Измельчители книг
В библиотеке жизни бродит зверь — химера под названием «цифровые гуманитарные науки». У нее тело литературного критика, голова статистика и растрепанная шевелюра Стивена Пинкера. Кое-кто полагает восторженно, что это всполох света в темной пещере. Другие презирают ее, как слюнявую собаку, вонзившую клыки в первое издание «Госпожи Бовари». Чем же занимается это существо? Просто превращает книги в набор данных.
1. Что теоретически может пойти не так?
В прошлом году я прочел замечательную книгу Бена Блатта «Любимое слово Набокова — лиловый», в которой тексты великих прозаиков анализируются с помощью статистических методов. Первая глава («Будьте умеренны») исследует известное клише — совет начинающим писателям: «Избегайте наречий». Стивен Кинг, например, однажды сравнил наречия с сорняками и предупредил: «Дорога в ад вымощена наречиями». Итак, Блатт подсчитал количество наречий, оканчивающихся на -ly (firmly — «непоколебимо», furiously — «яростно» и т.д.), в произведениях различных авторов. Вот что он обнаружил:
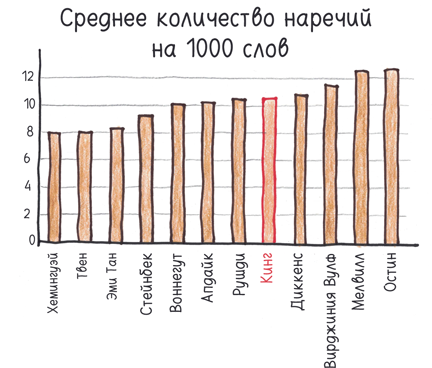
Пристрастие к наречиям, свойственное Джейн Остин, чьи романы входят в золотой фонд англоязычной прозы, казалось бы, убедительно опровергает такую точку зрения. Однако затем Блатт указал на забавную закономерность. Если взять весь корпус произведений того или иного автора, реже всего наречия встречаются в их величайших романах.
(Как измерялось «величие», рассказано в примечании.)
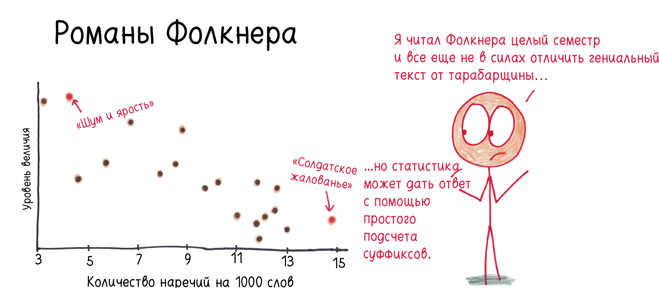
В каком романе Фрэнсиса Скотта Фицджеральда реже всего встречаются наречия? «Великий Гэтсби». А у Тони Моррисон? «Возлюбленная». Как насчет Чарльза Диккенса? «Повесть о двух городах», на втором месте «Большие надежды». Разумеется, есть исключения (Набоков чаще всего употребляет наречия в «Лолите», а эта его книга снискала, пожалуй, наибольшее признание), но тенденция ясна. Чем реже встречаются наречия, тем яснее и сильнее проза. Высокая частотность наречий свойственна рыхлым текстам второго эшелона.
Мне вспоминается, как однажды в колледже мой сосед по комнате Нилеш с улыбкой заметил: «Знаешь, что мне по душе? Ты очень часто говоришь “теоретически”. Это одно из твоих фирменных словечек».
Я оцепенел. Я задумался. И в тот момент слово «теоретически» исчезло из моего лексикона.
Нилеш оплакивал эту потерю месяцами, а я боролся с чувством вины за то, что предал сразу двух друзей: и слово, и соседа. Я ничего не мог с собой поделать. Призрак в моем мозгу, превращающий смыслы в слова, действует инстинктивно и расцветает в тени. Привлечение внимания к определенному слову отпугнуло призрака. Он пошел на попятную.
Когда я ознакомился со статистикой Блатта, ситуация повторилась. С тех пор я стал параноидально избегать наречий, превратился в неутомимого беглеца, опасаясь, что наречия проникнут в мою прозу, словно пауки залезут в рот, пока я сплю. Я признаю, что это ходульный, неестественный подход к языку, не говоря уже о том, что это наивный подход к статистике: корреляция еще не означает причинно-следственной связи. Но я ничего не могу с собой поделать. Таковы посулы и опасности цифровых гуманитарных наук, таковы они все до мозга костей (кстати, думаем-то мы другим мозгом, головным). Если рассматривать литературу всего лишь как наборы слов, то она, безусловно, содержит огромный массив данных. Но наборы слов — это еще не литература. Статистика устраняет контекст. Ее анализ начинается с уничтожения смысла. Будучи поклонником статистики, я доверяю ей. Будучи любителем книг, я содрогаюсь. Возможен ли компромисс между роскошью литературы и ледяной аналитической силой статистики? Или, как я часто опасаюсь, они прирожденные враги?
2. Да здравствуют статистики, борцы за демократию!
В 2010 году 14 ученых (под руководством Жан-Батиста Мишеля и Эреза Либермана Эйдена) опубликовали статью под названием «Количественный анализ культуры на основе миллионов оцифрованных книг», вошедшую в горячую десятку поисковой выдачи. Всякий раз, прочитывая первую фразу этой статьи, я не могу удержаться от возгласа: «Че-е-е-е-ерт!» Она начинается так: «Мы создали корпус оцифрованных текстов, включающий около 4% всех когда-либо опубликованных книг».
Че-е-е-е-ерт!
Как и все статистические проекты, это исследование потребовало кардинального упрощения. Первый шаг авторов заключался в том, что они разъяли весь набор данных (пять миллионов книг, около 500 миллиардов слов) на так называемые 1-граммы. Они поясняют этот термин: «“1-грамма” — это набор символов, не прерываемых пробелом: слова (“банан”, “скуби-дайвинг”), но, кроме того, числа (3,14159) и опечатки (“чересчурр”)».
Предложения, абзацы, тезисы — все это исчезает. Остаются лишь мельчайшие фрагменты текста.

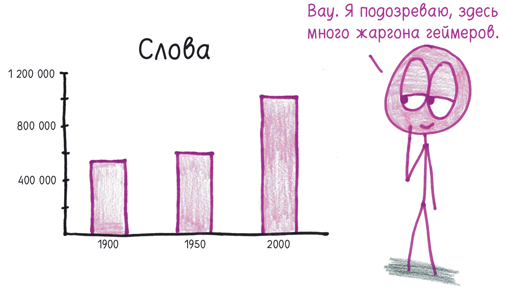
Дабы исследовать данные глубже, авторы составили перечень 1-грамм, встречающихся с частотой не менее чем один раз на миллиард. Если оценить начало, середину и конец XX столетия, мы увидим, что словарный запас англоязычных авторов растет.
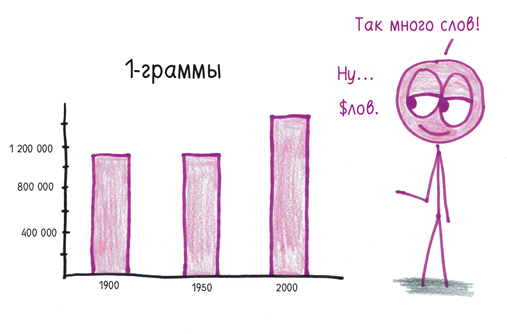
Выяснилось, что реальные слова на 1900 год составили меньше половины 1-грамм (по большей части это оказались числа, опечатки, аббревиатуры и т.д.), в то время как на 2000 год больше двух третей 1-грамм были именно слова. Проведя ручной подсчет в избранных фрагментах корпуса, авторы установили общее количество английских слов на каждый год.
Затем, сопоставив массив 1-грамм с двумя популярными толковыми словарями, они обнаружили, что лексикографы с трудом успевают следить за разрастанием массива слов и держать руку на пульсе. В частности, словари упускают большую часть редких 1-грамм.
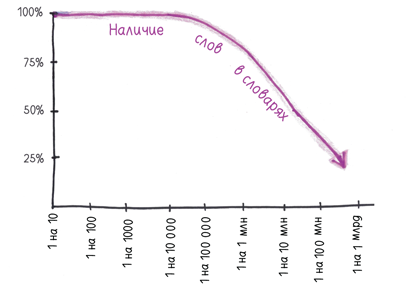
В тех текстах, которые читаю я, эти слова, не входящие в словари, почти не встречаются. Причина в том, что эти слова… ну… исключительные. Язык заселен тьмой никому не известных конструктов, встречающихся с частотой один раз на сто миллионов. В целом, по оценке авторов, «52% всего английского лексикона (большинство слов, встречающихся в англоязычных книгах) состоят из лексической “темной материи”, упущенной в стандартных словарных статьях». Лексикографы просеивают тысячи тонн словесной руды, пропуская драгоценные камни наподобие «slenthem» (яванский металлофон).
Изучение лексикона было всего лишь разминкой для этих исследователей. Авторы продолжили изучать эволюцию грамматики, перепады популярности словоупотребления, признаки цензуры и переменчивые закономерности исторической памяти. Все это изложено лишь на дюжине страниц; в основном в статье представлены результаты отслеживания частотности тщательно выбранных 1-грамм.
У читателей отвисли челюсти. Редакция журнала Science, понимая масштабы происходящего, выложила статью в открытый доступ. «Новое окно в культуру», — провозгласила газета The New York Times.
Литературоведы склонны изучать привилегированный канон, тонкий слой элитных авторов, требующих глубокого, сосредоточенного анализа. Морррисон. Джойс. Кот, который улегся на клавиатуру Джойса и набрал «Поминки по Финнегану». Но исследователи выбрали иную модель: обширнейший корпус, в котором внимания заслуживает весь массив книг, от знаменитых до малоизвестных. Статистике удалось свергнуть олигархов и установить демократию.
Теперь нет причин, по которым оба подхода не могут идти рука об руку. Внимательное чтение и статистика. Канон и корпус. Тем не менее такие фразы, как «высокоточное измерение», указывают на конфликт. Может ли смысл литературы быть измерен с высокой точностью? Насколько он в принципе поддается измерению? Или эти новые мощные инструменты уводят нас прочь от неведомых глубин искусства и мы просто забиваем гвозди микроскопом?
3. Эта фраза написана женщиной
Я склонен думать, что проза андрогинна. Мои тексты андрогинны, как морская губка, тексты Вирджинии Вулф — как галактика или божественное откровение. Но сама Вирджиния в книге «Своя комната» высказывает другую точку зрения. К 1800 году, утверждает она, преобладающий литературный стиль стал приютом мужских, а не женских мыслей. В темпе и структуре самой прозы было нечто гендерное.
Эта идея крутилась у меня в голове несколько месяцев, пока я не набрел на онлайн-проект под названием «Под волшебным соусом». Помимо прочих алгоритмических подвигов, программа может прочесть выдержки из ваших текстов и с помощью таинственного анализа идентифицировать ваш пол.
Я обязан был попробовать.

В интернет-угаре я потратил час на копипаст 25 записей в блоге, написанных с 2013 по 2015 год. В итоге результаты выглядели следующим образом:
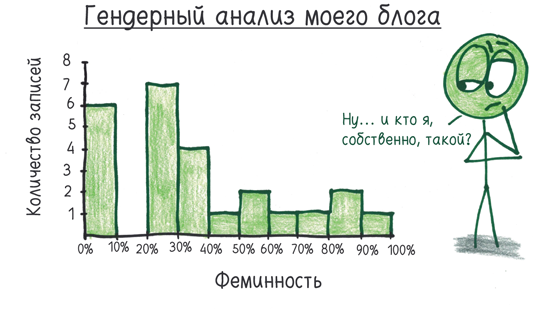
Поскольку команда проекта «Под волшебным соусом» сохраняет свою методику в секрете, я попытался разведать, каким образом может работать этот алгоритм. Он строит схему моих предложений? Вынюхивает скрытую патриархальность моих чувств? Проникает в мои мысли (полагаю, на это была способна Вирджиния Вулф), читая в книгах, словно в душах?
Нет. Скорее всего, он просто смотрит на частотность слов.
В статье «Автоматизированная гендерная классификация письменных текстов», опубликованной в 2001 году, три исследователя ухитрились добиться 80% точности, отличая авторов-мужчин от авторов-женщин, просто за счет подсчета частотности употребления нескольких простых слов. Более поздняя статья, озаглавленная «Пол, жанр и стиль письма в официальных письменных текстах», содержит изложение этого отличия в простых терминах. Во-первых, мужчины используют больше определяющих слов при существительных (определенный и неопределенный артикль, «некоторый», «самый» и т.д.). Во-вторых, женщины используют больше местоимений («мне», «он сам», «наш», «они» и т.д.).

Даже частотность одного-единственного невинного слова «ты» дает ключ к пониманию пола автора:
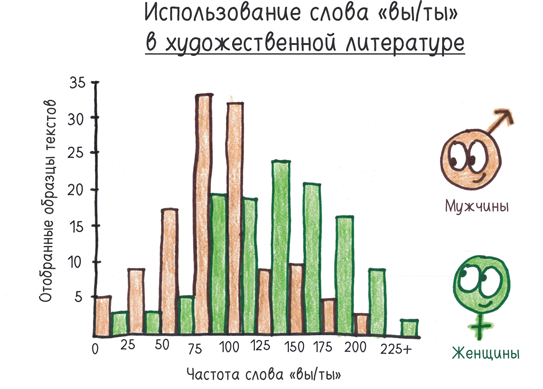
Точность системы особенно впечатляет, если учесть ее абсолютную простоту. Этот подход игнорирует весь контекст, весь смысл, чтобы сосредоточиться на словесных щепках. Блатт отмечает, что в соответствии с этой методикой фраза «Эта фраза написана женщиной», скорее всего, будет классифицирована как написанная мужчиной. Если вы посмотрите шире и будете учитывать все слова, а не только крошечные вспомогательные, результаты станут стереотипными. Когда компания по сбору данных под названием CrowdFlower обучила алгоритм определять пол пользователей Твиттера, он выдал следующий перечень слов, позволяющих предсказать пол:

В книге «Любимое слово Набокова — лиловый» Бен Блатт приводит свои изыскания по поводу маркеров пола автора в классической литературе:

Похоже, программа «Под волшебным соусом» тоже использует такого рода подсказки. Когда математик Кэти О’Нил опробовала этот алгоритм на текстах мужчин о моде, они определились как женские на 99%. А тексты женщин о математике оказались якобы на 99% мужскими. Три текста самой О’Нил оказались мужскими на 99%, 94% и 99%. «Моя выборка мала, — пишет она, — но я готова поспорить: эта модель основана на том стереотипе, что можно определить пол автора по выбранной им теме».
Несмотря на то что эти алгоритмы неточны, у меня по-прежнему холодок бежит по коже. Похоже, маскулинность настолько пронизала мои мысли, что алгоритм может выявить мой пол двумя независимыми путями: определив, насколько часто я использую те или иные местоимения или насколько нежно я привязан к Евклиду.
Я отдаю себе отчет, что в некотором роде все это оправдывает мнение Вирджинии Вулф. Она видела, что мужчины и женщины живут в разных мирах, и верила: борьба за то, чтобы дать голос женщинам, должна начаться на всех уровнях, вплоть до построения фразы. Грубая статистика подтверждает эту точку зрения: женщины пишут иначе, чем мужчины, и выбирают другие темы. И все же я немного удручен. Если тексты Вирджинии Вулф свидетельствуют о ее женственности, то мне нравится думать, что это связано с ее мудростью и чувством юмора, а не с низкой плотностью определителей при существительных. Когда Вирджиния Вулф разграничивает мужскую и женскую прозу, возникает ощущение, что ты обратился к проверенному врачу. Когда то же самое проделывает алгоритм, кажется, что тебя обыскивают в аэропорту.
4. Дом, кирпичи и известь
«Записки федералиста», написанные в 1787 году, помогли задать американскую форму правления. Они полны политической мудрости, изощренной аргументации и неустаревающих афоризмов («зрелище смут и раздоров» — вы оценили?). Это могло бы стать убойной строчкой в резюме, но есть одна загвоздка.
Авторы не подписали свои имена.
Историки смогли установить, что 43 письма написаны Александром Гамильтоном, 14 — Джеймсом Мэдисоном, пять — Джоном Джеем и еще три письма написаны в соавторстве. Однако оставалось тайной, кто авторы еще 12 писем. Гамильтон или Мэдисон? Даже два века спустя головоломка не была разгадана.
Наступили 1960-е годы, и на сцене появились два специалиста по статистике: Фредерик Мостеллер и Дэвид Уоллес. Фред и Дейв осознали всю тонкость проблемы. Предложения, написанные Гамильтоном, состояли в среднем из 34,55 слов; написанные Мэдисоном — в среднем из 34,59 слов. «По некоторым параметрам, — пишут исследователи, — авторы почти что близнецы». И дальше они сделали шаг, который совершают все специалисты по статистике, когда сталкиваются с изощренной проблемой.
Они порезали «Записки федералиста» на мелкие куски.
Контекст? Неважен. Смысл? Уничтожен. Пока «Записки» оставались набором текстов отцов-основателей, они были бесполезны. Они должны были стать клочками бумаги, совокупностью тенденций — иными словами, набором данных.
Даже после этого большинство слов оставались бесполезными. Их частотность зависела не от автора, а от темы. Например, «война». «Когда речь шла о вооруженных силах, частота предсказуемым образом была высокой, — пишут Фред и Дэйв. — Когда речь шла о выборах — низкой». Они присвоили таким словам статус «контекстуальные» и предприняли все усилия, чтобы избавиться от них. Они были слишком осмысленными.
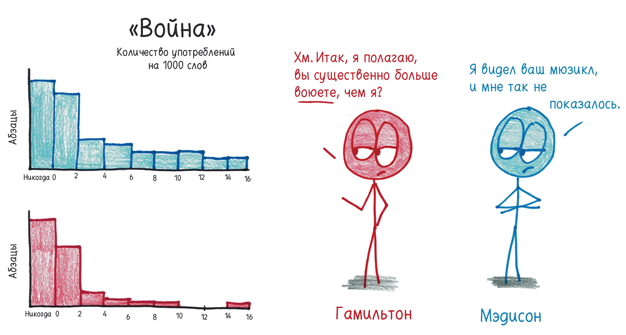
Их поиски лишенных смысла слов увенчались успехом, когда они взялись за предлог upon («на основании»), который Мэдисон не употреблял почти никогда, а Гамильтон при каждом удобном случае:
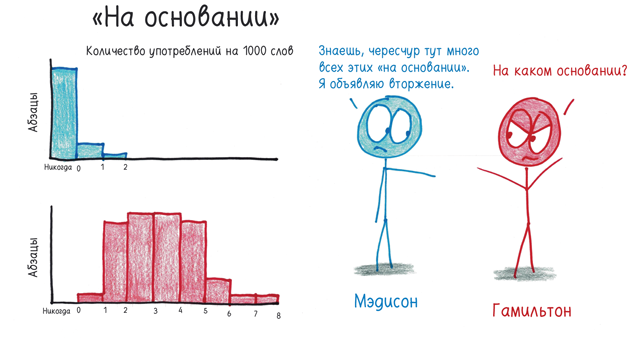
Вооруженные этими данными, Фред и Дейв смогли свести каждого автора к чему-то вроде колоды карт, раздающей те или иные слова с предсказуемой вероятностью. Затем, отследив частотность определенных слов в письмах с неустановленным авторством, они смогли узнать, из какой «колоды» взят каждый текст.
Метод сработал. Их вывод: «Практически наверняка эти 12 писем написаны Мэдисоном».
Полвека спустя эта технология стала стандартной. Она помогла установить авторство древнегреческой прозы, сонетов елизаветинцев и речей Рональда Рейгана. Бен Блатт применил этот алгоритм около 30 000 раз, используя 250 общеупотребительных слов, чтобы определить, кто из двух авторов написал определенную книгу. Он получил 99,4% верных ответов.
Мой разум знает, что здесь нет подвоха. Но мои чувства бунтуют. Как можно понять книгу, измельчив ее на биты?
В 2011 году команда авторов из Лаборатории литературоведения Стэнфорда совершила ловкий кульбит: они идентифицировали уже не авторов, а жанры. Они использовали два метода: анализ частотности употребления слов и более изощренный анализ на уровне предложений (под названием «Докускоп»). К их удивлению, оба метода позволили точно определять жанры текстов.
Присмотримся к фрагменту абзаца со страницы, которую компьютер счел наиболее «готической» во всем корпусе, включающем 250 романов:
Он шел по шатким плитам через двор, пока не достиг арки; здесь он остановился, ибо ему снова стало страшно. Однако, набравшись храбрости, он пошел дальше, все еще пытаясь следовать за той фигурой, и внезапно оказался в разрушенном зале, вид которого был более диким и пустынным, чем все увиденное им до сих пор. Охваченный непреодолимым ужасом, он направился обратно, но услышал ослабший измученный голос. Сердце замерло при этом звуке, его бросило в дрожь, и он был совершенно не в силах сойти с места. Звук, похожий на предсмертный стон, повторился…
У меня ползут мурашки по спине, и на то есть две причины. Во-первых, вся эта жуткая готика: разрушенные арки и предсмертные стоны. Во-вторых, жутковато, что компьютер распознал готическую атмосферу, даже не обратив внимания на слова «арка», «разрушенный» или «предсмертный стон». Он выделил этот отрывок на основе употребления местоимений, вспомогательных слов и глагольных конструкций.
Я нервничаю. Что такого знает алгоритм, чего не знаю я?
К моему облегчению, авторы высказали предположительный ответ. Нет ни одного элемента, позволяющего определить автора или жанр, ни одной уникальной черты, из которой следуют все остальные. Скорее проза имеет много отличительных черт, от галактической структуры романа до молекулярной структуры слогов. Статистические тенденции и глубокий смысл могут сосуществовать, живя бок о бок в одной и той же последовательности слов.
Большую часть времени я читаю ради архитектуры текста. Сюжет, тема, персонаж. Это высокоуровневая структура: аспекты, которые видны любому прохожему, но непроницаемы для статистики.
Если я присмотрюсь, то увижу кирпичную кладку. Клаузулы, конструкции предложений, оформление абзаца. Это микроуровневая структура, тщательно исследовать которую меня учили школьные учителя английского. Компьютер может научиться делать то же самое.
Есть и скрытая от глаз наноструктура: известь. Местоимения, предлоги, неопределенные артикли. Это строительный раствор, который скрепляет все вместе; он не заметен невооруженным глазом, но идеально подходит для химического статистического анализа.
Я знаю, что это всего лишь метафора, но призрак в моей голове говорит на языке метафор. Я воодушевленно подсчитал частоту употребления наречий в первой главе этой книги («Думать как математик»). Получилось 11 наречий на 1000 слов — почти как у Вирджинии Вулф, что я воспринял как благое знамение. Затем, не в силах удержаться, я убрал несколько наречий, пока их частота не снизилась до 8 на 1000 слов. Это уровень Хемингуэя и Тони Моррисона.
Я жульничал, и это было здорово.
Могут ли новые статистические методы гармонично сочетаться со старыми, более насыщенными, более человечными способами понимания языка? Да, теоретически.

