Как образуется визуализация данных
При кодировании чисел каждую единицу данных в наборе данных мы превращаем в объект – простую геометрическую фигуру: точку, линию, квадрат, круг. А различные количественные и качественные свойства этой единицы данных зашифровываем визуальными свойствами этого объекта. В качестве визуальных свойств обычно выступает размер, положение, цвет (оттенок, насыщенность, яркость), угол, наклон.
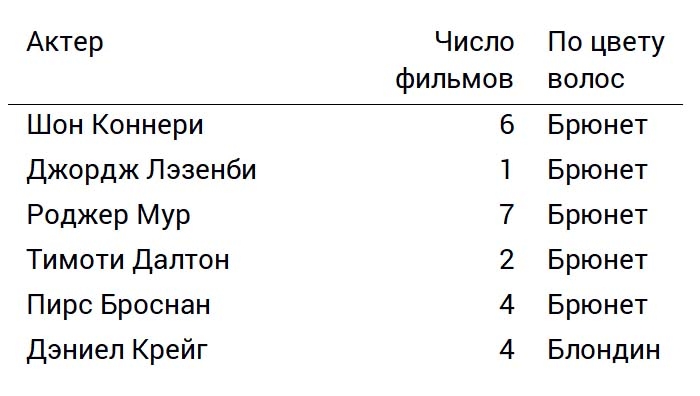
В этом датасете про актеров, которые играли Джеймса Бонда, каждый актер – это одна единица данных. Мы превращаем ее в объект – точку, у нас получается шесть точек. Количество фильмов, в которых актер участвовал, мы зашифровываем положением этой точки относительно базовой линии:

В зависимости от цвета волос (качественное свойство) мы изменяем цвет точек. Цвет точек, соответствующих актерам-брюнетам, сделаем черным. Точке, соответствующей актеру-блондину (он всего один – Дэниел Крейг), присвоим оранжевый:
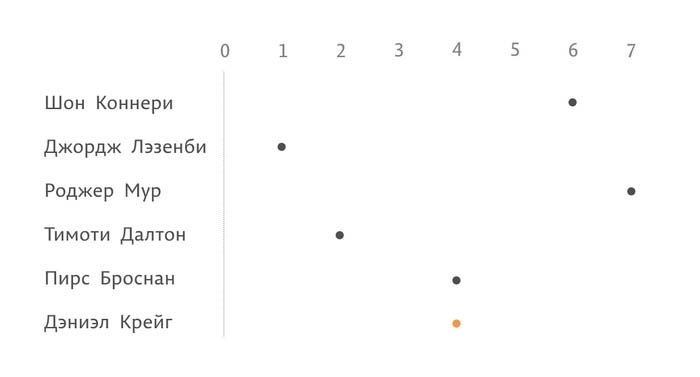
Добавим подпись для оси X. В легенде объясним значения цветов. По ней читатель сможет раскодировать информацию:
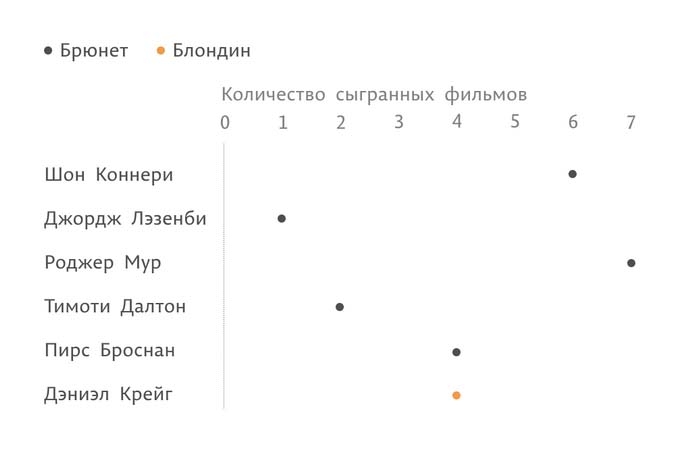
Проведем линию от ноля до точки, соответствующей количеству фильмов. Так будет удобнее сопоставлять актера и количество фильмов, в которых он сыграл.
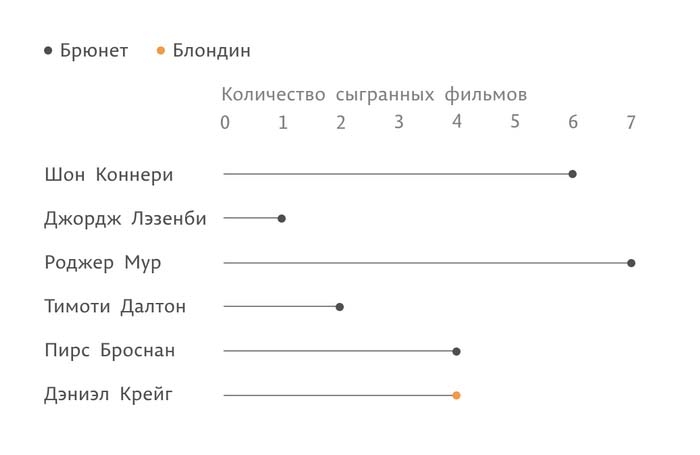
Мы наглядно увидели, как образуется визуализация данных. И сразу же познакомились с двумя задачами, которая она может решать: графически представлять данные и удобно их сравнивать. В нашем случае сравнение данных происходило за счет того, что все точки стояли на расстоянии, пропорциональном количеству фильмов.
Есть еще одна задача для визуализации: она может обеспечивать ранжирование данных – сортировку по определенному принципу (от большего к меньшему, по алфавиту и так далее). Никогда не стоит пренебрегать этой возможностью. На самом деле наши значения сейчас тоже ранжированы: актеры расположены в хронологическом порядке. Нагляднее будет, если разместить их по убыванию значений:
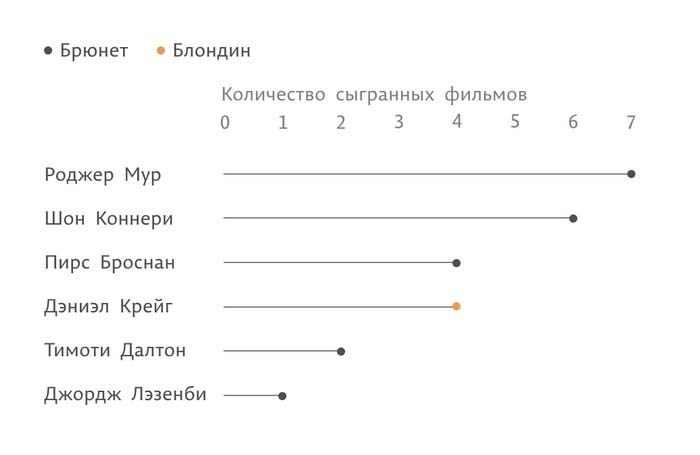
Определенная комбинация выбранного объекта и свойств образует вид визуализации: столбиковую диаграмму, линейный график и т. п. У нас получилась диаграмма, которая называется lollipop – леденцовая, своеобразный гибрид столбиковой и точечной. Она позволяет сфокусироваться на сравнении между собой окончаний линий, а не размеров столбиков. Ее можно использовать вместо столбиковой.
Эффективность вида визуализации как инструмента донесения сообщения определяется:
• Однозначностью считывания – понятностью. Когда человек быстро понимает, какие именно объекты и их свойства и как именно кодируют числовые значения.
• Тем, насколько удобно и точно он позволяет человеческому глазу раскодировать графические образы обратно в числовые значения.
• И, наконец, самое главное – тем, насколько тип визуализации подходит выбранным данным.
Именно последний пункт в значительной мере определяет эффективность донесения вашего сообщения.
Стоит избегать двойного кодирования, когда одно и то же свойство объекта кодируется сразу несколькими способами – например, длиной и цветом. Это вводит в заблуждение и сразу неоправданно повышает сложность визуализации:
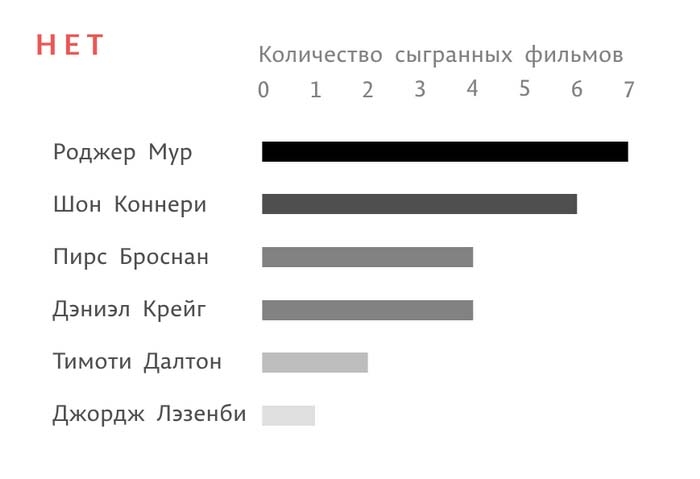

В первом случае количество фильмов закодировано только длиной столбика. Во втором – еще и степенью яркости цвета самого столбика. В этом нет необходимости.
Существует огромное количество геометрических фигур и их визуальных свойств. А число их комбинаций и вовсе стремится к бесконечности. Однако базовых типов визуализации данных совсем немного. Давайте посмотрим на них.
Назад: Суть визуализации данных
Дальше: Типы сравнения

