Книга: Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта
Назад: Контроверзы
Дальше: Дорога вперед
Недоразумения
Я покидал Пуэрто-Рико в убеждении, что начатый тут разговор о будущем AI следует продолжить, потому что это самый важный разговор нашего времени. Причем этот разговор касается нашего общего будущего, и поэтому не должен вестись только в кругу AI-экспертов. Именно поэтому я и написал эту книгу: я писал ее в надежде, дорогой читатель, что и вы присоединитесь к этому разговору! На какое будущее вы надеетесь? Надо ли нам развивать автономное летальное оружие? Какого рода автоматизации хотели бы вы у себя на работе? Какого образования вы бы хотели для своих детей? Предпочли бы вы, чтобы на смену старым профессиям пришли новые, или вам больше нравится общество бездельников, где каждый наслаждается досугом, а богатство создается машинами? Двигаясь дальше в том же направлении, находите ли вы благоприятной перспективу создания Жизни 3.0 и ее распространения по нашему космосу? Сможем ли мы управлять мыслящими машинами, или это они скорее начнут управлять нами? Заменят ли думающие машины нас, будем ли мы сосуществовать друг с другом или объединимся в некое единое целое? Что значит оставаться людьми в эпоху искусственного интеллекта? Какой ответ на этот вопрос вам представляется желательным, и как вы представляете себе возможность реализации этого ответа в нашей будущей жизни?
Цель этой книги – помочь вам присоединиться к нашему разговору. В нем разворачиваются увлекательнейшие контроверзы, о которых я уже упоминал и в которых величайшие мировые умы придерживаются противоположных позиций. Но кроме этого я был свидетелем множества скучнейших псевдо-контроверз, когда люди просто не понимают или даже не слушают друг друга. Для того чтобы сконцентрироваться на важных нерешенных проблемах, говорить о контроверзах, понимаемых спорящими одинаково, давайте для начала избавимся от некоторых расхожих недоразумений.
У таких важных и часто используемых понятий, как “жизнь”, “разум” и “сознание”, есть много общеупотребительных и конкурирующих определений, и недоразумения нередко возникают по вине людей, не отдающих себе отчет в том, что они используют одно и то же слово в двух разных значениях. Для того чтобы мы с вами не сваливались раз за разом в эту волчью яму, я составил шпаргалку (см. табл. 1.1), показывающую, как я использую те или иные слова в этой книге. Некоторые из содержащихся в ней определений будут даны и должным образом объяснены в следующих главах. И, пожалуйста, обратите внимание, что я не претендую на какую-то исключительность моих определений – они, может быть, ничуть не лучше, чем какие-то другие, но моя единственная цель состоит в том, чтобы избежать недоразумений, сразу выразив предельно ясно, что именно я имею в виду. Вы увидите, что я обычно отдаю предпочтение широким определениям, избегая антропоцентрического уклона и делая их приложимыми как к людям, так и к машинам. Пожалуйста, прочитайте мою шпаргалку сейчас и не ленитесь обращаться к ней потом, когда будете обескуражены тем, как я использовал то или иное слово – в особенности в главах 4–8.
Таблица 1.1
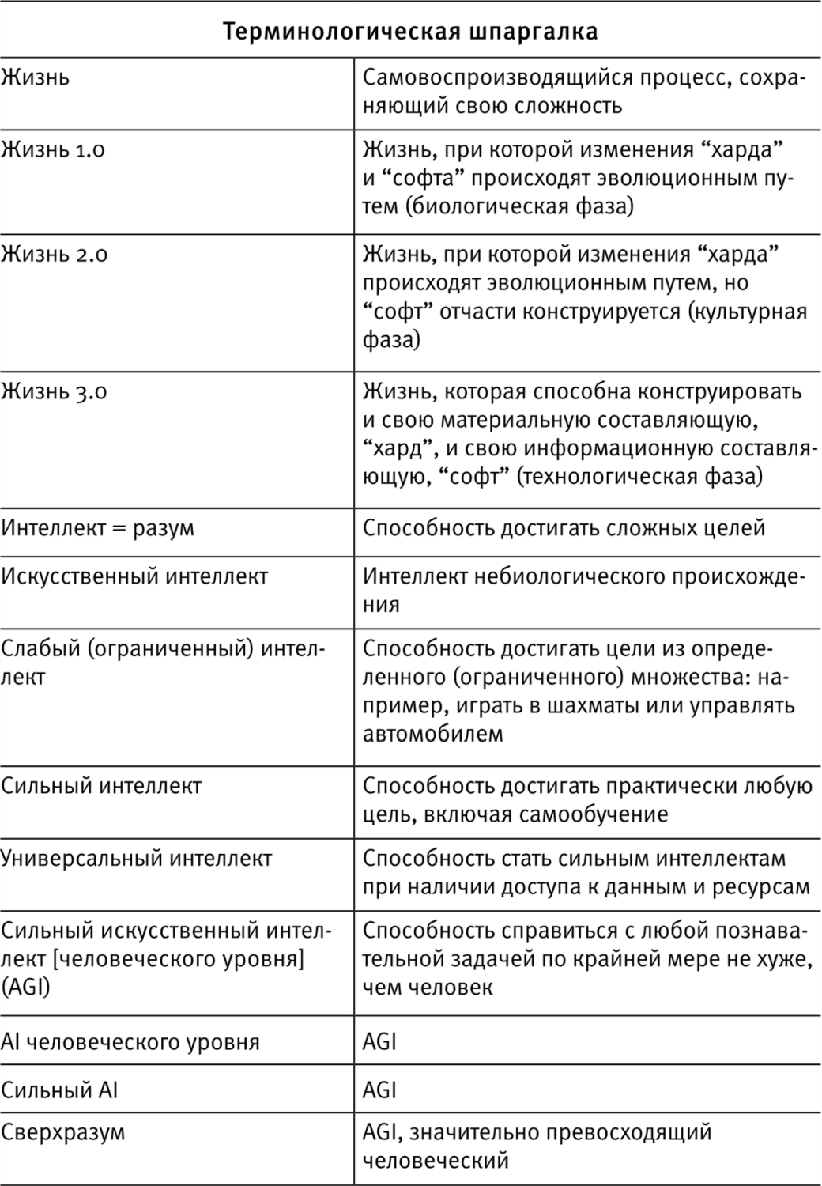
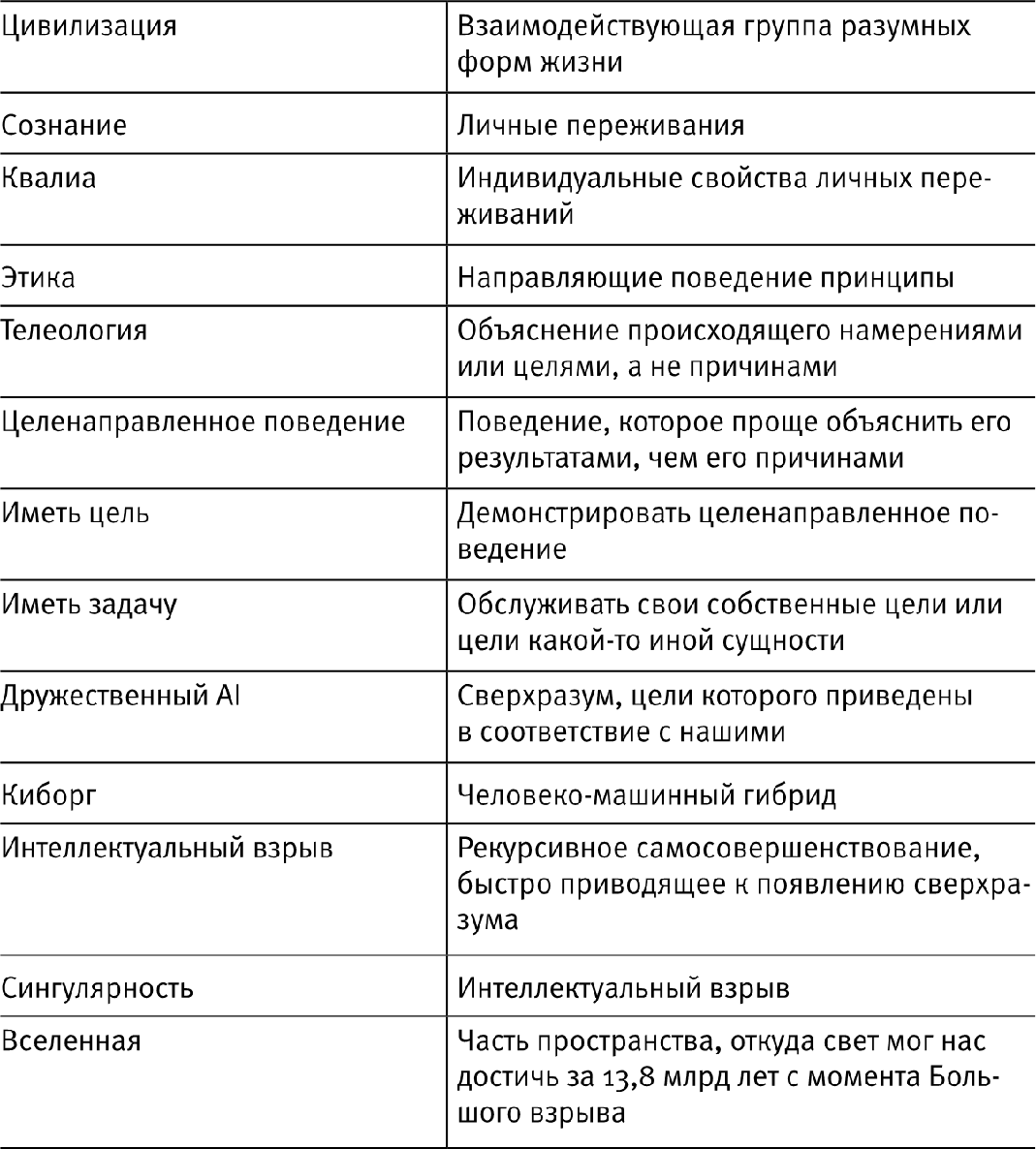
Многие недоразумения относительно искусственного интеллекта возникают из-за того, что люди используют приведенные в левой колонке слова для обозначения несхожих вещей. Здесь я привожу значения, в которых эти слова употребляются в этой книге. (Некоторые из этих определений будут введены и объяснены только в следующих главах книги.)
Кроме недоразумений, вызванных расхождениями в терминологии, я был свидетелем споров, возникавших по причине простых логических ошибок. Рассмотрим наиболее распространенные из них.
Хронологические мифы
Первый проиллюстрирован на рис. 1.5: сколько времени понадобится, чтобы машинный интеллект мог принципиально превзойти человеческий разум? Самая большая ошибка здесь заключается в уверенности, что мы можем знать это с большой степенью точности.
Так, один популярный миф утверждает, что мы можем не сомневаться в появлении суперинтеллекта к концу этого столетия. В самом деле, история полна примеров чрезмерного оптимизма в отношении технологических достижений будущего. Где все эти давно обещанные нам термоядерные электростанции и летающие автомобили? С AI в прошлом тоже было связано немало чрезмерно завышенных ожиданий, в том числе этим грешили и некоторые основатели самой этой области: например, Джону Маккарти (автору термина “искусственный интеллект”), Марвину Мински, Натаниелю Рочестеру и Клоду Шеннону принадлежит следующий пассаж, содержащий оптимистический прогноз относительно того, что может быть проделано при помощи двух компьютеров каменного века за два месяца: “Наш проект заключается в том, чтобы 10 человек проводили на протяжении двух месяцев летом 1956 года исследование искусственного интеллекта в Дартмутском колледже … Будет сделана попытка научить машины использовать язык, формировать абстракции и общие понятия, решать некоторые типы задач, в настоящее время доступных только людям, и самосовершенствоваться. Мы полагаем, что в одном или нескольких из предложенных направлений может быть достигнут существенный прогресс, если тщательно отобранная группа ученых будет заниматься ими на протяжении лета”.

Рис. 1.5
Типичные мифы об искусственном интеллекте.
С другой стороны, у нас есть и анти-миф: мы можем не сомневаться в том, что суперинтеллект не появится до конца этого столетия. Исследователи предлагают широкий спектр оценок того, как далеко мы находимся от сверхчеловеческого AGI, но мы никак не можем с уверенностью утверждать, что вероятность получить его к концу века равна нулю, особенно если примем во внимание всю историю удручающе низкой точности предсказаний подобного рода техноскептиков. Вспомним, как Эрнест Резерфорд, по общему признанию величайший физик-ядерщик своего времени, уже в 1933 году – всего лишь за 24 года до открытия Лео Сцилардом ядерных цепных реакций – называл возможность получения ядерной энергии “лунным светом”, или как в 1956 году королевский астроном Ричард Вули называл разговоры о полетах в космос “полной мутью”. Крайнюю форму этот миф принимает в рассуждениях об искусственном интеллекте, который никогда не сможет стать сверхчеловеческим, потому что это физически невозможно. Но физики знают, что мозг состоит из кварков и электронов, упорядоченных так, что они могут работать как мощный компьютер, и что нет такого физического закона, который мог бы помешать нам создать еще более разумный комок кварков.
Было проведено несколько крупных исследований на экспертных фокус-группах среди специалистов по искусственному интеллекту, где им предлагалось оценить, сколько времени от текущего момента может пройти, пока вероятность создания искусственного интеллекта человеческого уровня достигнет 50 %, и все эти исследования оканчивались одним и тем же: мнения ведущих мировых исследователей по этому поводу расходятся, так что мы просто не знаем. Например, во время такого опроса на нашей конференции в Пуэрто-Рико медианный ответ соответствовал 2055 году, но некоторые предсказывали сотни лет или даже больше.
Еще один имеющий отношение к тому же вопросу миф заключается в том, что люди, переживающие по поводу искусственного интеллекта, ждут его появления уже в ближайшие годы. На самом же деле подавляющее большинство из тех, чье мнение в данном вопросе значимо и кто действительно беспокоится о негативных последствиях создания AI, не ждут его раньше, чем через несколько десятилетий. Но они говорят: коль скоро у нас нет 100 % гарантий, что такое не может случиться уже в этом столетии, стоит начать вести исследования вопросов AI-безопасности уже сейчас и быть готовыми к неожиданностям. Как мы увидим в этой книге, некоторые из вопросов безопасности настолько сложны, что на их решение могут уйти десятилетия, и есть смысл заняться ими сейчас, а не накануне той ночи, когда какие-то попивающие “Рэд Булл” программисты решат запустить AGI человеческого уровня.
Мифы несогласных
Еще одно недоразумение часто возникает по причине распространенного заблуждения, заключающегося в том, что только современные луддиты, не очень-то знакомые с темой, могут выражать какие-то опасения по поводу искусственного интеллекта и призывать к исследованию связанных с ним рисков. Когда Стюарт Рассел сказал об этом во время своего выступления на конференции в Пуэрто-Рико, аудитория откликнулась громким смехом. С этим заблуждением связано еще одно общее недоразумение: что поддержка таких исследований – дело якобы исключительно спорное. В действительности для их проведения в разумных масштабах достаточно скромных инвестиций, и для этого не надо считать риски высокими – надо просто понимать, что ими невозможно пренебречь. Так, исходя из невозможности пренебречь очень невысокой вероятностью, что ваш дом сгорит дотла, вы отчисляете небольшую часть своего дохода на страхование недвижимости.
Мой собственный анализ проблемы привел меня к убеждению, что именно из-за тенденциозного освещения в масс-медиа вопросы АI-безопасности кажутся значительно более спорными, чем на самом деле. В конце концов, страх – востребованный товар, и вырванные из контекста цитаты, если из них можно сделать вывод о неминуемо надвигающейся катастрофе, соберут больше кликов, чем уравновешенный и детальной отчет о проблеме. Поэтому два человека, знающие о позиции друг друга только по опубликованным цитатам, скорее всего решат, что поводов не согласиться с мнением оппонента у них гораздо больше, чем на самом деле. Например, техноскептик, чьи представления о взглядах Билла Гейтса основаны исключительно на сведениях из британского таблоида, наверняка подумает, что тот полагает появление суперинтеллекта неминуемым, – и конечно же будет неправ. Похожим образом некто, выступающий за создание дружественного AI, прочитав процитированное выше высказывание Эндрю Ына относительно перенаселения Марса, подумает, что того не заботят проблемы AI-безопасности, и тоже ошибется. Я точно знаю, что они его заботят, – но все дело в том, что из-за его особой оценки временных масштабов возникающих проблем он отдает приоритет более близким по времени проблемам.
Мифы о природе рисков
Прочитав в Daily Mail заголовок “Стивен Хокинг предостерегает, что восстание роботов может оказаться катастрофическим для человечества”, я закрыл глаза. Я уже потерял счет таким статьям. Обычно они сопровождаются картинкой со злобным роботом, волокущим какое-нибудь оружие, и готовят нас к тому, что когда-нибудь роботы обретут сознание, преисполнятся злобой и поднимут восстание, которого нам следует опасаться. В определенном смысле такие статьи производят на меня сокрушительное впечатление, потому что в сжатой форме предлагают как раз тот самый сценарий, который никак не пугает моих коллег по исследованию AI. Этот сценарий содержит в себе сразу три глубочайших заблуждения, относящихся к трем разным понятиям: наше беспокойство должны вызывать сознание, злобность и вообще роботы.
Когда вы едете на машине по дороге, ваше восприятие световой и звуковой гамм субъективно. А есть ли субъективное восприятие у беспилотного автомобиля? Чувствует ли он себя настоящим беспилотником или просто катится по дороге, как неразумный зомби, лишенный всякого субъективного восприятия? Хотя эта загадка – что значит быть сознающим – сама по себе интересна и мы посвятим ей 8-ю главу, она не имеет никакого отношения к теме AI-рисков. Если на вас налетит беспилотный автомобиль, вам будет безразлично, осознавал ли он себя в этот момент. Точно так же нас беспокоит не то, что почувствует сверхчеловеческий разум, а что он будет делать.
Страх, что машины окажутся злонамеренными, – еще одна расхожая бессмыслица. Наше опасение вызывают их компетенции, а не злая воля. По определению сверхразумный AI исключительно эффективен в достижении своих целей, каковы бы они ни были, и нам важно, чтобы эти цели не противоречили нашим. Вряд ли вы относитесь к тем ненавистникам муравьев, кто топчет их по злобе, но если вы руководите проектом по постройке “зеленой” гидроэлектростанции и на предназначенном под затопление участке вдруг случайно окажется муравейник, то муравьям в нем не поздоровится. Движение за дружественный AI ставит перед собой задачу сделать так, чтобы люди никогда не оказывались в положении этих муравьев.
Недоразумение по поводу сознательных машин тесно связано с представлением, будто у машин не может быть целей. У машины, очевидно, могут быть цели в том смысле, что она может проявлять целеустремленное поведение: поведение ракеты, движущейся на источник тепла, наиболее естественно объяснить целью поразить самолет противника. Если вы испытываете беспокойство по поводу того, что цель машины каким-то образом расходится с вашими собственными целями, вам безразлично, до какой степени она себя осознает и какими намерениями движима. Когда вы увидите у себя на хвосте самонаводящуюся ракету, вы не станете успокаивать себя мыслью: “У машины не может быть целей!”.
Я с симпатией отношусь и к Родни Бруксу, и к другим пионерам робототехники, которые были возмущены тем, как сеющие ужас таблоиды несправедливо демонизируют их, когда их журналисты, зациклившиеся на роботах, начинают украшать свои статьи злобными металлическими монстрами с красными светящимися глазами. На самом же деле в центре внимания движения за дружественный AI вовсе не роботы, а сам искусственный интеллект, точнее говоря, – разум с целями, не совместимыми с нашими. Для того чтобы нарушить наш покой, такому не совместимому с нашим разуму вовсе не нужно тело робота, ему достаточно доступа в интернет – в главе 4 мы покажем, как, воспользовавшись этим, он купит и перепродаст всех на финансовых рынках, затмит изобретательностью любых изобретателей, покорит своей демагогией больше обывателей, чем любой человеческий политический лидер, и придумает оружие, принципов действия которого мы даже не будем понимать. Даже если бы создание роботов было физически невозможно, сверхразумный и сверхбогатый искусственный интеллект легко бы подкупал мириады человеческих существ и манипулировал бы ими, неумышленно вовлекая их в свои изощренные торговые операции, как это происходит в фантастическом романе Уильяма Гибсона Neuromancer.
Недоразумение с роботами напрямую связано с мифом, будто машины не могут управлять людьми. Разум – путь к управлению: человек может командовать тигром не потому, что сильнее, а потому, что умнее. Если мы уступим свое положение самых умных на планете, мы можем потерять и контроль над собой.
На рис. 1.5 все эти общие недоразумения собраны воедино, так чтобы мы могли покончить с ними раз и навсегда и сосредоточить наши дискуссии с друзьями и коллегами вокруг настоящих противоречий, в которых, как мы сейчас убедимся, нет недостатка.
Назад: Контроверзы
Дальше: Дорога вперед

