Книга: Свод знаний по управлению бизнес-процессами: BPM CBOK 4.0
Назад: 8.2. BPMS/iBPMS
Дальше: 9. Процессная трансформация
8.3. Перспективные технологии
Системы iBPMS становятся все более интеллектуальными. Системы нового поколения соединяют бизнес-правила с возможностями ИИ, предоставляют функциональность RPA, поддерживают автоматизацию всего спектра работы – структурированной, когнитивной, с помощью искусственного интеллекта. Не менее значимым стало появление динамического кейс-менеджмента с его моделью оркестровки работ, более развитой по сравнению с традиционными блок-схемами.
Эволюция iBPMS показана на следующем рисунке.
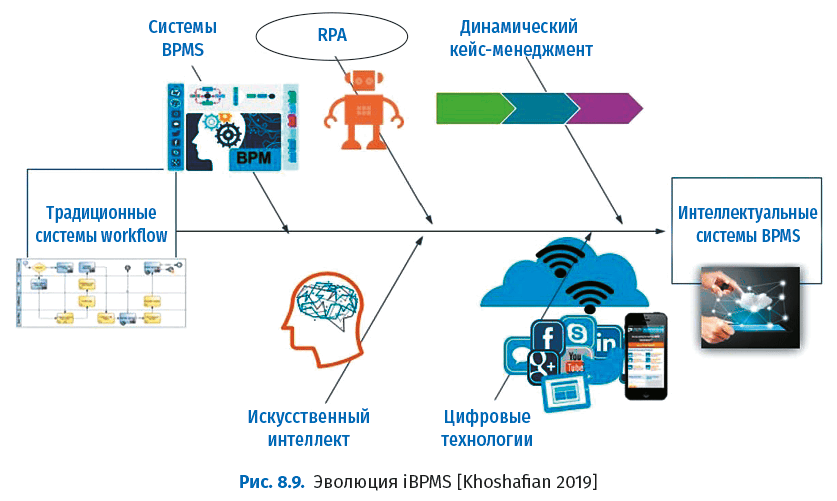
Системы iBPMS стали называть платформами цифровой автоматизации процессов (Digital Process Automation, DPA), подчеркивая этим их роль в качестве основного двигателя цифровой трансформации предприятий.
Прогресс в этой области делает реальностью интеллектуальное управление бизнес-процессами (Intelligent Business Process Management, iBPM), которое с помощью платформы автоматизации транслирует бизнес-цели в операции, позволяет лидерам оптимизировать процессы, повышать качество принимаемых решений и на основе глубокого анализа данных предпринимать незамедлительные действия.
8.3.1. RPA
Говоря попросту, RPA (Robotic Process Automation, роботизация процессов) – это программные роботы (их также называют ботами), имитирующие действия, выполняемые людьми.
Роботы RPA особенно полезны в автоматизации процессов, основанных на правилах и взаимодействующих с разрозненными ИТ-системами. С технической точки зрения RPA – это автоматизация бизнес-процессов, управляемая бизнес-логикой и структурированными входными данными. Более развернутое определение [Rouse 2019]:
RPA – это использование программного обеспечения с возможностями искусственного интеллекта (ИИ) и машинного обучения для выполнения большого объема повторяющихся задач, до этого выполнявшихся людьми. К таким задачам могут относиться запросы, расчеты, учет, ведение записей и транзакций.
RPA дает возможность запускать функции корпоративных систем без участия человека. RPA способен:
● устранить необходимость затыкания дыр дополнительными сотрудниками;
● качественно выполнять трудоемкие повторяющиеся задачи;
● масштабировать ресурсы при пиковых нагрузках;
● имитировать действия бизнес-пользователей;
● переложить контроль с программистов непосредственно на бизнес;
● окупить инвестиции в течение нескольких недель при использовании методологии аджайл.
Согласно Gartner, RPA является составной частью интеллектуальной автоматизации, и к 2020 году автоматизация в сочетании с ИИ снизит потребность общих центров обслуживания в персонале на 65 %.
8.3.1.1. Какие проблемы решает RPA
Авангард внедрения RPA составили операционные директора финансовых организаций, увидевшие в нем средство масштабирования бизнес-процессов без увеличения численности персонала и затрат. По данным Deloitte, один банк перепроектировал претензионную работу, внедрив в 13 процессах 85 ботов, обрабатывающих 1,5 миллиона запросов в год [Boulton 2018]. Это эквивалентно более 200 сотрудников на полной ставке, при этом затраты банка составили примерно 30 % от затрат на расширение персонала.
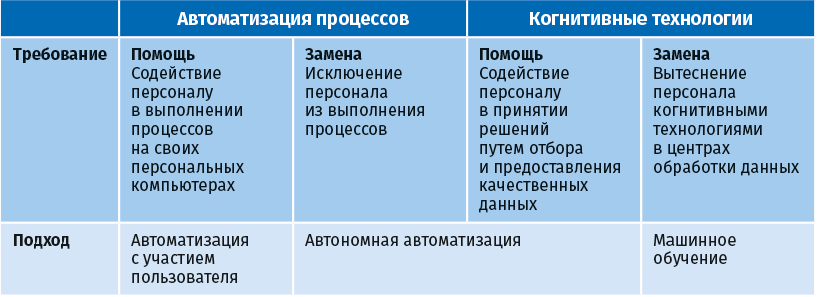
Обычно рутинные задачи автоматизируются с помощью ботов легко, без больших затрат, заказной разработки программного обеспечения или глубокой системной интеграции. Еще большего эффекта можно добиться, дополнив возможности RPA когнитивными технологиями, такими как машинное обучение, распознавание речи и обработка естественного языка. Это позволяет автоматизировать задачи более высокого уровня, требовавшие человеческого интеллекта.
RPA помогает решать типичные проблемы бизнеса. Характеристики типичного предприятия:
● Постоянно меняющийся деловой климат. Необходимость постоянно развивать свои товары, продажи, маркетинг и т. д., модернизировать и актуализировать процессы.
● Множество разрозненных систем. Типичное предприятие использует несколько разрозненных ИТ-систем. Эти системы не успевают за частыми изменениями процессов из-за ограниченного бюджета, сроков и сложности внедрения.
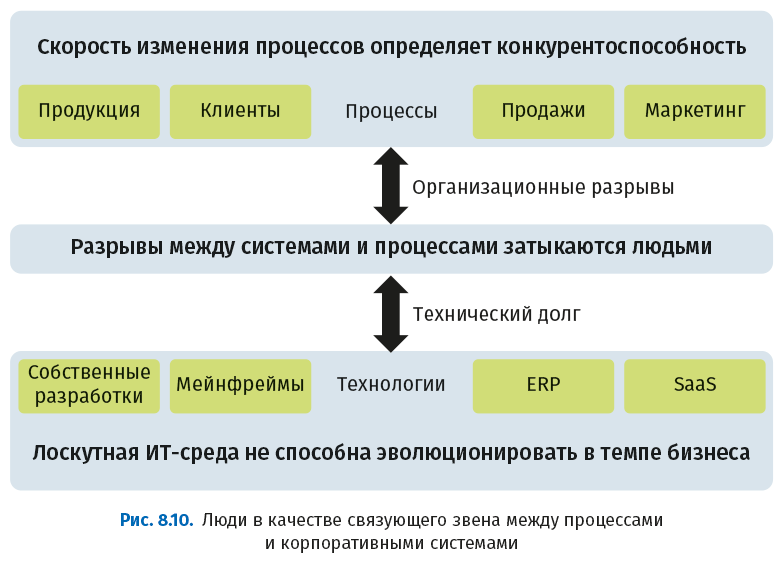
● Затыкание дыр путем привлечения дополнительных сотрудников. Чтобы заполнить пробелы между процессами и системами, компания нанимает персонал. Например, компания вносит изменения в процесс продаж. Для подтверждения резервирования заказа теперь требуются дополнительные действия. Компания нанимает дополнительных сотрудников, которые будут проверять платежные реквизиты и обрабатывать счета. Неэффективность этого процесса показана на рисунке 8.10.
При любом изменении бизнес-процессов компании придется нанимать новых сотрудников или переучивать имеющихся. Оба решения требуют времени и денег. RPA позволяет вместо этого задействовать виртуальных работников (ботов), имитирующих действия людей. В случае изменения процесса изменить несколько строк программного кода заведомо быстрее и дешевле, чем переобучить сотни сотрудников. На рис. 8.11 показано, как RPA обеспечивает гибкость бизнес-процессов, не затрагивая существующие системы.
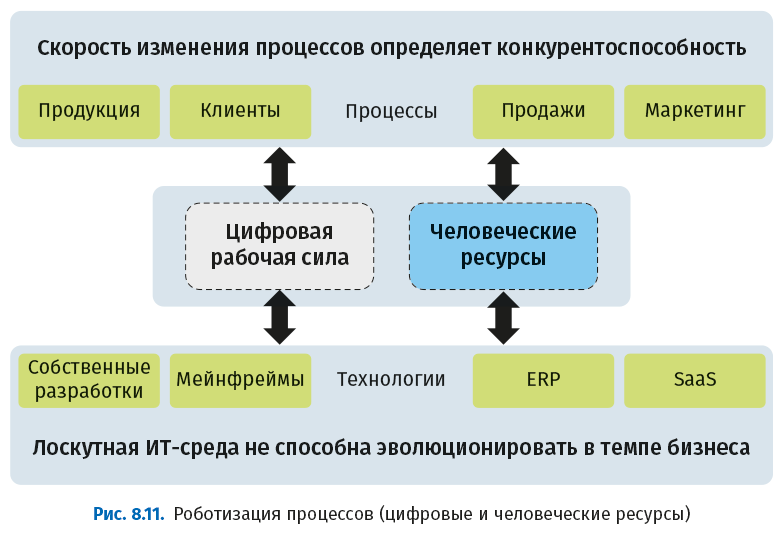
Роботизация процессов выгодна компаниям по следующим причинам:
● В отличие от человека, робот способен работать круглосуточно.
● Средняя производительность человека составляет 60 % при небольшом количестве ошибок; производительность робота – 100 % и без ошибок.
● Робот намного лучше человека справляется с одновременным выполнением нескольких задач.
Подход к автоматизации исходит из потребностей бизнеса – снижения затрат, повышения качества и ускорения развития предприятия. RPA дает эффект в трех областях:
● Защита сделанных инвестиций и возврат инвестиций:
○ поддержка модернизации стратегических платформ и регуляторных изменений;
○ цифровизация унаследованных систем для клиентского самообслуживания;
○ повышение удобства использования и облегчение внедрения новой системы;
○ работа в сложившейся ИТ-архитектуре (вне зависимости от продуктов и платформ).
● Экономия времени работников умственного труда:
○ повышение качества за счет смещения акцента с подготовки данных на их использование;
○ оптимизация без дорогостоящего реинжиниринга бизнес-процессов, простор для реинжиниринга ценностных предложений и роста;
○ обеспечение более точных и своевременных отчетов и аналитических выводов;
○ ускорение внедрения инноваций в продукцию и вовлечение клиентов, не зависящее от загрузки ИТ-службы.
● Оптимизация исполнения и результатов:
○ исключение ошибок в работе, улучшенная обработка исключений с использованием аудиторского следа;
○ масштабирование виртуальной рабочей силы при пиковых нагрузках без переплат (работа в режиме 24/7);
○ снижение числа часто повторяющихся задач на 50–70 %;
○ сокращение затрат;
■ за пределами США – одна треть стоимости штатной единицы;
■ в США – одна десятая стоимости штатной единицы.
(Штатная единица – объем человеческих ресурсов, эквивалентный одному сотруднику, занятому на полную ставку.)
8.3.1.2. RPA в контексте автоматизации
RPA является очередным шагом эволюции автоматизации бизнес-процессов. Это концепция автоматизации на основе правил, которая позволяет:
● экономить человеческие ресурсы;
● уменьшить количество дорогостоящих ошибок и повысить качество;
● делать больше за меньшее время, сократить критический путь;
● повысить отдачу от высококвалифицированных сотрудников, снизить риски выгорания;
● ускорить создание ценности и обеспечить аудит ручных процессов.
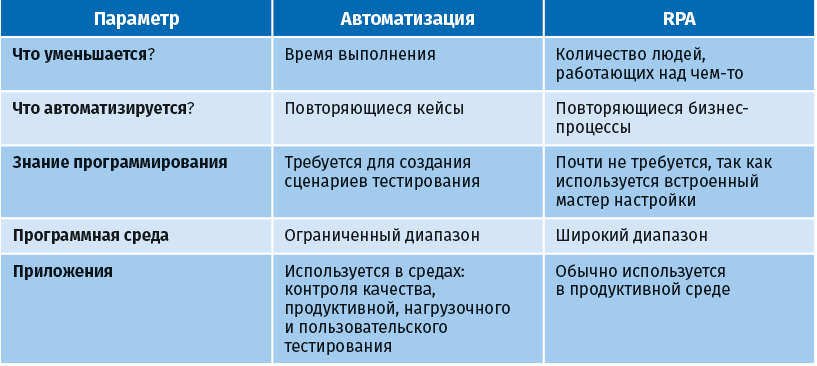
Автоматизация существовала и до появления RPA. Между ними есть множество параллелей, но в отличие от RPA автоматизация – это решение, требующее участия человека.
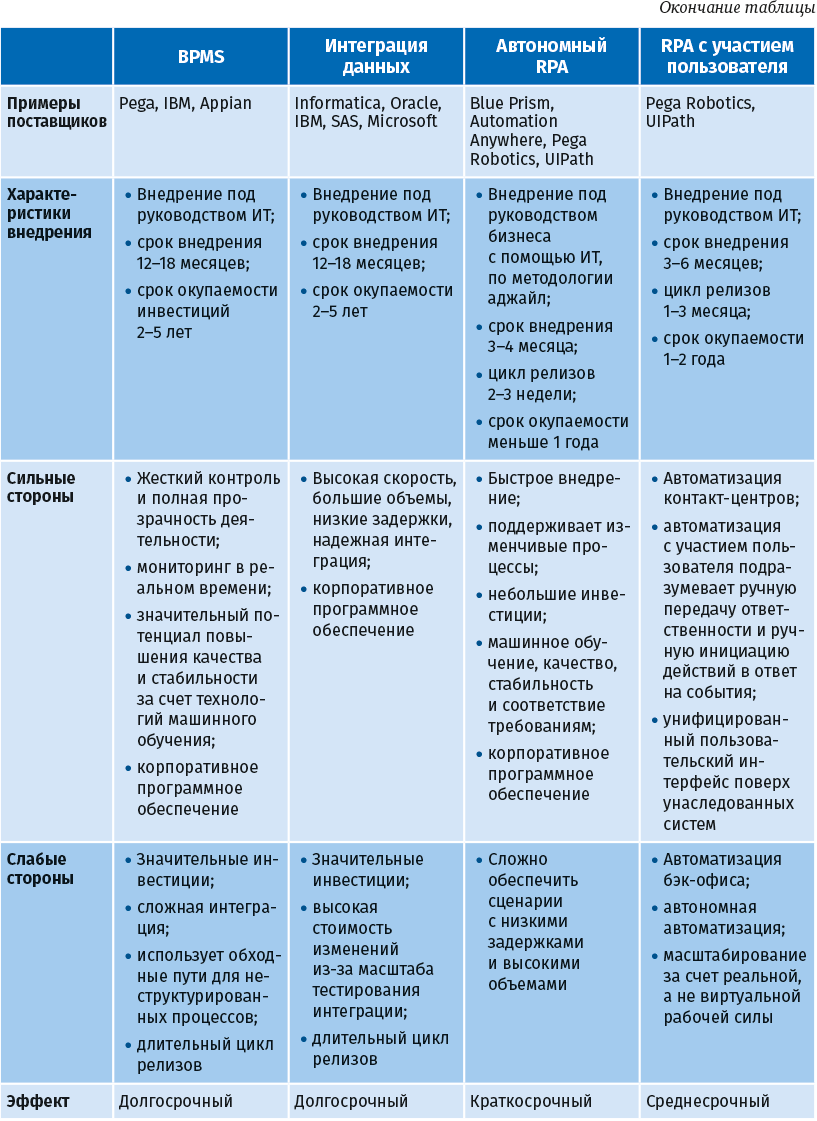
Различия между автоматизацией и RPA показаны в следующей таблице.
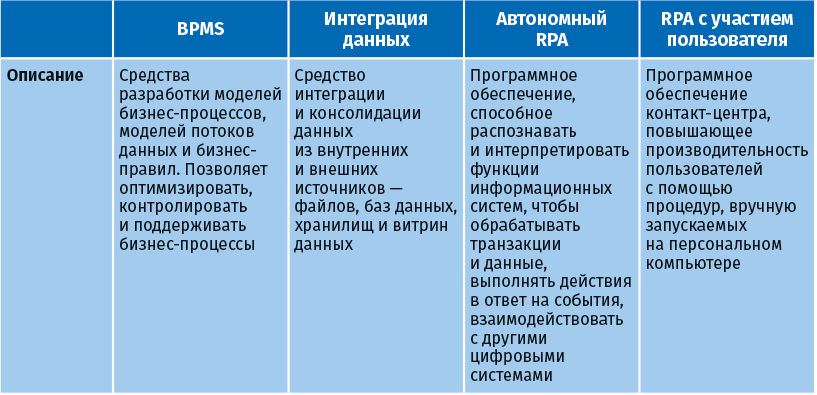
Автономный RPA и RPA с участием пользователя
Технология RPA может реализовываться в двух вариантах:
● Автономный (unattended) RPA – робот выполняет действия вместо человека без его участия (как правило, на сервере):
○ автоматическая обработка больших объемов данных;
○ робот должен реагировать на вариации отклика системы, неизвестные события и непредвиденные бизнес-сценарии, не прерывая работу;
○ тщательная проработка вопросов безопасности, планирования, аудита и управления исключениями;
○ защищенный централизованный сбор управленческой информации, аудиторских записей и журналов процессов;
○ несколько сотрудников должны быть способны поддерживать множество роботизированных решений.
● RPA с участием пользователя (attended RPA или desktop automation) – робот запущен на компьютере пользователя, выполняет действия по его команде (например, по нажатию на определенную кнопку на клавиатуре) или по определенному событию (например, по появлению определенной кнопки на экране):
○ программные скрипты для персональных задач;
○ выполняется на персональном компьютере;
○ повышает производительность сотрудников;
○ консолидирует информацию и обеспечивает стабильный уровень клиентского сервиса;
○ упрощает работу и оптимизирует процессы.
Второй вариант можно назвать половинчатой реализацией RPA: хотя процесс ускоряется и нагрузка на человека уменьшается, полностью обойтись без него по-прежнему нельзя. Но у него есть и преимущество: робот выполняет работу под присмотром человека, который может вмешаться, если что-то пошло не так. Это сильно снижает требования к надежности робота, а значит, упрощает его разработку.
В следующей таблице эти две реализации сравниваются с более традиционными подходами к автоматизации процессов.
RPA и искусственный интеллект
Сочетание RPA с когнитивными технологиями, такими как машинное обучение, распознавание речи и обработка естественного языка, позволяет автоматизировать задачи с большей добавленной ценностью, ранее требовавшие человеческого интеллекта. RPA позволяет цифровому предприятию приблизиться к полностью автоматической сквозной обработке (Straight Through Processing, STP) интеллектуальной цифровой рабочей силой.
Следующий рисунок иллюстрирует эволюцию функциональности RPA применительно к BPM.
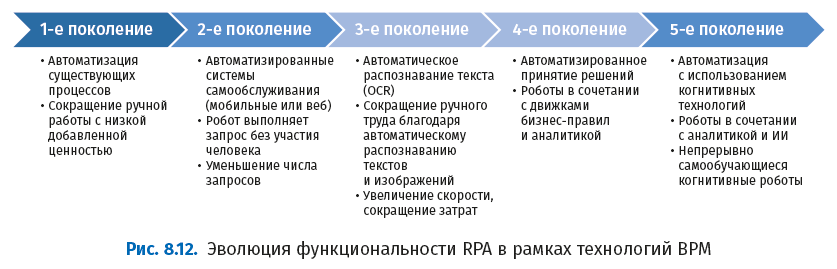
● Роботизация:
○ автоматизация на основе правил;
○ единая аутентификация (single sign-on);
○ взаимодействие с десктопными приложениями;
○ взаимодействие с веб-приложениями;
○ взаимодействие с приложениями на мейнфреймах;
○ Citrix и удаленные серверы;
○ автоматическое распознавание текста (OCR);
○ интуитивно понятная, использующая встроенные мастера настройки, дружественная по отношению к пользователю;
○ аудит и журналирование;
○ мониторинг бизнес-действий (Business Activity Monitoring, BAM).
● Когнитивные технологии:
○ структурированные, слабоструктурированные и неструктурированные данные;
○ машинное обучение;
○ обработка естественного языка;
○ распознавание речи;
○ искусственный интеллект;
○ контролируемое обучение модели;
○ решения, основанные на алгоритмах;
○ интеллектуальное извлечение информации;
○ онлайновое обучение;
○ автоматическая настройка модели.
● Машинное обучение:
○ использует большие массивы данных для помощи в принятии решений или для исключения субъективного принятия решений человеком;
○ интерпретирует контекстную информацию и делает понятные и предсказуемые выводы;
○ помогает оптимизировать процессы и маршрутизировать запросы;
○ в широких масштабах применяет логику рассуждений, сходную с человеческой (например, для мониторинга транзакций, выявления мошенничества, фильтрации обращений).
Сегодняшние лучшие практики RPA – интеграция программных роботов с когнитивными платформами [Le Clair, Craig and Miers 2016]. Следующая таблица дает рекомендации исходя из потребностей.
8.3.1.3. Область применения RPA
В следующей таблице приведены универсальные, не зависящие от отрасли области применения RPA:
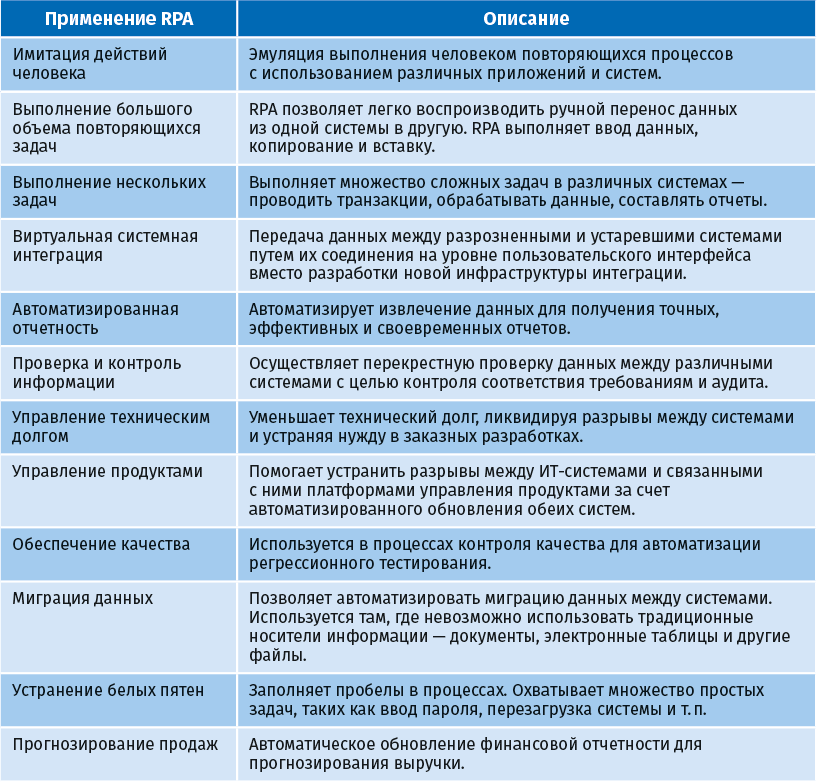
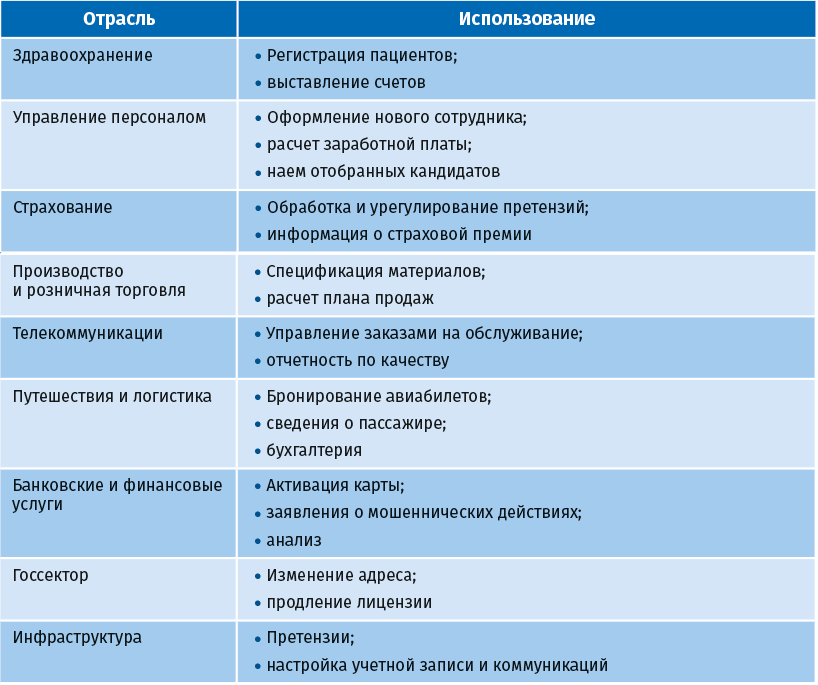
В следующей таблице показано, как RPA может использоваться в различных функциональных областях и отраслях.
RPA в цифровых закупках
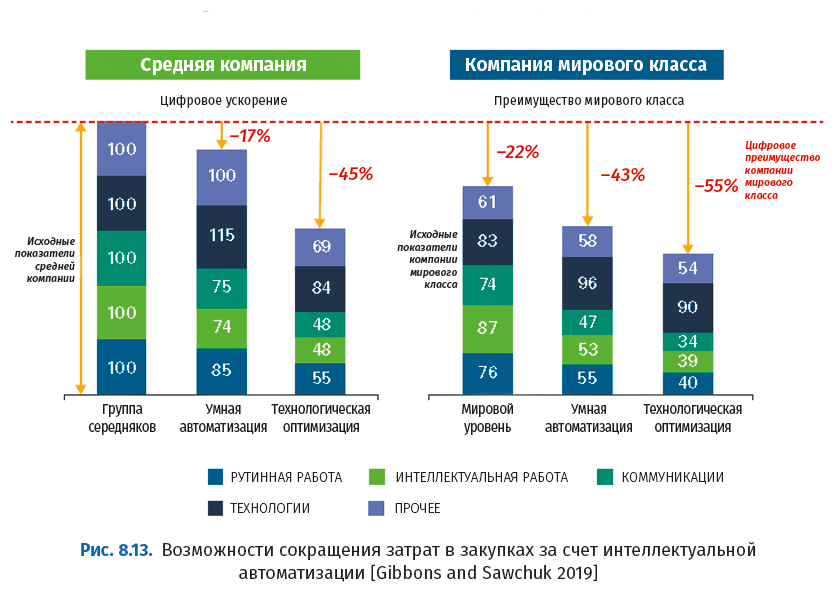
Закупки в основном являются транзакционным процессом – «от закупки до оплаты», «от поставщика до производства» и т. д., – и поэтому они хорошо подходят для роботизации. Интересные результаты содержатся в исследовании Hackett Group использования RPA в закупках: «Типичная компания может рассчитывать на снижение затрат на осуществление закупок за счет внедрения интеллектуальных технологий автоматизации, таких как RPA, интеллектуальное распознавание данных и когнитивная автоматизация, на 17 %, а мировые лидеры – на 21 %» [Gibbons and Sawchuk 2019].
Внедрение цифровых технологий в полном объеме способно снизить операционные затраты закупочной организации на 45 %, позволяя достичь сегодняшнего уровня эффективности организаций мирового класса. Согласно исследованию, закупочные организации мирового класса, которые сегодня тратят на 22 % меньше своих коллег, за счет всеобъемлющей цифровой трансформации могут сократить свои расходы еще на 33 % [Burnson 2019].
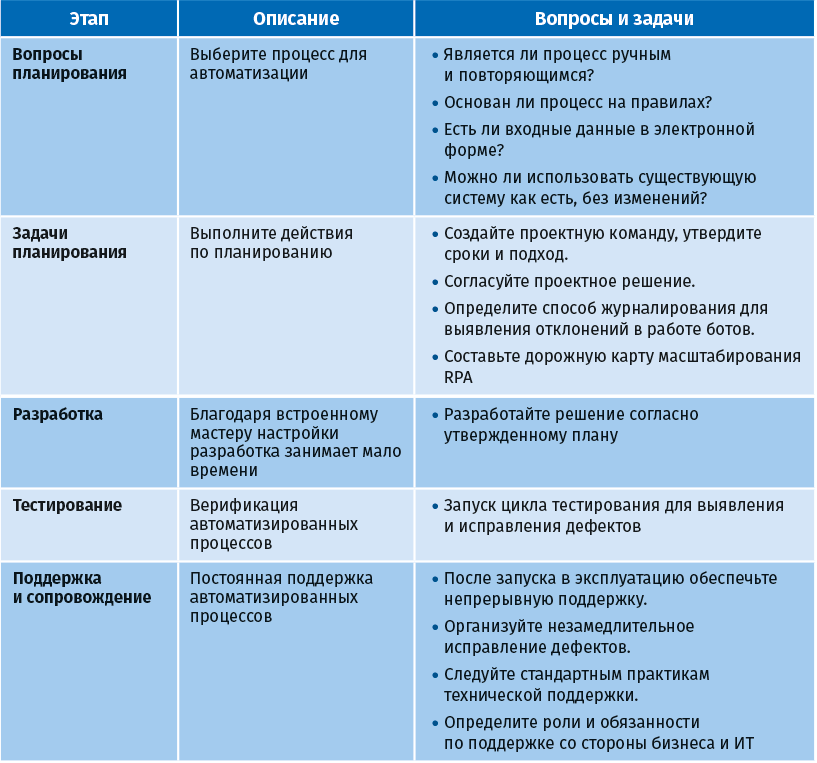
8.3.1.4. Внедрение RPA
Типичные этапы проекта внедрения RPA – планирование, разработка, тестирование, поддержка и сопровождение.
Выбор процесса для RPA
Решающее значение для успеха внедрения RPA имеет выбор подходящего процесса. В следующей таблице приведены восемь критериев выбора. Также учтите, что существующий процесс должен выполняться людьми.
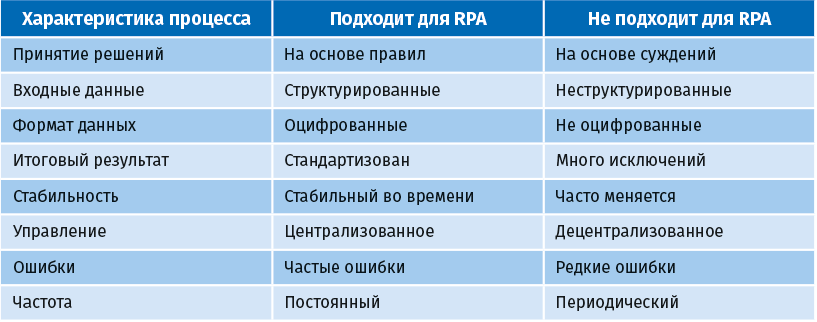
Выбор должен делаться исходя из возможности использования RPA, общей стоимости внедрения и окупаемости инвестиций.
Выбор программного обеспечения RPA
Выбор программного продукта RPA должен основываться на следующих критериях:
1. Данные. Простота чтения и записи данных в множество систем.
2. Преобладающие задачи. Простота настройки процессов, основанных на правилах, или процессов, основанных на знаниях.
3. Совместимость. Поддержка множества приложений.
4. Искусственный интеллект. Встроенная поддержка ИИ для имитации действий людей.
Эффект внедрения RPA
Основной эффект RPA складывается из следующих факторов:
● Снижение затрат. В диапазоне от 20 до 60 % от базовой ставки штатной единицы.
● Возврат инвестиций (ROI). Внедрение занимает примерно 9–12 месяцев; срок окупаемости – менее одного года.
● Точность. Снижение частоты ошибок на порядки.
● Единообразие. Идентичные процессы и задачи исключают вариации на выходе.
● Повышение скорости и производительности. Не добавляющая ценности работа заменяется более интеллектуальной.
● Низкий риск, неинвазивность. Заполняет пробелы между существующими системами.
● Отличная масштабируемость. Мгновенная адаптация производительности в соответствии со спросом.
● Надежность и соответствие требованиям. Работает в режиме 24/7/365, ведется аудиторский журналов для контроля соответствия требованиям.
Дополнительные преимущества RPA:
● Можно легко автоматизировать большое количество процессов.
● Автоматизация повторяющихся задач экономит драгоценное время и ресурсы.
● Для настройки софтверного робота навыки программирования не требуются – настроить бота или записать последовательность действий для автоматизации процесса способен сотрудник не из ИТ.
● Аудиторский журнал обеспечивает все стандартные процессы контроля соответствия требованиям.
● Быстрое моделирование и внедрение автоматизированных процессов.
● В каждом цикле релиза запускаются сценарии тестирования для выявления ошибок.
● Эффективное управление сборками и релизами.
● Выявление ошибок в реальном времени.
● Если в процессе нет людей, нет необходимости в обучении.
● Софтверные роботы никогда не устают.
● Повышение производительности ведет к большей масштабируемости.
8.3.1.5. Причины неудач внедрения RPA
Согласно журналу CIO, многие пилотные проекты RPA срываются из-за сочетания проблем, связанных с планированием, с персоналом и с внедрением. Пять причин, по которым проекты RPA терпят неудачу [Violino 2018]:
1. Нерешительность руководства. RPA разрушает существующий порядок вещей; большинство менеджеров не хотят что-то менять в своей работе.
2. Недостаточное обучение. Потратьте время и деньги на обучение широкого круга сотрудников. Недостаток квалифицированных сотрудников часто приводит к неудачам.
3. Неподходящее применение. Найдите баланс между скромным масштабом и умным вложением денег, чтобы добиться и вау-эффекта, и отдачи от инвестиций.
4. Недостаточное внимание к ИТ и информационной безопасности. Чтобы реализовать устойчивую и безопасную модель и не оказаться в полной зависимости от третьих сторон, критически важно привлечь ИТ-подразделение. Помощь ИТ необходима для долгосрочной поддержки инфраструктуры RPA и разрабатываемых ботов.
5. Игнорирование разработчиков приложений. Команда разработчиков приложений является их владельцами и контролирует внесение изменений после внедрения, поэтому их участие необходимо.
8.3.1.6. Лучшие практики RPA
В июльском выпуске за 2018 год журнал CIO выделяет восемь факторов успеха [Violino 2018]:
1. Проведите исследование:
● выберите программный продукт, соответствующий конкретным потребностям вашей организации;
● подготовьте бизнес-обоснование внедрения RPA, включающее оценки возврата инвестиций;
● проанализируйте текущие процессы и организационные аспекты, чтобы избежать политических проблем.
2. Проведите обучение сотрудников:
● внедрение RPA требует трансформации изнутри;
● это может быть непросто, учитывая нынешний ажиотаж вокруг роботизации и ИИ;
● люди не рвутся обучать роботов, которые смогут их заменить.
3. Определите, где технология будет работать лучше всего:
● Найдите процессы с наибольшими шансами на положительный эффект для бизнеса;
● это означает сконцентрироваться на процессах, создающих ценность;
● отличные кандидаты – повторяющиеся и массовые задачи.
4. Не усложняйте, используйте модульный подход:
● создавайте боты как стандартные, пригодные для повторного использования;
● создавайте как можно больше универсальных компонентов и экстернализируйте переменные и логику, чтобы минимизировать число потенциальных точек отказа.
5. Не пренебрегайте защитой данных:
● транзакции обрабатываются с невероятной скоростью, поэтому вопросы защиты данных имеют первостепенное значение;
● внедренные процессы должны быть надежно защищены.
6. Регулярно проводите тестирование:
● с внедрением RPA работа не заканчивается;
● тестируйте ботов регулярно, чтобы выявлять и устранять слабые места.
7. Создайте кросс-функциональный центр компетенций:
● создайте команду для обмена опытом и лучшими практиками;
● центр компетенций RPA должен входить в центр компетенций по управлению бизнес-процессами в виде выделенной подгруппы специалистов.
8. Будьте готовы к новым возможностям и новым вызовам:
● отслеживайте прогресс RPA, в частности в области когнитивных технологий;
● этот пункт должен быть зафиксирован в стратегии центра компетенций.
8.3.2. Искусственный интеллект
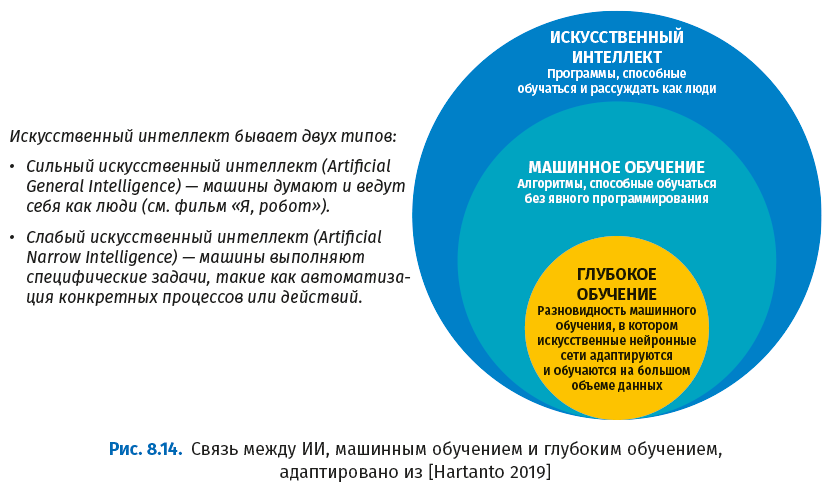
Этот раздел посвящен технологиям искусственного интеллекта (ИИ), машинного обучения и глубокого обучения. Глубокое обучение заслуживает внимания благодаря его роли в нейронных сетях и в таких приложениях, как распознавание образов. Дадим определения этих терминов.
Искусственным интеллектом называют компьютерную программу, каким-то образом имитирующую поведение человека. Согласно Оксфордскому словарю, искусственный интеллект – это теория и разработка компьютерных систем, способных выполнять задачи, обычно требующие человеческого интеллекта, такие как зрительное восприятие, распознавание речи, принятие решений и перевод с одного языка на другой. Словарь Вебстера определяет искусственный интеллект как способность машины имитировать разумное поведение человека.
Машинное обучение – это подмножество искусственного интеллекта. Машинное обучение – это ряд методов, обучающих компьютеры выполнять задачи без явного программирования. По сути, алгоритмы машинного обучения выявляют закономерности в данных и создают модели, предсказывающие или классифицирующие конкретные результаты. Основная задача машинного обучения – предсказание будущих результатов по некоторому набору входных данных. Эта задача решается обучением на исторических данных. Если требуется предсказать действительное число, то это регрессионная задача. Если требуется предсказать «да» или «нет», то это задача двоичной или бинарной классификации. Если требуется предсказать выбор более чем из двух вариантов, то это задача мультиномиальной классификации. К одному и тому же набору данных могут применяться различные алгоритмы. Примечательно, что нейронные сети могут использоваться для решения задач всех трех типов. Нейронные сети характеризуются высоким качеством, но при этом длительным временем обучения; это один из самых трудоемких, но и самых точных вариантов машинного обучения.
Глубокое обучение – это подмножество машинного обучения, нацеленное на очень сложные задачи. В нем используются алгоритмы глубокого обучения и глубокие нейронные сети. Глубокие нейронные сети – это нейронные сети, построенные из многих слоев (отсюда название «глубокие»), в которых чередуются линейные и нелинейные процессоры; для их обучения используются огромные массивы обучающих данных. В глубоких нейронных сетях может насчитываться 10–20 скрытых слоев, в то время как в обычных нейронных сетях – всего несколько. Чем больше слоев в сети, тем больше характеристик она способна распознать. К сожалению, чем больше слоев, тем больше времени уйдет на вычисления и тем сложнее будет обучение. Один из алгоритмов глубокого обучения – случайный лес (Random Decision Forests, RDFs). Он тоже построен из многих слоев, но состоящих не из нейронов, а из деревьев принятия решений, и результатом является статистическое среднее (или мода) предсказаний отдельных деревьев. В этом методе используется рандомизация набора обучающих данных – бэггинг (bootstrap-aggregating).
На следующем рисунке показано, что глубокое обучение – это подмножество машинного обучения, которое, в свою очередь, является подмножеством ИИ.
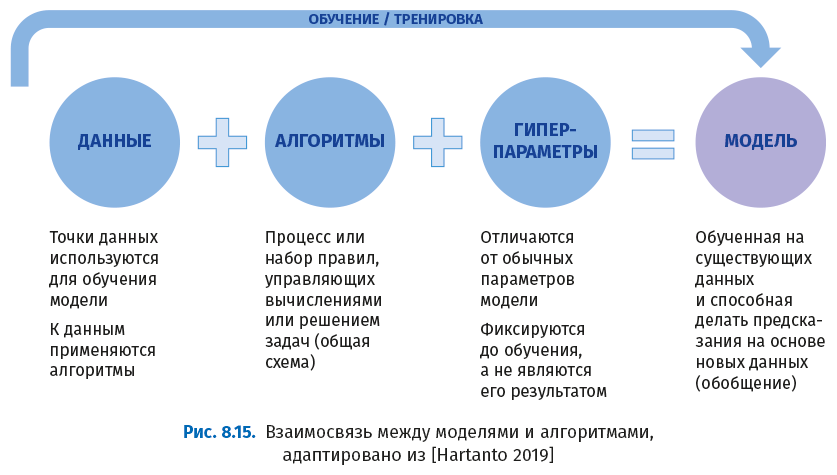
Машинное обучение использует алгоритмы, а глубокое обучение использует эти алгоритмы и добавляет гиперпараметры для построения окончательной модели обучения.
Компании, инвестирующие в ИИ, ведут разработку в трех направлениях:
1. Создать систему, думающую точно так же, как человек (сильный ИИ).
2. Просто создать работающую систему, не задаваясь вопросом о человеческом мышлении (слабый ИИ).
3. Использовать человеческое мышление в качестве модели, а не обязательно конечной цели.
Большинство сегодняшних разработок лидеров отрасли ИИ относятся к третьей категории – они нацелены на создание новых сервисов или новых продуктов, а не идеальной копии человеческого разума [Marr 2018].
Amazon, значительная часть бизнеса которого использует машинное обучение, определяет искусственный интеллект как «область информатики, занимающуюся решением когнитивных проблем, то есть тех, которые обычно ассоциируются с человеческим интеллектом, таких как обучение, решение проблем и распознавание образов». Для Amazon это очень важно – «без машинного обучения amazon.com не смог бы развить свой бизнес, улучшить уровень клиентского сервиса, повышать скорость и качество логистики».
Компаниям, стремящимся использовать большие данные, чтобы лучше понимать своих клиентов, машинное обучение и глубокое обучение дают возможность:
● построить модель организации на основе наблюдений;
● находить новые идеи, одновременно анализируя множество факторов и переменных (гораздо больше, чем способен человек за разумное время и за разумные деньги);
● постоянно самообучаться по мере поступления новых данных;
● количественно оценивать вероятность исходов (то есть предсказывать вероятный результат);
● предписывать конкретные действия по оптимизации результатов и показателей;
● быстро адаптироваться к новым бизнес-правилам за счет быстрого переобучения вместо медленного традиционного перепрограммирования.
ИИ, машинное обучение и глубокое обучение стали возможными благодаря быстрому росту объемов и разнообразия данных в сочетании со снижением затрат на компьютерное оборудование и хранение информации. ИИ, машинное обучение и глубокое обучение – это естественное развитие бизнес-аналитики.
В мае 2011 года дефицит менеджеров и аналитиков, умеющих пользоваться результатами анализа, составил 1,5 миллиона – на порядок больше, чем тех, кто анализ проводит (аналитиков и исследователей данных). Иными словами, точка отсчета в цепочке создания ценности из данных – это не данные и не аналитика, а способность разумно и учитывая контекст использовать данные и аналитику. Другими словами, сложность заключается в извлечении из данных контекстных подсказок (паттернов) [Manyika 2011].
На страницах Infoworld (2019) Джерри Хартанто (Jerry Hartanto) анализирует применение ИИ, машинного обучения и глубокого обучения в бизнесе:
ИИ, машинное обучение и глубокое обучение способны превратить эту кучу данных в актив, систематически оценивая ее важность, прогнозируя исходы, предписывая конкретные действия и автоматизируя принятие решений. Короче говоря, ИИ, машинное обучение и глубокое обучение позволяют организациям и предприятиям справляться с факторами, приводящими к усложнению бизнеса, в том числе:
● цепочки создания ценности и цепи поставок, которые становятся более глобальными, взаимосвязанными и сфокусированными на микросегментах;
● бизнес-правила, которые быстро меняются в связи с необходимостью идти в ногу с конкурентами, потребностями и предпочтениями клиентов;
● точное прогнозирование и планирование ограниченных ресурсов для оптимизации конкурирующих проектов/инвестиций и бизнес-показателей;
● необходимость повышать качество продукции и качество обслуживания клиентов при одновременном снижении затрат.
Во многих отношениях ИИ, машинное обучение и глубокое обучение превосходят обычное программирование и традиционный статистический анализ:
● Для достижения целевого результата знание бизнес-правил в действительности совсем не обязательно – достаточно просто обучить машину на примерах входных и выходных данных.
● Если бизнес-правила изменились таким образом, что те же самые входные данные больше не приводят к тем же самым результатам, то машину не надо перепрограммировать – достаточно просто переобучить, сократив тем самым время реакции и избавив людей от необходимости переучиваться.
● По сравнению с традиционным статистическим анализом, модели ИИ, машинного обучения и глубокого обучения строятся относительно быстро, что дает возможность быстро подбирать модель методом проб и ошибок.
Тем, кто хочет познакомиться с технологиями искусственного интеллекта поближе, мы рекомендуем установить один из пакетов глубокого обучения, изучить прилагаемую документацию и поэкспериментировать на тестовых образцах. Рекомендуемая литература:
● Neural Networks and Deep Learning, Michael Nielsen;
● A Brief Introduction to Neural Networks, David Kriesel;
● Deep Learning, Yoshua Bengio, Ian Goodfellow, Aaron Courville;
● A Course in Machine Learning, Hal Daumé III;
● The TensorFlow Playground, Daniel Smilkov, Shan Carter;
● Stanford CS class CS231n Convolutional Neural Networks for Visual Recognition.
8.3.2.1. Искусственный интеллект и бизнес-аналитика
В отличие от бизнес-аналитики (Business Intelligence, BI), которая описывает и диагностирует прошедшие события, ИИ, машинное обучение и глубокое обучение пытаются предсказать будущие события и предложить способы воздействия на эти вероятности. На следующем рисунке показан прогресс в направлении предсказательной аналитики на основе ИИ, машинного обучения и глубокого обучения.
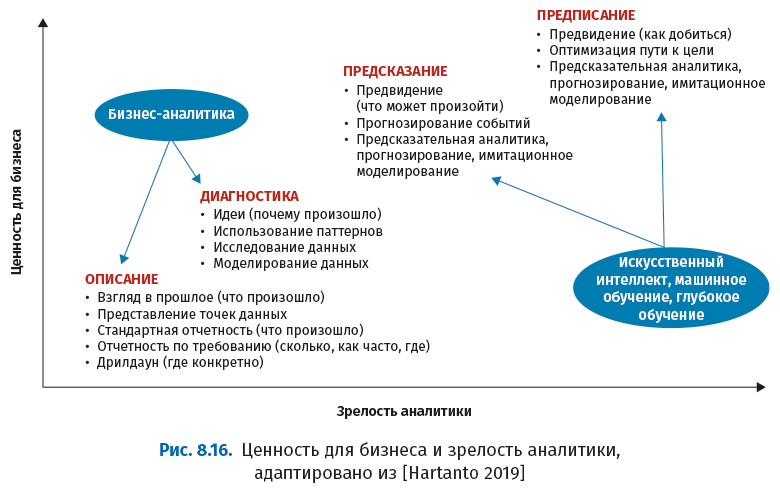
Проблема этих методов в том, что все они в настоящее время основаны на статистическом прогнозировании, которое содержит элемент ошибки, как показано на следующем рисунке.
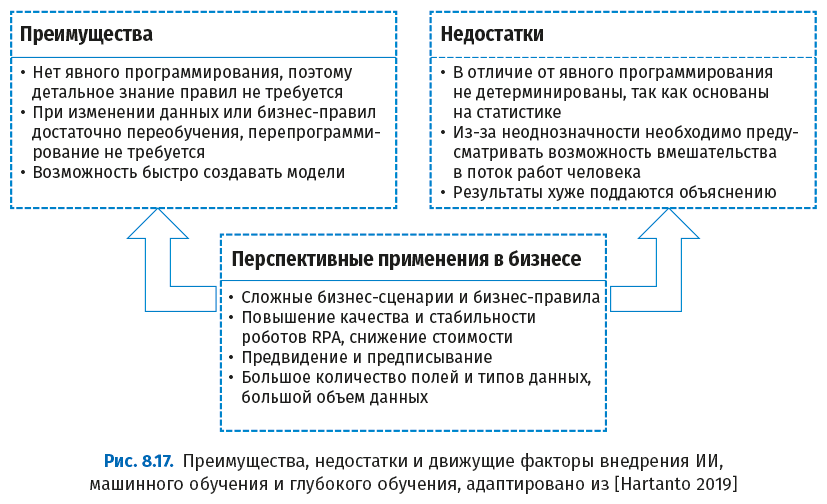
Разница между бизнес-аналитикой, статистикой и ИИ сформулирована ниже.
● Бизнес-аналитика традиционно ориентирована на запросы и опирается на аналитиков, выявляющих закономерности (например, какие клиенты самые прибыльные, почему они самые прибыльные и какие характеристики, такие как возраст или профессия, их отличают).
● Статистика также полагается на аналитиков, изучающих свойства (или структуру) данных, чтобы установить распределение данных, но ее отличает математическая строгость при экстраполяции (например, есть ли в реальности разница между потребительскими сегментами, обнаруженная в выборке).
● ИИ, машинное обучение и глубокое обучение полагаются на алгоритмы (а не на аналитиков), которые самостоятельно находят закономерности в данных, позволяющие давать прогнозы и рекомендации.
Хотя и статистическое моделирование, и машинное обучение используются для моделирования бизнес-сценариев, между ними есть некоторые существенные различия [Hartanto 2019].
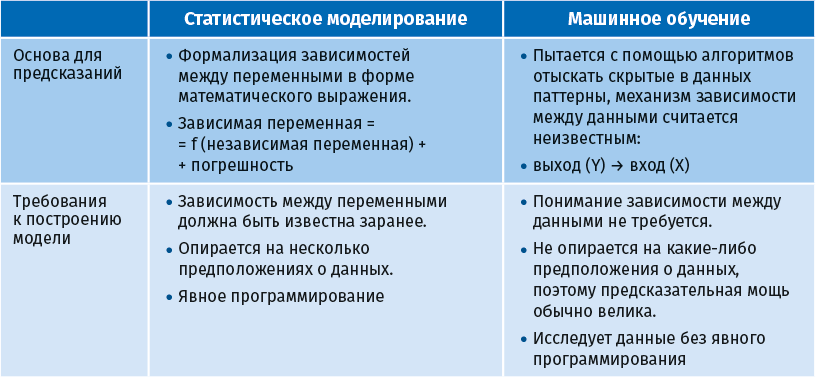
Некоторые дополнительные отличия:
● Статистическое моделирование подразумевает математическое уравнение, связывающее входы с выходами. В противоположность этому, машинное обучение и глубокое обучение не пытаются найти такое уравнение, а просто пытаются воспроизвести выходные данные по входным.
● Статистическое моделирование требует понимания используемых переменных и делает предположения о вероятностном распределении данных, а машинное обучение и глубокое обучение – нет.
8.3.2.2. Методы машинного обучения
Для обучения машин, как и для обучения людей, могут использоваться разные методы: с наблюдением, без наблюдения, с частичным наблюдением, с мотивацией, перенос знаний.
Обучение с наблюдением
При обучении с наблюдением преподаватель показывает, как правильно играть на пианино, а как неправильно. В идеале количество правильных и неправильных примеров равно. В случае машинного обучения данные состоят из целевой или результирующей (зависимой) переменной, которую требуется предсказать исходя из набора предикторов – независимых переменных. Используя эти наборы переменных, вы создаете функцию, которая сопоставляет входные данные с требуемыми выходными данными. Процесс обучения продолжается, пока модель не достигнет требуемого качества. Примером обучения с наблюдением являются заявки на получение кредита (предикторами здесь могут служить кредитная история, трудовая биография, владение активами, доход, образование), которые были или одобрены, или отклонены (целевые результаты и решения).
Обучение без наблюдения
При обучении без наблюдения вы предоставлены сами себе, никто не говорит вам, как играть на пианино. Вы составляете собственное представление о правильном и неправильном и оптимизируете параметры, которые считаете важными, такие как скорость завершения пьесы, соотношение громких и тихих нот или количество нажатий на клавиши. При машинном обучении без наблюдения к точкам данных не приклеены ярлыки правильно или неправильно. Цель в этом случае – каким-то образом организовать данные или описать их структуру. Организация данных может заключаться в их группировке в кластеры или в представления сложных данных таким образом, чтобы они выглядели более простыми или структурированными. Обучение без наблюдения обычно дает результат хуже, чем обучение с наблюдением, но без него не обойтись там, где нет ярлыков (другими словами, если правильные ответы неизвестны). Распространенный бизнес-пример – сегментация рынка. Часто бывает неясно, на какие сегменты делится рынок, и маркетологи ищут сегменты, объединенные естественными признаками, чтобы нацелить на них соответствующие слоганы, рекламные акции и товары.
Обучение с частичным наблюдением
Сочетание обучения с наблюдением и без наблюдения. Обучение с частичным наблюдением используется там, где наблюдаемых данных недостаточно. В примере с пианино вы получаете какие-то инструкции, но их немного (например, из-за того, что уроки дорогие или преподавателей не хватает).
Обучение с мотивацией
При обучении с мотивацией преподаватель не говорит вам, как правильно и неправильно играть на пианино. Вы не знаете, какой параметр вы пытаетесь оптимизировать, но вам говорят, когда вы делаете правильно, а когда неправильно. Инструктор бьет вас линейкой по пальцам, когда вы играете не ту ноту или не в том темпе. Если вы играете хорошо, вас похлопывают по плечу. Машинное обучение с мотивацией полезно в ситуациях, когда наблюдаемые данные скудны, но правильный ответ известен. Например, в шахматной игре слишком много вариантов ходов, чтобы все их задокументировать (приклеить ярлыки). Но обучение с мотивацией все же способно подсказать машине, когда она принимает правильные решения, приближающие победу, например взятие фигуры или усиление позиции.
Перенос знаний
Перенос знаний имеет место, когда вы используете свои знания игры на другом инструменте, например на трубе, чтобы научиться играть на пианино. Вы обучаетесь, используя уже приобретенные навыки, такие как умение читать ноты и гибкость пальцев. В машинном обучении перенос знаний используется для сокращения времени обучения, которое в случае моделей глубокого обучения может быть значительным (часы или даже дни).
8.3.2.3. Алгоритмы машинного обучения
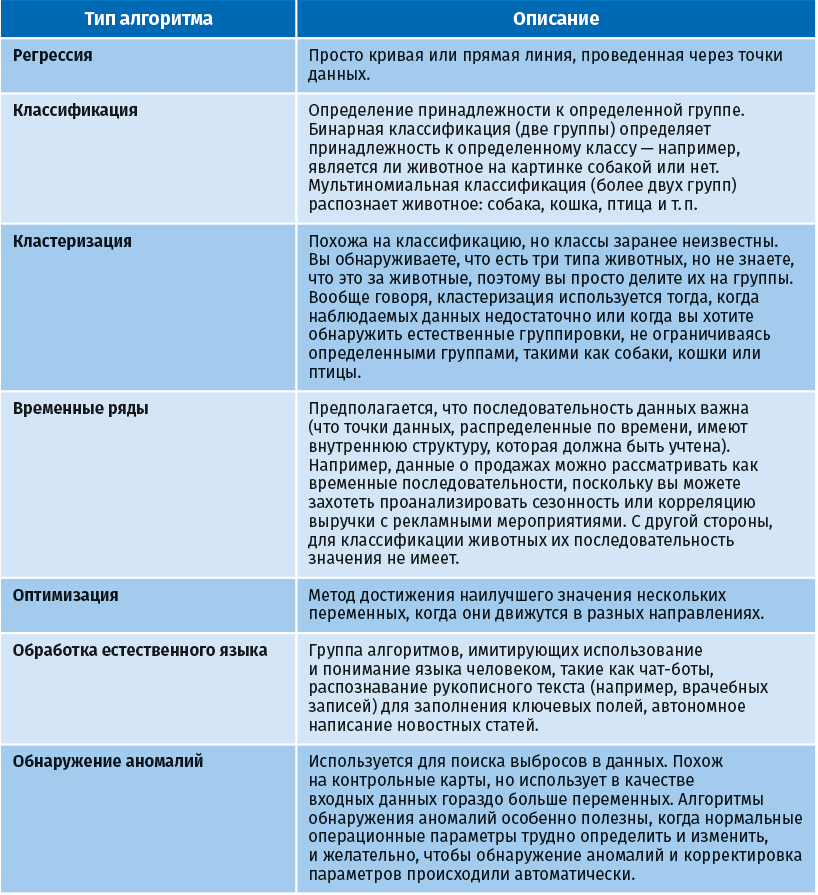
Алгоритмы машинного обучения превращают набор данных в модель. Наиболее подходящий тип алгоритма определяется типом задачи, располагаемыми вычислительными ресурсами и характером данных.
Основные типы алгоритмов приведены в следующей таблице.
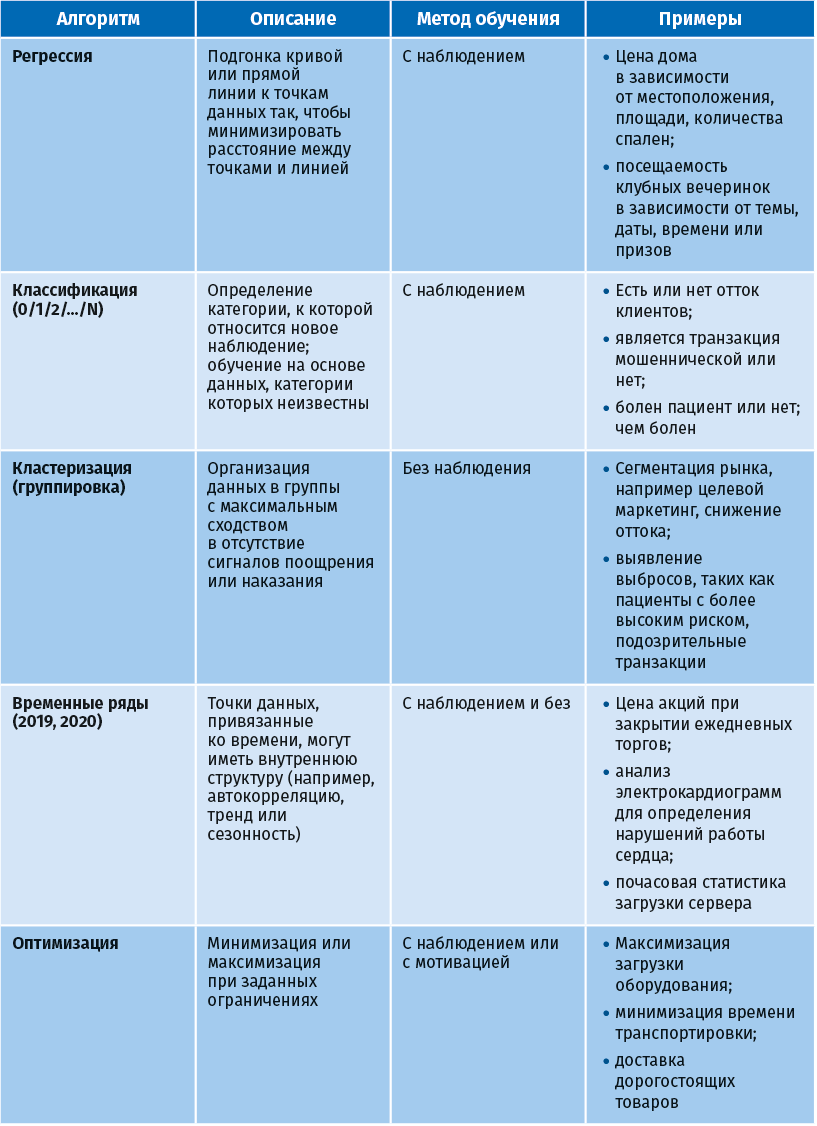
Следующая таблица показывает связь типов алгоритмов с методами обучения моделей [Hartanto 2019].
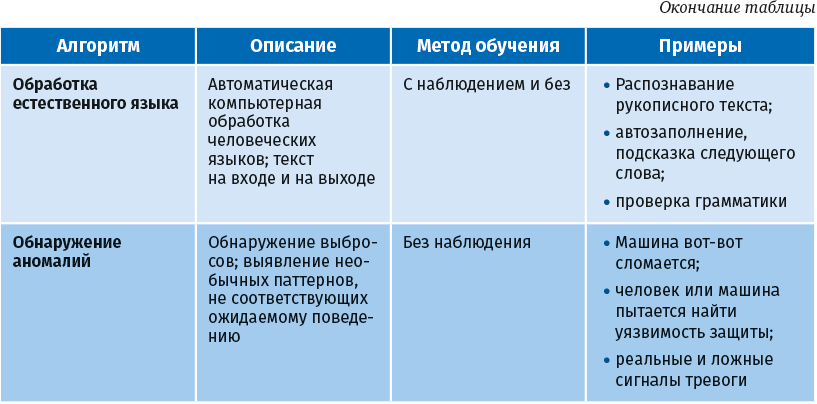
Следующий рисунок иллюстрирует концепцию моделей глубокого обучения, основанных на нейронных сетях.
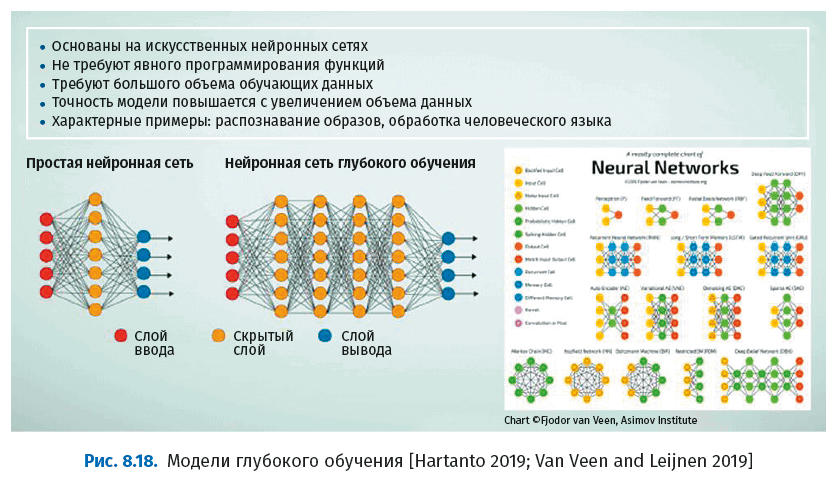
Глубокое обучение основано на концепции искусственных нейронных сетей. Нейронные сети функционируют подобно человеческому мозгу, где синапсы реагируют сильнее или слабее на основе обратной связи, а нейроны срабатывают при определенных условиях. С помощью моделей глубокого обучения решаются такие сложные задачи, как автономное вождение автомобиля, распознавание изображений, анализ видео и обработка языка.
Препятствия на пути использования моделей глубокого обучения:
● Большие объемы данных. Модели глубокого обучения требуют гораздо больше данных, чем модели машинного обучения. Без больших объемов данных глубокое обучение обычно работает плохо.
● Обучение и вычислительная мощность. Поскольку модели глубокого обучения требуют больших объемов данных, процесс обучения занимает много времени и требует больших вычислительных мощностей. Решить эту проблему помогают все более мощные и быстрые процессоры, память, новые графические процессоры и процессоры FPGA.
● Интерпретируемость. Модели глубокого обучения обычно поддаются интерпретации хуже, чем модели машинного обучения. Интерпретируемость глубокого обучения является одной из основных областей исследований, так что здесь возможен прогресс.
● Измерение. Как измерить эффективность модели машинного обучения? Модели, как и люди, оцениваются на предмет эффективности. Есть несколько способов измерения эффективности относительно простой регрессионной модели (метрики MAE, RMSE и R2 достаточно просты и очевидны).
8.3.2.4. Причины неудач внедрения ИИ
Большинство проектов ИИ терпят неудачу. Вот типичные причины, по которым это случается:
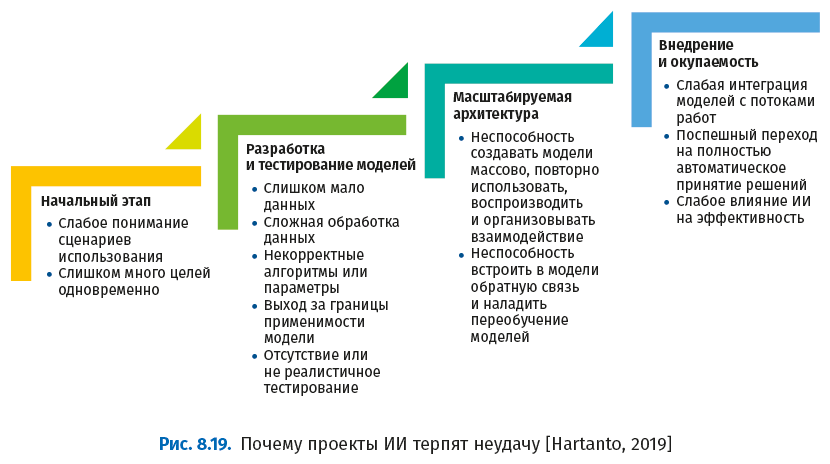
Сценарии использования
Первая причина неудач – выбор неподходящего сценария использования или слишком большого числа сценариев использования без достаточных возможностей и инфраструктуры. Чтобы выбрать задачи, наиболее подходящие для применения ИИ, используйте критерии, приведенные выше. Кроме того, имеет смысл выбирать сценарии использования, позволяющие постепенно наращивать возможности, знания и сложность технической реализации. К выбору подходящих сценариев использования рекомендуется привлекать следующих специалистов:
● сотрудники бизнес-подразделений, которые в курсе бизнес-проблем, контекста и ограничений, и у которых есть гипотезы, нуждающиеся в проверке;
● бизнес-аналитики, которые умеют задавать вопросы, проясняющие намерения и требования бизнеса, а также определять источники и необходимые преобразования данных;
● аналитики данных, которые умеют ставить задачи машинного обучения и глубокого обучения и строить модели, отвечающие гипотезам;
● инженеры данных и ИТ-специалисты, которые могут обеспечить доступ к данным.
Чтобы с самого начала организовать правильное управление проектом ИИ, требуется опытный кросс-функциональный руководитель, способный понять и сбалансировать эффект для бизнеса, операционные цели, ограничения и возможности потоков работ, потребности и ограничения со стороны данных, технологические факторы.
Разработка и тестирование
Вторая причина неудач заключается в неправильном построении самих моделей ИИ, а точнее в отсутствии двух условий.
● Дисциплина. Несмотря на то что наука о данных, как и другие науки, носит исследовательский характер (вы не знаете, что можно извлечь из данных, пока не поработаете с ними), подход должен быть четко определенным, дисциплинированным и нацеленным на получение результата в кратчайший срок.
● Квалифицированные специалисты. Хороший аналитик данных быстро ставит опыты, учится на своих опытах, видит разницу между перспективными и неэффективными подходами, изучает и внедряет передовые методы. Хороший специалист быстро, в параллельном режиме создает минимально жизнеспособные продукты.
Масштабирование
Третья причина неудач – недостаточный масштаб, отсутствие возможности быстро создавать и улучшать несколько моделей ИИ одновременно. Часто эта проблема сводится к тому, что аналитики данных не имеют возможности работать совместно, повторно использовать конвейеры обработки данных, рабочие процессы, модели и алгоритмы, а также воспроизводить результаты моделирования. Масштабирование также подразумевает отслеживание и быструю реакцию на обратную связь от операций (в тестовой, промежуточной или продуктивной средах). Массовая работа с ИИ требует как соответствующей инфраструктуры, так и правильного подхода к управлению моделью.
Внедрение и окупаемость
Четвертой причиной неудач является неспособность внедрить модель в операции и получить экономический эффект. Вообще говоря, разработка модели ИИ преследует одну из двух целей:
● чтобы прийти к ранее неизвестные выводам;
● чтобы автоматизировать принятие решений (как для снижения затрат, так и для повышения производительности).
Очевидно, что модель не может выполнить эти задачи, не выйдя за пределы лаборатории. Кроме того, необходимо не только внедрить модели (то есть сделать их доступными для людей и систем), но и включить их в потоки работ таким образом, чтобы они использовались в операциях. Возникающие исключения (например, когда модель не обеспечивает достаточно высокую вероятность правильного решения) должны грамотно обрабатываться (например, путем вмешательства человека, переобучения модели или отката к предыдущей версии). Внедрение и монетизация ИИ требует постепенной, но полной интеграции моделей с потоками работ, мониторинга входных данных и эффективности моделей, а также управления развертыванием моделей.
На следующем рисунке показан пример рамочной модели, в которой ИИ интегрируется с BPM.
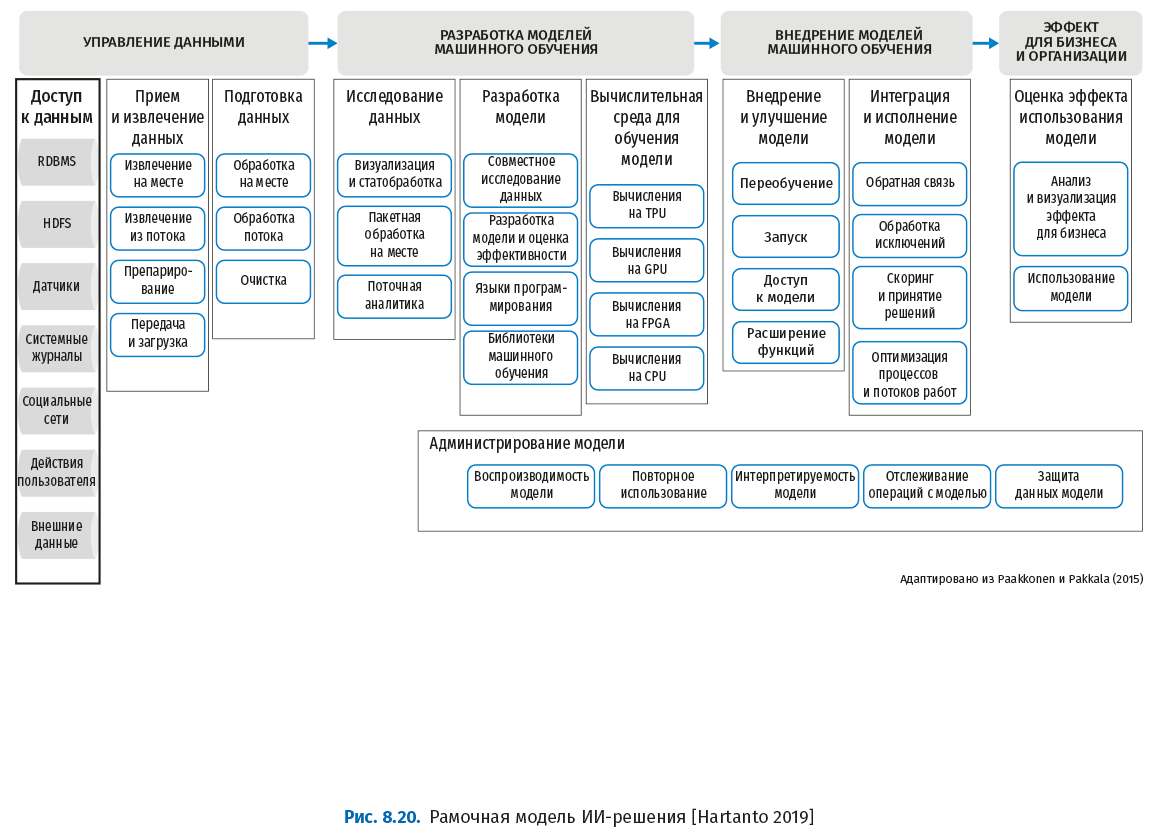
Эта модель включает четыре компоненты:
● управление данными;
● разработка модели;
● внедрение модели;
● эффект для компании и бизнеса.
Управление данными – это стандартная составляющая бизнес-аналитики, здесь мы его не рассматриваем.
Разработка модели машинного интеллекта включает две обширные области:
● определение и приоритизация сценариев использования, подходящих для моделей машинного обучения;
● массовое создание моделей машинного обучения.
Третья компонента – внедрение – включает не только развертывание моделей, но и процесс постоянной переподготовки и перемещения персонала, интеграцию моделей с потоками работ и обратную связь от операций к оптимизации моделей. Целью внедрения является монетизация моделей.
Наконец, четвертая компонента – эффект для компании и бизнеса – проста, но жизненно важна для будущего ИИ в организации. Бизнес-подразделения должны доверять моделям ИИ, понимать их ценность, реально их применять и получать отдачу. Проекты ИИ редко оказываются успешными без заинтересованной поддержки со стороны бизнеса.
Эти четыре составляющие требуют совместной работы ИТ-специалистов, инженеров данных, аналитиков данных и бизнес-подразделений. Искусственный интеллект – это командный спорт.
8.3.2.5. Искусственный интеллект и BPM
BPM неотделим от ИИ, как минимум в части технологий RPA и process mining. В значительной мере BPM является проекцией ИИ на мир бизнес-процессов.
В свою очередь, BPM для ИИ не менее важен, потому что в электронной коммерции бизнес-транзакции, делегированные ИИ, полностью выходят из-под контроля менеджмента. BPM – это единственная подушка безопасности, способная защитить компании от их новорожденных искусственных мозгов и сохранить контроль над управляемыми ИИ цифровыми платформами. Не случайно применение ведущих систем ИИ для бизнеса все чаще опирается на методы и методологию BPM.
В разделе, посвященном iBPMS, была упомянута концепция минимального кодирования (low-code), но следует иметь в виду, что она подходит для не самых сложных процессов, которые могут быть оптимизированы относительно быстро с минимальным вмешательством в работу компании. Для интеграции BPM с платформами ИИ, машинного и глубокого обучения лучше использовать микросервисы.
Согласно отчету Роба Копловица из Forrester, BPM будет развиваться в следующих направлениях:
● Машинное обучение позволит оптимизировать процессы. Аналитика проникнет повсюду, включая управление процессами. Раньше системы только предоставляли данные, появление ИИ позволяет сделать шаг вперед – рекомендовать действия.
● Неструктурированные данные систематизируются. BPM традиционно силен в автоматизации структурированных процессов. Неструктурированные процессы – это другая история, здесь шаблоны не столь очевидны. ИИ, в частности, технологии обработки естественного языка (Natural Language Processing, NLP), решает эту проблему, анализируя эмоциональную окраску сообщений и преобразуя неструктурированные данные в нечто более организованное.
● Новые интерфейсы, новые возможности. Новые технологии привели к появлению нового стиля взаимодействия с пользователем и новых интерфейсов, таких как управление голосом и чат-боты.
8.3.2.6. ИИ в цепях поставок
По мнению One Network Enterprises, успех внедрения ИИ в управление цепями поставок следует оценивать по восьми критериям:
● доступ к данным в режиме реального времени;
● доступ к общим данным цепи поставок;
● поддержка общих для всей сети целевых функций;
● инкрементный процесс принятия решений, учитывающий стоимость изменений;
● постоянное самообучение и самоконтроль в процессе принятия решений;
● системы ИИ должны являться автономными системами принятия решений;
● системы ИИ должны масштабироваться в широких пределах;
● система должна предусматривать взаимодействие с пользователями.
Доступ к данным в режиме реального времени
Новые системы ИИ должны устранить проблему устаревших данных, характерную для традиционных корпоративных систем с их пакетной обработкой. Большинство цепей поставок сегодня пытаются работать по планам, данные которых устарели на несколько дней, что негативно влияет на качество решений в цепи поставок и требует ручного вмешательства для устранения проблем. Без информации в реальном времени система ИИ просто будет быстрее принимать плохие решения.
Доступ к данным участников многосторонней цепи поставок
Алгоритмам ИИ, глубокого обучения и машинного обучения должны быть доступны данные за пределами вашего предприятия и в особенности данные сообщества ваших торговых партнеров.
До тех пор, пока система ИИ не сможет увидеть перспективный спрос, с одной стороны, и предложение – с другой, а также все ограничения и мощности цепи поставок, ее результаты будут не лучше, чем у традиционной системы планирования. К сожалению, для 99 % цепей поставок нормой является отсутствие прозрачности и доступа к актуальным данным участников.
Поддержка общесетевых целевых функций
Целевой функцией, или основной целью ИИ, является максимальный уровень обслуживания потребителей при минимально возможных затратах. Единственным потребителем готовой продукции является конечный потребитель. Оптимизация уровня обслуживания и затрат на обслуживание всеми участниками даст эффект, только если в итоге увеличится доход от продаж конечному потребителю.
Дальнейшие направления развития алгоритмов принятия решений – распределение ресурсов предприятия между клиентами для решения проблем дефицита и индивидуальные бизнес-правила. Таким образом, системы ИИ должны быть нацелены на потребности конечного клиента, даже если они наталкиваются на ограничения цепи поставок.
Процесс принятия решения должен быть инкрементным и учитывать стоимость изменений
Перепланирование и актуализация операционных планов в режиме реального времени может вызвать нервозность у партнеров по цепи поставок. Постоянные изменения без оценки их стоимости приводят к увеличению затрат большему, чем экономия, и снижают эффективность операций. При принятии решений система ИИ должна учитывать баланс затрат и эффекта.
Процесс принятия решений должен быть постоянным, самообучающимся и самоконтролируемым
В сетях поставок с множеством участников данные постоянно меняются. Колебания и задержки – это постоянные проблемы, приводящие к вариациям эффективности. Система ИИ должна работать постоянно, а не периодически, и должна учиться на собственном опыте – через корректировку правил выполнять тонкую настройку своих алгоритмов. К самообучению относится измерение и анализ эффективности с извлечением уроков.
Системы ИИ должны являться автономными системами принятия решений
Значительный эффект достигается, если разумное решение не только принято, но и выполнено. Более того, решение должно быть выполнено не только самим предприятием, но и его торговыми партнерами, когда это уместно. Такая автономность подразумевает, что система ИИ поддерживает потоки работ с множеством участников.
Системы ИИ должны масштабироваться в широких пределах
Для оптимизации цепи поставок с участием большого числа потребителей и поставщиков система должна быть способна быстро обрабатывать огромные объемы данных. Крупные интегрированные цепи поставок могут иметь дело с миллионами, если не сотнями миллионов, мест хранения. Системы ИИ должны уметь быстро принимать множество разумных решений.
Система должна предусматривать взаимодействие с пользователями
ИИ не должен быть «черным ящиком». Пользовательский интерфейс должен обеспечивать прозрачность критериев принятия решений и их последствий, а также информирование о проблемах, которые система сама решить не может. Пользователи должны иметь возможность контролировать принимаемые ИИ решения и при необходимости их корректировать или отменять. В то же время система ИИ должна работать самостоятельно и обращаться к пользователю только в случае возникновения исключительной ситуации, а также предоставлять пользователю возможность ввести дополнительную информацию, неизвестную ИИ [One Network Enterprises Staff 2017].
На следующем рисунке показана архитектура цепи поставок для применения ИИ.
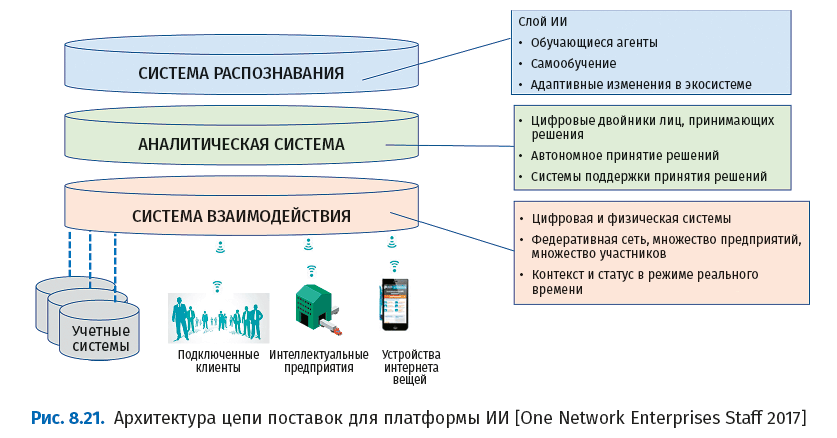
Примечательно, что в этой архитектуре ИИ представляет собой когнитивный слой, а RPA – интеллектуальный. Слой ИИ гораздо сложнее показанного на рис. 8.21; организациям нужна сквозная рамочная модель ИИ для использования в качестве эталонной.
8.3.3. Микросервисы
Микросервисы – это самодостаточные процессы, обеспечивающие конкретные бизнес-способности. Микросервисы разбивают деятельность на компоненты, которые легче поддерживать по отдельности. Их можно разворачивать по отдельности, в виде независимых бизнес-приложений. Микросервис обладает собственным хранилищем данных. Связываются друг с другом микросервисы обычно через HTTP и обмен сообщениями. Поскольку микросервисы не запоминают состояние, они легко масштабируются.
Микросервисная архитектура является противоположностью единого монолитного приложения. В традиционном приложении процессы неразрывно связаны друг с другом и с другими сервисами. В результате небольшая модификация одного процесса может сказаться на всей системе. В этом проблема low-code платформ BPM. Микросервисная архитектура эту проблему решает. Если микросервис нуждается в модификации, то такая доработка должна быть простой. Такая гибкость очень важна для предприятий. При традиционной разработке приложений вносимые изменения могут повлиять на всю систему. Преимущество микросервисов (при условии правильного проектирования) состоит в том, что их можно быстро и легко менять. Короче говоря, микросервис нацелен на одну бизнес-способность. Это не значит, что он делает что-то одно, просто у него очень конкретная цель.
В связи с постоянно растущей сложностью бизнес-систем узкоспециализированные микросервисы становятся все более популярными. Каждый микросервис решает отдельную задачу, а в совокупности они обеспечивают надлежащее внимание ко всем аспектам деятельности организации. Технология микросервисов специально разработана для встраивания в существующие приложения, такие как управление взаимоотношениями с клиентами (CRM), управление цепями поставок (SCM) или программное обеспечение для управления ресурсами (ERP). Микросервисная архитектура позволяет масштабировать разработку программного обеспечения. Через микросервисы стыкуются ИИ и BPM.
8.3.3.1. Проблемы микросервисов
Применение микросервисов не обходится без проблем:
● Сложность. Сложность становится проблемой. Добавление микросервисов может приводить к их дублированию, поскольку среда становится более распределенной.
● Коммуникации. Обеспечение коммуникаций является непростой задачей из-за распределенного развертывания микросервисов. Потенциальное большое число сервисов требует от разработчиков дополнительных усилий по надлежащему управлению коммуникациями. Из-за этого микросервисная архитектура может очень быстро усложниться. В результате коммуникации могут значительно замедлиться.
● Квалификация. Сложность микросервисной архитектуры требует талантливых разработчиков. Вам понадобится отдельный разработчик для сопровождения, обработки запросов пользователей и новых интеграций. Хотя микросервисы требуют большего объема программирования по сравнению с low-code аналогами, в конечном счете их проще контролировать и проще заменять при изменении технологий.
● Обязательства. Микросервисы – это долгосрочная стратегия. Но те, кто хочет большего контроля, легко принимают решение о переходе от low-code к микросервисам. Решимость научиться разбираться в системной архитектуре и в том, как управлять и поддерживать микросервисы, в долгосрочной перспективе окупается.
8.3.3.2. Low-code и микросервисы
Самые подходящие для применения микросервисов отрасли – разработка ПО и высокие технологии. Подход к BPM на основе микросервисов отлично подходит для создания корпоративных облачных приложений.
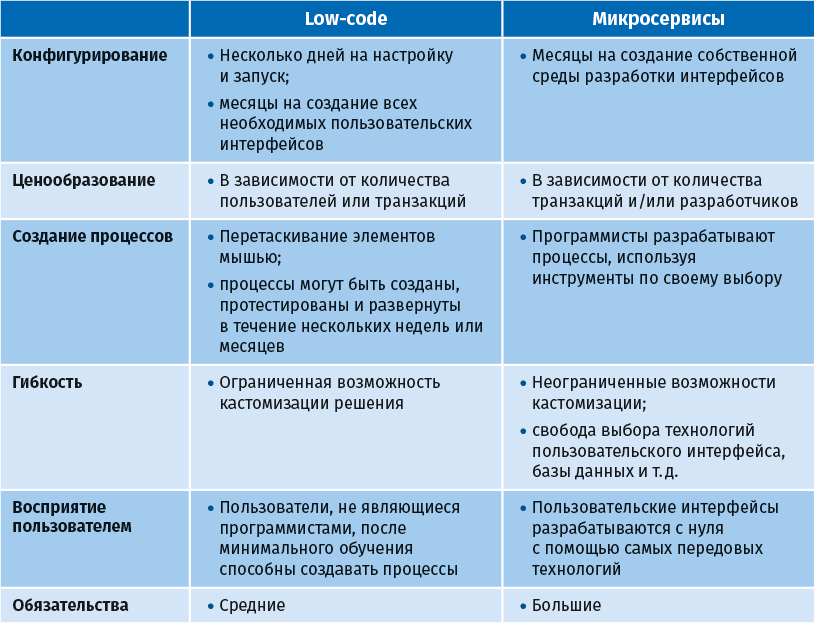
Особенно он может быть полезен независимым разработчикам корпоративного ПО для встраивания процессного движка в свои продукты. Преимуществом микросервисов является то, что компания-разработчик ПО может приобрести движок BPM и построить вокруг этого ядра все, что ему требуется. В следующей таблице приведено сравнение low-code и микросервисов с нескольких точек зрения [ProcessMaker Staff 2018].
8.3.4. Блокчейн
Блокчейн – это единый источник достоверной информации в виде структуры данных, которая позволяет создать децентрализованный, неизменяемый, защищенный, снабженный отметками времени цифровой реестр и предоставить к нему доступ независимым сторонам. Блокчейн называют также технологией цифрового реестра (digital ledger).
Отметим, что хотя термины биткоин и блокчейн часто используются как синонимы, это не одно и то же: биткоин – это название криптовалюты и ее экосистемы, а блокчейн – это класс компьютерных алгоритмов и программного обеспечения. Биткоин использует блокчейн в качестве протокола, обеспечивающего защищенную передачу криптовалюты.
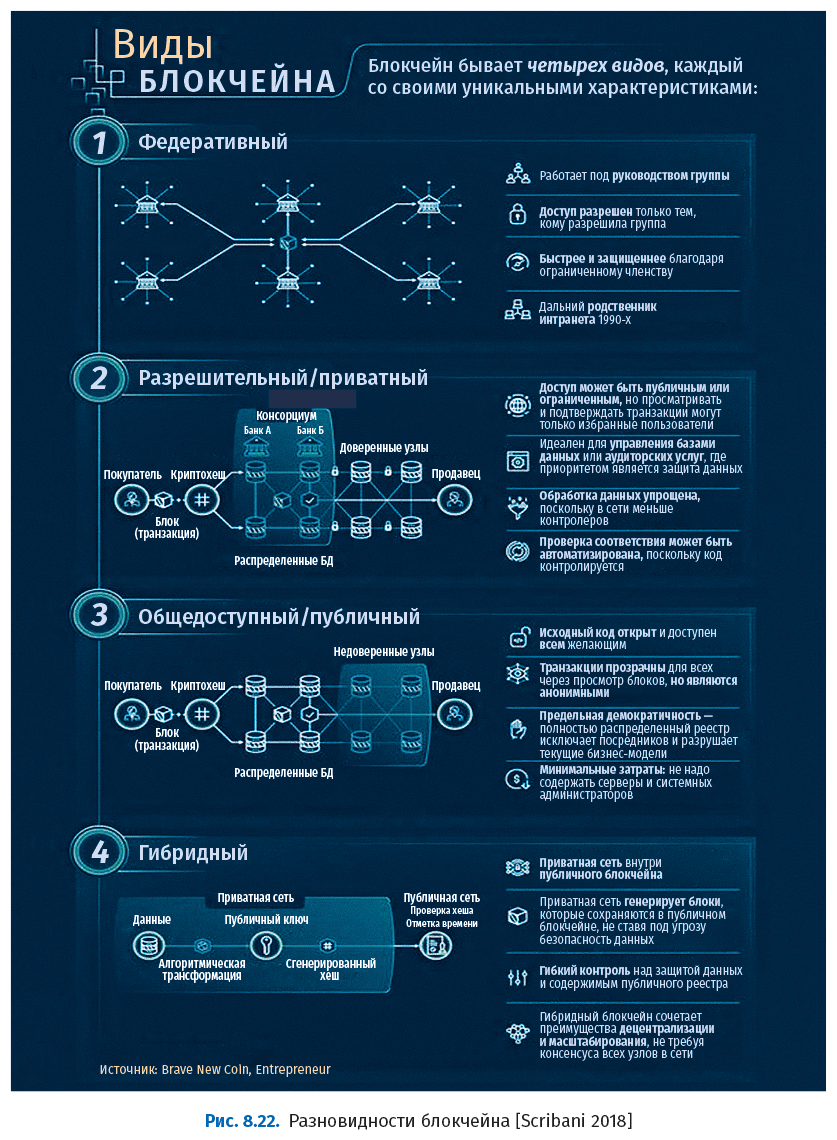
Существует несколько разновидностей блокчейна:
● Публичные (public) блокчейны – большие распределенные сети с собственными токенами. Они полностью открыты для участия на любом уровне и используют программное обеспечение с открытым исходным кодом, который поддерживает их сообщество.
● Разрешительные (permissioned) блокчейны – роли участников в них контролируются. Один из методов заключается в том, что процесс консенсуса контролируется предопределенным набором узлов. Как и публичные блокчейны, это большие распределенные системы, использующие собственные токены. Их исходный код может быть как открытым, так и закрытым.
● Приватные (private) блокчейны – как правило, меньше по размеру и не используют токены. Членство в них строго контролируется. Этому варианту отдают предпочтение консорциумы, в которых централизованно контролируется допуск доверенных членов, обменивающихся конфиденциальной информацией.
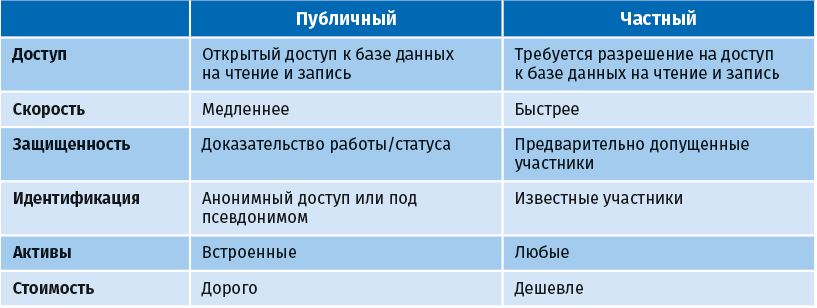
В следующей таблице сравниваются публичные и частные блокчейны [Voshmgir 2019], адаптировано.
На рисунке 8.22 представлена расширенная классификация.
Считается, что в электронной коммерции, скорее всего, будут доминировать гибриды публичных и разрешительных блокчейнов. Компании смогут совершать защищенные транзакции с партнерами и одновременно через открытый реестр доносить до клиентов информацию о продукции. По сути, гибридный блокчейн будет включать публичный, ориентированный на потребителей, и приватный для корпоративных транзакций за сценой.
Во всех блокчейнах используется криптография, позволяющая каждому участнику управлять реестром защищенным способом без обращения к какому-то центральному узлу. Отсутствие централизованного управления является одним из наиболее важных и ценных свойств блокчейна.
8.3.4.1. Алгоритмы блокчейна
Блокчейн состоят из трех основных элементов: блоков, цепочек и сети.
Блок
Набор транзакций за определенный период, который заносится в реестр. Размер, период и инициирующее запись блока событие зависят от реализации. Не во всех блокчейнах целью являются операции с криптовалютой. Но все блокчейны хранят информацию о движении своей криптовалюты или токенов. Рассматривайте транзакцию просто как запись данных. Присвоение данным значения (например, в случае финансовой транзакции) придает им определенную трактовку.
Цепочка
Хеш-функция математически связывает один блок с другим, составляя из них цепочку. Это одна из самых сложных концепций в блокчейне. Это математическая магия, склеивающая блокчейн в единое целое и создающая механизм доверия. Хеш рассчитывается по данным предшествующего блока. Хеш – это «отпечатки пальцев» данных, с помощью которых фиксируются порядок и временные маркеры блоков.
В отличие от блокчейна, хеширование известно давно, его изобрели больше 30 лет назад. Хеш представляет собой однонаправленную функцию, которую нельзя расшифровать. Хеш-функция реализует математический алгоритм, свертывающий данные любого объема в строку битов фиксированной длины, обычно укладывающуюся в 32 символа. Одна из криптографических хеш-функций, используемых в блокчейнах, – SHA (Secure Hash Algorithm). SHA-256 – стандартный алгоритм, который генерирует 256-битный (или 32-байтовый) хеш. С практической точки зрения хеш – это цифровые «отпечатки пальцев» блока, с помощью которого фиксируется его место в цепочке.
Сеть
Сеть состоит из полных узлов. Рассматривайте их как компьютеры, на которых запущен алгоритм, обеспечивающий защищенность сети. Каждый узел содержит полную запись всех транзакций, когда-либо записанных в данный блокчейн.
Блокчейн децентрализован, то есть представляет собой одноранговую систему без центрального узла. Ключом к устранению централизованного контроля при сохранении целостности данных является наличие большой распределенной сети независимых пользователей. Децентрализация означает, что компьютеры сети находятся в разных местах. Эти компьютеры часто называют полными узлами.
В широком смысле блокчейн – это реестр, в который новые транзакции записываются блоками, и каждый блок сопровождается криптографическим хешем. Одинаковые данные всегда дают один и тот же хеш, но воссоздать данные по хешу невозможно. Малейшие изменения данных транзакции приводят к совершенно другому хешу, а поскольку хеш каждого блока входит в данные следующего блока, хеши последующих блоков в результате также изменятся. Поэтому после того как данные попали в блокчейн, их чрезвычайно трудно изменить или удалить. Наличие криптографического хеша защищает реестр от подделки.
Когда кто-то хочет добавить в блокчейн транзакцию, полные узлы сети (их называют валидирующими) ее проверяют. Здесь все становится несколько сложнее, потому что разные реализации блокчейна немного по-разному подходят к вопросу о том, кто и как должен проверять транзакцию.
Защищенность базируется на том, что блокчейн хранится на множестве узлов. Чтобы изменить реестр, необходимо получить контроль по крайней мере над 50 % сети, что является очень трудной задачей, особенно в случае публичного блокчейна.
Консенсус
Блокчейн является мощной технологией, поскольку он позволяет создать честную систему, которая контролирует себя сама, не прибегая к третьей стороне. Соблюдение правил обеспечивается алгоритмом выработки консенсуса.
Блокчейн создает перманентные записи транзакций, но перманентными считаются только те записи, которые признаны таковыми сетью. В контексте блокчейна это означает, что с изменением должна согласиться большая часть узлов сети, при этом технология устроена так, что она стимулирует их не соглашаться с изменениями.
Алгоритмы консенсуса, то есть правила, по которым алгоритм обновляет реестр, в реализациях блокчейна различаются. На следующем рисунке показано, как узлы блокчейна приходят к консенсусу.
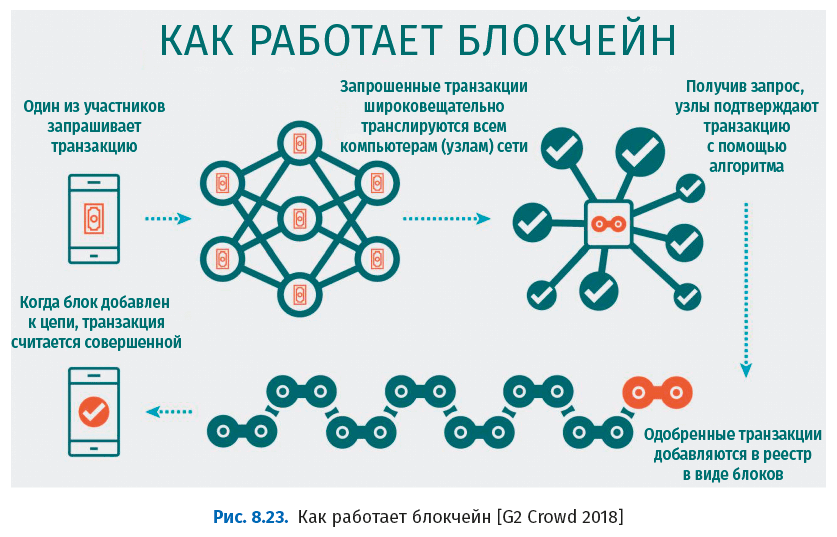
На следующем рисунке представлены алгоритмы консенсуса, используемые в реализациях блокчейна.
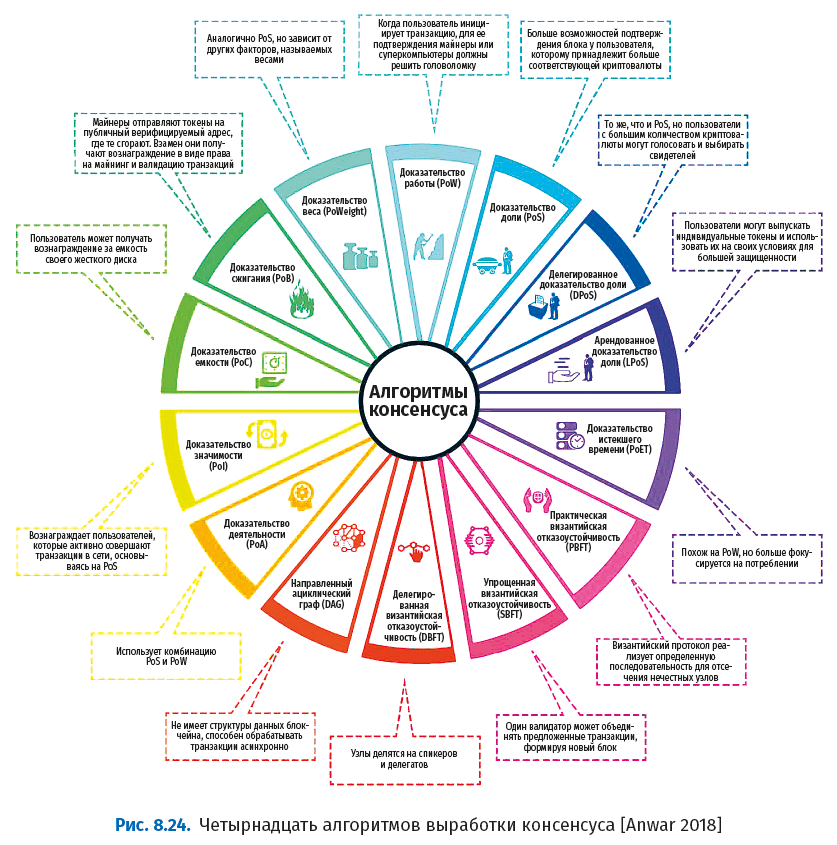
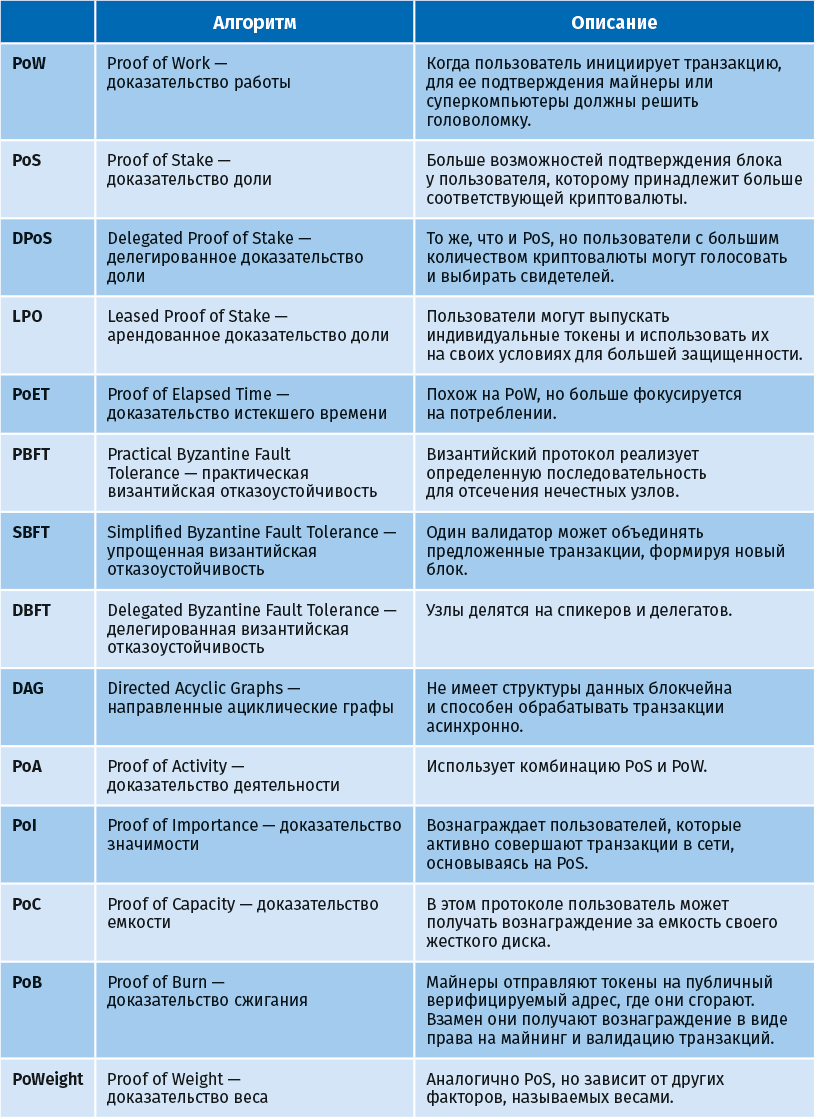
Описания этих алгоритмов приведены в следующей таблице.
8.3.4.2. Область применения блокчейна
Блокчейн является базовой технологией: его можно применять для разных целей в различных отраслях, но он не является законченным приложением. Требуется также пользовательский интерфейс, бизнес-логика и механизмы интеграции. В отличие от обычных баз данных, в настоящее время в блокчейне не реализована модель операций создания, чтения, обновления, удаления. Кроме того, блокчейн-платформы в настоящее время не совместимы друг с другом, хотя это может измениться по мере взросления технологии и сценариев ее применения.
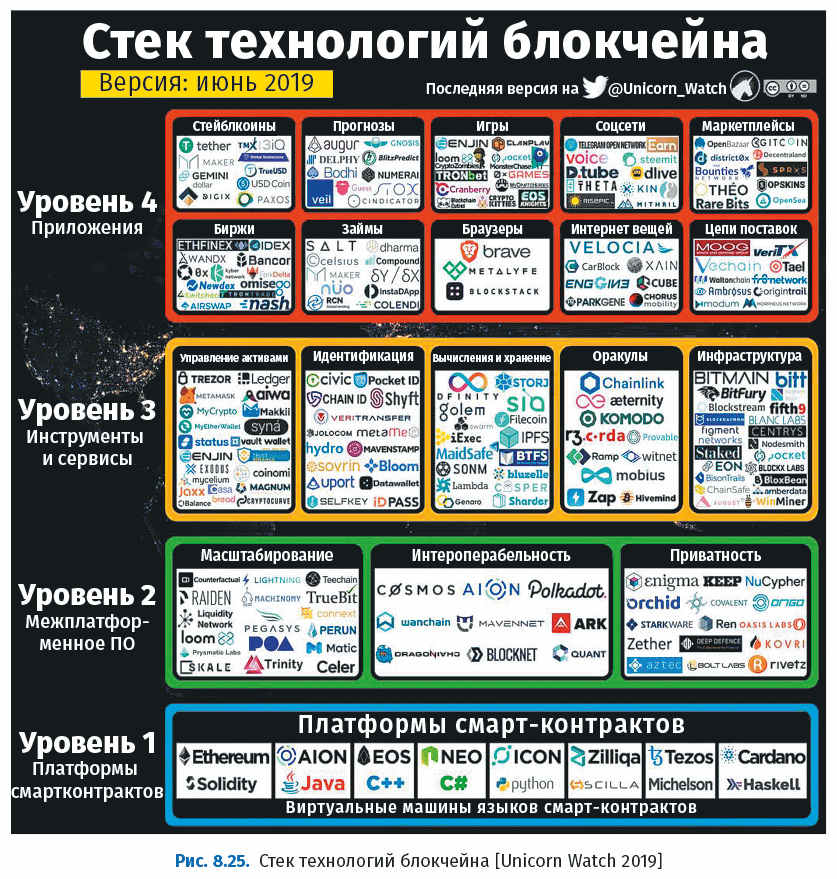
На следующем рисунке показан стек технологий блокчейна.
Некоторые применения технологии блокчейн:
● биткоин;
● первичное размещение монет (Initial Coin Offering, ICO);
● цепи поставок;
● реестры собственности;
● управление цифровыми правами;
● финансирование торговли.
По мнению Джорджа Гилдера (George Gilder), есть два обстоятельства, делающие блокчейн разрушительной технологией: новая архитектура безопасности и возвращение власти деньгам.
● Новая архитектура безопасности. Хакеры обожают централизованную архитектуру безопасности, потому что она сообщает им 1) что важно и 2) где это можно найти. В противоположность этому, блокчейн обеспечивает неизменяемость записей всех транзакций и распространяет данные по всей сети. Вся информация не собрана в одном месте, где она является легкой мишенью для хакеров.
● Возвращение власти деньгам. Правительства забыли, для чего нужны деньги и как они работают. В результате они печатают все больше и больше денег, видимо считая, что деньги являются богатством, и не понимая, что деньги богатство лишь измеряют. Возвращение к золотому стандарту устанавливает фиксированный курс валют вместо плавающего, не привязанного ни к чему. Блокчейн вместе с криптовалютами предлагает решение. Речь идет не только о создании новой формы денег, до которой не может дотянуться правительство. С помощью блокчейна некоторые криптовалюты в конечном итоге заменят реальные деньги и вытеснят валюты со свободно плавающими курсами. Есть даже попытки привязать криптовалюты к золоту. Это установит стабильный стандарт цифровых монет для ведения бизнеса [Guilder 2018].
На следующем рисунке показаны сценарии использования блокчейна: статический реестр, цифровые удостоверения, смарт-контракты, динамический реестр, платежи и инфраструктура и другие.
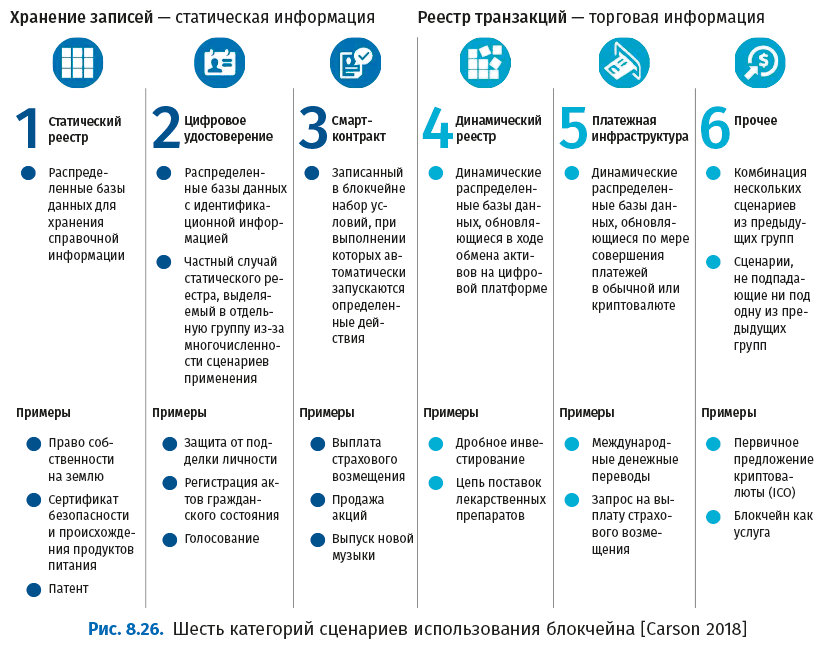
С развитием технологии могут появляться новые сценарии использования.
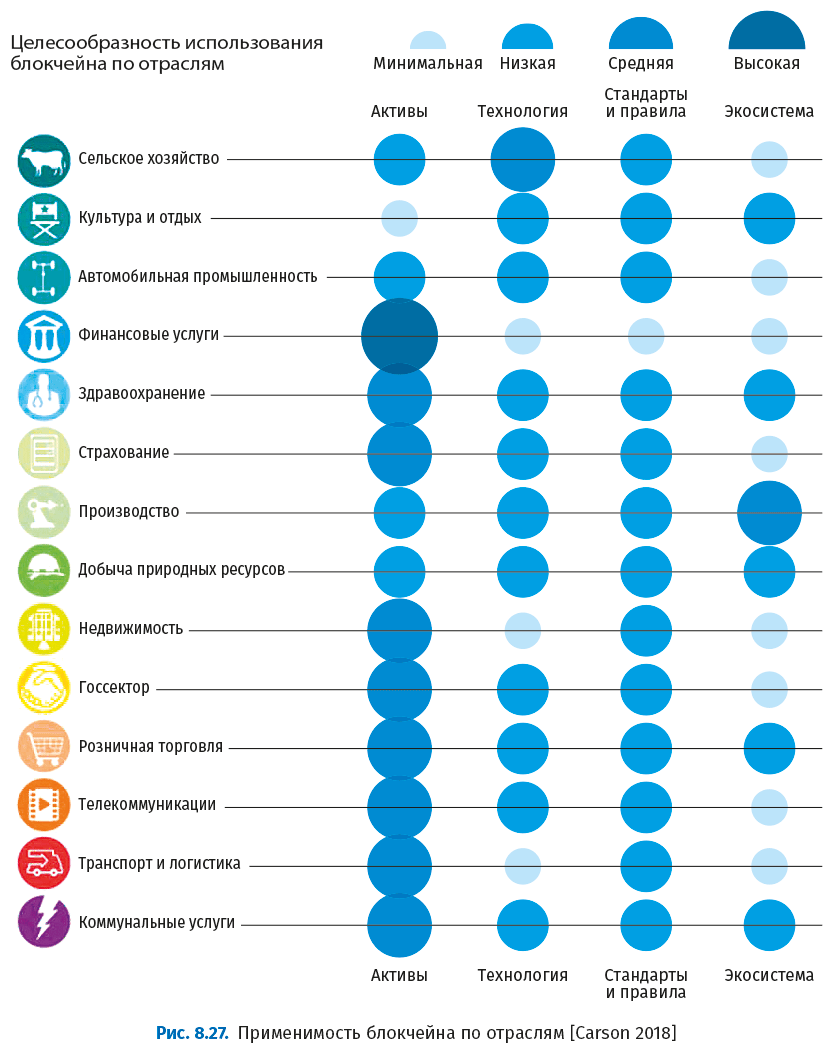
Применимость блокчейна зависит от отрасли, типа актива, зрелости технологии, стандартов и регулирования, а также экосистемы. На следующем рисунке показана применимость блокчейна для различных отраслей.
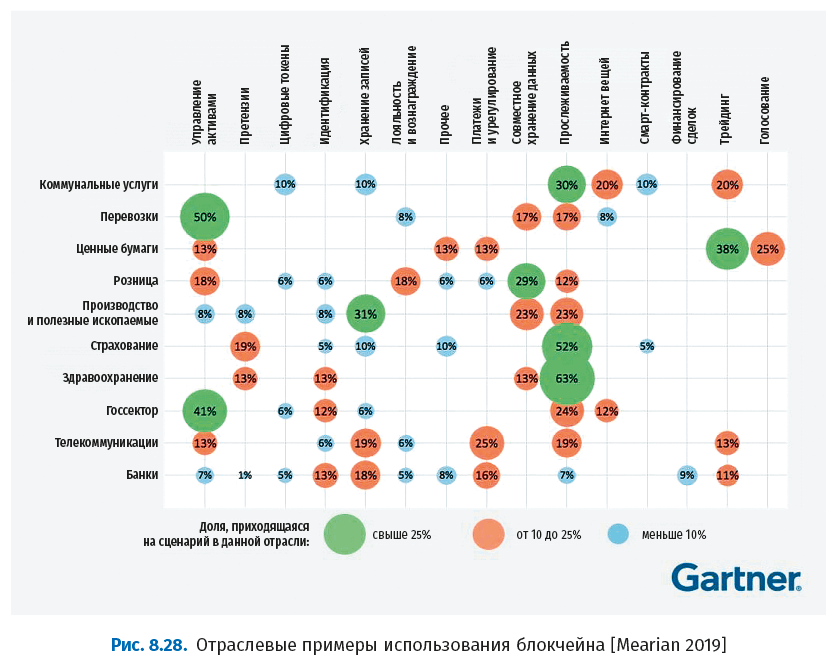
На следующем рисунке показаны примеры использования блокчейна в различных отраслях.
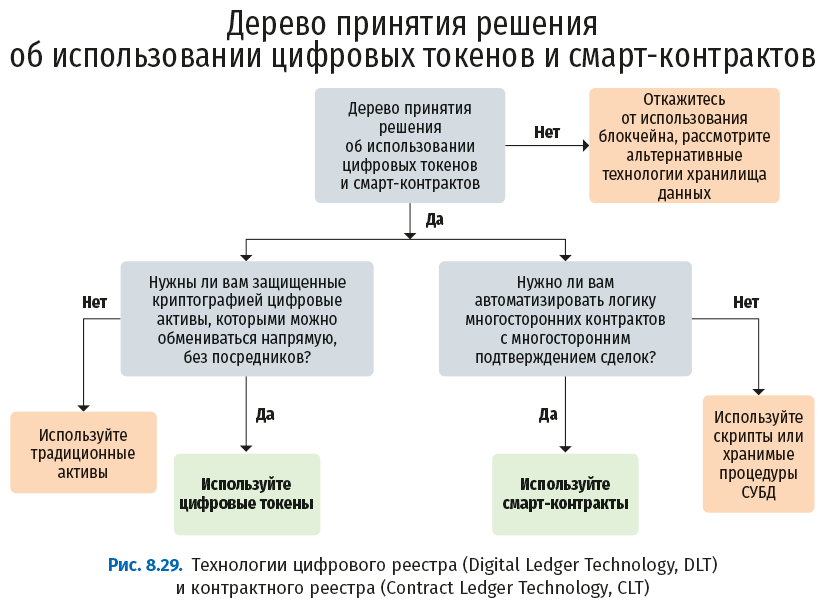
В связи с блокчейном возникают вопросы: нужен ли он вам, и если да, то что именно – цифровой токен или смарт-контракт? На следующем рисунке приведена блок-схема, помогающая ответить на эти вопросы.
Большинство блокчейнов и используемых в них технологий еще слишком молоды, чтобы замахиваться на глобальную торговлю. Кроме того, многие бизнес-руководители плохо их понимают. Но даже если бы уровень технологии и понимания ее руководителями были выше, остается проблема регулирования – не на уровне центральной власти, а на уровне технологий, дизайна, сетевых правил и особенно в том, как прийти к согласию, когда что-то пошло не так.
«Регулирование публичных блокчейнов, таких как Ethereum и Bitcoin, в основном направлено на технические вопросы и редко нацелено на поведение и мотивацию людей. ИТ-директора должны осознавать регуляторный риск для их проектов на блокчейне. Крупные организации должны подумать о формировании консорциумов, призванных помочь сформировать модели регулирования публичных блокчейнов» [Panetta 2019].
Еще одним вопросом регулирования является то, что по умолчанию блокчейн (в первую очередь публичный) открывает доступ к информации, которой вы, возможно, не хотели бы делиться. Хотя большинство этих проблем со временем будут решены, технологии блокчейн предстоит пройти большой путь, прежде чем она получит широкое распространение на предприятиях.
Сегодня на рыке технологий блокчейна мы наблюдаем множество игроков, и можно ожидать консолидации, которая сократит число поставщиков до более разумного, и из них будут выбираться компании для инвестиций.
8.3.4.3. Блокчейн и BPM
С точки зрения управления бизнес-процессами блокчейн переосмысляет бизнес-процессы на уровне транзакций, в которых сохраняются входные и выходные данные процессов.
Одно из самых перспективных применений блокчейна – в качестве коммуникационного слоя управления бизнес-процессами в финансовой отрасли. Смарт-контракты и проверяемые распределенные реестры могут облегчить реализацию процессов с множеством участников и специфическим регулированием. В этих сценариях технология используется главным образом для обмена информацией и отслеживания состояния транзакций. Интеграция с существующими процессами и бэк-офисными системами обеспечит всем участникам бóльшую прозрачность. Речь не идет о том, чтобы заставить всех перейти на совершенно новую платформу. Речь о простой интеграции унаследованной инфраструктуры в новую сеть, предоставляющую дополнительную функциональность.
От BPMS технология блокчейна отличается тем, что традиционные системы BPMS, как правило, имеют дело с потоками работ внутри одной организации. Они не управляют потоками работ и информации между организациями. А если они пытаются это делать, то попадают именно в ту ловушку, которой блокчейн помогает избежать, – централизованного репозитория информации, контролируемого третьей стороной (в данном случае – поставщиком BPMS). Если хранение данных и передачу их от одной организации к другой берет на себя третья сторона, то появляется потенциальная точка отказа и связанные с ней риски.
На основе технологии блокчейн можно создать одноранговую BPMS без центрального хранилища информации, в которой предприятия смогут обмениваться информацией непосредственно с контрагентами при гарантированной целостности процесса. Такая система позволит организациям контролировать, что каждый участник сети корректно выполнил определенные шаги. Особенно важна такая проверка для сделок, являющихся предметом регулирования. Блокчейн позволяет закодировать нормативные требования в виде смарт-контрактов, и контрагент сможет со своей стороны проконтролировать их выполнение. В результате каждый сможет добиваться выполнения правил всеми участниками и быть уверенным, что выполнены все предусмотренные процессом шаги. Блокчейн дает контрагентам возможность в реальном времени проводить аудит, подтверждающий, что никто не срезал угол по дороге.
Важное достоинство блокчейна для BPM – возможность для участников и контрагентов сохранять контроль над своими данными. Даже если сеть навязывает организациям-участникам свои правила, контроль над их данными остается у них, а не передается третьей стороне.
Еще одна проблема BPM, с которой может справиться технология блокчейн, – внутреннее мошенничество. Блокчейн заставляет подчиняться правилам проведения транзакций собственных сотрудников организации, не оставляя им возможности обойти правила и нормативы.
8.3.4.4. Блокчейн в цепях поставок
В сфере цепей поставок блокчейн уже прижился. По мнению экспертов Spend Matters, блокчейн вскоре может стать «операционной системой» цепи поставок, повысив эффективность решения таких задач, как:
● учет наличия и передач материальных ценностей, таких как поддоны, прицепы, контейнеры и т. п., в ходе их перемещения между узлами цепи поставок [Gonzalez 2015];
● отслеживание заказов на покупку, заказов на изменение, квитанций, уведомлений об отгрузке и других коммерческих документов;
● выдача и проверка сертификатов на физические товары; например, подтверждение химического состава товара или его товарного кода [Herzberg 2015];
● привязка физических товаров к серийным номерам, штрих-кодам, RFID и т. п.;
● обмен информацией о производственном процессе, сборке, поставке и обслуживании продукции с поставщиками и производителями.
Преимущества блокчейна для грузоотправителей:
● Больше прозрачности. Документирование перемещения товара по цепи поставок показывает его истинное происхождение и точки передачи собственности, что повышает доверие и помогает устранить предвзятость, типичную для сегодняшних непрозрачных цепей поставок. Производители также могут уменьшить количество отзывов товаров, предоставляя доступ к своим данным OEM-производителями и регулирующим органам [Gonzalez 2015].
● Повышение масштабируемости. Возможно подключение практически любого количества участников с любого количества терминалов [Forbes].
● Лучшая защищенность. Общий неизменяемый реестр с кодифицированными правилами потенциально может устранить необходимость в аудитах, требуемых внутренними системами и процессами [Spend Matters 2015].
● Больше инноваций. Благодаря децентрализованной архитектуре открывается множество возможностей для новых технологий.
8.3.5. Интернет вещей
Интернет вещей (Internet of Things, IoT) – это концепция подключения устройств к интернету и/или друг к другу. Устройства – это мобильные телефоны, кофеварки, стиральные машины, наушники, лампы, переносные устройства и вообще почти все, что может прийти в голову. Агрегаты, такие как двигатель самолета или бур на нефтяной вышке, также потенциально являются «вещами».
Gartner прогнозирует, что к 2020 году к интернету вещей будет подключено более 26 миллиардов устройств [Hung 2017]. Таким образом, интернет вещей – это просто гигантская сеть подключенных устройств или вещей. Можно предположить, что в будущем любое устройство, которое может быть подключено, будет подключено. Устройства не обязательно должны быть умными, то есть хранить у себя данные; скорее, все устройства будут подключаться к хранилищу данных.
8.3.5.1. Три категории вещей
В интернете вещей все устройства делятся на три категории:
● устройства, которые собирают информацию и затем отправляют ее;
● устройства, которые получают информацию и затем, исходя из нее, что-то делают;
● устройства, совмещающие первое и второе.
У каждой категории свои сильные стороны, дополняющие друг друга.
Сбор и отправка информации
Это просто датчики – температуры, движения, влажности, качества воздуха, освещенности и т. д. Датчики, будучи подключенными к сети, дают возможность автоматически собирать информацию из окружающей среды, что, в свою очередь, позволяет принимать более разумные решения. Люди ощущают мир через органы зрения, слуха, обоняния, осязания и вкуса; машины ощущают мир через датчики. Отличный пример – датчики температуры при транспортировке фармацевтической и другой продукции, требующей соблюдения температурного режима. Еще пример – датчики, автоматически собирающие информацию о влажности почвы, чтобы подсказать фермеру, когда пора поливать.
Получение информации и действия исходя из нее
Это распространенная категория устройств, которые получают информацию и что-то делают. Принтер получает документ и печатает его. Автомобиль принимает сигнал от ваших ключей и открывает двери.
Реальная сила интернета вещей проявляется в устройствах, которые могут делать и то и другое – собирать информацию и отправлять ее, получать информацию и действовать на ее основе.
Устройства, делающие и то и другое
В сельском хозяйстве датчики могут собирать информацию о влажности почвы, но в действительности для полива фермер не требуется. Система орошения может автоматически включаться по мере необходимости, исходя из информации от датчиков влажности. Эта система может также получать из интернета прогноз погоды и не поливать, если ожидается дождь.
Интернет вещей расширяет возможности интернета за пределы компьютера и периферийных устройств. Интернет вещей предоставляет людям и компаниям возможность понимать и контролировать 99 % объектов и сред, пока еще остающихся вне досягаемости интернета. Очевидно, что огромный объем данных, генерируемых интернетом вещей, требует глубокого анализа, что приводит нас в область применения ИИ.
8.3.5.2. Шесть категорий подключенных вещей
Категории подключенных вещей: товары, оборудование, транспорт, инфраструктура, рынки и люди.
Подключенные товары
От подключенных кофеварок в потребительском сегменте до подключенных промышленных насосов – в этой категории достигается сквозная прозрачность операций. Здесь ожидаются улучшения или даже кардинальный прорыв в таких аспектах, как соответствие нормативным требованиям и сервисное обслуживание.
Подключенное оборудование
В отличие от товаров, в эту категорию входят дорогостоящие, долговечные активы, такие как самолеты и станки. Подключенное оборудование связывает производственную систему с процессами производства и технического обслуживания, чтобы сократить простои, операционные и эксплуатационные расходы.
Подключенный транспорт
К этой категории относится все движимое имущество, от грузовиков и строительной техники до судов. Их надо отслеживать, осуществлять мониторинг и обслуживание, где бы они ни находились. Получение данных о состоянии движимого имущества всегда было делом сложным и дорогостоящим, поэтому перспективы использования интернета вещей здесь огромны.
Подключенная инфраструктура
Большинство датчиков станут частью инфраструктуры интернета вещей – от сетей программного обеспечения до электросетей и зданий. Потенциал здесь заложен в цифровой операционной аналитике, с помощью которой можно трансформировать физические системы. Целью является стимулирование экономического роста, повышение уровня обслуживания и операционной эффективности, снижение рисков.
Подключенные рынки
Сюда относится любая деятельность, связанная с физическим пространством, от торговых центров до полей и городов. Интернет вещей может помочь городам, сельским районам и другим рынкам оптимизировать использование активов и природных ресурсов; сократить потребление энергии, выбросы и транспортные пробки; повысить производительность и качество жизни.
Подключенные люди
Связывая людей и сообщества, открывая компаниям возможности для создания новых бизнес-моделей и формируя новый стиль жизни, эта категория нацелена на улучшения в работе, жизни и здоровье людей.
Проблемы, связанные с подключенными вещами
Внедрение интернета вещей сталкивается с проблемами в области управления, стандартов и безопасности. К актуальным проблемам относятся:
● Управление устройствами. Как мы подключаем и отключаем устройства? Как мы управляем данными, которые устройства добровольно передают облачным платформам?
● Семантические стандарты. Как подключенные вещи описывают себя в экосистеме интернета вещей, включая такие атрибуты, как тип устройства, серийный номер, и факторы окружающей среды, такие как местоположение и температура?
● Безопасность. Не было ли устройство взломано? Прослушивалась ли передача данных? Было ли сообщение доставлено?
8.3.5.3. Архитектура интернета вещей
Начать путешествие по корпоративному или промышленному интернету вещей можно разными дорогами. Важно, чтобы кажущаяся сложность интернета вещей не заслонила потенциально очень выгодные проекты.
На следующем рисунке показана простая эталонная архитектура интернета вещей.
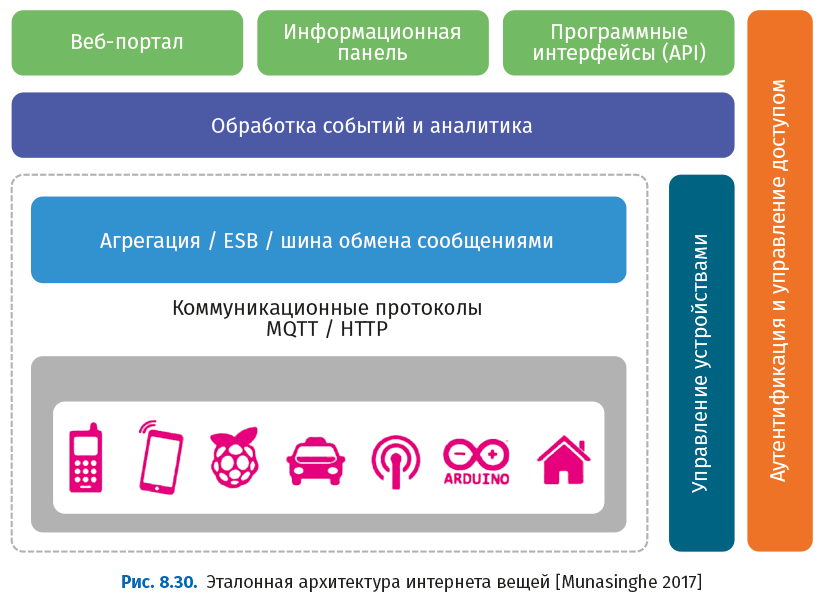
Начать стоит с закладки прочной основы для вашей системы интернета вещей.
Интернет вещей – это больше, чем подключенные к интернету потребительские устройства. Рано или поздно вашему ИТ-подразделению придется создать инфраструктуру для поддержки интернета вещей. Это подводит нас к вопросу об архитектуре интернета вещей.
Архитектурные слои интернета вещей:
● клиентские и внешние коммуникации (веб-портал, информационные панели, API);
● обработка событий и аналитика (включая хранение данных);
● уровень агрегации/шины (ESB и брокер сообщений);
● транспортный уровень (протоколы MQTT, HTTP, XMPP, CoAP, AMQP и другие);
● устройства.
Поперечный разрез:
● диспетчер устройств;
● управление идентификацией и доступом.
Инвестиции в создание подобной четырехкомпонентной архитектуры позволят поддержать множество существующих сегодня систем интернета вещей. Представьте себе эти четыре компоненты как этапы процесса, показанного на рис. 8.31. Эти этапы интегрированы и взаимно усиливают друг друга. Они доставляют данные из подключенных к сети вещей в производственные и ИТ-системы, чтобы исходя из них выполнялись определенные действия.
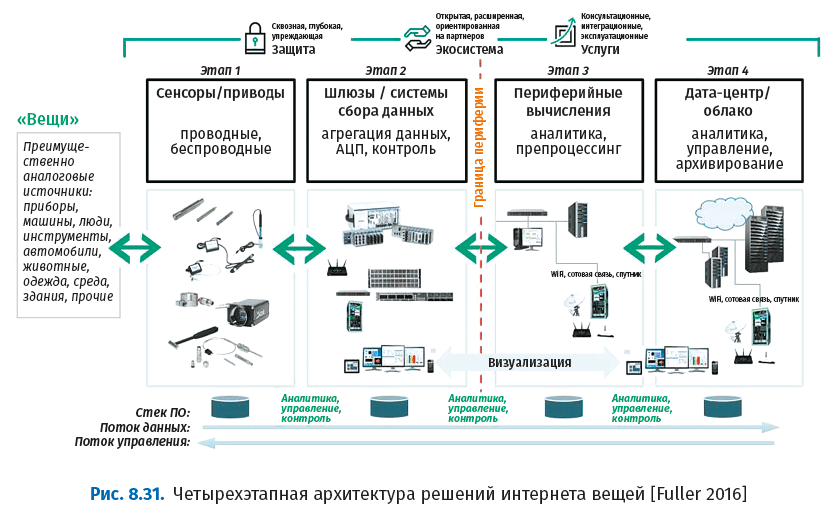
Четыре этапа архитектуры интернета вещей:
● Этап 1. Подключенные вещи – как правило, беспроводные датчики и исполнительные механизмы.
● Этап 2. Системы агрегирования поступающих от датчиков данных и аналого-цифровое преобразование данных.
● Этап 3. Периферийные ИТ-системы, выполняющие предварительную обработку данных перед отправкой их в центр обработки данных или в облако.
● Этап 4. Данные, которые анализируются, управляются и хранятся традиционными системами в центрах обработки данных.
Беспроводные датчики и исполнительные механизмы, очевидно, относятся к вотчине операционных технологов, как и этап 2 в целом. Этапы 3 и 4 обычно контролируются ИТ, при этом периферийные вычисления могут выполняться как на удаленной площадке, так и ближе к центру обработки данных. Пунктирная вертикальная линия с надписью «граница» является традиционной демаркационной линией между технологами и IT, она может быть размытой.
Интернет вещей продолжает глубоко и непредсказуемо изменять коммерческую, промышленную, научную и инженерную деятельность. Интернет вещей – это инструмент, который позволяет организациям подключать интеллектуальные технологии к вселенной объектов, генерирующих данные. Последствия для ИТ-инфраструктуры будут столь же далекоидущими.
8.3.5.4. Интернет вещей в цепях поставок
Многие стратегически мыслящие компании начинают экспериментировать с интернетом вещей, чтобы преобразовать сложные цепи поставок в полностью интегрированные сети. Например, с помощью данных от датчиков и меток RFID можно отслеживать активы, реализовать мониторинг и оповещения в режиме реального времени, чтобы в итоге оптимизировать задачи и минимизировать сбои. В более широком контексте, на основе этих данных можно сформировать бизнес-аналитику, которая поможет компании оптимизировать свою деятельность. Интернет вещей положительно сказывается на четырех аспектах цепей поставок: прозрачность, сотрудничество, активы и обслуживание клиентов.
Повышение прозрачности
Интернет вещей позволяет менеджерам цепей поставок подключать транспортные средства, другое оборудование и устройства и отслеживать статус работ в режиме реального времени. Можно добиться полной прозрачности всей цепи поставок, от склада до различных заинтересованных сторон и потребителей. Например, вместо статуса «у курьера» или «в пути» менеджер сможет увидеть точное местоположение автомобиля. На основе этой информации он сможет принять разумные и своевременные решения, направленные на максимально эффективное перемещение товаров. Дополнительный эффект для компании – снижение затрат и соблюдение нормативных требований.
Поощрение сотрудничества
Интернет вещей помогает компаниям получить целостное представление о влиянии цепи поставок на их бизнес. Это особенно важно для сложных цепей поставок, когда различные детали или узлы поставляют разные поставщики по разным маршрутам. Интернет вещей дает лицам, принимающим решения, доступ в режиме реального времени к подробной информации о статусах задач по всей цепочке, невзирая на организационные границы. Расширение сотрудничества между бизнес-функциями помогает выявлять проблемы и узкие места на более ранних этапах, принимать более разумные стратегические решения и повышать производительность.
Увеличение отдачи от активов
Постоянное подключение к сети дает возможность оптимизировать автопарк. Можно лучше выбирать маршрут и своевременно узнавать о пробках или о задержках из-за предыдущей доставки. Отслеживая коэффициент загрузки, менеджер может контролировать эффективность использования активов и оптимизировать распределение задач. Более глубокое понимание того, как используются и работают активы, обеспечивает возможность тонкой настройки бизнес-операций. Например, менеджеры цепей поставок могут планировать больше доставок или отгрузок, добиваясь более высокой производительности. Масштабирование на весь автопарк и на всю цепь поставок потенциально дает огромный прирост прибыли: исследования показали, что оптимизация маршрутизации и использования транспорта могут сократить трудозатраты водителя почти на 25 %. UPS делает это сегодня с помощью GPS-трекинга грузовиков и программного обеспечения для оптимизации маршрутов.
Улучшение обслуживания клиентов
Подключение цепи поставок к сети помогает повысить не только производительность, но и качество обслуживания клиентов. Прогнозирование доставки становится более точной наукой: менеджеры могут получить доступ к информации в офисе или через мобильное приложение и в реальном времени отслеживать местонахождение товара. Кроме этого, менеджеры могут на более раннем этапе выявлять потенциальные проблемы, связываться с клиентом, чтобы управлять его ожиданиями, и принимать альтернативные меры для обеспечения уровня обслуживания. Подключение транспортных средств позволяет автоматизировать обновление статуса для клиентов, держа их в курсе событий и сокращая тем самым количество обращений в контакт-центр.
Для любого устройства, подключенного к интернету вещей, BPM является жизненно важным элементом. С точки зрения интернета вещей BPM выполняет роль тоннеля передачи данных в процесс и из него. Выходы или результаты процесса либо дают желаемый результат, либо данные пересылаются в другие процессы или в другие устройства общей цепочки создания ценности.
При внедрении интернета вещей, как и любой новой технологии, организация должна обращать внимание на вопросы безопасности. В следующей таблице сопоставляются вопросы безопасности предприятия и безопасности интернета вещей [Acreto Staff 2019].
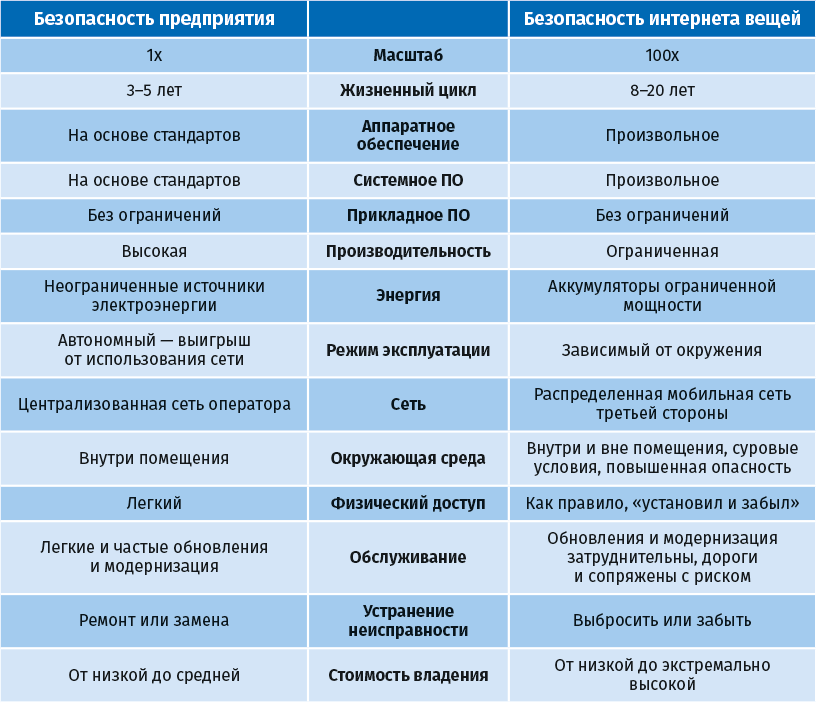
Назад: 8.2. BPMS/iBPMS
Дальше: 9. Процессная трансформация

