Двойная сеть
Двойная сеть кажется зеркальным отображением сети.
В настоящее время большинство тренингов по нейронной сети основаны на помеченных данных, то есть на контролируемом обучении. Маркировка данных является обременительной задачей. Согласно отчетам, база данных изображений с открытым исходным кодом Google, Google Open Image Datasets, содержит 9 миллионов изображений, а YouTube – 8 миллионов видео. ImageNet, самая первая коллекция фотографий, состоит из 14 миллионов объектов. Большинство данных было помечено за два года 50 000 сотрудниками на платформе трудового аутсорсинга Amazon Mechanical Turk.
Будущее направление развития искусственного интеллекта – внедрение в машину способности работать в отсутствие помеченных данных. В 2016 году на Neuro Information Processing Systems Conference доктор Цинь Тао из Microsoft Research Asia и его команда представили новую парадигму машинного обучения – двойное обучение. Общая идея:
Перевод с китайского на английский и с английского на китайский, распознавание речи и синтез речи, распознавание изображений и изображения – все они взаимосвязаны. Сгенерированный текст и сгенерированное изображение на основе текста взаимно двойственны. Вопрос и ответ взаимно противоположны. Поисковая система ищет связанные между собой веб-страницы. А ключевые слова являются взаимоисключающими. Эти дуалистические задачи ИИ могут образовывать цикл, который позволит машине учиться у немаркированных данных. Самый важный момент двойного обучения – обратная связь. Две взаимно двойственные задачи могут обеспечивать обратную связь друг другу, учиться друг у друга и улучшать друг друга.
Использование тонкой стратегии двойных сетей значительно снижает зависимость от маркированных данных, что в очередной раз подчеркивает философию эволюции: эволюция – это процесс самоотдачи и самоциркуляции, от А до Б, от Б до А. Два объекта являются зеркальными отражениями друг друга, но изображения в них не ясны – есть секреты и нет арбитража. Они могут влиять друг на друга.
Новые возможности глубокого обучения
Вышеупомянутые методы нейронной сети являются типичными представителями новых методов, которые появляются постоянно. Но ученые изучают и другие пути развития. Профессор Чжоу Чжихуа, известный специалист по компьютерному обучению Нанкинского университета, и его соавтор Фэн Вэй представили креативный алгоритм, который можно назвать алгоритм «глубокого леса» (gcForest), в статье, опубликованной 28 февраля 2017 года. Как следует из названия, алгоритм основан на традиционном дереве решений, но делает акцент на иерархии «дерева», а не на глубоком обучении и количестве слоев нейронной сети. Многоуровневые деревья решений образуют «лес». Сложные настройки алгоритма при небольших размерах данных и ресурсов распознавания изображения, звука, эмоций и т. д. не теряют результатов нейронной сети. Новый метод нечувствителен к параметрам нейросети. Кроме того, «древовидный» алгоритм легче проанализировать, чем нейронные сети. Это избавляет нас от проблемы «черного ящика» – невозможности понимания операционной логики машины.
Таблица 9-1. Сравнение точности распознавания лиц
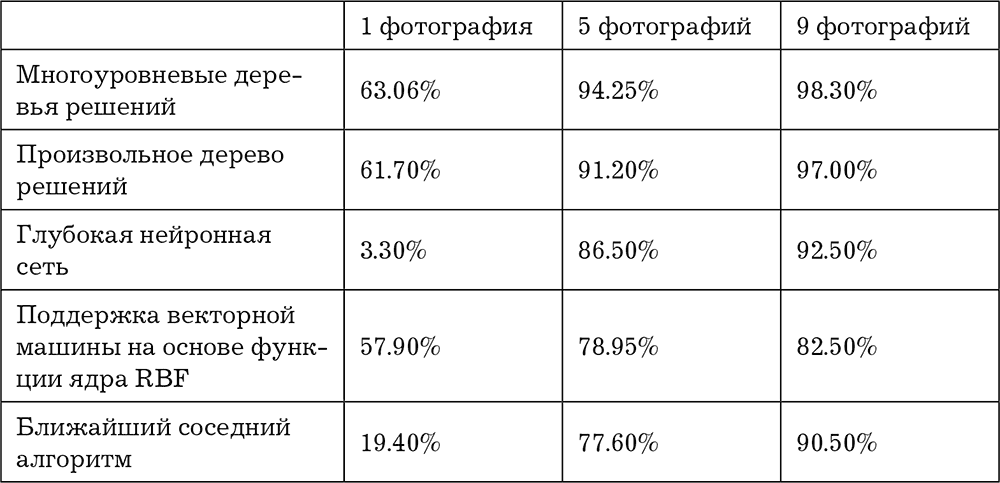
Таблица 9-2. Сравнение точности теста в базе данных GTZAN

Источник: https://arxiv.org/pdf/1702.08835.pd
Профессор Чжоу Чжихуа понимает, что методологическая значимость «глубокого леса» заключается в изучении возможности алгоритмов вне глубокой нейронной сети. Эффективная работа глубоких нейронных сетей требует огромных данных и вычислительной мощности, а «глубокий лес», скорее всего, предложит другие варианты. Конечно, «глубокий лес» использует ключевые идеи технологии нейронных сетей – способность выявлять сходства и строить модели. Поэтому он также является отраслью глубокого обучения.
Китайские исследователи добились мирового признания в области искусственного интеллекта. И мы считаем, что движущая сила научного прогресса – уверенность в себе и открытый ум.
Сегодня технологические компании занимаются разработкой алгоритмов защиты от искусственного интеллекта. Среди них лидирует платформа Google с открытым исходным кодом Tensorflow. Ученые полагают, что с экологической точки зрения должна существовать множественная платформа глубокого обучения. Конкуренция способствует процветанию и равновесию. В дополнение к платформам с открытым исходным кодом, таким как Caffe и Mxnet, в сентябре 2016 года Baidu разработала собственную платформу PaddlePaddle. Она имеет хорошую основу для последовательного и разреженного ввода, а также обучается на массивах данных. Поддержка графических процессоров, параллельных данных и моделей глубокого обучения значительно снижает стоимость технологии. Платформа позволяет обучать компьютеры и создавать разнообразные приложения. Она создает разнообразие, которое способствует развитию искусственного интеллекта.
В отдаленном будущем ИИ может стать достаточно сильным, чтобы управлять миром. Все его проблемы станут проблемами человечества. Мудрость ученых ИИ освещает дорогу опоздавшим. Даже те, кто не имеет отношения к искусственному интеллекту, должны быть в состоянии разрабатывать стратегии для вдохновения развития.
В начале 2017 года AlphaGo выиграл лучших мастеров Го из Китая и Кореи. Какими бы ни были люди: пессимистами, адвентистами, тусовщиками, научными мыслителями… Мы надеемся, что все они смогут изучить ИИ без лишних усилий.

