Чего еще предстоит добиться ИИ?
Достижения последних лет показывают, что мы уже далеко продвинулись по пути создания нейросетей, возможности которых сравнимы с мощью новой коры головного мозга. На сегодняшний день ИИ не хватает способностей учитывать контекст, использовать здравый смысл и участвовать в социальном взаимодействии.
Контекстная память – это способность отслеживать, каким образом меняются связи между мыслями, которые мы выражаем в ходе разговора или переписки. Количество возможных связей между идеями растет экспоненциально с увеличением длины контекста, который мы учитываем. В начале этой главы мы рассуждали о потолке сложности – те же закономерности работают и здесь. Поэтому задача расширения контекста, учитываемого языковой моделью, невероятно трудна с вычислительной точки зрения126. Если в предложении содержится 10 идей, каждую из которых можно обозначить словом (то есть токеном), то количество возможных взаимосвязей между ними равно числу подмножеств множества из 10 элементов и составляет 210–1, то есть 1,023. А если в одном параграфе будет 50 таких идей, это даст 1,12 квадриллиона возможных контекстных связей между токенами! Хотя большинство из этих гипотетических связей не имеют под собой оснований, тем не менее перебрать их все и запомнить контекст для главы или целой книги становится непосильной задачей. Именно поэтому GPT-4 постепенно забывает сказанное вами по ходу разговора. По этой же причине чат-бот пока не может написать роман со связным и логичным сюжетом.
Есть две хорошие новости: во-первых, разработчики успешно решают задачу по проектированию ИИ, который будет в состоянии сосредоточиться только на важных элементах контекста, а во-вторых, экспоненциальный рост вычислительной мощности, скорее всего, приведет к снижению стоимости вычислительных ресурсов на 99 % за следующие 10 лет127. Более того, совершенствование алгоритмов и разработка специализированного оборудования для задач ИИ приведут к тому, что соотношение цена/производительность для систем, на которых работают языковые модели, улучшится еще сильнее128. Например, только с августа 2022 по март 2023 года стоимость обработки одних и тех же токенов через API GPT-3.5 снизилась на 96,7 %129! Эта тенденция еще усилится благодаря тому, что ИИ будет активно участвовать в проектировании чипов, что уже начинает происходить130.
Еще одним важным аспектом, с которым пока не может справиться искусственный интеллект, является способность рассуждать, опираясь на здравый смысл. Речь идет об умении вообразить различные обстоятельства или предвидеть последствия своих действий в реальном мире. Например, вы, возможно, никогда не задумывались, что произойдет, если в вашей комнате внезапно «выключится» гравитация, однако вы легко нарисуете у себя в голове эту картину и к чему этот случай приведет. Мы задействуем этот тип мышления при установлении причинно-следственных связей. Если у вас есть собака, а по возвращении домой вы обнаружите разбитую вазу, вам не составит труда догадаться, что произошло. Несмотря на то что периодически у ИИ случаются подобные озарения, в целом он испытывает большие трудности с такими умозаключениями. Все потому, что у него пока нет полной модели реального мира, а обучающие данные редко содержат такие скрытые знания.
Наконец, в текстовых базах данных не всегда можно найти достаточно информации о тонкостях общения, таких как ирония в голосе. А ведь именно на текстовых данных в основном и обучается искусственный интеллект. Без такого рода знаний сложно создать «модель психики человека», то есть научиться понимать, что другие имеют взгляды и знания, отличающиеся от ваших; ставить себя на их место; делать предположения об их намерениях. Однако ИИ быстро развивается в этом направлении. В 2021 году Блез Агиера-и-Аркас, почетный сотрудник исследовательского центра компании Google, представил доклад о том, как нейросеть LaMDA справилась с классическим тестом на понимание чужого сознания из области детской психологии131. В рассмотренном сценарии Алиса забывает очки в тумбочке и выходит из комнаты. Пока ее нет, Боб достает очки из тумбочки и прячет их под подушку. Вопрос: где Алиса будет искать очки, когда вернется? LaMDA дала верный ответ: в тумбочке. За последние два года модели PaLM и GPT-4 значительно улучшили свои способности давать правильные ответы на вопросы, связанные с пониманием работы разума и психики. Развитие этой функции позволит ИИ обрести гибкость мышления, которой ему пока не хватает. Например, человек, играющий в го, способен не только демонстрировать высокий уровень игры, но и обращать внимание на происходящее за соседними столами, отпускать шутки в подходящий момент, а также прервать игру, если кому-то из окружающих понадобится медицинская помощь.
Мой оптимизм в отношении будущего искусственного интеллекта основывается на трех стремительно развивающихся тенденциях: во-первых, снижение стоимости вычислений делает процесс обучения глубоких нейронных сетей более доступным; во-вторых, благодаря накоплению обширных и подробных наборов тренировочных данных обучение становится более конструктивным; в-третьих, развитие алгоритмов позволяет ИИ учиться и делать выводы более эффективно132. Хотя с 2000 года стоимость вычислительных ресурсов падает вдвое примерно каждые 1,4 года, фактически после 2010-го нам удается удваивать количество операций, используемых при обучении передовых нейросетей, всего за 5,7 месяца, то есть за весь период это число выросло в 10 миллиардов раз133. Для сравнения: до появления нейросетей глубокого обучения, а именно с 1952 года (когда появилась первая система машинного обучения, за шесть лет до разработки знаменитого перцептрона) по 2010 год (когда начался расцвет эпохи больших данных), количество операций, используемых для обучения ИИ, удваивалось каждые два года. Это примерно соответствует закону Мура 134.
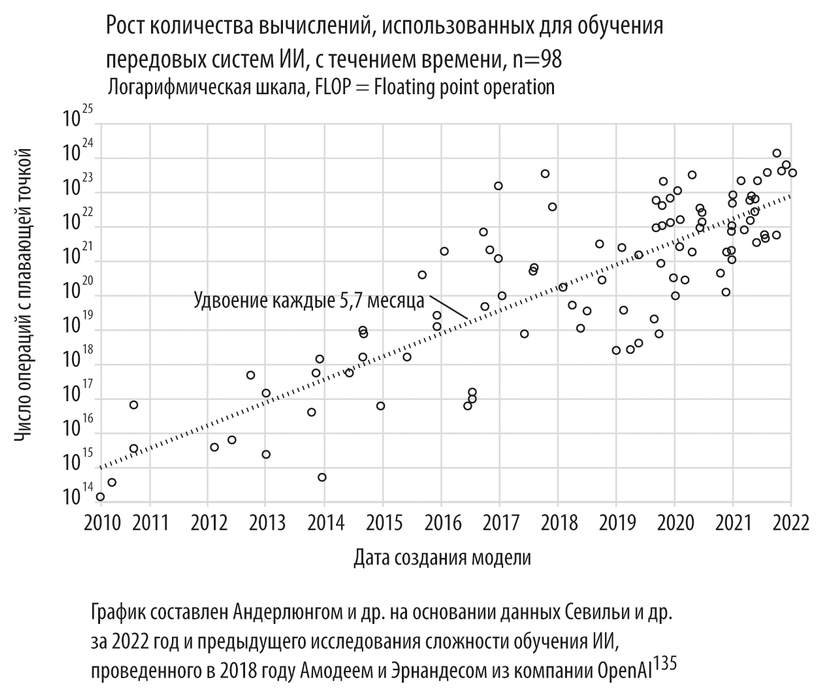
Если бы тенденция, наблюдавшаяся с 1952 по 2010 год, сохранилась до 2021 года, то за эти 11 лет вычислительная сложность обучения нейронной сети увеличилась бы менее чем в 75 раз вместо 10 миллиардов. Такой значительный скачок нельзя объяснить только уменьшением стоимости вычислений, поэтому дело не в революционном развитии аппаратного обеспечения. Основную роль сыграли два фактора. Во-первых, программисты разработали новые методы параллельных вычислений, что позволило задействовать больше чипов при работе над одной задачей машинного обучения. Во-вторых, благодаря большим объемам данных глубокое обучение стало более эффективным. В результате инвесторы по всему миру начали вкладывать больше средств в эту отрасль, надеясь на появление прорывных технологий.
Расходы на обучение искусственного интеллекта растут параллельно с увеличением объема полезных данных. За последние несколько лет стало окончательно ясно, что любая задача, для которой можно четко определить критерии успеха, может быть решена с помощью модели глубокого обучения на уровне, значительно превышающем человеческий.
Люди обладают множеством навыков, весьма неоднородных в том, что касается доступности данных для обучения. Для некоторых умений можно привести количественную оценку, и собрать обучающую выборку тоже не составит труда. Например, при игре в шахматы существуют три возможных исхода: победа, поражение или ничья, а система рейтинга Эло предоставляет удобный способ ранжировать оппонентов в соответствии с уровнем мастерства. Данные для тренировки тоже удобно строить, поскольку игра состоит из дискретных ходов и протокол партии можно представить в виде математической последовательности. Некоторые навыки в принципе измеримы, но сбор и анализ данных по ним существенно затруднены. Представление интересов в суде имеет однозначный итог: победа или проигрыш. Однако достоверно выделить вклад юриста в исход дела по сравнению с тем, насколько сильны были позиции сторон изначально и как сказался настрой присяжных, уже гораздо труднее. А каким образом можно оценить способности писать стихи или держать в напряжении читателей мистического романа? Но даже в этих случаях можно выработать вспомогательные методики для обучения ИИ. К примеру, читатели могли бы давать оценку поэтичности стихотворения по стобалльной шкале. Другим вариантом может быть использование данных функциональной магнитно-резонансной томографии (фМРТ) для оценки активности определенных зон мозга. Частота сердечных сокращений или уровень кортизола могут дать представление о степени вовлеченности читателя. Таким образом, даже если данных для обучения недостаточно, можно использовать косвенные и не вполне точные показатели, чтобы помочь ИИ совершенствоваться. Другое дело, что поиск таких метрик потребует изобретательности и готовности экспериментировать.
Новая кора человеческого мозга может составить некоторое представление о тренировочном наборе данных, но грамотно спроектированная нейронная сеть способна находить такие закономерности, которые биологическому мозгу попросту недоступны. Достаточный набор данных обеспечит сверхчеловеческий уровень анализа в самых разных задачах: поиск игровой стратегии, вождение автомобиля, постановка диагноза на основе снимков, моделирование структуры белковых молекул. Таким образом, тщательный сбор данных, на который ранее исследователи предпочитали не тратить ресурсы, теперь становится экономически оправданным.
В каком-то смысле данные – новая нефть, месторождения которой существенно отличаются в плане доступности136. Где-то нефть бьет из-под земли, остается только очистить и переработать без больших затрат. В других случаях требуется расходовать средства на бурение, гидроразрыв пласта или нагрев скалы для извлечения нефти из сланца. Когда цена на сырье падает, нефтяные компании начинают разработку только простых и дешевых месторождений. Однако по мере роста цен становится экономически выгодным добывать нефть из более труднодоступных запасов.
Аналогичным образом, когда анализ больших объемов данных не давал ощутимой выгоды, компании собирали информацию только в тех областях, где это не требовало больших затрат. Но по мере развития методов машинного обучения и удешевления оборудования экономическая (а заодно и социальная) значимость труднодоступных данных будет только возрастать. В самом деле, буквально за последний год или два наши возможности по сбору, хранению, сортировке и анализу информации, касающейся человеческих навыков, значительно расширились137. В Кремниевой долине все только и говорят о больших данных, и не зря: фундаментальное преимущество этой технологии в том, что благодаря ей методы машинного обучения начинают приносить практическую пользу, что было невозможно при использовании малых объемов данных. В течение 2020-х годов этот процесс затронет практически все человеческие навыки.
Говоря о прогрессе ИИ в освоении отдельных навыков, стоит упомянуть любопытный факт. Мы привыкли думать о человеческом интеллекте как о некоей цельной сущности, которой ИИ либо обладает, либо нет. Но гораздо точнее и полезнее с практической точки зрения рассматривать человеческий разум как хитросплетение множества различных когнитивных навыков. Частью из них, например способностью узнавать себя в зеркале, обладают даже высокоразвитые животные, такие как слоны или шимпанзе. Другие, такие как умение сочинять музыку, доступны исключительно людям, и то не всем в равной степени. Умственные способности могут различаться не только от человека к человеку; в рамках одной личности навыки тоже бывают выражены в очень разной степени. Кто-то может быть математическим гением, но ужасно играть в шахматы; или обладать эйдетической (фотографической) памятью, но совершенно не уметь общаться с людьми. Прекрасным примером является герой Дастина Хоффмана в кинофильме «Человек дождя».
Когда разработчики ИИ говорят об интеллекте уровня человеческого, они обычно имеют в виду возможности лучших представителей нашего вида в конкретной области. В каких-то задачах даже очень талантливый человек ненамного превосходит среднестатистического, например, в распознавании букв родного алфавита. В то же время в других областях, таких как исследования по теоретической физике, разница между обычным человеком и мастером своего дела поистине огромна. В последнем случае может пройти ощутимо больше времени между тем, когда ИИ научится выполнять работу на уровне обычного человека и сумеет превзойти мастеров. Пока сложно сказать, какие именно навыки машинам будет труднее всего освоить. Возможно, в 2034 году ИИ будет легко писать музыкальные хиты и завоевывать премии «Грэмми», но не сможет сочинить сценарий, достойный премии «Оскар»; решит математические «Задачи тысячелетия», но не предложит новых философских концепций. Таким образом, переходный период после того, как ИИ пройдет тест Тьюринга и превзойдет человека почти во всех областях, но все еще будет уступать гениям в некоторых особых навыках, может оказаться достаточно долгим.
Применительно к достижению Сингулярности главное – это умение программировать вычислительную технику, а также владение сопутствующими дисциплинами, таками как теоретические компьютерные исследования. Это ключевое умение, которое позволит создать сверхмощный ИИ. Как только мы разработаем ИИ, способный обучать себя программированию (самостоятельно либо с помощью программиста-ассистента), запустится цикл положительной обратной связи. Ирвинг Джон Гуд, коллега Алана Тьюринга, еще в 1965 году предвидел, что такой механизм приведет к «взрывному росту интеллекта»138. Компьютеры работают быстрее людей, поэтому, исключив программистов из процесса разработки ИИ, можно добиться невероятного прогресса. Теоретики в сфере ИИ в шутку называют этот феномен «ФУУУМ», как будто график результатов ИИ выходит за пределы шкалы, сопровождаемый звуковым эффектом из комиксов139.
Часть исследователей, например Элиезер Юдковский, считает, что этот переход произойдет крайне быстро, сродни вертикальному взлету, и займет считаные месяцы, если вообще не минуты. Другие, в частности Робин Хэнсон, уверены, что процесс будет идти постепенно, аналогично плавному «набору высоты», на протяжении нескольких лет140. Я придерживаюсь промежуточной позиции. На мой взгляд, физические ограничения, такие как недостаточная мощность аппаратного обеспечения, а также нехватка ресурсов и актуальных данных, не дадут «ФУУУМу» произойти мгновенно. Однако нам необходимо продумать план действий на случай, если вертикальный взлет пойдет не по выгодному для нас сценарию. Важно помнить, что взрывной рост способностей позволит ИИ быстро овладеть и другими навыками, более сложными для него, чем самопрограммирование.
Машинное обучение становится все более экономичным, поэтому маловероятно, что именно вычислительная мощность станет сдерживающим фактором в создании разума уровня человеческого. Суперкомпьютеры уже с большим запасом укладываются в требования, которые ставит перед ними задача симуляции мозга человека. В 2023 году самый мощный суперкомпьютер Frontier, построенный Национальной лабораторией Ок-Риджа, уже способен выполнять порядка 1018 вычислений в секунду141, что превосходит предполагаемую максимальную производительность человеческого мозга (1014 операций в секунду) в 10 000 раз142.
В книге «Сингулярность уже близка» я приводил оценку вычислительной мощности мозга: 1016 операций в секунду. Эта величина получилась с учетом того, что в мозгу содержится порядка 1011 нейронов, от каждого из которых отходит по 103 синапсов, способных посылать 102 сигналов в секунду143. Однако, как я тогда же отметил, мне нужна была верхняя оценка. На самом деле, как показывают исследования, мозг выполняет намного меньшее количество операций каждую секунду. Нейроны активируются гораздо реже, чем мы предполагали: не двести раз в секунду, как это могло бы быть теоретически, а примерно один раз в секунду144. Более того, исследователи в проекте AI Impacts, проанализировав потребление энергии мозгом, предположили, что каждый нейрон в среднем возбуждается 0,29 раза в секунду145. Это означает, что общее количество операций за секунду может составлять всего лишь 1013. Ханс Моравец, используя другой метод, получил такую же оценку, опубликованную в его книге «Дети разума: перспективы интеллекта роботов и людей»146.
Мы все еще рассуждаем в предположении, что для функционирования разума необходимы все нейроны мозга, хотя уже знаем, что это не так. Параллелизм операций в мозгу еще плохо изучен, но известно, что отдельные нейроны и целые модули выполняют дублирующие функции или операции, которые хотя бы в теории могли бы осуществляться в другой области. Подтверждением тому служат истории полного восстановления работоспособности людей после инсультов или травм, затрагивающих часть мозга147. Так что объем вычислений, необходимый для моделирования нейронных структур, имеющих отношение к разуму, будет еще скромнее, чем приведенные выше оценки. Поэтому величина 1014 операций в секунду кажется надежной верхней границей. По состоянию на 2023 год такое быстродействие может обеспечить электроника стоимостью всего в тысячу долларов148. Даже если в итоге потребуется 1016 операций в секунду, к 2032 году мы сможем уложиться в ту же сумму149.
Все эти оценки основываются на моем убеждении, что система, имитирующая активацию нейронов, станет полноценной моделью мозга. Может оказаться, что для возникновения субъективного сознания потребуется более подробная симуляция. Это философский вопрос, ответ на который нельзя найти с помощью научного метода. Тем не менее не исключено, что потребуется смоделировать отдельные ионные каналы внутри нейронов или взаимодействие молекул тысяч различных веществ, участвующих в обменных процессах в клетке. По оценкам Андерса Сандберга и Ника Бострома из оксфордского Института будущего человечества, описанные уровни абстракции потребуют выполнения 1022 или 1025 операций в секунду соответственно150. Но даже в последнем случае, согласно их расчетам, суперкомпьютер стоимостью в 1 миллиард долларов (в ценах 2008 года) сможет обеспечить необходимую вычислительную мощность к 2030 году. А к 2034 году такой компьютер и вовсе будет в состоянии смоделировать каждую молекулу белка каждого нейрона151. Со временем, конечно же, экспоненциальный рост эффективности вычислений значительно сократит эти затраты.
Я хотел бы еще раз подчеркнуть: даже при существенном изменении требований к симуляции мой основной прогноз остается в силе – компьютерное моделирование человеческого мозга в любой интересующей нас форме станет реальностью в ближайшие пару десятилетий, а не через сто лет. Так что именно нам, а не нашим внукам, предстоит разбираться с последствиями. Уже с 2020-х годов продолжительность жизни будет увеличиваться быстрыми темпами. Если вам сейчас меньше 80 лет и вы относительно здоровы, вы, вероятно, увидите это событие своими глазами. Тест Тьюринга будет пройден, когда дети, родившиеся в наше время, пойдут в начальную школу. А функциональная модель мозга будет создана, когда они будут учиться в колледже. И последняя точка отсчета: я заканчиваю писать эту книгу в 2023 году. Похоже, мы уже ближе к созданию полной модели мозга, чем к моменту выхода моей первой книги «Век духовных машин» в 1999 году, когда я впервые озвучил свои прогнозы.

