Книга: Супермышление. Как обходить ментальные ловушки и принимать эффективные решения
Назад: Остерегайтесь закона малых чисел
Дальше: Все относительно
Кривая нормального распределения
Когда имеете дело с большим количеством данных, используйте графики и сводную статистику, чтобы бороться с информационной перегрузкой. Термином статистика на самом деле просто называют числа, которые используются для обобщения наборов данных (и математический процесс, с помощью которого генерируются эти числа). Графики и сводная статистика кратко излагают факты о наборе данных.
Вы постоянно используете сводную статистику, даже не понимая этого. Если кто-то спросит вас: «Какова температура здорового человека?» – вы, скорее всего, ответите, что 98,6 ℉ или 37 ℃. На самом деле это сводная статистика, которая называется нормой, что, как мы только что объяснили, является другим названием среднего значения.Возможно, вы даже не помните, когда впервые узнали об этом факте, и еще вероятнее, что вы даже не знаете, откуда взялась эта цифра. Чтобы высчитать эту статистику, немецкий доктор Карл Вундерлих в XIX веке собрал и проанализировал больше миллиона температур, замеренных подмышкой у 25 000 пациентов (очень много подмышек).
И все же 98,6 ℉ – это не какая-то волшебная температура. Во-первых, более свежие данные отмечают более низкую норму, ближе к 98,2 ℉ (36,8 ℃). Во-вторых, вы могли заметить, что «нормальная» температура у вас или члена вашей семьи отклоняется от этого среднего значения. На самом деле женщины в среднем немного теплее мужчин, и для них температура до 99,9 ℉ (37,7 ℃) считается нормой. В-третьих, температура человеческого тела естественным образом меняется в течение дня, повышаясь в среднем на 0,9 ℉ (0,5 ℃) с утра до вечера.
Если вы просто скажете, что 98,6 ℉ – это нормальная температура, вы не учтете всех этих нюансов. Вот почему ряд сводных статистик или графиков часто используется для каждого случая в отдельности, чтобы обобщить данные. Норма (среднее или ожидаемое значение) показывает центральную тенденцию, или место, где значения склоняются к центру. Также центральную тенденцию измеряют медиана (средняя величина, которая делит данные на две половины) и мода (наиболее частый результат). Эти статистические данные помогают описать, как будет выглядеть «типичное» число для выбранного набора данных.
Для температуры тела, простое указание центральной тенденции типа нормы временами бывает слишком простым. Это подводит нас ко второму распространенному набору сводных статистических данных, которые измеряют дисперсию, или степень рассредоточения данных.
Самая простая дисперсионная статистика показывает диапазоны. Для температуры тела это диапазоны нормальных значений, например от минимума до максимума температуры здоровых людей, как показано на графике ниже (такой график называется гистограммой).
График выше отображает частоту 130 разных температур тела, измеренных у здоровых взрослых. Такая гистограмма – это простой способ визуально суммировать данные: сгруппировать значения в столбики, сосчитать, сколько точек данных в каждом столбике, и составить график из вертикальных столбиков – столбчатую гистограмму.
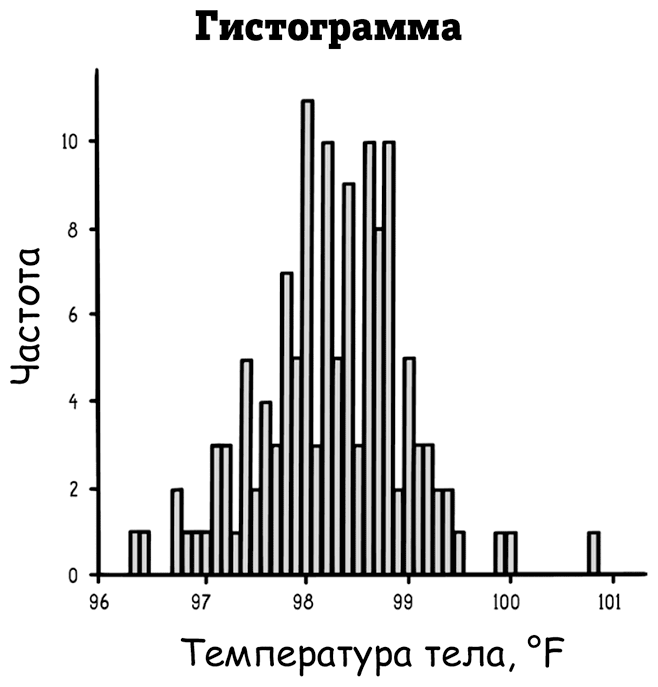
Прежде чем сообщить о диапазоне, вначале нужно найти выбросы – те точки данных, которые не соотносятся с остальными показателями. Это точки данных, которые находятся за пределами гистограммы, например температура 100,8 ℉ (38,2 ℃). Может быть, в выборку затесался больной человек. Иначе придется сказать, что нормальная температура варьируется от 96,3 до 100,0 ℉. Конечно, чем больше у вас данных, тем четче будет диапазон.
В этом наборе данных статистика центральных тенденций довольно схожа, поскольку показатели распределяются достаточно симметрично, и единственный пик наблюдается посередине. В результате нормой здесь является 98,25 ℉ (36,8 ℃), медианой – 98,3 ℉ (36,8 ℃), а модой – 98 ℉ (36,7 ℃). В других сценариях эти три сводные статистики могут существенно отличаться.
Чтобы проиллюстрировать это, ниже мы рассмотрим другую гистограмму, которая показывает распределение семейных доходов в США в 2016 году. Этот набор данных также имеет один пик, 20 000–24 999 долларов, но он асимметричен, смещен вправо. (Все доходы свыше 200 000 долларов сгруппированы в один столбик. Если этого не сделать, график будет иметь длинный хвост, уходящий далеко вправо.) В отличие от температуры тела, медианный доход в размере 59 039 долларов сильно отличается от среднего дохода в размере 83 143 доллара. Всякий раз, когда данные искажаются в одном направлении, как здесь, норма отодвигается от медианы в сторону смещения, так как ее сдвигают крайние значения.
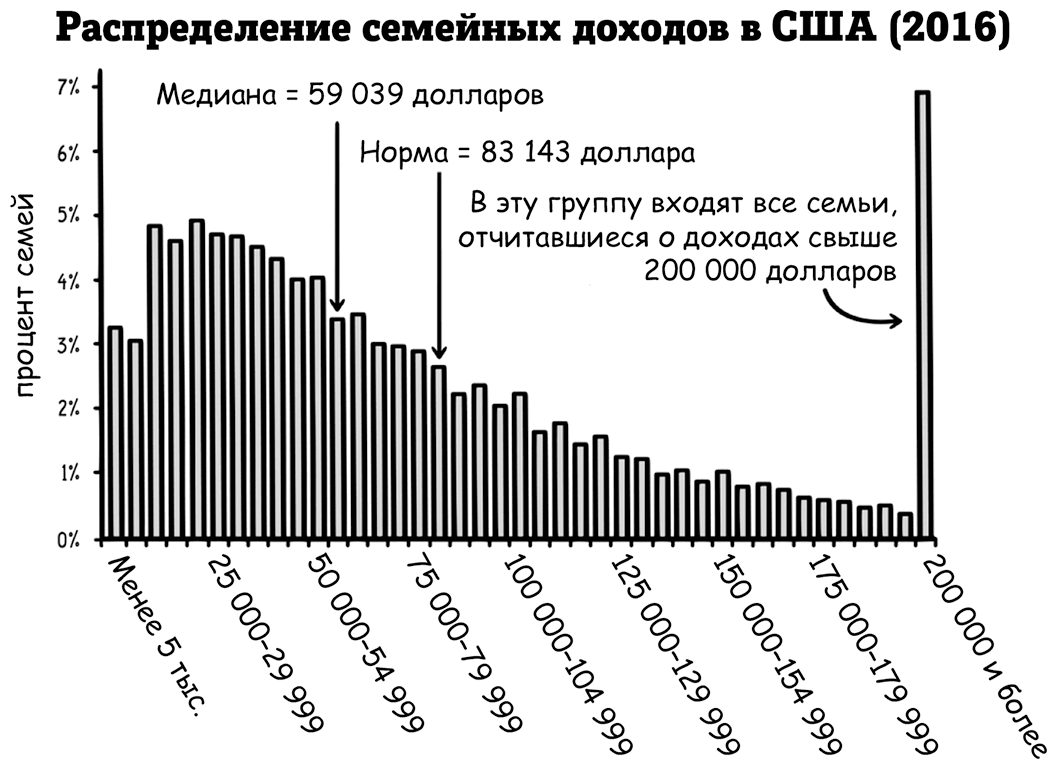
Минимальный и максимальный диапазон в данном случае менее информативны. Дисперсию лучше передает межквартильный диапазон, который определяет 25-й процентиль к 75-му процентилю данных, охватывающий средние 50 % доходов, от 27 300 до 102 350 долларов США.
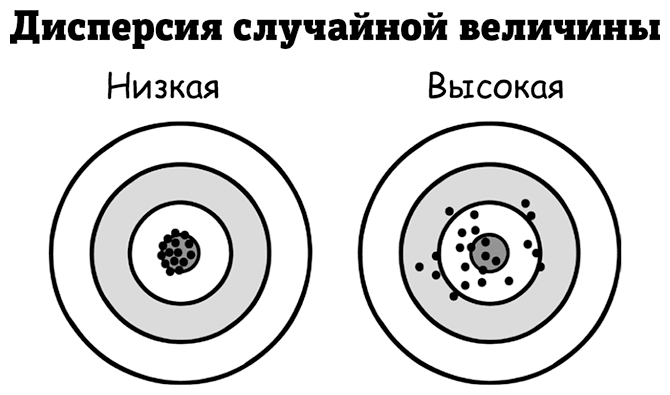
Наиболее распространенными статистическими показателями дисперсии являются дисперсия случайной величины и стандартный разброс (последнее обычно обозначается греческой буквой σ – сигмой). Обе эти меры показывают, как далеко числа в наборе данных отклоняются от нормы. Следующий пример показывает, как рассчитать их для набора данных.

Поскольку стандартный разброс – это всего лишь квадратный корень дисперсии случайной величины, если вы знаете последнюю, то вам легко будет рассчитать его. Более высокие величины каждого из них означают, что точки данных часто сильно отклоняются от нормы, как показано на мишенях ниже.
Наборы данных о температуре тела, изображенные ранее, отклоняются от стандарта на 0,73 ℉. Чуть более двух третей их значений находятся в пределах одного отклонения от нормы (97,52–98,8 ℉), 95 % – в двух отклонения от нормы (96,79–99,71 ℉). Как видите, эта закономерность является обычной для множества наборов измерительных данных (например, рост, артериальное давление, стандартизированные тесты).
Гистограммы такого типа имеют похожую форму колокола с кластером значений в центре ближе к норме и все меньшим и меньшим числом результатов по мере удаления от нормы. Когда набор данных имеет такую форму, предполагается, что он поступает из нормального распределения.
Нормальное распределение – это особый тип распределения вероятностей, математической функции, которая описывает, как распределены вероятности всех возможных исходов случайного явления. Например, если вы измерите температуру случайного человека, любой конкретный результат будет иметь определенную вероятность, при этом наиболее вероятным результатом является норма – 98,2 ℉, а величины, сильно отклоняющиеся от этой нормы, все менее вероятны. Учитывая, что распределение вероятностей описывает все возможные результаты, все вероятности в распределении сводятся к 100 % (или к единице).Чтобы лучше это понять, давайте рассмотрим еще один пример. Как мы уже упоминали, рост людей также примерно соответствует нормальному распределению. На графике ниже представлено распределение роста мужчин и женщин на основании данных Центров США по контролю и профилактике заболеваний. Оба распределения имеют типичную форму колокола, несмотря на то что стандарты роста для мужчин и женщин отличаются.
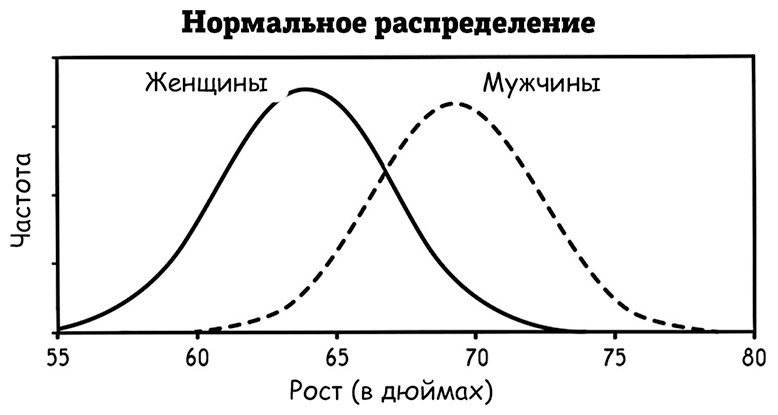
В подобных нормальных распределениях (как мы уже видели на примере температуры тела) около 68 % всех значений должны попадать в одно отклонение от нормы, около 95 % – в два и почти все (99,7 %) в три. Таким образом, нормальное распределение можно однозначно описать только его нормой и стандартным разбросом. Знание этих фактов особенно полезно, так как очень много явлений можно описать нормальным распределением.
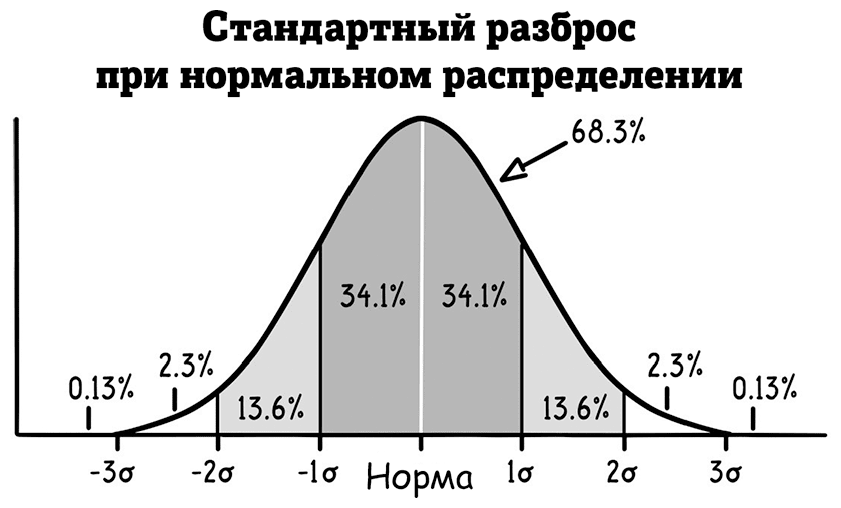
Таким образом, если вы остановите на улице случайную женщину, можно использовать эти факты, чтобы довольно точно угадать ее рост. Вариант 5 футов 4 дюйма (162 сантиметра) подойдет лучше всего, потому что это норма. Кроме того, вы можете с вероятностью приблизительно 2: 1 угадать, что ее рост будет от 5 футов 1 дюйма (156 см) до 5 футов 7 дюймов (170 см). Это связано с тем, что стандартный разброс для женского роста составляет чуть меньше 3 дюймов (8 см), поэтому около двух третей женщин будут примерно такого роста (в пределах одного отклонения от стандарта). Напротив, женщины ниже 4 футов 10 дюймов (147 см) или выше 5 футов 10 дюймов (178 см) составляют менее 5 % всех женщин (за пределами двух отклонений от стандарта).

Существует много других распределений вероятности помимо нормального распределения, которые используются в различных обстоятельствах. Некоторые из них изображены выше.
Но мы назвали этот раздел «Кривая нормального распределения», поскольку нормальное распределение особенно полезно благодаря одному из самых практичных результатов во всей статистике, который называется центральной предельной теоремой. Эта теорема утверждает, что, когда числа взяты из одного и того же распределения, а затем усреднены, полученный средний результат примерно соответствует нормальному распределению. Так получается даже тогда, когда изначальные числа взяты из совершенно иного распределения.
Чтобы понять эту теорему и ее пользу, вспомните известный опрос о рейтинге одобрения. Механика проведения таких опросов очень проста – человека спрашивают, одобряет он, например, политическую партию или нет. Это значит, что каждая точка данных сводится всего лишь к «да» и «нет».
Такой тип данных совершенно не похож на нормальное распределение, потому что каждая точка может иметь лишь одно из двух возможных значений. Подобные бинарные данные часто анализируются через другое распределение вероятностей, которое называется распределением Бернулли. Оно представляет собой результат одного эксперимента или вопроса типа да/нет, например в анкете. Такое распределение полезно в самых разных ситуациях, например при анализе рекламных кампаний (купили ли товар), в клинических испытаниях (подействовало ли лечение) и в А/В-тестировании (нажали ли кнопку).
Оценочный рейтинг одобрения – это среднее значение всех отдельных ответов (1 – одобрение, 0 – нет). Например, если было опрошено 1 000 человек и 240 ответили одобрительно, то рейтинг одобрения будет 24,0 %. Центральная предельная теорема сообщает, что это среднее статистическое значение (норма выборки) приблизительно нормально распределено (при условии, что в опросе приняло участие достаточно людей). График ниже наглядно показывает, как это работает с распределением Бернулли и двумя другими, которые тоже изначально совершенно не похожи на нормальное распределение.
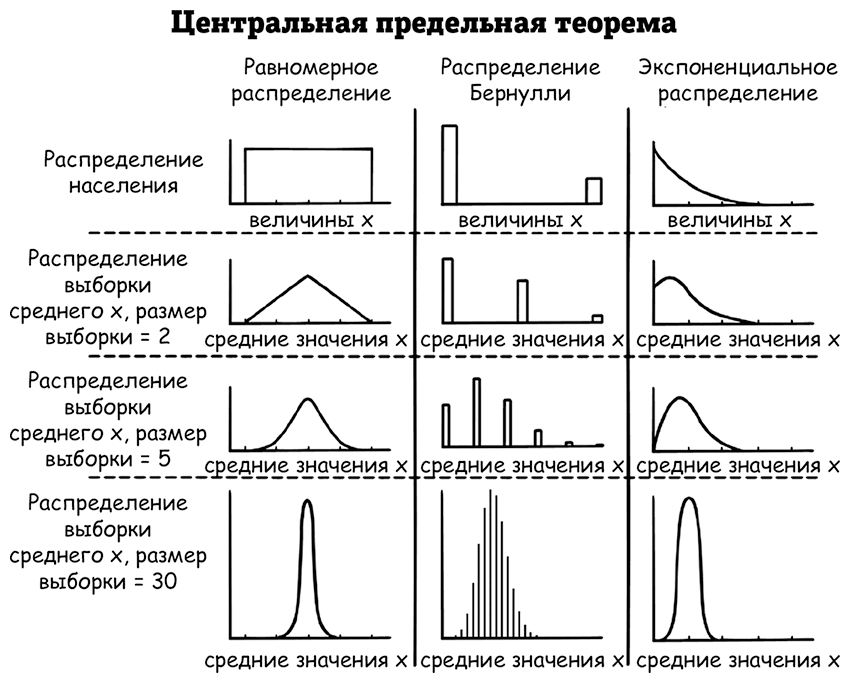
Центральный столбец показывает, что распределение нормы выборки из распределения Бернулли представляет собой серию единиц и нулей и в конце концов принимает вид колокола. Первая строка показывает распределение с 75 % шансом неодобрения (пик на 0 слева) и 25 % шансом одобрения (пик на 1 справа). Этот 25 % шанс основан на рейтинге одобрения по всей стране, если бы опросили всех до единого. Каждый человек в опросе входит в распределение населения.
Принимая участие в опросе, вы получаете лишь приблизительную оценку общего рейтинга одобрения (как приблизительные 24 %, упомянутые ранее). Когда вы так делаете, вы берете выборку из всего населения (например, опрашиваете 1 000 человек) и находите средний результат, чтобы сделать приблизительный подсчет. Эта норма также имеет распределение, которое называется распределением выборки и описывает шансы получить каждый возможный рейтинг одобрения из нее. Представим это распределение в виде графиков разных рейтингов одобрения (норм выборки), полученных из большого количества опросов.
Во второй строке показан график примера этого распределения выборки для рейтинга одобрения на основании опроса двух случайно выбранных людей. График отличается от изначального распределения, но все же совершенно не похож на нормальное, поскольку у него может быть только три результата: два одобрения (пик на 1), два неодобрения (пик на 0) либо одно одобрение и одно неодобрение (пик на 0,5).
Если вы опросите 5 человек, распределение выборки станет уже больше похоже на колокол с шестью возможными результатами (третья строка). Если опросить тридцать человек (31 результат, 4 строка), график начнет приобретать характерную форму кривой нормального распределения.
Чем больше людей вы опросите, тем больше распределение выборки будет походить на нормальное распределение с нормой в 25 % – тем самым рейтингом одобрения из распределения населения. Как и в случае с температурой тела или ростом, пока эта величина остается самой вероятной по результатам опроса. Величины, близкие к ней, будут также оставаться вероятными, например 24 %. Величины дальше и дальше от нее будут все менее вероятны, и их вероятности будут распределяться нормально.
Но насколько точна эта меньшая вероятность? Зависит от того, сколько человек вы опросите.
Чем больше будет опрошенных, тем выше будет распределение. Чтобы передать эту информацию, такие опросы обычно указывают погрешность. Статья, описывающая результаты опроса, может включать подобный текст: «Рейтинг одобрения Конгресса составляет 24 % с погрешностью ±3 %». Эти «±3 %» и есть предел погрешности, но откуда берется эта погрешность и что это вообще такое, редко объясняют. Теперь вы знаете!На самом деле допустимая погрешность – это тип доверительного интервала, приблизительного ряда чисел, которые, по вашему мнению, включают в себя истинное значение изучаемого параметра, например рейтинга одобрения. Этот диапазон обладает соответствующим уровнем доверия тому, что истинное значение параметра входит в интервал, который вы приблизительно вычислили. Например, уровень доверия 95 % подразумевает, что если вы проведете опрос много раз и подсчитаете много уровней доверия (по одному для каждого опроса), в среднем 95 % из них будет включать себя истинный рейтинг одобрения (то есть 25 %).
В большинстве сообщений СМИ не упоминают уровень доверия для вычисления погрешности, но обычно можно предположить 95 %. Напротив, в научных публикациях куда яснее пишут, какой уровень доверия был взят, чтобы показать неопределенность подсчетов (опять же, как правило, хоть и не всегда, это 95 %).
Для оценки рейтинга одобрения этот диапазон вычисляется с учетом центральной предельной теоремы: норма выборки приблизительно нормально распределена, поэтому следует ожидать, что 95 % возможных значений окажется в пределах двух отклонений от стандарта истинной нормы (то есть истинного рейтинга одобрения).
До сих пор мы не объяснили, что отклонение от стандарта в этом распределении, которое также называется стандартной ошибкой, не равно отклонению от стандарта выборки, о котором мы говорили ранее. Однако эти две величины напрямую связаны. В частности, стандартная ошибка равна отклонению от стандарта выборки, поделенному на квадратный корень размера выборки. Это означает, что,
если вы хотите уменьшить погрешность в два раза, вам нужно увеличить размер выборки в четыре. Для опроса «да/нет», как в рейтинге одобрения, погрешность 10 % при опросе 96 человек, 5 % – 384 человек, 3 % – 1067 человек и 2 % – 2401 человека. Поскольку предел погрешности выражает уверенность организаторов опроса в их подсчетах, логично, что он напрямую связан с размером выборки.Иллюстрация ниже показывает, как доверительные интервалы работают для повторных экспериментов. На ней изображены 100 доверительных интервалов со значением 95 % для вероятности выбросить решку. Каждый был рассчитан из эксперимента, который включал симуляцию броска симметричной монеты сто раз. Эти доверительные интервалы графически представлены в виде «усов», которые визуально отображают показатель неопределенности при подсчетах.
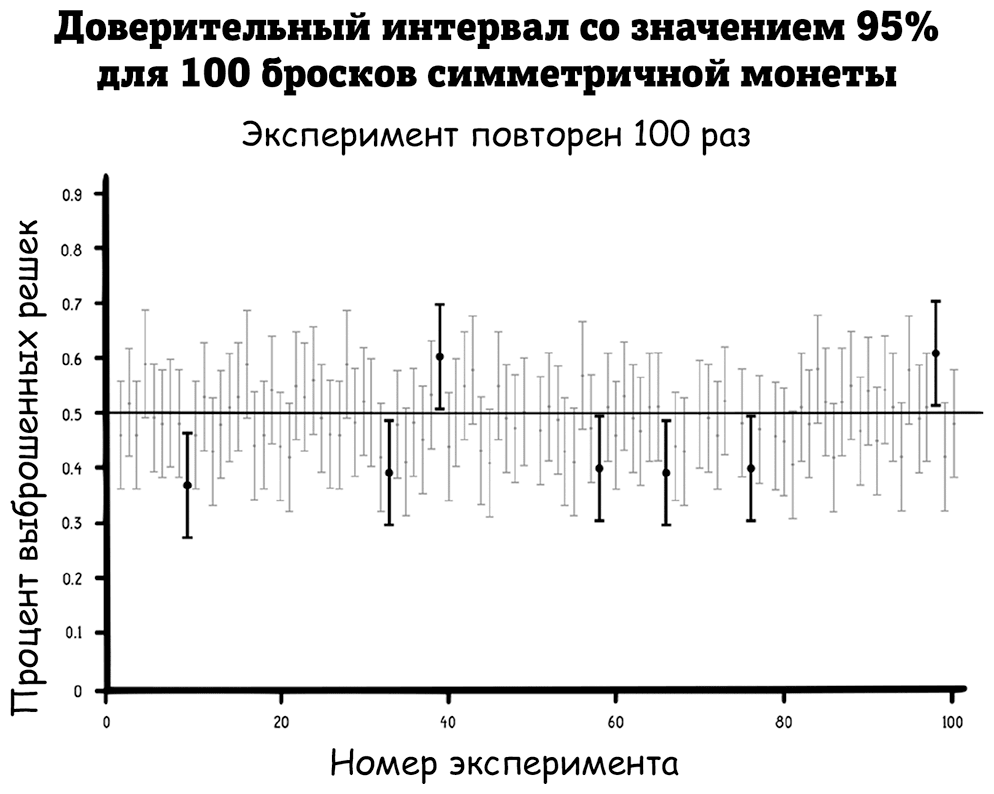
«Усы» не всегда являются доверительными интервалами. Их можно получить и из других расчетов погрешности. Точка по центру «уса» – это приблизительное вычисление параметра, в данном случае норма выборки, а линии на его концах обозначают максимум и минимум числового диапазона, в данном случае доверительный интервал.
«Усы» на графике варьируются в зависимости от того, что показали разные эксперименты, но каждый охватывает диапазон около 20 %, что соответствует ±10 %, упомянутым выше (когда размер выборки – одна сотня бросков). Учитывая уровень доверия 50 %, можно ожидать, что 95 этих доверительных интервалов будут включать в себя истинную норму в размере 50 %. В данном случае 93 интервала включают в себя 50 % (7 интервалов, не включившие в себя эту величину, выделены черным).
Такие доверительные интервалы часто используются для вычисления разумных значений параметра, такого как вероятность выбросить решку. Но, как вы только что видели, истинная норма параметра (в данном случае 50 %) иногда выходит за рамки доверительного интервала. Нужно понимать, что доверительный интервал – это не диапазон всех возможных величин и истинная величина необязательно будет входить в него.
Нас очень беспокоит, когда статистические данные публикуются в СМИ без упоминания погрешностей или доверительных интервалов. Не забывайте искать их, когда читаете отчеты, и включайте их в собственную работу. Без оценки погрешности вы не поймете, насколько можно верить этому числу – будет ли истинная величина действительно близка к нему или, может быть, очень от него далека? Это вам подскажет доверительный интервал!
Назад: Остерегайтесь закона малых чисел
Дальше: Все относительно

