9. Безопасность
Нам уже знакомы истории о пренебрежении мерами безопасности крупномасштабных систем, приведшие к выставлению наших данных на обозрение всякого рода сомнительным личностям. Но в последнее время откровения вроде тех, которыми поделился Эдвард Сноуден, повысили нашу осведомленность о ценности данных о нас, которые хранятся в различных компаниях, а также ценности данных о клиентах, которые мы сами храним в создаваемых нами системах. В этой главе будет дан краткий обзор ряда аспектов безопасности, которые следует принимать во внимание при разработке систем. Несмотря на то что предоставляемая информация не является исчерпывающей, она покажет ряд доступных вам основных вариантов и станет отправной точкой для ваших собственных дальнейших исследований.
Нам нужно подумать о том, в какой защите нуждаются наши данные при их перемещении из одной точки в другую и какая им нужна защита, когда они просто хранятся в системе. Нужно продумать вопросы обеспечения безопасности используемых операционных систем, а также сетевого оборудования. Перед нами обширное поле для размышлений и реальных действий! В какой мере нам следует обезопасить свою систему? Как определить критерии достаточности мер безопасности?
Но, кроме этого, нужно подумать и о людях. Как мы узнаем о том, кто есть кто и как следует действовать дальше? И какое отношение все это имеет к обмену данными между нашими серверами? С этого и начнем.
Аутентификация и авторизация
Когда речь заходит о людях и о том, что вступает во взаимодействие с нашей системой, основными понятиями являются аутентификация и авторизация. В контексте безопасности под аутентификацией понимается процесс подтверждения того, что сторона, заявившая о себе, таковой на самом деле и является. Для человека аутентификация обычно сводится к набору имени и пароля. Предполагается, что только этот человек имеет доступ к такой информации и потому лицо, набравшее ее, и должно быть данным человеком. Разумеется, существуют и другие, более сложные системы. Мой телефон теперь позволяет мне использовать отпечаток пальца, чтобы я мог подтвердить свою личность. В общем смысле, когда речь заходит о том, кто или что проходит аутентификацию, мы называем данную сторону принципалом.
Авторизация представляет собой механизм, с помощью которого мы переходим от принципала к действию, которое ему разрешено совершить. Зачастую, когда принципал проходит аутентификацию, нам предоставляется информация о нем, которая поможет принять решение о том, что ему будет позволено делать. Нам, к примеру, сообщат, в каком отделе или офисе он работает, то есть мы получим те части информации, которые могут использоваться нашей системой для принятия решения о том, что он может, а чего не может делать.
Если речь идет о единых, монолитных приложениях, то аутентификацией и авторизацией для вас занимается само приложение. К примеру, Django, веб-среда языка Python, поставляется с уже готовой системой управления пользователями. Что же касается распределенных систем, нам нужно подумать над созданием более совершенных схем. Мы не хотим, чтобы все регистрировались в различных системах отдельно, применяя для каждой системы разные имена пользователей и пароли. Наша цель состоит в создании единого идентификатора, позволяющего проходить аутентификацию только один раз.
Общепринятые реализации технологии единого входа
Общепринятым подходом к аутентификации и авторизации является использование какого-либо из решений единого входа (SSO). Соответствующие возможности в данной области предоставляются SAML — реализации, доминирующей в области промышленных предприятий, и OpenID Connect. В них применяются более или менее одинаковые основные понятия, хотя терминология немного различается. В данной главе будут использоваться термины, применяемые в SAML.
Когда принципал пытается получить доступ к ресурсу (например, интерфейсу на веб-основе), он перенаправляется на аутентификацию с участием провайдера идентификации. При этом у него могут быть запрошены имя пользователя и пароль или же может быть использовано что-то более совершенное — вроде двухфакторной аутентификации. После того как поставщик убедится в том, что принципал был аутентифицирован, он выдает информацию сервис-провайдеру, позволяя ему решать, нужно ли предоставлять принципалу доступ к ресурсу.
Провайдером идентификации может быть система на внешнем оборудовании или что-нибудь, что находится внутри вашей организации. Например, компанией Google предоставляется провайдер идентификации OpenID Connect. Но промышленным предприятиям свойственно иметь собственного провайдера идентификации, который может быть связан с сервисом каталогов вашей компании. Сервисом каталогов может быть какое-либо средство вроде Lightweight Directory Access Protocol (LDAP) или Active Directory. Эти системы позволяют хранить информацию о принципалах, свидетельствующую о тех ролях, которые они играют в организации. Зачастую сервис каталогов и провайдер идентификации представляют собой единое целое, а иногда они могут быть разделены, но тесно связаны друг с другом. Например, Okta содержит SAML-провайдер идентификации, выполняющий задачи двухфакторной идентификации, но как источник достоверных данных он может быть связан с сервисами каталогов вашей компании.
SAML представляет собой стандарт на основе использования SOAP-протокола, он известен тем, что с ним весьма непросто работать, несмотря на доступность поддерживающих его библиотек и инструментальных средств. OpenID Connect является стандартом, возникшим в качестве конкретной реализации OAuth 2.0 и основанным на способах управления технологией единого входа, принятых Google и рядом других компаний. В нем используются простые REST-вызовы, и, на мой взгляд, это сделано, скорее всего, для проникновения на рынок промышленных предприятий за счет простоты использования. Сейчас главным камнем преткновения является отсутствие поддерживающих его провайдеров идентификации. Для открытых для публичного просмотра сайтов может вполне подойти использование в качестве вашего провайдера средств компании Google, но для внутренних систем или систем, в которых требуются повышенный контроль и отображение того, как и где устанавливаются ваши данные, понадобится собственный домашний провайдер идентификации. На момент написания книги доступными в данном качестве были два из весьма немногих вариантов, OpenAM и Gluu, что не может сравниться с богатством выбора вариантов для SAML (включая средство Active Directory, которое, похоже, получило всеобщее распространение). До тех пор пока имеющиеся провайдеры идентификации не начали поддерживать OpenID Connect, распространение этого средства будет ограничено ситуациями, при которых люди будут вполне удовлетворены использованием публичных провайдеров идентификации.
Итак, несмотря на то, что, на мой взгляд, у OpenID есть будущее, вполне возможно, что на его широкое распространение понадобится время.
Шлюз технологии единого входа
При установке микросервиса вопрос о перенаправлении на провайдера идентификации и о квитировании связи с ним может решаться каждым сервисом. Очевидно, это приведет к многократному дублированию работы. Конечно, в решении вопроса может помочь общая библиотека, но мы ведь должны избегать связанности микросервисов, исходящей от общего кода. К тому же такое решение будет бесполезным в случае использования нескольких различных технологических стеков.
Вместо обременения каждого сервиса решением вопросов управления квитированием с вашим провайдером идентификации можно воспользоваться шлюзом, работающим в качестве прокси-сервера и располагающимся между вашими сервисами и внешним миром (рис. 9.1). Идея состоит в том, что мы можем централизовать поведение для перенаправления пользователя и выполнения квитирования в одном месте.
Но нам еще нужно решить проблему получения расположенными ниже сервисами такой информации о принципалах, как их имена пользователей или роли, которые они играют в организации. Если используется HTTP, эту информацию можно поместить в заголовки. Одним из средств, выполняющих эту задачу за вас, является Shibboleth, использование которого вместе с Apache для получения отличных результатов в управлении интеграцией с провайдерами идентификации на основе SAML мне уже приходилось наблюдать.
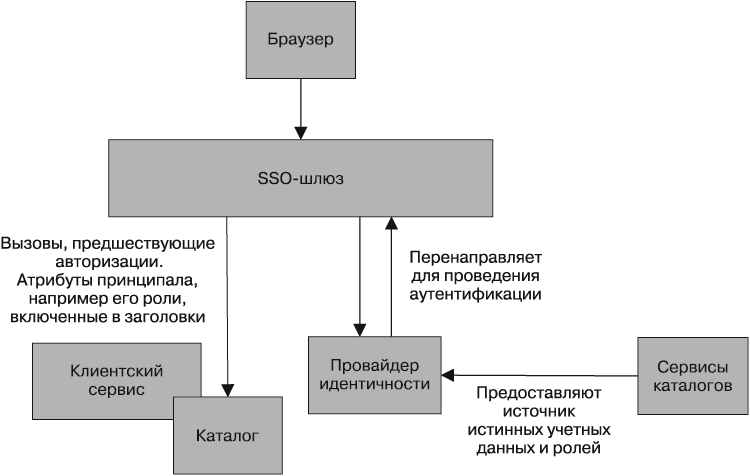
Рис. 9.1. Использование шлюза для управления единым входом (SSO)
Если будет принято решение о том, чтобы переложить ответственность за аутентификацию на шлюз, возникнет еще одна проблема, связанная с затруднениями при осмыслении поведения микросервисов, когда они рассматриваются в изоляции от всего остального. Помните, как в главе 7 исследовались затруднения, связанные с воспроизведением среды, подобной той, в которой ведется работа в производственном режиме? Если вы пойдете по пути использования шлюза, нужно гарантировать разработчикам возможность запуска их сервисов за этим шлюзом без приложения чрезмерных усилий.
И еще одной, последней проблемой, связанной с этим подходом, является возможность возникновения у вас ложного чувства безопасности. Мне нравится идея глубоко эшелонированной обороны — от периметра сети к подсети, брандмауэру, машине, операционной системе, используемому оборудованию. У вас есть возможность реализовать меры безопасности на всех этих рубежах, часть из которых мы вскоре рассмотрим. Мне встречались люди, которые клали все яйца в одну корзину, всецело полагаясь на шлюз. И нам всем известно, что происходит, когда у нас есть единая точка отказа…
Разумеется, шлюз можно применять и для других целей. Например, при использовании уровня Apache-экземпляров, выполняющих Shibboleth, на этом уровне можно также принимать решения о завершении HTTPS, запуске обнаружения вторжений и т. д. Но при этом нужно проявлять осторожность. На уровни шлюзов зачастую возлагается все больше и больше функциональных обязанностей, что может вылиться в возникновение гигантской точки связывания. И чем больше функциональных нагрузок, тем шире становится поле для проведения атак.
Авторизация с высокой степенью детализации
Шлюз может быть в состоянии обеспечить вполне эффективную широкомасштабную аутентификацию. Например, он может воспрепятствовать доступу к приложению технической поддержки любого незарегистрировавшегося пользователя. При условии, что шлюз в результате аутентификации может извлечь атрибуты, касающиеся принципала, можно рассчитывать на возможность принятия более гибких решений. Например, весьма распространено сведение людей в группы или присвоение им тех или иных ролей. Этой информацией можно воспользоваться, чтобы понять, что они могут делать. Следовательно, доступ к приложению технической поддержки можно предоставить только принципалам с конкретной ролью (например, только сотрудникам). Но, кроме разрешения (или запрещения) доступа к конкретным ресурсам или конечным точкам, нам нужно допустить всех остальных к самим микросервисам, а для этого следует принимать дальнейшие решения о том, какие действия разрешать.
Возвращаясь к приложению технической поддержки, нужно решить, следует ли позволять видеть абсолютно все подробности любому сотруднику организации? Скорее всего, их работа будет распределена по ролям. Например, принципалу из группы CALL_CENTER может быть разрешено просматривать любые информационные блоки, относящиеся к клиенту, за исключением подробностей, касающихся его платежей. Принципалу также может быть разрешено выдавать возвраты, но сумма может быть ограничена. А вот сотрудникам, имеющим роль CALL_CENTER_TEAM_LEADER, может быть позволено выдавать более крупные суммы возврата.
По отношению к отдельно взятому микросервису эти решения должны быть локальными. Мне встречались люди, применяющие различные атрибуты, предоставляемые провайдерами идентификации, самым ужасным образом, используя совершенно мелочные роли вроде CALL_CENTER_50_DOLLAR_REFUND (то есть специалист колл-центра с правами возврата сумм до 50 долларов), где они в конечном итоге помещали в свои службы каталогов информацию, относящуюся к какой-то небольшой части одной из характеристик нашего системного поведения. Поддержка таких установок превращается в настоящий кошмар и оставляет для наших сервисов весьма скромные возможности иметь собственный независимый жизненный цикл, поскольку вдруг оказывается, что часть информации, касающейся поведения сервиса, находится за его пределами, возможно, в системе, управляемой другой частью организации.
Вместо этого предпочтение нужно отдавать ролям более общего плана, смоделированным вокруг характера работы вашей организации. Если вспомнить все, о чем говорилось в предыдущих главах, можно сделать вывод: мы стремимся создавать такие программные средства, которые соответствуют порядку работы нашей организации. Поэтому и роли нужно выбирать, руководствуясь тем же принципом.
Взаимная аутентификация и авторизация сервисов
До сих пор термин «принципал» использовался для описания любых субъектов, способных пройти аутентификацию и авторизоваться для выполнения тех или иных действий, но фактически приводимые примеры касались людей, использующих компьютеры. А как насчет программ или других сервисов, проходящих взаимную аутентификацию?
Разрешение всего в пределах периметра
Нашим первым вариантом может быть простое предположение, что любые вызовы сервиса, которые делаются внутри нашего периметра, вызывают безоговорочное доверие.
В зависимости от степени конфиденциальности данных этот вариант может стать вполне приемлемым. Некоторые организации пытаются обеспечить безопасность по периметру своих сетей и, следовательно, предполагают, что, когда два сервиса общаются друг с другом, делать что-либо дополнительно не нужно. Но стоит только взломщику проникнуть в вашу сеть, у вас практически не будет защиты против посреднической атаки. Если взломщик решит перехватить и прочитать отправленные данные, внести в них изменения без вашего ведома или даже при некоторых обстоятельствах подделать диалог, вы об этом можете даже не догадаться.
Доверие внутри периметра, безусловно, наиболее распространенная из встречавшихся мне в организациях форм. Они могут решить запустить этот трафик через HTTPS-протокол, но не более того. Не могу сказать, что это подходящий вариант! Боюсь, что для большинства организаций, в которых я видел использование данной модели, безоговорочная доверительность не являлась осознанным решением, скорее большинство их представителей просто не понимало существующих рисков.
Стандарт HTTP(S) Basic Authentication
Стандарт HTTP Basic Authentication позволяет клиенту отправлять имя пользователя и пароль в стандартном HTTP-заголовке. После этого сервер может проверить эти элементы и подтвердить, что клиенту разрешен доступ к сервису. Преимущество заключается в том, что это предельно понятный и повсеместно поддерживаемый протокол. Проблема в том, что отправка по протоколу HTTP весьма проблематична, потому что имя пользователя и пароль не отправляются в безопасном режиме. Любая промежуточная инстанция может просмотреть информацию, находящуюся в заголовке, и увидеть данные. Поэтому HTTP Basic Authentication следует использовать с привлечением протокола HTTPS.
При использовании HTTPS клиент получает твердые гарантии, что сервер, с которым он ведет обмен данными, является тем самым сервером, с которым клиент задумал связаться. Кроме этого, дается гарантия защиты от подглядываний за трафиком между клиентом и сервером или от манипуляций с полезной нагрузкой.
Серверу нужно управлять собственными SSL-сертификатами, что может стать проблематичным при управлении несколькими машинами. Некоторые организации берут на себя процесс выдачи сертификатов, что становится дополнительной административной и рабочей нагрузкой. Инструментальные средства, занимающиеся автоматизированным управлением этим процессом, еще не достигли достаточного совершенства, и заниматься процессом выдачи вам не стоит. Самостоятельно подписанные сертификаты аннулировать нелегко, и поэтому требуется глубже продумывать сценарии возникновения аварийных ситуаций. Посмотрите, нельзя ли обойтись без всей этой работы, постаравшись полностью избежать применения самостоятельно сделанных подписей.
Еще один недостаток выражается в том, что трафик, проходящий через SSL, не может быть кэширован обратными прокси-серверами, подобными Varnish или Squid. Это означает, что если вам нужно кэшировать трафик, то это следует сделать либо внутри сервера, либо внутри клиента. Положение дел можно исправить, если завершать SSL-трафик в балансировщике нагрузки и размещать кэш-память за этим балансировщиком.
Нужно также подумать о том, что случится, если используется готовое SSO-решение, подобное SAML, у которого уже есть доступ к именам пользователей и паролям. Хотим ли мы, чтобы наш основной сервис аутентификации использовал тот же набор учетных данных, позволяя иметь один процесс для их выдачи и отзыва? Мы могли бы сделать это посредством сервиса, общающегося с тем же самым сервисом каталогов, который поддерживает SSO-решение. В противном случае придется хранить имена пользователей и пароли самостоятельно внутри сервиса, но тогда появится риск продублированности поведения.
Единственное замечание: при таком подходе серверу известно лишь, что у клиента есть имя пользователя и пароль. Мы не имеем ни малейшего понятия, исходит ли эта информация от той машины, от которой мы ее ожидаем, — она может приходить от кого угодно, находящегося в нашей сети.
Использование SAML или OpenID Connect
Если в качестве схемы аутентификации и авторизации вами уже используется SAML или OpenID Connect, этим можно воспользоваться и для взаимодействия между сервисами. Если используется шлюз, весь внутрисетевой трафик нужно будет также направлять через шлюз, но если каждый сервис справляется с интеграцией своими силами, этот подход должен работать просто замечательно. Преимущество заключается в использовании существующей инфраструктуры и получении возможности централизации всех ваших элементов управления доступом к сервисам в центральном сервере каталогов. Если же нужно предотвратить возможность атаки в пути следования данных, передачу все равно следует направлять через HTTPS.
У клиентов для прохождения аутентификации с помощью провайдера идентификации имеется набор учетных данных, который они и используют, а сервис для принятия решения по детализированной аутентификации получает эту информацию. Это означает, что вам нужны учетные записи для ваших клиентов, которые иногда называют учетными записями сервиса. Этот подход довольно часто используют многие организации. Но следует предупредить: если вы собираетесь создавать учетные записи сервисов, постарайтесь сузить рамки их использования. Продумайте возможность наличия у каждого микросервиса собственного набора учетных записей. Это упростит отзыв или изменение доступа в случае компрометации учетных данных, поскольку достаточно будет лишь аннулировать набор затронутых учетных данных.
Но есть еще два недостатка. В первую очередь, так же, как и при использовании Basic Auth, требуется обеспечить надежное хранение учетных данных: где должны находиться имя пользователя и пароль? Клиент должен найти безопасный способ хранения этих данных. Вторая проблема заключается в том, что некоторые технологии, имеющиеся в данной области для проведения аутентификации, требуют довольно утомительного программирования. В частности, SAML превращает реализацию клиента в довольно непростое дело. При использовании OpenID Connect выполняемые действия несколько проще, но, как уже говорилось, эта технология пока еще не имеет хорошей поддержки.
Клиентские сертификаты
Еще один подход к идентификации клиента заключается в использовании возможностей протокола безопасности транспортного уровня (Transport Layer Security (TLS)), последователя SSL, для формирования клиентских сертификатов. Здесь у каждого клиента имеется сертификат X.509, используемый при установке связи между клиентом и сервером. Сервер может проверить аутентичность клиентского сертификата, предоставляя твердые гарантии надежности клиента.
Рабочие задачи по управлению сертификатами здесь еще более обременительны, чем при использовании сертификатов на стороне сервера. И дело не только в ряде основных проблем, касающихся создания большего количества сертификатов и управления ими, а скорее в тех сложностях, которые касаются самих сертификатов. И вы должны быть готовы к тому, чтобы потратить много времени на определение причин, по которым сервис не признает то, что, по вашему мнению, будет совершенно допустимым клиентским сертификатом. И тогда, если произойдет самое худшее, нужно еще взять в расчет сложность аннулирования и повторного выпуска сертификатов. Помочь сможет применение групповых сертификатов, но это не решит всех проблем. Эта дополнительная нагрузка означает, что вы будете присматриваться к использованию данной технологии при особой обеспокоенности о конфиденциальности пересылаемых данных или при отправке данных по сети, не находящейся под вашем полным контролем. Поэтому вы, к примеру, можете принять решение о безопасном обмене только теми данными, которые имеют для сторон особую важность при их отправке по Интернету.
HMAC через HTTP
Как уже говорилось, использовать Basic Authentication через обычный HTTP, если вы обеспокоены компрометацией имени пользователя и пароля, не очень разумно. Традиционной альтернативой служит направление трафика через HTTPS, но у этого способа имеется ряд недостатков. Кроме управления сертификатами, издержки HTTPS-трафика могут стать причиной дополнительной нагрузки на серверы (хотя, если честно, сейчас в таком случае влияние на нагрузку значительно меньше, чем было несколько лет назад), да к тому же имеются сложности с кэшированием такого трафика.
Альтернативный способ подписи запроса, который активно используется API-интерфейсами S3 компании Amazon и является частью OAuth-спецификации, — применение кода проверки подлинности сообщений на основе хеш-функции (HMAC).
При использовании HMAC тело запроса хешируется закрытым ключом и получившийся хеш отправляется вместе с запросом. Затем сервер использует собственную копию закрытого ключа и тело запроса для воссоздания хеша. При совпадении запрос принимается. Приятным обстоятельством является то, что, если где-нибудь на дистанции кто-то проведет какие-либо манипуляции с запросом, хеш не совпадет и сервер будет знать, что запрос был подделан. А закрытый ключ в запросе никогда не пересылается, поэтому он не может быть скомпрометирован в пути! Дополнительным преимуществом является то, что затем трафик может намного легче кэшироваться и издержки на генерирование хешей могут быть намного ниже, чем на обработку HTTPS-трафика (хотя у вас может сложиться и другое мнение).
У этого подхода есть три недостатка. Во-первых, как клиенту, так и серверу нужен общий секрет, который каким-то образом должен быть передан. Как осуществляется его совместное использование? Он должен быть жестко задан на обоих концах, но затем в случае компрометации этого секрета возникнет проблема аннулирования доступа. Если пересылать этот ключ по какому-то альтернативному протоколу, то нужно быть уверенным в том, что этот протокол также обладает весьма высокой степенью безопасности!
Во-вторых, это схема, а не стандарт, поэтому существуют разные способы ее реализации. В результате наблюдается явная нехватка хороших, открытых и практичных реализаций этого подхода. В общем, если этот подход вам интересен, то можете обратиться к дополнительным источникам информации, чтобы разобраться в различных способах его реализации. Я бы предложил просто посмотреть, как он реализован компанией Amazon для ее S3, и скопировать их подход, особенно в использовании рациональной функции хеширования с соответствующим длинным ключом, таким как SHA-256. Стоит также присмотреться к веб-маркерам в формате JSON — JSON web tokens (JWT), поскольку в них реализуется очень похожий подход, который, кажется, набирает обороты. Но при этом имейте в виду, что выполнить все правильно нелегко. Мой коллега работал с командой, которая, занимаясь собственной JWT-реализацией, пропустила одну булеву проверку и сделала недействительным весь свой код аутентификации! Надеюсь, со временем мы увидим реализации библиотек, более пригодные к повторному использованию.
И в-третьих, следует понимать, что этот подход гарантирует только то, что никакая третья сторона не сможет провести манипуляции с запросом и сам закрытый ключ останется закрытым. Все остальные данные в запросе будут по-прежнему видны тем, кто шпионит в сети.
API-ключи
API-ключи используются всеми открытыми API-интерфейсами таких сервисов, как Twitter, Google, Flickr и AWS. API-ключи позволяют сервису идентифицировать того, кто осуществляет вызов, и наложить ограничения на то, что он может сделать. Зачастую ограничения выходят за рамки простого предоставления доступа к ресурсам и могут распространяться на такие действия, как ограничение скорости конкретных абонентов для обеспечения качества предоставления сервиса другим людям.
Когда речь заходит об использовании API-ключей в ваших собственных подходах к обмену данными между микросервисами, конкретный рабочий механизм будет зависеть от используемой технологии. В некоторых системах применяется один общий API-ключ и используется подход, похожий на недавно рассмотренный HMAC. Более распространенный подход заключается в применении пары из открытого и закрытого ключей. Обычно управление ключами осуществляется централизованно, так же, как мы бы централизованно управляли определением идентичности людей. В данной области очень популярна модель шлюза.
Частично популярность API-ключей обусловлена тем фактом, что их применение для программ совсем не сложно. В сравнении с обработкой SAML-квитирования аутентификация на основе API-ключа намного проще и понятнее.
Конкретные возможности систем сильно отличаются друг от друга, и у вас есть несколько вариантов как в коммерческой области, так и в области программ с открытым кодом. Некоторые средства просто обрабатывают обмен API-ключами и выполняют некоторые основные функции управления ключами. Другие средства предлагают все, вплоть до включения ограничения скорости трафика, монетизации, API-каталогов и систем обнаружения.
Некоторые API-системы позволяют создавать мост от API-ключей к существующим сервисам каталогов. Это дает возможность выпускать API-ключи для принципалов (представленных людьми или системами) в вашей организации и следить за жизненным циклом этих ключей примерно так же, как вы бы управляли их обычными учетными данными. Это дает возможность разрешать доступ к вашим сервисам различными способами, но при сохранении единого источника достоверности, например с использованием SAML при аутентификации людей для SSO и API-ключей — при обмене данными между сервисами (рис. 9.2).
Проблема помощника
Аутентификация принципала с помощью отдельно взятого микросервиса осуществляется довольно просто. А что получится, если этому сервису для завершения операции понадобится совершить дополнительные вызовы? Посмотрите на рис. 9.3, где показан сайт интернет-магазина MusicCorp. Наш интернет-магазин представляет собой написанный на JavaScript пользовательский интерфейс, работающий в среде браузера. Он совершает вызовы приложения магазина, находящегося на серверной стороне, используя схему внутренних интерфейсов для внешних интерфейсов, которая рассматривалась в главе 4. Вызовы, осуществляемые между браузером и сервером, могут быть аутентифицированы с помощью SAML, OpenID Connect или подобных им технологий. Пока нас все устраивает.
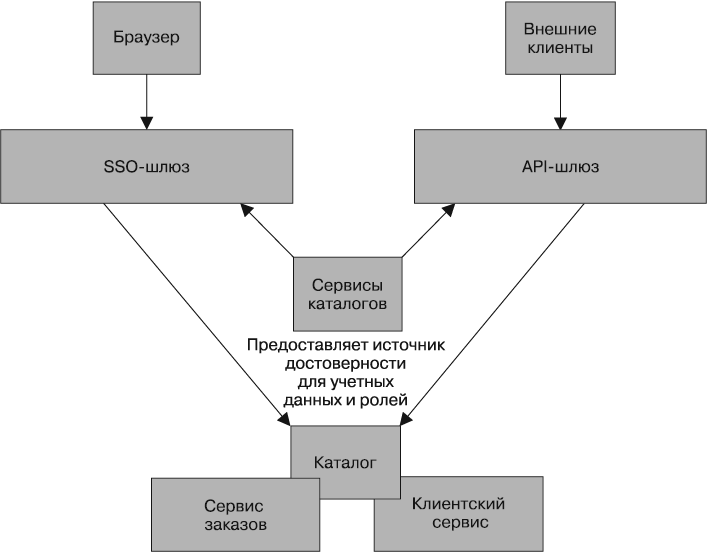
Рис. 9.2. Использование сервисов каталогов для синхронизации информации о принципалах между SSO и API-шлюзом
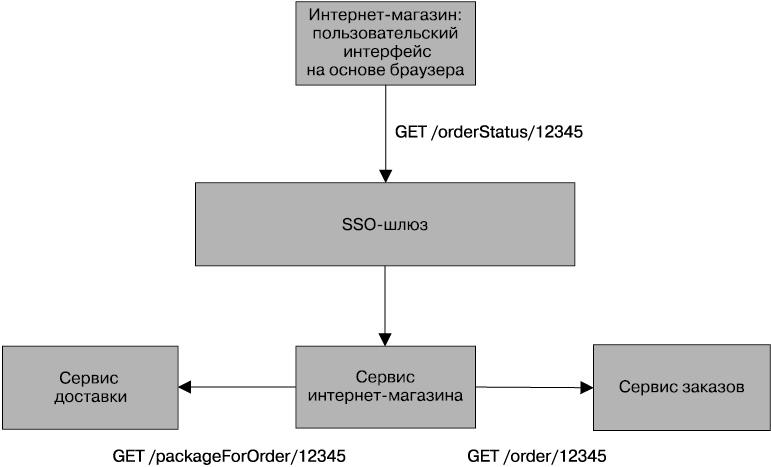
Рис. 9.3. Пример создания ситуации, при которой можно обмануть помощника
После регистрации я могу щелкнуть на ссылке и просмотреть подробности заказа. Для отображения информации следует извлечь исходный заказ из сервиса заказов, но, кроме этого, нужно просмотреть информацию о доставке заказа. Следовательно, щелчок на ссылке /orderStatus/12345 заставит интернет-магазин при запросе подробностей инициировать вызов из сервиса интернет-магазина как к сервису заказов, так и к сервису доставок. Но примут ли эти нижестоящие сервисы вызовы от интернет-магазина? Можно было бы принять установку подразумеваемого доверия, поскольку вызов поступил в границах периметра, что вполне допустимо. Можно было бы даже воспользоваться сертификатами или API-ключами, чтобы подтвердить, что информацию действительно запрашивает интернет-магазин. Но будет ли этого достаточно?
Здесь мы сталкиваемся с уязвимостью, которая называется проблемой обманутого помощника, что в контексте межсервисной связи относится к ситуации, при которой злоумышленник может обмануть сервис-помощник, заставив делать за него вызовы к нижестоящему сервису, на что он не должен быть способен. Например, в качестве клиента после входа в систему интернет-магазина я могу просмотреть подробности своей учетной записи. А что, если я смогу обмануть пользовательский интерфейс интернет-магазина и заставлю его сделать запрос на получение чьих-либо данных, возможно, осуществлением вызова с теми данными учетной записи, с которыми я входил в систему?
Что в данном примере остановит меня от вопросов относительно заказов, не имеющих ко мне никакого отношения? Раз уж я вошел в систему, то могу отправлять запросы, касающиеся чужих, не моих заказов, чтобы посмотреть, не могу ли я извлечь какую-либо полезную для себя информацию. Если такое произойдет, можно попытаться найти защиту внутри самого интернет-магазина, проверяя, какой заказ кому принадлежит, и выдавая отказ, если кто-нибудь станет запрашивать то, что не должен получать. Но если у нас имеется множество различных приложений, выявляющих эту информацию, то потенциально эта логика может быть продублирована в множестве мест.
Можно направлять запросы непосредственно из пользовательского интерфейса к сервису заказов и позволять ему проверять допустимость запроса, но тогда мы столкнемся с проявлением тех недостатков, которые рассматривались в главе 4. В качестве альтернативы при отправке интернет-магазином запроса сервису заказов может сообщаться не только какой именно заказ нужен, но и то, от чьего имени он запрашивается. Некоторые схемы аутентификации позволяют передавать нижестоящим сервисам исходные учетные данные принципала, хотя при использовании SAML это сродни какому-то кошмару с участием вложенных SAML-утверждений, который технически достижимы, но связаны с такими трудностями, что этим никто не хочет заниматься. Конечно же, это может усложниться еще больше. Представьте себе, что будет, если интернет-магазин, в свою очередь, востребует совершение дополнительных нисходящих вызовов. Насколько глубоко мы должны пойти в проверке допустимости для всех этих помощников?
К сожалению, данная проблема в силу своей сложности не имеет легких решений. Но вам следует знать о ее существовании. В зависимости от степени уязвимости рассматриваемой операции вам, возможно, придется выбирать между подразумеваемым доверием, проверкой идентичности вызывающей стороны или запросом у вызывающей стороны учетных данных исходного принципала.
Безопасность данных, находящихся в покое
Мы несем ответственность и за данные, расположенные в разных местах, особенно если речь идет о конфиденциальных данных. Будем надеяться на то, что мы сделали все возможное, чтобы предотвратить доступ злоумышленников в нашу сеть, а также на то, что они не могут взломать наши приложения или операционные системы, чтобы получить доступ к основной закрытой информации. Но мы должны быть готовы к их атакам, и помочь в этом сможет глубоко эшелонированная оборона.
Многие заметные взломы систем безопасности направлены на то, чтобы в руки злоумышленников попали данные, находящиеся в состоянии покоя, и чтобы злоумышленник мог прочитать их. Это случается либо из-за того, что данные хранились в незашифрованной форме, либо из-за того, что механизм, используемый для их защиты, имел существенный недостаток.
Существует множество различных механизмов, позволяющих защитить конфиденциальную информацию, но независимо от того, какой из них будет выбран, существует ряд общих положений, которые нужно учитывать.
Пользуйтесь хорошо известными средствами
Проще всего загубить шифрование данных попыткой реализации собственных алгоритмов шифрования или каких-то совершенно иных приемов шифрования. Независимо от используемого языка программирования вам нужно обращаться к пересматриваемым, постоянно совершенствующимся и заслужившим хорошую репутацию реализациям алгоритмов шифрования. Пользуйтесь именно такими алгоритмами! И подпишитесь на рассылки и консультации по выбранной вами технологии, чтобы быть уверенными в том, что обо всех уязвимостях вы узнаете сразу же, как только их обнаружат, и в том, что вы пользуетесь исправленными и обновленными версиями средств, являющихся реализацией данной технологии.
Что касается шифрования данных, находящихся в покое, то, если у вас нет весьма веских аргументов в пользу чего-либо другого, остановите свой выбор на широко известных реализациях AES-128 или AES-256, предназначенных для вашей платформы. Реализации AES, которые с высокой долей вероятности были всесторонне протестированы (и хорошенько подправлены), имеются в библиотеках времени выполнения как у Java, так и у .NET-технологии. Существуют и отдельные библиотеки для большинства других платформ, например библиотеки Bouncy Castle для Java и C#.
Что касается паролей, вам следует присмотреться к использованию технологии под названием «хеширование паролей со случайным набором символов».
Плохо реализованное шифрование еще хуже, чем его полное отсутствие, поскольку ложное чувство защищенности может привести к потере бдительности.
Все зависит от ключей
До сих пор речь шла о том, что шифрование зависит от реализации алгоритма, получающей шифруемые данные и ключ, после чего выполняющей шифрование данных. А где же хранятся сами ключи? Если я шифрую данные, переживая за то, что кто-нибудь может похитить всю мою базу данных, и храню ключи в той же самой базе данных, то поставленной цели я явно не добьюсь! Поэтому ключи нужно хранить в каком-нибудь другом месте. Но где именно?
Одним из решений может стать использование для шифровки и расшифровки данных отдельного безопасного устройства. Еще одно решение — применение отдельного хранилища ключей, которым ваш сервис может воспользоваться, когда ему понадобится ключ. Важнейшей операцией может стать управление жизненным циклом ключей (и доступ к их изменению), и справиться с этой операцией за вас могут соответствующие системы.
В некоторые системы управления базами данных даже включена встроенная поддержка шифрования, например Transparent Data Encryption в SQL Server, которая нацелена на выполнение данных функций незаметно для пользователей. Даже если выбранная вами база данных способна на подобные действия, разберитесь, как происходит обработка ключей, и выясните, ослабевает ли в результате этого угроза, от которой вы стараетесь защититься.
Еще раз хочу напомнить, что это дело непростое. Не пытайтесь реализовать собственный вариант и хорошенько изучите доступные средства!
Выберите защищаемые объекты
Установка на шифрование абсолютно всех данных может в каком-то смысле упростить ситуацию. Не нужно будет гадать, что стоит, а что не стоит защищать. Но вам все же придется думать о том, какие данные следует помещать в файлы журналов, чтобы проще было разбираться с проблемами. К тому же вычислительные издержки от шифрования всех данных могут стать весьма обременительными, что в результате выльется в необходимость использования более мощного оборудования. Все еще больше усложнится, когда частью ваших схем разбиения функциональных возможностей на более мелкие части станет применение миграций баз данных. В зависимости от характера вносимых изменений могут потребоваться расшифровка данных, их миграция и повторная шифровка.
Разбив вашу систему на большее количество узкоспециализированных сервисов, можно было бы определить единое хранилище данных, которое могло бы быть зашифровано целиком, но сомнительно, что из этого что-либо вышло бы. Более разумно будет зашифровать известный набор таблиц.
Расшифровка по требованию
Шифруйте данные при первой же возможности. Выполняйте их расшифровку только по требованию и сделайте так, чтобы они не могли храниться где-либо еще.
Шифровка резервных копий
Резервное копирование данных считается правилом хорошего тона. Нам необходимо выполнять резервное копирование особо важных данных, и те данные, которые определены как наиболее ценные и подлежащие шифрованию, в силу своей важности также достойны резервного копирования! Казалось бы, это очевидно, но мы все же должны убедиться в том, что резервные копии тоже зашифрованы. Это означает, что нам следует знать, какие ключи понадобятся для обработки той или иной версии данных, особенно если эти ключи меняются. Здесь проявляется особая важность наличия четкой системы управления ключами.
Глубоко эшелонированная оборона
Как уже упоминалось, мне не нравится класть все яйца в одну корзину. Я имею в виду глубоко эшелонированную оборону. Мы уже говорили об обеспечении безопасности передаваемых данных и о защите данных, находящихся в покое. Но можем ли мы повысить безопасность, применив какие-то другие средства защиты?
Брандмауэры
Весьма разумной мерой предосторожности является применение одного или нескольких брандмауэров. Некоторые из них устроены весьма просто и позволяют лишь ограничить доступ определенным типам трафика с помощью конкретных портов. Другие способны на более изощренные действия. ModSecurity, к примеру, является разновидностью приложения-брандмауэра, которое может содействовать дросселированию связи с конкретными диапазонами IP-адресов и определять разновидности попыток взлома.
Имеет смысл воспользоваться более чем одним брандмауэром. Например, вы можете принять решение обеспечивать безопасность хоста локальным использованием таблиц IP-адресов — IPTables, настроив допустимые входы и выходы. Эти правила могут быть привязаны к локально запущенным сервисам, а по периметру может быть выставлен брандмауэр, контролирующий общий доступ.
Регистрация
Качественная регистрация и особенно возможность объединения данных регистрационных журналов нескольких систем не относится к предохранительным мерам, но может способствовать определению причин и ликвидации последствий всевозможных негативных происшествий. Например, после применения исправлений в системе безопасности в журналах зачастую можно наблюдать случаи использования людьми конкретных уязвимостей. Внесение исправлений гарантирует невозможность повторения подобных случаев, но, если это уже произошло, вам может понадобиться перейти в режим восстановления данных. Доступность журналов позволяет отследить наступление неблагоприятных событий.
Но при этом следует иметь в виду, что к информации, которую мы сохраняем в журналах, нужно относиться со всей ответственностью! Конфиденциальную информацию следует отсеивать, чтобы гарантировать отсутствие утечки через журналы важных данных, которые могут стать отличной целью для взломщиков.
Система обнаружения (и предотвращения) вторжений
Система обнаружения вторжений (IDS) может вести мониторинг сетей или хостов с целью обнаружения подозрительного поведения и оповещения о проблемах по мере их возникновения. Система предотвращения вторжений (IPS) вдобавок к мониторингу подозрительных действий способна вмешиваться в них, не давая им совершиться. В отличие от брандмауэра, который в первую очередь анализирует окружающую обстановку, препятствуя проникновению вредоносного кода, IDS и IPS активно выискивают подозрительное поведение внутри периметра. Когда все начинается с нуля, благоразумнее устанавливать IDS. Эти системы основаны на эвристическом анализе, как и многие приложения-брандмауэры, и вполне возможно, что универсальный стартовый набор правил будет либо слишком мягким, либо недостаточно мягким по отношению к поведению вашего сервиса.
Использование более пассивной IDS-системы для предупреждения о возникающих проблемах может стать неплохим способом настройки правил, прежде чем вы перейдете к использованию более активных возможностей.
Обособление сетей
При использовании монолитной системы возможности структурирования сетей для предоставления дополнительной защиты ограничены. Но, применяя микросервисы, вы можете поместить их в разных сегментах сети, чтобы получить дополнительный контроль над тем, как сервисы общаются друг с другом. К примеру, AWS дает возможность автоматического предоставления виртуального закрытого облака (VPC), позволяющего хостам находиться в отдельных подсетях. Затем можно указать, какие VPC-облака могут видеть друг друга, установив правила пиринга, и даже направлять трафик через шлюзы для доступа к прокси-серверу, очерчивая фактически несколько периметров, на которых могут быть предприняты дополнительные меры безопасности.
Это дает вам возможность сегментировать сети на основе командной принадлежности или, возможно, степени риска.
Операционная система
Работа систем зависит от большого количества программных средств, создаваемых не нами, и может иметь уязвимости с точки зрения безопасности, которые способны отразиться на нашем приложении (имеются в виду операционные системы и другие вспомогательные средства, под управлением которых оно работает). Здесь вам может пригодиться ряд рекомендаций общего плана. Начните с запуска сервисов исключительно в качестве пользователей операционной системы, имеющих как можно меньше прав доступа, чтобы при компрометации их учетной записи мог быть нанесен минимальный вред.
Затем вносите исправления в свои программные средства. И делайте это регулярно. Этот процесс должен быть автоматизирован, и вы должны быть осведомлены о том, что ваши машины не синхронизированы с самыми последними пакетами исправлений. Здесь могут пригодиться такие средства, как SCCM от компании Microsoft или Spacewalk от RedHat, которые могут оповестить вас о том, что на машине не установлены самые последние исправления, и, если требуется, инициировать обновление программных средств. Если используются такие средства, как Ansible, Puppet или Chef, то проблем с автоматизированным получением изменений у вас, скорее всего, нет, поскольку эти средства могут успешно решать эту задачу, но абсолютно все за вас они делать не будут.
Именно такие средства и нужно использовать, но, как ни удивительно, мне довольно часто приходилось видеть, как весьма важные программные средства запускались на старых операционных системах без внесенных в них последних исправлений. Вы можете использовать наиболее известную и самую защищенную в мире систему безопасности на уровне приложения, но если при этом на вашей машине в качестве основы запущена старая версия веб-сервера с неисправленной ошибкой переполнения буфера, система по-прежнему будет слишком уязвимой.
Если вы используете Linux, то нужно обратить внимание также на наличие модулей безопасности для самой операционной системы. К примеру, AppArmour позволяет определить ожидаемое поведение вашего приложения и в нем имеется ядро, которое будет постоянно следить за приложением. Как только оно начнет делать что-нибудь, чем не должно заниматься, ядро вмешается в его работу. Кроме AppArmour, имеется также SeLinux. Хотя с технической точки зрения оба модуля могут работать на любой современной Linux-системе, на практике некоторые дистрибутивы поддерживают один из них лучше, чем другой. К примеру, AppArmour используется по умолчанию в Ubuntu и SuSE, а SELinux традиционно хорошо поддерживается дистрибутивом RedHat. Самым последним вариантом таких модулей является GrSSecurity, разработанный с прицелом на то, чтобы стать проще в использовании, чем AppArmour или GrSecurity, и с попыткой расширения до их возможностей, но ему для работы требуется собственное ядро. Я бы советовал присмотреться ко всем трем модулям, чтобы понять, который из них вам больше подойдет, но мне нравится идея использования в работе еще одного уровня защиты и профилактики.
Рабочий пример
Наличие системной архитектуры, состоящей из узкоспециализированных сервисов, дает нам больше свободы в реализации системы безопасности. Для тех частей, которые работают с наиболее конфиденциальной информацией или предоставляют наиболее полезные возможности, можно избрать оснащение с наиболее жесткими мерами безопасности. Насчет же других частей системы степень своего беспокойства можно значительно снизить.
Вернемся к проекту MusicCorp, объединив ряд концепций, чтобы посмотреть, где и в какой степени следует применить ряд технологий обеспечения безопасности. Основное внимание мы уделим обеспечению безопасности передаваемых и просто хранящихся данных. На рис. 9.4 показан поднабор всей системы, подлежащий анализу и страдающий от нашего вопиющего невнимания к вопросам его безопасной работы. Все данные здесь отправляются с использованием простого старого протокола HTTP.
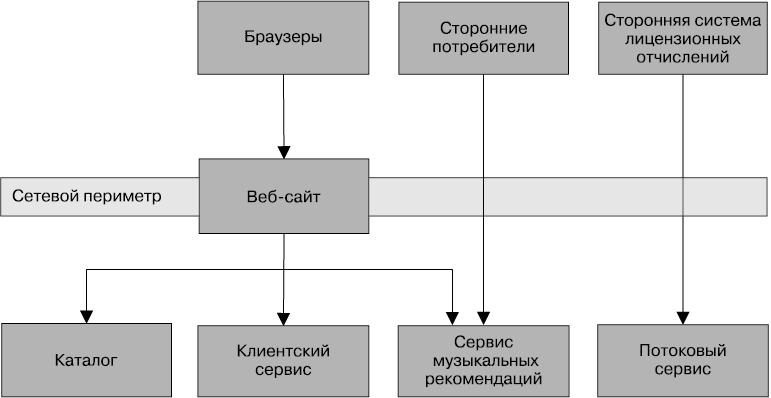
Рис. 9.4. Поднабор проекта MusicCorp, который, к сожалению, не обладает безопасной архитектурой
Здесь имеются стандартные браузеры, которые наши клиенты используют для осуществления покупок в магазине. Здесь также вводится концепция стороннего шлюза лицензионных отчислений: мы начали работать со сторонней компанией, которая будет заниматься лицензионными отчислениями для нашего нового потокового сервиса. Она выходит с нами на связь, чтобы забрать записи о том, какая музыка и когда была востребована потоковым сервисом, то есть получить информацию, которую мы старательно скрываем от конкурирующих компаний. И наконец, мы выставляем напоказ данные нашего каталога для других сторонних организаций, позволяя им, к примеру, вставлять в сайты музыкальных ревю метаданные об артистах и песнях. Внутри нашего сетевого периметра имеется несколько сотрудничающих сервисов исключительно для внутреннего потребления.
В браузере мы будем использовать сочетания стандартного HTTP-трафика для незащищенного содержания, чтобы ему было позволено находиться в кэше. Все надежно защищенное содержимое безопасных, прошедших регистрацию страниц будет отправляться по протоколу HTTPS, который обеспечит клиентам дополнительную защиту, если они будут пользоваться, к примеру, открытыми WiFi-сетями.
Что же касается сторонней системы лицензионных отчислений, то нас волнует не только характер выставляемых данных, но и легитимность получаемых запросов. Здесь мы настаиваем на том, чтобы сторонние партнеры пользовались клиентскими сертификатами. Все данные отправляются по надежному зашифрованному каналу, увеличивая возможность убедиться в том, что их запросил известный нам человек. Нам, конечно же, нужно подумать и о том, что произойдет, если данные выйдут из-под нашего контроля. Будет ли наш партнер заботиться о них так же тщательно, как и мы?
Что касается снабжения данными каталога, нам бы хотелось, чтобы эта информация распространялась как можно шире, облегчая людям покупку нашей музыки! Но нам не хочется, чтобы этой возможностью злоупотребляли, а также хочется знать, кто использует наши данные. В этом случае наиболее подходящими для нас будут API-ключи.
Внутри сетевого периметра все обстоит немного тоньше. Как противодействовать тем, кто пытается пробраться в нашу сеть? В идеале нам хотелось бы как минимум воспользоваться протоколом HTTPS, но управлять им довольно хлопотно. Вместо этого мы решили (хотя бы на первых порах) поместить всю работу в прочный сетевой периметр, имеющий настроенный соответствующим образом брандмауэр и выбирающий для отслеживания вредоносного трафика (например, сканирования портов или атак, вызывающих отказ от обслуживания) подходящее оборудование или программные приспособления для обеспечения безопасности.
При этом мы побеспокоились о некоторых наших данных и о тех местах, где они находятся. Нас не волнуют данные сервиса каталогов, ведь мы же сами захотели, чтобы они попали в общее пользование, и даже предоставили для этого соответствующий API-интерфейс! Но нас очень беспокоит безопасность клиентских данных. Поэтому мы решили зашифровать данные, хранящиеся в клиентском сервисе, и расшифровывать их при чтении. Если взломщики проберутся в нашу сеть, они смогут выдавать запросы к нашему API-интерфейсу клиентской службы, но текущая реализация не позволит извлекать клиентские данные в больших объемах. Если же реализация позволяет подобные действия, то лучше рассмотреть возможность использования для защиты информации клиентских сертификатов. Даже если взломщики проникнут в машину и в запущенную на ней базу данных и распорядятся скачать все ее содержимое, им понадобится доступ к ключу, чтобы расшифровать данные, которыми они собираются воспользоваться.
На рис. 9.5 показана окончательная картина происходящего. Как видите, наш технологический выбор основан на понимании характера защищаемой информации. Возможно, у вас будут совершенно иные взгляды на обеспечение безопасности используемой архитектуры, тогда вы сможете остановиться на решениях, не похожих на эти.
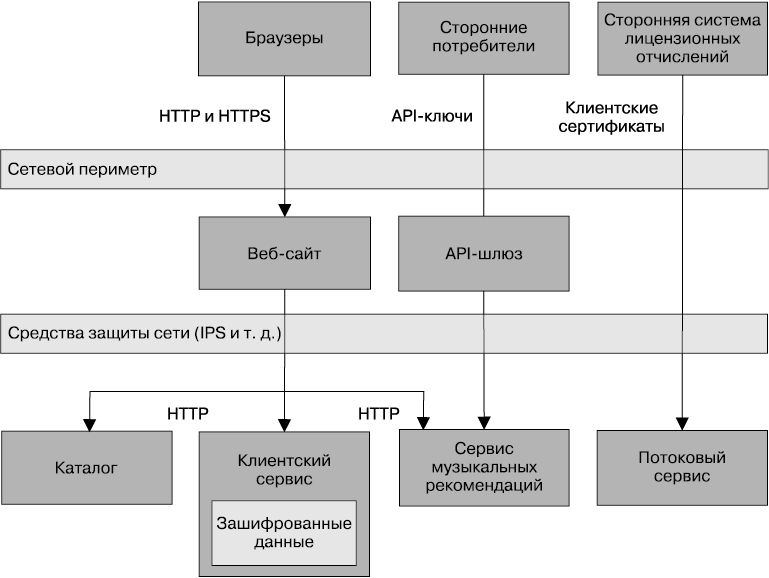
Рис. 9.5. Более безопасная система, используемая в проекте MusicCorp
Проявляйте сдержанность
По мере удешевления дискового пространства и роста возможностей баз данных получать и сохранять большие объемы информации становится все проще. Эти данные имеют ценность не только для бизнеса как такового, который все чаще рассматривает их в качестве ценного актива, но в равной степени и для пользователей, заботящихся о своей неприкосновенности. К данным, относящимся к индивидууму или позволяющим получить о нем информацию, нужно относиться с особым вниманием.
А что, если нам упростить ситуацию? Почему бы не стереть как можно больше личной информации и не сделать это как можно раньше? Нужно ли нам при регистрации запроса пользователя навечно сохранять весь IP-адрес или можно заменить последние несколько цифр символами «x»? Нужно ли сохранять чьи-то имя, возраст, пол и дату рождения, чтобы выложить предложения о покупке товара, или достаточно будет информации о примерном возрасте и почтового индекса?
Положительно ответив на эти вопросы, можно получить множество преимуществ. Во-первых, если не хранить эти данные, то никто их не сможет украсть. Во-вторых, если они у вас не хранятся, то никто (например, какое-нибудь правительственное агентство) не сможет их запросить!
Эту концепцию хорошо поясняет немецкий термин Datensparsamkeit (означающий минимизацию данных). Появившись в немецком законодательстве о конфиденциальности, он является воплощением концепции хранения только той информации, которая необходима для выполнения бизнес-операций или соответствия местным законам. Вполне очевидно, что это противоречит тенденции к хранению все более солидных объемов информации, но это толчок к пониманию того, что противоречие все же существует!
Человеческий фактор
Основная часть того, о чем здесь говорилось, касается основ реализации технологических мер безопасности для защиты ваших систем и данных от внешних взломщиков-злоумышленников. Но вам также нужны процессы и политики, имеющие дело с человеческим фактором в вашей организации. Как аннулировать доступ к учетным данным, когда кто-нибудь уйдет из организации? Как защититься от социальной инженерии? В качестве неплохого умственного упражнения рассмотрим, какой ущерб может нанести раздосадованный бывший сотрудник вашей системе, если ему захочется это сделать. Для того чтобы придумать защитные меры, неплохо будет поставить себя на место потенциального вредителя, ведь никакие злоумышленники не знают вашу организацию изнутри так хорошо, как бывший сотрудник!
Золотое правило
Если вам больше нечего почерпнуть из данной главы, возьмите хотя бы это: не создавайте собственную систему шифрования. Не изобретайте собственные протоколы системы защиты. Вы все равно не сможете изобрести ничего путного в шифровании или разработке криптографических средств защиты, если только вы не специалист по криптографии с многолетним стажем. Но, даже являясь специалистом в этой области, вы все равно можете сделать что-нибудь не так.
Многие из ранее упомянутых средств, подобных AES, представляют собой весьма зрелые промышленные технологии, в основу которых положены алгоритмы, прошедшие коллегиальное рецензирование, программная реализация которых тщательно тестировалась и исправлялась в течение многих лет. Эти средства вполне успешно справляются со своими задачами! Зачастую изобретение колеса превращается в пустую трату времени, но, когда дело касается безопасности, такая изобретательская деятельность может стать весьма рискованным занятием.
Создание системы безопасности
Как и в случае с автоматизированным функциональным тестированием, мы не хотим, чтобы вопросами безопасности занимались разные группы людей и делали это в последнюю очередь. Главное — помочь разработчикам в разъяснении проблем безопасности, поскольку подъем общего уровня информированности каждого разработчика о проблемах безопасности может в первую очередь сократить количество таких проблем. Для начала неплохо бы ознакомить людей с десятью самыми значимыми уязвимостями из открытого проекта обеспечения безопасности веб-приложений — списком OWASP Top Ten и средой тестирования безопасности — OWASP Security Testing Framework. Специалисты, конечно, народ занятой, но если у вас есть с ними деловой контакт, то попросите их помочь в данном вопросе.
Существует ряд автоматизированных инструментальных средств, способных испытать вашу систему на наличие уязвимостей, например на возможность атак с применением межсайтовых сценариев. Хорошим примером может послужить средство Zed Attack Proxy, известное также как ZAP. Будучи проинформированным о результатах работы, ZAP предпринимает попытки воссоздания вредоносных атак на ваш сайт. Существуют и другие средства, использующие статический анализ с целью поиска распространенных ошибок программирования, которые могут стать прорехами в системе безопасности, например Brakeman для Ruby. Если эти средства легко интегрировать в обычные CI-сборки, их следует включить в стандартные проверочные процедуры. Другие виды автоматизированного тестирования — более сложная процедура. Например, использование средств, подобных Nessus, для сканирования на предмет обнаружения уязвимостей происходит немного сложнее и может потребовать для интерпретации результатов человеческого вмешательства. Тем не менее эти тесты все же поддаются автоматизации, и, может быть, имеет смысл запускать их на том же этапе, что и нагрузочные тесты.
Хорошие разновидности моделей создания систем безопасности для команд поставки имеются также у разработанного компанией Microsoft процесса создания безопасных программных средств — Security Development Lifecycle. Некоторые аспекты этого процесса кажутся излишними, но вам нужно в нем разобраться, чтобы понять, какие из аспектов вписываются в ваш рабочий процесс.
Внешняя проверка
Я полагаю, что в вопросах обеспечения безопасности важную роль может сыграть возможность дать внешнюю оценку проделанной работе. Такие действия, как тест на проникновение, проводимые внешней стороной, фактически имитируют реальные попытки взлома. Тем самым можно будет взглянуть на работу со стороны и заметить допущенные командой ошибки, которые порой из-за близости проблемы к команде ей самой не видны. Если ваша компания довольно велика, в ней может существовать специально выделенная команда, занимающаяся безопасностью информационных систем, которая может помочь в этом деле. Если такой команды у вас нет, подыщите внешних исполнителей, способных выполнить эту работу. Обратитесь к ним заранее, выясните, как они хотели бы работать и сколько дней им нужно потратить на тестирование.
Следует также определить объем проверочной работы, который требуется выполнить перед каждым выпуском. Как правило, для небольших дополнительных выпусков проводить, к примеру, полный тест на проникновение не нужно, а при больших изменениях в выпусках он может оказаться весьма кстати. Ваши потребности зависят от выбранной степени допустимого риска.
Резюме
Итак, мы опять возвращаемся к основной теме книги, в которой утверждается, что наличие системы, разбитой на узкоспециализированные сервисы, дает нам множество вариантов решения проблемы. Возможность использования микросервисов не только позволяет уменьшить влияние любой отдельной бреши в системе безопасности, но и дает нам больше возможностей найти компромиссы в отношении издержек, связанных с более сложными и безопасными подходами в работе с конфиденциальными данными, и выбрать менее сложные подходы в тех случаях, когда риски оцениваются значительно ниже.
Как только вы осознаете уровни угроз для различных частей системы, вы должны приступить к осмыслению того, когда следует рассматривать вопросы обеспечения безопасности: при передаче данных, их хранении или ни в одном из этих процессов.
Наконец, вам следует осознать важность глубоко эшелонированной обороны и обеспечить постоянное внесение исправлений в используемую операционную систему. Но даже если вы считаете себя непревзойденным специалистом, не следует пытаться реализовать собственную криптографическую систему!
Если вы желаете ознакомиться с общим обзором решения проблем безопасности для приложений, создаваемых на основе использования браузера, то для начала хорошим подспорьем станет некоммерческий проект обеспечения безопасности веб-приложений Open Web Application Security Project (OWASP), в рамках которого постоянно обновляется документ, содержащий описание десяти наиболее существенных угроз безопасности, — Top 10 Security Risk, который должен стать настольным пособием для каждого разработчика. И наконец, если у вас есть желание получить более развернутое представление о криптографии, присмотритесь к вышедшей в издательстве Wiley книге Cryptography Engineering Нильса Фергюсона (Niels Ferguson), Брюса Шнайера (Bruce Schneier) и Тадаёси Коно (Tadayoshi Kohno).
Освоение мер безопасности зачастую зависит от сознательности людей и приемов их работы с нашими системами. Один еще не рассмотренный с точки зрения использования микросервисов аспект касается взаимодействия организационных структур и самих архитектур. Но, как и в вопросах обеспечения безопасности, мы увидим, что игнорирование человеческого фактора может стать весьма серьезной ошибкой.
В принципе, длина ключа увеличивает объем работы, требующейся для его взлома. Поэтому можно предположить, что чем длиннее ключ, тем лучше защищены ваши данные. Но весьма уважаемым специалистом в области обеспечения безопасности Брюсом Шнайером (Bruce Schneier) в отношении AES-256 для конкретных типов ключей были выявлены некоторые незначительные проблемы. Это одна из тех областей, в которых в ходе чтения данной книги нужно дополнительно просмотреть все последние советы специалистов!

