Книга: Машина эмоций
Назад: 5.6. Самоосознанная рефлексия
Дальше: 5.8. Представление воображаемых сцен
5.7. Воображение
Мы видим мир не таким, какой он есть, а таким, каковы мы сами.Анаис Нин
Когда Кэрол берет один из своих брусков, это действие кажется ей совершенно простым: она всего-навсего протягивает руку, обхватывает фигурку пальцами и поднимает его. Просто видя этот брусок, она уже знает, как ей действовать. Тут, как будто бы, не вмешиваются никакие «размышления».
Однако кажущаяся «прямота» видения мира – иллюзия, проистекающая из нашей неспособности чувствовать сложность собственного механизма восприятия; для нас было бы столь же бесполезно видеть, как вещи «выглядят на самом деле», как разглядывать случайные точки на ненастроенных телевизионных экранах. Если говорить более обобщенно, мы меньше всего осознаем то, что наш блистательный разум делает лучше всего. И в самом деле, большая часть того, что, как нам кажется, мы видим, исходит из наших знаний и воображения. Посмотрите для примера на портрет Авраама Линкольна, сделанный моим старым другом Леоном Хармоном, одним из основоположников компьютерной графики. (Справа – портрет Леона, сделанный мной.)


Как можно узнать черты лица на изображениях, настолько размытых, что носы и глаза на них – всего лишь смутные пятна света и тени? Мы все еще очень мало знаем о том, как мозг делает это, и относимся к нашим талантам в области восприятия как к чему-то обыденному. «Видение» кажется нам совершенно простым, потому что наш мозг практически слеп к процессам, которые для нас это делают.
В 1965 году нашей целью было создание машин, которые могли бы делать вещи, которые делают дети: например, наливать жидкость в чашку или строить арки и башни из деревянного конструктора. Для этого мы делали механические руки и электронные глаза, подключая их к нашему компьютеру, – и таким образом создали первого робота, который мог строить из брусков.
Поначалу робот делал сотни самых разных ошибок. Он пытался то ставить бруски сами на себя, то сразу два на одно и то же место, потому что не имел достаточного уровня житейских знаний о материальных объектах, времени или пространстве! (Даже сегодня до сих пор не существует компьютеризованной визуальной системы, которая хоть как-то приближалась бы к способности человека различать предметы в обычных ситуациях.) Но постепенно наша армия студентов разработала программы, которые могли достаточно хорошо «видеть» расположение обычных деревянных брусков, чтобы распознавать это изображение как «горизонтальный брусок лежит сверху на двух поставленных вертикально».

Мы потратили несколько лет на то, чтобы научить нашу программу («Строителя») строить арки или башни из разрозненной кучки брусков (один раз посмотрев, как это делается). Поначалу мы организовали систему как шестиуровневую последовательность процессов:
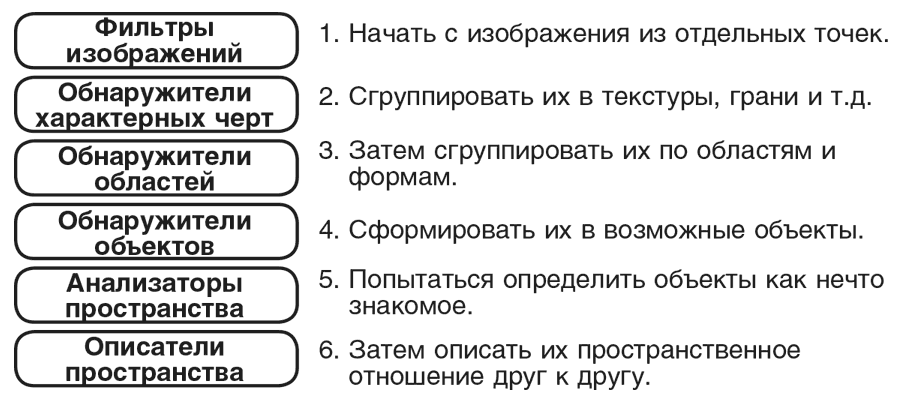
Однако программа то и дело терпела неудачу, так как эти процессы низкого уровня были зачастую неспособны распознать достаточное количество отличительных черт, чтобы сгруппировать объекты в более крупные структуры. Например, посмотрите на это увеличенное изображение нижнего переднего края верхнего бруска в арке:
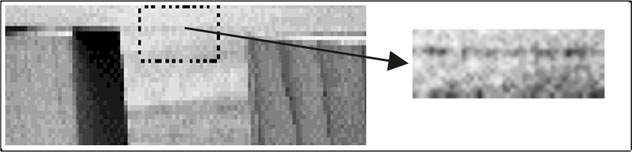
Этот край сложно выделить, потому что участки обеих его сторон имеют практически одинаковую текстуру. Мы пытались использовать дюжину разных способов распознать края, но ни один метод не работал сам по себе. В конце концов мы получили лучший результат, когда придумали, как их скомбинировать. И с такими же проблемами мы сталкивались на каждом уровне: ни одного метода не было достаточно самого по себе, но их комбинация повышала эффективность. И все равно в итоге эта модель поступательных действий не сработала, потому что «Строитель» продолжал совершать слишком много ошибок. Мы сделали следующий вывод: это произошло из-за того, что информация поступала в нашу систему только в направлении «вход – выход», и если на любом этапе совершалась ошибка, уже не было никакой возможности эту ошибку исправить. Чтобы помочь ситуации, нам пришлось добавить множество путей «верх – низ», так чтобы знания могли течь как вниз, так и вверх.
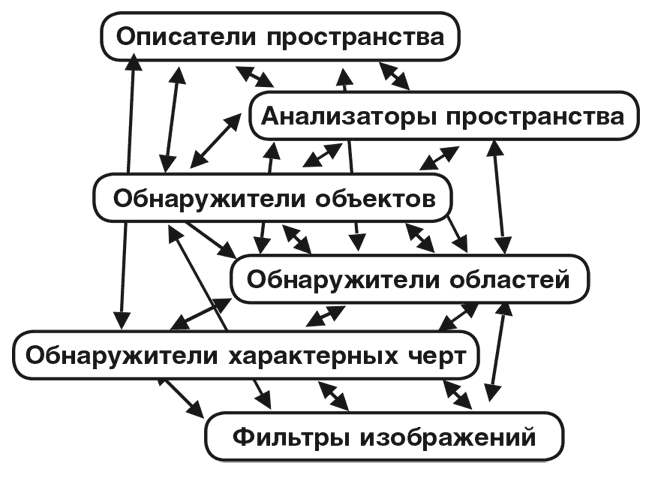
То же самое касается действий, которые мы предпринимаем. Ведь когда мы хотим изменить ситуацию, нам нужно составить план действий. Например, чтобы использовать правило из серии «Если видишь брусок, возьми его в руку», вам нужно сформировать план действий, направляющий ваши плечо, руку и пальцы на точное движение, которое не потревожит окружающие брусок предметы. То есть, опять-таки, здесь нужны процессы высокого уровня, а составление планов также требует использования нескольких уровней процессов, поэтому наша схема должна включать в себя следующие пункты:
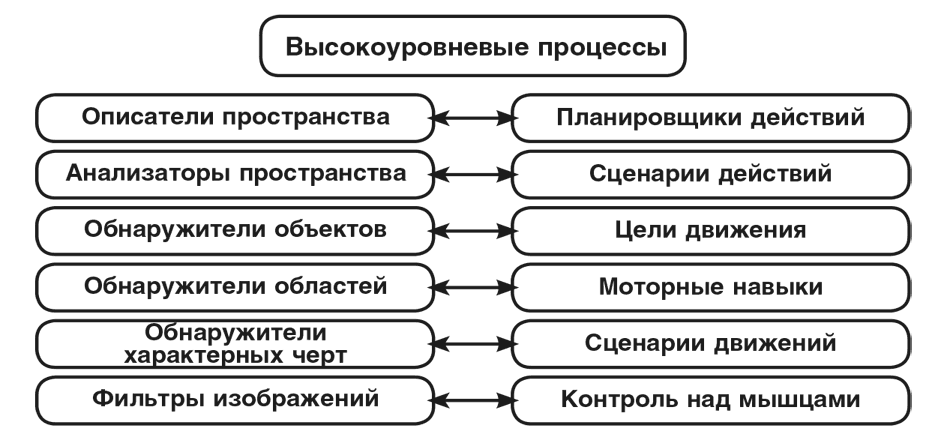
Каждый Планировщик действий реагирует на обстановку составлением последовательности Целей движения, каждая из которых заканчивается использованием Моторных навыков – таких как «тянуться», «хватать», «поднимать», а затем «перемещать». Каждый Моторный навык – специалист в контролировании движения определенных мышц и суставов, и то, что начинается как простая Машина реакций, в итоге превращается в большую и сложную систему, в которой каждые «если» и «действуй» включают множество шагов, а процессы на каждом этапе обмениваются сигналами сверху и снизу.
Раньше было распространено мнение о том, что наши зрительные системы работают «снизу вверх», сначала различая самые общие черты, затем объединяя их в области и формы и наконец распознавая предметы. Однако в последние годы стало ясно, что на то, что происходит на «самых ранних» стадиях, влияют наши высокоуровневые ожидания.
[Большинство старых теорий восприятия] основано на модели зрения «пожарная цепочка», которая сейчас уже не пользуется популярностью. Это иерархическая модель последовательных действий, которая приписывает наш эстетический отклик только самой последней стадии – мощному всплеску узнавания. По моему мнению… на каждой стадии визуальной сегментации, еще до финального «Ага!», происходит множество мини-всплесков. В самом деле, сам акт перцептуального захвата объектоподобных единиц может быть таким же приятным, как собирание пазла. Другими словами, искусство – это визуальная прелюдия перед финальной кульминацией распознавания.В. С. Рамачандран, 2004
На самом деле сейчас мы знаем, что зрительные системы нашего мозга получают гораздо больше сигналов от других областей мозга, чем от глаз.
Такой большой вклад хранящихся в мозге знаний в восприятие соотносится с недавно обнаруженной интенсивностью нисходящих связей в анатомии мозга. Примерно 80 % волокон, поступающих к передаточной станции латерального коленчатого тела, поступает вниз из коры головного мозга, и лишь 20 % – от сетчатки.Ричард Грегори, 1998
Предположительно, эти сигналы от остальных частей мозга выдвигают предположения для зрительной системы, какие черты распознавать или какого рода объекты могут встретиться в поле зрения. Таким образом, как только вы догадываетесь, что находитесь на кухне, вы с большей вероятностью начнете распознавать предметы как чашки или блюдца.
Все это означает, что более высокие уровни мозга никогда не воспринимают визуальную сцену как собрание пигментных пятен. Вместо этого ваши Описатели пространства представят арку из конструктора в более крупномасштабных терминах – например, так: «горизонтальный брусок лежит сверху на двух поставленных вертикально».
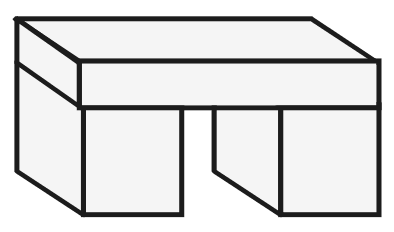
Без использования подобных высокоуровневых описаний правила реакций редко будут иметь практическое применение, и для того чтобы «Строитель» использовал визуальные подсказки, мы должны снабдить его знанием о том, что может означать его сенсорная информация. В данном случае область, которую должен был воспринять «Строитель», состояла в основном из прямоугольных брусков – и это знание привело к удивительным результатам: одна из программ «Строителя» часто могла распознать все бруски, находящиеся в определенной области, лишь по контуру или силуэту! У него получилось это сделать благодаря серии следующих предположений:
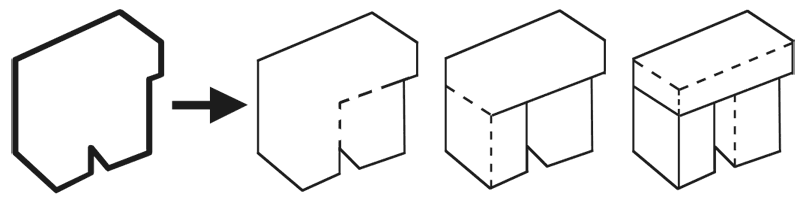
Как только программа различила внешние грани, она вообразила остальные части брусков, которые они очерчивали, и использовала эти догадки для поиска новых подсказок, снова и снова перемещаясь вверх-вниз по шести разным уровням визуальной обработки. Программа зачастую даже показывала лучшие результаты, чем исследователи, которые ее создали.
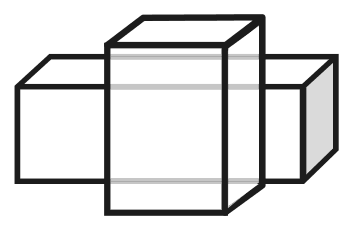
Мы также снабдили «Строителя» дополнительными знаниями о самых распространенных «значениях» углов и граней. Например, предположим, что программа находит грани таким образом:

Тогда «Строитель» предположит, что они все принадлежат одному бруску, и начнет искать другой объект, который, возможно, загораживает оставшуюся часть бруска.
Таким образом, наши системы низшего уровня, возможно, начинают с распознавания отдельных обрывков и фрагментов, но затем мы используем «контекст», чтобы догадаться об их значении, – и после этого пытаемся подтвердить догадки, используя другие виды обработки информации. Другими словами, мы «у-знаем» вещи с помощью «у-поминания» о знакомых предметах, которые могут встать на место отсутствующих фрагментов. Но нам все еще не хватает знаний о том, как наши высокоуровневые ожидания влияют на то, какие черты распознают системы низшего уровня.

