Глава 11
Хэширование на практике
Рассказ о сравнении данных и создании вычислительных головоломок
В главе 10 были представлены криптографические хэш-функции, а также рассматривались различные схемы применения хэш-функций к данным. Глава 10 может показаться скучной теоретической лекцией, но в действительности она имеет большое практическое значение. В текущей главе все внимание сосредоточено на практическом применении хэш-функций и хэш-значений в реальном мире. Рассматриваются основные варианты использования хэш-функций на практике и излагаются идеи, на которых основаны эти варианты. Также кратко объясняется, почему описываемые варианты использования работают именно так, как предполагается. В конце главы рассматривается применение хэш-значений в технологии блокчейна.
Сравнение данных
Это самый распространенный и самый понятный вариант использования хэш-значений, поэтому сравнение данных на основе их хэш-значений рассматривается в первую очередь.
Цель
Целью является сравнение данных (например, файлов или данных транзакций) без выполнения последовательного сравнения их содержимого по отдельным компонентам, а также реализация сравнения любых типов данных вне зависимости от их размера и содержимого в такой же простой форме, как сравнение двух чисел.
Основная идея
Вместо явного последовательного сравнения содержимого данных по отдельным компонентам сравниваются их криптографические хэш-значения.
Как это работает
Вычисляются и сравниваются криптографические хэш-значения всех исследуемых данных. Если все криптографические хэш-значения различны, то все рассматриваемые данные также различны. Если какие-либо криптографические хэш-значения одинаковы, то соответствующие исходные данные также одинаковы [36].
Почему это работает
Сравнение данных по их криптографическим хэш-значениям работает благодаря устойчивости к коллизиям криптографических хэш-функций.
Обнаружение изменений в данных
Концепцию сравнения данных на основе их хэш-значений легко расширить до варианта обнаружения изменений в данных.
Цель
Определить, изменялись ли данные (например, файл или данные транзакции), которые не должны подвергаться каким-либо изменениям, после конкретной даты, или после передачи их кому-либо, или после операции их сохранения в базе данных.
Основная идея
Сравнение криптографического хэш-значения исследуемых данных, вычисленного ранее, с новым криптографическим хэш-значением для тех же данных является основой процедуры обнаружения изменений. Если оба хэш-значения одинаковы, то данные не изменялись с момента генерации старого хэш-значения.
Как это работает
Генерируется криптографическое хэш-значение для данных, которые должны оставаться неизменными. В дальнейшем при необходимости проверки неизменности этих данных генерируется новое криптографическое хэш-значение этих же данных. Затем сравниваются новое и старое хэш-значения. Если оба значения одинаковы, то данные не изменились. В противном случае данные были изменены в интервале времени, прошедшем с момента создания первого хэш-значения. Точно такой же подход можно применять при передаче данных кому-либо. Перед отправкой данных генерируется первое хэш-значение, затем получатель вычисляет хэш-значение для принятых данных, после чего отправитель и получатель сравнивают оба хэш-значения. Если значения одинаковы, то в процессе передачи данные не изменились.
Почему это работает
Обнаружение изменений в данных в действительности представляет собой процесс сравнения одних и тех же данных до и после определенных событий, например по истечении некоторого интервала времени, после сохранения или извлечения из базы данных или после передачи данных по сети. Обнаружение изменений в данных, которые должны оставаться неизменными, работает благодаря устойчивости к коллизиям криптографических хэш-функций.
Обращение к данным, которые не должны изменяться
Сравнение данных и обнаружение изменений на основе соответствующих хэш-значений можно считать основными вариантами применения хэш-значений. Немного более сложный вариант – обращение к данным по хэш-ссылкам – рассматривается ниже.
Цель
Целью являются обращение к данным (например, к данным транзакции), которые хранятся где-либо отдельно (например, на жестком диске или в базе данных), и подтверждение того, что эти данные не изменились.
Основная идея
Объединение криптографического хэш-значения для хранимых данных с информацией о месте размещения этих данных. При каких-либо изменениях данных обе части информации перестают быть согласованными, следовательно, хэш-ссылка становится некорректной.
Как это работает
Ссылки на данные являются цифровым аналогом номерков (жетонов) в гардеробе. Гардеробный жетон указывает место хранения вашей куртки на гардеробных вешалках. Жетон необходим для получения своей куртки после хранения. В ИТ-области ссылки на данные работают аналогичным образом: это фрагменты данных, которые указывают (ссылаются) на другие данные. Компьютерные программы используют ссылки для обозначения мест хранения данных и последующего извлечения этих данных при необходимости. Хэш-ссылки (hash references) – это особый тип ссылок, использующих мощь криптографических хэш-значений. Для упрощения можно считать хэш-ссылки «гардеробными номерками», на которых обозначены хэш-значения вместо обычных чисел.
Хэш-ссылки указывают на другие данные, а кроме того, позволяют проверить тот факт, что данные не изменились с момента создания этой ссылки. В случае изменения данных по ссылке сама ссылка уже не позволяет извлечь данных. Такая хэш-ссылка считается поврежденной или некорректной. Это похоже на ситуацию с гардеробным номерком, который соответствует крючку вешалки, на котором уже нет вашей куртки. Гардеробщик не может выдать отсутствующую куртку.
Общая концепция хэш-ссылки – предотвращение извлечения пользователями данных, которые были изменены случайно из-за технических ошибок или преднамеренно некоторым лицом, не сообщившим об этом пользователям. Таким образом, хэш-ссылки используются во всех случаях, когда предполагается неизменность данных после их создания.
Схематическое описание
Технология блокчейна тесно связана с хэш-ссылками. Поэтому понимание их функционирования чрезвычайно важно для понимания блокчейна и для дальнейшего изучения материала книги. Следующие три рисунка позволяют достичь двух целей: во-первых, они схематически изображают функционирование хэш-ссылок. Во-вторых, на них показано графическое представление хэш-ссылок, которое будет использоваться и в следующих главах на схемах функционирования структур данных блокчейна.
На рис. 11.1 показана схема функционирования корректной хэш-ссылки. Серый кружок с надписью R1 обозначает корректную хэш-ссылку. Белый прямоугольник представляет некоторые данные, которые предположительно не должны изменяться. Стрелка от кружка к прямоугольнику соответствует функциональности хэш-ссылки и указывает направление от ссылки к соответствующим данным.
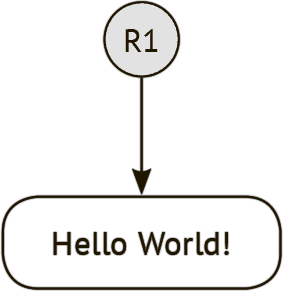
Рис. 11.1 Схематическое изображение корректной хэш-ссылки
На рис. 11.2 показано символическое представление поврежденной или некорректной хэш-ссылки.

Рис. 11.2 Схематическое изображение некорректной хэш-ссылки
Черный прямоугольник содержит измененную фразу, представляющую данные, изменения в которые были внесены после создания ссылки. Серый кружок продолжает обозначать изначально созданную хэш-ссылку. Молниеобразная стрелка от кружка к прямоугольнику подчеркивает, что хэш-ссылка R1 повреждена и больше не может обеспечить доступ к данным, потому что они были недавно изменены.
На рис. 11.3 показана ситуация, в которой новая хэш-ссылка была создана после изменения данных. Это состояние обозначено в виде черного прямоугольника с измененными данными, черного кружка, соответствующего новой созданной хэш-ссылке, и прямой стрелки, указывающей направление от кружка к прямоугольнику.
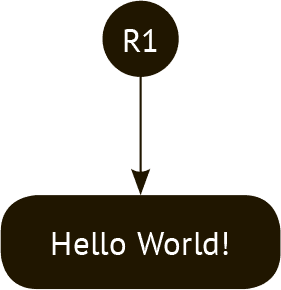
Рис. 11.3 Схематическое изображение новой созданной хэш-ссылки после изменения данных
Почему это работает
Главной особенностью хэш-ссылок является использование криптографических хэш-значений, которые могут рассматриваться как неповторяющиеся отпечатки пальцев данных. Поэтому весьма маловероятно, что два различных фрагмента данных будут иметь одинаковое хэш-значение. Таким образом, поврежденная хэш-ссылка рассматривается как доказательство факта изменения данных после создания этой ссылки.
Хранение данных, которые не должны изменяться
Концепцию ссылки на данные на основе их хэш-значений можно развивать и дальше. Естественным продолжением является хранение данных, изменение которых нежелательно или вообще недопустимо.
Цель
Хранение большого объема данных, например данных транзакций, которые должны оставаться неизменными. Любые изменения таких данных необходимо выявлять быстро и просто.
Основная идея
Номерки в гардеробе указывают на крючки вешалки, на которых висят куртки. Это просто и понятно. Но что мешает положить номерок в карман другой куртки и также сдать эту вторую куртку в гардероб? Второй номерок указывает на куртку, в кармане которой находится номерок, указывающий на другую куртку. В действительности можно создавать длинные и сложные цепочки курток с номерками в их карманах, указывающими на другие куртки, в карманах которых также находятся номерки, и так до бесконечности. Точно так же можно хранить данные с хэш-ссылками, указывающими на другие данные, в которых содержатся хэш-ссылки на следующие данные, и т. д. Если какие-либо данные или хэш-ссылки изменяются после создания, то все ссылки становятся поврежденными. Поскольку поврежденные хэш-ссылки служат доказательством факта изменения данных после создания этих ссылок, вся структура в целом хранит данные способом, при котором любые изменения сразу выявляются.
Как это работает
Существуют два типовых общеизвестных шаблона использования хэш-ссылок для хранения данных, которые не должны изменяться:
• цепочка (chain);
• дерево (tree).
Цепочка
Цепочка связанных данных, также называемая связанным списком (linked list) [9], образуется, когда каждый фрагмент данных содержит хэш-ссылку на другой фрагмент данных. Такая структура удобна для хранения и объединения данных, если не требуется одновременный доступ ко всем данным сразу, а выполняется последовательный проход по фрагментам. На рис. 11.4 показана схема этого подхода с использованием условных символьных обозначений, введенных в предыдущем разделе. Создание цепочки начинается с фрагмента данных «Данные 1» и хэш-ссылки R1. Как начальный фрагмент «Данные 1» не содержит никакой хэш-ссылки. Когда поступают новые данные, они размещаются вместе с хэш-ссылкой, указывающей на фрагмент «Данные 1». Хэш-ссылка R2 указывает на новые, только что полученные данные и на хэш-ссылку R1. Хэш-ссылка R3, которая указывает на фрагмент «Данные 3» и хэш-ссылку R2, создается точно так же.

Рис. 11.4 Данные, объединяемые в цепочку
Хэш-ссылка R3 – это все, что необходимо для доступа ко всем данным в цепочке в порядке, обратном по отношению ко времени их получения. Ссылка R3 также называется головой цепочки (head of the chain), потому что указывает на самый последний добавленный фрагмент данных. Очень важно не путать термин «голова» (head) (обозначающий фрагмент данных, который был добавлен самым последним) и термин «заголовок» (header), который будет рассматриваться в главе 14 при описании структуры данных блокчейна.
Дерево
На рис. 11.5 показано, как данные транзакций могут быть объединены с помощью хэш-ссылок в структуру, имеющую форму дерева.
Такую структуру также называют деревом Меркле (Merkle tree) [24], потому что ее впервые предложил использовать специалист по компьютерной криптографии Меркле (Merkle) и она действительно похожа на дерево, только перевернутое вверх корнем. Эта структура удобна для объединения множества различных фрагментов данных, доступ к которым обеспечивается одновременно через одну хэш-ссылку. Для формирования дерева, показанного на рис. 11.5, сначала создаются четыре фрагмента данных транзакций, изображенных в виде прямоугольников в нижней части схемы. В первую очередь создаются хэш-ссылки на отдельные фрагменты данных транзакций (R1-R4), после чего эти ссылки объединяются в пары. Далее создаются хэш-ссылки, указывающие на пары первых хэш-ссылок (R12 и R34). Процедура повторяется до тех пор, пока не будет создана единственная хэш-ссылка, которую также называют корнем (root) дерева Меркле (на схеме обозначена как R).
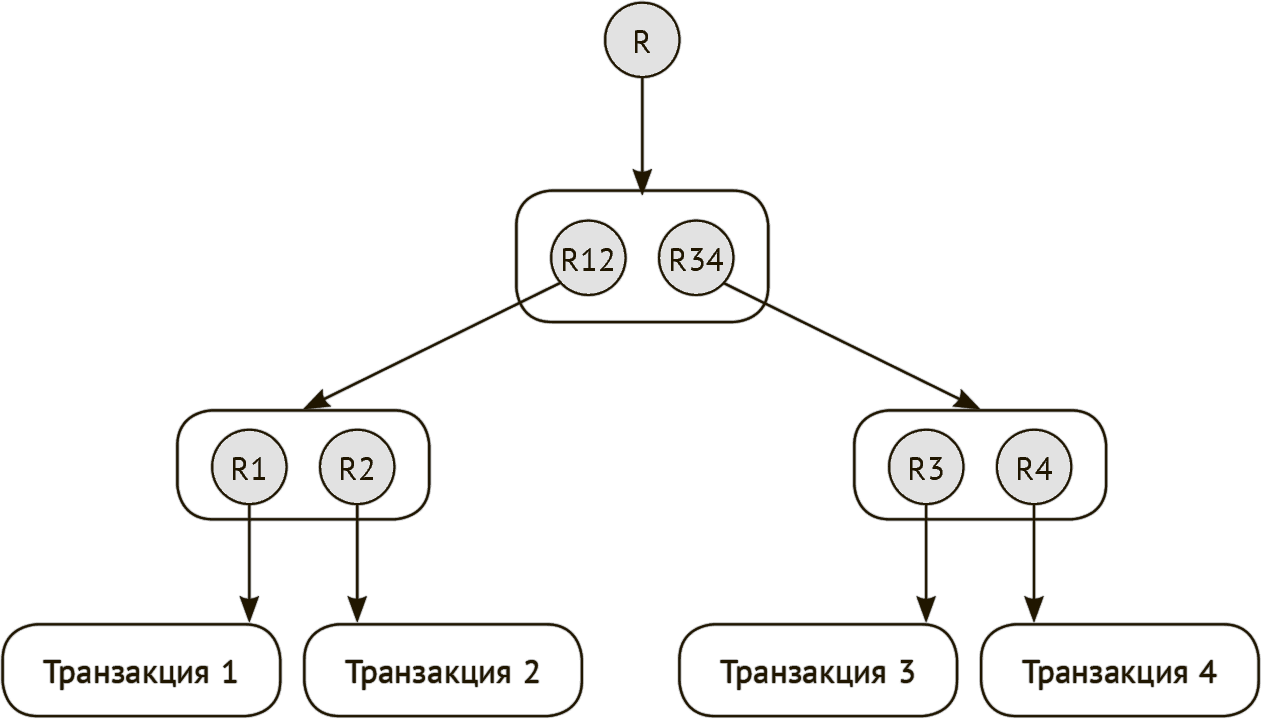
Рис. 11.5 Данные, объединяемые в древовидную структуру
Почему это работает
Описанные выше структуры хранят данные с возможностью обнаружения изменений в них, потому что в этих структурах данные объединяются и связываются с помощью хэш-ссылок. После создания ссылок любые изменения в соответствующих данных приводят к тому, что ссылки становятся поврежденными (некорректными). Таким образом, обнаружение поврежденной ссылки в подобной структуре является доказательством того факта, что данные были изменены после создания структуры. При корректности всех ссылок можно сделать вывод, что вся структура данных в целом не изменялась с момента своего создания.
Выполнение долговременных вычислений
Хэш-значения пригодны не только для безопасного и эффективного выполнения простых операций, таких как сравнение, хранение и обеспечение доступа по ссылкам. Хэш-значения также можно использовать, чтобы позволить компьютерам обращаться к другим компьютерам для привлечения их к разработке головоломок (puzzles). Возможно, сейчас это кажется несколько странным, но в дальнейшем вы увидите, что такое применение хэш-значений является одной из наиболее важных концепций технологии блокчейна.
Цель
По причинам, которые станут понятными в следующих главах, может возникать необходимость в создании головоломок, требующих для решения определенных вычислительных ресурсов. Эти головоломки не должны решаться на основе знаний или данных, хранящихся где-либо, или с помощью мыслительных процессов, как при прохождении IQ-теста или теста, проверяющего знания в какой-либо области. Единственным способом решения таких головоломок являются использование только вычислительных мощностей и выполнение огромного объема вычислений.
Основная идея
Замок с секретным кодом – это особенный замок, открыть который можно только с помощью специальной последовательности цифр. Если такая последовательность неизвестна, то можно попытаться систематически перебирать все возможные комбинации до тех пор, пока не будет набрана правильная последовательность, открывающая замок. Эта процедура гарантирует, что замок будет открыт, но на ее выполнение затрачивается очень много времени. Систематический перебор всех возможных комбинаций не требует каких-либо знаний или логических рассуждений. Методика вскрытия кодового замка основана исключительно на усердной и кропотливой работе. Хэш-головоломки – это вычислительные головоломки, решение которых можно считать аналогом решения задачи вскрытия кодового замка методом проб и ошибок.
Как это работает
Ниже перечислены элементы хэш-головоломки [1]:
• исходные данные, которые не должны изменяться;
• данные, которые можно свободно изменять, так называемый одноразовый случайный код (nonce);
• применяемая хэш-функция;
• ограничения для хэш-значения по объединенному хэшированию, также называемые уровнем сложности (difficulty level).
На рис. 11.6 показано формирование хэш-головоломки. Метод объединенного хэширования применяется к исходным данным и одноразовому случайному коду (nonce). Полученное хэш-значение должно соответствовать заданным ограничениям.
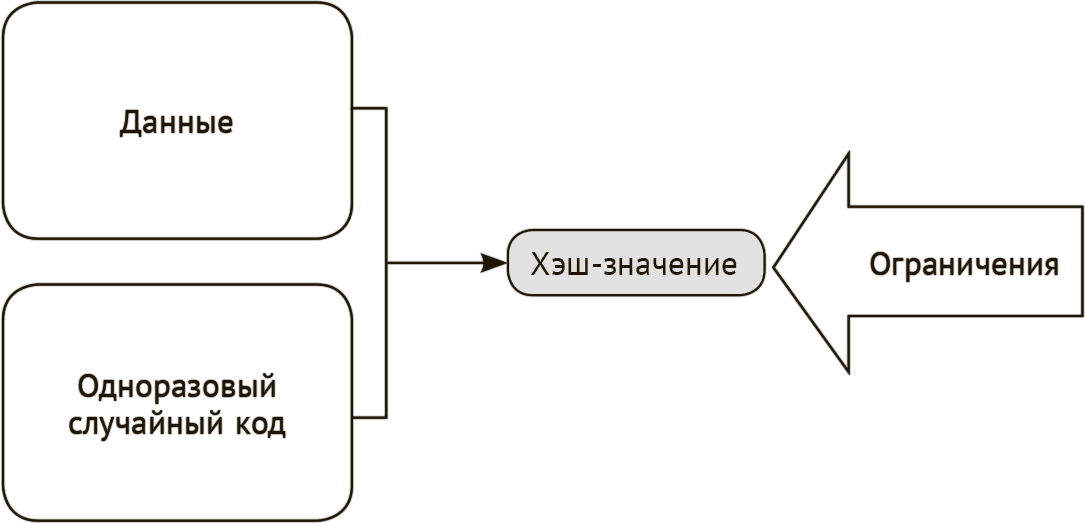
Рис. 11.6 Схема создания хэш-головоломки
Хэш-головоломки можно решить только методом проб и ошибок. Требуется угадать одноразовый случайный код, вычислить хэш-значение для объединенных данных с помощью заданной хэш-функции, затем вычислить итоговое хэш-значение на основе заданных ограничений. Если полученное хэш-значение соответствует ограничениям, то хэш-головоломка решена, иначе нужно продолжать вычисления с другим одноразовым случайным кодом до тех пор, пока не будет найдено решение. Одноразовый случайный код nonce, который при объединении с исходными данными дает хэш-значение, соответствующее ограничениям, называется решением. Если вы объявляете, что решили хэш-головоломку, то обязательно должны предъявить правильный одноразовый случайный код nonce.
Практический пример
Чтобы лучше понять функциональность хэш-головоломок, рассмотрим пример с реальными данными. В главе 10 для фразы Hello World! было вычислено укороченное хэш-значение 7F83B165. Но какие данные, объединенные с этой фразой, выдают итоговое укороченное хэш-значение, начинающееся с трех нулей? Таким образом, сформирована хэш-головоломка: найти одноразовый случайный код nonce, который при объединении с фразой Hello World! выдает укороченное хэш-значение, начинающееся с трех нулей.
Приступим к рутинной работе и попробуем несколько значений одноразового случайного кода. В табл. 11.1 приведены значения одноразового случайного кода, хэшируемого объединенного текста и полученного в результате вычислений итогового укороченного хэш-значения. Из таблицы можно видеть, что одноразовый случайный код 614 решает хэш-головоломку. Для поиска решения пришлось начать со значения 0 и с шагом 1 постепенно увеличивать значение одноразового случайного кода, то есть потребовалось 615 шагов. Если бы ограничение предписывало найти хэш-значение, начинающееся с одного нуля, то задача была бы решена после четырех шагов, так как объединенному тексту Hello World! 3 соответствует хэш-значение, начинающееся с одного нуля.
Таблица 11.1 Подбор значения одноразового случайного кода для решения хэш-головоломки

Вы можете самостоятельно проверить решение этой головоломки на веб-странице .
Уровень сложности
Условие соответствия хэш-значения определенным требованиям является ключевым для хэш-головоломки. Это означает, что ни само ограничение, ни его описание не выбираются произвольным образом. Напротив, ограничение, используемое в головоломках такого типа, стандартизировано таким образом, чтобы компьютеры могли предлагать другим компьютерам хэш-головоломки. В данном контексте ограничения часто называют сложностью (difficulty) или уровнем сложности (difficulty level). Сложность выражается натуральным числом и обозначает количество начальных нулей в искомом хэш-значении. Таким образом, сложность 1 означает, что хэш-значение должно начинаться (как минимум) с одного нуля, тогда как при сложности 10 необходимо найти хэш-значение, начинающееся, по меньшей мере, с 10 нулей. Чем выше сложность, тем больше начальных нулей требуется и тем труднее решить хэш-головоломку. Для решения более сложных хэш-головоломок необходим больший объем вычислительных ресурсов и/или большее время.
Почему это работает
Функциональность хэш-головоломок напрямую зависит от того факта, что хэш-функции являются односторонними функциями. Невозможно решить хэш-головоломку, изучив ограничения, которым должно соответствовать хэш-значение, и применив хэш-функцию в обратном направлении (то есть от желаемого выходного значения к требуемому входному значению). Хэш-головоломки можно решить только методом проб и ошибок, который требует огромного объема вычислительных мощностей, следовательно, много времени и энергии. Уровень сложности напрямую влияет на количество попыток, в среднем необходимых для решения головоломки, что, в свою очередь, влияет на потребление вычислительных ресурсов и/или расход времени при поиске решения.
Хэш-функции являются детерминированными и быстро генерируют хэш-значения для любых типов данных. Поэтому сразу после того, как решение найдено, легко проверить, что данные, объединенные с найденным одноразовым кодом nonce, действительно дают хэш-значение, соответствующее заданным ограничениям. Если вычисленное значение не соответствует заданному ограничению, то нельзя обвинять в этом хэш-функцию, потому что несоответствие возникает только из-за того, что головоломка не решена или решена неправильно.
Примечание
В контексте блокчейн хэш-головоломки часто называют подтверждением проделанной работы, так как предъявленное решение доказывает, что требуемая работа действительно выполнена.
Использование хэширования в блокчейне
В технологии блокчейна хэширование используется для выполнения следующих задач:
• хранение данных транзакций способом, при котором отслеживаются и контролируются любые изменения данных;
• создание цифровых отпечатков для данных транзакций;
• методика управления накладными расходами при обработке изменений структуры данных блокчейна.
Перспектива
В этой главе описаны основные варианты использования хэш-значений и кратко перечислены методы их применения в технологии блокчейна. В следующих главах будет подробно рассматриваться методика хэширования, используемая блокчейном.
Резюме
• Хэш-значения могут использоваться:
– для сравнения данных;
– для выявления фактов изменения данных, которые предположительно должны оставаться неизменными;
– для ссылок на данные способом, при котором отслеживаются и контролируются любые изменения предположительно неизменяемых данных;
– для хранения наборов данных способом, при котором отслеживаются и контролируются любые изменения предположительно неизменяемых данных;
– для создания задач, связанных с большими объемами вычислений и интенсивным потреблением вычислительных ресурсов.

