Прогнозирование и предупреждение заболеваний
Посвятив какое-то время работе с ведущими технологами и наблюдая за тем, как один за другим рушатся бастионы человеческой уникальности перед неизбежным наступлением инноваций, все труднее сохранять уверенность в том, что любая задача будет бесконечно сопротивляться.
Эрик Бриньолфссон и Эндрю Макафи. Второй век машин1
В течение следующих нескольких лет вы увидите, как везде появятся прогнозирующие технологии и умные помощники. Они будут не только в большинстве приложений, которыми вы пользуетесь, но и в вашем автомобиле, в вашей гостиной и в вашем офисе. Будут они и внутри предприятия — помогая врачам лучше лечить пациентов.
Тим Тaттл, генеральный директор Expect Labs2
В конце концов врач нам больше не потребуется. Машинное обучение делает лучшего доктора Хауса, чем сам доктор Хаус.
Винод Хосла3
Хотя врачи посвящают свою жизнь тому, чтобы помочь людям поправиться, кажется, они находят странное удовлетворение при виде того, как болезнь идет своим чередом.
Майкл Кинсли4
Самая большая неосуществимая мечта в здравоохранении — предотвращение хронических болезней. В США мы тратим 80% из почти $3 трлн ежегодно выделяемых на здравоохранение на то, чтобы справиться с грузом хронических болезней. А что, если бы был способ остановить их на этапе развития?
В медицине есть и другие большие мечты. До сих пор не могу забыть один график, который видел в The Economist (рис. 13.1) более 20 лет назад5. В 1994 г. журнал предсказывал, что рак и сердечные болезни станут «излечимыми» к 2040 г., а остальные самые серьезные болезни — к 2050-му. При этом ожидаемая продолжительность жизни при рождении вырастет до 100 лет. Все это казалось набором слишком смелых ожиданий, и многие из них и сегодня не стали более реальными, чем были в 1994 г. Некоторые пророчества, по крайней мере частично, воплощены в жизнь — например, роботизированная хирургия и эффективное лечение некоторых видов кистозного фиброза. Но, безусловно, это еще не «излечимость». Вероятно, это и не должно удивлять. Слово «излечение» обычно означает «восстановление здоровья», или «выздоровление после болезни», или «облегчение симптомов болезни или состояния». В медицине «излечений» поразительно мало. Некоторые из примеров — это снятие аритмии типа фибрилляции предсердий (у некоторых пациентов, которым повезло), антибиотики в случае пневмонии или один из новых видов лечения гепатита C с выздоровлением в 99% случаев (для самого широко распространенного генотипа-1, вирусного подвида). Обычно, когда человека настигает болезнь, с ней надо как-то справляться. На самом деле, несмотря на предсказания The Economist, большинство ученых, которые активно занимаются поиском способов лечения рака, надеются превратить его в хроническую болезнь: они уже умерили свои амбиции в отношении излечения. Когда наступает застойная сердечная недостаточность, хроническая обструктивная болезнь легких (ХОБЛ), почечная недостаточность, цирроз, деменция или серьезная недостаточность в работе какого-либо органа, на самом деле надежды на излечение нет.
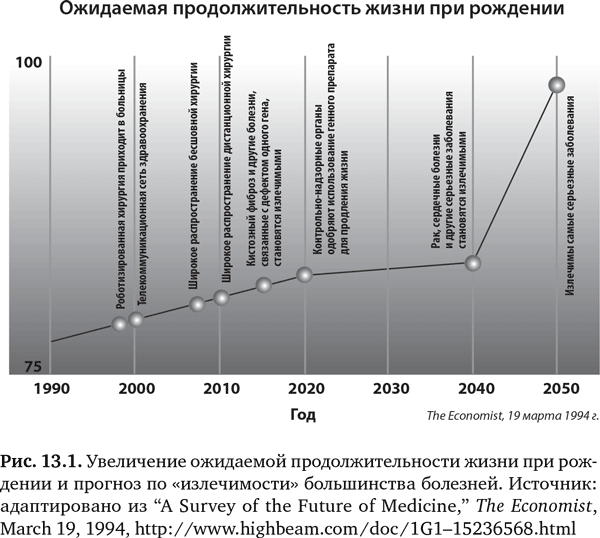
Это представляется весьма мрачным прогнозом. Но теперь, с приходом больших данных, неуправляемых алгоритмов, предиктивной аналитики, обучения машин, расширенной реальности и нейроморфных вычислений, медицина преобразуется в науку о данных. Все еще есть возможность изменить медицину к лучшему, и по крайней мере есть шанс на предупреждение болезней. То есть, если имеется точный сигнал перед тем, как болезнь когда-либо проявлялась у человека — и эта информация дает веские основания для действий, — болезнь можно предотвратить.
Однако эта мечта — не просто вопрос совершенствования науки о данных. Она косвенно связана с демократизацией медицины. Перспективы здесь невозможны без освоения людьми искусства наблюдения за самими собой — вспомните двойной смысл термина «персонализированная медицина»6. Улавливание сигнала задолго до того, как появляются какие-либо симптомы, зависит от ГИС человека, а не от ежегодных посещений врача. С помощью маленьких беспроводных устройств, которые мы носим с собой, и Интернета вещей мы развиваем способность к непрерывному, очень важному наблюдению за нашими телами в режиме реального времени. Для времени, когда такая способность будет развита в полной мере (а в конечном счете это случится), предсказания The Economist на следующие 30 лет в медицине не кажутся такими уж притянутыми за уши.
The Economist, можно сказать, погорячился, делая в 1994 г. такие прогнозы. Термины «углубленный анализ данных» и «предиктивная аналитика» определенно еще не были в моде и, вероятно, еще не были изобретены. Но концепция использования данных для предсказаний, как, например, актуарная (страховая) статистика на случай страховая жизни, используется уже очень давно. Отличие состоит в том, что наборы данных теперь цифровые, значительно больше и богаче и им соответствуют поразительная вычислительная мощность и алгоритмическая обработка. Именно это дало возможность Target предсказывать беременность некоторых своих покупательниц7а, Агентство национальной безопасности использует распечатки звонков с наших телефонов для выявления террористов, а больницы прогнозируют, кому из пациентов с застойной сердечной недостаточностью потребуется госпитализация7b, 7c. И именно это позволит нам «не рубить сплеча».
Предсказания на уровне населения
Некоторые вещи предсказать легко и делается это интуитивно. Примером может служить ситуация, когда болезнь публичного лица заставляет других людей искать в Интернете информацию об этой болезни или ее лечении8. Можно легко предсказать, что это случится, а поисковая активность просто отражает количественную сторону дела.
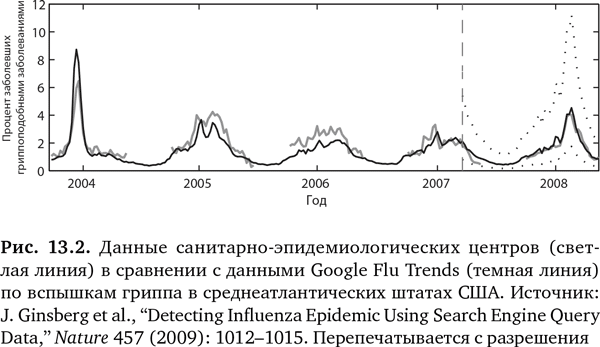
А что, если вы используете поисковики Google, чтобы с умом предсказывать болезнь, а не просто определить количество запросов? Это приводит нас к известной истории о гриппе, связанной с Google, — одному из самых цитируемых примеров предсказаний в здравоохранении9–16. Инициатива Google Flu Trends («Тенденции гриппа от Google») была запущена в 2008 г. и стала известна как «живой пример силы анализа больших данных». Сначала отслеживались 45 терминов, связанных с поиском информации по гриппу, и тенденции в миллиардах поисковых запросов в 29 странах10. Потом были выведены соответствия с помощью неуправляемых алгоритмов для предсказания начала эпидемии гриппа. Под неуправляемостью имеется в виду отсутствие заданной гипотезы — просто 50 млн поисковых терминов и алгоритмов делают свою работу. В широко цитируемых статьях в Nature12 и Public Library of Science (PLos) One11 авторы из Google (рис. 13.2) заявляли о своей способности использовать журналы поиска в Интернете для создания ежедневных оценок заражения гриппом, в отличие от обычных методов, которые предусматривают временной лаг от одной до двух недель. И далее, в 2011 г.: «Инициатива Google Flu Trends может обеспечить своевременные и точные оценки заболеваемости гриппом в США, в особенности во время пика эпидемии, даже в случае новой формы гриппа»11.
Но начало 2013 г. сопровождалось бурей противоречий: оказалось, что Google Flu Trends сильно переоценила вспышку гриппа (рис. 13.3). В дальнейшем группа из четырех очень уважаемых специалистов по обработке и анализу данных написала в Science, что Google Flu Trends систематически переоценивала распространение гриппа каждую неделю начиная с августа 2011 г. Далее эта группа критиковала «высокомерие больших данных», «распространенное представление, что большие данные скорее заменяют, чем дополняют традиционный сбор и анализ данных»17. Они ругали «динамику алгоритма» Google Flu Trends (GFT), указывая, что 45 терминов, используемых в поисковых запросах, не были документированы, ключевые элементы, как, например, основные условия поиска, не были представлены в публикациях, а изначальный алгоритм не подвергался постоянным настройкам и перепроверке. Более того, хотя алгоритм GFT был статичным, сам поисковик постоянно менялся, претерпев ни много ни мало 600 пересмотров за год, что в расчет не принималось. Многие другие авторы редакционных статей также высказались по данному вопросу13–15, 18, 19. Большинство из них обращали внимание на взаимосвязи вместо причинно-следственных связей и на критическое отсутствие контекста. Критиковали и методы выборки, так как краудсорсинг ограничивался теми, кто выполнял поиск в Google. Кроме того, наблюдалась серьезная аналитическая проблема: GFT проводила столько многочисленных сравнений данных, что была вероятность получения случайных результатов. Все это можно рассматривать как обычные ловушки, когда мы пытаемся понять мир через данные13. Как написали Кренчел и Мадсбьерг в Wired: «Высокомерие больших данных состоит не в том, что мы слишком уверены в наборе алгоритмов и методов, которых еще в общем-то нет. Скорее проблема в слепой вере в то, что достаточно, сидя за компьютером, перемалывать цифры, чтобы понять окружающий нас мир во всей его полноте»19. Нам нужны ответы, а не просто данные. Тим Харфорд выразился в Financial Times без обиняков: «Большие данные уже здесь, но великих озарений нет»18.
Некоторые принялись защищать GFT, указывая, что данные были всего лишь дополнением к санитарно-эпидемиологическим центрам, а Google никогда не заявляла, что обладает магическим инструментом. Наиболее взвешенную точку зрения выразили Гари Маркус и Эрнест Дэвис в своей статье «Восемь (нет, девять!) проблем с большими данными» (Eight (No, Nine!) Problems With Big Data)20. Я уже обращался ко многим их выводам, но мнение Маркуса и Дэвиса насчет беззастенчивой рекламы больших данных и относительно того, что́ большие данные могут (и чего не могут), заслуживает особого упоминания: «Большие данные повсюду. Кажется, что все их собирают, анализируют, делают на этом деньги и прославляют их силу или боятся их… Большие данные никуда не денутся, как и должно быть. Но давайте будем реалистами: это важный ресурс для всех, кто анализирует данные, а не серебряная пуля»20.
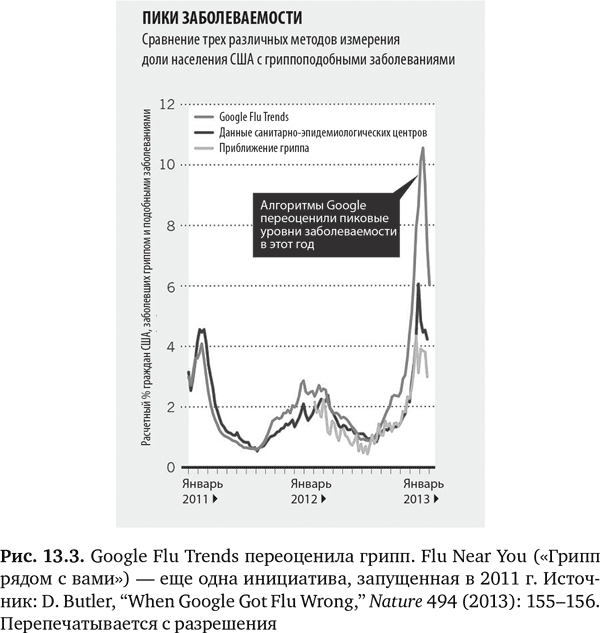
Несмотря на проблемы с GFT, подобные шаги никуда не ведут. Альтернативный и более поздний подход — это предсказание вспышки заболеваемости с использованием меньшей базы людей, которые активно поддерживали связь в Twitter, — так называемых «центральных узлов», когда люди по сути выступают в качестве датчиков21а. Это позволило обнаружить вспышки вирусных заболеваний на семь дней быстрее, чем когда рассматривалось население в целом. Точно так же алгоритм HealthMap, который проводит поиск в десятках тысяч социальных сетей и новостных СМИ, смог предсказать вспышку лихорадки Эбола в 2014 г. в Западной Африке на девять дней раньше Всемирной организации здравоохранения21b. Я углубился в историю, связанную с Google и гриппом и вспышками заразных болезней, потому что они отображают ранние этапы пути, по которому мы идем, и показывают, как мы можем заплутать, используя большие массивы данных для предсказаний в медицине. Но знать, как мы сбились в пути, важно, если мы собираемся по нему двигаться.
Предсказания на индивидуальном уровне
По сравнению с данными по всему населению, как в случае Google Flu Trends, более мощный эффект достигается комбинацией детальных данных отдельного человека21с с детальными данными остального населения. Вы уже сталкивались с этим раньше. Например, компания Pandora располагает базой данных с предпочитаемыми песнями по более чем 200 млн зарегистрированных пользователей, которые в общей сложности нажали на кнопки «нравится» или «не нравится» свыше 35 млн раз22. В компании знают, кто слушает музыку, когда ведет машину, у кого Android, а у кого iPhone и где живет каждый из них. В результате можно предсказать не только какая музыка понравится слушателю, но даже его политические предпочтения, и компания уже использовала это в целевой политической рекламе во время президентской избирательной кампании и выборов в конгресс. Эрик Бишке, главный научный сотрудник Pandora, cчитает, что их программы по сбору данных позволяют проникнуть в самую суть своих пользователей. И это действительно так, поскольку, чтобы дойти до сути, они интегрируют два слоя больших данных — ваши данные и данные миллионов других людей22.
Используя компании, торгующие данными, типа Acxiom (которые обсуждались в предыдущей главе), Медицинский центр Питтсбургского университета проводит углубленный анализ данных своих пациентов, включая характерное поведение во время шопинга, для предсказания вероятности пользования услугами пунктов оказания первой помощи23. Подобным образом поступает и Организация здравоохранения Северной и Южной Каролины, собирая данные о кредитных картах клиентов — 2 млн человек в своем регионе, чтобы определить пациентов с высокой степенью риска заболеваний (например, через покупки фастфуда, сигарет, спиртных напитков и лекарств)24. Предиктивная модель, используемая в Питтсбурге, показала, что потребители, которые делают больше всего покупок через Интернет и заказывают товары по почте, чаще обращаются в пункты оказания первой помощи, чего организации здравоохранения отнюдь не приветствуют. Обнаруженные взаимосвязи со временем обрастают новыми подробностями, когда информация о нынешних пациентах поступает повторно и большее количество пациентов включается в систему, чтобы лучше предсказывать определенные процессы. Но вопросы конфиденциальности и этичности остаются.
Эти примеры могут рассматриваться как рудиментарная форма искусственного интеллекта — машин или программного обеспечения, демонстрирующих интеллект, подобный человеческому. Другие примеры, которые, возможно, уже окружают вас, включают личных цифровых помощников типа Google Now, Future Control, Cortana25 и SwiftKey26, которые сводят информацию из электронных писем, СМС, ежедневников, записных книжек, истории поисковых запросов, местоположений, покупок, того, с кем вы проводите время, ваших пристрастий в искусстве и вашего поведения в прошлом27. Основываясь на том, что они узнают из этой информации, эти приложения появляются на вашем экране, чтобы напомнить о предстоящей встрече, показать пробки на вашем маршруте или сообщить новости по поводу вашего авиарейса. Читая то, что пишут в Twitter, Future Control ваши друзья, вам могут дать совет: «Ваша девушка грустит, пошлите ей цветы»28. SwiftKey даже вычисляет ваши ошибки при наборе текста и исправляет их, если вы все время нажимаете не на ту клавишу. Google Now работает с авиалиниями и организаторами мероприятий, чтобы иметь доступ к информации о билетах, и может даже слушать звук вашего телевизора, чтобы заранее обеспечить вас программой телевидения29. Как вы можете догадаться, это гораздо более мощные возможности, чем поиск соответствий, приводящий в действие Google Flu Trends, и они имеют непосредственное отношение к медицине.
Такая предсказательная сила полагается исключительно на обучение машин, ключевое свойство искусственного интеллекта. Чем больше данных вводится в программу или компьютер, тем большему они учатся, тем лучше алгоритмы и, предположительно, тем умнее они становятся.
Техники обучения машин и искусственного интеллекта — это то, что обеспечивало триумф суперкомпьютера IBM Watson над людьми в телевикторине Jeopardy! (Рискуй!). Требовалось быстро отвечать на сложные вопросы, ответы на которые не найти с помощью поисковика Google30–32. IBM Watson были обучены ответам на сотни тысяч вопросов, которые задавались в предыдущих играх-викторинах Jeopardy!, вооружены всей информацией из Википедии и запрограммированы на предиктивное моделирование. Здесь не предсказание будущего, а просто предсказание того, что у IBM Watson есть правильный ответ. В основе предсказательных возможностей суперкомпьютера был внушительный портфель систем для обучения машин, включая сети Байеса, цепи Маркова, метод опорных векторов и генетические алгоритмы33. Не стану больше в это углубляться: я недостаточно умен, чтобы все это понять, и, к счастью, это не особо относится к тому, куда мы с вами сейчас идем.
Еще один подвид искусственного интеллекта и обучения машин2, 20, 34–48, известный как глубинное обучение, имеет важное значение для медицины. Глубинное обучение стоит за способностью Siri декодировать речь, как и за экспериментами Google Brain с распознаванием образов. Исследователи из Google X извлекли из видеозаписей на YouTube 10 млн изображений и запустили их в сеть из 1000 компьютеров, чтобы посмотреть, что Google Brain, обладающий миллионом моделируемых нейронов и миллиардом моделируемых синапсов, способен предложить самостоятельно35, 36. Ответ — кошек. Интернет, по крайней мере сегмент YouTube (который занимает весьма существенную его часть), полон видеозаписей кошек. Кроме опознания кошки это открытие проиллюстрировало когнитивные вычисления, также известные как нейроморфные49а. Если компьютеры могут соревноваться с человеческим мозгом, как гласит теория, то можно добиться перехода их функциональных возможностей в плане восприятия, действия и понимания на следующий уровень. Прогресс в нейроморфных вычислениях идет с головокружительной скоростью. В прошлом году точность компьютерного зрения — например, распознавание пешехода, шлема, велосипедиста, автомобиля — улучшилась с 23% до 44%, при этом частота ошибок снизилась с 12% до менее 7%49b.
Несмотря на достижения Google Brain, нам пока нечем похвастаться. Человеческий мозг работает на малой мощности, порядка 20 ватт, а суперкомпьютеру требуются миллионы ватт для работы35, 49а — 57. В то время как мозг не нужно программировать (пусть даже иногда кажется, что он запрограммирован) и он теряет нейроны на протяжении своей жизни без существенного функционального истощения, компьютер, потерявший один-единственный чип, может сломаться, и обычно машины не могут адаптироваться к миру, с которым взаимодействуют50. Гари Маркус, нейробиолог из Нью-Йоркского университета, так сформулировал эту нейроморфную задачу в перспективе: «В такие времена я нахожу полезным вспомнить базовую истину: человеческий мозг — это самый сложный орган во Вселенной, и мы до сих пор не представляем, как он работает. Кто сказал, что копирование его восхитительной мощи будет простым?»58 Тем не менее наблюдается довольно большой прогресс в распознавании речи, лиц, жестов и снимков, в чем так силен человеческий мозг и слаб компьютер. Я посетил немало конференций и читал лекции в разных странах, с синхронным переводом, и меня особенно поразило одно достижение: Ричард Рашид, возглавлявший некогда научное подразделение в Microsoft, выступал с лекцией в Китае, и компьютер не только синхронно выдавал ее в иероглифах, но и переводил на китайский (смоделированным) голосом самого Рашида36. Программа DeepFace от Facebook, с самой большой в мире фотобиблиотекой, может определить, принадлежат ли две фотографии одному и тому же человеку, с точностью в 97,25%59, 60. Последствия для медицины очевидны. Ученые уже показывают, что компьютеры способны распознавать выражения лиц, например боль, точнее, чем люди, и происходит поразительный прогресс в распознавании лиц компьютерами61–63. Специалисты по информатике из Стэнфордского университета использовали кластер из 1600 компьютеров для подготовки к распознаванию снимков, тренировки проводились на 20 000 различных объектов. Больше к нашей теме относится то, что они использовали инструменты глубинного обучения для определения, является ли образец, взятый при биопсии в случае рака груди, злокачественным37. Эндрю Бек из Гарвардского университета разработал компьютеризованную систему для диагностики рака груди и прогнозирования шансов на выживание, основываясь на автоматической обработке снимков. Оказалось, что обучение на основе обработки данных в ЭВМ обеспечивает бо́льшую точность в сравнении с патологами, и это помогло распознать новые особенности, остававшиеся незамеченными на протяжении многих лет64. И нам не следует забывать об активной поддержке развития искусственного интеллекта, которая позволила создать видящие и слышащие устройства. Камера-датчик Orcam устанавливается на очках слабовидящих людей, она видит предметы и передает эту информацию через наушник, используя костную проводимость39. Слуховые аппараты GN ReSound Linx и Starkey —это подключаемые к смартфону приложения, которые «обеспечивают людям, потерявшим слух, возможность слышать лучше тех, кто нормально слышит»65. Есть инвалидные кресла для людей без четырех конечностей, контролируемые мыслью, в духе бионического будущего39. Поэтому способность искусственного интеллекта преображать вещный мир в медицине нельзя упускать из виду. Конечно, технологии могут легко соединяться с робототехникой. В Калифорнийском университете в Сан-Франциско больничная аптека полностью автоматизирована, и роботизированная выдача лекарственных препаратов пока происходит без единой ошибки.
Человек и Интернет медицинских вещей
Теперь мы готовы говорить о медицине и ее возросшей, благодаря нашим цифровым машинам и инфраструктуре, интеллектуальной мощи. В настоящее время количество данных, ежегодное производимое в мире в расчете на одного человека, составляет около одного терабайта, или пяти зеттабайтов, данных в год (или 40 секстильонов). Но вспомните из главы 5, когда мы говорили о человеческой ГИС, что только омики одного человека добавят по крайней мере еще пять терабайтов, а мы еще не достигли даже потокового поступления данных с биодатчиков в режиме реального времени, которые быстро заполонят объем генерируемых сейчас данных. И тем не менее едва ли достаточно добавить другие компоненты ГИС, в частности поток данных в пикселях медицинских снимков и предстоящий шквал информации из Интернета медицинских вещей, чтобы все преобразилось.
Но это, безусловно, не просто история исследования с участием одного человека (N = 1). Как было показано в главе 11, хотя иметь много данных о вас было бы полезно, для того, чтобы сделать данные максимально информативными, нужно сравнить их со всеми данными от каждого человека на планете (рис. 13.4). До всех людей мы никогда не доберемся, тем не менее чем их больше, тем лучше, и компании типа Facebook показывают, что можно сделать.
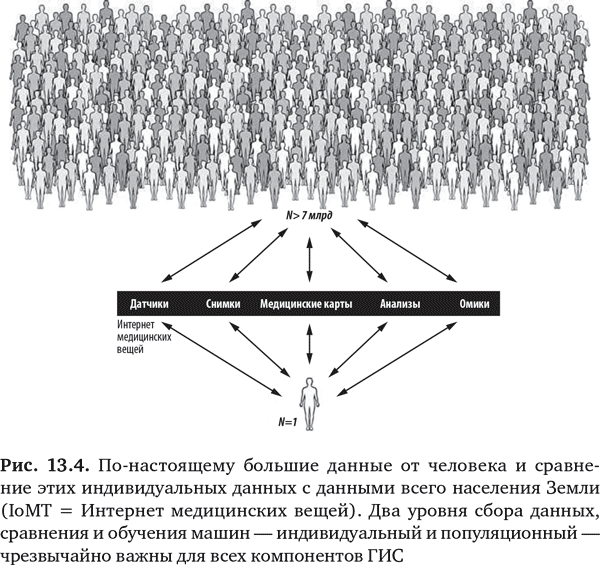
Главное, что обучение машин, подобных стоящим за IBM Watson и другими системами, позволяет нам идти вширь (N = 7 млрд) и вглубь (N = 1) не просто в поисках знаний, но и в поисках предсказаний и понимания. В отношении каждого человека нам нужно знать пусковые механизмы и сложные взаимосвязи на многочисленных уровнях — геномном, биологическом, физиологическом, средовом, — которые отвечают за предрасположенность к заболеванию или состоянию. Цель — не просто оценить риск в течение жизни человека, а в определенное время или момент. Многое мы узнаем и в результате углубленного исследования максимально возможного количества людей на предмет сигналов, обогащающих наше понимание того, что требуется для проявления болезни или для ее предотвращения. Только сейчас мы можем собрать такие паноромные данные по каждому отдельному человеку и в группах населения, и, обладая способностью управлять и обрабатывать огромные наборы данных, мы оказываемся в завидном положении предсказателей болезни. И, может быть, после того, как мы научимся все это делать хорошо, нам удастся даже предотвращать болезни у некоторых людей.
Предсказание болезни: кто, когда, как, почему и что?
Для начала убедимся в том, что мы различаем понятия «предсказание» и «диагноз». Онлайн-тестеры для проверки симптомов66 пользуются все большей популярностью и вниманием в Интернете и помогают людям проводить «самодиагностику» (с помощью компьютера), но они не предсказывают болезнь. В лучшем случае из набора симптомов, которые вводит человек, предлагается дифференциальная диагностика, и правильный диагноз входит в список вариантов. Это полезно и практично, но это ничего не предсказывает. Точно так же разработчики из Biovideo — которые разрабатывают приложение для суперкомпьютера IBM Watson, чтобы «мать с больным ребенком в четыре утра могла воспользоваться IBM Watson и спросить, что случилось с ее ребенком и получить точный ответ»67а, — могут создать что-то полезное, но это что-то не имеет отношения к прогнозу.
У нас очень серьезная проблема с ошибочной диагностикой: диагноз — неправильный или правильный — ставится пациенту слишком поздно, и эта проблема затрагивает 12 млн американцев в год67b, 67c. Для решения этой проблемы можно обратиться к технологиям и контекстуальным вычислениям. Популярный телесериал «Доктор Хаус» очень поучителен в этом плане. Главный герой, Грегори Хаус, — блестящий диагност, который разбирается с самыми редкими и таинственными случаями, ставящими в тупик других врачей68–71. Для того чтобы этого добиться, он использует байесовский подход, при котором вся информация — история болезни, медосмотр, лабораторные исследования, сканограммы — рассматривается в контексте всей ранее известной, относящейся к делу информации (что известно из теоремы Байеса как клиническая предсказуемость результата испытания). Ответ «да» или «нет» не получается. Скорее, есть вероятность, что у пациента диагноз X или Y. Это можно сравнить с распространенным подходом, предусматривающим «да» или «нет» на основании исключительно статистики вероятности (типа Р < 0,05, где Р — коэффициент вероятности). Модель доктора Хауса идеально подходит для компьютерной автоматизации в медицине, и точно так же работает IBM Watson70, 71. Вероятность предварительного диагноза учитывает всю медицинскую литературу, которая была опубликована до сегодняшнего дня. Когда вы вводите в IBM Watson все имеющиеся данные о конкретном пациенте в поиске диагноза, вы получаете список возможных вариантов. Каждому присваивается вес или вероятность (отношение правдоподобия).
Более того, байесовская модель для диагностики с помощью компьютера быстро становится частью клинической практики и может распространиться на рекомендации по лечению. Информационный ресурс в Сети под названием Modernizing Medicine (Модернизация медицины) включает информацию по более чем 15 млн посещений пациентов и 4000 врачей с лечением и результатами по каждому пациенту72. Так что помимо способности IBM Watson к дифференциальной диагностике может быть генерирован список назначений с взвешенной вероятностью и установлено соответствие данных пациента всем остальным в базе данных. (Кстати, специалистам по обработке и анализу данных, которые работают в здравоохранении, не нравится, когда их информационные ресурсы называют базами данных. Вот так-то!) Все это примеры использования искусственного интеллекта для дифференциальной диагностики и лечения в медицине. Но и это еще не предсказания.
Теперь надо убедиться в том, что сбор несметного количества данных не означает, что вы сможете предсказать что-то значительное. К 100-летию со дня рождения Алана Тьюринга в журнале Science был опубликован ряд материалов, включая статью о «доме, полностью оснащенном камерами и аудиооборудованием, [которые] постоянно записывали жизнь ребенка от рождения до трех лет, в результате набралось ~200 000 часов аудио- и видеозаписей, отображающих 85% жизни ребенка в периоды бодрствования»73. Хорошо, для сбора данных это триумф, но определенно без намерения или даже какой-либо вероятности предсказать болезнь. Это не упражнение и не эксперимент без заданной гипотезы. Точно так же есть много новых полномасштабных проектов по геномному секвенированию, которые охватывают 100 000 людей, — например, совместный проект компаний Geisenger-Regenerson и Human Longevity, Inc., государственная программа Великобритании Genomics England и инициатива Института системной биологии. В то время как эти программы несомненно внесут вклад в науку о геноме, зачисленные в эти программы люди не относятся ни к какому определенному фенотипу и не выдвигается никаких реальных гипотез. Просто считается, что это можно сделать, и этим стоит заниматься, и что в этих данных может оказаться что-то такое, что приведет к созданию нового лекарства. Однако, чтобы предсказать болезнь, нужны определенные гипотезы и очень точные цели, об этом мы поговорим ниже. В противном случае нас собьет с толку низкий показатель отношения сигнал/шум, убаюкает мысль о том, что у нас имеется полная картина данных по всей Вселенной, и введут в заблуждение ложные взаимосвязи.
Еще одно важное соображение состоит в том, что мы стараемся предсказать серьезную болезнь, а не биомаркер. Мы не пытаемся говорить, что у кого-то будет высокий уровень холестерина или аномальные показатели работы печени. В целом эти белковые или генные маркеры обманчивы, в медицинской литературе описано множество кандидатур, но лишь немногие из них когда-либо обследовались в клинике74. Дело в том, что, хотя результаты анализов могут быть полезны, чтобы помочь предсказать наступление болезни, прежде чем она начнется, этого мало.
Шаг в освоении больших данных для понимания процесса развития болезни предприняли исследователи из Дании, располагавшие информацией за 15 лет по 6,2 млн граждан страны75. Они смогли графически представить многие заболевания в виде так называемых траекторий, чтобы показать, как одна болезнь может в конце концов привести к другой, которая, казалось, никак не связана с первой. Это были временны́е связи без каких-либо установленных причинно-следственных отношений75.
Мы же пытаемся предсказывать так, чтобы можно было предотвратить, это главная цель. Если нет оснований для действий, то предсказание становится скорее научным упражнением. Например, много усилий тратится на попытки предсказать, у кого разовьется болезнь Альцгеймера, задолго до того, как начнутся когнитивные нарушения. Бесспорно, это одна из самых важных проблем здравоохранения, которая перед нами стоит, но на сегодняшний день, несмотря на значительные усилия, нет никаких проверенных превентивных стратегий.
Очень важны также время и место предсказания. Я живу в Сан-Диего, где вижу множество любителей серфинга, которые каждый день катаются на волнах в Тихом океане, не думая об акулах. Акулы убивают всего 10 человек в год из 7 млрд жителей планеты, поэтому мы можем сказать, что в среднем риск гибели в результате нападения акулы в Сан-Диего бесконечно мал. Но время от времени опасных акул замечают поблизости от берега. В такие дни редко увидишь кого-то из серфингистов. В том, что касается предсказаний, время и место играют решающую роль.
В предсказании болезней у людей время — это все. Мы можем каждому сказать определенно, что он умрет. Но бессмысленно предрекать: «Вас ожидает смерть, но мы не знаем, через две недели или через два десятка лет». На самом деле это даже хуже, чем бесполезно, потому что, если предсказание правдиво, оно может вызвать у пациента панику из-за отсутствия точного указания времени. Поэтому в попытке предотвратить болезни важны и «кто», и «когда».
Полезная аналогия для успешного медицинского предсказания — это предсказание сбоев в работе реактивных двигателей76, 77. Компании, подобные General Electric, ведут постоянное наблюдение за своими самолетными двигателями. Они используют сложные неуправляемые алгоритмы, искусственный интеллект и многоаспектную аналитику для определения предиктивных предвестников вроде тонкой трещинки, потому что требуется нулевая вероятность сбоя, так как во время каждого рейса рискуют сотни пассажиров. Большинство состояний, таких как инфаркт, приступ астмы, инсульт, аутоиммунная атака, подобны авиакатастрофам, только они происходят в человеческом теле. Мы можем использовать те же вычислительные инструменты. Величайшая разница в том, что медицинский мониторинг спасает набитые людьми самолеты, но только по одному «пассажиру» за раз.
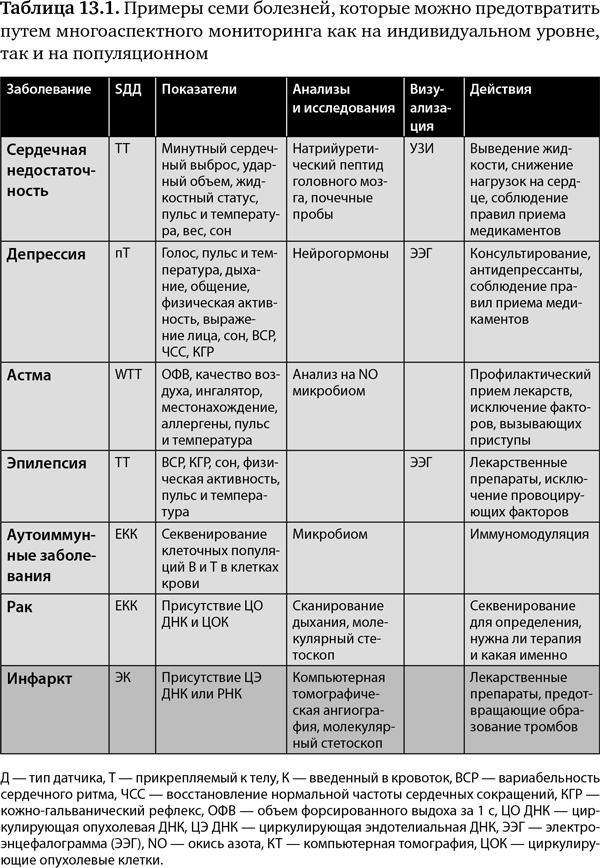
Теперь давайте рассмотрим некоторые болезни, которые, не исключено, можно будет предсказать и предупредить в будущем. Начнем с тех, которые можно отслеживать с помощью датчиков, прикрепляемых к телу, потому что они обеспечивают уникальный поток данных в режиме реального времени от людей, находящихся в группе риска, а информативность и предиктивность метода делают его самым лучшим и самым точным ударом по цели78. В первую очередь я обращаюсь к проблемам, решаемым с помощью датчиков, носимых на теле, которые, вероятно, скоро будут широкодоступны, а затем перейду к состояниям, которые будут в основном зависеть от датчиков, вводимых в кровоток. Астматические приступы — одна из главных причин смерти и обращений за неотложной помощью при угрозе жизни у детей, и, безусловно, они подрывают здоровье миллионов взрослых. У каждого астматика свои причины, вызывающие спазм дыхательных путей: у одних это загрязнение окружающей среды, у других — холод, физические нагрузки, цветочная пыльца или другие аллергены. Если задолго до первых признаков затруднения дыхания нам удастся улавливать момент, когда дыхательные мышцы начинают менять тонус, то удастся предупреждать приступы. Вероятно, это достижимо при использовании кластера датчиков, носимых для определения качества воздуха, присутствия в нем цветочной пыльцы, анализа использования ингалятора(-ов) и геолокации, анализа дыхания на присутствие и измерение количества окиси азота, а также измерения функции легких с использованием микрофона смартфона или подходящего подключаемого приложения. Поскольку иммунная функция тесно связана с микробиомом кишечника, пробы и анализ этого «ома» тоже заслуживают изучения. Наряду с этим может осуществляться пассивный мониторинг дыхательного ритма, температуры, насыщения крови кислородом, кровяного давления и скорости сердечных сокращений с помощью устройства в часах или браслета на запястье. Теперь приходит время для персонифицированного машинного обучения, чтобы на основании всех данных человека определить предвестники приступа астмы. После того как выявлены закономерности, остается предупредить человека о необходимости принимать дополнительное лекарство, избегать определенных воздействий или предложить еще какую-то комбинацию. Более того, эта информация становится более ценной, когда она получена от тысяч и сотен тысяч больных — у нас никогда не было возможности проводить подобный мониторинг людей «в естественных условиях». Теперь спусковые механизмы и связи неизбежно будут обнаружены. В конечном счете люди, у которых никогда не было приступа астмы, но находящиеся в группе высокого риска, выявленного на основании геномного секвенирования, наследственности и скрининга иммунной системы, могут использовать этот подход, чтобы этого никогда не случилось.
А как насчет депрессии и посттравматического стрессового расстройства (ПТСР)? Возьмем для примера военнослужащего, который вернулся из Афганистана и проходит скрининг на посттравматическое расстройство. Сегодня это делается с помощью вопросов, которые задают человеку, а он дает на них субъективные ответы. Есть много других более объективных способов выявления этого состояния, они включают тон голоса и интонацию, дыхание, выражение лица, пульс и температуру, кожно-гальванический рефлекс, вариабельность сердечного ритма и восстановление нормальной частоты сердцебиения, модели общения, движения и жизнедеятельности, осанку, качество и продолжительность сна и мозговые волны. Этот набор показателей, вероятно, поможет диагностировать склонность к посттравматическому стрессовому расстройству. От депрессии страдают свыше 20 млн американцев, и это заметно влияет на качество жизни и успешность. Если мы узнаем, что ускоряет, а что облегчает депрессию у каждого человека и у большой группы населения, то, вероятно, сможем лучше предотвращать депрессию или, по крайней мере, ее самые тяжелые формы. В случае людей, проходящих лечение, также можно легко отследить соблюдение правил приема препаратов, чтобы определить, является ли это провоцирующим фактором.
То же самое относится к застойной сердечной недостаточности. Теперь у нас есть способы непрерывно, удар за ударом, отслеживать работу сердца, жидкостный статус, качество сна и приступы апноэ одновременно с пульсом, температурой и весом. Смартфон можно использовать для измерения таких показателей, как натрийуретический пептид головного мозга, и для исследований почек, например определения азота мочевины в крови или креатинина, которые отражают жидкостный статус и силу сердечной мышцы. Выполнение лекарственных назначений можно отслеживать с помощью оцифрованных таблеток. В целом эти данные должны давать сигнал о приближении сердечного приступа, прежде чем человек почувствует, что ему не хватает воздуха. Если выявляется приближение сердечного приступа, есть несколько типов лекарственных препаратов, которые можно использовать для предотвращения прилива крови к легким.
То же самое относится к эпилепсии, которую, как было показано, можно предсказать у некоторых людей при помощи «электродермальных» датчиков в виде браслета путем мониторинга вариабельности сердечного ритма и кожно-гальванического рефлекса. Но если к этому добавить носимый на теле аппарат для ЭКГ, показатели качества сна и мониторинг пульса и температуры, то вполне можно предупредить приступ задолго до его вероятного наступления. И шансы возрастают, когда тысячи людей, страдающих эпилепсией, проходят всеобъемлющий мониторинг.
Университет Онтарио работает над проектом «Артемида» — это инициатива по сбору данных о тысячах недоношенных детей79. В случае недоношенных детей есть 25%-ный риск подхватить серьезную инфекцию, и 10% из этих новорожденных умрет, но до сегодняшнего дня было сложно предсказать, кто из младенцев особенно подвержен инфекциям и когда они могут проявиться. С помощью датчиков сердечного ритма был определен важный маркер изменения сердечного ритма. Теперь эти устройства для новорожденных, работающие по всему миру, могут отправлять данные мониторинга сердечного ритма через облачное хранилище данных для поминутного прочтения на базе «Артемиды» для постоянного обновления статистики вероятности. Точно так же существуют способы определить, кто из слабых пожилых людей, вероятно, упадет и когда80, 81а. Используя различные датчики в полу или то, что получило название «волшебный ковер», удается заметить изменения в походке человека и возросший риск падения. Такие падения представляют собой один из самых серьезных рисков для пожилых людей и часто приводят к перелому шейки бедра и фатальному исходу. Стратегия обучения машин могла бы особенно пригодиться для предотвращения подобных случаев.
Теперь обратимся к заболеваниям, которые, вероятно, потребуют введения датчиков (табл. 13.1), поскольку нет подходящего способа получить важную информацию или заглянуть внутрь (по крайней мере в настоящее время)81b. Если имплантировать в кровоток крошечный датчик, например, посредством миниатюрного стента, который вводят в вену в области запястья, то можно обеспечить постоянное наблюдение за нашим кровотоком. В случае аутоиммунных болезней, которые включают диабет (тип 1), рассеянный склероз, волчанку, ревматоидный артрит и псориатический артрит, болезнь Крона и язвенный колит, можно осуществлять мониторинг иммунной функции — и так называемых приобретенных и врожденных иммунных путей. На индивидуальном уровне это могло бы быть секвенирование В- и Т-лимфоцитов вместе с аутоантителами (антителами, направленными на самого человека) для определения видов иммунной атаки. После того как это будет сделано у десятков тысяч человек с иммунными расстройствами, мы лучше представим себе характер мониторинга кровотока у тех, кто находится в группе риска, или у тех, у кого уже было диагностировано одно из упомянутых заболеваний. Как и в случае с астмой, вероятно, имеет смысл периодически проводить анализы микробиома, в частности кишечника. Если задолго до появления каких-либо симптомов или какого-либо разрушения ткани типа островковых бета-клеток, нервной ткани или суставов (в случае диабета, рассеянного склероза и ревматоидного артрита соответственно) становится известно, что развивается иммунная атака, есть много различных видов терапии, которые смогут отключить соответствующий участок иммунной системы. Это гораздо более разумный путь профилактики заболеваний по сравнению с принятыми сегодня антикризисными мерами или длительной терапией даже тогда, когда иммунная система неактивна.
Молекулярный стетоскоп и обучение машин
Как мы видели, классический стетоскоп весьма ограничен с точки зрения сбора данных. Но считалось, что он видит человека насквозь и он незаменим при медосмотре и проверке здоровья человека. На самом деле он ничего не видел, но по крайней мере давал возможность слышать звуки внутри тела и на протяжении 200 лет формировал медицинскую практику.
Мы находимся на интересном этапе, когда действительно заглядываем внутрь человеческого тела и получаем удивительную информацию, которую сложно интерпретировать или ее слишком много. Например, когда беременная женщина проходит неинвазивный тест для беременных, чтобы определить, нет ли у плода хромосомных аномалий, таких, например, как синдром Дауна, то проба крови содержит и ее ДНК, и ДНК ребенка. К настоящему времени зарегистрировано немало случаев обнаружения опухолевой ДНК, и дальнейшие исследования этих беременных женщин подтвердили, что у них рак. Таким образом, простой анализ крови для выяснения информации о плоде приводит к неожиданным, серьезным молекулярным открытиям о матери. Но это лишь верхушка айсберга, потому что по мере нашего продвижения вперед очень вероятно, что анализы крови на бесклеточные ДНК и РНК, которые циркулируют у нас в крови, станут обычным лабораторным исследованием — молекулярным стетоскопом. Мы и в самом деле будем видеть организм изнутри, чего не могли никогда раньше. Когда это произойдет, окажется, что очень многие люди имеют опухолевую ДНК. Но есть ли у них рак?
Вполне может быть, что нормальный процесс старения и функции по наведению порядка в здоровом теле предполагают развитие мутаций в некоторых клетках тут и там, что в конечном счете может привести к раку. Но есть защитные механизмы, как, например, иммунная система, которые видят это ограниченное число аномальных клеток и останавливают процесс, не позволяя ему идти дальше. Тем не менее аномальная «неопухолевая» ДНК проявляется в крови. На самом деле мы не знаем, что с этим делать. Это может привести к очень обширным и дорогим обследованиям, чтобы определить, есть ли на самом у человека рак и где находится опухоль. Или же мы можем обратиться к обучению машин, чтобы понять проблему. Если у представителей одной и той же крупной когорты в разные моменты времени брать пробы, связанные с различными омиками, включая ДНК и РНК, это, вероятно, могло бы помочь разгадать загадку. После углубленного изучения мы в конце концов могли бы сказать любому пациенту, что эта опухолевая ДНК безобидна и означает, что здоровое тело выполняет свою работу, или что она представляет раннее выявление реального заболевания. Кто-то может задаться вопросом, зачем нам нужна такая сверхбдительность. Дело в том, что возможность обнаруживать рак задолго до того, как его можно увидеть на сканограмме или проявятся симптомы, по всей видимости, оптимальный выход. Особенно если будет показано, что обнаружение рака на таком раннем этапе проводит к отличным результатам.
Это всего один пример из многих вариантов применения молекулярного стетоскопа. Если у человека трансплантирован орган, то всегда остается риск отторжения, и это осложнение очень трудно обнаружить, обычно требуется биопсия. Но мы не хотим делать биопсию человеку, который отлично себя чувствует, хотя знаем, что отторжение гораздо легче лечить, когда процесс находится на ранней стадии. Недавние исследования показали, что если просто проверить, нет ли в его крови признаков ДНК донорского органа, то это может быть лучшим способом отслеживать процесс отторжения. Однако, как и в случае опухолевой ДНК, что означает наличие в крови незначительного количества донорской ДНК? Чтобы выяснить, что означает этот сигнал, мы вновь обращаемся к обучению машин: ведь нужно собрать как можно больше информации об огромном числе пациентов, которым были имплантированы самые разные органы. И предполагаемый ответ в каждый конкретный момент должен рассматриваться с учетом обновлений по мере добавления новой информации.
Похоже, что наиболее перспективным компонентом молекулярного стетоскопа является бесклеточная РНК, которая может быть потенциально использована для мониторинга любого органа82. Ранее это было немыслимо у здорового человека. Можно ли было вообразить проведение биопсии мозга или печени у человека в ходе обычного медосмотра? Используя высокопроизводительное секвенирование бесклеточной РНК в крови и сложные биоинформативные методы анализа этих данных, Стивен Квейк и его коллеги из Стэнфордского университета показали, что возможно проследить экспрессию генов каждого органа по простой пробе крови. И это постоянно меняется в каждом из нас. Это идеальный случай для глубинного обучения, чтобы определить, что означают эти динамические геномные сигнатуры, выяснить, что можно сделать для изменения естественного хода развития болезни, которая только зарождается, и разработать пути предотвращения. Более того, кроме анализа крови, который можно рассматривать время от времени, этот молекулярный стетоскоп потенциально может быть превращен во вживляемый датчик. Но пока еще неясно, приведет ли к успеху или окажется бессмысленной эта многообещающая перспектива молекулярных операций в теле, как и большинство из 150 000 биомаркеров, которые ведут в никуда74. Едва ли нужно напоминать, насколько сложна человеческая биология и что понимание всех взаимосвязанных взаимодействий — системная медицина — в случае каждого отдельного человека, вероятно, окажется крепким орешком.
Есть стратегии, которые представляют собой новые средства предотвращения серьезных заболеваний, и их еще предстоит подтвердить. Нетрудно вообразить, как невероятное количество генерируемых пациентами данных идет в смартфоны, подсоединенные к искусственному интеллекту, и обрабатывается им. А когда мы сможем использовать такую систему регистрации данных и предиктивную аналитику — как на индивидуальном уровне, так и на популяционном, — по мере превращения медицины в науку о данных мы и сами, возможно, начнем казаться довольно умными.

