4. Интеграция
На мой взгляд, правильная интеграция является наиболее важным аспектом технологии, связанной с микросервисами. При должном выполнении ваши микросервисы сохранят свою автономию, в то же время можно будет вносить в них изменения и выпускать их новые версии независимо от всей остальной системы. При ненадлежащем исполнении вас ждут серьезные неприятности. К счастью, прочитав эту главу, вы научитесь обходить самые большие из возможных просчетов, от которых страдают другие попытки применения сервис-ориентированной архитектуры и которые могут все еще поджидать вас на пути перехода к применению микросервисов.
Поиск идеальной интеграционной технологии
Для определения способа общения одного микросервиса с другим имеется широкое поле выбора. Но какой из вариантов будет правильным: SOAP, XML-RPC, REST, Protocol Buffers? Прежде чем углубиться в решение этой задачи, подумаем о том, что нам нужно получить от той технологии, на которую падет выбор.
Уклонение от разрушающих изменений
Время от времени мы можем вносить изменения, требующие изменений и от наших потребителей. Как с этим справиться, мы рассмотрим чуть позже, но хотелось бы подобрать такую технологию, которая бы гарантировала, что подобная ситуация станет возникать как можно реже. Например, если микросервис добавляет новые поля к той части данных, которые он куда-нибудь отправляет, это не должно касаться уже имеющихся потребителей.
Сохранение технологической независимости применяемых API
Если ваш стаж пребывания в IT-индустрии превышает 15 минут, то мне не нужно говорить вам о том, что мы работаем в быстро меняющемся пространстве. Что-то обязательно изменится. Все время появляются новые инструменты, среды программирования и языки, реализуются новые идеи, которые могут помочь нам работать быстрее и эффективнее. Сегодня вы можете пользоваться всем многообразием .NET-технологии. А что будет через год или через пять лет? Что, если вам захочется поэкспериментировать с набором альтернативной технологии, который может увеличить вашу продуктивность?
Я ярый сторонник свободы выбора и именно поэтому являюсь горячим приверженцем микросервисов. Это также является причиной того, что я считаю очень важным сохранение технологической независимости API, используемых для обмена данными между микросервисами. Это означает, что нужно избегать применения тех интеграционных технологий, которые диктуют, какие технологические наборы следует применять при реализации микросервисов.
Сохранение простоты использования сервиса потребителями
Хотелось бы сделать сервис для потребителей как можно более простым в использовании. Красиво представленный микросервис не может рассчитывать на что-то существенное, если цена его применения заоблачно высока! Поэтому задумаемся над средствами, упрощающими использование потребителями нашего замечательного нового сервиса. В идеале хотелось бы дать клиентам полную свободу технологического выбора, но в то же время предоставление клиентской библиотеки может упростить внедрение сервиса. И все же зачастую такие библиотеки несовместимы с другими вещами, которые хотелось бы реализовать. Например, клиентские библиотеки можно использовать в качестве послаблений для потребителей, но это может происходить и за счет повышения связанности.
Скрытие внутренних деталей реализации
Нам не хотелось бы, чтобы наши потребители были привязаны к внутренней реализации сервисов. Это приводит к повышению связанности. Из этого также следует, что при возникновении необходимости внести какие-либо изменения в микросервис мы можем расстроить потребителей, потребовав от них ответных изменений. Это повышает цену изменения, то есть происходит именно то, чего мы стремимся избежать. Это означает также, что нам, скорее всего, не захочется вносить изменения из-за опасений заставить своих потребителей что-либо обновлять, что может повлечь за собой увеличение объема технических обязательств внутри сервиса. Следовательно, нужно избегать любых технологий, вынуждающих нас выставлять напоказ внутренние представления деталей сервисов.
Взаимодействие с потребителями
После получения наставлений, которые могут помочь в выборе подходящей технологии, используемой для интеграции сервисов, рассмотрим некоторые из наиболее востребованных вариантов и попробуем определить, какой из них нам больше всего подходит. Чтобы проще было все обдумать, возьмем реальный пример из MusicCorp.
На первый взгляд создание клиентов можно рассматривать в виде простого набора CRUD-операций, но для большинства систем все далеко не так просто. Внесение в список нового клиента может потребовать инициирования дополнительных процессов, таких как создание финансовых платежей или отправка приветственных сообщений по электронной почте. А при изменении данных клиента или их удалении могут запускаться и другие бизнес-процессы.
Итак, помня об этом, мы должны рассмотреть ряд других способов работы с клиентами в системе MusicCorp.
Совместно используемая база данных
До сих пор самой распространенной в промышленности формой интеграции, известной мне или любому из моих коллег, является интеграция с использованием базы данных (DB). Если в этой среде другим сервисам нужно получить информацию от какого-нибудь другого сервиса, они обращаются к базе данных. И если им нужно внести в нее изменения, они также обращаются к базе данных! Действительно, на первый взгляд все просто, и для начала это, пожалуй, наиболее быстрый вид интеграции, чем, вероятно, и объясняется его популярность.
На рис. 4.1 показан пользовательский интерфейс регистрации, с помощью которого создаются клиенты путем выполнения SQL-операций непосредственно над базой данных. Там также показано приложение центра обработки заказов, из которого осуществляется просмотр или редактирование клиентских данных путем запуска SQL-запросов в адрес базы данных. А с товарного склада также путем запросов в адрес базы данных производится обновление информации о клиентских заказах. Это довольно широко распространенная схема, но и тут без трудностей не обходится.
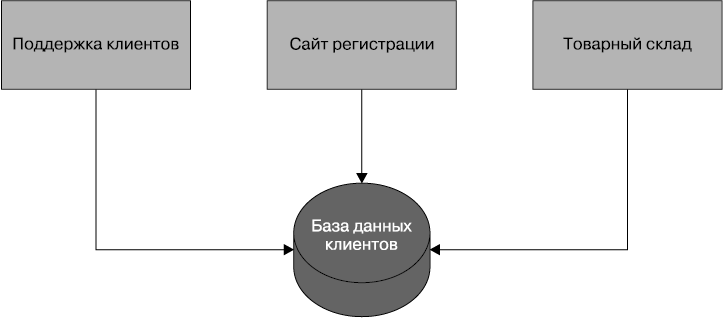
Рис. 4.1. Использование DB-интеграции для доступа к клиентской информации и внесения в нее изменений
Во-первых, разрешены просмотр подробностей внутренней реализации и привязка к ним извне. Структуры данных, хранящихся в базе, становятся законной добычей для любого, они во всей своей полноте используются всеми, кто имеет доступ к базе данных. Если мною будет принято решение изменить свою схему для более подходящего представления своих данных или упростить систему, я могу нарушить работу потребителей. Фактически база данных представляет собой слишком большой совместно используемый API, который к тому же весьма хрупок. Если мне потребуется внести изменения в логику, связанную, скажем, с управлением сервисом поддержки клиентов, и для этого нужно будет вносить изменения в базу данных, мне потребуется предельное внимание, чтобы не нарушить те части схемы, которые используются другими сервисами. Обычно в такой ситуации требуется большой объем регрессионного тестирования.
Во-вторых, мои потребители привязаны к конкретному технологическому выбору. Возможно, именно сейчас имеет смысл хранить сведения о клиентах в реляционной базе данных, и поэтому потребители для обращения с этими данными используют соответствующую (потенциально характерную для баз данных) управляющую программу. А что, если со временем станет понятно, что данные лучше хранить в нереляционной базе данных? Могу ли я принять такое решение? Следовательно, потребители тесно связаны с реализацией сервиса по обслуживанию клиентов. Как упоминалось ранее, мы действительно хотим обеспечить скрытие реализации деталей от потребителей, допуская приобретение нашим сервисом определенного уровня автономности в том, как со временем изменяется его внутреннее содержание. Придется распрощаться со слабой связанностью.
И наконец, на минутку задумаемся о поведении. Должна быть какая-то логика, связанная с тем, как вносятся изменения в данные о клиенте. Где же эта логика? Если потребители напрямую работают с базой данных, значит, связанной с этим логикой должны владеть именно они. Логика для выполнения подобных действий с данными клиентов может не распространяться среди нескольких потребителей. Если в редактировании информации о клиенте нуждаются сразу пользовательские интерфейсы товарного склада, системы регистрации и центра обработки заказов, устранять недочет или изменять поведение нужно в трех разных местах, а кроме того, нужно будет еще и развертывать такие изменения. И тут уже придется распрощаться с зацеплением.
Помните, что говорилось об основных принципах, закладываемых в качественные микросервисы? Сильное зацепление и слабая связанность. А с интеграцией при помощи базы данных мы теряем и то и другое. База данных упрощает для сервисов совместное использование данных, но ничего не может поделать с общим поведением. Внутреннее представление по сети выставляется напоказ другим потребителям, и избежать разрушительных изменений становится очень трудно, что неминуемо приводит к возникновению страха перед внесением любых изменений. А этого нужно избегать практически любой ценой.
Далее в главе будут рассмотрены разные стили интеграции, связывающие совместно работающие сервисы, которые сами скрывают собственное внутреннее представление.
Сравнение синхронного и асинхронного стилей
Перед тем как углубиться в особенности технологического выбора, нужно рассмотреть одно из наиболее важных принимаемых решений в понятиях способов совместной работы сервисов. Каким должен быть обмен данными, синхронным или асинхронным? Этот основополагающий выбор неминуемо приводит нас к конкретным деталям реализации.
При синхронном обмене данными делается вызов на удаленный сервер, блокирующий всю работу вплоть до завершения операции. При асинхронном обмене данными вызывающая сторона перед тем, как вернуть управление, не будет дожидаться завершения операции и даже может не беспокоиться о ее завершении.
Проще рассуждать о синхронном обмене данными. Мы знаем, когда все завершается удачно, а когда — нет. Асинхронный обмен данными может оказаться весьма полезным для продолжительных заданий, где долговременное удержание открытым подключения между клиентом и сервером непрактично. Оно также хорошо себя проявляет, когда не нужны большие задержки, при которых вызов блокирует работу в ожидании результата, что может замедлить весь процесс. Вследствие особенностей, присущих мобильным сетям и устройствам, выдача запросов при условии, что все продолжает работать (если не указано обратное), может гарантировать сохранение отзывчивости пользовательского интерфейса, даже если сеть будет сильно тормозить. В то же время, как мы вскоре узнаем, технология управления асинхронным обменом данными может быть несколько сложнее.
Эти два разных режима обмена данными могут допускать два различных идиоматических стиля совместной работы: «запрос — ответ» или «опора на события». При применении стиля «запрос — ответ» клиент инициирует запрос и ждет получения ответа. Эта модель полностью вписывается в синхронный обмен данными, но может работать и при асинхронном обмене. Можно начать операцию и зарегистрировать обратный вызов, обращаясь к серверу с просьбой дать знать о том, когда операция будет завершена.
При совместной работе, основанной на применении событий, все наоборот. Вместо того чтобы клиент инициировал запросы на выполняемые действия, он говорит о том, что случилось нечто конкретное, и ожидает того, что другие стороны знают, что им следует делать. О том, что нужно делать, никому другому никогда не говорится. По своей природе системы, основанные на использовании событий, относятся к асинхронным. Интеллектуальные решения распределяются более равномерно, то есть бизнес-логика не централизована в основных интеллектуальных ядрах, а вытеснена в различные совместно работающие сервисы. Кроме того, совместная работа на основе событий обладает высокой степенью разобщенности. Клиент, выдающий событие, не имеет возможности узнать, кто или как на него среагирует, что также означает: вы можете добавить новых подписчиков на эти события без необходимости уведомлять об этом клиента.
Итак, есть ли какие-нибудь другие побудительные причины, которые могли бы подтолкнуть нас к выбору того или иного стиля? Заслуживает рассмотрения то, насколько хорошо эти стили подходят для решения самых сложных задач: как мы справляемся с процессами, выходящими за границы сервисов и выполняемыми достаточно долго?
Сравнение оркестрового и хореографического принципов
Приступая к моделированию все более сложной логики, нам приходится справляться с проблемами управления бизнес-процессами, выходящими за границы отдельных сервисов. А при работе с микросервисами с этим ограничением приходится сталкиваться еще чаще. Возьмем пример из MusicCorp и посмотрим, что происходит при создании клиента.
1. В банке очков лояльности по отношению к клиенту создается новая запись.
2. Наша почтовая система отправляет набор приветственных сообщений.
3. Клиенту отправляется приветственное сообщение по электронной почте.
Концептуально это легко поддается моделированию в виде блок-схемы, что, собственно, и сделано на рис. 4.2.
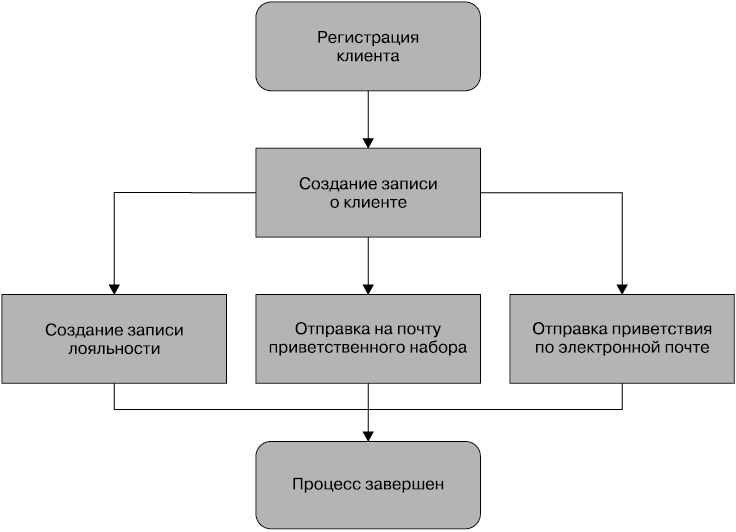
Рис. 4.2. Процессы, предназначенные для создания нового клиента
Когда наступает черед фактической реализации того, что изображено на блок-схеме, можно придерживаться двух стилей архитектуры. При использовании оркестрового принципа за основу берется центральный интеллект, направляющий процессы и управляющий ими, во многом напоминающий своими действиями дирижера оркестра. При использовании хореографического принципа каждую часть системы информируют о поставленной перед ней задаче, а детали разрешается прорабатывать самостоятельно, они подобны танцорам, находящим собственный путь и реагирующим на всех окружающих их артистов балета.
Подумаем, какой вид согласно этой блок-схеме приобретет решение по использованию оркестрового принципа. Здесь, наверное, проще всего было бы заставить наш сервис работать в качестве центрального интеллекта. Как показано на рис. 4.3, при создании через серию вызовов «запрос — ответ» происходит общение с банком очков лояльности по отношению к клиенту, сервисом электронной почты и сервисом обычной почты. В дальнейшем сервис клиентов самостоятельно может отслеживать положение клиента в этом процессе. Он может проверить установку учетной записи клиента, или отправку электронной почты, или доставку почтового сообщения. Мы можем взять блок-схему, показанную на рис. 4.2, и смоделировать ее непосредственно в коде. И даже можем воспользоваться инструментарием, который сделает это за нас, возможно, с применением соответствующего обработчика правил. Для этой цели существуют коммерческие инструменты в виде программ моделирования бизнес-процессов. Предположив, что используется синхронный стиль вида «запрос — ответ», мы даже можем узнать, пройден ли тот или иной этап.
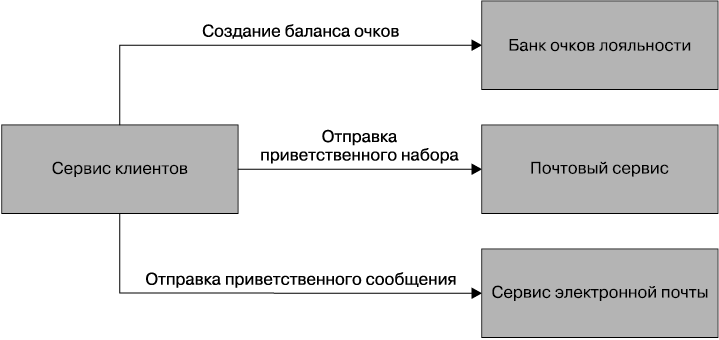
Рис. 4.3. Подход к созданию клиента с помощью оркестрового принципа
Недостаток подхода с использованием оркестрового принципа заключается в том, что сервис клиентов может получить излишне централизованные руководящие полномочия. Он может стать узлом в середине сети и центральной точкой, из которой исходит логика. Я видел, как такой подход приводит к возникновению небольшого количества «божественных» сервисов, предписывающих вялым сервисам на CRUD-основе, что им надлежит делать.
При подходе с использованием хореографического принципа вместо этого можно обязать сервис клиентов выдавать в асинхронной манере события, которые бы оповещали о создании клиента. Затем, как показано на рис. 4.4, сервис электронной почты, сервис обычной почты и банк очков лояльности просто подписались бы на подобные события и реагировали на них соответствующим образом. Этот подход имеет намного более разобщенный характер. Если какому-либо другому сервису потребуется добраться до создания клиента, ему просто нужно будет подписаться на события и выполнять по мере необходимости возложенную на него задачу. Недостатком является то, что явное представление бизнес-процесса, которое показано на рис. 4.2, теперь отражается в нашей системе лишь в неявном виде.
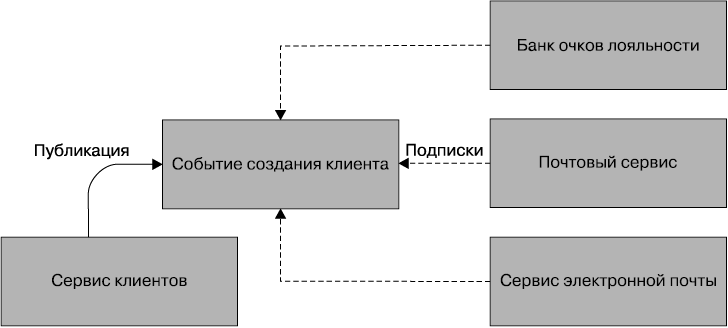
Рис. 4.4. Подход к созданию клиента с использованием хореографического принципа
Это означает необходимость выполнения дополнительной работы, дающей возможность наблюдать и отслеживать надлежащее развитие событий. Например, узнаете ли вы о том, что банк очков лояльности имеет некий изъян и по какой-то причине не завел нужную учетную запись? Одним из предпочитаемых мной подходов является построение системы наблюдения, которая в точности соответствует представлению бизнес-процессов, показанному на рис. 4.2, с последующим отслеживанием того, что делает каждый сервис в качестве независимой единицы. Это позволит замечать случайные исключения, отображаемые на более явное течение процесса. Рассмотренная ранее блок-схема является не побудительной причиной, а всего лишь одной из линз, через которую можно увидеть характер поведения системы.
Вообще-то я понял, что системы, больше тяготеющие к подходу с использованием хореографического принципа, обладают намного более слабой связанностью и большей гибкостью и податливостью к изменениям. Но при этом приходится выполнять дополнительную работу для наблюдения и отслеживания процессов, проходящих через системные границы. Я понял, что системы, обладающие самой сильной приверженностью к использованию оркестрового принципа, получаются слишком хрупкими и требующими более высоких затрат на внесение изменений. Помня об этом, я являюсь стойким приверженцем нацеливания на реализацию системы с использованием хореографического принципа, где каждый сервис обладает достаточным интеллектом для понимания своей роли во всем танце.
Мы можем рассмотреть довольно много факторов. Синхронные вызовы проще, и мы будем осведомлены о том, что все идет намеченным курсом. Если нам нравится семантика «запрос — ответ», но мы имеем дело с долговременными процессами, можем просто инициировать асинхронные запросы и ждать обратных вызовов. В то же время совместная работа с использованием асинхронных событий помогает ввести подход, использующий хореографический принцип, который может привести к созданию намного более разобщенных сервисов, к чему, собственно, мы и стремимся, чтобы обеспечить для своих сервисов независимую разъемность.
Разумеется, никто нам не мешает заняться смешиванием и подгонкой. К тому или иному стилю некоторые технологии могут подходить более естественно. Тем не менее нужно оценить особенности ряда различных технических реализаций, что в дальнейшем поможет сделать правильный выбор.
Для начала обратимся к двум технологиям, которые хорошо подходят для рассмотрения стиля «запрос — ответ»: удаленному вызову процедуры (RPC) и передаче репрезентативного состояния (REST).
Удаленные вызовы процедуры
Удаленный вызов процедуры является технологией локального вызова, который выполняется где-то на удаленном сервисе. У технологии RPC имеется множество разновидностей. Некоторые из них основаны на применении определенного интерфейса (SOAP, Thrift, Protocol Buffers). Использование отдельного определения интерфейса может облегчить создание клиентских и серверных заглушек для различных технологических стеков, таким образом, к примеру, у меня может быть Java-сервер, выставляющий SOAP-интерфейс, и .NET-клиент, созданный из определения интерфейса на языке описания веб-сервисов (WSDL). Другие технологии вроде Java RMI предусматривают более тесную связанность между клиентом и сервером, требующую, чтобы оба они использовали одинаковую исходную технологию, но при этом исключается необходимость в определении совместно используемого интерфейса. Но все эти технологии имеют одинаковые основные характеристики в том смысле, что они делают локальный вызов, похожий на удаленный вызов.
Многие из этих технологий, такие как Java RMI, Thrift или Protocol Buffers, являются двоичными по своей природе, в то время как в SOAP для форматов сообщений используется язык XML. Некоторые реализации привязаны к конкретному сетевому протоколу (например, SOAP, который номинально использует HTTP), в то время как другие могут допускать использование различных типов сетевых протоколов, которые сами по себе могут обеспечить дополнительные возможности. Например, TCP предоставляет гарантии доставки, а UDP их не дает, но имеет намного меньше издержек. Это может позволить применять различные сетевые технологии для различных вариантов использования.
Те RPC-реализации, которые позволяют создавать клиентские и серверные заглушки, содействуют весьма быстрому старту. Я могу в два счета отправлять контекст через сетевую границу. Зачастую это служит одним из основных аргументов в пользу RPC — эта технология проста в использовании. Тот факт, что я могу просто сделать обычный вызов метода и теоретически проигнорировать все остальное, является существенным подспорьем.
Но некоторые RPC-реализации не лишены недостатков, которые могут вызвать проблемы. Изначально эти проблемы могут быть не столь очевидными, но тем не менее могут оказаться довольно серьезными, чтобы это перевесило преимущества от простоты получения реализации и ее быстрой работы.
Технологическая связанность
Некоторые RPC-механизмы, такие как Java RMI, сильно привязаны к конкретной платформе, что может ограничить выбор технологий для применения на клиенте и сервере. У Thrift и Protocol Buffers имеется впечатляющий диапазон поддержки альтернативных языков, что может некоторым образом сгладить данный недостаток, но при этом следует иметь в виду, что у некоторых RPC-технологий существуют ограничения по возможностям взаимодействия.
В известном смысле эта технологическая связанность может быть одной из форм обнажения деталей внутренней технической реализации. Например, при использовании RMI осуществляется привязка к JVM не только клиента, но и сервера.
Локальные вызовы не похожи на удаленные
Основной замысел RPC заключается в скрытии сложности удаленного вызова. Но многие реализации RPC скрывают их слишком сильно. Управление в некоторых разновидностях RPC с целью сделать удаленный вызов метода похожим на локальный вызов скрывает тот факт, что эти два вызова очень не похожи друг на друга. Можно сделать огромное количество локальных вызовов в рамках одного и того же процесса, практически не переживая о потере производительности. Но при использовании RPC затраты на маршализацию и обратный ей процесс могут быть весьма существенными, даже если не обращать внимания на пересылку по сети. Это означает, что конструкцию удаленного API нужно продумывать иначе, чем конструкцию локальных интерфейсов. Нельзя просто взять локальный API и попытаться без дополнительных размышлений сделать из него границу сервиса, поскольку, скорее всего, ничего, кроме проблем, вы не получите. Если абстракция слишком непрозрачна, то в самых худших примерах разработчики могут использовать удаленные вызовы, даже не зная об этом.
Нужно подумать и о самой сети. Когда речь идет о распределенном вычислении, самым распространенным первым заблуждением является уверенность в надежности сети. Сети не могут быть абсолютно надежными. Они могут и будут отказывать, даже если речь идет о вполне благополучных клиентах и серверах. Они могут сбоить часто или редко, а могут и вовсе портить ваши пакеты. Всегда нужно предполагать, что сети могут подвергнуться воздействию недоброжелателей, готовых в любой момент излить на вас свою злость. Поэтому можно ожидать всяческих отказов. Сбой может быть вызван тем, что удаленный сервер возвратил ошибку, или тем, что вы составили неверный вызов. Можете вы отличить одно от другого, и если да, то можете ли что-то с этим сделать? А что делать, когда удаленный сервер просто начинает медленно реагировать на ваши вызовы? К этой теме мы еще вернемся, когда в главе 11 будем рассматривать эластичность системы.
Хрупкость
Некоторые из наиболее популярных реализаций RPC могут стать причиной опасных форм хрупкости, и хорошим примером этого может послужить Java RMI. Рассмотрим весьма простой Java-интерфейс, который мы решили сделать удаленным API для нашего сервиса клиентов. В примере 4.1 объявляются методы, которые мы собираемся удаленно представить на всеобщее обозрение. Затем Java RMI сгенерирует клиентскую и серверную заглушки для нашего метода.
Пример 4.1. Определение конечной точки сервиса с помощью Java RMI
import java.rmi.Remote;
import java.rmi.RemoteException;
public interface CustomerRemote extends Remote {
public Customer findCustomer(String id) throws RemoteException;
public Customer createCustomer(String firstname, String surname, String emailAddress)
throws RemoteException;
}
В данном интерфейсе findCustomer получает имя, фамилию и адрес электронной почты. А что произойдет, если будет принято решение разрешить объекту Customer также быть созданным лишь с адресом электронной почты? В данном случае мы без особого труда можем добавить следующий новый метод:
...
public Customer createCustomer(String emailAddress) throws RemoteException;
...
Проблема в том, что теперь необходимо заново создать также клиентские заглушки. Клиенты, желающие использовать новый метод, нуждаются в новых заглушках, и в зависимости от характера изменений в спецификации тем потребителям, которые не нуждаются в новом методе, также может потребоваться обновление их заглушек. Конечно, с этим можно справиться, но до определенного момента. Дело в том, что подобные изменения встречаются довольно часто. На поверку конечные точки RPC зачастую имеют множество методов для различных способов создания объектов или взаимодействия с ними. Отчасти это связано с тем, что мы до сих пор думаем об этих удаленных вызовах как о локальных.
Но есть еще одна разновидность хрупкости. Посмотрим, на что похож наш объект Customer:
public class Customer implements Serializable {
private String firstName;
private String surname;
private String emailAddress;
private String age;
}
Что, если теперь выяснится, что, несмотря на выставление на всеобщее обозрение в наших объектах Customer поля возраста age, никто из потребителей им не пользуется? Мы решим, что поле нужно удалить. Но если серверная реализация удаляет поле age из своего определения данного типа, а мы не сделаем того же самого для всех потребителей, даже если они никогда не воспользуются этим полем, код, связанный с десериализацией объекта Customer на стороне потребителя, будет поврежден. Чтобы отменить это изменение, я буду вынужден одновременно развернуть как новый сервер, так и новых клиентов. В этом и состоит основная проблема с использованием любого RPC-механизма, продвигающего создание двоичной заглушки: вы не получаете возможности отдельных развертываний клиента и сервера. При использовании данной технологии в будущем вас ожидают такие вот одновременные выпуски с блокировкой всей работы.
Такая же проблема возникнет при желании реструктурировать объект Customer, даже если я не стану удалять какие-либо поля, например, если мне захочется для упрощения управления заключить firstName и surname в новый поименованный тип. Разумеется, я могу справиться с этим путем повсеместной передачи словарных типов в качестве параметров своего вызова, но тогда мне придется расстаться со многими преимуществами создания заглушек, поскольку мне все равно придется вручную искать соответствия и извлекать нужные поля.
На практике объекты, используемые как часть двоичной сериализации отправляемых по сети данных, могут рассматриваться как типы, предназначенные только для раскрытия. Такая хрупкость приводит к типам, раскрываемым для всех, кто находится в сети, и превращаемым во множество полей, часть из которых больше не используются, но не могут быть безопасно удалены.
Неужели RPC настолько страшен?
Несмотря на все недостатки RPC, я не стану сгущать краски и называть его страшным. Некоторые из наиболее распространенных реализаций, с которыми мне приходилось сталкиваться, могли приводить к возникновению тех проблем, которые здесь уже были очерчены. Из-за сложностей использования RMI я, конечно же, постарался бы обойтись без этой технологии. В модель на основе RPC неплохо вписываются многие операции, а более современные механизмы, такие как Protocol Buffers или Thrift, сглаживают некоторые из прошлых грехов, исключая необходимость одновременных выпусков кода клиента и сервера с блокировкой всей работы.
Собираясь остановить свой выбор на этой модели, вы должны быть в курсе всех потенциально возможных подводных камней, связанных с использованием RPC. Не нужно доводить свои удаленные вызовы до такого состояния, при котором использование сети полностью скрыто и следует обеспечить возможность такого развития серверного интерфейса, которое исключало бы необходимость настоятельного требования обновления кода клиентов в режиме блокировки всей работы. К примеру, очень важно выдерживать правильный баланс клиентского кода. Нужно гарантировать, что клиенты не будут обращать никакого внимания на тот факт, что будет производиться вызов по сети. В контексте RPC часто используются клиентские библиотеки, и при неправильной структуризации они могут вызвать ряд проблем. Более подробно данный вопрос будет рассмотрен чуть позже.
По сравнению с интеграцией с использованием баз данных, RPC, несомненно, совершеннее, когда рассматриваются варианты для совместной работы в стиле «запрос — ответ». Но есть и другие варианты для рассмотрения.
REST
Передача репрезентативного состояния (REpresentational State Transfer (REST)) представляет собой архитектурный стиль, инспирированный Всемирной сетью. У REST-стиля имеется множество принципов и ограничений, но мы собираемся сконцентрировать внимание на тех из них, которые действительно помогут нам при встрече с интеграционными трудностями в мире микросервисов и поиске стилей интерфейсов для наших сервисов, выступающих в качестве альтернативы RPC.
Наиболее важным является понятие ресурсов. Под ресурсами можно понимать то, о чем знает сам сервис, например Customer. В запросе сервер создает различные образы (или репрезентации) этого объекта Customer. Теперь ресурс, выставляемый напоказ, полностью разобщен с тем своим представлением, которое находится на внутреннем хранении. Клиент, к примеру, может запросить JSON-репрезентацию объекта Customer, даже если он сохранен совершенно в другом формате. Получив репрезентацию этого объекта Customer, он может делать запросы на его изменение и сервер может их выполнять или не выполнять.
Существует множество различных стилей REST, но здесь они будут рассмотрены весьма поверхностно. Я настоятельно рекомендую вам ознакомиться с интернет-ресурсом Richardson Maturity Model, где сравниваются различные стили REST.
В самой REST-технологии речь об исходных протоколах не идет, хотя чаще всего при ее реализации используется протокол HTTP. Ранее мне попадались реализации REST, использующие разные протоколы, такие как последовательный протокол или USB, хотя это может потребовать довольно высоких трудозатрат. Некоторые из свойств, предоставляемые нам протоколом HTTP в качестве части своей спецификации, например глаголы, упрощают реализацию REST по HTTP, тогда как при использовании других протоколов приходится справляться с реализацией подобных свойств самостоятельно.
REST и HTTP
В самом протоколе HTTP определяется ряд весьма полезных возможностей, которые очень хорошо работают на реализацию REST-стиля. Например, фигурирующие в HTTP-спецификации глаголы, такие как GET, POST и PUT, имеют вполне понятный смысл, определяющий характер их работы с ресурсами. Фактически архитектурный стиль REST подсказывает нам, что эти методы будут вести себя так же и в отношении всех ресурсов, и получается, что HTTP-спецификация уже определила тот набор методов, которыми мы можем воспользоваться. GET извлекает ресурс идемпотентным способом, а POST создает новый ресурс. Это означает, что можно исключить применение многочисленных методов createCustomer или editCustomer. Вместо этого можно просто воспользоваться глаголом POST с репрезентацией клиента, чтобы сделать запрос на сервер с целью создания репрезентации ресурса, и инициировать GET-запрос для извлечения репрезентации ресурса. Концептуально в этих сценариях имеется одна конечная точка в форме ресурса Customer, а операции, которые мы можем выполнить в ней, готовятся в HTTP-протоколе.
HTTP привносит также обширную экосистему поддерживающих инструментов и технологий. Мы получаем в свое распоряжение такие кэширующие прокси-серверы HTTP, как Varnish, и такие балансировщики нагрузки, как mod_proxy, а также множество средств мониторинга, у которых уже имеется великолепная поддержка HTTP. Эти строительные блоки позволяют справляться с большими объемами HTTP-трафика и осуществлять их интеллектуальную маршрутизацию абсолютно прозрачным способом. С HTTP мы также получаем в свое распоряжение всевозможные средства управления безопасностью обмена данными. Экосистема HTTP дает нам множество инструментов, упрощающих процесс защиты данных, начиная с обычной аутентификации и заканчивая клиентской сертификацией. Более подробно эта тема будет рассматриваться в главе 9. Это говорит о том, что для получения всех этих преимуществ нужно использовать HTTP должным образом. Применение этого протокола неподобающим образом может превратить его в небезопасное и трудно масштабируемое средство, что, впрочем, справедливо и в отношении любой другой используемой в данной сфере технологии. Но при правильном применении вы сможете получить от него весьма большое подспорье.
Следует заметить, что HTTP может использоваться также при реализации RPC. К примеру, SOAP проходит машрутизацию по протоколу HTTP, но, к сожалению, использует весьма скромную часть его спецификации. Глаголы игнорируются, как, впрочем, и такие простые вещи, как коды ошибок HTTP. У меня слишком часто возникает ощущение, что уже существующие и вполне понятные стандарты и технологии игнорируют в угоду новым стандартам, которые можно реализовать только с помощью совершенно новой технологии, любезно предоставляемой теми же самыми компаниями, которые в первую очередь содействуют разработке новых стандартов!
Гиперсреда как механизм определения состояния приложения
Еще одним принципиальным нововведением, представленным в REST и способным помочь нам избежать связанности клиента с сервером, является гиперсреда, используемая в качестве механизма определения состояния приложения, часто обозначаемая аббревиатурой HATEOAS, смысл использования которой мне непонятен. Это довольно сжатая формулировка и весьма интересная концепция, поэтому немного в ней разберемся.
Гиперсреда является понятием, в соответствии с которым часть содержимого содержит ссылки на другие части содержимого, представленного разнообразными форматами (например, в виде текста, изображений, звуков). Вам это должно быть знакомо, поскольку тем же самым занимается типовая веб-страница: для просмотра родственного содержимого вы следуете по ссылкам, являющимся формой элементов управления гиперсредой. Идея, положенная в основу HATEOAS, заключается в том, что клиенты должны взаимодействовать с сервером (что потенциально приводит к передаче состояния) посредством этих ссылок на другие ресурсы. При этом, зная, на какой идентификатор ресурса (URI) нужно попасть, не требуется знать, где именно на сервере располагаются данные о клиентах. Вместо этого клиент, чтобы найти нужную информацию, ищет ссылки и переходит по ним.
Это немного необычная концепция, поэтому сначала отвлечемся и посмотрим, как люди работают с веб-страницей, на которой, как уже известно, имеется множество элементов управления гиперсредой.
Рассмотрим торговый сайт Amazon.com. Со временем местонахождение корзины для виртуальных покупок меняется. Меняется графическое представление, меняется ссылка. Но люди достаточно сообразительны для того, чтобы все равно распознавать эту корзину и работать с нею. Мы понимаем, что означает корзина для покупок, даже если изменяются ее конкретная форма и используемый элемент управления. Мы знаем, что при желании увидеть корзину нам нужно работать вот с этим элементом управления. Поэтому со временем веб-страницы могут постепенно изменяться. Пока эти подразумеваемые соглашения между потребителем и сайтом соблюдаются, изменениям не нужно быть разрушительными.
Используя элементы управления гиперсредой, мы пытаемся достичь такого же уровня сообразительности для наших электронных потребителей. Посмотрим на элементы управления гиперсредой, которые подошли бы для MusicCorp. В примере 4.2 мы получаем доступ к ресурсу, представляющему собой запись каталога для заданного альбома. Вместе с информацией об альбоме мы видим номера элементов управления гиперсредой.
Пример 4.2. Элементы управления гиперсредой, используемые для перечня произведений альбома
<album>
<name>Give Blood</name>
<link rel="/artist" href="/artist/theBrakes" /> (1)
<description>
Awesome, short, brutish, funny and loud. Must buy!
</description>
<link rel="/instantpurchase" href="/instantPurchase/1234" /> (2)
</album>
Этот элемент управления гиперсредой показывает нам, где найти информацию об артисте.
А если нужно приобрести альбом, мы знаем, куда перейти.
В данном документе присутствуют два элемента управления гиперсредой. Клиент, который читает такой документ, должен знать, что элемент управления, относящийся к артисту, переводит к информации об артисте и что instantpurchase является частью протокола, используемого для приобретения альбома. Клиент должен понимать семантику API во многом так же, как человеку нужно понимать, что на торговом сайте корзина будет находиться там же, где и потенциальные покупки.
Как клиент, я не должен знать, к какой именно URI-схеме нужно обращаться, чтобы купить альбом, мне нужно просто получить доступ к ресурсу, найти элемент управления, связанный с покупкой, и с его помощью выполнить переход. Элемент управления, связанный с покупкой, может изменить местоположение, может измениться URI-идентификатор, или сайт может даже отослать меня вообще к другой службе, и, как клиента, меня это не должно волновать. Тем самым мы получаем большое количество развязок между клиентом и сервером.
Здесь мы сильно отдалились от исходных деталей. До тех пор пока клиент все еще будет в состоянии находить элемент управления, соответствующий его представлению протокола, мы можем полностью изменить реализацию представления элемента управления. Точно так же элемент управления торговой корзины может из простой ссылки превратиться в более сложный элемент с кодом на JavaScript. Мы также можем вполне свободно добавлять к документу новые элементы управления, возможно, представляющие новые передачи состояния, которые можно будет задействовать в работе с рассматриваемым ресурсом.
Потребителей можно сбить с толку, только если основательно изменить семантику одного из элементов управления, кардинально изменив тем самым его поведение, или если вообще удалить элемент управления. Применение таких элементов управления для разобщения клиента и сервера со временем приносит существенные выгоды, с лихвой компенсирующие небольшое повышение расхода времени, которое занимают оформление и выполнение используемых протоколов. Следуя по ссылкам, клиент получает возможность постепенного раскрытия API, что становится весьма удобным при реализации новых клиентов.
Одним из недостатков навигации по элементам управления является ее возможная многословность, поскольку клиенту для поиска нужной операции приходится следовать по ссылкам. В конечном счете это разумный компромисс. Я советую начать с обеспечения для клиентов возможности переходить по этим элементам, а чуть позже оптимизировать систему, если это потребуется. Следует помнить, что мы получаем большой объем уже готовой помощи от использования HTTP, о чем говорилось ранее. Вред от преждевременной оптимизации мы уже рассматривали, поэтому здесь развивать эту тему я не буду. Нужно также отметить, что для создания распределенных систем с гиперсредами было разработано множество подобных подходов и не все они могут нам подойти! Иногда вы можете поймать себя на мысли об ожидании хорошо зарекомендовавшего себя старомодного удаленного вызова процедур (RPC).
Лично я сторонник того, чтобы в качестве средства навигации по конечным точкам API предоставить потребителям не что иное, как ссылки.
Преимущества постепенного раскрытия API и уменьшения степени связанности могут стать весьма существенными аргументами. Тем не менее понятно, что не все можно реализовать, и я не вижу возможности повсеместного использования этой технологии, как бы мне этого ни хотелось. Я полагаю, что суть данного вопроса в том, что требуется некий авансовый задел, а награды за его создание зачастую приходят позже.
JSON, XML или что-то другое?
Применение стандартных текстовых форматов дает клиентам гибкость в потреблении ресурсов, а REST с использованием HTTP позволяет применять различные форматы. В ранее показанных примерах применялся XML, но на данном этапе намного более популярным форматом содержимого для сервисов, работающих с использованием HTTP, является JSON.
Тот факт, что JSON — намного более простой формат, означает, что его использование также дается проще. Сторонники этого формата также указывают на его относительную компактность по сравнению с XML как на еще один выигрышный фактор, хотя в реальности это не так уж и существенно.
Но у JSON есть и недостатки. В XML определяется элемент управления link, который ранее использовался нами в качестве элемента управления гиперсредой. В стандарте JSON ничего подобного не определяется, поэтому для содействия этой концепции часто используются внутренние стили. В прикладном гипертекстовом языке (Hypertext Application Language (HAL)) предпринимается попытка исправить ситуацию путем определения общих стандартов для создания гиперссылок в JSON (а также в XML, хотя XML, возможно, меньше нуждается в такой помощи). Если следовать стандарту HAL, то для выявления элементов управления гиперсредой можно воспользоваться такими инструментами, как HAL-браузер на веб-основе, который может существенно упростить задачу создания клиента.
Но мы, конечно же, не ограничены этими другими форматами. При желании через HTTP можно отправить практически все что угодно, даже двоичный код. Я все чаще и чаще вижу, как в качестве формата вместо XML используется просто HTML. Для некоторых интерфейсов HTML помогает убить сразу двух зайцев при его применении как в качестве пользовательского интерфейса, так и в качестве API, но при этом все же следует обойти ряд подводных камней, поскольку взаимодействие с человеком и с компьютером — слишком разные вещи! Но это, конечно, весьма привлекательная идея. В конце концов, для HTML существует множество парсеров.
Но лично я предпочитаю XML. У него более подходящая инструментальная поддержка. Например, когда нужно извлечь только вполне определенную часть полезной нагрузки (эта технология будет рассмотрена позже, в разделе «Управление версиями»). Можно воспользоваться XPATH — широко распространенным стандартом, который поддерживают многие инструментальные средства, или даже CSS-селекторами — их многие считают еще более простыми. При использовании JSON есть JSONPATH, но он не получил широкой поддержки. Я считаю странным, что люди выбирают JSON из-за его красоты и легкости применения, затем пытаются внедрить в него такие понятия, как элементы управления гиперсредой, которые уже имеются в XML. Но я понимаю, что, наверное, в данном вопросе отношусь к меньшинству и что JSON является форматом, который выбирает большинство!
Опасайтесь слишком больших удобств
С ростом популярности REST появились среды, помогающие создавать веб-сервисы RESTFul. Но в некоторых из них кроется слишком много компромиссов с краткосрочными приобретениями и долгосрочными проблемами. В попытке ускорить процесс эти среды могут потворствовать неприемлемому поведению. Например, некоторые среды действительно упрощают получение представления объектов, сформированных в базах данных, проводя их десериализацию в объекты, встроенные в процесс, после чего эти объекты выставляются на всеобщее обозрение. Я помню, как на конференции состоялся показ с использованием Spring Boot, где все это выдавалось за главное преимущество. Унаследованная связанность, провоцируемая такой системой, зачастую становится причиной куда более серьезных проблем, чем приложение усилий, необходимых для правильного разобщения этих представлений.
Здесь следует заняться решением более общей задачи. Нас в первую очередь должно интересовать решение вопроса о способах хранения данных и их показа потребителям. В одной из схем, увиденной мною и успешно применяемой одной из наших команд, предусматривалась задержка реализации должного постоянства микросервиса вплоть до достаточной стабилизации интерфейса. В промежуточный период образы просто сохранялись в файле на локальном диске, что, конечно же, не было подходящим долговременным решением. Тем самым гарантировалось, что решения по конструкции и реализации диктовались способом использования сервиса потребителями. В обосновании, подтвержденном результатами, утверждалось, что способ хранения объектов нашей предметной области в основном хранилище слишком легко и открыто влияет на те модели, которые посылаются по сети нашим сотрудникам. Одним из недостатков такого подхода является то, что мы откладываем работу, необходимую для подключения к сети хранилища данных. Но я полагаю, что для определения границ нового сервиса это вполне приемлемый компромисс.
Недостатки REST с использованием HTTP
Если говорить о простоте потребления, то создать клиентскую заглушку для REST с применением HTTP так же просто, как при использовании RPC, не удастся. Несомненно, факт применения HTTP означает, что при этом вы можете воспользоваться преимуществами великолепных клиентских библиотек HTTP, но если в качестве клиента вам потребуется реализовать и использовать элементы управления гиперсредой, то во многом придется рассчитывать на собственные силы. Лично я полагаю, что клиентские библиотеки могли бы справляться со своим предназначением намного лучше, чем сейчас, и, конечно же, сейчас они лучше, чем в прошлом, но я увидел, что их явное усложнение приводит к тому, что люди втайне склоняются к возврату к RPC с применением HTTP или создают общие клиентские библиотеки. Совместно используемый клиентом и сервером код может быть очень опасен, о чем будет говориться в разделе «DRY и риски повторного использования кода в мире микросервисов».
Еще одним негативным обстоятельством является то, что в некоторых средах веб-серверов фактически отсутствует качественная поддержка всех HTTP-глаголов. Это означает, что для вас может быть проще создать обработчик GET- или POST-запросов, но, чтобы добиться работы PUT- или DELETE-запросов, возможно, придется заняться прыжками через обруч. У надлежащих REST-сред, таких как Jersey, этих проблем не существует, и со всем этим можно нормально работать, но, если вы замкнуты на выбор конкретных сред, это может ограничить количество доступных для использования стилей REST.
Проблемой может стать также производительность. Полезная нагрузка REST с использованием HTTP может фактически быть более компактной, чем SOAP, поскольку здесь поддерживаются альтернативные форматы вроде JSON или даже двоичный код, но все же эта технология даже не приблизится к той лаконичности двоичного протокола, которая может быть предоставлена языком Thrift. Издержки HTTP для каждого запроса могут также стать проблемой для систем с требованиями малого времени ожидания.
Хотя технология HTTP может оказаться вполне подходящей при больших объемах трафика, с обменом данными, требующим малого времени ожидания, она справляется хуже, если сравнивать ее с альтернативными протоколами, являющимися надстройками над протоколом управления передачей (Transmission Control Protocol (TCP)), или с другими сетевыми технологиями. Несмотря на свое название, протокол WebSocket, к примеру, имеет очень мало общего с Web. После первоначального HTTP-квитирования он представляет собой простое TCP-соединение клиента и сервера, но при этом может стать намного более эффективным способом передачи потоковых данных для браузера. Если вас интересует именно это, следует заметить, что HTTP в нем используется по минимуму, не говоря уже о том, что он не имеет ничего общего с REST.
Для обмена данными между серверами, при котором особую важность приобретает малое время ожидания или малый размер сообщений, связь на основе HTTP вообще может показаться неприемлемой затеей. Для достижения желаемой производительности может понадобиться подобрать другие исходные протоколы, такие как протокол пользовательских датаграмм (User Datagram Protocol (UDP)), и многие RPC-среды будут вполне успешно работать поверх сетевых протоколов, отличных от TCP.
Само же использование полезных нагрузок требует большего объема работы, чем тот, который предоставляется некоторыми RPC-реализациями, поддерживающими улучшенные механизмы сериализации и десериализации. Это само по себе может стать точкой связанности между клиентом и сервером, поскольку реализация приемлемых механизмов чтения данных является не такой уж простой задачей (о чем мы вскоре поговорим), но с точки зрения получения готовой работоспособной технологии они могут быть весьма привлекательными.
Несмотря на указанные недостатки, REST с использованием HTTP является вполне разумным исходным выбором для взаимодействия между сервисами. Если хотите углубить свои знания, я рекомендую почитать книгу REST in Practice (O’Reilly), в которой тема REST с использованием HTTP раскрывается намного лучше.
Реализация асинхронной совместной работы на основе событий
Мы уже немного поговорили о некоторых технологиях, содействующих реализации схем «запрос — ответ». А как насчет асинхронного обмена данными на основе событий?
Выбор технологии
Нам предстоит рассмотреть две основные части: способ выдачи микросервисами событий и способ определения потребителями момента наступления того или иного события.
Традиционно такие брокеры сообщений, как RabbitMQ, стараются охватить сразу обе проблемы. Поставщики используют API для публикации события брокеру. Брокер обрабатывает подписки, позволяя потребителям получить информацию при поступлении того или иного события. Такие брокеры могут даже обрабатывать состояние потребителей, например содействуя отслеживанию того, какие сообщения они видели ранее. Эти системы обычно разрабатываются с возможностями масштабирования и приспособляемости, но это даром не обходится. Возможно, расплачиваться придется усложнением процесса развертывания, поскольку для разработки и тестирования ваших сервисов может понадобиться запуск еще одной системы. Для сохранения работоспособности этой инфраструктуры могут также понадобиться дополнительные машины и наличие определенного опыта. Но если удастся справиться со всеми трудностями, это может стать очень эффективным способом реализации слабо связанных архитектур, управляемых событиями. В общем, я являюсь сторонником именно такого подхода.
Но со связующими системами нужно проявлять разумную осторожность, ведь брокер сообщений составляет лишь малую их часть. В череде поставок имеется еще множество весьма полезных программ. Поставщики, как правило, стремятся включить в пакет наряду с основной массу других программ, способных развить интеллектуальную составляющую, внедряемую в связующие системы, о чем свидетельствуют такие программы, как Enterprise Service Bus. Вы должны понимать, что именно приобретаете: связующие системы не должны проявлять какую-либо инициативу, а интеллектуальные компоненты должны оставаться только в конечных точках.
Еще один подход заключается в попытке использования HTTP в качестве способа распространения событий. Для публикации каналов ресурсов используется такая REST-совмеcтимая спецификация, как ATOM, в которой наряду с другими вещами определяется соответствующая семантика. Существует множество клиентских библиотек, позволяющих создавать и потреблять подобные каналы. Поэтому наш сервис обслуживания клиентов может просто опубликовать событие в таком канале при каких-либо происходящих в нем изменениях. Потребители просто подписываются на канал в поисках изменений. Тот факт, что мы можем воспользоваться уже существующей спецификацией ATOM и любой связанной с ней библиотекой, можно считать положительным, и нам известно, что HTTP весьма неплохо справляется с масштабируемостью. Но HTTP недостаточно хорошо справляется с требованиями малого времени ожидания (в чем преуспевают некоторые брокеры сообщений), и нам все еще нужно считаться с тем фактом, что потребителям требуется отслеживать просматриваемые сообщения и управлять собственным графиком опроса.
Мне попадались люди, тратившие много времени на реализацию все новых и новых линий поведения, которые позволяли воспользоваться ими с соответствующим брокером сообщений и приспособить ATOM для работы в ряде различных сценариев. Например, в системе Competing Consumer описывается метод, позволяющий организовать соревнование за получение сообщений среди нескольких рабочих экземпляров, хорошо подходящий для расширения количества исполнителей, обрабатывающих список независимых заданий. Но нам хотелось бы избежать такого сценария, при котором два и более исполнителя выискивают одно и то же сообщение, поскольку в результате мы получим выполнение одного и того же задания большее количество раз, чем требуется. При использовании брокера сообщений с этим справляется обычная очередь. А при использовании ATOM нам потребуется управлять нашим общим состоянием, вовлекая в это всех исполнителей с целью уменьшения воспроизводимых усилий.
Если вам уже доступен неплохой приспособляемый брокер сообщений, подумайте о том, чтобы воспользоваться им для обработки публикаций и подписки на события. Если же такой брокер отсутствует, рассмотрите возможность использования спецификации ATOM, но при этом отдавайте себе отчет в неизбежности издержек. Если потребуется более объемная поддержка по сравнению с предлагаемой брокером сообщений, то рано или поздно вам, наверное, захочется изменить свой подход.
В понятиях того, что фактически мы отправляем с использованием этих асинхронных протоколов, мы можем исходить из тех же соображений, которые применялись при синхронном обмене данными. Если на текущий момент вас вполне устраивают зашифрованные запросы и ответы с использованием JSON, то на этом можно и остановиться.
Сложности асинхронных архитектур
В асинхронности есть нечто забавное, не правда ли? Казалось бы, архитектуры, управляемые событиями, обусловливают более разобщенные, масштабируемые системы. И от них этого можно добиться. Но применяемые при этом стили программирования вызывают повышение сложности. Это не только те усложнения, которые, как мы уже выяснили, требуются для управления публикациями и подписками на сообщения, но и другие проблемы, с которыми можно столкнуться. Например, при рассмотрении долгосрочных асинхронных запросов — ответов нам нужно подумать о том, что делать при возвращении ответа. Возвращается ли он на тот же узел, который инициировал запрос?
Если да, то что, если этот узел вышел из строя? Если нет, то нужно ли где-нибудь сохранить информацию, чтобы на нее можно было соответствующим образом среагировать? Краткосрочной асинхронностью может быть проще управлять, если используются надлежащие API, но даже при этом у программистов, привыкших к вызовам синхронных сообщений внутри процессов, должен появиться другой способ мышления.
Здесь самое время рассказать поучительную историю. В далеком 2006 году я работал над созданием системы ценообразования для банка. Мы следили за событиями на рынке и решали, какие элементы в портфеле ценных бумаг требовали переоценки. Как только определялся список всего, над чем нужно было поработать, мы помещали все это в очередь сообщений. Для создания пула исполнителей мы прибегали к использованию сетки, позволявшей по запросу увеличивать и уменьшать ценовую структуру. Для этих исполнителей использовалась система соревновательного потребления, каждый из них выхватывал сообщения как можно быстрее, пока не становилось нечего обрабатывать.
Система была готова к работе, и мы были удовлетворены. Но в один прекрасный день, как раз после выпуска новой версии, столкнулись с весьма неприятной проблемой. Наши исполнители стали гибнуть, и гибнуть, и гибнуть.
В конце концов мы отследили причину возникновения проблемы. В программу вкралась ошибка, при которой конкретный запрос на ценообразование приводил к аварии исполнителя. Нами использовалась очередь, работавшая по принципу транзакции: как только исполнитель выходил из строя, срок его блокировки на запросе истекал, запрос на ценообразование возвращался в очередь, но только для того, чтобы быть выбранным другим исполнителем, который тут же выходил из строя. Это был классический пример того, что Мартин Фаулер называл катастрофическим аварийным переключением.
Кроме самой ошибки, мы не удосужились определить лимит максимального числа попыток для запуска задания в очереди. Мы исправили ошибку, а также настроили максимальное количество повторных попыток. А кроме этого, поняли, что нужен способ просмотра и потенциального воспроизведения подобных ошибочных сообщений. В итоге мы пришли к выводу, что нужно создать изолятор сообщения (или очередь мертвых точек), куда должны попадать сбойные сообщения. Мы также создали пользовательский интерфейс для просмотра таких сообщений и повторной попытки их обработки по мере надобности. Если раньше вы сталкивались только с синхронным обменом данными двух конечных корреспондентов, то сразу же заметить подобные проблемы вам было бы нелегко.
В общем, связанные с архитектурами, управляемыми событиями и асинхронным программированием сложности приводят меня к мысли, что вместо того, чтобы бурно принимать эти идеи, лучше проявлять осмотрительность. Следует убедиться в наличии подходящей системы слежения и серьезно продумать использование взаимосвязи идентификаторов, что позволит проследить запросы по границам процесса. Более подробно эти вопросы будут рассмотрены в главе 8.
Я также настоятельно рекомендую ознакомиться с книгой Enterprise Integration Patterns (Addison-Wesley), в которой содержится намного больше подробностей о различных шаблонах программирования, чем вам может понадобиться рассмотреть в данной области.
Сервисы как машины состояний
Если вы решите стать мастером REST-технологии или остановите свой выбор на таком механизме на основе RPC, как SOAP, в действие вступит понятие сервиса как машины состояния. Раньше мы уже достаточно (возможно, даже чрезмерно) наговорились о сервисах, выстраиваемых вокруг ограниченных контекстов. Наши потребительские микросервисы содержат всю логику, связанную с поведением в конкретном контексте.
Когда потребитель хочет внести изменения в данные о клиенте, он отправляет соответствующий запрос в сервис клиентов. Этот сервис, основываясь на своей логике, принимает решение, принять этот запрос или нет. Наш сервис клиентов сам контролирует все события жизненного цикла, связанные с клиентом. Хотелось бы избежать создания немых, безжизненных сервисов, представляющих собой практически простые CRUD-оболочки. Если решение о том, какие изменения разрешено вносить в данные о клиенте, будет вытекать из самого сервиса клиентов, мы утратим зацепление.
Когда жизненный цикл основных понятий заданной области четко смоделирован подобным образом, достигается вполне приемлемый эффект. У нас получается не только одно место для рассмотрения несоответствий состояния (например, когда кто-то пытается обновить данные об уже удаленном клиенте), но также место для придания поведения на основе таких изменений состояния.
Я все-таки полагаю, что REST с использованием HTTP способствует созданию гораздо более практичной технологии интеграции, чем многие остальные решения, но независимо от того, на чем остановится ваш выбор, имейте эти соображения в виду.
Реактивные расширения
Реактивные расширения (reactive extensions, часто сокращается до Rx) представляют собой механизм компоновки результатов нескольких вызовов и запуска операций по их обработке. Сами вызовы могут быть как блокирующими, так неблокирующими. В основном Rx меняют порядок традиционных потоков. Вместо запрашивания каких-либо данных с последующим выполнением в отношении этих данных каких-либо операций изучается исход операции (или набора операций) и происходит реагирование на какие-либо изменения. Некоторые реализации Rx позволяют выполнять какие-либо функции над этими наблюдаемыми результатами, например в RxJava допускается использование таких традиционных функций, как map или filter.
Различные Rx-реализации очень неплохо прижились в распределенных системах. Они позволяют абстрагироваться от подробностей того, каким образом осуществляются вызовы, и намного проще рассуждать о происходящем. Наблюдается результат вызова какого-либо нижестоящего сервиса. И тут все равно, блокирующий это вызов или нет, ожидается лишь ответ, на который происходит какая-либо реакция. Вся красота в том, что можно компоновать результаты нескольких вызовов, существенно упрощая тем самым обработку конкурирующих вызовов к нижестоящим сервисам.
Если обнаружится, что количество вызовов к сервису возрастает, особенно когда делается несколько вызовов для выполнения одной-единственной операции, присмотритесь к реактивным расширениям для выбранного стека технологий. И вы можете удивиться тому, насколько они смогут упростить вашу жизнь.
DRY и риски повторного использования кода в мире микросервисов
Одним из часто употребляемых акронимов является DRY: don’t repeat yourself — «не повторяйтесь». Хотя это определение зачастую упрощенно рассматривается как попытка избежать использования продублированного кода, более точное значение DRY заключается в стремлении избежать продублированности поведения и осведомленности нашей системы. В целом это весьма разумный совет. Наличие большого количества строк кода, выполняющих одно и то же, делает объем исходного кода больше необходимого, затрудняя тем самым его осмысление. При желании изменить поведение, продублированное во многих частях системы, совсем не трудно забыть о каких-либо местах, в которые нужно вносить изменения, что может привести к появлению ошибок. Поэтому в целом придерживаться DRY-принципа все же стоит.
DRY приводит к созданию кода, пригодного для повторного использования. Повторяющийся код помещается в абстракции, которые затем можно вызывать из нескольких мест. Возможно, мы дойдем и до создания общей библиотеки, которую можно будет использовать повсеместно! Но в архитектуре микросервисов этот подход может оказаться обманчиво опасным.
Обстоятельствами, которых мы избегаем любой ценой, являются излишняя связанность микросервисов и такое их применение, при котором любое, даже самое мелкое изменение самого микросервиса может повлечь за собой ненужные изменения со стороны потребителя. Порой использование общего кода может вылиться в подобную чрезмерную связанность. Например, для одного клиента у нас имелась библиотека общих для заданной области объектов, представляющих основные понятия, используемые в системе. Эта библиотека использовалась для всех имеющихся сервисов. Но когда в один из них были внесены изменения, потребовалось обновление всех сервисов. Обмен данными в системе велся через очередь сообщений, которая также должна опустошаться от теперь уже негодных контекстов, и горе тому, кто это забудет.
Если используется общий код, вечно раскрываемый за пределами границ вашего сервиса, значит, вы ввели потенциальную форму связанности. Использование общего кода наподобие регистрирующих библиотек вполне приемлемо, поскольку они являются внутренними понятиями, невидимыми внешнему миру. В RealEstate.com.au, чтобы помочь в создании с нуля нового сервиса, используется шаблон специализированных сервисов. Вместо того чтобы делать этот код общим, компания копирует его для каждого нового сервиса, чтобы гарантировать невозможность утечки связанности.
Я придерживаюсь следующего практического правила: не нужно навязывать применение DRY-принципов внутри микросервиса, но не стоит опасаться внедрения DRY через все сервисы. Вред от чрезмерной связанности сервисов намного больше вреда от проблем, вызываемых повторяемостью кода. Но все же есть один конкретный сценарий использования, который стоит рассмотреть.
Клиентские библиотеки. Мне приходилось общаться не с одной командой, настаивающей на том, что создание клиентских библиотек для сервисов является наиболее важной частью создания самих сервисов. В качестве подкрепляющих аргументов приводились облегчение использования сервисов и возможность избежать дублирования кода, необходимого для использования сервиса как такового.
Разумеется, есть проблема, связанная с тем, что, если одни и те же люди создают как серверный, так и клиентский API, существует опасность перетекания логики, которая должна присутствовать в сервере, в сторону клиента. Я должен знать: я сделал это сам. Чем больше логики прокрадывается в клиентскую библиотеку, тем сильнее начинает распадаться зацепление, и вы, внедряя исправления в свой сервер, сталкиваетесь с необходимостью внесения изменений в несколько клиентов. Кроме того, ограничивается простор выбора технологий, особенно если декларативно навязывается применение клиентской библиотеки.
В качестве понравившейся мне модели клиентских библиотек можно назвать Amazon Web Services (AWS). Подразумеваемые SOAP- или REST-вызовы веб-сервиса могут быть сделаны напрямую, но каждый из них заканчивается использованием только одного из существующих наборов средств разработки программ (Software Development Kits (SDK)), предоставляющего абстракции поверх основного API. Но эти SDK написаны сообществом разработчиков AWS, а не теми, кто работал над самим API. Похоже, что такая степень разделения сработала и позволила избежать некоторых подводных камней клиентских библиотек. Одна из причин такого успеха заключается в том, что клиент знает, когда происходит обновление. Если вы сами пойдете по пути использования клиентских библиотек, обеспечьте точно такое же развитие событий.
Упор на клиентские библиотеки делается в определенных местах и компанией Netflix, но я подозреваю, что люди смотрят на это только через призму избавления от дублирования кода. Фактически клиентские библиотеки, используемые Netflix, предназначены в основном для обеспечения надежности и масштабируемости систем этой компании. Клиентские библиотеки Netflix занимаются обнаружением сервиса, состояниями отказов, журналированием и другими аспектами, которые не имеют отношения к особенностям самого сервиса. Без этих общих клиентских библиотек было бы сложно обеспечить соответствующее поведение каждой из частей клиент-серверного обмена данными в том крупном масштабе, в котором работает Netflix. Их использование в Netflix, несомненно, облегчает получение работоспособных систем и повышение производительности при обеспечении надлежащего поведения системы. Но, по мнению по крайней мере одного человека из Netflix, со временем это приводит к определенной степени связанности клиента и сервера, вызывающей проблемы.
Если вы задумали воспользоваться подходом с применением клиентской библиотеки, то важным моментом может стать отделение клиентского кода для управления исходным транспортным протоколом, который сможет справляться с обнаружением сервисов и сбоев, от всего, что связано с самим целевым сервисом. Нужно решить, будете ли вы настаивать на применении клиентской библиотеки или же позволите людям использовать другие технологические стеки для вызовов исходного API. И наконец, гарантируйте осведомленность клиентов о необходимости обновления их клиентских библиотек: нам нужно обеспечить сохранение возможности выпуска наших сервисов независимо друг от друга!
Доступ по ссылке
Один из вопросов, которого я хочу коснуться, относится к способу оповещения обо всем, что имеется в нашей области. Мы должны прийти к тому, что микросервис будет охватывать весь жизненный цикл наших основных доменных ресурсов, таких, например, как Customer. Мы уже говорили о важности содержания логики, связанной с изменениями ресурса Customer в клиентском сервисе, и о том, что при желании внести изменения нужно отправить запрос клиентскому сервису. Но из этого также следует, что клиентская служба должна рассматриваться как источник истины для ресурсов Customer.
Когда из клиентской службы извлекается заданный ресурс Customer, мы, сделав запрос, получаем возможность увидеть, что он собой представляет. Вполне возможно, что после того, как мы запросили ресурс Customer, кто-то другой внес в него изменения. В результате мы получаем память о том, как когда-то выглядел ресурс Customer. Чем дольше мы держимся за эту память, тем выше шансы, что память будет содержать недостоверную информацию. Разумеется, если мы не станем запрашивать данные чаще, чем это требуется, наши системы станут гораздо эффективнее.
Иногда в памяти будут вполне приемлемые данные, но во всех остальных случаях нужно быть в курсе их изменений. Поэтому, решив обратиться к тому образу ресурса, который был в памяти, нужно также включить ссылку на исходный ресурс, позволяющую извлечь его новое состояние.
Рассмотрим пример обращения к сервису электронной почты на отправку сообщения о том, когда был выслан заказ. Теперь мы можем отправить запрос к сервису электронной почты с подробностями в виде электронного адреса клиента, его имени и заказа. Но если сервис электронной почты уже выстроил очередь из таких запросов или вынул их из очереди, то за время нахождения в ней могли произойти изменения. Может быть, рациональнее было бы просто отправить URI ресурсов Customer и Order и позволить серверу электронной почты просмотреть их, когда настанет срок отправки электронного сообщения.
Отличный контрапункт этому возникает при рассмотрении возможностей совместной работы на основе событий. Работая с событиями, мы говорим о факте случившегося, но нам нужно знать, что именно случилось. Например, если мы получаем обновления, связанные с ресурсом Customer, ценной для нас информацией будет то, на что стал похож Customer, когда событие произошло. Так как мы получили также ссылку на сам ресурс, можно посмотреть на его текущее состояние и взять из обоих миров то, что нам больше подходит.
Разумеется, при получении доступа по ссылке можно пойти и на другие компромиссы. Если при просмотре в ресурсе Customer информации о заданном клиенте мы всегда обращаемся к клиентскому сервису, нагрузка на этот сервис может быть весьма значительной. Если при извлечении ресурса предоставляется дополнительная информация, оповещающая о том, сколько времени ресурс провел в заданном состоянии и, возможно, как долго можно считать эту информацию свежей, то мы можем получить существенные выгоды от кэширования данных и снижения нагрузки на сервис. HTTP предоставляет нам для поддержки всего этого уже готовые решения с широким разнообразием средств управления кэш-памятью, часть из которых более подробно рассматриваются в главе 11.
Еще одна проблема связана с тем, что некоторым сервисам может быть и не нужна информация обо всем ресурсе Customer и, настаивая на том, чтобы они ее искали, мы потенциально усиливаем связанность. Например, может случиться так, что сервис электронной почты должен работать в более простом режиме и ему нужно отправить лишь электронный адрес и имя клиента. Вывести на этот счет какое-либо непреложное правило, конечно, нельзя, но при обходе в запросах тех данных, о степени свежести которых ничего не известно, нужно проявлять крайнюю осмотрительность.
Управление версиями
Практически на каждой лекции о микросервисах мне задавали вопрос о том, как я справляюсь с управлением версиями. У людей возникало вполне законное беспокойство о том, что со временем в интерфейс сервиса придется вносить изменения, и они хотели понять, как это можно сделать. Разобьем эту проблему на части и посмотрим на те этапы, которые нужно будет пройти, чтобы с ней справиться.
Откладывание изменений на максимально возможный срок
Наилучшим способом уменьшить влияние внесения критических изменений в первую очередь является отказ от их внесения. Основным способом достижения этого может стать выбор правильной технологии интеграции, о чем и говорилось в данной главе. Интеграция путем использования базы данных является хорошим примером технологии, которая может существенно затруднить отказ от критических изменений. А вот REST помогает достичь желаемого результата, поскольку изменения, вносимые в тонкости внутренней реализации, скорее всего, не приведут к изменениям интерфейса сервиса.
Еще одним ключом к отсрочке внесения критических изменений является содействие правильному поведению ваших клиентов, в первую очередь удержание их от слишком жесткой привязки к вашим сервисам. Рассмотрим сервис электронной почты, чьей задачей является периодическая отправка электронных сообщений клиентам. Он получает задачу на отправку сообщения о высылке заказа клиенту с идентификатором ID 1234. Затем приступает к работе: извлекает данные о клиенте с указанным ID и получает в ответ что-либо подобное показанному в примере 4.3.
Пример 4.3. Пример ответа от клиентского сервиса
<customer>
<firstname>Sam</firstname>
<lastname>Newman</lastname>
<</email>
<telephoneNumber>555-1234-5678</telephoneNumber>
</customer>
Теперь для отправки сообщения по электронной почте нужны только поля firstname, lastname и email. Нам не нужно знать содержимое поля telephoneNumber. Требуется просто извлечь те поля, которые нас интересуют, проигнорировав все остальные. Некоторые технологии связывания, в особенности те, которые используются строго типизированными языками, могут попытаться связать все поля независимо от того, нужны они потребителю или нет. Что произойдет, если мы поймем, что поле telephoneNumber никто не использует, и решим его удалить? Это может привести к совершенно ненужному нарушению режима работы потребителей.
А что, если нам придет в голову изменить структуру нашего объекта Customer так, чтобы она поддерживала более подробные данные, возможно, путем добавления некой дополнительной структуры, как в примере 4.4? А сервису электронной почты по-прежнему нужны все те же данные и под теми же именами, но, если в коде делаются абсолютно четкие предположения о том, где именно будут храниться данные полей firstname и lastname, то он опять может стать неработоспособным. В таком случае вместо этого для извлечения нужных нам полей можно воспользоваться XPath, что позволит безразлично относиться к тому, где именно находятся поля, поскольку мы все равно сможем их найти. Именно такая схема, предполагающая создание системы считывания данных, способной проигнорировать те изменения, которые нас не волнуют, получила от Мартина Фаулера название толерантного считывателя (Tolerant Reader).
Пример 4.4. Ресурс Customer с измененной структурой: данные никуда не делись, но сможет ли потребитель их найти?
<customer>
<naming>
<firstname>Sam</firstname>
<lastname>Newman</lastname>
<nickname>Magpiebrain</nickname>
<fullname>Sam "Magpiebrain" Newman</fullname>
</naming>
<</email>
</customer>
Пример клиента, старающегося быть как можно гибче в использовании сервиса, демонстрирует закон Постела, известный также как принцип живучести (robustness principle), который гласит: «Будь требователен к тому, что отсылаешь, и либерален к тому, что принимаешь». Исходной средой для проявления этой мудрости служило взаимодействие сетевых устройств, при котором следует ожидать всевозможных странностей. В контексте же нашего взаимодействия в режиме «запрос — ответ» он может привести нас к стремлению сделать сервис приспособленным к изменениям и не требовать никаких изменений от нас.
Выявление критических изменений на самой ранней стадии
Очень важно гарантировать выявление изменений, способных нарушить работу потребителей как можно раньше, потому что, даже выбрав наилучшую из возможных технологий, мы все равно не будем застрахованы от критических сбоев. Для содействия выявлению этих проблем на ранней стадии я настоятельно рекомендую воспользоваться контрактами, задаваемыми потребителями (consumer-driven contracts), которые рассматриваются в главе 7. Если вы поддерживаете сразу несколько различных клиентских библиотек, то еще одной вспомогательной технологией может стать выполнение тестов с использованием каждой поддерживаемой вами библиотеки в отношении самого последнего сервиса. Как только обнаружится состояние, близкое к нарушению режима работы потребителя, перед вами встает выбор либо попытаться вообще избежать этого нарушения, либо смириться с возникшим состоянием и приступить к переговорам с теми, кто сопровождает сервисы-потребители.
Использование семантического управления версиями
Разве плохо будет, если вы в качестве клиента получите возможность с одного взгляда на номер версии сервиса тут же понять, сможете ли вы интегрироваться с ним или нет? Семантическое управление версиями представляет собой спецификацию, позволяющую получить именно такую возможность. При семантическом управлении версиями у каждой версии есть номер, имеющий форму MAJOR.MINOR.PATCH (важный.второстепенный.исправление). Когда происходит увеличение MAJOR-части номера, это означает, что были внесены изменения, исключающие обратную совместимость. Когда увеличивается MINOR-часть номера, это означает, что была добавлена новая функциональная возможность, которая не должна нарушить обратную совместимость. И наконец, когда меняется PATCH-часть номера, это означает, что в существующие функциональные возможности были внесены исправления, устраняющие какие-либо недостатки.
Чтобы убедиться в пользе семантического управления версиями, рассмотрим простой практический пример. Приложение по поддержке клиентов было создано для работы с версией клиентского сервиса, имеющей номер 1.2.0. Если будет добавлено какое-либо новое свойство, которое станет причиной изменения номера версии сервиса на 1.3.0, приложение не заметит никаких изменений в поведении сервиса и от него не будет ожидаться внесения каких-либо изменений в работе. Но мы не можем гарантировать, что будем в состоянии работать с версией 1.1.0 клиентского сервиса, поскольку можем зависеть от наличия тех функциональных возможностей, которые были добавлены при выпуске версии 1.2.0. Мы также можем ожидать необходимости внесения изменений в приложение, если выйдет новый выпуск клиентского сервиса с номером версии 2.0.0.
Решение о применении семантического управления версиями может быть принято как для всего сервиса, так и для его отдельно взятой конечной точки, если вы допускаете сосуществование сразу нескольких конечных точек, подробно рассматриваемое в следующем разделе.
Такая схема управления версиями позволяет помещать всего лишь в три поля достаточный объем информации и предположений. Полные изложения спецификации в очень простой форме обозначают те предположения, которые могут быть сделаны клиентами при изменении представленных номеров частей, и помогают упростить процесс сообщения о том, должны ли изменения каким-либо образом повлиять на потребителей. К сожалению, мне нечасто приходилось наблюдать применение данного подхода к распределенным системам.
Сосуществование различных конечных точек
После того как сделано все возможное, чтобы избежать появления критических изменений интерфейса, следующим заданием станет ограничение влияния. При этом нужно постараться не допустить принуждения потребителей к созданию обновлений вслед за нами, поскольку мы неизменно стремимся обеспечить возможность выпуска микросервисов независимо друг от друга. Одним из подходов, успешно применявшихся мною при решении этой задачи, являлось сосуществование старого и нового интерфейсов в одном и том же работающем сервисе. То есть, нацелившись на выпуск критических изменений, мы развертываем новую версию сервиса, которая выставляет как старую, так и новую версию конечной точки.
Это позволяет нам получить новый микросервис как можно быстрее и с новым интерфейсом, но дает потребителям время на раскачку. Как только все потребители полностью откажутся от использования старой конечной точки, ее можно будет удалить вместе со всем связанным с ней кодом (рис. 4.5).
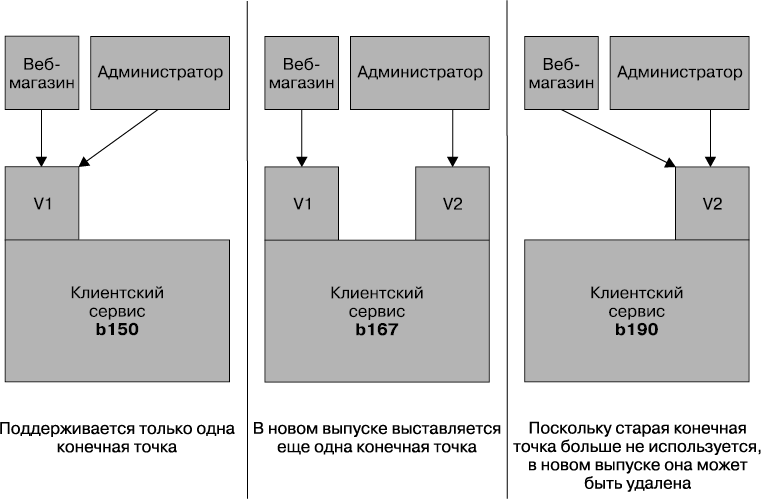
Рис. 4.5. Сосуществование различных версий конечных точек, позволяющее клиентам осуществлять постепенный переход
Когда я в последний раз использовал этот подход, мы слегка запутались с количеством имеющихся у нас потребителей и внесенных критических изменений. Это означало, что у нас фактически сосуществовали три различные версии конечных точек. Я бы такое не стал рекомендовать! Дополнительно нагружать себя поддержкой всего требующегося для этого кода и проведением связанного с ним тестирования, призванного убедить в том, что все это работает, совершенно ни к чему. Чтобы привести все в более управляемое состояние, мы внутренне перевели все запросы к конечной точке V1 в запросы к конечной точке V2, а затем все запросы к V2 — в запросы к конечной точке V3. Это означало, что мы могли четко очертить тот код, который подлежал удалению при выходе из употребления той или иной прежней конечной точки.
По сути, это является примером применения шаблона расширения и свертывания (expand and contract pattern), допускающего постепенный ввод критических изменений. Мы расширяем предлагаемые возможности, поддерживая как старый, так и новый путь получения какого-либо результата, и как только старые потребители станут работать по-новому, мы свертываем часть нашего API, удаляя старые функциональные возможности.
Если вы намереваетесь допустить сосуществование конечных точек, то для этого потребуется способ соответствующего перенаправления запросов вызывающих сторон. Я видел, как это делается для систем, использующих HTTP, с помощью указания номеров версий как в заголовках запросов, так и в самих URI, например /v1/customer/ или /v2/customer/. Я не могу сказать, какой из этих подходов рациональнее. С одной стороны, мне не нравятся сложные URI-индикаторы, поскольку я не хочу заставлять клиентов пользоваться жестко закодированными URI-шаблонами, но с другой — такой подход делает многое весьма очевидным и может упростить маршрутизацию запросов.
При использовании RPC все может оказаться несколько сложнее. Я справлялся с этой задачей с помощью буферов протокола, помещая свои методы в различные пространства имен, например v1.createCustomer и v2.createCustomer, но когда делается попытка поддержки различных версий одних и тех же типов, отправляемых по сети, возникают серьезные трудности.
Использование нескольких параллельных версий сервиса
Еще одним часто упоминаемым решением для управления версиями является сосуществование различных версий сервиса, при котором прежние потребители направляют свой трафик к прежней версии, а новые потребители видят новую версию (рис. 4.6). Такой подход весьма умеренно используется в компании Netflix в ситуациях, когда цена внесения изменений в системы прежних потребителей слишком высока, особенно в тех редких случаях, когда устаревшие устройства все еще привязаны к старым версиям API. Лично я такую идею не приветствую и понимаю, почему Netflix пользуется этим приемом крайне редко. Во-первых, если в моем сервисе нужно исправить какой-либо внутренний дефект, я знаю, что исправление и развертывание нужно провести в отношении двух различных наборов сервисов. Весьма вероятно, что для этого понадобится разветвлять исходный код моего сервиса, что всегда вызывает проблемы. Во-вторых, это означает, что необходимо придумать способ направления потребителей к нужному им микросервису. Связанные с этим функции в итоге неизбежно должны попасть в какую-либо связующую программу или в пакет Nginx-сценариев, затрудняя тем самым понимание причин поведения системы. И наконец, следует рассматривать любое постоянное состояние, которым может управлять наш сервис. Клиенты, создаваемые любой из версий сервиса, должны быть сохранены и должны стать видимыми всем сервисам независимо от того, какая из версий была первоначально использована для создания данных. Это может стать дополнительным источником затруднений.
Сосуществование параллельных версий сервисов на непродолжительное время может быть вполне оправданно, особенно при синих и зеленых развертываниях или канареечных выпусках (более подробно эти схемы рассматриваются в главе 7). В таких ситуациях параллельно работающие версии могут существовать всего несколько минут или, возможно, часов, и обычно это будут только две разные версии сервиса. Чем больше времени займут обновление, выполняемое потребителями до более новой версии, и выпуск этой версии, тем больше следует склоняться к сосуществованию различных конечных точек в одном и том же микросервисе, а не к сосуществованию совершенно разных версий. Я по-прежнему не думаю, что такую работу стоит делать при выполнении обычного проекта.
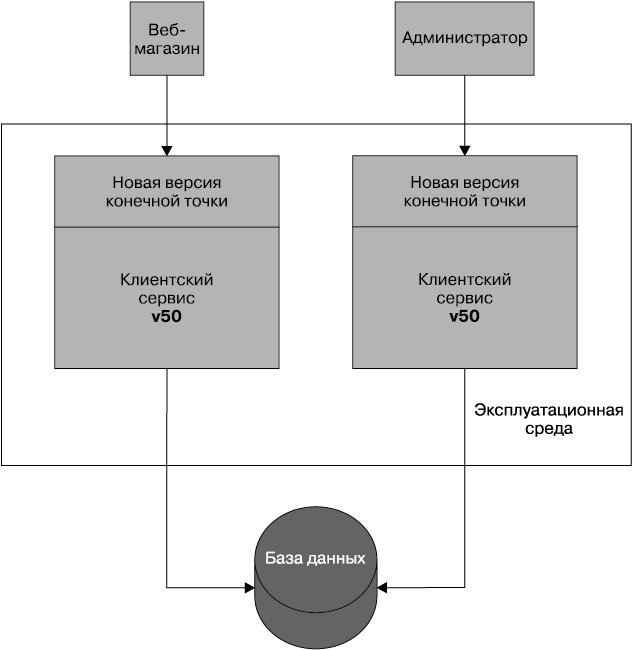
Рис. 4.6. Выполнение нескольких версий одного и того же сервиса с целью поддержки старых конечных точек
Пользовательские интерфейсы
До сих пор мы еще всерьез не касались пользовательского интерфейса. Возможно, некоторые из нас и предоставляют своим клиентам весьма неприглядный, строгий и минималистичный интерфейс, но многие предпочитают создавать красивые и функциональные пользовательские интерфейсы, способные обрадовать клиентов. Но в действительности мы должны думать о них в контексте интеграции. Все же пользовательский интерфейс является местом сбора всех микросервисов в нечто, имеющее смысл для наших клиентов.
В прошлом, когда я только начал заниматься программированием, разговоры шли главным образом о солидных толстых клиентах, работающих за настольными компьютерами. Я проводил много времени с Motif, а затем со Swing, стараясь максимально украсить свои программы. Зачастую системы предназначались всего лишь для создания локальных файлов и работы с ними, но у многих из них имелся компонент серверной стороны. Моя первая работа в ThoughtWorks заключалась в создании системы электронной торговой точки на основе Swing, которая была всего лишь фрагментом большого количества подвижных частей, многие из которых находились на сервере.
Затем пришло время Интернета. И мы стали продумывать пользовательские интерфейсы в более скромных красках с присутствием основной логики на серверной стороне. Поначалу наши программы на серверной стороне выдавали целиком всю страницу и отправляли ее клиентскому браузеру, работа которого сводилась к минимуму. Любое взаимодействие обрабатывалось на серверной стороне посредством GET- и POST-запросов, инициируемых после щелчка пользователя на ссылках или заполнения форм. Со временем наиболее популярным средством придания динамичности пользовательскому интерфейсу на основе использования браузера стал язык JavaScript, и тогда появилась возможность придать некоторым приложениям прежний солидный вид, который был свойственен старым клиентским приложениям на настольных компьютерах.
Движение в направлении к единым цифровым устройствам
За последние пару лет организации стали изменять свое представление о том, что интернет-системы и мобильные устройства должны рассматриваться в разных ключах, в результате чего появилось некое цельное представление обо всех цифровых устройствах. Так какой же наилучший способ использования сервисов мы можем предложить клиентам? И что для этого нужно сделать с нашей системной архитектурой? Осознание того, что мы не можем в точности предсказать, как в итоге клиент будет взаимодействовать с нашей компанией, привело к принятию на вооружение API с более мелкой структурой, такой, какую могут предоставить микросервисы. Путем объединения различными способами возможностей, которые выставляются нашими сервисами напоказ, мы можем курировать различные виды восприятия наших клиентов, возникающие при использовании ими приложений для настольных компьютеров, мобильных устройств, переносных устройств, или даже предоставлять их в физической форме, если клиенты посетят наш магазин стройматериалов.
Следовательно, пользовательские интерфейсы нужно рассматривать в виде композиционных уровней, то есть мест, в которых мы сплетаем в единое целое различные ветви предлагаемых нами возможностей. Итак, памятуя о сказанном, как же все-таки мы можем сплести все это в единое целое?
Ограничения
Ограничения представляют собой различные формы взаимодействия пользователей с нашей системой. Например, при использовании веб-приложения для настольной системы мы рассматриваем ограничения в виде того, чем пользуются посетители браузера или каким разрешением обладает его экран. А вот мобильные устройства приносят нам целый ряд новых ограничений. Влияние может оказать тот способ, который используется нашими мобильными приложениями для обмена данными с сервером. Свою роль может сыграть даже ограничение пропускной способности мобильной сети, которое заставит задуматься именно о ширине полосы пропускания. Различные виды взаимодействия могут приводить к быстрой разрядке батарей, отсекая тем самым часть потребителей.
Изменяется и характер взаимодействий. Я, к примеру, не могу так же запросто, как на простых компьютерах, щелкнуть правой кнопкой мыши, если работаю на планшете. А для мобильного телефона у меня может возникнуть желание разработать интерфейс под преимущественное управление одной рукой, чтобы большинство операций можно было вызвать с помощью манипуляций большим пальцем. А где-то еще, в местах с очень высокой платой за ширину полосы пропускания, например в странах со средним уровнем развития, где SMS используются в качестве интерфейса весьма часто, я могу позволить людям взаимодействовать с сервисами с помощью SMS.
Итак, несмотря на то, что наши основные сервисы или же основные предложения могут быть одинаковыми, нужен способ их адаптации под различные ограничения, существующие для каждого типа интерфейса. Рассматривая различные стили композиций пользовательского интерфейса, мы должны удостовериться в том, что они отвечают решению этой непростой задачи. Рассмотрим несколько моделей пользовательских интерфейсов, чтобы посмотреть, как можно будет достичь желаемого результата.
API-композиция
Предположим, что наши сервисы уже общаются друг с другом посредством XML или JSON через HTTP и очевидный доступный нам вариант заключается в непосредственном взаимодействии пользовательского интерфейса с теми API, которые показаны на рис. 4.7. В пользовательском интерфейсе на основе веб-технологий для извлечения данных можно воспользоваться написанными на JavaScript GET-запросами, а для изменения этих данных можно воспользоваться POST-запросами. Даже для чисто мобильных приложений инициировать обмен данными по протоколу HTTP довольно легко. Для пользовательского интерфейса затем придется создать различные компоненты, составляющие интерфейс, справляющиеся с синхронизацией состояния и тому подобным с сервером. Если для обмена данными между серверами использовался двоичный протокол, ситуация может усложниться для клиентов, работающих на основе веб-технологий, но при этом может вполне подойти для чисто мобильных устройств.
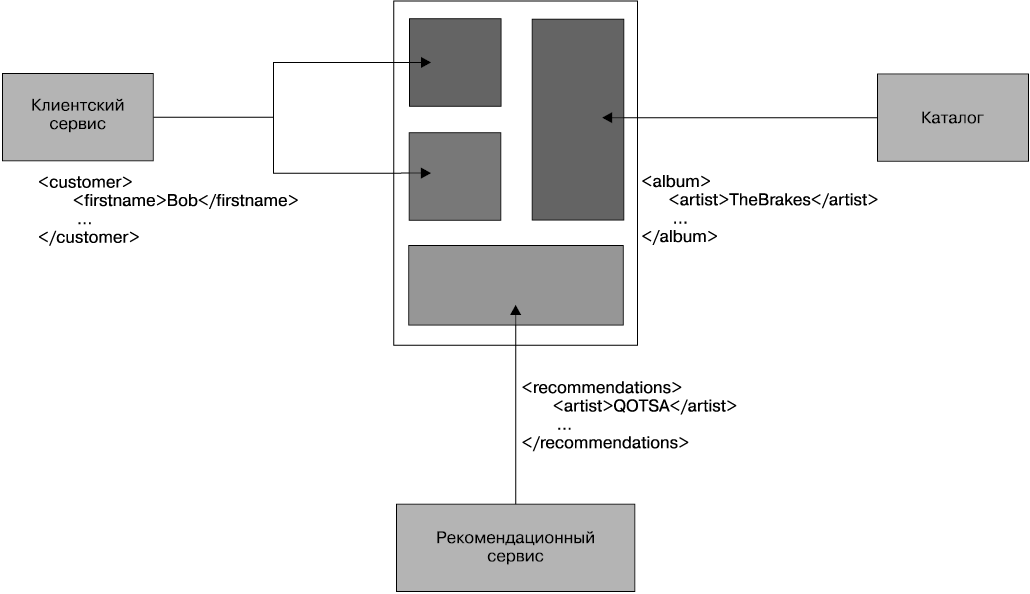
Рис. 4.7. Использование нескольких API для представления пользовательского интерфейса
Но у этого подхода есть ряд недостатков. В первую очередь это ограниченный круг возможностей для адаптации ответов под устройства различных типов. Например, должен ли я при извлечении записи клиента вытаскивать все те же данные для мобильного магазина, что и для приложения службы поддержки клиентов? При таком подходе одним из решений может стать разрешение пользователям указывать, какие поля извлекать при выдаче ими запроса, но это предполагает, что такой вид взаимодействия должен поддерживаться всеми сервисами.
И еще один ключевой вопрос: кто создает пользовательский интерфейс? Тех, кто приглядывает за сервисами, не беспокоит то, как их сервисы появляются перед пользователями. Например, если пользовательский интерфейс создает другая команда, мы можем вернуться к прежним не самым благополучным временам многоуровневой архитектуры, когда внесение даже самых незначительных изменений вело к перемене требований сразу к нескольким командам.
Этот обмен данными может быть слишком многословным. Открытие множества вызовов непосредственно к сервисам может оказаться слишком обременительным для мобильных устройств и привести к весьма неэффективному расходу мобильного плана клиента! Здесь может помочь наличие API-шлюза, поскольку вы сможете выдать вызовы, объединяющие несколько исходных вызовов, хотя само по себе это может иметь ряд недостатков, которые мы вскоре рассмотрим.
Составление фрагментов пользовательского интерфейса
Вместо того чтобы пользовательский интерфейс занимался API-вызовами и отображал все обратно на свои элементы управления, мы можем сделать так, чтобы сервисы предоставляли части пользовательского интерфейса напрямую, а затем, как показано на рис. 4.8, просто вставить эти фрагменты с целью создания пользовательского интерфейса. Представьте себе, к примеру, что рекомендационный сервис предоставляет рекомендационный виджет, который с целью создания полноценного пользовательского интерфейса объединяется с другими элементами управления или фрагментами этого интерфейса. Он может отображаться на веб-странице наряду с другим ее содержимым в виде блока.
Рис. 4.8. Сервисы, непосредственно обслуживающие компоненты пользовательского интерфейса, предназначенные для создания сборки
Разновидностью такого подхода, который может вполне достойно справиться со своей работой, является сборка крупномодульных частей пользовательского интерфейса. Здесь вместо создания небольших виджетов собираются вместе целые панели солидного клиентского приложения или, возможно, набор страниц для сайта.
Эти довольно крупные фрагменты подаются приложениями серверной стороны, которые, в свою очередь, делают соответствующие API-вызовы. Эта модель лучше всего работает, когда фрагменты точно распределяются по принадлежности между командами. Например, возможно, команда, которая несет ответственность за управление заказами в музыкальном магазине, обслуживает все страницы, связанные с управлением заказами.
Для того чтобы собрать все эти части вместе, понадобится некий сборочный уровень. Этот вопрос может быть решен простым созданием шаблонов на серверной стороне, или же там, где каждый набор страниц поставляется другим приложением, вам, наверное, потребуется некая интеллектуальная URI-маршрутизация.
Одним из ключевых преимуществ этого подхода является то, что та же команда, которая вносит изменения в сервисы, может также заниматься внесением изменений в соответствующие части пользовательского интерфейса. Это позволяет ускорить получение изменений. Но с этим подходом все же связаны некоторые проблемы.
В первую очередь нужно обратить внимание на обеспечение соответствия пользовательского восприятия. Пользователям хочется получать цельное восприятие, чтобы у них не возникало ощущения, что разные части интерфейса работают по-разному или что они представляют разные языки дизайна. Но существуют технологии, позволяющие обойти эту проблему, например действенные стилевые ориентиры (living style guides), где такие ресурсы, как HTML-компоненты, CSS и изображения, могут использоваться совместно, содействуя тем самым выдерживанию определенного уровня взаимного соответствия.
А вот с другой проблемой справиться сложнее. Что происходит с чистыми приложениями или полноценными клиентами? Мы не можем обслуживать компоненты пользовательского интерфейса. Можно применить гибридный подход и использовать для обслуживания HTML-компонентов чистые приложения, но в этом подходе постоянно обнаруживаются недостатки. Поэтому, если вам требуется получить естественное восприятие, придется вернуться назад, к подходу, при котором интерфейсное приложение самостоятельно осуществляет API-вызовы и управляет пользовательским интерфейсом. Но даже если рассматривать только пользовательские интерфейсы на основе веб-технологий, все равно может потребоваться иметь совершенно разную трактовку для разного типа устройств. Разумеется, помочь в данном вопросе может создание отзывчивых компонентов.
У этого подхода имеется еще одна ключевая проблема, в вероятности решения которой я не уверен. Иногда возможности, предлагаемые сервисом, не вписываются в виджет или страницу. Конечно, мне может потребоваться выдать какие-либо общие рекомендации в блоке страницы нашего сайта, а что, если я захочу создать систему динамических рекомендаций где-либо в другом месте? При поиске я, к примеру, хочу, чтобы набираемый текст автоматически продолжался выводом новых рекомендаций. Чем больше сквозных форм взаимодействия, тем меньше надежд на то, что эта модель подойдет, и больше подозрений, что придется вернуться назад, к простой выдаче API-вызовов.
Внутренние интерфейсы, предназначенные для внешних интерфейсов
Обычным решением проблемы многословных интерфейсов внутренних сервисов, или проблемы, связанной с необходимостью изменения содержимого для разных типов устройств, является использование объединяющей конечной точки на серверной стороне, или API-шлюза. Тем самым можно будет выстраивать несколько внутренних вызовов в случае необходимости изменять и собирать содержимое для различных устройств и, как показано на рис. 4.9, обслуживать все это. Я видел, что подобные конечные точки на серверной стороне, становясь довольно мощными уровнями со слишком развитым поведением, приводили к катастрофе. Все заканчивалось тем, что ими управляли различные команды разработчиков и они становились еще одним местом, где функциональные изменения приводили к необходимости внесения изменений в логику работы.
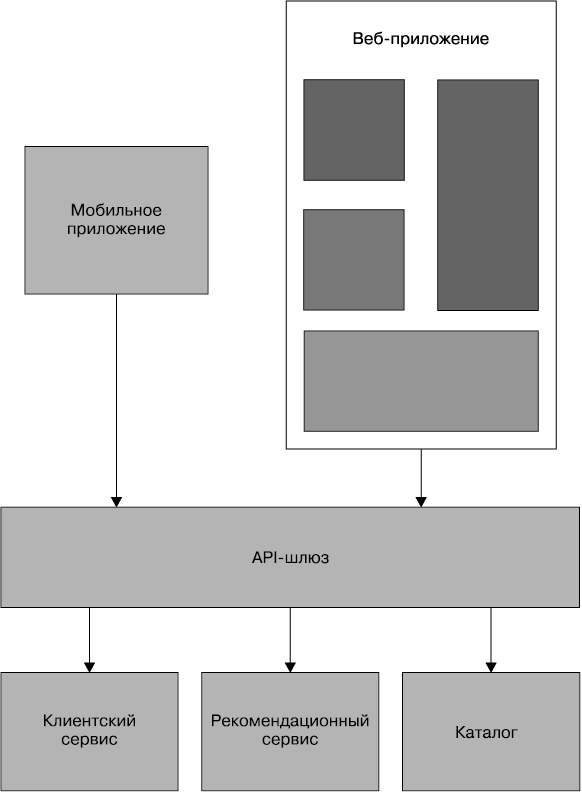
Рис. 4.9. Использование единого монолитного шлюза для управления вызовами из пользовательских интерфейсов и к самим этим интерфейсам
Может возникнуть проблема, связанная с тем, что у нас вполне естественным образом получится просто гигантский уровень для всех наших сервисов. Это приведет к тому, что все будет свалено в кучу и мы внезапно начнем терять изолированность различных пользовательских интерфейсов, что ограничит возможности независимой реализации. Я отдаю предпочтение работоспособной, на мой взгляд, модели (рис. 4.10), которая заключается в сведении использования таких внутренних интерфейсов к одному конкретному пользовательскому интерфейсу или приложению.
Рис. 4.10. Использование для внешних интерфейсов предназначенных конкретно для них внутренних интерфейсов
Эту схему иногда называют внутренними интерфейсами для внешних интерфейсов (backends for frontends (BFF)). Она позволяет команде, отвечающей за любой отдельно взятый пользовательский интерфейс, вдобавок ко всему обслуживать его собственные компоненты, находящиеся на стороне сервера. Эти внутренние интерфейсы можно рассматривать как часть пользовательского интерфейса, встроенную в сервер. Некоторые типы пользовательских интерфейсов требуют минимальной площади опоры на сервере, а некоторым нужна опора посолиднее. Если нужен уровень API-аутентификации и авторизации, то он может располагаться между BFF-интерфейсами и пользовательскими интерфейсами. Более подробно этот вопрос рассматривается в главе 9.
Опасности, подстерегающие при выборе этого подхода, аналогичны тем, которые связаны с любым объединяющим уровнем: он может содержать логику, которой в нем быть не должно. Бизнес-логика для различных возможностей, используемых этими внутренними интерфейсами, должна содержаться в самих сервисах. Эти BFF-интерфейсы должны обладать только поведением, характерным для создания конкретного пользовательского восприятия.
Гибридный подход
Многие из вышеупомянутых вариантов не должны целиком располагаться только на одной стороне. Мне приходилось видеть организации, взявшие на вооружение для создания сайтов подход, заключающийся в сборке на основе фрагментов, но при этом, когда дело касалось их мобильных приложений, использовалось создание внутренних интерфейсов для внешних интерфейсов. Главное здесь — сохранять единство основных возможностей, предлагаемых пользователям. Нам нужно обеспечить нахождение логики, связанной с заказом музыки или изменением данных о клиентах внутри тех сервисов, которые занимаются этими операциями, и не позволять ей размываться по всей нашей системе. Нужно, соблюдая искусный баланс, избежать ловушки, возникающей при помещении в промежуточные уровни слишком большого объема поведенческой логики.
Интеграция с программами сторонних разработчиков
Мы рассмотрели подходы разбиения на части существующих систем, находящихся в нашем ведении. А как быть с теми системами, в которые мы не можем вносить изменения, но с которыми вынуждены вести информационный обмен? По многим весьма уважительным причинам организации, для которых мы работаем, приобретают готовые коммерческие программы (commercial off-the-shelf software (COTS)) или пользуются программами в виде сервисов (software as a service (SaaS)), предлагающими услуги, управление которыми с нашей стороны имеет весьма ограниченный характер. Так как же провести разумную интеграцию с такими системами?
Если вы читаете эту книгу, то, наверное, работаете в организации, создающей программный код. Вы можете разрабатывать программы для собственных внутренних целей, или для внешнего клиента, или и для того и для другого. Тем не менее, даже если вы представляете организацию, способную создавать существенные объемы заказных программ, вы все равно пользуетесь программными продуктами, предоставляемыми внешними сторонами, будь то коммерческие продукты или программы с открытым кодом. Почему именно так это и происходит?
Во-первых, ваша организация почти наверняка испытывает большие потребности в программных средствах, которые нельзя удовлетворить своими силами. Подумайте обо всех продуктах, которыми пользуетесь, от инструментов, применяемых в офисах, типа Excel до операционных систем и систем начисления заработной платы. Создание всего этого для внутреннего потребления может стать непосильной затеей. Во-вторых, что более важно, это будет экономически невыгодно! Например, стоимость создания собственной системы электронной почты будет значительно больше стоимости использования существующих сочетаний почтового сервера и клиента, даже если это будут коммерческие варианты.
Мои клиенты часто задаются вопросом: «Создавать или покупать?» Обычно, когда происходит подобный разговор с обычной предпринимательской организацией, я и мои коллеги даем совет, который сводится к следующему: «Создавать, если то, что вы сделаете, будет уникальным и может считаться стратегическим активом, и покупать, если нужный инструмент к данной категории не относится».
Например, используемая в обычной организации система начисления заработной платы может не считаться стратегическим активом. Людям во всем мире начисляют зарплату одинаково. Точно так же большинство организаций склоняются к приобретению готовых систем управления контентом (CMSes), если использование подобного инструментария не рассматривается как что-то ключевое по отношению к их бизнесу. Однако в прежние времена меня привлекали к переделке сайта Guardian, и было принято решение создать заказную систему управления контентом, поскольку она была основой газетного бизнеса.
Поэтому намерение временами использовать коммерческие программные продукты сторонних производителей вполне обоснованно и может только приветствоваться. Но многие из нас в конечном счете проклинают некоторые из таких систем. Почему же так происходит?
Отсутствие должного контроля
Одна из проблем, связанных с объединением с COTS-продуктами CMS- или SaaS-инструментов и расширением их возможностей, заключается в том, что многие технические решения, как правило, уже были сделаны для вас. Как интегрироваться с инструментом? Это решение поставщика. Каким языком программирования можно воспользоваться для расширения возможностей инструмента? Это зависит от поставщика. Можно ли сохранить конфигурацию инструмента в системе управления версиями и восстановить ее с нуля, чтобы иметь возможность непрерывной интеграции в настройках? Это зависит от выбора, сделанного поставщиком.
Если вам повезет, то вопрос о том, насколько легко или трудно работать с инструментом с точки зрения разработчика, будет рассмотрен как часть процесса выбора инструмента. Но даже при том вы фактически уступаете некоторый уровень контроля внешней стороне. Вся хитрость заключается в том, чтобы вернуться к проведению интеграции и адаптации на своих условиях.
Адаптация
Многие инструментальные средства, приобретаемые предпринимательскими организациями, продаются с возможностью глубокой адаптации именно под ваши потребности. Осторожно! Зачастую из-за самой природы цепочки инструментов, к которой у вас есть доступ, стоимость адаптации может быть значительно выше создания с нуля какого-нибудь продукта на заказ! Если вы решили приобрести продукт, чьи конкретные возможности не предназначены специально для вас, то, может быть, более разумным решением будет подстроить под него порядок работы организации, чем заниматься сложной адаптацией этого продукта под свои нужды.
Хорошим примером опасности подобного рода могут послужить системы управления контентом. Мне приходилось работать с несколькими CMS, которые по своей конструкции не поддерживали непрерывную интеграцию, у которых были ужасные API и в которых даже несущественное обновление исходного инструментария могло разрушить любые сделанные вами настройки.
Наиболее проблемным в этом смысле является продукт компании Salesforce. На протяжении многих лет компания проталкивала свою платформу Force.com, которая требовала использования языка программирования Apex, существовавшего только внутри экосистемы Force.com!
Тонкости интеграции
Еще одной проблемой является порядок интеграции с инструментальным средством. Как уже говорилось, важно весьма тщательно продумать порядок интеграции между сервисами, а в идеале желательно вывести стандарты в отношении весьма небольшого количества типов интеграции. Но если для одного продукта решено использовать собственный двоичный протокол, для другого предпочтение отдано SOAP, а для третьего выбрана технология XML-RPC, то что делать? Еще хуже те инструменты, которые позволяют вам добираться до их базовых хранилищ данных, что вызывает те же проблемы связанности, о которых уже говорилось.
На наших собственных условиях
Продукты COTS и SaaS занимают свое место по праву, и невозможно, да и неразумно большинству из нас создавать все с нуля. Так как же все-таки решить все эти проблемы? Суть заключается в том, чтобы делать все на своих условиях.
Основная идея состоит в том, чтобы производить всю адаптацию на той платформе, которой вы можете управлять, и в том, чтобы ограничить количество различных потребителей самого инструментального средства. Чтобы подробно исследовать эту идею, рассмотрим два примера.
Пример: CMS в качестве сервиса
Мой опыт свидетельствует: CMS является наиболее часто используемым продуктом, нуждающимся в адаптации или создании с ним интеграции. Причина в том, что, если не нужен простой статичный сайт, обычная предпринимательская организация желает обогатить функциональность своего сайта динамическим содержимым вроде клиентских записей или предложений о приобретении продуктов из самых последних поступлений. Источником этого динамичного содержимого обычно являются другие сервисы внутри организации, возможно, созданные собственными силами.
Соблазн, а зачастую и привлекательность, возникающие при продаже CMS, состоят в том, что вы можете адаптировать CMS для того, чтобы она вбирала в себя это специализированное содержимое и демонстрировала его всему внешнему миру. Но разработочная среда для обычной CMS оставляет желать лучшего.
То, на чем специализируется обычная CMS и для чего мы ее, возможно, приобретаем, — это создание контента и управление им. Большинство CMS весьма посредственно справляются даже с макетированием страниц, обычно предоставляя инструменты для перетаскивания, которые не подслащивают эту горькую пилюлю. И даже при этом вы сталкиваетесь с необходимостью иметь кого-то, кто разбирается в HTML и CSS для подстройки CMS-шаблонов. Платформа для создания пользовательского кода из них, как правило, никудышная.
Так как же быть? Поставить впереди CMS собственный сервис, представляющий сайт внешнему миру (рис. 4.11). Считайте CMS сервисом, чья роль состоит в том, чтобы позволить ему создавать контекст и возвращать его. В собственном сервисе вы пишете код и интегрируете его с сервисами по своему усмотрению. У вас есть контроль над масштабированием сайта (чтобы справиться с нагрузкой, многие коммерческие CMS предоставляют собственные дополнительные компоненты), и вы можете выбрать систему создания шаблонов, имеющую для вас определенный смысл.
Рис. 4.11. Скрытие CMS с помощью своего собственного сервиса
Многие CMS также предоставляют API, позволяющие создавать контент, поэтому у вас есть возможность поставить впереди них фасад из собственного сервиса. В некоторых ситуациях мы даже использовали такой фасад для отвлечения от API, предназначенного для извлечения контента.
В последние несколько лет мы неоднократно использовали данную схему в компании ThoughtWorks, и сам я делал это не один раз. Одним примечательным примером был клиент, искавший возможность выпустить новый сайт для своих продуктов. Сначала он хотел сделать все на CMS, но ему еще предстояло выбрать, на какой именно системе это делать. Вместо этого мы предложили ему рассматриваемый здесь подход и приступили к разработке лицевого сайта. В ожидании выбора CMS мы имитировали такую систему с помощью веб-сервиса, который просто выставлял наружу статический контент. В итоге у нас при использовании сервиса-имитатора контекста, производящего выставляемое для живого сайта содержимое, получился вполне работоспособный сайт еще до выбора CMS. Чуть позже мы смогли просто вставить выбранный наконец-то инструментарий, не внося никаких изменений в лицевое приложение.
Используя данный подход, мы свели к минимуму работу CMS и переместили адаптацию в собственный технологический стек.
Пример: многоцелевая CRM-система
CRM, или Customer Relationship Management, то есть система управления взаимосвязями с клиентами, — это часто встречающийся инструмент, считающийся неким чудовищем, способным вселить страх в душу даже самого отважного архитектора. Этот сектор, судя по характеристикам таких поставщиков, как Salesforce или SAP, изобилует примерами инструментов, пытающихся все делать за вас. Это может привести к тому, что сам инструмент может стать и единственной точкой сбоя, и запутанным узлом зависимостей. Многие реализации CRM-инструментов, попадавшиеся мне на глаза, являли собой массу наилучших примеров связанных (в отличие от сцепленных) сервисов.
Обычно поначалу масштабы применения такого инструмента невелики, но со временем он становится все более важной частью стиля работы вашей организации. Проблема в том, что направления и варианты в рамках этой теперь уже жизненно важной для вас системы зачастую выбираете не вы, а сам поставщик инструмента.
Недавно я участвовал в попытке возвращения управления. Организация, с которой я работал, пришла к выводу, что, хотя CRM-инструментарий использовался в ней для решения многих задач, от увеличения стоимости платформы особой выгоды они не получали. В то же время несколькими внутренними системами для интеграции использовались далеко не идеальные API CRM. Мы хотели переместить архитектуру системы в то место, в котором имелись сервисы, моделирующие нашу область бизнеса, а также заложить основу для потенциальной миграции.
Сначала мы определили для нашей области основные концепции, которыми уже владела CRM-система. Одной из них была концепция проектов, то есть то, что может быть назначено штатному сотруднику. Проектная информация нужна была нескольким другим системам. То, чем мы занимались, заменяло сервис проектов. Этот сервис выставлял проекты в виде RESTful-ресурсов, и внешние системы могли перемещать свои точки интеграции на новый сервис, с которым было легче работать. Внутри сервис проектов представлял собой всего лишь фасад, за которым скрывались детали основной интеграции. Все это можно увидеть на рис. 4.12.
Рис. 4.12. Использование фасадных сервисов в качестве маскировки основного CRM
Работа, которая в момент написания этих строк еще продолжалась, заключалась в определении в нужной области других понятий, с которыми справлялась система CRM, и создании скорее фасадов для них. Когда настанет время уйти от базовой CRM, можно будет по очереди пересмотреть каждый фасад, чтобы решить, есть ли соответствующие требованиям внутренние программные решения или что-либо из готовых программных продуктов.
Шаблон Strangler (Дроссель)
Когда дело доходит до устаревших или даже COTS-платформ, которые находятся полностью под вашим контролем, приходится справляться с ситуациями, при которых нужно их удалить или по крайней мере от них отойти. В таком случае пригодится шаблон под названием Strangler Application Pattern. Во многом подобно примеру выстраивания лицевой части CMS с помощью собственного кода, с использованием шаблона Strangler добывают и перехватывают вызовы к старой системе. Это дает возможность принять решение, нужно ли направлять эти вызовы существующему устаревшему коду или же направлять их к новому коду, который вы могли написать. Это позволяет со временем заменить функциональные свойства, не требуя для этого больших переделок кода.
Когда же дело касается микросервисов, то для выполнения перехвата вместо использования одного монолитного приложения, перехватывающего все вызовы к существующей устаревшей системе, можно воспользоваться серией микросервисов. Захват и перенаправление исходных вызовов может оказаться в этой ситуации намного сложнее, что может потребовать использования прокси-сервиса, делающего все это за вас.
Резюме
Мы рассмотрели ряд вариантов интеграции, и я поделился своими размышлениями о том, какие решения могут скорее всего обеспечить то, что наши микросервисы останутся как можно более разобщенными со всем, с чем они совместно работают.
• Любой ценой избегайте интеграции с помощью баз данных.
• Разберитесь с компромиссами между REST и RPC, но как следует присмотритесь к REST как к хорошей стартовой точке для интеграции по схеме «запрос — ответ».
• Отдавайте предпочтение хореографическому, а не оркестровому принципу.
• Избегайте критических изменений и необходимости прибегать к управлению версиями, разобравшись с законом Постела и использованием толерантных считывателей.
• Подумайте о пользовательских интерфейсах как о композиционных уровнях.
Здесь было рассмотрено множество тем, углубиться в которые мы просто не могли. Тем не менее это может послужить неплохой основой для задания вашему пути верного направления, если вы захотите продолжить изучение.
Мы также потратили время на рассмотрение порядка работы с системами, которые не полностью нами контролируются и относятся к COTS-продуктам. Оказывается, данное описание может быть с легкостью применено и к программам, которые мы пишем сами!
Некоторые из показанных здесь подходов могут с одинаковой эффективностью применяться и к устаревшим программным продуктам, но что делать, если нужно решить такие проблемы, как подчинение устаревших систем своим интересам и их разбиение на более полезные для нас части? Подробно данный вопрос рассматривается в следующей главе.

