Как Google и другие крупные компании анализируют большие данные?
Как мы уже писали, у Target есть данные о сотнях миллионов клиентов. Но как они могут анализировать их, создавая такие показатели, как прогнозирование беременности? Вряд ли какой-то аналитик может просто взять и открыть файл Excel на своем ноутбуке. Данные занимают слишком большой объем, чтобы хранить или проводить их анализ на одном компьютере, пусть и самом мощном. Попытайтесь умножить два 500-значных числа на калькуляторе с четырьмя функциями – независимо от того, насколько он хорош, у вас ничего не получится.
Создание мощного или достаточно большого суперкомпьютера для обработки всех этих данных обошлось бы слишком дорого. Вместо этого решение заключается в том, чтобы разбить данные и вычисления на более управляемые части, передав их целой армии обычных дешевых компьютеров. Все они могут работать одновременно, и как только будет получен результат последнего компьютера, можно объединять его с остальными, чтобы получить окончательный ответ.
В качестве аналогии представьте, что хотите сосчитать всех жителей города. Можно бегать самому и лично учитывать каждого, но это займет слишком много времени. Вместо этого отправьте по одному другу в каждый район и попросите их подсчитать там всех жителей. Каждый друг сообщает вам итоговую цифру, и, получив информацию от последнего друга, вам просто нужно сложить все результаты воедино, чтобы узнать ответ. Это гораздо быстрее, чем считать в одиночку, поскольку друзья одновременно работают над менее объемными и более короткими задачами. (Интересный факт: именно так в Римской империи проходила перепись населения!)
MapReduce
Google использует эту стратегию для своих знаменитых алгоритмов MapReduce: Map – ваши друзья – считают количество жителей каждого района, а Reduce – вы складываете результаты.
В известном инструменте обработки больших данных Hadoop используется алгоритм MapReduce. Идея заключается в том, что клиент хранит все данные на нескольких серверах обычного размера – суперкомпьютеры не нужны! – а затем запускает ПО Hadoop, чтобы произвести вычисления. Прелесть этого метода заключается в том, что компьютерам не требуется физическое подключение, а чтобы добавить больше данных, нужно просто увеличить число компьютеров. Hadoop быстро становится отраслевым стандартом. Кроме Target, Hadoop пользуются такие компании, как Netflix, eBay, Facebook и многие другие. Вообще, один анализ спрогнозировал, что 80 % компаний из списка Fortune 500 к 2020 году будут использовать Hadoop.
Одним словом, анализ больших данных гораздо сложнее расчетов в Excel: существуют специальные инструменты и методы, которыми необходимо пользоваться. Анализ больших данных настолько сложный и важный процесс, что появилась целая новая область исследований: наука о данных.
Почему цены на Amazon меняются каждые 10 минут?
Не нравится цена товара на Amazon? Подождите 10 минут. Она запросто может измениться.
Цены на товары на Amazon меняются 2,5 млн раз в день, то есть цена среднего продукта меняется каждые 10 минут. Это в пятьдесят раз чаще, чем у Walmart и Best Buy! Постоянные изменения цен раздражают некоторых покупателей, особенно если они видят, что цена товара упала сразу после его покупки, но за их счет прибыль Amazon увеличилась на 25 %.
Как они это делают? У Amazon есть тонны данных. У них 1,5 млрд товаров для продажи и 200 млн пользователей. Это один миллиард гигабайт данных о товарах и пользователях. Если перенести эти данные на жесткие диски с памятью 500 ГБ и уложить в стопку, она будет в восемь раз выше, чем Эверест. Вот что представляет собой часть больших данных.
С этими данными Amazon каждые 10 минут анализирует схемы покупок, цены конкурентов, размер прибыли, наличие товара и множество других факторов, влияющих на ценообразование.
В ходе работы компания разработала полезную стратегию, которая заключается в том, чтобы предложить пользующиеся спросом товары дешевле, чем у конкурентов. Но фактически Amazon просто поднимает цены на непопулярные товары: например, снижает стоимость бестселлеров и повышает цену на малоизвестные книги. Идея состоит в том, что большинство людей будут искать наиболее распространенные продукты (которые, в конечном итоге, будут дешевле на Amazon), и поэтому решат, что у компании в целом более низкие цены. Клиенты Amazon попадутся на крючок, и в дальнейшем будут переплачивать за менее популярные товары.
Прогнозирование, основанное на больших данных
У Amazon есть много других способов использовать данные о клиентах, чтобы хорошо на этом заработать. Основываясь на истории покупок, Amazon может засыпать клиентов рекомендациями – обратите внимание на предложения, которыми изобилует Amazon: «Вдохновленные вашей историей просмотров в браузере» или «Покупатели, которые купили этот товар, также купили». Компания даже может обратиться к словам, которые вы выделяете на Kindle, чтобы понять, что же вы собираетесь купить.
Amazon создает эти рекомендации, находя закономерности в покупках предыдущих клиентов. Предположим, что Amazon заметила, что миллионы клиентов покупают арахисовое масло, желе и хлеб одновременно. Затем вы покупаете там арахисовое масло и хлеб. На основании найденного шаблона Amazon может предложить вам купить желе.
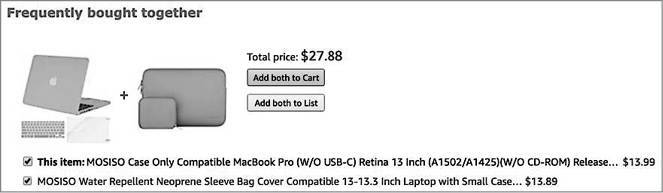
У Amazon также есть опция «С этим товаром часто покупают», в которой предлагается дополнительный товар. Пара обычно создается на основании истории просмотров других пользователей. Источник: Amazon
Прогнозирование покупок выходит далеко за рамки одних только рекомендаций. Рассмотрим запатентованное изобретение Amazon, которое называется Anticipatory Shipping Model (метод по доставке товаров до того, как покупатель нажал на кнопку «купить»). Прогнозируя покупку (например, как Target прогнозирует беременность и роды), Amazon может отправить товар на склад рядом с вашим домом, поэтому когда вы, в конечном итоге, нажмете кнопку «купить», служба доставки доберется до вас быстро и дешево.
Как видите, большие данные имеют огромную экономическую ценность – настолько большую, что газета New York Times однажды сравнила их с золотом.

