Отступление
Современная нехватка талантов – общая проблема. Предприятия откапывают подающих надежды специалистов в колледжах. Ученые один за другим меняют лаборатории на бизнес, чтобы реализовать свою мечту. Друг Ву Энда, ученый Бенгио (Бенсио) боится, что ученые, занятые в развитии технологии глубокого обучения, переходя на предприятия, сокращают количество талантливых людей. Компания Baidu не только занимается экспортом талантов из колледжей, но и создает условия для развития подающих надежды молодых людей с помощью стипендий для обучения в университетах.
Раздел 9. Технические особенности – искусственный интеллект бросает вызов сам себе
Роботы, заменившие людей, стали главными героями научной фантастики. Но для ученых, которые «опережают жизнь», роботы – это сегодняшние проблемы искусственного интеллекта. ИИ все еще зависит от мудрости людей.
В настоящее время данные в мире почти не контролируются. Для их классификации и расчета требуется огромное количество инноваций. Человечество еще не адаптировалось к жизни на основе данных и ритму работы крупных заводов. Это является источником глубоких противоречий.
Противоречия являются движущей силой. Сегодняшние противоречия и противоречия индустриальной революции имеют некоторые сходства.
Пример челнока и машины «Дженни» является показательным. В 1733 году изобретение челнока ускорило производство. Появилась проблема: текстильная промышленность требовала сырья – хлопчатобумажной пряжи, производить которую уже не успевали. Компенсировать низкую скорость производства пряжи можно было только за счет увеличения числа прядильных машин. В 1764 году появилась машина «Дженни», которая удвоила скорость прядения. Следом за ней один за другим последовали изобретения роторной и вращающейся прядильных машин. Тогда стала отставать технология челночного ткачества, и был изобретен гидравлический ткацкий станок. Совершенствование процессов происходило поочередно, что подстегивало развитие. Приблизительно в то же время появился паровой двигатель Ватта, и проснулась новая сфера. Промышленная революция никогда не заключалась в бесконечном потоке машин.
Как найти выход из «Ловушки Мальтуса»
Сегодняшние отношения искусственного интеллекта и данных аналогичны отношениям челнока и «Дженни». Люди стремились создать метод глубокого обучения, но страдали от нехватки данных. Интернет решил эту проблему. Но спровоцировал такой поток информации, что развития потребовали аппаратные возможности и вычислительные мощности.
Катастрофические проблемы с данными
Первые воины, которые научились использовать данные, учреждали крупные интернет-компании, такие как BAT. Гиганты поняли, как оперировать массивами данных. Alibaba раньше использовала базу данных Oracle для хранения данных. Но архитектура эпохи Internet 1.0 не выдержала взрывного роста данных электронной торговли. Компании пришлось полностью изменить инструмент, построить и использовать собственную базу данных.
До 2013 года Jingdong часто сталкивался со сбоями в работе сервера из-за роста трафика. Поэтому пришлось обновить архитектуру и заменить технологию.net на Java.
Самой запоминающейся катастрофой на интернет-рынке для китайского народа несколько лет назад стала проблема «12306». На Новый год в Китае существует традиция возвращения домой. Но большое количество населения на каждый праздник Весны создает «цифровой» коллапс. В физическом мире с человеческим потоком не справлялся транспорт. Люди толпились в поездах без всяких удобств. Со строительством высокоскоростного железнодорожного транспорта проблема была решена. Но перегрузка переключилась на сеть. Для того, чтобы упростить покупку билетов, Министерство путей сообщения запустило веб-сайт 12306. Но никто не ожидал вызова, брошенного людьми Интернету. Сайт должен был упростить покупку, но сначала породил неудобства – сотни миллионов людей одновременно запрашивали и выкупали билеты, и сервер зависал. Появились недовольные – те, кто считал, что программисты не разбираются в том, что делают. Они полагали, что электронная коммерция решит проблему.
Действительность такова, что вычислительная мощность не может идти в ногу с развитием данных. Кто-то специально сравнивал веб-сайт электронной коммерции с веб-сайтом 12306. «Double Eleven», Taobao и другие подобные сайты также принимают во внимание поведение большого числа людей. Но заказы распространяются на большое число разных товаров, корреляция между которыми очень низка. На каждый поезд приходится более тысячи мест. И каждое из них вызывает интерес десятков и даже сотен людей. Каждый раз, когда совершается покупка билета, система продажи не только анализирует все данные станций. Она подсчитывает количество выкупленных билетов и обновляет число доступных в режиме реального времени. Объем данных и вычислений растет в геометрической прогрессии. И все операции должны производиться мгновенно. Здесь нет ничего общего с электронной коммерцией. Даже дополнительные серверы не облегчат ситуацию. Решению проблемы способствовало изучение новой вычислительной архитектуры и методов.
Компания Baidu первой столкнулась с проблемой больших данных BAT. «Спроси у Baidu и будешь знать» – поиск отправляет огромное количество данных на сервер компании. Информация, растущая днем и ночью, также дает сведения об ошибках поисковой системы. Она использует предварительный поиск и поиск по ключевым и подобным словам. В режиме предварительного поиска система автоматически осуществляет поиск и корректирует результаты при низкой загруженности сервера (например, ранним утром). Когда пользователь посылает запрос и получает на него ответ, сервер не должен вновь запускать задачу поиска. Рекомендованные схожие слова тоже представляют собой систему баз данных, которая использует четкую функциональную структуру для анализа поведения пользователей. Например, вы вводите в строку поиска три буквы TPP (Trans-Pacific Partnership Agreement). Всплывающее меню порекомендует посмотреть результаты по другим схожим запросам: что означает TPP, влияние TPP на Китай, члены TPP12, протокол TPP и т. д. Разумеется, система знает, что некоторые пользователи этими буквами выражают фонетическую аббревиатуру «Купить билет» (от кит. tao piaopiao). Она будет указана в менее приоритетном положении. Выбор этих вариантов понятен и отвечает большинству потребностей пользователей.
Нижняя часть страницы поиска посвящена схожим по теме запросам, например новый Президент США, вход Америки в TPP. Результаты поиска по запросу TPP представлены на рисунке 9-1.
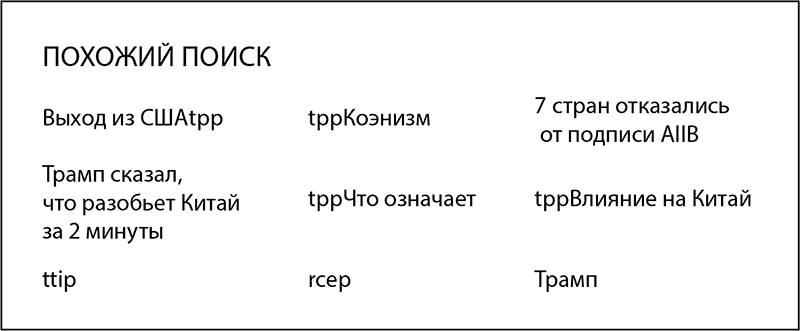
Рис. 9-1. Результаты поиска слов, связанных с TPP.
Поисковая система также составит список горячих новостей по теме TPP на основе предыдущих запросов пользователя. Такой подход очень удобен в использовании.
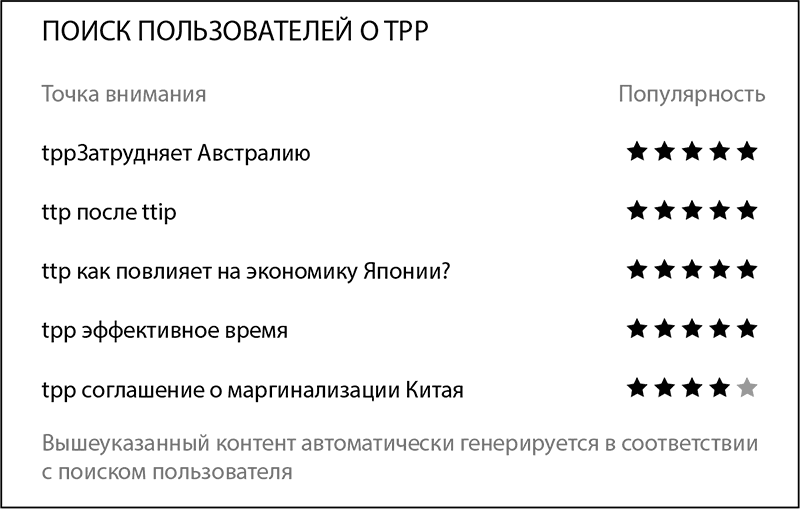
Рис. 9-2. Горячие новости по запросу TPP.
Подборка новостей формируется на основе статистики запросов пользователей. Это значительно ускоряет и оптимизирует поиск, а также облегчает обработку данных.
Проблемы, порожденные массивами данных, отличаются своими странностями. Данные не являются однородным битом. Они связаны со множеством сценариев человеческой жизни. И поэтому обработка данных сталкивается с различными проблемами. Но по сути своей это все еще противостояние челонока и «Дженни» – прогресс аппаратного обеспечения уничтожается вычислительными способностями и ростом объема данных. Аппаратные возможности удваиваются приблизительно раз в 18-24 месяца с сохранением стоимости (Закон Мура). Данные растут гораздо быстрее. Почему?

