6. Развертывание
Монолитные системы развертываются довольно просто. А вот с развертыванием микросервисов с их взаимозависимостями придется повозиться. Если выбрать неверный подход к развертыванию, оно настолько усложнится, что ваша жизнь превратится в сплошные мучения. В этой главе будет рассматриваться ряд приемов и технологий, призванных помочь в развертывании микросервисов в мелкоструктурных архитектурах.
Но начнем мы с того, что рассмотрим вопросы непрерывной интеграции и непрерывной поставки. Эти родственные, но различные понятия помогут наметить контуры других решений, которые будут приниматься в ходе размышлений о том, что именно создавать, как создавать и как развертывать созданное.
Краткое введение в непрерывную интеграцию
Понятие непрерывной интеграции (continuous integration (CI)) существует уже несколько лет. Но на объяснение ее основ все же стоит потратить немного времени, особенно при обдумывании отображений между микросервисами, сборок и хранилищ управления версиями, требующем рассмотрения нескольких разных вариантов.
При использовании CI основной целью является поддержка всеобщего синхронизированного состояния, которая достигается путем проверки того, что только что введенный в эксплуатацию код интегрируется с существующим кодом должным образом. Для достижения этой цели CI-сервер определяет переданный код и проводит ряд проверок, убеждаясь в том, что код скомпилирован и тесты с ним проходят без сбоев.
В качестве части данного процесса часто создается артефакт (или артефакты), используемый для дальнейшей проверки, например развертывания работающего сервиса с целью запуска для него ряда тестов. В идеале нам потребуется создавать эти артефакты только один раз и использовать их для всех развертываний той или иной версии кода. Это делается для того, чтобы избежать многократного повторения одних и тех же действий и чтобы можно было подтвердить, что развернутый нами артефакт уже прошел тестирование. Чтобы допустить повторное использование этих артефактов, мы помещаем их в особое хранилище, либо предоставляемое самим CI-инструментарием, либо находящееся в отдельной системе.
Вскоре мы рассмотрим, какого именно сорта артефакты можно будет использовать для микросервисов, а о тестировании более подробно поговорим в главе 7.
CI предоставляет ряд преимуществ. Мы получаем некое довольно быстро формируемое представление о качестве кода. Непрерывная интеграция позволяет автоматизировать создание двоичных артефактов. Весь код, требующийся для создания артефакта, проходит самостоятельное управление версиями, поэтому при необходимости артефакт можно создать заново. Мы также получаем некоторую возможность отслеживания, проходящего от развернутого артефакта назад к его коду, и в зависимости от возможностей CI-инструментария можем наблюдать, какие тесты запущены в отношении как кода, так и артефакта. Именно эти обстоятельства и обусловили успешное применение CI.
А вам приходилось этим заниматься? Подозреваю, что вы уже использовали непрерывную интеграцию в своей организации. Если нет, то пора приступить к ее применению. Дело в том, что это основной способ, позволяющий быстрее и легче вносить изменения, и без него путь к микросервисам будет слишком труден. Мне приходилось работать с командами, которые, несмотря на заявления о применении CI, вообще ею не пользовались. Они путали применение CI-инструментария с внедрением практического использования CI. Инструментарий — лишь средство, позволяющее применить сам подход.
Мне нравятся три вопроса, которые Джез Хамбл (Jez Humble) задает людям, чтобы проверить, правильно ли они понимают, что такое CI.
• Вы проходите ежедневную проверку в основной программе?
Вам нужно убедиться в том, что ваш код интегрируется в систему. Если не проводить частые проверки своего кода вместе с чьими-либо изменениями, можно существенно усложнить будущую интеграцию. Даже при использовании для управления изменениями недолговечных ответвлений интеграцию с единой основной ветвью нужно проводить как можно чаще.
• Имеется ли у вас набор тестов для проверки правильности вносимых вами изменений?
Без тестов мы просто знаем, что синтаксически интеграция работает, но не знаем, не нарушим ли поведение системы. CI без ряда проверок, подтверждающих ожидаемое поведение кода, — это не CI.
• Служит ли исправление неисправной сборки главным приоритетом команды?
Проход зеленой сборки означает, что изменения были безопасно интегрированы. Красная сборка означает, что последнее изменение, возможно, не прошло интеграцию. Нужно остановить все последующие проверки, не применяемые для исправления сборок, чтобы пройти тесты повторно. Если нагромоздить большое количество изменений, время исправления сборки существенно возрастет. Мне приходилось работать с командами, у которых сборка оставалась неисправной по нескольку дней, что приводило к необходимости прикладывать существенные усилия для получения в итоге проходящей тесты сборки.
Отображение непрерывной интеграции на микросервисы
Размышляя о микросервисах и непрерывной интеграции, нужно подумать о том, как средство CI создает отображение на отдельно взятые микросервисы. Как я уже не раз говорил, нужно убедиться в том, что мы можем внести изменение в отдельный микросервис и развернуть его независимо от остальных микросервисов. Как, памятуя об этом, мы отображаем отдельно взятые микросервисы на CI-сборки и исходный код?
Если начать с самого простого варианта, то можно было бы свалить все в кучу. У нас есть одно огромное хранилище, в котором находится весь код (рис. 6.1). Любая проверка этого исходного кода запустит сборку, где мы запустим все этапы верификации, связанные с микросервисами, и создадим несколько артефактов, имеющих обратную связь с той же самой сборкой.
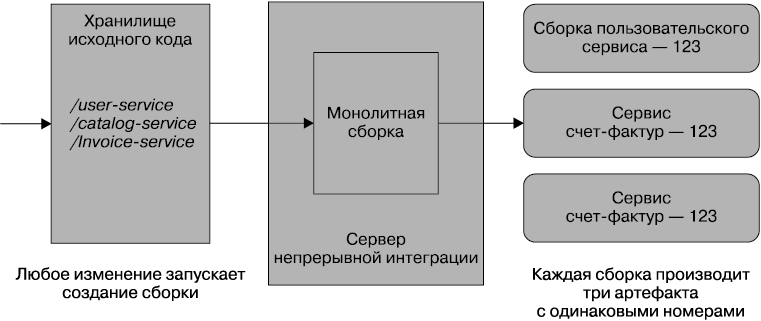
Рис. 6.1. Использование единого хранилища исходного кода и CI-сборки для всех микросервисов
На первый взгляд все кажется намного проще других подходов: меньше приходится беспокоиться о хранилищах, да и создание сборок концептуально выглядит проще. С точки зрения разработчика, все также выглядит довольно просто. Нужно лишь проверять находящийся внутри код. Если приходится работать сразу с несколькими сервисами, следует беспокоиться только об одном совершаемом действии.
Такая модель может работать весьма успешно при условии, что вы придерживаетесь замысла жестко регламентированных выпусков, где вас не смущает одновременное развертывание сразу нескольких сервисов. Вообще-то это именно тот шаблон, которого следует всячески избегать, но на самой ранней стадии проекта, особенно если над проектом работает одна команда, его кратковременное применение имеет определенный смысл.
У данной модели есть ряд весьма существенных недостатков. При внесении самых незначительных изменений в какой-либо сервис, например при изменении поведения пользовательского сервиса, показанного на рис. 6.1, должны быть собраны и верифицированы все остальные сервисы. На это может уйти больше времени, чем требуется в других обстоятельствах, поскольку придется ожидать прохождения тестов там, где в тестировании нет никакого смысла. Это влияет на продолжительность цикла и скорость, с которой мы можем пройти путь от разработки до внедрения отдельного изменения. Но большее беспокойство вызывает мысль о том, что нужно знать, какие артефакты должны быть развернуты, а какие — нет. Знаю ли я о том, нужно ли развертывать все собранные сервисы для того, чтобы запустить мои небольшие изменения в производство? Ответ на этот вопрос может вызвать затруднения, нелегко бывает догадаться, какие сервисы действительно подверглись изменениям, в процессе простого чтения сообщений о совершении действий. Организации, использующие такой подход, часто склоняются к одновременному развертыванию всех сервисов, чего нужно избегать.
Более того, если вносимое мной в пользовательский сервис незначительное изменение испортит сборку, то, пока неисправность не будет устранена, вносить какие-либо иные изменения в другие сервисы будет невозможно. И подумайте о сценарии, при котором эту гигантскую сборку совместно используют сразу несколько команд разработчиков. Какая из них будет главной?
Разновидность этого подхода (рис. 6.2) предусматривает наличие единого дерева для всего исходного кода и нескольких CI-сборок, отображаемых на части этого дерева. При четко заданной структуре можно без особых усилий отобразить сборки на конкретные части дерева исходного кода. Вообще-то я не сторонник данного подхода, поскольку эта модель может вызывать смешанные чувства. С одной стороны, проверочный или наладочный процесс может упроститься, поскольку беспокоиться приходится только об одном хранилище. С другой — проверка исходного кода сразу для нескольких сервисов может легко войти в привычку, что может так же легко перейти в привычку внесения изменений сразу в несколько сервисов. Но этот подход по сравнению с подходом, предусматривающим создание единой сборки для нескольких сервисов, я считаю предпочтительным.
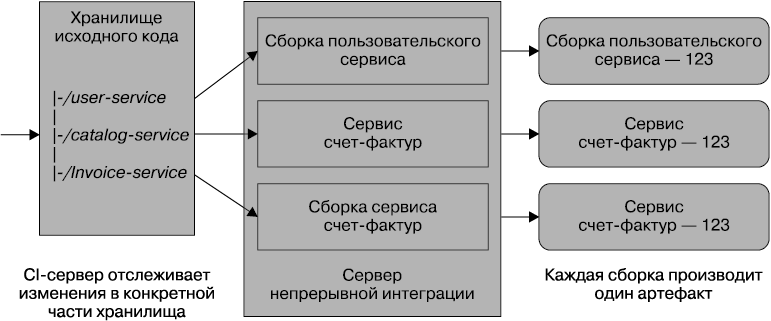
Рис. 6.2. Единое хранилище исходного кода с подкаталогами, отображаемыми на независимые сборки
А есть ли еще одна альтернатива? Предпочитаемый мною подход предполагает наличие одной CI-сборки для каждого микросервиса, что позволяет быстро вносить изменение и проверять его работоспособность еще до развертывания в производственной среде (рис. 6.3). Здесь у каждого микросервиса имеется собственное хранилище исходного кода, отображаемое на его собственную CI-сборку. При внесении изменения запускается и тестируется только нужная мне сборка. И для развертывания я получаю только один артефакт. Группировка по командной принадлежности также становится понятнее. Кто владеет сервисом, тот владеет и хранилищем и сборкой. Правда, при этом немного усложняется внесение изменений, затрагивающих сразу несколько хранилищ, но я считаю, что с этим справиться намного проще (например, с помощью сценариев командной строки), чем с теми недостатками, которые присущи монолитному процессу управления исходным кодом и сборками.
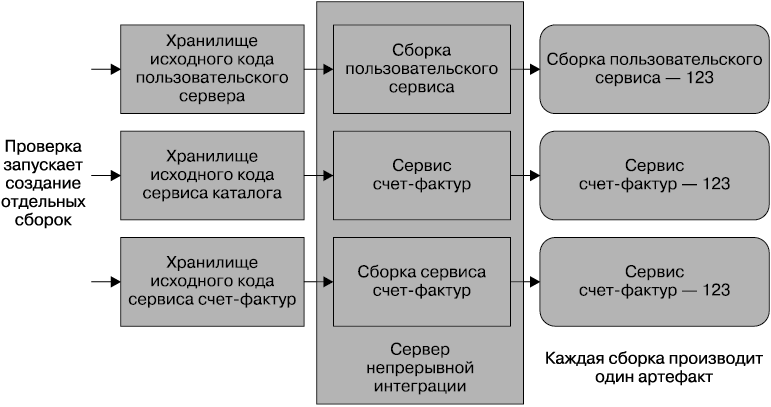
Рис. 6.3. Использование для каждого микросервиса одного хранилища и одной CI-сборки
Наряду с исходным кодом микросервисов в системе управления версиями должны находиться тесты для конкретного микросервиса, чтобы мы всегда знали, какие тесты для какого конкретного сервиса должны запускаться.
Итак, у каждого микросервиса будут собственное хранилище исходного кода и собственный процесс CI-сборки. Этот процесс в полностью автоматическом режиме будет использоваться и для готовых к развертыванию артефактов. Теперь отвлечемся от CI, чтобы увидеть, как в общую картину вписывается непрерывная доставка.
Сборочные конвейеры и непрерывная доставка
В самом начале использования непрерывной интеграции мы поняли важность наличия временами внутри сборки нескольких стадий. В качестве весьма распространенного проявления этой особенности можно назвать тесты. Может использоваться множество быстрых, весьма ограниченных по области применения тестов и небольшое количество широкомасштабных медленных тестов. Если запустить сразу все тесты, то в режиме ожидания завершения широкомасштабных медленных тестов можно не дождаться быстрого получения ответного результата на сбой при проведении быстрых тестов. А если быстрые тесты не будут пройдены, то запускать медленные тесты не будет никакого смысла! Решением этой проблемы является использование различных стадий сборки путем создания того, что называется сборочным конвейером. Одна стадия будет для быстрых тестов, а другая — для медленных.
Концепция конвейерной сборки предоставляет отличный способ отслеживания хода обработки программы по мере прояснения ситуации на каждой стадии, помогая выяснить качество программы. Мы осуществляем сборку нашего артефакта, и этот артефакт используется на всем протяжении конвейера. По мере прохождения артефакта через все его стадии растет уверенность в том, что программа будет работать в производственной среде.
Непрерывная доставка (CD) построена на этой и некоторых других концепциях. Как подчеркивается в книге с таким же названием, авторами которой являются Джез Хамбл и Дэйв Фарли (Dave Farley), непрерывная доставка представляет собой такой подход, при котором мы получаем постоянный отклик о производственной готовности абсолютно каждой проверяемой сборки и, кроме того, каждую проверяемую сборку рассматриваем в качестве сдаточной версии.
Чтобы полностью усвоить суть данной концепции, нужно промоделировать все процессы, вовлеченные в перевод программы из проверочного в производственное состояние, и знать, на какой стадии находится каждая заданная версия программы с точки зрения уверенности в ее готовности к выпуску. При применении CD это делается путем расширенного толкования идеи многоступенчатого конвейера сборки для моделирования каждой стадии, через которую должна пройти программа, как в ручном, так и в автоматическом режиме. Простой, возможно, уже знакомый вам конвейер показан на рис. 6.4.

Рис. 6.4. Стандартный процесс выпуска, смоделированный в виде сборочного конвейера
И теперь нам очень нужен инструмент, включающий в себя CD в качестве одной из главных концепций. Мне встречались многие, кто пытался внедриться в CI и заняться ее расширением до получения CD, что часто заканчивалось созданием сложных систем, которые не могли считаться простыми в использовании средствами, встраиваемыми в CD с самого начала. Средства, полностью поддерживающие CD, позволяют определять и визуализировать конвейеры и моделировать весь путь программы к производству. Во время продвижения версии кода по конвейеру, пройдя одну из автоматизированных стадий верификации, она переходит к следующей стадии. Остальные стадии могут запускаться вручную. Например, для моделирования процесса ручного тестирования на приемлемость для пользователя (UAT) при его наличии можно будет воспользоваться CD-средством. Я смогу увидеть следующую доступную сборку, готовую к развертыванию в UAT-среде, осуществить ее развертывание и, если она пройдет ручные проверки, отметить эту стадию как успешно пройденную, позволив двигаться дальше.
Благодаря моделированию всего пути программы к производству мы существенно улучшаем возможность оценить ее качество, а также можем значительно сократить время между выпусками, поскольку наблюдение за процессом сборки и выпуска ведется из одного места и у нас имеется вполне определенный координационный центр для внесения улучшений.
В мире микросервисов, где требуется обеспечить возможность выпуска сервисов независимо друг от друга, получается, что, как и в случае с CI, нужен отдельный конвейер для каждого сервиса. В наших конвейерах находится создаваемый артефакт, который нужно провести по всему пути к производству. Как всегда, оказывается, что артефакты могут иметь разнообразные размеры и формы. Вскоре мы рассмотрим некоторые наиболее распространенные и доступные варианты.
Неизбежные исключения. Как и в каждом хорошем правиле, здесь существуют исключения, также требующие рассмотрения. Подход «один микросервис на каждую сборку» должен стать вашей абсолютной целью, но есть ли случаи, когда имеет смысл воспользоваться чем-то другим? Когда команда приступает к разработке нового проекта, особенно в новом для нее ключе, когда работа начинается с чистого листа бумаги, высока вероятность того, что на пути встретится большая мешанина с точки зрения работы за пределами проложенных границ сервиса. Есть весьма веские причины задавать сервисам в начальной стадии их разработки больший размер, пока не появится понимание того, что они приобрели достаточную стабильность.
Пока все перемешано, высока вероятность внесения изменений, не соблюдающих границ сервисов, а также необходимости частого изменения того, что входит или не входит в сервисы. В этот период может быть целесообразнее содержать все сервисы в одной сборке, чтобы сократить затраты на те изменения, которые не соблюдают границ сервисов.
Но из этого не следует, что нужно позволить всем сервисам собраться в пучок. Этот период должен иметь сугубо переходный характер. Как только стабилизируются API сервисов, нужно приступать к их перемещению в собственные сборки. Если по истечении нескольких недель (или в крайнем случае пары месяцев) вам не удастся добиться стабильности в отношении границ сервисов, определяемых с целью их приемлемого разделения, снова объедините их в более монолитный сервис, сохраняя модульное разделение в пределах границ, и выделите время для того, чтобы разобраться с областью их применения. В таком подходе отражается опыт нашей собственной команды SnapCI, уже упоминавшийся в главе 3.
Артефакты для конкретных платформ
У многих технологических стеков имеются как своеобразные высококачественные артефакты, так и инструментальные средства, поддерживающие их создание и установку. У Ruby есть Gem-пакеты, у Java — JAR- и WAR-файлы, а у Python — egg-пакеты. Разработчики с опытом работы с одним из стеков будут неплохо разбираться в работе с этими артефактами (и, надеюсь, в их создании).
Но с точки зрения создателя микросервисов, зависящей от выбранного вами технологического стека, этот артефакт может быть несамодостаточным. Наряду с тем, что в Java JAR-файл может быть создан исполнительным и способным запускать встроенный HTTP-процесс, для Ruby- и Python-приложений ожидается применение диспетчера процессов, запускаемого внутри Apache или Nginx. Поэтому нам может понадобиться некий способ установки и настройки других программ, необходимых для развертывания и запуска наших артефактов. В этом случае можно обратиться за помощью к таким средствам автоматизированного управления настройками, как Puppet и Chef.
Другим недостатком в данном случае является то, что эти артефакты относятся только к определенному технологическому стеку, что может еще больше усложнить развертывание при задействовании набора технологий. Оцените складывающуюся ситуацию с точки зрения того, кто пытается развернуть сразу несколько сервисов. Вполне возможно, что какому-нибудь разработчику или тестировщику захочется протестировать работу некоторых функций или же понадобится кто-то, берущий на себя управление развертыванием производственных сборок. А теперь представьте, что в имеющихся сервисах используются три совершенно разных механизма развертывания. Возможно, это Ruby Gem, JAR-файл и nodeJS NPM-пакет. Кто-нибудь скажет вам спасибо?
Существенную помощь в скрытии различий в механизмах развертывания имеющихся артефактов может оказать автоматизация. Кроме того, несколько различных широко распространенных сборок артефактов на основе конкретных технологий поддерживаются такими средствами, как Chef, Puppet и Ansible. Но есть несколько различных типов артефактов, работать с которыми можно еще проще.
Артефакты операционных систем
Одним из способов избежать проблем, связанных с артефактами на основе конкретных технологий, является создание артефактов, характерных для используемой операционной системы. Например, для систем на основе RedHat или CentOS можно создать RPM-пакеты, для Ubuntu — deb-пакет или для Windows — MSI-пакет.
Преимущество использования артефактов, характерных для той или иной операционной системы, заключается в том, что по отношению к развертыванию не нужно обращать внимания на то, какая именно технология положена в основу артефакта. Для установки пакета просто применяются средства, характерные для используемой операционной системы. Эти средства могут помочь также в удалении пакетов или получении о них нужной информации или даже предоставить хранилища пакетов, в которые наши CI-средства могут помещать свои данные. Основная часть работы, проделываемая диспетчером пакетов операционной системы, может также содержать ту работу, которую иначе пришлось бы выполнять в таких средствах, как Puppet или Chef. К примеру, на всех Linux-платформах, которыми я пользовался, можно определить зависимости ваших пакетов от других пакетов, и средства операционной системы автоматически установят для вас и эти пакеты.
В качестве недостатка можно в первую очередь назвать сложность создания пакетов. Что касается Linux, диспетчер пакетов FPM предоставляет весьма неплохую абстракцию для создания пакетов этой операционной системы, а преобразование из развертывания на основе tarball в развертывание на основе средств операционной системы может проводиться без особого труда. С Windows дела обстоят немного сложнее. Возможности присущей ей системы создания пакетов в виде MSI-установщиков и т. п. по сравнению с возможностями, предоставляемыми Linux, оставляют желать лучшего. Помочь в решении возникающих сложностей, по крайней мере в плане содействия управлению библиотеками, используемыми при разработках, призвана система создания пакетов NuGet. В последнее время этот замысел был расширен — выпущено средство Chocolatey NuGet, предоставляющее диспетчер пакетов для Windows, разработанный для развертывания инструментальных средств и сервисов, который намного больше похож на диспетчеры пакетов в Linux-среде. Конечно же, это шаг в правильном направлении, хотя идиоматический стиль в Windows, по-прежнему связанный с развертыванием каких-либо средств в IIS, означает, что такой подход может стать непривлекательным для некоторых команд, ведущих разработки под Windows.
Другим недостатком может быть, конечно же, развертывание, проводимое в нескольких различных операционных системах. Издержки, связанные с управлением артефактами для различных операционных систем, могут быть слишком велики. Если создаются приложения, предназначенные для установки другими людьми, может создаться безвыходное положение. Но если программа устанавливается на машины, находящиеся в вашем распоряжении, то я бы предложил вам присмотреться к унификации или, по крайней мере, сокращению числа используемых операционных систем. Тем самым можно существенно уменьшить колчество вариантов поведения при переходе от машины к машине и упростить решение задач развертывания и обслуживания.
В общем, встречавшиеся мне команды, перешедшие на управление пакетами на основе средств операционных систем, упростили свой подход к развертыванию и стремятся не попадать в ловушку больших и сложных сценариев развертывания. Это может стать хорошим способом упрощения развертывания микросервисов при использовании разнородных технологических стеков, особенно если работа ведется под управлением Linux.
Настраиваемые образы
Одной из проблем использования таких автоматизированных систем управления настройками, как Puppet, Chef и Ansible, может стать время, затрачиваемое на выполнение can-сценариев на машине. Рассмотрим простой пример сервера, предназначенного и настроенного для развертывания Java-приложения. Предположим, что для предоставления сервера, использующего стандартный образ Ubuntu, применяется AWS. Первое, что нужно сделать, — установить Oracle JVM для запуска Java-приложения. Я видел, что этот простой процесс занимал около пяти минут, при этом две минуты затрачивались предоставляемой машиной и чуть больше времени требовалось на установку JVM-машины. Затем можно было подумать о размещении на ней нашей программы.
Вообще-то это весьма тривиальный пример. Чаще всего приходится устанавливать другие объемы часто востребуемых программных средств. Например, может потребоваться использование collectd для сбора статистических сведений об операционной системе, logstash — для регистрации собранных данных, а также, возможно, придется устанавливать соответствующие объемы nagios для мониторинга систем (более подробно эта программа рассматривается в главе 8). Со временем может добавляться что-нибудь еще, что станет требовать все большего времени, затрачиваемого на предоставление всех этих зависимостей.
Puppet, Chef, Ansible и им подобные средства могут быть достаточно интеллектуальными, чтобы не устанавливать уже имеющиеся программы. Это не означает, что выполнение сценариев на существующих машинах всегда будет осуществляться быстро, к сожалению, требует времени и выполнение всех проверок. Хотелось бы также избежать слишком долгого задействования машин и не хотелось бы допускать слишком широкого разброса настроек (этот вопрос вскоре будет рассмотрен более подробно). И если используется компьютерная платформа, выделяемая по требованию, то мы могли бы ежедневно, если не чаще, выключать и запускать новые экземпляры, поэтому заявленные особенности этих средств управления настройками могут иметь весьма ограниченное применение.
Со временем наблюдение за одним и тем же инструментарием, устанавливающимся снова и снова, может превратиться в зеленую тоску. Если пытаться сделать это по нескольку раз в день, возможно, как часть разработки или CI, то в плане обеспечения быстрой отдачи это становится настоящей проблемой. Это может привести и к увеличению простоя при развертывании производственной версии, если ваша система не позволяет выполнять развертывание без простоев, поскольку перед установкой программы придется ждать установки на машины всех предварительно востребованных средств. Смягчить условия могут модели синего или зеленого развертывания (рассматриваются в главе 7), позволяющие проводить развертывание новой версии сервиса, не переводя старую версию в автономный режим работы.
Один из подходов, позволяющий сократить подготовительный период, заключается в создании образа виртуальной машины, в котором зафиксирован ряд наиболее часто встречающихся из используемых нами зависимостей (рис. 6.5). Все платформы виртуализации, которыми мне приходилось пользоваться, позволяли создавать собственные образы, и средства, предназначенные для решения этой задачи, намного совершеннее тех, что существовали всего несколько лет назад. Это меняет наши взгляды. Теперь можно зафиксировать самые распространенные средства в нашем собственном образе. Когда потребуется развернуть программу, нужно будет запустить экземпляр этого заранее настроенного образа, и тогда останется только установить самую последнюю версию сервиса.
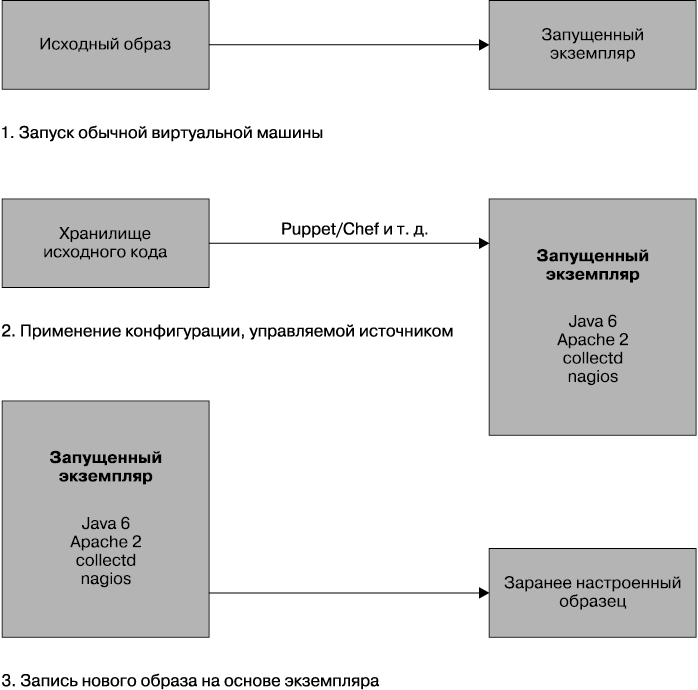
Рис. 6.5. Создание заранее настроенного VM-образа
Образ создается всего один раз, поэтому при последующих запусках его копий не нужно тратить время на установку зависимостей, поскольку они уже есть в образе. Это может привести к существенной экономии времени. Если основные зависимости не меняются, новые версии сервиса могут продолжать использовать исходный образ.
Но у этого подхода имеются некоторые недостатки. Создание образов может занять довольно много времени. Это означает, что для разработчиков можно применять другие способы развертывания сервисов, чтобы не заставлять их ждать по полчаса только для того, чтобы создать развертывание двоичной среды. Второй недостаток заключается в том, что получающиеся образы могут быть слишком большими. При создании собственных VMWare-образов это может стать реальной проблемой, поскольку переместить по сети, к примеру, образ объемом 20 Гбайт не так-то просто. Вскоре будет рассмотрена контейнерная технология, в частности такое средство, как Docker, позволяющее избавиться от некоторых упомянутых здесь недостатков.
Исторически сложилось так, что одной из проблем является изменение от платформы к платформе цепочки инструментов, требующейся для создания нужного нам образа. Создание VMWare-образа отличается от создания AWS AMI, Vagrant- или Rackspace-образа. Конечно, если у вас повсеместно одна и та же платформа, то волноваться не о чем, но этим могут похвастаться далеко не все организации. И даже если это так, с инструментами в этом пространстве зачастую трудно работать и они не всегда хорошо вписываются в тот инструментарий, который может использоваться для конфигурации машины.
Чтобы значительно упростить создание образа, было создано средство Packer. Используя настроечные сценарии по вашему выбору (поддерживаются Chef, Ansible, Puppet и многие другие средства), Packer позволяет создавать образы для различных платформ из одной и той же конфигурации. На момент написания книги это средство поддерживало VMWare, AWS, Rackspace Cloud, Digital Ocean и Vagrant, и мне встречались команды, успешно использующие его для создания образов под Linux и Windows. Это означает, что из одной и той же конфигурации можно создавать образ для развертывания в вашей производственной среде AWS и соответствующего Vagrant-образа для локального развертывания и тестирования.
Образы как артефакты
Итак, мы можем создать образы виртуальной машины с зафиксированными зависимостями для ускорения отдачи, но стоит ли на этом останавливаться? Можно ведь пойти дальше и зафиксировать сервис в самом образе, приспособить модель артефакта сервиса в качестве образа. Теперь, запуская образ, мы получаем готовый к работе сервис. Этот действительно быстрый способ подготовки к работе является причиной того, что в Netflix была принята модель фиксирования его собственных сервисов в качестве AWS AMI-образов.
Как и в случае применения пакетов, характерных для конкретной операционной системы, эти VM-образы становятся отличным способом абстрагирования от различий в технологических стеках, используемых для создания сервисов. Разве нас волнует, что сервис, запущенный в образе, написан на Ruby или Java и использует gem-пакет или JAR-файл? Нам интересно только то, что все это работает. Тогда мы можем сконцентрировать усилия на автоматизации создания и развертывания этих образов. К тому же это становится отличным способом реализации другой концепции развертывания — неизменяемого сервера.
Неизменяемые серверы
При хранении всех наших настроек в системе управления версиями мы стремимся обеспечить возможность автоматизированного воспроизводства сервисов и, надеюсь, при желании — всей среды. Но что случится, если мы запустили процесс развертывания, а кто-то войдет в систему и внесет изменения независимо от того, что находится в системе управления версиями? Эту проблему часто называют дрейфом конфигурации — код в системе управления версиями больше не является отражением конфигурации на работающем хосте.
Во избежание этого можно обеспечить невозможность внесения изменений в работающий сервис. Любое, даже самое незначительное, изменение должно пройти через сборочный конвейер, чтобы была создана новая машина. Эту схему можно реализовать без использования развертывания на основе образа, но оно также является логическим расширением использования образов в качестве артефактов. Например, в ходе создания образа можно отключить SSH, гарантируя тем самым, что никто не сможет даже войти в систему для внесения какого-либо изменения!
Разумеется, ранее высказанные предостережения относительно времени цикла применимы и в данном случае. И нужно также обеспечить, чтобы интересующие нас данные, сохраненные в компьютере, хранились бы в другом месте. Наряду с этими сложностями мне приходилось наблюдать случаи, когда использование этой схемы приводило к более простым развертываниям и созданию более обоснованных сред. И, как уже было сказано, нужно делать все, чтобы добиться упрощения!
Среды
При проходе программы через стадии CD-конвейера она также будет развернута в средах различных типов. Если обратиться к примеру сборочного конвейера (см. рис. 6.4), то нужно, наверное, рассмотреть как минимум четыре различные среды: для запуска медленных тестов, тестирования на приемлемость для пользователя, тестирования на производительность и работы в производственном режиме. Наш микросервис должен быть везде одинаков, но среды будут разными. По крайней мере, они должны быть обособленными, с отдельными наборами конфигураций и хостов. Но зачастую они могут отличаться друг от друга еще значительнее. Например, среда, предназначенная для работы сервиса в производственном режиме, может состоять из нескольких сбалансированных по нагрузке хостов, разбросанных по двум дата-центрам, а все компоненты среды, предназначенной для тестирования, могут быть запущены всего на одном хосте. Такие различия в средах могут вызвать ряд проблем.
Мне приходилось испытывать это на себе много лет назад. Мы развертывали веб-сервис Java в производственном кластерном контейнере WebLogic-приложения. Этот WebLogic-кластер реплицировал состояние сессии между несколькими узлами, обеспечивая некоторую степень устойчивости при сбое отдельного узла. Но лицензии на использование WebLogic, под которыми было развернуто приложение, а также машины, на которых оно было развернуто, обходились довольно дорого. Поэтому среда для тестирования и программы были развернуты на одной машине в некластерной конфигурации.
И во время одного из выпусков это обстоятельно нанесло нам существенный вред. Чтобы у WebLogic была возможность копировать состояние сессии между узлами, данные сессии должны поддаваться сериализации. К сожалению, одна из наших фиксаций разрушала этот процесс, поэтому при развертывании для работы в производственном режиме репликация сессии дала сбой. В итоге мы решили проблему, приложив большие усилия для имитации кластеризованной настройки в нашей среде тестирования.
Предназначенный для развертывания сервис одинаков для различных сред, но каждая из сред служит для разных целей. На разработочном ноутбуке мне нужно быстро развернуть сервис, имея в потенциале заглушки, имитирующие его сотрудников, чтобы запустить тесты или выполнить ручную проверку поведения, в то время как при развертывании в производственной среде мне может понадобиться развернуть несколько копий сервиса для соблюдения сбалансированности нагрузки, возможно, с разбрасыванием по одному или нескольким дата-центрам из соображений живучести.
По мере перехода с ноутбука на сборочный сервер, с него — в среду тестирования на приемлемость для пользователя, а дальше — в производственную среду нужно обеспечивать, чтобы среды постепенно приобретали все больше и больше свойств производственной среды, чтобы можно было отловить проблемы, связанные с разницей этих сред, как можно раньше. Этот баланс будет носить постоянный характер. Иногда затраты времени и средств на воспроизводство сред, сходных с производственными, бывают непомерно высокими, поэтому приходится идти на компромиссы. Кроме того, иногда использование сред, сходных с производственными, может замедлить циклы получения ответных результатов, поскольку ожидание того, пока на 25 машинах установится ваша программа в AWS, может быть намного продолжительнее простого развертывания сервиса, к примеру на локальном Vagrant-экземпляре.
Баланс между средами, подобными производственной среде, и быстрым получением ответных результатов не будет статичным. Следите за количеством ошибок, выявляемых по мере прохождения сред, и за показателями сроков получения обратных ответов и перенастраивайте этот баланс по мере необходимости.
Управление средами для монолитных систем с одним артефактом может даваться весьма нелегко, особенно если у вас нет доступа к легко автоматизируемым системам. А если подумать о нескольких средах для каждого микросервиса, то все может показаться еще страшнее. Вскоре мы рассмотрим ряд различных платформ развертывания, которые могут существенно упростить складывающуюся ситуацию.
Конфигурация сервиса
Наши сервисы нуждаются в настройках. В идеале их должно быть немного и они должны быть ограничены теми свойствами, которые меняются от одной среды к другой, например ответами на вопросы о том, какими именем пользователя и паролем нужно воспользоваться для подключения к базе данных. Настройка этих изменений при переходе от одной среды к другой должна сводиться к абсолютному минимуму. Чем больше настроек изменяет основное поведение сервиса и чем больше эти настройки варьируются от одной среды к другой, тем больше будет возникать проблем, касающихся только определенных сред и проявляющихся в экстремальных ситуациях.
Следовательно, если у нас есть некая настройка для сервиса, изменяющаяся от одной среды к другой, как мы можем справиться с этим как с частью процесса развертывания? Одним из вариантов является создание по одному артефакту для каждой среды с конфигурацией внутри самого артефакта. Поначалу этот вариант представляется весьма разумным. Конфигурация встроена, нужно лишь развернуть артефакт, и все будет работать. Но так ли это? Не так-то все просто. Вспомните о концепции непрерывной доставки. Нам нужно создать артефакт, представляющий сдаточную версию, и провести его по конвейеру, убеждаясь, что он вполне подходит для передачи в производство. Представим, что мною созданы артефакты для тестирования клиентской службы — Customer-Service-Test и для ее работы в производственном режиме — Customer-Service-Prod. Если артефакт Customer-Service-Test пройдет тесты, а я фактически развертываю артефакт Customer-Service-Prod, могу ли я быть уверенным в том, что проверена была программа, которая окажется в производстве?
Существуют и другие трудности. Во-первых, на создание этих артефактов затрачивается дополнительное время. Во-вторых, на время сборки нужно знать, какие среды существуют. А как справиться с важными конфиденциальными данными? Мне не нужна информация о паролях производственного режима, проверяемая вместе с исходным кодом, но она нужна во время создания сборки для создания всех этих артефактов, и этого очень трудно избежать.
Более подходящим подходом будет создание одного-единственного артефакта и раздельное управление конфигурацией. Это могут быть файл свойств, имеющийся для каждой среды, или различные параметры, передаваемые в процесс установки. Еще одним широко распространенным вариантом, особенно при работе с большим количеством микросервисов, является использование для предоставления конфигурации специально выделенной системы, которая подробнее исследуется в главе 11.
Отображение сервиса на хост
Когда речь заходит о микросервисах, в самом начале возникает вопрос: «А сколько сервисов может быть на каждой машине?» Перед тем как дать ответ, нужно подобрать более подходящее понятие, чем «машина» или даже использованное мною ранее более универсальное понятие «стойка». В нашу эру виртуализации отображение между отдельно взятым хостом, на котором работает операционная система, и используемой физической инфраструктурой может варьироваться в самых широких пределах. Я, например, склонен говорить о хостах, используя их как универсальную единицу изолированности, а именно как операционную систему, под управлением которой могу установить и запустить свои сервисы. Если развертывание ведется вами непосредственно на физические машины, тогда один физический сервер отображается на один хост (что, возможно, будет не вполне корректной терминологией в данном контексте, но за неимением лучшей может считаться подходящей). Если используется виртуализация, то отдельная физическая машина может отображаться на несколько независимых хостов, каждый из которых может содержать один сервис и более.
Следовательно, когда мы думаем о различных моделях развертывания, речь идет о хостах. Итак, сколько же у нас должно быть сервисов на хост?
У меня есть вполне определенный взгляд на то, какой из моделей отдать предпочтение, но есть несколько факторов, которые нужно рассмотреть, определяя, какая из моделей будет самой подходящей именно для вас. Кроме того, важно понять, что некоторые варианты, которые мы выбираем в связи с этим, будут ограничивать круг доступных нам вариантов развертывания.
Несколько сервисов на каждый хост
Размещение на каждом хосте нескольких сервисов (рис. 6.6) по ряду причин является весьма привлекательным решением. Во-первых, из соображений более простого управления хостом. Там, где инфраструктурой управляет одна команда, а программой другая, рабочая нагрузка той команды, которая управляет инфраструктурой, зачастую зависит от количества управляемых хостов. Если на отдельном хосте будет размещено больше сервисов, то с увеличением их количества рабочая нагрузка, связанная с управлением хостами, не увеличится. Во-вторых, нужно принять во внимание расходы. Даже при наличии доступа к виртуализированной платформе, позволяющего и предоставлять виртуальные хосты, и изменять их размеры, виртуализация может повлечь за собой накладные расходы, сокращающие исходные ресурсы, доступные вашим сервисам. На мой взгляд, обе эти проблемы могут быть решены с помощью новых рабочих приемов и технологий, которые вскоре будут рассмотрены.

Рис. 6.6. Размещение на каждом хосте нескольких сервисов
Эта модель знакома и тем, кто вел развертывание в каких-нибудь разновидностях приложений-контейнеров. В некотором роде использование приложений-контейнеров является особым случаем модели нескольких сервисов на каждом хосте, поэтому мы рассмотрим этот вопрос отдельно. Эта модель может упростить жизнь разработчика. Развертывание нескольких сервисов на одном хосте, работающем в производственном режиме, равносильно развертыванию нескольких сервисов на локальной рабочей станции или ноутбуке. Если нужно посмотреть на альтернативные модели, следует найти способ сохранения концептуальной простоты для разработчиков.
Но у этой модели есть ряд проблем. Так, она может затруднить проведение мониторинга. Например, нужно ли при отслеживании загруженности центрального процессора отслеживать загруженность процессора одним сервисом независимо от других? Или нужно ли рассматривать центральный процессор компьютерной стойки как единое целое? Трудно будет также избежать побочных эффектов. Если один сервис находится под большой нагрузкой, это может выразиться в сокращении объемов ресурсов, доступных другим частям системы. Компания Gilt столкнулась с этой проблемой при увеличении количества запущенных сервисов. Изначально на одной стойке сосуществует множество сервисов, но при неравномерной нагрузке на один из сервисов мы получим вредное влияние на работу всех остальных сервисов, запущенных на хосте. Ко всему прочему, это еще больше затруднит анализ влияния сбоев хоста — выход одного узла из строя может вызвать большой резонансный эффект.
Может также стать более трудным развертывание сервисов, поскольку забот прибавляет необходимость обеспечить отсутствие отрицательного влияния одного развертывания на другие. Например, если для подготовки хоста используется Puppet, но у каждого сервиса имеются различные (потенциально несовместимые) зависимости, то как можно справиться с этой работой? Мне встречались специалисты, которые при наихудшем развитии событий в попытке упростить развертывание нескольких сервисов на одном хосте связывали вместе развертывание сразу нескольких сервисов и развертывали на этом хосте несколько различных сервисов в один прием. На мой взгляд, незначительные упрощения не перевесят отказа от одного из ключевых преимуществ микросервисов — стремления к независимым выпускам программных средств. Если внедрять модель размещения нескольких сервисов на одном хосте, нужно убедиться в том, что у вас есть идея, как каждый сервис может быть развернут независимо от всех остальных.
Эта модель может также воспрепятствовать автономии команд. Если сервисы, поддерживаемые разными командами, установлены на один и тот же хост, то кто получит возможность настройки хоста под свои сервисы? По всей вероятности, это закончится получением управления централизованной командой, которая будет иметь больше возможностей для координации развертывания сервисов.
Еще одна проблема состоит в том, что этот вариант может ограничить варианты развертывания артефактов. Если несколько различных серверов не будут связаны друг с другом в единый артефакт, чего нужно всеми силами избегать, то развертывания на основе образов будут недоступны, равно как и неизменяемые серверы.
Факт наличия нескольких сервисов на одном хосте означает, что для масштабирования особо нуждающегося в этом сервиса нужно будет приложить огромные усилия. Аналогично этому, если один микросервис обрабатывает данные и проводит операции с весьма высокой степенью конфиденциальности, для этого может потребоваться иная настройка используемого хоста или даже помещение самого хоста в отдельный сегмент сети. Присутствие абсолютно всего на одном хосте означает, что мы можем в конечном счете прийти к тому, что ко всем сервисам нужно будет относиться одинаково, даже если их потребности отличаются друг от друга.
Как говорит мой коллега Нил Форд (Neal Ford), многие наработанные нами приемы развертывания и управления хостом представляют собой попытку оптимизировать дефицит ресурсов. В прошлом при необходимости получения другого хоста у нас был единственный выбор: купить или арендовать другую физическую машину. Зачастую время выполнения заказа было весьма продолжительным, что приводило к возникновению долгосрочных финансовых обязательств. Поставка новых серверов лишь через каждые два-три года была для клиентов, с которыми мне приходилось работать, вполне обычным явлением, и получить дополнительные машины вне этого графика было очень трудно. Но компьютерные платформы, предоставляемые по требованию, резко снизили цены на вычислительные ресурсы, а развитие технологий виртуализации означало даже для внутренней инфраструктуры на основе использования хостов придание ей большей гибкости.
Приложения-контейнеры
Если вы знакомы с развертыванием .NET-приложений за IIS- или Java-приложениями в контейнер сервлетов, то должны были хорошо ознакомиться с моделью, в которой несколько отличающихся друг от друга сервисов или приложений находятся внутри единого приложения-контейнера, которое, в свою очередь, находится на отдельном хосте (рис. 6.7). Замысел состоит в том, что приложение-контейнер, в котором находятся ваши сервисы, дает вам преимущества с точки зрения повышения управляемости, например поддержку кластеризации для обработки группировок из нескольких собранных вместе экземпляров, инструменты для проведения мониторинга и т. п.
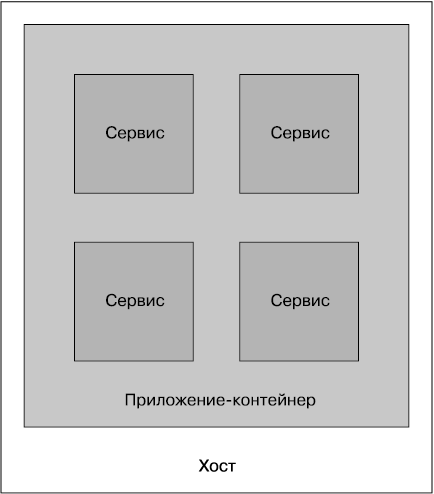
Рис. 6.7. Размещение на каждом хосте нескольких сервисов
Эта настройка может выразиться также в преимуществах по сокращению издержек, присущих средам выполнения программ на тех или иных языках программирования. Рассмотрим выполнение пяти Java-сервисов в одном контейнере сервлетов Java. Все издержки сводятся к одной-единственной JVM-машине. Сравним это с выполнением пяти независимых JVM-машин на том же самом хосте при использовании встроенных контейнеров. Тем не менее я все же чувствую, что эти приложения-контейнеры имеют довольно много недостатков, и вам нужно хорошенько подумать, прежде чем решить, что без них вам никак не обойтись.
Первым из недостатков нужно отметить то, что они неизбежно ограничивают выбор технологий. Вам приходится использовать технологический стек. Это может ограничить не только выбор технологий для реализации самого сервиса, но и варианты автоматизации ваших систем и управления ими. В соответствии с тем, что вскоре будет рассматриваться, одним из способов, позволяющих избежать издержек управления несколькими хостами, является автоматизация, при которой ограничение доступных вариантов разрешения проблемы может нанести двойной ущерб.
Я также усомнился бы в некоторых полезных свойствах контейнера. Многие из них рекламируют в качестве возможностей управлять кластерами для поддержки совместно используемого хранящегося в памяти состояния сессии, то есть того, чего мы, безусловно, стремимся избежать в любом случае из-за сложностей, возникающих при масштабировании сервисов. Недостаточно будет и обеспечиваемых ими контролирующих возможностей, поскольку, как будет показано в главе 8, нам в мире микросервисов нужен присоединяемый мониторинг. Многие из контейнеров имеют довольно длительный период подготовки к работе, отрицательно влияющий на циклы получения разработчиками ответной информации.
Имеются и другие проблемы. Попытки получения приемлемого управления жизненным циклом приложений поверх таких платформ, как JVM, могут вызвать ряд проблем и представляются более сложными, нежели простой перезапуск JVM. Анализ использования ресурсов и потоков также дается намного сложнее, поскольку приходится иметь дело с несколькими приложениями, совместно использующими один и тот же процесс. И запомните, даже если вы действительно видите ценность в контейнерах, создаваемых по конкретным технологиям, бесплатно они вам не обойдутся. Кроме того что многие из них носят коммерческий характер и поэтому имеют определенную стоимость, сами по себе они добавляют издержки на ресурсы.
В конечном счете этот подход является еще одной попыткой оптимизировать дефицит ресурсов, которые могут просто больше не вмещаться. Если вы примете решение в качестве модели развертывания разместить несколько сервисов на одном хосте, я бы настоятельно рекомендовал присмотреться к независимо развертываемым микросервисам как к артефактам. Применяя .NET-технологию, этого можно добиться с помощью использования таких средств, как Nancy, а в Java эта модель поддерживается на протяжении многих лет. Например, имеющий довольно почтенный возраст встроенный контейнер Jetty создается для весьма облегченного автономного HTTP-сервера, составляющего ядро стека Dropwizard. Известно, что в Google встроенные Jetty-контейнеры весьма успешно используются для непосредственного обслуживания статического контента и, следовательно, что все это может работать в широких масштабах.
Размещение по одному сервису на каждом хосте
При использовании модели размещения по одному сервису на каждом хосте (рис. 6.8) мы избавляемся от побочных эффектов, характерных для нескольких сервисов, размещаемых на одном хосте, существенно упрощая возможности контроля и внесения исправлений. Потенциально сокращается и количество критических точек сбоя. Выход из строя одного хоста повлияет только на один сервис, хотя это не всегда так, когда используется виртуализированная платформа. Более подробно создание разработок с прицелом на масштабирование и устойчивость к сбоям рассматривается в главе 11. Кроме того, упрощается масштабирование одного сервиса независимо от всех других, а сосредоточение внимания только на сервисе и требующем этого внимания хосте упрощают решение вопросов обеспечения безопасности.
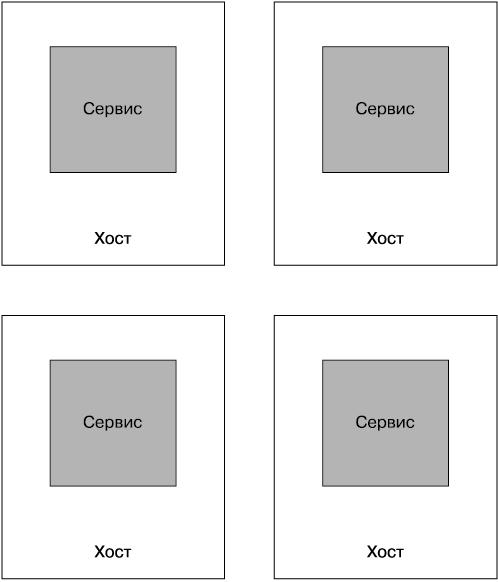
Рис. 6.8. Размещение по одному сервису на каждом хосте
Не менее важно и то, что мы открыли потенциал для использования альтернативных технологий развертывания, например рассмотренных ранее технологий развертывания на основе применения образов или технологий развертывания с использованием неизменяемого сервера.
При внедрении архитектуры микросервисов все сильно усложняется. Выискивать источники всевозможных сложностей хотелось бы в последнюю очередь. Я считаю, что если у вас нет доступной и жизнеспособной PaaS-платформы, то эта модель хорошо справляется с сокращением общесистемных сложностей. Модель размещения по одному сервису на каждом хосте существенно легче поддается обоснованию и может содействовать упрощению системы. Если вы все же не сможете принять эту модель, я не стану говорить, что микросервисы не для вас. Но при этом хочу предложить, чтобы вы присмотрелись к переходу на эту модель в будущем, поскольку она позволяет уменьшить сложности, которые могут быть привнесены архитектурой микросервисов.
Но в увеличивающемся количестве хостов также кроются потенциальные недостатки. Растут число серверов, требующих управления, и затраты, связанные с запуском большего количества отличных друг от друга хостов. Несмотря на эти проблемы, все же это модель, которой я отдаю предпочтение при создании микросервисных архитектур. И вскоре мы рассмотрим ряд мероприятий, которые можно выполнить для снижения издержек управления большим количеством хостов.
Платформа в качестве услуги
При использовании платформы в качестве услуги (PaaS) работа ведется на более высоком уровне абстракции, чем когда дело касается отдельного хоста. Большинство таких платформ полагаются на принятие артефактов с конкретными технологиями, такими как Java WAR-файл или gem-пакет Ruby, и автоматически предоставляют и запускают их для вас. Некоторые из этих платформ будут самостоятельно пытаться подгонять под ваши нужды масштаб системы вверх и вниз, хотя более распространенный (и, исходя из моего опыта, менее подверженный ошибкам) способ позволяет сохранить за вами контроль над количеством узлов, на которых может быть запущен сервис, справляясь со всем остальным самостоятельно.
На момент написания этих строк большинство самых лучших, наиболее совершенных решений PaaS уже было принято. Когда думаешь о первоклассных средствах в этой области, на память приходит Heroku. Эта платформа не только справляется с запуском вашего сервиса, но и с легкостью поддерживает такие сервисы, как базы данных.
В этой области есть и самостоятельно принимаемые решения, хотя они и менее зрелые, чем те решения, которые уже были приняты.
Когда PaaS-решения работают хорошо, то качества их работы вполне достаточно. Но когда они подходят вам не в полной мере, зачастую вы испытываете дефицит контроля в области внесения каких-либо внутренних исправлений. В этом заключается часть принимаемых нами компромиссов. Хочу заметить, что, исходя из моего опыта, чем более интеллектуальными пытаются быть PaaS-решения, тем чаще допускают ошибки. Мне приходилось пользоваться несколькими PaaS-платформами, которые пытались выполнять автоматическое масштабирование на основе востребованности приложением, но делали это крайне неудачно. Конечно же, эвристика, являющаяся движущим механизмом этого интеллекта, старается подстроиться под некое среднее приложение, а не под ваш конкретный случай. Чем более нестандартный характер имеет приложение, тем выше вероятность того, что оно не сможет идеально сработаться с PaaS-платформой.
Поскольку качественные PaaS-решения справляются с решением довольно многих задач за вас, они могут стать замечательным способом избавления от растущих издержек, возникающих с появлением все большего количества движущихся частей. И тем не менее я все еще не уверен, что в это пространство укладываются абсолютно все модели, а ограниченные, самостоятельно принимаемые варианты означают, что этот подход для решения ваших задач может не сработать. Но я ожидаю, что в ближайшее десятилетие мы станем скорее нацеливаться на развертывание PaaS-платформы, чем развертывать отдельные сервисы на самоуправляемых хостах.
Автоматизация
Ответ на столь большое количество вопросов, заданных до сих пор, сводится к автоматизации. При небольшом количестве машин всем можно управлять вручную. Для меня это дело привычное. Помню, когда в работе был небольшой набор производственных машин, я собирал регистрируемые данные, развертывал программные средства и контролировал процессы, заходя в вычислительную систему вручную. Казалось, что моя продуктивность была ограничена количеством окон терминала, открываемых одновременно, а второй монитор стал огромным шагом вперед. Но все это рухнуло очень быстро.
Один из негативных взглядов на размещение по одному сервису на каждом хосте основывался на впечатлении, что объем накладных расходов на управление этими хостами будет увеличиваться. И это действительно так, если все делать вручную. Удваивается количество серверов, удваивается и объем работы! Но если автоматизировать управление хостами и развертывание сервисов, тогда не станет причин для линейного роста объема рабочей нагрузки в зависимости от количества добавляемых хостов.
Но даже при сохранении небольшого количества хостов мы все же собираемся манипулировать большим количеством сервисов. Это означает, что нужно справляться с несколькими развертываниями, отслеживать работу нескольких сервисов и собирать регистрируемые данные. И автоматизация в этом деле играет весьма важную роль.
Автоматизация может обеспечить также поддержание высокой продуктивности разработчиков. Ключом для облегчения жизни разработчиков является предоставление им возможности обеспечения самообслуживания отдельных сервисов и групп сервисов. В идеале разработчики должны иметь доступ абсолютно к такой же цепочке инструментов, которая используется для развертывания сервисов в производственном режиме, чтобы можно было обнаруживать проблемы на самых ранних стадиях. В данной главе будут рассмотрены многие технологии, включающие это представление.
Выбор технологии автоматизации играет весьма важную роль. Он начинается со средств управления хостами. Можете ли вы написать строку кода для запуска виртуальной машины или ее выключения? Можете ли провести автоматическое развертывание написанной вами программы? Можете ли развернуть изменения, внесенные в базу данных без ручного вмешательства? Если вы хотите справиться со сложностями архитектур микросервисов, то без усвоения культуры автоматизации вам не обойтись.
Два конкретных примера изучения эффективности автоматизации. Наверное, объяснить эффективность качественной автоматизации полезнее всего на двух конкретных примерах. Одним из наших клиентов является компания RealEstate.com.au (REA) из Австралии. Кроме всего прочего, она предоставляет объекты недвижимости для розничной торговли и коммерческих клиентов в Австралии и в других местах Азиатско-Тихоокеанского региона. В течение ряда лет компания переводит свою платформу на распределенную микросервисную модель. В самом начале этого пути ей пришлось потратить много времени на получение подходящих для сервисов инструментов, облегчающих разработчикам предоставление машин, развертывание их кода или отслеживание его работы. Для запуска проекта пришлось сконцентрировать все усилия с самого начала.
За первые три месяца REA смогла перевести в производственный режим использования только два новых микросервиса, при этом команда разработчиков взяла на себя полную ответственность за их сборку, развертывание и поддержку. В следующие три месяца удалось запустить в том же режиме еще 10–15 сервисов. К концу 18-месячного периода в REA работали свыше 70 сервисов.
Действенность подобной схемы подтверждается и опытом компании Gilt, с 2007 года занимающейся продажей через Интернет модной одежды. Использовавшееся в Gilt монолитное Rails-приложение стало испытывать трудности с масштабированием, и в 2009 году компания решила приступить к декомпозиции системы на микросервисы. И опять автоматизация, особенно оснащенная инструментарием для помощи разработчикам, стала ключевым обоснованием активного перехода компании Gilt к использованию микросервисов. Год спустя у Gilt работали десять микросервисов, к 2012-му — уже свыше 100, а в 2014 году, по собственному подсчету Gilt, — свыше 450 микросервисов. Иными словами, на каждого разработчика в Gilt приходилось примерно по три сервиса.
От физического к виртуальному
Одним из ключевых инструментов, доступных нам при управлении большим количеством хостов, является поиск способов разбиения существующих физических машин на более мелкие части. Огромные преимущества в сокращении издержек на управление хостами могут быть получены с помощью таких традиционных средств виртуализации, как VMWare, или с помощью использования AWS. Но в данной области есть и новые достижения, которые стоит исследовать, поскольку они могут открыть еще более интересные возможности для работы с нашей архитектурой микросервисов.
Традиционная виртуализация
Почему использование большого количества хостов обходится так дорого? Когда для каждого хоста нужен физический сервер, ответ вполне очевиден. Если вы работаете именно в такой обстановке, то вам, наверное, подойдет модель размещения нескольких сервисов на одном хосте, хотя не удивлюсь, если это станет еще более сложным препятствием. Но я подозреваю, что большинство из вас использует какую-либо виртуализацию. Виртуализация позволяет разбить физический сервер на несколько обособленных хостов, на каждом из которых могут запускаться разные программные средства. Следовательно, если нам нужно разместить по одному сервису на каждом хосте, можем ли мы просто разбить физическую инфраструктуру на все более мелкие и мелкие куски?
Ну кто-то это, вероятно, и может сделать. Но разбиение машины на постоянно увеличивающееся количество виртуальных машин не дается бесплатно. Представим нашу физическую машину ящиком для носков. Если поставить в ящике много деревянных перегородок, то больше или меньше носков мы сможем в нем хранить? Правильный ответ — меньше: разделители также занимают место! Нужно, чтобы с нашим ящиком было проще работать и проще наводить в нем порядок, и, возможно, теперь мы решим положить в него не только носки, но еще и футболки, но чем больше разделителей, тем меньше будет общее пространство.
В мире виртуализации у нас есть такие же издержки, как и перегородки в ящике для носков. Чтобы понять природу возникновения этих издержек, посмотрим, как чаще всего выполняется виртуализация. На рис. 6.9 для сравнения представлены два типа виртуализации. Слева показано использование нескольких различных уровней так называемой виртуализации второго типа, которая реализуется в AWS, VMWare, VSphere, Xen и KVM. (К виртуализации первого типа относятся технологии, при которых виртуальные машины запускаются непосредственно на оборудовании, а не в виде надстройки над другой операционной системой.) В нашей физической инфраструктуре имеется основная операционная система. Под управлением этой операционной системы запускается так называемый гипервизор, имеющий две основные задачи. Во-первых, он отображает ресурсы, подобные ресурсам центрального процессора и памяти, с виртуального хоста на физический хост. Во-вторых, он работает в качестве уровня управления, позволяющего манипулировать самими виртуальными машинами.
Внутри виртуальных машин мы получаем то, что похоже на совершенно различные хосты. На них можно запустить их собственные операционные системы с их собственными ядрами. Их можно рассматривать почти как загерметизированные машины, изолированные гипервизором от используемого физического хоста и от других виртуальных машин.
Проблема в том, что для выполнения своей работы гипервизору нужно выделять ресурсы. Это отнимает ресурсы центрального процессора, системы ввода-вывода и памяти, которые могли бы использоваться в других местах. Чем большим количеством хостов управляет гипервизор, тем больше ресурсов ему требуется. К определенному моменту эти издержки станут препятствовать дальнейшему разбиению физической инфраструктуры. На практике это означает, что часто при нарезке физической машины на все более мелкие части убывает отдача ресурсов, поскольку пропорционально этому все больше и больше этих ресурсов уходит на издержки гипервизора.
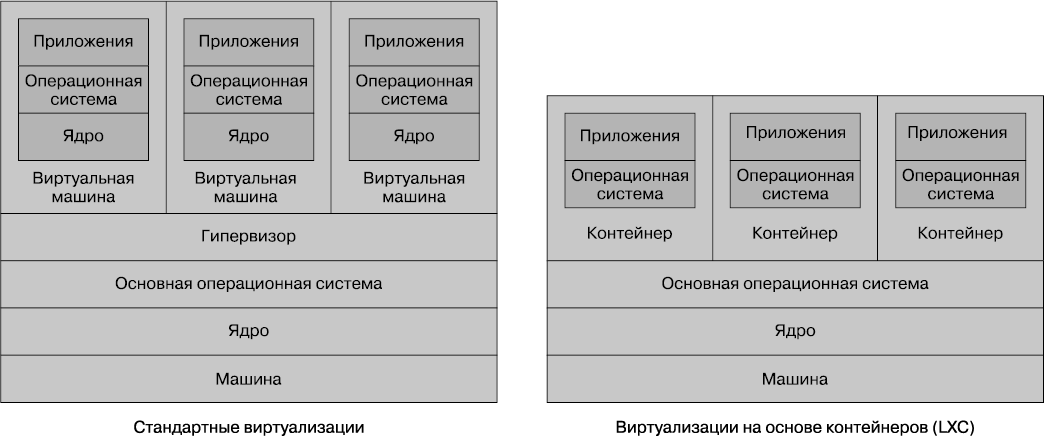
Рис. 6.9. Сравнение стандартной виртуализации второго типа и облегченных контейнеров
Vagrant
Vagrant представляет собой весьма полезную платформу развертывания, которая используется скорее для разработки и тестирования, чем для работы в производственном режиме. Vagrant предоставляет вам на вашем ноутбуке виpтуальное облако. Снизу она использует стандартную систему виртуализации (обычно VirtualBox, хотя может использовать и другие платформы). Она позволяет определять набор виртуальных машин в текстовом файле, а также определять, как виртуальные машины связаны по сети и на каких образах они должны быть основаны. Этот тестовый файл может проверяться и совместно использоваться сотрудниками команды.
Это упрощает для вас создание среды подобной той, что используется в производственном режиме на вашей локальной машине. Одновременно можно запускать несколько виртуальных машин, останавливать работу отдельных машин для тестирования сбойных режимов и отображать виртуальные машины на локальные каталоги, чтобы можно было вносить изменения и тут же отслеживать реакцию на них. Даже для тех команд, которые используют такие облачные платформы, выделяющие ресурсы по запросу, как AWS, более быстрая реакция от применения Vagrant может стать большим подспорьем в разработке.
Один из недостатков заключается в том, что запуск большого количества виртуальных машин может привести к перегрузке разработочной машины. Если у нас на каждой виртуальной машине имеется по одному сервису, то может исчезнуть возможность переноса всей системы на свою локальную машину. Это может привести к тому, что вам, чтобы добиться управляемости, придется ставить заглушки на некоторые зависимости, и это станет еще одной задачей, с которой нужно будет справиться, чтобы обеспечить качественное проведение развертывания и тестирования.
Контейнеры Linux
У пользователей Linux имеется альтернатива виртуализации. Вместо использования гипервизора для сегментирования и управления отдельными виртуальными хостами Linux-контейнеры создают обособленное пространство для процессов, в котором проходят остальные процессы.
В Linux процесс запускается конкретным пользователем и имеет конкретные возможности, основанные на особенностях настройки прав пользователей. Процессы могут порождать другие процессы. Например, если я запущу процесс в терминале, то этот процесс обычно считается дочерним процессом процесса терминала. Обслуживанием дерева процессов занимается ядро Linux.
Linux-контейнеры являются расширением этого замысла. Каждый контейнер, по сути, является поддеревом общесистемного дерева процессов. У этих контейнеров могут быть выделенные им физические ресурсы, и этим ядро управляет для нас. Этот общий подход был воплощен во многих формах, таких как Solaris Zones и OpenVZ, но наибольшую популярность снискал LXC-контейнер. LXC в готовом виде доступен во многих современных ядрах Linux.
Если посмотреть на блок-схему для хоста с работающим LXC-контейнером (см. рис. 6.9), можно увидеть несколько различий. Во-первых, нам не нужен гипервизор. Во-вторых, хотя каждый контейнер может запускать собственный дистрибутив операционной системы, он должен совместно использовать одно и то же ядро (поскольку процесс дерева запускается именно в ядре). Это означает, что в качестве основной операционной системы может быть запущена Ubuntu, а в контейнерах — CentOS, поскольку обе они могут совместно использовать одно и то же ядро.
Но мы не только получаем преимущества от ресурсов, сэкономленных за счет ненужности гипервизора. Мы также выигрываем из-за ускоренной обратной реакции. Linux-контейнеры предоставляются намного быстрее, чем полноценные виртуальные машины. Для виртуальных машин вполне в порядке вещей тратить несколько минут на запуск, а при использовании Linux-контейнеров запуск может занять всего несколько секунд. Вы приобретаете также более тонкий контроль над самими контейнерами в плане выделения им ресурсов, что существенно упрощает тонкую подстройку под получение большей отдачи от использующегося оборудования.
Благодаря более легким характеристикам контейнеров мы можем получить от них намного большую отдачу при запуске на одном и том же оборудовании, которую возможно было бы получить при использовании виртуальных машин. За счет развертывания по одному сервису в каждом контейнере (рис. 6.10) мы получаем определенную степень изолированности от других контейнеров (хотя ее нельзя назвать идеальной) и можем получить более высокий экономический эффект, чем тот, который был бы возможен, если бы нам захотелось запустить каждый сервис на его собственной виртуальной машине.
Контейнеры могут использоваться также с полноценной виртуализацией. Мне приходилось видеть не один проект с предоставлением довольно крупного экземпляра AWS EC2 и запуском на нем LXC-контейнеров для получения наилучших качеств, присущих обоим мирам: предоставляемую по запросу эфемерную вычислительную платформу в виде EC2 в сочетании с весьма гибкими и быстрыми контейнерами, запущенными на ее основе.
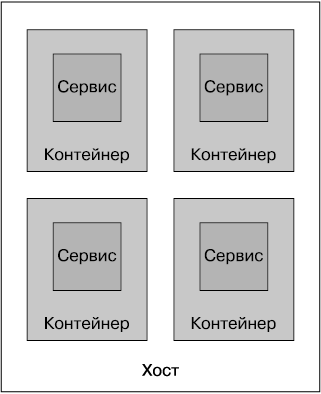
Рис. 6.10. Запуск сервисов в отдельных контейнерах
Но у Linux-контейнеров есть и свои проблемы. Представьте, что у меня имеется масса микросервисов, запущенных в их собственных контейнерах на хосте. Как они станут видны внешнему миру? Нужен некий способ, направляющий внешний мир через используемые контейнеры, то есть то, чем при обычной виртуализации занимаются многие гипервизоры. Я видел, как многие тратили уйму времени на настройку перенаправления портов с использованием для непосредственного показа контейнеров таблиц IPTables. Кроме этого, следует принять во внимание, что эти контейнеры нельзя рассматривать как абсолютно герметичные по отношению друг к другу. Существует множество задокументированных и известных способов, позволяющих процессу из одного контейнера сбежать и вступить во взаимодействие с другими контейнерами или с используемым хостом. Некоторые из этих проблем вызваны конструктивными особенностями, а часть из них связана с недочетами, находящимися в процессе устранения, но в любом случае, если не испытывается доверие к запускаемому коду, не ждите, что сможете запустить его в контейнере и при этом остаться в безопасности. Если нужна повышенная изолированность, то следует присмотреться к использованию виртуальных машин.
Docker
Docker представляет собой платформу, являющуюся надстройкой над облегченными контейнерами. Она вместо вас справляется с большим объемом работы по управлению контейнерами. В Docker ведется создание и развертывание приложений, что для мира виртуальных машин является синонимом образов, хотя и на платформе, основанной на применении контейнеров. Docker управляет предоставлением контейнеров, справляется за вас с некоторыми проблемами использования сетей и даже предоставляет собственное понятие реестра, позволяющее хранить сведения о Docker-приложениях и фиксировать их версии.
Абстракция Docker-приложений для нас полезна, поскольку точно так же, как и с образами виртуальных машин, основная технология, используемая для реализации сервиса, скрыта от нас. У нас имеются наши сборки для сервисов, создающие Docker-приложения и сохраняющие их в Docker-реестре, и больше ничто нас не интересует.
Docker может также смягчить некоторые недостатки от локального запуска множества сервисов в целях разработки и тестирования. Вместо использования Vagrant для размещения нескольких независимых виртуальных машин, в каждой из которых содержится ее собственный сервис, мы можем разместить одну виртуальную машину в Vagrant, на которой выполняется экземпляр Docker-платформы. Затем Vagrant используется для установки и удаления самой платформы Docker и использования Docker для быстрого предоставления отдельных сервисов.
Для получения преимуществ от использования платформы Docker были разработаны несколько технологий. С прицелом на использование Docker была разработана очень интересная операционная система CoreOS. Это урезанная до минимума операционная система Linux, предоставляющая только важнейшие службы, позволяющие работать платформе Docker. Это означает, что она потребляет меньше ресурсов, чем другие операционные системы, позволяя выделять используемой машине еще больше ресурсов для наших контейнеров. Вместо использования диспетчера пакетов, подобного deb- или RPM-диспетчерам, все программы устанавливаются как независимые Docker-приложения, каждое из которых запускается в собственном контейнере.
Сам Docker всех проблем за нас не решает. Его нужно представлять в качестве простой PaaS-платформы, работающей на одной машине. Если требуется инструментарий, помогающий управлять сервисами, разбросанными по нескольким Docker-экземплярам и нескольким машинам, нужно поискать другие программы, добавляющие такие возможности. К основным потребностям относится уровень диспетчеризации, позволяющий запрашивать контейнер, после чего он находит Docker-контейнер, который может запустить для вас. Оказать помощь в этой области могут принадлежащая Google недавно разработанная технология с открытым кодом Kubernetes и имеющиеся в CoreOS кластерные технологии. И похоже, что новички в этой области появляются чуть ли не каждый месяц. Еще одним интересным средством на основе Docker является Deis. Оно пытается предоставить поверх Docker PaaS-платформу, похожую на Heroku.
Ранее я уже говорил о PaaS-решениях. Я всегда вел борьбу с ними из-за того, что они довольно часто неправильно понимают уровень абстракции, а самостоятельно принимаемые решения существенно отстают от таких уже принятых решений, как Heroku. Docker получает намного больше прав, и резкий подъем интереса в этой области означает, как я предполагаю, что это средство через несколько лет станет намного более жизнеспособной платформой для всех разновидностей развертываний и всех разнообразных вариантов применения. Во многих отношениях Docker с соответствующим уровнем диспетчеризации располагается между решениями IaaS и PaaS, и для его описания уже использовался термин «контейнеры в качестве сервиса» (Containers as a Service (CaaS)).
Docker используют в производственном режиме несколько компаний. Он совместно со средствами, помогающими исключить многие недостатки, обеспечивает множество преимуществ, присущих облегченным контейнерам, в показателях эффективности и скорости предоставления контейнеров. Если вас интересуют альтернативные платформы развертывания, то я настоятельно советую присмотреться к Docker.
Интерфейс развертывания
Независимо от используемой платформы и артефактов наличие унифицированного интерфейса для развертывания исходного сервиса жизненно необходимо. Нам потребуется запускать развертывание микросервиса по мере необходимости в разнообразных ситуациях, от развертывания на локальной машине для разработки и тестирования до развертывания для работы в производственном режиме. И от разработки до производства нам нужно поддерживать как можно более однообразный механизм развертывания, поскольку крайне нежелательно столкнуться с проблемами в производстве из-за того, что при развертывании используется совершенно иной процесс!
Проработав в этой области много лет, я убежден, что наиболее разумным способом запуска любого развертывания является единый вызов инструкции командной строки с указанием нужных параметров. Инструкция может вызываться из сценария, ее выполнение может инициироваться вашим CI-средством, или же она может набираться вручную. Для выполнения этой работы я создавал сценарии-оболочки в различных технологических стеках, от пакетных файлов Windows до bash, а также до Python Fabric-сценариев и т. д., но все инструкции командной строки использовали один и тот же основной формат.
Нам нужно знать, что именно мы развертываем, следовательно, нужно предоставить имя известного объекта или же в данном случае микросервиса. Нам также нужно знать, какая версия объекта нами востребована. Ответ на вопрос о версии, скорее всего, будет одним из трех возможных. При работе на локальной машине это будет версия для работы на этой машине. При тестировании понадобится самая последняя зеленая сборка, которая может быть просто самым последним подходящим артефактом в нашем хранилище артефактов. А при тестировании или диагностировании проблем может потребоваться развернуть конкретную сборку.
Третье и последнее, о чем нам нужно знать, — это в какой среде следует развертывать микросервис. Как уже говорилось, топология наших микросервисов от среды к среде может быть разной, но здесь она должна быть скрыта от нас.
Итак, представим, что мы создали простой сценарий развертывания, получающий три параметра. Скажем, проводится локальное развертывание сервиса каталога в нашу локальную среду. Я могу набрать следующую инструкцию:
$ deploy artifact=catalog environment=local version=local
После того как будет проведена проверка, CI-сборка сервиса получает изменение и создает новый сборочный артефакт, присваивая сборке номер b456 в соответствии со стандартом, принятым в большинстве CI-средств. Это значение проводится по всему конвейеру. Когда запускается наша стадия тестирования, при выполнении CI-стадии может быть написано следующее:
$ deploy artifact=catalog environment=ci version=b456
Тем временем контролю качества потребовалось поместить последнюю версию сервиса каталога в интегрированную тестовую среду для выполнения исследовательского тестирования и оказания помощи в оформлении проспекта. Эта команда написала следующую инструкцию:
$ deploy artifact=catalog environment=integrated_qa version=latest
Чаще всего для этого я пользуюсь Fabric, библиотекой языка Python, предназначенной для отображения вызовов командной строки на функции, наряду с такой хорошей поддержкой задач обработки на удаленных машинах, как SSH. Соедините это с такой клиентской библиотекой AWS, как Boto, и у вас будет все необходимое для полной автоматизации очень крупных сред AWS. Для Ruby в некотором роде аналогом Fabric может послужить Capistrano, а для Windows можно воспользоваться PowerShell.
Определение среды. Разумеется, чтобы все это заработало, нужен способ определения того, на что похожа наша среда и на что похож наш сервис в заданной среде. Определение среды можно представить себе как отображение микросервиса на вычислительные ресурсы, сетевые ресурсы или ресурсы хранилища. Раньше я делал это с помощью YAML-файлов и для помещения в них данных использовал свои сценарии. В примере 6.1 показана упрощенная версия той работы, которую я делал года два назад для проекта, использующего AWS.
Пример 6.1. Пример определения среды
development:
nodes:
–ami_id: ami-e1e1234
size: t1.micro (1)
credentials_name: eu-west-ssh (2)
services: [catalog-service]
region: eu-west-1
production:
nodes:
–ami_id: ami-e1e1234
size: m3.xlarge (1)
credentials_name: prod-credentials (2)
services: [catalog-service]
number: 5 (3)
1. Размер используемых экземпляров варьируется с целью получения более высокого экономического эффекта. Для исследовательского тестирования не нужна 16-ядерная стойка с 64 Гбайт оперативной памяти!
2. Ключевой является возможность указать различные полномочия для разных сред. Полномочия для конфиденциальных сред хранились в различных репозиториях исходного кода, и к ним могли получать доступ только избранные.
3. Мы решили, что по умолчанию, если у сервиса имелось более одного сконфигурированного узла, для него будет автоматически создаваться система обеспечения сбалансированности нагрузки.
Некоторые детали для краткости были удалены.
Информация о сервисе каталога была сохранена в другом месте. Как видно из примера 6.2, от среды к среде она не изменяется.
Пример 6.2. Пример определения среды
catalog-service:
puppet_manifest : catalog.pp (1)
connectivity:
–protocol: tcp
ports: [ 8080, 8081 ]
allowed: [ WORLD ]
4. Это было имя запускаемого Puppet-файла. Так уж получилось, что в данной ситуации мы использовали только Puppet, но теоретически могли бы воспользоваться и поддержкой альтернативных систем управления настройками.
Вполне очевидно, что многие моменты поведения были основаны на соглашениях. Например, мы решили нормализовать используемые сервисом порты, где бы он ни запускался, и автоматически настроили систему обеспечения сбалансированности нагрузки в том случае, если у сервиса имеется более одного экземпляра (в AWS с этим довольно легко справляется ELB).
Создание систем, подобных этой, требует существенного объема работы. Усилия зачастую нужно прикладывать на начальном этапе, но они могут иметь большое значение для управления возникающими сложностями развертывания. Я надеюсь, что в будущем вам не придется делать это самим. Уже есть новейшее средство под названием Terraform от Hashicorp, которое работает именно в этой области. Я, как правило, уклоняюсь от упоминания в книге подобных новых средств, поскольку она посвящена скорее идеям, а не технологиям, но попытки создания средств с открытым кодом, работающих в данном направлении, предпринимаются. Хотя говорить об этом еще слишком рано, но уже существующие возможности представляются весьма интересными. Имея возможность нацеливания развертываний на различные платформы, в будущем вы можете сделать это средство своим рабочим инструментом.
Резюме
В данной главе было рассмотрено множество вопросов, о которых я хочу напомнить по порядку. Сначала мы сконцентрировали внимание на поддержании способности выпуска одного сервиса независимо от другого и на гарантиях того, чтобы она сохранялась независимо от выбираемой технологии. Я предпочитаю использовать по одному хранилищу для каждого микросервиса, но, если вы хотите развертывать микросервисы независимо друг от друга, я еще больше убежден в том, что вам нужна одна CI-сборка на каждый микросервис.
Затем, если есть такая возможность, перейдите к схеме, предполагающей размещение одного сервиса на каждом хосте или в каждом контейнере. Чтобы удешевить и облегчить управление перемещаемыми частями, обратите внимание на альтернативные технологии, такие как LXC или Docker, но при этом отнеситесь с пониманием к тому, что, какую бы технологию вы ни взяли на вооружение, ключом к управлению всеми аспектами служит культура автоматизации. Автоматизируйте все, что можно, и если используемая вами технология не позволяет этого сделать, перейдите на новую технологию! Когда дело дойдет до автоматизации, огромные преимущества вам даст возможность использования платформы, подобной AWS.
Удостоверьтесь в том, что вы усвоили степень влияния сделанного вами выбора, связанного с разработкой, на самих разработчиков, а также в том, что им тоже нравится ваш выбор. Особую важность имеет создание средств, предназначенных для самостоятельного развертывания любого конкретного сервиса в нескольких различных средах. Эти средства помогут и тем, кто занимается разработкой, тестированием и эксплуатацией сервисов.
И наконец, если вы хотите изучить эту тему глубже, я настоятельно рекомендую прочитать книгу Джеза Хамбла (Jez Humble) и Дэвида Фарли (David Farley) Continuous Delivery (Addison-Wesley), в которой намного больше подробностей, касающихся конструирования конвейеров и управления артефактами.
В следующей главе мы углубимся в тему, которой уже коснулись в данной главе. А именно, как проводить тестирование микросервисов, чтобы убедиться в их работоспособности.

