов у нас было слишком много тестов сервисов и сквозных тестов (и последние были наиболее критикуемыми в плане продолжительности циклов получения ответов), поэтому упорно работали над переходом к тестам, имеющим менее широкую область действия.
Известным антишаблоном является то, что часто называют тестированием рожка с мороженым, или перевернутой пирамидой. Этот неверный подход характерен практическим отсутствием тестов с ограниченной областью действия, и все сводится к тестам, имеющим широкую область действия. Такие проекты зачастую характеризуются «замороженным» выполнением тестов и очень длинными циклами получения ответных результатов. Если такие тесты запускаются в рамках непрерывной интеграции, то количество получаемых сборок не будет большим и сроки, характерные для создания сборок, будут означать, что сами сборки в случае каких-либо сбоев могут находиться в нерабочем состоянии на протяжении весьма длительного времени.
Реализация тестов сервисов
В целом реализация блочных тестов дается намного проще всего остального, и существует множество различных документов, описывающих порядок их создания. Нам же намного интереснее будет разобраться в создании сервисных и сквозных тестов.
Тесты сервисов предназначены для тестирования той доли функциональности, которая распространяется на весь сервис, но, для того, чтобы изолироваться от других сервисов, нужно найти некий способ, позволяющий заглушить всех соучастников процесса. Следовательно, если нужно написать подобный тест для клиентского сервиса, показанного на рис. 7.3, следует развернуть экземпляр клиентского сервиса и, как уже говорилось, заглушить все взаимодействующие сервисы.
Первое, что нужно сделать при изготовлении сборки в рамках непрерывной интеграции, — создать для сервиса артефакт двоичного кода, поскольку его развертывание проводится довольно просто. Но как справиться с подделкой работы взаимодействующих сервисов?
Сервисный тестовый набор нуждается в запуске сервисов-заглушек для любого взаимодействующего с ним участника (или в гарантии того, что они запущены) и в настройке тестируемого сервиса на подключение к сервисам-заглушкам. Затем нужно настроить заглушки на отправку обратных ответов с целью имитации работы настоящих сервисов. Например, можно настроить заглушку банка бонусных баллов на возвращение заранее известного количества баллов, скопленных конкретными клиентами.
Использование имитации или применение заглушки
Когда речь заходит о создании заглушек взаимодействующих участников, подразумевается создание сервиса-заглушки, выдающей заранее заготовленные ответы на известные запросы того сервиса, который тестируется. Например, можно задать сервису-заглушке банка бонусных баллов при запросе баланса клиента 123 возвращать значение 15 000. Количество вызовов заглушки, будь то 0, 1 или 100, никакого влияния на прохождение теста не оказывает. Как вариант, вместо заглушки можно использовать имитатор.
При применении имитатора дело заходит чуть дальше и обеспечивается совершение вызова. Если ожидаемый вызов не сделан, тест считается непройденным. Реализация такого подхода требует более интеллектуального приема при создании имитации взаимодействующих сотрудников, а в случае слишком интенсивного использования имитатора могут возникнуть трудности при прохождении теста. А заглушку, как уже говорилось, можно вызывать 0, 1 и более раз.
Но иногда при желании получить ожидаемые побочные эффекты имитаторы могут принести существенную пользу. Например, мне может понадобиться проверить, что при создании нового клиента для него устанавливается новый остаток бонусных баллов. Соблюдение баланса между вызовами заглушек и имитаторов — дело тонкое и требующее серьезного отношения к себе при проведении как тестов сервисов, так и блочных тестов. Но фактически в тестах сервисов заглушки я использую значительно чаще имитаторов. Связанные с их использованием компромиссы более подробно рассматриваются в книге Стива Фримена (Steve Freeman) и Ната Прайса (Nat Pryce) Growing Object-Oriented Software, Guided by Tests (Addison-Wesley).
Вообще-то я редко использую имитаторы для тестов подобного рода. Но наличие инструментальных средств, способных быть как заглушками, так и имитаторами, считаю полезным.
На мой взгляд, разница между заглушками и имитаторами вполне очевидна, но я все же допускаю, что у кого-то могут возникнуть сложности с ее восприятием, особенно когда вместо этих понятий в ход идут другие, наподобие подделок, шпионов и ловушек. Мартин Фаулер называл все это, включая заглушки и имитаторы, тестовыми дублерами.
Более интеллектуальный сервис-заглушка
Обычно я создаю сервисы-заглушки самостоятельно. Для подобного тестирования мне приходилось использовать все, от Apache или Nginx до Jetty-контейнеров или даже запускаемых из командной строки веб-сервисов на Python. И, возможно, при создании этих заглушек я снова и снова занимался одним и тем же. А вот мой коллега Брендон Брайарс (Brandon Bryars) из ThoughtWorks создал сервер заглушек-имитаторов под названием Mountebank, чем потенциально освободил многих из нас от части работы.
Mountebank можно рассматривать как небольшое программное приспособление, программируемое через HTTP. И любому вызывающему сервису абсолютно безразличен тот факт, что это приспособление было написано на NodeJS. При запуске этому приспособлению отправляются команды, сообщающие, на какой из портов вешать заглушку, какой протокол обрабатывать (в настоящий момент поддерживаются TCP, HTTP и HTTPS, но планируется поддержка и многих других протоколов) и какие ответы следует отправлять после получения запроса. Если нужно воспользоваться имитатором, то это приспособление поддерживает также установку ожидаемых побочных эффектов. При желании конечные точки заглушек можно добавлять или удалять, позволяя одному экземпляру Mountebank служить заглушкой более чем для одной взаимодействующей зависимости.
Следовательно, если нужно запустить тесты сервисов только для одного клиентского сервиса, то можно запустить клиентский сервис и экземпляр Mountebank, работающий как банк бонусных баллов. И если намеченные тесты будут пройдены, я могу с легкой душой развернуть клиентский сервис! Или все же не могу? А как в таком случае быть с теми сервисами, которые вызывают клиентский сервис, — с сервисом технической поддержки и веб-магазином? Знаем ли мы, что внесенное изменение не станет причиной нарушения работы этих сервисов? Ну конечно же, мы упустили из виду весьма важные тесты, находящиеся на вершине пирамиды, — сквозные тесты.
Сложности, связанные со сквозными тестами
В микросервисных системах те возможности, которые становятся видны благодаря пользовательским интерфейсам, поставляются несколькими сервисами. Смысл сквозных тестов, обозначенный в пирамиде Майка Кона, заключается в передаче функциональных возможностей через эти пользовательские интерфейсы всему, что находится ниже, чтобы мы смогли получить представление о множестве компонентов системы.
Следовательно, для реализации сквозного теста нам нужно развернуть вместе сразу несколько сервисов, а затем запустить тест в отношении всех этих сервисов. Вполне очевидно, что область действия этого теста значительно шире, что даст нам больше уверенности в работоспособности системы! В то же время такие тесты выполняются медленнее и выявить источник ошибки в ходе их проведения значительно труднее. Присмотримся к ним пристальнее, воспользовавшись предыдущим примером, и посмотрим, как такие тесты могут быть к нему применены.
Представьте, что нам нужно внедрить новую версию клиентского сервиса. Развернуть изменения для работы в производственном режиме следует как можно скорее, но при этом есть опасения, что внесенные изменения могут нарушить работу либо сервиса технической поддержки, либо веб-магазина. Я думаю, это нам по силам. Развернем разом все наши сервисы и запустим тесты в отношении сервиса техподдержки и веб-магазина, чтобы посмотреть, не допустили ли мы какой-нибудь ошибки. Теперь вполне естественным шагом станет добавление этих тестов к концу конвейера клиентского сервиса (рис. 7.7).

Рис. 7.7. Правильно ли мы поступаем, добавляя сюда этап сквозных тестов?
Вроде пока все идет хорошо. Но прежде всего напрашивается вопрос: какими версиями других сервисов мы должны воспользоваться? Должны ли мы проводить свои тесты в отношении версий сервиса техподдержки и веб-магазина, которые используются в процессе работы в производственном режиме? Было бы, конечно, разумно именно так и сделать, но если настала очередь запуска новой версии либо сервиса техподдержки, либо веб-магазина, как нам поступить в таком случае?
И еще один вопрос: если у нас имеется набор тестов клиентского сервиса, развертывающий множество сервисов и запускающий тесты для проверки их работоспособности, то что можно сказать о сквозных тестах, запускаемых в интересах других сервисов? Если при их проведении тестируются те же самые возможности, то можно поймать себя на мысли, что мы занимаемся одним и тем же и можем в первую очередь повторно потратить время и силы на развертывание всех этих сервисов.
На оба этих вопроса можно найти весьма изящный ответ: нужны несколько конвейеров, объединяющихся в стадию проведения сквозного теста. Как только будет выпущена новая сборка одного из наших сервисов, мы запускаем сквозные тесты, пример которых показан на рис. 7.8. Такие сходящиеся модели могут быть присущи некоторым CI-средствам с расширенной поддержкой сборочных конвейеров.
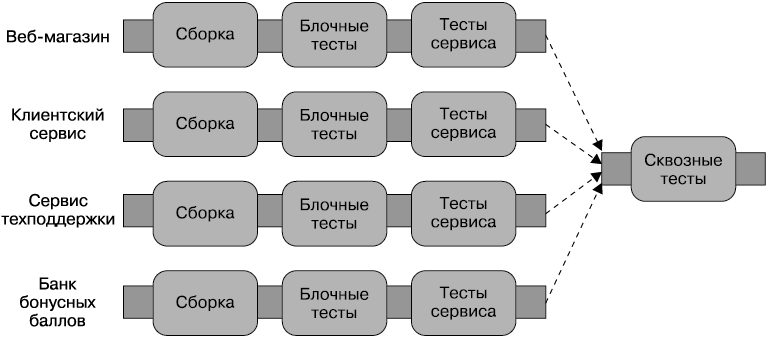
Рис. 7.8. Стандартный способ проведения сквозных тестов в отношении сервисов
Итак, при каждом изменении сервисов мы запускаем тесты, имеющие локальное применение к измененному сервису. Если они будут пройдены, мы запускаем интеграционные тесты. Вроде бы все логично? Но нерешенные проблемы все же остаются.
Недостатки сквозного тестирования
К сожалению, у сквозного тестирования имеется множество недостатков.
Тесты со странностями, не дающие четкого представления об источнике сбоя
Область действия тестов расширяется, а вместе с этим увеличивается и количество активных компонентов. При наличии множества таких компонентов сбои в процессе тестирования могут не показывать, какие именно из тестируемых функций стали причиной сбоя, что не позволит выявить наличие других проблемных мест. К примеру, если проводится тест с целью проверки возможности размещения заказа на одном компакт-диске, но этот тест запускается в отношении четырех или пяти сервисов, то при отказе одного из них мы получим сбой, не имеющий никакого отношения к характеру самого теста. Точно так же временный сетевой сбой может привести к провалу теста без получения какого-либо результата в отношении тестируемых функциональных возможностей.
Чем больше активных компонентов, тем более капризными и менее информативными в заданных для них областях могут стать наши тесты. Если есть такие тесты, которые время от времени дают сбой, но все просто их перезапускают, поскольку они могут быть пройдены при последующих запусках, значит, это тесты со странностями. Ими могут быть не только тесты, охватывающие множество различных процессов, которые могут в данной ситуации стать виновниками сбоя. Часто проблемный характер приобретают тесты, которые охватывают функции, выполняемые в нескольких потоках, где сбой может означать возникновение конфликтной ситуации, истечение времени ожидания или настоящий сбой той или иной функции. Тесты со странностями — ваши враги. Когда они дают сбой, они не вскрывают всю его подоплеку. Мы перезапускаем CI-сборки в надежде, что позже они все же будут пройдены, только для того, чтобы увидеть, как накапливаются отметки о прохождении, и неожиданно оказываемся у разбитого корыта.
Когда проявляются странности теста, важно приложить все силы, чтобы от него избавиться. В противном случае мы начнем терять веру в набор тестов, «который всегда так сбоит». Набор, содержащий тесты со странностями, может попасть под определение того, что Диана Воган (Diane Vaughan) называет нормализацией отклонения, то есть идеи, что со временем мы можем настолько привыкнуть к тому, что все идет не так, что примем это за нормальное, беспроблемное положение вещей. Такое свойственное человеку восприятие действительности означает, что нам нужно выявить тесты со странностями и как можно скорее от них избавиться, не дожидаясь привыкания к тому, что тесты, проявляющие порой свой сбойный характер, нужно воспринимать как норму.
В работе Eradicating Non-Determinism in Tests Мартин Фаулер высказал свое отношение к тестам со странностями и сказал, что их нужно отслеживать и, если они не смогут быть немедленно исправлены, просто убирать из набора тестов. Посмотрите, нельзя ли их переписать таким образом, чтобы избежать выполнения тестируемого кода в нескольких потоках. Посмотрите, нельзя ли исходную среду сделать более стабильной. А еще лучше посмотрите, можно ли заменить тест со странностями тестом с меньшей областью действия, при использовании которого появление проблем менее вероятно. В некоторых случаях правильнее будет внести изменения в тестируемый код, упростив таким образом его тестирование.
Кто создает все эти тесты
Разумнее начать с того, что тесты, запускаемые в рамках конвейера для конкретного сервиса, должна создавать та же самая команда, в чьей собственности находится данный сервис (подробнее о владении сервисом мы поговорим в главе 10). А если речь идет о том, что к работе могут быть привлечены сразу несколько команд и теперь сквозные тесты фактически используются ими совместно, то кто тогда должен создавать эти тесты и заниматься их сопровождением?
Мне приходилось наблюдать множество неверных решений, принимаемых в подобной ситуации. Этими тестами занимались все кому не лень, любая команда могла, не разбираясь в общем состоянии всего набора, добавлять в них что угодно. Зачастую это приводило к дискредитации контрольных примеров, а иногда к тестированию по принципу упоминавшегося ранее рожка с мороженым. Наблюдались и такие ситуации, при которых отсутствие явного хозяина данных тестов приводило к игнорированию их результатов. Когда тесты проваливались, всем казалось, что проблема связана с работой других команд, поэтому за прохождение тестов не стоит волноваться.
Иногда организации реагировали на это выделением для написания тестов отдельной команды. Такой подход может иметь весьма плачевные последствия. Команда, разрабатывающая программу, все больше отдалялась от тестирования своего кода. Время цикла увеличивалось, поскольку владельцы сервиса дожидались, пока команда, разрабатывающая тесты, сподобится создать сквозные тесты для проверки функционирования только что написанного кода. Поскольку тесты пишет другая команда, та команда, которая создавала сервис, к ним практически не привлекается и поэтому, скорее всего, не знает, как запускать эти тесты и вносить в них исправления. Так как, к моему великому сожалению, такая организационная схема все еще применяется, хочу отметить большой урон, который наносит дистанцирование команды от тестов кода, создаваемого этой командой.
Выработать правильную точку зрения на решение данной проблемы действительно нелегко. Не хотелось бы дублировать усилия, равно как и полностью централизовать их до такой степени, чтобы команды, создающие сервисы, слишком сильно отстранялись от подобных дел. Наиболее удачным из встречавшихся мне случаев соблюдения баланса интересов было отношение к набору сквозных тестов как к общей базе кодов с совместным владением. Команды могли обращаться с этим набором абсолютно свободно, но команды, ведущие разработку сервисов, должны были нести общую ответственность за работоспособность всего набора. Если требуется широкое использование сквозных тестов сразу несколькими командами, то я считаю, что такой подход имеет весьма большое значение, но, по моим наблюдениям, он все еще применяется очень редко и никогда не обходится без проблем.
Насколько продолжительными бывают тесты
На проведение сквозных тестов может уйти немало времени. Мне приходилось наблюдать, как на них тратился целый день, если не больше, а в одном из проектов, над которыми мне пришлось работать, задействование полного регрессионного набора заняло шесть недель! Мне редко попадаются команды, реально курирующие свои наборы сквозных тестов для сокращения накладок в охвате тестами или затрачивающие достаточно времени на повышение их быстродействия.
Эта медлительность в сочетании с тем фактом, что тесты могут оказаться со странностями, может стать серьезной проблемой. Набор тестов, выполнение которых занимает весь день и зачастую проходит со сбоями, не имеющими ничего общего с функциональными изъянами тестируемого кода, является сущей катастрофой. Даже если имеется функциональный сбой, на его выявление может уйти множество часов. К этому моменту большинство из нас уже перейдет к другим делам, и переключение сознания на осмысление ситуации и устранение проблемы будет даваться с большим трудом.
Частично смягчить ситуацию можно запуском тестов в параллельном режиме, например воспользовавшись таким средством, как Selenium Grid. Но этот подход не заменит настоящего понимания того, что должно быть протестировано, и отказа от тестов, надобность в которых уже миновала.
Удаление тестов иногда чревато неприятностями, и я подозреваю, что становлюсь похожим на тех людей, которые хотят избавиться от конкретных мер безопасности в аэропортах. Неважно, насколько безрезультатными могут быть меры безопасности, любым разговорам об их отмене зачастую противопоставляется мгновенная отрицательная реакция с утверждениями о том, что при этом пострадает забота о безопасности людей, или ожиданием победы терроризма. Трудно вести взвешенный разговор о ценности тех или иных дополнений в сравнении с вызываемыми ими осложнениями. Также может быть довольно трудно найти компромисс между рисками и благодарностями. Поблагодарит ли вас кто-нибудь за удаление теста? Вполне возможно. Но вас, несомненно, начнут проклинать, если удаление теста повлечет за собой пропуск какого-либо изъяна. И когда речь заходит о тестовых наборах с обширной областью действия, то без такой возможности нам просто не обойтись. Если одну и ту же функцию проверяют 20 различных тестов, то, поскольку их выполнение занимает десять минут, возможно, от половины из них мы можем отказаться! Для этого требуется более четкое осознание риска, в чем люди пока не преуспели. В результате это разумное курирование и управление тестами, имеющими широкий функциональный охват и высокую нагрузку, происходит крайне редко. Желание заняться этим еще не означает реального проведения этой работы.
Сплошное нагромождение
Когда дело доходит до производительности труда разработчиков, проблема состоит не только в продолжительности циклов получения обратных результатов, связанных с проведением сквозных тестов. При длительном выполнении наборов тестов любой сбой требует времени на устранение, что снижает степень наших ожиданий относительно времени прохождения сквозных тестов. Если мы станем развертывать только те программы, которые успешно прошли все тесты (что, собственно, мы и должны делать!), это будет означать, что степени готовности к развертыванию для работы в производственном режиме достигнет только малая часть наших сервисов.
Это может привести к нагромождению невыполненных дел. Пока будут устраняться изъяны, вызванные сбоем теста интеграции, могут накопиться следующие изменения от взаимодействующих команд. Помимо того что это может усилить сборку, это означает увеличение масштаба изменений развертываемого кода. Эту проблему можно решить тем, чтобы не дать хода изменениям при сбоях сквозных тестов, но при наличии довольно долго выполняемого набора тестов это зачастую не представляется практичным. Попробуйте сказать: «Эй вы, тридцать разработчиков, не вздумайте поставить себе галочку, пока мы не потратим семь часов на отладку сборки!»
Чем шире область действия разработки и выше риск ее выпуска, тем выше вероятность что-нибудь испортить. Возможность частого выпуска нашей программы базируется в основном на идее выпуска небольших изменений сразу же по мере их готовности.
Метаверсия
По окончании сквозного тестирования вполне можно прийти к мысли: раз все эти сервисы данной версии могут работать вместе, почему бы их вместе и не развернуть? Вскоре это превращается в разговор о том, почему бы не воспользоваться номером версии для всей системы. Все по Брэндону Брайарсу (Brandon Bryars): «Теперь у вас 2.1.0 проблем».
Объединяя в единую версию изменения, внесенные сразу в несколько сервисов, мы фактически принимаем идею приемлемости одновременного изменения и развертывания сразу нескольких сервисов. Это становится нормой, не вызывающей сомнений. Поступая таким образом, мы отказываемся от одного из основных преимуществ микросервисов — возможности развертывания отдельно взятого сервиса независимо от всех других сервисов.
Зачастую привычка принимать как должное развертывание вместе сразу нескольких сервисов постепенно приводит к ситуации, в которой сервисы оказываются связанными друг с другом. Вскоре ранее удачно разделенные сервисы все больше запутываются в связях с другими сервисами, и вы этого никогда не замечаете, поскольку никогда не пытаетесь развертывать их по отдельности. В конце концов возникает сплошная путаница, при которой вам приходится дирижировать развертыванием сразу нескольких сервисов, и, как уже говорилось, связанность такого рода может оставить нас в ситуации еще более незавидной, чем та, в которой мы оказались бы при наличии единого монолитного приложения.
И в этом нет ничего хорошего.
Тестируйте маршруты, а не истории
Несмотря на указанные недостатки, при использовании одного или двух сервисов многие пользователи все же смогут справиться с управлением сквозными тестами, проведение которых в подобных ситуациях представляется вполне разумным действием. А что, если используются 3, 4, 10 или 20 сервисов? Очень быстро эти наборы тестов станут весьма сильно раздутыми, что в худшем случае приведет к взрывному росту тестируемых сценариев.
Ситуация усугубится еще больше, если мы попадемся на крючок добавления новых сквозных тестов для каждой крупицы добавляемых функциональных возможностей. Покажите мне набор исходных кодов, где каждая новая история приводит к созданию нового сквозного теста, и я покажу вам раздутый набор тестов с плохим показателем циклов получения ответных данных и огромными перекрытиями охватываемых тестами областей.
Наилучшим противопоставлением этой перспективе является сконцентрированность на небольшом количестве основных маршрутов тестирования для всей системы. Любые функциональные возможности, не охватываемые этими основными маршрутами, должны быть охвачены тестами, анализирующими сервисы в изоляции от всех других тестов. Эти маршруты должны быть взаимосогласованными и находиться в совместном владении. В случае с нашим музыкальным магазином можно сфокусироваться на таких действиях, как заказ компакт-диска, возврат товара или, может быть, создание нового клиента, то есть на особо значимых взаимодействиях в весьма ограниченных количествах.
Концентрация на небольшом количестве тестов (небольшое количество в моем понимании выражается весьма скромной двузначной цифрой даже для сложных систем) позволит сократить количество недостатков интеграционных тестов, но избежать всех недостатков нам, конечно же, не удастся. А может быть, есть какой-нибудь более подходящий способ?
Тесты на основе запросов потребителей, спасающие ситуацию
С какой из ключевых проблем при использовании упомянутых ранее интеграционных тестов мы пытаемся справиться? Мы стараемся гарантировать, что при развертывании нового сервиса для работы в производственном режиме внесенные нами изменения не внесут разлад в работу потребителей. Одним из способов добиться обозначенной цели без необходимости проведения тестов с участием реальных потребителей является использование контрактов, составленных на основе запросов потребителей (CDC).
При использовании CDC определяются ожидания потребителя от сервиса (или поставщика). Ожидания потребителей оформляются в виде кода тестов, который затем запускается в отношении поставщика. При правильной постановке вопроса эти CDC должны запускаться как часть CI-сборки поставщика, гарантируя, что он никогда не будет развернут при нарушении хотя бы одного из этих контрактов. Что очень важно с точки зрения получения обратного ответа при тестировании, эти тесты должны запускаться только в отношении отдельно взятого поставщика, находящегося в изоляции, поэтому они могут выполняться быстрее и надежнее тех сквозных тестов, которые могут быть ими подменены.
В качестве примера еще раз обратимся к нашему сценарию клиентского сервиса. У него есть два отдельных потребителя: сервис техподдержки и веб-магазин. У обоих этих сервисов-потребителей есть ожидания того, как будет вести себя клиентский сервис. В данном примере создаются два набора тестов: по одному для каждого потребителя, представляющего использование клиентского сервиса сервисом техподдержки и веб-магазином. Здесь правилом хорошего тона считается совместный вклад в создание тестов, вносимый как командами потребителей, так и командой поставщика, поэтому вполне вероятно, что их созданием будут заниматься представители команд сервиса техподдержки и веб-магазина с представителями команды клиентского сервиса.
Поскольку эти CDC являются ожиданиями того, как себя будет вести клиентский сервис, их можно запускать в отношении самого клиентского сервиса с любыми заглушенными нижестоящими по отношению к нему зависимостями (рис. 7.9). С точки зрения области действия эти контракты занимают тот же уровень в тестовой пирамиде, что и тесты сервисов, хотя и с совершенно иным фокусом (рис. 7.10). Эти тесты фокусируются на том, как сервис будет использоваться потребителем, и причины их сбоев совсем другие, нежели причины сбоев при проведении тестов сервиса. Если в ходе сборки клиентского сервиса будут нарушены эти CDC, станет совершенно понятно, на кого из потребителей это повлияет. В таком случае можно будет либо устранить проблему, либо обсудить внесение критических изменений в том порядке, который рассматривался в главе 4. Итак, используя CDC, можно идентифицировать критическое изменение до запуска программного средства в работу в производственном режиме без необходимости применения потенциально недешево обходящихся сквозных тестов.
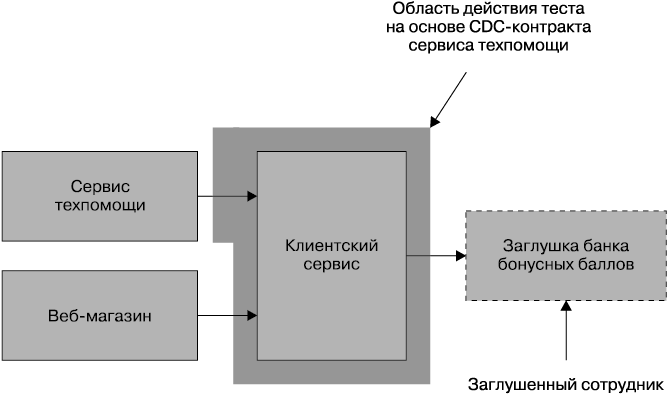
Рис. 7.9. Тесты на основе запросов потребителей в контексте примера клиентского сервиса
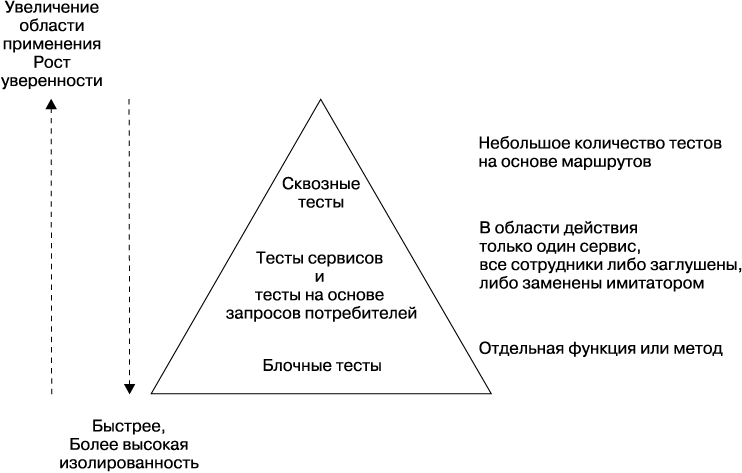
Рис. 7.10. Интеграция тестов на основе запросов потребителей в тестовую пирамиду
Pact
Pact представляет собой средство тестирования на основе запросов потребителей, которое первоначально было разработано для внутренних нужд компании Real-Estate.com.au, а теперь является средством с открытым кодом, основной разработкой которого руководил Бет Скурри (Beth Skurrie). Предназначенное сначала только для Ruby средство тестирования Pact теперь включает порты JVM и .NET.
Блок-схема, приведенная на рис. 7.11, показывает, что Pact работает весьма интересным образом. Потребитель начинает с того, что определяет ожидания от производителя с использованием Ruby DSL. Затем вы запускаете локальный сервер-имитатор и в отношении его запускаете ожидания для создания файла спецификации Pact. Этот Pact-файл является не чем иным, как формальной JSON-спецификацией, которую вы, конечно, можете создать и вручную, но с использованием API-интерфейса языка это делается намного проще. Кроме того, вы получаете запущенный сервер-имитатор, который может применяться для последующих изолированных тестов потребителя.
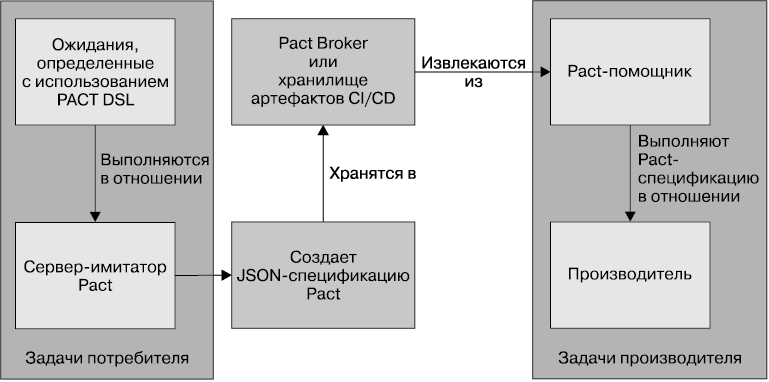
Рис. 7.11. Обзор возможностей тестирования на основе запросов потребителей с использованием Pact
Затем с использованием JSON-спецификации Pact на стороне производителя проверяется соблюдение этой спецификации потребителя для управления вызовами вашего API-интерфейса и проверки ответов. Чтобы все это работало, набор исходных кодов производителя должен иметь доступ к Pact-файлу. Как уже говорилось в главе 6, ожидается, что потребитель и производитель будут находиться в разных сборках. Особенно приятной чертой является использование независимой от выбираемых языков программирования JSON-спецификации. Это означает, что создавать спецификацию потребителя можно с применением Ruby-клиента, но использовать ее для проверки Java-производителя с помощью принадлежащего Pact JVM-порта.
Поскольку JSON-спецификация Pact создается потребителем, это требует доступа к ней со стороны того артефакта, который создается поставщиком. Эту спецификацию можно сохранить в хранилище артефактов вашего CI/CD-средства или же можно воспользоваться средством Pact Broker, позволяющим хранить несколько версий ваших Pact-спецификаций. Это может позволить вам запускать тесты на основе потребительских запросов в отношении нескольких различных версий потребителей, если потребуется, скажем, применить тесты в отношении версии, используемой в производственном режиме, и в отношении версии, представленной самой последней сборкой.
Как ни странно, у компании ThoughtWorks имеется проект с открытым кодом под названием Pacto, который также является написанным на Ruby средством, использующимся для тестирования на основе запросов потребителей. У него есть возможность записи взаимодействий клиента и сервера для создания ожиданий. Это существенно упрощает создание контрактов для существующих сервисов, составленных на основе запросов потребителей. При использовании Pacto созданные ожидания имеют более или менее статичный характер, а с применением Pact ожидания создаются у потребителя с каждой новой сборкой. Функция определения ожиданий возможностей поставщика, которых пока еще нет, наилучшим образом вписывается в рабочий процесс, в рамках которого сервис-поставщик еще находится (или вскоре будет находиться) в разработке.
О переговорах
В обычной жизни истории называют заполнителями разговоров. CDC также можно рассматривать в данном ключе. Они становятся кодификацией ряда дискуссий о том, как должен выглядеть API-интерфейс сервиса, и когда контракты нарушаются, они становятся поводом для разговоров о том, как должен развиваться API-интерфейс.
Важно понимать, что CDC требуют активного обмена данными и доверия между потребителем и сервисом-поставщиком. Если обе стороны относятся к одной и той же команде (или это один и тот же человек!), то никаких трудностей возникать не должно. Но если вы являетесь потребителем сервиса, предоставляемого сторонним производителем, общение может быть нечастым или же могут отсутствовать доверительные отношения, способствующие работе CDC. В таких ситуациях вам, возможно, придется довольствоваться ограниченным числом интеграционных тестов с более широкой областью действия, охватывающей ненадежный компонент. Кроме того, если API-интерфейс создается для нескольких тысяч потенциальных потребителей, как в случае API общедоступного веб-сервиса, то для определения этих тестов вам, вероятно, придется играть роль потребителя самостоятельно (или же работать выборочно со своими потребителями). Игнорирование ожиданий огромного количества внешних потребителей нам не подойдет, поэтому ориентироваться нужно на возрастание важности CDC!
А нужно ли вообще пользоваться сквозными тестами?
В данной главе уже были описаны во всех подробностях многие недостатки сквозных тестов, число которых по мере вовлечения в тестирование все большего количества активных компонентов стремительно растет. Из разговоров со специалистами, имевшими вполне достаточный опыт реализации микросервисов, я понял, что многие из них со временем полностью избавились от сквозных тестов, отдав предпочтение таким инструментам, как CDC, и уделив внимание совершенствованию мониторинга. Но выбрасывать эти тесты они все равно не спешили. Многие из сквозных маршрутных тестов стали использоваться для мониторинга системы, работающей в производственном режиме, с помощью технологии под названием «семантический мониторинг», которая более подробно рассматривается в главе 8.
Результаты сквозных тестов можно использовать, чтобы подстраховаться перед развертыванием для работы в производственном режиме. Пока вы будете вникать в характер работы CDC и совершенствовать производственный мониторинг и технологии развертывания, сквозные тесты могут стать весьма полезной страховочной сеткой при достижении разумного компромисса между временем цикла тестирования и уменьшением степени риска. Но при улучшениях в других областях можно приступать к сокращению зависимости от сквозных тестов вплоть до полного отказа от них.
Кроме того, ваша работа может проходить в такой обстановке, когда никто не будет стремиться к тому, чтобы быстрее запустить систему в производство и изучить ее поведение в ходе эксплуатации, и все силы будут брошены на избавление от дефектов до производственного развертывания системы, даже если это повлечет за собой затягивание сроков поставки программных продуктов. Пока вы не сможете обрести уверенность в том, что все источники дефектов устранены, и не поймете, что вам в процессе эксплуатации все же нужны эффективные средства мониторинга и внесения поправок, решение об использовании сквозных тестов может иметь под собой вполне разумные основания.
Разумеется, вы лучше меня сможете разобраться в управлении рисками в своей собственной организации, но я призываю как следует подумать о том, какие объемы тестирования реально нужны вашей системе.
Тестирование после перевода в производственный режим работы
Основной объем тестирования проводится перед развертыванием системы для работы в производственном режиме. Используя тесты, мы определяем ряд моделей, с помощью которых надеемся доказать, что система работает и ведет себя в соответствии с нашими пожеланиями как с функциональной, так и с нефункциональной точки зрения. Но если наши модели не отличаются совершенством, то при эксплуатации системы мы испытаем раздражение, столкнувшись с проблемами, ошибками, просочившимися в производство, обнаружением новых сбойных режимов работы и тем, что пользователи будут применять систему совершенно неожиданным для нас образом.
Одной из реакций на подобный результат зачастую является разработка все новых и новых тестов и улучшение моделей с целью отлова как можно большего количества дефектов на ранней стадии тестирования и сокращения количества проблем, с которыми приходится сталкиваться в системе, работающей в производственном режиме. Но в определенный момент нам приходится признавать, что отдача от такого подхода снижается. Тестированием, предшествующим развертыванию, мы не можем снизить вероятность сбоев до нуля.
Отделение развертывания от выпуска
Одним из способов отлавливания большего количества дефектов еще до того, как они смогут проявиться в производственном режиме, является выведение области запуска тестов за пределы традиционных этапов, проводимых до развертывания. Если можно развернуть программное средство и протестировать его по месту до направления на него производственной нагрузки, можно выявить дефекты, характерные для заданной среды. Довольно распространенным примером этого может послужить набор для проведения дымового теста, то есть коллекция тестов, разработанная для запуска в отношении только что развернутого программного средства с целью подтверждения работоспособности его кода. Эти тесты помогают выявить любые проблемы локальной среды. Если для развертывания любого отдельно взятого микросервиса используется инструкция командной строки (как, собственно, это и следует делать), эта инструкция должна запускать дымовые тесты автоматически.
Еще одним примером может послужить так называемое сине-зеленое развертывание, при котором имеются две одновременно развернутые копии программного средства, но при этом реальные запросы получает только одна из версий.
Рассмотрим пример, показанный на рис. 7.12. В производстве у нас используется клиентский сервис версии v123. Нужно развернуть новую версию v456. Мы развертываем ее рядом с v123, но трафик на нее не направляем. Вместо этого мы проводим тестирование только что развернутой версии на месте. После успешного прохождения тестов производственная нагрузка направляется на новую версию клиентского сервиса v456. Принято на некоторое время старую версию оставлять на прежнем месте, что в случае обнаружения ошибок даст возможность произвести быстрый откат.
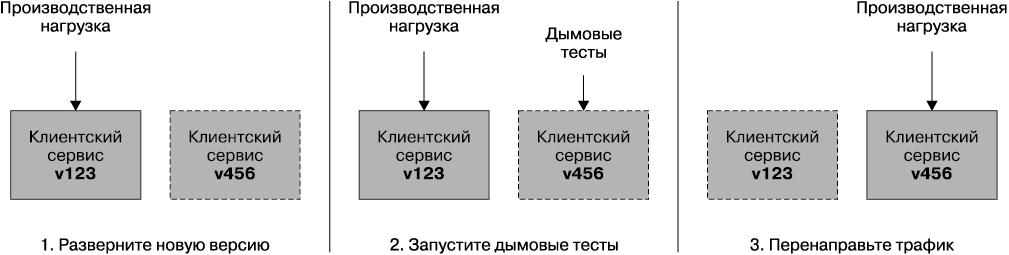
Рис. 7.12. Использование сине-зеленых развертываний для отделения развертывания от выпуска
Для реализации сине-зеленого развертывания требуется выполнить несколько условий. Во-первых, нужна возможность направления производственного трафика на различные хосты (или наборы хостов). Это можно сделать, изменив DNS-записи или обновив конфигурацию балансировки нагрузки. Во-вторых, нужно иметь возможность предоставления достаточного количества хостов для одновременной работы обеих версий микросервиса. При использовании поставщика облачных услуг, предоставляющего возможности их расширения, выполнить это условие будет нетрудно. Использование сине-зеленых развертываний позволяет сократить риск развертывания, а в случае возникновения какой-нибудь проблемы — вернуться в прежнее состояние. Если у вас все получится, процесс может быть полностью автоматизирован либо с полным запуском нового процесса, либо с возвратом в прежнее состояние без участия человека.
Помимо преимуществ, заключающихся в возможностях тестирования сервиса на месте до отправки на него производственного трафика, сохраняя старую версию, работающую в процессе выпуска новой версии, мы существенно сокращаем время простоя, связанного с выпуском программного средства. В зависимости от конкретного механизма, используемого для реализации перенаправления трафика, переход от одной версии к другой может быть абсолютно незаметен для клиента, позволяя проводить развертывание с нулевым временем простоя.
В связи с этим стоит подробнее рассмотреть еще одну технологию, которую иногда путают с сине-зелеными развертываниями, поскольку в ней могут использоваться такие же технические реализации. Эта технология называется канареечным выпуском.
Канареечный выпуск
С помощью канареечного выпуска только что развернутое программное средство проверяется путем направления на систему некоторых объемов производственного трафика с целью выявления ожидаемого функционирования. Функционирование в соответствии с ожиданиями может охватывать несколько аспектов как функциональных, так и нефункциональных. Например, мы могли бы проверить, что только что развернутый сервис реагирует на запросы в течение 500 мс или что мы наблюдаем пропорциональный уровень ошибок, производимых новым и старым сервисами. Но можно пойти еще дальше. Представьте, что выпускается новая версия сервиса рекомендаций. Можно запустить обе версии одновременно и посмотреть, будут ли рекомендации, выданные новой версией сервиса, приводить к достаточному количеству ожидаемых продаж, что убедит нас в том, что мы не выпустили версию с неоптимальным алгоритмом.
Если новый выпуск окажется плохим, можно быстро вернуть все в прежнее состояние. Если он окажется хорошим, можно запустить увеличивающийся объем трафика через новую версию. Канареечный выпуск отличается от сине-зеленого развертывания тем, что можно рассчитывать на сосуществование версий в течение более длительного времени с частым варьированием объема трафика.
Такой подход активно используется компанией Netflix. До выпуска новые версии сервисов развертываются возле базового кластера, представляющего ту же версию, которая работает в производственном режиме. Затем Netflix запускает часть производственной нагрузки на несколько часов как в адрес новой версии, так и в адрес базовой версии, ведя подсчет в отношении обеих версий. Если канареечный выпуск проходит испытание, компания полностью запускает его в работу в производственном режиме.
При рассмотрении возможности использования канареечного выпуска нужно решить, собираетесь ли вы отводить часть производственных запросов к этому выпуску или будете копировать производственную нагрузку. Некоторые команды могут создавать теневой производственный трафик и направлять его на свой канареечный выпуск. При этом производственная и канареечная версии могут видеть совершенно одинаковые запросы, но внешне будут видны только результаты обработки запросов производственной версией. Тем самым можно будет проводить сравнительный анализ, исключая при этом то, что сбои в канареечном выпуске станут видны клиентскому запросу. Но работа по созданию теневого производственного трафика может быть нелегкой, особенно если воспроизводимые события или запросы не являются идемпотентными.
Канареечные выпуски являются весьма эффективной технологией и могут помочь в проверке новых версий программных средств при обработке реального трафика, предоставляя при этом инструменты управления риском запуска в производство некачественного выпуска. Но эта технология требует более сложных настроек, чем сине-зеленое развертывание, и более тщательного обдумывания. При этом можно допустить более продолжительное сосуществование различных версий ваших сервисов, чем при использовании сине-зеленого развертывания, что может повлечь за собой более продолжительное, чем раньше, привлечение соответствующего оборудования. Кроме того, понадобится более сложная маршрутизация трафика, поскольку для обретения уверенности в работоспособности вашего выпуска может потребоваться повышать или снижать объем обрабатываемого им трафика. Если вы уже практиковали сине-зеленое развертывание, то уже можете иметь ряд строительных блоков и для канареечного выпуска.
Что важнее: среднее время восстановления работоспособности или среднее время безотказной работы?
Посмотрев на такие технологии, как сине-зеленое развертывание или канареечный выпуск, мы нашли способ тестирования, близкий к работе в производственном режиме (или даже внедренный в эту работу), а также создали средства, помогающие справляться со сбоями в случае их появления. Использование этих подходов является негласным признанием того, что мы не в состоянии обозначить и решить все проблемы до практического выпуска программного средства.
Иногда затрата таких же усилий на совершенствование средств корректировки выпуска может быть намного выгоднее добавления дополнительных автоматизированных тестов. В мире веб-операций это часто рассматривается как компромисс между оптимизацией под среднее время безотказной работы (MTBF) и среднее время восстановления работоспособности (MTTR).
Технологии сокращения времени восстановления работоспособности могут быть не сложнее быстрого отката в сочетании с хорошо организованным мониторингом (который рассматривается в главе 8), что похоже на сине-зеленые развертывания. Если проблема при работе в производственном режиме обнаруживается на самой ранней стадии и мы тут же проводим откат, то отрицательное воздействие на работу клиентов уменьшается. Мы также можем воспользоваться технологиями, подобными сине-зеленому развертыванию, при развертывании новой версии программного средства и тестировании его на месте до перенаправления пользователей на работу с новой версией.
Для различных организаций компромисс между MTBF и MTTR будет варьироваться, и здесь очень многое зависит от осознания реального влияния сбоев на производственную среду. Hо большинство встречавшихся мне организаций тратило время на создание функциональных тестовых наборов и уделяло совсем мало времени совершенствованию мониторинга или разработке средств восстановления работоспособности или вообще не прикладывало к этому никаких усилий. Получалось, что, устраняя ряд дефектов, проявившихся с самого начала, они не могли устранить абсолютно все дефекты и не были готовы к тому, чтобы справиться с их проявлением при работе в производственном режиме.
Существуют и другие компромиссы, не связанные с MTBF и MTTR. Например, прежде чем создавать трудоемкое программное средство, будет намного целесообразнее сначала попытаться определить, станет ли кто-нибудь им пользоваться, чтобы убедиться в актуальности замысла или бизнес-модели. При таких обстоятельствах тестирование может быть излишним, поскольку определение жизнеспособности самой идеи намного важнее, чем сведения о наличии дефектов при работе в производственном режиме. В подобных ситуациях вполне разумно вообще отказаться от тестирования до испытания в условиях производства.
Межфункциональное тестирование
Основная часть этой главы посвящена тестированию конкретных функциональных возможностей и особенностям его проведения в отношении систем на основе использования микросервисов. Но есть и другой вид тестирования, который важно рассмотреть. Для описания характеристик системы, не поддающихся простой реализации в виде обычной функции, существует обобщающий термин «нефункциональные требования». Эти требования включают в себя такие аспекты, как приемлемая задержка при выводе веб-страницы, количество пользователей, которое должно поддерживаться системой, показатель приспособленности пользовательского интерфейса к работе с ним людей с ограниченными возможностями, степень безопасности клиентских данных.
Термин «нефункциональные» никогда мне не нравился. Некоторые подпадающие под него понятия представляются весьма функциональными по своей природе! Одна из моих коллег, Сара Тарапоревалла (Sarah Taraporewalla), придумала вместо него словосочетание «межфункциональное тестирование» (Cross-Functional Requirements (CFR)), которому я всецело отдаю предпочтение. Оно говорит скорее о том, что эти элементы поведения системы действительно проявляются только в результате большого объема комплексной работы.
Многие, если не большинство CFR-требований могут быть соблюдены только в ходе работы в производственном режиме. Из этого следует, что нужно определить тестовые стратегии, помогающие понять, насколько мы приблизились к соответствию намеченным целям. Эта разновидность тестов попадает в сектор тестирования свойств. Хорошим примером таких тестов может послужить тест производительности, который мы вскоре рассмотрим более подробно.
Выполнение некоторых CFR-требований, возможно, придется отследить на отдельном сервисном уровне. Например, может быть принято решение, что вам необходима более высокая живучесть сервиса платежей, но вполне устраивает более продолжительный простой сервиса музыкальных рекомендаций, поскольку известно, что основной бизнес может сохранить живучесть, если вы не сможете порекомендовать исполнителей, похожих на Metallica, в течение десяти минут или около того. Эти компромиссы окажут большое влияние на принципы конструирования и развития вашей системы, и здесь снова высокая степень детализации, присущая системам на основе использования микросервисов, даст вам высокие шансы успешно справиться с этими компромиссами.
Тесты выполнения CFR-требований также должны вписываться в пирамидальную схему. Некоторые из них должны носить сквозной характер, например тесты работы при полной нагрузке, другие же не должны быть сквозными. Например, при обнаружении в результате проведения сквозного теста работы при полной нагрузке узких мест, снижающих производительность, следует написать тест с более узкой областью действия, помогающий определить причину возникновения проблемы в будущем. Другие проверки выполнения CFR-требований вполне вписываются в быстрые тесты. Помнится, мне приходилось работать над проектом, где мы настаивали на обеспечении использования HTML-разметки соответствующих функций, помогающих пользоваться сайтом людям с ограниченными возможностями. Проверка созданной разметки на присутствие соответствующих элементов управления может быть проведена очень быстро и без какого-либо обмена данными по сети.
Зачастую бывает так, что размышлять об CFR-требованиях начинают слишком поздно. Я настоятельно рекомендую рассматривать CFR-требования как можно раньше, а также регулярно заниматься их пересмотром.
Тесты производительности. Есть смысл вызывать тесты производительности непосредственно как способ убедиться в соблюдении некоторых межфункциональных требований. При разбиении систем на более мелкие микросервисы повышается количество вызовов, производимых через сетевые границы. Там, где прежде операция могла повлечь за собой один вызов базы данных, теперь она может стать причиной трех или четырех вызовов других сервисов через сетевые границы с соответствующим количеством вызовов баз данных. Все это может снизить скорость работы системы. При этом отслеживание источников задержек приобретает особую важность. Когда имеется последовательность из нескольких синхронных вызовов, замедление работы любой из частей этой последовательности затрагивает всю ее целиком, что потенциально приводит к существенному отрицательному воздействию. Это придает еще большую важность наличию какого-либо способа проведения теста производительности приложений, чем это могло бы быть при использовании более монолитной системы. Зачастую смысл выполнения такого тестирования возникает не сразу, поскольку изначально у системы для него недостаточно компонентов. Суть данной проблемы мне понятна, но довольно часто это приводит к совершенно необоснованному затягиванию и проведению тестов производительности непосредственно перед первым выпуском средства в производственную среду или же вообще к игнорированию этих тестов! Не попадайтесь на эту удочку.
Как и в случае с функциональными тестами, может понадобиться проведение неких тестовых комбинаций. Можно прийти к решению о необходимости выполнения тестов производительности, изолирующих отдельные сервисы, но начать с тестов, проверяющих основные маршруты, существующие в системе. Вам может представиться возможность взять сквозные тесты маршрутов и провести их в полном объеме.
Для получения полноценных результатов данные сценарии зачастую нужно будет запускать с постепенным увеличением количества имитируемых клиентов. Это позволит увидеть изменение задержек вызовов по мере роста рабочей нагрузки. Следовательно, выполнение тестов производительности может занять довольно много времени. Кроме того, чтобы гарантировать отображение в полученных результатах той производительности, которой можно ожидать при работе в производственном режиме, потребуется максимально приблизить систему к производственным параметрам. Это может означать, что вам потребуется достичь более похожего на производственную нагрузку объема данных и понадобится большее количество машин, чтобы соответствовать производственной инфраструктуре, а выполнить подобные задачи может быть весьма нелегко. Даже если вам трудно приблизить параметры тестовой среды к производственным, тесты все равно будут иметь ценность, выражающуюся в выявлении узких мест системы. Но все же нужно знать, что при этом вы можете получать недостоверные негативные или, что еще хуже, недостоверные позитивные результаты.
Из-за большого количества времени, затрачиваемого на проведение тестов производительности, возможность их выполнения в каждом контрольном случае представляется не всегда. Согласно сложившейся практике, запускать поднабор тестов нужно ежедневно, а более крупный набор — еженедельно. Но какой бы из подходов вы ни выбрали, следует запускать эти тесты как можно регулярнее. Чем дальше вы продвинетесь в своей работе без тестов производительности, тем сложнее будет отследить виновников ее снижения. Проблемы производительности весьма трудно устранить, поэтому, если есть такая возможность, нужно уменьшить количество изменений, требующих внимания, с целью выявления новых проблем, и тогда ваша работа станет значительно легче.
И непременно вникайте в результаты! Я был крайне удивлен количеством встреченных мною команд, тративших массу усилий на разработку и выполнение тестов и никогда не анализирующих получаемые значения. Зачастую это происходит по причине незнания того, как должны выглядеть приемлемые результаты. Вам нужны четко поставленные цели. Тогда вы сможете, основываясь на результатах, сделать сборку красной или зеленой и понять, что нужно сделать с красной (не прошедшей тесты) сборкой.
Тесты производительности должны выполняться в сочетании с мониторингом реальной производительности системы (который более подробно рассматривается в главе 8), и в идеале в среде проведения тестов производительности для визуализации поведения системы должны применяться те же инструменты, которые используются и при работе в производственном режиме. Это может существенно упростить сравнение работы в режиме тестирования и в производственном режиме.
Резюме
Все затронутое в данной главе обобщенно можно назвать целостным подходом к тестированию, рассмотрение которого, я надеюсь, даст вам ряд верных направлений проведения таких тестов в ваших собственных системах. Повторим основные положения.
• Проводите оптимизацию в целях получения быстрых ответных результатов и соответствующего разделения тестов на типы.
• Избегайте использования сквозных тестов там, где можно воспользоваться контрактами на основе запросов потребителей.
• Используйте контракты на основе запросов потребителей для фокусировки вокруг них переговоров между командами разработчиков.
• Постарайтесь добиться разумного компромисса и решить, к чему все же следует прикладывать больше усилий — к тестированию или к ускоренному выявлению проблемных моментов при работе в производственном режиме (проводя оптимизацию либо под MTBF, либо под MTTR).
Если вы заинтересованы в получении дополнительных сведений о тестировании, я могу порекомендовать книгу Agile Testing (Addison-Wesley), написанную Лизой Криспин (Lisa Crispin) и Джанет Грегори (Janet Gregory), в которой, кроме всего прочего, более подробно рассмотрены вопросы использования секторов тестирования.
Основное внимание в данной главе уделялось приобретению уверенности в том, что код работает еще до того, как он попадет в работу в производственном режиме, но нам также нужно знать, как убедиться в том, что код будет работоспособен после развертывания. В следующей главе мы посмотрим, как проводить мониторинг систем, основанный на применении микросервисов.
Vaughan D. The Challenger Launch Decision: Risky Technology, Culture, and Deviance at NASA. — Chicago: University of Chicago Press, 1996.

