3. Как моделировать сервисы
Рассуждения моего оппонента напоминают мне о язычниках, которые на вопрос о том, на чем стоит мир, отвечали: «На черепахе». А на чем тогда стоит черепаха? «На другой черепахе».
Джозеф Баркер (1854)
Итак, вам известно, что такое микросервисы, и, будем надеяться, вы понимаете, в чем их основные преимущества. Теперь, наверное, вам не терпится приступить к их созданию, не так ли? Но с чего начать? В этой главе будет рассмотрен подход к определению границ ваших микросервисов, что, надеюсь, позволит максимизировать их положительные качества и избежать ряда потенциальных недостатков. Но сначала нам нужно что-нибудь, с чем можно будет работать.
Представление MusicCorp
Книги о замыслах лучше воспринимаются, если в них есть примеры. Там, где это возможно, я буду делиться с вами историями из реальной жизни, но в то же время я пришел к выводу, что не менее полезно иметь под рукой какую-либо вымышленную область, с которой можно будет работать. В книге мы еще не раз будем обращаться к этой области, наблюдая за тем, как в ней работает концепция микросервисов.
Итак, перед нами современный онлайн-продавец MusicCorp. Совсем недавно компания MusicCorp занималась традиционной розничной торговлей, но, когда бизнес по продаже грампластинок рухнул, их усилия все больше стали сосредотачиваться на онлайн-торговле. У компании имеется сайт, и в ней зреет стремление удвоить свои онлайн-продажи. Ведь все эти iPod всего лишь дань моде (плееры Zune, конечно, лучше), и истинные музыкальные фанаты готовы ждать доставки на дом компакт-дисков. Качество превыше удобства, не так ли? Исходя из этого, можно ли говорить о каком-то стриминговом сервисе Spotify, который, по сути, может пользоваться успехом только у подростков?
Несмотря на некоторое отставание от общих тенденций, у MusicCorp большие амбиции. К счастью, в компании было принято решение о том, что завоевать мир будет легче всего путем максимального упрощения внесения изменений. И для победы нужны микросервисы!
Как создать хороший сервис
Перед тем как команда из MusicCorp рванет по дистанции, создавая сервис за сервисом в попытке доставлять всем подряд восьмидорожечные ленты, притормозим и немного поговорим о наиболее важном основном замысле, которого нужно придерживаться. Как создать хороший сервис? Если вы уже испытали на себе горечь поражения при создании сервис-ориентированной архитектуры, то вполне можете понять, к чему я клоню. Но на случай, если сия участь вас миновала, хочу выделить две основные концепции: слабую связанность и сильное зацепление. Конечно, в книге будут подробно рассматриваться и другие замыслы и инструкции, но все усилия по их воплощению в жизнь будут тщетны, если неверно истолкованы эти две концепции.
Несмотря на то что эти два понятия используются довольно широко, особенно в контексте объектно-ориентированных систем, стоит все же поговорить о том, что они означают, когда речь идет о микросервисах.
Слабая связанность
Когда между сервисами наблюдается слабая связанность, изменения, вносимые в один сервис, не требуют изменений в другом. Для микросервиса самое главное —возможность внесения изменений в один сервис и его развертывания без необходимости вносить изменения в любую другую часть системы. И это действительно очень важно.
Что вызывает необходимость тесной связанности? Классической ошибкой является выбор такого стиля интеграции, который тесно привязывает один сервис к другому, что при изменении внутри сервиса требует изменений в его потребителях. Более подробно способы, позволяющие избегать подобных ситуаций, будут рассматриваться в главе 4.
Слабо связанные сервисы имеют необходимый минимум сведений о сервисах, с которыми приходится сотрудничать. Это также, наверное, означает лимитирование количества различных типов вызовов одного сервиса из другого, потому что, помимо потенциальных проблем производительности, слишком частые связи могут привести к тесной связанности.
Сильное зацепление
Хотелось бы, чтобы связанное поведение находилось в одном месте, а несвязанное родственное поведение — где-нибудь в другом. Почему? Да потому, что при желании изменить поведение нам хотелось бы иметь возможность произвести все изменения в одном месте и как можно быстрее выпустить их. Если же придется изменять данное поведение во многих разных местах, то для выпуска изменения нужно будет выпускать множество различных служб (вероятнее всего, одновременно). Изменения во многих разных местах выполняются медленнее, а одновременное развертывание множества сервисов очень рискованно, и оба этих обстоятельства нам нужно как-то обойти.
Следовательно, нужно найти в нашей проблемной области границы, которые помогут обеспечить нахождение связанного поведения в одном месте; требуется также, чтобы эти границы имели как можно более слабую связь с другими границами.
Ограниченный контекст
В книге Эрика Эванса (Eric Evans) Domain-Driven Design (Addison-Wesley) основное внимание уделялось способам создания систем, моделирующих реально существующие области. В книге множество великолепных идей вроде использования единого языка, хранилища абстракций и т. п., а еще там представлено одно очень важное понятие, которое я поначалу упустил из виду: ограниченный контекст (bounded context). Суть его в том, что каждая отдельно взятая область состоит из нескольких ограниченных контекстов и то, что в каждом из них находится, — это предметы (Эрик широко использует слово «модель», что, наверное, лучше предмета), которые не должны общаться с внешним миром, а также предметами, которые во внешнем мире используются совместно с другими ограниченными контекстами. У каждого ограниченного контекста имеется четко определенный интерфейс, где он решает, какие модели использовать совместно с другими контекстами.
Мне нравится еще одно определение ограниченного контекста: «конкретная ответственность, обеспечиваемая четко обозначенными границами». Если нужна информация из ограниченного контекста или нужно сделать запросы на какие-либо действия внутри ограниченного контекста, происходит обмен данными с его четко обозначенной границей с помощью моделей. В своей книге Эванс использовал аналогию с клетками: «Клетки могут существовать благодаря своим мембранам, определяющим, что попадает внутрь, что выходит наружу и что именно может через них проходить».
Ненадолго вернемся к бизнесу MusicCorp. Нашей областью будет весь бизнес, в пределах которого мы действуем. Он охватывает все: от товарного склада до регистратуры и от финансов до заказов. Мы можем создавать или не создавать модели всего этого в наших программах, но это все равно будет нашей рабочей областью. Рассмотрим части этой области, похожие на ограниченные контексты, на которые ссылался Эванс. В MusicCorp центром активности является товарный склад, где управляют доставляемыми заказами (и случайными возвратами), принимают новые запасы, разъезжают вилочные погрузчики и т. д. А в финансовом отделе, возможно, не так оживленно, но все же там происходят весьма важные внутриведомственные дела. Его работники занимаются начислением зарплаты, ведут счета компании и составляют важные отчеты. Множество отчетов. И у них, наверное, есть и другая интересная бумажная работа.
Общие и скрытые модели
Финансовый отдел и товарный склад MusicCorp можно рассматривать как два отдельных ограниченных контекста. У них обоих имеется вполне определенный интерфейс для связи с внешним миром (в понятиях отчетов об инвентаризации, квитанциях об оплате и т. д.) и существуют детали, о которых должны знать только они (например, вилочные погрузчики и калькуляторы).
Финансовому отделу не нужно знать ничего о подробностях работ, выполняемых внутри товарного склада. Но ему все-таки нужно знать об определенных вещах, например о складских запасах, чтобы поддерживать счета в актуальном состоянии. На рис. 3.1 показан пример схемы контекстов. На ней можно увидеть те понятия, которые являются внутренними для товарного склада, такие как сборщик (человек, составляющий заказы), полки, представляющие собой места хранения, и т. д. Аналогично главная бухгалтерская книга относится к внутренним понятиям финансового отдела и не является предметом общего пользования вне подразделения.
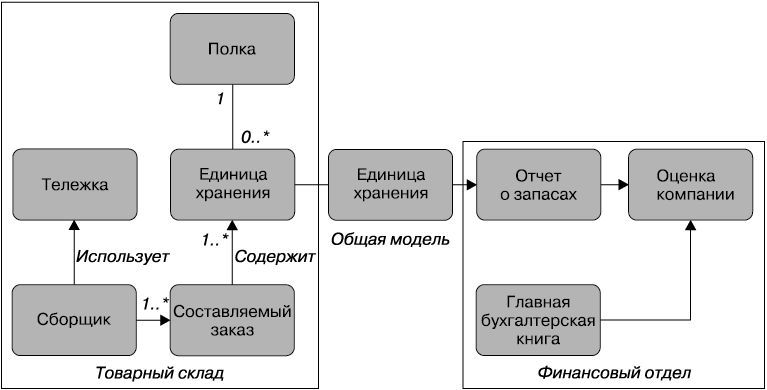
Рис. 3.1. Модель, совместно используемая финансовым отделом и товарным складом
Но чтобы провести оценку компании, работникам финансового отдела нужна информация о складских запасах. Поэтому общей моделью между двумя контекстами становится единица хранения. При этом следует заметить, что совсем не нужно безоглядно показывать все, что касается единицы хранения, из контекста товарного склада. Например, несмотря на то, что внутренняя запись о единице хранения содержится в том виде, в котором она присутствует на товарном складе, показывать абсолютно все в общей модели не нужно. Следовательно, имеется только внутреннее представление и внешнее представление, выставляемое напоказ. Во многом это предваряет рассмотрение REST в главе 4.
Иногда можно столкнуться с моделями с одинаковыми именами, у которых совершенно разное назначение, а также совершенно разные контексты. Например, может существовать такое понятие, как return («возврат»), представляющее собой то, что потребитель отправляет назад. В контексте потребителя понятие return касается распечатки ярлыка доставки, выдачи заказа на посылку и ожидания поступления наложенного платежа. Для товарного склада это понятие может представлять собой поступающую посылку и единицу хранения, запасы которой пополняются. Из этого следует, что в среде товарного склада мы сохраняем дополнительную информацию, связанную с return, которая относится к будущим задачам, например, на ее основе может быть создан запрос на пополнение запасов. Общая модель return становится связанной с разными процессами и поддерживающей объекты внутри каждого ограниченного контекста, но во многом это внутренняя проблема в пределах самого контекста.
Модули и сервисы
Проясняя вопрос о том, какие модули должны применяться совместно, не допуская при этом совместного использования своих внутренних представлений, мы обходим один из потенциальных подвохов, который может вылиться в тесную связанность (то есть в прямо противоположное желаемому результату). Мы также определяем границу внутри нашей области, в пределах которой должны находиться все однотипные бизнес-возможности, дающие нам желаемое сильное зацепление. Впрочем, эти ограниченные контексты сами по себе играют роль структурных границ.
Как говорилось в главе 1, у нас есть вариант использования модулей в пределах границы процесса, при котором можно держать связанный код вместе и пытаться снизить уровень связанности с другими модулями системы. Это может послужить неплохой отправной точкой при создании нового кода. Итак, если в вашей области обнаружились ограниченные контексты, нужно обеспечить их моделирование внутри кода в виде модулей с наличием как общих, так и скрытых моделей.
Затем эти модульные границы превращают их в превосходных кандидатов в микросервисы. Вообще-то, микросервисы нужно четко вписывать в ограниченные контексты. С обретением достаточного опыта вы можете решиться пропустить этап моделирования ограниченного контекста в виде модулей в составе более монолитной системы и сразу перейти к отдельному сервису. Но на начальном этапе нужно сохранять монолитность новой системы. Неверное определение границ сервиса может обойтись довольно дорого, поэтому нужно дождаться стабилизации представлений, чтобы справиться с новой областью более разумно. Подробнее данный вопрос, а также технологии, помогающие разбить существующие системы на микросервисы, рассматриваются в главе 5.
Итак, если границы нашего сервиса вписываются в ограниченный контекст в нашей области и наши микросервисы представляют собой подобные ограниченные контексты, значит, мы взяли хороший старт в обеспечении слабой связанности и сильного зацепления микросервисов.
Преждевременная декомпозиция
В ThoughtWorks мы сами столкнулись с проблемами слишком быстрого разбиения на микросервисы. Помимо консалтинга, мы также создали несколько продуктов. Одним из них был SnapCI — работающий на хост-машине инструментарий непрерывной интеграции и непрерывной доставки (эти понятия будут рассматриваться в главе 6). Ранее команда работала над другим подобным продуктом, Go-CD — инструментом доставки с открытым исходным кодом, который может развертываться локально, а не размещаться в облаке.
Хотя на самой ранней стадии в проектах SnapCI и Go-CD существовал повторно используемый код, в конечном итоге SnapCI оказался обладателем совершенно нового кода. Тем не менее предыдущий опыт команды в области разработки инструментария по доставке компакт-дисков стимулировал разработчиков к более быстрому определению границ и построению создаваемой системы в виде набора микросервисов.
Через несколько месяцев стало понятно, что сценарий использования SnapCI имел достаточно отличий, чтобы признать изначально определенные границы сервисов не совсем правильными. Это повлекло за собой внесение в сервисы множества изменений и связанные с этим большие затраты. В итоге команда опять объединила сервисы в единую монолитную систему, чтобы лучше понять, где должны пролегать границы. Год спустя команда смогла разбить монолитную систему на микросервисы, границы которых оказались гораздо более стабильными. И это далеко не единственный известный мне пример подобной ситуации. Преждевременная декомпозиция системы на микросервисы может обойтись весьма дорого, особенно если область вам плохо известна. Во многих отношениях куда проще иметь весь исходный код, требующий декомпозиции и разбиения на микросервисы, чем пытаться создавать микросервисы с самого начала.
Бизнес-возможности
Приступая к обдумыванию ограниченных контекстов, имеющихся в вашей организации, нужно размышлять не в понятиях совместно используемых данных, а в понятиях возможностей, предоставляемых такими контекстами всей остальной области. Товарный склад, к примеру, может предоставить возможность получения текущего списка запасов, а финансовый контекст — выдать состояние счетов на конец месяца или позволить внести новичка в платежную ведомость. Для этих возможностей может понадобиться взаимный обмен информацией, то есть совместно используемые модели, но мне довольно часто приходилось наблюдать, что обдумывание данных приводило к созданию безжизненных, основанных на CRUD (create — «создание», read — «чтение», update — «обновление», delete — «удаление») сервисов. Поэтому сначала нужно задать себе вопрос «Чем этот контекст занимается?», а затем уже вопрос «А какие данные ему для этого нужны?».
При проведении моделирования в виде сервисов эти возможности становятся ключевыми операциями, которые могут быть показаны по сети другим участникам системы.
Внизу сплошные черепахи
В самом начале вы, наверное, определите ряд приблизительных ограниченных контекстов. Но они, в свою очередь, могут содержать следующие ограниченные контексты. Например, можно разбить товарный склад по признакам возможностей, связанных с выполнением заказа, управлением запасами или получением товаров. Рассуждая о границах своих микросервисов, сначала нужно оперировать понятиями наиболее крупных, приблизительных ограниченных контекстов, а затем, выискивая преимущества разбиения в пределах этих границ, приступать к дальнейшему дроблению на вложенные контексты.
Для пущего эффекта я видел эти вложенные контексты скрытыми ото всех остальных сотрудничающих микросервисов. Для внешнего мира они по-прежнему используются с целью реализации бизнес-возможностей на товарном складе, но при этом не знают, что, как показано на рис. 3.2, их запросы фактически открыто отображаются на два и более отдельных сервиса. Временами, как показано на рис. 3.3, можно прийти к решению, что для ограниченного контекста более высокого уровня больше смысла в том, чтобы не быть промоделированным в качестве границы сервиса, и вместо единой границы товарного склада можно выделить запасы, выполнение заказов и получение товаров.
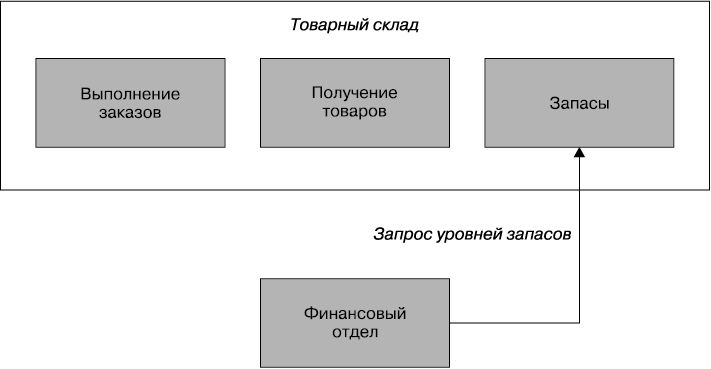
Рис. 3.2. В микросервисах представляются вложенные ограниченные контексты, скрытые внутри товарного склада
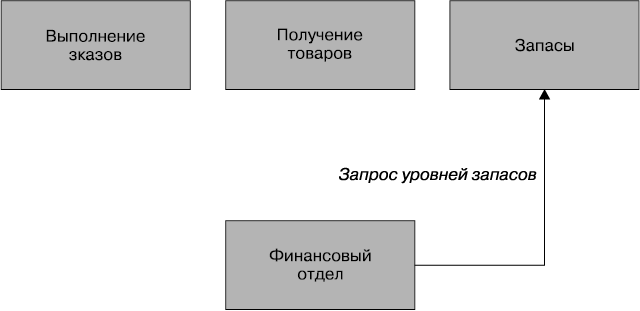
Рис. 3.3. Ограниченные контексты внутри товарного склада, выскочившие на свои собственные контексты самого верхнего уровня
В общем, какого-либо непреложного правила о том, какой из подходов имеет больший смысл, просто не существует. Но выбор подхода с вложенными контекстами, а не подхода с полным отделением должен основываться на структуре вашей организации. Если выполнение заказов, управление запасами и получение товаров управляются разными командами, то они, по-видимому, заслуживают своего статуса микросервисов самого верхнего уровня. Если же все они управляются одной командой, больше смысла будет в модели с вложениями. Все дело во взаимосвязанности организационных структур и архитектуры программного продукта, которая рассматривается ближе к концу книги, в главе 10.
Еще одной причиной, по которой нужно отдавать предпочтение подходу с использованием вложений, может быть разбиение архитектуры на части с целью упрощения тестирования. Например, при тестировании сервисов, использующих товарный склад, не нужно будет ставить заглушки на каждый сервис внутри контекста товарного склада, как при более приблизительном API. Это также может дать вам единицу изолированности при рассмотрении более масштабных тестов. К примеру, я могу принять решение об использовании сквозных тестов при запуске всех сервисов внутри контекста товарного склада, но для всех других сотрудничающих компонентов системы могу их заглушить. Более подробно тестирование и изоляция будут рассматриваться в главе 7.
Обмен данными с точки зрения бизнес-концепций
Изменения, реализуемые в нашей системе, зачастую относятся к изменениям, требующимся бизнесу, чтобы определить поведение системы. Мы изменяем функциональность, то есть возможности, которые раскрываются для наших потребителей. Если наши системы прошли декомпозицию по ограниченным контекстам, представляющим область, изменения, которые нужно произвести, скорее всего, должны быть изолированы одной отдельно взятой границей микросервиса. Это сократит количество мест, в которые нужно вносить изменение, и позволит быстро развернуть это изменение.
Важно также продумать обмен данными между этими микросервисами с точки зрения одних и тех же бизнес-концепций. Моделирование программного продукта относительно вашей области бизнеса не должно останавливаться на замысле ограниченных контекстов. Одинаковые понятия и идеи, совместно используемые отделами вашей организации, должны быть отображены в интерфейсах. Было бы полезно продумать формы, отправляемые между этими микросервисами, почти так же, как и формы, отправляемые в пределах всей организации.
Техническая граница
Полезно было бы взглянуть на то, что может пойти не так, когда сервисы смоделированы неправильно. В недавнем прошлом я с рядом коллег работал с клиентом из Калифорнии, помогая компании внедрить несколько инструкций по очищению кода и приближению к автоматизированному тестированию. Начали мы с самого легкодоступного — декомпозиции сервиса и тут заметили нечто более тревожное. Я не могу вдаваться в подробности того, чем занималось приложение, но оно относилось к категории общедоступных и имело обширную глобальную клиентскую базу.
Команда и система разрослись. Изначально в представлении отдельно взятого человека система вбирала в себя все больше и больше функций и у нее становилось все больше и больше пользователей. В конце концов организация решила увеличить штат команды — создать новую группу разработчиков, находящуюся в Бразилии, и переложить на нее часть работы. Система подверглась разбиению, причем одна половина приложения, по существу, утратила конкретное «гражданство» и стала представлять собой общедоступный сайт (рис. 3.4). Другая половина системы стала простым интерфейсом удаленного вызова процедуры (Remote Procedure Call (RPC)) в отношении хранилища данных. Представьте, что вы, по сути, берете в своем исходном коде уровень хранилища данных и превращаете его в отдельный сервис.
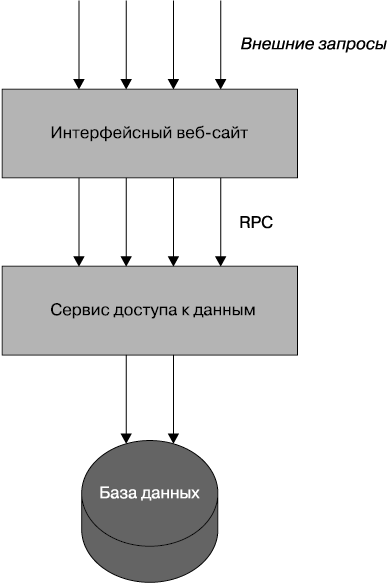
Рис. 3.4. Граница сервиса, проложенная по техническому стыку
В оба сервиса пришлось часто вносить изменения. И оба сервиса рассматривались в понятиях низкоуровневого вызова методов в RPC-стиле, которые обладали излишней хрупкостью (этот вопрос будет рассматриваться в главе 4). Сервисный интерфейс был также слишком многословен, что влекло за собой проблемы с производительностью. Все это вылилось в необходимость усовершенствования механизмов RPC-пакетирования. Я назвал это луковой архитектурой, поскольку в ней имелось множество уровней и она заставляла меня плакать, когда ее приходилось разрезать.
На первый взгляд идея разбиения ранее монолитной системы по географическим или организационным линиям была вполне осмысленной, и ее развернутое представление будет рассмотрено в главе 10. Но в данном случае вместо того, чтобы разрезать стек по вертикали на бизнес-ориентированные куски, команда сделала выбор в пользу того, что ранее было API внутри процесса, и произвела горизонтальный разрез.
Принятие решения о моделировании границ сервиса по техническим стыкам нельзя признать абсолютно неправильным. Я действительно видел оправданность такого подхода, когда организация, к примеру, рассчитывала на достижение определенных целей в повышении производительности. Но поиск подобных стыков должен стать вторичной, но отнюдь не первичной побудительной причиной.
Резюме
В данной главе вы научились в какой-то мере определять критерии хорошего сервиса, а также узнали о способах поиска стыков в своем проблемном пространстве, что дает нам двойные преимущества — как слабой связанности, так и сильного зацепления. Жизненно важным инструментом, помогающим нам находить такие стыки, являются ограниченные контексты, а вписывание микросервисов в определяемые ими границы позволяет гарантировать, что получающаяся в результате система имеет все шансы сохранить свои достоинства неизменными. Кроме того, была дана подсказка о том, как можно выполнить дальнейшее дробление на микросервисы, а углубленное рассмотрение этого вопроса будет приведено чуть позже. Кроме того, состоялось представление MusicCorp, области, взятой в качестве примера, которая будет использоваться в книге и в дальнейшем.
Идеи, представленные Эриком Эвансом в книге Domain-Driven Design, весьма полезны при поиске разумных границ наших сервисов, и мы пока что рассмотрели их весьма поверхностно. Чтобы разобраться в практических аспектах данного подхода, я рекомендую обратиться к книге Вона Вернона (Vaughn Vernon) Implementing Domain-Driven Design (Addison-Wesley).
В данной главе мы прошлись в основном по верхнему уровню, а далее необходимо углубиться в технические подробности. При реализации интерфейсов между сервисами нас подстерегает множество подвохов, вызывающих разнообразные проблемы, и если мы стремимся уберечь свои системы от сплошной путаницы, в эту тему придется углубиться.
.

