U N D E S I R E D B E H A V I O R
// In the 2021 edition of Rust, `TryFromìs in the prelude, so this
// ùsè statement is no longer needed.
use std::convert::TryFrom;
let inputs: Vec< i64> = vec![0, 1, 2, 3, 4];
let result: Vec< u8> = inputs
.into_iter()
.map(|v| < u8>::try_from(v).unwrap())
.collect();
Item 9: Consider using iterator transforms instead of explicit loops | 73
This works until some unexpected input comes along:
let inputs: Vec< i64> = vec![0, 1, 2, 3, 4, 512];
and causes a runtime failure:
thread 'main' panicked at 'called `Result::unwrap()òn an Èrr` value:
TryFromIntError(())', iterators/src/main.rs:266:36
note: run with `RUST_BACKTRACE=1ènvironment variable to display a backtrace
Following the advice given in , we want to keep the Result type in play and use
the ? operator to make any failure the problem of the calling code. The obvious mod‐
ification to emit the Result doesn’t really help:
let result: Vec<Result< u8, _>> =
inputs.into_iter().map(|v| < u8>::try_from(v)).collect();
// Now what? Still need to iterate to extract results and detect errors.
However, there’s an alternative version of collect(), which can assemble a Result
holding a Vec, instead of a Vec holding Results.
Forcing use of this version requires the turbofish (::<Result<Vec<_>, _>>):
let result: Vec< u8> = inputs
.into_iter()
.map(|v| < u8>::try_from(v))
.collect::<Result<Vec<_>, _>>()?;
Combining this with the question mark operator gives useful behavior:
• If the iteration encounters an error value, that error value is emitted to the caller
and iteration stops.
• If no errors are encountered, the remainder of the code can deal with a sensible
collection of values of the right type.
Loop Transformation
The aim of this Item is to convince you that many explicit loops can be regarded as
something to be converted to iterator transformations. This can feel somewhat
unnatural for programmers who aren’t used to it, so let’s walk through a transforma‐
tion step by step.
Starting with a very C-like explicit loop to sum the squares of the first five even items
of a vector:
let mut even_sum_squares = 0;
let mut even_count = 0;
for i in 0..values.len() {
if values[i] % 2 != 0 {
continue;
}
74 | Chapter 1: Types
even_sum_squares += values[i] * values[i];
even_count += 1;
if even_count == 5 {
break;
}
}
The first step is to replace vector indexing with direct use of an iterator in a for-each
loop:
let mut even_sum_squares = 0;
let mut even_count = 0;
for value in values.iter() {
if value % 2 != 0 {
continue;
}
even_sum_squares += value * value;
even_count += 1;
if even_count == 5 {
break;
}
}
An initial arm of the loop that uses continue to skip over some items is naturally
expressed as a filter():
let mut even_sum_squares = 0;
let mut even_count = 0;
for value in values.iter().filter(|x| *x % 2 == 0) {
even_sum_squares += value * value;
even_count += 1;
if even_count == 5 {
break;
}
}
Next, the early exit from the loop once five even items have been spotted maps to a
take(5):
let mut even_sum_squares = 0;
for value in values.iter().filter(|x| *x % 2 == 0).take(5) {
even_sum_squares += value * value;
}
Every iteration of the loop uses only the item squared, in the value * value combi‐
nation, which makes it an ideal target for a map():
let mut even_sum_squares = 0;
for val_sqr in values.iter().filter(|x| *x % 2 == 0).take(5).map(|x| x * x)
{
even_sum_squares += val_sqr;
}
Item 9: Consider using iterator transforms instead of explicit loops | 75
These refactorings of the original loop result in a loop body that’s the perfect nail to
fit under the hammer of the sum() method:
let even_sum_squares: u64 = values
.iter()
.filter(|x| *x % 2 == 0)
.take(5)
.map(|x| x * x)
.sum();
When Explicit Is Better
This Item has highlighted the advantages of iterator transformations, particularly
with respect to concision and clarity. So when are iterator transformations not appro‐
priate or idiomatic?
• If the loop body is large and/or multifunctional, it makes sense to keep it as an
explicit body rather than squeezing it into a closure.
• If the loop body involves error conditions that result in early termination of the
surrounding function, these are often best kept explicit—the try_..() methods
help only a little. However, collect()’s ability to convert a collection of Result
values into a Result holding a collection of values often allows error conditions
to still be handled with the ? operator.
• If performance is vital, an iterator transform that involves a closure should get
optimized so that explicit code. But if performance of a core loop is that important, measure different variants and tune
appropriately:
— Be careful to ensure that your measurements reflect real-world performance—
the compiler’s optimizer can give overoptimistic results on test data (as
— t the compiler spits out.
Most importantly, don’t convert a loop into an iteration transformation if the conver‐
sion is forced or awkward. This is a matter of taste to be sure—but be aware that your
taste is likely to change as you become more familiar with the functional style.
76 | Chapter 1: Types
CHAPTER 2
Traits
The second core pillar of Rust’s type system is the use of traits, which allow the
encoding of behavior that is common across distinct types. A trait is roughly equiv‐
alent to an interface type in other languages, but they are also tied to Rust’s generics
), to allow interface reuse without runtime overhead.
The Items in this chapter describe the standard traits that the Rust compiler and the
Rust toolchain make available, and provide advice on how to design and use trait-
encoded behavior.
Item 10: Familiarize yourself with standard traits
Rust encodes key behavioral aspects of its type system in the type system itself,
through a collection of fine-grained standard traits that describe those behaviors (see
).
Many of these traits will seem familiar to programmers coming from C++, corre‐
sponding to concepts such as copy-constructors, destructors, equality and assign‐
ment operators, etc.
As in C++, it’s often a good idea to implement many of these traits for your own
types; the Rust compiler will give you helpful error messages if some operation needs
one of these traits for your type and it isn’t present.
Implementing such a large collection of traits may seem daunting, but most of the
common ones can be automatically applied to user-defined types, using
derive macros generate code with the “obvious” implementation of the trait for that type (e.g., field-by-field comparison for Eq on a struct); this normally
requires that all constituent parts also implement the trait. The auto-generated
77
implementation is usual y what you want, but there are occasional exceptions dis‐
cussed in each trait’s section that follows.
The use of the derive macros does lead to type definitions like:
#[derive(Clone, Copy, Debug, PartialEq, Eq, PartialOrd, Ord, Hash)]
enum MyBooleanOption {
Off,
On,
}
where auto-generated implementations are triggered for eight different traits.
This fine-grained specification of behavior can be disconcerting at first, but it’s
important to be familiar with the most common of these standard traits so that the
available behaviors of a type definition can be immediately understood.
Common Standard Traits
This section discusses the most commonly encountered standard traits. Here are
rough one-sentence summaries of each:
Items of this type can make a copy of themselves when asked, by running user-
defined code.
If the compiler makes a bit-for-bit copy of this item’s memory representation
(without running any user-defined code), the result is a valid new item.
It’s possible to make new instances of this type with sensible default values.
There’s a for items of this type—any two items can be definitively compared, but it may not always be true that x==x.
There’s an for items of this type—any two items can be definitively compared, and it is always true that x==x.
Some items of this type can be compared and ordered.
All items of this type can be compared and ordered.
Items of this type can produce a stable hash of their contents when asked.
78 | Chapter 2: Traits
Items of this type can be displayed to programmers.
Items of this type can be displayed to users.
These traits can all be derived for user-defined types, with the exception of Display
(included here because of its overlap with Debug). However, there are occasions when
a manual implementation—or no implementation—is preferable.
The following sections discuss each of these common traits in more detail.
Clone
The Clone trait indicates that it’s possible to make a new copy of an item, by calling
t to C++’s copy-constructor but is more explicit: the compiler will never silently invoke this method on its own (read on
to the next section for that).
Clone can be derived for a type if all of the item’s fields implement Clone themselves.
The derived implementation clones an aggregate type by cloning each of its mem‐
bers in turn; again, this is roughly equivalent to a default copy-constructor in C++.
This makes the trait opt-in (by adding #[derive(Clone)]), in contrast to the opt-out
behavior in C++ (MyType(const MyType&) = delete;).
This is such a common and useful operation that it’s more interesting to investigate
the situations where you shouldn’t or can’t implement Clone, or where the default
derive implementation isn’t appropriate.
• You shouldn’t implement Clone if the item embodies unique access to some
resource (such as an RAII type; ), or when there’s another reason to
restrict copies (e.g., if the item holds cryptographic key material).
• You can’t implement Clone if some component of your type is un-Cloneable in
turn. Examples include the following:
— Fields that are mutable references (&mut T), because the borrow checker
(utable reference at a time.
— Standard library types that fall into the previous category
(restricts copies for thread safety).
• You should manual y implement Clone if there is anything about your item that
won’t be captured by a (recursive) field-by-field copy or if there is additional
bookkeeping associated with item lifetimes. For example, consider a type that
tracks the number of extant items at runtime for metrics purposes; a manual
Clone implementation can ensure the counter is kept accurate.
Item 10: Familiarize yourself with standard traits | 79
Copy
The Copy trait has a trivial declaration:
pub trait Copy: Clone { }
There are no methods in this trait, meaning that it is a marker trait (as described in
): it’s used to indicate some constraint on the type that’s not directly expressed in the type system.
In the case of Copy, the meaning of this marker is that a bit-for-bit copy of the mem‐
ory holding an item gives a correct new item. Effectively, this trait is a marker that
says tha.
This also means that the Clone trait bound can be slightly confusing: although a Copy
type has to implement Clone, when an instance of the type is copied, the clone()
method is not invoked—the compiler builds the new item without any involvement
of user-defined code.
In contrast to userCopy has a special significance to
the compiler (as do several of the other marker traits in std::marker) over and above
being available for trait bounds—it shifts the compiler from move semantics to copy
semantics.
With move semantics for the assignment operator, what the right hand giveth, the left
hand taketh away:
D O E S N O T C O M P I L E
#[derive(Debug, Clone)]
struct KeyId(u32);
let k = KeyId(42);
let k2 = k; // value moves out of k into k2
println!("k = {k:?}");
error[E0382]: borrow of moved value: `k`
--> src/main.rs:60:23
|
58 | let k = KeyId(42);
| - move occurs becausèk` has typèmain::KeyId`, which does
| not implement thèCopy` trait
59 | let k2 = k; // value moves out of k into k2
| - value moved here
60 | println!("k = {k:?}");
| ^^^^^ value borrowed here after move
|
= note: this error originates in the macrò$crate::format_args_nl`
help: consider cloning the value if the performance cost is acceptable
80 | Chapter 2: Traits
|
59 | let k2 = k.clone(); // value moves out of k into k2
| ++++++++
With copy semantics, the original item lives on:
#[derive(Debug, Clone, Copy)]
struct KeyId(u32);
let k = KeyId(42);
let k2 = k; // value bitwise copied from k to k2
println!("k = {k:?}");
This makes Copy one of the most important traits to watch out for: it fundamentally
changes the behavior of assignments—including parameters for method invocations.
In this respect, there are again overlaps with C++’s copy-constructors, but it’s worth
emphasizing a key distinction: in Rust there is no way to get the compiler to silently
invoke user-defined code—it’s either explicit (a call to .clone()) or it’s not user-
defined (a bitwise copy).
Because Copy has a Clone trait bound, it’s possible to .clone() any Copy-able item.
However, it’s not a good idea: a bitwise copy will always be faster than invoking a trait
method. Clippy (
U N D E S I R E D B E H A V I O R
let k3 = k.clone();
warning: using `cloneòn typèKeyId` which implements thèCopy` trait
--> src/main.rs:79:14
|
79 | let k3 = k.clone();
| ^^^^^^^^^ help: try removing thèclonè call: `k`
|
As with Clone, it’s worth exploring when you should or should not implement Copy:
• The obvious: don’t implement Copy if a bitwise copy doesn’t produce a valid item.
That’s likely to be the case if Clone needed a manual implementation rather than
an automatically derived implementation.
• It may be a bad idea to implement Copy if your type is large. The basic promise of
Copy is that a bitwise copy is valid; however, this often goes hand in hand with an
assumption that making the copy is fast. If that’s not the case, skipping Copy pre‐
vents accidental slow copies.
• You can’t implement Copy if some component of your type is un-Copyable in
turn.
Item 10: Familiarize yourself with standard traits | 81
• If all of the components of your type are Copyable, then it’s usually worth deriv‐
ing Copy. The compiler has an off-by-default lint
that points out opportunities for this.
Default
The Default trait defines a default constructor method. This trait can be derived for user-defined types, provided that all of the subtypes involved have
a Default implementation of their own; if they don’t, you’ll have to implement the
trait manually. Continuing the comparison with C++, notice that a default construc‐
tor has to be explicitly triggered—the compiler does not create one automatically.
The Default trait can also be derived for enum types, as long as there’s a #[default]
attribute to give the compiler a hint as to which variant is, well, default:
#[derive(Default)]
enum IceCreamFlavor {
Chocolate,
Strawberry,
#[default]
Vanilla,
}
The most useful aspect of the Default trait is its combination with
This syntax allows struct fields to be initialized by copying or moving their contents from an existing instance of the same struct, for any fields that aren’t explicitly
initialized. The template to copy from is given at the end of the initialization, after ..,
and the Default trait provides an ideal template to use:
#[derive(Default)]
struct Color {
red: u8,
green: u8,
blue: u8,
alpha: u8,
}
let c = Color {
red: 128,
..Default::default()
};
This makes it much easier to initialize structures with lots of fields, only some of
which have nondefault values. (The builder pattern, , may also be appropriate
for these situations.)
82 | Chapter 2: Traits
PartialEq and Eq
The PartialEq and Eq traits allow you to define equality for user-defined types.
These traits have special significance because if they’re present, the compiler will
automatically use them for equality (==) checks, similarly to operator== in C++. The
default derive implementation does this with a recursive field-by-field comparison.
The Eq version is just a marker trait extension of PartialEq that adds the assumption
of reflexivity: any type T that claims to support Eq should ensure that x == x is true
for any x: T.
This is sufficiently odd to immediately raise the question, When wouldn’t x == x?
The primary rationale behind this split relates to and specifically to the special “not a number” value NaN (f32::NAN / f64::NAN in Rust). The
floating point specifications require that nothing compares equal to NaN, including
NaN itself; the PartialEq trait is the knock-on effect of this.
For user-defined types that don’t have any float-related peculiarities, you should
implement Eq whenever you implement PartialEq. The full Eq trait is also required if
you wanHash trait).
You should implement PartialEq manually if your type contains any fields that do
not affect the item’s identity, such as internal caches and other performance optimiza‐
tions. (Any manual implementation will also be used for Eq if it is defined, because Eq
is just a marker trait that has no methods of its own.)
PartialOrd and Ord
The ordering traits PartialOrd and Ord allow comparisons between two items of a
type, returning Less, Greater, or Equal. The traits require equivalent equality traits
to be implemented (PartialOrd requires PartialEq; Ord requires Eq), and the two
have to agree with each other (watch out for this with manual implementations in
particular).
As with the equality traits, the comparison traits have special significance because the
compiler will automatically use them for comparison operations (<, >, <=, >=).
The default implementation produced by derive compares fields (or enum variants)
lexicographically in the order they’re defined, so if this isn’t correct, you’ll need to
implement the traits manually (or reorder the fields).
1 Of course, comparing floats for equality is always a dangerous game, as there is typically no guarantee that rounded calculations will produce a result that is bit-for-bit identical to the number you first thought of.
Item 10: Familiarize yourself with standard traits | 83
Unlike PartialEq, the PartialOrd trait does correspond to a variety of real situa‐
tions. For example, it could be used to express a subset relationship among collec‐
{1, 2} is a subset of {1, 2, 4}, but {1, 3} is not a subset of {2, 4}, nor vice
versa.
However, even if a partial order does accurately model the behavior of your type, be
wary of implementing just PartialOrd and not Ord (a rare occasion that contradicts
the advice in to encode behavior in the type system)—it can lead to surprising
results:
U N D E S I R E D B E H A V I O R
// Inherit thèPartialOrd` behavior from `f32`.
#[derive(PartialOrd, PartialEq)]
struct Oddity(f32);
// Input data with NaN values is likely to give unexpected results.
let x = Oddity(f32::NAN);
let y = Oddity(f32::NAN);
// A self-comparison looks like it should always be true, but it may not be.
if x <= x {
println!("This line doesn't get executed!");
}
// Programmers are also unlikely to write code that covers all possible
// comparison arms; if the types involved implemented Òrd`, then the
// second two arms could be combined.
if x <= y {
println!("y is bigger"); // Not hit.
} else if y < x {
println!("x is bigger"); // Not hit.
} else {
println!("Neither is bigger");
}
Hash
The Hash trait is used to produce a single value that has a high probability of being
different for different items. This hash value is used as the basis for hash-bucket–
based data structures like ; as such, the type of the keys in these data structures must implement Hash (and Eq).
2 More generally, any .
84 | Chapter 2: Traits
Flipping this around, it’s essential that the “same” items (as per Eq) always produce
the same hash: if x == y (via Eq), then it must always be true that hash(x) ==
hash(y). If you have a manual Eq implementation, check whether you also need a man‐
ual implementation of Hash to comply with this requirement.
Debug and Display
The Debug and Display traits allow a type to specify how it should be included in
output, for either normal ({} format argument) or debugging purposes ({:?} format
argument), roughly analogous to an operator<< overload for iostream in C++.
The differences between the intents of the two traits go beyond which format speci‐
fier is needed, though:
• Debug can be automatically derived, Display can only be manually implemented.
• The layout of Debug output may change between different Rust versions. If the
output will ever be parsed by other code, use Display.
• Debug is programmer-oriented; Display is user-oriented. A thought experiment
that helps with this is to consider what would happen if the program was
t the authors don’t speak—Display is appropriate if the content should be translated, Debug if not.
As a general rule, add an automatical y generated Debug implementation for your types
unless they contain sensitive information (personal details, cryptographic material,
etc.). To make this advice easier to comply with, the Rust compiler includes a
lint that points out types without Debug. This lint is disabled by default but can be enabled for your code with either of the following:
#![warn(missing_debug_implementations)]
#![deny(missing_debug_implementations)]
If the automatically generated implementation of Debug would emit voluminous
amounts of detail, then it may be more appropriate to include a manual implementa‐
tion of Debug that summarizes the type’s contents.
Implement Display if your types are designed to be shown to end users in textual
output.
Standard Traits Covered Elsewhere
In addition to the common traits described in the previous section, the standard
library also includes other standard traits that are less ubiquitous. Of these additional
standard traits, the following are the most important, but they are covered in other
Items and so are not covered here in depth:
Item 10: Familiarize yourself with standard traits | 85
, and
Items implementing these traits represent closures that can be invoked. See
.
Items implementing this trait represent error information that can be displayed
to users or programmers, and that may hold nested suberror information. See
.
Items implementing this trait perform processing when they are destroyed,
which is essential for RAII patterns. See .
nd
Items implementing these traits can be automatically created from items of some
other type but with a possibility of failure in the la
an
Items implementing these traits are pointer-like objects that can be dereferenced
nd friends
Items implementing these traits represent collections that can be iterated over.
Items implementing this trait are safe to transfer between multiple threads. See
Items implementing this trait are safe to be referenced by multiple threads. See
None of these traits are deriveable.
Operator Overloads
The final category of standard traits relates to operator overloads, where Rust allows
various built-in unary and binary operators to be overloaded for user-defined types,
by implemen
not derivable and are typically needed only for types that represent “algebraic”
objects, where there is a natural interpretation of these operators.
However, experience from C++ has shown that it’s best to avoid overloading operators
for unrelated types as it often leads to code that is hard to maintain and has unexpec‐
ted performance properties (e.g., x + y silently invokes an expensive O(N) method).
86 | Chapter 2: Traits
To comply with the principle of least astonishment, if you implement any operator
overloads, you should implement a coherent set of operator overloads. For example, if
x + y has an overload (), and -y , then you should also implement x - yx + (-y).
The items passed to the operator overload traits are moved, which means that non-
Copy types will be consumed by default. Adding implementations for &'a MyType can
help with this but requires more boilerplate to cover all of the possibilities (e.g., there
are 4 = 2 × 2 possibilities for combining reference/non-reference arguments to a
binary operator).
Summary
This item has covered a lot of ground, so some tables that summarize the standard
traits that have been touched on are in order. First, covers the traits that this Item covers in depth, all of which can be automatically derived except Display.
Table 2-1. Common standard traits
Trait
Compiler use
Bound
Methods
let y = x;
Clone
Marker trait
x == y
x == y
PartialEq
Marker trait
x < y, x <= y, …
PartialEq
x < y, x <= y, …
Eq + PartialOrd
format!("{:?}", x)
format!("{}", x)
The opera. None of these can be derived.
Table 2-2. Operator overload traits
Trait
Compiler use
Bound
Methods
x + y
x += y
x & y
x &= y
x | y
x |= y
x ^ y
x ^= y
Item 10: Familiarize yourself with standard traits | 87
Trait
Compiler use
Bound
Methods
x / y
x /= y
x * y
x *= y
-x
!x
x % y
x %= y
x << y
x <<= y
x >> y
x >>= y
x - y
x -= y
Some of the names here are a little cryptic—e.g., Rem for remainder and Shl for shift left—but the
documentation makes the intended use clear.
For completeness, the standard traits that are covered in other items are included in
deriveable (but Send and Sync may be automati‐
cally implemented by the compiler).
Table 2-3. Standard traits described in other Items
Trait
Compiler use
Bound
Methods
Item
x(a)
FnMut
x(a)
FnOnce
x(a)
Display + Debug
Borrow
*x, &x
*x, &mut x
Deref
x[idx]
x[idx] = ...
Index
88 | Chapter 2: Traits
Trait
Compiler use
Bound
Methods
Item
format("{:p}", x)
for y in x
Iterator
Iterator
} (end of scope)
Marker trait
cross-thread transfer
Marker trait
cross-thread use
Marker trait
Item 11: Implement the Drop trait for RAII patterns
Never send a human to do a machine’s job.
—Agent Smith
RAII stands for “Resource Acquisition Is Initialization,” which is a programming pat‐
tern where the lifetime of a value is exactly tied to the lifecycle of some additional
resource. The RAII pattern was popularized by the C++ programming language and
is one of C++’s biggest contributions to programming.
The correlation between the lifetime of a value and the lifecycle of a resource is enco‐
ded in an RAII type:
• The type’s constructor acquires access to some resource
• The type’s destructor releases access to that resource
The result of this is that the RAII type has an invariant: access to the underlying
resource is available if and only if the item exists. Because the compiler ensures that
local variables are destroyed at scope exit, this in turn means that the underlying
resources are also released at scope exit.
This is particularly helpful for maintainability: if a subsequent change to the code
alters the control flow, item and resource lifetimes are still correct. To see this, con‐
sider some code that manually locks and unlocks a mutex, without using the RAII
pattern; this code is in C++, because Rust’s Mutex doesn’t allow this kind of error-
prone usage!
3 This also means that RAII as a technique is mostly available only in languages that have a predictable time of destruction, which rules out most garbage-collected languages (although Go’ achieves some of the same ends).
Item 11: Implement the Drop trait for RAII patterns | 89
// C++ code
class ThreadSafeInt {
public:
ThreadSafeInt(int v) : value_(v) {}
void add(int delta) {
mu_.lock();
// ... more code here
value_ += delta;
// ... more code here
mu_.unlock();
}
A modification to catch an error condition with an early exit leaves the mutex locked:
U N D E S I R E D B E H A V I O R
// C++ code
void add_with_modification(int delta) {
mu_.lock();
// ... more code here
value_ += delta;
// Check for overflow.
if (value_ > MAX_INT) {
// Oops, forgot to unlock() before exit
return;
}
// ... more code here
mu_.unlock();
}
However, encapsulating the locking behavior into an RAII class:
// C++ code (real code should use std::lock_guard or similar)
class MutexLock {
public:
MutexLock(Mutex* mu) : mu_(mu) { mu_->lock(); }
~MutexLock() { mu_->unlock(); }
private:
Mutex* mu_;
};
means the equivalent code is safe for this kind of modification:
// C++ code
void add_with_modification(int delta) {
MutexLock with_lock(&mu_);
// ... more code here
value_ += delta;
// Check for overflow.
if (value_ > MAX_INT) {
return; // Safe, with_lock unlocks on the way out
90 | Chapter 2: Traits
}
// ... more code here
}
In C++, RAII patterns were often originally used for memory management, to ensure
that manual allocation (new, malloc()) and deallocation (delete, free()) operations
were kept in sync. A general version of this memory management was added to the
C++ standard library in C++11: the std::unique_ptr<T> type ensures that a single
place has “ownership” of memory but allows a pointer to the memory to be “bor‐
rowed” for ephemeral use (ptr.get()).
In Rust, this behavior for memory pointers is built in
Implement Drop for any types that hold resources that must be released, such as the following:
• Access to operating system resources. For Unix-derived systems, this usually
means something that holds a
hold onto system resources (and will also eventually lead to the program hitting
the per-process file descriptor limit).
• Access to synchronization resources. The standard library already includes mem‐
ory synchronization primitives, but other resources (e.g., file locks, database
locks, etc.) may need similar encapsulation.
• Access to raw memory, for unsafe types that deal with low-level memory man‐
agement (e.g., for foreign function interface [FFI] functionality).
The most obvious instance of RAII in the Rust standard librar
item returned by tions, which tend to be widely used for programs that use the shared-staThis is roughly anal‐
ogous to the final C++ example shown earlier, but in Rust the MutexGuard item acts
as a proxy to the mutex-protected data in addition to being an RAII item for the held
lock:
use std::sync::Mutex;
struct ThreadSafeInt {
value: Mutex< i32>,
}
impl ThreadSafeInt {
fn new(val: i32) -> Self {
Self {
value: Mutex::new(val),
4 RAII is also still useful for memory management in low-level unsafe code, but that is (mostly) beyond the scope of this book.
Item 11: Implement the Drop trait for RAII patterns | 91
}
}
fn add(&self, delta: i32) {
let mut v = self.value.lock().unwrap();
*v += delta;
}
}
use blocks to restrict the scope of RAII items. This leads to slightly odd indentation, but it’s
worth it for the added safety and lifetime precision:
impl ThreadSafeInt {
fn add_with_extras(&self, delta: i32) {
// ... more code here that doesn't need the lock
{
let mut v = self.value.lock().unwrap();
*v += delta;
}
// ... more code here that doesn't need the lock
}
}
Having proselytized the uses of the RAII pattern, an explanation of how to implement
it is in order. The trait allows you to add user-defined behavior to the destruction of an item. This trait has a single method, piler runs just before the memory holding the item is released:
#[derive(Debug)]
struct MyStruct(i32);
impl Drop for MyStruct {
fn drop(& mut self) {
println!("Dropping {self:?}");
// Code to release resources owned by the item would go here.
}
}
The drop method is specially reserved for the compiler and can’t be manually
invoked:
D O E S N O T C O M P I L E
x.drop();
error[E0040]: explicit use of destructor method
--> src/main.rs:70:7
|
70 | x.drop();
| --^^^^--
92 | Chapter 2: Traits
| | |
| | explicit destructor calls not allowed
| help: consider using `drop` function: `drop(x)Ìt’s worth understanding a little bit about the technical details here. Notice that the Drop::drop method has a signature of drop(&mut self) rather than drop(self): it
takes a mutable reference to the item rather than having the item moved into the
method. If Drop::drop acted like a normal method, that would mean the item would
still be available for use afterward—even though all of its internal state has been tid‐
ied up and resources released!
D O E S N O T C O M P I L E
{
// If calling `drop` were allowed...
x.drop(); // (does not compile)
// `x` would still be available afterwards.
x.0 += 1;
}
// Also, what would happen when `x` goes out of scope?
The compiler suggested a straightforward alterna
function to manually drop an item. This function does take a moved argument, and
the implementation of drop(_item: T) is just an empty body { }—so the moved
item is dropped when that scope’s closing brace is reached.
Notice also that the signature of the drop(&mut self) method has no return type,
which means that it has no way to signal failure. If an attempt to release resources can
fail, then you should probably have a separate release method that returns a Result,
so it’s possible for users to detect this failure.
Regardless of the technical details, the drop method is nevertheless the key place for
implementing RAII patterns; its implementation is the ideal place to release resources
associated with an item.
Item 12: Understand the trade-offs between
generics and trait objects
described the use of traits to encapsulate behavior in the type system, as a col‐
lection of related methods, and observed that there are two ways to make use of traits:
as trait bounds for generics or in trait objects. This Item explores the trade-offs between these two possibilities.
Item 12: Understand the trade-offs between generics and trait objects | 93
As a running example, consider a trait that covers functionality for displaying graphi‐
cal objects:
#[derive(Debug, Copy, Clone)]
pub struct Point {
x: i64,
y: i64,
}
#[derive(Debug, Copy, Clone)]
pub struct Bounds {
top_left: Point,
bottom_right: Point,
}
/// Calculate the overlap between two rectangles, or `Noneìf there is no
/// overlap.
fn overlap(a: Bounds, b: Bounds) -> Option<Bounds> {
// ...
}
/// Trait for objects that can be drawn graphically.
pub trait Draw {
/// Return the bounding rectangle that encompasses the object.
fn bounds(&self) -> Bounds;
// ...
}
Generics
Rust’s generics are roughly equivalent to C++’s templates: they allow the programmer
to write code that works for some arbitrary type T, and specific uses of the generic
code are generated at compile time—a process known as monomorphization in Rust,
and template instantiation in C++. Unlike C++, Rust explicitly encodes the expecta‐
tions for the type T in the type system, in the form of trait bounds for the generic.
For the example, a generic function that uses the trait’s bounds() method has an
explicit Draw trait bound:
/// Indicate whether an object is on-screen.
pub fn on_screen<T>(draw: & T) -> bool
where
T: Draw,
{
overlap(SCREEN_BOUNDS, draw.bounds()).is_some()
}
This can also be written more compactly by putting the trait bound after the generic
parameter:
94 | Chapter 2: Traits
pub fn on_screen<T: Draw>(draw: & T) -> bool {
overlap(SCREEN_BOUNDS, draw.bounds()).is_some()
}
or by using impl Trait as the type of the argumen
pub fn on_screen(draw: & impl Draw) -> bool {
overlap(SCREEN_BOUNDS, draw.bounds()).is_some()
}
If a type implements the trait:
#[derive(Clone)] // nòDebug`
struct Square {
top_left: Point,
size: i64,
}
impl Draw for Square {
fn bounds(&self) -> Bounds {
Bounds {
top_left: self.top_left,
bottom_right: Point {
x: self.top_left.x + self.size,
y: self.top_left.y + self.size,
},
}
}
}
then instances of that type can be passed to the generic function, monomorphizing it
to produce code that’s specific to one particular type:
let square = Square {
top_left: Point { x: 1, y: 2 },
size: 2,
};
// Calls òn_screen::<Square>(&Square) -> bool`
let visible = on_screen(&square);
If the same generic function is used with a different type that implements the relevant
trait bound:
#[derive(Clone, Debug)]
struct Circle {
center: Point,
radius: i64,
}
5 Using isn’t exactly equivalent to the previous two versions, because it removes the ability for a caller to explicitly specify the type parameter with something like on_screen::<Cir cle>(&c).
Item 12: Understand the trade-offs between generics and trait objects | 95
impl Draw for Circle {
fn bounds(&self) -> Bounds {
// ...
}
}
then different monomorphized code is used:
let circle = Circle {
center: Point { x: 3, y: 4 },
radius: 1,
};
// Calls òn_screen::<Circle>(&Circle) -> bool`
let visible = on_screen(&circle);
In other words, the programmer writes a single generic function, but the compiler
outputs a different monomorphized version of that function for every different type
that the function is invoked with.
Trait Objects
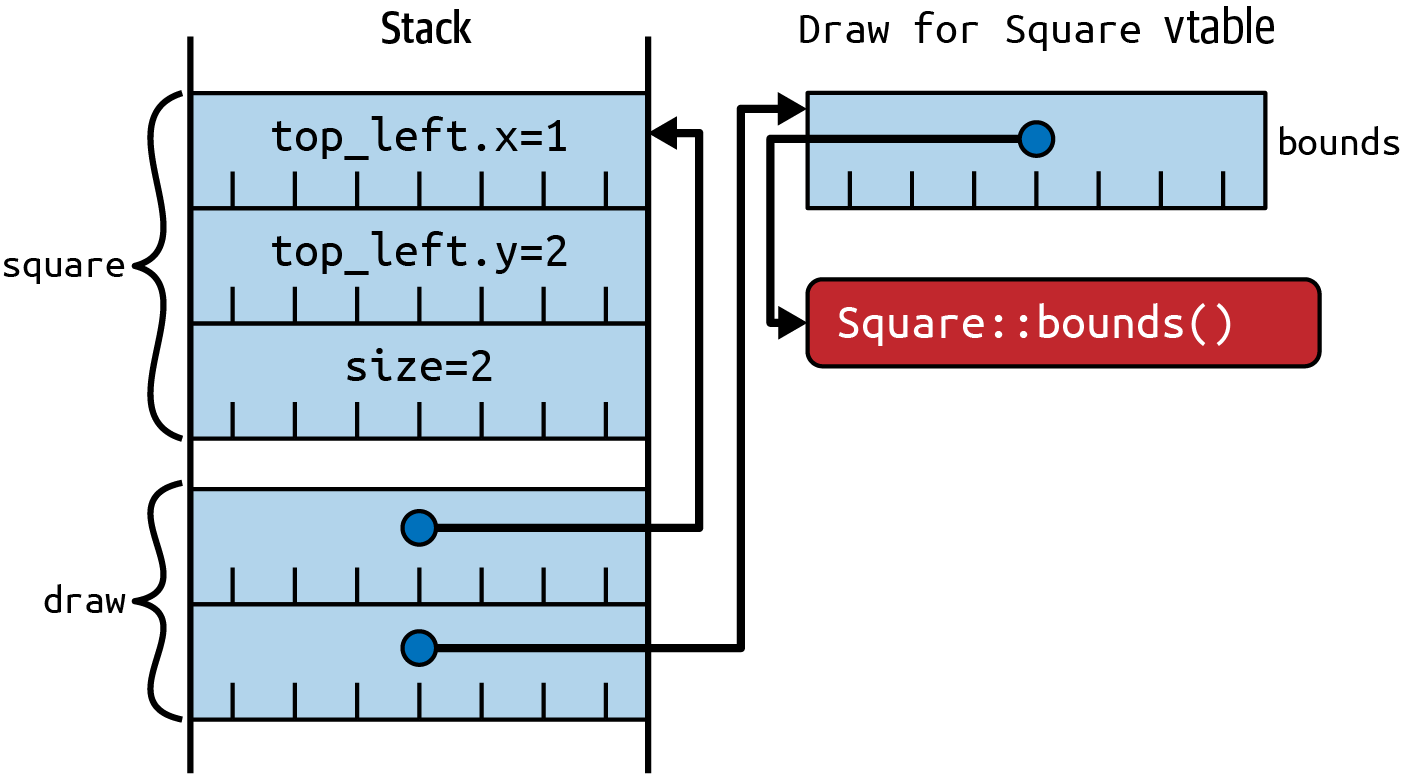
In comparison, trait objects are fat poin) that combine a pointer to the
underlying concrete item with a pointer to a vtable that in turn holds function point‐
ers for all of the trait implementation’s methods, as depicted in
let square = Square {
top_left: Point { x: 1, y: 2 },
size: 2,
};
let draw: & dyn Draw = □
Figure 2-1. Trait object layout, with pointers to concrete item and vtable
96 | Chapter 2: Traits
This means that a function that accepts a trait object doesn’t need to be generic and
doesn’t need monomorphization: the programmer writes a function using trait
objects, and the compiler outputs only a single version of that function, which can
accept trait objects that come from multiple input types:
/// Indicate whether an object is on-screen.
pub fn on_screen(draw: & dyn Draw) -> bool {
overlap(SCREEN_BOUNDS, draw.bounds()).is_some()
}
// Calls òn_screen(&dyn Draw) -> bool`.
let visible = on_screen(&square);
// Also calls òn_screen(&dyn Draw) -> bool`.
let visible = on_screen(&circle);
Basic Comparisons
These basic facts already allow some immediate comparisons between the two
possibilities:
• Generics are likely to lead to bigger code sizes, because the compiler generates a
fresh copy (on_screen::<T>(&T)) of the code for every type T that uses the
generic version of the on_screen function. In contrast, the trait object version
(on_screen(&dyn T)) of the function needs only a single instance.
• Invoking a trait method from a generic will generally be ever-so-slightly faster
than invoking it from code that uses a trait object, because the latter needs to per‐
form two dereferences to find the location of the code (trait object to vtable, vta‐
ble to implementation location).
• Compile times for generics are likely to be longer, as the compiler is building
more code and the linker has more work to do to fold duplicates.
In most situations, these aren’t significant differences—you should use optimization-
related concerns as a primary decision driver only if you’ve measured the impact and
found that it has a genuine effect (a speed bottleneck or a problematic occupancy
increase).
A more significant difference is that generic trait bounds can be used to conditionally
make different functionality available, depending on whether the type parameter
implements multiple traits:
// The àreà function is available for all containers holding things
// that implement `Draw`.
fn area<T>(draw: & T) -> i64
where
T: Draw,
{
let bounds = draw.bounds();
Item 12: Understand the trade-offs between generics and trait objects | 97
(bounds.bottom_right.x - bounds.top_left.x)
* (bounds.bottom_right.y - bounds.top_left.y)
}
// Thèshow` method is available only if `Debugìs also implemented.
fn show<T>(draw: & T)
where
T: Debug + Draw,
{
println!("{:?} has bounds {:?}", draw, draw.bounds());
}
let square = Square {
top_left: Point { x: 1, y: 2 },
size: 2,
};
let circle = Circle {
center: Point { x: 3, y: 4 },
radius: 1,
};
// Both `Squareànd `Circleìmplement `Draw`.
println!("area(square) = {}", area(&square));
println!("area(circle) = {}", area(&circle));
// `Circleìmplements `Debug`.
show(&circle);
// `Squarè does not implement `Debug`, so this wouldn't compile:
// show(&square);
A trait object encodes the implementation vtable only for a single trait, so doing
something equivalent is much more awkward. For example, a combination Debug
Draw trait could be defined for the show() case, together with a blanket implementa‐
tion to make life easier:
trait DebugDraw: Debug + Draw {}
/// Blanket implementation applies whenever the individual traits
/// are implemented.
impl<T: Debug + Draw> DebugDraw for T {}
However, if there are multiple combinations of distinct traits, it’s clear that the combi‐
natorics of this approach rapidly become unwieldy.
98 | Chapter 2: Traits
More Trait Bounds
In addition to using trait bounds to restrict what type parameters are acceptable for a
generic function, you can also apply them to trait definitions themselves:
/// Anything that implements `Shapè must also implement `Draw`.
trait Shape: Draw {
/// Render that portion of the shape that falls within `bounds`.
fn render_in(&self, bounds: Bounds);
/// Render the shape.
fn render(&self) {
// Default implementation renders that portion of the shape
// that falls within the screen area.
if let Some(visible) = overlap(SCREEN_BOUNDS, self.bounds()) {
self.render_in(visible);
}
}
}
In this example, the render() method’s default implementation (
of the trait bound, relying on the availability of the bounds() method from Draw.
Programmers coming from object-oriented languages often confuse trait bounds
with inheritance, under the mistaken impression that a trait bound like this means
that a Shape is-a Draw. That’s not the case: the relationship between the two types is
better expressed as Shape also-implements Draw.
Under the covers, trait objects for traits that have trait bounds:
let square = Square {
top_left: Point { x: 1, y: 2 },
size: 2,
};
let draw: & dyn Draw = □
let shape: & dyn Shape = □
have a single combined vtable that includes the methods of the top-level trait, plus
Shape includes the bounds method from the Draw trait, as well as the two methods
from the Shape trait itself.
At the time of writing (and as of Rust 1.70), this means that there is no way to
“upcast” from Shape to Draw, because the (pure) Draw vtable can’t be recovered at run‐
time; there is no way to convert between related trait objects, which in turn means
. However, this is likely to change in later versions of Rust—see
Item 12: Understand the trade-offs between generics and trait objects | 99
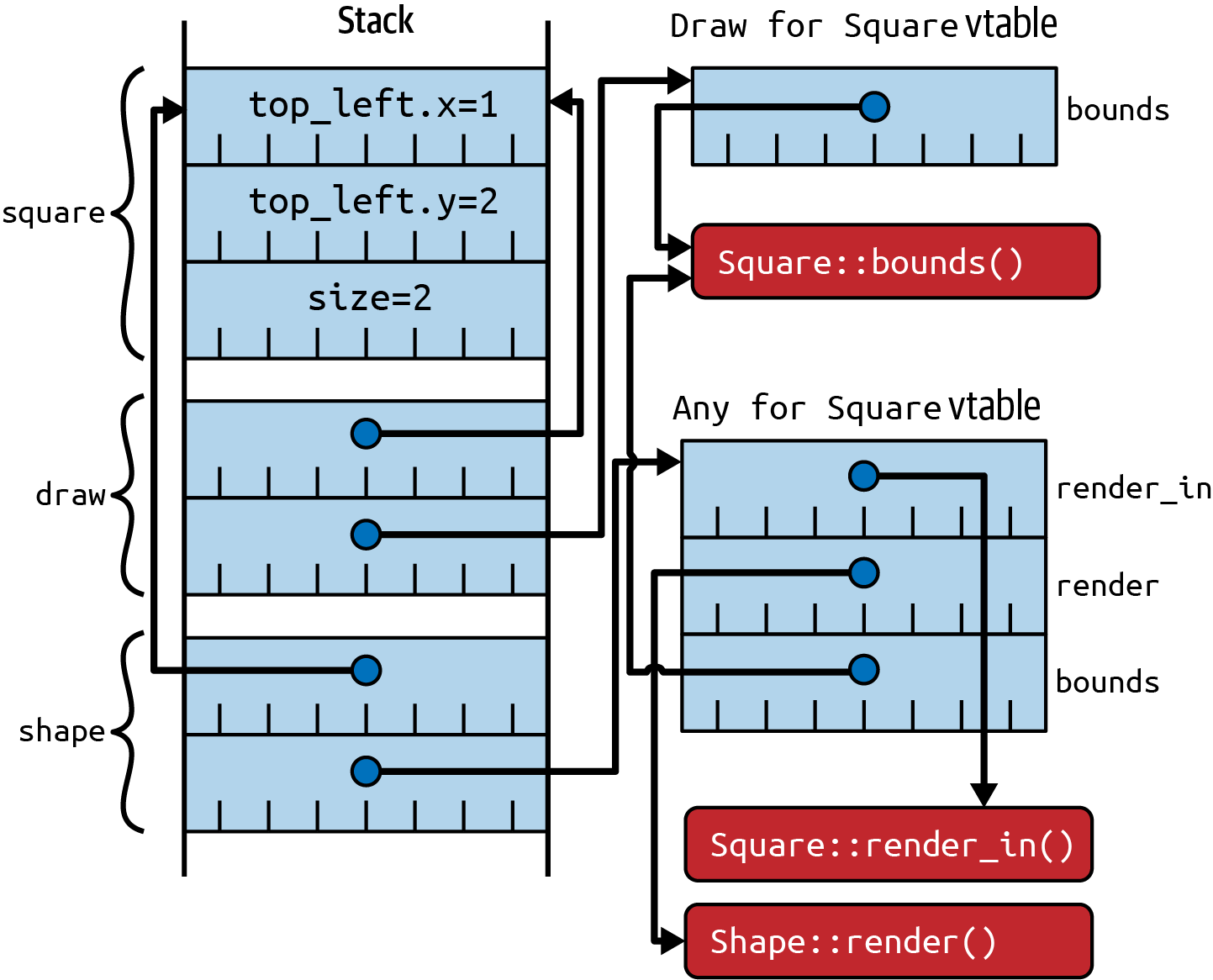
Figure 2-2. Trait objects for trait bounds, with distinct vtables for Draw and Shape
Repeating the same point in different words, a method that accepts a Shape trait
object has the following characteristics:
• It can make use of methods from Draw (because Shape also-implements Draw, and
because the relevant function pointers are present in the Shape vtable).
• It cannot (yet) pass the trait object onto another method that expects a Draw trait
object (because Shape is-not Draw, and because the Draw vtable isn’t available).
In contrast, a generic method that accepts items that implement Shape has these
characteristics:
• It can use methods from Draw.
• It can pass the item on to another generic method that has a Draw trait bound,
because the trait bound is monomorphized at compile time to use the Draw meth‐
ods of the concrete type.
100 | Chapter 2: Traits
Trait Object Safety
Another restriction on trait objects is the requirement for t comply with the following two rules can be used as trait objects:
• The trait’s methods must not be generic.
• The trait’s methods must not involve a type that includes Self, except for the
receiver (the object on which the method is invoked).
The first restriction is easy to understand: a generic method f is really an infinite set
of methods, potentially encompassing f::<i16>, f::<i32>, f::<i64>, f::<u8>, etc.
The trait object’s vtable, on the other hand, is very much a finite collection of func‐
tion pointers, and so it’s not possible to fit the infinite set of monomorphized imple‐
mentations into it.
The second restriction is a little bit more subtle but tends to be the restriction that’s
hit more often in practice—traits that impose Copy or Clone
immediately fall under this rule, because they return Self. To see why it’s disallowed,
consider code that has a trait object in its hands; what happens if that code calls (say)
let y = x.clone()? The calling code needs to reserve enough space for y on the
stack, but it has no idea of the size of y because Self is an arbitrary type. As a result,
return types that mention Self lead to a trait that is not object safe.
There is an exception to this second restriction. A method returning some Self-
related type does not affect object safety if Self comes with an explicit restriction to
types whose size is known at compile time, indicated by the Sized marker trait as a
trait bound:
/// ÀStamp` can be copied and drawn multiple times.
trait Stamp: Draw {
fn make_copy(&self) -> Self
where
Self: Sized;
}
let square = Square {
top_left: Point { x: 1, y: 2 },
size: 2,
};
// `Squareìmplements `Stamp`, so it can call `make_copy()`.
let copy = square.make_copy();
6 At the time of writing, the restriction on methods that return Self includes types like Box<Self> that could be safely stored on the stack; this restriction .
Item 12: Understand the trade-offs between generics and trait objects | 101
// Because thèSelf`-returning method has àSized` trait bound,
// creating àStamp` trait object is possible.
let stamp: & dyn Stamp = □
This trait bound means that the method can’t be used with trait objects anyway,
because trait objects refer to something that’s of unknown size (dyn Trait), and so
the method is irrelevant for object safety:
D O E S N O T C O M P I L E
// However, the method can't be invoked via a trait object.
let copy = stamp.make_copy();
error: thèmake_copy` method cannot be invoked on a trait object
--> src/main.rs:397:22
|
353 | Self: Sized;
| ----- this has àSized` requirement
...
397 | let copy = stamp.make_copy();
| ^^^^^^^^^
Trade-Offs
The balance of factors so far suggests that you should prefer generics to trait objects,
but there are situations where trait objects are the right tool for the job.
The first is a practical consideration: if generated code size or compilation time is a
concern, then trait objects will perform better (as described earlier in this Item).
A more theoretical aspect that leads toward trait objects is that they fundamentally
involve type erasure: information about the concrete type is lost in the conversion to a
use it allows for collections of heterogeneous objects—because the code just relies on the
methods of the trait, it can invoke and combine the methods of items that have differ‐
ent concrete types.
The traditional OO example of rendering a list of shapes is one example of this: the
same render() method could be used for squares, circles, ellipses, and stars in the
same loop:
let shapes: Vec<& dyn Shape> = vec![&square, &circle];
for shape in shapes {
shape.render()
}
A much more obscure potential advantage for trait objects is when the available types
are not known at compile time. If new code is dynamically loaded at runtime (e.g., via
102 | Chapter 2: Traits
), then items that implement traits in the new code can be invoked only via a trait object, because there’s no source code to monomorphize over.
Item 13: Use default implementations
to minimize required trait methods
The designer of a trait has two different audiences to consider: the programmers who
will be implementing the trait and those who will be using the trait. These two audien‐
ces lead to a degree of tension in the trait design:
• To make the implementor’s life easier, it’s better for a trait to have the absolute
minimum number of methods to achieve its purpose.
• To make the user’s life more convenient, it’s helpful to provide a range of variant
methods that cover all of the common ways that the trait might be used.
This tension can be balanced by including the wider range of methods that makes the
user’s life easier, but with default implementations provided for any methods that can
be built from other, more primitive, operations on the interface.
A simple example of this is the , which is an Iterator that knows how many things it is iterating overThis method
has a default implementation tha
fn is_empty(&self) -> bool {
self.len() == 0
}
The existence of a default implementation is just that: a default. If an implementation
of the trait has a different way of determining whether the iterator is empty, it can
replace the default is_empty() with its own.
This approach leads to trait definitions that have a small number of required methods,
plus a much larger number of default-implemented methods. An implementor for the
trait has to implement only the former and gets all of the latter for free.
It’s also an approach that is widely followed by the Rust standard library; perhaps the
best example there is the trait, which has a single required method (
but includes a panoply of pre-provided methods (t the time of
writing.
Trait methods can impose trait bounds, indicating that a method is only available if
the types involved implement particular traits. The Iterator trait also shows that this
7 The is_empty() method is currently a .
Item 13: Use default implementations to minimize required trait methods | 103
is useful in combination with default method implementations. For example, the
tor method has a trait bound and a default implementation: fn cloned<'a, T>(self) -> Cloned<Self>
where
T: 'a + Clone,
Self: Sized + Iterator<Item = &'a T>,
{
Cloned::new(self)
}
In other words, the cloned() method is available only if the underlying Item type
implements ; when it does, the implementation is automatically available.
The final observation about trait methods with default implementations is that new
ones can usual y be safely added to a trait even after an initial version of the trait is
released. An addition like this preserves backward compa
users and implementors of the trait, as long as the new method name does not clash
with the name of a method from some other trait that the type implemen
So follow the example of the standard library and provide a minimal API surface for
implementors but a convenient and comprehensive API for users, by adding methods
with default implementations (and trait bounds as appropriate).
8 If the new method happens to match a method of the same name in the concrete type, then the concrete method—known as an —will be used ahead of the trait method. The trait method can be explicitly selected instead by casting: <Concrete as Trait>::method().
104 | Chapter 2: Traits
CHAPTER 3
Concepts
The first two chapters of this book covered Rust’s types and traits, which helps pro‐
vide the vocabulary needed to work with some of the concepts involved in writing
Rust code—the subject of this chapter.
The borrow checker and lifetime checks are central to what makes Rust unique; they
are also a common stumbling block for newcomers to Rust and so are the focus of the
first two Items in this chapter.
The other Items in this chapter cover concepts that are easier to grasp but are never‐
theless a bit different from writing code in other languages. This includes the
following:
• Advice on Rust’s unsafe mode and how to avoid it ()
• Good news and bad news about writing multithreaded code in R
• Advice on avoiding runtime aborts (
• Information about Rust’s approach to reflection ()
• Advice on balancing optimization against maintainability (
It’s a good idea to try to align your code with the consequences of these concepts. It’s
possible to re-create (some of) the behavior of C/C++ in Rust, but why bother to use
Rust if you do?
105
Item 14: Understand lifetimes
This Item describes Rust’s lifetimes, which are a more precise formulation of a concept
that existed in previous compiled languages like C and C++—in practice if not in
theory. Lifetimes are a required input for the borrow checker ; taken together, these features form the heart of Rust’s memory safety guarantees.
Introduction to the Stack
Lifetimes are fundamentally related to the stack, so a quick introduction/reminder is
in order.
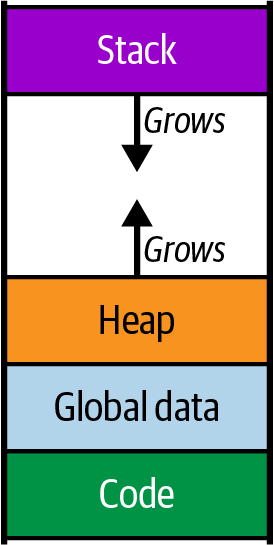
While a program is running, the memory that it uses is divided up into different
chunks, sometimes called segments. Some of these chunks are a fixed size, such as the
ones that hold the program code or the program’s global data, but two of the
chunks—the heap and the stack—change size as the program runs. To allow for this,
they are typically arranged at opposite ends of the program’s virtual memory space, so
one can grow downward and the other can grow upward (at least until your program
runs out of memory and crashes), as summarized in
Figure 3-1. Program memory layout, including heap growing up and stack growing
down
Of these two dynamically sized chunks, the stack is used to hold state related to the
currently executing function. This state can include these elements:
• The parameters passed to the function
• The local variables used in the function
• Temporary values calculated within the function
• The return address within the code of the function’s caller
106 | Chapter 3: Concepts
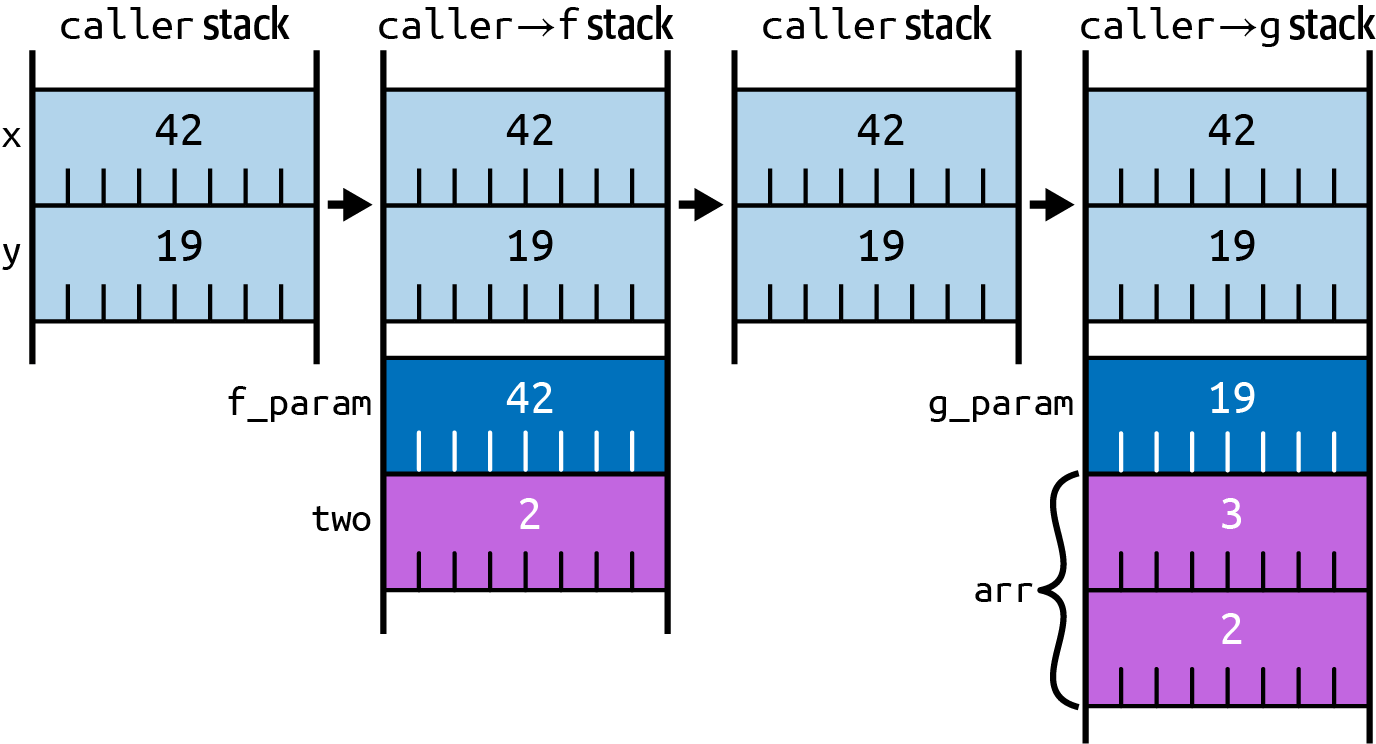
When a function f() is called, a new stack frame is added to the stack, beyond where
the stack frame for the calling function ends, and the CPU normally updates a regis‐
ter—the stack pointer—to point to the new stack frame.
When the inner function f() returns, the stack pointer is reset to where it was before
the call, which will be the caller’s stack frame, intact and unmodified.
If the caller subsequently invokes a different function g(), the process happens again,
which means that the stack frame for g() will reuse the same area of memory that f()
previously used (as depicted in
fn caller() -> u64 {
let x = 42u64;
let y = 19u64;
f(x) + g(y)
}
fn f(f_param: u64) -> u64 {
let two = 2u64;
f_param + two
}
fn g(g_param: u64) -> u64 {
let arr = [2u64, 3u64];
g_param + arr[1]
}
Figure 3-2. Evolution of stack usage as functions are cal ed and returned from
Item 14: Understand lifetimes | 107
Of course, this is a dramatically simplified version of what really goes on—putting
things on and off the stack takes time, and so real processors will have many opti‐
mizations. However, the simplified conceptual picture is enough for understanding
the subject of this Item.
Evolution of Lifetimes
The previous section explained how parameters and local variables are stored on the
stack and pointed out that those values are stored only ephemerally.
Historically, this allowed for some dangerous footguns: what happens if you hold
onto a pointer to one of these ephemeral stack values?
Starting back with C, it was perfectly OK to return a pointer to a local variable
(although modern compilers will emit a warning for it):
U N D E S I R E D B E H A V I O R
/* C code. */
struct File {
int fd;
};
struct File* open_bugged() {
struct File f = { open("README.md", O_RDONLY) };
return &f; /* return address of stack object! */
}
You might get away with this, if you’re unlucky and the calling code uses the returned
value immediately:
U N D E S I R E D B E H A V I O R
struct File* f = open_bugged();
printf("in caller: file at %p has fd=%d\n", f, f->fd);
in caller: file at 0x7ff7bc019408 has fd=3
This is unlucky because it only appears to work. As soon as any other function calls
happen, the stack area will be reused and the memory that used to hold the object will
be overwritten:
U N D E S I R E D B E H A V I O R
investigate_file(f);
108 | Chapter 3: Concepts
/* C code. */
void investigate_file(struct File* f) {
long array[4] = {1, 2, 3, 4}; // put things on the stack
printf("in function: file at %p has fd=%d\n", f, f->fd);
}
in function: file at 0x7ff7bc019408 has fd=1592262883
Trashing the contents of the object has an additional bad effect for this example: the
file descriptor corresponding to the open file is lost, and so the program leaks the
resource that was held in the data structure.
Moving forward in time to C++, this latter problem of losing access to resources was
solved by the inclusion of destructors). Now, the things on the stack have the ability to tidy themselves up: if the object holds some kind of
resource, the destructor can tidy it up, and the C++ compiler guarantees that the
destructor of an object on the stack gets called as part of tidying up the stack frame:
// C++ code.
File::~File() {
std::cout << "~File(): close fd " << fd << " \n";
close(fd);
fd = -1;
}
The caller now gets an (invalid) pointer to an object that’s been destroyed and its
resources reclaimed:
U N D E S I R E D B E H A V I O R
File* f = open_bugged();
printf("in caller: file at %p has fd=%d\n", f, f->fd);
~File(): close fd 3
in caller: file at 0x7ff7b6a7c438 has fd=-1
However, C++ did nothing to help with the problem of dangling pointers: it’s still
possible to hold onto a pointer to an object that’s gone (with a destructor that has
been called):
// C++ code.
void investigate_file(File* f) {
long array[4] = {1, 2, 3, 4}; // put things on the stack
std::cout << "in function: file at " << f << " has fd=" << f->fd << " \n";
}
in function: file at 0x7ff7b6a7c438 has fd=-183042004
As a C/C++ programmer, it’s up to you to notice this and make sure that you don’t
dereference a pointer that points to something that’s gone. Alternatively, if you’re an
Item 14: Understand lifetimes | 109
attacker and you find one of these dangling pointers, you’re more likely to cackle
maniacally and gleefully dereference the pointer on your way to an exploit.
Enter Rust. One of Rust’s core attractions is that it fundamentally solves the problem
of dangling pointers, immedia
Doing so requires moving the concept of lifetimes from the background (where
C/C++ programmers just have to know to watch out for them, without any language
support) to the foreground: every type that includes an ampersand & has an associ‐
ated lifetime ('a), even if the compiler lets you omit mention of it much of the time.
Scope of a Lifetime
The lifetime of an item on the stack is the period where that item is guaranteed to stay
in the same place; in other words, this is exactly the period where a reference (pointer)
to the item is guaranteed not to become invalid.
This starts at the point where the item is created, and extends to where it is either
dropped (Rust’s equivalent to object destruction in C++) or moved.
The ubiquity of the latter is sometimes surprising for programmers coming from
C/C++: Rust moves items from one place on the stack to another, or from the stack to
the heap, or from the heap to the stack, in lots of situations.
Precisely where an item gets automatically dropped depends on whether an item has
a name or not.
Local variables and function parameters have names, and the corresponding item’s
lifetime starts when the item is created and the name is populated:
• For a local variable: at the let var = ... declaration
• For a function parameter: as part of setting up the execution frame for the func‐
tion invocation
The lifetime for a named item ends when the item is either moved somewhere else or
when the name goes out of scope:
#[derive(Debug, Clone)]
/// Definition of an item of some kind.
pub struct Item {
contents: u32,
}
{
let item1 = Item { contents: 1 }; // ìtem1` created here
1 For example, the Chromium project estimates that .
110 | Chapter 3: Concepts
let item2 = Item { contents: 2 }; // ìtem2` created here
println!("item1 = {item1:?}, item2 = {item2:?}");
consuming_fn(item2); // ìtem2` moved here
} // ìtem1` dropped here
It’s also possible to build an item “on the fly,” as part of an expression that’s then fed
into something else. These unnamed temporary items are then dropped when they’re
no longer needed. One oversimplified but helpful way to think about this is to imag‐
ine that each part of the expression gets expanded to its own block, with temporary
variables being inserted by the compiler. For example, an expression like:
let x = f((a + b) * 2);
would be roughly equivalent to:
let x = {
let temp1 = a + b;
{
let temp2 = temp1 * 2;
f(temp2)
} // `temp2` dropped here
}; // `temp1` dropped here
By the time execution reaches the semicolon at the end of the original line, the tem‐
poraries have all been dropped.
One way to see what the compiler calculates as an item’s lifetime is to insert a deliber‐
ate error for the borrow checker (or example, hold onto a refer‐
ence to an item beyond the scope of the item’s lifetime:
D O E S N O T C O M P I L E
let r: & Item;
{
let item = Item { contents: 42 };
r = &item;
}
println!("r.contents = {}", r.contents);
The error message indicates the exact endpoint of item’s lifetime:
error[E0597]: ìtem` does not live long enough
--> src/main.rs:190:13
|
189 | let item = Item { contents: 42 };
| ---- binding ìtem` declared here
190 | r = &item;
| ^^^^^ borrowed value does not live long enough
191 | }
| - ìtem` dropped here while still borrowed
Item 14: Understand lifetimes | 111
192 | println!("r.contents = {}", r.contents);
| ---------- borrow later used here
Similarly, for an unnamed temporary:
D O E S N O T C O M P I L E
let r: & Item = fn_returning_ref(& mut Item { contents: 42 });
println!("r.contents = {}", r.contents);
the error message shows the endpoint at the end of the expression:
error[E0716]: temporary value dropped while borrowed
--> src/main.rs:209:46
|
209 | let r: &Item = fn_returning_ref(&mut Item { contents: 42 });
| ^^^^^^^^^^^^^^^^^^^^^ - temporary
| | value is freed at the
| | end of this statement
| |
| creates a temporary value which is
| freed while still in use
210 | println!("r.contents = {}", r.contents);
| ---------- borrow later used here
|
= note: consider using àlet` binding to create a longer lived value
One final point about the lifetimes of references: if the compiler can prove to itself that
there is no use of a reference beyond a certain point in the code, then it treats the
endpoint of the reference’s lifetime as the last place it’s used, rather than at the end of
the enclosing scope. This feature, known as
checker to be a little bit more generous:
{
// `sòwns thèString`.
let mut s: String = "Hello, world".to_string();
// Create a mutable reference to thèString`.
let greeting = & mut s[..5];
greeting.make_ascii_uppercase();
// .. no use of `greetingàfter this point
// Creating an immutable reference to thèStringìs allowed,
// even though there's a mutable reference still in scope.
let r: & str = &s;
println!("s = '{}'", r); // s = 'HELLO, world'
} // The mutable referencègreeting` would naively be dropped here.
112 | Chapter 3: Concepts
Algebra of Lifetimes
Although lifetimes are ubiquitous when dealing with references in Rust, you don’t get
to specify them in any detail—there’s no way to say, “I’m dealing with a lifetime that
extends from line 17 to line 32 of ref.rs.” Instead, your code refers to lifetimes with
arbitrary names, conventionally 'a, 'b, 'c, …, and the compiler has its own internal,
inaccessible representation of what that equates to in the source code. (The one
exception to this is the 'static lifetime, which is a special case that’s covered in a
subsequent section.)
You don’t get to do much with these lifetime names; the main thing that’s possible is
to compare one name with another, repeating a name to indicate that two lifetimes
are the “same.”
This algebra of lifetimes is easiest to illustrate with function signatures: if the inputs
and outputs of a function deal with references, what’s the relationship between their
lifetimes?
The most common case is a function that receives a single reference as input and
emits a reference as output. The output reference must have a lifetime, but what can
it be? There’s only one possibility (other than 'static) to choose from: the lifetime of
the input, which means that they both share the same name, say, 'a. Adding that
name as a lifetime annotation to both types gives:
pub fn first<'a>(data: &'a [Item]) -> Option<&'a Item> {
// ...
}
Because this variant is so common, and because there’s (almost) no choice about what
the output lifetime can be, Rust has lifetime elision rules that mean you don’t have to
explicitly write the lifetime names for this case. A more idiomatic version of the same
function signature would be the following:
pub fn first(data: &[Item]) -> Option<&Item> {
// ...
}
The references involved still have lifetimes—the elision rule just means that you don’t
have to make up an arbitrary lifetime name and use it in both places.
What if there’s more than one choice of input lifetimes to map to an output lifetime?
In this case, the compiler can’t figure out what to do:
Item 14: Understand lifetimes | 113
D O E S N O T C O M P I L E
pub fn find(haystack: &[u8], needle: &[u8]) -> Option<&[u8]> {
// ...
}
error[E0106]: missing lifetime specifier
--> src/main.rs:56:55
|
56 | pub fn find(haystack: &[u8], needle: &[u8]) -> Option<&[u8]> {
| ----- ----- ^ expected named
| lifetime parameter
|
= help: this function's return type contains a borrowed value, but the
signature does not say whether it is borrowed from `haystackòr
`needlè
help: consider introducing a named lifetime parameter
|
56 | pub fn find<'a>(haystack: &'a [u8], needle: &'a [u8]) -> Option<&'a [u8]> {
| ++++ ++ ++ ++
A shrewd guess based on the function and parameter names is that the intended life‐
time for the output here is expected to match the haystack input:
pub fn find<'a, 'b>(
haystack: &'a [u8],
needle: &'b [u8],
) -> Option<&'a [u8]> {
// ...
}
Interestingly, the compiler suggested a different alternative: having both inputs to the
function use the same lifetime 'a. For example, the following is a function where this
combination of lifetimes might make sense:
pub fn smaller<'a>(left: &'a Item, right: &'a Item) -> &'a Item {
// ...
}
This appears to imply that the two input lifetimes are the “same,” but the scare quotes
(here and previously) are included to signify that that’s not quite what’s going on.
The raison d’être of lifetimes is to ensure that references to items don’t outlive the
items themselves; with this in mind, an output lifetime 'a that’s the “same” as an
input lifetime 'a just means that the input has to live longer than the output.
When there are two input lifetimes 'a that are the “same,” that just means that the
output lifetime has to be contained within the lifetimes of both of the inputs:
{
let outer = Item { contents: 7 };
114 | Chapter 3: Concepts
{
let inner = Item { contents: 8 };
{
let min = smaller(&inner, &outer);
println!("smaller of {inner:?} and {outer:?} is {min:?}");
} // `min` dropped
} // ìnner` dropped
} // òuter` dropped
To put it another way, the output lifetime has to be subsumed within the smal er of
the lifetimes of the two inputs.
In contrast, if the output lifetime is unrelated to the lifetime of one of the inputs, then
there’s no requirement for those lifetimes to nest:
{
let haystack = b"123456789"; // start of lifetime 'a
let found = {
let needle = b"234"; // start of lifetime 'b
find(haystack, needle)
}; // end of lifetime 'b
println!("found={:?}", found); // `foundùsed within 'a, outside of 'b
} // end of lifetime 'a
Lifetime Elision Rules
In addition to the “one in, one out
t mean that lifetime names can be
omitted.
The first occurs when there are no references in the outputs from a function; in this
case, each of the input references automatically gets its own lifetime, different from
any of the other input parameters.
The second occurs for methods that use a reference to self (either &self or &mut
self); in this case, the compiler assumes that any output references take the lifetime
of self, as this turns out to be (by far) the most common situation.
Here’s a summary of the elision rules for functions:
• One input, one or more outputs: assume outputs have the “same” lifetime as the
input:
fn f(x: & Item) -> (&Item, &Item)
// ... is equivalent to ...
fn f<'a>(x: &'a Item) -> (&'a Item, &'a Item)
• Multiple inputs, no output: assume all the inputs have different lifetimes:
fn f(x: & Item, y: & Item, z: & Item) -> i32
// ... is equivalent to ...
fn f<'a, 'b, 'c>(x: &'a Item, y: &'b Item, z: &'c Item) -> i32
Item 14: Understand lifetimes | 115
• Multiple inputs including &self, one or more outputs: assume output lifetime(s)
are the “same” as &self’s lifetime:
fn f(&self, y: & Item, z: & Item) -> & Thing
// ... is equivalent to ...
fn f(&'a self, y: &'b Item, z: &'c Item) -> &'a Thing
Of course, if the elided lifetime names don’t match what you want, you can always
explicitly write lifetime names that specify which lifetimes are related to each other.
In practice, this is likely to be triggered by a compiler error that indicates that the eli‐
ded lifetimes don’t match how the function or its caller are using the references
involved.
The 'static Lifetime
The previous section described various possible mappings between the input and out‐
put reference lifetimes for a function, but it neglected to cover one special case. What
happens if there are no input lifetimes, but the output return value includes a refer‐
ence anyway?
D O E S N O T C O M P I L E
pub fn the_answer() -> & Item {
// ...
}
error[E0106]: missing lifetime specifier
--> src/main.rs:471:28
|
471 | pub fn the_answer() -> &Item {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there
is no value for it to be borrowed from
help: consider using thè'static` lifetime
|
471 | pub fn the_answer() -> &'static Item {
| +++++++
The only allowed possibility is for the returned reference to have a lifetime that’s
guaranteed to never go out of scope. This is indicated by the special lifetime 'static,
which is also the only lifetime that has a specific name rather than an arbitrary place‐
holder name:
pub fn the_answer() -> &'static Item {
The simplest way to get something with the 'static lifetime is to take a reference to
a global variable that’: 116 | Chapter 3: Concepts
static ANSWER: Item = Item { contents: 42 };
pub fn the_answer() -> &'static Item {
&ANSWER
}
The Rust compiler guarantees that a static item always has the same address for the
entire duration of the program and never moves. This means that a reference to a
static item has a 'static lifetime, logically enough.
In many cases, a reference to a const item will also be to have a 'static lifetime, but there are a couple of minor complications to be aware of. The first is that
this promotion doesn’t happen if the type involved has a destructor or interior
mutability:
D O E S N O T C O M P I L E
pub struct Wrapper(pub i32);
impl Drop for Wrapper {
fn drop(& mut self) {}
}
const ANSWER: Wrapper = Wrapper(42);
pub fn the_answer() -> &'static Wrapper {
// `Wrapper` has a destructor, so the promotion to thè'static`
// lifetime for a reference to a constant does not apply.
&ANSWER
}
error[E0515]: cannot return reference to temporary value
--> src/main.rs:520:9
|
520 | &ANSWER
| ^------
| ||
| |temporary value created here
| returns a reference to data owned by the current function
The second potential complication is that only the value of a const is guaranteed to
be the same everywhere; the compiler is allowed to make as many copies as it likes,
wherever the variable is used. If you’re doing nefarious things that rely on the under‐
lying pointer value behind the 'static reference, be aware that multiple memory
locations may be involved.
Item 14: Understand lifetimes | 117
There’s one more possible way to get something with a 'static lifetime. The key
promise of 'static is that the lifetime should outlive any other lifetime in the pro‐
gram; a value that’s allocated on the heap but never freed also satisfies this constraint.
A normal heap-allocated Box<T> doesn’t work for this, because there’s no guarantee
(as described in the next section) that the item won’t get dropped along the way:
D O E S N O T C O M P I L E
{
let boxed = Box::new(Item { contents: 12 });
let r: &'static Item = &boxed;
println!("'static item is {:?}", r);
}
error[E0597]: `boxed` does not live long enough
--> src/main.rs:344:32
|
343 | let boxed = Box::new(Item { contents: 12 });
| ----- binding `boxed` declared here
344 | let r: &'static Item = &boxed;
| ------------- ^^^^^^ borrowed value does not live long enough
| |
| type annotation requires that `boxedìs borrowed for `'static`
345 | println!("'static item is {:?}", r);
346 | }
| - `boxed` dropped here while still borrowed
Howeververts an owned Box<T> to a mutable reference to T. There’s no longer an owner for the value, so it can never be dropped—which
satisfies the requirements for the 'static lifetime:
{
let boxed = Box::new(Item { contents: 12 });
// `leak()` consumes thèBox<T>ànd returns `&mut T`.
let r: &'static Item = Box::leak(boxed);
println!("'static item is {:?}", r);
} // `boxed` not dropped here, as it was already moved intòBox::leak()`
// Becausèrìs now out of scope, the Ìtemìs leaked forever.
The inability to drop the item also means that the memory that holds the item can
never be reclaimed using safe Rust, possibly leading to a permanent memory leak.
(Note that leaking memory doesn’t violate Rust’s memory safety guarantees—an item
in memory that you can no longer access is still safe.)
118 | Chapter 3: Concepts
Lifetimes and the Heap
The discussion so far has concentrated on the lifetimes of items on the stack, whether
function parameters, local variables, or temporaries. But what about items on the
heap?
The key thing to realize about heap values is that every item has an owner (excepting
special cases like the deliberate leaks described in the previous section). For example,
a simple Box<T> puts the T value on the heap, with the owner being the variable hold‐
ing the Box<T>:
{
let b: Box<Item> = Box::new(Item { contents: 42 });
} // `b` dropped here, so Ìtem` dropped too.
The owning Box<Item> drops its contents when it goes out of scope, so the lifetime of
the Item on the heap is the same as the lifetime of the Box<Item> variable on the
stack.
The owner of a value on the heap may itself be on the heap rather than the stack, but
then who owns the owner?
{
let b: Box<Item> = Box::new(Item { contents: 42 });
let bb: Box<Box<Item>> = Box::new(b); // `b` moved onto heap here
} // `bb` dropped here, sòBox<Item>` dropped too, so Ìtem` dropped too.
The chain of ownership has to end somewhere, and there are only two possibilities:
• The chain ends at a local variable or function parameter—in which case the life‐
time of everything in the chain is just the lifetime 'a of that stack variable. When
the stack variable goes out of scope, everything in the chain is dropped too.
• The chain ends at a global variable marked as static—in which case the lifetime
of everything in the chain is 'static. The static variable never goes out of
scope, so nothing in the chain ever gets automatically dropped.
As a result, the lifetimes of items on the heap are fundamentally tied to stack
lifetimes.
Lifetimes in Data Structures
The earlier section on the algebra of lifetimes concentrated on inputs and outputs for
functions, but there are similar concerns when references are stored in data
structures.
If we try to sneak a reference into a data structure without mentioning an associated
lifetime, the compiler brings us up sharply:
Item 14: Understand lifetimes | 119
D O E S N O T C O M P I L E
pub struct ReferenceHolder {
pub index: usize,
pub item: & Item,
}
error[E0106]: missing lifetime specifier
--> src/main.rs:548:19
|
548 | pub item: &Item,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
546 ~ pub struct ReferenceHolder<'a> {
547 | pub index: usize,
548 ~ pub item: &'a Item,
|
As usual, the compiler error message tells us what to do. The first part is simple
enough: give the reference type an explicit lifetime name 'a, because there are no life‐
time elision rules when using references in data structures.
The second part is less obvious and has deeper consequences: the data structure itself
has to have a lifetime parameter <'a> that matches the lifetime of the reference con‐
tained within it:
// Lifetime parameter required due to field with reference.
pub struct ReferenceHolder<'a> {
pub index: usize,
pub item: &'a Item,
}
The lifetime parameter for the data structure is infectious: any containing data struc‐
ture that uses the type also has to acquire a lifetime parameter:
// Lifetime parameter required due to field that is of a
// type that has a lifetime parameter.
pub struct RefHolderHolder<'a> {
pub inner: ReferenceHolder<'a>,
}
The need for a lifetime parameter also applies if the data structure contains slice
types, as these are again references to borrowed data.
If a data structure contains multiple fields that have associated lifetimes, then you
have to choose what combination of lifetimes is appropriate. An example that finds
common substrings within a pair of strings is a good candidate to have independent
lifetimes:
120 | Chapter 3: Concepts
/// Locations of a substring that is present in
/// both of a pair of strings.
pub struct LargestCommonSubstring<'a, 'b> {
pub left: &'a str,
pub right: &'b str,
}
/// Find the largest substring present in both `left`
/// and `right`.
pub fn find_common<'a, 'b>(
left: &'a str,
right: &'b str,
) -> Option<LargestCommonSubstring<'a, 'b>> {
// ...
}
whereas a data structure that references multiple places within the same string would
have a common lifetime:
/// First two instances of a substring that is repeated
/// within a string.
pub struct RepeatedSubstring<'a> {
pub first: &'a str,
pub second: &'a str,
}
/// Find the first repeated substring present in `s`.
pub fn find_repeat<'a>(s: &'a str) -> Option<RepeatedSubstring<'a>> {
// ...
}
The propagation of lifetime parameters makes sense: anything that contains a refer‐
ence, no matter how deeply nested, is valid only for the lifetime of the item referred
to. If that item is moved or dropped, then the whole chain of data structures is no
longer valid.
However, this also means that data structures involving references are harder to use—
the owner of the data structure has to ensure that the lifetimes all line up. As a result,
prefer data structures that own their contents where possible, particularly if the code
doesn’t need to be highly optimized (t’s not possible, the various
smart pointer types (e.g., can help untangle the lifetime constraints.
Anonymous Lifetimes
When it’s not possible to stick to data structures that own their contents, the data
structure will necessarily end up with a lifetime parameter, as described in the previ‐
ous section. This can create a slightly unfortunate interaction with the lifetime elision
rules described earlier in the Item.
Item 14: Understand lifetimes | 121
For example, consider a function that returns a data structure with a lifetime parame‐
ter. The fully explicit signature for this function makes the lifetimes involved clear:
pub fn find_one_item<'a>(items: &'a [Item]) -> ReferenceHolder<'a> {
// ...
}
However, the same signature with lifetimes elided can be a little misleading:
pub fn find_one_item(items: &[Item]) -> ReferenceHolder {
// ...
}
Because the lifetime parameter for the return type is elided, a human reading the
code doesn’t get much of a hint that lifetimes are involved.
The anonymous lifetime '_ allows you to mark an elided lifetime as being present,
without having to fully restore al of the lifetime names:
pub fn find_one_item(items: &[Item]) -> ReferenceHolder<'_> {
// ...
}
Roughly speaking, the '_ marker asks the compiler to invent a unique lifetime name
for us, which we can use in situations where we never need to use the name else‐
where.
That means it’s also useful for other lifetime elision scenarios. For example, the decla‐
raymous lifetime to indicate that the Formatter instance has a different lifetime than &self, but it’s not important
what that lifetime’s name is:
pub trait Debug {
fn fmt(&self, f: & mut Formatter<'_>) -> Result<(), Error>;
}
Things to Remember
• All Rust references have an associated lifetime, indicated by a lifetime label (e.g.,
'a). The lifetime labels for function parameters and return values can be elided in
some common cases (but are still present under the covers).
• Any data structure that (transitively) includes a reference has an associated life‐
time parameter; as a result, it’s often easier to work with data structures that own
their contents.
• The 'static lifetime is used for references to items that are guaranteed never to
go out of scope, such as global data or items on the heap that have been explicitly
leaked.
122 | Chapter 3: Concepts
• Lifetime labels can be used only to indicate that lifetimes are the “same,” which
means that the output lifetime is contained within the input lifetime(s).
• The anonymous lifetime label '_ can be used in places where a specific lifetime
label is not needed.
Item 15: Understand the borrow checker
Values in Rust have an owner, but that owner can lend the values out to other places
in the code. This borrowing mechanism involves the creation and use of references,
subject to rules policed by the borrow checker—the subject of this Item.
Under the covers, Rust’s references use the same kind of pointer values () that are so prevalent in C or C++ code but are girded with rules and restrictions to make
sure that the sins of C/C++ are avoided. As a quick comparison:
• Like a C/C++ pointer, a Rust reference is created with an ampersand: &value.
• Like a C++ reference, a Rust reference can never be nullptr.
• Like a C/C++ pointer or reference, a Rust reference can be modified after cre‐
ation to refer to something different.
• Unlike C++, producing a reference from a value always involves an explicit (&)
conversion—if you see code like f(value), you know that f is receiving owner‐
ship of the value. (However, it may be ownership of a copy of the item, if the
value’s type implemen.)
• Unlike C/C++, the mutability of a newly created reference is always explicit
(&mut). If you see code like f(&value), you know that value won’t be modified
(i.e., is const in C/C++ terminology). Only expressions like f(&mut value) have
the potential to change the contents of value
The most important difference between a C/C++ pointer and a Rust reference is indi‐
cated by the term borrow: you can take a reference (pointer) to an item, but you can’t
keep that reference forever. In particular, you can’t keep it longer than the lifetime of
the underlying item, as tracked by the compiler and explored in
These restrictions on the use of references enable Rust to make its memory safety
guarantees, but they also mean that you have to accept the cognitive costs of the bor‐
row rules, and accept that it will change how you design your software—particularly
its data structures.
2 Note that all bets are off with expressions like m!(value) that involve a macro (), because that can expand to arbitrary code.
Item 15: Understand the borrow checker | 123
This Item starts by describing what Rust references can do, and the borrow checker’s
rules for using them. The rest of the Item focuses on dealing with the consequences of
those rules: how to refactor, rework, and redesign your code so that you can win
fights against the borrow checker.
Access Control
There are three ways to access the contents of a Rust item: via the item’s owner (item),
a reference (&item), or a mutable reference (&mut item). Each of these ways of accessing the item comes with different powers over the item. Putting things roughly in
(create/read/update/delete) model for storage (using Rust’s drop terminology in place of delete):
• The owner of an item gets to create it, read from it, update it, and drop it.
• A mutable reference can be used to read from the underlying item and update it.
• A (normal) reference can be used only to read from the underlying item.
There’s an important Rust-specific aspect to these data access rules: only the item’s
owner can move the item. This makes sense if you think of a move as being some
combination of creating (in the new location) and dropping the item’s memory (at the
old location).
This can lead to some oddities for code that has a mutable reference to an item. For
example, it’s OK to overwrite an Option:
/// Some data structure used by the code.
#[derive(Debug)]
pub struct Item {
pub contents: i64,
}
/// Replace the content of ìtem` with `val`.
pub fn replace(item: & mut Option<Item>, val: Item) {
*item = Some(val);
}
but a modification to also return the previous value falls foul of the move restriction:
3 The compiler’s suggestion doesn’t help here, because item is needed on the subsequent line.
124 | Chapter 3: Concepts
D O E S N O T C O M P I L E
/// Replace the content of ìtem` with `val`, returning the previous
/// contents.
pub fn replace(item: & mut Option<Item>, val: Item) -> Option<Item> {
let previous = *item; // move out
*item = Some(val); // replace
previous
}
error[E0507]: cannot move out of `*item` which is behind a mutable reference
--> src/main.rs:34:24
|
34 | let previous = *item; // move out
| ^^^^^ move occurs becausè*item` has type
| Òption<inner::Item>`, which does not
| implement thèCopy` trait
|
help: consider removing the dereference here
|
34 - let previous = *item; // move out
34 + let previous = item; // move out
|
Although it’s valid to read from a mutable reference, this code is attempting to move
the value out, just prior to replacing the moved value with a new value—in an
attempt to avoid making a copy of the original value. The borrow checker has to be
conservative and notices that there’s a moment between the two lines when the muta‐
ble reference isn’t referring to a valid value.
As humans, we can see that this combined operation—extracting the old value and
replacing it with a new value—is both safe and useful, so the standard library pro‐
vides the nder the covers, replace uses unsafe (as per ) to perform the swap in one go:
/// Replace the content of ìtem` with `val`, returning the previous
/// contents.
pub fn replace(item: & mut Option<Item>, val: Item) -> Option<Item> {
std::mem::replace(item, Some(val)) // returns previous value
}
For Option types in particular, this is a sufficiently common pattern that there is also
Option itself:
/// Replace the content of ìtem` with `val`, returning the previous
/// contents.
pub fn replace(item: & mut Option<Item>, val: Item) -> Option<Item> {
item.replace(val) // returns previous value
}
Item 15: Understand the borrow checker | 125
Borrow Rules
There are two key rules to remember when borrowing references in Rust.
The first rule is that the scope of any reference must be smaller than the lifetime of
the item that it refers to. Lifetimes are explored in detail in , but it’s worth not-ing that the compiler has special behavior for reference lifetimes; the non-lexical life‐
times feature allows reference lifetimes to be shrunk so they end at the point of last
use, rather than the enclosing block.
The second rule for borrowing references is that, in addition to the owner of an item,
there can be either of the following:
• Any number of immutable references to the item
• A single mutable reference to the item
However, there can’t be both (at the same point in the code).
So a function that takes multiple immutable references can be fed references to the
same item:
/// Indicate whether both arguments are zero.
fn both_zero(left: & Item, right: & Item) -> bool {
left.contents == 0 && right.contents == 0
}
let item = Item { contents: 0 };
assert!(both_zero(&item, &item));
but one that takes mutable references cannot:
D O E S N O T C O M P I L E
/// Zero out the contents of both arguments.
fn zero_both(left: & mut Item, right: & mut Item) {
left.contents = 0;
right.contents = 0;
}
let mut item = Item { contents: 42 };
zero_both(& mut item, & mut item);
error[E0499]: cannot borrow ìtemàs mutable more than once at a time
--> src/main.rs:131:26
|
131 | zero_both(&mut item, &mut item);
| --------- --------- ^^^^^^^^^ second mutable borrow occurs here
| | |
126 | Chapter 3: Concepts
| | first mutable borrow occurs here
| first borrow later used by call
The same restriction is true for a function that uses a mixture of mutable and immut‐
able references:
D O E S N O T C O M P I L E
/// Set the contents of `left` to the contents of `right`.
fn copy_contents(left: & mut Item, right: & Item) {
left.contents = right.contents;
}
let mut item = Item { contents: 42 };
copy_contents(& mut item, &item);
error[E0502]: cannot borrow ìtemàs immutable because it is also borrowed
as mutable
--> src/main.rs:159:30
|
159 | copy_contents(&mut item, &item);
| ------------- --------- ^^^^^ immutable borrow occurs here
| | |
| | mutable borrow occurs here
| mutable borrow later used by call
The borrowing rules allow the com: tracking when two different pointers may or may not refer to the same underlying
item in memory. If the compiler can be sure (as in Rust) that the memory location
pointed to by a collection of immutable references cannot be altered via an aliased
mutable reference, then it can generate code that has the following advantages:
It’s better optimized
Values can be, for example, cached in registers, secure in the knowledge that the
underlying memory contents will not change in the meantime.
It’s safer
Data races arising from unsynchronized access to memory between threads
) are not possible.
Owner Operations
One important consequence of the rules around the existence of references is that
they also affect what operations can be performed by the owner of the item. One way
to help understand this is to imagine that operations involving the owner are per‐
formed by creating and using references under the covers.
Item 15: Understand the borrow checker | 127
For example, an attempt to update the item via its owner is equivalent to making an
ephemeral mutable reference and then updating the item via that reference. If
another reference already exists, this notional second mutable reference can’t be
created:
D O E S N O T C O M P I L E
let mut item = Item { contents: 42 };
let r = &item;
item.contents = 0;
// ^^^ Changing the item is roughly equivalent to:
// (&mut item).contents = 0;
println!("reference to item is {:?}", r);
error[E0506]: cannot assign to ìtem.contents` because it is borrowed
--> src/main.rs:200:5
|
199 | let r = &item;
| ----- ìtem.contentsìs borrowed here
200 | item.contents = 0;
| ^^^^^^^^^^^^^^^^^ ìtem.contentsìs assigned to here but it was
| already borrowed
...
203 | println!("reference to item is {:?}", r);
| - borrow later used here
On the other hand, because multiple immutable references are allowed, it’s OK for the
owner to read from the item while there are immutable references in existence:
let item = Item { contents: 42 };
let r = &item;
let contents = item.contents;
// ^^^ Reading from the item is roughly equivalent to:
// let contents = (&item).contents;
println!("reference to item is {:?}", r);
but not if there is a mutable reference:
D O E S N O T C O M P I L E
let mut item = Item { contents: 42 };
let r = & mut item;
let contents = item.contents; // i64 implements `Copy`
r.contents = 0;
error[E0503]: cannot use ìtem.contents` because it was mutably borrowed
--> src/main.rs:231:20
|
230 | let r = &mut item;
128 | Chapter 3: Concepts
| --------- ìtemìs borrowed here
231 | let contents = item.contents; // i64 implements `Copy`
| ^^^^^^^^^^^^^ use of borrowed ìtem`
232 | r.contents = 0;
| -------------- borrow later used here
Finally, the existence of any sort of active reference prevents the owner of the item
from moving or dropping the item, exactly because this would mean that the refer‐
ence now refers to an invalid item:
D O E S N O T C O M P I L E
let item = Item { contents: 42 };
let r = &item;
let new_item = item; // move
println!("reference to item is {:?}", r);
error[E0505]: cannot move out of ìtem` because it is borrowed
--> src/main.rs:170:20
|
168 | let item = Item { contents: 42 };
| ---- binding ìtem` declared here
169 | let r = &item;
| ----- borrow of ìtemòccurs here
170 | let new_item = item; // move
| ^^^^ move out of ìtemòccurs here
171 | println!("reference to item is {:?}", r);
| - borrow later used here
This is a scenario where the non-lexical lifetime fea is particularly helpful, because (roughly speaking) it terminates the lifetime of a reference at
the point where the reference is last used, rather than at the end of the enclosing
scope. Moving the final use of the reference up before the move happens means that
the compilation error evaporates:
let item = Item { contents: 42 };
let r = &item;
println!("reference to item is {:?}", r);
// Referencèrìs still in scope but has no further use, so it's
// as if the reference has already been dropped.
let new_item = item; // move works OK
Winning Fights Against the Borrow Checker
Newcomers to Rust (and even more experienced folk!) can often feel that they are
spending time fighting against the borrow checker. What kinds of things can help you
win these battles?
Item 15: Understand the borrow checker | 129
Local code refactoring
The first tactic is to pay attention to the compiler’s error messages, because the Rust
developers have put a lot of effort into making them as helpful as possible:
D O E S N O T C O M P I L E
/// If `needleìs present in `haystack`, return a slice containing it.
pub fn find<'a, 'b>(haystack: &'a str, needle: &'b str) -> Option<&'a str> {
haystack
.find(needle)
.map(|i| &haystack[i..i + needle.len()])
}
// ...
let found = find(&format!("{} to search", "Text"), "ex");
if let Some(text) = found {
println!("Found '{text}'!");
}
error[E0716]: temporary value dropped while borrowed
--> src/main.rs:353:23
|
353 | let found = find(&format!("{} to search", "Text"), "ex");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ - temporary value
| | is freed at the end of this statement
| |
| creates a temporary value which is freed while still in
| use
354 | if let Some(text) = found {
| ----- borrow later used here
|
= note: consider using àlet` binding to create a longer lived value
The first part of the error message is the important part, because it describes what
borrowing rule the compiler thinks you have broken and why. As you encounter
enough of these errors—which you will—you can build up an intuition about the
borrow checker that matches the more theoretical version encapsulated in the previ‐
ously stated rules.
The second part of the error message includes the compiler’s suggestions for how to
fix the problem, which in this case is simple:
let haystack = format!("{} to search", "Text");
let found = find(&haystack, "ex");
if let Some(text) = found {
println!("Found '{text}'!");
}
// `found` now references `haystack`, which outlives it
130 | Chapter 3: Concepts
This is an instance of one of the two simple code tweaks that can help mollify the
borrow checker:
Lifetime extension
Convert a temporary (whose lifetime extends only to the end of the expression)
into a new named local variable (whose lifetime extends to the end of the block)
with a let binding.
Lifetime reduction
Add an additional block { ... } around the use of a reference so that its lifetime
ends at the end of the new block.
The latter is less common, because of the existence of non-lexical lifetimes: the com‐
piler can often figure out that a reference is no longer used, ahead of its official drop
point at the end of the block. However, if you do find yourself repeatedly introducing
an artificial block around similar small chunks of code, consider whether that code
should be encapsulated into a method of its own.
The compiler’s suggested fixes are helpful for simpler problems, but as you write
more sophisticated code, you’re likely to find that the suggestions are no longer useful
and that the explanation of the broken borrowing rule is harder to follow:
D O E S N O T C O M P I L E
let x = Some(Rc::new(RefCell::new(Item { contents: 42 })));
// Call function with signature: `check_item(item: Option<&Item>)`
check_item(x.as_ref().map(|r| r.borrow().deref()));
error[E0515]: cannot return reference to temporary value
--> src/main.rs:293:35
|
293 | check_item(x.as_ref().map(|r| r.borrow().deref()));
| ----------^^^^^^^^
| |
| returns a reference to data owned by the
| current function
| temporary value created here
In this situation, it can be helpful to temporarily introduce a sequence of local vari‐
ables, one for each step of a complicated transformation, and each with an explicit
type annotation:
D O E S N O T C O M P I L E
let x: Option<Rc<RefCell<Item>>> =
Some(Rc::new(RefCell::new(Item { contents: 42 })));
Item 15: Understand the borrow checker | 131
let x1: Option<&Rc<RefCell<Item>>> = x.as_ref();
let x2: Option<std::cell::Ref<Item>> = x1.map(|r| r.borrow());
let x3: Option<&Item> = x2.map(|r| r.deref());
check_item(x3);
error[E0515]: cannot return reference to function parameter `r`
--> src/main.rs:305:40
|
305 | let x3: Option<&Item> = x2.map(|r| r.deref());
| ^^^^^^^^^ returns a reference to
| data owned by the current function
This narrows down the precise conversion that the compiler is complaining about,
which in turn allows the code to be restructured:
let x: Option<Rc<RefCell<Item>>> =
Some(Rc::new(RefCell::new(Item { contents: 42 })));
let x1: Option<&Rc<RefCell<Item>>> = x.as_ref();
let x2: Option<std::cell::Ref<Item>> = x1.map(|r| r.borrow());
match x2 {
None => check_item(None),
Some(r) => {
let x3: & Item = r.deref();
check_item(Some(x3));
}
}
Once the underlying problem is clear and has been fixed, you’re then free to recoa‐
lesce the local variables back together so that you can pretend you got it right all
along:
let x = Some(Rc::new(RefCell::new(Item { contents: 42 })));
match x.as_ref().map(|r| r.borrow()) {
None => check_item(None),
Some(r) => check_item(Some(r.deref())),
};
Data structure design
The next tactic that helps for battles against the borrow checker is to design your data
structures with the borrow checker in mind. The panacea is your data structures
owning all of the data that they use, avoiding any use of references and the conse‐
quent propagation of lifetime annota.
However, that’s not always possible for real-world data structures; any time the inter‐
nal connections of the data structure form a graph that’s more interconnected than a
132 | Chapter 3: Concepts
tree pattern (a Root that owns multiple Branches, each of which owns multiple Leafs,
etc.), then simple single-ownership isn’t possible.
To take a simple example, imagine a simple register of guest details recorded in the
order in which they arrive:
#[derive(Clone, Debug)]
pub struct Guest {
name: String,
address: String,
// ... many other fields
}
/// Local error type, used later.
#[derive(Clone, Debug)]
pub struct Error(String);
/// Register of guests recorded in order of arrival.
#[derive(Default, Debug)]
pub struct GuestRegister(Vec<Guest>);
impl GuestRegister {
pub fn register(& mut self, guest: Guest) {
self.0.push(guest)
}
pub fn nth(&self, idx: usize) -> Option<&Guest> {
self.0.get(idx)
}
}
If this code also needs to be able to efficiently look up guests by arrival and alphabeti‐
cally by name, then there are fundamentally two distinct data structures involved, and
only one of them can own the data.
If the data involved is both small and immutable, then just cloning the data can be a
quick solution:
mod cloned {
use super::Guest;
#[derive(Default, Debug)]
pub struct GuestRegister {
by_arrival: Vec<Guest>,
by_name: std::collections::BTreeMap<String, Guest>,
}
impl GuestRegister {
pub fn register(& mut self, guest: Guest) {
// Requires `Guest` to bèClonè
self.by_arrival.push(guest.clone());
// Not checking for duplicate names to keep this
// example shorter.
Item 15: Understand the borrow checker | 133
self.by_name.insert(guest.name.clone(), guest);
}
pub fn named(&self, name: & str) -> Option<&Guest> {
self.by_name.get(name)
}
pub fn nth(&self, idx: usize) -> Option<&Guest> {
self.by_arrival.get(idx)
}
}
}
However, this approach of cloning copes poorly if the data can be modified. For
example, if the address for a Guest needs to be updated, you have to find both ver‐
sions and ensure they stay in sync.
Another possible approach is to add another layer of indirection, treating the
Vec<Guest> as the owner and using an index into that vector for the name lookups:
mod indexed {
use super::Guest;
#[derive(Default)]
pub struct GuestRegister {
by_arrival: Vec<Guest>,
// Map from guest name to index intòby_arrival`.
by_name: std::collections::BTreeMap<String, usize>,
}
impl GuestRegister {
pub fn register(& mut self, guest: Guest) {
// Not checking for duplicate names to keep this
// example shorter.
self.by_name
.insert(guest.name.clone(), self.by_arrival.len());
self.by_arrival.push(guest);
}
pub fn named(&self, name: & str) -> Option<&Guest> {
let idx = *self.by_name.get(name)?;
self.nth(idx)
}
pub fn named_mut(& mut self, name: & str) -> Option<& mut Guest> {
let idx = *self.by_name.get(name)?;
self.nth_mut(idx)
}
pub fn nth(&self, idx: usize) -> Option<&Guest> {
self.by_arrival.get(idx)
}
pub fn nth_mut(& mut self, idx: usize) -> Option<& mut Guest> {
self.by_arrival.get_mut(idx)
}
}
}
134 | Chapter 3: Concepts
In this approach, each guest is represented by a single Guest item, which allows the
named_mut() method to return a mutable reference to that item. That in turn means
that changing a guest’s address works fine—the (single) Guest is owned by the Vec
and will always be reached that way under the covers:
let new_address = "123 Bigger House St";
// Real code wouldn't assume that "Bob" exists...
ledger.named_mut("Bob").unwrap().address = new_address.to_string();
assert_eq!(ledger.named("Bob").unwrap().address, new_address);
However, if guests can deregister, it’s easy to inadvertently introduce a bug:
U N D E S I R E D B E H A V I O R
// Deregister thèGuestàt position ìdx`, moving up all
// subsequent guests.
pub fn deregister(& mut self, idx: usize) -> Result<(), super::Error> {
if idx >= self.by_arrival.len() {
return Err(super::Error::new("out of bounds"));
}
self.by_arrival.remove(idx);
// Oops, forgot to updatèby_namè.
Ok(())
}
Now that the Vec can be shuffled, the by_name indexes into it are effectively acting
like pointers, and we’ve reintroduced a world where a bug can lead those “pointers” to
point to nothing (beyond the Vec bounds) or to point to incorrect data:
U N D E S I R E D B E H A V I O R
ledger.register(alice);
ledger.register(bob);
ledger.register(charlie);
println!("Register starts as: {ledger:?}");
ledger.deregister(0).unwrap();
println!("Register after deregister(0): {ledger:?}");
let also_alice = ledger.named("Alice");
// Alice still has index 0, which is now Bob
println!("Alice is {also_alice:?}");
let also_bob = ledger.named("Bob");
// Bob still has index 1, which is now Charlie
println!("Bob is {also_bob:?}");
Item 15: Understand the borrow checker | 135
let also_charlie = ledger.named("Charlie");
// Charlie still has index 2, which is now beyond the Vec
println!("Charlie is {also_charlie:?}");
The code here uses a custom Debug implementation (not shown), in order to reduce
the size of the output; this truncated output is as follows:
Register starts as: {
by_arrival: [{n: 'Alice', ...}, {n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: {"Alice": 0, "Bob": 1, "Charlie": 2}
}
Register after deregister(0): {
by_arrival: [{n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: {"Alice": 0, "Bob": 1, "Charlie": 2}
}
Alice is Some(Guest { name: "Bob", address: "234 Bobton" })
Bob is Some(Guest { name: "Charlie", address: "345 Charlieland" })
Charlie is None
The preceding example showed a bug in the deregister code, but even after that bug
is fixed, there’s nothing to prevent a caller from hanging onto an index value and
using it with nth()—getting unexpected or invalid results.
The core problem is that the two data structures need to be kept in sync. A better
approach for handling this is to use Rust’s smart pointers instead (). Shifting to a combination of and avoids the invalidation problems of using indices as pseudo-pointers. Updating the example—but keeping the bug in it—gives the
following:
U N D E S I R E D B E H A V I O R
mod rc {
use super::{Error, Guest};
use std::{cell::RefCell, rc::Rc};
#[derive(Default)]
pub struct GuestRegister {
by_arrival: Vec<Rc<RefCell<Guest>>>,
by_name: std::collections::BTreeMap<String, Rc<RefCell<Guest>>>,
}
impl GuestRegister {
pub fn register(& mut self, guest: Guest) {
let name = guest.name.clone();
let guest = Rc::new(RefCell::new(guest));
self.by_arrival.push(guest.clone());
self.by_name.insert(name, guest);
}
136 | Chapter 3: Concepts
pub fn deregister(& mut self, idx: usize) -> Result<(), Error> {
if idx >= self.by_arrival.len() {
return Err(Error::new("out of bounds"));
}
self.by_arrival.remove(idx);
// Oops, still forgot to updatèby_namè.
Ok(())
}
// ...
}
}
Register starts as: {
by_arrival: [{n: 'Alice', ...}, {n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: [("Alice", {n: 'Alice', ...}), ("Bob", {n: 'Bob', ...}),
("Charlie", {n: 'Charlie', ...})]
}
Register after deregister(0): {
by_arrival: [{n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: [("Alice", {n: 'Alice', ...}), ("Bob", {n: 'Bob', ...}),
("Charlie", {n: 'Charlie', ...})]
}
Alice is Some(RefCell { value: Guest { name: "Alice",
address: "123 Aliceville" } })
Bob is Some(RefCell { value: Guest { name: "Bob",
address: "234 Bobton" } })
Charlie is Some(RefCell { value: Guest { name: "Charlie",
address: "345 Charlieland" } })
The output no longer has mismatched names, but a lingering entry for Alice remains
until we fix the bug by ensuring that the two collections stay in sync:
pub fn deregister(& mut self, idx: usize) -> Result<(), Error> {
if idx >= self.by_arrival.len() {
return Err(Error::new("out of bounds"));
}
let guest: Rc<RefCell<Guest>> = self.by_arrival.remove(idx);
self.by_name.remove(&guest.borrow().name);
Ok(())
}
Register after deregister(0): {
by_arrival: [{n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: [("Bob", {n: 'Bob', ...}), ("Charlie", {n: 'Charlie', ...})]
}
Alice is None
Bob is Some(RefCell { value: Guest { name: "Bob",
address: "234 Bobton" } })
Charlie is Some(RefCell { value: Guest { name: "Charlie",
address: "345 Charlieland" } })
Item 15: Understand the borrow checker | 137
Smart pointers
The final variation of the previous section is an example of a more general approach:
use Rust’s smart pointers for interconnected data structures.
described the most common smart pointer types provided by Rust’s standard
library:
• Rc allows shared ownership, with multiple things referring to the same item. Rc is
often combined with RefCell.
• RefCell allows interior mutability so that internal state can be modified without
needing a mutable reference. This comes at the cost of moving borrow checks
from compile time to runtime.
• Arc is the multithreading equivalent to Rc.
• Mutex (and RwLock) allows interior mutability in a multithreading environment,
roughly equivalent to RefCell.
• Cell allows interior mutability for Copy types.
For programmers who are adapting from C++ to Rust, the most common tool to
reach for is Rc<T> (and its thread-safe cousin Arc<T>), often combined with RefCell
(or the thread-safe alternative Mutex). A naive translation of shared pointers (or even
s) to Rc<RefCell<T>> instances will generally give something that works in Rust without too much complaint from the borrow checker.
However, this approach means that you miss out on some of the protections that Rust
gives you. In particular, situations where the same item is m
) while another reference exists result in a runtime panic! rather than a compile-time error.
For example, one pattern that breaks the one-way flow of ownership in tree-like data
structures is when there’s an “owner” pointer back from an item to the thing that
. These owner links are useful for moving around the
data structure; for example, adding a new sibling to a Leaf needs to involve the own‐
ing Branch.
138 | Chapter 3: Concepts
Figure 3-3. Tree data structure layout
Implementing this pattern in Rust can make use of Rc<T>’s more tentative partner,
:
use std::{
cell::RefCell,
rc::{Rc, Weak},
};
// Use a newtype for each identifier type.
struct TreeId(String);
struct BranchId(String);
struct LeafId(String);
struct Tree {
id: TreeId,
branches: Vec<Rc<RefCell<Branch>>>,
}
struct Branch {
id: BranchId,
leaves: Vec<Rc<RefCell<Leaf>>>,
owner: Option<Weak<RefCell<Tree>>>,
}
struct Leaf {
id: LeafId,
owner: Option<Weak<RefCell<Branch>>>,
}
The Weak reference doesn’t increment the main refcount and so has to explicitly check
whether the underlying item has gone away:
impl Branch {
fn add_leaf(branch: Rc<RefCell<Branch>>, mut leaf: Leaf) {
leaf.owner = Some(Rc::downgrade(&branch));
branch.borrow_mut().leaves.push(Rc::new(RefCell::new(leaf)));
}
Item 15: Understand the borrow checker | 139
fn location(&self) -> String {
match &self.owner {
None => format!("<unowned>.{}", self.id.0),
Some(owner) => {
// Upgrade weak owner pointer.
let tree = owner.upgrade().expect("owner gone!");
format!("{}.{}", tree.borrow().id.0, self.id.0)
}
}
}
}
If Rust’s smart pointers don’t seem to cover what’s needed for your data structures,
there’s always the final fallback of writing unsafe code that uses raw (and decidedly
un-smart) pointers. However, as per y much be a last resort—
someone else might have already implemented the semantics you want, inside a safe
interface, and if you search the standard library and crates.io, you might find just
the tool for the job.
For example, imagine that you have a function that sometimes returns a reference to
one of its inputs but sometimes needs to return some freshly allocated data. In line
, an enum that encodes these two possibilities is the natural way to express
this in the type system, and you could then implement various pointer traits
described in . But you don’t have to: the standard library already includes the
t covers exactly this scenario once you know it exists.
Self-referential data structures
One particular battle with the borrow checker always stymies programmers arriving
at Rust from other languages: attempting to create self-referential data structures,
which contain a mixture of owned data together with references to within that owned
data:
D O E S N O T C O M P I L E
struct SelfRef {
text: String,
// The slice of `text` that holds the title text.
title: Option<& str>,
}
4 Cow stands for clone-on-write; a copy of the underlying data is made only if a change (write) needs to be made to it.
140 | Chapter 3: Concepts
At a syntactic level, this code won’t compile because it doesn’t comply with the life‐
time rules described in : the reference needs a lifetime annotation, and that
means the containing data structure would also need a lifetime parameter. But a life‐
time would be for something external to this SelfRef struct, which is not the intent:
the data being referenced is internal to the struct.
It’s worth thinking about the reason for this restriction at a more semantic level. Data
structures in Rust can move: from the stack to the heap, from the heap to the stack,
and from one place to another. If that happens, the “interior” title pointer would no
longer be valid, and there’s no way to keep it in sync.
A simple alternative for this case is to use the indexing approach explored earlier: a
range of offsets into the text is not invalidated by a move and is invisible to the bor‐
row checker because it doesn’t involve references:
struct SelfRefIdx {
text: String,
// Indices intòtext` where the title text is.
title: Option<std::ops::Range< usize>>,
}
However, this indexing approach works only for simple examples and has the same
drawbacks as noted previously: the index itself becomes a pseudo-pointer that can
become out of sync or even refer to ranges of the text that no longer exist.
A more general version of the self-reference problem turns up when the compiler
deals with async piler bundles up a pending chunk
of async code into a closure, which holds both the code and any captured parts of the
environment that the code works with (as described in ). This captured envi‐
ronment can include both values and references to those values. That’s inherently a
self-referential data structure, and so async support was a prime motivation for the
type in the standard library. This pointer type “pins” its value in place, forcing the value to remain at the same location in memory, thus ensuring that internal self-references remain valid.
So Pin is available as a possibility for self-referential types, but it’s tricky to use cor‐
rectly—be sure to read the .
Where possible, avoid self-referential data structures, or try to find library crates that
encapsula).
5 Dealing with async code is beyond the scope of this book; to understand more about its need for self-
referential data structures, see Chaon Gjengset (No Starch Press).
Item 15: Understand the borrow checker | 141
Things to Remember
• Rust’s references are borrowed, indicating that they cannot be held forever.
• The borrow checker allows multiple immutable references or a single mutable
reference to an item but not both. The lifetime of a reference stops at the point of
last use, rather than at the end of the enclosing scope, due to non-lexical life‐
times.
• Errors from the borrow checker can be dealt with in various ways:
— Adding an additional { ... } scope can reduce the extent of a value’s lifetime.
— Adding a named local variable for a value extends the value’s lifetime to the
end of the scope.
— Temporarily adding multiple local variables can help narrow down what the
borrow checker is complaining about.
• Rust’s smart pointer types provide ways around the borrow checker’s rules and so
are useful for interconnected data structures.
• However, self-referential data structures remain awkward to deal with in Rust.
Item 16: Avoid writing unsafe code
The memory safety guarantees—without runtime overhead—of Rust are its unique
selling point; it is the Rust language feature that is not found in any other mainstream
language. These guarantees come at a cost: writing Rust requires you to reorganize
your code to mollify the borrow checker () and to precisely specify the refer‐
ence types that you use ().
Unsafe Rust is a superset of the Rust language that weakens some of these
restrictions—and the corresponding guarantees. Prefixing a block with the unsafe
keyword switches that block into unsafe mode, which allows things that are not sup‐
ported in normal Rust. In particular, it allows the use of raw pointers that work more
like old-style C pointers. These pointers are not subject to the borrowing rules, and
the programmer is responsible for ensuring that they still point to valid memory
whenever they’re dereferenced.
So at a superficial level, the advice of this Item is trivial: why move to Rust if you’re
just going to write C code in Rust? However, there are occasions where unsafe code
is absolutely required: for low-level library code or for when your Rust code has to
in).
The wording of this Item is quite precise, though: avoid writing unsafe code. The
emphasis is on the “writing,” because much of the time, the unsafe code you’re likely
to need has already been written for you.
142 | Chapter 3: Concepts
The Rust standard libraries contain a lot of unsafe code; a quick search finds around
1,000 uses of unsafe in the alloc library, 1,500 in core, and a further 2,000 in std.
This code has been written by experts and is battle-hardened by use in many thou‐
sands of Rust codebases.
Some of this unsafe code happens under the covers in standard library features that
we’ve already covered:
• The smart pointer types—Rc, RefCell, Arc use
unsafe code (often raw pointers) internally to be able to present their particular
semantics to their users.
• The synchronization primitives—Mutex, RwLock, and associated guards—from
unsafe OS-specific code internally by Mara Bos (O’Reilly) is recommended if you want to understand the subtle details
involved in these primitives.
The standard library also has other functionality covering more advanced features,
implemented with unsafe internally:
• forces an item to not move in memor). This allows self-referential da for new arrivals to Rust.
• ter: the same pointer can be used for both reading and writing, and a clone of the underlying data happens only if and when a write occurs.
• Various functions (y to be manipulated without falling foul of the borrow checker.
These features may still need a little caution to be used correctly, but the unsafe code
has been encapsulated in a way that removes whole classes of problems.
Moving beyond the standard library, the ecosystem also includes many crates that encapsulate unsafe code to provide a frequently used feature:
Provides a way to have something like global variables, initialized exactly once.
Provides random number generation, making use of the lower-level underlying
features provided by the operating system and CPU.
6 In practice, most of this std functionality is actually provided by core and so is available to no_std code as
Item 16: Avoid writing unsafe code | 143
Allows raw bytes of data to be converted to and from numbers.
Allows C++ code and Rust code to interoperate (also men).
There are many other examples, but hopefully the general idea is clear. If you want to
do something that doesn’t obviously fit within the constraints of Rust (especially
Items and unt through the standard library to see if there’s existing functionality that does what you need. If you don’t find what you need, try also hunting
through crates.io. After all, it’s unusual to encounter a unique problem that no one
else has ever faced before.
Of course, there will always be places where unsafe is forced, for example, when you
need to interact with code written in other languages via a foreign function interface
(FFI), as discussed in ’s necessary, consider writing a wrapper layer that holds all the unsafe code that’s required so that other programmers can then
follow the advice given in this Item. This also helps to localize problems: when some‐
thing goes wrong, the unsafe wrapper can be the first suspect.
Also, if you’re forced to write unsafe code, pay attention to the warning implied by
• Add that document the preconditions and invariants that the unsafe code relies on. Clippy ( to remind you about this.
• Minimize the amount of code contained in an unsafe block, to limit the potential
blast radius of a mistake. so that explicit unsafe blocks are required when performing unsafe operations,
even when those operations are performed in a function that is unsafe itself.
• Write even more tests (
• R, consider
running Miri over your unsafe code interprets the intermediate level output from the compiler, that allows it to detect classes of errors that are invisible to
the Rust compiler.
• Think carefully about multithreaded use, particularly if there’s shared state
).
Adding the unsafe marker doesn’t mean that no rules apply—it means that you (the
programmer) are now responsible for maintaining Rust’s safety guarantees, rather
than the compiler.
144 | Chapter 3: Concepts
Item 17: Be wary of shared-state parallelism
Even the most daring forms of sharing are guaranteed safe in Rust.
—
The official documentation describes R
Item will explore why (sadly) there are still some reasons to be afraid of concurrency,
even in Rust.
This Item is specific to shared-state parallelism: where different threads of execution
communicate with each other by sharing memory. Sharing state between threads gen‐
erally comes with two terrible problems, regardless of the language involved:
Data races
These can lead to corrupted data.
Deadlocks
These can lead to your program grinding to a halt.
Both of these problems are terrible (“causing or likely to cause terror”) because they
can be very hard to debug in practice: the failures occur nondeterministically and are
often more likely to happen under load—which means that they don’t show up in
unit tests, integration tests, or an), but they do show up in production.
Rust is a giant step forward, because it completely solves one of these two problems.
However, the other still remains, as we shall see.
Data Races
Let’s start with the good news, by exploring data races and Rust. The precise technical
definition of a data race varies from language to language, but we can summarize the
key components as follows:
A data race is defined to occur when two distinct threads access the same memory
location, under the following conditions:
• At least one of them is a write.
• There is no synchronization mechanism that enforces an ordering on the accesses.
Data races in C++
The basics of this are best illustrated with an example. Consider a data structure that
tracks a bank account:
Item 17: Be wary of shared-state parallelism | 145
U N D E S I R E D B E H A V I O R
// C++ code.
class BankAccount {
public:
BankAccount() : balance_(0) {}
int64_t balance() const {
if (balance_ < 0) {
std::cerr << "** Oh no, gone overdrawn: " << balance_ << "! **\n"; std::abort();
}
return balance_;
}
void deposit(uint32_t amount) {
balance_ += amount;
}
bool withdraw(uint32_t amount) {
if (balance_ < amount) {
return false;
}
// What if another thread changes `balance_àt this point?
std::this_thread::sleep_for(std::chrono::milliseconds(500));
balance_ -= amount;
return true;
}
private:
int64_t balance_;
};
This example is in C++, not Rust, for reasons that will become clear shortly. However,
the same general concepts apply in many other (non-Rust) languages—Java, or Go, or
Python, etc.
This class works fine in a single-threaded setting, but consider a multithreaded
setting:
BankAccount account;
account.deposit(1000);
// Start a thread that watches for a low balance and tops up the account.
std::thread payer(pay_in, &account);
// Start 3 threads that each try to repeatedly withdraw money.
std::thread taker(take_out, &account);
std::thread taker2(take_out, &account);
std::thread taker3(take_out, &account);
146 | Chapter 3: Concepts
Here several threads are repeatedly trying to withdraw from the account, and there’s
an additional thread that tops up the account when it runs low:
// Constantly monitor the àccount` balance and top it up if low.
void pay_in(BankAccount* account) {
while (true) {
if (account->balance() < 200) {
log("[A] Balance running low, deposit 400");
account->deposit(400);
}
// (The infinite loop with sleeps is just for demonstration/simulation
// purposes.)
std::this_thread::sleep_for(std::chrono::milliseconds(5));
}
}
// Repeatedly try to perform withdrawals from the àccount`.
void take_out(BankAccount* account) {
while (true) {
if (account->withdraw(100)) {
log("[B] Withdrew 100, balance now " +
std::to_string(account->balance()));
} else {
log("[B] Failed to withdraw 100");
}
std::this_thread::sleep_for(std::chrono::milliseconds(20));
}
}
Eventually, things will go wrong:
** Oh no, gone overdrawn: -100! **
The problem isn’t hard to spot, particularly with the helpful comment in the with
draw() method: when multiple threads are involved, the value of the balance can
change between the check and the modification. However, real-world bugs of this
sort are much harder to spot—particularly if the compiler is allowed to perform all
kinds of tricks and reorderings of code under the covers (as is the case for C++).
The various sleep calls are included in order to artificially raise the chances of this
bug being hit and thus detected early; when these problems are encountered in the
wild, they’re likely to occur rarely and intermittently—making them very hard to
debug.
The BankAccount class is thread-compatible, which means that it can be used in a
multithreaded environment as long as the users of the class ensure that access to it is
governed by some kind of external synchronization mechanism.
Item 17: Be wary of shared-state parallelism | 147
The class can be converted to a thread-safe class—meaning that it is safe to use from multiple threads—by adding internal synchronization opera
// C++ code.
class BankAccount {
public:
BankAccount() : balance_(0) {}
int64_t balance() const {
// Lock mu_ for all of this scope.
const std::lock_guard<std::mutex> with_lock(mu_);
if (balance_ < 0) {
std::cerr << "** Oh no, gone overdrawn: " << balance_ << " **! \n"; std::abort();
}
return balance_;
}
void deposit(uint32_t amount) {
const std::lock_guard<std::mutex> with_lock(mu_);
balance_ += amount;
}
bool withdraw(uint32_t amount) {
const std::lock_guard<std::mutex> with_lock(mu_);
if (balance_ < amount) {
return false;
}

