Глава 10
Хэширование данных
Идентификация данных по их цифровым отпечаткам пальцев
В этой главе рассматривается одна из наиболее важных технологий, лежащих в основе блокчейна: хэш-значения (hash values). Здесь обсуждаются важные свойства криптографических хэш-функций и демонстрируются типовые примеры применения хэш-функций к данным.
Метафора
Отпечатки пальцев – это следы контакта с какой-либо поверхностью складок кожи всех или некоторых пальцев человеческой руки. Считается, что с помощью отпечатков пальцев можно однозначно идентифицировать человека. Исследование отпечатков пальцев применяется при расследовании преступлений, для установления личности правонарушителей и для оправдания невиновных. В этой главе вводится концепция идентификации данных, которую можно рассматривать как цифровой аналог отпечатков пальцев. Эта концепция называется криптографическим хэш-значением (cryptographic hash value), и технология блокчейна активно ее использует. Таким образом, понимание криптографического хэширования является обязательным условием для понимания технологии блокчейна.
Цель
В распределенной пиринговой системе вы имеете дело с огромным объемом данных транзакций. При этом необходимы однозначная идентификация этих данных и их сравнение наиболее быстрым и простым способом. Следовательно, устанавливается цель – идентифицировать данные транзакций и, возможно, любые типы данных вполне однозначным образом по их цифровым отпечаткам пальцев.
Как это работает
Хэш-функции – это небольшие компьютерные программы, которые выполняют преобразование любого типа данных в число определенной длины вне зависимости от размера исходных данных [38]. Хэш-функции получают доступ только к одному фрагменту данных в любой рассматриваемый момент времени, используют этот фрагмент как входные данные и создают хэш-значение (hash value) на основе значений битов и байтов, составляющих исходные данные. Хэш-значения могут содержать начальные незначащие нули для обеспечения требуемой длины числа. Существует много версий хэш-функций, отличающихся друг от друга длиной генерируемых ими хэш-значений. Важная группа хэш-функций носит название криптографические хэш-функции (cryptographic hash functions). Эти функции создают цифровые отпечатки пальцев для любых типов данных. Криптографические хэш-функции обладают следующими свойствами [31]:
• быстрая генерация хэш-значений для любого типа данных;
• детерминированность;
• обеспечение псевдослучайности хэш-значений;
• односторонние функции;
• устойчивость к коллизиям.
Быстрая генерация хэш-значений для любого типа данных
Это свойство в действительности является сочетанием двух свойств. Во-первых, хэш-функция способна вычислять хэш-значения для любых типов данных. Во-вторых, хэш-функция производит эти вычисления быстро. Оба эти свойства важны, поскольку крайне нежелательно, чтобы хэш-функция делала бесполезные вещи, например выдавала сообщения об ошибках или тратила огромное количество времени на получение результатов.
Детерминированность
Детерминированность (deterministic) означает, что хэш-функция всегда выдает одинаковые хэш-значения для одинаковых входных данных. Таким образом, любые замеченные несовпадения в хэш-значениях всегда должны считаться следствием несоответствий во входных данных, а не внутренних действий хэш-функции.
Обеспечение псевдослучайности хэш-значений
Псевдослучайность (pseudorandom) означает, что значение, возвращаемое хэш-функцией, непредсказуемо изменяется при изменении входных данных. Даже если изменение входных данных крайне незначительно, выдаваемое хэш-значение будет другим, и предсказать его невозможно. Другими словами, хэш-значение измененных данных всегда должно быть неожиданным. Поэтому необходимо обеспечить невозможность предсказания хэш-значения на основе входных данных.
Односторонние функции
Односторонняя функция (one-way function) не позволяет никаким способом получить входные данные из возвращаемого значения. То есть одностороннюю функцию невозможно использовать в обратном порядке. Другими словами, невозможно восстановить исходные данные по полученному хэш-значению. Это означает, что хэш-значения ничего не сообщают о содержимом входных данных – точно так же, как отдельный отпечаток пальца ничего не говорит о человеке, оставившем его. Односторонние функции также называют необратимыми (noninvertible).
Устойчивость к коллизиям
Хэш-функцию называют устойчивой к коллизиям (collision resistant), если очень трудно найти два или более различных фрагмента данных, для которых она выдает одинаковые хэш-значения. Другими словами, если вероятность получения одинаковых хэш-значений для различных фрагментов данных мала, то такая хэш-функция является устойчивой к коллизиям. В этом случае можно считать, что хэш-значения, генерируемые этой хэш-функцией, уникальны и могут использоваться для однозначной идентификации данных. Если получены одинаковые хэш-значения для различных фрагментов данных, то налицо коллизия хэш-функции. Коллизия хэш-функций (hash collision) представляет собой цифровой эквивалент наличия двух людей с одинаковыми отпечатками пальцев. Устойчивость к коллизиям является обязательным условием для хэш-значений, применяемых в качестве цифровых отпечатков пальцев. Внутренняя реализация устойчивости к коллизиям в хэш-функциях не рассматривается в данной книге, но вы можете быть уверенными в том, что разработчики затратили немало усилий для снижения вероятности возникновения хэш-коллизий.
Проверка на практике
Этот раздел поможет вам приобрести уверенность при использовании хэш-функций. Для этого приводится простой пример. Я предлагаю читателям посетить веб-сайт, предоставляющий инструментальное средство создания хэш-значений для простых текстовых данных: .
После перехода на эту веб-страницу в браузере вы увидите панель ввода и панель вывода, как показано на рис. 10.1. Введите текст «Hello World!» в панели ввода слева и щелкните по кнопке с надписью «Calculate Hash Value» (Вычислить хэш-значение), расположенной ниже текстового поля ввода. Будьте внимательны и точно наберите текст в поле ввода, иначе выведенные результаты будут отличаться от показанных на рис. 10.1.

Рис. 10.1 Вычисление хэш-значений короткого фрагмента текста
После щелчка по кнопке в панели вывода справа появятся хэш-значения для введенного текста, вычисленные с помощью четырех различных хэш-функций. Хэш-значения часто рассматриваются как хэш-числа, поскольку в них используются не только цифры от 0 до 9, но и буквы латинского алфавита от A до F, представляющие значения от 10 до 15 соответственно. Такие числа называются шестнадцатеричными (hexadecimal numbers). ИТ-специалисты используют эти числа по причинам, которые мы не будем здесь обсуждать. Отметим, что показанные на рисунке хэш-значения неодинаковы из-за различий в подробностях реализации хэш-функций, генерирующих эти значения. Будем считать доказанной правильность этих значений, иначе можно просто заблудиться в хитросплетениях обширной темы реализации хэш-функций.
Длина криптографических хэш-значений достаточно велика, поэтому они трудны для чтения, тем более для сравнения человеком. Но по ходу текущей главы мы все же будем сравнивать различные методы хэширования данных, применяя для этого чтение и сравнение хэш-значений. Подобные действия с криптографическими хэш-значениями быстро становятся утомительной задачей. Поэтому в учебных целях я воспользовался укороченной версией криптографического хэш-значения SHA256 в оставшейся части главы. Все хэш-значения можно воспроизвести с помощью инструментального средства, предоставленного страницей вебсайта: .
После перехода на эту веб-страницу в браузере вы увидите панель ввода простых текстов и кнопку со стрелкой, указывающей на панель вывода, как показано на рис. 10.2. При щелчке по кнопке со стрелкой в панели вывода появится укороченное хэш-значение для текста, набранного в панели ввода.
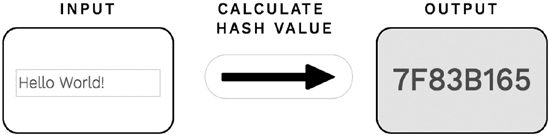
Рис. 10.2 Вычисление укороченного хэш-значения для текста
Шаблоны хэширования данных
К настоящему моменту вы узнали, что фрагмент данных может использоваться как входные данные для хэш-функции, которая генерирует хэш-значение для этих данных. Предполагается, что каждый независимый фрагмент данных имеет собственное уникальное криптографическое хэш-значение. Но что следует делать, если вас попросили предоставить единое хэш-значение для набора независимых фрагментов данных? Ведь мы помним, что хэш-функции принимают только один фрагмент данных. Нет хэш-функций, принимающих одновременно набор независимых данных, но на практике часто необходимо объединенное хэш-значение для большого набора данных. В частности, структура данных блокчейна работает со множеством данных транзакций и требует одного хэш-значения для всего объема данных в целом. Как решить эту задачу?
Ответ заключается в использовании следующих шаблонов применения хэш-функций к данным:
• независимое хэширование;
• повторяющееся хэширование;
• комбинированное хэширование;
• последовательное хэширование;
• иерархическое хэширование.
Независимое хэширование
Независимое хэширование (independent hashing) означает применение хэш-функции к каждому фрагменту данных независимо друг от друга. На рис. 10.3 схематически показана эта концепция, согласно которой отдельно вычисляется укороченное хэш-значение для двух различных слов.
Каждый белый прямоугольник на схеме содержит слово, представляющее хэшируемые данные, а в серых кругах показаны соответствующие хэш-значения. Стрелки, направленные от прямоугольников к кругам, обозначают процедуру преобразования данных в хэш-значения. По рис. 10.3 можно видеть, что по различным словам генерируются различные хэш-значения.
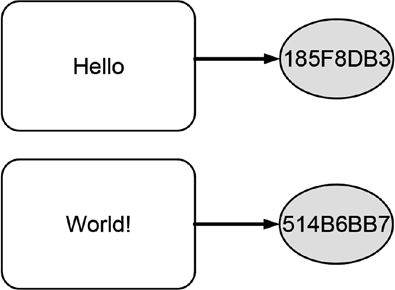
Рис. 10.3 Схема независимого хэширования двух различных фрагментов данных
Вам уже известно, что хэш-функции выполняют преобразование любого произвольного фрагмента данных в хэш-значение. Само хэш-значение может рассматриваться как фрагмент данных. Поэтому существует возможность передачи хэш-значения как входных данных в хэш-функцию и вычисления нового хэш-значения. Это действительно работает. Повторяющееся хэширование – это повторное применение хэш-функции к ее собственным выходным данным. На рис. 10.4 схематически изображена концепция повторного вычисления укороченного хэш-значения. Для текста «Hello World!» генерируется хэш-значение 7F83B165, которое, в свою очередь, дает укороченное хэш-значение 45A47BE7.
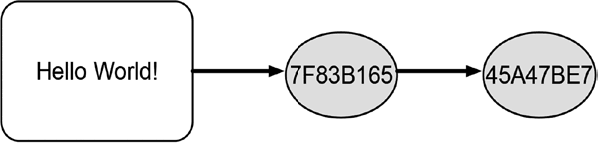
Рис. 10.4 Схема повторного вычисления хэш-значений
Комбинированное хэширование
Цель комбинированного хэширования – получение единственного хэш-значения для нескольких фрагментов данных за одно обращение к функции. Объединение всех независимых фрагментов данных в один блок данных с последующим вычислением его хэш-значения является способом достижения этой цели. В частности, это удобно, если нужно создать одно хэш-значение для набора данных, доступных в определенный момент времени. Поскольку операция объединения данных требует вычислительных ресурсов, времени и некоторого объема памяти, комбинированное хэширование должно применяться только для небольших фрагментов данных. Другой недостаток комбинированного хэширования – хэш-значения отдельных фрагментов данных недоступны, так как хэш-функция обрабатывает только объединенные данные.
На рис. 10.5 показана схема концепции комбинированного хэширования. Сначала отдельные слова объединяются в одно слово с символом пробела между ними, после чего полученная фраза хэшируется. Полученное хэш-значение, показанное на рис. 10.5, совпадает с первым хэш-значением на рис. 10.4, что вполне объяснимо. Отметим, что хэш-значение объединенных данных напрямую зависит от способа объединения данных. На рис. 10.5 два слова были объединены простым последовательным размещением с символом пробела между ними, что в результате составило фразу «Hello World!». Иногда для обозначения места объединения данных используются специальные символы, такие как плюс (+) или хэштег (#), и это влияет на итоговое хэш-значение.
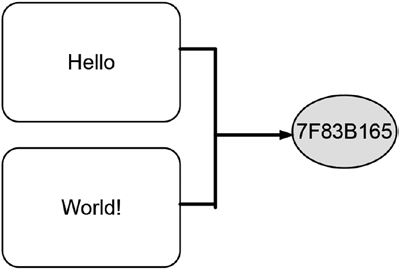
Рис. 10.5 Объединение данных и последующее вычисление хэш-значения
Последовательное хэширование
Цель последовательного хэширования – последовательное (инкрементальное) обновление хэш-значения по мере поступления новых данных. Для этого одновременно используются комбинированное и повторяющееся хэширования. Существующее хэш-значение объединяется с новыми данными, затем передается в хэш-функцию для получения обновленного хэш-значения. Последовательное хэширование особенно удобно, если нужно сопровождать единственное хэш-значение в течение некоторого времени и обновлять его сразу же после поступления новых данных. Преимущество этого типа хэширования заключается в том, что в любой момент времени имеется определенное хэш-значение, изменения которого можно проследить в обратном порядке, восстановив состояние до получения новых данных.
На рис. 10.6 схематично показана концепция последовательного хэширования, в соответствии с которой сначала отдельно обрабатывается слово Hello, и в результате получается укороченное хэш-значение 185F8DB3. После получения новых данных, представленных словом World! эти данные объединяются с существующим хэш-значением, и объединенный блок передается как входные данные в хэш-функцию. Для исходного текста World! 185F8DB3 генерируется укороченное хэш-значение 5795A986.
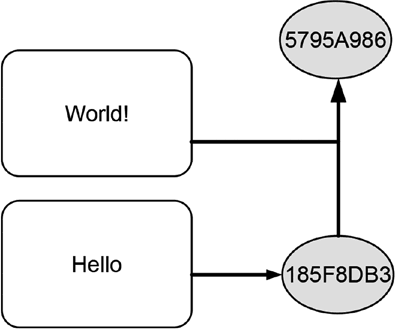
Рис. 10.6 Последовательное вычисление хэш-значений
Иерархическое хэширование
На рис. 10.7 показана концепция иерархического хэширования.
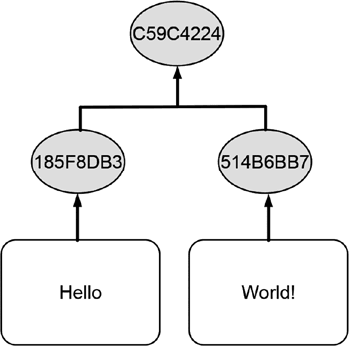
Рис. 10.7 Вычисление хэш-значений по иерархической схеме
Применение комбинированного хэширования к паре хэш-значений образует небольшую иерархию с отдельным хэш-значением в вершине. Подобно комбинированному хэшированию, основная идея иерархического хэширования состоит в создании единственного хэш-значения для набора данных. Иерархическое хэширование более эффективно, потому что в этом случае объединяются хэш-значения, уже имеющие фиксированный размер, а не исходные данные, размер которых может быть произвольным. Кроме того, при иерархическом хэшировании на каждом шаге объединяются только два хэш-значения, в то время как при комбинированном хэшировании объединяются все одновременно обрабатываемые фрагменты данных.
Перспектива
В этой главе описывались теоретические концепции хэш-функций. В главе 11 рассматривается, как хэш-значения используются в реальной жизни, и особое внимание уделяется их применению в технологии блокчейна.
Резюме
• Хэш-функции выполняют преобразование любого типа данных в число определенной длины вне зависимости от размера исходных данных.
• Существует много версий хэш-функций, отличающихся друг от друга длиной генерируемых ими хэш-значений.
• Криптографические хэш-функции представляют собой важную группу хэш-функций, которые создают цифровые отпечатки пальцев для любых типов данных.
• Криптографические хэш-функции обладают следующими свойствами:
– быстрая генерация хэш-значений для любого типа данных;
– детерминированность;
– обеспечение псевдослучайности хэш-значений;
– односторонние функции;
– устойчивость к коллизиям.
• Применение хэш-функций к данным может быть выполнено по следующим шаблонам или типовым схемам:
– независимое хэширование;
– повторяющееся хэширование;
– комбинированное хэширование;
– последовательное хэширование;
– иерархическое хэширование.

