5. Разбиение монолита на части
Мы уже выясняли, на что похож хороший сервис и почему более мелкие сервисы могут подойти лучше. Также рассмотрели важность получения возможности развития конструкций наших систем. Но как справиться с тем, что уже может существовать большой объем исходных кодов, по своей сути не отвечающих принятым нами схемам? Как справиться с декомпозицией этих монолитных приложений, не ввязываясь в широкомасштабное переписывание кода?
Со временем монолит разрастается. Он с устрашающей скоростью обзаводится новыми функциональными возможностями и новыми строками кода. Вскоре он становится большим, ужасным гигантом, живущим в нашей организации, страшно к нему прикасаться или вносить в него изменения. Но еще не все потеряно! Имея в своем распоряжении нужные инструменты, мы можем убить этого зверя.
Все дело в стыках
В главе 3 мы согласились с тем, что наши сервисы должны обладать слабой связанностью и сильным зацеплением. Проблема монолита в том, что зачастую он обладает прямо противоположными качествами. Вместо стремления к сильному зацеплению и группировке, вместо всего того, что обычно изменяется вместе, мы получаем и сцепляем всевозможный неродственный код. Слабая связанность также практически отсутствует: как только понадобится внести изменения в строку кода, это можно будет сделать довольно легко, но я не могу выполнить развертывание этого изменения без потенциального распространения влияния на основную часть монолита, и мне, несомненно, придется заново развертывать всю систему.
Майкл Физерс (Michael Feathers) в своей книге Working Effectively with Legacy Code (Prentice-Hall) дал определение понятия стыка как порции кода, которая не может рассматриваться изолированно и работать, не влияя на весь остальной исходный код. Нам также нужно дать определение стыкам. Но вместо поиска определения для более четкого понимания исходного кода нужно определить стыки, которые могут превратиться в границы сервисов.
Итак, по каким же критериям можно определить хороший стык? Как уже говорилось, превосходными стыками могут послужить ограниченные контексты, поскольку по определению они представляют собой сильно зацепленные, но все же слабо связанные границы внутри организации. Следовательно, первым шагом должно стать определение этих границ в нашем коде.
В большинстве языков программирования имеется понятие пространства имен, позволяющее группировать вместе соответствующий код. Понятие из пакета Java представляет собой, конечно, довольно слабый пример, но, по большому счету, соответствует нашим потребностям. Все остальные широко распространенные языки программирования имеют сходные встроенные понятия, и только JavaScript, вероятно, является исключением.
Разбиение MusicCorp на части
Представим себе, что имеется большой внутренний монолитный сервис, определяющий основное поведение онлайн-систем MusicCorp. Для начала в соответствии с приемами, рассмотренными в главе 3, нужно определить границы ограниченных контекстов высокого уровня, которые, как мы понимаем, имеются в организации. Затем нужно будет попытаться понять, на какие ограниченные контексты отображается монолит. Представим, что изначально были определены четыре контекста, которые охватывает монолитный внутренний сервис.
• Каталог. Все, что касается метаданных товарных позиций, предлагаемых на продажу.
• Финансы. Отчеты по счетам, платежам, возмещению убытков и т. д.
• Товарный склад. Отправка и возвращение заказов клиентов, управление уровнем запасов и т. д.
• Рекомендации. Ожидающая патентования революционная система выдачи рекомендаций, представляющая собой весьма сложный код, написанный командой, в которой больше кандидатов наук, чем в обычной научной лаборатории.
Сначала нужно создать пакеты, представляющие эти контексты, а затем переместить в них существующий код. Используя современные IDE-среды, переместить код можно автоматически посредством рефакторинга, и сделать это пошагово, занимаясь другими делами. Но, чтобы отловить повреждения, возникающие в связи с перемещением кода, нужно все же проводить тестирование, особенно если используется язык с динамической типизацией, в котором IDE-средам выполнять рефакторинг довольно трудно. Со временем мы начинаем замечать, какой код поддается этому легче, а какой совершенно непригоден для данной процедуры. Этот оставшийся код зачастую будет определять, возможно, пропущенные нами ограниченные контенты!
В ходе этого процесса можно также воспользоваться кодом для анализа зависимостей между пакетами. Код должен представлять организацию, поэтому пакеты, представляющие ограниченные контенты, в организации должны взаимодействовать точно так же, как взаимодействуют между собой настоящие подразделения организации в данной области бизнеса. Например, такой инструмент, как Structure 101, позволяет увидеть графический образ зависимостей между пакетами. Если будет замечено что-то неправильное, например что пакет товарного склада зависит от кода в финансовом пакете, хотя в реальной организации такой зависимости нет, мы сможем понять суть проблемы и попытаться ее решить.
Этот процесс может занять целый день при небольшом объеме исходного кода или несколько недель и даже месяцев, когда придется работать с миллионами строк кода. Вам может не понадобиться сортировка всего кода по ориентированным на отдельные области пакетам перед выделением своего первого сервиса, и даже более того, может оказаться полезнее сконцентрироваться на одном месте. Эта работа не должна представлять собой стремительный процесс. Ее можно сделать пошагово, день за днем, и в нашем распоряжении имеется множество инструментов для отслеживания процесса.
Итак, мы организовали исходный код по стыкам. Что же делать дальше?
Мотивы для разбиения монолита на части
Для начала подойдет такое решение: вам хотелось бы, чтобы монолитный сервис или приложение имели меньший объем. Я бы настоятельно рекомендовал урезать эти системы. По ходу дела вы постепенно изучите микросервисы, и это поможет ограничить влияние неверных шагов на всю работу (а таких шагов вам просто не избежать!). Подумайте о нашем монолите как о куске мрамора. Мы могли бы сразу взорвать его, но это редко заканчивается хорошо. Намного разумнее обтесывать кусок постепенно.
Итак, если мы собрались разбивать монолит по кусочку, то с чего начать? Теперь у нас есть стыки, но какой из них нужно вынуть первым? Нужно подумать о том, где вы собираетесь получить наибольшую выгоду от части исходного кода, подлежащей выделению, а не просто разбивать ради самого разбиения. Рассмотрим ряд определяющих аспектов, которые помогут управлять долотом.
Темпы изменений
Возможно, мы знаем, что находимся на пороге больших изменений в способах управления запасами. Если теперь мы сделаем скол по стыку товарного склада и представим отколовшийся кусок в виде сервиса, то сможем внести изменения в этот сервис быстрее, поскольку теперь он станет автономной единицей.
Структура команды
Команда доставки MusicCorp фактически разделена между двумя географическими регионами. Одна команда находится в Лондоне, а другая на Гавайях (везет же людям!). Было бы здорово выделить код, с которым работает преимущественно гавайская команда, чтобы он перешел в ее полное владение. Эта идея рассматривается в главе 10.
Безопасность
Компания MusicCorp проверила систему безопасности и решила ужесточить меры защиты конфиденциальной информации. На данный момент все управляется кодом, связанным с финансовыми операциями. Если вычленить этот сервис, то можно будет обеспечить для него дополнительные меры защиты в плане мониторинга, защиты передаваемых данных и защиты содержащихся данных. Эти меры защиты подробнее рассматриваются в главе 9.
Технология
Команда, присматривавшая за нашей системой рекомендаций, столкнулась с трудностями применения новых алгоритмов с использованием библиотеки логического программирования на языке Clojure. Ее члены посчитали, что это сможет принести пользу клиентам, повысив качество того, что мы им предлагаем. Если бы можно было вычленить код системы выдачи рекомендаций в отдельную службу, то вопрос о ее альтернативной реализации с возможностью тестирования решался бы намного проще.
Запутанные зависимости
Другой вопрос, который нужно рассмотреть, когда определены несколько стыков для разделения монолита, касается переплетения этого кода со всей остальной системой. Нам по возможности нужно выявить такой стык, у которого меньше всего зависимостей. Если есть возможность просмотреть различные стыки в виде непосредственного ациклического графа зависимостей (иногда для этого отлично подходят ранее упомянутые мною пакеты средств моделирования), это может помочь в выявлении тех стыков, которые, скорее всего, будет сложнее освободить от зависимостей.
Это подводит нас к тому, что часто служит источником запутанных зависимостей, — к базе данных.
База данных
Проблемы использования баз данных в качестве средства интеграции нескольких сервисов подробно обсуждались ранее. Как я абсолютно ясно дал понять, я не сторонник этого способа интеграции! Это означает, что нам нужно найти стыки и в базе данных, чтобы по ним можно было провести четкое разбиение. Но базы данных — весьма хитрые звери.
Решение проблем
Для начала нужно посмотреть на сам код и понять, какие его части занимаются чтением из базы данных и записью в нее. Обычно для привязки кода к базе данных и облегчения отображения объектов или структур данных на базу данных и обратно используется уровень хранилища, поддерживаемый какой-либо средой вроде Hibernate. Если до сих пор вы следовали нашим предписаниям, то у вас должен быть код, сгруппированный в пакеты, являющиеся представлениями наших ограниченных контекстов. С кодом доступа к базам данных мы хотим сделать то же самое. Для этого может потребоваться разбиение уровня хранилища на несколько частей (рис. 5.1).
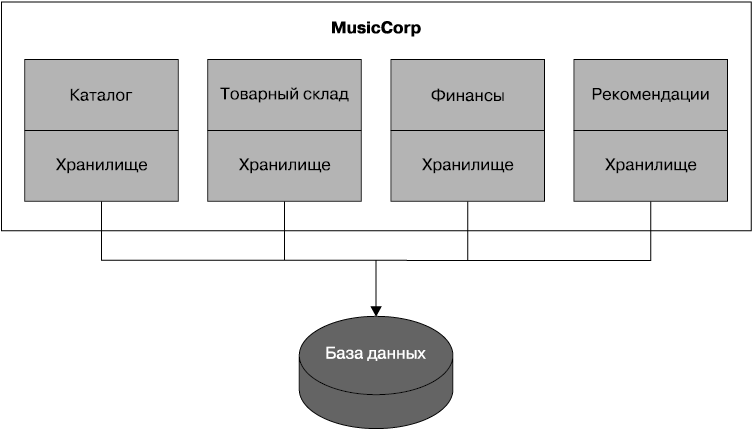
Рис. 5.1. Разбиение уровней хранилищ
Наличие кода отображения на базу данных, расположенного внутри кода для заданного контекста, может помочь разобраться в том, какие части базы данных используются тем или иным фрагментом кода. Например, среда Hibernate может прояснить ситуацию, если вы используете что-либо вроде файла отображения для каждого ограниченного контекста.
Но полной картины мы, конечно же, не получим. Например, мы можем получить возможность определения того, что код финансов использует таблицу главной бухгалтерской книги, а код каталога — таблицу товарных позиций, но при этом может быть не выяснено, что база данных использует внешний ключ, связывающий первую таблицу со второй. Чтобы на уровне базы данных увидеть такие ограничения, на которых можно споткнуться, нужно воспользоваться другим инструментальным средством визуализации данных. Для начала было бы неплохо воспользоваться таким свободно распространяемым средством, как SchemaSpy, которое может сгенерировать графическое представление взаимоотношений между таблицами.
Все это помогает разобраться в связях между таблицами, которые могут перекрывать то, что со временем станет границами сервисов. Но как разорвать эти связи? И что делать в том случае, когда одни и те же таблицы используются из нескольких ограниченных контекстов? Разобраться с подобными проблемами не так-то просто, и на эти вопросы есть масса ответов, но все же это выполнимо.
Возвращаясь к конкретным примерам, еще раз рассмотрим наш музыкальный магазин. Мы определили четыре ограниченных контекста и хотим пойти дальше и сделать на их основе четыре различных, совместно работающих сервиса. Мы собираемся рассмотреть несколько конкретных примеров тех проблем, с которыми могли бы столкнуться, а также потенциальные решения этих проблем. И хотя некоторые из этих примеров относятся именно к тем сложностям, которые встречаются в ходе работы со стандартными реляционными базами данных, сходные проблемы могут возникнуть и во время работы с другими магазинами, в программных средствах которых используется язык SQL.
Пример 1: разрыв взаимоотношений, использующих внешние ключи
В этом примере код каталога использует типичная таблица товарных позиций, хранящая информацию об альбоме. А для отслеживания финансовых транзакций код финансов использует таблицу главной бухгалтерской книги. В конце каждого месяца нам нужно составлять отчеты для различных должностных лиц организации, чтобы они могли видеть состояние наших дел. Хочется сделать отчеты красивыми и легкими для чтения, поэтому вместо того, чтобы сообщить: «Мы продали 400 копий SKU 12345 и выручили на этом 1300 долларов», есть желание добавить дополнительную информацию о том, что именно было продано (то есть «Мы продали 400 копий Bruce Springsteen’s Greatest Hits и выручили на этом 1300 долларов»). Чтобы добиться желаемого результата, код составления отчетов в финансовом пакете должен добраться до таблицы товарных позиций и извлечь заголовок для SKU. В нем, как показано на рис. 5.2, могут существовать ограничения, связанные с использованием внешнего ключа от таблицы главной бухгалтерской книги к таблице товарных позиций.
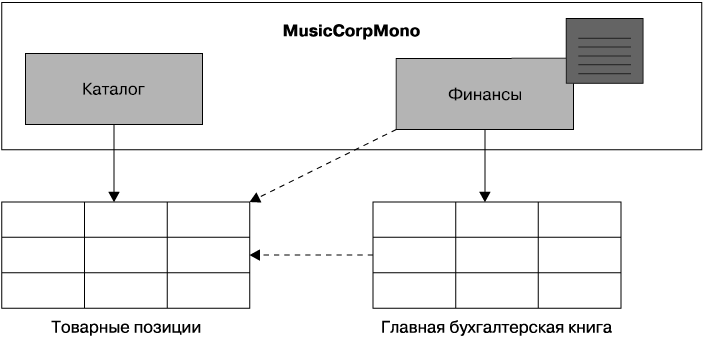
Рис. 5.2. Взаимоотношения, обусловленные наличием внешнего ключа
Итак, как же здесь можно исправить положение? Нужно внести изменения в двух местах. Следует прекратить доступ финансового кода к таблице товарных позиций, поскольку эта таблица принадлежит коду каталога, а мы не хотим, чтобы при вступивших в свои права сервисах каталога и финансов происходила интеграция посредством базы данных. Быстрее всего решить эту проблему, заменив тот код в финансах, который обращался к таблице товарных позиций, выставлением данных через обработку в пакете каталога API-вызова, совершаемого кодом финансов. Как показано на рис. 5.3, этот API-вызов может быть предвестником того вызова, который мы сделаем по сети.
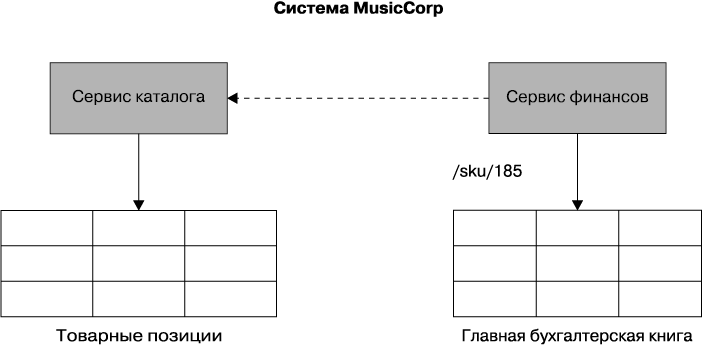
Рис. 5.3. Ситуация после отказа от использования внешних ключей
Теперь уже понятно, что для составления отчета мы можем обойтись двумя вызовами, направляемыми к базе данных. И это правильно. То же самое произойдет при наличии двух отдельных сервисов. Обычно разговор о производительности при этом не идет. На это у меня есть довольно простой ответ: насколько быстрой должна быть ваша система? И насколько быстро она работает сейчас? Если есть возможность протестировать ее текущую производительность и разобраться в том, что значит высокая производительность, тогда можно почувствовать уверенность в правильности вносимых изменений. Иногда намеренно допускается замедление работы каких-либо компонентов, чтобы взамен получить какие-то другие преимущества, особенно если такое замедление вполне приемлемо.
А как же насчет взаимоотношений, обусловленных наличием внешних ключей? Мы их просто теряем. Теперь обязанность управления вменяется получающимся у нас сервисам и снимается с уровня базы данных. Это может означать, что нам придется постоянно проверять согласованность сервисов или предпринимать иные активные действия для очистки взаимосвязанных данных. Вопрос о необходимости таких действий зачастую не относится к выбору, осуществляемому технологом. Например, если прежний сервис содержал перечень идентификаторов для элементов каталога, то что произойдет, если элемент каталога удален и теперь заказ ссылается на неверный идентификатор каталога? Должны ли мы допускать подобную ситуацию? Если да, то как это должно быть представлено в заказе при выводе его на экран? Если нет, то как мы можем проверить отсутствие нарушений? На эти вопросы должны ответить те люди, которые определяют порядок поведения системы по отношению к ее пользователям.
Пример 2: совместно используемые статичные данные
Наверное, мне попадалось столько же много кодов стран в базах данных (рис. 5.4), сколько я написал классов StringUtils для собственных Java-проектов. Это позволяет предположить, что мы планируем вносить изменения в страны, поддерживаемые нашей системой, чаще, чем будет развертываться новый код, но какой бы ни была реальная причина, в этих примерах совместного использования статичных данных, хранящихся в базах данных, придумано много нового. Итак, что же нам предпринять для музыкального магазина, если все потенциальные сервисы считывают данные из одной и той же таблицы?
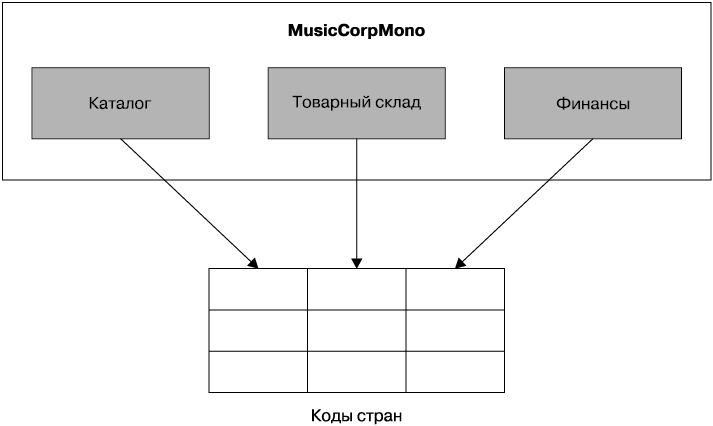
Рис. 5.4. Коды стран в базе данных
Итак, у нас есть несколько вариантов. Один из них предполагает дублирование этой таблицы для каждого из наших пакетов с тем, чтобы в долгосрочной перспективе она была продублирована также в каждом сервисе. Разумеется, это приводит к потенциальным осложнениям с согласованностью данных: что будет, если обновить одну таблицу с целью отображения создания некой страны Ньюмантопии на восточном побережье Австралии, оставив другие таблицы без изменений?
Второй вариант состоит в том, чтобы рассматривать совместно используемые статичные данные как код. Возможно, он мог бы содержаться в файле свойств, развернутом в виде части сервиса, или может использоваться в виде простого перечисления. Проблема с согласованностью данных остается, но опыт подсказывает, что намного проще поместить изменения в конфигурационные файлы, чем вносить их в действующие таблицы баз данных. Зачастую такой подход считается вполне разумным.
Третий, возможно, экстремальный вариант заключается в том, чтобы поместить статические данные в отдельный полноправный сервис. В двух ситуациях, с которыми мне приходилось сталкиваться, объема, сложности и количества правил, связанных со статическими ссылочными данными, было достаточно для того, чтобы считать такой подход оправданным, а вот когда дело касается просто кодов стран, он, вероятнее всего, будет излишним!
Лично я в большинстве ситуаций стараюсь помещать эти данные в конфигурационные файлы или непосредственно в код, поскольку чаще всего этот вариант оказывается самым простым.
Пример 3: совместное использование данных
Теперь углубимся в более сложный пример из разряда решений типичных проблем, возникающих при попытке препарировать независимые системы, — пример совместного использования изменяющихся данных. Наш финансовый код отслеживает платежи, осуществляемые клиентами за сделанные ими заказы, а также отслеживает возврат средств клиентам при возврате ими товара. Тем временем код товарного склада обновляет записи, чтобы показать отправку заказов клиентам или их возврат от клиентов. Все эти данные отображаются в одном удобном месте на сайте, позволяя клиентам наблюдать за всем происходящим с их учетной записью. Чтобы избежать усложнения, вся эта информация хранилась в универсальной таблице клиентских записей (рис. 5.5).
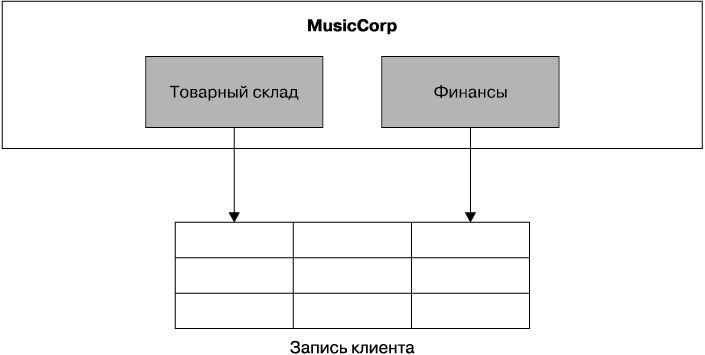
Рис. 5.5. Доступ к клиентским данным: мы ничего не упустили?
Как финансовый, так и складской код ведет запись и, возможно, время от времени осуществляет чтение из одной и той же таблицы. Как можно препарировать ее на части? Здесь мы имеем то, что вам будет попадаться довольно часто, — понятие области, не промоделированной в коде и фактически полностью смоделированной в базе данных. В этом случае пропущенным понятием области является Customer (Клиент).
Нам нужно превратить текущее абстрактное понятие клиента в конкретное. В качестве промежуточного этапа мы создаем новый пакет под названием Customer. Затем можно будет воспользоваться API для открытия кода Customer другим пакетам, например финансовому или складскому. Проделав все это, мы можем в итоге получить отдельный клиентский сервис (рис. 5.6).
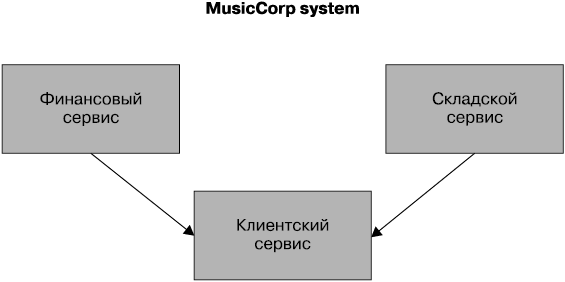
Рис. 5.6. Распознавание ограниченного контекста клиента
Пример 4: совместно используемые таблицы
На рис. 5.7 показан последний пример. Каталогу нужно сохранять название и цену продаваемых музыкальных записей, а товарному складу — вести электронный учет материально-технических ресурсов. Мы решили содержать и то и другое в одном и том же месте — в универсальной таблице товарных позиций. Раньше, когда весь код составлял единое целое, нам не было понятно, что мы фактически объединяем интересы, но теперь можно увидеть, что действительно есть два различных понятия, которые должны сохраняться по-разному.
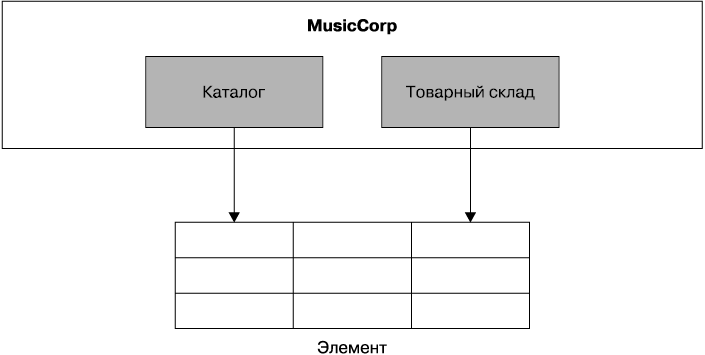
Рис. 5.7. Таблицы, совместно используемые различными контекстами
Ответ заключается в разбиении таблицы и получении двух таблиц (рис. 5.8), возможно, с созданием таблицы товарных позиций для склада и таблицы записей каталога для подробностей, необходимых сервису каталогов.
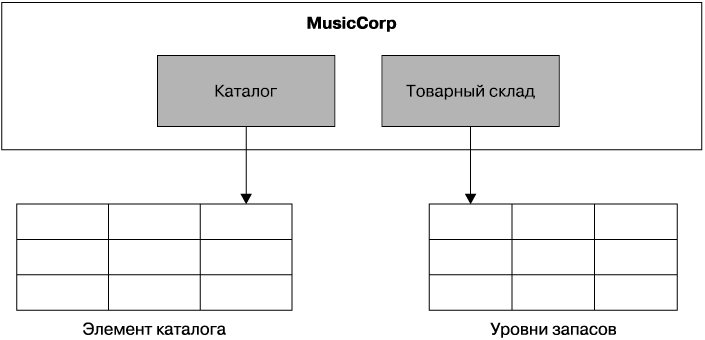
Рис. 5.8. Разбиение совместно используемой таблицы
Перестройка баз данных
То, что было рассмотрено в предыдущих примерах, относится к перестройкам баз данных, способствующих разделению ваших схем. Для более подробного изучения предмета можно обратиться к книге Скотта Дж. Амблера (Scott J. Ambler) и Прамода Садаладжа (Pramod J. Sadalage) Refactoring Databases (Addison-Wesley).
Поэтапное разбиение. Итак, уже найдены стыки в коде приложения, код сгруппирован вокруг ограниченных контекстов, все это использовано для нахождения стыков в базе данных и приложены все силы для ее разбиения. А что же дальше? Нужно ли выполнять радикальное разбиение, переходя от одного монолитного сервиса с единой схемой к двум сервисам, каждый из которых имеет собственную схему? Я настоятельно рекомендую разбить схему, но не разделять сервис до разбиения кода приложения на два отдельных микросервиса (рис. 5.9).
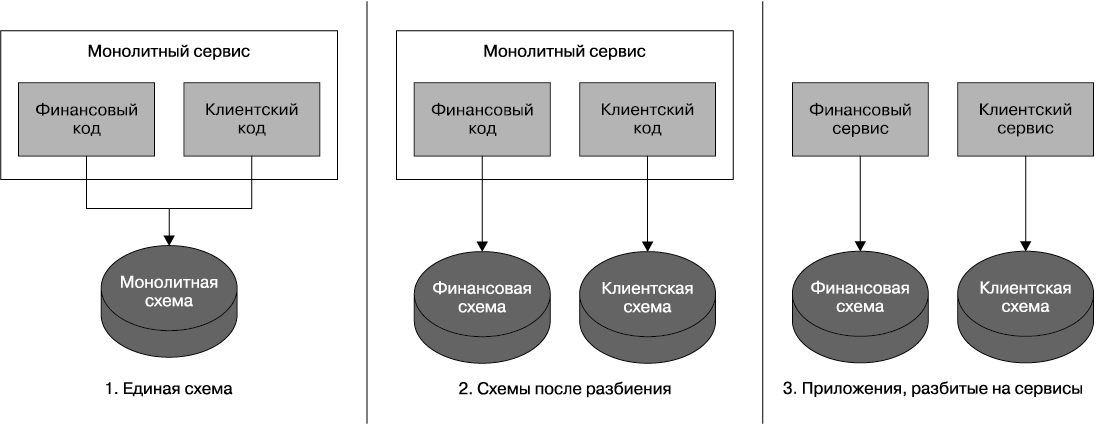
Рис. 5.9. Поэтапное разбиение сервиса
При отдельной схеме число потенциальных вызовов для выполнения одного действия будет потенциально увеличиваться. Там, где прежде можно было получать все нужные данные при выполнении одной инструкции SELECT, теперь придется извлекать данные из двух мест и объединять их в памяти. Кроме того, в результате перехода к двум схемам получается нарушение целостности транзакции, которое может существенно повлиять на наше приложение, о чем мы поговорим в следующем разделе. При разбиении схемы и неразбитом коде приложения мы оставляем для себя возможность вернуться к прежней схеме или продолжить настройки, никак не влияя на потребителей сервиса. Как только мы удостоверимся в том, что разделение базы данных имеет смысл, можно будет подумать и о разбиении кода приложения на два сервиса.
Транзакционные границы
Транзакции — вещь полезная. Они позволяют быть уверенным в том, что либо данные события произойдут вместе, либо не случится ни одно из них. Особую пользу они приобретают при вставке данных в базу, давая возможность одновременно обновлять сразу несколько таблиц и знать при этом, что в случае сбоя произойдет полный откат к прежнему состоянию, что исключит ситуацию, при которой данные будут находиться в несогласованном состоянии. Проще говоря, транзакции позволяют группировать вместе несколько различных действий, которые переносят нашу систему из одного согласованного состояния в другое, при этом либо все срабатывает, либо ничего не изменяется.
Транзакции применимы не только к базам данных, хотя наиболее часто они используются именно в их контексте. Например, брокеры сообщений уже давно позволяют вам публиковать и получать сообщения также внутри транзакций.
При монолитной схеме все операции по созданию или изменению, скорее всего, будут проводиться в рамках единой транзакционной границы. Когда мы разбиваем на части наши базы данных, то утрачиваем ту безопасность, которая обеспечивается при наличии единой транзакции. Рассмотрим простой пример в контексте MusicCorp. При создании заказа мне нужно обновить таблицу заказов, утвердив тем самым создание клиентского заказа, а также поместить запись в таблицу для команды товарного склада, чтобы оповестить ее о существовании заказа, который нужно скомплектовать для отгрузки. Мы добрались до распределения кода приложения на отдельные пакеты, в достаточной степени разделили клиентскую и складскую части схемы и приготовились поместить эти части в их собственные схемы, предваряя тем самым разделение кода приложения.
В имеющейся у нас монолитной схеме создание заказа и вставка записи для складской команды производились в рамках одной транзакции (рис. 5.10).
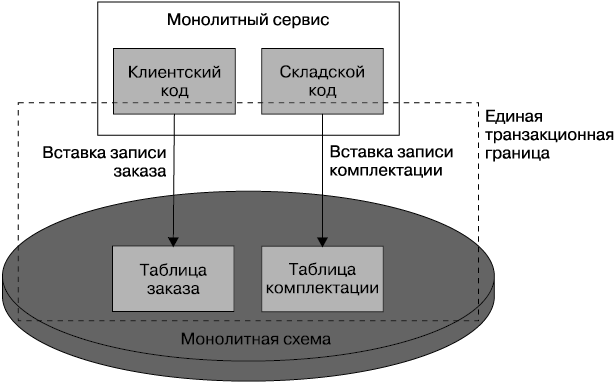
Рис. 5.10. Обновление двух таблиц в рамках одной транзакции
Но если мы разбили схему на две отдельные схемы: одну для данных, связанных с клиентом, а другую для склада, — мы утратили транзакционную безопасность. Процесс размещения заказа теперь охватывает две обособленные транзакционные границы (рис. 5.11). Если при вставке в таблицу заказов произойдет сбой, то мы, конечно же, можем все остановить, сохраняя согласованное состояние. Но что получится, если вставка в таблицу заказов пройдет успешно, а при вставке в таблицу комплектации произойдет сбой?
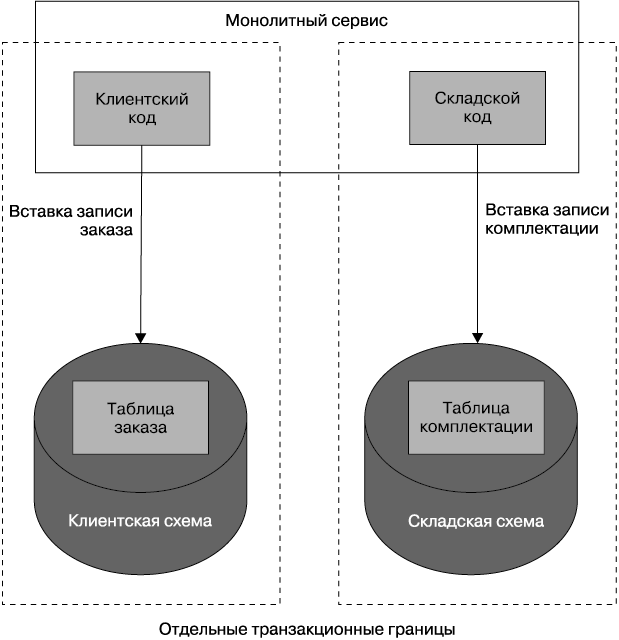
Рис. 5.11. Распространение границ транзакций для единой операции
Повторная попытка
Самого факта получения и размещения заказа может быть для нас достаточно, и позднее мы можем принять решение о повторной вставке записи комплектации в складскую таблицу. Эту часть операции можно будет поставить в очередь или занести в файл журнала и повторить попытку чуть позже. Для некоторых видов операций в этом есть определенный смысл, но мы должны гарантировать, что повторная попытка исправит ситуацию.
Во многих смыслах это еще одна форма того, что называется возможной согласованностью. Вместо использования транзакционной границы как гарантии согласованного состояния по окончании транзакции мы допускаем, что система сама приведет себя в согласованное состояние в какой-то будущий момент времени. Такой подход особенно хорош для продолжительных бизнес-операций. Более подробно он будет рассмотрен в главе 11 при изучении особенностей масштабируемых шаблонов.
Отмена всей операции
Еще один вариант заключается в отмене всей операции. В этом случае систему нужно вернуть в прежнее согласованное состояние. С таблицей комплектации все просто, поскольку вставка дала сбой, но в таблице заказов мы имеем уже зафиксированную транзакцию. Поэтому нужно сделать откат. Необходимое действие выполняется в рамках компенсационной транзакции, то есть запуска новой транзакции для отката всего, что только что случилось. В нашем случае все может свестись к простой выдаче инструкции удаления DELETE, предназначенной для удаления заказа из базы данных. Затем нужно будет отчитаться в пользовательском интерфейсе о сбое операции. В монолитной системе наше приложение может справиться с обоими аспектами, а вот когда код приложения уже разбит на части, нужно призадуматься о том, что делать. Где именно должна находиться логика управления компенсационной транзакцией, в клиентском сервисе или где-то еще?
А как быть, если произойдет сбой компенсационной транзакции? Вероятность этого не исключена. Тогда у нас в таблице заказов будет заказ, не имеющий соответствующей ему инструкции по комплектации. В такой ситуации нужно либо провести компенсационную транзакцию повторно, либо позволить какому-нибудь внутреннему процессу убрать несогласованность чуть позже. Можно было бы просто воспользоваться экраном обслуживания с доступом только со стороны административного персонала или же использовать автоматизированный процесс.
А теперь подумайте о том, что будет, если у нас не одна или две операции, согласованности которых нужно придерживаться, а три, четыре или пять операций. Проведение компенсационных транзакций для каждого сбойного режима очень трудно не то что реализовать, но даже осмыслить.
Распределенные транзакции
Альтернативой ручной организации компенсационных транзакций является использование распределенной транзакции. Распределенные транзакции пытаются объединить в себе сразу несколько транзакций, используя для управления различными транзакциями, проводимыми в базовых системах, общий управляющий процесс, называемый диспетчером транзакций. Точно так же, как и обычная транзакция, распределенная транзакция старается гарантировать пребывание всего в согласованном состоянии, только она пытается сделать это в рамках нескольких систем, запущенных в различных процессах, связь между которыми зачастую осуществляется через сетевые границы.
Наиболее распространенный алгоритм управления распределенными транзакциями — особенно теми, которые носят кратковременный характер, как в случае с нашим клиентским заказом, — заключается в использовании двухфазной фиксации. При этом сначала следует фаза голосования, при которой каждый участник (также называемый в данном контексте партнером) распределенной транзакции сообщает диспетчеру транзакций о том, считает ли он, что его локальная транзакция может начинаться. Если диспетчер транзакций получит положительный ответ от всех участников, он дает им команду на начало транзакций и выполняет их фиксацию. Для того чтобы совершить откат всех транзакций, диспетчеру транзакций хватает единственного отрицательного ответа.
Такой подход предполагает, что все участники останавливаются, пока центральный координационный процесс не даст команду на продолжение работы. Это означает, что мы не застрахованы от остановки работы. Если диспетчер транзакций зависнет, отложенные транзакции никогда не завершатся. Если партнер не ответит в процессе голосования, все будет заблокировано. И неизвестно, что произойдет, если фиксация даст сбой после голосования. В этом алгоритме есть безусловное предположение о том, что такого никогда не случится: если партнер сказал «да» при голосовании, значит, мы должны предполагать, что его транзакция будет зафиксирована. Партнерам нужен способ, позволяющий заставить фиксацию происходить в нужный момент. Это означает, что данный алгоритм не защищен от сторонних сбоев, вернее, он предусматривает попытку обнаружения большинства случаев сбоев.
Этот координационный процесс предусматривает также установку блокировок, то есть отложенная транзакция должна удерживать блокировку ресурсов. Блокировка ресурсов может привести к конкуренции, существенно усложняя масштабируемые системы, особенно в контексте распределенных систем.
Распределенные транзакции были реализованы для конкретных технологических стеков, таких как Transaction API в Java, что позволяет таким разрозненным ресурсам, как база данных и очередь сообщений, участвовать в одной и той же всеобъемлющей транзакции. Разобраться в различных алгоритмах довольно трудно, поэтому я советую отказаться от попытки создания собственных алгоритмов. Если вы считаете, что нужно пойти именно этим путем, лучше досконально исследуйте данную тему и посмотрите, можно ли воспользоваться какой-либо из уже имеющихся реализаций.
Так что же делать?
Все эти решения усложняют систему. Как видите, разобраться в распределенных транзакциях довольно трудно и фактически они могут воспрепятствовать масштабированию. О системах, которые в конечном итоге сводятся к компенсационной логике повторов, труднее рассуждать, и для устранения несогласованности данных они могут нуждаться в ином компенсационном поведении.
Когда вам встречаются бизнес-операции, проводимые в данный момент в рамках единой транзакции, задайте себе вопрос, действительно ли они должны это делать. Не могут ли они проводиться в различных локальных транзакциях и полагаться на концепцию возможной согласованности? Создавать такие системы и заниматься их масштабированием намного проще (более подробно этот вопрос рассматривается в главе 11).
Если попадется такое состояние, необходимость в согласованности которого не вызывает никаких сомнений, то в первую очередь сделайте все возможное, чтобы избежать разбиения. Приложите для этого все усилия. Если же разбиения будет не избежать, подумайте об изменении чисто технического взгляда на процесс (например, транзакции в базе данных) и создайте конкретные понятия, представляющие саму транзакцию. Это даст вам возможность зацепиться за запуск других операций, подобных компенсационным транзакциям, а также за способ отслеживания этих более сложных понятий в вашей системе и управления ими. Например, можно прийти к идее незавершенного заказа, которая даст вам реальное место для концентрации всей логики вокруг сквозной обработки заказа (и работы с исключениями).
Создание отчетов
Как мы уже видели, при разбиении сервиса на более мелкие части нужно также в потенциале разбить на части и способы хранения этих данных. Но это создает проблему, когда дело доходит до жизненно важного и весьма распространенного случая — создания отчетов.
Такие фундаментальные изменения в архитектуре, как переход к микросервисам, вызовет множество разрушений, но это не означает, что нужно отказываться от всего, что мы делаем. Аудиторию наших систем отчетности, как и любых других систем, составляют пользователи, и мы должны учитывать их запросы. Фундаментальная перестройка архитектуры была бы преувеличением наших возможностей, поэтому ее нужно просто приспособить под новые нужды. Я, конечно, не берусь утверждать, что пространство создания отчетов не должно подвергаться разрушению, — это неизбежно, и тут важно сначала определить порядок работы с существующими процессами. Иногда нам придется выбирать пути борьбы.
База данных для создания отчетов
Создание отчетов обычно требует группировать данные, поступающие из нескольких подразделений организации, с целью генерации полезных выходных данных. Например, нам нужно расширить данные из главной бухгалтерской книги описанием того, что было продано, и взять это описание из каталога. Или же отследить интересы, которые проявляют при покупках конкретные особо ценные покупатели, которым может потребоваться информация из истории их покупок и клиентского профиля.
При стандартной монолитной архитектуре сервиса все данные хранятся в одной большой базе данных. Это означает, что все они находятся в одном месте, поэтому создание отчетов по всей информации выполняется довольно легко и мы можем просто объединить данные в SQL-запросах или чем-то подобном. Обычно создание отчетов не запускается на основной базе данных из опасения того, что нагрузка на них, создаваемая запросами, повлияет на производительность основной системы, поэтому зачастую системы создания отчетов привязывают к копии базы данных, предназначенной для чтения (рис. 5.12).
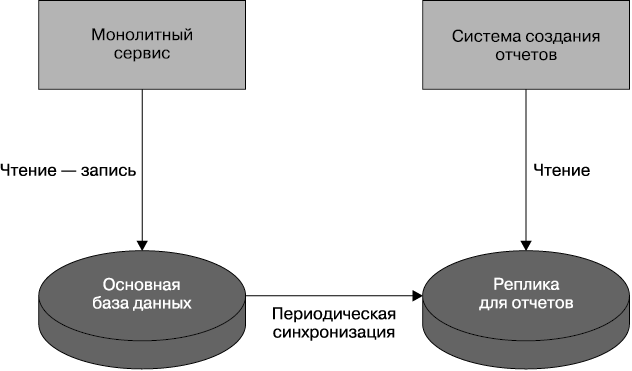
Рис. 5.12. Стандартная копия для чтения данных
При таком подходе мы получаем весьма большое преимущество, заключающееся в том, что все данные уже находятся в одном месте. Это позволяет воспользоваться весьма простым инструментарием для их запроса. Но есть также пара недостатков. Во-первых, схема базы данных теперь фактически представляет собой API, совместно используемый работающими монолитными сервисами и любой системой создания отчетов. Поэтому изменение, вносимое в схему, должно быть тщательно отрегулировано. В действительности мы получаем еще одно препятствие, уменьшающее шансы любого желающего взяться за решение задачи внесения такого изменения и его согласования.
Во-вторых, у нас весьма ограничен выбор вариантов того, как может быть оптимизирована база данных для обоих случаев ее использования — поддержки основной системы и системы создания отчетов. Некоторые базы данных позволяют проводить оптимизацию копий, предназначенных для чтения, чтобы ускорить создание отчетов и повысить его эффективность. Например, MySQL позволит запускать различные виды внутренней обработки, не создающие издержек при управлении транзакциями. Но мы не можем структурировать данные по-разному с целью ускорения создания отчетов, если сделанные для этого изменения в структуре данных плохо повлияют на рабочую систему. Часто случается, что схема хороша для одного сценария использования и нехороша для другого или же она становится наименьшим общим знаменателем, не обеспечивающим наилучший вариант ни для одной из целей ее использования.
И наконец, доступные нам варианты баз данных недавно уже были отвергнуты. Поскольку стандартные реляционные базы данных выставляют на всеобщее обозрение интерфейсы SQL-запросов, которые работают со многими инструментами создания отчетов, они не всегда являются наилучшим вариантом хранения данных для работающих у нас сервисов.
Что, если данные нашего приложения лучше моделируются как граф в Neo4j? Или если нам лучше будет воспользоваться таким хранилищем документов, как MongoDB? А что, если для нашей системы создания отчетов захочется присмотреться к использованию основанной на понятии столбцов базе данных Cassandra, которая упрощает масштабирование более существенных объемов данных? Ограничивая себя необходимостью использования одной базы данных в обеих целях, мы часто лишаемся возможности подобного выбора и исследования новых вариантов.
Итак, пусть это далеко от совершенства, но оно работает (чаще всего). А что нам делать, если информация хранится в нескольких различных системах? Есть ли способ собрать все данные вместе для запуска системы создания отчетов? И можем ли мы потенциально отыскать способ избавления от ряда недостатков, присущих стандартной модели создания отчетов на основе использования базы данных?
Оказывается, в нашем распоряжении есть сразу несколько весьма жизнеспособных альтернатив этому подходу. Какое из решений будет наиболее подходящим именно для вас, зависит от ряда факторов, но мы изучим несколько вариантов, которые мне встречались на практике.
Извлечение данных посредством служебных вызовов
Существует множество вариантов этой модели, но все они основаны на извлечении запрошенных данных из исходной системы посредством API-вызовов. Для очень простой системы создания отчетов, подобной панели мониторинга, на которой может быть нужно всего лишь показывать количество заказов, размещенных за последние 15 минут, это может оказаться вполне подходящим вариантом. Чтобы создать отчет на основе данных от двух и более систем, нужно для сбора этих данных сделать несколько вызовов.
Но при вариантах, требующих более крупных объемов данных, этот подход быстро становится непригодным. Представьте такой вариант использования, при котором нужно составить отчет о предпочтениях в покупках клиента нашего музыкального магазина за последние 24 месяца с рассмотрением различных тенденций в его поведении и того, как это влияло на выручку. Для этого необходимо извлечь большие объемы данных как минимум из клиентской и финансовой систем. Сохранять локальную копию этих данных в системе создания отчетов опасно, поскольку мы будем не в курсе происходящих изменений (задним числом могут изменяться даже исторические данные), поэтому для создания точного отчета нужны все финансовые и клиентские записи за последние два года. Даже при скромном числе клиентов можно будет заметить, что вскоре эта операция станет проводиться очень медленно.
Системы создания отчетов часто зависят от программных инструментов сторонних производителей, ожидающих получения данных вполне определенным способом, и предоставление SQL-интерфейса в данном случае является самым быстрым путем обеспечения наиболее простой интеграции с ними вашей цепочки средств создания отчетов. Разумеется, мы могли бы воспользоваться этим подходом для периодического получения данных в базе данных SQL, но это все же будет создавать для нас ряд проблем.
Одной из ключевых проблем является то, что API, доступные в различных микросервисах, могут быть не предназначены для использования их в сценариях создания отчетов. Например, сервис клиентов может позволить найти клиента по его идентификатору или же отыскать его по тем или иным полям, но не факт, что он раскроет API для извлечения данных обо всех клиентах. Это может привести к выдаче множества вызовов для извлечения всех данных. Например, чтобы последовательно перебрать список всех клиентов, придется делать отдельный вызов для каждого клиента. Это не только может сделать неэффективной работу системы создания отчетов, но и создаст большую нагрузку на задействованный сервис.
Можно, конечно, ускорить извлечение данных путем добавления к ресурсам, раскрываемым нашим сервисом, заголовков кэша и кэшированием этих данных где-нибудь вроде прокси-сервера, который будет выглядеть для клиента как исходный сервер, но особенность создания отчетов предполагает получение доступа к длинной веренице данных. Это означает, что мы можем запросить такие ресурсы, которые прежде не запрашивались никогда (или по крайней мере довольно долго), а это приведет к потенциально дорогостоящему непопаданию в кэш.
Для упрощения создания отчетов данную проблему можно решить путем раскрытия пакетных API. Например, наш сервис клиентов может позволить прохождение по списку идентификаторов пользователей для извлечения данных о них в пакетах или даже раскрыть интерфейс, позволяющий пролистывать данные обо всех клиентах. Более экстремальным вариантом этого действия будет моделирование пакетного запроса в качестве самостоятельного ресурса. Например, клиентский сервис может раскрыть что-то вроде конечной точки ресурса BatchCustomerExport. Вызывающая система будет выдавать POST-запрос BatchRequest, возможно, передавая сведения о месте, где может находиться файл со всеми данными. Клиентский сервис в качестве ответа вернет код HTTP 202, показывающий, что запрос был принят, но еще не обработан. Затем вызывающая система может опрашивать ресурс, ожидая возвращения от него статуса выполнения 201 Created, свидетельствующего о выполнении запроса и о том, что вызывающая система может перейти к извлечению данных. Это может позволить потенциально большим файлам данных экспортироваться без издержек, связанных с их отправкой по HTTP. Вместо этого система может просто сохранить CSV-файл в место совместного доступа.
Мне приходилось видеть предыдущий подход, используемый для пакетной вставки данных, с чем он вполне справлялся. Но он представляется мне менее подходящим для системы создания отчетов, поскольку я чувствую, что есть и другие, потенциально более простые решения, поддающиеся более эффективному масштабированию, чем при работе с традиционными отчетными потребностями.
Программы перекачки данных
Вместо того чтобы заставлять системы создания отчетов извлекать данные, можно перемещать данные в эти системы. Одним из недостатков извлечения данных посредством стандартных HTTP-вызовов являются издержки HTTP при отправке большого количества вызовов наряду с издержками, связанными с необходимостью создания API, которые могут пригодиться только для создания отчетов. Альтернативным вариантом может послужить использование отдельной программы, имеющей прямой доступ к базе данных сервиса, являющегося источником данных, и перекачивающей данные в отчетную базу данных (рис. 5.13).
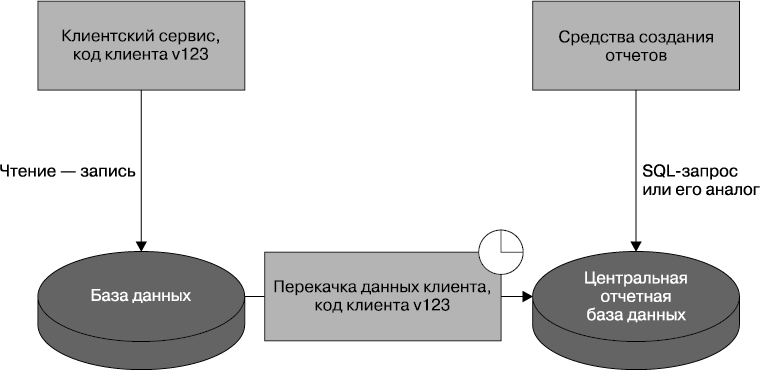
Рис. 5.13. Использование программы перекачки данных для их периодического перемещения в центральную отчетную базу данных
И вот здесь вы можете возразить: «Сэм, ты же говорил, что лучше не использовать программы, интегрированные посредством базы данных!» По крайней мере, я надеюсь на такое ваше замечание, учитывая настойчивость, с которой я высказывал возражения по данному вопросу! Этот подход при надлежащей реализации является весьма интересным исключением, в котором недостатки связанности более чем компенсированы легкостью создания отчетов.
Для начала программы перекачки данных должны создаваться и управляться той же командой, которая управляет сервисом. Она должна быть такой же простой, как программа командной строки, запускаемая с помощью Cron. Эта программа должна довольно много знать и о внутренней базе данных для сервиса, и о схеме для создания отчетов. Задача перекачки данных заключается в отображении одного на другое. Мы постараемся сократить проблемы со связанностью за счет того, что перекачкой и сервисом будет управлять одна и та же команда. Фактически я хочу предложить, чтобы управление версиями этих средств велось совместно и чтобы сборки программы перекачки данных создавались в виде дополнительного побочного продукта и являлись частью сборки самого сервиса в предположении, что при развертывании одной из этих сборок происходит развертывание и другой сборки. Поскольку об их совместном развертывании и о недопустимости открытия доступа к схеме где-либо за пределами команды сервиса мы сделали явное заявление, многие из традиционных проблем интеграции на основе использования баз данных значительно смягчаются.
Связанность в самой схеме создания отчетов остается, но мы должны считать ее публикуемым API, который трудно изменить. Некоторые базы данных предоставляют технологии, позволяющие и дальше снижать цену за использование такого подхода. На рис. 5.14 показан пример, касающийся реляционных баз данных, где можно иметь одну схему в отчетной базе данных для каждого сервиса, используя нечто вроде материализованных представлений для создания агрегированного представления. В этом случае для программы перекачки данных клиента раскрывается только схема создания отчетов для клиентских данных. Но будет ли это чем-нибудь, что можно сделать в произвольном стиле, зависит от возможностей выбранной для отчетов базы данных.
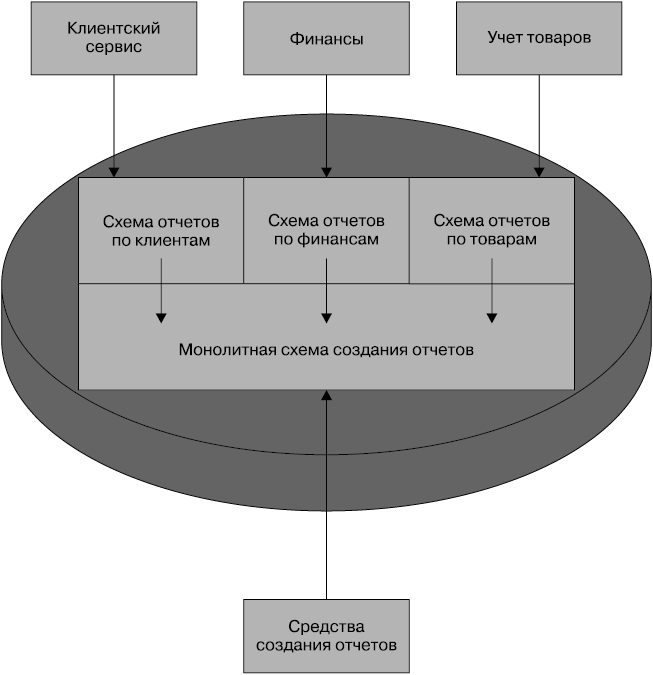
Рис. 5.14. Использование материализованных представлений для создания единой монолитной схемы создания отчетов
Разумеется, здесь сложность интеграции упрятана глубже в схему и будет зависеть от возможностей базы данных добиться от такой структуры высокой производительности. Хотя в целом я считаю программы перекачки данных весьма разумным и работоспособным предложением, у меня остаются сомнения в том, что сложность сегментированной схемы сможет себя оправдать, особенно если учитывать проблемы в управлении изменениями в базе данных.
Альтернативные направления
В одном из проектов с моим участием мы использовали серии программ перекачки данных для заполнения JSON-файлов в AWS S3, эффективно применяя S3 для маскировки огромной ярмарки данных! Этот подход работал весьма исправно до тех пор, пока нам не потребовалось расширить данное решение, и на момент написания книги мы искали, чем заменить программы перекачки, чтобы вместо этого заполнить куб, который мог быть интегрирован со стандартными средствами создания отчетов, такими как Excel и Tableau.
Перекачка данных на основе событий
В главе 4 упоминалась идея микросервисов, выдающих события на основе изменения состояния тех объектов, которыми они управляли. Например, наш клиентский сервис может выдавать событие при создании, или обновлении, или удалении клиента. Для микросервисов, выставляющих напоказ выдачу событий, имеется вариант написания своего подписчика на события, который перекачивает данные в отчетную базу данных (рис. 5.15).
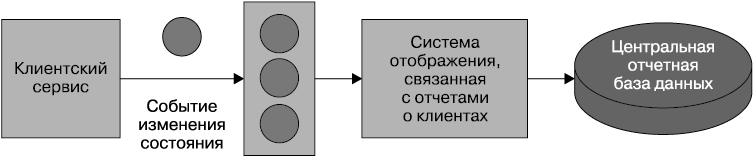
Рис. 5.15. Программа перекачки данных на основе событий, использующая события изменения состояния для наполнения отчетной базы данных
Связанности в используемой базе данных исходного микросервиса теперь удалось избежать. Взамен мы просто привязались к событиям, выдаваемым сервисом, который разработан открытым для внешних потребителей. При условии, что у этих событий временный характер, мы получаем также более простую возможность проявить интеллект в том, какие данные отправлять центральному хранилищу отчетности. Мы можем отправить данные системе создания отчетов, как только увидим событие, позволяя данным быстрее перетекать в отчетную систему, и не быть зависимыми от регулярного графика, как при обычной перекачке данных.
Кроме того, если сохранять информацию о том, какие события уже были обработаны, мы сможем просто обработать новое событие сразу же по его поступлении, предполагая при этом, что старые события уже были отображены на систему создания отчетов. Это означает, что внедрение будет более эффективным, поскольку нам нужно лишь отправить различия. Аналогичные действия можно выполнить и с программой перекачки данных, но управлять этим придется самостоятельно, принимая во внимание абсолютно временный характер потока событий (x случается с меткой времени y), что существенно нам поможет.
Поскольку программа перекачки данных на основе событий имеет меньшую связанность с внутренними механизмами сервиса, будет также проще рассматривать вопрос управления всем этим отдельной группой той команды, которая присматривает за самим микросервисом. Поскольку по своей природе поток событий не слишком связывает подписчиков в их возможностях внесения изменений в сервис, эта система отображения событий может развиваться независимо от сервиса, который на нее подписан.
Основной недостаток такого подхода состоит в том, что вся необходимая информация должна передаваться в виде событий и может масштабироваться под большие объемы данных не так широко, как при использовании программы перекачки данных, у которой есть преимущество работы непосредственно на уровне базы данных. Тем не менее более слабая связанность и более свежие данные, доступные благодаря этому подходу, делают его весьма привлекательным для рассмотрения, если соответствующие события выставляются на всеобщее обозрение.
Перекачка данных на основе систем резервного копирования
Этот вариант основан на подходе, используемом в Netflix, в котором применяются существующие решения по созданию резервных копий, а также решаются некоторые проблемы масштабирования, с которыми приходится сталкиваться компании. Отчасти его можно рассматривать в качестве особого средства перекачки данных, но, похоже, такое интересное решение вполне заслуживает включения в наш арсенал.
Компания Netflix решила использовать базу данных Cassandra в качестве стандартного резервного хранилища своих многочисленных сервисов. Netflix потратила немало времени на создание средств, облегчающих работу с Cassandra, многими из которых компания делится с остальным миром посредством ряда проектов с открытым кодом. Конечно же, необходимость резервного копирования тех данных, которые хранятся в Netflix, вполне очевидна. Для резервного копирования данных, хранящихся в базе данных Cassandra, стандартным подходом является создание копий поддерживающих ее файлов и сохранение их в безопасном месте. Netflix сохраняет эти файлы, известные как SSTables, в принадлежащем компании Amazon хранилище объектов S3, твердо гарантирущем долговечность хранения данных.
Netflix нуждается в отчетах по всем этим данным, но с учетом задействованных масштабов решить эту задачу нелегко. В выбранном компанией подходе применяется среда Hadoop, которая использует резервные копии SSTable в качестве источника для своих заданий. Напоследок компания Netflix завершила реализацию конвейера, способного с использованием рассматриваемого подхода обрабатывать большой объем данных, которые она затем превратила в проект с открытым кодом под названием Aegisthus. Но как и при использовании программ перекачки данных, при применении этой модели мы по-прежнему сталкиваемся с наличием связанности с целевой схемой составления отчетов (или с целевой системой).
Возможно, применение аналогичного подхода, то есть систем отображения, создающих резервные копии, позволит выработать вполне работоспособное решение и в других контекстах. А если вы уже используете базу данных Cassandra, то компания Netflix сделала основную часть работы за вас!
Переход к реальности
Многие из ранее выделенных моделей представляют собой различные способы получения большого объема данных из множества различных мест и помещения их в одно место. Но неужели идея создания всех отчетов из одного места по-прежнему имеет право на существование? У нас имеются отчетные данные, выводимые на панель управления, разного рода предупреждения, финансовые отчеты, аналитика, связанная с пользовательской активностью, — и все это предъявляет различные требования к точности и своевременности, что может найти выражение в выборе различных технических приемов для их получения. В соответствии с уточнениями, которые даются в главе 8, мы перемещаем все больше и больше данных по направлению к универсальным системам обработки событий, способным направлять данные в несколько разных мест в зависимости от наших потребностей.
Цена внесения изменений
В книге приводится немало причин, по которым я поддерживаю необходимость внесения незначительных, постепенных изменений, но одним из основных стимулов является понимание влияния каждого вносимого изменения и корректировка их направления, если она потребуется. Это позволяет более эффективно снижать цену ошибок, но не может полностью исключить вероятность их совершения. Мы можем и будем делать ошибки, и нужно принимать это как должное. Но, кроме этого, мы должны понимать, как наилучшим образом можно уменьшить цену этих ошибок.
Как мы уже поняли, цена перемещения кода в его исходном источнике относительно невелика. В нашем распоряжении имеется множество вспомогательных средств, и если возникнет проблема, ее, как правило, можно быстро устранить. Но разбиение на части базы данных требует намного большего объема работы, а откат изменений, вносимых в базу данных, является довольно-таки непростой задачей. Точно так же весьма нелегким делом может оказаться распутывание излишней связующей интеграции сервисов или необходимость полного переписывания API, используемого несколькими потребителями. Высокая цена изменений означает, что эти операции имеют все более высокую степень риска. Как можно управлять степенью риска? Мой подход заключается в допущении тех ошибок, отрицательное воздействие которых будет наименьшим.
Я стараюсь все рассматривать в том месте, где цена изменений и цена ошибок будут наименьшими: на доске в лекционной аудитории. Изобразите краткое представление предлагаемой конструкции. Посмотрите, что получится, когда вы запускаете варианты использования через предполагаемые границы сервиса. Например, можно представить, каковы будут для музыкального магазина последствия того, что клиент ищет запись, регистрируется на сайте или приобретает альбом. Какие для этого делаются вызовы? Замечаете ли вы случайные циклические ссылки? Замечаете ли вы два сервиса, ведущих между собой слишком интенсивный обмен данными, который может быть признаком того, что они должны составлять единое целое?
Здесь неплохо было бы внедрить подход, который более типичен при обучении созданию объектно-ориентированных систем: применение карт событийного взаимодействия классов (CRC). При использовании CRC-карт создается одна индексная карта с именем класса, на которой указывается, за что он отвечает и с чем взаимодействует. При проработке предложенной конструкции для каждого сервиса перечисляется все, за что он отвечает в понятиях предоставляемых им возможностей, также на схеме указываются совместно работающие с ним сервисы. По мере проработки все большего количества вариантов использования вы начинаете понимать, насколько правильно все это сообразуется друг с другом.
Умение разбираться в основных причинах
Мы рассмотрели способы разбиения крупных сервисов на более мелкие, но в чем первопричина того, что сервисы разрослись до таких больших размеров? Сначала нужно понять, что разрастание сервиса до определенного объема, требующего его разбиения, — это вполне нормальное явление. Нам нужно, чтобы архитектура системы со временем изменялась. Главное — разобраться в том, что она требует разбиения еще до того, как такое разбиение станет обходиться слишком дорого.
Однако на практике многие из нас видели, как сервисы разрастаются, приобретая размеры, абсолютно не отвечающие здравому смыслу. Несмотря на то что нам известно, что с меньшим набором сервисов проще работать, чем с тем огромным чудовищем, которое у нас получилось, мы по-прежнему занимаемся выращиванием чудовища. Почему?
Часть проблемы заключается в том, чтобы знать, с чего начать, и я надеюсь, что эта глава помогла вам в этом разобраться. Но другой проблемой являются затраты, связанные с разбиением сервисов на части. Нелегкими задачами будут поиск среды для запуска сервиса, раскрутка нового стека сервисов и т. д. Как же со всем этим справиться? Если дело нужное, но сложное, мы должны попытаться все упростить. Снизить затраты, связанные с созданием нового сервиса, может ставка на применение библиотек и облегченных сред сервисов. Упростить предоставление и тестирование систем может обеспечение людям доступа к самообслуживаемым виртуальным машинам или даже создание платформы в качестве услуги (PaaS). В следующих главах будет рассмотрен ряд способов, позволяющих снизить эти затраты.
Резюме
Мы разбиваем систему на части путем поиска стыков, по которым могут проходить границы сервисов, и применение этого подхода может носить поэтапный характер. Совершенствуя в первую очередь поиск этих стыков и работу по снижению стоимости разбиения сервисов, мы можем продолжить наращивание и развитие систем, реагируя на все встречающиеся на этом пути требования. Как вы уже могли заметить, часть этой работы требует особого усердия. Но сам по себе тот факт, что это можно делать постепенно, означает, что этой работы не нужно бояться.
Итак, мы можем разбивать сервисы, но при этом проявляются некоторые новые проблемы. Теперь у нас намного больше движущихся частей, требующих доводки до работы в производственном режиме! Следовательно, настало время погрузиться в мир развертывания микросервисов.

