Книга: Вероятности и неприятности. Математика повседневной жизни
Назад: Как возможность ошибиться делает науку наукой
Дальше: Где заканчивается свобода в математике?
Запутываем статистикой и помогаем распутаться
Очень важно подчеркнуть: если статистические данные говорят о том, что нулевая гипотеза может быть отвергнута, это не значит, что мы тем самым доказали истинность какой-либо альтернативной гипотезы. Вспомним постулат Персига: «Число разумных гипотез, объясняющих любое данное явление, бесконечно». Опровержение нулевой гипотезы не делает все остальные верными. Отвергая ее, мы освобождаем место для нового умозаключения, как в легенде об убийстве деспота-дракона.
Вообще математическая статистика и теория вероятностей рассуждают вовсе не о ложности или истинности каких-либо утверждений. Их следует крайне осторожно смешивать с логикой; здесь кроется масса трудноуловимых ошибок, особенно когда в дело вступят зависимые события. Вот пример такого смешения. Очень маловероятно, что человек может стать папой римским (примерно один к семи миллиардам); следует ли из этого, что папа Иоанн Павел II не был человеком? Утверждение кажется абсурдным.
А вот другой пример: проверка показала, что мобильный тест на содержание алкоголя в крови дает не более 1 % как ложноположителых, так и ложноотрицательных результатов. Следовательно, в 98 % случаев он верно выявит пьяного водителя. Это правильный вывод, но он вступает в кажущееся противоречие со следующими рассуждениями. Протестируем 1000 водителей, и пусть 100 из них будут действительно пьяны. В результате мы получим 900 × 1 % = 9 ложноположительных и 100 × 1 % = 1 ложноотрицательный результат: на одного проскочившего пьяницу придется девять невинно обвиненных случайных водителей. Выходит, речь должна идти лишь о 10 % правильных ответов, а не о 98 %. Чем не закон подлости! Паритет возникнет, только если доля пьяных водителей окажется равна 1/2 либо если отношение долей ложноположительных и ложноотрицательных результатов будет близким к реальному отношению пьяных водителей к трезвым. Причем чем трезвее обследуемая нация, тем несправедливее будет применение описанного нами прибора!
Здесь мы столкнулись с зависимыми событиями. Введем понятие условной вероятности — вероятности наступления одного события, если известно, что произошло другое событие. Для двух событий A и B (причем P(B)>0) она обозначается P(A|B) и вычисляется следующим образом:
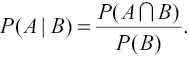
Пример: мы бросили игральную кость. Пусть событие A = {выпала 1}. P(A) = 1/6. Пусть теперь известно, что при бросании произошло событие B = {выпало нечетное число}. Теперь, очевидно, вместо шести возможных вариантов есть всего три, так что P(A|B) = 1/3. Именно это мы и получаем по нашему определению: A∩B = {выпала 1}, P(A∩B) = 1/6, P(B) = 1/2, откуда 1/6:1/2=1/3.
Если наступление события B не меняет вероятность наступления события A, то должно быть P(A|B) = P(A). В силу определения условной вероятности это значит, что P(A∩B) = P(A)P(B). Это соотношение оказывается определением важнейшего понятия в теории вероятностей — независимости: события A и B называются независимыми, если P(A∩B) = P(A)P(B). Определение работает, даже если вероятности событий A или B равны 0.
Из определения условной вероятности можно получить выражение для пересечения произвольных событий:
P(A∩B) = P(A)P(B).
Пересечение множеств — операция коммутативная, A∩B = B∩A. Отсюда немедленно следует, что P(A∩B) = P(B∩A), и теорема Байеса:
P(A|B)P(B) = P(A∩B),
которую можно использовать для вычисления условных вероятностей.
Применим эти новые определения и соотношения, чтобы разобраться в примере с водителями и тестом на алкогольное опьянение. Мы имеем следующие события: A — водитель пьян, B — тест выдал положительный результат. Вероятности: P(A) = 10 % — для случая, когда остановленный водитель пьян; P(B|A) = 99 % — тест выдаст положительный результат, если известно, что водитель пьян (исключается 1 % ложноотрицательных результатов), P(A|B) = 99 % — тестируемый пьян, если тест дал положительный результат (исключается 1 % ложноположительных результатов). Вычислим вероятность того, что тест даст верный результат, не обвинит невиновного и не пропустит виноватого. Оба эти варианта независимы и вероятность того, что не случится ни та, ни другая ошибка, равна P(B|A)P(A|B) = 98,02 %. Это близко к тому, что ожидалось интуитивно. О чем же мы рассуждали, говоря о несправедливости теста? Мы вычислили P(B) — вероятность получить положительный результат теста на дороге:
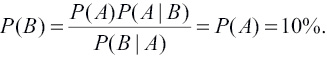
Понятие условной вероятности позволяет корректно вести логические рассуждения на языке теории вероятностей. Неудивительно, что теорема Байеса нашла широкое применение в теории принятия решений, системах распознавания образов, спам-фильтрах, программах, проверяющих тексты на плагиат, и многих других информационных технологиях. Подобные примеры тщательно разбираются студентами, изучающими медицинские тесты или юридические практики. Но, боюсь, журналистам и политикам не преподают ни математическую статистику, ни теорию вероятностей. Зато они охотно апеллируют к статистическим данным, вольно интерпретируют их и несут полученное «знание» в массы.
Разберем еще один пример ошибочной интерпретации статистических данных. В июне 2011 года был выпущен публичный отчет о росте уровня занятости в США, он составил 18 тысяч новых работников по всей стране. В газетах штата Висконсин об этом была опубликована статья, в которой отмечалось, что более половины роста (9,8 тысячи человек) приходится именно на этот штат. Статья завершалась хвалебным отзывом о плодотворной работе правительства штата и позже с удовольствием цитировалась политиками и чиновниками. Притом что обе цифры верны и подтасовок в них нет, штат Висконсин никак не может претендовать на доминирующий вклад в общий рост уровня занятости. В том же году в штате Массачусетс появилось 10,4 тысячи новых рабочих мест (58 % от общей цифры), а в Калифорнии — 28,8 тысячи (160 %). Я полагаю, читатель начинает догадываться, что приводимые тут проценты не имеют большого смысла, поскольку в этом же году в ряде штатов, например в Миссури или Вирджинии, произошло сокращение рабочих мест. Таким образом, 18 тысяч — сумма всех положительных и отрицательных изменений.
Назад: Как возможность ошибиться делает науку наукой
Дальше: Где заканчивается свобода в математике?

