Книга: ДНК и её человек [litres]
Назад: Салат из ДНК и саузерн-блоттинг
Дальше: Дело об иммигрантах из Ганы
STR и момент “эврика!”
Казалось бы, вот он, путь к изучению человеческого разнообразия. Но путь, с учетом тогдашних технических возможностей, не слишком удобный. Таких однобуквенных замен в геноме человека очень много – около 10 млн у каждого из нас. (Правильнее называть их однонуклеотидными полиморфизмами – single nucleotide polymorphism, SNP, или просто снипы; запомним этот термин, нам с ним еще встречаться и встречаться!) Но невозможно угадать заранее, какой сайт рестрикции может быть испорчен нуклеотидной заменой у конкретного человека. “Их [SNP] трудно найти и проанализировать, и они не очень-то много говорят о разнообразии людей: ты или видишь отличие, или не видишь”, – говорил Джеффрис. Современных специалистов по ДНК-идентификации снипы очень интересуют, но тогда – нужен был другой метод. Что-то другое в геноме человека, то, что есть у всех, но при этом достаточно разнообразно и может использоваться в качестве индивидуальных характеристик.
И такие участки в геноме существуют. Теперь, после изобретения Джеффриса, кажется, будто эволюция их специально разработала для нужд судебных экспертов! Тандемные повторы ДНК – короткие участки, которые повторяются много раз, как сказка про белого бычка; тандемными они называются потому, что идут друг за другом, “голова в хвост”, в отличие от повторов диспергированных, которые друг к другу не примыкают. Возникают такие повторы, в частности, из-за “проскальзывания” ферментного комплекса по матрице при копировании ДНК (в результате участок копируется повторно) или из-за ошибок рекомбинации (обмена участками между парными хромосомами).
Хромосом у нас, как у большинства животных, двойной комплект: каждая представлена двумя копиями, одна получена от матери, другая от отца. Именно поэтому и гены в норме у нас представлены двумя копиями, не всегда идентичными – все по Грегору Менделю. А в процессе образования яйцеклеток и сперматозоидов гомологичные, или парные, хромосомы обмениваются участками – рекомбинируют. Это дополнительно разнообразит наборы наследственных признаков у потомства.
Интуитивно понятно, что число таких повторов должно быть изменчивым – где появились два или три повтора, там могут появиться и четыре, и шесть, по тем же самым причинам. К тому же если это некодирующие участки, то мутации в них не портят никаких белков и не приводят к болезням, следовательно такие мутации не отсекаются естественным отбором и могут накапливаться. Значит, можно предположить, что число тандемных повторов может быть индивидуальным признаком – у одного человека в определенном участке три повтора, у другого пять или восемь. Но это тоже приведет к полиморфизму длины фрагментов рестрикции: чем больше повторяющихся фрагментов окажется между сайтами, распознаваемыми рестриктазой, тем длиннее получится кусок.
Тандемные повторы бывают разные. Если длина повторяющегося мотива 7–60 нуклеотидов, это минисателлиты. Один из их видов – гипервариабельные минисателлиты (VNTR, variable number of tandem repeats), они расположены в некодирующих регионах и, в соответствии с названием, число их может быть различным у разных особей. Если же длина повторяющегося участка меньше, от 2 до 6 нуклеотидов, – это микросателлиты, или короткие тандемные повторы (STR, short tandem repeats). Сейчас золотым стандартом в установлении личности по ДНК считается исследование STR (потом разберемся почему), но начиналось все с VNTR. Впрочем, чтобы всех запутать, в некоторых источниках оба типа повторов называют VNTR.А есть еще сателлитные повторы, наибольшие по размеру повторяющегося участка, – они в криминалистике не используются.
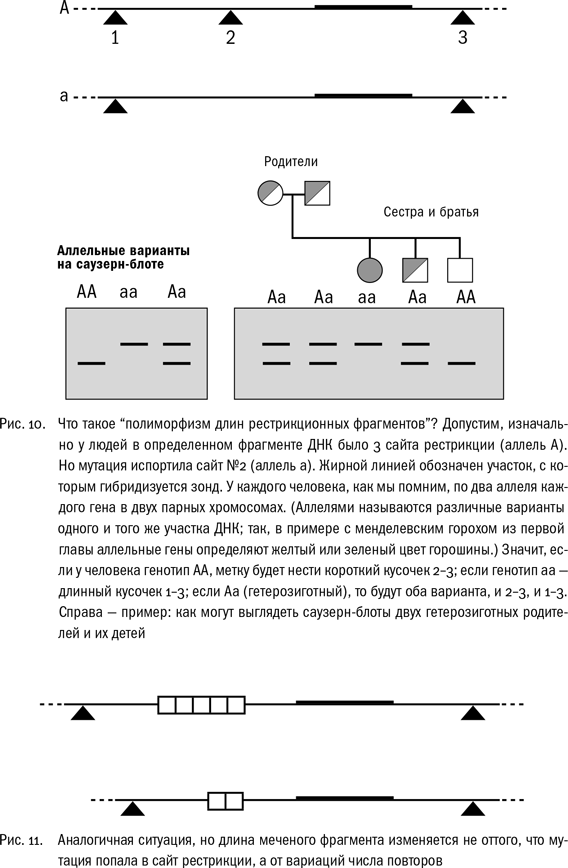
Но, чтобы получать картинки методом саузерн-блоттинга, мало полиморфизма длины фрагментов – еще нужна метка. Чем пометить полоски, содержащие повторы, чтобы сделать их видимыми? И еще хотелось бы, чтоб метка была для всех одинаковая (ее же надо готовить заранее), а рисунок полосок получался индивидуальным, своим для каждого человека.
Помощь пришла из совершенно другого проекта. В лаборатории Джеффриса изучали человеческий ген миоглобина – белка, который переносит кислород в мышцах, однако начать пришлось с гена серого тюленя. Тюлень – зверь ныряющий, кислорода ему нужно много, поэтому с его гена миоглобина активно считывается мРНК. Если выделить мРНК и синтезировать на ее матрице комплементарную ДНК (кДНК), она будет очень похожа на искомый ген. В природе у млекопитающих ДНК не синтезируется на матрице РНК, но для исследования это удобно, необходимый для этого фермент ревертазу можно позаимствовать у вирусов. А через ген тюленя, используя его как зонд, исследователи планировали выйти на ген миоглобина человека: при всем нашем внешнем несходстве с тюленями и другими зверями гены млекопитающих в целом довольно похожи.
“Подлинная история ДНК-фингерпринта началась в штаб-квартире Британской антарктической службы в Кембридже, – вспоминал профессор Джеффрис. (Вопреки названию, эта служба занимается не только Антарктикой, но и Арктикой. – Прим. авт.) – Я взял большой кусок тюленьего мяса из их морозилки, запиравшейся на ключ, и, коротко говоря, мы получили ген миоглобина тюленя, поглядели на ген миоглобина человека – и там, внутри интрона этого гена, нашли тандемные повторы ДНК – минисателлиты”. Собственно, слово “минисателлиты” и придумали Джеффрис с соавторами.
Для начала, что такое интроны? Дело в том, что гены белков высших организмов состоят из экзонов – областей, кодирующих аминокислотные последовательности белка, – и интронов – областей, “ничего не означающих”, вроде типографской “рыбы”, – бессмысленного текста для технических надобностей. Перед тем как синтезировать белок, интроны приходится вырезать из матричной РНК и склеивать экзоны между собой. Почему эволюция вставила в гены куски, которые потом все равно надо вырезать, – отдельная история. Но, кстати, существование интронов в гене бета-глобина кролика впервые продемонстрировали Джеффрис и Флавелл.
А почему “минисателлиты”, причем тут спутники? Этот термин уходит корнями в методы молекулярной биологии. Биомолекулы, ДНК в том числе, разделяют не только электрофорезом, но и центрифугированием: пробирки с раствором устанавливают в специальные роторы и быстро вращают – скорость может достигать десятков тысяч оборотов в минуту. В центробежном поле частицы, имеющие разную плотность, форму и размеры, осаждаются с разной скоростью, то есть образуют зоны на различной высоте от донышка. Так вот, ДНК, богатая повторами, при центрифугировании попадала в отдельную фракцию – ее плотность чуть выше за счет более высокого содержания GC-пар. За это ее и назвали “сателлитной ДНК”, а позже название перешло на любопытные вещи, которые в ней были найдены. Сателлитная ДНК находится главным образом в центромерных и теломерных участках хромосом (иными словами, в серединках и на концах), но тандемные повторы могут встречаться и в других местах, в том числе внутри гена, в интроне.
Возникла идея использовать миоглобиновые минисателлиты, которые нашел Джеффрис с соавторами, в качестве зонда, чтобы поискать еще такие же последовательности. Когда это удалось, найденные участки отсеквенировали и обнаружили источник сходства – так называемую сердцевинную, или ко́ровую последовательность (core sequence) – участок ДНК, который очень похож у разных минисателлитов. В разных местах генома повторялись разные “слова”, но эти повторы везде перемежались одним и тем же мотивом, содержащим GGGCAGGARG, где R – любой нуклеотид. Повторы, а в них другие повторы – будет понятнее, если посмотрите на рис. 12.
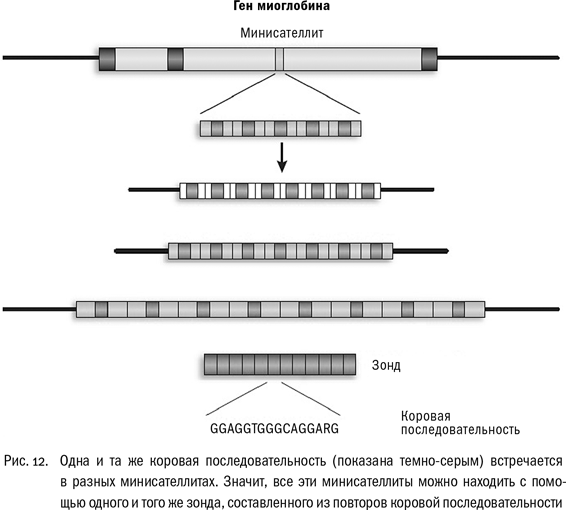
Зонд из повторов коровой последовательности мог прицепляться к множеству минисателлитов одновременно. Надо было проверить, как это будет работать, и Джеффрис поставил электрофорез с ДНК людей и других биообъектов, у которых тоже могли оказаться похожие минисателлиты.
Впоследствии он даже не мог вспомнить, где было какое животное, – радиоавтограф этого блота вместе с записями в журнале был продан на благотворительном аукционе за 180 фунтов, и позже покупатель мог считать, что ему повезло. Так или иначе, три дорожки слева занимали ДНК лаборантки Джеффриса и ее родителей, а самую правую дорожку – ДНК табака.
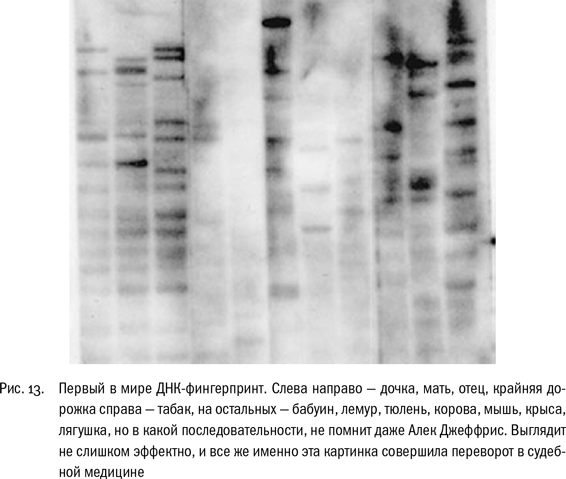
Момент истины наступил утром 10 сентября 1984 г., когда Джеффрис проявлял радиоавтографы. “Я взглянул, подумал «что за каша», а потом вдруг увидел закономерность. Уровень индивидуальной специфичности – во многих световых годах от всего, что наблюдалось раньше”.
В “лесенках” горизонтальных линий были видны совпадения и расхождения, связанные с родством – ДНК ребенка, мамы и папы проявляли семейное сходство. Каждый фрагмент ДНК ребенка соответствовал по длине какому-нибудь фрагменту материнской либо отцовской ДНК. Не все родительские фрагменты присутствовали у дочери (что естественно: мы получаем от каждого родителя только половину его генетического материала), но “лишних” фрагментов, взявшихся из ниоткуда, в ДНК ребенка не было, каждый – или от папы, или от мамы.
Индивидуальные характеристики ДНК, передаваемые по наследству, от родителей к детям. Путь к созданию методики, за которую любой криминалист отдаст правую руку, – способ устанавливать однозначное соответствие между биоматериалом и индивидом. Безошибочно определять, кому принадлежит след крови, спермы, волосы или лоскуток кожи. И наоборот – идентифицировать человека, который не может или не хочет себя назвать, по анализу крови, как если бы в каждой клетке его тела был записан номер паспорта. Фотографии устаревают, документы можно подделать, отпечатки пальцев изменить хирургическими методами, но эта метка всегда остается неизменной. Да, и еще дополнительный бонус – возможность выявлять родственные связи между индивидами.
“Это был момент «эврика!». Пока я стоял перед этой картинкой в фотокомнате, моя жизнь сделала крутой поворот”, – писал Джеффрис.
В тот же день сотрудники лаборатории набросали список возможных применений – судмедэкспертиза, установление отцовства, установление идентичности или неидентичности близнецов, мониторинг трансплантатов, охрана природы и сохранение редких видов. А вечером жена Джеффриса Сью добавила еще один пункт: разрешение спорных вопросов об иммиграции – установление родственных связей в этих вопросах играет первостепенную роль.
Все это сбылось. Но метод еще предстояло улучшить, избавиться от “каши”. Выяснилось также, что высоковариабельных участков, пригодных для фингерпринта, в геноме много, что анализировать их можно независимо и что по ДНК-фингерпринту, как и было задумано, можно различать даже ближайших родственников (кроме идентичных близнецов, естественно.) Джеффрис с соавторами опубликовали статью, и мир изменился.
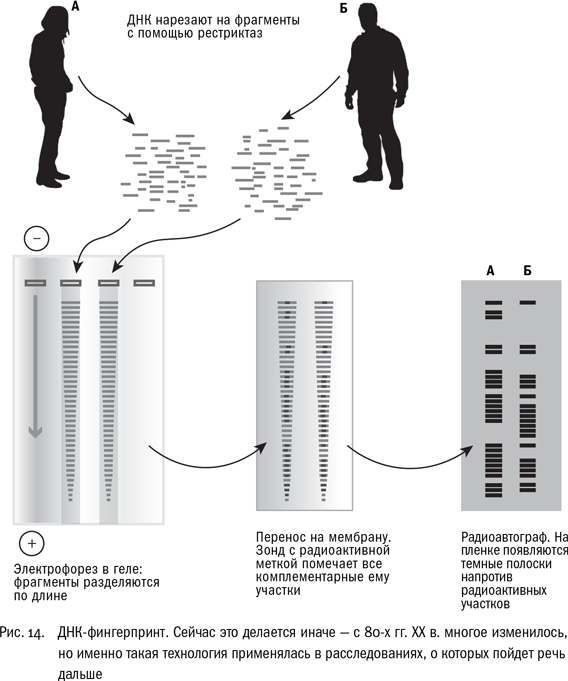
Подытожим, как получают ДНК-фингерпринт по Джеффрису. Выделяют ДНК из образца – пятна крови, спермы и т. п. Обрабатывают рестриктазами, фрагменты разгоняют на электрофорезе, затем делают саузерн-блоттинг, молекулы ДНК переносятся на мембрану. Мембрану с отпечатками ДНК инкубируют с радиоактивно меченным зондом, содержащим коровую последовательность. Затем накладывают на рентгеновскую пленку, выдерживают, проявляют и видят рисунок – индивидуальный штрихкод человека.Сразу хочется спросить, много ли ДНК можно извлечь из типичного образца на месте преступления. На форез-то хватит? Вопрос в точку, и мы вернемся к нему в главе про полимеразную цепную реакцию.
Назад: Салат из ДНК и саузерн-блоттинг
Дальше: Дело об иммигрантах из Ганы

