Книга: Ценность ваших данных
Назад: Глава 7. Построение цепочек
Дальше: Глава 9. Управление данными: принципы и структуры
Часть 2. Данные: Извлечение ценности
От планирования к расширению возможностей применения
Глава 8. Данные как объект управления
8.1. Источники данных и виды информационных активов
Организации, которые не знают, какими данными они располагают, не могут использовать их в качестве актива. В книге Дагласа Лейни «Инфономика: информация как актив: монетизация, оценка, управление» приводится справедливое высказывание директора по информационным технологиям крупной страховой компании: «Глупо, что у кого-то в компании есть опись нашей офисной мебели, но ни у кого нет описи того, какими данными мы располагаем».
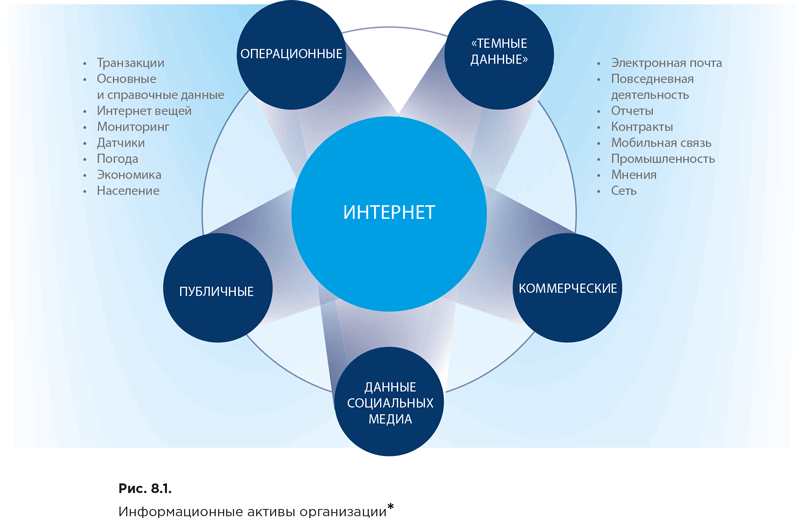
При инвентаризации информационных активов целесообразно в первую очередь разделить их на группы в зависимости от источников поступления данных. Лейни выделяет пять основных групп (рис. 8.1).
Операционные данные
Это данные о клиентах, поставщиках, партнерах и сотрудниках, доступные в процессе онлайн-обработки транзакций и (или) полученные из онлайн базы данных аналитической обработки. Часто такие сведения успешно собираются с помощью датчиков в ходе мониторинга процессов предприятий. Например, кассовые аппараты, подключенные к банковской системе, интеллектуальные счетчики, голосовая связь, радиочастотная идентификация и т. д.
«Темные (dark) данные»
Информация, которая не хранится или не собирается организациями специально, а формируется случайно в процессе ведения бизнеса или взаимодействия с сетевыми сервисами и остается в интернет-архивах. Такие данные являются общедоступными и частично структурированными для анализа, включают электронные письма, электронные договоры, документы, мультимедиа, системные журналы и т. д.
* Laney D. B. Infonomics: How to Monetize, Manage, and Measure Information as an Asset for Competitive Advantage; Routledge; 1st edition, 2017. (Русский перевод: Даглас Лейни. Инфономика: информация как актив: монетизация, оценка, управление. – М.: Точка, 2020. – [Библиотека «Айтеко»].)
Публичные данные
Информация, распространяемая государственными органами (заявления, пресс-релизы, прогноз погоды, сведения о планах муниципального развития; открытые публичные реестры, опубликованные нормативные акты, включая их проекты), одна из наиболее достоверных и чаще всего структурированная. Ценность таких данных раскрывается в совокупности с другими источниками сведений, поскольку позволяет определить направления развития бизнеса или целой индустрии в рамках отдельного города, страны или на международном уровне.
Коммерческие данные
Уже давно в разных отраслях промышленности существуют агрегаторы коммерчески ценной информации. Указанные агрегаторы предоставляют полный доступ к собственным каталогам информации по подписке. Но с учетом перенаправления современных рыночных отношений в сторону открытия информации для потенциальных инвесторов и клиентов многие сведения, представляющие коммерческий интерес, открыто размещаются в цифровой среде. Распространенной стала практика размещения информации об активах на открытых площадках, в особенности если речь идет о принадлежащих компаниям объектах интеллектуальной собственности.
Данные социальных медиа
Вовлеченность бизнеса и частных лиц в функционал крупных социальных сетей создала еще один источник данных о спросе, тенденциях в определенных сегментах рыночных отношений, новых и перспективных продуктах, услугах и компаниях. Сообщения, комментарии, репосты активно используют для выявления и прогнозирования целевых клиентов, коммерческих возможностей, конкурентных отношений, бизнес-рисков и потенциальных партнеров.
Открытые данные
Эта категория данных на рисунке 8.1 не отражена, поскольку она тесно связана с категорией публичных данных. Термин «открытые данные» появился в 1995 году в американском научном сообществе в виде призыва свободно обмениваться данными. Несмотря на общую открытость публичных и открытых данных, между ними существует принципиальная разница. Она заключается в том, что использование публичных данных определяется законом – доступ к ним можно получить, например, по специальному запросу. Суть открытых данных в обратном – данные должны быть опубликованы еще до того, как кому-то понадобятся,.
8.2. Классификация данных
На практике при организации управления данными их обычно классифицируют по следующим признакам.
По назначению и области применения обычно выделяют:
● метаданные – данные, описывающие структуру и характеристики данных;
● справочные данные – данные из справочников, международных, общероссийских и отраслевых классификаторов и т. п.;
● основные данные – структурированные данные об объектах учета;
● транзакционные данные – сведения, отражающие результат изменения данных, относящиеся к фиксированному моменту времени, не изменяющиеся в будущем;
● данные контроля и аудита – сведения, фиксируемые в различных журналах регистрации,,.
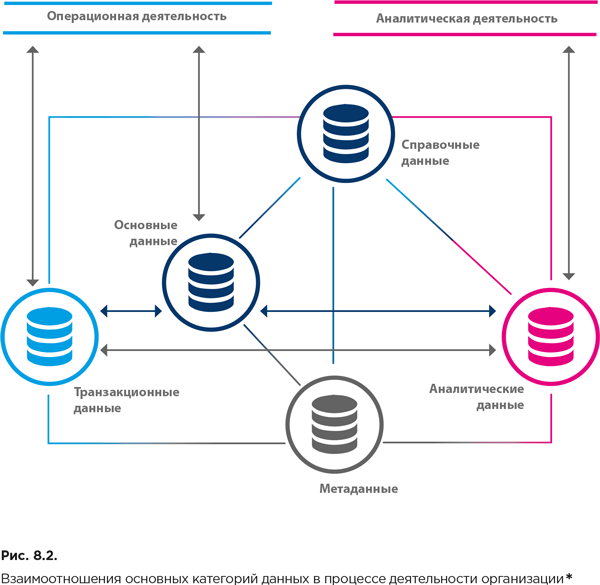
Часто в отдельную категорию относят аналитические данные – эти данные фактически образуются из основных, справочных и транзакционных данных. Они используются в аналитической деятельности организации (рис. 8.2).
На рисунке 8.2 отражены взаимоотношения перечисленных категорий данных в процессе деятельности организации.
* Van Gils B. Data Management: a Gentle Introduction: Balancing Theory and Practice. Van Haren Publishing, 2020.
На рисунке 8.3 отражены роли, которые играет каждая из категорий данных в информационном обеспечении процессов организации. Следует обратить внимание на фундаментальную роль справочных и основных данных и на важность поддержания высокого уровня их качества. Например, при наличии ошибок в данных о номере товара или типе клиента цена заказа на доставку может быть определена некорректно (см. связи, отраженные пунктирными стрелками), что может привести к серьезным финансовым последствиям.

* McGilvray D. Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information (TM). Morgan Kaufmann, 2008.
* Deng Z. MIS2502: Data Analytics: Semi-structured Data Analytics. Fox School of Business. Temple University, 2019. – URL: .
По степени структурированности можно выделить:
● структурированные данные – данные, имеющие строго фиксированную структуру, определяемую формальной моделью данных (например, реляционной схемой);
● полуструктурированные данные – данные, не имеющие строго определенной структуры, но предполагающие наличие установленных правил, позволяющих выделять семантические элементы при их интерпретации (прежде всего, правил расстановки тегов и других маркеров, отмечающих и выделяющих элементы данных);
● неструктурированные данные – данные, произвольные по форме, не имеющие строго определенной структуры и не организованные по определенным правилам.
Схемы, представленные на рисунках 8.2 и 8.3, в основном отражают взаимосвязи между структурированными данными. Однако в деятельности предприятий и учреждений не менее важны данные полуструктурированные и неструктурированные (в частности, к ним относятся отмеченные выше данные контроля и аудита). Они могут быть самыми разнообразными по назначению и области применения. C каждым годом роль этих данных становится все более заметной и существенной.
На рисунке 8.4 приведены примеры форматов хранения и передачи данных по каждой из перечисленных категорий.
* Smith P., Edge J., Parry S., Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.
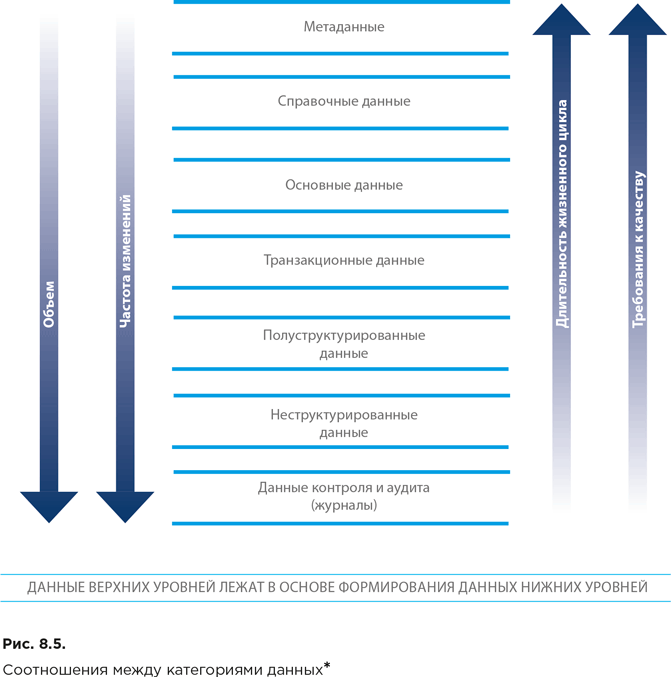
С точки зрения управления данными полезно представить их в виде диаграммы (рис. 8.5), укрупненно отражающей соотношения между основными категориями.
Данные, относящиеся к категориям, расположенным сверху, как правило, являются базовыми для формирования данных, относящихся к категориям, расположенным ниже (данные верхних категорий участвуют в формировании данных нижних категорий). Поэтому по мере продвижения вверх по списку категорий требования к качеству соответствующих данных возрастают.
Также по мере продвижения вверх по списку категорий увеличивается продолжительность жизненного цикла данных. При этом при продвижении вниз по списку категорий увеличивается объем самих данных, а также частота их изменений.
Говоря о данных контроля и аудита, следует отдельно определить такие категории данных, как машинные данные и потоковые данные.
К машинным данным относится информация, автоматически генерируемая компьютером, процессом, приложением или устройством без вмешательства человека. Они становятся одним из основных источников информации, а это в первую очередь относится к данным контроля и аудита.
Потоковые данные могут относиться почти к любой из перечисленных выше категорий, однако у них имеется одно дополнительное свойство. Данные поступают в систему непрерывно по мере возникновения тех или иных событий, а не загружаются в хранилище данных дискретно большими массивами.
К особой категории можно отнести большие данные (big data). Термин «большие данные» связан преимущественно с техническими аспектами формирования и обработки. Он не предполагает конкретные виды данных (эта категория может включать и структурированные, и неструктурированные, и полуструктурированные данные). Традиционно принято определять большие данные по трем признакам (3V): Volume, Velocity, Variety,. Коротко о них скажем.
● Volume – объем. К 2020 году общий объем информации, созданный в цифровой среде, достиг 44 ЗБ. По прогнозам Всемирного экономического форума, к 2025 году объем ежедневного интернет-трафика данных по всему миру достигнет 463 ЭБ. С точки зрения наглядной оценки такого огромного объема информации следует отметить, что для его записи потребуется больше 212 млн DVD-дисков. Информация, которая образует объем больших данных, поступает от миллионов используемых электронных сетевых устройств и приложений. Важно иметь в виду, что на этапе накопления big data отбора ненужных данных не производится. Обычные инструменты хранения и анализа не способны справляться с таким объемом.
● Velocity – скорость. Указанные выше объемы данных поступают в обработку в режиме реального времени, в отличие от традиционной обработки пакетов данных. Это означает, что они накапливаются моментально, при этом не имеет значения продолжительность потока самих данных. Таким образом, при работе с большими данными не только фиксируются их потоки, но и производится их запись и обработка в таком виде, чтобы не было потерь.
● Variety – разнообразие. Большие данные формируются из поступающих от различных источников сведений в разнообразных форматах (видеоданные, фотографии, звуковые записи, текстовые сообщения, файлы транзакций, комментарии, использование ссылок и фиксация просмотров страниц и т. д.). Наибольший объем составляют полуструктурированные и неструктурированные данные социальных сетей и социальных медиасервисов. Таким образом, термин big data не относится исключительно к большим данным в понимании объема. Он значительно шире, поскольку подразумевает также большие скорости поступления данных и большое разнообразие источников и форматов получаемой информации.
Со временем правило 3V в отношении больших данных стали расширять за счет дополнительных признаков,, в частности:
● Veracity – достоверность. Из-за большого объема и вариативности источников поступающих данных сложно проконтролировать их достоверность. Соответствие, точность и правдивость получаемой информации могут быть подтверждены только в результате тщательного анализа и сопоставления.
● Variability – вариативность. При обработке и сопоставлении исходные значения полученных данных могут меняться. В первую очередь данный признак проявляется при работе с речевыми и текстовыми данными. Для понимания точного значения отдельных слов необходима разработка сложных программных продуктов, позволяющих определять смысловую нагрузку исходя не только из прямого значения, но и из контекста.
● Visualization – визуализация. Полученные в результате сбора данные непригодны для восприятия человеком. Поэтому требуется их обработка для представления в доступной форме – визуализация. Характерный пример визуализации данных – построение графиков и диаграмм, отображающих результаты анализа данных. Важна возможность самостоятельной настройки. Необходимые параметры представления пользователи определяют сами, в зависимости от поставленных целей и задач.
● Value – ценность. Потенциальная ценность больших данных крайне высока. На ценность влияют тщательный и точный анализ данных, актуальность информации и полученные в результате визуализации выводы. Наибольший коммерческий и научный интерес представляют те сведения, которые можно использовать для решения текущих задач конкретного пользователя, а также результаты анализа, которые способствуют генерации новых идей.
Наконец, в зависимости от носителя данных, могут быть выделены:
● данные на бумажных носителях;
● данные в электронном виде.
8.3. Жизненный цикл данных, цепочка данных и происхождение данных
Как и у любого другого актива, у данных есть свой жизненный цикл. Для эффективного управления информационными активами организации необходимо его понимание и планирование.
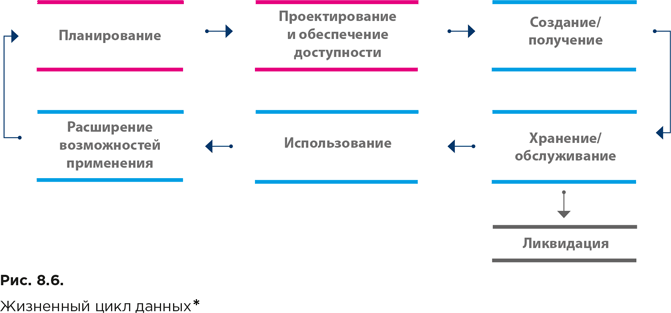
Концептуально жизненный цикл данных описывается достаточно просто (рис. 8.6). Он включает:
● процессы планирования, а также проектирования и обеспечения доступности данных;
● процессы, которые создают или получают данные;
● процессы, которые осуществляют их перемещение, преобразование, хранение, а также обеспечивают обслуживание данных и предоставление совместного доступа к ним;
● процессы использования и расширения возможностей применения данных;
● процессы, обеспечивающие их ликвидацию.
Кроме того, на протяжении всего их жизненного цикла данные могут очищаться, преобразовываться, подвергаться слиянию или агрегироваться.
Требования к организации отдельных этапов жизненного цикла могут существенно различаться в зависимости от вида данных. Поскольку к данным разных категорий предъявляются различные требования, им присущи различные риски и отведены различные роли в организации, многие инструменты управления данными всецело сфокусированы на различных аспектах классификации и контроля. Например, основные данные имеют иное назначение и области применения, нежели транзакционные, соответственно и требования к управлению данными двух этих категорий предъявляются различные.
Специфика конкретного жизненного цикла данных в отдельно взятой организации может оказаться весьма запутанной, поскольку в течение цикла данные обычно перемещаются из одного места в другое внутри организации, а также за ее пределами. По сравнению с остальными видами активов ситуация с данными усложняется за счет такой характеристики, как возможность совместного использования неограниченным количеством потребителей. Поэтому при управлении данными, наряду с управлением на отдельных фазах их жизненного цикла, важно обеспечивать контроль их движения по различным участкам хранения и обработки.
* DAMA International. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
Для обозначения набора процессов и систем, участвующих в перемещении данных, часто используются термины «цепочка данных» (data chain) и «информационная цепочка» (information chain). Хотя у них есть не менее часто употребляемые синонимы – «поток данных» и «информационный поток», метафора цепочки может оказаться очень полезной. Она подразумевает связь процессов и систем. Если одно звено обрывается, это негативно сказывается на всей последовательности элементов. При этом заметим, что для отражения реальных взаимосвязей в большинстве организаций (когда один набор данных может быть звеном многих цепочек) более точной была бы метафора сети данных.
С жизненным циклом данных и цепочкой данных связано такое понятие, как «происхождение данных» (data lineage). Под происхождением (lineage) обычно понимается линия связи с предком. Большинство людей, интересующихся происхождением данных, хотят осознать два аспекта.
Во-первых, их интересует подтвержденная информация о самом раннем экземпляре (первоисточнике) данных. В искусстве для обозначения истории владения художественным произведением (с того момента, как оно было создано, и по настоящее время) используется термин «провенанс» (provenance). В отношении данных существует аналогичный термин data provenance. Его можно перевести просто как «провенанс данных».
Во-вторых, люди хотят знать, как (а иногда и почему) данные менялись в процессе перехода от самого раннего экземпляра. Изменения могут происходить внутри одной системы или при передаче между системами. Понимание изменений в данных требует понимания цепочки данных, правил, которые применялись к данным по мере их перемещения по цепочке, и того, какое влияние эти правила оказали на данные.
Происхождение данных (data lineage) включает в себя и их провенанс, и сведения об изменениях данных (сведения о последовательности шагов по изменению при движении по цепочке данных, в том числе и при подготовке к применению для различных целей). Используя метафору цепочки легко представить, что данные по мере своего перемещения по ее звеньям будут сохранять некоторые (но не все) свойства своих предыдущих состояний и приобретать новые в процессе преобразования.
Следует заметить, что трактовки понятий data chain, data lineage и data provenance в разных источниках могут несколько различаться. Часто data lineage и data provenance рассматриваются отдельно. Здесь мы ориентируемся на книгу выпускающего редактора DMBOK2 Лауры Себастьян-Коулман «Измерение качества данных в целях постоянного совершенствования: Рамочная модель для оценки качества данных».
Наличие подробной информации о происхождении дает возможность проводить анализ влияния на данные (data impact analysis) – выяснять, какие элементы данных в целевой базе данных или в приложении будут затронуты, если мы изменим тот или иной элемент в предшествующих звеньях цепочки данных. На рисунке 8.7 представлен простейший пример описания происхождения элемента данных. Мы видим, что элемент «Сумма заказа», физически реализованный в базе данных как столбец zz_total, зависит от трех связанных с ним элементов: «Цена за шт.» (yy_unit_cost), «Скидка» (yy_disc) и «Заказано (шт.)» (yy_qty).

* DAMA International. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
8.4. Системы и люди (организации, подразделения, сотрудники) в процессах управления данными
Как мы уже отмечали, наличие у данных такой отличительной характеристики, как возможность совместного использования неограниченным количеством потребителей, обусловливает их частое перемещение между информационными системами. При рассмотрении процессов управления данными целесообразно разделить системы на несколько укрупненных категорий в соответствии с их ролями в информационных цепочках.
Обратимся еще раз к рисунку 8.2. Он поможет составить представление об основных видах информационных систем, которые обычно функционируют в организациях.
Прежде всего нужно выделить целевые системы (target systems). Наиболее часто к таким системам относятся базы и хранилища аналитических данных, используемые в аналитической деятельности организации.
Целевые системы получают данные из исходных систем (source systems). Преимущественно в этом качестве выступают операционные (транзакционные) системы, обеспечивающие деловые операции (транзакции). Они поддерживают такие функции, как создание записей для клиентов, обработка заказов и оплата счетов. Как правило, цель этих систем – не хранение исторических данных для использования в анализе и при принятии решений (хотя иногда бывает и так). Их назначение – обеспечение возможности совершения бизнес-транзакций.
Термины «целевая система» и «исходная система» относительны. Целевая система, данные из которой непосредственно используются в рамках одной функциональной области, может быть исходной системой для хранилища данных, используемого в другой области.
Обрабатываемые сведения обычно поступают по сложной цепочке данных, поэтому между исходными системами целесообразно проводить границу. Например, система, в которой данные были первоначально созданы, выделяется как система-первоисточник или система происхождения (system of origin), а система, из которой данные фактически поступают в целевое хранилище, называется системой – непосредственным источником (direct source system).
Отдельно следует выделить системы записи (systems of record) – системы, которые отвечают за хранение наиболее полных и достоверных описаний объектов того или иного вида. В практике управления основными данными такие описания называются «золотыми записями» (golden records), а системы записи также называются «системами истины» (system of truth).
В главе 7 мы говорили об управлении данными в контексте формирования цепочек поставок данных. Теперь кратко рассмотрим основные укрупненные роли, которые могут играть как системы, так и люди (подразделения организаций или отдельные сотрудники, а также организации в целом) именно с точки зрения цепочек поставок. Тут нужно обратить внимание на следующие позиции.
Производители данных (data producers)
Производители данных – это люди и системы, которые данные создают. Данные могут создаваться специально с целью предоставления для использования или генерироваться как побочный продукт какого-либо процесса. Хотя производители обычно контролируют то, что выпускают, в отношении данных невозможно отследить все варианты их дальнейшего применения. Данные, созданные для одних целей, могут впоследствии использоваться для других. Важнейшая подгруппа производителей данных – владельцы бизнес-процессов, в рамках которых они создаются. Используются ли данные немедленно или передаются дальше по потоку, владельцы бизнес-процессов оказывают важное влияние на цепочку поставок. Они хорошо знают цели и функции процессов, которыми владеют, и могут вносить в эти процессы изменения, гарантирующие, что производимые данные отвечают требованиям потребителей.
Потребители данных (data consumers)
Потребители данных – это люди и системы, которые используют данные. Слово «потребитель» здесь не совсем уместно, поскольку, как мы знаем, информация не истощается. Однако оно гораздо лучше отражает суть этой роли в контексте цепочки поставок данных, по сравнению, например, со словом «пользователь».
Брокеры данных (data brokers)
Брокеры данных, также называемые информационными брокерами (information brokers), иногда упускаются из виду в модели производитель – потребитель. В управлении данными они выполняют функции посредников. Брокеры не производят данные, но предоставляют другим возможность их использования. Они похожи на дистрибьюторов промышленных товаров. Информационных брокеров важно распознавать, поскольку они часть цепочки поставок и могут влиять на структуру и содержимое информационных массивов, а также на доступность и своевременность данных (а следовательно, и на их качество).
Владельцы данных (data owners)
Выработка единого понимания концепции владения данными для большинства организаций – сложная задача. Данные нематериальны и не всегда воспринимаются как актив. Когда они признаются активом, то обычно считаются активом организации, но в итоге такой подход может означать, что о данных никто не заботится. У большинства других организационных активов владельцы, по сути, отсутствуют. Подразделения, управляющие оборудованием, могут нести за него ответственность, но им не владеют. Аналогичным образом, финансовая служба отвечает за денежные активы, которые ей не принадлежат. Активами владеет сама организация. Разница между данными и другими активами заключается в том, что за остальные активы четко определена ответственность (но не владение), и обычно она сосредоточена в одном подразделении или функции внутри организации. Отличие данных, как мы видели, состоит в том, что они перемещаются между подразделениями и функциями.
В то время как блок ИТ безусловно несет ответственность за системы, в которых хранятся и обрабатываются данные, ответственность за эти данные исторически им отрицается. Как правило, ИТ-менеджеры не вникают в содержание информационных ресурсов и не хотят отвечать, если оно не соответствует требованиям бизнеса. Но, поскольку ИТ-подразделения отвечают за системы, они все же в значительной степени контролируют данные в любой из них, а также перемещение данных между системами. Это горизонтальное перемещение вносит еще большую неопределенность в вопросы ответственности, так как по мере движения данных по информационной цепочке они могут быть скопированы или преобразованы в информационные массивы, контролируемые другими системами или командами.
Желание определить владельцев данных можно рассматривать как стремление разрешить указанные проблемы, в частности исправить положение, при котором данные организации не отвечают ее потребностям. Когда сотрудники чувствуют, что данные неполны, противоречивы или неупорядоченны, они ищут владельца, который мог бы лучше контролировать информационные активы.
Как и другими активами организации, данными необходимо управлять. Управление включает в себя знание того, какими данными располагает организация, как их использовать для достижения целей организации и как свести к минимуму любые риски, связанные с их использованием. Данными трудно управлять, поскольку они не только нематериальны, но и очень легко множатся, а также потому, что многие организации не проводят четкой границы между управлением данными и управлением системами, в которых хранятся данные. Часто конфликтные отношения между ИТ-менеджерами и специалистами со стороны бизнеса делают границу между данными и системами еще более размытой. Сбалансировать затраты и выгоды при принятии решений относительно управления данными очень непросто, поскольку сотрудники могут ясно представить себе затраты на ИТ-системы, но им не всегда очевидны выгоды от обрабатываемых в организации данных. Сам собой напрашивается вывод о том, что если ввести роль владельца данных, то будут даны ответы на все возникающие вопросы и управлять данными будет легко.
К сожалению, простого решения сложных задач управления данными не существует. Однако известны эффективные подходы. Один из них – обеспечение внутри организации строгой подотчетности за данные на протяжении всего их жизненного цикла. При этом (так, в частности, считает Лаура Себастьян-Коулман) организациям вовсе не обязательно называть соответствующую сферу ответственности владением данными, но если они считают это полезным, то роли владельцев данных целесообразно ввести.
Распорядители данных (data stewards)
Распорядителем обычно называют лицо, чья работа заключается в управлении собственностью другого лица. Поскольку выше мы обсудили сферу ответственности, которую можно обозначить как владение данными, логично предположить, что в организации должны быть сотрудники, осуществляющие непосредственное управление информационными активами от имени владельцев данных в интересах организации. Такие сотрудники называются распорядителями данных.
Согласно определению из DMBOK2 распоряжением данными называется деятельность, связанная с несением ответственности и подотчетностью за данные и процессы, обеспечивающие эффективный контроль и использование информационных активов. Распорядители данных выполняют широкий круг функций и различаются по своей позиции в организации и направлению работы. Основные категории этих специалистов мы рассмотрим в главах 10 («Руководство данными») и 16 («Организационные аспекты управления данными»).
8.5. Эволюция управления данными в организациях и референтные модели
Управление данными рассматривается как отдельная область практики и исследования начиная с тех пор, как компании и правительственные учреждения в начале 1980-х годов стали активно использовать для поддержки своей деятельности базы данных и прикладные системы. За прошедшее время роль данных в организациях существенно изменилась и были накоплены обширные знания, связанные с управлением данными. Одна из особенностей области управления данными – большое количество референтных моделей с представительной базой активных пользователей. Это дает возможность изучить и проанализировать, как референтные модели позволяют накапливать знания в области, имеющей решающее значение для цифровизации.
Можно выделить три основных этапа развития концепции управления данными (см. табл. 8.1). Они обусловлены технологическим прогрессом и изменениями роли данных. Каждый этап направлен на решение проблем, возникающих в результате этих изменений, и вводит новые подходы к управлению данными, расширяя базу имеющихся знаний.
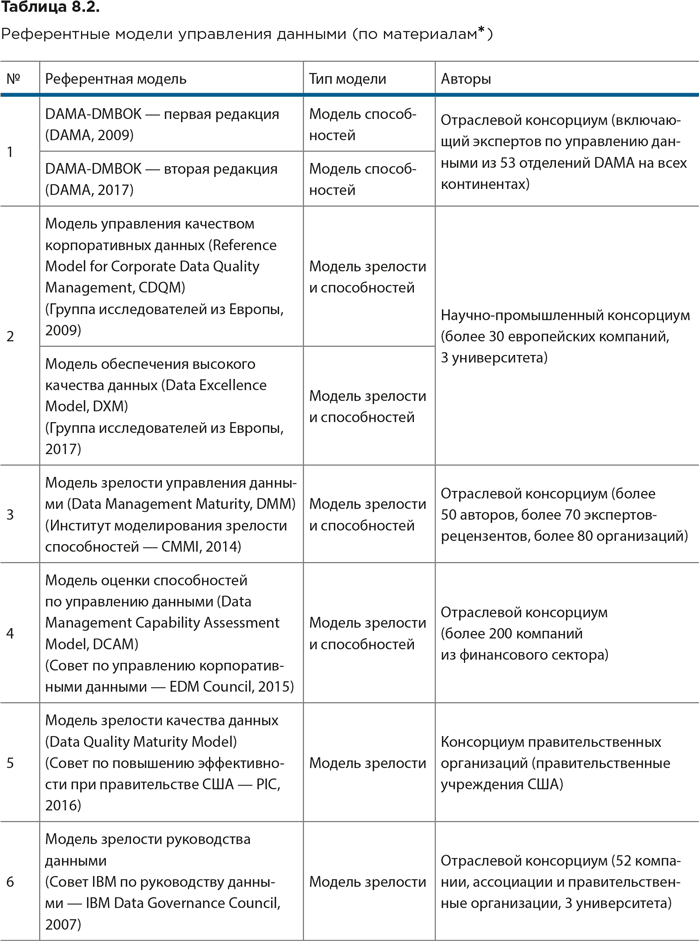
В таблице 8.2 собраны сведения о наиболее известных референтных моделях управления данными. Для каждой модели указаны организация-поставщик и год ее появления. В списке представлены только те модели, которые имеют практическое значение. Модели концептуального или маркетингового характера в него не вошли.
Из приведенного списка только модели, относящиеся к позициям 1–4, охватывают третий этап развития концепции управления данными. Из них две модели под номером 2 (CDQM и DXM) носят скорее исследовательский характер и довольно сложны для практического применения в большинстве организаций.

* Legner C., Pentek T., Otto B. Accumulating Design Knowledge with Reference Models: Insights from 12 Years’ Research into Data Management // Journal of the Association for Information Systems, 2020, 21(3): 735–770. DOI: 10.17705/1jais.00618. – URL: .
* Legner C., Pentek T., Otto B. Accumulating Design Knowledge with Reference Models: Insights from 12 Years’ Research into Data Management // Journal of the Association for Information Systems, 2020, 21(3): 735–770. DOI: 10.17705/1jais.00618. – URL: .
Как уже было отмечено в главе 6, в настоящее время, по мнению ряда специалистов, наиболее полные и ценные с методической точки зрения (а также не зависящие от поставщика соответствующих решений) референтные модели управления данными – это DAMA-DMBOK и CMMI DMM. При этом первая ориентирована на формирование способностей организации по управлению данными, а вторая – на оценку зрелости этих способностей.
Литература к главе 8
• Aiken P., Harbour T. Data Strategy and the Enterprise Data Executive: Ensuring that Business and IT are in Synch in the Post-Big Data Era. Technics Publications, 2017.
• Deng Z. MIS2502: Data Analytics: Semi-structured Data Analytics. Fox School of Business. Temple University, 2019. – URL: .
• Ladley J. Data Governance: How to Design, Deploy, and Sustain an Effective Data Governance Program: 2nd Edition. Academic Press, 2020.
• Управление данными в госсекторе. Навигатор для начинающих / под ред. О. М. Гиацинтова, В. А. Сазонова, М. С. Шклярук. – М.: РАНХиГС, 2022.

