Книга: Голая статистика. Самая интересная книга о самой скучной науке
Назад: Ложь, наглая ложь и статистика
Дальше: Приложение к главе 2
2. Описательная статистика
Кто же все-таки лучший бейсболист всех времен и народов?
Давайте подумаем над двумя на первый взгляд не связанными между собой вопросами:
1. Что происходит с экономическим благополучием американского среднего класса?
2. Кого же все-таки считать лучшим бейсболистом всех времен и народов?
Первый вопрос крайне важен и, как правило, ложится в основу президентских кампаний и других социальных движений. Средний класс, если можно так выразиться, – это сердце Америки, поэтому его экономическое благополучие является индикатором общего экономического благосостояния страны. Второй вопрос тривиален (в буквальном смысле этого слова), однако любители бейсбола готовы до бесконечности спорить по этому поводу. Объединяет оба вопроса то, что они позволяют проиллюстрировать сильные и слабые стороны описательной статистики, которая представляет собой числа и вычисления, используемые для обобщения исходных данных.
Если я захочу продемонстрировать вам, что Дерек Джетер является великим игроком в бейсбол, то смогу описать каждый удачно посланный им мяч в каждом матче Высшей бейсбольной лиги, в котором он принимал участие. Это будут исходные данные, и, чтобы упорядочить их, потребуется какое-то время (с учетом того, что Джетер провел семнадцать сезонов в составе New York Yankees и за это время совершил 9868 удачных бросков).
Или я просто могу вам сказать, что к концу сезона 2011 года средний результат Дерека Джетера за всю его карьеру составлял 0,313. Это описательная, или «сводная» статистика.
Однако такой средний показатель – явное упрощение достижений Джетера за семнадцать сезонов игры в Высшей бейсбольной лиге. Да, он весьма элегантен в своей простоте, но не отражает всех нюансов спортивной карьеры Джетера. В распоряжении экспертов по бейсболу есть целый арсенал описательных статистик, которые они считают более ценными, чем данный показатель. Я позвонил Стиву Мойеру, президенту Baseball Info Solutions (фирмы, которая предоставила большой объем исходных данных для спортивной драмы Moneyball), чтобы задать ему два вопроса: 1) каковы самые важные статистические показатели для оценки бейсбольного таланта и 2) кто, по его мнению, величайший бейсболист всех времен и народов? Я познакомлю вас с ответами Стива, когда мы получим больше контекста.
А пока вернемся к менее тривиальному предмету – экономическому благополучию среднего класса. В идеале было бы желательно найти экономический эквивалент среднего показателя (или что-нибудь получше). Нас устроил бы какой-либо простой, но точный показатель того, как за последние годы изменилось экономическое благосостояние типичного американского рабочего. Стали ли люди, которых мы определяем как средний класс, богаче, беднее или в их финансовом положении ничего не изменилось? Подходящий вариант ответа на этот вопрос – который ни в коем случае нельзя рассматривать как «правильный» – рассчитать изменение дохода на душу населения в Соединенных Штатах на протяжении жизни одного поколения (примерно тридцать лет). Доход на душу населения вычисляется путем деления совокупного дохода на численность населения. Согласно этому показателю, средний доход в США повысился с 7787 долларов в 1980 году до 26 487 долларов в 2010-м (последний год, за который правительство располагает соответствующими данными). Вот так-то! Принимайте поздравления.
Есть, правда, одна проблема. Мой быстрый подсчет технически правилен и совершенно неверен с точки зрения ответа на интересующий нас вопрос. Начнем хотя бы с того, что в приведенных выше цифрах отсутствует поправка на инфляцию. (Величина дохода на душу населения 7787 долларов в 1980 году составляет примерно 19 600 долларов в 2010-м.) Такой корректив внести относительно просто. Более серьезная проблема заключается в том, что средний доход в Америке не равняется доходу среднего американца. Попытаемся расшифровать это утверждение.
Чтобы вычислить величину дохода на душу населения, мы берем весь национальный доход и делим его на численность населения. Однако полученный таким образом показатель абсолютно ничего не говорит нам о том, кто и сколько при этом зарабатывает – хоть в 1980 году, хоть в 2010-м. Как сказали бы участники акции Occupy Wall Street, взрывообразный рост доходов 1 % самых богатых людей Америки способен существенно повысить значение дохода на душу населения, ничего при этом не изменив в карманах остальных 99 % американцев. Иными словами, средний доход может повышаться без помощи среднего класса.
Как и в случае бейсбольной статистики, мне хотелось узнать мнение авторитетного эксперта о том, как нам следовало бы измерять экономическое благосостояние американского среднего класса. Я спросил у двух известных специалистов по трудовым отношениям, в том числе у ведущего экономического советника президента Обамы, какие описательные статистики они использовали бы для оценки экономического благополучия типичного американца. Вы узнаете их ответы после того, как ознакомитесь с кратким обзором описательных статистик и лучше уясните их смысл.
Будь то бейсбол, доход или что-то еще, самая фундаментальная задача при работе с данными – обобщить их огромные массивы. Численность населения Соединенных Штатов составляет примерно 330 миллионов человек. Электронная таблица, в которой указывались бы фамилия и история доходов каждого американца, содержала бы всю информацию, которая могла потребоваться для оценки экономического благосостояния страны, однако эта информация была бы настолько громоздкой, что извлечь из нее хоть какую-то пользу было бы практически невозможно. Ирония судьбы заключается в том, что чем большим количеством данных мы располагаем, тем труднее выделить в них главное. Поэтому мы вынуждены прибегать к упрощениям. Мы выполняем вычисления, которые сводят сложный массив данных к нескольким числам, описывающим эти данные, точно так же как пытаемся оценить разноплановую программу выступления гимнаста на Олимпийских играх одним числом: 9,8 балла.
Плюс состоит в том, что описательные статистики дают нам некое обобщенное и осмысленное представление исходного явления. О чем, собственно, и идет речь в этой главе. Минус же в том, что любое упрощение порождает манипулирование. Описательные статистики можно сравнить с анкетами на сайтах знакомств: технически они точны и тем не менее сильно вводят в заблуждение.
Допустим, сидя на работе, вы от нечего делать бродите по интернету и наталкиваетесь на онлайн-дневник известной светской львицы Ким Кардашьян, в котором она рассказывает о своей «долгой» (целых семьдесят два дня!) супружеской жизни с профессиональным баскетболистом Крисом Хэмфри. И вот в тот самый момент, когда вы добрались до описания седьмого дня их супружеской жизни, в комнату неожиданно заходит ваш босс с двумя огромными папками данных. В одной из папок собрана информация о гарантийных претензиях по каждому из 57 334 лазерных принтеров, которые ваша фирма продала в прошлом году. (По каждому из проданных лазерных принтеров перечисляются все проблемы с качеством, зафиксированные в течение гарантийного периода.) В другой содержится такая же информация по каждому из 994 773 лазерных принтеров, которые продал за тот же период ваш главный конкурент. Босс хотел бы сравнить качество принтеров вашей компании с качеством принтеров конкурента.
К счастью, на компьютере, на котором вы почитывали дневник Кардашьян, установлен пакет основных статистических методов, но с чего в данном случае начать? Ваша интуиция, по-видимому, подсказывает вам правильное решение: первой описательной задачей зачастую становится поиск некоего показателя «середины» совокупности данных, или того, что статистики называют «центральной тенденцией». Что является типичным показателем качества для ваших принтеров по сравнению с принтерами конкурента? Обычно самым фундаментальным показателем «середины» какого-либо распределения считается среднее значение. В данном случае нам нужно определить среднее количество проблем с качеством на каждый проданный принтер для вашей фирмы и фирмы вашего конкурента. Вы могли бы просто подсчитать общее число выявленных проблем с качеством для всех принтеров в течение гарантийного периода, а затем разделить его на общее количество проданных принтеров. (Учтите, что в течение гарантийного периода в одном и том же принтере может возникнуть несколько проблем с качеством.) Эту операцию можно проделать для каждой компании, создав важную описательную статистику: среднее количество проблем с качеством на каждый проданный принтер.
Предположим, выяснилось, что среднее количество проблем с качеством в течение гарантийного периода у принтеров вашего конкурента равно 2,8 на каждый проданный принтер, тогда как соответствующий показатель для вашей фирмы составляет 9,1. Как видите, вывести среднее значение совсем не сложно. Вы просто использовали информацию для миллиона принтеров, проданных двумя разными компаниями, и извлекли из нее суть интересующей вас проблемы: ваши принтеры ломаются слишком часто. Похоже, самое время отправить боссу по электронной почте краткое уведомление с численным подтверждением столь тревожного факта, а затем вернуться к более увлекательному занятию: чтению дневника Ким Кардашьян.
А может, не стоит торопиться? Я ведь не зря выразился довольно туманно, упомянув о какой-то там «середине» распределения. В этом отношении у среднего значения есть определенные проблемы, а именно: оно подвержено существенным искажениям со стороны «отщепенцев», то есть значений, резко отклоняющихся от центра. Чтобы вам было легче уяснить эту концепцию, вообразите десяток парней, сидящих у стойки бара какого-нибудь питейного заведения в Сиэтле, рассчитанного на представителей среднего класса. Каждый из парней зарабатывает по 35 000 долларов в год; стало быть, средний годовой доход этой группы составляет 35 000 долларов. Внезапно в заведение входит Билл Гейтс с говорящим попугаем на плече (вообще-то в данном примере говорящий попугай не играет никакой особой роли; это не более чем деталь, призванная несколько оживить повествование и придать ему определенный колорит) и усаживается на одиннадцатый стул за стойкой бара; при этом средний годовой доход его завсегдатаев резко повышается до 91 миллиона долларов. Очевидно, что первые десять посетителей бара могут лишь мечтать о таком уровне годового дохода (хотя все они, наверное, надеются, что Билл Гейтс расщедрится и угостит их стаканчиком-другим). Если бы я написал, что средний годовой доход посетителей заведения составляет 91 миллион долларов, то данный вывод был бы статистически правильным, однако не имел бы ничего общего с реальным положением вещей. Этот бар отнюдь не относится к числу заведений, где коротают свободное время мультимиллионеры, – здесь обычно отдыхают молодые люди с относительно невысоким уровнем годовых доходов. Просто сегодня им повезло оказаться в компании с Биллом Гейтсом и его говорящим попугаем. Именно высокая чувствительность среднего значения к значениям, резко отклоняющимся от центра, не позволяет нам измерять экономическое благополучие среднего класса с помощью такого показателя, как величина дохода на душу населения. Поскольку в последнее время наблюдается резкий рост доходов в верхней части распределения – глав компаний, управляющих хедж-фондами и выдающихся спортсменов, таких как Дерек Джетер, – величина среднего дохода в США может быть сильно искажена, как в вышеупомянутом баре, где несколько парней с относительно скромными доходами случайно оказались в компании Билла Гейтса.
По этой причине нам приходится пользоваться еще одной статистикой, которая также является отражением «середины» распределения, однако делает это несколько иначе. Речь идет о так называемой медиане. Медиана – это точка, которая делит распределение пополам таким образом, что одна половина наблюдений располагается выше медианы, а другая половина – ниже. (При наличии четного количества наблюдений медиана представляет собой среднюю точку между двумя средними наблюдениями.) Если мы вернемся к примеру с баром, то срединный (медианный) годовой доход для десяти человек, сидевших поначалу за стойкой, равняется 35 000 долларов. Когда в заведении появился – и уселся на одиннадцатый стул – Билл Гейтс с говорящим попугаем, срединный годовой доход для одиннадцати человек по-прежнему составлял 35 000 долларов. Если представить, что посетители бара расселись за его стойкой в порядке возрастания их доходов, то доход посетителя, сидящего на шестом стуле, будет срединным для данной группы людей. Даже если бы в заведение зашел Уоррен Баффет и уселся рядом с Биллом Гейтсом на двенадцатый стул, медиана все равно осталась бы неизменной.
В случае распределений без «отщепенцев» срединное (медиана) и среднее значения совпадают. Выше говорилось о гипотетической сводке данных, отражающих качество принтеров конкурирующей фирмы. В частности, я представил эти данные в виде так называемого частотного распределения (гистограммы). Число проблем с качеством на один принтер представлено на горизонтальной оси (внизу); высота каждого вертикального столбца соответствует проценту проданных принтеров, у которых наблюдалось такое число проблем с качеством. Например, у 36 % принтеров конкурента в течение гарантийного периода возникало по две проблемы с качеством. Поскольку это распределение включает все возможные случаи проблем с качеством (в том числе и их отсутствие), сумма всех долей (процентов) должна равняться 1 (или 100 %).
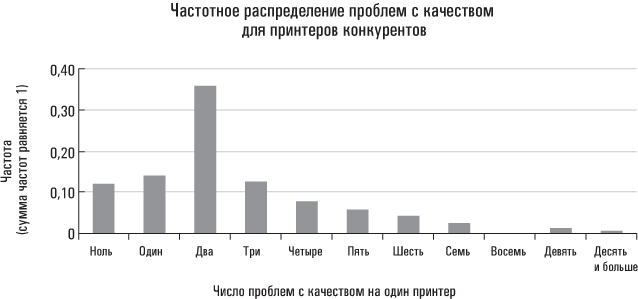
Поскольку такое распределение почти симметрично, среднее и срединное значения довольно близки друг к другу. Распределение слегка скошено вправо, что объясняется малым количеством принтеров, имеющих множественные дефекты. Эти «отщепенцы» слегка смещают среднее значение вправо, однако на медиану это не влияет. Допустим, что перед тем как составить для босса отчет о качестве принтеров, вы принимаете решение вычислить медианы, то есть число проблем с качеством для принтеров, проданных вашей и конкурирующей компанией. Нажав всего несколько клавиш, вы получите результат. Медиана проблем с качеством для принтеров конкурента равняется 2; а для принтеров вашей фирмы – 1.
Что из этого следует? Оказывается, медиана проблем с качеством на каждый принтер вашей фирмы фактически меньше, чем у вашего конкурента. Поскольку супружеская жизнь Ким Кардашьян становится однообразной, а полученный результат вас заинтриговал, вы распечатываете распределение частот проблем с качеством у принтеров, проданных вашей компанией.
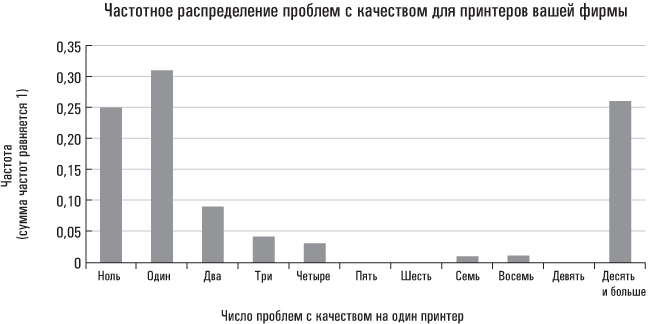
Из приведенных выше гистограмм становится ясно, что для вашей компании нехарактерно равномерное распределение проблем с качеством. Напротив, у вас налицо проблема «лимона»: у малого числа ваших принтеров наблюдается большое количество дефектов. Эти «отщепенцы» способствуют наращиванию среднего значения, тогда как медиана остается неизменной. Более важным с производственной точки зрения является то обстоятельство, что вам нет необходимости переоснащать весь производственный процесс; достаточно лишь определить, какое из предприятий компании выпускает некачественную продукцию, и исправить ситуацию.
Вычисление среднего и медианы не представляет особых трудностей; самое главное в этом случае – определить, какой именно показатель «середины» более точен в каждой конкретной ситуации (именно этот фактор нередко используется для манипулирования средними показателями). Между тем у медианы имеются весьма полезные «родственники». Как указывалось выше, медиана делит любое распределение пополам. Затем его можно разбить на четверти, или, как их еще называют, квартили. Первый квартиль состоит из нижних 25 % наблюдений; второй из следующих 25 % наблюдений и т. д. Еще один вариант – разделить распределение на децили, каждый из которых заключает в себе 10 % наблюдений. (Если ваш доход находится в верхнем дециле американского распределения доходов, то это означает, что вы зарабатываете больше, чем 90 % ваших коллег-рабочих.) Можно пойти еще дальше и разбить распределение на сотые доли, или процентили. Каждый процентиль представляет 1 % распределения; таким образом, первый процентиль представляет нижний 1 % данного распределения, а 99-й – его верхний 1 %.
Преимущество описательных статистик такого рода заключается в том, что они указывают, где именно располагается то или иное конкретное наблюдение по сравнению с остальными. Например, информация, что ваш ребенок по результатам теста на понимание прочитанного материала получил третий процентиль, должна сказать вам о том, что вы уделяете недостаточно внимания совместному обсуждению книг, прочитанных вашим ребенком. Вам вовсе не обязательно знать подробности самого теста или точное количество вопросов, на которые ваш ребенок ответил правильно. Однако его попадание в определенный процентиль в любом случае говорит о том, насколько успешно ваш ребенок сдал этот тест по сравнению с другими его участниками. Если тест был сравнительно легким, то большинство его участников правильно ответят на подавляющее число вопросов, при этом количество правильных ответов у вашего ребенка все равно будет меньшим, чем у большинства других участников тестирования. Если же тест был очень трудным, то у всех его участников окажется малое число правильных ответов, однако и в этом случае «рейтинг» вашего ребенка будет несколько ниже, чем у остальных.
Сейчас самый подходящий момент познакомить вас с новой терминологией. «Абсолютная» сумма баллов, «абсолютный» показатель или «абсолютное» значение обладают неким внутренним, самостоятельным смыслом. Если я набираю 83 балла в результате бросков по восемнадцати лункам при игре в гольф, то речь идет об абсолютном показателе. Я мог бы продемонстрировать такой результат в день, когда температура достигала 41 градуса, что также является абсолютным показателем. Абсолютные показатели, как правило, можно интерпретировать без какого-либо контекста или дополнительной информации. Когда я сообщаю, что набрал 83 балла, вам, чтобы оценить достигнутый мною результат, вовсе не обязательно знать, сколько баллов набрали в тот день другие гольфисты. (Исключением может быть ситуация, когда условия проведения игры особенно неблагоприятны или площадка для гольфа имеет очень сложный или, напротив, очень простой рельеф.) Если же по итогам турнира я оказался на девятом месте, то это относительная статистика. «Относительное» значение, или «относительный» показатель имеет смысл лишь в сравнении с чем-либо или в каком-либо более широком контексте, например в сравнении с восемью гольфистами, получившими более высокие баллы, чем я. Результаты большинства стандартизованных тестов тоже представляют интерес лишь как относительная статистика. Если я сообщу, что по итогам проведения единого экзамена штата Иллинойс ученик третьего класса одной из начальных школ штата набрал 43 балла из 60 возможных, то этот абсолютный показатель скажет вам не так много. Но если я преобразую его в процентиль – то есть помещу в некое распределение, содержащее показатели всех учеников третьих классов начальных школ штата Иллинойс, – то он обретет гораздо больший практический смысл. Поскольку 43 правильных ответа попадают в 83-й процентиль, знания этого ученика гораздо выше, чем у большинства его сверстников в штате Иллинойс. Если бы этот ученик оказался в 8-м процентиле, то уровень его знаний оценивался бы как весьма посредственный. В этом случае процентиль (относительный результат) несет в себе гораздо больше информации, чем количество правильных ответов (абсолютный показатель).
Еще одной статистикой, которая позволяет описывать большие нагромождения данных, является среднеквадратическое (или, как его еще называют, стандартное) отклонение – показатель разброса данных по отношению к их среднему значению. Другими словами, среднеквадратическое отклонение представляет собой показатель рассредоточенности наблюдений. Допустим, я собрал информацию о весе 250 человек, направляющихся на самолете в Бостон; кроме того, у меня есть данные о весе выборки (численность которой также составляет 250 человек) участников Бостонского марафона. Допустим также, что средний вес у членов обеих групп примерно одинаков и составляет 155 фунтов. Каждый, кому приходилось летать в забитом под завязку самолете, знает, что многие пассажиры типичного коммерческого рейса весят больше 155 фунтов. Однако завсегдатаям таких рейсов также хорошо известно, что среди пассажиров встречается немалое число крикливых грудных младенцев и непоседливых детишек дошкольного и младшего школьного возраста, вес которых явно недотягивает до указанного значения. Когда нам приходится вычислять средний вес пассажиров самолета, то масса 320-фунтовых футболистов, сидящих по обе стороны от вашего кресла, наверняка компенсируется визгливым грудным младенцем, занимающим место с другой стороны прохода между креслами, и шестилетним мальчуганом, сидящим позади вас и пинающим ногами спинку вашего кресла.
На основе уже известных вам описательных инструментов мы приходим к выводу, что вес пассажиров самолета и участников марафона примерно одинаков. Однако на самом деле это не совсем так. Да, вес этих двух групп приблизительно одинаков «в среднем», но у пассажиров самолета гораздо больший разброс относительно этого среднего значения, то есть показатели их веса сильнее удалены от него. Мой восьмилетний сынишка сказал бы, что бегуны-марафонцы кажутся людьми, имеющими примерно одинаковый вес, тогда как среди пассажиров самолета встречаются как миниатюрные люди, так и настоящие здоровяки. Показатели веса пассажиров самолета характеризуются «большим разбросом», что обязательно нужно учитывать при описании веса этих двух групп. Среднеквадратическое отклонение является описательной статистикой, которая позволяет выразить данный разброс по отношению к среднему значению единственным числом. Формулы для вычисления среднеквадратического отклонения и дисперсии (еще один широко распространенный показатель разброса, на основе которого вычисляется среднеквадратическое отклонение) включены в , приведенное в конце этой главы. А сейчас давайте подумаем над тем, зачем нам измерять разброс.
Допустим, вы приходите в кабинет врача. С тех пор как вас выдвинули на руководящую должность, назначив главой Отдела борьбы за повышение качества североамериканских принтеров, вы чувствуете хроническую усталость. У вас берут кровь на анализ, и через пару дней ассистент врача отправляет вам на автоответчик сообщение о том, что некий показатель (назовем его условно HCb2) у вас в крови равняется 134. Вы быстро отправляете соответствующий поисковый запрос в интернет и выясняете, что величина HCb2 для людей вашего возраста составляет 122 (и медиана почти такая же. Черт побери! Случись нечто подобное со мной, я поспешил бы составить завещание – так, на всякий случай. Итак, вы пишете слезные письма родственникам, детям и близким друзьям. У вас возникает мысль прыгнуть напоследок с парашютом (ваша жизнь была так бедна на острые ощущения!) или попытаться как можно быстрее написать роман (а вдруг в вас скрывался недюжинный писательский талант?). У вас даже может появиться желание отправить по электронной почте письмо своему боссу, в котором вы сравните его с некой частью человеческого тела (и набрать весь текст письма ЗАГЛАВНЫМИ БУКВАМИ).
Между тем ничего этого вам, скорее всего, делать не следует (а идея с оскорбительным письмом боссу – глупая в любом случае). Когда вы повторно приходите к врачу, чтобы получить от него направление в хоспис, ассистент врача сообщает вам, что результаты вашего анализа крови находятся в пределах нормы. Как такое возможно? «Мой показатель HCb2 превышает среднее значение на целых 12 пунктов!» – недоумеваете вы.
«Среднеквадратическое отклонение для HCb2 равняется 18», – успокаивает вас ассистент врача.
Что все это значит?
Дело в том, что у HCb2, как и у большинства других биологических явлений (например, роста человека), существует вполне естественный разброс значений. В то время как среднее значение HCb2 действительно может составлять 122, у огромного числа здоровых людей оно может быть несколько выше или ниже. Опасность возникает только тогда, когда значение HCb2 намного выше или ниже указанного среднего значения. Но что именно следует понимать под «намного» в данном контексте? Как уже говорилось, среднеквадратическое отклонение является показателем разброса, то есть оно демонстрирует, насколько плотно группируются наблюдения вокруг среднего значения. Для многих типичных распределений данных высокая доля наблюдений располагается в пределах одного среднеквадратического отклонения от среднего значения (это означает, что они находятся в диапазоне, простирающемся от одного среднеквадратического отклонения ниже среднего значения до одного среднеквадратического отклонения выше среднего значения). Проиллюстрируем это на простом примере. Средний рост взрослого мужчины-американца равняется 5 футам 10 дюймам. Среднеквадратическое отклонение составляет примерно 3 дюйма. Рост значительной доли взрослых мужчин находится между 5 футами 7 дюймами и 6 футами 1 дюймом.
То же самое можно сформулировать несколько иначе: любой мужчина в этом диапазоне роста не считался бы слишком высоким или низким. Это возвращает нас к результатам количественного анализа HCb2, которые так нас встревожили. Да, значение HCb2 на 12 пунктов выше среднего, но это меньше, чем одно среднеквадратическое отклонение, что является аналогом роста, близкого к 6 футам, – следовательно, никакой особой аномалии здесь не наблюдается. Разумеется, гораздо меньшее число наблюдений находится на расстоянии двух стандартных отклонений от среднего значения; еще меньшее число наблюдений находится на расстоянии трех или четырех стандартных отклонений. (Что касается роста, то американский мужчина выше среднего роста на три среднеквадратических отклонения достигал бы 6 футов 7 дюймов или был бы даже еще выше.)
Некоторые распределения более рассредоточены, чем другие. Следовательно, среднеквадратическое отклонение значений веса 250 пассажиров самолета будет выше, чем значений веса 250 бегунов-марафонцев. Распределение частот веса пассажиров самолета оказалось бы более «разбросанным», чем бегунов-марафонцев. После того как мы узнаем среднее значение и стандартное отклонение для какой-либо совокупности данных, мы получаем о ней весьма ценные сведения. Допустим, я сообщаю вам, что по результатам проведения единого экзамена по математике какого-либо штата средняя сумма баллов составила 500 при стандартном отклонении, равном 100. Как и в случае с ростом мужчин, большая часть учащихся, сдаваших экзамен, продемонстрировала результаты в пределах одного среднеквадратического отклонения от среднего значения, то есть между 400 и 600 баллами. Сколько учеников, по вашему мнению, получили 720 и выше? Наверное, очень немногие, поскольку такой показатель превышает два среднеквадратических отклонения от среднего значения.
Теперь не мешало бы уточнить, что в данном случае имеется в виду под словами «очень немногие». Думаю, самое время познакомить читателей с одним из наиболее важных, полезных и распространенных распределений в статистике – нормальным распределением. Данные, которые распределены согласно этому закону, располагаются симметрично относительно своего среднего значения, причем это распределение имеет колоколообразную форму, которая наверняка вам хорошо знакома.
Нормальное распределение описывает многие явления, часто встречающиеся в жизни. Представьте себе распределение частот, описывающее, как стреляют зерна воздушной кукурузы (попкорна) на плите. Некоторые зерна начинают лопаться раньше остальных, издавая примерно один-два хлопка в секунду; через десять или пятнадцать секунд зерна уже взрываются как сумасшедшие. Постепенно количество хлопков в секунду сокращается приблизительно до частоты, наблюдавшейся в самом начале поджаривания. Значения роста мужчин-американцев распределены практически в соответствии с законом нормального распределения, то есть расположены почти симметрично относительно среднего значения (5 футов 10 дюймов). Каждый тест SAT специально разрабатывается таким образом, чтобы обеспечить нормальное распределение результатов со средним значением 500 при среднеквадратическом отклонении, равном 100. Согласно Wall Street Journal, американцы даже склонны по закону нормального распределения парковать свои автомобили у крупных торговых центров: большинство автомобилей паркуются напротив центрального входа в торговый центр («вершина» кривой нормального распределения), а «хвосты» машин расходятся вправо и влево от центрального входа.
Красота нормального распределения – его мощь, изящество и элегантность – обусловлена тем, что нам по определению известно, какая именно доля наблюдений в нормальном распределении находится в пределах одного среднеквадратического отклонения от среднего значения (68,2 %), двух среднеквадратических отклонений от среднего значения (95,4 %), трех среднеквадратических отклонений от среднего значения (99,7 %) и т. д. Хотя все это может показаться тривиальным, это именно тот фундамент, на котором строится значительная часть статистики. Мы вернемся к концепции нормального распределения чуть позже, чтобы рассмотреть ее подробнее.
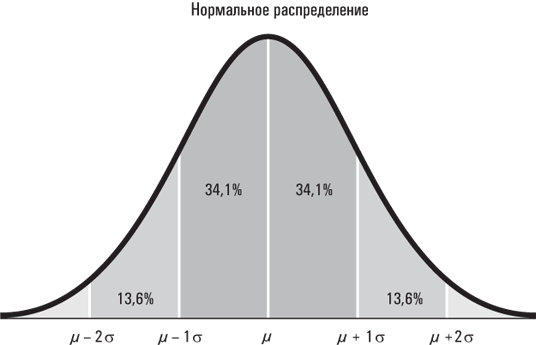
Средним значением является средняя линия, которую часто обозначают греческой буквой µ. Среднеквадратическое (стандартное) отклонение зачастую обозначают греческой буквой σ. Каждая вертикальная полоса на графике представляет одно среднеквадратическое отклонение.
Описательные статистики часто служат для сравнения двух значений или величин. Я на один дюйм выше своего брата; сегодня температура воздуха на девять градусов больше «исторического среднего» для этой даты и т. д. Такие сравнения имеют смысл, поскольку большинство из нас признают используемые в этих случаях шкалы единиц измерения. Один дюйм – не так много, когда речь идет о человеческом росте, поэтому вы можете заключить, что у нас с братом примерно одинаковый рост. И напротив, девять градусов – значительное отклонение температуры воздуха практически для любого климата в любое время года; поэтому, если в какой-то из дней было зафиксировано превышение средней температуры на девять градусов, это существенная аномалия. Но допустим, я сообщу, что хлопья Granola Cereal A содержат на 31 миллиграмм больше натрия, чем хлопья Granola Cereal B. Если вы не знакомились со специальной литературой, в которой рассматриваются последствия употребления в пищу натрия, и не знаете, о какой величине порции хлопьев идет в данном случае речь, на основе приведенной выше информации вы не сделаете полезных выводов. А если я скажу вам, что мой кузен Эл заработал в текущем году на 53 000 долларов меньше, чем в прошлом? Следует ли нам тревожиться за судьбу Эла? А что если он управляющий хедж-фонда, для которого сумма 53 000 долларов соизмерима с ошибкой округления при подсчете его годового дохода?
В примерах с содержанием натрия в хлопьях и доходом Эла отсутствует контекст, который позволил бы оценить масштаб проблемы, если таковая имеется. Самый простой способ придать смысл этим сравнениям – использовать процентные величины. Если бы я сообщил вам, что хлопья Granola Cereal A содержат на 50 % больше натрия, чем хлопья Granola Cereal B, а доход моего кузена Эла сократился в прошлом году на 47 %, это позволило бы вам сделать определенные выводы. Оценка тех или иных изменений в процентах предоставляет нам нечто наподобие шкалы.
Поскольку в школе вас наверняка научили вычислять проценты, не исключено, что у вас возникнет соблазн не читать несколько следующих абзацев. Что ж, возможно, вы правы. Однако прежде чем принять окончательное решение, выполните одно простое упражнение. Допустим, в универмаге продается платье за 100 долларов. Заместитель директора универмага решает снизить цену всех товаров на 25 %. Но впоследствии его увольняют за то, что он зависает в баре с Биллом Гейтсом, а новый заместитель директора распоряжается повысить все цены на 25 %. Какой окажется окончательная цена платья? Если вы скажете (или подумаете), что 100 долларов, то вам лучше все же читать текст подряд.
В действительности окончательная цена платья составит 93,75 доллара. Этот нехитрый трюк принесет вам порцию аплодисментов и восхищение присутствующих на какой-нибудь вечеринке. Процентные величины – полезнейшая вещь, но подчас они порождают в головах людей путаницу и даже способны ввести в заблуждение. Формула для вычисления разности (или изменения) процентов такова: (новая величина – исходная величина) / исходная величина. Числитель (верхняя часть дроби) дает нам величину изменения в абсолютных значениях; знаменатель (нижняя часть дроби) помещает это изменение в контекст путем его сравнения с нашей исходной точкой. Поначалу это кажется очевидным, как в случае, когда заместитель директора универмага снижает цену платья (100 долларов) на 25 %. Двадцать пять процентов от первоначальной цены (100 долларов) составляют 25 долларов; это скидка, в результате цена платья становится 75 долларов. Вы можете вставить соответствующие числа в указанную выше формулу и проделать простые вычисления, чтобы убедиться в правильности моих подсчетов: (100 долл. – 75 долл.) / 100 долл. = 0,25, или 25 %.
Платье продается за 75 долларов до тех пор, пока новый заместитель директора универмага не примет решение повысить цену на 25 %. Именно в этом месте многие совершают ошибку, поскольку 25-процентное повышение цены вычисляется как процент от новой, сниженной цены платья, которая равняется 75 долларов. Повышение цены составит 0,25 × 75 долл. = 18,75 долл.; вот так и получается окончательная цена платья – 75 долл. + 18,75 долл. = 93,75 долл. (а не 100 долларов). Дело в том, что любое процентное изменение всегда дает значение какого-то числа относительно чего-либо еще. Следовательно, нам нужно лучше понять, что же представляет собой это «что-то еще».
Однажды я инвестировал деньги в компанию, основанную моим приятелем, с которым мы проживали в одной комнате студенческого общежития во время учебы в колледже. Поскольку это был частный бизнес, от его владельца не требовалось предоставлять акционерам строго определенный перечень сведений о его деятельности. В течение нескольких лет мне ничего не было известно о судьбе моей инвестиции – бывший приятель предпочитал не распространяться на сей счет. Наконец я получил по почте письмо, в котором говорилось, что прибыль компании выросла на 46 % по сравнению с предыдущим годом. Какой была эта прибыль в абсолютных показателях, в письме не сообщалось, стало быть, я по-прежнему не имел ни малейшего представления об эффективности своих инвестиций. Допустим, в прошлом году эта фирма заработала 27 центов (то есть практически ничего), а в текущем – 39 центов (то есть опять-таки почти ничего). Тем не менее прибыль компании выросла с 27 центов до 39 центов, то есть на 47 %! Очевидно, что рассылка такого письма акционерам – если бы в нем указывалось, что прибыль, накопленная фирмой за два года, меньше стоимости чашки кофе в сети Starbucks, – принесла бы им не радость, а жестокое разочарование.
К чести моего приятеля должен заметить, что в конечном счете он продал свою компанию за несколько сотен миллионов долларов, заработав для меня стопроцентную прибыль на вложенный капитал. (Поскольку вы не знаете, какую именно сумму я вложил в этот бизнес, вы не можете знать, сколько денег я в результате заработал. Впрочем, это лишь подтверждает правильность мыслей, высказанных мною выше.)
Читателям следует уяснить еще одно важное различие. Процентное изменение не следует путать с изменением, выраженным в процентных пунктах. Ставки зачастую выражаются в процентах. Ставка налога с продаж в штате Иллинойс равняется 6,75 %. Я выплачиваю своему агенту 15 % с авторских гонораров, которые получаю за свои книги. Эти ставки применяются к той или иной величине (например, к доходу в случае ставки подоходного налога). Очевидно, что ставки могут изменяться в ту или иную сторону. Менее очевидным является то обстоятельство, что такие изменения ставок можно описывать по-разному. Самым показательным примером в этом отношении может служить недавнее повышение ставки индивидуального подоходного налога в штате Иллинойс с 3 % до 5 %. Такое изменение налога можно выразить двумя способами, причем оба технически корректны. Представители Демократической партии США, которые инициировали это повышение, объясняли (кстати говоря, совершенно правильно), что ставка подоходного налога в этом штате выросла на 2 процентных пункта (с 3 % до 5 %). Представители Республиканской партии США отмечали (также совершенно правильно), что подоходный налог в штате увеличился на 67 %. [Это является весьма удобным способом проверки формулы, приведенной выше: (5 ‒ 3) / 3 = ⅔, что приблизительно соответствует 67 %.]
Демократы сосредоточили внимание на абсолютном изменении налоговой ставки; республиканцы предпочли сфокусироваться на изменении величины налогового бремени. Как указывалось выше, оба описания правильны с технической точки зрения, хотя я настаиваю, что описание, предложенное республиканцами, более точно отражает влияние изменения этого налога, поскольку его величина, которую мне предстоит выплачивать государству – ведь именно она меня интересует, а вовсе не способ ее вычисления, – действительно повысится на 67 %.
Многие явления окружающей нас действительности невозможно идеально описать посредством какой-то одной статистики. Допустим, куортербек Аарон Роджерс выполняет броски на 365 ярдов, которые, однако, не являются тачдаун-пасами. Между тем Пейтон Мэннинг совершает броски лишь на 127 ярдов – но с тремя тачдаун-пасами. Мэннинг зарабатывал больше очков, но, возможно, именно Роджерс приносил своей команде больше тачдаунов (то есть пересечений мячом или игроком с мячом линии зачетного поля соперника). Кого из них считать более ценным игроком? В главе 1 я обсуждал так называемый рейтинг распасовщика, который по идее должен решить эту статистическую проблему и широко применяется Национальной футбольной лигой. Рейтинг распасовщика – пример индекса, представляющего собой описательную статистику, составленную из других описательных статистик. После того как разные показатели эффективности действий куортербеков удалось объединить в один, такая статистика может использоваться для сравнения игры куортербеков в определенный день или даже на протяжении всей спортивной карьеры. Если бы единый индекс такого рода существовал в бейсболе, то вопрос о том, кого следует считать лучшим бейсболистом всех времен и народов, удалось бы давно решить, не так ли?
Преимущество любого индекса заключается в том, что он консолидирует в едином показателе большой объем сложной информации. После этого мы можем сопоставлять между собой вещи, которые в противном случае не поддаются простому сравнению (речь может идти о чем угодно, от сравнения эффективности действий куортербеков до конкурсов красоты или работы разных колледжей). При проведении конкурса «Мисс Америка» победитель определяется по результатам пяти отдельных соревнований: личное интервью, купальник, вечернее платье, индивидуальные способности и вопрос на сцене. («Мисс конгениальность» выбирают сами участницы путем индивидуального голосования.)
Парадокс, но то, что любой индекс консолидирует в едином показателе большой объем сложной информации, является также его недостатком. Вывести единый показатель можно бессчетным множеством способов, причем все они могут приводить к разным результатам. Малкольм Гладуэлл блестяще доказывает этот факт в одной из своих статей в еженедельнике The New Yorker, где высмеивает неизбывную тягу американцев к присвоению рейтингов буквально всему, что их окружает. (Особенно досталось от Малкольма тем, кто составляет рейтинги учебных заведений.) Гладуэлл приводит пример присвоения журналом Car and Driver («Автомобиль и водитель») рейтинга трем моделям спортивных автомобилей: Porsche Cayman, Chevrolet Corvette и Lotus Evora. Используя формулу, которая включает двадцать одну переменную, Car and Driver поставил на первое место Porsche Cayman. Однако Гладуэлл указывает, что в формуле Car and Driver такой показатель, как «дизайн кузова», оценивается всего в 4 % от совокупного рейтинга, что для спортивного автомобиля смехотворно мало. Если бы «дизайн кузова» оценивался, к примеру, в 25 %, то на первом месте оказался бы Lotus Evora.
Но это еще не все. Гладуэлл также отмечает, что в формуле Car and Driver такой показатель, как рекомендованная цена автомобиля, тоже имел ничтожный вес. Если бы этому важному показателю был присвоен больший вес (так, чтобы у цены, дизайна кузова и характеристик двигателя были одинаковые весовые коэффициенты), то на первом месте оказался бы Chevrolet Corvette.
Любой индекс очень чувствителен к описательным статистикам, которые включены в его состав, а также к весу, присваиваемому каждой из составляющих. В результате диапазон индексов простирается от полезных, но весьма несовершенных инструментов, до полнейших курьезов. Примером первого может служить так называемый индекс человеческого развития (Human Development Index – HDI), применявшийся ООН. HDI разрабатывался как более широкий показатель экономического благосостояния, чем доход как таковой. Доход является лишь одним из компонентов HDI, который включает также показатели средней продолжительности жизни и уровня образования. По объему производства на душу населения Соединенные Штаты находятся на одиннадцатом месте в мире (пропустив вперед такие богатые запасами нефти страны, как Катар, Бруней и Кувейт), а по индексу человеческого развития занимают четвертое место в мире. Правда, HDI-рейтинги слегка изменились бы в результате трансформации составных частей индекса, но вряд ли это бы привело к примерному равенству рейтингов Зимбабве и Норвегии. Иными словами, индекс HDI неплохо отражает текущую картину, касающуюся жизненных стандартов в разных странах мира.
Описательные статистики дают нам понимание сути интересующих нас явлений. Исходя из этого мы можем вернуться к вопросам, поставленным в начале главы. Кого же считать лучшим бейсболистом всех времен и народов? С точки зрения целей этой главы, гораздо важнее было бы выяснить, какие описательные статистики больше всего помогли бы нам ответить на этот вопрос. Согласно Стиву Мойеру, президенту Baseball Info Solutions, тройку ключевых статистик (кроме возраста) для оценивания эффективности действий любого игрока, за исключением питчера (подающего), составили бы следующие:
1. Процент попаданий в базу (on-base percentage – OBP), иногда называемый средним показателем попаданий в базу (on-base average – OBA). Оценивает процент успешных попаданий игрока в базу, в том числе и так называемые уоки (которые не учитываются в среднем показателе).
2. Процент отбивания (slugging percentage – SLG). Измеряет процент отбивания мячей путем вычисления совокупного количества попаданий в базу на каждый отбитый мяч. Одинарный оценивается в 1, двойной соответствует 2, тройной – 3, а хоумран – 4. Таким образом, процент отбивания у беттера (отбивающего), который отбил одинарный и тройной из пяти попаданий, составил бы (1 + 3) / 5, или 0,800.
3. Попадания (at bats – AB). Этот показатель помещает все сказанное выше в единый контекст. Любой игрок может продемонстрировать потрясающую статистику в одной-двух играх. Но лишь суперзвезда накапливает впечатляющие показатели на протяжении многих лет выступления за профессиональные бейсбольные команды.
По мнению Стива Мойера (которое я полностью разделяю), лучшим бейсболистом всех времен и народов является Бейб Рут из-за его уникальной способности отбивать броски и выполнять точные подачи. Именно Бейбу Руту до сих пор принадлежит рекорд Высшей лиги «процент отбивания, достигнутый на протяжении всей карьеры бейсболиста»: 0,690.
Теперь обратимся ко второму вопросу: что происходит с экономическим благополучием американского среднего класса? Как и в первом случае, я поинтересовался мнением экспертов, обратившись по электронной почте к Джеффу Гроггеру (моему коллеге по Чикагскому университету) и Алану Крюгеру (вы, наверное, помните: именно он изучал причины терроризма, а в настоящее время занимает пост председателя Совета экономических консультантов Барака Обамы). Ни тот ни другой не смог дать мне однозначного ответа на этот вопрос. Чтобы оценить экономическое благополучие американского среднего класса, нам следует проанализировать изменения медианной заработной платы (с поправкой на инфляцию) за последние несколько десятилетий. Кроме того, они порекомендовали проанализировать изменения величины заработных плат в 25-м и 75-м процентилях (есть все основания интерпретировать их как верхнюю и нижнюю границы для среднего класса).
Стоит также упомянуть еще об одном различии. При оценивании экономического благосостояния мы можем анализировать доход или заработную плату. Это не одно и то же. Заработная плата – это то, что нам платят за некое фиксированное количество труда (например, она может быть почасовой или понедельной). Доход представляет собой сумму всех платежей из разных источников. Если у работника есть вторая работа или он отработал большее количество часов, его доход может увеличиться, тогда как заработная плата останется прежней. (Именно поэтому доход может расти даже в случае, когда заработная плата снижается, – при условии, что работник трудится дольше.) Если, однако, работнику приходится больше работать, чтобы больше получать, то оценить, как это скажется на его благосостоянии, довольно сложно. Заработная плата является менее неоднозначным показателем того, как оплачивается труд американцев; чем она выше, тем больше человек получает за каждый час, проведенный на работе.
В дополнение к вышесказанному я привожу график заработной платы американцев за последние три десятилетия. Я также добавил 90-й процентиль, чтобы проиллюстрировать изменения заработной платы работников, относящихся к среднему классу, в сравнении (за тот же период времени) с заработной платой работников, находящихся на вершине этого распределения.
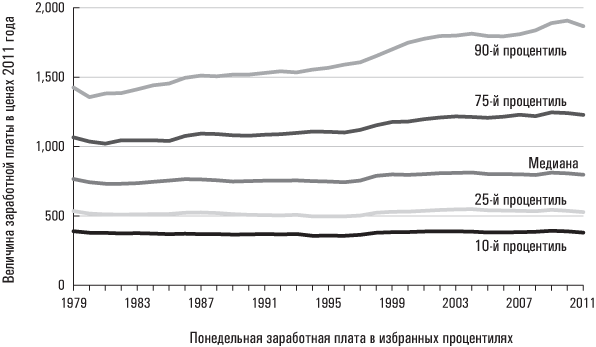
Источник: Changes in the Distribution of Workers’ Hourly Wages between 1979 and 2009, Congressional Budget Office, 16 февраля 2011 года. Данные для этой диаграммы можно найти на сайте
На основе этих данных можно сделать немало выводов. Они не позволяют получить единственный «правильный» ответ на вопрос о том, в какую сторону изменяется экономическое благополучие американского среднего класса, зато четко показывают, что типичный американский рабочий, получающий медианную заработную плату, на протяжении почти тридцати лет «топчется на месте». Работники в 90-м процентиле добились за это время гораздо больших успехов. Описательные статистики помогают очертить проблему. Какие именно действия мы предпримем в ответ на это (если вообще предпримем) – вопрос сугубо идеологический и политический.
* * *
Назад: Ложь, наглая ложь и статистика
Дальше: Приложение к главе 2

