balance_ -= amount;
return true;
}
private:
mutable std::mutex mu_; // protects balance_
int64_t balance_;
};
The internal balance_ field is now protected by a mutex mu_: a synchronization
object that ensures that only one thread can successfully hold the mutex at a time. A
caller can acquire the mutex with a call to std::mutex::lock(); the second and sub‐
sequent callers of std::mutex::lock() will block until the original caller invokes
std::mutex::unlock(), and then one of the blocked threads will unblock and pro‐
ceed through std::mutex::lock().
All access to the balance now takes place with the mutex held, ensuring that its value
is consistent between check and modificais also worth highlighting: it’s an RAII class (see t calls lock() on creation and
unlock() on destruction. This ensures that the mutex is unlocked when the scope
7 The third category of behavior is thread-hostile: code that’s dangerous in a multithreaded environment even if all access to it is externally synchronized.
148 | Chapter 3: Concepts
exits, reducing the chances of making a mistake around balancing manual lock()
and unlock() calls.
However, the thread safety here is still fragile; all it takes is one erroneous modifica‐
tion to the class:
// Add a new C++ method...
void pay_interest(int32_t percent) {
// ...but forgot about mu_
int64_t interest = (balance_ * percent) / 100;
balance_ += interest;
}
and the thread safety has been destroyed.
Data races in Rust
For a book about Rust, this Item has covered a lot of C++, so consider a straightfor‐
ward translation of this class into Rust:
pub struct BankAccount {
balance: i64,
}
impl BankAccount {
pub fn new() -> Self {
BankAccount { balance: 0 }
}
pub fn balance(&self) -> i64 {
if self.balance < 0 {
panic!("** Oh no, gone overdrawn: {}", self.balance);
}
self.balance
}
pub fn deposit(& mut self, amount: i64) {
self.balance += amount
}
pub fn withdraw(& mut self, amount: i64) -> bool {
if self.balance < amount {
return false;
}
self.balance -= amount;
true
}
}
8 The Clang C++ compiler includes a option, sometimes known as annotalysis, that allows data to be annotated with information about which mutexes protect which data, and functions to be annotated with information about the locks they acquire. This gives compile-time errors when these invariants are broken, like Rust; however, there is nothing to enforce the use of these annotations in the first place—for example, when a thread-compatible library is used in a multithreaded environment for the first time.
Item 17: Be wary of shared-state parallelism | 149
along with the functions that try to pay into or withdraw from an account forever:
pub fn pay_in(account: & mut BankAccount) {
loop {
if account.balance() < 200 {
println!("[A] Running low, deposit 400");
account.deposit(400);
}
std::thread::sleep(std::time::Duration::from_millis(5));
}
}
pub fn take_out(account: & mut BankAccount) {
loop {
if account.withdraw(100) {
println!("[B] Withdrew 100, balance now {}", account.balance());
} else {
println!("[B] Failed to withdraw 100");
}
std::thread::sleep(std::time::Duration::from_millis(20));
}
}
This works fine in a single-threaded context—even if that thread is not the main
thread:
{
let mut account = BankAccount::new();
let _payer = std::thread::spawn(move || pay_in(& mut account));
// At the end of the scope, thè_payer` thread is detached
// and is the sole owner of thèBankAccount`.
}
but a naive attempt to use the BankAccount across multiple threads:
D O E S N O T C O M P I L E
{
let mut account = BankAccount::new();
let _taker = std::thread::spawn(move || take_out(& mut account));
let _payer = std::thread::spawn(move || pay_in(& mut account));
}
immediately falls foul of the compiler:
error[E0382]: use of moved value: àccount`
--> src/main.rs:102:41
|
100 | let mut account = BankAccount::new();
| ----------- move occurs because àccount` has type
| `broken::BankAccount`, which does not implement the
150 | Chapter 3: Concepts
| `Copy` trait
101 | let _taker = std::thread::spawn(move || take_out(&mut account));
| ------- ------- variable
| | moved due to
| | use in closure
| |
| value moved into closure here
102 | let _payer = std::thread::spawn(move || pay_in(&mut account));
| ^^^^^^^ ------- use occurs due
| | to use in closure
| |
| value used here after move
The rules of the borrow checker () make the problem clear: there are two
mutable references to the same item, one more than is allowed. The rules of the bor‐
row checker are that you can have a single mutable reference to an item, or multiple
(immutable) references, but not both at the same time.
This has a curious resonance with the definition of a data race at the start of this Item:
enforcing that there is a single writer, or multiple readers (but never both), means
that there can be no data races. By enforcing memory safety
.
As with C++, some kind of synchronization is needed to make this struct thread-
safe. ust version “wraps”
the protected data rather than being a standalone object (as in C++):
pub struct BankAccount {
balance: std::sync::Mutex< i64>,
}
The Mutex object with RAII behavior, like C++’s std::lock_guard: the mutex is automatically released at the end
of the scope when the guard is dropped. (In contrast to C++, Rust’s Mutex has no
methods that manually acquire or release the mutex, as they would expose developers
to the danger of forgetting to keep these calls exactly in sync.)
To be more precise, lock() actually returns a Result that holds the MutexGuard, to
cope with the possibility that the Mutex has been poisoned. Poisoning happens if a
thread fails while holding the lock, because this might mean that any mutex-protected
invariants can no longer be relied on. In practice, lock poisoning is sufficiently rare
(and it’s sufficiently desirable that the program terminates when it happens) that it’s
common to just .unwrap() the Result (despite the advice in
The MutexGuard object also acts as a proxy for the data that is enclosed by the Mutex,
by implementing the Deref and DerefMut), allowing it to be used both
for read operations:
Item 17: Be wary of shared-state parallelism | 151
impl BankAccount {
pub fn balance(&self) -> i64 {
let balance = *self.balance.lock().unwrap();
if balance < 0 {
panic!("** Oh no, gone overdrawn: {}", balance);
}
balance
}
}
and for write operations:
impl BankAccount {
// Note: no longer needs `&mut self`.
pub fn deposit(&self, amount: i64) {
*self.balance.lock().unwrap() += amount
}
pub fn withdraw(&self, amount: i64) -> bool {
let mut balance = self.balance.lock().unwrap();
if *balance < amount {
return false;
}
*balance -= amount;
true
}
}
There’s an interesting detail lurking in the signatures of these methods: although they
are modifying the balance of the BankAccount, the methods now take &self rather
than &mut self. This is inevitable: if multiple threads are going to hold references to
the same BankAccount, by the rules of the borrow checker, those references had better
not be mutable. It’s also another instance of the interior mutability pattern described
in : borrow checks are effectively moved from compile time to runtime but
now with cross-thread synchronization behavior. If a mutable reference already
exists, an attempt to get a second blocks until the first reference is dropped.
Wrapping up shared state in a Mutex mollifies the borrow checker, but there are still
) to fix:
D O E S N O T C O M P I L E
{
let account = BankAccount::new();
let taker = std::thread::spawn(|| take_out(&account));
let payer = std::thread::spawn(|| pay_in(&account));
// At the end of the scope, àccountìs dropped but
// thè_takerànd `_payer` threads are detached and
// still hold (immutable) references to àccount`.
}
152 | Chapter 3: Concepts
error[E0373]: closure may outlive the current function, but it borrows àccount`
which is owned by the current function
--> src/main.rs:206:40
|
206 | let taker = std::thread::spawn(|| take_out(&account));
| ^^ ------- àccountìs
| | borrowed here
| |
| may outlive borrowed value àccount`
|
note: function requires argument type to outlivè'static`
--> src/main.rs:206:21
|
206 | let taker = std::thread::spawn(|| take_out(&account));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
help: to force the closure to take ownership of àccount` (and any other
referenced variables), use thèmovè keyword
|
206 | let taker = std::thread::spawn(move || take_out(&account));
| ++++
error[E0373]: closure may outlive the current function, but it borrows àccount`
which is owned by the current function
--> src/main.rs:207:40
|
207 | let payer = std::thread::spawn(|| pay_in(&account));
| ^^ ------- àccountìs
| | borrowed here
| |
| may outlive borrowed value àccount`
|
note: function requires argument type to outlivè'static`
--> src/main.rs:207:21
|
207 | let payer = std::thread::spawn(|| pay_in(&account));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
help: to force the closure to take ownership of àccount` (and any other
referenced variables), use thèmovè keyword
|
207 | let payer = std::thread::spawn(move || pay_in(&account));
| ++++
The error message makes the problem clear: the BankAccount is going to be dropped
at the end of the block, but there are two new threads that have a reference to it and
that may carry on running afterward. (The compiler’s suggestion for how to fix the
problem is less helpful—if the BankAccount item is moved into the first closure, it will
no longer be available for the second closure to receive a reference to it!)
The standard tool for ensuring that an object remains active until all references to it
are gone is a reference-counted pointer, and Rust’s variant of this for multithreaded
use is
Item 17: Be wary of shared-state parallelism | 153
let account = std::sync::Arc::new(BankAccount::new());
account.deposit(1000);
let account2 = account.clone();
let _taker = std::thread::spawn(move || take_out(&account2));
let account3 = account.clone();
let _payer = std::thread::spawn(move || pay_in(&account3));
Each thread gets its own copy of the reference-counting pointer, moved into the clo‐
sure, and the underlying BankAccount will be dropped only when the refcount drops
to zero. This combination of Arc<Mutex<T>> is common in Rust programs that use
shared-state parallelism.
Stepping back from the technical details, observe that Rust has entirely avoided the
problem of data races that plagues multithreaded programming in other languages.
Of course, this good news is restricted to safe Rust—unsafe code () and FFI
y not be data-race free—but it’s still a remarka‐
ble phenomenon.
Standard marker traits
There are two standard traits that affect the use of Rust objects between threads. Both
of these traits are marker traits () that have no associated methods but have special significance to the compiler in multithreaded scenarios:
• trait indicates that items of a type are safe to transfer between threads; ownership of an item of this type can be passed from one thread to another.
• trait indicates that items of a type can be safely accessed by multiple threads, subject to the rules of the borrow checker.
Another way of saying this is to observe that Send means T can be transferred
between threads, and Sync means that &T can be transferred between threads.
Both of these traits are piler automatically derives them for new types, as long as the constituent parts of the type also implement Send/Sync.
The majority of safe types implement Send and Sync, so much so that it’s clearer to
understand what types don’t implement these traits (written in the form impl !Sync
for Type).
A type that doesn’t implement Send is one that can be used only in a single thread.
The canonical example of this is the unsynchronized reference-counting pointer
plementation of this type explicitly assumes single-threaded use (for speed); there is no attempt at synchronizing the internal refcount for multi-154 | Chapter 3: Concepts
threaded use. As such, transferring an Rc<T> between threads is not allowed; use
Arc<T> (with its additional synchronization overhead) for this case.
A type that doesn’t implement Sync is one that’s not safe to use from multiple threads
via non-mut references (as the borrow checker will ensure there are never multiple
mut references). The canonical examples of this are the types that provide interior
mutability in an unsynchronized way. Use Mutex<T> or to provide interior mutability in a multithreaded environment.
Raw pointer types like *const T and *mut T also implement neither Send nor Sync;
see I.
Deadlocks
Now for the bad news. Although Rust has solved the problem of data races (as previ‐
ously described), it is still susceptible to the second terrible problem for multithreaded
code with shared state: deadlocks.
Consider a simplified multiple-player game server, implemented as a multithreaded
application to service many players in parallel. Two core data structures might be a
collection of players, indexed by username, and a collection of games in progress,
indexed by some unique identifier:
struct GameServer {
// Map player name to player info.
players: Mutex<HashMap<String, Player>>,
// Current games, indexed by unique game ID.
games: Mutex<HashMap<GameId, Game>>,
}
Both of these data structures are Mutex-protected and so are safe from data races.
However, code that manipulates both data structures opens up potential problems. A
single interaction between the two might work fine:
impl GameServer {
/// Add a new player and join them into a current game.
fn add_and_join(&self, username: & str, info: Player) -> Option<GameId> {
// Add the new player.
let mut players = self.players.lock().unwrap();
players.insert(username.to_owned(), info);
// Find a game with available space for them to join.
let mut games = self.games.lock().unwrap();
for (id, game) in games.iter_mut() {
if game.add_player(username) {
return Some(id.clone());
}
}
Item 17: Be wary of shared-state parallelism | 155
None
}
}
However, a second interaction between the two independently locked data structures
is where problems start:
impl GameServer {
/// Ban the player identified by ùsernamè, removing them from
/// any current games.
fn ban_player(&self, username: & str) {
// Find all games that the user is in and remove them.
let mut games = self.games.lock().unwrap();
games
.iter_mut()
.filter(|(_id, g)| g.has_player(username))
.for_each(|(_id, g)| g.remove_player(username));
// Wipe them from the user list.
let mut players = self.players.lock().unwrap();
players.remove(username);
}
}
To understand the problem, imagine two separate threads using these two methods,
where their execution happens in the order shown in
Table 3-1. Thread deadlock sequence
Thread 1
Thread 2
Enters add_and_join() and immediately
acquires the players lock.
Enters ban_player() and immediately
acquires the games lock.
Tries to acquire the games lock; this is held
by thread 2, so thread 1 blocks.
Tries to acquire the players lock; this is held
by thread 1, so thread 2 blocks.
At this point, the program is deadlocked: neither thread will ever progress, nor will
any other thread that does anything with either of the two Mutex-protected data
structures.
The root cause of this is a lock inversion: one function acquires the locks in the order
players then games, whereas the other uses the opposite order (games then players).
This is a simple example of a more general problem; the same situation can arise with
longer chains of nested locks (thread 1 acquires lock A, then B, then it tries to acquire
C; thread 2 acquires C, then tries to acquire A) and across more threads (thread 1
locks A, then B; thread 2 locks B, then C; thread 3 locks C, then A).
156 | Chapter 3: Concepts
A simplistic attempt to solve this problem involves reducing the scope of the locks, so
there is no point where both locks are held at the same time:
/// Add a new player and join them into a current game.
fn add_and_join(&self, username: & str, info: Player) -> Option<GameId> {
// Add the new player.
{
let mut players = self.players.lock().unwrap();
players.insert(username.to_owned(), info);
}
// Find a game with available space for them to join.
{
let mut games = self.games.lock().unwrap();
for (id, game) in games.iter_mut() {
if game.add_player(username) {
return Some(id.clone());
}
}
}
None
}
/// Ban the player identified by ùsernamè, removing them from
/// any current games.
fn ban_player(&self, username: & str) {
// Find all games that the user is in and remove them.
{
let mut games = self.games.lock().unwrap();
games
.iter_mut()
.filter(|(_id, g)| g.has_player(username))
.for_each(|(_id, g)| g.remove_player(username));
}
// Wipe them from the user list.
{
let mut players = self.players.lock().unwrap();
players.remove(username);
}
}
(A better version of this would be to encapsulate the manipulation of the players
data structure into add_player() and remove_player() helper methods, to reduce
the chances of forgetting to close out a scope.)
This solves the deadlock problem but leaves behind a data consistency problem: the
players and games data structures can get out of sync with each other, given an exe‐
cution sequence like the one shown in
Item 17: Be wary of shared-state parallelism | 157
Table 3-2. State inconsistency sequence
Thread 1
Thread 2
Enters add_and_join("Alice") and adds Alice to the
players data structure (then releases the players lock).
Enters ban_player("Alice") and removes Alice
from all games (then releases the games lock).
Removes Alice from the players data structure; thread
1 has already released the lock, so this does not block.
Carries on and acquires the games lock (already released by
thread 2). With the lock held, adds “Alice” to a game in progress.
At this point, there is a game that includes a player that doesn’t exist, according to the
players data structure!
The heart of the problem is that there are two data structures that need to be kept in
sync with each other. The best way to do this is to have a single synchronization
primitive that covers both of them:
struct GameState {
players: HashMap<String, Player>,
games: HashMap<GameId, Game>,
}
struct GameServer {
state: Mutex<GameState>,
// ...
}
Advice
The most obvious advice for avoiding the problems that arise with shared-state paral‐
lelism is simply to avoid shared-state parallelism. The quotes from the
unicate by sharing memory; instead, share memory by communicating.”
The Go language has channels that are suitable for this ; for Rust, equivalent functionality is included in the standard library in the
returns a (Sender, Receiver) pair that allows values of a particular type to be communicated between threads.
If shared-state concurrency can’t be avoided, then there are some ways to reduce the
chances of writing deadlock-prone code:
• Put data structures that must be kept consistent with each other under a single lock.
• Keep lock scopes small and obvious; wherever possible, use helper methods that
get and set things under the relevant lock.
158 | Chapter 3: Concepts
• Avoid invoking closures with locks held; this puts the code at the mercy of whatever closure gets added to the codebase in the future.
• Similarly, avoid returning a MutexGuard to a cal er: it’s like handing out a loaded
gun, from a deadlock perspective.
• Include deadlock detection tools in your CI system (
,
• As a last resort: design, document, test, and police a locking hierarchy that
describes what lock orderings are allowed/required. This should be a last resort
because any strategy that relies on engineers never making a mistake is likely to
be doomed to failure in the long term.
More abstractly, multithreaded code is an ideal place to apply the following general
advice: prefer code that’s so simple that it is obviously not wrong, rather than code
that’s so complex that it’s not obviously wrong.
Item 18: Don’t panic
It looked insanely complicated, and this was one of the reasons why the snug plastic cover it
fitted into had the words DON’T PANIC printed on it in large friendly letters.
—Douglas Adams
The title of this Item would be more accurately described as prefer returning a Result
to using panic! (but don’t panic is much catchier).
Rust’s panic mechanism is primarily designed for unrecoverable bugs in your pro‐
gram, and by default it terminates the thread that issues the panic!. However, there
are alternatives to this default.
In particular, newcomers to Rust who have come from languages that have an excep‐
tion system (such as Ja
as a way to simulate exceptions, because it appears to provide a mechanism for catch‐
ing panics at a point further up the call stack.
Consider a function that panics on an invalid input:
fn divide(a: i64, b: i64) -> i64 {
if b == 0 {
panic!("Cowardly refusing to divide by zero!");
}
a / b
}
Trying to invoke this with an invalid input fails as expected:
// Attempt to discover what 0/0 is...
let result = divide(0, 0);
Item 18: Don’t panic | 159
thread 'main' panicked at 'Cowardly refusing to divide by zero!', main.rs:11:9
note: run with `RUST_BACKTRACE=1ènvironment variable to display a backtrace
A wrapper that uses catch_unwind to catch the panic:
fn divide_recover(a: i64, b: i64, default: i64) -> i64 {
let result = std::panic::catch_unwind(|| divide(a, b));
match result {
Ok(x) => x,
Err(_) => default,
}
}
appears to work and to simulate catch:
let result = divide_recover(0, 0, 42);
println!("result = {result}");
result = 42
Appearances can be deceptive, however. The first problem with this approach is that
panics don’t always unwind; there is a (which is also accessible via a Cargo.toml ) that shifts panic behavior so that it immediately aborts the process:
thread 'main' panicked at 'Cowardly refusing to divide by zero!', main.rs:11:9
note: run with `RUST_BACKTRACE=1ènvironment variable to display a backtrace
/bin/sh: line 1: 29100 Abort trap: 6 cargo run --release
This leaves any attempt to simulate exceptions entirely at the mercy of the wider
project settings. It’s also the case that some target platforms (for example, WebAssem‐
bly) always abort on panic, regardless of any compiler or project settings.
A more subtle problem that’: if a panic occurs midway through an operation on a data structure, it removes any guarantees
that the data structure has been left in a self-consistent state. Preserving internal
invariants in the presence of exceptions has been known to be extremely difficult
this is one of the main reasons why
Finally, panic propagation also with FFI (foreign function interface) boundaries (); use catch_unwind to prevent panics in Rust code from propagat-ing to non-Rust cal ing code across an FFI boundary.
So what’s the alternative to panic! for dealing with error conditions? For library
code, the best alterna, by returning a Result with an appropria). This allows the library user to make
9 Tom Cargill’s 1994 plate code, as does Herb Sutter’.
160 | Chapter 3: Concepts
their own decisions about what to do next—which may involve passing the problem
on to the next caller in line, via the ? operator.
The buck has to stop somewhere, and a useful rule of thumb is that it’s OK to panic!
(or to unwrap(), expect(), etc.) if you have control of main; at that point, there’s no
further caller that the buck could be passed to.
Another sensible use of panic!, even in library code, is in situations where it’s very
rare to encounter errors, and you don’t want users to have to litter their code
with .unwrap() calls.
If an error situation should occur only because (say) internal data is corrupted, rather
than as a result of invalid inputs, then triggering a panic! is legitimate.
It can even be occasionally useful to allow panics that can be triggered by invalid
input but where such invalid inputs are out of the ordinary. This works best when the
relevant entrypoints come in pairs:
• An “infallible” version whose signature implies it always succeeds (and which
panics if it can’t succeed)
• A “fallible” version that returns a Result
For the former, Rust’ suggest that the panic! should be documented in a specific section of the inline documenta
and entrypoints in the standard library are an example of the latter (although in this case, the panics are
actually deferred to the point where a String constructed from invalid input gets
used).
Assuming that you are trying to comply with the advice in this Item, there are a few
things to bear in mind. The first is that panics can appear in different guises; avoiding
panic! also involves avoiding the following:
•
•
•
Item 18: Don’t panic | 161
Harder to spot are things like these:
• slice[index] when the index is out of range
• x / y when y is zero
The second observation around avoiding panics is that a plan that involves constant
vigilance of humans is never a good idea.
However, constant vigilance of machines is another matter: adding a check to your
continuous integration (see t spots new, potentially panicking
code is much more reliable. A simple version could be a simple grep for the most
common panicking entrypoints (as shown previously); a more thorough check could
involve additional tooling from the Rust ecosystem (
build variant tha crate.
Item 19: Avoid reflection
Programmers coming to Rust from other languages are often used to reaching for
reflection as a tool in their toolbox. They can waste a lot of time trying to implement
reflection-based designs in Rust, only to discover that what they’re attempting can
only be done poorly, if at all. This Item hopes to save that time wasted exploring dead
ends, by describing what Rust does and doesn’t have in the way of reflection, and
what can be used instead.
Reflection is the ability of a program to examine itself at runtime. Given an item at
runtime, it covers these questions:
• What information can be determined about the item’s type?
• What can be done with that information?
Programming languages with full reflection support have extensive answers to these
questions. Languages with reflection typically support some or all of the following at
runtime, based on the reflection information:
• Determining an item’s type
• Exploring its contents
• Modifying its fields
• Invoking its methods
Languages that have this level of reflection support also tend to be dynamically typed
languages (e.g., uby), but there are also some notable statically typed languages tha.
162 | Chapter 3: Concepts
Rust does not support this type of reflection, which makes the advice to avoid reflec‐
tion easy to follow at this level—it’s just not possible. For programmers coming from
languages with support for full reflection, this absence may seem like a significant gap
at first, but Rust’s other features provide alternative ways of solving many of the same
problems.
C++ has a more limited form of reflection, known as run-time type identification
(RTtor returns a unique identifier for every type, for objects of polymorphic type (roughly: classes with virtual functions):
typeid
Can recover the concrete class of an object referred to via a base class reference
Allows base class references to be converted to derived classes, when it is safe and
correct to do so
Rust does not support this RTTI style of reflection either, continuing the theme that
the advice of this Item is easy to follow.
Rust does support some features that provide similar
module, but they’re limited (in ways we will explore) and so best avoided unless no
other alternatives are possible.
The first reflection-like feature from std::any looks like magic at first—a way of
determining the name of an item’s type. The following example uses a user-defined
tname() function:
let x = 42u32;
let y = vec![3, 4, 2];
println!("x: {} = {}", tname(&x), x);
println!("y: {} = {:?}", tname(&y), y);
to show types alongside values:
x: u32 = 42
y: alloc::vec::Vec<i32> = [3, 4, 2]
The implementation of tname() reveals what’s up the compiler’s sleeve: the function is
generic (as per vocation of it is actually a different function (tname::<u32> or tname::<Square>):
fn tname<T: ?Sized>(_v: & T) -> &'static str {
std::any::type_name::<T>()
}
Item 19: Avoid reflection | 163
The implementa library function, which is also generic. This function has access only to compile-time information;
there is no code run that determines the type at runtime. Returning to the trait object
demonstrates this:
let square = Square::new(1, 2, 2);
let draw: & dyn Draw = □
let shape: & dyn Shape = □
println!("square: {}", tname(&square));
println!("shape: {}", tname(&shape));
println!("draw: {}", tname(&draw));
Only the types of the trait objects are available, not the type (Square) of the concrete
underlying item:
square: reflection::Square
shape: &dyn reflection::Shape
draw: &dyn reflection::Draw
The string returned by type_name is suitable only for diagnostics—it’s explicitly a
“best-effort” helper whose contents may change and may not be unique—so don’t
attempt to parse type_name results. If you need a globally unique type identifier, use
use std::any::TypeId;
fn type_id<T: 'static + ?Sized>(_v: & T) -> TypeId {
TypeId::of::<T>()
}
println!("x has {:?}", type_id(&x));
println!("y has {:?}", type_id(&y));
x has TypeId { t: 18349839772473174998 }
y has TypeId { t: 2366424454607613595 }
The output is less helpful for humans, but the guarantee of uniqueness means that the
result can be used in code. However, it’s usually best not to use TypeId directly but to
use the trait instead, because the standard library has additional functionality for working with Any instances (described below).
The Any trait has a single method , which returns the TypeId value for the type that implements the trait. You can’t implement this trait yourself, though,
because Any already comes with a blanket implementation for most arbitrary types T:
impl<T: 'static + ?Sized> Any for T {
fn type_id(&self) -> TypeId {
TypeId::of::<T>()
}
}
164 | Chapter 3: Concepts
The blanket implementation doesn’t cover every type T: the T: 'static lifetime
bound means that if T includes any references that have a non-'static lifetime, then
TypeId is not implemented for T. This is a t’s imposed because lifetimes aren’t fully part of the type: TypeId::of::<&'a T> would be the
same as TypeId::of::<&'b T>, despite the differing lifetimes, increasing the likeli‐
hood of confusion and unsound code.
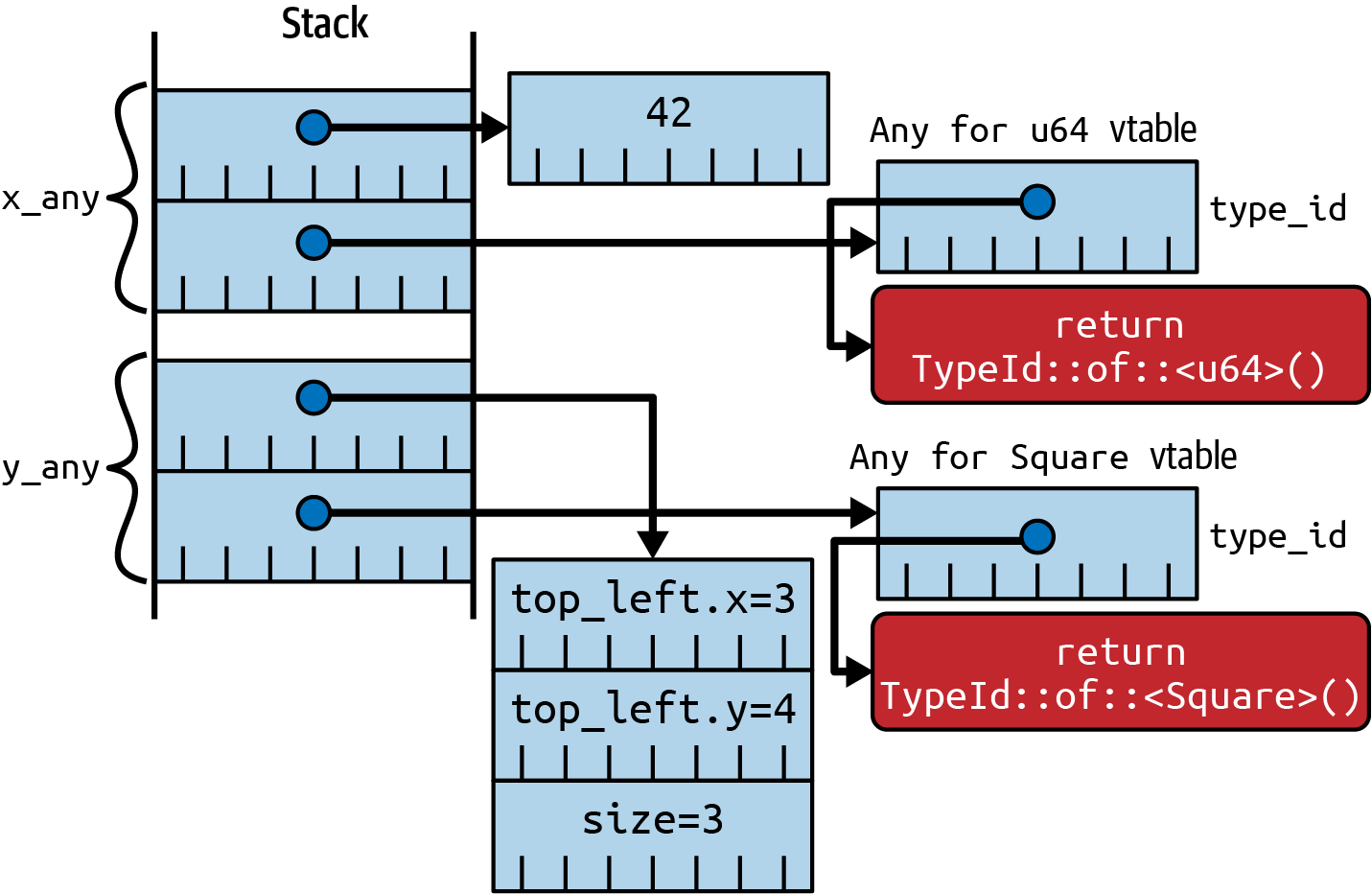
that a trait object is a fat pointer that holds a pointer to the underlying item, together with a pointer to the trait implementation’s vtable. For Any, the
vtable has a single entry, for a type_id() method that returns the item’s type, as
shown in
let x_any: Box< dyn Any> = Box::new(42u64);
let y_any: Box< dyn Any> = Box::new(Square::new(3, 4, 3));
Figure 3-4. Any trait objects, each with pointers to concrete items and vtables
Item 19: Avoid reflection | 165
Aside from a couple of indirections, a dyn Any trait object is effectively a combina‐
tion of a raw pointer and a type identifier. This means that the standard library can
offer some additional generic methods that are defined for a dyn Any trait object;
these methods are generic over some additional type T:
Indicates whether the trait object’s type is equal to some specific other type T
Returns a reference to the concrete type T, provided that the trait object’s type
matches T
Returns a mutable reference to the concrete type T, provided that the trait object’s
type matches T
Observe that the Any trait is only approximating reflection functionality: the pro‐
grammer chooses (at compile time) to explicitly build something (&dyn Any) that
keeps track of an item’s compile-time type as well as its location. The ability to (say)
downcast back to the original type is possible only if the overhead of building an Any
trait object has already happened.
There are comparatively few scenarios where Rust has different compile-time and
runtime types associated with an item. Chief among these is trait objects: an item of a
concrete type Square can be coerced into a trait object dyn Shape for a trait that the
type implements. This coercion builds a fat pointer (object + vtable) from a simple
pointer (object/item).
that Rust’s trait objects are not really object-oriented. It’s not the case that a Square is-a Shape; it’s just that a Square implements Shape’s interface.
The same is true for trait bounds: a trait bound Shape: Draw does not mean is-a; it
just means also-implements because the vtable for Shape includes the entries for the
methods of Draw.
For some simple trait bounds:
trait Draw: Debug {
fn bounds(&self) -> Bounds;
}
trait Shape: Draw {
fn render_in(&self, bounds: Bounds);
fn render(&self) {
self.render_in(overlap(SCREEN_BOUNDS, self.bounds()));
}
}
166 | Chapter 3: Concepts
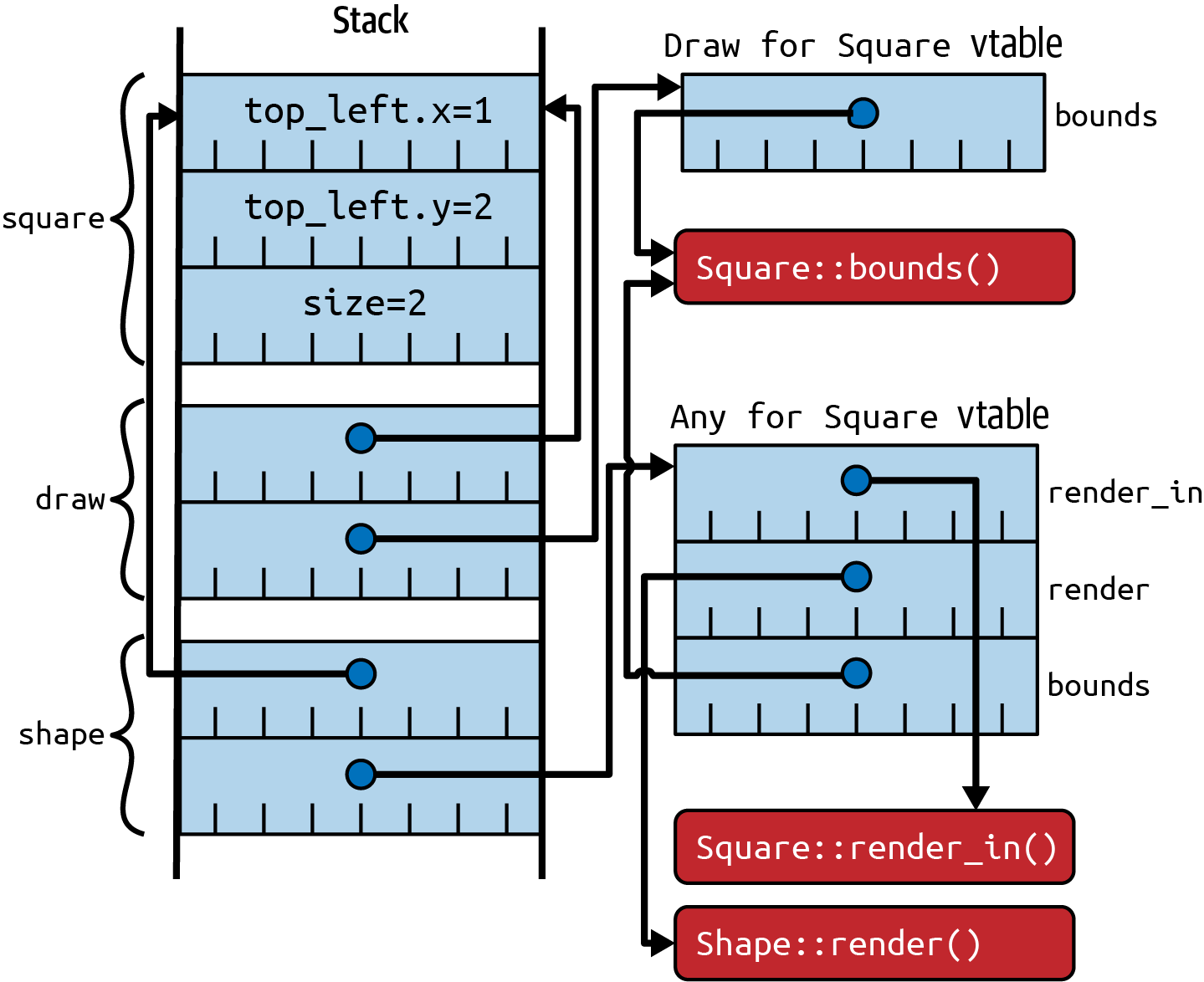
the equivalent trait objects:
let square = Square::new(1, 2, 2);
let draw: & dyn Draw = □
let shape: & dyn Shape = □
have a layout with arrows (shown in ; repeated from t make the problem clear: given a dyn Shape object, there’s no immediate way to build a dyn
Draw trait object, because there’s no way to get back to the vtable for impl Draw for
Square—even though the relevant part of its contents (the address of the
Square::bounds() method) is theoretically recoverable. (This is likely to change in
later versions of Rust; see the final section of this Item.)
Figure 3-5. Trait objects for trait bounds, with distinct vtables for Draw and Shape
Comparing this with the previous diagram, it’s also clear that an explicitly construc‐
ted &dyn Any trait object doesn’t help. Any allows recovery of the original concrete
type of the underlying item, but there is no runtime way to see what traits it imple‐
ments, or to get access to the relevant vtable that might allow creation of a trait object.
So what’s available instead?
Item 19: Avoid reflection | 167
The primary tool to reach for is trait definitions, and this is in line with advice for
other languages— Effective Java Item 65 recommends, “Prefer interfaces to reflection.”
If code needs to rely on the availability of certain behavior for an item, encode that
behavior as a trait (ven if the desired behavior can’t be expressed as a set of method signatures, use marker traits to indicate compliance with the desired behavior—it’s safer and more efficient than (say) introspecting the name of a class to check
for a particular prefix.
Code that expects trait objects can also be used with objects having backing code that
was not available at program link time, because it has been dynamically loaded at
runtime (via dlopen(3) or equivalent)—which means that monomorphization of a
’t possible.
Relatedly, reflection is sometimes also used in other languages to allow multiple
incompatible versions of the same dependency library to be loaded into the program
at once, bypassing linkage constraints that There Can Be Only One. This is not
needed in Rust, where Cargo already copes with multiple versions of the same library
).
Finally, macros—especially derive macros—can be used to auto-generate ancillary
code that understands an item’s type at compile time, as a more efficient and more
type-safe equivalent to code that parses an item’s contents at runtime. dis‐
cusses Rust’s macro system.
Upcasting in Future Versions of Rust
The text of this Item was first written in 2021, and remained accurate all the way until
the book was being prepared for publication in 2024—at which point a new feature is
due to be added to Rust that changes some of the details.
enables upcasts that convert a trait object dyn T to a trait object dyn U, when U is one of T’s supertraits (trait T: U {...}). The feature
is gated on #![feature(trait_upcasting)] in advance of its official release,
expected to be Rust version 1.76.
For the preceding example, that means a &dyn Shape trait object can now be con‐
verted to a &dyn Draw trait object, edging closer to the is-a relationship of
version has a knock-on effect on the internal details of the vtable implementation, which are likely to become more complex than the versions
shown in
However, the central points of this Item are not affected—the Any trait has no super‐
traits, so the ability to upcast adds nothing to its functionality.
168 | Chapter 3: Concepts
Item 20: Avoid the temptation to over-optimize
Just because Rust al ows you to write super cool non-al ocating zero-copy algorithms safely,
doesn’t mean every algorithm you write should be super cool, zero-copy and non-al ocating.
—
Most of the Items in this book are designed to help existing programmers become
familiar with Rust and its idioms. This Item, however, is all about a problem that can
arise when programmers stray too far in the other direction and become obsessed
with exploiting Rust’s potential for efficiency—at the expense of usability and main‐
tainability.
Data Structures and Allocation
Like pointers in other languages, Rust’s references allow you to reuse data without
making copies. Unlike other languages, Rust’s rules around reference lifetimes and
borrows allow you to reuse data safely. However, complying with the borrow check‐
) that make this possible can lead to code that’s harder to use.
This is particularly relevant for data structures, where you can choose between allo‐
cating a fresh copy of something that’s stored in the data structure or including a ref‐
erence to an existing copy of it.
As an example, consider some code that parses a data stream of bytes, extracting data
encoded as type-length-value (TLV) structures where data is transferred in the fol‐
lowing format:
• One byte describing the type of the value (stored in the type_code field here)
• One byte describing the length of the value in bytes (used here to create a slice of
the specified length)
• Followed by the specified number of bytes for the value (stored in the value
field):
/// A type-length-value (TLV) from a data stream.
#[derive(Clone, Debug)]
pub struct Tlv<'a> {
pub type_code: u8,
pub value: &'a [u8],
}
pub type Error = &'static str; // Some local error type.
10 The field can’t be named type because that’s a reserved keyword in Rust. It’s possible to work around this restriction by using the r# (giving a field r#type: u8), but it’s normally easier just to rename the field.
Item 20: Avoid the temptation to over-optimize | 169
/// Extract the next TLV from the ìnput`, also returning the remaining
/// unprocessed data.
pub fn get_next_tlv(input: &[u8]) -> Result<(Tlv, &[u8]), Error> {
if input.len() < 2 {
return Err("too short for a TLV");
}
// The TL parts of the TLV are one byte each.
let type_code = input[0];
let len = input[1] as usize;
if 2 + len > input.len() {
return Err("TLV longer than remaining data");
}
let tlv = Tlv {
type_code,
// Reference the relevant chunk of input data
value: & input[2..2 + len],
};
Ok((tlv, &input[2 + len..]))
}
This Tlv data structure is efficient because it holds a reference to the relevant chunk
of the input data, without copying any of the data, and Rust’s memory safety ensures
that the reference is always valid. That’s perfect for some scenarios, but things become
more awkward if something needs to hang onto an instance of the data structure (as
discussed in
For example, consider a network server that is receiving messages in the form of
TLVs. The received data can be parsed into Tlv instances, but the lifetime of those
instances will match that of the incoming message—which might be a transient
Vec<u8> on the heap or might be a buffer somewhere that gets reused for multiple
messages.
That induces a problem if the server code ever wants to store an incoming message so
that it can be consulted later:
pub struct NetworkServer<'a> {
// ...
/// Most recent max-size message.
max_size: Option<Tlv<'a>>,
}
/// Message type code for a set-maximum-size message.
const SET_MAX_SIZE: u8 = 0x01;
impl<'a> NetworkServer<'a> {
pub fn process(& mut self, mut data: &'a [u8]) -> Result<(), Error> {
while !data.is_empty() {
let (tlv, rest) = get_next_tlv(data)?;
match tlv.type_code {
170 | Chapter 3: Concepts
SET_MAX_SIZE => {
// Save off the most recent `SET_MAX_SIZÈ message.
self.max_size = Some(tlv);
}
// (Deal with other message types)
// ...
_ => return Err("unknown message type"),
}
data = rest; // Process remaining data on next iteration.
}
Ok(())
}
}
This code compiles as is but is effectively impossible to use: the lifetime of the Net
workServer has to be smaller than the lifetime of any data that gets fed into its pro
cess() method. That means that a straightforward processing loop:
D O E S N O T C O M P I L E
let mut server = NetworkServer::default();
while !server.done() {
// Read data into a fresh vector.
let data: Vec< u8> = read_data_from_socket();
if let Err(e) = server.process(&data) {
log::error!("Failed to process data: {:?}", e);
}
}
fails to compile because the lifetime of the ephemeral data gets attached to the longer-
lived server:
error[E0597]: `datà does not live long enough
--> src/main.rs:375:40
|
372 | while !server.done() {
| ------------- borrow later used here
373 | // Read data into a fresh vector.
374 | let data: Vec<u8> = read_data_from_socket();
| ---- binding `datà declared here
375 | if let Err(e) = server.process(&data) {
| ^^^^^ borrowed value does not live
| long enough
...
378 | }
| - `datà dropped here while still borrowed
Switching the code so it reuses a longer-lived buffer doesn’t help either:
Item 20: Avoid the temptation to over-optimize | 171
D O E S N O T C O M P I L E
let mut perma_buffer = [0u8; 256];
let mut server = NetworkServer::default(); // lifetime within `perma_buffer`
while !server.done() {
// Reuse the same buffer for the next load of data.
read_data_into_buffer(& mut perma_buffer);
if let Err(e) = server.process(&perma_buffer) {
log::error!("Failed to process data: {:?}", e);
}
}
This time, the compiler complains that the code is trying to hang on to a reference
while also handing out a mutable reference to the same buffer:
error[E0502]: cannot borrow `perma_bufferàs mutable because it is also
borrowed as immutable
--> src/main.rs:353:31
|
353 | read_data_into_buffer(&mut perma_buffer);
| ^^^^^^^^^^^^^^^^^ mutable borrow occurs here
354 | if let Err(e) = server.process(&perma_buffer) {
| -----------------------------
| | |
| | immutable borrow occurs here
| immutable borrow later used here
The core problem is that the Tlv structure references transient data—which is fine for
transient processing but is fundamentally incompatible with storing state for later.
However, if the Tlv data structure is converted to own its contents:
#[derive(Clone, Debug)]
pub struct Tlv {
pub type_code: u8,
pub value: Vec< u8>, // owned heap data
}
and the get_next_tlv() code is correspondingly tweaked to include an additional
call to .to_vec():
// ...
let tlv = Tlv {
type_code,
// Copy the relevant chunk of data to the heap.
// The length field in the TLV is a single ù8`,
// so this copies at most 256 bytes.
value: input[2..2 + len].to_vec(),
};
172 | Chapter 3: Concepts
then the server code has a much easier job. The data-owning Tlv structure has no
lifetime parameter, so the server data structure doesn’t need one either, and both var‐
iants of the processing loop work fine.
Who’s Afraid of the Big Bad Copy?
One reason why programmers can become overly obsessed with reducing copies is
that Rust generally makes copies and allocations explicit. A visible call to a method
like .to_vec() or .clone(), or to a function like Box::new(), makes it clear that
copying and allocation are occurring. This is in contrast to C++, where it’s easy to
inadvertently write code that blithely performs allocation under the covers, particu‐
larly in a copy-constructor or assignment operator.
Making an allocation or copy operation visible rather than hidden isn’t a good reason
to optimize it away, especially if that happens at the expense of usability. In many sit‐
uations, it makes more sense to focus on usability first, and fine-tune for optimal effi‐
ciency only if performance is genuinely a concern—and if benchmarking (see
indicates that reducing copies will have a significant impact.
Also, the efficiency of your code is usually important only if it needs to scale up for
extensive use. If it turns out that the trade-offs in the code are wrong, and it doesn’t
cope well when millions of users start to use it—well, that’s a nice problem to have.
However, there are a couple of specific points to remember. The first was hidden
behind the weasel word general y when pointing out that copies are generally visible.
The big exception to this is Copy types, where the compiler silently makes copies
willy-nilly, shifting from move semantics to copy semantics. As such, the advice in
bears repeating here: don’t implement Copy unless a bitwise copy is valid and
fast. But the converse is true too: do consider implementing Copy if a bitwise copy is
valid and fast. For example, enum types that don’t carry additional data are usually eas‐
ier to use if they derive Copy.
The second point that might be relevant is the potential trade-off with no_std use.
t it’s often possible to write code that’s no_std-compatible with
only minor modifications, and code that avoids allocation altogether makes this more
straightforward. However, targeting a no_std environment that supports heap alloca‐
tion (via the alloc library, also described in y give the best balance of
usability and no_std support.
Item 20: Avoid the temptation to over-optimize | 173
References and Smart Pointers
So very recently, I’ve consciously tried the experiment of not worrying about the hypothetical
perfect code. Instead, I call .clone() when I need to, and use Arc to get local objects into
threads and futures more smoothly.
And it feels glorious.
—
Designing a data structure so that it owns its contents can certainly make for better
ergonomics, but there are still potential problems if multiple data structures need to
make use of the same information. If the data is immutable, then each place having its
own copy works fine, but if the information might change (which is very commonly
the case), then multiple copies means multiple places that need to be updated, in sync
with each other.
Using Rust’s smart pointer types helps solve this problem, by allowing the design to
shift from a single-owner model to a shared-owner model. The Rc (for single-
threaded code) and Arc (for multithreaded code) smart pointers provide reference
counting that supports this shared-ownership model. Continuing with the assump‐
tion that mutability is needed, they are typically paired with an inner type that allows
interior mutability, independently of Rust’s borrow checking rules:
RefCell
For interior mutability in single-threaded code, giving the common
Rc<RefCell<T>> combination
Mutex
For interior mutability in m
mon Arc<Mutex<T>> combination
This transition is covered in more detail in the GuestRegister exam,
but the point here is that you don’t have to treat Rust’s smart pointers as a last resort.
It’s not an admission of defeat if your design uses smart pointers instead of a complex
web of interconnected reference lifetimes— smart pointers can lead to a simpler, more
maintainable, and more usable design.
174 | Chapter 3: Concepts
CHAPTER 4
Dependencies
When the Gods wish to punish us, they answer our prayers.
—Oscar Wilde
For decades, the idea of code reuse was merely a dream. The idea that code could be
written once, packaged into a library, and reused across many different applications
was an ideal, realized only for a few standard libraries and for corporate in-house
tools.
The growth of the internet and the rise of open source software finally changed that.
The first openly accessible repository that held a wide collection of useful libraries,
prehensive Perl Archive Network, online since 1995. Today, almost every modern language has a
comprehensive collection of open source libraries available, housed in a package
repository tha
However, new problems come along with that ease, convenience, and speed. It’s usu‐
al y still easier to reuse existing code than to write it yourself, but there are potential
pitfalls and risks that come along with dependencies on someone else’s code. This
chapter of the book will help you be aware of these.
The focus is specifically on Ry of the concerns, topics, and issues covered apply equally well to other toolchains (and other
languages).
1 With the notable exception of C and C++, where package management remains somewhat fragmented.
175
Item 21: Understand what semantic versioning promises
If we acknowledge that SemVer is a lossy estimate and represents only a subset of the possible
scope of changes, we can begin to see it as a blunt instrument.
—Titus Winters, Software Engineering at Google (O’Reilly)
Cargo, Rust’s package manager, allows automa
for Rust code according to semantic versioning (semver). A Cargo.toml stanza like:
[dependencies]
serde = "1.4"
indicates to cargo what ranges of semver versions are acceptable for this dependency.
The ying precise ranges of acceptable versions, but the following are the most commonly used variants:
"1.2.3"
Specifies that any version that’s semver-compatible with 1.2.3 is acceptable
"^1.2.3"
Is another way of specifying the same thing more explicitly
"=1.2.3"
Pins to one particular version, with no substitutes accepted
"~1.2.3"
Allows versions that are semver-compatible with 1.2.3 but only where the last
specified component changes (so 1.2.4 is acceptable but 1.3.0 is not)
"1.2.*"
Accepts any version that matches the wildcard
Examples of what these specifica.
Table 4-1. Cargo dependency version specification
Specification
1.2.2 1.2.3 1.2.4 1.3.0 2.0.0
"1.2.3"
No
Yes
Yes
Yes
No
"^1.2.3"
No
Yes
Yes
Yes
No
"=1.2.3"
No
Yes
No
No
No
"~1.2.3"
No
Yes
Yes
No
No
"1.2.*"
Yes
Yes
Yes
No
No
"1.*"
Yes
Yes
Yes
Yes
No
"*"
Yes
Yes
Yes
Yes
Yes
176 | Chapter 4: Dependencies
When choosing dependency versions, Cargo will generally pick the largest version
that’s within the combination of all of these semver ranges.
Because semantic versioning is at the heart of cargo’s dependency resolution process,
this Item explores more details about what semver means.
Semver Essentials
The essentials of semantic versioning are listed in the
, reproduced here:
Given a version number MAJOR.MINOR.PATCH, increment the:
• MAJOR version when you make incompatible API changes
• MINOR version when you add functionality in a backward compatible manner
• PATCH version when you make backward compatible bug fixes
An important point lurks in the
3. Once a versioned package has been released, the contents of that version MUST
NOT be modified. Any modifications MUST be released as a new version.
Putting this into different words:
• Changing anything requires a new patch version.
• Adding things to the API in a way that means existing users of the crate still com‐
pile and work requires a minor version upgrade.
• Removing or changing things in the API requires a major version upgrade.
There is one more important ver rules:
4. Major version zero (0.y.z) is for initial development. Anything MAY change at any
time. The public API SHOULD NOT be considered stable.
Cargo adapts this last rule slightly, “left-shifting” the earlier rules so that changes in
the leftmost non-zero component indicate incompatible changes. This means that
0.2.3 to 0.3.0 can include an incompatible API change, as can 0.0.4 to 0.0.5.
Semver for Crate Authors
In theory, theory is the same as practice. In practice, it’s not.
As a crate author, the first of these rules is easy to comply with, in theory: if you touch
anything, you need a new release. Using Git tch releases can help with this—by default, a tag is fixed to a particular commit and can be moved only with a
manual --force option. Cra also get automatic policing of Item 21: Understand what semantic versioning promises | 177
this, as the registry will reject a second attempt to publish the same crate version. The
main danger for noncompliance is when you notice a mistake just after a release has
gone out, and you have to resist the temptation to just nip in a fix.
The semver specification covers API compatibility, so if you make a minor change to
behavior that doesn’t alter the API, then a patch version update should be all that’s
needed. (However, if your crate is widely depended on, then in practice you may need
to be aware of
someone out there is likely to
unchanged.)
The difficult part for crate authors is the latter rules, which require an accurate deter‐
mination of whether a change is back compatible or not. Some changes are obviously
incompatible—removing public entrypoints or types, changing method signatures—
and some changes are obviously backward compatible (e.g., adding a new method to
a struct, or adding a new constant), but there’s a lot of gray area left in between.
To help with this, the goes into considerable detail as to what is and is not back compatible. Most of these details are unsurprising, but there are a few areas
worth highlighting:
• Adding new items is usual y safe—but may cause clashes if code using the crate
already makes use of something that happens to have the same name as the new
item.
— , because all of the crate’s items are then automatically in the user’s main namespace.
— Even without a wildcard im (with a default implementation; has a chance of clashing with an existing name.
• Rust’s insistence on covering all possibilities means that changing the set of avail‐
able possibilities can be a breaking change.
— Performing a match on an enum m
, that’s a breaking change (unless the enum is already marked as adding non_exhaustive is also a breaking change).
— Explicitly creating an instance of a struct requires an initial value for all
fields, so is a breaking change. Structures that have private fields are OK, because crate
users can’t explicitly construct them anyway; a struct can also be marked
as non_exhaustive to prevent external users from performing explicit
construction.
178 | Chapter 4: Dependencies
• Changing a trait so it is (y users that build trait objects for the trait will stop being able to compile their
code.
• Adding a new blanket implementation for a trait is a breaking change; any users
that already implement the trait will now have two conflicting implementations.
• Changing the license of an open source crate is an incompatible change: users of
your crate who have strict restrictions on what licenses are acceptable may be
broken by the change. Consider the license to be part of your API.
• Changing the default fea) of a crate is potentially a breaking
change. Removing a default feature is almost certain to break things (unless the
feature was already a no-op); adding a default feature may break things depend‐
ing on what it enables. Consider the default feature set to be part of your API.
• Changing library code so that it uses a new feature of Rust might be an incompat‐
ible change, because users of your crate who have not yet upgraded their com‐
piler to a version that includes the feature will be broken by the change. However,
most Rust crates treat a minimum supported Rust version (MSRV) increase as a
, so consider whether the MSRV forms part of your API.
An obvious corollary of the rules is this: the fewer public items a crate has, the fewer
things there are that can induce an incompa).
However, there’s no escaping the fact that comparing all public API items for compat‐
ibility from one release to the next is a time-consuming process that is likely to yield
only an approximate (major/minor/patch) assessment of the level of change, at best.
Given that this comparison is a somewhat mechanical process, hopefully tooling
) will arrive to make the process easier
If you do need to make an incompatible major version change, it’s nice to make life
easier for your users by ensuring that the same overall functionality is available after
the change, even if the API has radically changed. If possible, the most helpful
sequence for your crate users is as follows:
1. Release a minor version update that includes the new version of the API and that
marks the older variantion of how to migrate.
2. Release a major version update that removes the deprecated parts of the API.
A more subtle point is make breaking changes breaking. If your crate is changing its
behavior in a way that’s actually incompatible for existing users but that could reuse
2 For example, is a tool that attempts to do something along these lines.
Item 21: Understand what semantic versioning promises | 179
the same API: don’t. Force a change in types (and a major version bump) to ensure
that users can’t inadvertently use the new version incorrectly.
For the less tangible parts of your API—such as the or the license—consider
t detects changes, using tooling (e.g., cargo-deny;
see
Finally, don’t be afraid of version 1.0.0 because it’s a commitment that your API is
now fixed. Lots of crates fall into the trap of staying at version 0.x forever, but that
reduces the already-limited expressivity of semver from three categories (major/
minor/patch) to two (effective-major/effective-minor).
Semver for Crate Users
For the user of a crate, the theoretical expectations for a new version of a dependency
are as follows:
• A new patch version of a dependency crate Should Just Work.™
• A new minor version of a dependency crate Should Just Work,™ but the new parts
of the API might be worth exploring to see if there are now cleaner or better ways
of using the crate. However, if you do use the new parts, you won’t be able to
revert the dependency back to the old version.
• All bets are off for a new major version of a dependency; chances are that your
code will no longer compile, and you’ll need to rewrite parts of your code to
comply with the new API. Even if your code does still compile, you should check
that your use of the API is still valid after a major version change, because the con‐
straints and preconditions of the library may have changed.
In practice, even the first two types of change may cause unexpected behavior
changes, even in code that still compiles fine, due to Hyrum’s Law.
As a consequence of these expectations, your dependency specifications will com‐
monly take a form like "1.4.3" or "0.7", which includes subsequent compatible ver‐
sions; avoid specifying a completely wildcard dependency like "*" or "0.*". A
completely wildcard dependency says that any version of the dependency, with any
API, can be used by your crate—which is unlikely to be what you really want. Avoid‐
ing wildcards is also a requirement for publishing to crates.io; submissions with
"*"
180 | Chapter 4: Dependencies
However, in the longer term, it’s not safe to just ignore major version changes in
dependencies. Once a library has had a major version change, the chances are that no
further bug fixes—and more importantly, security updates—will be made to the pre‐
vious major version. A version specification like "1.4" will then fall further and fur‐
ther behind as new 2.x releases arrive, with any security problems left unaddressed.
As a result, you need to either accept the risks of being stuck on an old version or
eventual y fol ow major version upgrades to your dependencies. Tools such as cargo
update(tes are available; you can then schedule the upgrade for a time that’s convenient for you.
Discussion
Semantic versioning has a cost: every change to a crate has to be assessed against its
criteria, to decide the appropriate type of version bump. Semantic versioning is also a
blunt tool: at best, it reflects a crate owner’s guess as to which of three categories the
current release falls into. Not everyone gets it right, not everything is clear-cut about
exactly what “right” means, and even if you get it right, there’s always a chance you
may fall foul of Hyrum’s Law.
However, semver is the only game in town for anyone who doesn’t have the luxury of
working in an environmen. As such, understanding its concepts and limitations is necessary for managing dependencies.
Item 22: Minimize visibility
Rust allows elements of the code to either be hidden from or exposed to other parts of
the codebase. This Item explores the mechanisms provided for this and suggests
advice for where and when they should be used.
Visibility Syntax
Rust’s basic unit of visibility is the module. By default, a module’s items (types, meth‐
ods, constants) are private and accessible only to code in the same module and its
submodules.
Code that needs to be more widely available is marked with the pub keyword, making
it public to some other scope. For most Rust syntactic features, making the feature
pub does not automatically expose the contents—the types and functions in a pub mod
are not public, nor are the fields in a pub struct. However, there are a couple of
exceptions where applying the visibility to the contents makes sense:
• Making an enum public automatically makes the type’s variants public too
(together with any fields that might be present in those variants).
Item 22: Minimize visibility | 181
• Making a trait public automatically makes the trait’s methods public too.
So a collection of types in a module:
pub mod somemodule {
// Making àstruct` public does not make its fields public.
#[derive(Debug, Default)]
pub struct AStruct {
// By default fields are inaccessible.
count: i32,
// Fields have to be explicitly marked `pub` to be visible.
pub name: String,
}
// Likewise, methods on the struct need individual `pub` markers.
impl AStruct {
// By default methods are inaccessible.
fn canonical_name(&self) -> String {
self.name.to_lowercase()
}
// Methods have to be explicitly marked `pub` to be visible.
pub fn id(&self) -> String {
format!("{}-{}", self.canonical_name(), self.count)
}
}
// Making an ènum` public also makes all of its variants public.
#[derive(Debug)]
pub enum AnEnum {
VariantOne,
// Fields in variants are also made public.
VariantTwo(u32),
VariantThree { name: String, value: String },
}
// Making àtrait` public also makes all of its methods public.
pub trait DoSomething {
fn do_something(&self, arg: i32);
}
}
allows access to pub things and the exceptions previously mentioned:
use somemodule::*;
let mut s = AStruct::default();
s.name = "Miles".to_string();
println!("s = {:?}, name='{}', id={}", s, s.name, s.id());
let e = AnEnum::VariantTwo(42);
println!("e = {e:?}");
#[derive(Default)]
182 | Chapter 4: Dependencies
pub struct DoesSomething;
impl DoSomething for DoesSomething {
fn do_something(&self, _arg: i32) {}
}
let d = DoesSomething::default();
d.do_something(42);
but non-pub things are generally inaccessible:
let mut s = AStruct::default();
s.name = "Miles".to_string();
println!("(inaccessible) s.count={}", s.count);
println!("(inaccessible) s.canonical_name()={}", s.canonical_name());
error[E0616]: field `countòf struct `somemodule::AStructìs private
--> src/main.rs:230:45
|
230 | println!("(inaccessible) s.count={}", s.count);
| ^^^^^ private field
error[E0624]: method `canonical_nameìs private
--> src/main.rs:231:56
|
86 | fn canonical_name(&self) -> String {
| ---------------------------------- private method defined here
...
231 | println!("(inaccessible) s.canonical_name()={}", s.canonical_name());
| private method ^^^^^^^^^^^^^^
Some errors have detailed explanations: E0616, E0624.
For more information about an error, try `rustc --explain E0616`.
The most common visibility marker is the bare pub keyword, which makes the item
visible to anything that’s able to see the module it’s in. That last detail is important: if a
somecrate::somemodule module isn’t visible to other code in the first place, anything
that’s pub inside it is still not visible.
However, there are also some more-specific variants of pub that allow the scope of the
visibility to be constrained. In descending order of usefulness, these are as follows:
pub(crate)
Accessible anywhere within the owning crate. This is particularly useful for crate-
wide internal helper functions that should not be exposed to external crate users.
pub(super)
Accessible to the parent module of the current module and its submodules. This
is occasionally useful for selectively increasing visibility in a crate that has a deep
module structure. It’s also the effective visibility level for modules: a plain mod
mymodule is visible to its parent module or crate and the corresponding
submodules.
Item 22: Minimize visibility | 183
pub(in <path>)
Accessible to code in <path>, which has to be a description of some ancestor
module of the current module. This can occasionally be useful for organizing
source code, because it allows subsets of functionality to be moved into submod‐
ules that aren’t necessarily visible in the public API. For example, the Rust stan‐
dard library consolidates all of the iterator to
and has the following:
• A pub(in crate::iter) visibility marker on all of the required adapter
• A pub use of all of the adapters::.
pub(self)
Equivalent to pub(in self), which is equivalent to not being pub. Uses for this
are very obscure, such as reducing the number of special cases needed in code-
generation macros.
The Rust compiler will warn you if you have a code item that is private to the module
but not used within that module (and its submodules):
pub mod anothermodule {
// Private function that is not used within its module.
fn inaccessible_fn(x: i32) -> i32 {
x + 3
}
}
Although the warning indicates that the code is “never used” in its owning module, in
practice this warning often indicates that code can’t be used from outside the module,
because the visibility restrictions don’t allow it:
warning: function ìnaccessible_fnìs never used
--> src/main.rs:56:8
|
56 | fn inaccessible_fn(x: i32) -> i32 {
| ^^^^^^^^^^^^^^^
|
= note: `#[warn(dead_code)]òn by default
Visibility Semantics
Separate from the question of how to increase visibility is the question of when to do
so. The generally accepted answer to this is as little as possible, at least for any code
that may possibly get used and reused in the future.
The first reason for this advice is that visibility changes can be hard to undo. Once a
crate item is public, it can’t be made private again without breaking any code that uses
the crate, thus necessitating a major version bum). The converse is not true: 184 | Chapter 4: Dependencies
moving a private item to be public generally needs only a minor version bump and
leaves craand notice how many are relevant only if there are pub items in play.
A more important—but more subtle—reason to prefer privacy is that it keeps your
options open. The more things that are exposed, the more things there are that need
to stay fixed for the future (absent an incompatible change). If you expose the internal
implementation details of a data structure, a putative future change to use a more effi‐
cient algorithm becomes a breaking change. If you expose internal helper functions,
it’s inevitable that some external code will come to depend on the exact details of
those functions.
Of course, this is a concern only for library code that potentially has multiple users
and a long lifespan. But nothing is as permanent as a temporary solution, and so it’s a
good habit to fall into.
It’s also worth observing that this advice to restrict visibility is by no means unique to
this Item or to Rust:
• The R.
• , 3rd edition, (Addison-Wesley Professional) has the following:
— Item 15: Minimize the accessibility of classes and members.
— Item 16: In public classes, use accessor methods, not public fields.
• Effective C++ by Scott Meyers (Addison-Wesley Professional) has the following
in its second edition:
— Item 18: Strive for class interfaces that are complete and minimal (my italics).
— Item 20: Avoid data members in the public interface.
Item 22: Minimize visibility | 185
Item 23: Avoid wildcard imports
Rust’s use statement pulls in a named item from another crate or module and makes
that name available for use in the local module’s code without qualification. A wild‐
card import (or glob import) of the form use somecrate::module::* says that every
public symbol from that module should be added to the local namespace.
As described in te may add new items to its API as part of a
minor version upgrade; this is considered a backward-compatible change.
The combination of these two observations raises the worry that a nonbreaking
change to a dependency might break your code: what happens if the dependency adds
a new symbol that clashes with a name you’re already using?
At the simplest level, this turns out not to be a problem: the names in a wildcard
import are treated as being lower priority, so any matching names that are in your
code take precedence:
use bytes::*;
// Local `Bytes` type does not clash with `bytes::Bytes`.
struct Bytes(Vec< u8>);
Unfortunately, there are still cases where clashes can occur. For example, consider the
case when the dependency adds a new trait and implements it for some type:
trait BytesLeft {
// Name clashes with thèremaining` method on the wildcard-imported
// `bytes::Buf` trait.
fn remaining(&self) -> usize;
}
impl BytesLeft for &[u8] {
// Implementation clashes with ìmpl bytes::Buf for &[u8]`.
fn remaining(&self) -> usize {
self.len()
}
}
If any method names from the new trait clash with existing method names that apply
to the type, then the compiler can no longer unambiguously figure out which method
is intended:
D O E S N O T C O M P I L E
let arr = [1u8, 2u8, 3u8];
let v = &arr[1..];
assert_eq!(v.remaining(), 2);
186 | Chapter 4: Dependencies
as indicated by the compile-time error:
error[E0034]: multiple applicable items in scope
--> src/main.rs:40:18
|
40 | assert_eq!(v.remaining(), 2);
| ^^^^^^^^^ multiplèremaining` found
|
note: candidate #1 is defined in an impl of the trait `BytesLeft` for the
typè&[u8]`
--> src/main.rs:18:5
|
18 | fn remaining(&self) -> usize {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
= note: candidate #2 is defined in an impl of the trait `bytes::Buf` for the
typè&[u8]`
help: disambiguate the method for candidate #1
|
40 | assert_eq!(BytesLeft::remaining(&v), 2);
| ~~~~~~~~~~~~~~~~~~~~~~~~
help: disambiguate the method for candidate #2
|
40 | assert_eq!(bytes::Buf::remaining(&v), 2);
| ~~~~~~~~~~~~~~~~~~~~~~~~~
As a result, you should avoid wildcard imports from crates that you don’t control.
If you do control the source of the wildcard import, then the previously mentioned
concerns disappear. For example, it’s common for a test module to do use
super::*;. It’s also possible for crates that use modules primarily as a way of dividing

