Книга: Графики, которые убеждают всех
Назад: Быть аналитиком. Задавать вопросы
Дальше: Формулируем сообщение
Создание новых данных внутри датасета
Чаще всего, чтобы найти что-то действительно важное и значимое в датасете, вам придется создавать сводные таблицы или новые данные внутри набора.
Уровень агрегированности (обобщенности, детализации) данных может быть разным. Скажем, в таблице с зарплатами тренеров данные представлены в неагрегированной форме. Для каждого тренера выделена отдельная строка с уровнем годовой зарплаты в абсолютных числах. Как вы помните, инструмент Гугл Таблиц для анализа самостоятельно догадался провести агрегацию по результату команд. Сервис посчитал среднюю зарплату тренеров команд, не вышедших из группы и прошедших дальше.
Иногда же таблицы к вам поступают (например, от аналитиков) уже агрегированными (сводными). Это удобно, так как вам не нужно проводить эту работу. Однако, если данные сильно различаются в широком диапазоне, их усреднение может сильно исказить общую картину.
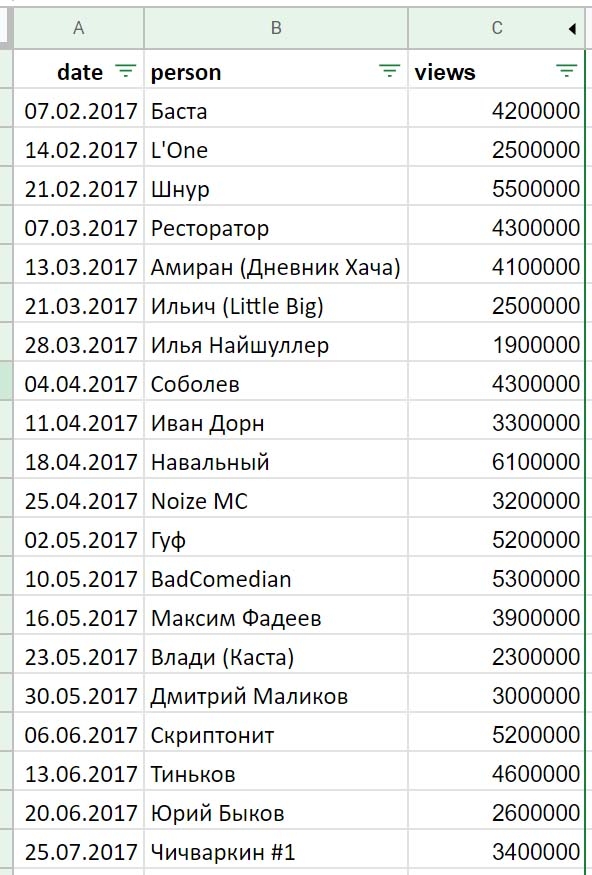
Вот таблица со статистикой посещаемости первого сезона ютуб-программы «вДудь»:
Сначала проведем статистический анализ, а затем приступим к визуальному, в ходе которого будем создавать поисковые визуализации данных. Оформление не имеет для них существенного значения. Это важно для финальных графиков, которые готовятся к размещению в презентации или для публикации. А для поисковых визуализаций мы просто оставим стандартные настройки программы (в данном случае для визуального анализа мы использовали Tableau).
Прежде всего получим ключевые числа, описывающие датасет. Общее количество просмотров всех роликов – чуть более 124 млн, всего роликов за период – 34, среднее количество просмотров каждого ролика – 3,64 млн, минимальное (режиссер Хлебников) – 1,6 млн, максимальное (Слава КПСС) – 6,6 млн.
Первый ролик вышел 7 февраля, последний – 18 октября 2017 года.
Посмотрим динамику просмотров по датам:
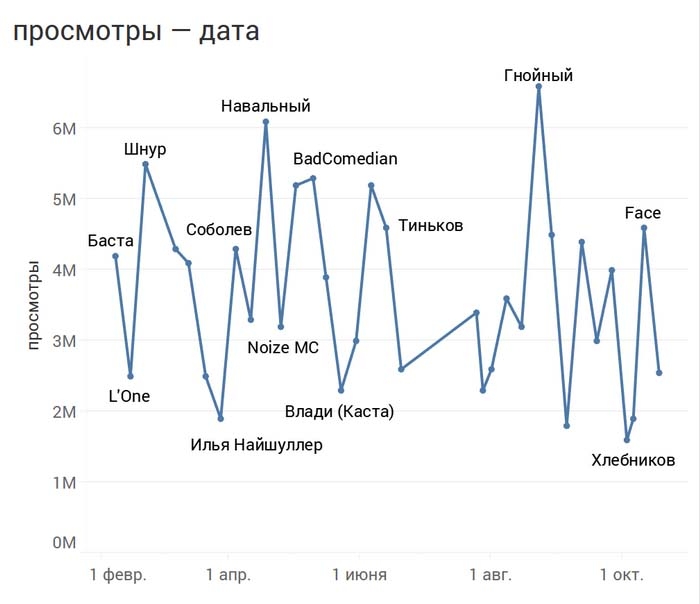
Очень удачная визуализация, которая дает представление о взлетах и падениях популярности выпусков, позволяет увидеть наиболее и наименее популярные ролики.
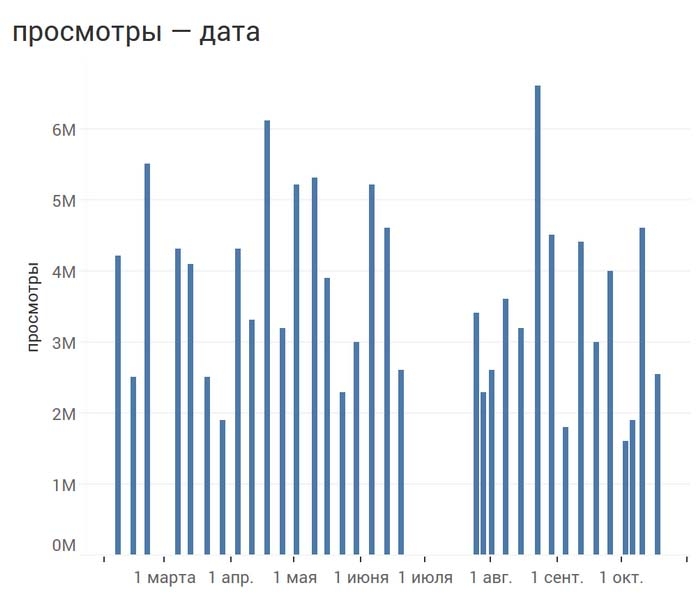
Чтобы нагляднее увидеть распределение выпусков по датам и обнаружить значительный по времени перерыв, заменим линейный график на столбиковую диаграмму:
Становится интересно, в какие дни чаще всего выходили интервью, смотрим:
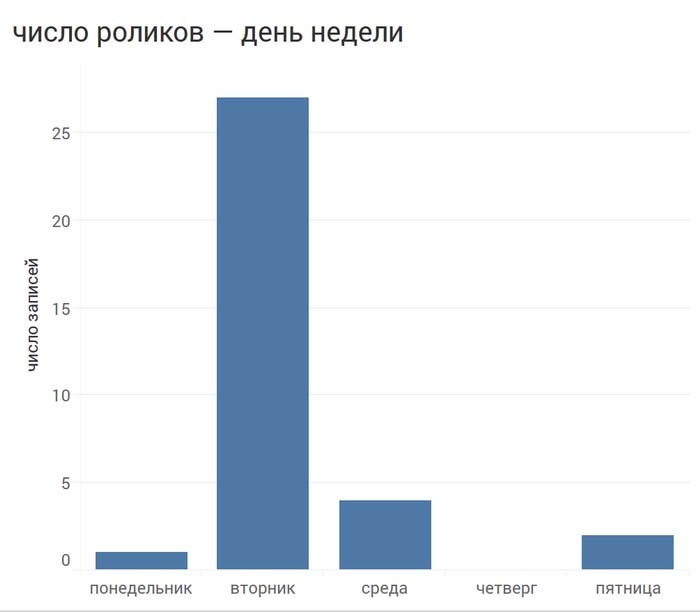
Выпусков в среду было меньше, чем во вторник, но медиана просмотров у них больше. Медиана – это число в середине набора чисел. Половина чисел расположена ниже этого значения, половина – выше.
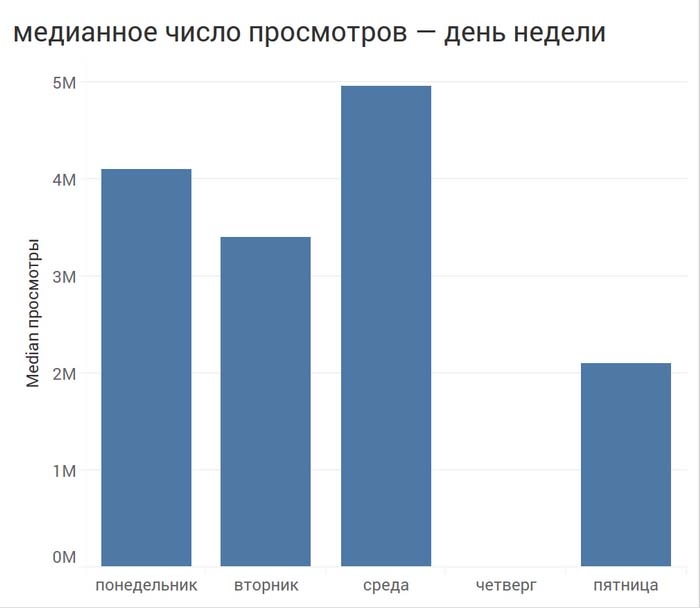
Чтобы понять почему так вышло, посмотрим, какие именно интервью пришлись на среду. Это БэдКомедиан, Гнойный, Фейс и Познер.
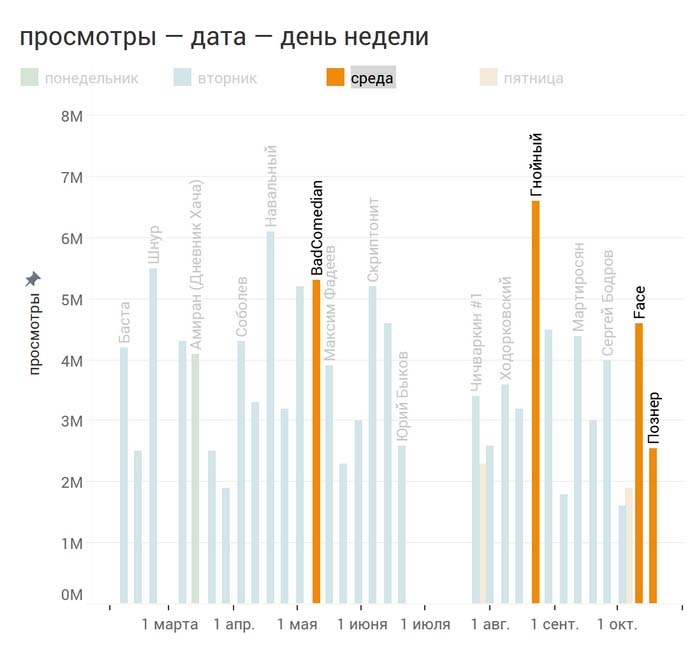
Однако, разумеется, вторничные просмотры принесли гораздо больше трафика, чем какие-либо другие:
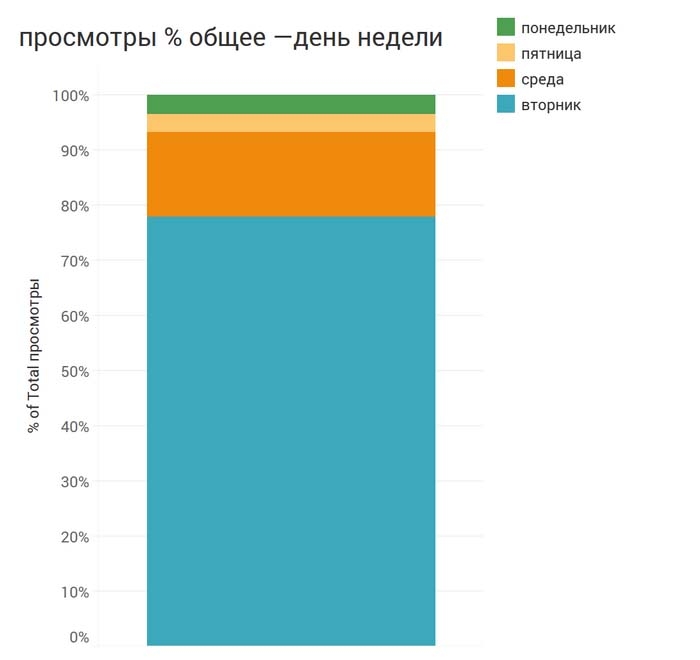
Самое время более наглядно изучить, какие ролики самые популярные, а какие – наоборот:
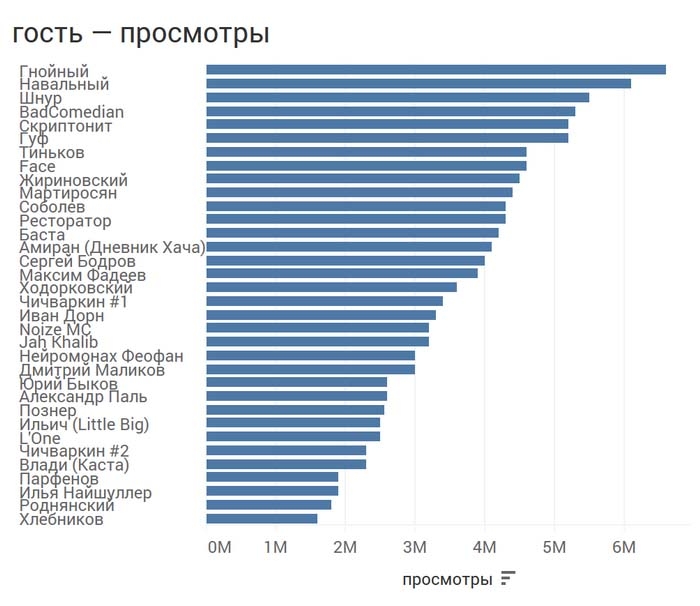
По-хорошему нам надо сделать поправки на то, как долго ролик находится на ютубе и на количество подписчиков в момент выхода программы. Например, видео с Познером добавлено ровно в день составления датасета и наберет еще немало просмотров. Сейчас мы опустим эти моменты для понимания главного.
Что еще может нас заинтересовать? Вот распределение роликов по месяцам и по количеству просмотров:
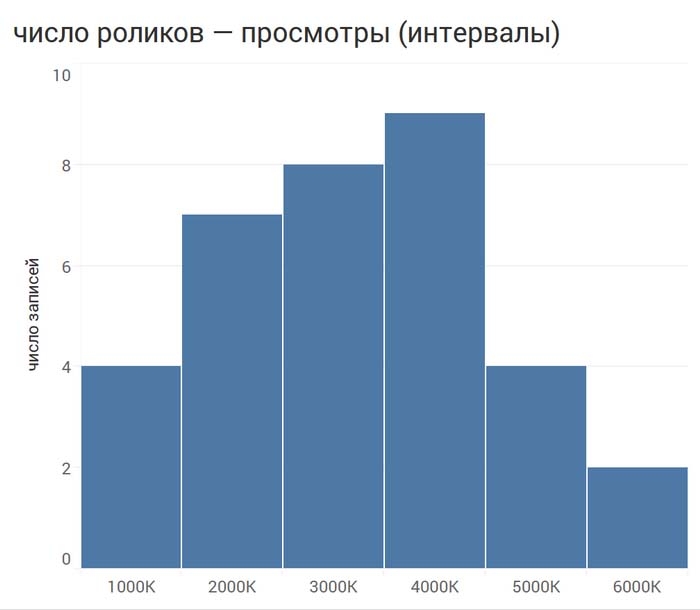
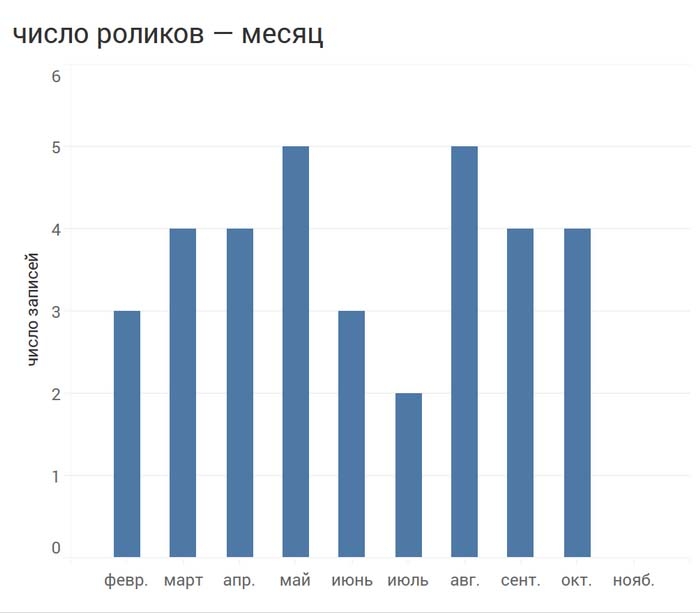
Мы, разумеется, не охватили и половины того, что могли бы проанализировать. Однако даже в процессе беглого анализа мы уже агрегировали и создавали новые данные в наборе! Мы объединяли данные, когда считали распределение количества роликов по дням недели и месяцам, распределение по просмотрам. Мы создавали новые данные, когда считали процент просмотров, пришедшихся на разные дни недели.
Новые данные в набор (скажем, даты рождения участников) мы можем добавить и из других датасетов или определить самостоятельно. Давайте добавим новый столбец, в котором укажем основную область деятельности участников интервью:
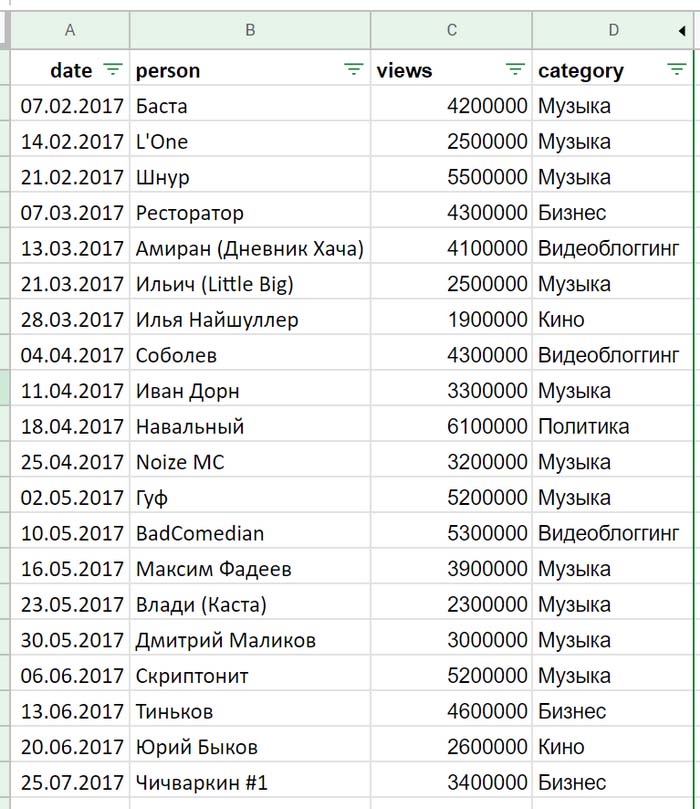
Теперь мы можем не только увидеть, кто из гостей Дудя более популярен, но и узнать, персонажи из каких сфер людям более интересны.
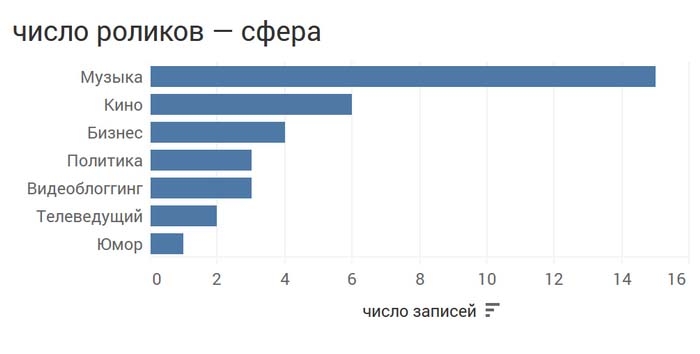
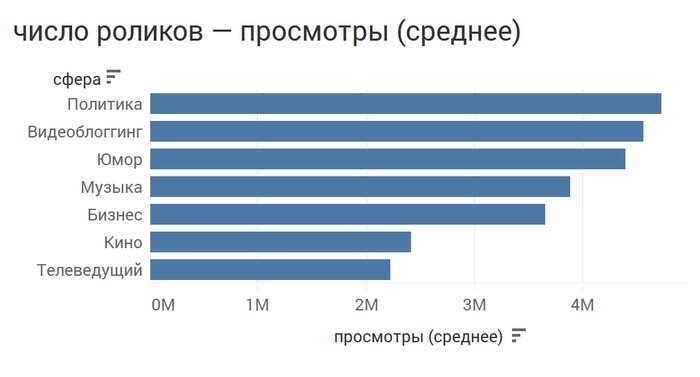
Или объединить их:
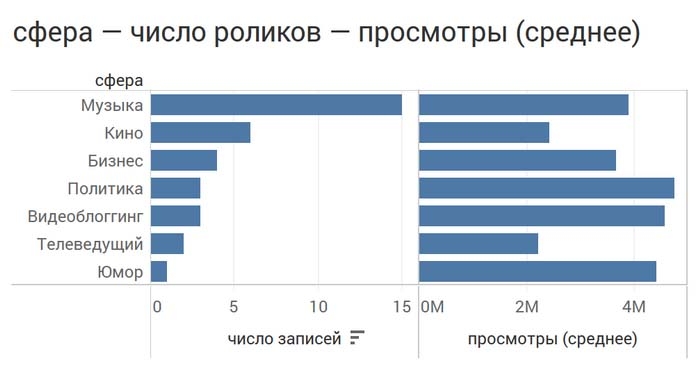
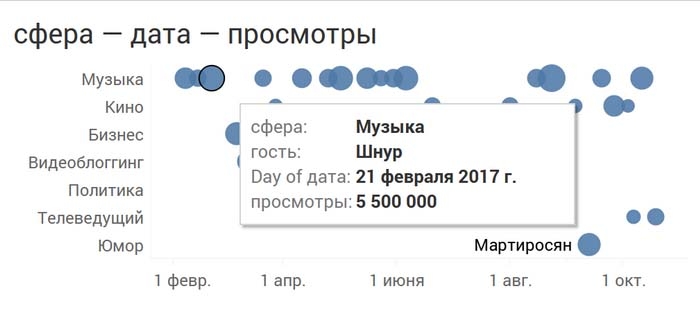
Или даже посмотреть, когда именно и как часто гости из разных сфер приходили к Дудю:
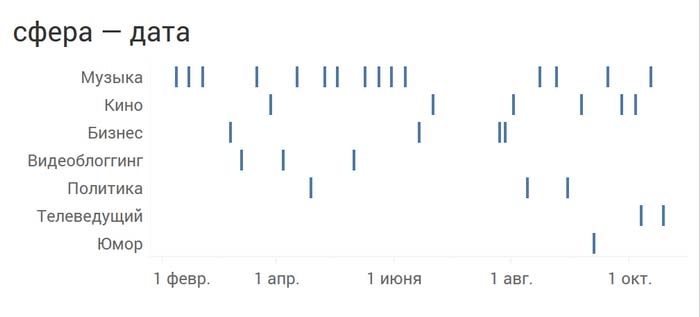
А теперь размером кружочка закодируем число просмотров, то есть добавим еще одно измерение:
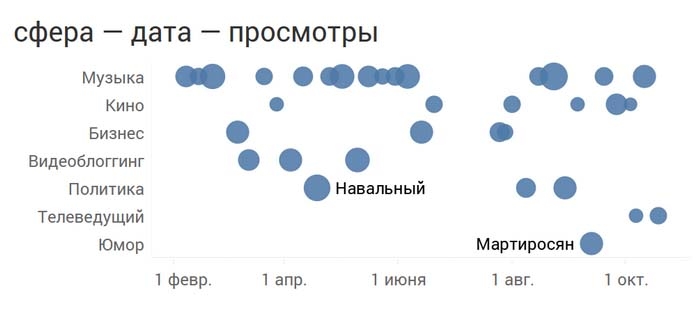
Эти визуализации дают нам много интересной информации. Например, что в марте-мае Дудь пообщался с тремя видеоблогерами и больше их не звал, что кинодеятели приходят примерно через равные промежутки времени. Чтобы получать детальную информацию, можно использовать интерактивные возможности вашего софта для визуального анализа:
Чтобы находить в датасетах интересное, вам наверняка придется агрегировать данные и создавать новые – качественные и количественные.
Назад: Быть аналитиком. Задавать вопросы
Дальше: Формулируем сообщение

