8. Мониторинг
Я надеюсь, мне уже удалось показать вам, что разбиение системы на более мелкие, имеющие более высокую степень детализации микросервисы приводит к получению многочисленных преимуществ. Но при этом усложняется мониторинг систем, работающих в производственном режиме. В данной главе будут рассмотрены трудности, связанные с мониторингом и выявлением проблем в наших имеющих более высокую степень детализации системах, а также намечены некоторые подходы, которые можно применить для достижения вполне приемлемых результатов!
Представим следующую ситуацию. Пятница, вторая половина дня, команда уже собралась пораньше улизнуть в какой-нибудь бар, чтобы развеяться и славно встретить предстоящие выходные дни. И тут вдруг приходит сообщение по электронной почте: сайт стал чудить! В Twitter полно гневных посланий в адрес компании, ваш босс рвет и мечет, а перспективы спокойных выходных медленно тают.
В чем нужно разобраться в первую очередь? Что, черт возьми, пошло не так?
Когда работа ведется с монолитным приложением, по крайней мере есть на что свалить вину. Сайт замедлился? Виноват монолит. Сайт выдает странные ошибки? И в этом тоже он виноват. Центральный процессор загружен на все 100 %? Это монолит. Запах дыма? Ну вы уже поняли. Наличие единого источника всех бед отчасти упрощает расследование причин!
А теперь подумаем о нашей собственной системе, основанной на работе микросервисов. Возможности, предлагаемые пользователям, возникают из множества мелких сервисов, часть из которых в ходе выполнения своих задач обмениваются данными еще с несколькими сервисами. У такого подхода есть масса преимуществ (и это хорошо, иначе написание данной книги стало бы пустой тратой времени), но с точки зрения мониторинга мы сталкиваемся с более сложной проблемой.
Теперь у нас есть несколько отслеживаемых серверов, несколько регистрационных файлов, которые нужно будет переворошить, и множество мест, где сетевые задержки могут вызвать проблемы. И как ко всему этому подступиться? Нужно понять, что может стать причиной хаоса и путаницы, с которыми не хотелось бы столкнуться в пятничный полдень (да и в любое другое время!).
На все это есть довольно простой ответ: нужно отслеживать небольшие области, а для получения более общей картины использовать объединение. Чтобы посмотреть, как это делается, начнем с самого простого из возможного — с отдельного узла.
Один сервис на одном сервере
На рис. 8.1 представлена весьма простая установка: на одном хосте запущен один сервис. Теперь нам нужно проводить его мониторинг, чтобы быть в курсе, если что-то пойдет не так, и иметь возможность все исправить. Итак, что именно мы должны отслеживать?
Рис. 8.1. Один сервис на одном хосте
В первую очередь нужно отслеживать сам хост. Центральный процессор, память — полезно отслеживать работу всех этих компонентов. Нужно знать, в каком состоянии они должны быть в нормальной обстановке, чтобы можно было поднять тревогу, когда они выйдут за границы этого состояния. Если нужно запустить программу мониторинга, то можно воспользоваться чем-нибудь вроде Nagios или же применить такой размещаемый прямо на хосте сервис, как New Relic.
Затем нам потребуется доступ к регистрационным журналам с самого сервера. Если пользователь сообщает об ошибке, эти журналы должны зарегистрировать ее и, я надеюсь, сообщить нам о том, когда и где произошла ошибка. В этот момент, имея в распоряжении единственный сервер, мы можем, наверное, получить эти данные, просто зарегистрировавшись на хосте и воспользовавшись для сканирования журнала средством, запускаемым из командной строки. Можно пойти еще дальше и воспользоваться logrotate, чтобы убрать старые журналы и не дать им заполнить все дисковое пространство.
И наконец, нужно отслеживать работу самого приложения. Как минимум неплохо будет отслеживать время отклика сервиса. Вероятнее всего, это удастся сделать путем просмотра журналов, поступающих либо из веб-сервера, являющегося фасадом вашего сервиса, либо, возможно, из самого сервиса. При желании получить более совершенную систему можно отслеживать количество ошибок, попавших в отчеты.
Время не стоит на месте, нагрузка растет, и появляется необходимость в расширении…
Один сервис на нескольких серверах
Теперь у нас есть несколько копий сервиса, запущенных на отдельных хостах (рис. 8.2), а запросы к различным экземплярам сервиса распределяются с помощью балансировщика нагрузки. Ситуация начинает усложняться. Нам по-прежнему нужно отслеживать все то же самое, что и раньше, но это следует делать таким образом, чтобы можно было найти источник проблемы.
Будет ли при высокой загруженности центрального процессора, от которой не застрахован ни один из хостов, что-либо указывать на проблему в самом сервисе, или же признак этого будет изолирован на самом хосте, указывая на то, что проблема касается именно его и, возможно, связана с нештатным поведением процесса операционной системы?
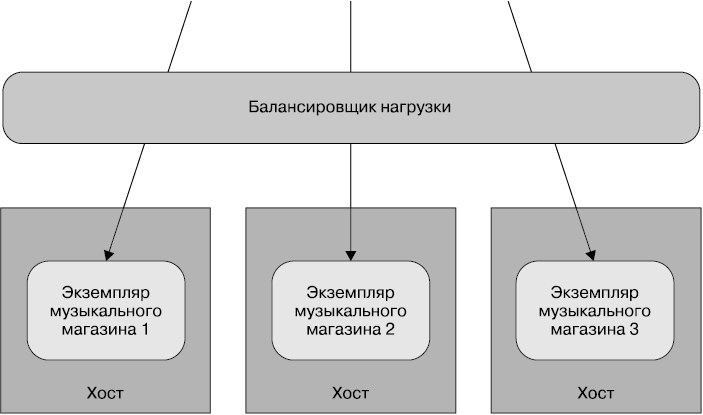
Рис. 8.2. Один сервис, распределенный по нескольким хостам
Итак, в данный момент нам также требуется отслеживать показатели на уровне отдельно взятого хоста и получать оповещения в случае отклонения от норм. Но теперь нужно видеть показатели по всем хостам, а также индивидуальные показатели каждого хоста. Иными словами, нам нужно их объединить, но при этом сохранить возможность рассматривать по отдельности. Подобную группировку хостов допускает Nagios, и пока это нас вполне устроит. Такого подхода, вероятно, будет достаточно для нашего приложения.
Теперь о журналах. Поскольку сервис запущен на более чем одном сервере, нам, чтобы заглянуть вовнутрь, придется, наверное, регистрироваться на каждом из них. Если количество хостов невелико, можно воспользоваться таким средством, как SSH-мультиплексор, которое позволяет запускать одни и те же команды сразу на нескольких хостах. Затем понадобятся большой монитор и поиск виновника с помощью команды grep "Error" app.log.
Для задач типа отслеживания времени отклика мы можем, не проводя специального объединения, довольствоваться отслеживанием балансировщика нагрузки. Но нужно, разумеется, отслеживать работу и самого балансировщика: если он начнет барахлить, у нас возникнут проблемы. Тут, наверное, нужно побеспокоиться и о том, как должен выглядеть нормально работающий сервис, поскольку мы будем настраивать балансировщик нагрузки на удаление из приложения неисправных узлов. Надеюсь, что, дойдя до этого места, мы уже сможем выдать несколько идей на сей счет…
Несколько сервисов на нескольких серверах
На рис. 8.3 можно наблюдать еще более интересную картину. Несколько сервисов совместно работают для предоставления определенных возможностей пользователям, и эти сервисы запущены на нескольких хостах, неважно, физических или виртуальных. Как найти искомые ошибки в тысячах строк регистрационных журналов на нескольких хостах? Как определить ненормальную работу одного из серверов или систематический характер ее проявления? И как отследить ошибку в глубине цепочки вызовов между несколькими хостами и определить причину ее появления?
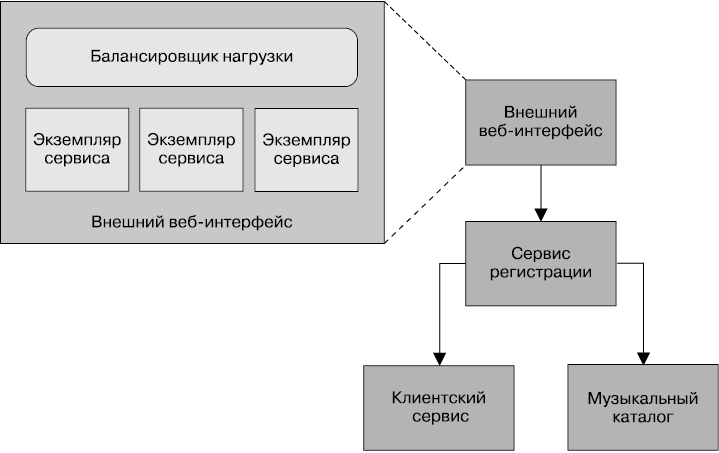
Рис. 8.3. Несколько совместно работающих сервисов, распределенных по нескольким хостам
Ответом могут стать сбор и централизованное объединение всего, до чего только могут дотянуться наши руки: от регистрационных журналов до показателей приложений.
Журналы, журналы и еще журналы…
Теперь сложности начинает создавать количество запущенных нами хостов. Похоже, что SSH-мультиплексирование в данном случае не собирается облегчать ситуацию с извлечением журналов и не существует достаточно больших экранов, чтобы на них могли уместиться терминалы, открытые для каждого хоста. Вместо этого для сбора журналов и предоставления централизованного доступа к ним мы присматриваемся к использованию специализированных подсистем. Одним из примеров может послужить такое средство, как logstash, способное провести парсинг нескольких форматов журнальных файлов и организовать их отправку нижестоящим системам для дальнейшего исследования.
На рис. 8.4 показана система Kibana, построенная на движке ElasticSearch и предназначенная для просмотра журналов. Для поиска по журналам можно воспользоваться синтаксисом запросов, позволяющим ограничивать диапазоны времени и дат или использовать регулярные выражения для поиска соответствующих им строк. Kibana может даже генерировать из журналов диаграммы и отправлять их в ваш адрес, позволяя вам, к примеру, с первого взгляда замечать количество ошибок, зарегистрированных за определенное время.
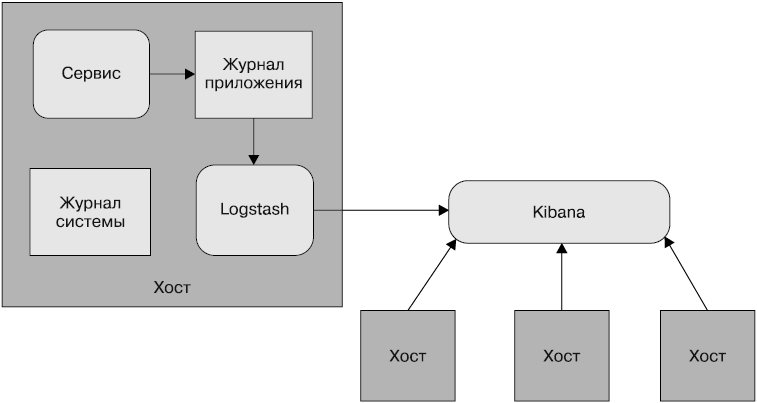
Рис. 8.4. Использование Kibana для просмотра объединенных журналов
Отслеживание показателей сразу нескольких сервисов
Наряду с решением сложностей с просмотром журналов различных хостов нам нужно подыскать наилучшие способы для сбора и просмотра показателей. При рассмотрении показателей более сложных систем может быть трудно узнать, как именно выглядят приемлемые параметры. На нашем сайте замечено около 50 HTTP-ошибок в секунду с кодами 4XX. Плохо ли это? Загруженность центрального процессора сервисом каталогов увеличилась в обеденное время на 20 % — это нормально? Секрет осведомленности о том, когда следует поднимать тревогу, а когда можно расслабиться, кроется в сборе показателей о поведении системы за период времени, достаточно длительный для того, чтобы могла проявится четкая схема.
В более сложной среде инициализация новых экземпляров сервисов будет происходить довольно часто, поэтому нам нужно выбрать такую систему, которая бы облегчила сбор показателей с новых хостов. Нужно иметь возможность просматривать объединенные показатели для всей системы, например среднюю загруженность центральных процессоров, но также следует объединить показатели для всех экземпляров заданного сервиса или даже показатели для отдельного экземпляра этого сервиса. Это означает, что нужно иметь возможность связать метаданные с показателем, что позволит делать заключения об этой структуре.
Graphite — одна из таких систем, способная существенно упростить решение данной задачи. Она предоставляет очень простой API-интерфейс и позволяет вам отправлять показатели в реальном времени. Затем она позволяет запрашивать эти показатели для создания диаграмм и других наглядных представлений для оценки ситуации. Представляет интерес способ, используемый этим средством для обработки объема данных. Фактически оно настраивается так, чтобы снизить анализ более старых показателей, гарантируя тем самым, что объем не станет разрастаться слишком сильно. Так, к примеру, можно делать одну запись показателей центрального процессора для хостов каждые десять секунд за последние десять минут, затем для каждого последнего дня делать объединенный показатель каждую минуту, опускаясь, возможно, до одного образца каждые 30 минут за несколько последних лет. Таким образом можно хранить информацию о поведении системы за довольно продолжительный период времени, не нуждаясь в хранилище большого объема.
Graphite также позволяет вам объединять образцы или же добираться до их отдельных серий, предоставляя возможность наблюдать время отклика для всей вашей системы, группы сервисов или отдельного экземпляра. Если Graphite у вас по какой-то причине не работает, нужно обеспечить получение сходных возможностей с помощью любого другого инструментального средства. И конечно же, следует обеспечить доступ к необработанным данным для возможности получения своей собственной отчетности или показаний инструментальной панели, если есть потребность в ее использовании.
Еще одно преимущество от знания тенденций проявляется при планировании объемов. Достигли ли мы их пределов? Сколько еще можно проработать до возникновения потребностей в дополнительных хостах? В прошлом, когда мы ставили физические хосты, эта работа зачастую носила ежегодный характер. В новые времена, когда вычислительные мощности предоставляются поставщиками инфраструктур как служб (IaaS) по требованию, мы можем расширять и сужать возможности системы за считаные минуты, если не секунды. Значит, если мы разбираемся в своих схемах использования, то можем удостовериться в том, что в нашем распоряжении имеется достаточно элементов инфраструктуры для удовлетворения текущих потребностей. Чем интеллектуальнее подход к отслеживанию тенденций и пониманию того, как на них реагировать, тем более экономически оправданной и отзывчивой может стать наша система.
Рабочие показатели сервисов
Операционные системы, под которыми мы работаем, генерируют большое количество показателей, в чем можно убедиться, найдя время для установки на Linux-машине такого средства, как collectd, и указания на него в Graphite. Такие вспомогательные подсистемы, как Nginx или Varnish, также раскрывают весьма полезную информацию, например показатели времени откликов или попаданий в кэш-память. Ну а как насчет вашего собственного сервиса?
Я настоятельно рекомендую предусматривать в ваших сервисах выставление основных показателей их работы. В самом скромном варианте для веб-сервиса нужно, наверное, выставить такие показатели, как время отклика и коэффициент ошибок, что будет жизненно важно, если ваш сервер не имеет в качестве внешнего интерфейса веб-сервера, выполняющего эту работу для вас. Но можно пойти и дальше. Например, для сервиса учетных записей может иметь смысл выставить количество просмотров клиентами их последних заказов, а веб-магазину может быть полезно отследить сумму выручки за последний день.
Зачем все это нужно? По целому ряду причин. Во-первых, существует довольно старое поверье, что 80 % возможностей программных средств никогда не используются. Сейчас я не берусь комментировать его точность, но как человек, создающий программные средства почти 20 лет, я знаю, что потратил много времени на разработку возможностей, которые фактически не находили применения. Разве не хочется вам узнать о том, что это за возможности?
Во-вторых, нам непременно нужно реагировать на то, как пользователи используют систему, чтобы вырабатывать свои взгляды на ее улучшение. Показатели, информирующие о поведении системы, могут всего лишь оказать нам помощь в данном вопросе. Мы выдаем новую версию сайта и определяем количество поисков по жанру, поступивших прямо в сервис каталогов. Каков этот показатель, проблематичный или ожидаемый?
И наконец, мы можем никогда не узнать, какие данные окажутся полезными! Бесчисленное количество раз мне хотелось отследить данные, которые могли бы мне помочь понять что-нибудь, только после того, как шанс сделать это был уже упущен. Чтобы справиться с этим позже, я склонялся к ошибке выставления напоказ буквально всего, что можно было, чтобы полагаться на систему показателей.
Для различных платформ существуют библиотеки, позволяющие сервисам отправлять показатели стандартным системам. Одним из примеров такой библиотеки для JVM может послужить Codahale Metrics. Она позволяет сохранять показатели в виде счетчиков, таймеров или измерений, поддерживать показатели за определенный период времени (можно указать показатели вроде «количество заказов за последние пять минут»), а также выходить во внешнюю среду за счет поддержки отправки данных средству Graphite и другим системам объединения данных и создания отчетов.
Искусственный мониторинг
Определить факт работы сервиса в штатном режиме можно попытаться, к примеру приняв решение о том, какой уровень загруженности центрального процессора или какое время отклика считать приемлемым. Если система отслеживания обнаружит, что текущие значения выходят за приемлемый уровень, она может подать сигнал тревоги. На это и не только способно такое средство, как Nagios.
Во многих отношениях эти значения на один шаг отстоят от того, что мы действительно хотим отследить, а именно: работает система или нет? Чем сложнее взаимодействия между сервисами, тем больше мы отдаляемся от фактического ответа на этот вопрос. А что, если запрограммировать системы мониторинга на действия, чем-то напоминающие действия пользователей и способные отрапортовать, если что-нибудь пойдет не так?
Впервые я сделал это в далеком 2005 году. Тогда я входил в небольшую команду ThoughtWorks, создававшую систему для инвестиционного банка. За торговый день происходила масса событий, оказывающих влияние на рынок. Наша задача заключалась в реагировании на эти изменения и отслеживании их влияния на портфолио банка. Работа велась в условиях постановки жестких сроков готовности, и целью было вместить все наши вычисления менее чем в десять секунд после наступления события. Система состояла из пяти отдельных сервисов, из которых минимум один был запущен на вычислительной grid-архитектуре, которая, помимо прочего, забирала неиспользуемые циклы центральных процессоров у примерно 250 хостов на базе настольных систем в пользу банковского центра восстановления после аварий.
Количество активных элементов в системе подразумевало генерирование большого количества шумовых помех от многих собираемых нами низкоуровневых показателей. Мы не могли получить преимущества от постепенного наращивания системы или ее работы в течение нескольких месяцев чтобы понять, как выглядят приемлемые показатели уровня загруженности центрального процессора или даже задержек некоторых отдельных компонентов. Наш подход состоял в выдаче фиктивных событий для оценки части портфолио, не фиксировавшихся нижестоящими системами. Примерно раз в минуту мы заставляли средство Nagios запускать задание командной строки, которое вставляло фиктивное событие в одну из наших очередей. Система его забирала и запускала разнообразные вычисления, как при любом другом задании. Разница заключалась в том, что результаты появлялись в черновой ведомости, использовавшейся только для тестирования. Если новая оценка не появлялась в заданное время, Nagios рапортовал об этом как о возникшей проблеме.
Эти создаваемые нами фиктивные события являли собой пример искусственной транзакции. Мы использовали искусственную транзакцию, чтобы убедиться, что система вела себя семантически правильно. Именно поэтому такая технология зачастую называется семантическим мониторингом.
На практике я убедился в том, что использование искусственных транзакций для подобного семантического мониторинга является намного более удачным индикатором наличия проблем в системе, чем получение тревожных сигналов от низкоуровневых показателей. Но они не подменяют необходимости получения низкоуровневых показателей, поскольку нам все же нужно иметь подробные сведения, когда возникает потребность в определении причин, по которым семантический мониторинг свидетельствует о наличии проблемы.
Реализация семантического мониторинга
В прошлом реализация семантического мониторинга была весьма непростой задачей. Но мир не стоит на месте, а это означает, что теперь мы можем справиться с ней, не прилагая особых усилий! Вам ведь приходилось запускать на вашей системе тесты? Если нет, прочитайте главу 7 и возвращайтесь сюда. Готово? Ну и отлично!
Если посмотреть на имеющиеся тесты, с помощью которых проводится полное тестирование исходного сервиса или даже всей системы, то обнаружится, что у нас есть многое из того, что нужно для реализации семантического мониторинга. Система уже дает нам все зацепки, необходимые для запуска тестов и проверки результатов. Следовательно, почему бы не запустить поднабор этих тестов на постоянной основе, применив его в качестве способа мониторинга нашей системы?
Разумеется, нам нужно сделать кое-что еще. Во-первых, позаботиться о требованиях, предъявляемых к данным наших тестов. Может понадобиться найти способ, позволяющий приспособить тесты к различным актуальным данным, если они со временем изменяются, или же установить разные источники данных. Например, у нас может быть набор фиктивных пользователей, задействованных в производственном режиме с заранее известным набором данных.
Во-вторых, нужно гарантировать, что мы не вызовем случайно непредвиденные побочные эффекты. Друзья рассказали мне историю об одной компании электронной торговли, в которой случайно запустили тесты в отношении производственных систем составления заказов. Они не замечали своей ошибки до тех пор, пока в головной офис не прибыло большое количество посудомоечных машин.
Идентификаторы взаимосвязанности
Когда для того, чтобы предоставить конечному пользователю любую заданную возможность, происходит взаимодействие большого количества сервисов, один инициализирующий вызов может вылиться в генерирование нескольких вызовов нижестоящих сервисов. Рассмотрим пример. Регистрирующийся клиент заполняет в форме все поля, касающиеся его данных, и щелкает на кнопке отправки. Мы с помощью сервиса платежей скрытно проверяем действительность данных его кредитной карты, даем команду почтовому сервису отправить по почте пакет с проспектами, а сервису электронной почты — отправить приветственное сообщение на электронный адрес клиента. А теперь подумаем, что произойдет, если вызов сервиса платежей закончится выдачей случайной ошибки? Более детально устранение сбоев рассматривается в главе 11, а здесь мы поговорим о сложности диагностики причин случившегося.
Если посмотреть в журналы, то ошибка будет зарегистрирована только в сервисе платежей. Если повезет, мы сможем определить, какой запрос стал причиной возникновения проблемы, и даже просмотреть параметры вызова. А теперь примем во внимание, что это слишком простой пример и что исходный запрос может повлечь за собой целую цепочку вызовов нижестоящих сервисов. Может оказаться так, что события, повлекшие за собой сбой, обрабатывались в асинхронном режиме. Как мы сможем реконструировать весь путь вызовов, чтобы воспроизвести и устранить проблему? Зачастую нужно рассмотреть эту ошибку в более широком контексте исходного вызова — иными словами, провести трассировку цепочки вызовов наверх примерно так же, как делается трассировка стека.
Одним из подходов, который может помочь в данной ситуации, является использование идентификаторов взаимосвязанности. Когда делается первый вызов, для него можно сгенерировать глобальный уникальный идентификатор (GUID). Затем (рис. 8.5) он передается по очереди всем последующим вызовам и может быть помещен в ваши журналы в структурированном виде. Это очень похоже на то, что вы уже делали с такими компонентами, как уровень журнала или дата. При правильном применении инструментов объединения журналов после этого появится возможность выполнить трассировку этого события по всей системе:
15-02-2014 16:01:01 Web-Frontend INFO [abc-123] Register
15-02-2014 16:01:02 RegisterService INFO [abc-123] RegisterCustomer ...
15-02-2014 16:01:03 PostalSystem INFO [abc-123] SendWelcomePack ...
15-02-2014 16:01:03 EmailSystem INFO [abc-123] SendWelcomeEmail ...
15-02-2014 16:01:03 PaymentGateway ERROR [abc-123] ValidatePayment ...
Вам, конечно же, следует обеспечить осведомленность каждого сервиса о необходимости передачи идентификатора взаимосвязанности. Здесь нужны стандартизация и настойчивость при внедрении этого правила во всей вашей системе. Но когда это будет сделано, понадобится создать инструментарий для отслеживания всех видов взаимодействия. Этот инструментарий может пригодиться при отслеживании шквала событий, нестандартных случаев или даже идентификации наиболее дорогих транзакций, поскольку можно будет отобразить весь каскад вызовов.
Отследить вызовы, проходящие через несколько системных границ, поможет также такое программное средство, как Zipkin. Основываясь на идеях, заложенных в Dapper — собственной системе отслеживания компании Google, Zipkin может предоставить подробно детализированные результаты отслеживания вызовов между сервисами, а также пользовательский интерфейс, помогающий представить полученные данные. Лично я считаю требования, выдвигаемые Zipkin в плане обычных клиентов и систем сбора данных, несколько тяжеловатыми. При условии, что объединение журналов вам уже требуется для других целей, представляется, что будет намного проще вместо этого воспользоваться уже собранными данными, чем придерживаться обязательств по использованию дополнительных источников данных. Тем не менее, если окажется, что вам для отслеживания подобных межсервисных вызовов нужны более совершенные инструменты, вы можете присмотреться и к ним.
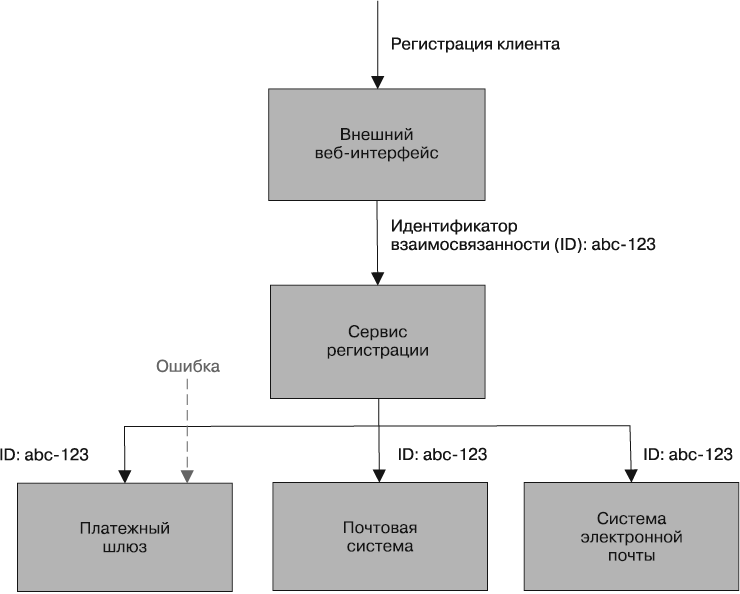
Рис. 8.5. Использование идентификаторов взаимосвязанности для отслеживания цепочек вызовов между несколькими сервисами
Настоящей проблемой, касающейся идентификаторов взаимосвязанности, является то, что зачастую вы не знаете, что нуждаетесь в них, до тех пор, пока не возникнут трудности, причины которых могут быть определены, только если эти идентификаторы использовались с самого начала! Проблема усугубляется тем, что переоснастить код идентификаторами взаимосвязанности очень трудно. С ними нужно будет работать, используя стандартные приемы, чтобы можно было легко провести реконструкцию цепочки вызовов. Изначально все это может показаться дополнительной работой, однако я бы настоятельно рекомендовал вам присмотреться к их размещению в коде при первой же возможности, особенно если предполагается применение в системе архитектурных схем на основе использования событий, что может привести к несколько странно проявляющемуся поведению.
Необходимость выполнения задач, связанных с постоянной передачей по цепочке идентификаторов взаимосвязанности, может стать весомым аргументом для применения узкоспециализированных совместно используемых клиентских библиотек-оболочек. При достижении определенных масштабов становится трудно обеспечить соблюдение всеми однообразных правильных способов вызова нижестоящих сервисов и сбор нужных данных. Достаточно не сделать этого всего лишь одному входящему в цепочку сервису, и важная информация будет утрачена. Если вы решитесь на создание внутренней клиентской библиотеки, позволяющей добиться безупречной работы подобных механизмов, нужно обеспечить ее самую узкую специализацию и отсутствие привязанности к любому отдельно взятому производственному сервису. Например, если вы используете в качестве исходного протокола обмена данными HTTP, то просто сделайте оболочку из стандартной клиентской библиотеки HTTP, добавив в нее код, обеспечивающий распространение идентификаторов взаимосвязанности в заголовках.
Каскадные сбои
Особенно опасными могут стать сбои, имеющие каскадный характер. Представьте себе ситуацию, при которой даст сбой сетевое соединение между сайтом нашего музыкального магазина и сервисом каталогов. Сами сервисы не дают повода сомневаться в их работоспособности, но они не могут обмениваться данными. Если следить только за работоспособностью отдельно взятого сервиса, определить причину возникновения проблемы не удастся. Выявить проблему можно, используя искусственный мониторинг, например при подражании клиенту в поиске песни. Но для определения ее причины нам нужно будет также получить сведения о том, что одному сервису не виден другой сервис.
Поэтому главную роль начинает играть мониторинг точек интеграции систем. Каждый экземпляр сервиса должен отслеживать и показывать общее состояние нисходящих зависимостей от базы данных до других сотрудничающих сервисов. Следует также позволить выполнять объединение этой информации с целью получения развернутой картины происходящего. Нужно будет наблюдать за временем отклика на нисходящие вызовы, а также замечать возвращение сообщений об ошибках.
Для реализации выключателей сетевых вызовов, помогающих разобраться в каскадных сбоях более изящным образом, допускающим постепенное упрощение вашей системы, можно воспользоваться библиотеками, о которых подробнее поговорим в главе 11. Некоторые из этих библиотек, например Hystrix для JVM, неплохо справляются и с предоставлением вам подобных возможностей проведения мониторинга.
Стандартизация
Как уже говорилось, к числу обязательных, постоянно выполняемых работ по соблюдению баланса относится определение тех мест, где допускается принятие решений с узкой направленностью на отдельно взятый сервис, и тех мест, где нужна стандартизация, распространяющаяся на всю систему. Я считаю, что мониторинг является той самой областью, где крайне важна стандартизация. При наличии сервисов, сотрудничающих множеством различных способов для предоставления пользователям возможностей применения нескольких интерфейсов, нужно иметь целостный взгляд на систему.
Можно постараться вести записи в журналах в стандартном формате. Вам определенно понадобится содержать все показатели в одном месте, а также использовать перечень стандартных названий показателей, чтобы не допускать весьма раздражающих моментов, когда у одного сервиса будет показатель под названием ResponseTime, а у другого — точно такой же показатель, но названный RspTimeSecs.
Как всегда, для проведения каждой стандартизации имеются вспомогательные средства. Как уже говорилось, ключом к облегчению данной задачи являются правильные действия, поэтому почему бы не предоставить заранее настроенный образ виртуальной машины с готовыми к работе logstash и collectd наряду с прикладными библиотеками, позволяющими реально упростить общение с таким средством, как Graphite?
Расчет на аудиторию
Все данные собирают для вполне определенной цели. Точнее, мы проводим сбор всех этих данных для разных людей, чтобы помочь им справиться с поставленными перед ними задачами. Эти данные побуждают к действию. Часть данных нужна как сигнал к незамедлительному побуждению к действию нашей команды поддержки, например, в случае, когда не проходит один из тестов искусственного мониторинга. Другая часть данных, наподобие того факта, что нагрузка на центральный процессор увеличилась по сравнению с прошлой неделей на 2 %, потенциально представляет интерес, только если мы выполняем планирование использования ресурсов. Возможно также, что ваш начальник хочет немедленно узнать о том, что после последнего выпуска выручка упала на 25 %, но, скорее всего, волноваться не о чем, так как за последний час поиск по ключевым словам Justin Bieber возрос на 5 %.
То, что нашим людям нужно видеть и на что реагировать прямо сейчас, отличается от того, что им нужно при более глубоком анализе. Поэтому при разделении на категории людей, просматривающих данные мониторинга, нужно исходить из того:
• о чем они хотят знать в текущий момент;
• что им может понадобиться чуть позже;
• как они хотят воспользоваться данными.
Оповещайте о том, что они должны знать прямо сейчас. Создайте большое окно с данной информацией, располагающееся в углу экрана. Предоставьте легкий доступ к данным, о которых они хотят узнать чуть позже. И уделите время общению с ними, чтобы узнать, как они хотят воспользоваться данными. Обсуждение всех нюансов графического отображения количественной информации, конечно же, выходит за рамки данной книги, но для начала отличным подспорьем может послужить прекрасная книга Стивена Фью (Stephen Few) Information Dashboard Design: Displaying Data for Ata-Glance Monitoring (Analytics Press).
Перспективы
Мне известно множество организаций, в которых показатели разбросаны по разным системам. Показатели на уровне приложений, например количество размещенных заказов, оказываются в собственных аналитических системах вроде Omniture, которые зачастую доступны только избранным участникам бизнес-процессов, или же попадают в те страшные хранилища данных, где им и суждено будет сгинуть. Получить отчеты из подобных систем в реальном времени зачастую невозможно, хотя ситуация начинает выправляться. В то же время такие системные показатели, как время отклика, частота появления ошибок и загруженность центрального процессора, хранятся в системах, к которым могут иметь доступ рабочие команды. Эти системы обычно доступны для составления отчетов в реальном времени, и, как правило, их суть состоит в побуждении к немедленному вызову действия.
Исторически сложилось так, что узнавать о бизнес-показателях на день или два позже было вполне приемлемо, поскольку обычно все равно быстро реагировать на эти данные и предпринимать что-нибудь в ответ мы не могли. Но теперь мы работаем в такой обстановке, когда многие из нас могут выдать и несколько выпусков в день. Теперь команды оценивают себя не по тому, сколько пунктов они могут завершить, а по тому, сколько времени будет потрачено на то, чтобы код из ноутбука ушел в производство. В такой среде, чтобы совершать правильные действия, нужно иметь все показатели под рукой. Как ни странно, в отличие от наших операционных систем, те самые системы, которые сохраняют бизнес-показатели, зачастую не настроены на незамедлительный доступ к данным.
Так зачем же обрабатывать оперативные и деловые показатели одинаково? В конечном счете оба типа показателей разбиваются на события, которые свидетельствуют о чем-то случившемся в момент времени X. Следовательно, если есть возможность унифицировать системы, используемые для сбора, объединения и хранения этих событий и открывающие к ним доступ для составления отчетов, то мы получим намного более простую архитектуру.
Частью подобного решения может стать Riemann — сервер событий, позволяющий на довольно высоком уровне выполнять объединение и маршрутизацию событий. В этой же области работает и средство Suro, являющееся конвейером данных компании Netflix. В Suro явным образом обрабатываются как показатели, связанные с пользовательским поведением, так и большинство оперативных данных, фиксируемых в журналах приложений. Затем эти данные могут быть направлены различным системам вроде системы Storm, предназначенной для выполнения анализа в реальном времени, системы Hadoop, служащей для пакетной обработки в автономном режиме, или системы Kibana, предназначенной для анализа журнальных записей.
Многие организации движутся в совершенно ином направлении: отказываются от использования цепочек специализированных инструментальных средств для разных типов показателей и склоняются к применению более универсальных систем маршрутизации событий, способных на существенное расширение. Эти системы используются для предоставления намного большей гибкости при реальном упрощении нашей архитектуры.
Резюме
Итак, мы усвоили довольно большой объем информации! Я попытаюсь свести содержимое главы к нескольким легко воспринимаемым советам.
Для каждого сервиса:
• отслеживайте как минимум возвращающееся время отклика. Затем займитесь частотой появления ошибок, после чего приступайте к работе над показателями на уровне приложения;
• отслеживайте приемлемость всех ответов от нижестоящих сервисов, включая как минимум время отклика при вызовах нижестоящих сервисов, а в лучшем случае — частоту появления ошибок. Помочь в этом могут такие библиотеки, как Hystrix;
• приведите к общему стандарту способ и место сбора показателей;
• помещайте регистрационные записи в стандартном месте и по возможности используйте для них стандартный формат. Если для каждого сервиса будут применяться разные форматы, объединение будет сильно затруднено;
• отслеживайте показатели исходной операционной системы, чтобы можно было выявлять отклоняющиеся от нормы процессы и планировать использование ресурсов.
Для системы:
• объединяйте показатели на уровне хоста, например показатели загруженности центрального процессора с показателями на уровне приложения;
• выбирайте такие инструменты хранения показателей, которые позволяют выполнять их объединение на системном или сервисном уровне и извлекать их для отдельно взятых хостов;
• выбирайте такие инструменты хранения показателей, которые позволяют сохранять данные достаточно долго для того, чтобы можно было отследить тенденции в работе вашей системы;
• используйте для объединения и хранения регистрационных записей единое средство, поддерживающее обработку запросов;
• строго придерживайтесь стандартизации при использовании идентификаторов взаимосвязанности;
• разберитесь, чему для перехода к действию требуется вызов, и выстройте соответствующим образом структуру оповещения и вывода на панель отслеживания;
• исследуйте возможность унификации способов объединения всевозможных показателей, выяснив, пригодятся ли вам для этого такие средства, как Suro или Riemann.
Я также попытался обозначить направление, в котором развивается мониторинг: уход от систем, специализирующихся на выполнении какой-нибудь одной задачи, и переход к разработке типовых систем обработки событий, позволяющих составить более целостное представление о вашей системе. Это очень интересная и постоянно развивающаяся область, и хотя ее полноценное исследование не входит в задачи данной книги, я надеюсь, что для начала полученной вами информации вполне достаточно. При желании расширить познания можете обратиться к моей более ранней публикации Lightweight Systems for Realtime Monitoring (O’Reilly), где глубже рассматриваются как некоторые из этих, так и многие другие идеи.
В следующей главе мы коснемся другого целостного представления наших систем и рассмотрим ряд уникальных преимуществ, предоставляемых архитектурами с высокой степенью детализации в области решения задач обеспечения безопасности, а также ряд сложностей, с которыми при этом придется столкнуться.

