9.6. Генеральная совокупность против выборки
Теперь пару слов о совокупности. Мы измеряли признаки всех возможных вариантов выпадения кубика, хорошо и годно все посчитали. Но в реальности результаты экспериментов сосчитать трудно, потому что мы гораздо чаще имеем дело с выборками, а не со всей совокупностью результатов. Возьмем, например, дерево. Хотим мы оценить количество его листьев, берем 5 веток и считаем на них среднее количество листьев. Потом умножаем их на количество веток, и у нас получится примерная (но неплохая) оценка количества листьев на дереве.
Так вот, реальное среднее количество листьев на ветке мы не знаем, а лишь приблизительно определили из пяти наших веток. Его принято обозначать не иксом, а иксом с чертой, и оно тем ближе к иксу, чем ближе количество отобранных нами веток к количеству веток на всем дереве. Если мы возьмем несколько отличающихся веток (а не только самые длинные, например), то наша выборка будет лучше отражать свойства всего дерева. Так и с людьми – если в исследуемой группе есть представители разных городов, профессий, возрастов, то выводы будут точнее и вернее, чем если опросить только вечно пьяных студентов МИРЭА.
В Америке был интересный казус с репрезентативностью выборки, когда журнал «Литерари Дайджест» опросил аж 10 миллионов человек насчет выборов президента. Это огромное количество респондентов: для достоверной статистики хватило бы 2–3 тысячи правильно собранных ответов. Журнал предсказал победу республиканцу Альфу Лэндону со значительным перевесом (60 на 40), а выборы выиграл демократ Франклин Рузвельт – как раз с таким же перевесом, но в обратную сторону. Дело в том, что большинство подписчиков журнала были республиканцами, а в попытке сгладить это несоответствие журнал рассылал бюллетени по телефонным книгам. Но не учел забавного факта: телефоны тогда были доступны только среднему и высшему классу общества, а это были в основном республиканцы.
9.7. Дисперсия
Пока мы говорили лишь о средствах измерения основной тенденции, но еще нам потребуется средство измерения ее вариативности, иными словами, разброс ее значений. Дисперсия случайной величины – это как она меняется от одного измерения до другого. Обозначается она как σ2, греческая сигма в квадрате. А просто сигма – это так называемое стандартное отклонение. Это корень из дисперсии.
Дисперсия – это сумма квадратов расстояний от каждого результата до среднего результата, деленная на их количество. Квадратов – потому что какие-то результаты отличаются от среднего в меньшую сторону, и чтобы при складывании отрицательных отклонений сумма не уменьшалась, придумали возводить разницу в квадрат и складывать уже квадраты отклонений (которые всегда положительны).
Тут плохо то, что дисперсия размерностью не совпадает с изучаемым явлением. Если мы измеряем сантиметры, то дисперсия окажется в квадратных сантиметрах. Поэтому из нее берут корень. Чтобы не лопнул мозг, вспомним про кубик. Так вот для шестигранника дисперсия получается 2,92 (сами посчитаете? Я вам помогу), ну а корень из этого – 1,71. То есть в среднем у нас выпадает 3,5, но разброс результатов от среднего равен 1,71. Чем больше этот разброс, тем больше квадраты расстояний до среднего, тем больше дисперсия. Чем дисперсия больше, тем сильнее наша случайная величина варьируется.
Оценивать дисперсию всей совокупности по выборке не совсем правильно. Возвращаясь к нашему примеру с деревом, разброс между количеством листьев у выбранных нами веток будет, естественно, меньше, чем у всех веток дерева. Поэтому, чтобы узнать дисперсию всей совокупности, ее делят не на n результатов, а на n-1, это называется коррекция смещения, придумал ее в 19-м веке Фридрих Бессель, ученик Гаусса.
На этом о дисперсии и оценках выборки все. Там есть, конечно, еще куча мелочей, но мы будем говорить о теорвере лишь в контексте инвестиций. Это именно та область, где нам нужен высокий доход, а вот дисперсия совершенно не нужна.
ВЫСОКОЕ МАТОЖИДАНИЕ ДОХОДА – ДОБРО, А ВЫСОКАЯ ДИСПЕРСИЯ – ЗЛО, ПОТОМУ ЧТО ЭТО РИСК, ЭТО НЕИЗВЕСТНОСТЬ.
Все финансовые теории в конечном счете стремятся получить высокий доход с минимальным риском.
Жалко, что у них ничего не получается.
9.8. Корреляция, ковариация и регрессия
Еще одна важная концепция – это ковариация. Это показатель того, насколько две переменные движутся вместе. Насколько похоже их поведение? Если эксперимент выдает нам икс и игрек и мы подмечаем, что когда икс высокий, то игрек тоже имеет свойство быть высоким, или наоборот, оба низкие, тогда ковариация будет положительной. Отрицательная ковариация – это когда при высоком икс игрек низкий, и наоборот – то есть они ходят в противоположном направлении.
Пройдем к корреляции. Это ковариация с поправкой на дисперсию наших изменяющихся величин, всегда число от минус одного до плюс одного. Сейчас много кто употребляет этот термин, ну, например, кто-то считает, какая корреляция между результатами ЕГЭ и институтскими оценками чеченских отличников, знаменитых знатоков русского языка. У них, возможно, корреляция меньше нуля, а у всех остальных отличников – больше 0.5.
Корреляция не означает причинности, а лишь отмечает созависимость. Причина ли в том, что одна влияет на другую, или что-то третье на них влияет, – этого мы из одной цифры определить не можем. Если график доллара весной похож на график температуры, не стоит думать, что осенью он повалится обратно. Хотя весной корреляция была.
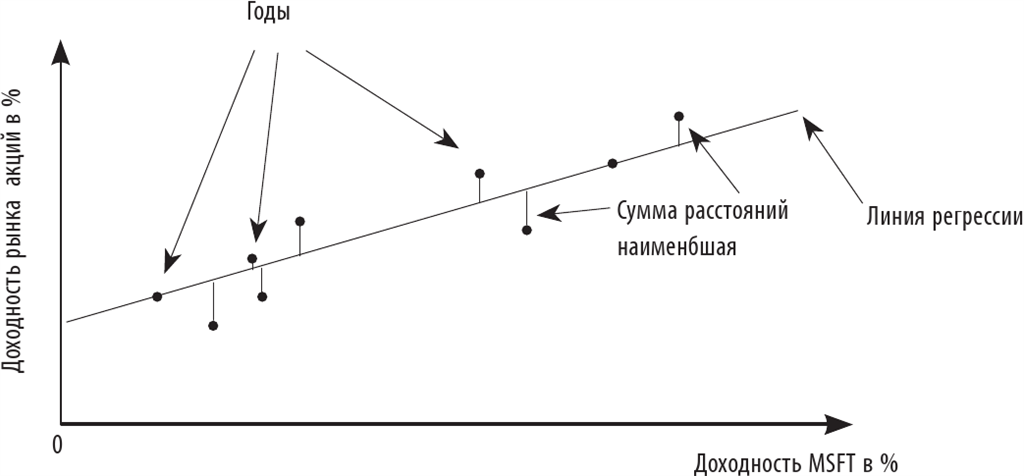
Доходность рынка акций в %
Теперь регрессия. Это тоже базовая концепция из статистики, но в финансах у нее особенное предназначение. Разрабатывал ее тот же Карл Гаусс, рисуя линии через кучу точек на графике. Если отложить по оси x доходность по годам какой-нибудь компании, например, Майкрософта, а по оси y – доходность рынка, то мы получим много точек, по одной на каждый год.
И вот Гаусс говорит, давайте-ка проведем линию через эти точки. Линию, Карл! Назвал он ее линией регрессии. А провел он ее таким образом, чтобы минимизировать сумму расстояний от точек до этой линии. То есть квадратов расстояний. Чтобы прямая наиболее точно отражала все точки, надо ее провести таким хитроумным образом, чтобы расстояния до нее были минимальны. Эта прямая и называется линией регрессии, в финансах ее пересечение с осью игрек называется альфой, а наклон – бетой. Таким образом, бета акций, например, Майкрософта – это наклон этой линии, а альфа – пересечение. Альфа – насколько бумага обгоняет рынок, а бета – насколько она двигается вместе с рынком. Пока непонятно, но не переживайте; я об этом еще расскажу поподробней.