Performance improvements
We learnt in the previous section that the ad distribution system needs to be very fast and capable of handling a large number of requests as compared to a website. In addition, the system should be always available, with the least possible downtime (none if possible). The ads have to be relevant so that merchants obtain the desired response. Let us look at a few parameters that will improve Solr's performance by optimally using the inbuilt caching mechanism.
An index searcher, which is used to process and serve search queries, is always associated with a Solr cache. As long as an index searcher is valid, the associated cache also remains valid. When a new index searcher is opened after a commit, the old index searcher keeps on serving requests until the new index searcher is warmed up. Once the new index searcher is ready, it will start serving all the new search requests. The old index searcher will be closed after it has served all the remaining search requests. When a new index searcher is opened, its cache is auto-warmed using the data from the cache of an old index searcher. The caching implementations in Solr are LRUCache (Least Recently Used), FastLRUCache, and LFUCache (Least Frequently Used).
fieldCache
Lucene, the search engine inside Solr, has an inbuilt caching mechanism for a field known as fieldCache. Field cache contains field names as keys and a map of document ids corresponding to field values as values in the map. Field cache is primarily used for faceting purposes. This does not have any configuration options and cannot be managed by Solr. We can use the newSearcher and firstSearch event listeners in Solr to explicitly warm the field cache. Both the events are defined in the solrconfig.xml file:
<listener event="newSearcher" class="solr.QuerySenderListener"> <arr name="queries"> <lst> <str name="q">anything</str> <str name="sort">impressions desc, enddt asc</str> </lst> </arr> </listener> <listener event="firstSearcher" class="solr.QuerySenderListener"> <arr name="queries"> <!-- seed common sort fields --> <lst> <str name="q">anything</str> <str name="sort">impressions desc, enddt asc</str> </lst> </lst> <!-- seed common facets and filter queries --> <lst> <str name="q">anything</str> <str name="facet.field">merchant</str> <str name="fq">size:200px50px</str> </lst> </arr> </listener>
We can see the performance of the fieldCache from the statistics page in Solr:
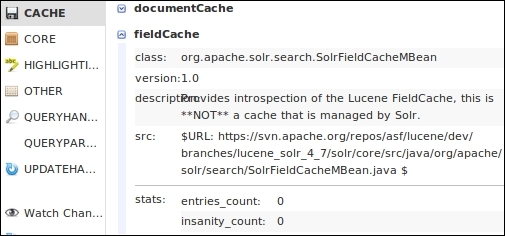
fieldCache Statistics
entries_count defines the total number of items in fieldCache, and insanity_count defines the number of insane instances. Insane indicates that something is wrong with the working of fieldCache. It is not critical and may not require an immediate fix.
fieldValueCache
It is similar to FieldCache in Lucene, but it is inside Solr and supports multiple values per item. This cache is mainly used for faceting. The keys are field names and the values contain large data structures that map docId parameters to values. The following screenshot shows an output from the Solr statistics page for fieldValueCache:
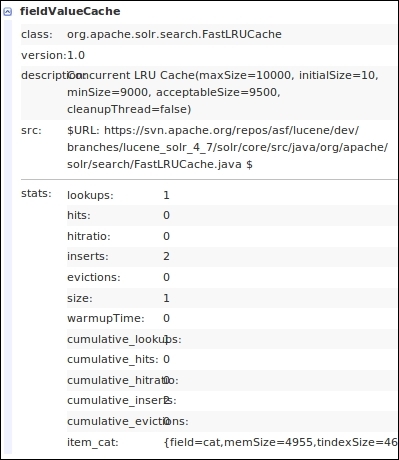
fieldValueCache statistics
documentCache
It stores Lucene documents that have been previously fetched from the disk. The size of the document cache should be greater than the estimated (max no of results) * (max concurrent queries) value for this cache for it to be used effectively. If these criteria are met, Solr may not need to fetch documents from disk, except for the first time (when not in cache). The following code snippet shows how documentCache is configured in the solrConfig.xml file:
<!-- Document Cache Caches Lucene Document objects (the stored fields for each document). Since Lucene internal document ids are transient, this cache will not be autowarmed. --> <documentCache class="solr.LRUCache" size="102400" initialSize="1024" autowarmCount="0"/>The document cache should not be auto-warmed, as the document IDs and fields within a document may change when a document is re-indexed. Memory usage can be high for this cache, and the usage depends on the number of fields stored in the documents in the index. The higher the number of stored fields, the more will be the memory usage.
The statistics for the usage of documentCache is shown on the Solr admin stats interface:
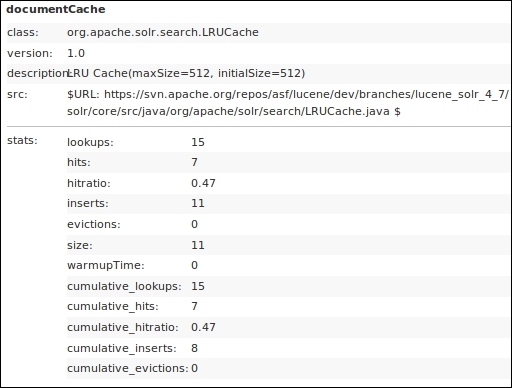
documentCache statistics
Solr has a concept of lazy loading of fields that can be enabled by the enableLazyFieldLoading parameter.
<enableLazyFieldLoading>true</enableLazyFieldLoading>
When lazy loading is enabled, only fields specified in the fl parameter in the query are obtained from the index and stored in DocumentCache. Other fields are marked as LOAD_LAZY. When there is a cache hit on that document at a later date, the fields that are already present in the document are returned directly, while the fields that are marked as LOAD_LAZY are loaded from the index. The document object is updated with data for fields that were earlier marked as LOAD_LAZY. In this case as well, we notice an increase in memory usage without any increase in the number of cached documents.
filterCache
A filter cache is mainly used for caching the results of filter queries. It stores a set of document IDs that match with a filter query. The filter cache can be used for faceting in some cases. The filterCache class is configured in the solrconfig.xml file with the following configuration options:
<filterCache class="solr.FastLRUCache" size="409600" initialSize="40690" autowarmCount="4096"/>The filterCache class can also be used for sorting results by enabling the following parameter in the solrconfig.xml file:
<useFilterForSortedQuery>true</useFilterForSortedQuery>
The following screenshot shows an output from the Solr admin statistics page that shows the usage of the filterCache class:
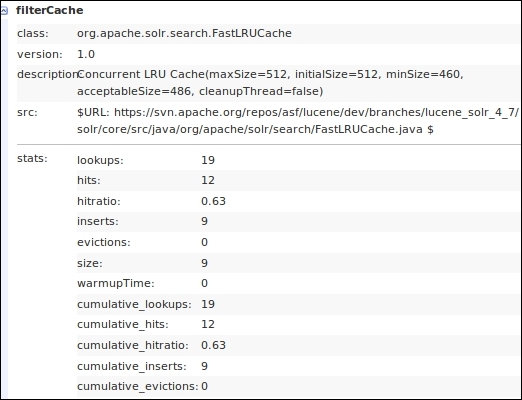
filterCache usage statistics
Passing the parameter {!cache=false} will prevent the filter cache from being used in that query. The following is a sample filter query that does not use a filter:
fq={!cache=false}inStock=truequeryResultCache
The queryResultCache class is used to prevent repeated searches on the index. The cache stores the ordered set of document IDs for a particular query. It is defined in the solrconfig.xml file by the queryResultCache parameter:
<queryResultCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0"/>The statistics on the Solr admin page can be referred to in order to judge the performance of the cache.
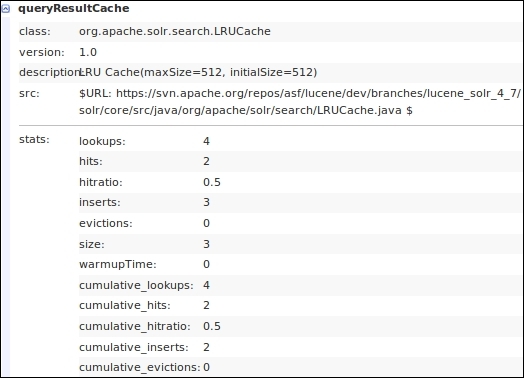
queryResultCache usage statistics
The usage statistics for different caches is almost the same. We have the size statistic that specifies the number of objects in the cache. The inserts statistic tells us about the number of inserts that were made into the cache. When the size is full, inserts will happen but size will not increase. Instead evictions will happen where the least recently used object will be removed from the cache memory. We have the lookups parameter that specifies the number of times the cache was queried, and the hits parameter specifies the number of times the cache query provided results. The higher the hit ratio, the better is the cache performance.
Tip
Query cache can also be ignored for a particular request using cache local parameter.
Refer to the following usage example:
q={!cache=false}*:*Application cache
In addition to the caches provided by Solr and Lucene, most advertising applications have their own local cache. This cache can be used to reduce the search time to less than 1 millisecond. Remember that we require a fast search in order to achieve the CPM / CPC target.
The application will also need to handle cache invalidation and refresh whenever any updates happen in the index.
Garbage collection
Java performs Garbage Collection (GC) at certain intervals to clean up unused objects from the memory. During full garbage collection, Solr or any Java application comes to a standstill. Depending on the amount of heap memory allocated, the pause time can go up to 1 second or higher for large heaps. The aim here is to avoid full GC and work on concurrent GC. There are certain parameters in Java or Tomcat that can be used for concurrent garbage collection.
These parameters can be added to the Tomcat environment variables to enable better garbage collection:
FULL_GC_OPTS="-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+SurvivorRatio=8 -XX:MaxTenuringThreshold=32 -XX:TargetSurvivorRatio=90"
Note
For other servers such as Jetty or Resin, please refer to the respective guides on how to add these variables to the environments.
For more information on the variables passed to the Tomcat environment, refer to the following description:
UseConcMarkSweepGC: This acts as a concurrent collector. The related GC algorithm attempts to do most of the garbage collection work in the background without stopping application threads while it works. However, there are phases where it has to stop application threads, but these phases are attempted to be kept to a minimum.UseParNewGC: This function uses a parallel version of the young-generation copying collector alongside the default collector. It minimizes pauses by using all available CPUs in parallel.SurvivorRatio: This class serves to increase the survivor spaces in order to keep survivors alive longer.MaxTenuringThreshold: This class serves to prevent objects from being copied to the tenured space too early.TargetSurvivorRatio: This class serves to increase the maximum percentage of available survivor space.
We need to tune the parameters as per our requirements. With upgrades, the Java Virtual Machine (JVM) will have much better ways of handling garbage collection, which will have to be looked into.

