Книга: 0,05. Доказательная медицина от магии до поисков бессмертия
Назад: Глава 13 Как разрабатывают лекарства
Дальше: Глава 15 Доказательная медицина
Глава 14
Золотой стандарт
Эта глава может показаться чуть сложнее, чем остальные, но она очень важна. Без нее может сложиться ошибочное впечатление, что мы живем в эпоху триумфа доказательной медицины, ее инструменты повсеместно приняты и используются по назначению, а двойное слепое рандомизированное клиническое исследование – гарант эффективности и безопасности лекарства. Кроме того, прочитав эту главу, вы сможете самостоятельно находить в научных статьях наиболее очевидные случаи манипуляции данными.
Кризис воспроизводимости
Двойные слепые рандомизированные исследования не зря называют золотым стандартом. Именно такие эксперименты лучше всего отвечают на вопрос о полезности и безопасности метода лечения. Их проведение – обязательное условие для рассмотрения заявок на регистрацию новых лекарств в большинстве стран.
С 2000 по 2017 год только зарегистрированных клинических испытаний было проведено 250 тысяч. Добавим к ним как минимум еще столько же незарегистрированных. Конечно, не всегда исследователи приходили к выводу, что изучаемый метод лечения эффективен. Но даже если считать, что результат был положителен лишь в каждом десятом случае, 50 тысяч успешных клинических испытаний, проведенных только за эти 17 лет, уже должны были переполнить мир эффективными лекарствами от всех возможных болезней. Однако этого не происходит. Несмотря на отдельные успехи медицины, большинство болезней пока неизлечимо. За всю историю человечества лишь одно заболевание было уничтожено полностью.
Причин несоответствия объемов результативных исследований и реальных успехов медицины несколько. Одна из них в том, что существуют сотни способов провести клиническое испытание неправильно и сделать неверный вывод. И намного чаще это ложноположительные, а не ложноотрицательные результаты. Организаторы исследований, как правило, заинтересованы обнаружить эффект, и это приносит свои плоды. В первую очередь речь о финансовых интересах: разрабатывая лекарство, фармацевтическая компания рассчитывает получить разрешение на продажу препарата и вернуть вложенные в разработку деньги.
Конечно, исследования проходят не только за счет производителей лекарств. Но возможных источников денег не так много. Клинические испытания могут финансироваться специальными государственными структурами, такими как Национальные институты здравоохранения США или изучавший стрептомицин и патулин Совет по медицинским исследованиям Великобритании. Иногда деньги могут поступать от пациентских организаций. Но большинство КИ оплачивают именно фармацевтические компании. Даже в США, где традиционно развиты некоммерческие исследования, производители лекарств спонсируют не менее 75% клинических испытаний. В России – почти 100%.
Результаты исследований, оплаченных фармацевтическим бизнесом и проведенных за счет государственных или некоммерческих организаций, не раз сравнивали. Итог неизменен: исследования, спонсированные индустрией, чаще приходят к выводу об эффективности и безопасности вещества. Разница огромна – анализ 2003 года показал, что это происходит в пять раз чаще, чем при других источниках финансирования. Эта разница постепенно уменьшается, что можно объяснить ужесточением требований к клиническим испытаниям и более пристальным контролем. Но до полного ее исчезновения еще далеко.
Заинтересованность исследователей играет не меньшую роль, чем заинтересованность инвестора. Как много вы видели новостных заголовков, сообщающих, что ученые исследовали новое лекарство от рака и не нашли эффекта? Как много Нобелевских премий выдано тем, кто всю жизнь проверял различные гипотезы и все их опроверг? Как много вошло в историю ученых, которые ничего не открыли? К сожалению, наше общество признает только положительные результаты. Именно они могут дать славу, признание, карьеру и деньги.
Кроме того, работать без положительных результатов непросто психологически. Поставьте себя на место исследователя, тратящего годы на поиски лекарства от неизлечимой болезни. Как бы осторожны и скептически настроены вы ни были, неужели в глубине души вы не будете мечтать о том, чтобы тяжкий труд, волнения, споры и бессонные ночи оказались не зря и когда-нибудь у вас получилось? А если очень хотеть, то рано или поздно обязательно получится, даже там, где “получаться” абсолютно нечему.
Что с медицинскими исследованиями не все ладно, понятно давно. Но о масштабе бедствия стали говорить относительно недавно. В 2011 году работающие на фармацевтическую компанию Bayer ученые сообщили, что их попытки повторить результаты ранее опубликованных доклинических исследований в онкологии и кардиологии завершились успехом лишь в 20–25% случаев. В остальных результат повторных экспериментов был иным, чем в исходных. Годом позже о такой же проблеме сообщил сотрудник компании Amgen. Там пытались воспроизвести результаты пятидесяти трех важных исследований, но удалось это сделать лишь для шести.
Затем последовали пересмотры результатов ряда очень влиятельных клинических испытаний. В 2013 году был проведен повторный анализ РКИ, которое рекомендовало людям с невысоким риском сердечно-сосудистых заболеваний принимать с целью увеличения продолжительности жизни снижающие уровень холестерина статины. Пересмотр показал, что эффект статинов незначителен и его с лихвой перекрывают тяжелые побочные эффекты – статины увеличивают риск диабета и миопатии. А в 2014 году увенчались успехом три с половиной года попыток получить от компании Roche полные данные по исследованиям противовирусного препарата озельтамивир, а от компании GlaxoSmithKline – по зенамивиру. После анализа данных независимыми исследователями выводы о некотором сокращении продолжительности гриппа остались в силе. Но вывод о снижении смертности от гриппа, на основе которого делались массовые закупки этих препаратов, был пересмотрен.
Растущее количество свидетельств того, что качество многих медицинских исследований не дотягивает до минимально приемлемого уровня, а результаты не воспроизводятся при повторении независимыми исследователями, побудило описать сложившуюся ситуацию как кризис воспроизводимости. Хотя дело не столько в невозможности воспроизвести эти работы, сколько в понимании, что значительной их части нельзя доверять по причине некорректного дизайна, анализа или интерпретации результатов. По оценкам некоторых скептиков, доля таких исследований достигает 85%.
Рыцари халата и ланцета
Существует множество способов “слегка поправить” результаты исследования, и большинство из них грозит манипулятору лишь репутационными рисками. Поэтому откровенный прямой подлог встречается относительно нечасто. Но уж если встречается, масштаб и наглость поражают воображение. С явного криминала мы и начнем.
Профессор анестезиологии университета Тафтса в Бостоне Скотт Рюбен считался одним из ведущих исследователей боли до тех пор, пока не получил девять месяцев тюрьмы за мошенничество. Хотя опубликованные им работы повлияли на то, как лечили миллионы пациентов, исследований, описанных им в двадцать одной научной статье, просто никогда не было. В качестве соавторов Рюбен указывал других ученых, которые даже не догадывались об этом. Статьи Рюбена сообщали об эффективности производимых компанией Pfizer обезболивающих “Бекстра”, “Целебрекс” и “Лирика”, а также выпускаемого Merck препарата “Виокс”. С 2002 по 2007 год Рюбен получил от Pfizer пять исследовательских грантов, а также был хорошо оплачиваемым спикером компании – он выступал перед другими врачами с докладами о ее лекарствах. К тому моменту, когда коллеги насторожились, афера Рюбена продолжалась уже почти тринадцать лет.
Доктор Роберт Фиддес, директор компании Southern California Research Institute, выполнявшей клинические испытания по заказу фармацевтических компаний, был известен умением быстро найти нужное количество пациентов. Однако за невероятной продуктивностью скрывалось мошенничество длиною в десять лет. Фиддес включал в исследования не только пациентов, не соответствовавших критериям отбора, но и тех, кто никогда не рождался на свет. Рутинной практикой была фальсификация результатов лабораторных анализов, показателей артериального давления и данных ЭКГ. Образцы мочи и крови могли не принадлежать больным – например, один из сотрудников с протеинурией получал за образцы своей мочи, которую затем выдавали за мочу пациентов, по 25 долларов за порцию.
Мошенничеству не мешали многочисленные проверки. Оно вскрылось лишь после доноса одного из сотрудников, знавшего о махинациях. Опубликованная в New York Times статья рассказывает:
Согласившись признать свою вину, др. Фиддес во время допросов выставлял себя человеком, попавшим в ловушку окружающих его нечестных людей. Он уверял, что большинство исследователей вынуждены мошенничать, поскольку фармацевтические компании предъявляют к участникам экспериментов требования, которые будут хорошо смотреться в маркетинговых материалах, но в реальной жизни невыполнимы. Не предъявляя доказательств, он утверждал, что все, кто преуспевает в этом бизнесе, вынуждены обходить правила.
Известный дерматолог Гарри Снайдер руководил спонсируемым компанией BioCryst Pharmaceutical клиническим исследованием, в то время как его жена Рене Пежо была в нем координатором. Они исследовали вещество BCX-34, которое предполагали использовать для лечения псориаза и кожной Т-клеточной лимфомы, опасного онкологического заболевания. По завершении РКИ пресс-релиз компании сообщил о высокой эффективности вещества. Однако новый директор BioCryst засомневался в достоверности результатов. Последовавший аудит выявил манипуляции в ходе рандомизации, которые помогли выставить BCX-34 в незаслуженно выгодном свете.
Результаты исследования были отозваны с пометкой “лекарственный эффект не обнаружен”, а Снайдер и Пежо получили по 3 и 2,5 года тюремного заключения соответственно. Снайдер опубликовал письмо, в котором писал, что “вроде бы и понимал, зачем нужны правила проведения исследований, но считал, что на них надо ориентироваться, а не следовать им слепо”. Как акционеры BioCryst и Снайдер, и его жена были напрямую заинтересованы в положительном результате.
В 2005 году медицинский журнал The Lancet опубликовал наблюдательное исследование норвежского врача Йона Субдё, где на основании данных о 454 больных анализировалось влияние разных факторов риска на заболеваемость раком ротовой полости. Выводы делались сенсационные: нестероидные противовоспалительные препараты снижают заболеваемость этим видом рака, в том числе и у курильщиков. Однако вскоре статья была отозвана. В ходе проверки выяснилось, что все до единого участники исследования были плодом фантазии Субдё. Причем фантазии настолько ленивой, что у 250 из них были указаны одинаковые даты рождения. Позже признаки фальсификации были обнаружены в других его статьях и в диссертации. В отличие от России, где ни один диссертационный скандал не привел к серьезному наказанию, в Норвегии фальсификация диссертаций воспринимается как тяжелейший проступок: статьи и ученая степень Субдё были отозваны, а самому ему запретили заниматься медициной.
Японский анестезиолог Ёситака Фудзии за двадцать лет работы опубликовал более двух сотен статей с результатами 168 проведенных им исследований. Внимание на себя обратили одинаковые цифры в разных исследованиях. Результаты проверки ошеломляли: из 212 изученных статей признаки мошенничества обнаружились в 172. Данные 126 работ были сфабрикованы от первого слова до последнего.
Из-за мошенничества в сфере медицинских исследований печальную известность также получили: онколог Вернер Бесвода, сфальсифицировавший результаты применения комбинации химиотерапии и стволовых клеток, якобы показавшего высокую эффективность при раке молочной железы; анестезиолог Йоким Болдт, подделавший данные об эффективности применения гидроксиэтилкрахмала у пациентов в критическом состоянии; британский врач Эндрю Уэйкфилд, опубликовавший в The Lancet статью о якобы найденной им связи между вакциной MMR и аутизмом и впоследствии уличенный в том, что получил более 400 тысяч фунтов стерлингов от адвокатов, пытавшихся отсудить у производителей вакцин астрономические суммы за якобы нанесенный детям ущерб; американский исследователь Донг Пью Хан, чья команда получила грант в 19 миллионов долларов, после того как сфальсифицировала успешное применение вакцины против ВИЧ; и многие, многие другие.
Насколько распространена явная, масштабная и осознанная фальсификация научных исследований? С одной стороны, собранная в США статистика показывает, что за двадцать лет правительство объявило лишь о 200 таких эпизодах. С учетом сотен тысяч работающих в этой сфере людей – выглядит неплохо. Однако выявляют далеко не каждый случай. Судя по тому, что подобные преступления не замечают десятилетиями, мы можем иметь дело лишь с верхушкой айсберга.
Регулярный аудит исследовательской работы – явление нечастое, но в тех случаях, когда он проводится, частота мошенничества уже ощутима. Группа, которая проводит аудит исследований, финансируемых Национальным институтом рака в США, находит мошенничество в 0,25% случаев. Похожие проверки в Великобритании – в 0,4%. Притом следует помнить, что эта статистика основана на доказанных случаях злого умысла и реальная частота мошенничества наверняка выше.
Если же говорить обо всех серьезных нарушениях, по данным FDA, их частота достигает 10%. Печальную картину дополняют многочисленные анонимные опросы. Так, 27% ученых сообщили Американской ассоциации развития науки, что сталкивались с теми или иными нарушениями при проведении клинических испытаний. О том же сообщили 19% координаторов исследований, добавив, что в трети случаев информация о нарушениях осталась тайной. При опросе сотрудников британских медицинских учреждений о нарушениях упомянул каждый второй.
В некоторых странах ситуация еще хуже. В Китае, где качество медицинских исследований до недавнего времени практически не контролировалось, случился скандал. В 2016 году Управление по контролю за качеством пищевых продуктов и лекарств попыталось навести порядок и устроило массовую проверку клинических испытаний, на основании которых регистрировали препараты. Результаты оказались катастрофическими. Из 1622 заявок на регистрацию 1308 содержали либо явно сфабрикованные, либо глубоко ошибочные и неадекватные данные. Открытой статистики такого рода по России просто не существует, но стоит ожидать, что она ближе к китайской, чем к британской или американской. Россия относится к странам, где аудит клинических исследований почти не проводится, а требования к их качеству низки. По сообщениям экспертов и косвенным признакам манипуляция данными клинических испытаний российских препаратов – массовое явление.
Лучше, чем что?
Если выполнить эксперимент абсолютно правильно и предельно честно, он все равно будет бесполезен, если отвечает на бессмысленный с точки зрения интересов пациента вопрос. Один из способов провести такое исследование – выбрать неподходящее контрольное вмешательство.
Мы много говорили об использовании в качестве контроля плацебо, но это допустимо лишь тогда, когда нет эффективного и безопасного лечения. Если оно существует, то сравнивать новое лекарство нужно именно с ним, а не с плацебо. Это требование четко сформулировано в Хельсинкской декларации.
Польза, риски, неудобства и эффективность нового вмешательства должны оцениваться в сравнении с лучшими из проверенных вмешательств…
Новое лечение отвечает интересам пациентов, только если оно более эффективно, более безопасно, более дешево или более удобно, чем созданное ранее. Однако оценка новых регистрируемых в США препаратов показала, что только 70% имели на момент регистрации информацию об эффективности по сравнению с существующими методами, а 30% сравнивались только с пустышкой-плацебо. Препараты от заболеваний, для которых не существовало другого эффективного лекарства, были из этого анализа исключены.
Но даже при сравнении с лучшей альтернативой на рынке есть способы подать свой препарат в выгодном свете. Например, используя недостаточную дозу контрольного препарата. В разгар эпидемии менингококковой инфекции в Нигерии, убившей 12 тысяч человек, фармацевтическая компания Pfizer организовала РКИ нового антибиотика тровафлоксацина. Контрольная группа получала уже ставший стандартным лечением цефтриаксон. Из двухсот детей погибли пятеро в группе тровафлоксацина и шестеро в группе цефтриаксона. Расследование показало, что цефтриаксон давали в дозе 33 мг/кг, в то время как рекомендованная доза равна 50–100 мг/кг. Последовало судебное разбирательство в США и крупные выплаты семьям пострадавших.
В зависимости от стратегии создателей препарата лекарство в контрольной группе могут применять и в дозах, сильно превышающих необходимую. Это позволяет усилить побочные эффекты, и на этом фоне новый препарат будет выглядеть более безопасно. Так поступали с некоторыми антипсихотическими препаратами, которые сравнивали с высокими дозами галоперидола, гарантированно дающими тяжелые побочные эффекты.
Эффективно для кого?
Один из самых важных вопросов, который мы должны задавать в отношении каждого клинического эксперимента: какие пациенты в нем участвовали? Исследователи далеко не всегда описывают, как проводили отбор, что чревато ошибочным распространением выводов на другие группы пациентов.
В надежде получить положительный результат на этапе отбора из исследования могут исключить самых старых, страдающих самой тяжелой формой или находящихся на самой поздней стадии заболевания. Понятно, что полученные на такой выборке результаты могут быть неприменимы ко всей популяции. Часто отбирают только тех, у кого нет сопутствующих патологий, кто не получает лечение от других болезней и не имеет серьезных вредных привычек. Но как много таких людей среди реальных больных?
Масштаб проблемы довольно велик. Исследования показывают, что в клинические испытания включают в среднем 15–30% тех, кого рассматривали. В некоторых случаях отбор еще более жесткий и доля отобранных падает до 6–10%. Оставшиеся отличаются от тех, кого отбраковали, не только по среднему возрасту, но и полу, национальному составу и социальному статусу. Так, обзор клинических испытаний нестероидных противовоспалительных препаратов показал, что в среднем в них участвовали лишь 2,1% людей в возрасте 65 лет и старше, хотя эти лекарства часто назначают именно пожилым.
Стерильные условия клинических испытаний предполагают не только идеальных пациентов, но и идеальных врачей. Клинические испытания эндартерэктомии при бессимптомном сужении каротидной артерии показали пятипроцентное снижение смертности по сравнению с контрольной группой. Однако стало известно, что во время клинического испытания 40% хирургов не подпускали к операционному столу. Это были врачи, имевшие неоптимальную статистику неудачных исходов и побочных эффектов. Впоследствии было показано, что без строгого отбора хирургов смертность от этого метода в восемь, а риск инсульта в три раза выше, чем в контрольной группе, что ставит целесообразность каротидной эндартерэктомии при бессимптомном течении болезни под сомнение.
Доверять ли биомаркерам?
Одно из самых важных решений, принимаемых перед началом клинических испытаний, – выбор исходов (или конечных точек), по которым будет оценен результат. Здесь возможны два подхода. Первый – использовать клинически значимые исходы (еще их называют твердыми конечными точками). Это то, что важно для пациента: продолжительность жизни, ее качество, отсутствие тяжелых осложнений.
Но многие РКИ ориентируется на суррогатные исходы (их также называют биомаркерами или мягкими конечными точками) – это результаты анализов или приборных исследований, которые предсказывают изменения клинически значимых исходов. Например, изучая лекарственный препарат от сердечно-сосудистых заболеваний, мы можем ориентироваться на продолжительность жизни пациентов или частоту инфарктов миокарда – это клинически значимые исходы. Но такое исследование будет очень долгим, а значит, дорогим. Альтернатива – ориентироваться на изменения уровня холестерина или результатов ЭКГ, это суррогатные исходы. Конечно, пациенту без разницы, как лечение повлияло на уровень его холестерина: от этого он не испытает никаких изменений самочувствия. Но мы предполагаем, что уровень холестерина предсказывает частоту инфарктов или продолжительность жизни.
Как бы хорошо это ни звучало в теории, на практике суррогатные результаты часто разочаровывают. Показательна история эзетимиба, препарата, который должен был уменьшать смертность от сердечно-сосудистых заболеваний, влияя как раз на уровень холестерина в крови: известно, что высокий холестерин липопротеидов низкой плотности коррелирует с сердечно-сосудистыми заболеваниями и смертью от них. Эзетимиб подавляет всасывание холестерина в кишечнике. Действительно, прием препарата снижал уровень холестерина, что и было продемонстрировано в регистрационных РКИ. Однако последующие исследования не обнаружили ни уменьшения риска развития атеросклероза, ни снижения частоты сердечных приступов или смертности от болезней сердца и сосудов.
Объяснений может быть несколько. Хотя согласно данным наблюдательных исследований уровень холестерина и частота сердечно-сосудистых заболеваний коррелируют, первое не обязательно является причиной второго. Или же на развитие заболевания влияет множество причин, а не только уровень холестерина, и наш препарат меняет уровень холестерина в благоприятную сторону, а другие факторы – в неблагоприятную. Или у него есть побочные эффекты, которые могут увеличивать смертность по другим причинам, и этот отрицательный эффект перевешивает положительный либо сводит его на нет. Последнее как раз и происходит в случае применения статинов у людей без повышенного риска сердечно-сосудистых заболеваний.
Еще один классический пример ошибки, спровоцированной суррогатными исходами, – применение антиаритмических препаратов у пациентов с инфарктом миокарда. Только в США четверть миллиона пациентов с инфарктом ежегодно получали энкаинид и флекаинид, исходя из простой логики: у таких больных высока вероятность внезапной смерти от аритмии. Электрокардиография подтверждала нормализацию сердечного ритма, поэтому врачи считали, что приносят пациентам безусловную пользу. Тем сильнее был шок, когда четырехлетнее клиническое исследование показало, что прием антиаритмических препаратов при инфаркте увеличивает смертность в три раза. Вероятно, эти препараты стимулировали неизвестный опасный процесс. При этом не факт, что они вообще приносили какую-либо пользу, – аритмия могла быть не причиной смерти, а побочным следствием приводящего к гибели процесса.
Еще один показательный пример – применение фторида натрия для профилактики переломов. Известно, что вероятность переломов тем выше, чем ниже плотность костей. Остеопороз, уменьшение плотности костей, – серьезная проблема пожилых людей, особенно женщин. Для ее решения было предложено использовать фторид натрия. Клинический эксперимент показал, что его прием значительно увеличивает плотность костей. Но в следующем трехлетнем РКИ оценили не только изменение плотности костей, но и частоту переломов. Прием фторида натрия действительно увеличивал плотность костной ткани. Но частота переломов не снижалась, а увеличивалась на 30% для переломов позвоночника и почти в три раза для всех остальных. Судя по всему, при приеме фторида натрия образовывалась более хрупкая костная ткань.
Полностью отказаться от суррогатных исходов невозможно. Они могут значительно уменьшить количество участников, продолжительность эксперимента, а значит, и его стоимость. Однако полагаться на единичные суррогатные исходы опасно, и к их выбору нужно относиться очень серьезно. Нельзя использовать биомаркер лишь на основании обнаруженной в наблюдательных исследованиях статистической корреляции c важным для пациента исходом и биологически правдоподобной связи между ними. Нужно, чтобы надежность суррогатного исхода подтверждалась и данными многочисленных клинических экспериментов.
P < 0,05
Предложенный Рональдом Фишером критерий статистической значимости p < 0,05 надежно закрепился в качестве порога, разделяющего результаты научных исследований на положительные и отрицательные. Практически во всех медицинских исследованиях используют тот или иной метод расчета p, и в большинстве 0,05 выбрано как пороговое значение. Однако недавно эта практика, которой скоро исполнится уже сто лет, была подвергнута жесткой критике и названа одной из главных причин кризиса воспроизводимости.
В 2017 году несколько ведущих статистиков опубликовали в журнале Nature манифест “Пересмотреть статистическую значимость”, в котором призвали отказаться от критерия p < 0,05 и заменить его на p < 0,005. Авторы пообещали, что этот простой шаг немедленно приведет к улучшению ситуации с воспроизводимостью научных исследований во многих областях. В чем же проблема с проверенным десятилетиями и привычным большинству ученых и врачей p < 0,05?
Многие из тех, кто читает и даже пишет научные статьи, неправильно понимают смысл p-значения. Распространена ошибочная интерпретация p как вероятности ложноположительного результата. А значит, при p < 0,05 вероятность, что нулевая теория верна и отклонена ошибочно, не превышает 5%. Ошибка в том, что p-значение – это не вероятность правильности нулевой теории при условии получения наблюдаемых данных. Это вероятность наблюдать такие данные при условии, что нулевая теория верна. Разница принципиальная. Так, вероятность, что вы беременны, если вы женщина, не равна вероятности того, что вы женщина, если вы беременны. В первом случае она равна 3%, во втором же стремится к 100%.
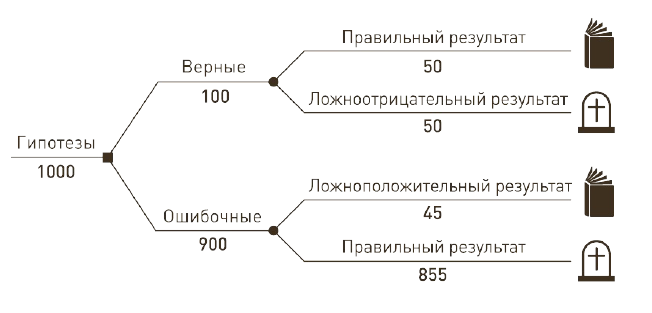
Так какова же реальная вероятность, что мы ошибочно отклонили нулевую теорию и пришли к выводу о существовании эффекта там, где его нет, если мы ориентируемся на p < 0,05? Предположим, что верны 10% выдвигаемых экспериментаторами гипотез. Судя по доле лекарств, которые доходят от начала клинических испытаний до регистрации, даже эта цифра оптимистична. Тогда из 1000 экспериментов в 900 будет верна нулевая гипотеза (лекарство не работает), а в 100 – альтернативная (лекарство работает). При пороговом p=0,05 или чуть меньшем нулевая гипотеза будет ошибочно опровергнута в 900 × 0,05=45 случаях из 900.
Чтобы понять, что произойдет с теми 100 экспериментами, где нулевая гипотеза ошибочна, то есть эффект лекарства реально существует, нам нужно учесть статистическую мощность. По некоторым оценкам, в клинических испытаниях она, как правило, недостаточна и в среднем составляет примерно 50%. А значит, мы обнаружим существующий эффект в 50 случаях из 100.
Итак, будут опубликованы 95 положительных результатов, 45 из которых, то есть почти половина, будут ошибочны. Доля ложноположительных результатов в этом случае 47%, а вовсе не 5%. Соответственно, на более ранних этапах поиска, например при доклинических исследованиях, где доля ошибочных гипотез намного выше, соотношение ошибочных и реальных положительных результатов будет еще больше смещаться в сторону первых. Очевидно, что p < 0,05 абсолютно не пригодно в качестве единственного критерия, разделяющего результаты клинических испытаний на положительные и отрицательные.
Предложение снизить критерий статистической значимости до p < 0,005 встретило бурное сопротивление. Некоторые были против, поскольку такое изменение потребовало бы значительно увеличить количество участников, а значит, и стоимость исследований. Помимо этого, очевидно, что будет поставлена под сомнение реальность невероятного количества найденных ранее эффектов в диапазоне 0,005 < p < 0,05.
Другие критики обратили внимание, что если на практике доля воспроизведенных результатов в интервале p-значения 0,005–0,05 равна 24%, то для p < 0,005 она тоже далека от идеальной и составит 49%. Судя по всему, простое снижение порогового p-значения улучшит ситуацию, но не решит проблему полностью. Причина в том, что кризис воспроизводимости вызван не p < 0,05 самим по себе, а различными приемами, которые исследователи применяют для того, чтобы искусственно протолкнуть результаты своих исследований за столь желанный порог статистической значимости. Такая манипуляция данными в процессе статистического анализа называется p-хакингом.
Как стать p-хакером
В 1980 году группа исследователей провела контролируемый эксперимент, для которого было отобрано 1075 пациентов с заболеваниями сосудов сердца. Их рандомизировали в две группы, назначив каждой определенное лечение, назовем их А и В. Рандомизация была проведена корректно, и исходно группы были похожи по основным параметрам. После лечения выживаемость в обеих группах оказалась одинаковой. Но, разделив группы на несколько подгрупп – по возрасту, количеству пораженных сосудов и некоторым важным симптомам, – исследователи получили интересные результаты. Выживаемость группы А стала статистически значимо выше в подгруппе с поражением трех сосудов сердца и аномальным сокращением левого желудочка (p < 0,025), а в подгруппе с поражением трех сосудов, аномальным сокращением левого желудочка и отсутствием признаков сердечной недостаточности критерий статистической значимости для разницы был еще ниже (p < 0,01).
Отлично, разве не для этого мы проводим рандомизированные клинические исследования? Однако исследователи не спешили рекомендовать лечение А пациентам с поражением трех сосудов, аномальным сокращением левого желудочка и отсутствием признаков сердечной недостаточности. На самом деле в этом эксперименте ни одна из групп не получила никакого лечения. Да и пациентов никаких не было: их роль выполнили истории болезни из базы данных медицинского центра при Университете Дьюка. Они содержали данные о возрасте и поле когда-то лечившихся там пациентов, симптомах болезни, количестве пораженных сосудов и о том, сколько они прожили после лечения. Всех пациентов лечили одним и тем же методом. Статистически значимые различия между группами A и B обнаружили там, где их не должно было быть.
Что же произошло? Авторы исследования-имитации всего лишь задействовали пару приемов, используемых для p-хакинга – преодоления порога статистической значимости в отсутствие реальной разницы между группами. Легко представить, что, будучи примененными в реальном РКИ, эти манипуляции позволят легко обосновать ложный вывод об эффективности бесполезного лекарства.
Масштаб p-хакинга помогает осознать опубликованная в интернете база данных tidypvals, где собрано два с половиной миллиона p-значений из разных областей науки. Ее создатели предположили, что если p-хакинг существует и распространен, то при анализе распределения опубликованных в научных журналах p-значений будет виден “горбик” – заметное увеличение количества p-значений, которые лишь немногим меньше 0,05. Действительно, для большинства областей науки он оказался явно выражен, и медицина – одна из тех, где проблема наиболее наглядна. При этом внутри медицины есть сегменты, например альтернативная медицина, диетология, фармакология и стоматология, где она особенно бросается в глаза.
У p-хакеров богатый инструментарий. Формирование гипотез после того, как получены результаты, называют харкингом (от англ. HARKing, Hypothesizing After the Results are Known – “строить гипотезы, когда результат уже известен”). Представьте стрелка, который делает пять выстрелов в мишень и попадает в две единицы, двойку, семерку и молоко. Не очень меткий стрелок, скажете вы. А если он скажет, что таким и был изначально его план и он точно выполнил его с первого раза? Пользуясь этой методикой, любой может немедленно стать блестящим снайпером: достаточно говорить, в чем состояла задача, уже отстрелявшись. Понятно, что формулировка задачи будет зависеть от случайного результата, который вы перед этим получили.
Харкинг реализуется последовательной проверкой различных гипотез, пока одна из них случайным образом не даст желаемое p < 0,05. При достаточном количестве попыток это рано или поздно произойдет, даже если все гипотезы ошибочны. Другой подход – сделать как можно больше параллельных сравнений, например замерив и сравнив в двух группах все возможные симптомы одновременно. Какие-то сравнения в силу случайных колебаний преодолеют порог статистической значимости. После этого можно объявлять, что именно они и были основным исходом, который изучал эксперимент. А остальные измерения, по которым критерий статистической значимости не достигнут, могут быть вообще не упомянуты в публикации. Сравнение протоколов РКИ и итоговых публикаций показало, что в среднем авторы отчитываются лишь о половине проанализированных исходов.
Распространенная тактика – разделить пациентов на множество подгрупп, например по полу, возрасту и особенностям заболевания, и сравнивать эти подгруппы по отдельности. При достаточном количестве сравнений порог статистической значимости наверняка будет достигнут. Подобный анализ приводил, например, к ошибочным выводам о полезности амлодипина для пациентов с хронической сердечной недостаточностью, вызванной неишемической кардиомиопатией, но не для пациентов с ишемической кардиомиопатией. Или о том, что аспирин снижает риск сердечно-сосудистых заболеваний у мужчин, но не у женщин. Лекарство и правда может по-разному действовать на разные группы пациентов. Например, не стоит ожидать, что определенный режим физических упражнений будет одинаково полезен для молодых и пожилых. Однако такие гипотезы должны быть немногочисленны и обоснованны, а также сформулированы и зафиксированы до начала эксперимента.
Множественные сравнения увеличивают вероятность ложноположительных результатов и делают получение ничего не значащего p < 0,05 практически неизбежным. Поэтому в таких случаях нужно использовать другие статистические тесты или делать специальные математические поправки на множественное сравнение, например поправку Бонферрони: делим исходный критерий статистической значимости на количество сравнений. Если мы проверяем 20 гипотез одновременно, то пороговое p-значение должно снизиться в 20 раз и стать равным 0,05/20=0,0025.
В погоне за статистической достоверностью исследователи сплошь и рядом забывают применить поправку на множественные сравнения. Иногда это приводит к забавным результатам. В клиническом испытании препарата “Визомитин” для лечения синдрома сухого глаза авторы разбили и так не очень большую роговицу глаза на пять участков (верхний, нижний, центральный, темпоральный, назальный) и отдельно сравнили с контрольной группой изменения на каждом из них. В результате порог p < 0,05 был преодолен лишь для центрального участка, но не для остальных. Но еще дальше пошли сотрудники кафедры детских болезней Первого МГМУ им. И. М. Сеченова. В ходе исследования эффективности гомеопатического препарата “Коризалия” при лечении насморка они измерили симптомы для каждой ноздри отдельно и получили статистически значимый результат для левой, но не для правой ноздри. Ни в том, ни в другом случае поправки на множественное сравнение не делались.
Важно понимать, что такие поправки не исключают риск ложноположительного результата полностью, они просто возвращают его на тот же уровень, что и при единичном сравнении. В описанном выше эксперименте-имитации в Университете Дьюка применение поправки Бонферрони исключило статистическую достоверность лишь для одной из подгрупп, второй “эффект” остался значимым. Это еще раз иллюстрирует, что исходный уровень статистической значимости p < 0,05 не годится в качестве единственного критерия положительного результата.
Заставить вероятности работать на себя можно и раздробив эксперимент на несколько более мелких. Или повторив его столько раз, сколько нужно для получения значимого результата. Или замеряя результаты как можно чаще и остановив эксперимент не когда это планировалось сделать, а ровно в тот момент, когда будет обнаружена статистическая значимость: случайные колебания разницы между группами могут в какой-то момент дать желанный результат. Вывод об эффективности лекарства будет в этом случае так же обоснован, как если вы заявите, что владеете телекинезом, потому что можете заставить все игральные кубики выпасть одной стороной, только получается у вас это когда на девяносто седьмой попытке, а когда на двести четвертой.
Много возможностей открывает перебор существующих инструментов статистического анализа. Есть множество методов, позволяющих получить несколько различающиеся результаты. Сравним, например, две группы, в одной из которых определенный исход наступил с частотой 1/10, а в другой – 6/10. Точный тест Фишера даст статистически незначимый результат p=0,057, но вычисление критерия Mid-P – значимое p=0,030. Расчет критерия хи-квадрат по методу Пирсона тоже дает значимое p=0,019, но рассчитанный с поправкой Ийтса – незначимое p=0,061, а с поправкой Вальда – значимое p=0,035. Конечно, наиболее чувствительны к перебору методов пограничные значения p, близкие к 0,05.
Что можно делать по-другому?
Оставим в стороне рассуждения о том, что полностью решить проблему можно, лишь устранив прямую заинтересованность исследователей и производителей в положительных результатах. Возможно, так оно и есть, но абсолютно непонятно, как добиться этого на практике. Реалистичнее двигаться в сторону большей прозрачности: если все данные клинических экспериментов публичны и могут быть проверены независимыми специалистами, это затруднит p-хакинг.
Уже упомянутое снижение уровня статистической значимости до p < 0,005 тоже будет полезно. Однако важнее перестать ориентироваться на p-значение как на единственный критерий положительного результата. Отбросить нулевую гипотезу можно, только если на ее ошибочность указывают и другие статистические инструменты.
В последнее время звучат предложения перейти от расчета p-значений к байесианским методам анализа. Это направление статистики возникло в середине XVIII века благодаря английскому математику и священнику Томасу Байесу, автору теоремы Байеса. В рамках байесианской статистики был сформулирован альтернативный подход к нулевой гипотезе: использовать в качестве альтернативы p-значению фактор Байеса (BF), который рассчитывается так:

В отличие от p-значения, смысл фактора Байеса интуитивно понятен. Он говорит о том, насколько такие данные вероятнее наблюдать при верной нулевой гипотезе (эффекта нет), чем если при верной альтернативной (эффект есть). Его значение интерпретируют следующим образом: обычно, если BF > 3, мы принимаем нулевую гипотезу, а если BF < 1/3 – альтернативную. Интересно, что во многих ситуациях p-значению в диапазоне 0,03–0,05 соответствует BF > 1. То есть наблюдать такие данные вероятнее, когда никакого эффекта нет. Но при этом p-значение меньше порогового и дает основания считать результат статистически значимым.
Фактор Байеса позволяет легко перейти от вероятности получения наблюдаемых данных к оценке вероятностей самих гипотез. Мы рассчитываем вероятность и нулевой, и альтернативной гипотезы и можем, сравнив их, выбрать из двух гипотез более убедительную. Расчет p-значения ничего не говорит о вероятности альтернативной гипотезы: мы оценим только данные против нулевой, на основе чего отбрасываем или оставляем ее. Здесь преимущество байесианского подхода очевидно: возможны ситуации, когда вероятность нулевой гипотезы невелика, но при этом вероятность альтернативной еще ниже.
Проиллюстрировать это можно тем же примером с беременностью. Примем, что нулевая гипотеза гласит – вы женщина, а альтернативная – вы мужчина. При этом вы беременны. Тогда p-значение, то есть вероятность наблюдать такие данные (беременность) при условии корректности нулевой теории (вы женщина), будет равно 0,03, удовлетворяя распространенному критерию статистической значимости p < 0,05. Соответственно, если вы беременны, мы должны отвергнуть нулевую гипотезу. Руководствуясь этой логикой, вы беременны, значит, вы мужчина. Расчет фактора Байеса приведет нас к более разумному выводу: 0,03, деленное на бесконечно малую вероятность наблюдать беременность у мужчины, даст бесконечно большое значение фактора Байеса и будет сильнейшим аргументом за то, чтобы признать беременную женщиной.
Однако есть и серьезный недостаток. Для расчета фактора Байеса необходимо знать вероятность наблюдения данных при условии, что верна альтернативная гипотеза. В клинических экспериментах ситуации, похожие на пример с беременностью, возникают редко, и мы неизбежно сталкиваемся с необходимостью определять этот параметр на основе предположений. Это вносит в расчеты ту субъективность, за которую критикуют байесианские методы. Пока их применение в медицинских экспериментах ограниченно, а между сторонниками и противниками идут горячие споры.
Какие бы критерии выбора в пользу нулевой или альтернативной теории мы ни использовали, сам факт признания того, что различия между группами не случайны, содержит мало информации для врачей и не дает достаточно оснований применять метод лечения. Как правило, он ничего не говорит о силе эффекта. Поэтому мало отметить, что различия статистически значимы, важно рассчитать такие показатели, как индекс потенциальной пользы, показывающий, сколько человек нужно пролечить, чтобы предотвратить один нежелательный исход (например смерть или инфаркт), и индекс потенциального вреда, с помощью которого можно описать распространенность побочных эффектов. В РКИ эти показатели не менее важны, чем в наблюдательных исследованиях.
Если мы используем расчет p-значений, желательно обозначить разницу между группами не просто одним числом – оно ничего не говорит о степени неопределенности результата, является ли он окончательным или требуется продолжение исследований. Больше информации дает расчет доверительных интервалов (ДИ), ставший в последнее время стандартной частью анализа результатов РКИ. Доверительные интервалы обозначают диапазон, в котором с определенной надежностью (обычно это 95%) лежит результат. Чем выше выбранная надежность, тем шире будут границы диапазона. Если доверительный интервал разницы между группами включает в себя ноль, мы не можем уверенно говорить ни об отрицательном, ни о положительном результате эксперимента.
Доверительные интервалы записывают следующим образом.
Выживаемость в группе ингибиторов АПФ была на 10,0% выше (95% ДИ 7,0 13,0).
В этом случае 7,0 – это нижняя граница доверительного интервала, 13,0 – верхняя, а 95% – значение надежности, для которого рассчитан ДИ. Это результат A на рисунке ниже.
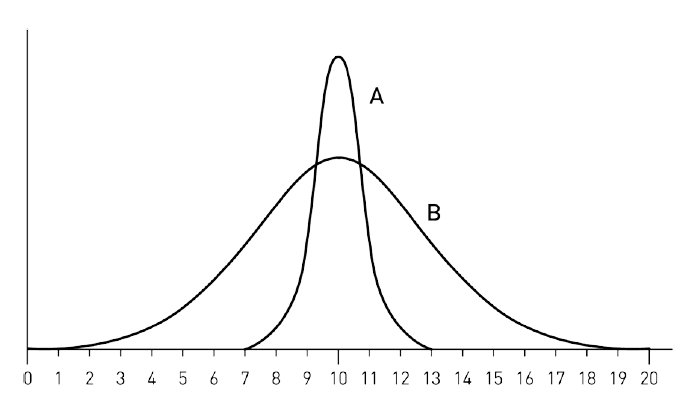
На рисунке изображены результаты двух экспериментов. Если мы ограничимся указанием среднего значения одной цифрой, то результаты A и B будут одинаковы. Различия между группами в обоих случаях 10% и статистически значимы. Однако доверительные интервалы разные: для А (7,0 13.0), для B (0,1 19,9). И если в первом случае мы знаем, что эффект лежит в достаточно узком диапазоне 7–13% и наверняка имеет клиническое значение, то во втором он может быть ничтожно мал (как, впрочем, и очень велик), поэтому нужны дальнейшие эксперименты. Они помогут сузить доверительный интервал и получить более точное представление о диапазоне, в котором лежит размер наблюдаемого эффекта.
В восьмидесятые годы прошлого века специалисты по статистике провели вполне успешную кампанию за обязательное использование доверительных интервалов либо вместо расчета p-значений, либо в дополнение к ним. Сейчас это стало правилом хорошего тона, которое, впрочем, нередко игнорируется.
Разобрать в рамках этой главы все возможные способы провести клиническое испытание и проанализировать его результаты неправильно – абсолютно невыполнимая задача. Тем, кто хочет узнать об этом больше, можно посоветовать книгу Триши Гринхалдж “Основы доказательной медицины” – она опубликована на русском языке. А мы поговорим еще об одной проблеме, приводящей к катастрофическим последствиям: результаты многих клинических экспериментов остаются практически никому не известными.
Последнее решение
В 1980 году группа британских врачей провела испытание антиаритмического препарата лоркаинид у пациентов с инфарктом миокарда. В то время считалось, что, поскольку аритмия – одна из причин гибели после инфаркта, антиаритмические препараты должны повышать выживаемость пациентов. Из 49 пациентов в группе лоркаидина погибло 9, тогда как в группе плацебо – только один из 47. Поскольку фармкомпания решила не выводить препарат на рынок по причинам, не связанным с результатами этого исследования, они так и не были опубликованы. Как написал позже один из участников исследовательской группы: “Мы утратили интерес… и забыли об этом”.
Восемь лет спустя клиническое испытание CAST показало, что вопреки ожиданиям антиаритмические препараты могут не снижать, а увеличивать смертность пациентов с инфарктом. Участники испытания 1980 года осознали, что результаты их исследования могли в свое время стать первым тревожным звонком. Благодаря ему крупные исследования вроде CAST начались бы раньше и многие пациенты могли быть спасены. В назидание другим экспериментаторам они рассказали об этой истории, чтобы те помнили, насколько важно последнее связанное с исследованием решение: публиковать ли его результаты и если да, то насколько полно.
Публикации в научных журналах – главный источник информации о медицинских исследованиях. Именно на них опираются правила лечения пациентов – информация, которую разработчики лекарств передают в регистрирующие организации, такие как российское министерство здравоохранения, непублична и недоступна для большинства. Насколько корректны эти правила, если до 90% исследований остаются неопубликованными?
Неопубликованные исследования отличаются от опубликованных. В 2008 году были изучены РКИ, на основе которых регистрировали антидепрессанты. Из 74 исследований по 12 препаратам 31% не были опубликованы. Что же именно осталось в ящиках столов? Из 38 успешных РКИ не опубликовали только одно. Из 36 отрицательных – опубликовали только 3, 22 не опубликовали, а оставшиеся 11 опубликовали, заменив отрицательный вывод на положительный. Получается, хотя положительный результат был получен только в половине РКИ, изучение научных публикаций создает впечатление, будто эффективность препаратов подтверждена в 94% исследований.
В результате избирательной публикации складывается ложное впечатление, что эффективность и безопасность препаратов выше, чем на самом деле. Ситуацию усугубляет и то, что исследования с положительным результатом публикуются заметно быстрее: для тех отрицательных, что все-таки доходят до печати, от момента завершения до появления в журналах в среднем проходит в полтора раза больше времени.
Не меньший вред может принести неполная публикация результатов. В сентябре 2004 года фармацевтическая компания Merck & Co отозвала с рынка противовоспалительный препарат рофекоксиб (торговая марка “Виокс”) в связи с тем, что он ощутимо повышает риск сердечных приступов и инсультов. Относящийся к группе коксибов препарат был очень популярен как лекарство от артрита, на пике его принимало до 80 миллионов человек по всему миру. Выручка от продажи “Виокса” за год до отзыва составила 2,5 миллиарда долларов США.
Препарат вышел на рынок в 1999 году, связанные с сердечно-сосудистыми заболеваниями побочные эффекты не упоминались. В клиническом испытании RIGOR, на основе которого “Виокс” был зарегистрирован, его сравнили с более старым напроксеном и пришли к выводу, что “Виокс” безопаснее. Однако со временем стала появляться информация о сердечно-сосудистых рисках, связанных с “Виоксом”, и затем крупное РКИ подтвердило, что препарат увеличивает эти риски в несколько раз.
Однако через некоторое время после отзыва препарата разразилась настоящая буря: выяснилось, что “Виокс” вообще не должен был появляться на рынке. Редакторы журнала The New England Journal of Medicine обнаружили, что из результатов RIGOR каким-то образом исчезли три инфаркта миокарда и другие побочные эффекты в группе “Виокса” и это ощутимо повлияло на выводы. Еще позже, в 2006 году, стало известно, что в ходе ADVANTAGE, другого исследования “Виокса”, проведенного Merck & Co в 2000 году, были получены данные, показывающие семикратное увеличение смертности от сердечно-сосудистых причин в группе “Виокса”. Отчет о результатах ADVANTAGE Merck & Co опубликовала только в 2003 году. В анализе упомянули лишь часть смертей, благодаря чему нежелательный эффект остался статистически незначимым.
Располагая данными о побочных эффектах “Виокса” еще до выхода препарата на рынок, Merck & Co скрывала их, защищая коммерчески успешный препарат до конца. Началась маркетинговая кампания, призванная выставить препарат в наилучшем свете. По мере распространения информации о побочных эффектах Merck & Co лишь усиливала сопротивление. Компания даже пыталась судить испанского фармаколога, чтобы вынудить внести поправки в его статью, но не добилась успеха. Последовавшие за скандалом с “Виоксом” судебные разбирательства привели к обнародованию электронных писем и внутренних документов Merck & Co. Примечательны, например, тренинговые материалы для сотрудников компании, содержавшие готовые ответы на щекотливые вопросы о побочных эффектах и набранный заглавными буквами совет “УВОРАЧИВАЙТЕСЬ!”.
Последовавшие суды нанесли ущерб репутации Merck & Co и резко снизили стоимость ее акций. Но ни огласка, ни компенсационные выплаты не могли вернуть потерянные жизни и утраченное здоровье. Многолетнее умалчивание и неполная публикация результатов исследований привели к тому, что на рынке несколько лет присутствовал опасный препарат. По разным оценкам, за время применения “Виокса” от него пострадали от 89 до 130 тысяч пациентов.
Узнать о неполноте или искажении опубликованных данных можно, только сверяя статьи в медицинских журналах с информацией, направленной регулирующим организациям, или с протоколами, полученными от этических комитетов, дававших одобрение на проведение испытания. Предполагается, что исследование проводят в точном соответствии с заранее подготовленным протоколом, а если есть отклонения, исследователи сообщают об этом и объясняют причину. Однако сопоставление информации из этих источников показывают одну и ту же тенденцию: в публикациях подчеркивают позитивные результаты и преуменьшают негативные находки, а исходы, по которым оценивают результаты РКИ, и методы анализа меняют без каких-либо объяснений. Так, до четверти основных исходов, фигурирующих в протоколах, не упомянуты в статьях. И в основном это исходы, представляющие препарат в негативном свете.
Крупный скандал разразился в связи с пароксетином (торговая марка “Паксил”). В 1992 году этот антидепрессант был выведен на рынок фармацевтической компанией SmithKline Beecham, а в 2012 году производителя оштрафовали на 3 миллиарда долларов США за сокрытие информации об исследовании № 329, в котором изучали лечение подростковых депрессий. Исследование показало, что эффективность пароксетина не лучше, чем у плацебо, и обнаружило побочные эффекты, в частности суицидальное поведение. SmithKline Beecham отказалась от идеи получить разрешение на использование “Паксила” в педиатрии, но у руководства возникли опасения, что эта неудача может подорвать популярность препарата – он уже применялся для взрослых и пользовался коммерческим успехом. Только в США “Паксил” приносил 12 миллиардов долларов в год, такими фантастическими продажами нельзя было рисковать.
Было принято решение “эффективно управлять распространением информации, с тем чтобы минимизировать потенциальный негативный коммерческий эффект”, для чего опубликовать “позитивные данные исследования 329”. Чтобы сделать “из дерьма конфетку”, было нанято агентство по медицинским коммуникациям. За сумму, чуть превышающую 17 тысяч долларов, агентство взялось написать несколько вариантов статьи и обеспечить взаимодействие с редакторами журналов. В качестве исходного материала в агентство был передан подробный отчет об исследовании на 1400 страницах. Конечно, формулировки в отчете смягчали найденные проблемы, но он не создавал ложного впечатления, что препарат эффективен и безопасен. Уже в первом варианте написанной агентством статьи выводы резко изменились. Число первичных исходов увеличилось с двух до восьми, показатели четырех из них были ожидаемо лучше в группе “Паксила”. Побочные эффекты были приуменьшены, а выводы сообщали, что “препарат хорошо переносится и эффективен при лечении депрессии у подростков”.
Статья была опубликована в Journal of the American Academy of Child and Adolescent Psychiatry. Конечно, редакторы журнала не могли знать о происходящем, но признаки того, что с данными не все в порядке, должны были насторожить. Статья, написанная маркетинговым агентством, впоследствии цитировалась в других научных работах 226 раз и использовалась для обоснования применения пароксетина.
В отдел маркетинга SmithKline Beecham статья поступила с сопроводительным комментарием сотрудника отдела продаж о “революционном исследовании”, демонстрирующем “исключительную эффективность и безопасность “Паксила” для лечения подростковой депрессии”. Так буквально за два шага неэффективный препарат с опасным побочным действием превратился в чудо медицины – надежное и безопасное. Попытка спасти легитимные продажи взрослым превратилась в рекламу офф-лейбл применения (калька с англ. off-label, “за пределами инструкции, этикетки”) для подростков: под этим термином понимают назначение разрешенного препарата по показаниям, не входящим в перечень официально разрешенных, – не всегда законная, но достаточно распространенная практика.
В 2003 году британский регулятор MHRA проанализировал исследование № 329 и другие и обнаружил сокрытие информации. Последовал запрет на применение пароксетина для лечения подростков и возбуждение уголовного дела. Через четыре года уголовные обвинения были сняты, но помимо трехмиллиардного штрафа GSK выплатила еще миллиард по иску о связи 450 самоубийств с приемом пароксетина. Компания обязалась создать публичный реестр всех данных о проводимых ею клинических испытаниях. Вслед за ней аналогичные реестры в интернете создали Pfizer, Eli Lilly и Merck & Co.
Под влиянием этой истории Международный комитет редакторов медицинских журналов заявил в 2005 году, что входящие в него журналы не будут публиковать исследования, которые не были предварительно зарегистрированы. Под предварительной регистрацией понимают публикацию еще до начала исследования на стороннем независимом ресурсе всех связанных с исследованием деталей, таких как дизайн, исходы, принцип отбора пациентов, методы анализа данных: это мешает публиковать результаты избирательно или не публиковать их вовсе – останутся следы того, что испытание проводилось, и перечень исходов, которые планировалось оценить. В США такая база доступна в интернете по адресу ClinicalTrials.gov еще с 2000 года. Однако ее существование долго игнорировалось, и только требование Международного комитета редакторов медицинских журналов переломило ситуацию – всего за месяц количество зарегистрированных в базе клинических исследований увеличилось вдвое.
Вслед за этим некоторые журналы потребовали предоставлять вместе со статьей исходные протоколы испытаний. А в 2007 году FDA сделало предварительную регистрацию клинических исследований обязательной и объявило о грозящих нарушителям наказаниях. В 2008 году вышла обновленная версия Хельсинкской декларации, в которой теперь четко прописали, что “любое клиническое исследование должно быть зарегистрировано в общедоступной базе данных до того, как в испытание включен первый участник”. В настоящее время такие публичные базы созданы в еще двух десятках стран, существует и международная база ВОЗ. К сожалению, в России обязательная публичная предварительная регистрация медицинских исследований носит формальный характер и реализуется таким образом, что в принципе не может выполнять предписанных ей функций.
Другая инициатива, направленная на то, чтобы публикации содержали полную и объективную информацию, – CONSORT (Consolidated Standards Of Reporting Trials, консолидированный стандарт отчета об исследованиях). Это расширенный список всего, что обязательно должно быть включено в описывающую клиническое исследование статью. Его задача – помочь предотвратить сокрытие важной для интерпретации исследования информации. Хотя CONSORT – всего лишь ориентир и носит рекомендательный характер, многие крупные журналы отталкиваются от его требований, когда решают, отвергнуть статью или принять к публикации. Анализ показал, что использование CONSORT значительно улучшает качество публикуемых статей.

