Глава 4
Классификация
Меня окружают человеческие черепа. В этой комнате их почти пятьсот, собранных в первые десятилетия 1800-х годов. Все они покрыты лаком, а на лобной кости черными чернилами написаны номера. Аккуратные каллиграфические круги отмечают участки черепа, ассоциирующиеся в френологии с определенными качествами, включая «Благожелательность» и «Почитание». Некоторые описания сделаны большими буквами, например, слова «Голландец», «Перуанец из расы инков» или «Лунатик». Каждый из них был тщательно взвешен, измерен и промаркирован американским краниологом Сэмюэлем Мортоном. Мортон был врачом, естествоиспытателем и членом Академии естественных наук Филадельфии. Он собирал человеческие черепа со всего мира, сотрудничая с сетью ученых и охотников за черепами, которые приносили образцы для его экспериментов, иногда разграбляя могилы. К концу своей жизни в 1851 году Мортон собрал более тысячи черепов – самую большую на тот момент коллекцию в мире. Большая часть архива сейчас хранится в отделе физической антропологии Пеннского музея в Филадельфии.
Мортон не принадлежал к классическим френологам, поскольку не верил, что характер человека можно узнать по форме головы. Скорее, его целью являлась «объективная» классификация и ранжирование человеческих рас путем сравнения физических характеристик черепов. Для этого он разделил их на пять «рас» мира: африканскую, коренную американскую, европеоидную, малайскую и монгольскую – типичная таксономия того времени и отражение колониалистского менталитета, который доминировал в его геополитике. Это была точка зрения полигенизма – вера в то, что различные человеческие расы развивались отдельно в разное время – узаконенная белыми европейскими и американскими учеными, и приветствуемая колониальными исследователями как оправдание расистского насилия и лишения собственности. Краниометрия стала одним из их ведущих методов, поскольку претендовала на точную оценку различий и достоинств человека.
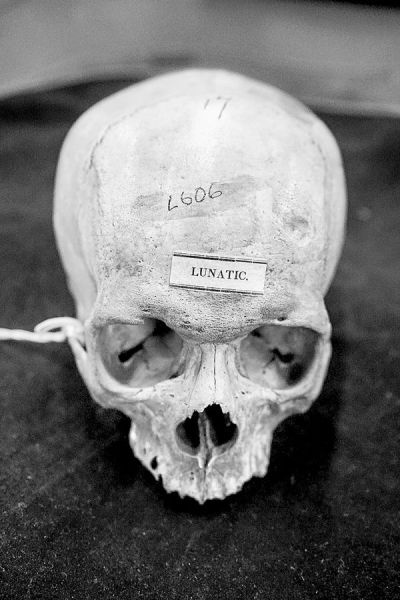
Череп из коллекции черепов Мортона с надписью «Лунатик». Фотография Кейт Кроуфорд
Многие из черепов, которые я вижу, принадлежат людям, родившимся в Африке, но умершим в рабстве в Америке. Мортон измерял их, заполняя черепные полости свинцовой дробью, затем заливая дробь обратно в цилиндры и измеряя объем свинца в кубических дюймах. Он опубликовал результаты исследований, сравнив их с теми черепами, которые он приобрел в других местах: например, он утверждал, что у белых людей самые большие черепа, а чернокожие люди находятся в нижней части шкалы. Таблицы Мортона со средним объемом черепа в зависимости от расы считались передовым достижением науки того времени. На его работы ссылались до конца века как на объективные, неопровержимые данные, доказывающие относительный интеллект человеческих рас и биологическое превосходство европеоидной расы. Эти исследования использовались в США для поддержания законности рабства и расовой сегрегации. Считаясь научным достижением того времени, они использовались для оправдания расового угнетения еще долгое время после того, как на эти исследования перестали ссылаться.
Однако работа Мортона оказалась не тем доказательством, каким изначально планировала быть. Как описывает Стивен Джей Гулд в своей книге «Неправильное измерение человека»:
Одним словом, если говорить начистоту, резюме Мортона – это лоскутное одеяло из подтасовок и махинаций в явных интересах контроля априорных убеждений. Тем не менее – и это самый интригующий аспект его дела – я не нахожу никаких доказательств сознательного мошенничества. С другой стороны, распространенность бессознательного мошенничества позволяет сделать общий вывод о социальном контексте науки. Ведь если ученые могут честно обманываться до такой степени, как Мортон, то предварительные предубеждения можно найти где угодно, даже в основах измерения костей и подсчета сумм.
Гулд и многие другие после него повторно взвесили черепа и перепроверили доказательства Мортона. Мортон допустил ошибки и просчеты, а также процедурные упущения, такие как игнорирование основного факта, что более крупные люди имеют более крупный мозг. Он выборочно отобрал образцы, которые поддерживали его убеждение о превосходстве белых, и удалил те из них, которые отклонялись от средних показателей по группам. Современная оценка черепов в Пеннском музее не выявила существенных различий между людьми – даже при использовании данных Мортона. Однако прежние предрассудки – способ видения мира – сформировали то, что Мортон считал объективной наукой, и это была замкнутая петля, которая повлияла на его выводы не меньше, чем сами черепа, наполненные свинцом.
Краниометрия являлась, как отмечает Гулд, «ведущей числовой наукой биологического детерминизма в девятнадцатом веке» и была основана на «вопиющих ошибках» с точки зрения основных исходных предположений: что размер мозга равен интеллекту; что существуют отдельные человеческие расы, которые являются отдельными биологическими видами; и что эти расы можно расположить в иерархии в соответствии с их интеллектом и врожденным характером. В конечном итоге эта наука была развенчана, но, как утверждает Корнел Уэст, ее доминирующие метафоры, логика и категории не только поддерживали господство белой расы, но и делали возможными определенные политические идеи.
Наследие Мортона предвещает эпистемологические проблемы с измерением и классификацией в искусственном интеллекте. Соотнесение морфологии черепа с интеллектом и претензиями на законные права служит техническим алиби для колониализма и рабства. Хотя и существует тенденция сосредоточиться на ошибках в измерениях черепа и на том, как их исправить, гораздо большая проблема кроется в мировоззрении, лежащем в основе этой методологии. Таким образом, цель должна состоять не в том, чтобы призвать к более точным или «справедливым» измерениям черепа для укрепления расистских моделей интеллекта, а в том, чтобы полностью осудить этот подход. Практика классификации, которую использовал Мортон, изначально была политической, а его ошибочные предположения об интеллекте, расе и биологии имели далеко идущие социальные и экономические последствия.
Политика классификации является основной практикой в искусственном интеллекте. Практика классификации определяет, как распознается и производится машинный интеллект – от университетских лабораторий до технологической индустрии. Как мы убедились в предыдущей главе, артефакты превращаются в данные путем извлечения, измерения, маркировки и упорядочивания, и это становится – намеренно или нет – скользкой базовой истиной для технических систем, обученных на этих данных. И когда системы ИИ показывают дискриминационные результаты по расовым, классовым, гендерным, инвалидным или возрастным категориям, компании сталкиваются со значительным давлением, заставляющим их реформировать свои инструменты или диверсифицировать данные. Однако в результате часто получается узконаправленный ответ, обычно представляющий собой попытку устранить технические ошибки и исказить данные, чтобы система ИИ выглядела более справедливой. При этом часто отсутствует более фундаментальный набор вопросов: как классификация функционирует в машинном обучении? Что стоит на кону? Каким образом она взаимодействует с классифицируемыми? И какие негласные социальные и политические теории лежат в ее основе?
В своем знаковом исследовании классификации Джеффри Боукер и Сьюзен Ли Стар пишут, что «классификации – это мощные технологии. Встроенные в рабочие инфраструктуры, они становятся относительно незаметными, не теряя при этом своей силы». Классификация – это акт власти, будь то маркировка изображений в обучающих наборах ИИ, отслеживание людей с помощью распознавания лиц или заливка свинцовой дроби в черепа. Тем не менее, классификации могут исчезать, как отмечают Боукер и Стар, «в инфраструктуре, в привычке, в чем-то само собой разумеющемся». Мы запросто можем забыть, что классификации, случайно выбранные для создания технической системы, способны играть динамическую роль в формировании социального и материального мира.
Стремление сосредоточиться на проблеме предвзятости в искусственном интеллекте отвлекает нас от оценки основных методов классификации в ИИ, а также от сопутствующей им политики. Чтобы рассмотреть этот вопрос в действии, в настоящей главе мы изучим некоторые обучающие наборы данных двадцать первого века и проследим, как их схемы социального упорядочивания натурализуют иерархии и увеличивают неравенство. Мы также рассмотрим границы дебатов о предвзятости в ИИ, где математический паритет часто предлагается для создания «более справедливых систем» вместо того, чтобы бороться с лежащими в основе социальными, политическими и экономическими структурами. Короче говоря, мы рассмотрим, как искусственный интеллект использует классификацию для кодирования власти.
Системы циркулярной логики
Еще десятилетие назад предположение о том, что в искусственном интеллекте может существовать проблема предвзятости, считалось неординарным. Однако сейчас примеры дискриминационных систем многочисленны: от гендерной предвзятости в алгоритмах кредитоспособности Apple до расизма в программе оценки криминальных рисков COmpAS и возрастной предвзятости в таргетинге рекламы Facebook. Инструменты распознавания изображений неправильно классифицируют лица темнокожих; чат-боты используют расистские и женоненавистнические выражения; программы распознавания голоса не различают женские голоса, а платформы социальных сетей показывают больше объявлений о высокооплачиваемой работе мужчинам, чем женщинам. Как продемонстрировали такие ученые, как Руха Бенджамин и Сафия Ноубл, существуют сотни примеров во всей экосистеме технологий. И многие из них никогда не были обнаружены или публично признаны.
Типичная структура одного из эпизодов в продолжающемся повествовании о предвзятости ИИ начинается с журналистского расследования или разоблачителя, раскрывающего, как система ИИ дает дискриминационные результаты. Эта история получает широкое распространение, и компания, о которой идет речь, обещает решить эту проблему. Затем либо система заменяется чем-то новым, либо производятся технические вмешательства в попытке получить результаты с большим паритетом. Эти результаты и технические усовершенствования остаются закрытыми и секретными, а общественность успокаивают тем, что болезнь предвзятости «вылечена». Гораздо реже проводятся публичные дебаты о том, почему эти формы дискриминации повторяются и не кроются ли здесь более фундаментальные проблемы, чем просто неадекватный базовый набор данных или плохо продуманный алгоритм.
Один из самых ярких примеров предвзятости в действии – это отчет Amazon. В 2014 году компания решила поэкспериментировать с автоматизацией процесса рекомендации и найма работников. Если автоматизация способствовала повышению прибыли при рекомендации товаров и организации склада, то, по логике, она могла бы повысить и эффективность найма. По словам одного инженера, «они буквально хотели создать механизм, который возьмет 100 резюме, выдаст пять лучших, а мы уже возьмем их на работу». Система машинного обучения предназначалась для ранжирования людей по шкале от одного до пяти, зеркально отражая систему рейтингов товаров Amazon. Для создания базовой модели инженеры Amazon использовали набор данных, состоящий из резюме сотрудников за десять лет, а затем обучили статистическую модель на пятидесяти тысячах терминов, которые там встречались. Вскоре система стала придавать меньшее значение широко используемым инженерным терминам, таким как языки программирования, поскольку их указывали все. Вместо этого модели стали ценить более тонкие признаки. Главное предпочтение отдавалось определенным глаголам. В качестве примера инженеры приводили «выполнил» и «запечатлел».
Рекрутеры начали использовать эту систему в качестве дополнения к своей обычной практике. Но вскоре возникла серьезная проблема: система не рекомендовала женщин. Она активно снижала рейтинг резюме кандидатов, которые учились в женских колледжах, а также любых резюме, где даже присутствовало слово «женщина». Даже после правки системы для устранения влияния явных ссылок на гендер, предубеждения никуда не исчезли. Показатели гегемонистской маскулинности продолжали появляться в гендерном использовании языка. Модель предвзято относилась к женщинам не только как к категории, но и к общепринятым гендерным формам речи.
По неосторожности компания Amazon создала диагностический инструмент. Подавляющее большинство инженеров, нанятых Amazon за десять лет, являлись мужчинами, поэтому созданные ими модели научились рекомендовать мужской пол для будущего найма. Практика найма в прошлом и настоящем формирует инструменты найма в будущем. Система Amazon неожиданно показала, что предвзятость уже существует, начиная с того, как маскулинность закодирована в языке, в резюме и в самой компании. Этот инструмент усилил существующую динамику Amazon и подчеркнул отсутствие разнообразия в индустрии искусственного интеллекта в прошлом и настоящем.
В конечном итоге Amazon свернула свой эксперимент по найму сотрудников. Но масштаб проблемы предвзятости простирается гораздо глубже, чем одна система или неудачный подход. Индустрия ИИ традиционно понимала проблему предвзятости так, как будто это ошибка, которую нужно устранить, а не особенность самой классификации. В результате основное внимание уделялось корректировке технических систем для достижения большего количественного паритета между разрозненными группами, что, как мы увидим, создало свои собственные проблемы. Понимание связи между предвзятостью и классификацией требует не только анализа производства знания – например, определения того, является ли набор данных объективным или нет, – но и изучения самой механики построения знания, того, что социолог Карин Кнорр Цетина называет «эпистемическим механизмом». Чтобы понять это, необходимо проследить, как модели неравенства в истории формируют доступ к ресурсам и возможностям, которые, в свою очередь, формируют данные. Затем эти данные извлекаются для использования в технических системах классификации и распознавания образов, что приводит к результатам, которые воспринимаются как некие объективные. В итоге получается статистический уроборос: машина дискриминации, усиливающая социальное неравенство под прикрытием технической нейтральности.
Пределы системы
Чтобы лучше понять ограничения в анализе предвзятости ИИ, мы можем обратиться к попыткам ее исправить. В 2019 году компания IBM попыталась ответить на опасения по поводу необъективности в своих системах ИИ, создав, по словам компании, более «инклюзивный» набор данных под названием Diversity in Faces (DiF). DiF – это часть ответной реакции отрасли на революционную работу, опубликованную годом ранее исследователями Джоем Буоламвини и Тимнит Гебру, которая показала, что несколько систем распознавания лиц, включая системы IBM, Microsoft и Amazon, имеют гораздо более высокий процент ошибок в отношении людей с темной кожей, особенно женщин. В результате, все три компании прилагали усилия, чтобы показать прогресс в исправлении проблемы.
«Мы ожидаем, что распознавание лиц станет работать без погрешностей», – пишут исследователи IBM. Однако единственным способом решения «проблемы разнообразия» оказалось создание «набора данных, состоящего из лиц каждого человека в мире». Исследователи IBM решили воспользоваться уже существующей базой данных из ста миллионов изображений, взятых из Flickr, крупнейшей на тот момент общедоступной коллекции в Интернете. Затем они взяли один миллион фотографий в качестве небольшой выборки и измерили черепно-лицевые расстояния между ориентирами на каждом лице: глаза, ширина носа, высота губ, высота бровей и так далее. Подобно Мортону, измерявшему черепа, исследователи IBM стремились распределить показатели и создать категории различий.
Команда IBM утверждала, что их целью являлось увеличение разнообразия данных распознавания лиц. Несмотря на благие намерения, используемые ими классификации раскрывают политику того, что означает разнообразие в данном контексте. Например, чтобы обозначить пол и возраст лица, команда поручила пользователям создать субъективные аннотации, используя ограничительную модель бинарного пола. Любой человек, который, как казалось, выходил за рамки этой бинарной модели, удалялся из базы. Видение IBM о многообразии подчеркивало обширные варианты высоты черепной орбиты и переносицы, но не учитывало существование транс- и небинарных людей. «Справедливость» свелась к более высокой точности машинного распознавания лиц, а «разнообразие» означало широкий спектр лиц для обучения модели. Краниометрический анализ функционирует как приманка и подмена, в конечном итоге деполитизируя идею разнообразия и заменяя ее акцентом на вариативности. Создатели получают возможность решать, что такое переменные и как люди распределяются по категориям. Опять же, практика классификации – это централизация власти: власти решать, какие различия имеют значение.
Далее исследователи IBM делают еще более проблематичный вывод: «Аспекты нашего наследия – включая расу, этническую принадлежность, культуру, географию – и наша индивидуальная идентичность – возраст, пол и видимые формы самовыражения – отражаются на наших лицах». Это утверждение противоречит десятилетиям исследований, которые опровергли идею о том, что раса, пол и идентичность являются скорее биологическими категориями, чем политическими, культурными и социальными. Встраивание убеждений об идентичности в технические системы, как будто они являются фактами, наблюдаемыми со стороны, является примером того, что Симона Браун называет «цифровой эпидермализацией», навязыванием расы телу. Браун определяет этот феномен как осуществление власти, когда бесплотный взгляд технологий наблюдения «делает работу по отчуждению субъекта, производя „правду“ о теле и своей идентичности (или идентичностях) вопреки утверждениям субъекта».
Основополагающие проблемы подхода IBM к классификации разнообразия проистекают из такого рода централизованного производства идентичности под руководством методов машинного обучения, которые были доступны команде. Определение цвета кожи делается потому, что это возможно сделать, а не по той причине, что это говорит о расе или о глубоком понимании культуры. Аналогично, использование измерения черепа происходит потому, что это метод, который может быть выполнен с помощью машинного обучения. Возможности инструментов становятся горизонтом истины. Возможность применения черепных измерений и цифровой эпидермализации в масштабе стимулирует желание найти смысл в этих подходах, даже если этот метод не имеет ничего общего с культурой, наследием или разнообразием. Они используются для повышения проблематичного понимания точности. Технические утверждения о достоверности и производительности обычно пронизаны политическим выбором категорий и норм, но редко признаются таковыми. Эти подходы основаны на идеологической предпосылке биологии как предназначения, где наши лица становятся нашей судьбой.
Множество определений необъективности
С древности акт классификации ассоциировался с властью. В теологии способность называть и разделять вещи считалась божественным актом. Слово «категория» происходит от древнегреческого katēgoríā, образованного из двух корней: kata (против) и agoreuo (говорить публично). В греческом языке это слово означает либо логическое утверждение, либо обвинение в судебном процессе, что указывает как на научные, так и на юридические методы категоризации.
Историческая родословная «предубеждения (bias)» как термина намного более поздняя. Впервые он появляется в геометрии XIV века, где обозначает косую или диагональную линию. К шестнадцатому веку он приобрел нечто похожее на свое нынешнее значение – «неоправданное предубеждение». К 1900-м годам «bias» приобрел более техническое значение в статистике, где обозначает систематические различия между выборкой и популяцией, когда выборка не является истинным отражением целого. Именно из этой статистической традиции область машинного обучения черпает свое понимание предвзятости, где она связана с рядом других понятий: обобщение, классификация и дисперсия.
Системы машинного обучения разработаны таким образом, чтобы иметь возможность обобщать данные из большого обучающего набора примеров и правильно классифицировать новые наблюдения, не включенные в обучающую базу данных. Другими словами, системы машинного обучения способны выполнять своеобразную инспекцию, изучая конкретные примеры (например, резюме соискателей), и решать, какие элементы следует искать в новых примерах (например, группы слов в резюме новых соискателей). В таких случаях термин «предвзятость» относится к типу ошибки, которая может произойти во время процесса обобщения – а именно, систематическая или последовательно воспроизводимая ошибка классификации, которую система демонстрирует при предъявлении новых примеров.
Этот тип часто противопоставляется другому виду ошибки обобщения – дисперсии, которая относится к чувствительности алгоритма к различиям в обучающих данных. Модель с высокой погрешностью и низкой дисперсией может недостаточно соответствовать данным – не улавливать все их значимые особенности или сигналы. В качестве альтернативы, модель с высокой дисперсией и низкой погрешностью может оказаться слишком приближенной к данным, в результате чего она потенциально будет улавливать «шум» в дополнение к значимым характеристикам данных.
За пределами машинного обучения «предвзятость» имеет множество других значений. Например, в юриспруденции она означает субъективное представление или мнение, суждение, основанное на предубеждениях, в отличие от решения, принятого на основе беспристрастной оценки фактов. В психологии Амос Тверски и Дэниел Канеман изучают «когнитивные предубеждения», или способы, с помощью которых человеческие суждения систематически отклоняются от вероятностных ожиданий. Более современные исследования подчеркивают, как неосознанные установки и стереотипы «приводят к поведению, расходящемуся с заявленными или одобренными убеждениями или принципами человека». Здесь необъективность – это не просто тип технической ошибки; она также распространяется на человеческие убеждения, стереотипы или формы дискриминации. Эти различия в определении ограничивают полезность термина, особенно когда он используется специалистами из разных дисциплин.
Технические разработки, безусловно, возможно доработать и обеспечить более точный контроль над процессом возникновения перекосов и дискриминационных результатов в их системах. Однако более сложные вопросы о причинах, по которым системы ИИ увековечивают формы неравенства, обычно игнорируются в спешке, направленной на поиск узких технических решений статистической предвзятости, как будто это достаточное средство для решения более глубоких структурных проблем. В целом вопрос о том, каким образом инструменты познания в ИИ отражают и служат стимулам более широкой добывающей экономики, не был решен. Остается только сохраняющаяся асимметрия власти, когда технические системы поддерживают и расширяют структурное неравенство, независимо от намерений разработчиков.
Каждый набор данных, используемый для обучения систем машинного обучения, – будь то в контексте контролируемого или неконтролируемого процесса, и независимо от того, считается ли он технически предвзятым или нет, – содержит мировоззрение. Создать обучающую базу – значит взять почти бесконечно сложный и разнообразный мир и разложить его на таксономии, состоящие из классификаций отдельных точек данных, – процесс, который требует политического, культурного и социального выбора. Обращая внимание на эти классификации, мы можем увидеть различные формы власти, которые встроены в архитектуру построения мира ИИ.
Обучающие наборы как механизмы классификации на примере ImageNet
В прошлой главе мы рассмотрели историю ImageNet и узнали, как этот эталонный обучающий набор данных повлиял на исследования в области компьютерного зрения с момента его создания в 2009 году. Рассмотрев структуру ImageNet более подробно, мы можем понять, как он упорядочен и какова его логика отображения мира объектов. Структура ImageNet представляет собой сложный лабиринт, обширный и полный неожиданностей. Базовая семантическая структура ImageNet была взята из WordNet, базы данных классификаций слов, впервые разработанной в Лаборатории когнитивных наук Принстонского университета в 1985 году и финансируемой Управлением военно-морских исследований США. WordNet задумывался как машиночитаемый словарь, в котором пользователи будут осуществлять поиск на основе семантического, а не алфавитного сходства. Он стал важным источником информации для областей вычислительной лингвистики и обработки естественного языка. Команда WordNet собрала как можно больше слов, начав с Brown Corpus, коллекции из миллиона фраз, составленной в 1960-х годах. Слова в Brown Corpus взяты из газет и ветхой коллекции книг, включая «Новые методы парапсихологии», «Семейное убежище» и «Кто правит супружеской постелью?»
WordNet пытается организовать весь английский язык в наборы синонимов, или синсеты. Исследователи ImageNet отобрали только существительные, полагая, что существительные – это предметы, которые могут быть изображены на картинках, и этого будет достаточно для обучения машин автоматическому распознаванию объектов. Таксономия Image Net организована в соответствии с вложенной иерархией, полученной из WordNet, где каждый синсет представляет отдельное понятие, а синонимы сгруппированы вместе (например, «автомобиль» и «машина» рассматриваются как принадлежащие к одному набору). Иерархия движется от более общих понятий к более конкретным. Например, понятие «стул» находится в разделе артефакт → обстановка → мебель → сиденье → стул. Эта система классификации неудивительно вызывает в памяти многие предшествующие таксономические ранги, от Линнеевской системы биологической классификации до упорядочивания книг в библиотеках.
Но первым признаком истинной чуждости мировоззрения ImageNet являются его девять категорий верхнего уровня, которые он взял из WordNet: растение, геологическое образование, природный объект, спорт, артефакт, гриб, человек, животное и разное. Это любопытные категории, в которые должно быть упорядочено все остальное. Ниже он разрастается на тысячи странных и специфических вложенных классов, внутри которых, как русские матрешки, размещаются миллионы изображений. Существуют категории для яблок, яблочного масла, яблочных пельменей, яблочной герани, яблочного желе, яблочного сока, яблочных личинок, яблочной ржавчины, яблочных деревьев, яблочных тележек и яблочного сока. Там представлены изображения горячих труб, горячих тарелок, горячих кастрюль, горячих стержней, горячего соуса, горячих источников, горячих напитков, горячих ванн, горячих воздушных шаров, горячего помадного соуса и бутылок с горячей водой. Это буйство слов, упорядоченных в странные категории, напоминает энциклопедию Хорхе Луиса Борхеса. Я уже молчу про изображения. Некоторые из них – это фотографии высокого разрешения, другие – размытые фотографии, снятые на телефон при плохом освещении. Другие – это снимки детей. Третьи – кадры из порнографии. Некоторые – карикатуры. Найдутся даже религиозные иконы, известные политики, голливудские знаменитости и итальянские комики. Все это варьируется от профессионального до любительского, от священного до вульгарного.
Классификации людей – отличное средство, чтобы рассмотреть политику классификации в действии. В ImageNet категория «тело человека» относится к ветви Естественный объект → Тело → Тело человека. Ее подкатегории включают «мужское тело», «человек», «ювенильное тело», «взрослое тело» и «женское тело». Категория «взрослое тело» содержит подклассы «взрослое женское тело» и «взрослое мужское тело». Существует неявное предположение, что только «мужское» и «женское» тела признаются «естественными». Существует категория ImageNet для термина «гермафродит», но она расположена в ветви Человек → Сенсуалист → Бисексуал (наряду с категорией «Псевдогермафродит»).
Еще до того, как мы рассмотрим более спорные категории в ImageNet, мы уже видим политику классификационной схемы. Подобная классификация закрепляет гендер как бинарную биологическую конструкцию, а трансгендерные или гендерно небинарные люди либо не существуют, либо помещены в категории сексуальности. Конечно, такой подход не является новым. Иерархия классификации пола и сексуальности в ImageNet напоминает о более ранних формах категоризации, таких как классификация гомосексуальности как психического расстройства в Руководстве по диагностике и статистике. Эта глубоко разрушительная категоризация использовалась для оправдания подвергания людей так называемой репрессивной терапии, и потребовались годы активных действий, прежде чем Американская психиатрическая ассоциация отменила ее в 1973 году.
Сведение людей к бинарным гендерным категориям и превращение трансгендерных людей в невидимых или «девиантных» – общие черты схем классификации в машинном обучении. Исследование Оса Киса, посвященное автоматическому определению пола при распознавании лиц, показывает, что почти 95 процентов работ в этой области рассматривают пол как бинарный, причем большинство описывают его как неизменный и физиологический. Хотя кое-кто и скажет, что все можно запросто исправить, создав больше категорий, это не устраняет более глубокий ущерб, связанный с распределением людей по гендерным или расовым категориям без их участия или согласия. Эта практика имеет долгую историю. Административные системы на протяжении веков пытались сделать людей понятными, присваивая им фиксированные ярлыки и наделяя определенными свойствами. Работа по эссенциализации и упорядочиванию на основе биологии или культуры давно используется для оправдания форм насилия и угнетения.
Несмотря на то, что эти классификационные логики рассматриваются как естественные и фиксированные, на самом деле они представляют собой движущиеся мишени: они не только влияют на людей, которых классифицируют, но и способ их воздействия, в свою очередь, изменяет сами классификации. Хакинг называет это явление «эффектом зацикливания», возникающим, когда науки занимаются «изобретением людей». Боукер и Стар также подчеркивают, что после создания классификаций они могут стабилизировать спорную политическую категорию таким образом, который трудно заметить. Если им не оказывать активного сопротивления, они становятся само собой разумеющимися. Мы наблюдаем этот феномен в области ИИ, когда очень влиятельные инфраструктуры и наборы учебных данных выдаются за чисто технические, тогда как на самом деле они содержат политические вмешательства в свои таксономии: они натурализуют определенное упорядочивание мира и производят оправдывающие его эффекты.
Право определять понятие «личность»
Наложение порядка на недифференцированную массу, приписывание явлений к какой-либо категории, то есть присвоение имени вещи, в свою очередь, является средством подтверждения существования этой категории.
В случае 21841 категории, изначально включенных в иерархию ImageNet, такие классы существительных, как «яблоко» или «яблочное масло», могут показаться достаточно бесспорными, однако не все существительные созданы равными. Если воспользоваться идеей лингвиста Джорджа Лакоффа, понятие «яблоко» является более многозначным существительным, чем понятие «свет», которое, в свою очередь, более многозначно, чем такое понятие, как «здоровье». Существительные занимают различные места на оси от конкретного к абстрактному, от описательного к оценочному. В логике ImageNet эти градиенты стерты. Все сплющено и прикреплено к ярлыку, как бабочки за витриной. Хотя такой подход имеет эстетику объективности, он, тем не менее, является глубоко идеологическим упражнением.
В течение десятилетия ImageNet содержал 2832 подкатегории под категорией верхнего уровня «Человек». Подкатегорией с наибольшим количеством ассоциированных изображений была «девушка» (с 1664 изображениями), за которой следовали «дедушка» (1662), «папа» (1643) и генеральный директор (1614 – большинство из них мужчины). В этих категориях мы уже замечаем очертания мировоззрения. ImageNet содержит огромное количество классификационных категорий, включая категории расы, возраста, национальности, профессий, экономического статуса, поведения, характера и даже морали. Существует множество проблем, связанных с попытками ImageNet классифицировать фотографии людей с помощью логики распознавания объектов. Несмотря на то, что в 2009 году создатели сети удалили некоторые явно оскорбительные синсеты, остались категории расовой и национальной принадлежности, включая коренных жителей Аляски, англо-американцев, черных, черных африканцев, черных женщин (но не белых), латиноамериканцев, мексиканских американцев, никарагуанцев, пакистанцев, индейцев Южной Америки, испанских американцев, техасцев, узбеков, белых и зулусов. Представление их в качестве логических категорий организации людей вызывает беспокойство еще до того, как они используются для распределения на основе внешности. Другие люди обозначаются по профессиям или увлечениям: есть бойскауты, чирлидеры, когнитивные нейробиологи, парикмахеры, аналитики разведки, мифологи, розничные торговцы, пенсионеры и так далее. Существование этих категорий предполагает, что люди могут быть визуально упорядочены в соответствии с их профессией, что напоминает такие детские книги, как «Город добрых дел» Ричарда Скарри. ImageNet также содержит категории, которые не имеют никакого смысла для классификации изображений, такие как должник, босс, знакомый, брат и дальтоник. Это все невизуальные понятия, которые описывают отношения, будь то отношения с другими людьми, финансовой системой или самим визуальным полем. Набор данных содержит эти категории и связывает их с изображениями, чтобы похожие фотографии могли быть «распознаны» будущими системами.
Многие действительно оскорбительные и вредные категории скрывались в глубинах категорий «Человек» ImageNet. Некоторые из них являлись женоненавистническими, расистскими, возрастными и инвалидными. Вот несколько примеров: Плохой Человек, Девушка по вызову, Королева Туалета, Чудак, Заключенный, Сумасшедший, Тупоглазый, Наркоман, Неудачник, Лузер, Ублюдок, Лицемер, Клептоман, Меланхолик, Нелюдь, Извращенец, Примадонна, Шизофреник, Второсортный, Шлюха, Старая Дева, Уличная Проститутка, Жеребец, Придурок, Неквалифицированный Человек, Распутник, Слабак. Оскорбления, расистские оскорбления и моральные осуждения просто изобилуют.
Эти оскорбительные термины оставались в ImageNet в течение десяти лет. Поскольку ImageNet обычно используется для распознавания объектов, конкретная категория «Человек» редко обсуждалась на технических конференциях и не привлекала особого внимания общественности, пока в 2019 году не стал вирусным проект ImageNet Roulette: возглавляемый художником Тревором Пагленом, проект включал приложение, позволяющее людям загружать изображения, чтобы увидеть, как они будут классифицированы на основе категорий Person в ImageNet. Приложение привлекло значительное внимание СМИ к тому факту, что во влиятельной коллекции долгое время присутствовали расистские и сексистские термины. Вскоре после этого создатели ImageNet опубликовали документ под названием «Toward Fairer Datasets», в котором попытались «удалить небезопасные синсеты». Они попросили двенадцать аспирантов отметить все категории, которые казались им небезопасными, поскольку были либо «оскорбительными по своей сути» (например, содержащими ненормативную лексику или «расовые или гендерные оскорбления»), либо «чувствительными» (не оскорбительными по своей сути, но терминами, которые «могут вызвать оскорбление при неуместном применении, например, классификация людей на основе сексуальной ориентации и религии»). Хотя этот проект был направлен на оценку оскорбительности категорий ImageNet путем опроса аспирантов, авторы, тем не менее, продолжают поддерживать автоматизированную классификацию людей на основе фотографий, несмотря на заметные проблемы.
Команда ImageNet в конечном итоге удалила 1593 из 2832 категорий «Люди» – примерно 56 процентов, – посчитав их и 60040 изображений «небезопасными». Оставшиеся полмиллиона были «временно признаны безопасными». Но что считать безопасным, когда речь идет о классификации людей? Вся таксономия ImageNet показывает сложность и опасность человеческой категоризации. Такие термины, как «микроэкономист» или «баскетболист» поначалу могут показаться менее значимыми, чем, скажем, «неквалифицированный человек», «мулат» или «деревенщина», однако когда мы смотрим на людей, обозначенных в этих категориях, мы видим множество предположений и стереотипов, включая расу, пол, возраст и способности. В метафизике ImageNet существуют отдельные категории изображений для «профессоров» – как будто, когда кто-то получает повышение, ее или его биометрический профиль должен отражать изменение звания.
На самом деле в ImageNet не существует нейтральных категорий, потому что выбор изображений всегда взаимодействует со значением слов. Политика заложена в логику классификации, даже если слова не являются оскорбительными. В этом смысле ImageNet – это наглядный пример того, что происходит, когда людей классифицируют как объекты. Однако эта практика стала более распространенной только в последние годы, часто внутри технологических компаний. Схемы классификации, используемые в таких компаниях, как Facebook, гораздо сложнее исследовать и критиковать: собственные системы предлагают мало способов для сторонних исследователей или аудита того, как изображения упорядочиваются или интерпретируются.
Кроме того, возникает вопрос о том, откуда берутся изображения в категориях «Человек» ImageNet. Как мы видели в предыдущей главе, создатели ImageNet массово собирали изображения из поисковых систем Google, извлекали селфи и отпускные фотографии людей без их ведома, а затем платили работникам Mechanical Turk за их маркировку. Все перекосы и предубеждения относительно результатов, выдаваемых поисковыми системами, затем ложатся в основу последующих технических систем, которые отбирают их и маркируют. На низкооплачиваемых краудворкеров возлагается непосильная задача – осмыслить изображения со скоростью пятьдесят в минуту и распределить их по категориям, основанным на системах WordNet и определениях Википедии. Возможно, нет ничего удивительного в том, что когда мы исследуем подстилающий слой этих маркированных изображений, мы обнаружим, что они изобилуют стереотипами, ошибками и абсурдом. Женщина, лежащая на пляжном полотенце, – «клептоманка», подросток в спортивной майке – «неудачник», а изображение актрисы Сигурни Уивер классифицируется как «гермафродит».
Изображения, как и все формы данных, отягощены всевозможными потенциальными значениями, неразрешимыми вопросами и противоречиями. Пытаясь разрешить эти двусмысленности, метки ImageNet сжимают и упрощают сложность. Акцент на том, чтобы сделать обучающие наборы «более справедливыми» путем удаления оскорбительных терминов, не позволяет бороться с властной динамикой классификации и исключает более тщательную оценку лежащей в ее основе логики. Даже если худшие примеры будут исправлены, подход все равно в основе своей построен на экстрактивных отношениях с данными, оторванными от людей и мест, откуда они поступили. Данные опираются на техническое мировоззрение, которое стремится объединить сложные и разнообразные культурные материалы. И мировоззрение ImageNet в этом смысле не является чем-то необычным. На самом деле это типичный случай многих наборов данных для обучения ИИ, раскрывающий проблемы нисходящих схем, которые упрощают сложные социальные, культурные, политические и исторические отношения до количественно измеримых сущностей. Это явление, пожалуй, наиболее очевидно и коварно, когда речь заходит о широко распространенных попытках классифицировать людей по расе и полу в технических системах.
Моделирование расы и гендера
Сосредоточившись на классификации в ИИ, мы можем проследить, как гендер, раса и сексуальность ошибочно принимаются за естественные, фиксированные и поддающиеся обнаружению биологические категории. Исследователь Симона Браун отмечает: «Существует определенное предположение, что с помощью технологий можно четко определить категории гендерной идентичности и расы. Машина может быть запрограммирована на присвоение гендерных категорий или определение того, что должны обозначать тела и части тела». Фактически, идея о том, что раса и пол могут быть автоматически определены в машинном обучении, рассматривается как предполагаемый факт и редко ставится под сомнение техническими дисциплинами, несмотря на глубокие политические проблемы, которые создает этот процесс.
Например, набор данных UTKFace (созданный группой из Университета Теннесси в Ноксвилле) состоит из более чем двадцати тысяч изображений лиц с аннотациями возраста, пола и расы. Авторы утверждают, что база может быть использована для решения различных задач, включая автоматическое определение лиц, оценку возраста и процесс старения. Аннотации к каждому изображению включают предполагаемый возраст каждого человека, выраженный в годах от нуля до Пол – это обязательный показатель: либо ноль для мужского пола, либо единица для женского. Во-вторых, раса подразделяется на пять классов: Белый, Черный, Азиат, Индеец и Другие. Политика гендера и расы здесь столь же очевидна, сколь и вредна. Тем не менее, подобные опасные редуктивные категоризации широко используются во многих обучающих наборах для классификации людей и являются частью производственных конвейеров ИИ на протяжении многих лет.
Узкая классификационная схема UTKFace повторяет проблематичные расовые классификации двадцатого века, такие как система апартеида в Южной Африке. Как подробно описали Боукер и Стар, в 1950-х годах правительство Южной Африки приняло закон, который создал грубую схему расовой классификации для разделения граждан на «европейцев, азиатов, лиц смешанной расы или цветных, и „туземцев“ или чистокровных представителей расы банту». Этот расистский правовой режим управлял жизнью людей, в основном чернокожих южноафриканцев, передвижение которых было ограничено, и которые были насильно выселены со своей земли. Политика расовой классификации распространялась на самые интимные стороны жизни людей. Межрасовая сексуальность была запрещена, что привело к тому, что к 1980 году было вынесено более 11500 обвинительных приговоров, в основном в отношении небелых женщин. Сложная централизованная база данных этих классификаций была разработана и поддерживалась IBM, но фирме часто приходилось перестраивать систему и переклассифицировать людей, поскольку на практике единых чистых расовых категорий не существовало.
Прежде всего, эти системы нанесли огромный вред людям, и концепция чистого «расового» обозначения всегда оставалась спорной. В своей работе о расе Донна Харауэй отмечает: «В этих таксономиях, которые, в конце концов, являются маленькими машинами для уточнения и разделения категорий, сущность, которая всегда ускользала от классификатора, была проста: сама раса». Чистый типаж, оживляющий мечты, науки и ужасы, постоянно проскальзывает сквозь все типологические таксономии и бесконечно их приумножает. И все же в таксономиях наборов данных и в системах машинного обучения, которые на них обучаются, миф о чистом типаже возник снова, претендуя на авторитет науки. В статье об опасностях распознавания лиц исследователь медиа Люк Старк отмечает, что «внедряя различные классификационные логики, которые либо подтверждают существующие расовые категории, либо порождают новые, автоматизированные системы распознавания лиц, генерирующие шаблоны, не только воспроизводят системное неравенство, но и усугубляют его».
Некоторые методы машинного обучения выходят за рамки прогнозирования возраста, пола и расы. Широко известны попытки определить ориентацию по фотографиям на сайтах знакомств, определить наличие судимости по фотографиям из водительских прав. Подобные подходы глубоко проблематичны по многим причинам, не последней из которых является то, что такие характеристики, как «судимость», «раса» и «пол» – являются глубоко реляционными, социально обусловленными категориями. Это не врожденные фиксированные характеристики; они контекстуальны и меняются в зависимости от времени и места. Чтобы делать такие прогнозы, системы машинного обучения стремятся классифицировать полностью реляционные вещи в фиксированные категории и справедливо критикуются как научно и этически проблематичные.
Системы машинного обучения вполне реально моделируют расу и пол: они определяют мир в установленных ими терминах, что имеет долгосрочные последствия для людей, которых они классифицируют. Когда такие системы превозносят как научные инновации для предсказания личности и будущих действий, это стирает технические недостатки того, как эти системы были созданы, приоритеты того, зачем они были разработаны, и многочисленные политические процессы категоризации, которые их формируют. Исследователи в сфере проблем инвалидности уже давно указывают на то, как классифицируются так называемые нормальные тела и как это приводит к стигматизации различий. Как отмечается в одном из отчетов, сама история инвалидности – это «рассказ о том, как различные системы классификации (т. е. медицинские, научные, юридические) взаимодействуют с социальными институтами и их системами власти и знаний». Акт определения категорий на многих уровнях создает внешнюю сторону: формы отклонений и различий. Технические системы осуществляют политические и нормативные интервенции, когда дают названия чему-то столь динамичному и реляционному, как идентичность, и они обычно делают это, используя редуктивный набор возможностей. Таким образом, ограничивается диапазон восприятия и представления людей, а также сужается горизонт распознаваемых образов.
Как отмечает Ян Хакинг, классификация людей – это имперский ход: подданные классифицировались империями, когда их завоевывали, а затем упорядочивались институтами и экспертами. Эти акты именования представляли собой утверждение власти и колониального контроля, и негативные последствия таких классификаций могут пережить сами империи. Классификации – это технологии, которые производят и ограничивают способы познания, и они встроены в логику ИИ.
Ограничения измерений
Так что же нужно делать? Если так много классификационных слоев в учебных данных и технических системах являются формами власти и политики, представленными в виде объективных измерений, как нам следует это исправить? Как разработчики систем должны учитывать рабство, угнетение и сотни лет дискриминации одних групп в пользу других? Другими словами, как системы искусственного интеллекта должны представлять социальный аспект?
Выбор информации, на основе которой системы ИИ создают новые классификации, является важным моментом принятия решений: но кто и на каком основании делает выбор? Проблема компьютерной науки заключается в том, что справедливость в системах ИИ никогда не будет чем-то, что можно закодировать или вычислить. Это требует перехода к оценке систем, выходящей за рамки оптимизационных показателей и статистического равенства, и понимания того, где рамки математики и инженерии вызывают проблемы. Это также означает понимание взаимодействия систем ИИ с данными, работниками, окружающей средой и людьми, на жизнь которых повлияет его использование, и принятие решения о том, где ИИ не должен использоваться.
Боукер и Стар делают вывод, что плотность столкновений классификационных схем требует нового подхода, чувствительности к «топографии таких вещей, как распределение двусмысленности; к текучей динамике столкновения классификационных систем». «Но он также требует внимания к неравномерному распределению преимуществ и недостатков, поскольку „характер этого выбора и понимание невидимого процесса сопоставления составляют суть этического проекта“». Классификации без согласия представляют серьезные риски, как и нормативные предположения об идентичности, однако эти практики стали стандартными. Это должно измениться.
В этой главе мы рассмотрели, какие пробелы и противоречия содержит классификационная инфраструктура: она обязательно уменьшает уровень сложности и удаляет значимый контекст, чтобы сделать мир более вычислимым. Кроме того, они также распространяются в системах машинного обучения – в том, что Умберто Эко назвал «хаотическим реестром». На определенном уровне детализации похожие и непохожие вещи становятся достаточно соизмеримыми, так что их сходства и различия поддаются машинному чтению, но в действительности их характеристики не поддаются определению. В данном случае вопросы выходят далеко за рамки определения правильности или неправильности классификации. Мы наблюдаем странные, непредсказуемые повороты, когда машинные категории и люди взаимодействуют и меняют друг друга, пытаясь найти четкость в в трансформирующемся ландшафте, чтобы соответствовать нужным категориям и попасть в наиболее прибыльные каналы. В условиях машинного обучения эти вопросы не менее актуальны, поскольку их довольно трудно заметить. Речь идет не только об историческом любопытстве или странном ощущении несоответствия, но и о том, что каждая классификация имеет свои последствия.
История классификации демонстрирует, что самые вредные формы категоризации человека – от системы апартеида до патологизации гомосексуальности – не просто исчезают под воздействием научных исследований и этической критики. Скорее, изменения требовали политической организации, постоянного протеста и публичных агитационных кампаний на протяжении многих лет. Классификационные схемы вводят и поддерживают сформировавшие их структуры власти, и они не меняются без значительных усилий. По словам Фредерика Дугласа, «власть ничего не уступает без требования. Она никогда не уступала и никогда не уступит». В невидимых режимах классификации в машинном обучении труднее выдвигать требования и противостоять их внутренней логике.
Обнародованные обучающие наборы, такие как ImageNet, UTKFace и DiF, дают нам некоторое представление о видах категоризации, которые распространяются в промышленных системах ИИ и исследовательской практике. Но по-настоящему масштабными двигателями классификации являются те, которыми в глобальном масштабе управляют частные технологические компании, включая Facebook, Google, TikTok и Baidu. Эти компании работают без особого контроля за тем, как они классифицируют и нацеливают пользователей, и не предлагают значимых путей для публичного оспаривания. Когда процессы подбора ИИ действительно скрыты, а люди не знают, почему и как они получают преимущества или недостатки, необходим коллективный политический ответ – даже если это становится все труднее.


