Советы по прогнозированию дохода
Поговорим о каждом способе отдельно, оформив их в виде советов начинающим аналитикам.
Совет 1. ARMA, ARIMA
О сезонности мы достаточно много поговорили в предыдущем разделе, а здесь давайте обратимся к методам ARMA и ARIMA.
Эти модели являются развитием модели авторегрессии. Собственно, авторегрессия входит в них, и AR в их названиях как раз ее и обозначает. А MA обозначает скользящее среднее (Moving Average), и это говорит нам о том, что данные модели еще глубже проникают в данные, лучше распознавая их внутренние закономерности.
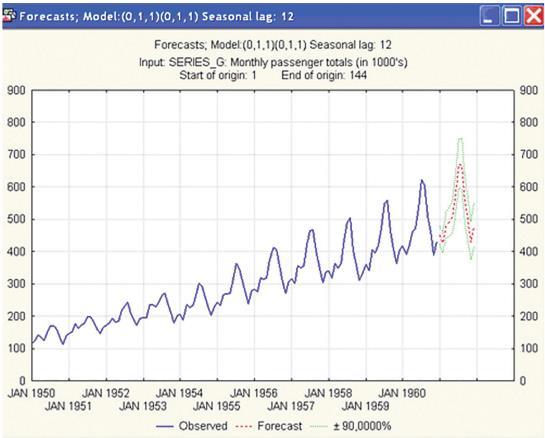
Пример реализации модели ARIMA в пакете Statistica
В Excel реализовать их уже не так просто (хотя уже есть соответствующие надстройки), но по-прежнему возможно. Лучше всего, конечно, воспользоваться статистическими инструментами. Я бы рекомендовал SPSS или Statistica, но моя рекомендация базируется всего лишь на опыте личного использования. Также, конечно, есть соответствующие пакеты на R и Python.
Как правило, ARMA и ARIMA дают прогнозы более точные, чем простая авторегрессия, но прирост точности уже не так велик, как у авторегрессии по сравнению с трендами и сезонностью. Поэтому если вам нужен быстрый прогноз, то в сторону ARMA и ARIMA можно не копать.
Совет 2. Не забывайте о регрессионных моделях
Вообще регрессия – метод довольно универсальный. Его преимущество перед временными рядами в том, что в случае временных рядов вы делаете прогноз только на основании значений дохода за предыдущие периоды, а в регрессионных моделях вы рассматриваете еще и другие метрики.
Случай из жизни
Однажды, еще до того, как я обосновался в игровой индустрии, я работал с администрацией города. Я сделал красивую и вполне точную модель прогнозирования чего-то (уже и не упомню), связанного с налогами, а значит, пополняющего городскую казну. На презентации модели собралось много городских чиновников, и к ним вышел я. Вчерашний выпускник, несколько волнуюсь, надел красивый костюм и выучил речь. Модель была, конечно же, регрессионная, я о ней рассказал и перешел к тем перспективам, которые откроются чиновникам, если они внедрят мою модель.
Но что-то пошло не так. А именно то, что я был прерван одним из чиновников, который, надо сказать, довольно возмущенно сказал: «Погодите! А почему модель у вас регрессионная? У нас ведь город прогрессивный, и мы смотрим в будущее, а вы тут о регрессе, понимаешь ли!»
Смех смехом, но для меня это стало уроком. Не стоит переоценивать того, насколько люди действительно говорят с тобой на одном языке и владеют той же терминологией, что и ты. В частности, чаще всего ответом на вопрос «Знакомы ли вы с математикой и статистикой?» будет: «Ну, когда-то изучали», а поэтому никогда не будет лишним заранее проговорить основы и раскрыть те термины, которые собираешься использовать.
Существует несколько способов посчитать доход. Например, доход – это аудитория, умноженная на ARPU (доход с пользователя). Аудитория – количественная метрика, она говорит о масштабе проекта, на нее сильно влияет трафик. А доход с пользователя – метрика качественная, говорящая о том, насколько ваши пользователи готовы платить. И эти метрики можно и нужно рассматривать и прогнозировать отдельно: они ведут себя по-разному и на них влияют разные факторы.
Похожие рассуждения можно проделать, рассмотрев и другую формулу дохода: платящие пользователи, умноженные на доход с платящего (ARPPU). Да и вообще, теоретически можно «скормить» регрессионной модели все имеющиеся у вас метрики, пускай сама все считает и находит закономерности.
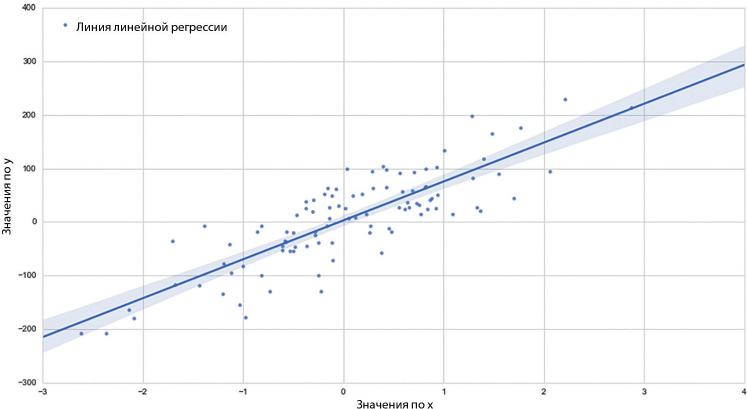
Пример реализации линейной регрессии на Python
Буквально несколько советов.
– Если это возможно (в Excel – не всегда), то включайте в модель только значимые переменные. Если вы даете на вход сто метрик, то необязательно все они должны участвовать в итоговом уравнении.
– Старайтесь, чтобы метрики, которые вы даете на вход, были максимально независимы друг от друга и слабо коррелировали. В противном случае вы рискуете получить неустойчивый результат (который хорошо повторит ваши исходные данные, но будет выдавать что-то странное, когда речь пойдет о прогнозе).
– Изучайте остатки. Если вы изучали регрессию в вузе, то наверняка помните страшное слово «гетероскедастичность» – речь о ней самой. Если вы все сделали правильно, то, взглянув на график остатков, вы ничего не сможете сказать: там будет непредсказуемая случайная величина с математическим ожиданием, равным нулю. Если же вы видите в остатках какую-то закономерность (допустим, синусоиду), то, возможно, вы как раз нарвались на гетероскедастичность – то есть не учли дополнительную логику, по которой распределены данные. И в этом случае вам надо просто изменить уравнение регрессии, добавив в него неучтенное уравнение (в нашем случае – синусоиду).
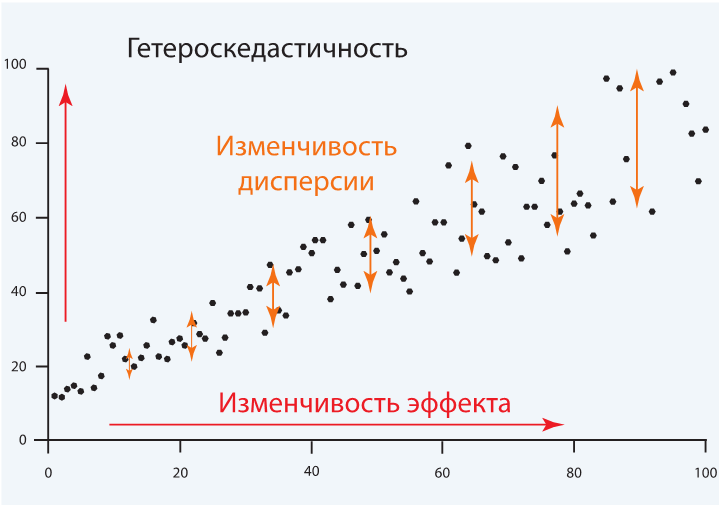
Пример гетероскедастичности: на графике остатков видно, что в них наблюдается как минимум линейная закономерность. Стоит перестроить уравнение регрессии
Совет 3. Стройте кастомные модели под свой проект
На временных рядах и регрессии свет клином не сошелся. Вы всегда можете строить свои модели, учитывающие логику вашего продукта.
Вот вам пример модели, которую люблю строить я.
– Мы можем посчитать, сколько пользователей в данный момент проживает свой первый, второй, третий и т. д. месяц в проекте.
– Мы можем посчитать процент пользователей, которые остаются активными и на второй месяц. А также процент перехода из второго месяца в третий и т. д.
– Наконец, мы можем посчитать, сколько в среднем платит пользователь, уже N-й месяц живущий в проекте, в течение этого месяца. Иначе говоря, ARPU месяца.
Этого достаточно, чтобы построить модель: вы будете знать, как ваши пользователи «перетекают» из месяца в месяц и сколько они платят. К слову, необязательно месяц: можно год, неделю или теоретически даже день (хотя день я не пробовал, надо признать) – любой значимый для вас период в зависимости от того, сколько пользователи живут в вашем проекте.
С помощью такой модели вы легко можете планировать вливания трафика, надо лишь увеличить число новых пользователей в конкретный месяц.

